For large sparse graphs with millions, or billions, of nodes, learning the exact spectrum using eigen-decomposition is unfeasible due to the
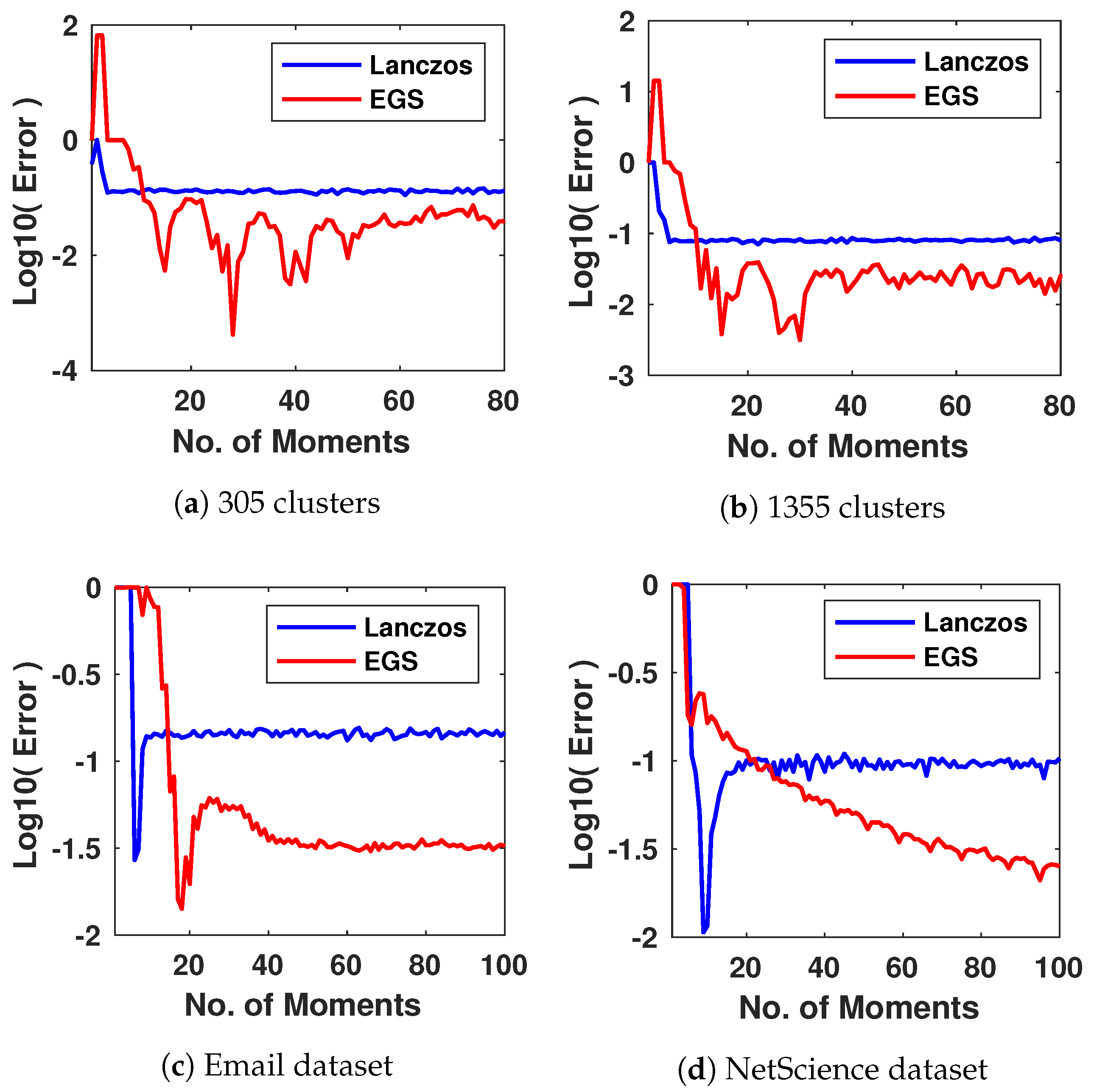
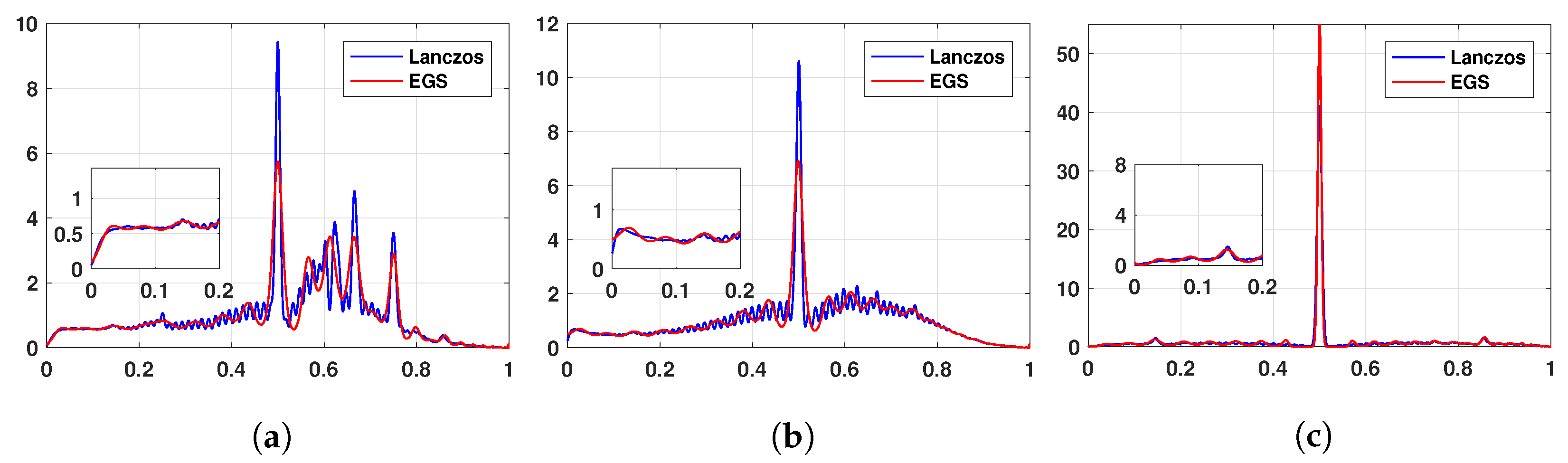
cost. Powerful iterative methods (such as the Lanczos algorithm, kernel polynomial methods, Chebyshev/Taylor approximations, the Haydock method and many more), which only require matrix-vector multiplications and hence have a computational cost scaling with the number of non-zero entries in the graph matrices, are often used. There is extensive literature documenting the performance of these methods. Ref. [
16] states that the Lanczos algorithm is significantly more accurate than other methods (including the kernel polynomial methods), followed by the Haydock method. Ref. [
17] shows that the convergence of the Lanczos algorithm is twice that of the Chebyshev approximation. Hence given the superior theoretical guarantees and empirical performance of the Lanczos algorithm, we employ it as a sole baseline against our MaxEnt method. The Lanczos algorithm [
17] approximates the graph spectrum with a sum of weighted Dirac delta functions, closely matching the first
m moments (where
m is the number of iterative steps used, as detailed in
Section 4.1.1) of the spectral density:
where
, and
denotes the
i-th eigenvalue in the spectrum. This can be seen as an
m-moment matched discrete approximation to the spectral density of the graph. However, such an approximation is undesirable because natural divergence measures between densities, such as the information-based relative entropy, i.e., the KL divergence
[
18,
19], can be infinite for densities that are mutually singular. The use of the Jensen-Shannon divergence simply re-scales the divergence into
.
The Argument against Kernel Smoothing
To alleviate these limitations, practitioners typically generate a smoothed spectral density by convolving the Dirac mixture of spectral components with a smooth kernel
[
12,
20], often a Gaussian or Cauchy [
20] to facilitate visualisation and comparison. The smoothed spectral density, with reference to Equation (
2), thus takes the form:
We make some assumptions regarding the nature of the kernel function,
, in order to prove our main theoretical result about the effect of kernel smoothing on the moments of the underlying spectral density. Both of our assumptions are met by (the commonly employed) Gaussian kernel.
Assumption A1. The kernel function is supported on the real line .
Assumption A2. The kernel function is symmetric and permits all moments.
Theorem 1. The m-th moment of a Dirac mixture , which is smoothed by a kernel satisfying Assumptions 1 and 2, is perturbed from its unsmoothed counterpart by an amount , where if m is even and otherwise. denotes the -th central moment of the kernel function .
Proof. The moments of the Dirac mixture are given as
The moments of the modified smooth function (Equation (
3)) are
We have used the binomial expansion and the fact that the infinite domain is invariant under shift reparameterisation and the odd moments of a symmetric distribution are 0. □
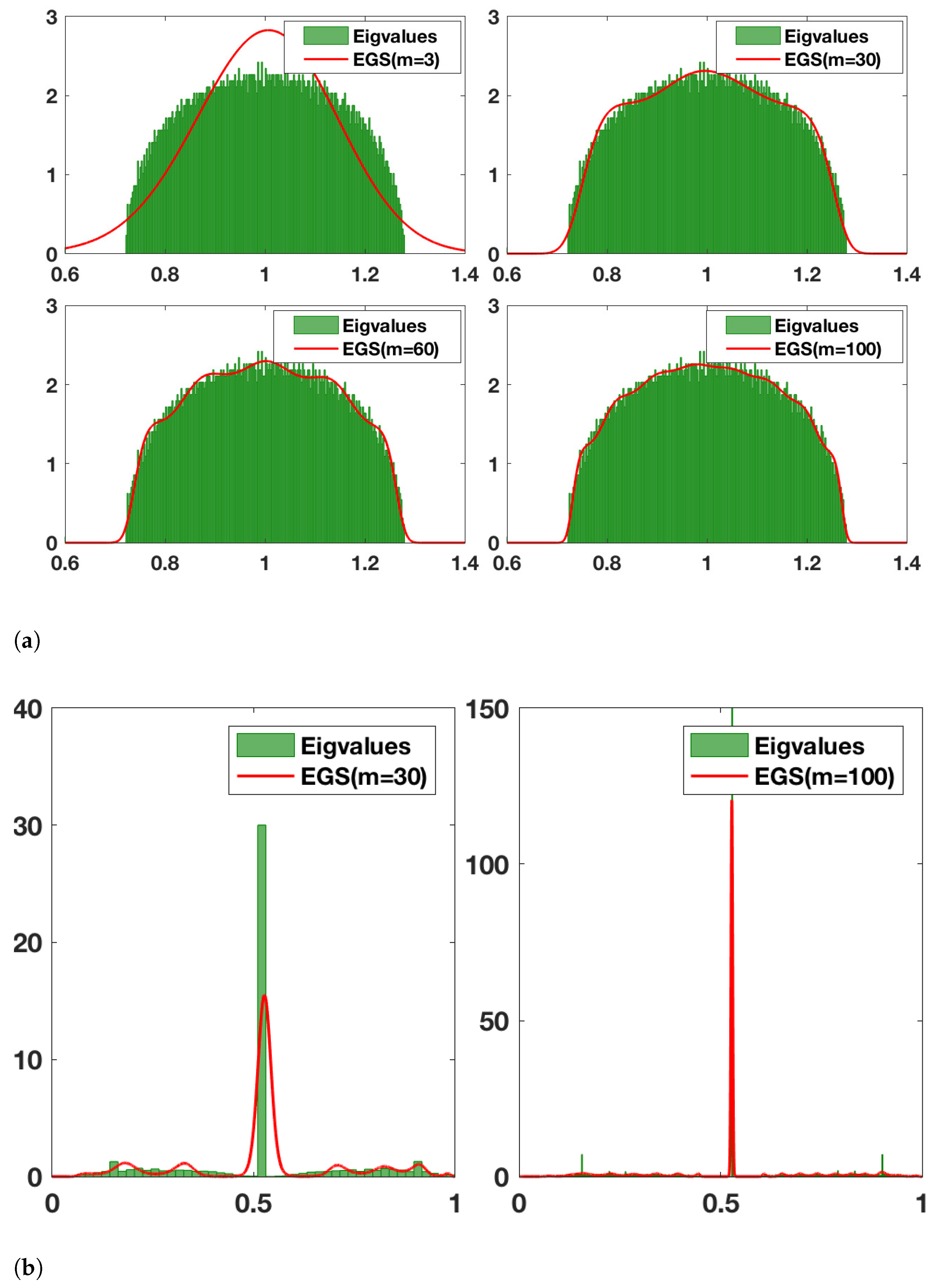
Remark 1. The above proves that kernel smoothing alters moment information, and that this process becomes more pronounced for higher moments. Furthermore, given that , and (for the normalised Laplacian) , the corrective term is manifestly positive, so the smoothed moment estimates are biased.
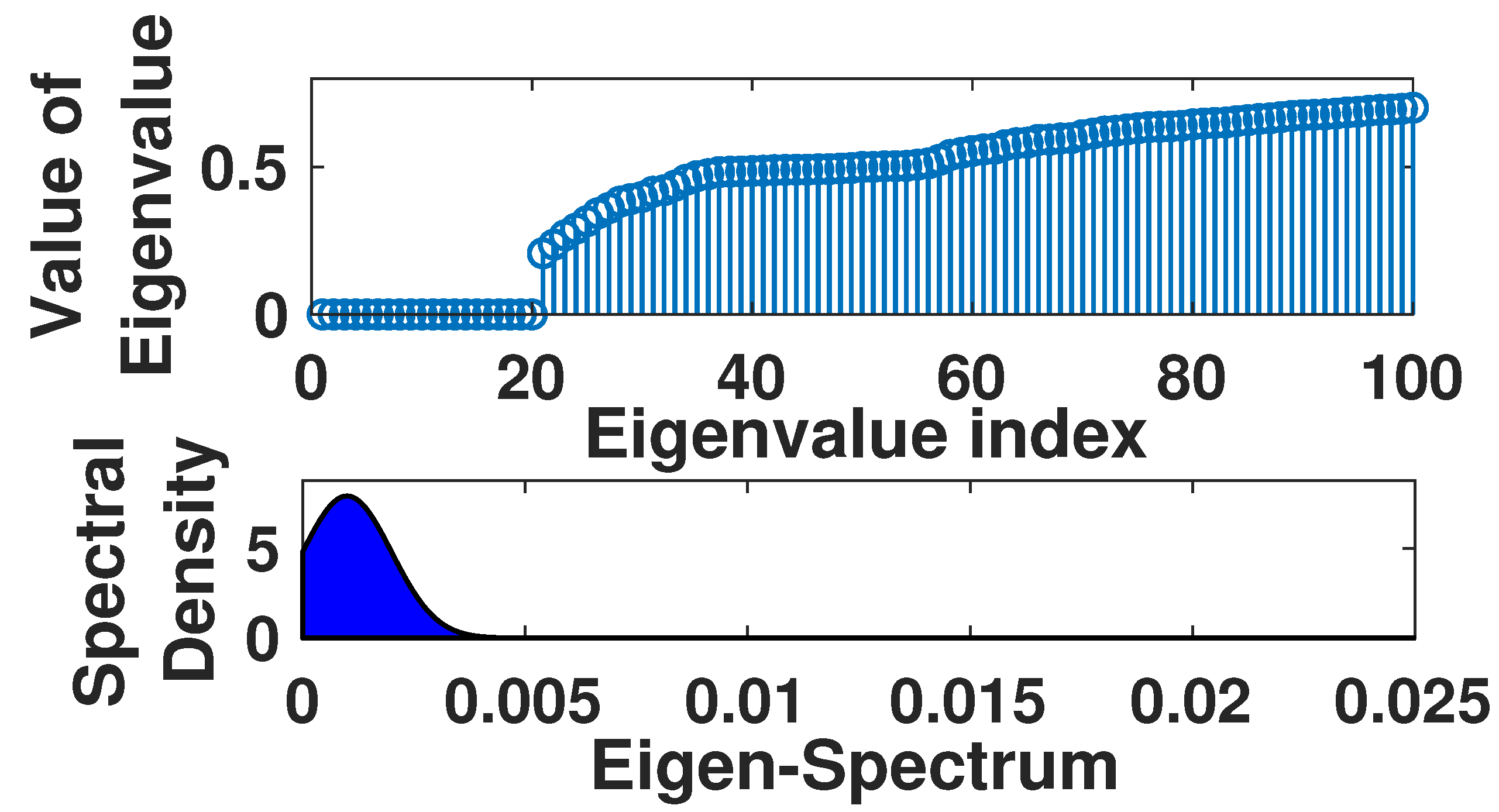
Remark 2. For large random graphs, the moments of a generated instance converge to those averaged over many instances, hence by biasing our moment information we limit our ability to learn about the underlying stochastic process. We include a detailed discussion regarding the relationship between the moments of the graph and the underlying stochastic process in Section 5.2. Note, of course, that even though our argument here is using the approximate m moment approximation, the same argument would hold if we used the full n-moment information of the underlying matrix (i.e., all the eigenvalues).


 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}