2.1. Preliminaries
We model road networks as directed graphs
. A node
represents an intersection and an arc
with
represents a road segment. Every arc
a has a
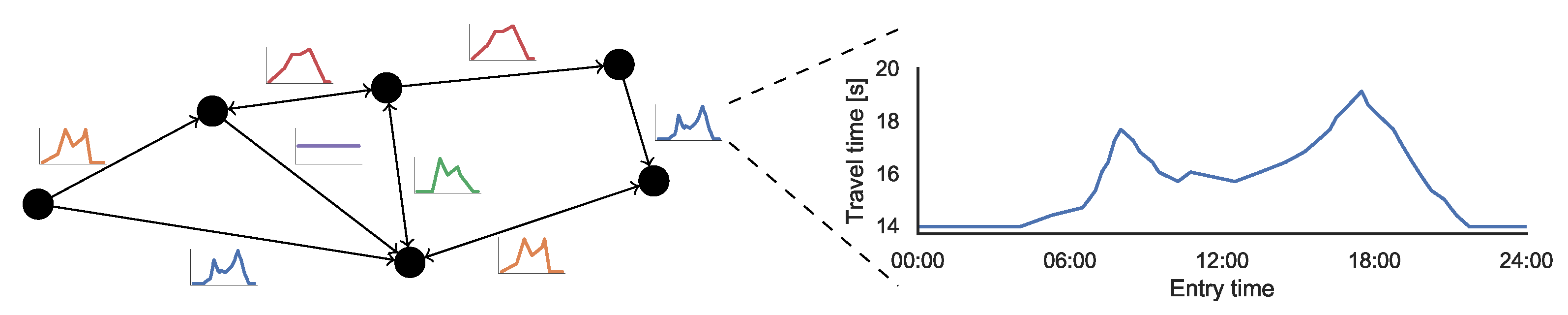
travel time function mapping departure time to travel time. These functions are also referred to as
travel time profiles. We assume that travel time functions fulfill the
First-In-First-Out (FIFO) property, that is, for any
with
,
has to hold. Informally, this means that it is not possible to arrive earlier by starting later. If there are arcs that do not fulfill the FIFO property, the shortest path problem becomes
-hard [
22] if waiting is not allowed. In our implementation, travel time functions are periodic piecewise linear functions represented by a sequence of
breakpoints. We denote the number of breakpoints in a function
f by its
complexity. A path is a sequence of nodes
such that
. We denote the concatenation of two paths by
. The travel time to traverse a path
can be evaluated by successively evaluating each link’s travel time: EVAL
.
Given two travel time functions f and g for arcs and , we are often interested in the travel time function of traversing first and then , that is . Computing this function is called linking. In a slight abuse of notation, we write for this linked function. When combining two travel time functions f and g for different paths with the same start and end, we often want to know the travel time of the best path between u and v, that is . Computing this function is called merging. Both linking and merging can be implemented with coordinated linear sweeps over the breakpoints of both functions.
Given a departure time
and nodes
s and
t, an
earliest-arrival query asks for earliest point in time one can arrive at
t when starting from
s at
. Such a query can be handled by Dijkstra’s algorithm [
1] with minor modifications [
23]. The algorithm keeps track of the earliest known arrival time
at each node
v. These labels are initialized with
for
s and
∞ for all other nodes. A priority queue is initialized with
. In each step, the node
u with minimal earliest arrival
is popped from the queue and outgoing arcs are
relaxed. To relax an arc
, the algorithm checks if
improves
and updates label and queue position of
v accordingly.
When nodes are popped from the queue, their earliest arrival is final. This property is denoted as label-setting. Once t is extracted from the queue, the earliest arrival at t is known. To retrieve the shortest path, one can use parent pointers which store the previous node on the shortest path from s for each node. We refer to this algorithm as TD-Dijkstra.
A profile query asks for the shortest travel time function between two nodes s and t for a time interval T. This query type can also be solved by a variant of Dijkstra’s algorithm. For each node v, instead of the earliest arrival time a tentative travel time function from s to v is maintained. Initially, is set to ∞ for all and to zero for s. In the priority queue, nodes are ordered by the current lower bound of their travel time function. The queue is initialized with . When a node is popped from the queue, outgoing arcs are relaxed. Here, relaxing an arc means linking with and merging the result with the travel time function of v: . If the travel time to v can be improved, its label and queue position will be updated accordingly.
This algorithm is not label-setting. Nodes may be popped several times from the queue. The algorithm can terminate as soon as the minimum key in the queue is greater than . We refer to this algorithm as TD-Profile-Dijkstra.
The
A* algorithm [
11] is an extension to Dijkstra’s algorithm. It reduces the number of explored nodes by guiding the search towards
t. Each node
u has a potential
which is an estimate of the distance to
t. The priority queue is then ordered by
.
2.1.1. Contraction Hierarchies
Contraction Hierarchies (CH) [
6] is a speed-up technique exploiting the inherent hierarchy in road networks. It was initially developed for networks with scalar edge weights. Nodes are heuristically ranked by their importance. Nodes with higher rank should cover more shortest paths. During preprocessing, all nodes are
contracted in order of ascending importance. Contracting a node
v means removing it from the network but preserving all shortest distances among remaining higher ranked nodes. For this,
shortcut arcs are inserted between the neighbors of
v if a shortest path goes through
v. A shortcut is only necessary if it represents the only remaining shortest path between its endpoints. This can be checked with a local Dijkstra search (called
witness search) between the endpoints. The result of the preprocessing is called an
augmented graph.
Queries can be answered by performing a bidirectional Dijkstra search on the augmented graph. The forward search starts at s and relaxes only forward arcs to higher ranked nodes. The backward search starts at t and traverses arcs in reverse direction and also only searches to higher ranked nodes. The construction of the augmented graph guarantees that the searches will meet and find a path that has the same length as shortest paths in the original graph. The higher ranked nodes reachable from a node are referred to as the node’s CH search space.
2.1.2. Customizable Contraction Hierarchies
Customizable Contraction Hierarchies (CCH) [
5] is a CH extension. It splits CH preprocessing into two phases where only the second uses weights. In the first phase, a separator decomposition and an associated nested dissection order [
24,
25] are computed. This order determines the node ranks. Nodes in the top-level separators have the highest ranks, followed by the nodes of each cell, recursively ordered by the same method. Since all shortest paths between different cells have to use separator nodes, these nodes cover many shortest paths. Thus, a nested dissection order is a good CH order.
Then, nodes are contracted iteratively ordered by ascending rank. Because weights are not considered in this phase, no witness search can be performed. All potential shortcuts between the higher ranked neighbors of the current node will be inserted. The upward neighbors become a clique. This phase is performed on the bidirected input graph with arcs where each arc exists in both directions.
In the second phase called customization, arc weights are computed. Arcs in the augmented graph corresponding to an input graph arc are initialized with the corresponding weight. All other arc weights are set to ∞. Then, all arcs are processed in ascending order of their lower ranked endpoint. To process an arc , all lower triangles, where w has lower rank than u and v are enumerated, checking if the path is shorter than . If so, the weight of is set to the length of the . We denote this as lower triangle relaxation.
The result of this basic customization fulfills all necessary properties for the CH query algorithm to find correct shortest distances. However, it contains many unnecessary arcs. These can optionally be removed using the perfect customization algorithm. Here, all arcs are processed in descending order of their higher ranked endpoint. For each arc , upper and intermediate triangles are enumerated, i.e., the third node w has greater rank than either u or v. The weight of will then be decreased if possible to the weight of the path . Once all arcs have been processed, all arcs where the weight changed can be removed. The augmented graph is now as small as possible.
The CH query algorithm can be reused without modifications. Another query algorithm is described in [
5] which does not need priority queues. It is based on the
elimination tree. A node’s parent in the elimination tree is its lowest-ranked upward neighbor in the augmented graph. The ancestors of a node in the elimination tree are exactly the set of nodes that are reachable in a CH search from this node [
24]. Thus, instead of exploring the search space through Dijkstra searches, the elimination tree query searches the same nodes by traversing the path to the root in the elimination tree.
2.2. Shortcut Unpacking Data
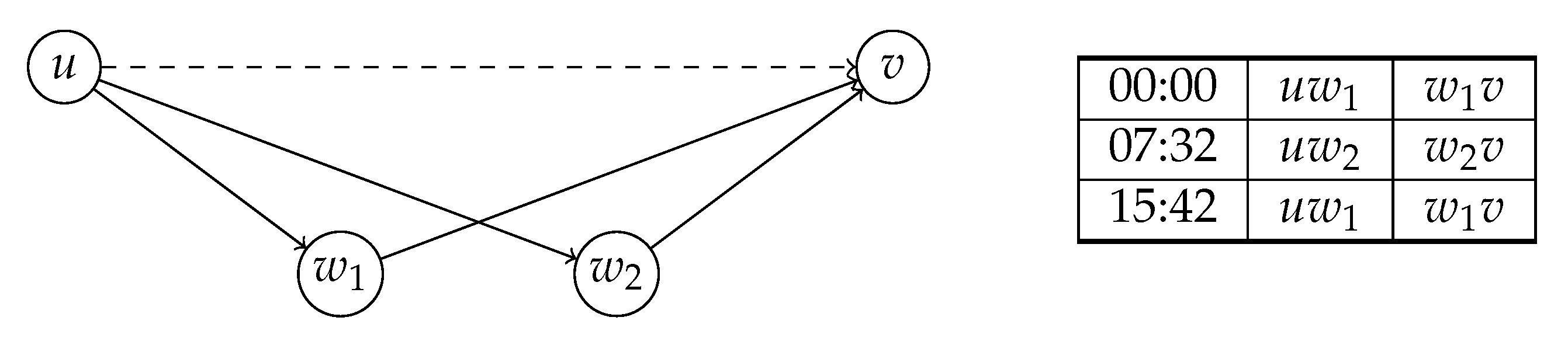
The key element of our approach is the information we store with each arc of the augmented graph. We store time-dependent unpacking information, which allows us to efficiently reconstruct the original path represented by a shortcut for a point in time. In (C)CH, shortcuts are inserted when a node w is contracted and the arcs and exist. Thus, a shortcut always skips over a triangle . However, there may be several triangles and which one is the fastest may change over time. There may also be an arc in the input graph which might sometimes be the fastest path. This is the information our unpacking data structure has to capture.
For each arc
, we store a set of time-dependent
expansions for unpacking.
Figure 3 presents an example. For an expansion
, we denote the time during which
x represents the shortest path as the
validity interval of
x. When formally referring to the path represented by an expansion, we use the
expand function .
E either maps to an original arc or to the middle node
of the lower triangle
. Knowing the middle node for each expansion is also sufficient to obtain longer paths. These can be computed by unpacking shortcuts recursively.
In our implementation, the expansion information is represented as an array of triples . is the beginning of the validity interval and and are arc ids. This information can be stored in 16 bytes for each entry—8 bytes for the timestamp and 4 bytes for each arc id. An expansion can also represent an original arc or no arc at all during a certain time interval. Both these cases are represented as special arc id values. Two invalid arc ids indicate no arc at all. One invalid id indicates that the other arc id represents an original arc. Beside the expansions, we also maintain a scalar lower bound and an upper bound on the travel time for each arc.
During preprocessing, we have to compute the bounds and expansion sets for each arc in the augmented graph. This is done using the same schema as in CCH. We iterate over all arcs and relax their lower triangles. Algorithm 1 depicts the routine for each triangle. The routine requires travel time functions for all involved arcs. We maintain these functions during preprocessing but discard them later. To relax the lower triangle , the functions and are linked and the result is merged with the current function of . Where is faster, new expansions are inserted into . Where the current travel time is faster, the current expansions are kept. The bounds are updated with the new minimum and maximum of the merged function.
Once the unpacking information for an arc is complete, we can use it to compute the arc’s travel time, unpack it to the path in the original graph or compute the travel time function for the arc. All these operations follow the same basic schema: Determine the relevant expansions and apply the operation recursively until arcs from the input graph are reached. The simplest case is the travel time evaluation. Algorithm 2 depicts this operation. First, the relevant expansion is determined using binary search. If it points to an original arc, this arc’s travel time can be evaluated and returned. If the expansion points to a lower triangle, we first recursively evaluate the first arc of the triangle. Then, the second arc can be evaluated at the entry time plus the travel time of the first arc.
| Algorithm 1:LowerTriangleRelax |
| Input: Preliminary unpacking data for arc : and travel time function . Travel time functions of lower triangle arcs and . |
| Output: Improved data and function . |
| 1 |
| 2 |
| 3 |
4Xuv ← {NewExpansion(x, Πuv ∩ Πx)∣ x ∈
Xuv} ∪ {NewExpansion([u, w, v], Π[uwv])} |
| 5 |
| 6 |
| 7 |
| 8return |
| Algorithm 2:Eval |
 |
Algorithm 3 depicts the procedure for determining the path represented by an expansion set for a given time. The recursive schema is the same as for
Eval but the result is a path instead of a travel time. Nevertheless, when unpacking lower triangles, we still need to evaluate the first arcs travel time to determine the time for unpacking the second arc.
| Algorithm 3:Unpack |
 |
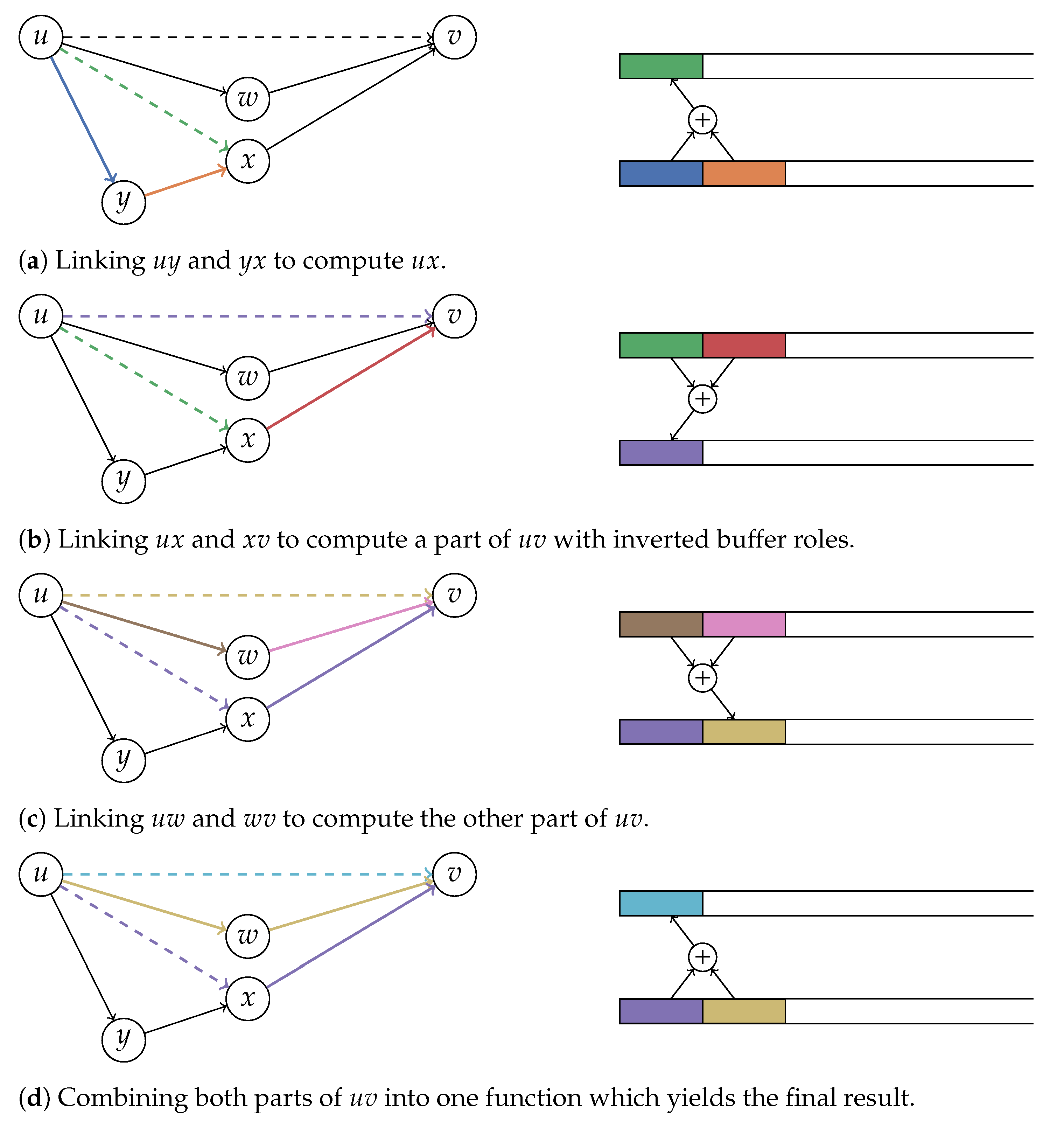
Constructing the travel time function is also similar and shown in Algorithm 4. We recursively unpack expansions until we reach arcs of the original graph where exact travel time functions are available. We may need to unpack several expansions for different times and combine them. For each expansion we check if its validity overlaps with the time range for which we want to construct the travel time function. If so, we recursively retrieve the function for the first arc during this overlap. Then, we calculate the function for the second arc during the overlap. For the second arc, the time interval must be shifted by the travel time of the first arc at the start and end of the time interval. Both functions are then linked and appended to the final function.
Implementing this algorithm naively may cause performance issues since many memory allocations are performed for intermediate results. We avoid this by keeping all intermediate results in two buffers which are reused for all invocations of this algorithm. The buffers are stored as dynamically sized arrays (C++ vectors) and can grow dynamically but will never shrink. Once they have grown to an appropriate size, no more memory allocations will be necessary. Each buffer can contain many travel time functions stored consecutively. The link operation will read the last two functions from one buffer and append the result to the other buffer. Then, the two input functions will be truncated from the first buffer. After swapping, the buffers can be used again for the next link operation. Swapping is necessary, because it is not possible to read from and write to the same buffer during the same operation. The same schema can be employed for joining partial functions (see
Figure 4 for a visualization).
| Algorithm 4:ReconstructTravelTimeFunction |
 |
2.3. Preprocessing
In this section, we present our preprocessing algorithms. The first phase of CCH preprocessing is performed only on the topology of the graph. Since no travel time functions are involved, we can adapt the algorithms of Dibbelt et al. [
5] without modification. We use InertialFlowCutter [
26] to obtain the nested dissection order. To generate the augmented graph, we implement an improved contraction algorithm first presented in [
27]. When contracting a node, we insert all upward neighbors of the current node only into the neighborhood of its lowest ranked upward neighbor. This algorithm can be implemented to run in linear time in the size of the output graph.
The goal of the second phase of preprocessing—the customization—for classical CCH is to compute the shortcut weights. For our approach, we have to compute the travel time bounds and time-dependent expansions for all arcs in the augmented graph. Recall that a shortcut always bypasses one or many lower triangles for different nodes , where has lower rank than u and v. For the bounds, we want to find the minimum and maximum travel time of the fastest travel time function between u and v over any . For the expansions, we need to determine for each point in time which lower triangle is the fastest. Assuming we know the final travel time functions of all and , we can compute this using the LowerTriangleRelax algorithm (see Algorithm 1). This leads to the following algorithmic schema: Maintain a set of necessary travel time functions in memory starting with the functions from the input graph. Iterate over all arcs in the augmented graph in a bottom-up fashion. For each arc enumerate lower triangles. Link and merge their functions to compute the function, bounds and expansions of the current arc. Keep the current arc’s travel time function in memory until it is no longer needed.
We implement this schema as follows: We process all arcs
ordered ascending by their lower ranked endpoint. Since the middle node
w of a lower triangle
has always lower rank than
u and
v, the arcs
and
will have been processed already. To process an arc
we enumerate lower triangles
. Perform
LowerTriangleRelax for each triangle in both directions. Once all arcs
have been processed where
u is the lower ranked endpoint, we drop the travel time functions of all arcs
where
u is the higher ranked endpoint. Algorithm 5 depicts this in pseudo code.
| Algorithm 5:Customization |
 |
When enumerating triangles, we order them ascending by . This way, we process triangles first, which are likely faster. This gives us preliminary bounds on the travel time of . Before linking the functions of another triangle and , we check if . If so, the linked path would be dominated by the shortcut, and we can skip linking and merging completely. If not, we link and and obtain . We still can skip merging if one function is strictly smaller than the other, that is either or . Even if the bounds overlap, one function might still dominate the other. To check for this case, we simultaneously sweep over the breakpoints of both functions, determining the value of the respectively other function by linear interpolation. Only when this check fails, we perform the merge operation.
Before the time-dependent customization, we first use the basic and perfect customization algorithms from [
5] to compute preliminary scalar upper and lower bounds for all arcs. With these bounds, we can skip additional linking and merging operations. Employing perfect customization, we can remove some arcs completely, when a dominating path through higher ranked nodes exists.
Parallelization We employ both loop based and task based parallelism. The original CCH publication [
5] suggests processing arcs with their lower ranked endpoint on the same
level in parallel. The level of a node is the maximum level of its downward neighbors increased by one, or zero if the node does not have downward neighbors. We use this approach to process arcs in the top-level separators. However, this approach requires a synchronization step on each level. This is detrimental to load balancing. Thus, we use a different strategy when possible.
In [
28], a task based parallelism approach utilizing the separator decomposition of the graph is proposed. Each task is responsible for a subgraph
. Removing the top-level separator in
decomposes the subgraph into two or more disconnected components. For each component, a new task is spawned to process the arcs the component. After all child tasks are completed, the arcs in the separator are processed utilizing the loop based parallelization schema. If the size of subgraph
is below a certain threshold, the task processes the arcs in
sequentially without spawning subtasks. We use
as the threshold with
c being the number of cores and the tuning parameter
set to 32, as suggested by Buchhold et al. [
28].
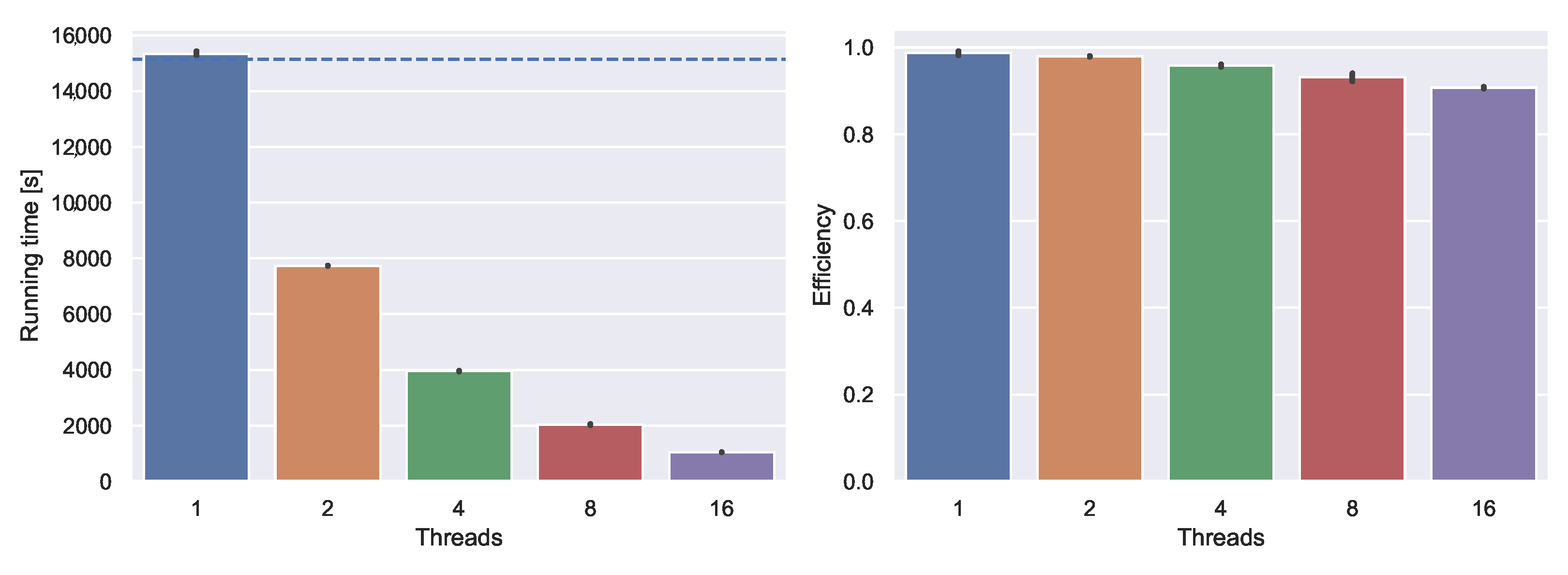
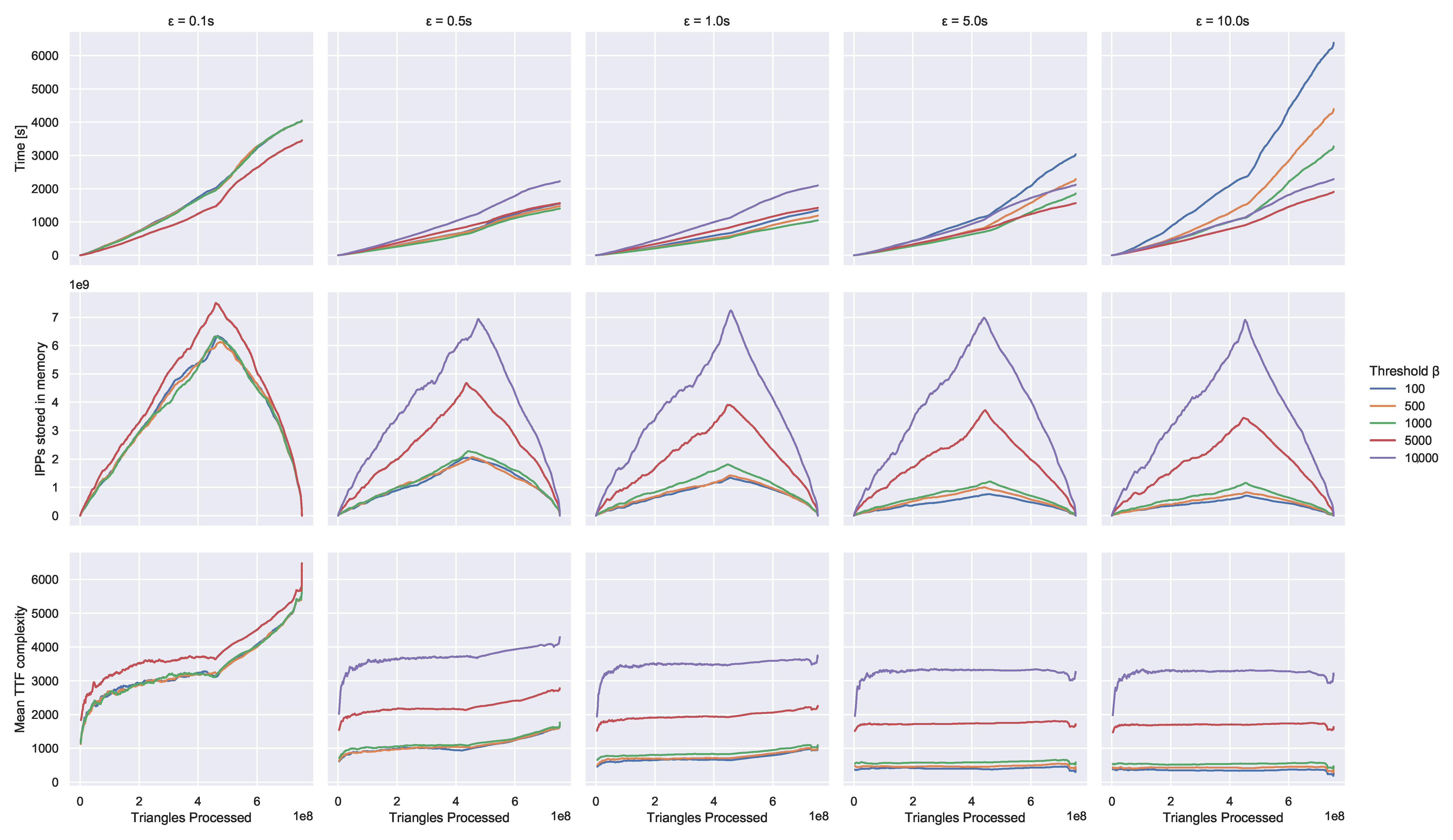
Approximation As we process increasingly higher ranked arcs, the associated travel time functions become increasingly complex. This leads to two problems. First, linking and merging becomes very time-consuming as running times scale with the complexity of the functions. Second, storing these functions—even though it is only temporary—requires a lot of memory. We employ approximation to mitigate these issues. However, for exact queries, we need exact unpacking information. We achieve this by lazily reconstructing parts of exact travel time functions during merging.
When approximating, we do not store one approximated function but two—a lower bound function and an upper bound function with maximum difference
where
is a configurable parameter. These approximations replace the exact function stored for later merge operations and will also be dropped when no longer needed. To obtain the bound functions, we first compute an approximation using the algorithm of Douglas and Peucker [
29]. Previous works [
8,
9] have reported using the algorithm of Imai and Iri [
30] for approximation. Given a maximum error bound
, this algorithm can compute in linear time the piecewise linear function with the minimum number of breakpoints within the given bound. The Douglas–Peucker algorithm has a quadratic worst case running time and no such guarantees on the number of breakpoints in the approximation. However, the theoretic guarantees of the Imai–Iri algorithm come at the cost of considerable implementation complexity and high constant runtime factors. Preliminary experiments showed that, compared to Imai–Iri, our Douglas–Peucker implementation actually produces insignificantly more breakpoints and also runs faster due to better constants. In addition, the implementation needs 30 instead of 400 lines of code, so we use the Douglas–Peucker variant. Then, we add or subtract
to the value of each breakpoint to obtain an upper or lower bound, respectively. This bounds are valid, but they may not be as tight as possible. Therefore, we iterate over all approximated points and move each point back towards the original function. Both adjacent segments in the approximated functions have a minimum absolute error to the original function. We move the breakpoint by the smaller of the two errors. This yields sufficiently good bounds.
When linking approximated functions, we link both lower and both upper bound functions. Linking two lower bounds yields a valid lower bound of the linked exact functions because of the FIFO property. The same argument holds for upper bounds.
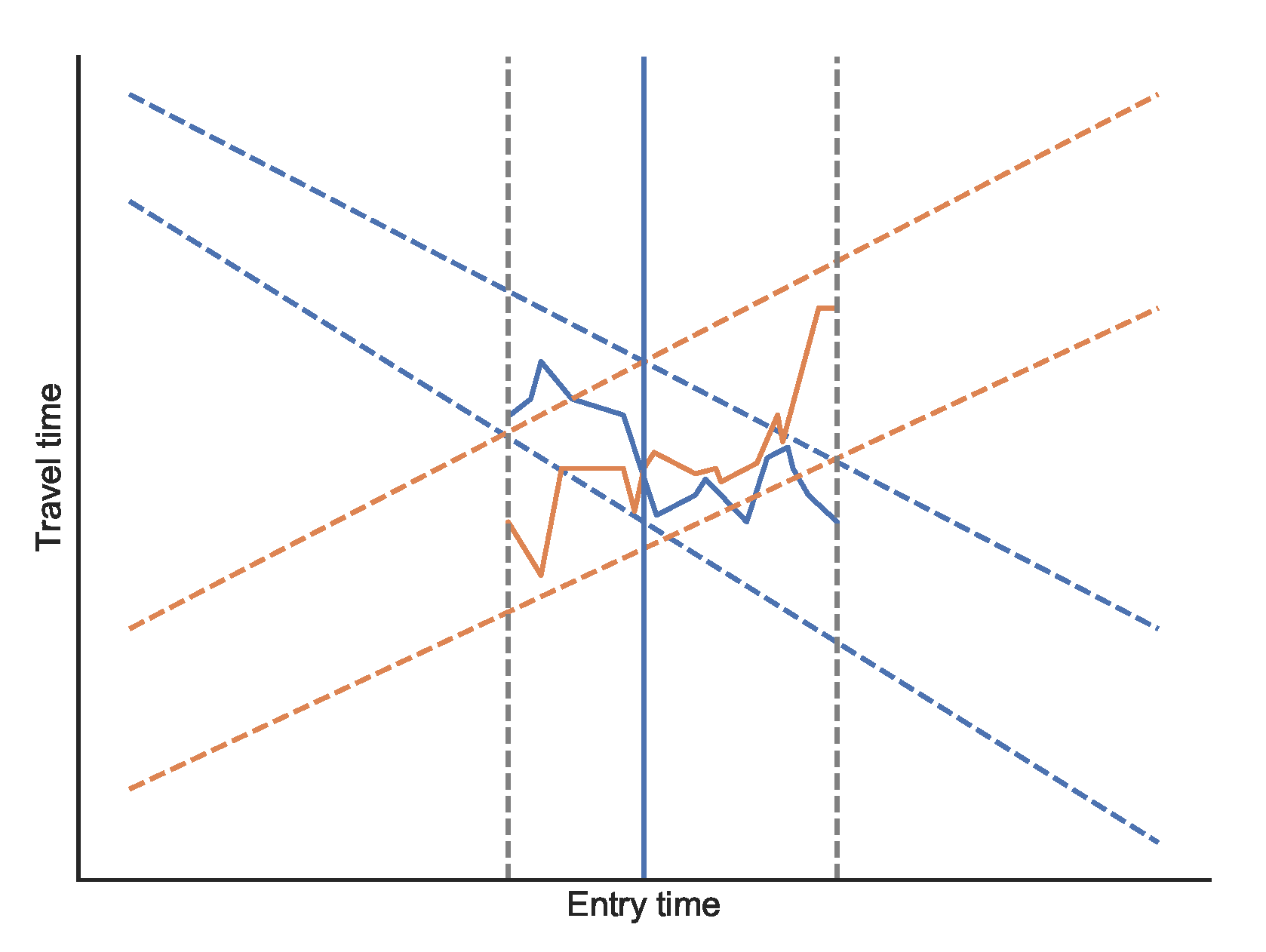
Merging approximated functions is slightly more involved. Our goal is to determine the exact expansions for each arc. We use the approximated bounds to narrow down the time ranges where intersections are possible. To identify these parts, we merge the first function’s lower bound with the second function’s upper bound and vice versa. Where the bounds overlap, an intersection might occur. We then obtain the exact functions in the overlapping parts using Algorithm 4 and perform the exact merging. To obtain approximated upper and lower bounds of the merged function, we merge both lower bounds and both upper bounds (see
Figure 5 for a visualization).
We approximate whenever a function has more than
breakpoints after merging. This includes already approximated functions. Both
and the maximum difference
are tuning parameters which influence the performance (but not the correctness). We evaluate different choices in
Section 3.3.1.
2.4. Queries
2.4.1. Earliest Arrival Queries
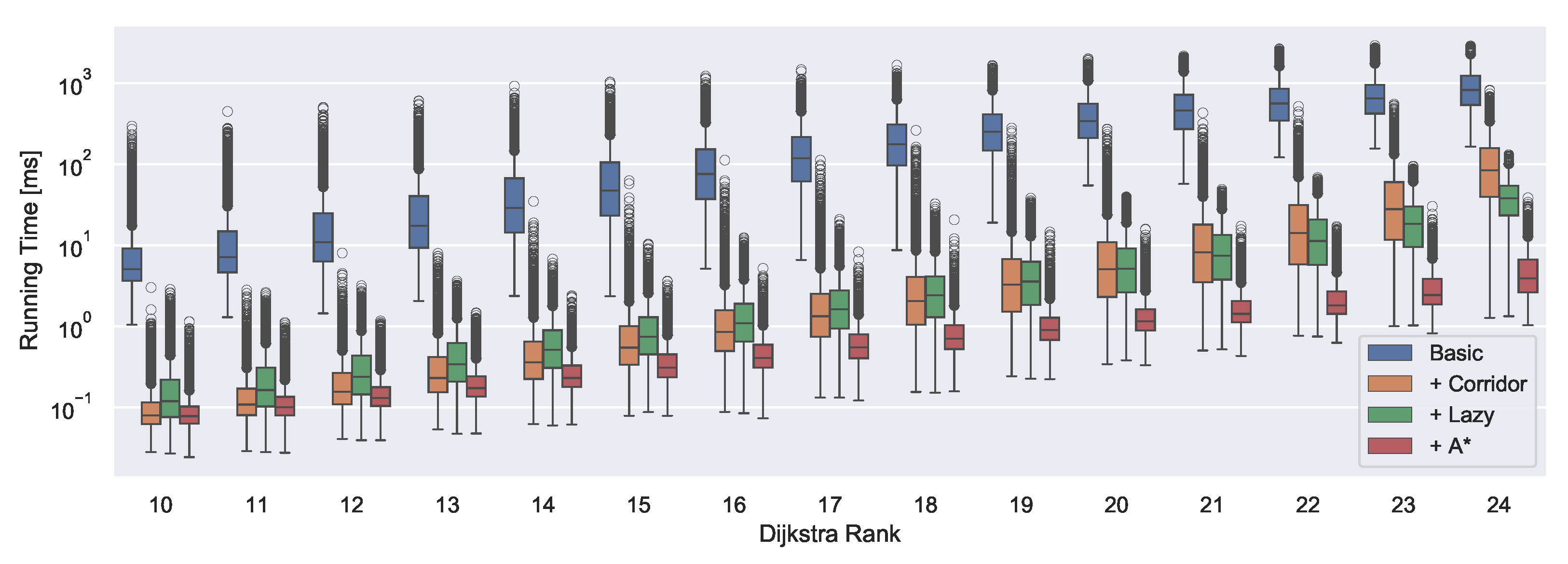
Recall that, for an earliest arrival query, we are given a source node s, a target t and a departure time from s. The goal is to obtain the earliest arrival at t. Compared to a standard (C)CH query, our query algorithm has to deal with two challenges. First, we cannot simply perform a backwards search, as we do not know the arrival time at the target node. Second, to evaluate the travel time of a shortcut, we need to obtain the path in the original graph which is an expensive operation. To address the first challenge, the query is split in two phases. In the first phase we obtain a subgraph on which we can run a forward-only Dijkstra-like search in the second phase. We now present the basic query algorithm and later introduce optimizations to address the second challenge.
In the first phase, the union of the subgraphs reachable through arcs to higher ranked neighbors from s and t is obtained. We construct these subgraphs by traversing the elimination tree starting from both s and t to the root and marking all encountered arcs as part of the search space. The backward search from t maintains parent pointers to represent the subgraph: For each encountered arc (where v has the higher rank), we store the arc id and the tail u at v. This allows efficiently traversing these downward arcs in the forward-only Dijkstra in the second phase. In the second phase, we run Dijkstra’s algorithm on the combined search spaces. Shortcut travel times are evaluated with Algorithm 2.
By the construction of CH, the search space contains the shortest path, thus Dijkstra’s algorithm will find it and this algorithm will determine the correct earliest arrival at t. However, the search space is bigger than strictly necessary. This slows down the query. In the next paragraph, we discuss how to construct smaller subgraphs using an elimination tree interval query.
Elimination Tree Interval Query The elimination tree interval query is a bidirectional search starting from both the source node
s and the target node
t. It constructs a smaller subgraph for the second phase. We denote this subgraph as a
shortest path corridor. Node labels contain an upper
and a lower bound
on the travel time to/from the search origin and a parent pointer to the previous node and the respective arc id. The bounds
,
,
,
are all initialized to zero in their respective direction, all other bounds to infinity. We also track tentative travel time bounds for the total travel time from
s to
t. For both directions, the path from the start node to the root of the elimination tree is traversed. For each node
u, all arcs
to higher ranked neighbors are relaxed, that is checking if
or
and improving the bounds of
v if possible. When the new travel time bounds from an arc relaxation overlap with the current bounds, more than one label has to be stored. As an optimization [
28], nodes can be skipped if the lower bound on the travel time to it is already greater than the tentative upper bound on the total travel time between
s and
t. After both directions are finished, we have several nodes in the intersection of the search spaces. Where the sum of the forward and backward distance bounds of such a node overlaps with the total travel time bounds, the parent pointers are traversed to the search origin and all arcs on the paths are marked as part of the shortest path corridor.
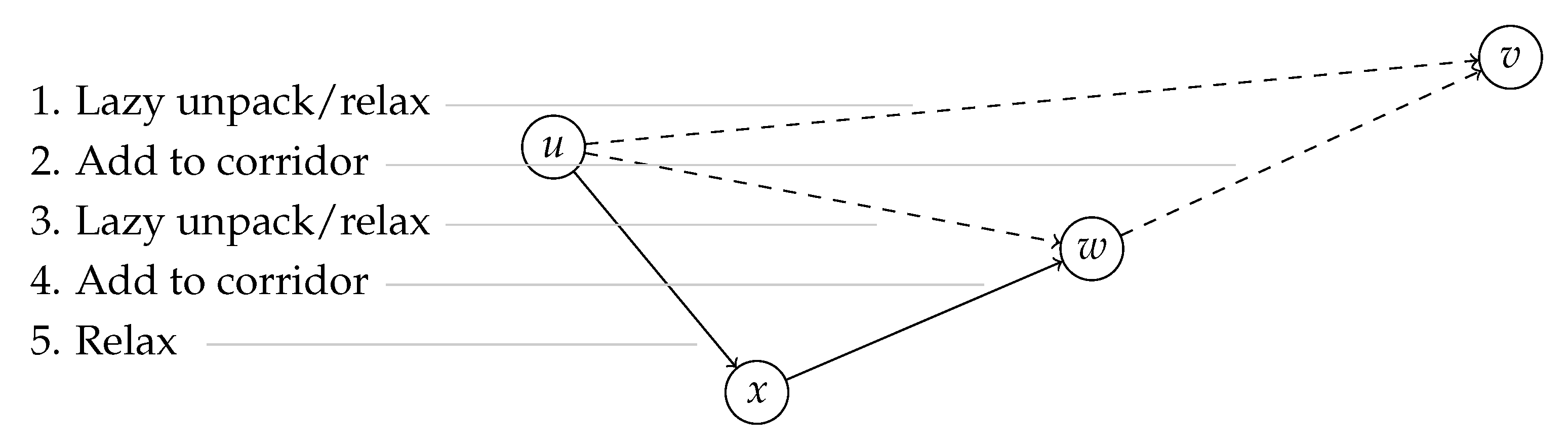
Lazy Shortcut Unpacking In the second query phase, we perform Dijkstra’s algorithm on the corridor obtained in the first phase. In the basic query, shortcuts are unpacked completely to evaluate their travel time. However, this may cause unnecessary and duplicate unpacking work. We now describe an optimized version of the algorithm which performs unpacking lazily. The algorithm starts with the same initialization as a regular TD-Dijkstra. All earliest arrivals are set to infinity, except for the start node which is set to the departure time. The start node is inserted into the queue. Then, nodes are popped from the queue until it is empty or the target node is reached. For each node, all outgoing arcs within the shortest path corridor are relaxed. When an arc is from the input graph, its travel time function can be evaluated directly. Shortcut arcs, however, need to be unpacked. The lazy unpacking algorithm defers as much work as possible: Only the first arc of the triangle of each shortcut will be recursively unpacked until an input arc is reached, the second arc will be added to the corridor.
Figure 6 shows an example. This way, we unpack only the necessary parts and avoid relaxing arcs multiple times when shortcuts share the same paths.
Corridor A* The query can be accelerated further, by using the lower bounds obtained during the elimination tree interval query as potentials for an A*-search. For nodes in the CH search space of t, the lower bounds from the backward search can be used. For nodes in the CH search space of s, we start at the meeting nodes from the corridor search and propagate the bounds backwards down along the parent pointers. This yields potentials for all nodes in the initial corridor. However, we also need potentials for nodes added to the corridor through unpacking. These potentials are computed during the shortcut unpacking. When unpacking a shortcut into the arcs and , then will be set to .
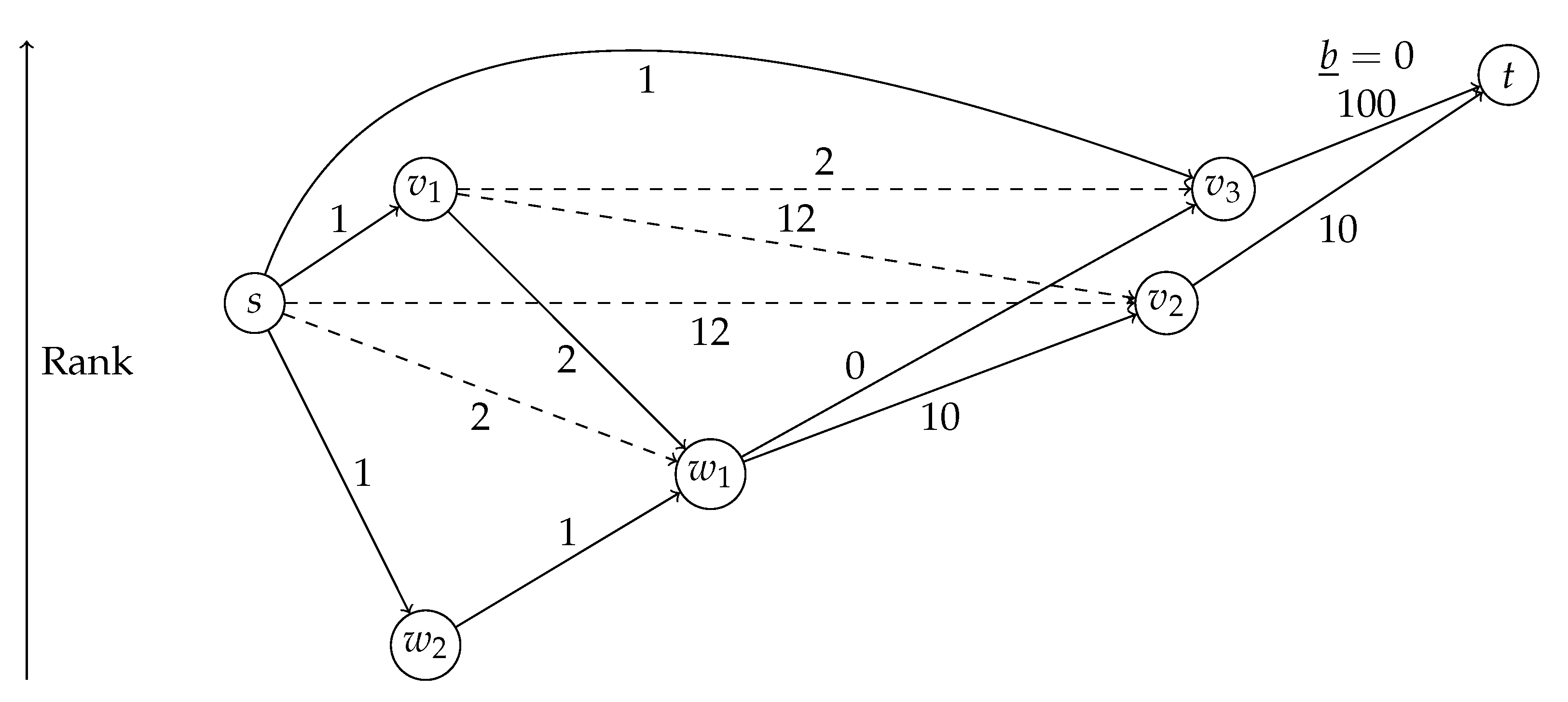
Justifying that A* with these potentials will always find the correct earliest arrival is surprisingly non-trivial. In fact, these potentials are not
feasible in the sense that
[
10].
Figure 7 shows an example where the term becomes negative and the same node has to be popped several times from the queue. Assume that all arcs have a constant travel time for the departure time of this query and lower bounds are equal to the travel time. The exception is
which has constant travel time 100 during this query but the lower bound is zero. We use zero weights to simplify the example. They are not strictly necessary for such an example. The shortest path from
s to
t is
and has length 22. After
s is settled, the queue will contain
with key
(distance plus lower bound to
t),
with key
and
with key
. Then,
will be settled which will insert
t with key
into the queue. Then,
will be settled and
will be inserted into the queue with key
. Then,
will be settled even though the current distance of 3 is greater than the actual shortest distance of 2. This will insert
with key
into the queue. Now,
will be popped and the distance to
will be improved and it will be reinserted into the queue with key
.
will be popped immediately afterwards which improves the distance and key of
which is the next node to be popped from the queue. After it has been processed, the final distance to
t (22) is known, and
t is the final node to be settled.
Nevertheless, we claim that once t is popped from the queue the algorithm always has found the correct earliest arrival. The reason is that for all nodes v on the shortest path holds. Since this is the queue key, all nodes on the shortest path will have been popped (possibly several times) before t. Let be the desired shortest path from s to t when departing from s at and the subpath from a node to t. We denote the global lower bound on the travel time between a node v and t by and the lower bound travel time on by . For nodes in the initial corridor obtained by the interval query, always holds because the potential is set to the global lower bound . However, nodes u added later to the corridor through unpacking may have a greater potential than , as depicted in the example. However, their final potential cannot be greater than the lower bound of the travel time on the shortest path . This is enough to satisfy . In addition, the potential value will be set to this final value before t is settled. Assume for contraction that is the first node on P for which this statement does not hold. cannot be a node from the initial corridor. However, will be set at most to once is settled which by assumption happens before t is settled. This is a contraction. Thus, holds for all nodes and the query algorithm always finds the correct earliest arrival when terminating once t is popped from the queue.
2.4.2. Profile Queries
A profile query asks for the function of the fastest travel time between two nodes over a given time period
T. Without loss of generality, we assume that the
T equals the entire time period covered by the input network. As discussed in
Section 2.1, such a query can be answered with TD-Profile-Dijkstra. However, TD-Profile-Dijkstra exhibits both prohibitive running time and memory consumption. Consider a path
where the travel time function of each arc has
b breakpoints. In general, linking two functions
f and
g creates a new function with
breakpoints. Thus, the travel time function from
to node
contains
breakpoints. Thus, when applying TD-Profile-Dijkstra to compute the function between
and
, the total memory consumption and the running time grows quadratically with the length of the path. We conclude that Dijkstra-based approaches to profile queries are not a promising direction. The experiments with Dijkstra-based TCH profile queries in [
8] support this conclusion. We also performed preliminary experiments with a proof-of-concept implementation where we adapted our earliest arrival query algorithm to the profile query setting. The Dijkstra-based approach was more than an order of magnitude slower than the approach described in the following. Instead of a Dijkstra-like search, our algorithm uses contraction and methods from the preprocessing to construct the desired profile.
Our algorithm has four phases. The first phase uses the elimination tree interval query to obtain a shortest path corridor and is the same as for earliest arrival queries. In the second phase, we obtain travel time functions for all arcs in the shortest path corridor. During the third phase, additional shortcuts will be inserted and their unpacking data will be computed, reusing the preprocessing algorithms. The result is a new shortcut with exact expansions . From this unpacking information, the exact travel time function (among other things) can be obtained in the fourth phase. We now describe Phases 2–4 in detail.
Reconstruction In this phase, we obtain travel time functions for all arcs in the shortest path corridor. Similar to the customization, the obtained travel time functions may be either exact, or approximated upper and lower bound functions. This keeps the memory consumption low and linking and merging operations fast. We obtain these functions by first recursively reconstructing the travel time functions of all arcs referenced by expansions. The reconstructed functions will be saved for both arcs in the corridor and unpacked arcs, in case another reconstruction operation might reuse an arc. If all arcs referenced by the expansions have an exact function available, we can compute an exact travel time function for the current arc. If not, we end up with an approximation. After reconstruction, we always check if a function has more than
breakpoints. If that is the case, we approximate it to reduce the complexity as described in
Section 2.3.
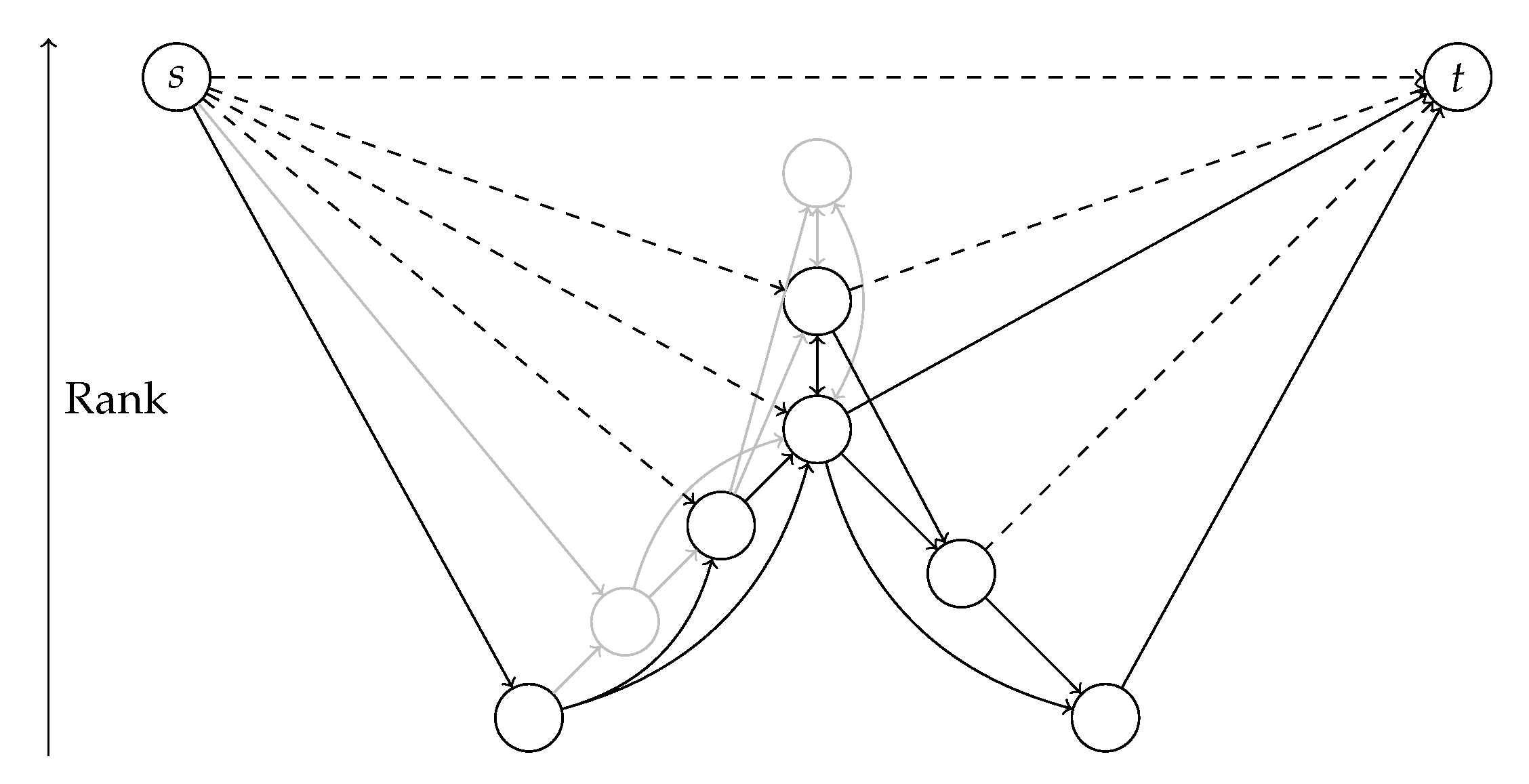
Contraction In the third phase, we insert additional shortcuts and compute their unpacking data by simulating the contraction of the nodes in the shortest path corridor. We reuse the existing nested dissection order. The ranks of
s and
t are increased such that they are higher in the hierarchy than all other nodes. This construction leads to a shortcut between
s and
t, one between
s and each node in the corridor on the path from
s to the elimination tree root and one from each node in the corridor on the path from
t to the root to
t. Some of these shortcuts may already exist (see
Figure 8 for an illustration).
These new shortcuts are now processed as in Algorithm 5 to compute their unpacking data. We initialize the shortcut bounds with the bounds obtained from the elimination tree query. This allows to prune unnecessary operations. We process shortcuts ordered by their lower ranked endpoint. For each shortcut we enumerate and relax lower triangles using Algorithm 1. We can enumerate these triangles efficiently using the parent pointer from the interval query. Each shortcut has an endpoint node in the corridor. The parent pointers of this node correspond to the triangles that need to be relaxed. The shortcuts from s and the shortcuts to t are independent of each other and can be processed in parallel. The lower triangles of the shortcut can be enumerated by iterating over the meeting nodes from the interval query. We also employ the triangle sorting optimization.
Extraction In this final phase, we can use the unpacking information of the
shortcut to efficiently compute the final result. The shortcut already contains a possibly approximated travel time function from the contraction phase. This may suffice for some applications. If the shortcut contains only an approximation, but we need an exact travel time profile, we can use Algorithm 4 to compute it. For some practical applications, the different shortest paths over the day may be more useful than the travel time profile. Algorithm 6 depicts a routine to compute path switches and the associated shortest paths. The algorithm follows the same schema as all unpacking algorithms. The operation is recursively applied to all expansions limited to the validity time of the expansion. Only the
Combine operation is more involved. It performs a coordinated linear sweep over the path sets from
and
and appends the paths where the validity intervals overlap. For the paths from
to
v, we only know the validity times with respect to departure at
. To obtain the corresponding departure time at
u, we reverse evaluate the current
path, i.e., we successively evaluate the inverted arrival time function of all arcs on the path in reverse order.
| Algorithm 6:UnpackPaths |
 |









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










