
Branching Densities of Cube-Free and Square-Free Words

Abstract
1. Introduction
- We construct infinite paths in the prefix tree of with the branching density as small as (Theorem 5);
- We establish the upper bound on the branching density in the prefix tree of and construct infinite paths, with the branching density as big as (Theorem 6).
2. Preliminaries
3. Positions Fixed by Big Cubes
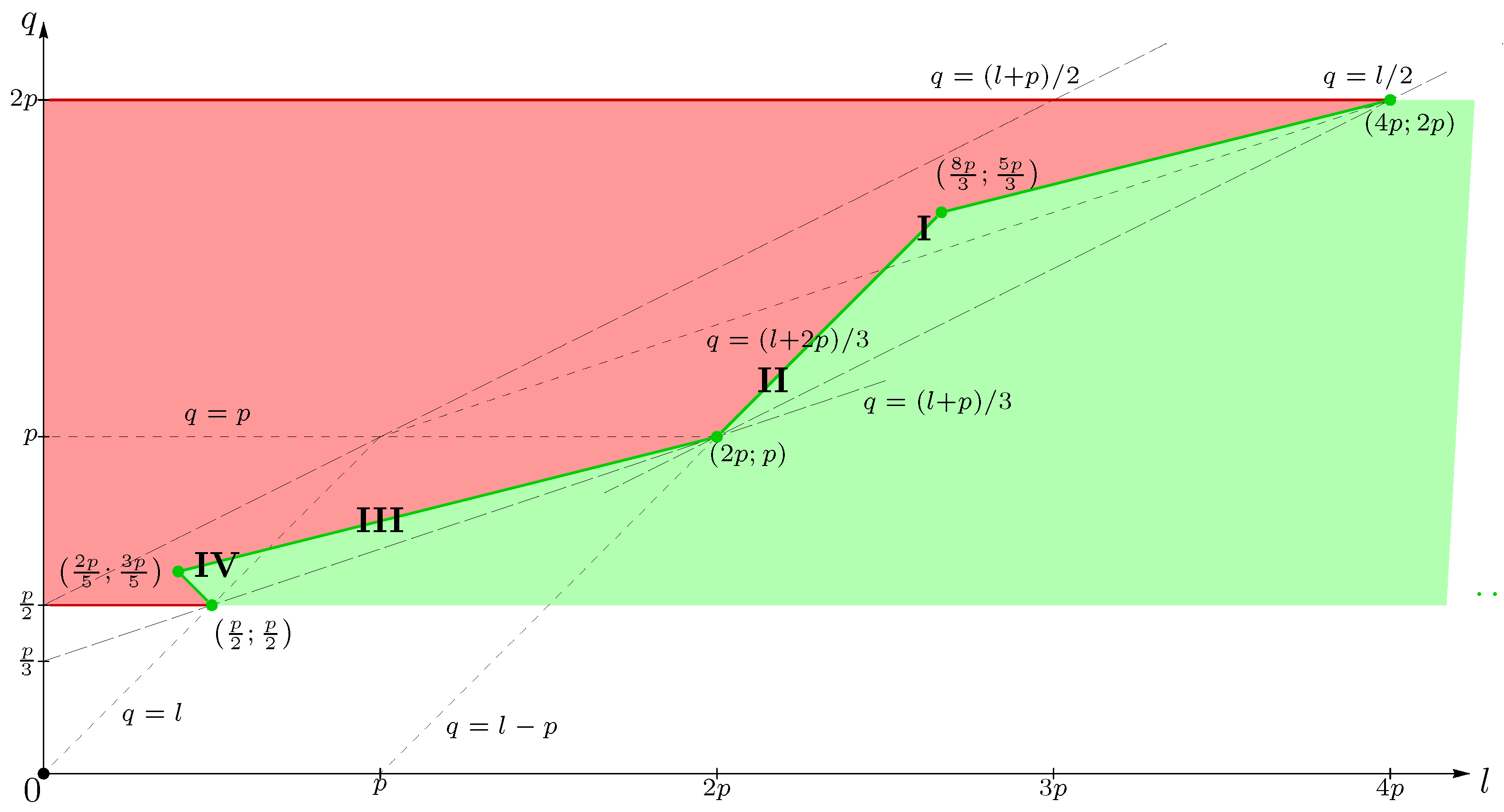
- Let be positions in w containing letters fixed by cubes with periods , respectively, where for all i; find a lower bound for (as a function of s and p) which applies for every sequence .
- , where the point is on the border of the red polygon in Figure 2, in which , , and .
- (*)
- for any fixed , the function monotonically increases for .
- T1:
- given a sequence , replace by 1 if and by otherwise.
- T2:
- given a sequence , replace by if and by otherwise.
- T3:
- given a sequence with a canonical suffix , replace by if ; by if ; and by 1 otherwise.
- T4:
- given a sequence with a canonical suffix and , replace by 1.
- T5:
- given a sequence with a canonical suffix , replace by .
4. Positions Fixed by Small Cubes
4.1. Regular Approximations and Aho–Corasick Automata
- List all p-cubes with periods and build the prefix tree of these words; then, the leaves of are exactly the p-cubes, and all internal nodes are cube-free words:
- Consider as a partial dfa with the initial state and complete this dfa, adding transitions by the Aho–Corasick rule: if there is no transition from a state u by a letter c, add the transition , where v is the longest suffix of , present in ;
- Delete all leaves of from the obtained automaton.
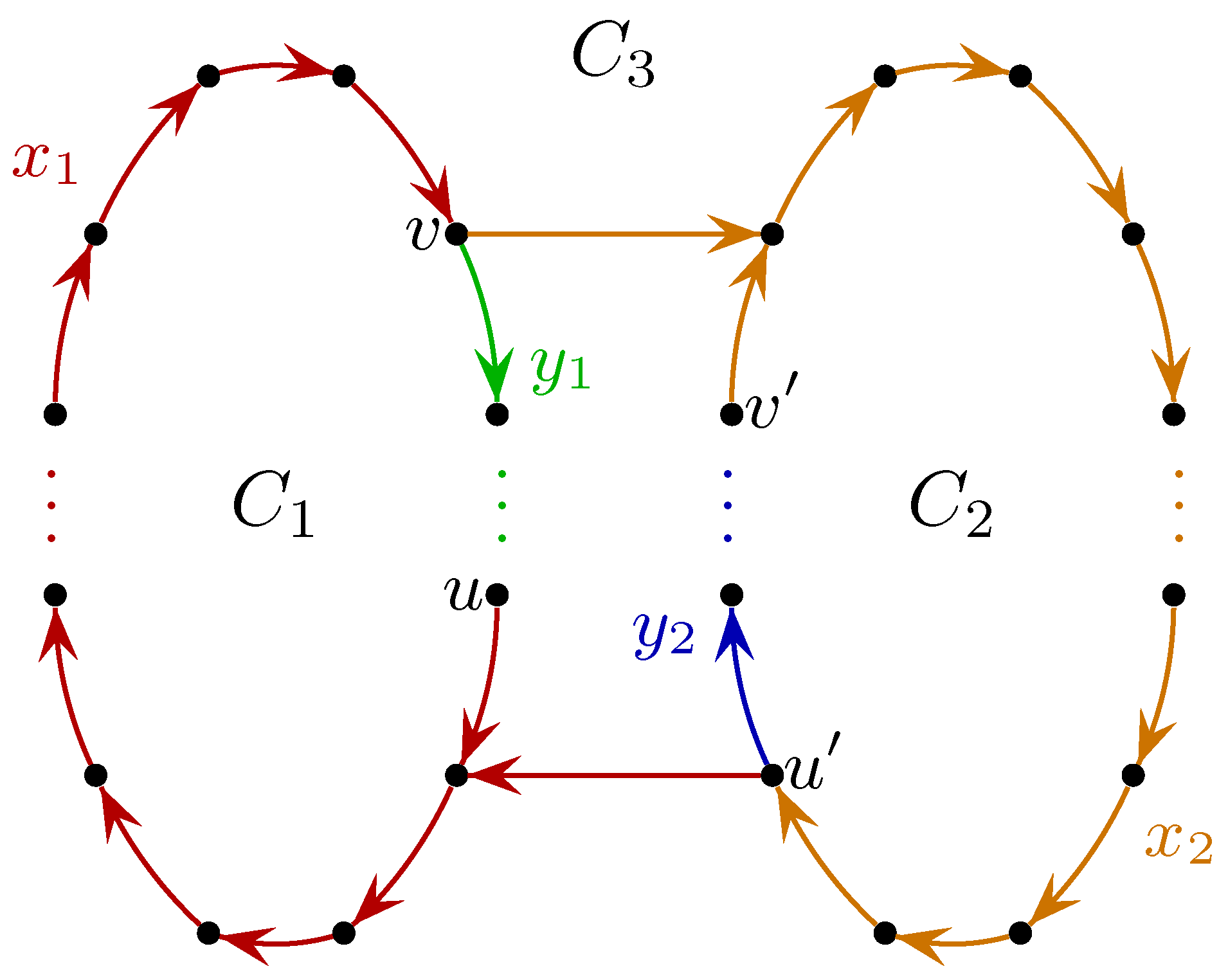
4.2. Lower Bounds on Branching Density
4.3. Cube-Free Words with Small Branching Density
- ;
- and have no occurrences in other than x-blocks.
5. The Bounds on Maximum Branching Density
6. Discussion and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Thue, A. Über unendliche Zeichenreihen. Nor. Vid. Selsk. Skr. Mat. Nat. Kl. 1906, 7, 1–22. [Google Scholar]
- Restivo, A.; Salemi, S. Overlap free words on two symbols. In Automata on Infinite Words, Proceedings of the Ecole de Printemps d’Informatique Theorique, Le Mont Dore, France, 14–18 May 1984; Nivat, M., Perrin, D., Eds.; Springer: Berlin/Heidelberg, Germany, 1985; Volume 192, pp. 198–206. [Google Scholar]
- Shur, A.M.; Gorbunova, I.A. On the growth rates of complexity of threshold languages. RAIRO Inform. Théor. App. 2010, 44, 175–192. [Google Scholar] [CrossRef][Green Version]
- Karhumäki, J.; Shallit, J. Polynomial versus exponential growth in repetition-free binary words. J. Combin. Theory. Ser. A 2004, 104, 335–347. [Google Scholar] [CrossRef]
- Ochem, P. A generator of morphisms for infinite words. RAIRO Inform. Théor. App. 2006, 40, 427–441. [Google Scholar] [CrossRef]
- Kolpakov, R.; Rao, M. On the number of Dejean words over alphabets of 5, 6, 7, 8, 9 and 10 letters. Theoret. Comput. Sci. 2011, 412, 6507–6516. [Google Scholar] [CrossRef]
- Tunev, I.N.; Shur, A.M. On two stronger versions of Dejean’s conjecture. In Proceedings of the 37th International Symposium on Mathematical Foundations of Computer Science (MFCS 2012), Bratislava, Slovakia, 27–31 August 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7464, pp. 801–813. [Google Scholar]
- Currie, J.D.; Mol, L.; Rampersad, N. The Number of Threshold Words on n Letters Grows Exponentially for Every n ≥ 27. J. Integer Seq. 2020, 23, 1–12. [Google Scholar]
- Shur, A.M. Growth properties of power-free languages. Comput. Sci. Rev. 2012, 6, 187–208. [Google Scholar] [CrossRef]
- Thue, A. Über die gegenseitige Lage gleicher Teile gewisser Zeichenreihen. Nor. Vid. Selsk. Skr. Mat. Nat. Kl. 1912, 1, 1–67. [Google Scholar]
- Jungers, R.M.; Protasov, V.Y.; Blondel, V.D. Overlap-free words and spectra of matrices. Theoret. Comput. Sci. 2009, 410, 3670–3684. [Google Scholar] [CrossRef]
- Guglielmi, N.; Protasov, V. Exact Computation of Joint Spectral Characteristics of Linear Operators. Found. Comput. Math. 2013, 13, 37–97. [Google Scholar] [CrossRef]
- Carpi, A. On the centers of the set of weakly square-free words on a two-letter alphabet. Inform. Process. Lett. 1984, 19, 187–190. [Google Scholar] [CrossRef]
- Shur, A.M. Deciding context equivalence of binary overlap-free words in linear time. Semigroup Forum 2012, 84, 447–471. [Google Scholar] [CrossRef]
- Bean, D.A.; Ehrenfeucht, A.; McNulty, G. Avoidable patterns in strings of symbols. Pac. J. Math. 1979, 85, 261–294. [Google Scholar] [CrossRef]
- Currie, J.D. On the structure and extendibility of k-power free words. Eur. J. Comb. 1995, 16, 111–124. [Google Scholar] [CrossRef][Green Version]
- Currie, J.D.; Shelton, R.O. The set of k-power free words over Σ is empty or perfect. Eur. J. Comb. 2003, 24, 573–580. [Google Scholar] [CrossRef]
- Petrova, E.A.; Shur, A.M. Constructing premaximal ternary square-free words of any level. In Proceedings of the 37th International Symposium on Mathematical Foundations of Computer Science (MFCS 2012), Bratislava, Slovakia, 27–31 August 2012; Volume 7464, pp. 752–763. [Google Scholar]
- Petrova, E.A.; Shur, A.M. On the tree of ternary square-free words. In Combinatorics on Words, Proceedings of the 10th International Conference (WORDS 2015), Kiel, Germany, 14–17 September 2015; Springer: Cham, Switzerland, 2015; Volume 9304, pp. 223–236. [Google Scholar]
- Shelton, R. Aperiodic words on three symbols. II. J. Reine Angew. Math. 1981, 327, 1–11. [Google Scholar]
- Shelton, R.O.; Soni, R.P. Aperiodic words on three symbols. III. J. Reine Angew. Math. 1982, 330, 44–52. [Google Scholar]
- Petrova, E.A.; Shur, A.M. Constructing premaximal binary cube-free words of any level. Internat. J. Found. Comp. Sci. 2012, 23, 1595–1609. [Google Scholar] [CrossRef]
- Petrova, E.A.; Shur, A.M. On the tree of binary cube-free words. In Developments in Language Theory, Proceedings of the 21st International Conference (DLT 2017), Liège, Belgium, 7–11 August 2017; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10396, pp. 296–307. [Google Scholar]
- Lothaire, M. Combinatorics on Words; Volume 17, Encyclopedia of Mathematics and Its Applications; Addison-Wesley: Reading, MA, USA, 1983. [Google Scholar]
- Lyndon, R.C.; Schützenberger, M.P. The equation aM=bNcP in a free group. Mich. Math. J. 1962, 9, 289–298. [Google Scholar] [CrossRef]
- Fine, N.J.; Wilf, H.S. Uniqueness theorems for periodic functions. Proc. Am. Math. Soc. 1965, 16, 109–114. [Google Scholar] [CrossRef]
- Crochemore, M.; Mignosi, F.; Restivo, A. Automata and forbidden words. Inform. Process. Lett. 1998, 67, 111–117. [Google Scholar] [CrossRef]
- Shur, A.M. Growth rates of complexity of power-free languages. Theoret. Comput. Sci. 2010, 411, 3209–3223. [Google Scholar] [CrossRef]
- Petrova, E.A.; Shur, A.M. Transition property for cube-free words. In Computer Science—Theory and Applications, Proceedings of the 14th International Computer Science Symposium in Russia (CSR 2019), Novosibirsk, Russia, 1–5 July 2019; Springer: Berlin, Germany, 2019; Lecture Notes in Computer Science; Volume 11532, pp. 311–324. [Google Scholar]
- Karp, R.M. A characterization of the minimum cycle mean in a digraph. Discret. Math. 1978, 23, 309–311. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
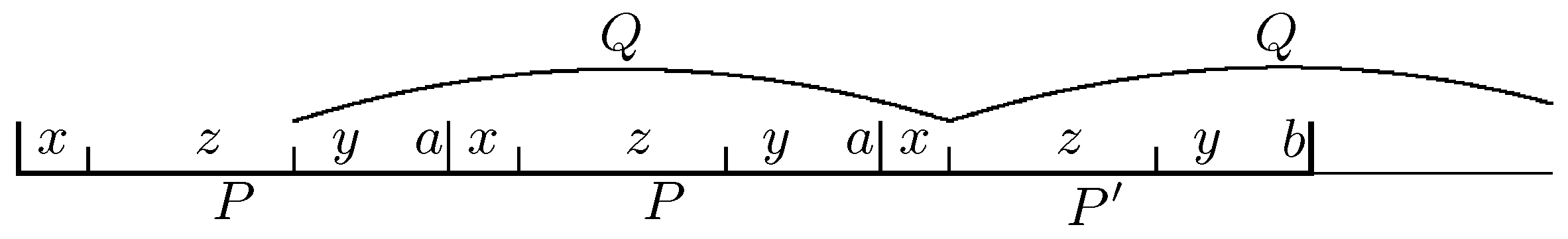{kind=link}
{kind=link}
{kind=link}
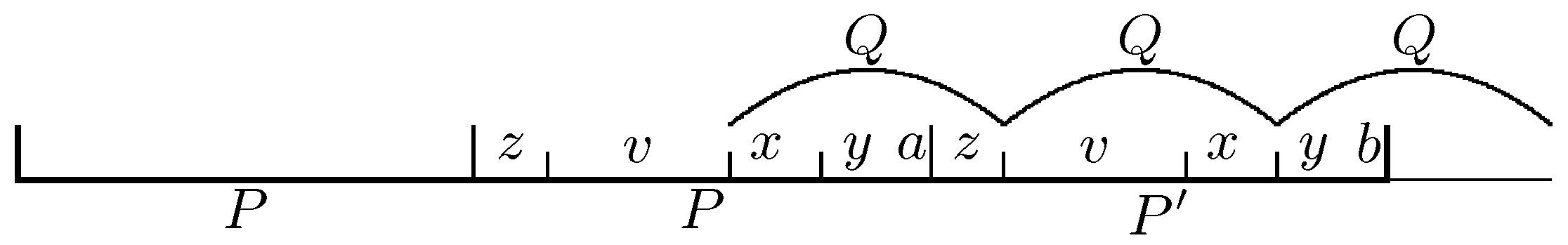{kind=link}
{kind=link}
| Point | Word w ( is bold, is underlined) |
|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Petrova, E.A.; Shur, A.M. Branching Densities of Cube-Free and Square-Free Words. Algorithms 2021, 14, 126. https://doi.org/10.3390/a14040126
Petrova EA, Shur AM. Branching Densities of Cube-Free and Square-Free Words. Algorithms. 2021; 14(4):126. https://doi.org/10.3390/a14040126
Chicago/Turabian StylePetrova, Elena A., and Arseny M. Shur. 2021. "Branching Densities of Cube-Free and Square-Free Words" Algorithms 14, no. 4: 126. https://doi.org/10.3390/a14040126
APA StylePetrova, E. A., & Shur, A. M. (2021). Branching Densities of Cube-Free and Square-Free Words. Algorithms, 14(4), 126. https://doi.org/10.3390/a14040126