
Iterative Image Reconstruction Algorithm with Parameter Estimation by Neural Network for Computed Tomography


Abstract
1. Introduction
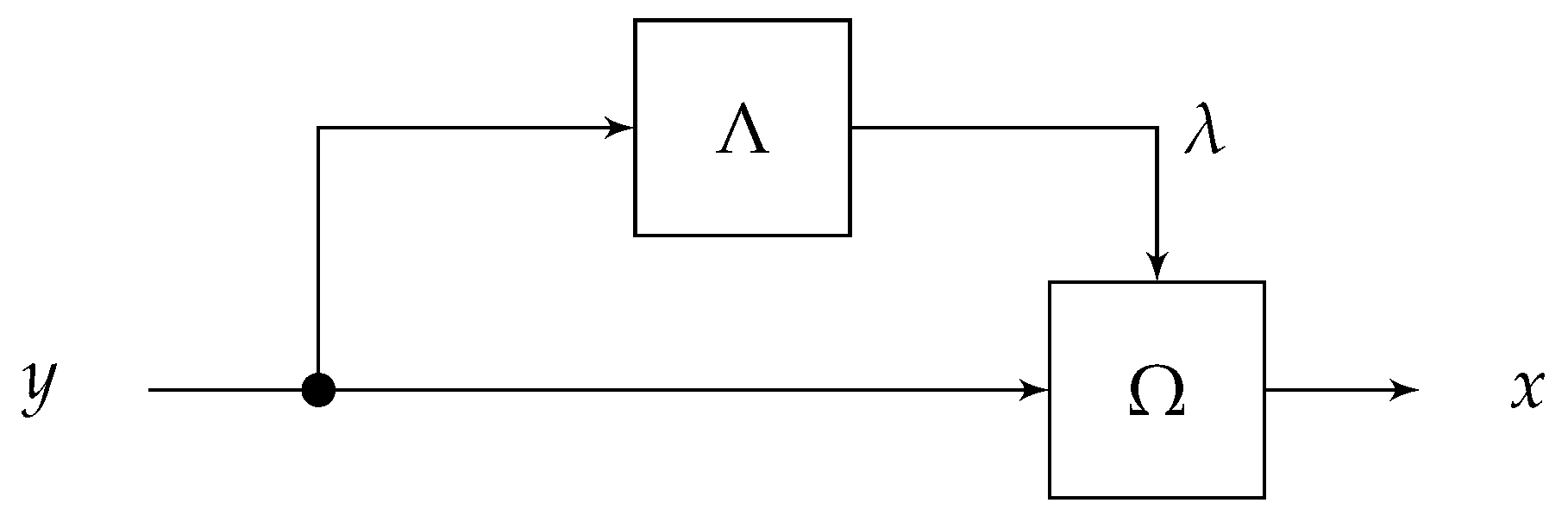
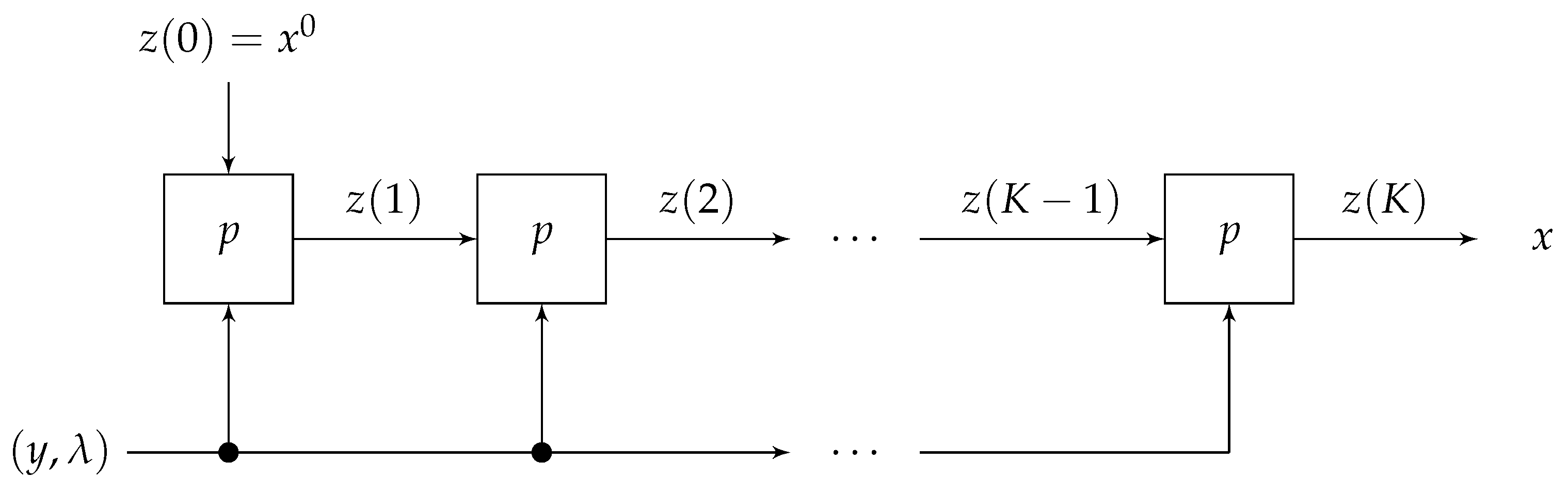
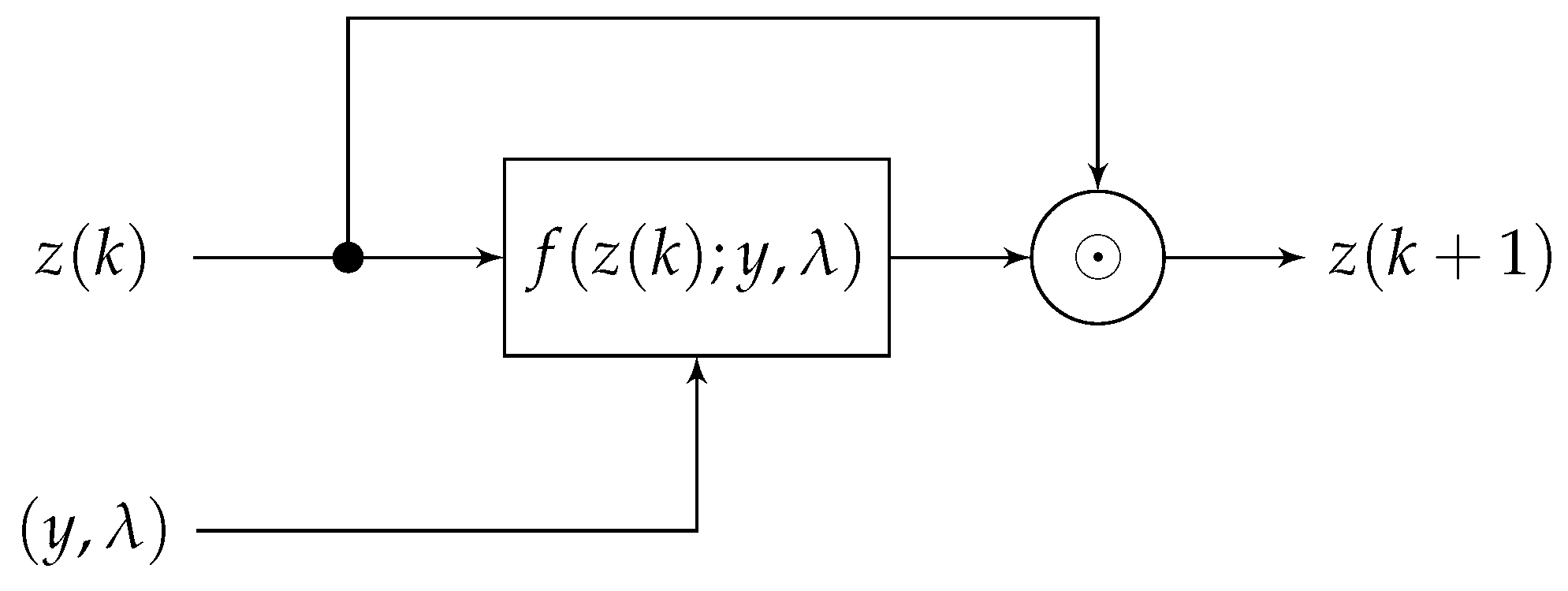
2. Problem Description
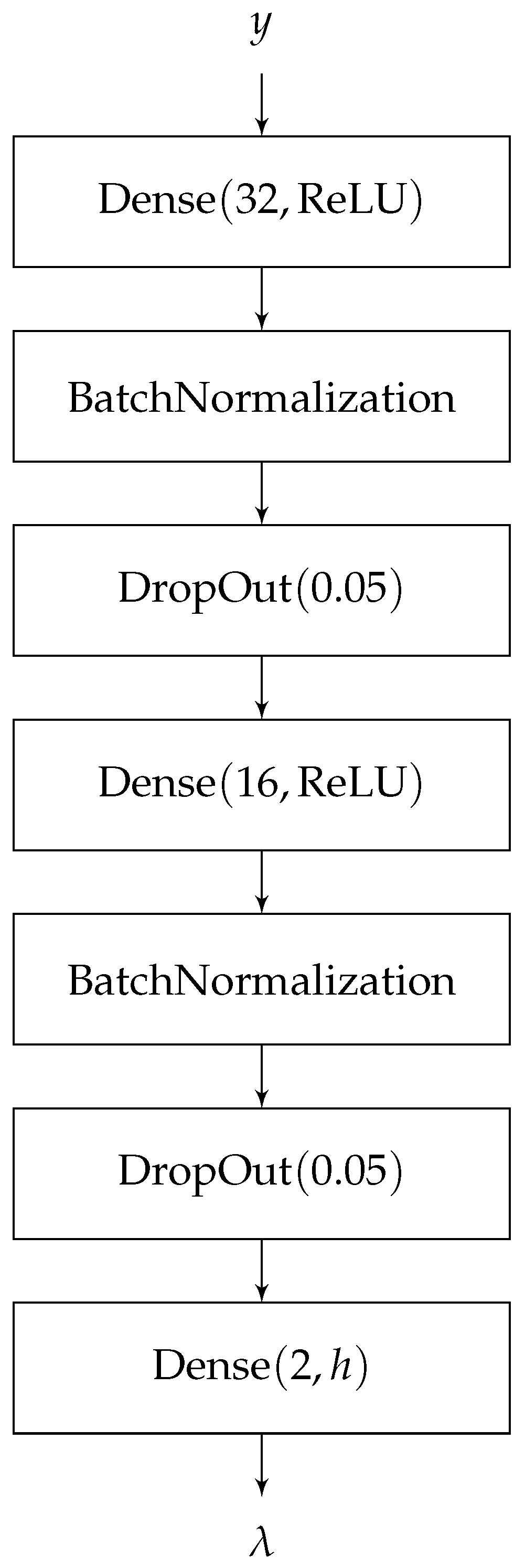
3. Proposed Method
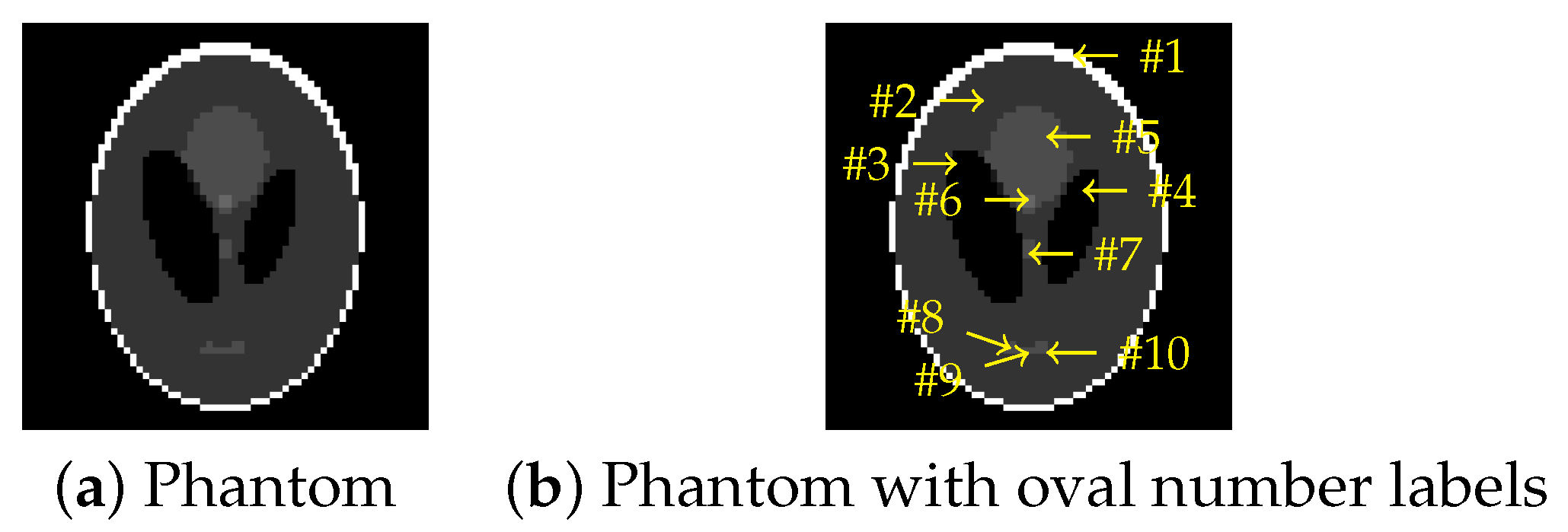
4. Results and Discussion
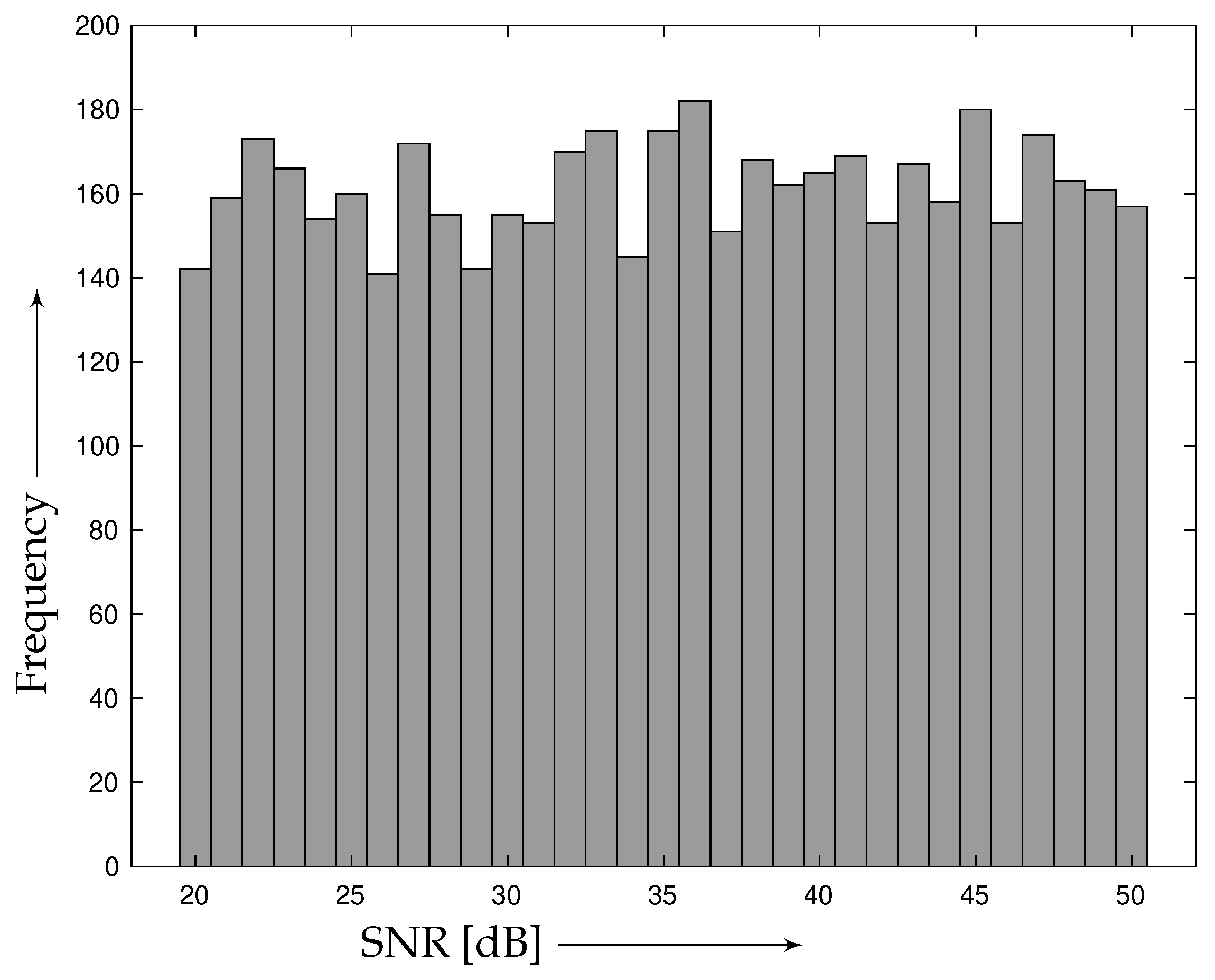
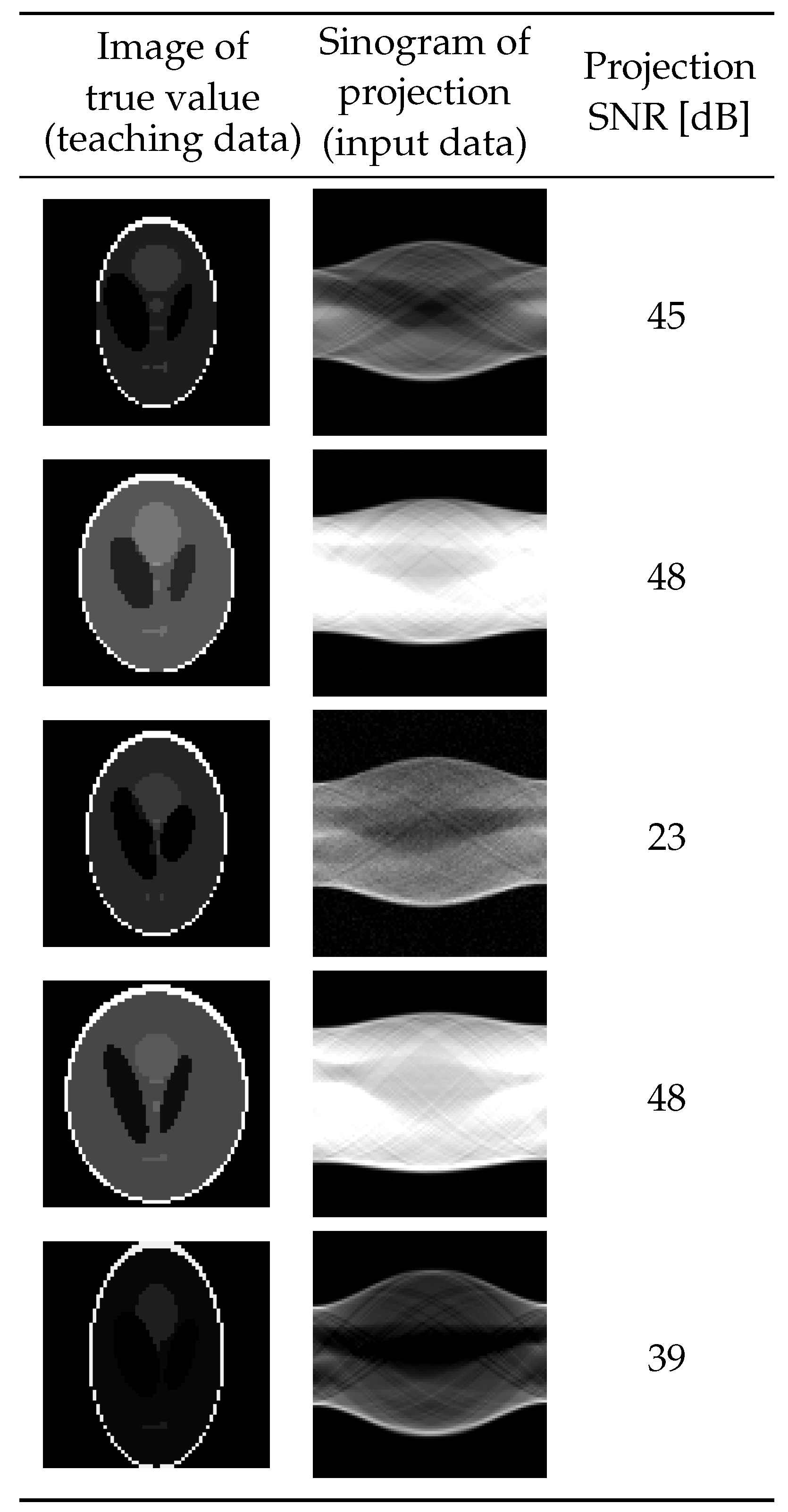
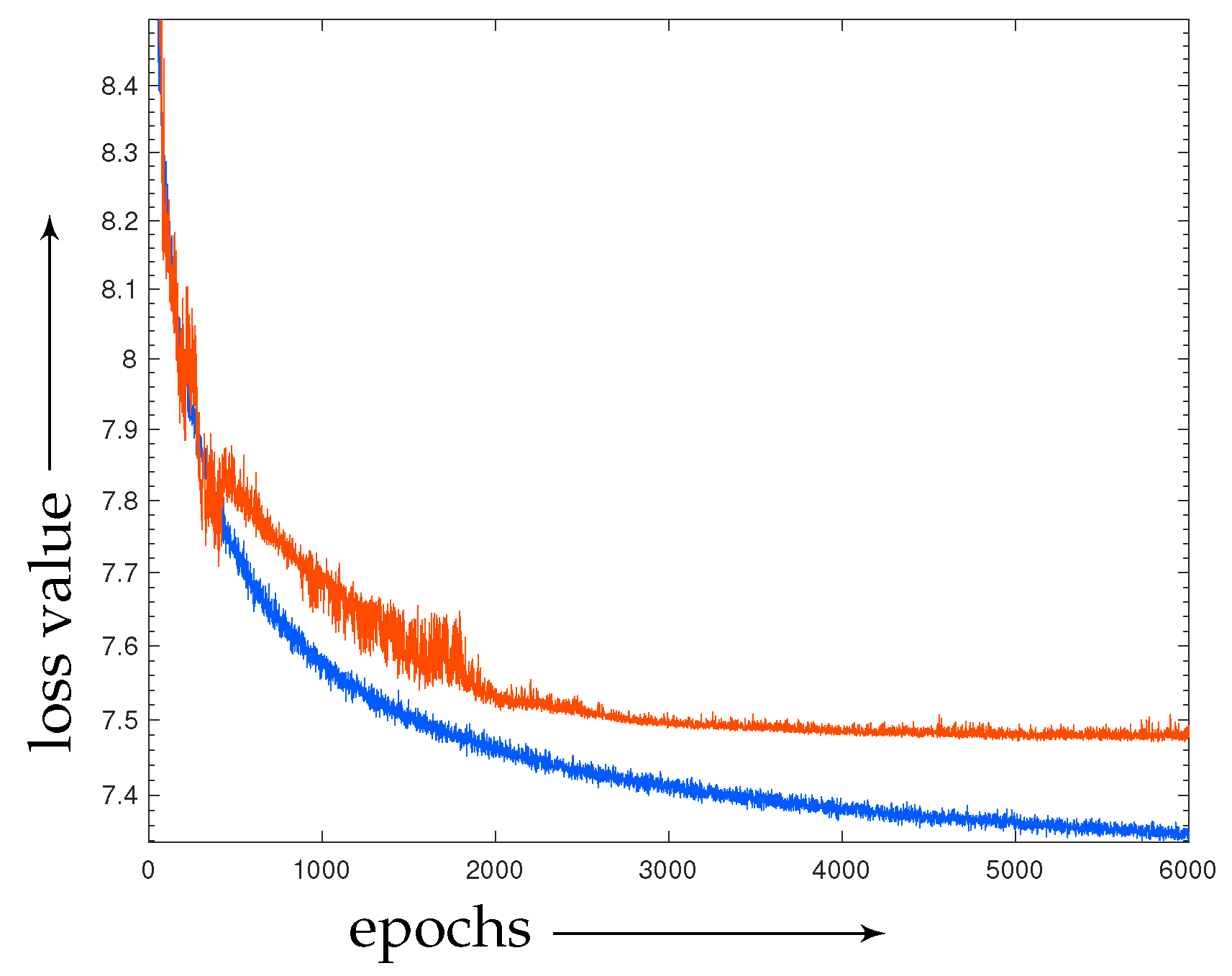
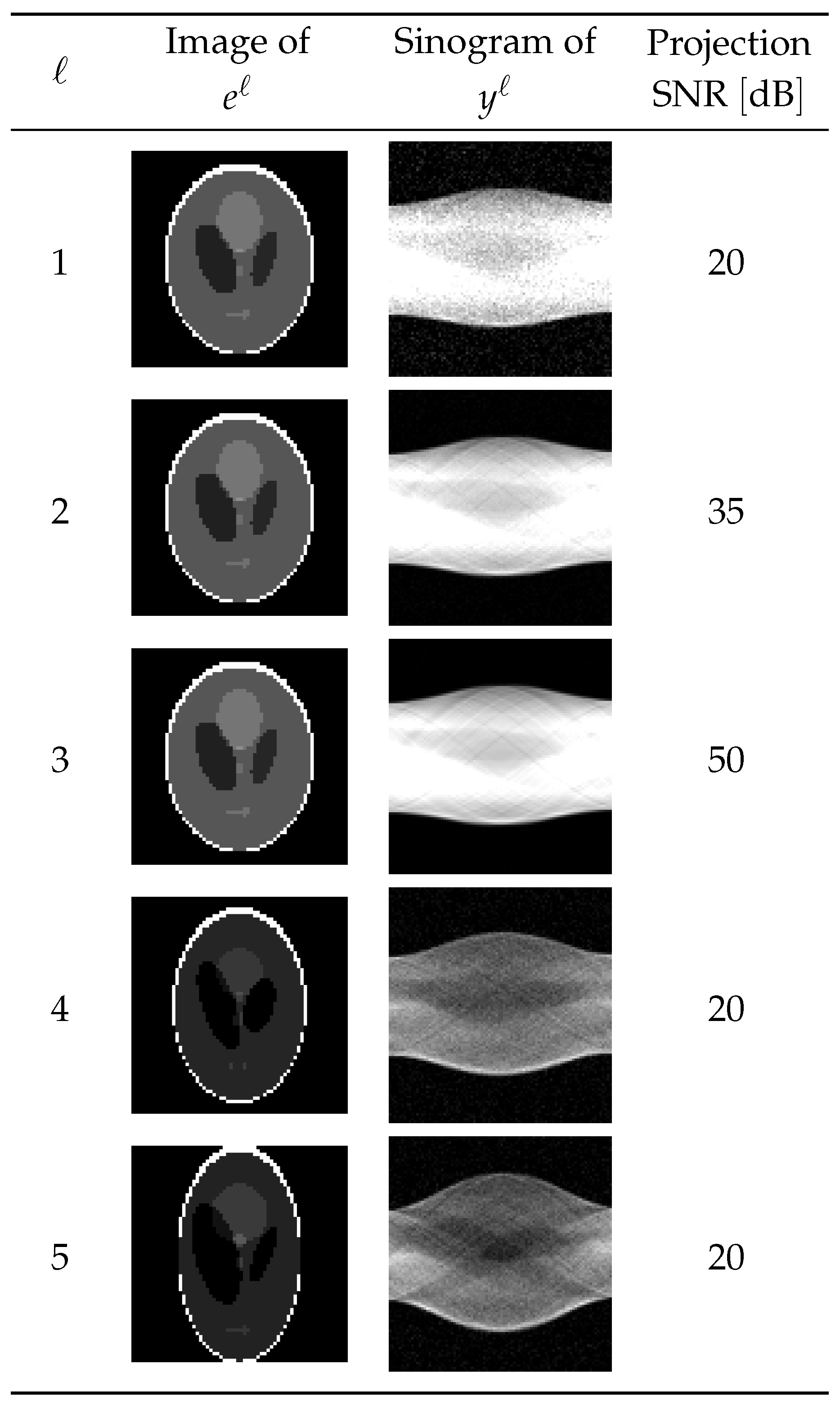
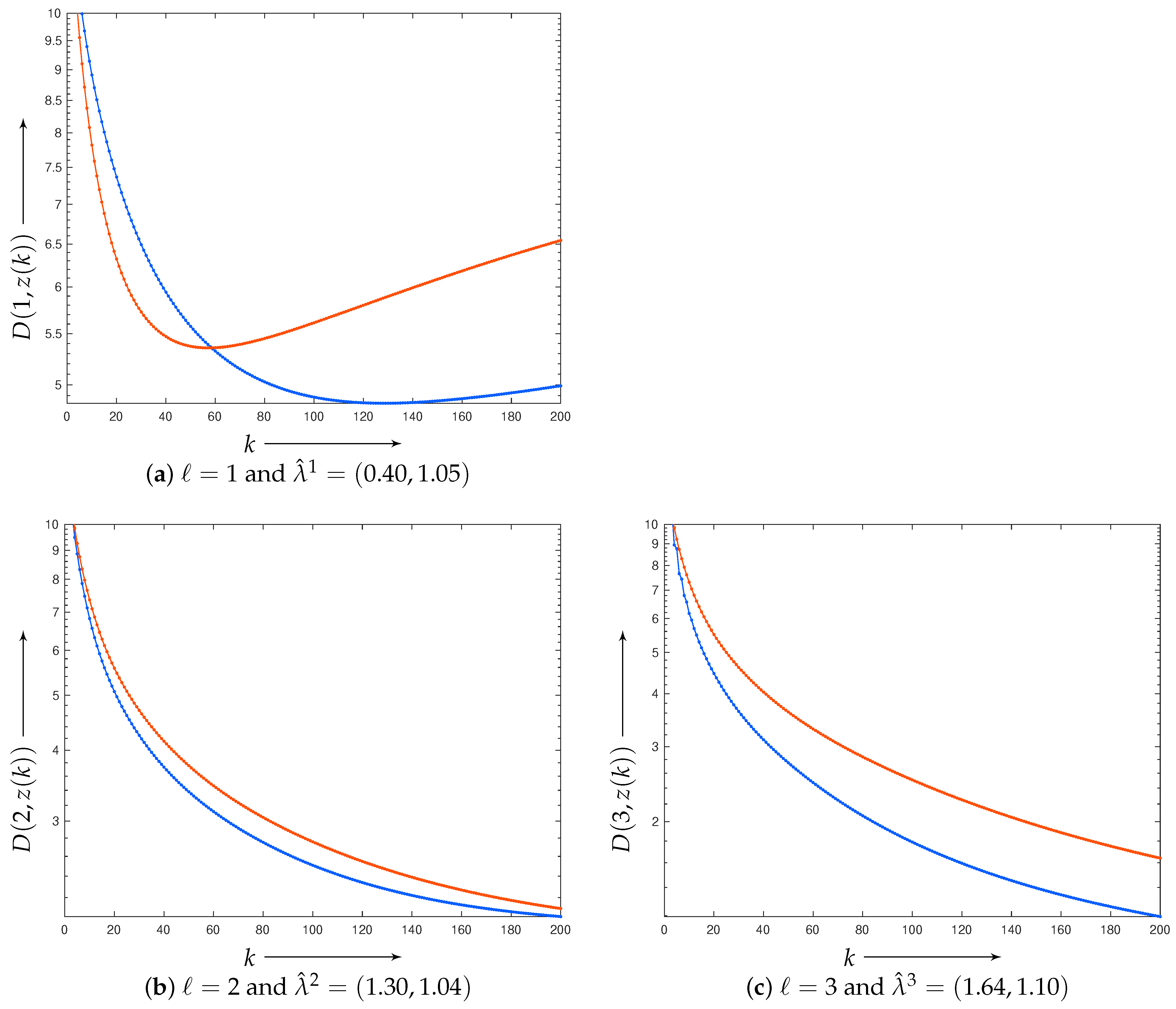
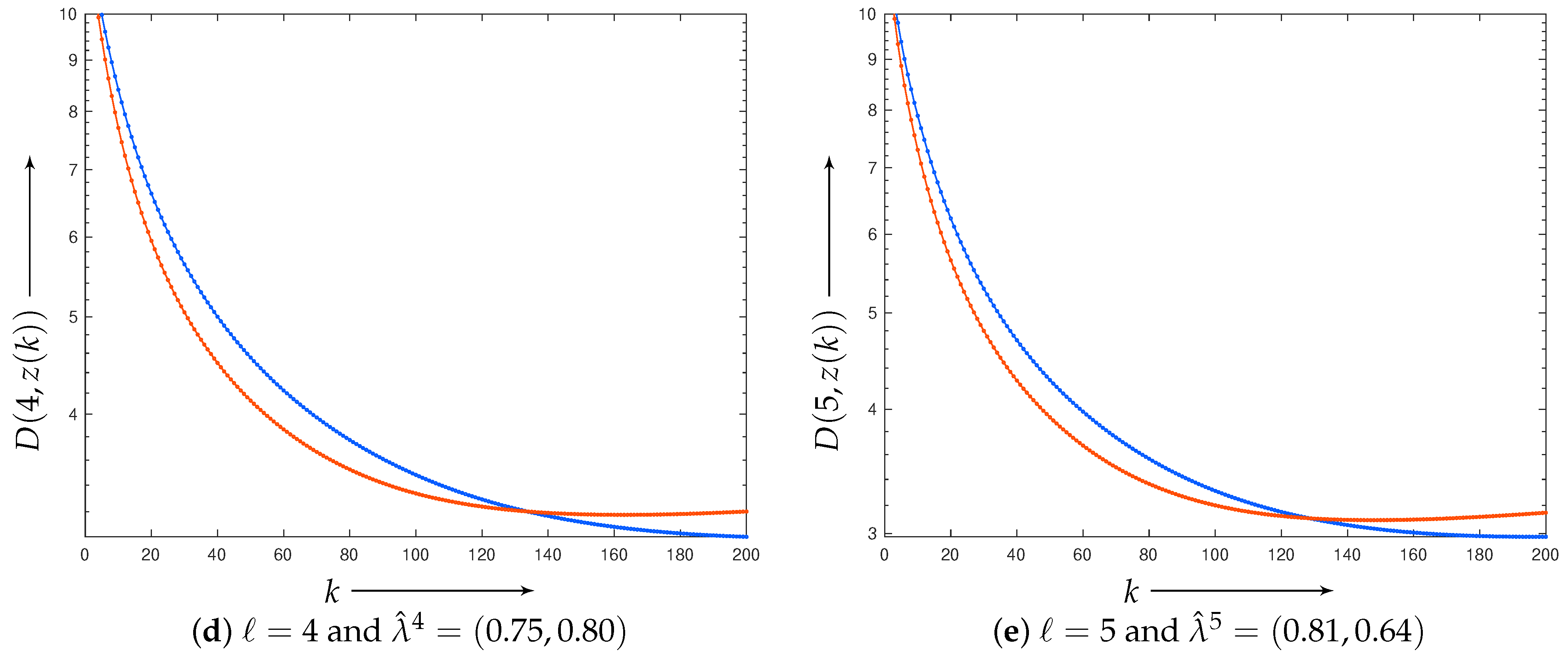
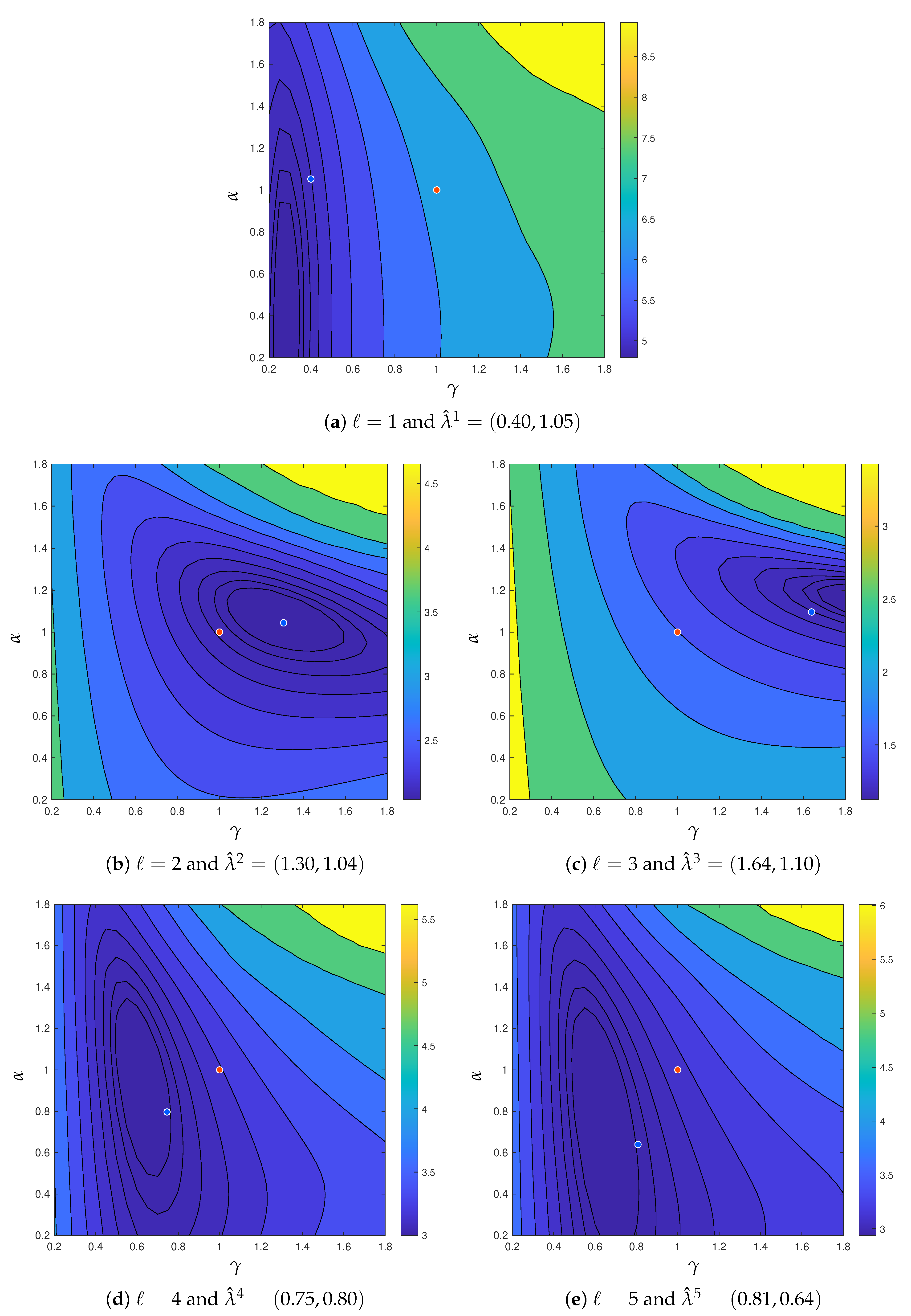
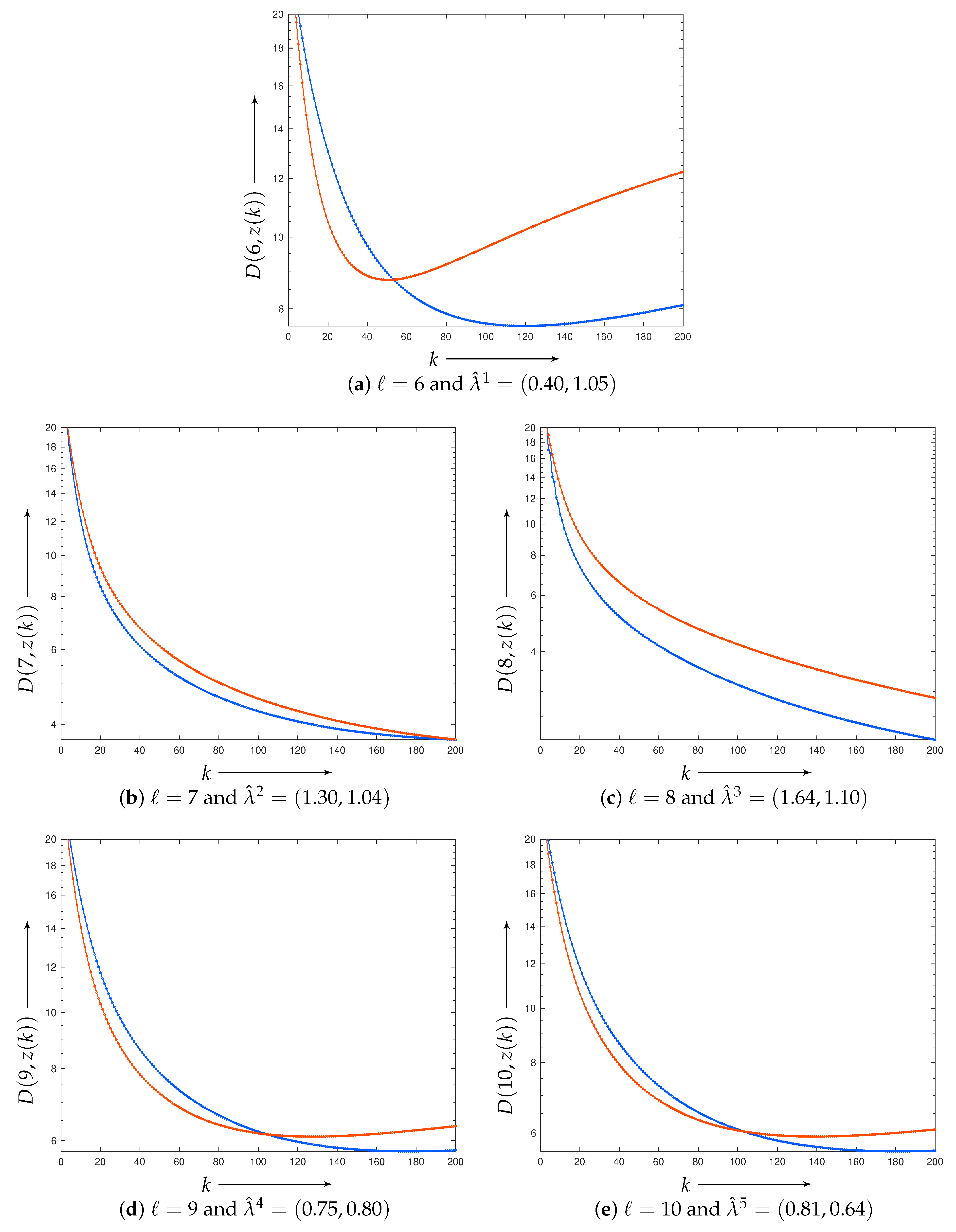
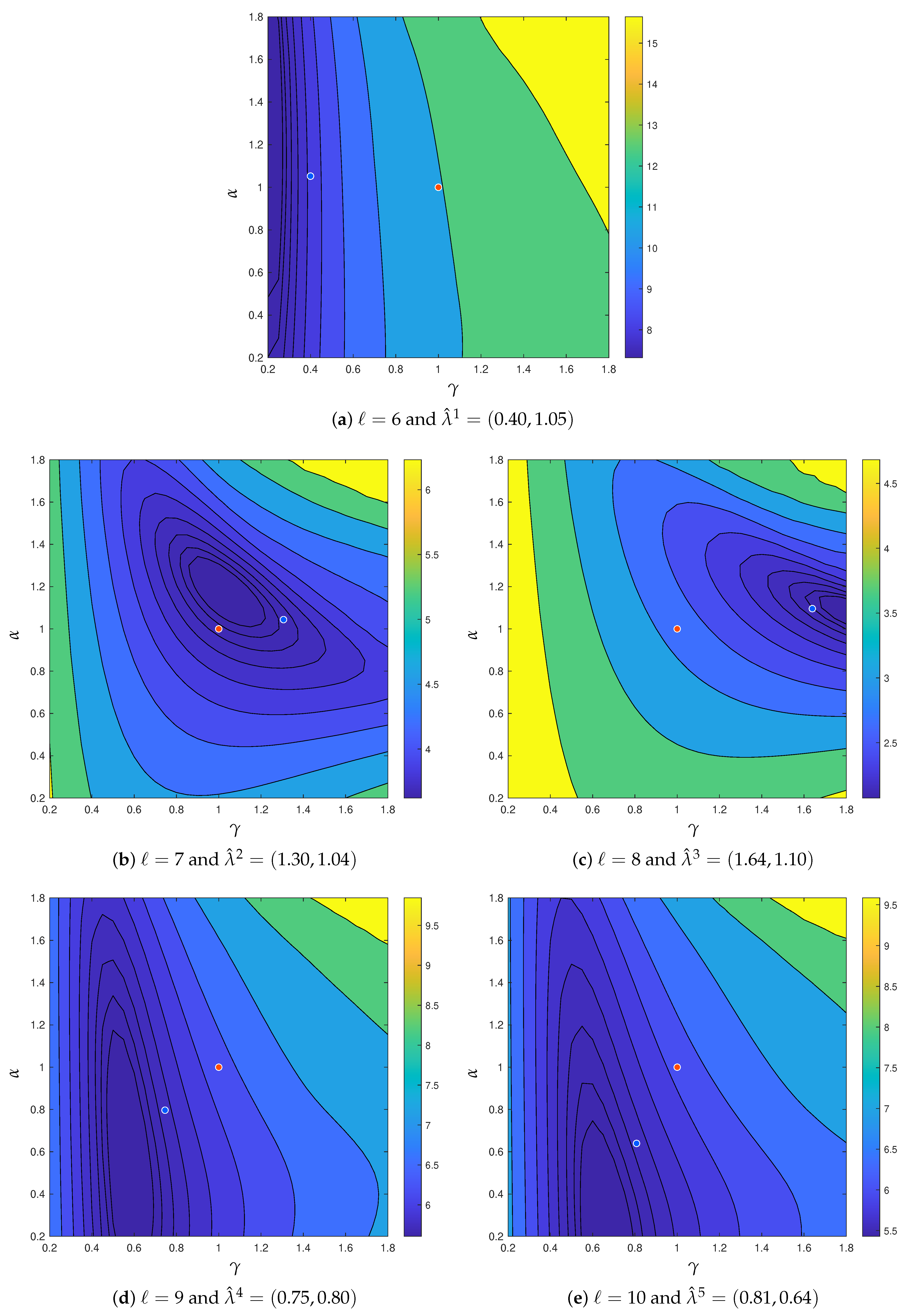
4.1. Results of Learning
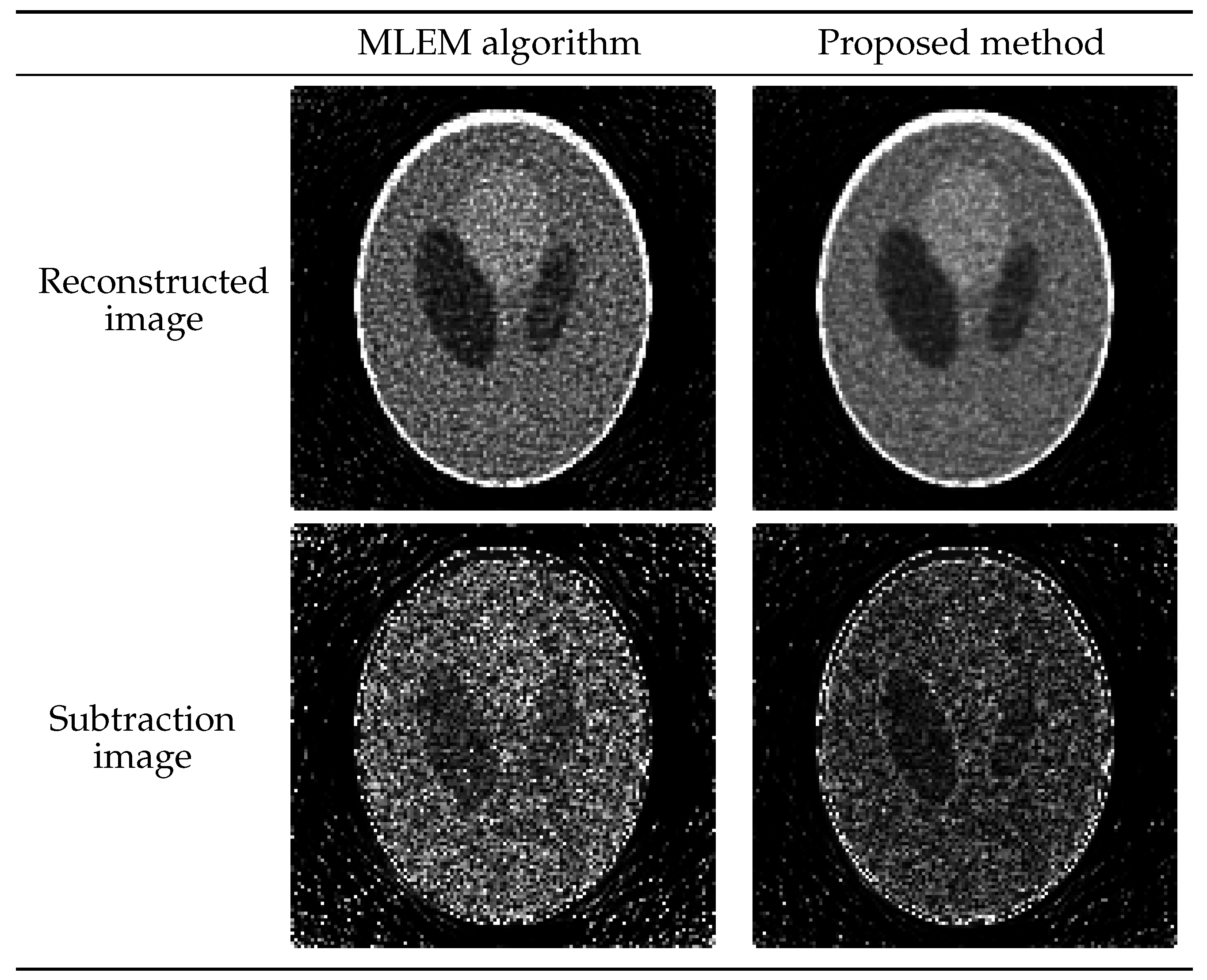
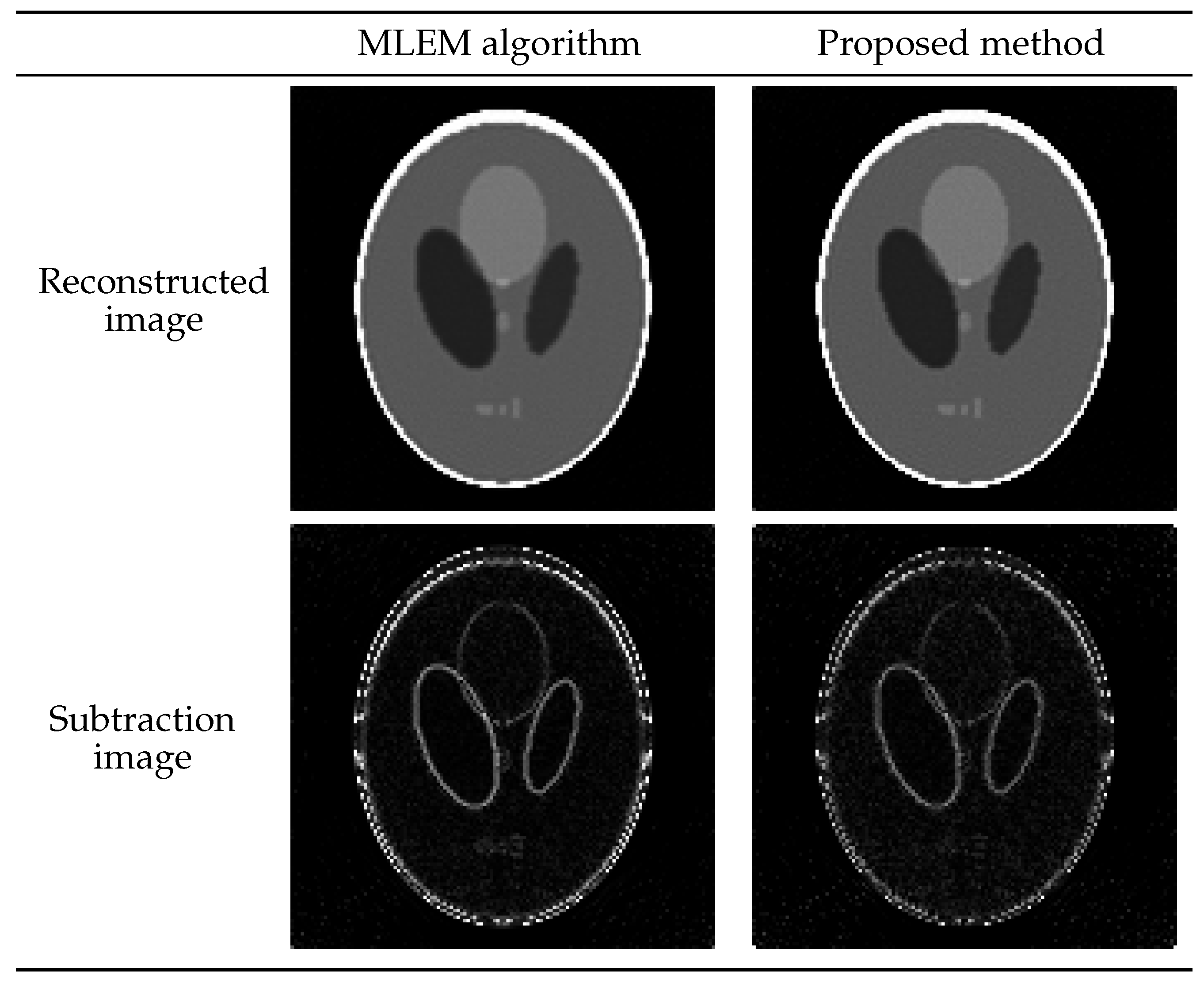
4.2. Application of Estimated Parameters to Reconstruction of Larger Images
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ramachandran, G.N.; Lakshminarayanan, A.V. Three-dimensional reconstruction from radiographs and electron micrographs: Application of convolutions instead of Fourier transforms. Proc. Natl. Acad. Sci. USA 1971, 68, 2236–2240. [Google Scholar] [CrossRef] [PubMed]
- Shepp, L.A.; Vardi, Y. Maximum Likelihood Reconstruction for Emission Tomography. IEEE Trans. Med. Imaging 1982, 1, 113–122. [Google Scholar] [CrossRef] [PubMed]
- Lewitt, R.M. Reconstruction algorithms: Transform methods. Proc. IEEE 1983, 71, 390–408. [Google Scholar] [CrossRef]
- Natterer, F. Computerized tomography. In The Mathematics of Computerized Tomography; Springer: Berlin/Heidelberg, Germany, 1986; pp. 1–8. [Google Scholar]
- Stark, H. Image Recovery: Theory and Application; Academic Press: Washington, DC, USA, 1987. [Google Scholar]
- Hudson, H.M.; Larkin, R.S. Accelerated image reconstruction using ordered subsets of projection data. IEEE Trans. Med. Imaging 1994, 13, 601–609. [Google Scholar] [CrossRef]
- Kak, A.C.; Slaney, M. Principles of Computerized Tomographic Imaging; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2001. [Google Scholar]
- Gordon, R.; Bender, R.; Herman, G.T. Algebraic reconstruction techniques (ART) for three-dimensional electron microscopy and X-ray photography. J. Theor. Biol. 1970, 29, 471–481. [Google Scholar] [CrossRef] [PubMed]
- Badea, C.; Gordon, R. Experiments with the nonlinear and chaotic behaviour of the multiplicative algebraic reconstruction technique (MART) algorithm for computed tomography. Phys. Med. Biol. 2004, 49, 1455. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Liese, F.; Vajda, I. On divergences and informations in statistics and information theory. IEEE Trans. Inf. Theory 2006, 52, 4394–4412. [Google Scholar] [CrossRef]
- Read, T.R.; Cressie, N.A. Goodness-of-Fit Statistics for Discrete Multivariate Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Pardo, L. Statistical Inference Based on Divergence Measures; Chapman and Hall/CRC: New York, NY, USA, 2018. [Google Scholar]
- Pardo, L. New Developments in Statistical Information Theory Based on Entropy and Divergence Measures. Entropy 2019, 21, 391. [Google Scholar] [CrossRef]
- Kasai, R.; Yamaguchi, Y.; Kojima, T.; Abou Al-Ola, O.M.; Yoshinaga, T. Noise-Robust Image Reconstruction Based on Minimizing Extended Class of Power-Divergence Measures. Entropy 2021, 23, 1005. [Google Scholar] [CrossRef]
- Schropp, J. Using dynamical systems methods to solve minimization problems. Appl. Numer. Math. 1995, 18, 321–335. [Google Scholar] [CrossRef]
- Airapetyan, R.G.; Ramm, A.G.; Smirnova, A.B. Continuous analog of gauss-newton method. Math. Model. Methods Appl. Sci. 1999, 9, 463–474. [Google Scholar] [CrossRef]
- Airapetyan, R.G.; Ramm, A.G. Dynamical systems and discrete methods for solving nonlinear ill-posed problems. In Applied Mathematics Reviews; Ga, A., Ed.; World Scientific Publishing Company: Singapore, 2000; Volume 1, pp. 491–536. [Google Scholar]
- Airapetyan, R.G.; Ramm, A.G.; Smirnova, A.B. Continuous methods for solving nonlinear ill-posed problems. In Operator Theory and its Applications; Ag, R., Pn, S., Av, S., Eds.; American Mathematical Society: Providence, RI, USA, 2000; Volume 25, pp. 111–136. [Google Scholar]
- Ramm, A.G. Dynamical systems method for solving operator equations. Commun. Nonlinear Sci. Numer. Simul. 2004, 9, 383–402. [Google Scholar] [CrossRef]
- Li, L.; Han, B. A dynamical system method for solving nonlinear ill-posed problems. Appl. Math. Comput. 2008, 197, 399–406. [Google Scholar] [CrossRef]
- Fujimoto, K.; Abou Al-Ola, O.M.; Yoshinaga, T. Continuous-time image reconstruction using differential equations for computed tomography. Commun. Nonlinear Sci. Numer. Simul. 2010, 15, 1648–1654. [Google Scholar] [CrossRef]
- Abou Al-Ola, O.M.; Fujimoto, K.; Yoshinaga, T. Common Lyapunov function based on Kullback–Leibler divergence for a switched nonlinear system. Math. Probl. Eng. 2011, 2011, 723509. [Google Scholar] [CrossRef]
- Yamaguchi, Y.; Fujimoto, K.; Abou Al-Ola, O.M.; Yoshinaga, T. Continuous-time image reconstruction for binary tomography. Commun. Nonlinear Sci. Numer. Simul. 2013, 18, 2081–2087. [Google Scholar] [CrossRef]
- Tateishi, K.; Yamaguchi, Y.; Abou Al-Ola, O.M.; Yoshinaga, T. Continuous Analog of Accelerated OS-EM Algorithm for Computed Tomography. Math. Probl. Eng. 2017, 2017, 1564123. [Google Scholar] [CrossRef]
- Kasai, R.; Yamaguchi, Y.; Kojima, T.; Yoshinaga, T. Tomographic Image Reconstruction Based on Minimization of Symmetrized Kullback-Leibler Divergence. Math. Probl. Eng. 2018, 2018, 8973131. [Google Scholar] [CrossRef]
- Abou Al-Ola, O.M.; Kasai, R.; Yamaguchi, Y.; Kojima, T.; Yoshinaga, T. Image Reconstruction Algorithm Using Weighted Mean of Ordered-Subsets EM and MART for Computed Tomography. Mathematics 2022, 10, 4277. [Google Scholar] [CrossRef]
- Lyapunov, A.M. The general problem of the stability of motion. Int. J. Control. 1992, 55, 531–534. [Google Scholar] [CrossRef]
- Gregor, K.; LeCun, Y. Learning fast approximations of sparse coding. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 399–406. [Google Scholar]
- Sprechmann, P.; Bronstein, A.M.; Sapiro, G. Learning efficient sparse and low rank models. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1821–1833. [Google Scholar] [CrossRef] [PubMed]
- Xin, B.; Wang, Y.; Gao, W.; Wipf, D.; Wang, B. Maximal sparsity with deep networks? Adv. Neural Inf. Process. Syst. 2016, 29, 4347–4355. [Google Scholar]
- Sun, J.; Li, H.; Xu, Z.; Yang, Y. Deep ADMM-Net for compressive sensing MRI. Adv. Neural Inf. Process. Syst. 2016, 29, 10–18. [Google Scholar]
- Borgerding, M.; Schniter, P.; Rangan, S. AMP-inspired deep networks for sparse linear inverse problems. IEEE Trans. Signal Process. 2017, 65, 4293–4308. [Google Scholar] [CrossRef]
- Zhang, J.; Ghanem, B. ISTA-Net: Interpretable optimization-inspired deep network for image compressive sensing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1828–1837. [Google Scholar]
- Monga, V.; Li, Y.; Eldar, Y.C. Algorithm Unrolling: Interpretable, Efficient Deep Learning for Signal and Image Processing. IEEE Signal Process. Mag. 2021, 38, 18–44. [Google Scholar] [CrossRef]
- Eckstein, J.; Bertsekas, D.P. On the Douglas—Rachford splitting method and the proximal point algorithm for maximal monotone operators. Math. Program. 1992, 55, 293–318. [Google Scholar] [CrossRef]
- Beck, A.; Teboulle, M. A Fast Iterative Shrinkage-Thresholding Algorithm for Linear Inverse Problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- Hochreiter, S.; Bengio, Y.; Frasconi, P.; Schmidhuber, J.; Schmidhuber, J. Gradient Flow in Recurrent Nets: The Difficulty of Learning Long-Term Dependencies; IEEE Press: New York, NY, USA, 2001; pp. 237–243. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Andrychowicz, M.; Denil, M.; Gomez, S.; Hoffman, M.W.; Pfau, D.; Schaul, T.; Shillingford, B.; de Freitas, N. Learning to Learn by Gradient Descent by Gradient Descent. arXiv 2016, arXiv:1606.04474. [Google Scholar] [CrossRef]
- Li, K.; Malik, J. Learning to Optimize. arXiv 2016, arXiv:1606.01885. [Google Scholar] [CrossRef]
- Wichrowska, O.; Maheswaranathan, N.; Hoffman, M.W.; Colmenarejo, S.G.; Denil, M.; de Freitas, N.; Sohl-Dickstein, J. Learned Optimizers that Scale and Generalize. arXiv 2017, arXiv:1703.04813. [Google Scholar] [CrossRef]
- Lv, K.; Jiang, S.; Li, J. Learning Gradient Descent: Better Generalization and Longer Horizons. arXiv 2017, arXiv:1703.03633. [Google Scholar] [CrossRef]
- Bello, I.; Zoph, B.; Vasudevan, V.; Le, Q.V. Neural Optimizer Search with Reinforcement Learning. arXiv 2017, arXiv:1709.07417. [Google Scholar] [CrossRef]
- Metz, L.; Maheswaranathan, N.; Nixon, J.; Freeman, C.D.; Sohl-Dickstein, J. Understanding and correcting pathologies in the training of learned optimizers. arXiv 2018, arXiv:1810.10180. [Google Scholar] [CrossRef]
- Metz, L.; Maheswaranathan, N.; Freeman, C.D.; Poole, B.; Sohl-Dickstein, J. Tasks, stability, architecture, and compute: Training more effective learned optimizers, and using them to train themselves. arXiv 2020, arXiv:2009.11243. [Google Scholar] [CrossRef]
- Maheswaranathan, N.; Sussillo, D.; Metz, L.; Sun, R.; Sohl-Dickstein, J. Reverse engineering learned optimizers reveals known and novel mechanisms. arXiv 2020, arXiv:2011.02159. [Google Scholar] [CrossRef]
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Lustig, M.; Donoho, D.; Pauly, J.M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn. Reson. Med. Off. J. Int. Soc. Magn. Reson. Med. 2007, 58, 1182–1195. [Google Scholar] [CrossRef]
- Zhang, Q.; Ye, X.; Chen, Y. Extra Proximal-Gradient Network with Learned Regularization for Image Compressive Sensing Reconstruction. J. Imaging 2022, 8, 178. [Google Scholar] [CrossRef]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; Volume 87. [Google Scholar]
- Rybaczuk, M.; Kȩdzia, A.; Zieliński, W. The concept of physical and fractal dimension II. The differential calculus in dimensional spaces. Chaos Solitons Fractals 2001, 12, 2537–2552. [Google Scholar] [CrossRef]
- Shepp, L.A.; Logan, B.F. The Fourier reconstruction of a head section. IEEE Trans. Nucl. Sci. 1974, 21, 21–43. [Google Scholar] [CrossRef]
- Create Head Phantom Image—MATLAB phantom—MathWorks. Available online: https://www.mathworks.com/help/images/ref/phantom.html (accessed on 12 December 2022).
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Group | Oval Numbers | Intensity | Minor Axis Length | Major Axis Length | Horizontal Position | Vertical Position | Angle of Rotation |
|---|---|---|---|---|---|---|---|
| 1 | #1, #2 | * | * | ||||
| 2 | #3, #4, #5 | ||||||
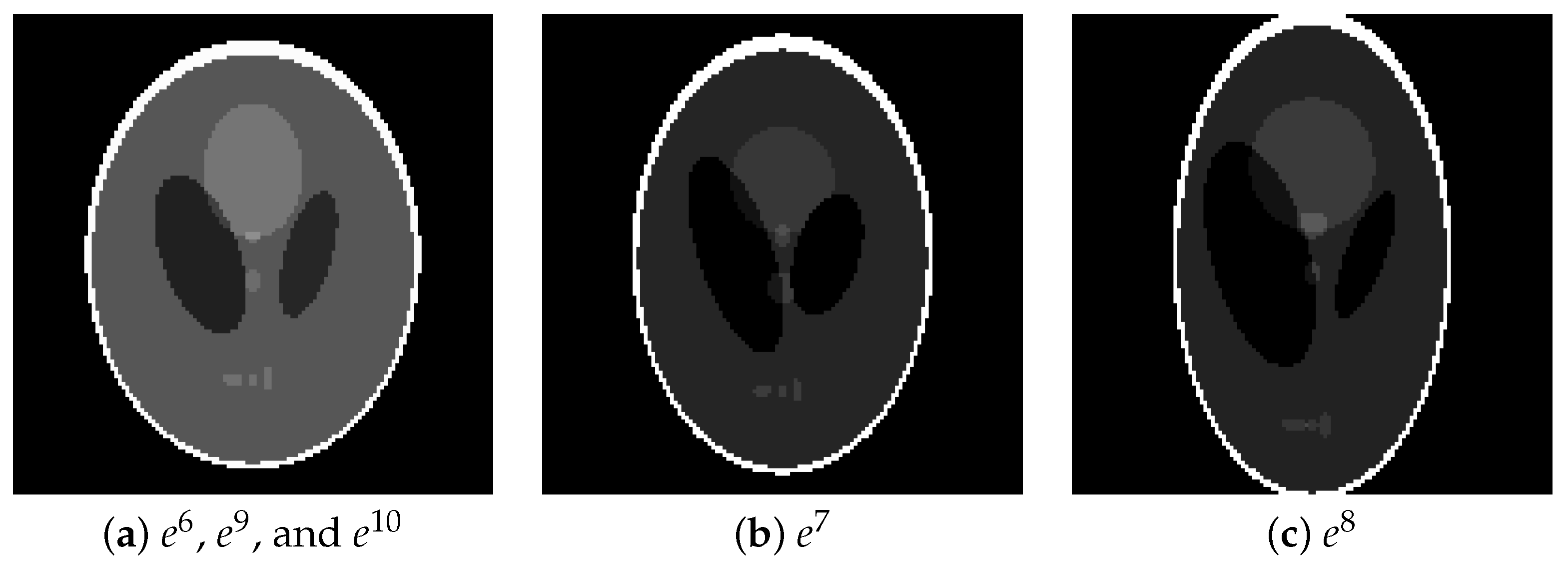
| 3 | #6, #7 | ||||||
| 4 | #8, #9, #10 | * | * | * | * | * |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kojima, T.; Yoshinaga, T. Iterative Image Reconstruction Algorithm with Parameter Estimation by Neural Network for Computed Tomography. Algorithms 2023, 16, 60. https://doi.org/10.3390/a16010060
Kojima T, Yoshinaga T. Iterative Image Reconstruction Algorithm with Parameter Estimation by Neural Network for Computed Tomography. Algorithms. 2023; 16(1):60. https://doi.org/10.3390/a16010060
Chicago/Turabian StyleKojima, Takeshi, and Tetsuya Yoshinaga. 2023. "Iterative Image Reconstruction Algorithm with Parameter Estimation by Neural Network for Computed Tomography" Algorithms 16, no. 1: 60. https://doi.org/10.3390/a16010060
APA StyleKojima, T., & Yoshinaga, T. (2023). Iterative Image Reconstruction Algorithm with Parameter Estimation by Neural Network for Computed Tomography. Algorithms, 16(1), 60. https://doi.org/10.3390/a16010060