1. Introduction
As the highest content of organic compounds in human body, protein is the main bearer of human life activities, The “Amino Acid Sequence—3-Dimensional Structure—Protein Function” paradigm of protein was generally accepted [
1]. However, in the past few decades, it has been found that not all proteins have a fixed three-dimensional structure in the whole sequence, and a protein lacking a specific three-dimensional structure has been continuously discovered by researchers [
2]. These proteins lack a stable three-dimensional structure in at least one region and can also perform normal biological functions, so they are called intrinsically disordered proteins (IDPS). IDPS play an important role in physiological processes such as DNA transcription and translation [
3]. Studies have shown that disordered proteins are associated with some major human diseases. For example, the lack of IDPS functionality may induce heart disease, Parkinson’s disease, nerve tissue disease, cancer, etc. [
4,
5,
6,
7,
8]. For example, the first pathogenic mutation in the SNCA gene, encoding for α-synuclein was discovered in cases of familial Parkinson’s disease [
9], some of these point mutations cause Parkinson’s with high penetrance. In addition, the severity of cognitive impairment in Alzheimer’s disease was later shown to better correlate with low-molecular weight and soluble amyloid-beta aggregates, when amyloid-beta is highly disorganized in shape, it’s actually less likely to stick together and form toxic clusters that lead to brain cell death [
10]. A considerable number of biophysical studies have shown, type-2 diabetic islets are characterized by islet amyloid protein derived from islet amyloid peptide (IAPP), a protein co-expressed by beta cells with insulin that, when misfolded and present in aggregated form, may lead to beta cell failure [
11]. Therefore, more and more attention has been paid to the study of disordered proteins in recent years, and the research on the characteristics, functions and prediction of disordered proteins has also been greatly developed.
In the past few decades, there are various schemes for predicting IDPS that continue to emerge, and these methods are roughly divided into two categories: physicochemical-based and calculation-based. The first method is to detect IDPs by using amino acid propensity scale and physicochemical properties of protein sequence, such as GlobPlot [
12], IUPred [
13], FoldIndex [
14] and IsUnstruct [
15]. Compared with the physicochemical-based method, The second method distinguishes ordered and disordered proteins with positive samples and negative samples, effectively combines various features, and uses machine learning to make predictions, such as support vector machines (SVM), Naive Bayes (NB), K nearest neighbors (KNN) and decision trees (DT). These schemes include DISOPRED3 [
16], SPINE-D [
17], ESpritz [
18] and MetaDisorder [
19]. DISOPRED3 calculates the Position-Specific Substitution Matrix (PSSM) of all residues using three iterations of PSI-BLAST, and predicts the disordered regions and protein binding sites by using support vector machines as classifiers. SPINE-D uses a neural network to predict disorder regions, the algorithm makes a ternary prediction of all residues (ordered residues, short disordered region residues and long disordered region residues), then simplifies it to a binary prediction and trains both short disordered regions and long disordered regions. It is worth mentioning that the hybrid scheme based on various predictors can integrate a plurality of single schemes, and can better utilize the prediction advantages of different aspects of each single scheme, so as to improve the prediction accuracy. For example, MetaDisorder integrates predictors including DISOPRED2 [
20], Globplot, IUpred, PrDOS [
21], POODLE [
22], DISPI [
23], RONN [
24], etc., So that its prediction results score higher than a single prediction result.
Most of the above IDPS prediction schemes use a large number of features, resulting in too high computational complexity to meet the requirements of making efficient predictions on a large number of data sets. Disordered proteins often have repetitive regions in their amino acid sequences, so they have lower sequence complexity than ordered proteins [
25], We propose a new feature extraction scheme based on sequence complexity, which uses five features including Shannon entropy, topological entropy, permutation entropy and two amino acid preferences. Through the proposed preprocessing strategy, the selected features can better reflect the features of disordered regions, and has lower computational complexity than the existing prediction scheme. Finally, two boosting algorithm are used to verify the feasibility of the scheme.
The specific steps of the scheme are as follows:
Step 1: Download the latest 2209 intrinsically disordered protein sequences from DisProt (
https://www.disprot.org/, accessed on 6 October 2021). The data set includes 1,217,223 amino acid residues, of which 995,189 residues are ordered and 222,034 residues are disordered.
Step 2: Since the nucleotides of the disordered protein coding gene are different from the ordered protein, the amino acid sequence of the disordered protein shows a more obvious bias. Compared with ordered proteins, disordered proteins have a lower content of hydrophobic residues. We corresponded the 20 amino acids to the numbers 0 and 1, which were used to calculate the permutation entropy.
Step 3: select a suitable sliding window, calculate the Shannon entropy, topological entropy, permutation entropy and two amino acid preferences of each residue, and finally acquire a 1,217,223 × 5 data set DIS2209.
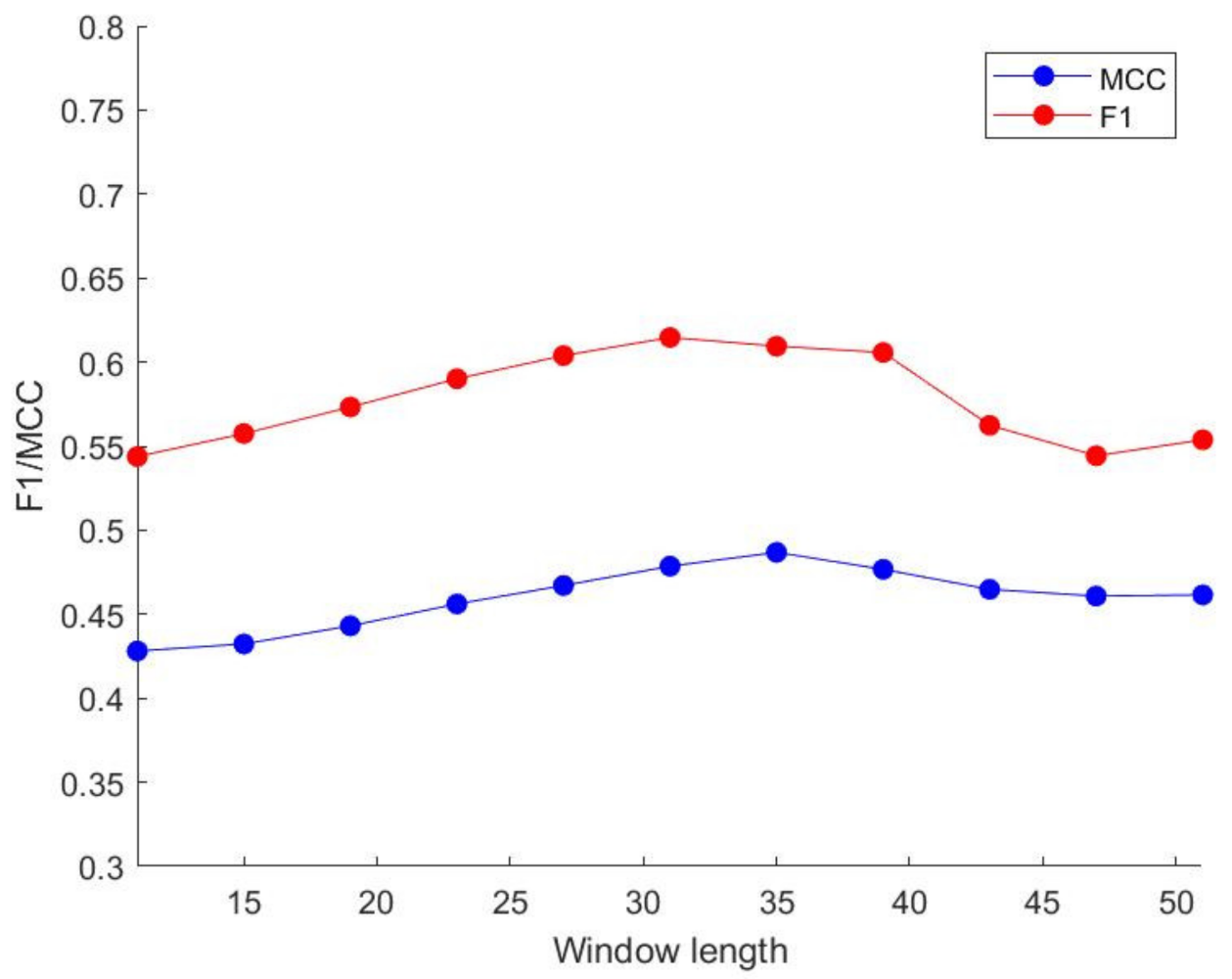
Step 4: Due to the imbalance of the data samples, we performed three oversampling schemes on the data, and selected the comprehensive sampling with better performance. In addition, we used ten-fold cross-validation, using 90% of the DIS2209 data set randomly as the training set and 10% as the test set, and then using the grid search method to find the optimal parameter combination of the trainer, and finally calculating our Four indicators needed: Sensitivity (Sens), Specificity (Spec), F1 score (F1), Matthews Correlation Coefficient (MCC).
Step 5: compare our schemes with the existing schemes.
2. Feature Selection and Preprocessing Process
The amino acid sequence of disordered proteins often has repeated regions, which is lower in sequence complexity than that of ordered proteins. According to this characteristic, we use Shannon entropy, topological entropy, permutation entropy and two amino acid preferences to describe the sequence complexity of proteins. A detailed description of these features follows.
2.1. Shannon Entropy
The Shannon entropy [
26] is a standard measure for the order state of sequences and has been applied previously to protein sequences, it quantifies the probability density function of the distribution of values. If the length of a protein sequence
is
, its Shannon entropy can be expressed as:
where
(
) represents the frequency of the 20 amino acids in the sequence, and the formula can be expressed as:
When , , otherwise .
2.2. Topological Entropy
Topological entropy [
27,
28,
29,
30] can also reflect the complexity of protein sequences very well, calculate the complexity function of the protein sequence
of length
:
representing the total number of different -length subwords of , where is the subsequence of length () in the sequence. For example, given the sequence ,, then the subsequence of are , so .
For a sequence
of length
and a subsequence length of
, the following formula needs to be satisfied:
Denote the segment consisting of
consecutive characters in the first paragraph of
as
, namely:
Then the topological entropy of the protein sequence
can be expressed as:
where
can be calculated by Equation (3), which represents the number of different subsequences of length n contained in the first segment of length
in sequence
. If fragment
contains all subsequences of length
, then
, If fragment
only contains one subsequence of length
, then
.
In order to further optimize the calculation result of topological entropy, we use the method of sequence traversal to calculate the topological entropy of each segment, and take the average value as the final topological entropy calculation result:
However, Equation (7) only needs to make the length of the protein sequence greater than 400 for the case of
, which exceeds the length of most protein sequences. Therefore, according to the nature of the disordered protein that there are few hydrophobic residues [
31], we map the sequence to 0 and 1: map hydrophobic (I,L,V,F,W,Y) residues to 1, and map other residues to 0, as shown in
Table 1. Then the Equation (7) can be changed to:
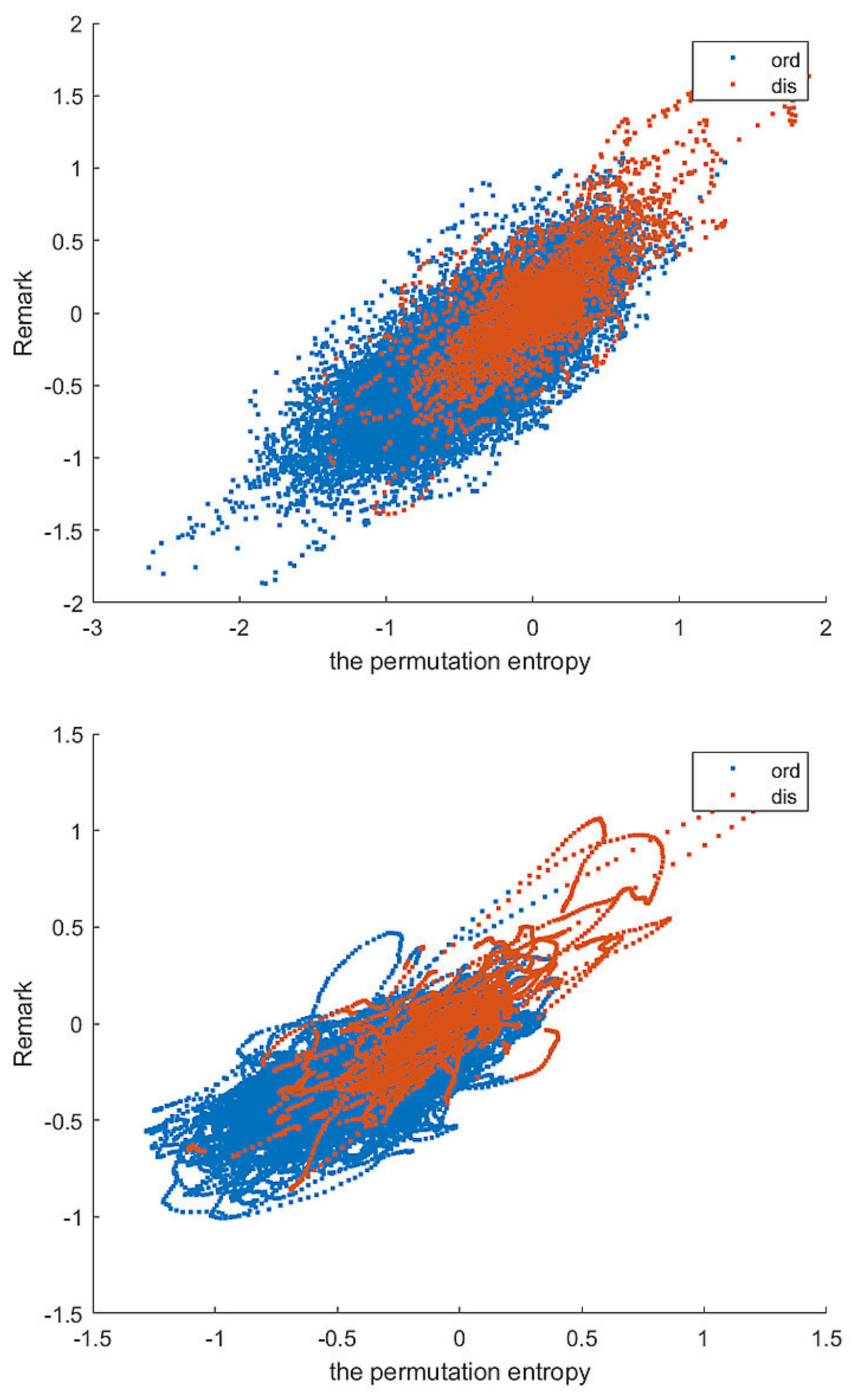
2.3. Permutation Entropy
In order to better highlight the complexity of protein sequences, we introduced the permutation entropy for the first time. Permutation entropy introduces the idea of permutation when calculating the complexity of reconstructed subsequences, it can be calculated for arbitrary real-world time series. Since the method is extremely fast and robust, it is preferable when there are huge data sets and no time for preprocessing and fine-tuning of parameters [
32].
Given a protein sequence
of length
, specify an embedding dimension
and a time delay
to reconstruct the original sequence:
Each row in the matrix can be regarded as a reconstructed subsequence, and there are
reconstruction subsequence in total. The
-th reconstructed subsequence of
is
. Sort in ascending order based on numerical value:
If the two values are equal, which is
, they are sorted according to the index
of
. In this way, a subsequence
is mapped to
. Therefore, each row in the matrix reconstructed by the protein sequence
can acquire a set of symbol sequences:
where
, and
, so every m-dimensional subsequence
is mapped to one of
permutations.
Through the above steps, we can represent the continuous -dimensional subspace with a sequence of symbols, in which there are . The probability distribution of all symbols is represented by , where .
Finally, the permutation entropy of the protein sequence
is calculated as:
For the convenience of calculation, we use 0 and 1 to represent the 20 amino acids of the protein sequence, as shown in
Table 1. If the specified value of
is too small, the reconstructed sequence will contain too few states and the subsequences will lose validity and meaning. If the value of
is too large, the protein sequence will be homogenized, increasing the amount of calculation and failing to reflect the inherent subtleties of the protein sequence. Therefore, the embedding dimension
is generally 3 ~ 7, and
in this article. The influence of the delay time
can be ignored, usually
. The overall calculation process is shown in
Figure 1.
2.4. Two Amino Acid Preferences
On the basis of the above three entropies, we also added two amino acid propensity indicators to calculate the complexity of the protein sequence, namely Remark465 and Deleage/Roux given in the GlobPlot NAR article. We use Equation (11) to calculate the values of two amino acid preferences:
represents the mapping value of the
-th amino acid preference,
correspond to Remark465, Deleage/Roux, respectively, as shown in
Table 2.
2.5. Preprocessing Process
The prediction results after directly calculating all the above feature values for training are not ideal, so we use the sliding window to continuously intercept the area of the window length, calculate the five selected features, and assign them to all residues at the corresponding positions.
Given a protein sequence of length
, select a sliding window of length
, and add
zeros at both ends of the protein sequence. As the sliding window slides, calculate the mean value
of the five-dimensional feature vector of each window, including Shannon entropy, topological entropy, permutation entropy, and two amino acid preferences, and assign
to all residues in the window. Finally, Dividing the accumulated value of all residues by the number of accumulations, the five-dimensional feature vector
of each residue can be obtained:
Since the 995,189 residues in the DIS2209 data set are ordered, the 222,034 residues are disordered, and the number of positive and negative samples is unbalanced, we have added an oversampling method to increase the sample size and generate according to the law of samples with fewer categories. More samples of this label make the data tend to be balanced and the prediction results are more accurate. Compared with some existing oversampling schemes, we adopted SMOTE oversampling. The specific steps are as follows:
Step 1: For each sample of the minority class, use Euclidean distance as the standard to calculate the distance from all samples in the minority class sample set to obtain its k nearest neighbors.
Step 2: Set a sampling ratio according to the sample imbalance ratio to determine the sampling magnification . For each minority sample , randomly select several samples from its nearest neighbors, assuming that the selected nearest neighbor is .
Step 3: For each neighbor selected at random, it is defined as:
3. Algorithm Scheme
For the problem of data imbalance, common processing methods include: sampling (over-sampling or under-sampling), cost-sensitive learning, and Ensemble learning methods. As mentioned above, we have adopted the method of oversampling to increase the number of samples in the minority class, so that the data tends to be balanced, but when the learner encounters this situation, it will encounter many repeated samples, so it will learn A special mode, which greatly increases the probability of overfitting. The ensemble learning algorithm is the result of merging multiple base classifiers, and fully considers the uncertainty and the possibility of misclassification of the sample.
Therefore, based on the ensemble learning (Boosting) algorithm, we used the oversampling method to preprocess the data and predict the data set DIS2209.
Figure 2 shows the specific flow chart.
3.1. Gradient Boosting Decision Tree
Gradient Boosting Decision Tree (GBDT) is an algorithm to classify and regress data by using an additive model (that is, a linear combination of basis functions) and using the negative gradient of the loss function to fit the approximate value of the current round of loss.
For a given sample set, first determine the cut point
:
For the number of iterations
, assuming the number of samples
, calculate the negative gradient:
Use
to fit a regression tree to acquire the leaf node area
of the
th tree, where
is the number of leaf nodes. For each sample in the leaf node, we find the smallest loss function, which is the best output value of the fitting leaf node:
Strong learners updated to this round:
Finally acquire the learner expression:
By fitting the negative gradient of the loss function, we have found a general way to fit the loss error, so whether it is a classification problem or a regression problem, we can use GBDT to fit the negative gradient of the loss function Solve our classification regression problem. The only difference lies in the different negative gradients caused by different loss functions.
3.2. LightGBM
LightGBM is a framework that implements the GBDT algorithm. It is optimized on the traditional GBDT algorithm, which can speed up the training speed of the GBDT model without compromising the accuracy, and further improve the accuracy of predicting IDPS. The specific optimization is:
Using Histogram’s decision tree algorithm, this algorithm can reduce memory usage and computing time through feature discretization.
Using the Leaf-wise algorithm with depth limitation, this strategy can split the same layer of leaves at the same time by traversing the data once, and it is easy to perform multi-thread optimization, and it is also easy to control the complexity of the model, and it is not easy to overfit.
The single-sided gradient sampling algorithm is used to exclude most of the samples with small gradients, and only the remaining samples are used to calculate the information gain. This algorithm can achieve a balance between reducing the amount of data and ensuring accuracy.
The use of mutually exclusive feature bundling algorithm can transform many mutually exclusive features into low-dimensional dense features, effectively avoiding unnecessary calculation of zero-value features.
Supports efficient parallelism, including feature parallelism, data parallelism, and voting parallelism.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}