
No-Wait Job Shop Scheduling Using a Population-Based Iterated Greedy Algorithm

Abstract
:1. Introduction
2. No-Wait Job Shop Scheduling Problem (NWJSP) with Makespan Minimization
2.1. Problem Statement
2.2. Problem Formulation
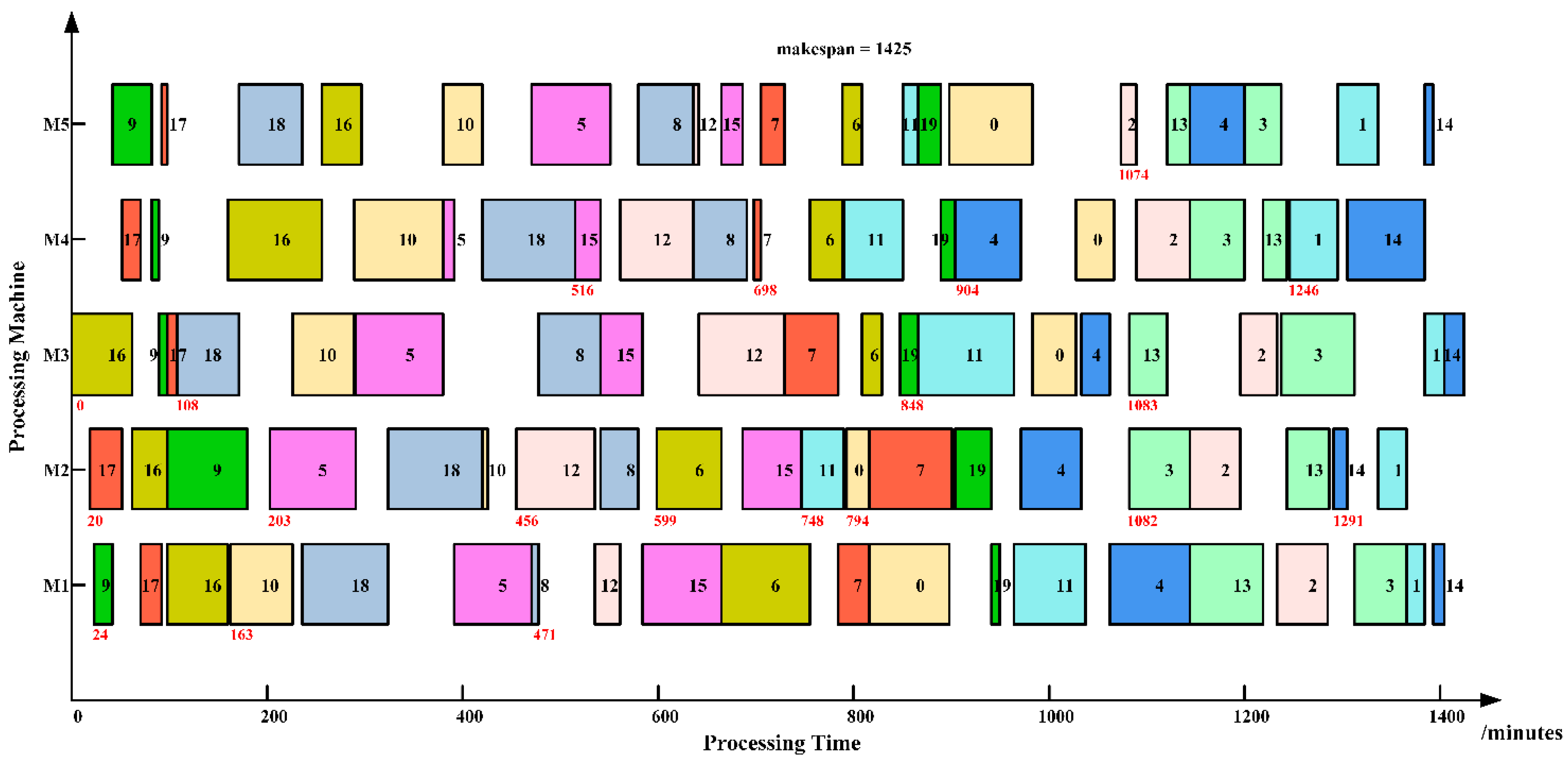
2.3. Timetabling Methods
3. Population-Based Iterated Greedy Algorithm
3.1. Iterated Greedy Procedure
3.1.1. Destruction and Construction
| Algorithm 1. The destruction and construction (DC) operator. |
| 1: choose d unrepeated jobs s1, …, sd randomly, delete them from π, and a sequence with n – d jobs is obtained. 2: for i from 1 to d 3: insert si into the n – d + i positions of πF, evaluate the obtained n – d + i sequences, and replace πF with the best one. 4: endfor. |
3.1.2. Local Search
| Algorithm 2. Insertion-based local search (IBLS). |
| 1: = a permutation generated randomly 2: i = 0, h = 1 3: while (i < n) 4: let s = 5: find 6: if ( is better than π) 7: 8: i = 1 9: else 10: i = i + 1 11: endif 12: h = (h + 1) % n 13: endwhile |
3.2. Initialization
3.3. Competitive Co-Evolutionary Scheme
| Algorithm 3. Competitive Strategy. |
| 1: randomly select three solutions from all and find the worst one. 2: if (rand < pb) 3: πC := πG 4: md(k*) := mdbest 5: else if (mdbest) 6: πC := πL 7: md(k*) := true 8: else 9: πC := πI 10: md(k*) := false 11: endif 12: endif 13: perform DC on with parameter D and obtain a perturbation solution 14: := |
3.4. Procedure of the Population-Based Iterated Greedy (PBIG) Algorithm
| Algorithm 4. Procedure of the PBIG. |
| 1: set parameters d, p, D, pb. 2: initialize πk (k = 1, …, p), πL, πI, πG, md, mdbest, Temp. 3: while (not termination) 4: for (each πk) //perform each IG procedure 5: perform the DC operator on πk and then the IBLS, and obtain a new solution . If is better than πk, then let πk := and update πL, πI, πG, mdbest if possible. 6: endfor 7: perform competitive strategy. 8: endwhile |
4. Computational Results and Comparisons
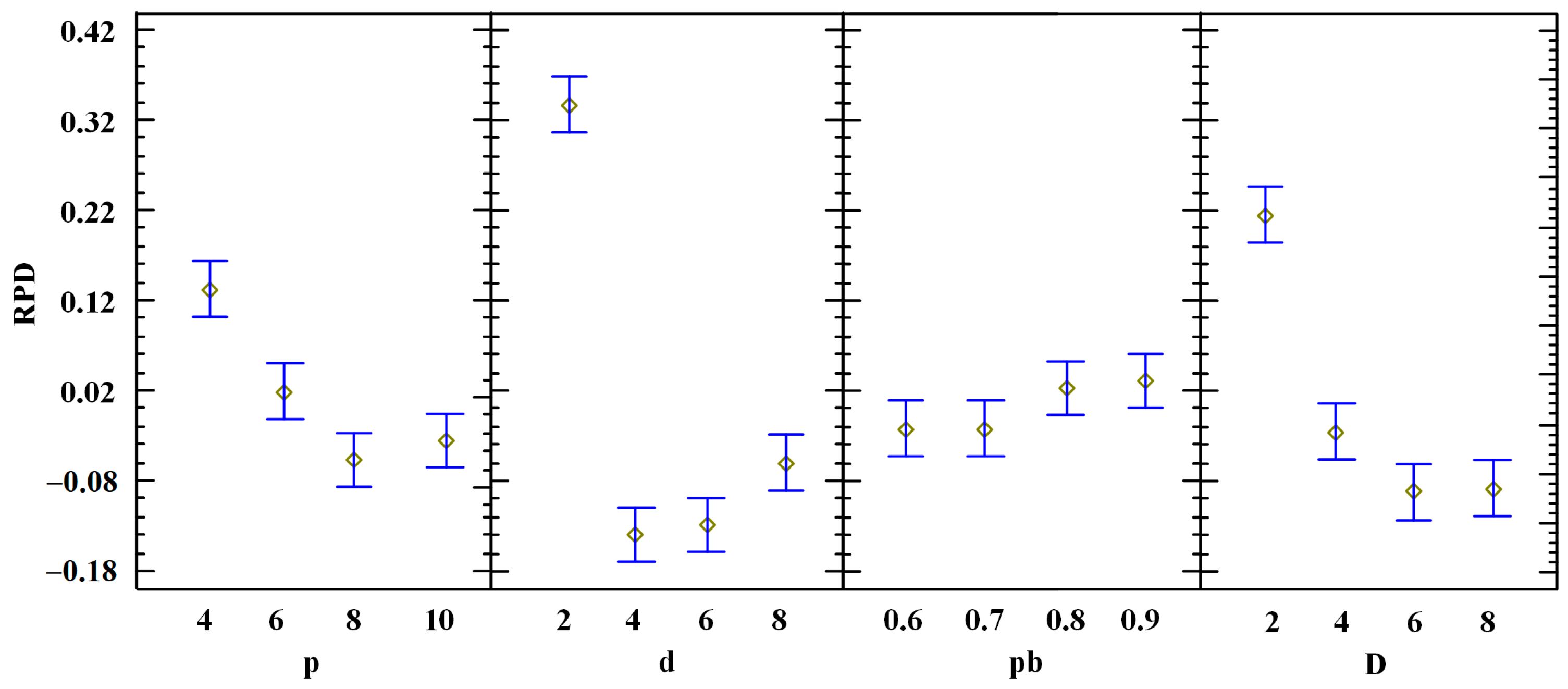
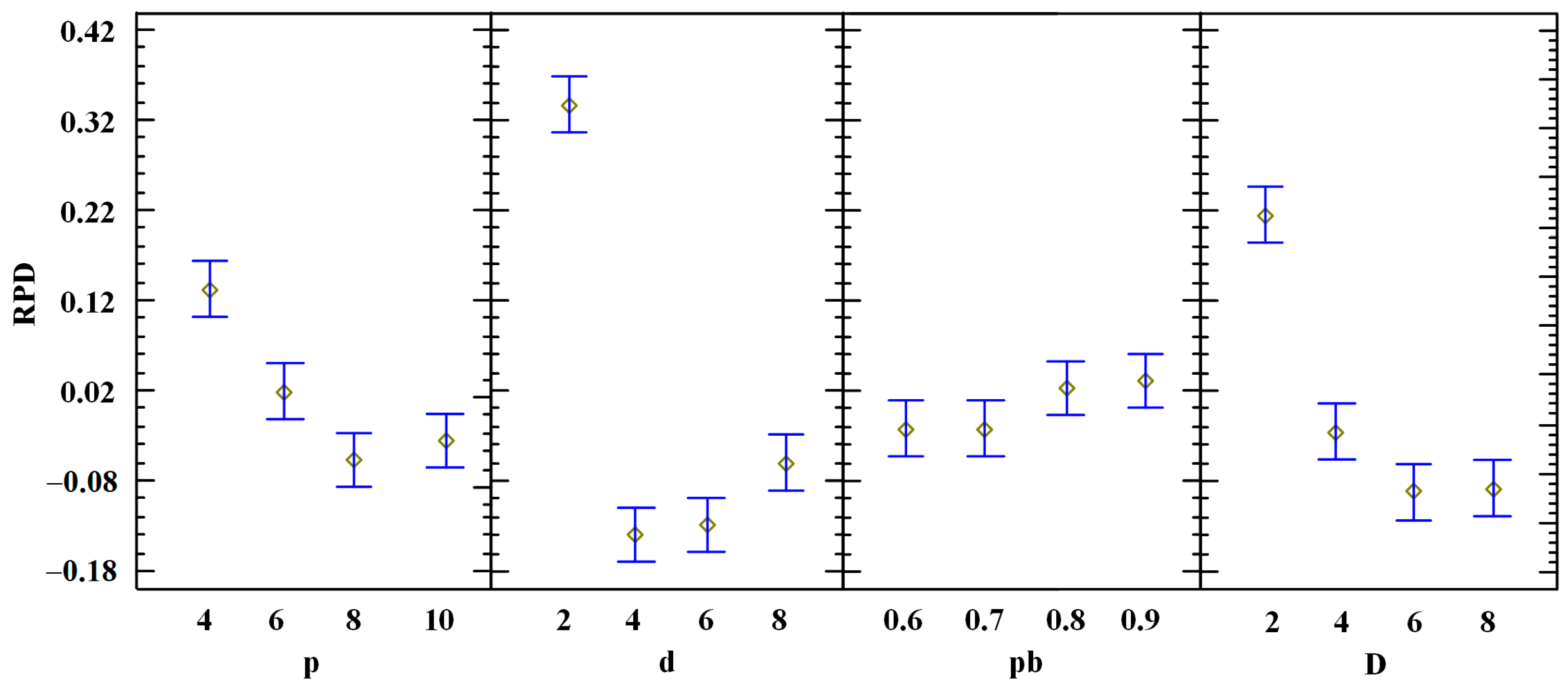
4.1. Calibration of the PBIG Algorithm
4.2. Comparisons with Other Metaheuristics
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pinedo, M. Scheduling: Theory, Algorithms, and Systems, 5th ed.; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Tang, L.; Liu, J.; Rong, A.; Yang, Z. A mathematical programming model for scheduling steelmaking-continuous casting production. Eur. J. Oper. Res. 2000, 120, 423–435. [Google Scholar] [CrossRef]
- Grabowski, J.; Pempera, J. Sequencing of jobs in some production system. Eur. J. Oper. Res. 2000, 125, 535–550. [Google Scholar] [CrossRef]
- Rajendran, C. A no-wait flow shop scheduling heuristic to minimize makespan. Eur. J. Oper. Res. 1994, 45, 472–478. [Google Scholar]
- Hall, N.; Sriskandarajah, C. A survey of machine scheduling problems with blocking and no-wait in process. Oper. Res. 1996, 44, 510–525. [Google Scholar] [CrossRef]
- Lenstra, J.K.; Kan, A.H.G.R.; Brucker, P. Complexity of machine scheduling problems. Ann. Discret. Math. 1997, 1, 343–362. [Google Scholar]
- Sahni, S.; Cho, Y. Complexity of scheduling shops with no-wait in process. Math. Oper. Res. 1979, 4, 448–457. [Google Scholar] [CrossRef]
- Mascis, A.; Pacciarelli, D. Job-shop scheduling with blocking and no-wait constraints. Eur. J. Oper. Res. 2002, 143, 498–517. [Google Scholar] [CrossRef]
- Van den Broek, J. MIP-Based Approaches for Complex Planning Problems. Ph.D. Thesis, Technische Universiteit Eindhoven, Eindhoven, The Netherlands, 2009. [Google Scholar]
- Bürgy, R.; Gröflin, H. Optimal job insertion in the no-wait job shop. J. Comb. Optim. 2013, 26, 345–371. [Google Scholar] [CrossRef]
- Macchiaroli, R.; Mole, S.; Riemma, S. Modelling and optimization of industrial manufacturing processes subject to no-wait constraints. Int. J. Prod. Res. 1999, 37, 2585–2607. [Google Scholar] [CrossRef]
- Schuster, C.; Framinan, J. Approximate procedures for no-wait job shop scheduling. Oper. Res. Lett. 2003, 31, 308–318. [Google Scholar] [CrossRef]
- Schuster, C. No-wait job shop scheduling: Tabu search and complexity of subproblems. Math. Methods Oper. Res. 2006, 63, 473–491. [Google Scholar] [CrossRef]
- Framinan, J.M.; Schuster, C. An enhanced timetabling procedure for the no-wait job shop problem: A complete local search approach. Comput. Oper. Res. 2006, 331, 1200–1213. [Google Scholar] [CrossRef]
- Zhu, J.; Li, X.; Wang, Q. Complete local search with limited memory algorithm for no-wait job shops to minimize makespan. Eur. J. Oper. Res. 2009, 198, 378–386. [Google Scholar] [CrossRef]
- Zhu, J.; Li, X. An effective meta-heuristic for no-wait job shops to minimize makespan. IEEE Trans. Autom. Sci. Eng. 2012, 9, 189–198. [Google Scholar] [CrossRef]
- Mokhtari, H. A two-stage no-wait job shop scheduling problem by using a neuro-evolutionary variable neighborhood search. Int. J. Adv. Manuf. Technol. 2014, 74, 1595–1610. [Google Scholar]
- Aitzai, A.; Benmedjdoub, B.; Boudhar, M. Branch-and-bound and PSO algorithms for no-wait job shop scheduling. J. Intell. Manuf. 2016, 27, 679–688. [Google Scholar] [CrossRef]
- Li, X.; Xu, H.; Li, M. A memory-based complete local search method with variable neighborhood structures for no-wait job shops. Int. J. Adv. Manuf. Technol. 2016, 87, 1401–1408. [Google Scholar]
- Sundar, S.; Suganthan, P.N.; Jin, C.T.; Xiang, C.T.; Soon, C.C. A hybrid artificial bee colony algorithm for the job-shop scheduling problem with no-wait constraint. Soft Comput. 2017, 21, 1193–1202. [Google Scholar]
- Ruiz, R.; Stutzle, T. A simple and effective iterated greedy algorithm for the permutation flowshop scheduling problem. Eur. J. Oper. Res. 2007, 177, 2033–2049. [Google Scholar]
- Lee, C.H. A dispatching rule and a random iterated greedy metaheuristic for identical parallel machine scheduling to minimize total tardiness. Int. J. Prod. Res. 2018, 56, 2292–2308. [Google Scholar] [CrossRef]
- Ruiz, R.; Pan, Q.K.; Naderi, B. Iterated greedy methods for the distributed permutation fowshop scheduling problem. OMEGA 2019, 83, 213–222. [Google Scholar] [CrossRef]
- Ribas, I.; Companys, R.; Tort-Martorell, X. An iterated greedy algorithm for solving the total tardiness parallel blocking flow shop scheduling problem. Expert Syst. Appl. 2019, 121, 347–361. [Google Scholar] [CrossRef]
- Samarghandi, H.; ElMekkawy, T.Y.; Ibrahem, A.M. Studying the effect of different combinations of timetabling with sequencing algorithms to solve the no-wait job shop scheduling problem. Int. J. Prod. Res. 2013, 51, 4942–4965. [Google Scholar] [CrossRef]
- Deng, G.; Su, Q.; Zhang, Z.; Liu, H.; Zhang, S.; Jiang, T. A population-based iterated greedy algorithm for no-wait job shop scheduling with total flow time criterion. Eng. Appl. Artif. Intell. 2020, 88, 103369. [Google Scholar] [CrossRef]
- Nawaz, M.; Enscore, J.E.E.; Ham, I. A heuristic algorithm for the m-machine, n-job flow-shop sequencing problem. Omega 1983, 11, 91–95. [Google Scholar] [CrossRef]
- Fisher, H.; Thompson, G.L. Probabilistic Learning Combinations of Local Job-Shop Scheduling Rules. Industrial Scheduling; Prentice-Hall: Englewood Cliffs, NJ, USA, 1963; pp. 225–251. [Google Scholar]
- Applegate, D.; Cook, W. A computational study of the job-shop problem. ORSA J. Comput. 1991, 3, 149–156. [Google Scholar] [CrossRef]
- Adams, J.; Balas, E.; Zawack, D. The shifting bottleneck procedure for job shop scheduling. Manag. Sci. 1988, 34, 391–401. [Google Scholar] [CrossRef]
- Lawrence, S. Resource Constrained Project Scheduling: An Experimental Investigation of Heuristic Scheduling Techniques; Technical Report; Carnegie-Mellon University: Pittsburgh, PA, USA, 1984. [Google Scholar]
- Storer, R.H.; Wu, S.D.; Vaccari, R. New search spaces for sequencing instances with application to job shop scheduling. Manag. Sci. 1992, 38, 1495–1509. [Google Scholar] [CrossRef]
- Deng, G.; Zhang, Z.; Jiang, T.; Zhang, S. Total flow time minimization in no-wait job shop using a hybrid discrete group search optimizer. Appl. Soft Comput. 2019, 81, 105480. [Google Scholar] [CrossRef]
- Montgomery, D.C. Design and Analysis of Experiments, 8th ed.; Wiley: New York, NY, USA, 2012. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Notation. | Description | Notation | Description |
|---|---|---|---|
| m | number of machines | ti | start time of Ji |
| n | number of jobs | job permutation | |
| M = {M1, M2, …, Mm} | set of m machines | t[i] | start time of |
| J = {J1, J2, …, Jn} | set of n jobs | operation of on | |
| oi,u | u-th operation of Ji | processing time of | |
| Mi,u | machine on which oi,u is processed | start time difference set | |
| pi,u | processing time of oi,u | makespan of | |
| Pi,u = | cumulated processing time of Ji when oi,u is finished | start time table of | |
| = {(u,v)| Mi,u = Mj,v} | pairs of operations processed on the same machine | cumulated processing time of when is finished | |
| Li | total processing times of Ji |
| Source | Sum of Squares | Df | Mean Square | F-Ratio | p-Value |
|---|---|---|---|---|---|
| MAIN EFFECTS | |||||
| A: p | 54.9931 | 3 | 18.3310 | 16.8500 | 0.0000 |
| B: d | 343.396 | 3 | 114.465 | 105.220 | 0.0000 |
| C: pb | 5.45246 | 3 | 1.81749 | 1.67000 | 0.1737 |
| D: D | 142.747 | 3 | 47.5825 | 43.7400 | 0.0000 |
| E: instance | 7962.73 | 6 | 1327.12 | 1219.90 | 0.0000 |
| REDIDUAL | 9797.72 | 8941 | 1.09582 | ||
| TOTAL (CORRECTED) | 18307.0 | 8959 |
| Instance. | n, m | BKS | MCLM | HABC | PBIG | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| RPDB | ARPD | TA(s) | RPDB | ARPD | TA(s) | RPDB | ARPD | TA(s) | |||
| Ft06 | 6, 6 | 73 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.15 | 0.00 | 0.00 | 0.65 |
| La01 | 10, 5 | 971 | 0.00 | 0.00 | 4.55 | 0.41 | 0.41 | 0.78 | 0.00 | 0.02 | 1.50 |
| La02 | 10, 5 | 937 | 0.00 | 0.00 | 7.60 | 2.56 | 2.56 | 1.41 | 0.00 | 0.00 | 1.50 |
| La03 | 10, 5 | 820 | 0.00 | 0.00 | 3.10 | 0.00 | 0.00 | 0.70 | 0.00 | 0.00 | 1.50 |
| La04 | 10, 5 | 887 | 0.00 | 0.00 | 6.25 | 0.00 | 0.00 | 0.87 | 0.00 | 0.00 | 1.50 |
| La05 | 10, 5 | 777 | 0.51 | 0.90 | 3.90 | 0.51 | 0.51 | 1.14 | 0.00 | 0.00 | 1.50 |
| Ft10 | 10, 10 | 1607 | 0.00 | 0.00 | 7.85 | 0.00 | 0.00 | 9.86 | 0.00 | 0.00 | 3.00 |
| Orb01 | 10, 10 | 1615 | 0.00 | 0.00 | 6.65 | 0.00 | 0.00 | 8.00 | 0.00 | 0.00 | 3.00 |
| Orb02 | 10, 10 | 1485 | 2.16 | 2.16 | 6.70 | 0.00 | 0.00 | 6.86 | 0.00 | 0.00 | 3.00 |
| Orb03 | 10, 10 | 1599 | 0.00 | 0.00 | 13.75 | 0.00 | 0.00 | 10.07 | 0.00 | 0.00 | 3.00 |
| Orb04 | 10, 10 | 1653 | 0.00 | 0.12 | 7.85 | 0.00 | 0.00 | 5.28 | 0.00 | 0.00 | 3.00 |
| Orb05 | 10, 10 | 1365 | 0.00 | 0.00 | 8.50 | 0.37 | 0.37 | 4.77 | 0.15 | 0.15 | 3.00 |
| Orb06 | 10, 10 | 1555 | 0.00 | 0.00 | 3.55 | 0.00 | 0.00 | 5.76 | 0.00 | 0.00 | 3.00 |
| Orb07 | 10, 10 | 689 | 0.00 | 0.00 | 7.25 | NA | NA | NA | 0.00 | 0.00 | 3.00 |
| Orb08 | 10, 10 | 1319 | 0.00 | 0.00 | 6.40 | 0.00 | 0.00 | 8.99 | 0.00 | 0.00 | 3.00 |
| Orb09 | 10, 10 | 1445 | 0.00 | 0.00 | 4.25 | 0.00 | 0.28 | 4.10 | 0.00 | 0.00 | 3.00 |
| Orb10 | 10, 10 | 1557 | 0.00 | 0.00 | 11.85 | 0.00 | 0.00 | 5.51 | 0.00 | 0.00 | 3.00 |
| La16 | 10, 10 | 1575 | 1.84 | 1.84 | 5.65 | 0.00 | 0.00 | 5.43 | 0.00 | 0.00 | 3.00 |
| La17 | 10, 10 | 1371 | 0.00 | 0.12 | 11.85 | 0.00 | 0.00 | 4.62 | 0.00 | 0.00 | 3.00 |
| La18 | 10, 10 | 1417 | 2.82 | 2.82 | 6.15 | 0.00 | 5.22 | 7.13 | 0.00 | 0.00 | 3.00 |
| La19 | 10, 10 | 1482 | 0.00 | 0.61 | 5.00 | 0.00 | 0.43 | 3.44 | 0.00 | 0.00 | 3.00 |
| La20 | 10, 10 | 1526 | 1.31 | 1.31 | 5.40 | 0.00 | 0.00 | 3.00 | 0.00 | 0.00 | 3.00 |
| Average | 0.39 | 0.45 | 6.55 | 0.23 | 0.47 | 4.63 | 0.01 | 0.01 | 2.55 | ||
| Instance | n, m | BKS | MCLM | HABC | PBIG | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Best | RPDB | ARPD | TA(s) | Best | RPDB | ARPD | TA(s) | Best | RPDB | ARPD | TA(s) | |||
| La06 | 15, 5 | 1248 | 1248 | 0.00 | 0.75 | 90.00 | 1248 | 0.00 | 0.00 | 39.99 | 1248 | 0.00 | 0.00 | 67.50 |
| La07 | 15, 5 | 1172 | 1178 | 0.51 | 2.46 | 83.00 | 1172 | 0.00 | 0.92 | 90.19 | 1172 | 0.00 | 0.44 | 67.50 |
| La08 | 15, 5 | 1244 | 1244 | 0.00 | 0.47 | 80.00 | 1244 | 0.00 | 0.15 | 85.63 | 1244 | 0.00 | 0.48 | 67.51 |
| La09 | 15, 5 | 1358 | 1365 | 0.52 | 0.73 | 106.00 | 1362 | 0.29 | 0.67 | 34.43 | 1362 | 0.29 | 0.61 | 67.50 |
| La10 | 15, 5 | 1287 | 1287 | 0.00 | 0.04 | 69.00 | 1294 | 0.54 | 0.70 | 65.42 | 1294 | 0.54 | 0.84 | 67.50 |
| La11 | 20, 5 | 1671 | 1635 | −2.15 | −0.58 | 439.00 | 1627 | −2.63 | −1.97 | 259.37 | 1621 | −2.99 | −1.08 | 120.02 |
| La12 | 20, 5 | 1452 | 1429 | −1.58 | 0.57 | 593.00 | 1434 | −1.24 | 0.00 | 168.97 | 1425 | −1.86 | 0.17 | 120.02 |
| La13 | 20, 5 | 1624 | 1605 | −1.17 | −0.15 | 303.00 | 1580 | −2.71 | −1.47 | 222.40 | 1582 | −2.59 | −0.09 | 120.02 |
| La14 | 20, 5 | 1691 | 1648 | −2.54 | −1.16 | 314.00 | 1640 | −3.02 | −2.24 | 156.58 | 1640 | −3.02 | −1.96 | 120.02 |
| La15 | 20, 5 | 1694 | 1685 | −0.53 | 1.09 | 424.00 | 1679 | −0.89 | −0.09 | 240.56 | 1677 | −1.00 | 0.35 | 120.02 |
| La21 | 15, 10 | 2048 | 2048 | 0.00 | 0.11 | 78.00 | 2043 | −0.24 | 0.27 | 71.42 | 2043 | −0.24 | −0.04 | 135.01 |
| La22 | 15, 10 | 1887 | 1902 | 0.80 | 0.99 | 142.00 | 1852 | −1.85 | −1.12 | 91.66 | 1852 | −1.85 | −1.19 | 135.01 |
| La23 | 15, 10 | 2032 | 2022 | −0.49 | 1.47 | 50.00 | 2032 | 0.00 | 0.71 | 120.56 | 2032 | 0.00 | 0.14 | 135.01 |
| La24 | 15, 10 | 2015 | 2015 | 0.00 | 0.77 | 98.00 | 1994 | −1.04 | −0.02 | 97.64 | 1994 | −1.04 | −0.30 | 135.01 |
| La25 | 15, 10 | 1917 | 1930 | 0.68 | 2.07 | 71.00 | 1906 | −0.57 | −0.57 | 92.53 | 1906 | −0.57 | −0.57 | 135.01 |
| La26 | 20, 10 | 2553 | 2532 | −0.82 | 1.91 | 349.00 | 2506 | −1.84 | 0.30 | 223.46 | 2506 | −1.84 | 1.66 | 240.02 |
| La27 | 20, 10 | 2747 | 2715 | −1.17 | 0.28 | 388.00 | 2674 | −2.66 | −2.62 | 154.83 | 2673 | −2.69 | −2.19 | 240.02 |
| La28 | 20, 10 | 2624 | 2560 | −2.44 | 1.77 | 313.00 | 2560 | −2.44 | 0.62 | 197.33 | 2581 | −1.64 | 0.77 | 240.03 |
| La29 | 20, 10 | 2489 | 2367 | −4.90 | −2.48 | 445.00 | 2389 | −4.02 | −2.70 | 531.94 | 2405 | −3.37 | −2.18 | 240.03 |
| La30 | 20, 10 | 2665 | 2544 | −4.54 | −1.51 | 376.00 | 2452 | −7.99 | −3.00 | 248.25 | 2452 | −7.99 | −3.50 | 240.03 |
| La31 | 30, 10 | 3745 | 3575 | −4.54 | −1.40 | 3099.00 | 3592 | −4.09 | −2.60 | 1716.18 | 3479 | −7.10 | −2.35 | 540.16 |
| La32 | 30, 10 | 4028 | 3835 | −4.79 | 0.56 | 3314.00 | 3913 | −2.86 | −0.35 | 1590.40 | 3877 | −3.75 | −0.68 | 540.19 |
| La33 | 30, 10 | 3749 | 3574 | −4.67 | −1.52 | 3003.00 | 3529 | −5.87 | −3.37 | 1544.34 | 3560 | −5.04 | −2.51 | 540.18 |
| La34 | 30, 10 | 3824 | 3684 | −3.66 | −0.88 | 3375.00 | 3610 | −5.60 | −2.76 | 1405.05 | 3615 | −5.47 | −2.55 | 540.20 |
| La35 | 30, 10 | 3760 | 3698 | −1.65 | 1.27 | 3083.00 | 3593 | −4.44 | −0.41 | 1797.55 | 3687 | −1.94 | 0.43 | 540.19 |
| La36 | 15, 15 | 2685 | 2736 | 1.90 | 4.98 | 189.00 | 2685 | 0.00 | 0.29 | 76.42 | 2685 | 0.00 | 0.00 | 202.51 |
| La37 | 15, 15 | 2962 | 2962 | 0.00 | 0.11 | 93.00 | 2938 | −0.81 | 0.98 | 184.41 | 2831 | −4.42 | 0.06 | 202.51 |
| La38 | 15, 15 | 2617 | 2525 | −3.52 | −1.73 | 91.00 | 2525 | −3.52 | −1.08 | 311.66 | 2525 | −3.52 | −2.80 | 202.51 |
| La39 | 15, 15 | 2697 | 2729 | 1.19 | 2.43 | 116.00 | 2703 | 0.22 | 0.88 | 146.87 | 2687 | −0.37 | 0.34 | 202.51 |
| La40 | 15, 15 | 2594 | 2580 | −0.54 | −0.54 | 61.00 | 2594 | 0.00 | 0.00 | 190.51 | 2594 | 0.00 | 0.00 | 202.51 |
| Swv01 | 20, 10 | 2328 | 2333 | 0.22 | 0.37 | 516.00 | 2318 | −0.43 | −0.02 | 874.70 | 2318 | −0.43 | −0.17 | 240.02 |
| Swv02 | 20, 10 | 2418 | 2418 | 0.00 | 0.38 | 488.00 | 2417 | −0.04 | −0.02 | 961.12 | 2417 | −0.04 | −0.02 | 240.02 |
| Swv03 | 20, 10 | 2415 | 2381 | −1.41 | −0.41 | 517.00 | 2381 | −1.41 | −0.92 | 1018.02 | 2381 | −1.41 | −0.89 | 240.02 |
| Swv04 | 20, 10 | 2506 | 2462 | −1.76 | −0.30 | 426.00 | 2506 | 0.00 | 0.29 | 1728.64 | 2462 | −1.76 | −0.10 | 240.02 |
| Swv05 | 20, 10 | 2333 | 2333 | 0.00 | 0.00 | 285.00 | 2333 | 0.00 | 0.00 | 535.69 | 2333 | 0.00 | 0.00 | 240.02 |
| Swv06 | 20, 15 | 3291 | 3291 | 0.00 | 1.69 | 747.00 | 3291 | 0.00 | 0.40 | 885.67 | 3291 | 0.00 | 0.05 | 360.02 |
| Swv07 | 20, 15 | 3271 | 3219 | −1.59 | −0.95 | 584.00 | 3188 | −2.54 | −2.54 | 829.20 | 3188 | −2.54 | −2.43 | 360.01 |
| Swv08 | 20, 15 | 3530 | 3423 | −3.03 | −2.21 | 413.00 | 3423 | −3.03 | −1.78 | 1150.09 | 3423 | −3.03 | −2.56 | 360.02 |
| Swv09 | 20, 15 | 3307 | 3270 | −1.12 | −0.28 | 448.00 | 3246 | −1.84 | −0.86 | 1531.08 | 3246 | −1.84 | −1.12 | 360.02 |
| Swv10 | 20, 15 | 3488 | 3451 | −1.06 | 0.12 | 520.00 | 3462 | −0.75 | −0.22 | 1425.36 | 3462 | −0.75 | −0.64 | 360.02 |
| Average | −1.25 | 0.28 | 654.48 | −1.73 | −0.64 | 577.40 | −1.88 | −0.64 | 238.16 | |||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, M.; Zhang, S.; Deng, G. No-Wait Job Shop Scheduling Using a Population-Based Iterated Greedy Algorithm. Algorithms 2021, 14, 145. https://doi.org/10.3390/a14050145
Xu M, Zhang S, Deng G. No-Wait Job Shop Scheduling Using a Population-Based Iterated Greedy Algorithm. Algorithms. 2021; 14(5):145. https://doi.org/10.3390/a14050145
Chicago/Turabian StyleXu, Mingming, Shuning Zhang, and Guanlong Deng. 2021. "No-Wait Job Shop Scheduling Using a Population-Based Iterated Greedy Algorithm" Algorithms 14, no. 5: 145. https://doi.org/10.3390/a14050145
APA StyleXu, M., Zhang, S., & Deng, G. (2021). No-Wait Job Shop Scheduling Using a Population-Based Iterated Greedy Algorithm. Algorithms, 14(5), 145. https://doi.org/10.3390/a14050145