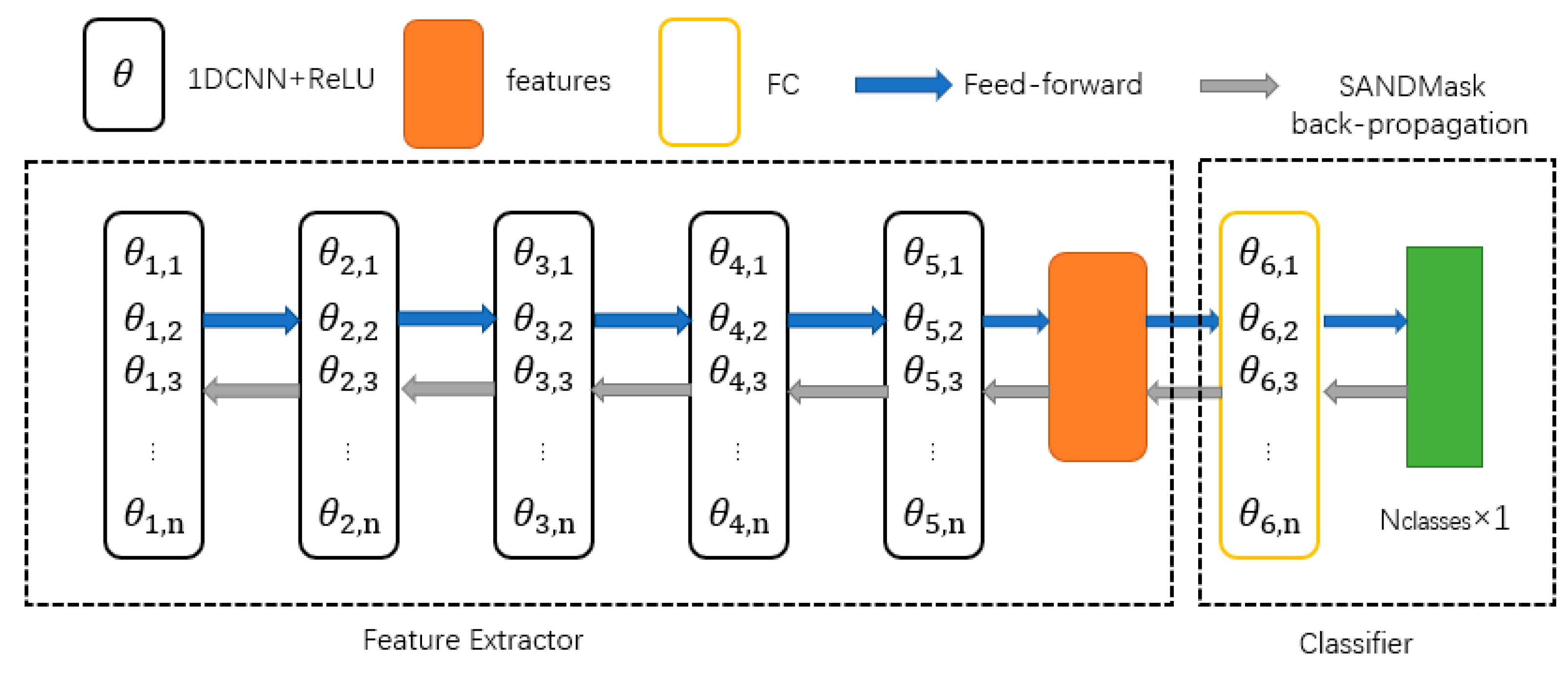
3.2.1. Experimental Comparison with Other Generalization Methods in Recent Years
In recent years, there have been a number of approaches for domain generalization, including IB_IRM [
32] (Information bottleneck—invariant risk minimization) and IB_ERM [
32] (information bottleneck—empirical risk minimization), IRM [
33] (invariant risk minimization), Fishr [
34] (a new regularization named Fishr), and RSC [
35] (representation). By comparing the DCNG model proposed in this paper with other generalization methods, the effectiveness of DCNG model compared with other generalization methods in the field of fault diagnosis is illustrated.
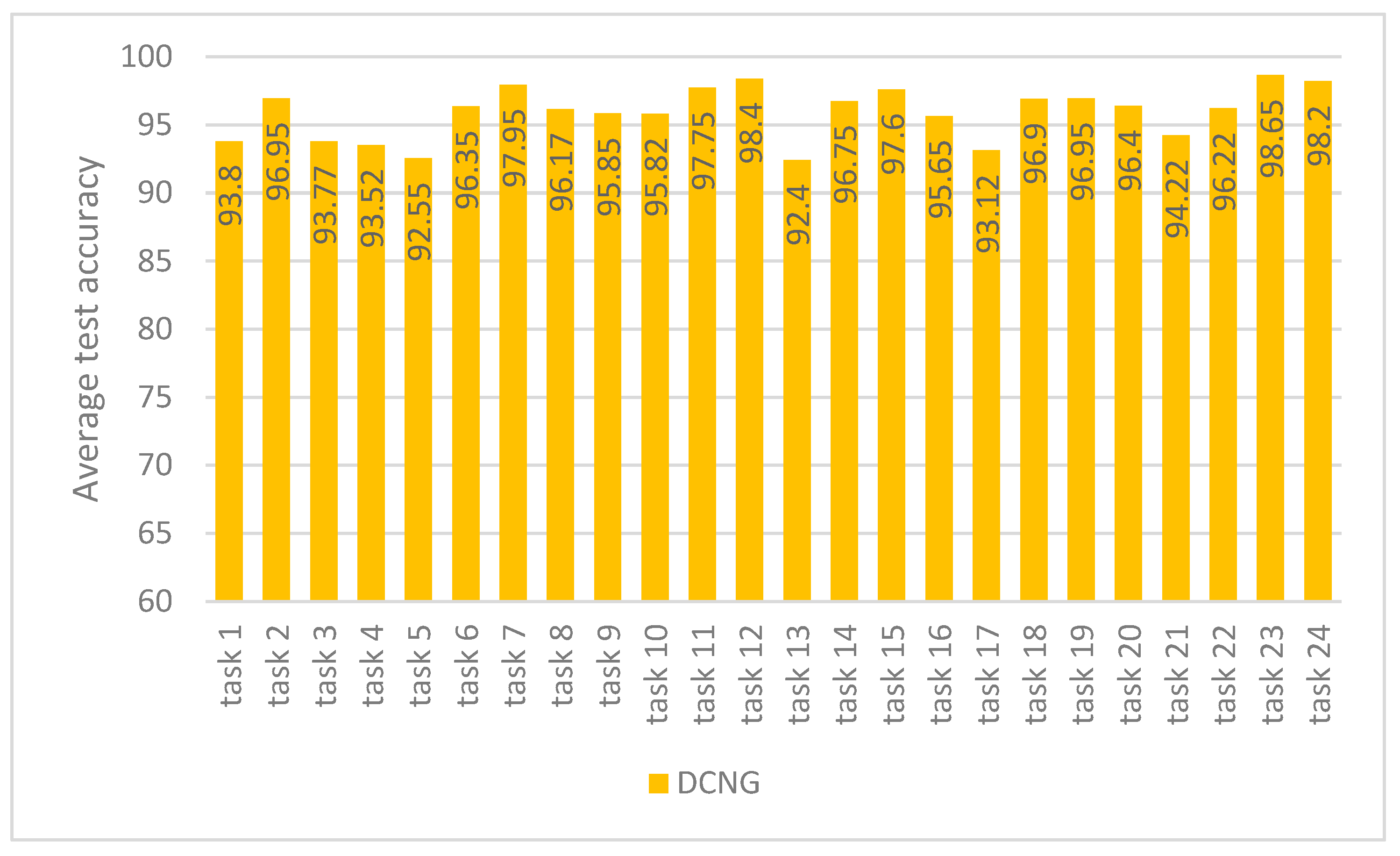
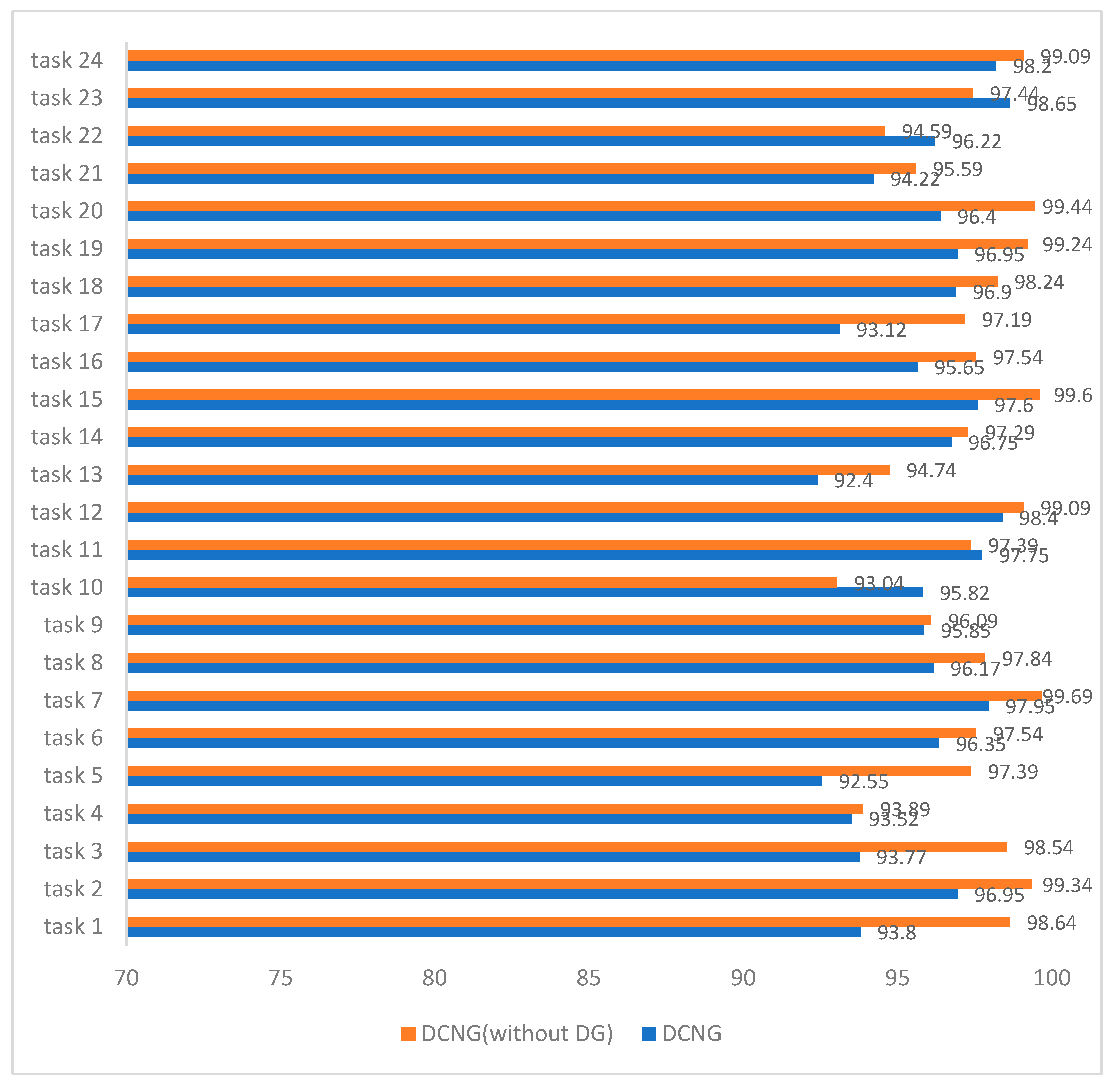
Figure 4 shows the results of DCNG on 24 transfer tasks in the CWRU dataset. It can be seen from the figure that the highest classification result is 98.65% on task 23 and the lowest classification result is 92.4% on task 13, with a 6.25% difference between them. NCNG performed above 92% on all transfer tasks.
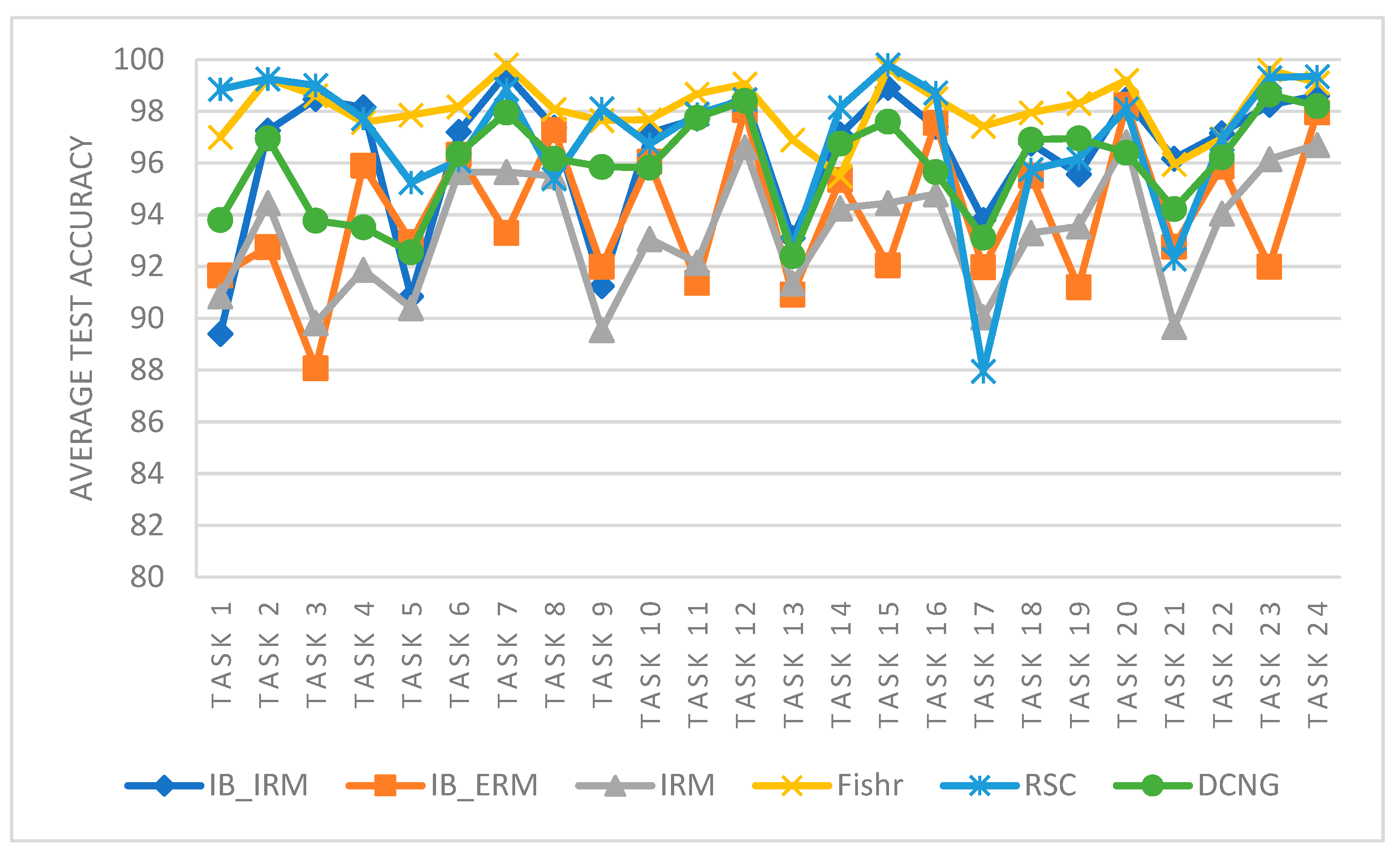
The performance of different generalization methods is analyzed from the perspective of a single task. As shown in
Figure 5, the transfer performance of IB_IRM, IB_ERM, and IRM methods is lower than that of Fishr, RSC, and DCNG methods on a single task. For RSC and DCNG methods, the overall transfer result of RSC is higher than that of DCNG. However, in some transfer tasks, such as task 17, the performance of Fishr is lower than that of theDCNG method, and in the overall transfer tasks, the performance of Fishr is better than that of the DCNG model. The specific significance of the tasks is shown in
Table 2.
The performance of different generalization methods was analyzed from the perspective of the entire task. IB_IRM, IB_ERM, and IRM methods fluctuated greatly in each transfer task, especially in the odd transfer task. The Fishr method was the most stable and superior for the DCNG model. Although RSC performs better than the DCNG model on some transfer tasks, the results varied greatly between tasks and are not as stable as the DCNG model.
- 2.
Compared with other generalization methods on the MFPT data set
Compared with the CWRU data set, there were 90 transfer tasks on the MFPT data set, and the MFPT data set had larger variations in working conditions, which was conducive for exploring the influence of a single condition on the generalization method in the scenario of changing working conditions.
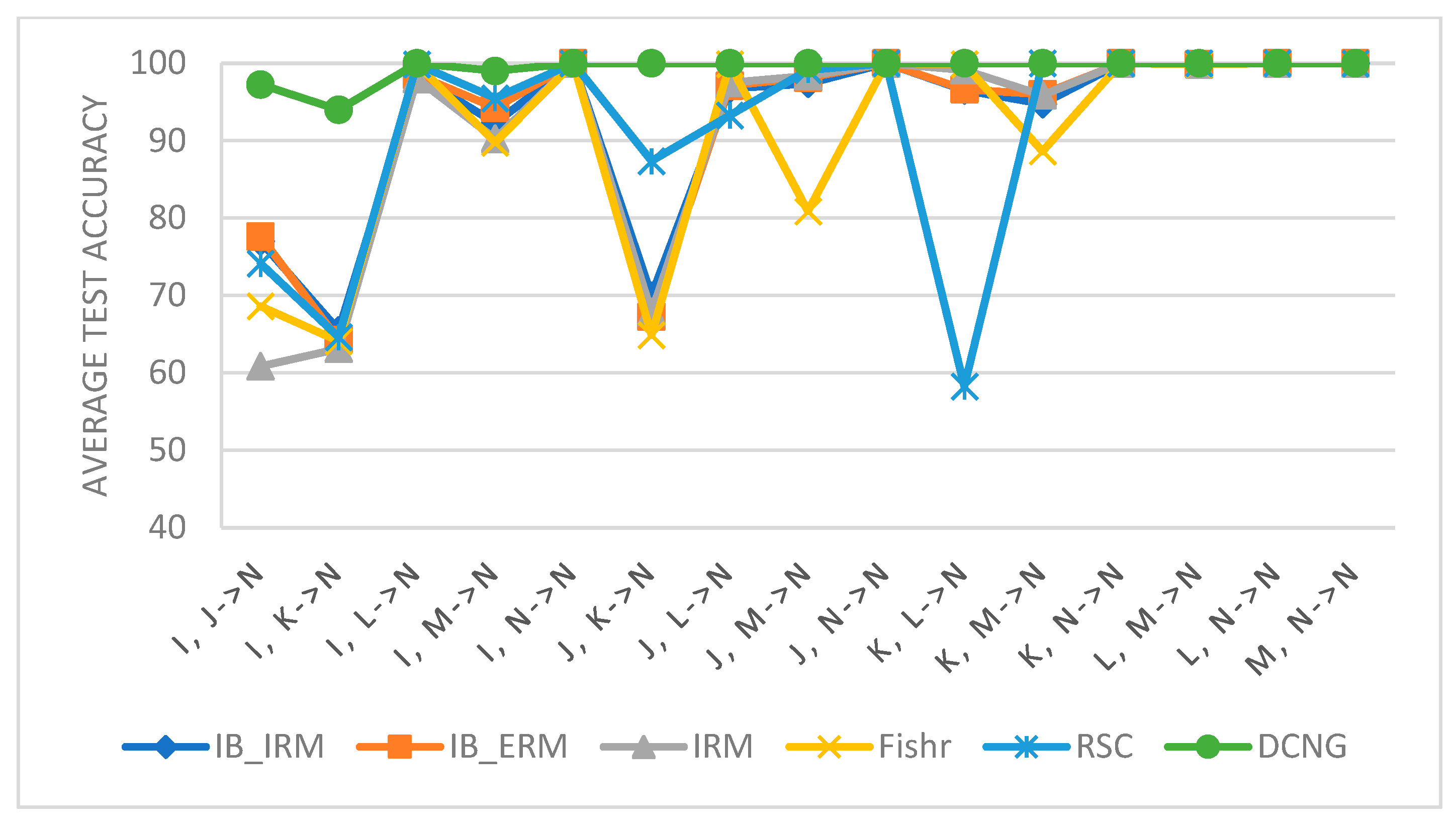
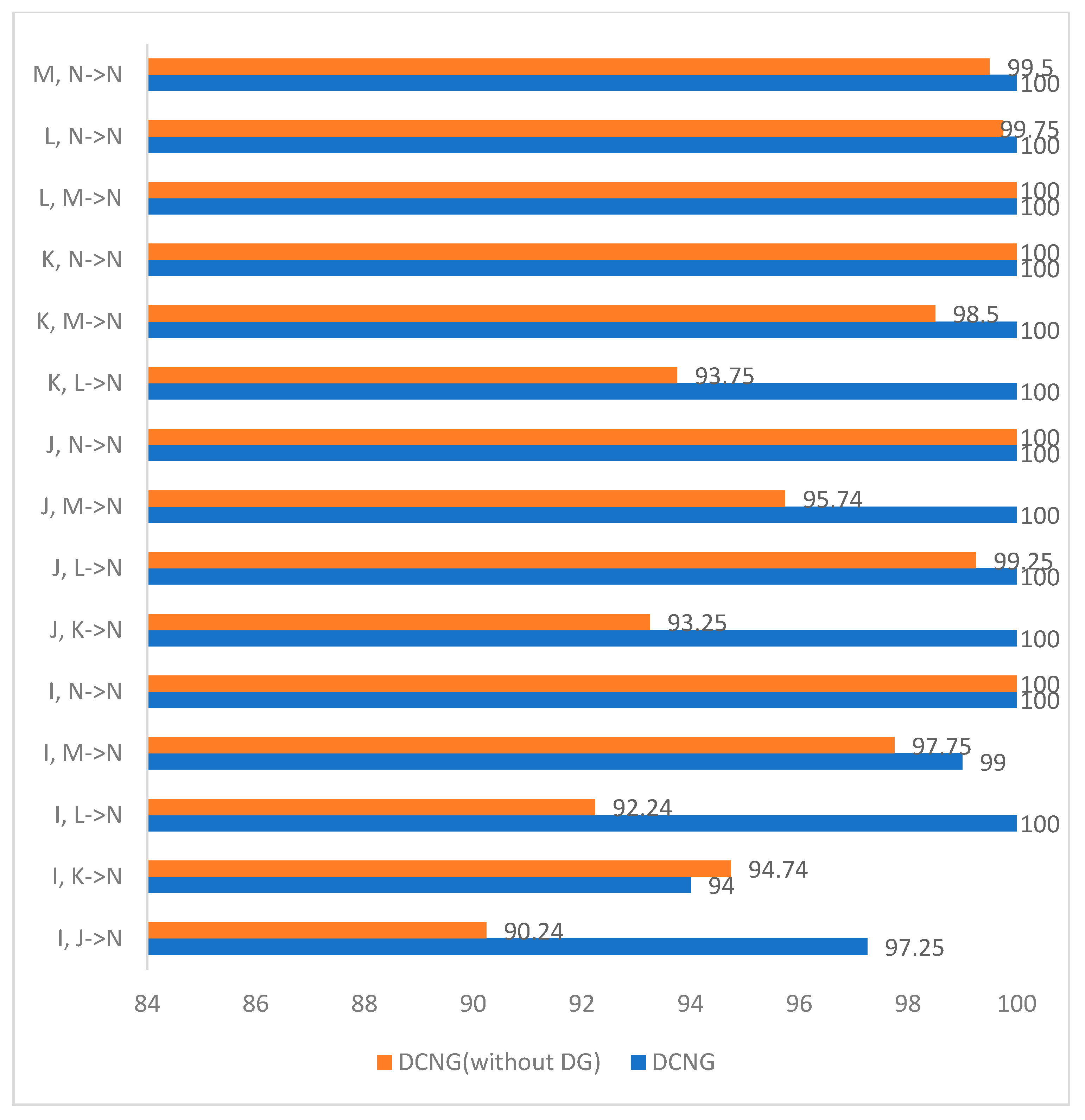
Table 3 shows the results of DCNG model on 90 transfer tasks of MFPT data set. The average result of DCNG model on the transfer task of condition with target domain N is 99.35%, and the lowest result is 94% on the transfer task I, K-> N. Although the DCNG model achieved good results on different transfer tasks. However, when the “distance” of working conditions increased, transfer performance fluctuated.
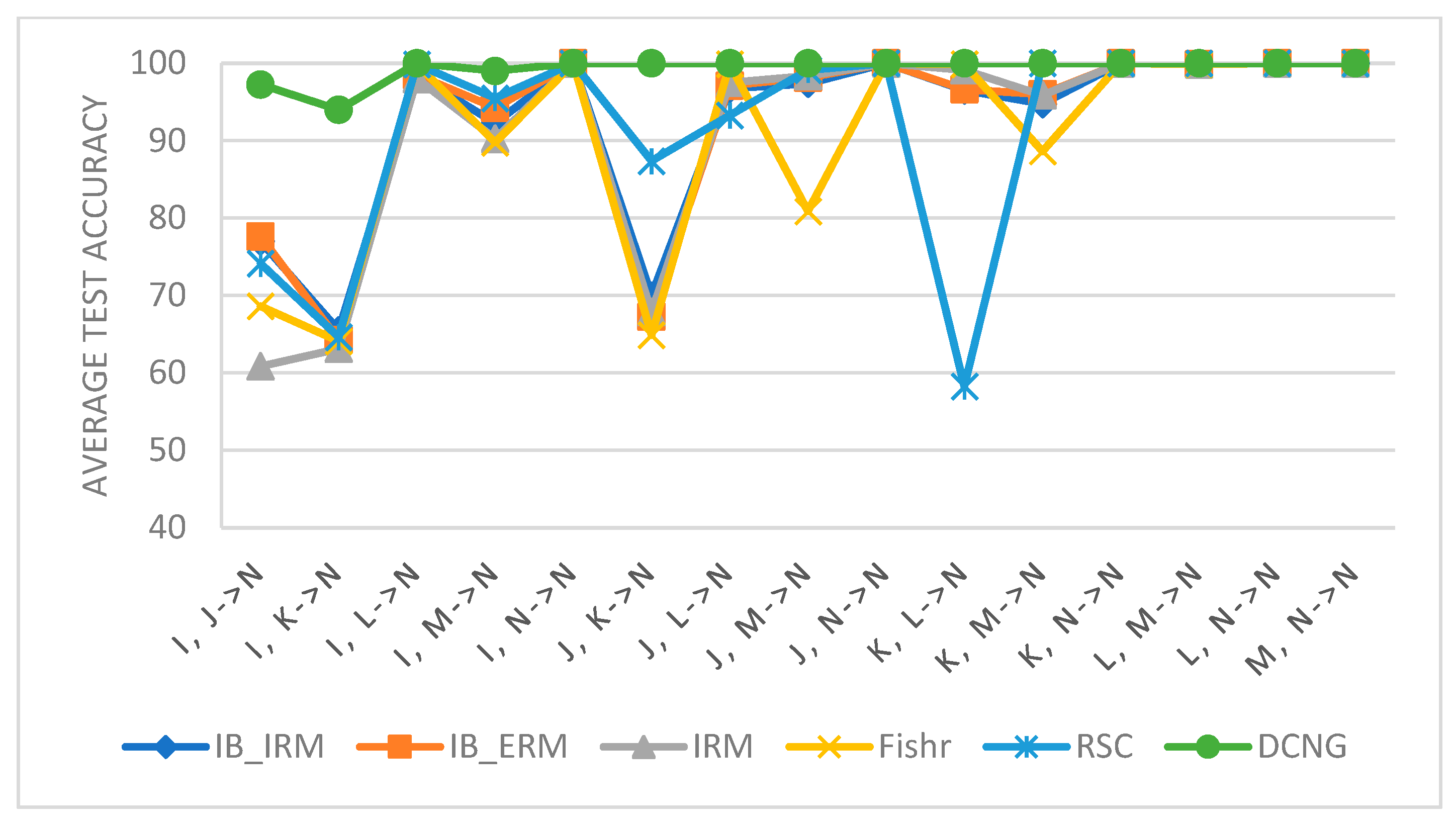
As shown in
Figure 6, the results of different generalization methods are almost the same for other tasks outside the target domain N; thus, only results of the condition transfer task with the target domain N are displayed. It can be seen from
Figure 6 that the performance of IB_IRM, IB_ERM, IRM, and other methods is higher than that of I, J -> N, I, K -> N, and J, K -> N. In addition, these tasks all belong to tasks that do not contain condition N in the source domain and directly generalize condition N. The transfer results on these tasks indicate that IB_IRM, IB_ERM, and IRM methods have poor generalization performance in conditions with large “distance”.
For the DCNG model, although generalization performance fluctuates in the conditions with large “distance”, it has little impact on the transfer performance of the model on the overall task, so the DCNG model has better generalization performance compared with other generalization methods.
- 3.
Compared with other generalization methods on the KAT data set
In the KAT data set, there are four working conditions and a total of 24 transfer tasks. The performance of different generalization methods will be tested on 24 transfer tasks, as shown in
Table 4.
Different from CWRU and MFPT datasets, KAT datasets have more operating conditions than the other two datasets, and the changes between working conditions are more complex and difficult to transfer. Transfer performance on KAT datasets can better reflect the size of model generalization abilities.
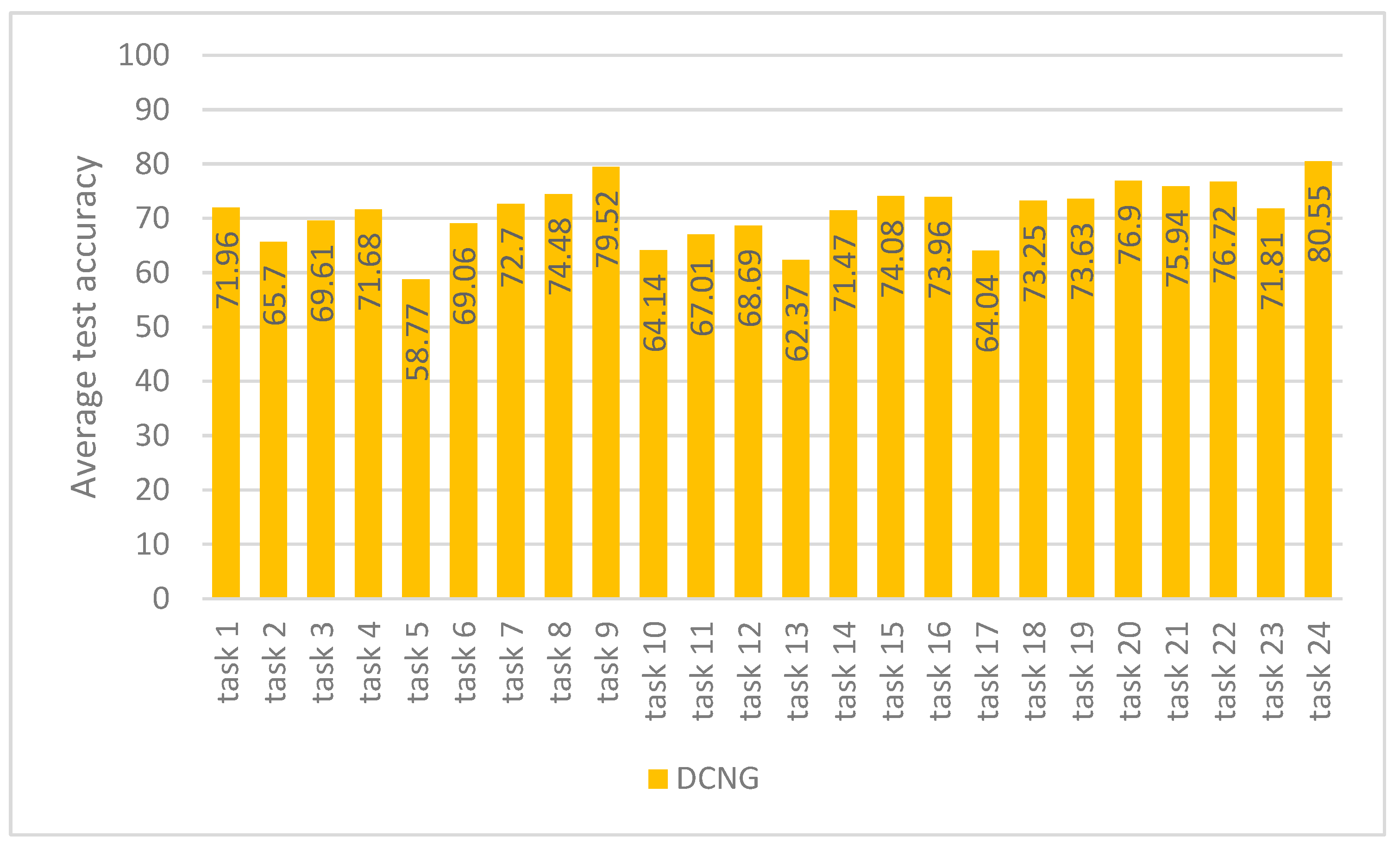
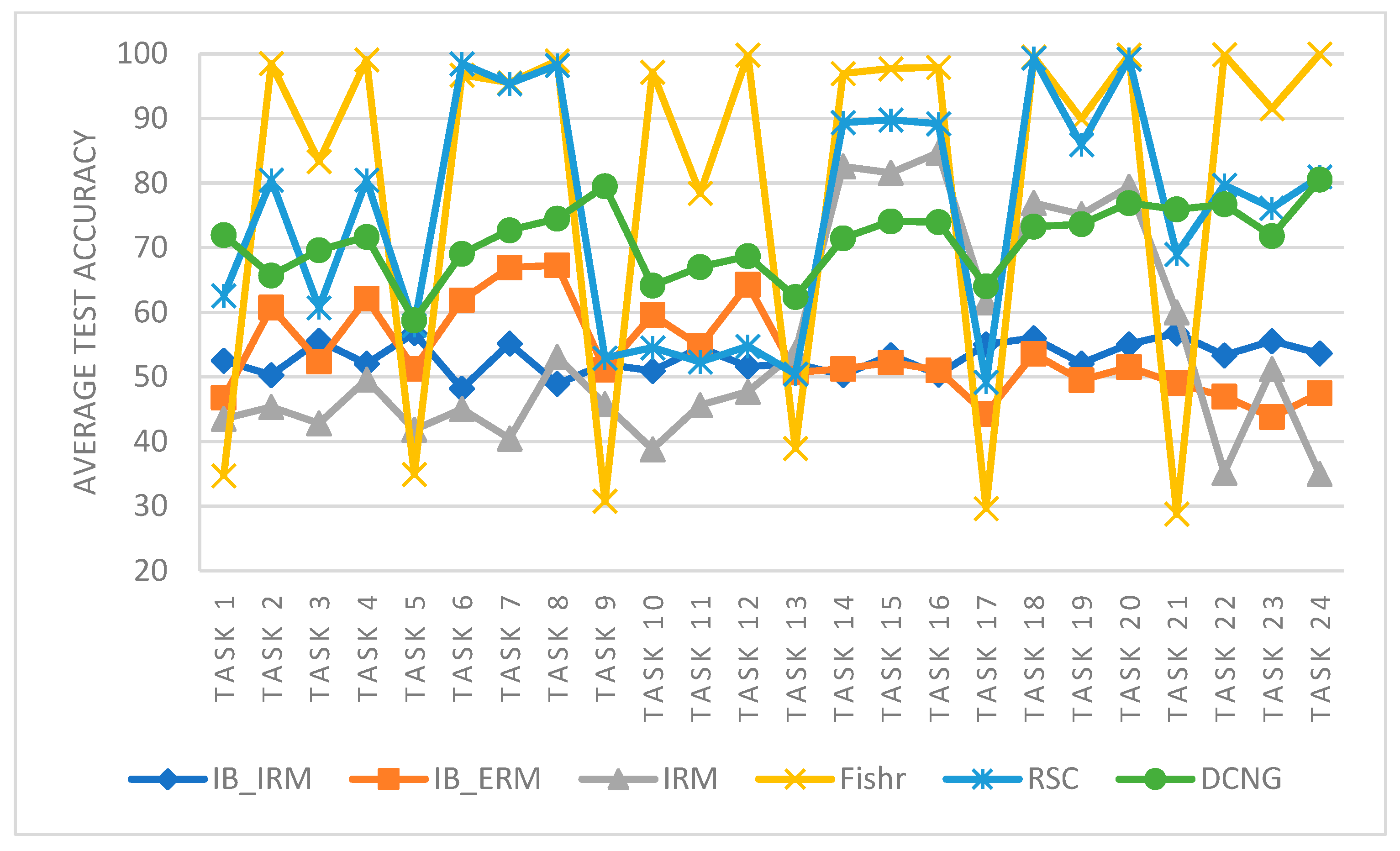
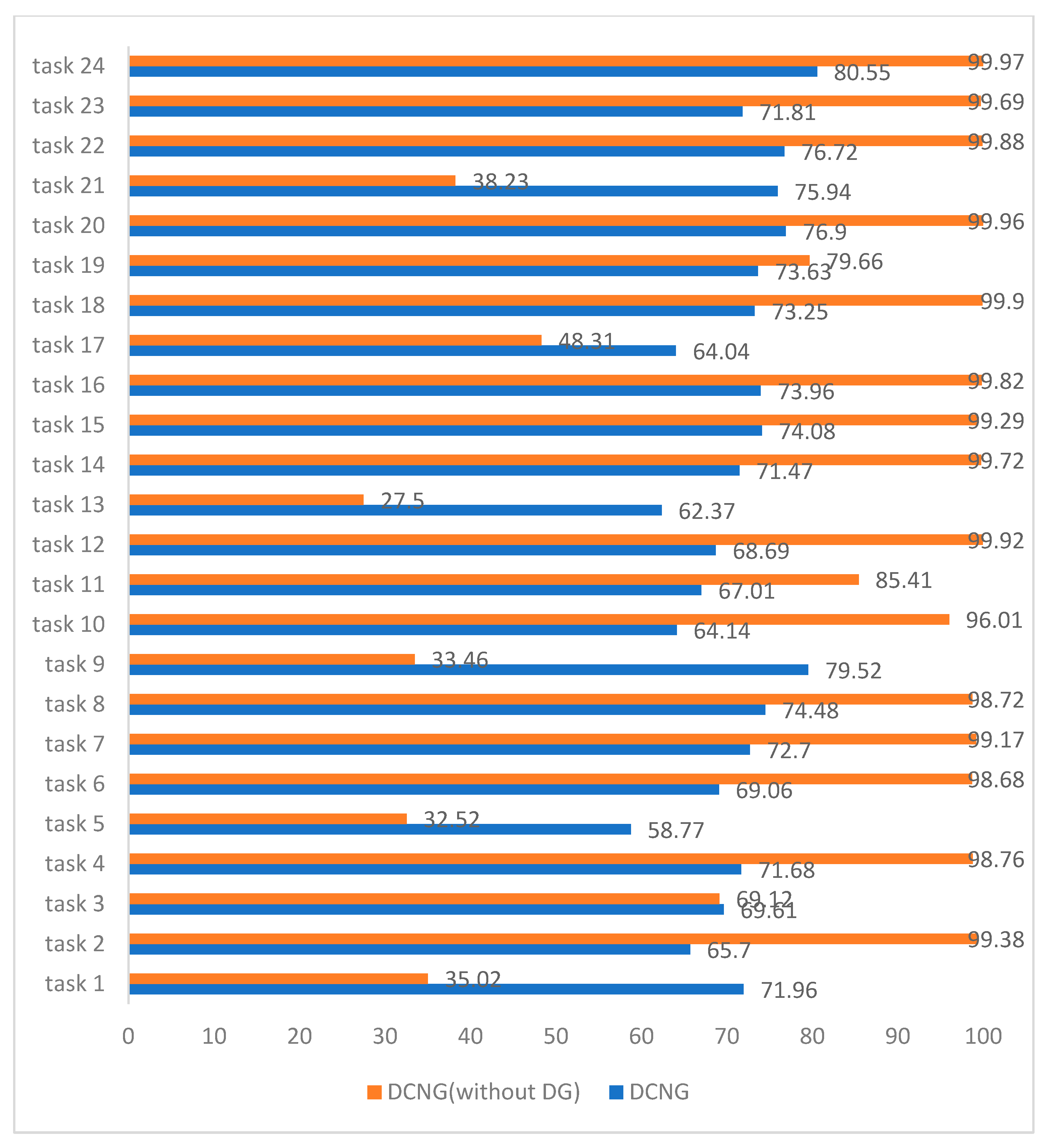
Figure 7 shows that the results of DCNG on 24 transfer tasks of the KAT data set. The highest transfer result is 80.55% on task 24 and the lowest transfer result is 58.77% on task 5, with a difference of 21.78%. The results on other tasks are all above 62%.
The average result of DCNG on the overall transfer task is 71.16%. When the “distance” of working conditions changes, it has little influence on the transfer performance of DCNG model, which is better than other generalization methods.
From the perspective of transfer performance of a single task, the variation range of Fishr, IRM, and RSC methods is larger than the other three methods, and the results of different transfer tasks are not stable, As shown in
Figure 8. For IB_ERM and IB_IRM, the fluctuation range is small, but the overall transfer result is too low, and the result is about 50%. The DCNG method overcomes the instability of Fishr, IRM, and RSC methods, and it improves the transfer result of IB_ERM and IB_IRM methods, which has more application advantages in practical scenarios.
3.2.2. Influence of Different Parameter Settings on DCNG Model
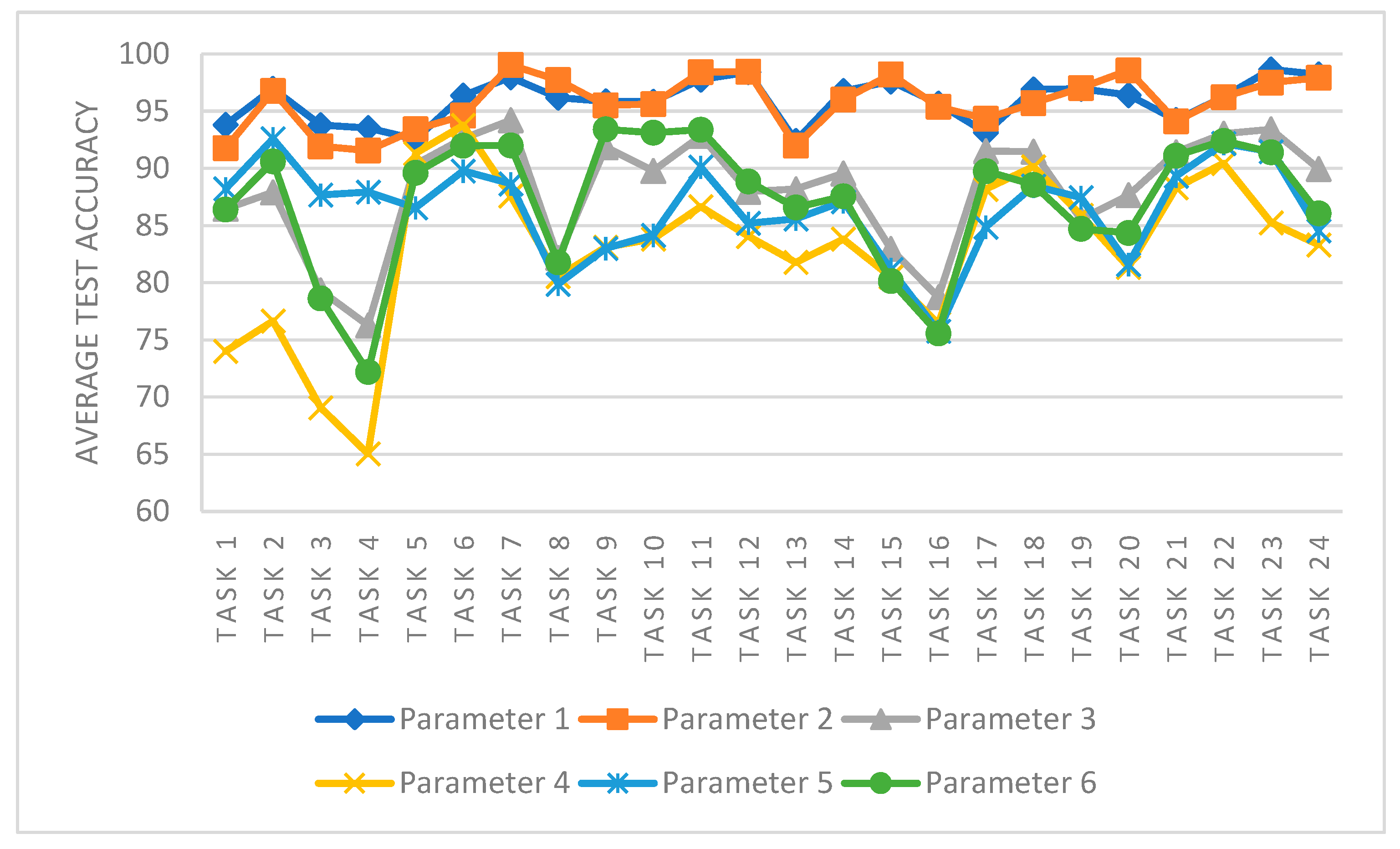
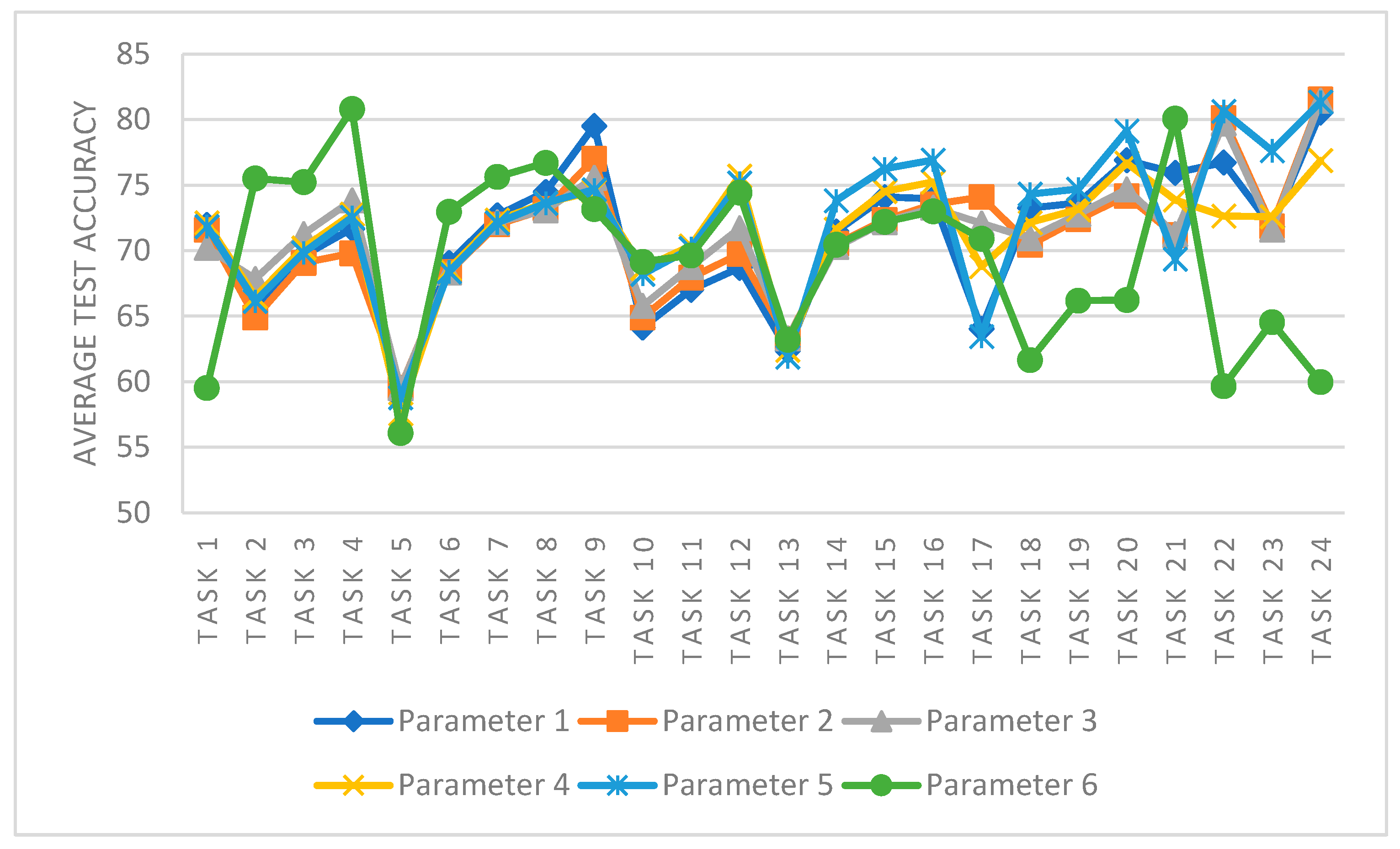
As shown in
Figure 9, the performance of DCNG model in the CWRU data set under different parameter settings is shown in
Table 5. From the perspective of different tasks, even in the same task, different parameter settings will affect the transfer performance of DCNG model. When
values of parameters 1, 2, 5, and 6 increase and
values remain constant, the DCNG model’s effect on the transfer task decreases and the larger
value increases, which is more obvious on task 1 and task 4. The value of
increases and the value of
remains constant in the settings of parameter 3 and parameter 4 and the performance of transfer decreases gradually, which is more obvious in the first 15 transfer tasks.
From the observation of the entire transfer task, it can be analyzed that with an increase in and values, the transfer results of DCNG model in the entire CWRU data set fluctuated more and more, and the stability of the model became worse. The optimal model parameters are .
- 2.
Influence of different parameters on the DCNG model in the MFPT data set
Figure 10 shows the performance of DCNG model under different parameter settings on the MFPT dataset. Since both CWRU and MFPT datasets belong to the scenario where the working condition changes due to a single condition, the influence of parameter ρ is not as great as that of the
τ value. Therefore, for the
ρ value, we selected the optimal value in the CWRU data set and the specific parameter settings are shown in
Table 6. With the increase in
τ, the transfer performance on a single transfer task begins to decrease. From I, J -> N and I, K -> N, the transfer results of N and other tasks can still be analyzed, and it can be concluded that the difficulty of transfers will increase with the increase in the “distance” of working conditions and the performance of the transfer task with the large “distance” of working conditions is an important basis to investigate the model’s generalization ability.
It can be observed from the entire transfer task that the DCNG model “wobbles” in the transfer task with the increase in τ value, and the generalization ability of DCNG model decreases. The optimal parameters are ρ = 100.0 and τ = 0.4.
- 3.
Influence of different parameters on DCNG model in KAT data set
Figure 11 shows the performance of the DCNG model under different parameter settings on the KAT data set, As shown in
Table 7. It can be directly observed from the figure that the transfer performance of DCNG model in KAT transfer task is lower than that of the CWRU data set and MFPT data set, and the degree of “jitter” is more severe than that of the two data sets. The results show that the scenarios with multiple conditions leading to the change of working conditions are more complex and more difficult to transfer than those with single conditions.
τ values of parameters 1, 4, 5, and 6 increase while
ρ values remain constant, and the performance of the model decreases in different degrees for each transfer task. The values of
ρ in parameters 1, 2, and 3 increase continuously, while
τ remains constant. The performance of the DCNG model on transfer task does not change significantly.
Observed from the entire transfer task, the results of DCNG model varied roughly between 55 and 80%. There was a large performance gap between different transfer tasks, indicating that the change of “distance” between working conditions was more complex and challenging for the generalization ability of the model in the scenario where multiple conditions led to a change in working conditions. The optimal parameters of DCNG model on KAT data set are ρ = 100.0 and τ = 0.6.
3.2.3. Compared with the Model without SAND Mask
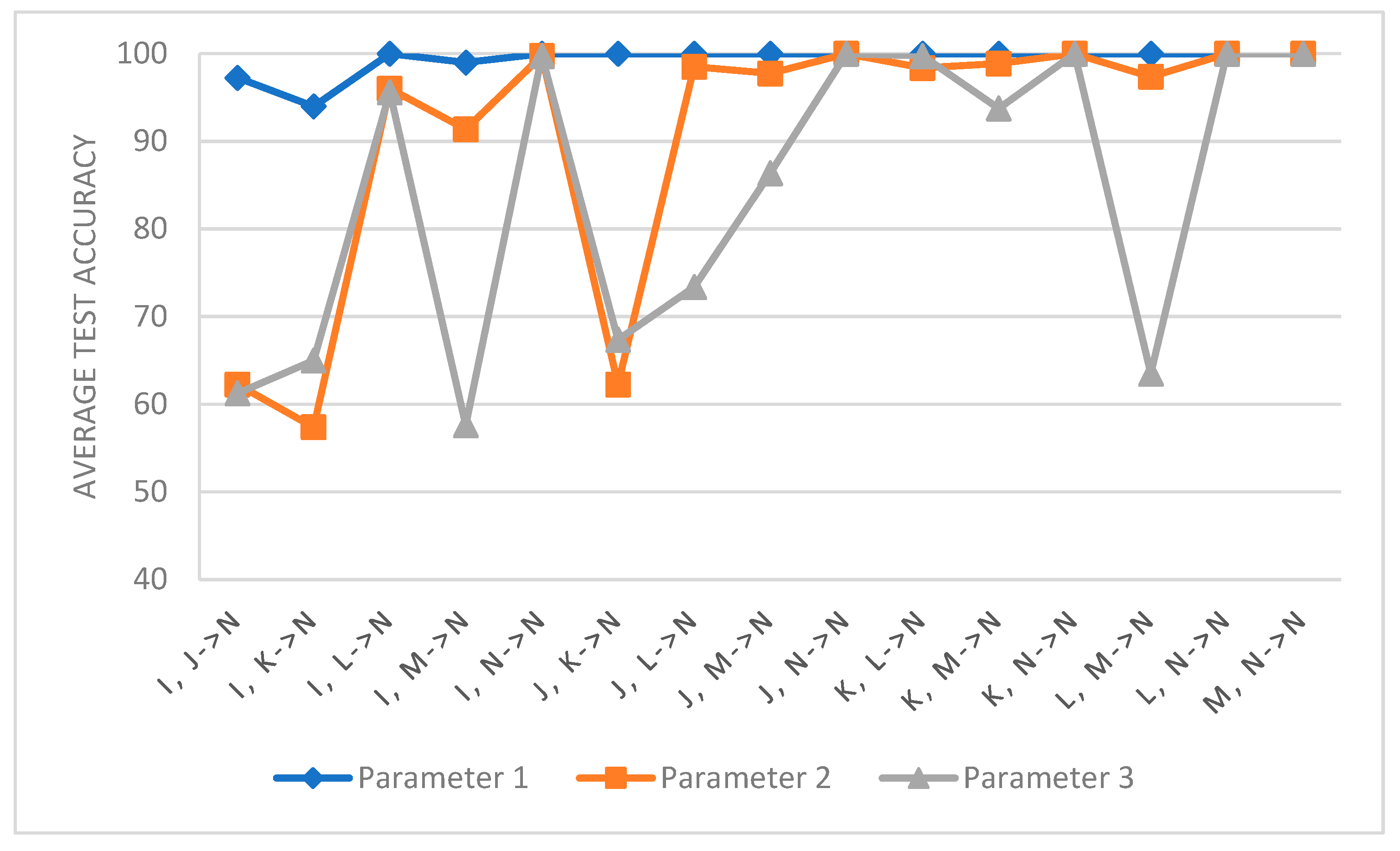
Figure 12 shows the comparison between the generalized model DCNG and the ungeneralized model on the CWRU data set, where the ungeneralized model represents the same network structure as the model DCNG but without generalization measure SAND-Mask. The average transfer result of the ungeneralized model on the entire transfer task is 97.43%, the highest transfer result on task 7 is 99.69%, and the lowest transfer result on task 10 is 93.04%. The average transfer result of the generalized model DCNG on the overall transfer task was 95.91%, the highest transfer result on task 23 was 98.65%, and the lowest transfer result on task 13 was 92.4%.
The average transfer performance of the ungeneralized model is 1.52% higher than that of the DCNG model, indicating that the smaller “distance” between the working conditions is easier to generalize in the scenario where the single condition causes a change in working conditions and the DCNG model has a good generalization effect on the CWRU data set.
- 2.
Compare the generalized model DCNG and the ungeneralized model on the MFPT data set
The DCNG model without generalization measures was compared with the generalized model, and the results of the DCNG model without generalization measures on the MFPT dataset are shown in
Table 8.
Figure 13 shows the comparison between the results of the generalized model DCNG and the ungeneralized model on 15 transfer tasks with N working conditions as the target domain in the MFPT dataset. The results of the ungeneralized model on the transfer task with N working conditions as the target domain are quite different from those of the DCNG model, so we only compare the results on the migration task with N working conditions as the target domain. The average result of the ungeneralized model on 15 transfer tasks is 96.98%, while the average result of the generalized model on 15 transfer tasks is 99.35%.
There is a 2.37% difference between the average transfer results of the generalized model and the ungeneralized model. Relatively speaking, the performance of the ungeneralized model fluctuates greatly in the transfer task with N conditions as the target domain, and the model is greatly affected by the “distance” of conditions.
The stability of the model on MFPT data set is lower than that on the CWRU data set, indicating that the “distance” of operating conditions increases when operating conditions change, and the direct generalization of operating conditions in the target domain cannot meet actual requirements.
- 3.
Compare the generalized model DCNG and the ungeneralized model on the KAT data set
Figure 14 shows the comparison between the results of the generalized model DCNG and the ungeneralized model in 24 transfer tasks of KAT data set. The average result of the ungeneralized model on the overall transfer task was 80.75%, among which the transfer result on task 24 was 99.97%, and the transfer result on task 13 was 27.5%, with a difference of 72.47%. The average transfer result of the generalized model DCNG on the overall transfer task was 71.16%, the highest transfer result on task 24 was 80.55%, and the lowest transfer result on task 5 was 58.77%, with a 21.78% difference between them. Although the effect of the ungeneralized model on some transfer tasks is higher than that of the generalized model DCNG, the effect of the ungeneralized model on different transfer tasks is not balanced, and the maximum gap can reach 72.47%. In a sense, the ungeneralized model is invalid in some transfer tasks.
According to the performance of the generalization model on each transfer task in
Figure 14, it can be found that the transfer effect on task 1, task 3, task 5, task 9, task 13, task 17, and task 21 is worse than other tasks. From
Table 4, we found that the task’s working condition of the target domain of migration is E; from a physical sense, E’s speed change is larger than that of the other conditions and the ungeneralized model is almost ineffectual for these tasks. Although the transfer effect of the generalized model DCNG on the KAT data set does not reach more than 80%, the DCNG model has good stability and is less affected by the change of working conditions; thus, it has a very promising prospect for engineering applications in practical scenarios.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}