Abstract
In industrial applications, the processes of optimal sequential decision making are naturally formulated and optimized within a standard setting of Markov decision theory. In practice, however, decisions must be made under incomplete and uncertain information about parameters and transition probabilities. This situation occurs when a system may suffer a regime switch changing not only the transition probabilities but also the control costs. After such an event, the effect of the actions may turn to the opposite, meaning that all strategies must be revised. Due to practical importance of this problem, a variety of methods has been suggested, ranging from incorporating regime switches into Markov dynamics to numerous concepts addressing model uncertainty. In this work, we suggest a pragmatic and practical approach using a natural re-formulation of this problem as a so-called convex switching system, we make efficient numerical algorithms applicable.
1. Introduction
Decision-theoretic planning is naturally formulated and solved using Markov Decision Processes (MDPs, see [1]). This theory provides a fundamental and intuitive formalism not only for sequential decision optimization, but also for diverse learning problems in stochastic domains. A typical goal in such framework is to model an environment as a set of states and actions that can be performed to control these states. Thereby, the goal is to drive the system maximizing specific performance criteria.
The methodologies of MDPs have been successfully applied to (stochastic) planning, learning, robot control, and game playing problems. In fact, MDPs nowadays provide a standard toolbox for learning techniques in sequential decision making. To explain our contribution to this traditional and widespread area, let us consider a simplified example of motion control. Suppose that a robot is moving in two horizontal directions on a rectangular grid whose cells are identified with the states of the system. At any time step, there are four actions to guide the robot from the current position to one of the neighboring cells. These actions are UP, DOWN, RIGHT, LEFT, which command a move to the corresponding direction. However, the success of these actions is uncertain and is state-dependent: For instance, a command (UP) may not always cause a transition to the intended (upper) cell, particularly if the robot is at the (upper) boundary. The controller aims to reach a pre-specified target cell at minimal total costs. These costs are accumulated each time when a control is applied and depend on the current position—the cell currently occupied—accounting for obstacles and other adverse circumstances that may be encountered at some locations. In mathematical terms, such a motion is determined by a so-called controlled discrete-time discrete-space Markov chain. In a more realistic situation, the environment is dynamic: The target can suddenly change its location, or navigation through certain cells can become more difficult, changing the control costs and transitions. In principle, such problems can be addressed in terms of the so-called partially observable Markov decision processes (POMDPs, see [2]), but this approach may turn out to be cumbersome due its higher complexity than that of ordinary MDPs. Instead, we suggest a technique which overcomes this difficulty by a natural and direct modeling in terms of a finite number of Markov decision processes (sharing the same set of sets and actions), each active in a specific regime, when the regime changes, another Markov decision processes takes over. Thereby, the regime is not directly observable, thus the controller must guess which of those Markov decision processes is valid at the current decision time: Determining an optimal control becomes challenging due to regime switches. Surprisingly, one can re-formulate such control problems as a convex switching system [3], in order to take advantage from efficient numerical schemes and advanced error control. As a result, we obtain sound algorithms for solutions of regime-modulated Markov decision problems.
This work models random environment as selection of a finite-number ordinary Markov Decision Processes which are mixed by uncertain observations. On this account, we follow a traditional path facing well-known difficulties originated from high-dimensional state spaces and all problems from incorporating an information flow into a centralized decision process. However, let us emphasize that there is an approach which aims to bypass some of the problems through an alternative modeling. Namely, a game-theoretic framework has attracted significant attention (see [4,5]) as an alternative to the traditional centralized decision optimization within a random and dynamic environment. Here, individual agents aiming at selfishly maximizing their own wealth are acting in a game whose equilibrium replaces a centralized decision optimization. In such a context, the process of gathering and utilizing information is easier to model and manage since the individual strategy optimization is simpler and more efficient in collecting and processing all relevant information which may be private, noisy and highly dispersed.
Before we turn to technical details, let us we summarize in the notations and abbreviations used in this work Table 1.

Table 1.
Notations and measurement units.
2. Discrete-Time Stochastic Control
First, let us review a finite-horizon control theory. Consider a random dynamics within a time horizon whose state x evolves in a state space (subset of a Euclidean space) and is controlled by actions a from a finite action set A. The mapping , describing the action that the controller takes at time in the situation is referred to as decision rule. A sequence of decision rules is called a policy. Given a family of
there exists an appropriately constructed probability space which supports a stochastic process such that for each initial point and each policy there exists a measure and such that
holds for for each measurable . Such a system is called controlled Markovian evolution. The interpretation is that if at time t the process state is and the action is applied, then the distribution randomly changes the state from to .
Stochastic kernels are equivalently described in terms of transition operators. The transition operator, associated with the stochastic kernel will be denoted by the same letter, but it acts on functions by
whenever the above integrals are well-defined.
Having introduced such controlled Markovian dynamics, let us turn to control costs now. Suppose that for each time , we are given the t-step reward function where represents the reward for applying an action when the state of the system is at time t. At the end of the time horizon, at time T, it is assumed that no action can be taken. Here, if the system is in a state x, a scrap value , described by a pre-specified scrap function is collected. The expectation of the cumulative reward from following a policy is referred to as policy value:
where denotes the expectation over the controlled Markov chain whose distribution is defined by (1). For , introduce the backward induction operator
which acts on each measurable function where is well-defined. The policy value is obtained as a result of the recursive procedure
which is referred to as the policy iteration. The value of a “best possible” policy is addressed using
where runs through the set of all policies, the function is called the value function. The goal of the optimal control is to find a policy where the above maximization is attained:
Such policy optimization is well-defined (see [6], p. 199). Thereby, the calculation of an optimal policy is performed in the following framework: For , introduce the Bellman operator
which acts on each measurable function where is well-defined for all . Further, consider the Bellman recursion, (also called backward induction)
There solution to the above Bellman recursion returns the value function and determines an optimal policy via
Remark 1.
In practice, discounted versions the above stochastic control are popular. These are obtained by replacing the stochastic kernel by in the backward induction where is a discount factor. The advantage of this approach is that for long time horizons, the optimal policy becomes stationary, provided that all rewards and transition kernels are time-independent.
3. Markov Decisions under Partial Observation
In view of the general framework from Section 2, the classical Markov Decision Processes (MDPs) are obtained by specifying controlled Markovian evolution in terms of assumptions on the state space and on the transition kernels. Here, the state space is given by a finite set P such that states are driven in terms of
indexed by a finite number of actions with the interpretation that stands for the transition probability from to if the action was taken. In this settings, the stochastic kernels are acting functions by
There is no specific assumption on scrap and reward functions, they are given by following mappings on the state space P:
In this work, we consider control problems where a finite number of Markov decision problems are involved, sharing the same state space: each is activated by a certain regime. For this reason, we introduce a selection of MDPs indexed by a finite set S of regimes. Here, we assume that stochastic matrices as in (9) and control costs as in (11) are now indexed by S:
Let us now consider decision making under incomplete information. Given family of Markov decision problems as in (12), the controller deals with a dynamic mixture of these problems in the sense that each of these MDPs becomes valid under a certain regime which changes exogenously in an uncontrolled way and is not observed directly. More precisely, interpreting each probability distribution on S as controllers believe about the current regime, we introduce the following convex mixtures of the ingredients (12):
where stands for the simplex of all probability distributions on S. That is, the transition kernels and the control costs are now modulated by an external variable which represents the evolution of controller’s believe about the current situation. To describe its dynamics, we suppose that the information is updated dynamically through the observation of another process which follows the so-called hidden Markov dynamics. Let us introduce this concept before we finish the definition of our regime-changing Markov decision problem.
Consider a time-homogeneous Markov chain evolving on a
Assume that this Markov chain is governed by the stochastic matrix . It is supposed that the evolution of is unobservable, representing a hidden regime. The available information is realized by another stochastic process taking values in a space Y, such that at any time t, the distribution of the next observation depends on the past through the recent state only. More precisely, we suppose that follows a Markov process whose transition operators are acting on functions as
Here, stands for the family of distributions for the next-time observation of , conditioned on . For each , we assume that the distribution is absolutely continuous with respect to a reference measure on Y and introduce the densities
Since the state evolution is not available, one must rely on the believe distribution of the state , conditioned on the observations . With this, the hidden state estimates yield a process that takes values in the set of all probability measures on S which is identified with the convex hull of S due to (14). It turns out that although the observation process is non-Markovian, it can be augmented by the believes process to obtain which follows a Markov process on the state space . This process is driven by the transition kernels acting on functions as
for all . In this formula, stands for the diagonal matrix whose diagonal elements are given by , whereas represents the usual norm.
Remark 2.
In the Formula (16) the quantity
represents the updated believe state under the assumption that prior to the observation , the believe state was . On this account, this vector must be an element of , which is seen as follows (the author would like to thank to anonymous referee for highlighting out this point): Having observed that all entries of and of are non-negative (ensured by multiplication of by matrices with non-negative entries), we have to verify that they sum up to one, thus (17) represents a probability distribution on S. For this, we introduce a vector of ones with our believe state dimension, in order to verify that the scalar product is
in other words, all entries of sum up to one. Here, we have used that since all rows of stochastic matrix Γ are probability vector whose norm is representable by a scalar product with .
The optimal control for such modulated MDP is formulated in terms of the transitions operators, rewards and scrap functions which we define now. With notations introduced above, consider a state space with . First, introduce a controlled Markovian dynamics in terms of the transition operators acting on functions as
for all , , . This kernel describes the following evolution: Based on the current situation , a transition to the next decision state occurs according to the mixture of transition probabilities introduced in (13). Furthermore, our believe state evolves due to the information update based on the new observations , as described in (16). Obviously, this transformation does not depend on the decision variable , with abbreviation introduced by the last equality of (18). Finally, we introduce the control costs that are expressed by scrap and reward functions in terms of mixtures (13):
for , , , and . Note that (18), (20) and (19) uniquely define a sequential decision problem in terms of specific instances to controlled dynamics and its control costs. In what follows, we show that this problem seamlessly falls under the umbrella of a general scheme that allows an efficient numerical treatment.
4. Approximate Algorithmic Solutions
Although there are a number theoretical and computational methods to solve stochastic control problems, many industrial applications exhibit complexity and size driving numerical techniques to their computational limits. For an overview on this topic we referrer the reader to [7]. One of the major difficulties originates from high-dimensionality. Here, approximate methods have been proposed based on state and action space discretization or approximations of functions on this space. Among function approximation methods, the least-squares Monte Carlo approach represents a traditional way to approximate the value function s in [8,9,10,11,12,13]. However, function approximation methods have also been used to capture local behavior of value functions and advanced regression methods such as kernel methods [14,15], local polynomial regression [16], and neural networks [17], have been suggested.
Considering partial observability, several specific approaches are studied in [18], with bound estimation presented in [19]. The work [20] provides an overview of modern algorithms in this field with the main focus on the so-called point-based solvers. The main aspect of any point-based POMDP algorithm (see [21]) is a dynamical adaptation of the state-discretized grid.
In this work, we treat our regime switching Markov decision problem in terms of efficient numerical schemes, which deliver an approximate solution along with its diagnostics. The following section presents this methodology and elaborates on specific assumptions, required in this setting. The numerical solution method is based on function approximations which require convexity and linear state dynamics. For technical details, we refer the interested reader to [22]. Furthermore, there are applications to pricing financial options [23], natural resource extraction [3], battery management [24] and optimal asset allocation under hidden state dynamics [25], many applications are illustrated using R in [26].
Suppose that the state space is a Cartesian product of a finite set P and the Euclidean space . Consider a controlled Markovian process that consists of two parts. The discrete-space component describes the evolution of a finite-state controlled Markov chain, taking values in a finite set P, while the continuous-space component follows uncontrolled evolution with values in . More specifically, we assume that at any time in an arbitrary state the controller chooses an action a from A in order to trigger the one-step transition from the mode to the mode with probability , given in terms of pre-specified transition probability matrices indexed by actions . Note that these transition probabilities can depend on continuous state component . For the continuous-state process , we assume an uncontrolled evolution which is governed by linear state dynamics
with independent disturbance matrices , thus the transition operators are
acting on all function where the required expectations exist. Furthermore, we suppose that the reward and the scrap functions
The numerical treatment aims determining approximations to the true value functions and to the corresponding optimal policies . Under some additional assumptions, the value functions turn out to be convex and can be approximated by piecewise linear and convex functions.
To obtain an efficient (approximative) numerical treatment of these operations, the concept of the so-called sub-gradient envelopes was suggested in [22]. A sub-gradient of a convex function at a point is an affine–linear functional supporting this point from below . Given a finite grid , the sub-gradient envelope of f on G is defined as a maximum of its sub-gradients
which provides a convex approximation of the function f from below and enjoys many useful properties. Using the sub-gradient envelope operator, define the double-modified Bellman operator as
where the probability weights correspond to the distribution sampling of each disturbance matrix . The corresponding backward induction
yields the so-called double-modified value functions . Under appropriate assumptions on increasing grid density and disturbance sampling, the double-modified value functions converge uniformly to the true value functions on compact sets (see [22]). The crucial point of our algorithm is a treatment of piecewise linear convex functions in terms of matrices. To address this aspect, let us agree on the following notation: Given a function f and a matrix F, we write whenever holds for all , and call Fa matrix representative of f. To be able to capture a sufficiently large family of functions by matrix representatives, an appropriate embedding of the actual state space into a Euclidean space might be necessary: For instance, to include constant functions, one adds a dimension to the space and amends all state vectors by a constant 1 in this dimension.
It turns out that the sub-gradient envelope operation acting on convex piecewise linear functions corresponds to a certain row-rearrangement operator acting on the matrix representatives of these functions, in the sense that
Such row-rearrangement operator , associated with the grid
acts on each matrix F with d columns as follows:
If piecewise linear and convex functions are given in terms of their matrix representatives , such that
then it holds that
where the operator ⊔ denotes binding matrices by rows (for details, we refer the reader to [22]) and to ([23]). The algorithms presented there use the properties (29)–(31) to calculate approximate value functions in terms of their matrix representatives as follows:
- Pre-calculations: Given a grid , implement the row rearrangement operator and the row maximization operator . Determine a distribution sampling of each disturbance with corresponding weights for . Given reward functions and scrap value , assume that the matrix representatives of their sub-gradient envelopes are given byfor , and . The matrix representatives of each double-modified value functionare obtained via the following matrix-form of the approximate backward induction (also depicted in the Algorithm 1.
- Initialization: Start with the matrices
- Recursion: For and for calculate
| Algorithm 1: Value Function Approximation. |
 |
Here, the term stands for the matrix representative of the sub-gradient envelope of the product function
which must be calculated from both factors using the product rule. The product rule has to be modified due to the assumption that in our context, the sub-gradient of a function f at a point g is an affine–linear function, which represents the Taylor approximation developed at g to the linear term. For such sub-gradients, the product is given by . The concrete implementation of this operation depends on how the matrix representative of a constant function is expressed. In Section 6.1, we provide a code which realizes such a product rule, based on the assumption that the state space is represented by probability vectors.
Having calculated matrix representatives , approximations to expected value functions are obtained as
for all , , and . Furthermore, an approximately optimal strategy is obtained for by
In what follows, we apply this technique to our regime-switching Markov decision problems.
5. HMM-Modulated MDP as a Convex Switching Problem
Now, we turn to the main step—an appropriate extension of the state space (as introduced in Section 3). This procedure will allow treating our regime-switching Markov decision problems by numerical methodologies described in the previous section.
With notations and conventions of Section 3, we consider the so-called positively homogeneous function extensions: A function is called positively homogeneous if holds for all and . Obviously, for each the definition
yields a positively-homogeneous extension of v.
Given the stochastic kernel (18), we construct a probability space supporting a sequence of independent identically distributed random variables, each following the same distribution in order to introduce the random matrices (disturbances)
These disturbances are used to define the following stochastic kernels in :
acting on all functions where the above expectations are well-defined. A direct verification shows that for each and it holds that
The kernels (36) satisfy the linear dynamics assumption (21) required in (22) and define a control problem of convex switching type whose value functions also solve the underlying regime-switching Markov decision problem.
Proposition 1.
Given a regime modulated Markov decision problem whose dynamics are defined by the stochastic kernel (18) with control costs given by (19) and (20), consider the value functions returned by the corresponding backward induction
Moreover, consider functions returned by
where , are positively homogeneous extensions of , and is from (36). Then for it holds that
Proof.
Let us prove (40) inductively. Starting at , assertion (40) holds since is a positively homogeneous extension of . Having assumed that (40) holds for with a positively homogeneous , we apply observation (37) to conclude that
thus adding , which is a positively homogeneous extension of and maximizing over yields (40).
6. Algorithm Implementations and Performance Analysis
The stylized algorithm presented in Algorithm 1 is appropriate for problems whose scale is similar to that of the illustration provided in the next section. In this example, although we have used a relatively slow scripting language R, all calculations are performed within a few seconds. This shows a practical relevance of such implementations for small and medium-size applications. However, to address larger problems, a significant increase in calculation performance is needed and can be achieved by approximations, which are based on a standard technique from big data analysis, the so-called next-neighbor search. A realization of this concept within a package for the statistical language R is described in [26]. With all critical parts of the algorithm written in C, this implementation shows a reasonable performance which is examined and discussed in [26]. For technical details, we address the reader to [23,27]. Let us merely highlight the main idea here. The point is that the computational performance of our approach suffers from the fact that most of the calculation time is being spent on matrix rearrangements required by the operator . Namely, in order to calculate an expression
as in (25), the row-rearrangement must be performed n times, once for each disturbance matrix multiplication. This task becomes increasingly demanding for larger values of the disturbance sampling sizes n, particularly in high state space dimensions. Let us omit and p in (43) to clarify the idea of efficiency improvement developed in [23]. This approach focuses on the two major computational problems
and
It turns out that one can approximate the procedure in (44) by replacing the row-rearrangement operation with an appropriate matrix multiplication using next-neighbor techniques. To address (45) each random disturbance matrix is represented as the linear combination
with non-random matrices and , and random coefficients whose dimension J is preferably significantly lower than the dimension of the state space. Both techniques are applicable and save a significant amount of calculations. Only the disturbances are identically distributed, so that all pre-calculations have to be done only once. However, since a detailed discussion of this approximation and its performance gain are out of the scope here, we refer the reader to [23,26,27].
Note that an application of convex switching techniques under partial observations requires some adaptations, due to the non-observable nature of the state space. More precisely, the user must realize a recursive filter to extract believe states from the current information flow, before optimal decisions can be made. In other words, filtering must be followed by the application of the decision policy, returned from the optimization. A stylized realization of this approach is depicted in Figure 1.
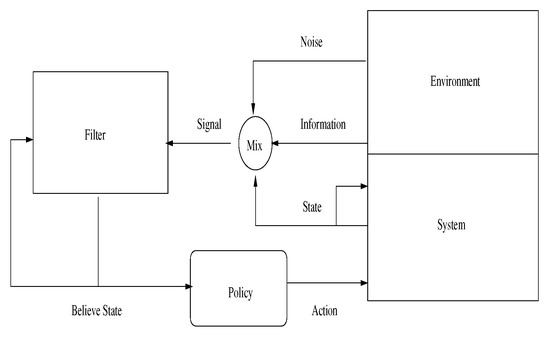
Figure 1.
Stylized implementation of the control flow within a realistic application.
6.1. An illustration
Let us consider a typical application of Markov decision theory to agricultural management [28] which addresses a stochastic forest growth model in the context of timber harvesting optimization. The work [28] re-considers the classical results of Faustmann in the framework of random growth and potential ecological hazards (for a derivation of Faustmann’s result from 1849 and its discussion, we refer the reader to [28]). The idea is that as a reasonable approximation, one supposes that the only stochastic element is the growth of trees: That is, the timber volume per hectare defines the state. To facilitate the analysis, this timber volume (cubic meter per hectare) is discretized as shown in the first row of the Table 2. Furthermore, the costs of action (in USD per hectare) are shown in the second row, assuming that the action means timber harvest for all states (state 2–state 6) followed by re-forestation with the exception of the bare land (state 1), where there is re-forestation only. There are no costs if no action is taken, as seen from the third row of Table 2.
Table 2.
Discrete states and their control costs.
Given the state space and control costs as defined in Table 2, define the action space , where 1 means being idle and 2 means acting. Assuming decision intervals of 20 years, a Markov decision problem is determined with the action-dependent stochastic matrices
Note that the transitions to state 1 (bare land) from higher state in may be interpreted as a result of a natural disaster, whereas those to a neighboring state may describe a randomness in the forest growth. The matrix describes the timber harvest followed by re-forestation. The work [28] discusses an optimal policy for this model assuming an infinite time horizon with a discounting which is inferred from the interest rate effects. The optimal policy is compared to that from a non-random growth model, represented by the same parameters with the exception of the free-growth transition , being replaced by
This non-random model resembles the well-known results of Faustmann, claiming that the only optimal strategy is a roll-over of harvesting and re-planting after a number of years. In the above Markov decision problem, the discount factor is set to (corresponding to annual interest rates). Here, it turns out that it is optimal to reforest in state 1, do nothing in state 2 and 3, and cut and reforest in states 4, 5, and 6. That is, the resulting roll-over is three times the decision period, 60 years. In contrast, the random model suggests that in the presence of ecological risks, it is optimal to reforest in state 1, do nothing in state 2, and cut and reforest in states 3,4, 5, and 6, giving a shorter roll-over of two decision periods, 40 years.
Using our techniques, the optimal forest management can be refined significantly. Major improvement can be achieved by incorporating all adverse ecological situations into a selection of transition matrices representing a random forest evolution within appropriate regimes. The regime switch can be monitored and estimated using stochastic filtering techniques as described above. For instance, the potential climate change with an anticipated increase of average temperature and extended drought periods can be managed adaptively. In what follows, we consider a simplified numerical example based on the stochastic forest growth model presented above.
First, let us replicate the results of [28] in the following code


Indeed, the above plot shows that in the stochastic forest growth model, it is optimal to do nothing in state 2, but harvest and replant in all other states—an optimal roll-over of two periods, 40 years. Running the same algorithm for the deterministic growth, returns the value functions and policies given below—an optimal roll-over over three periods, 60 years.

Now let us illustrate an adaptive forest management in presence of regime-changing risk. First, let us specify the hidden Markovian dynamics of the information process . For this, a stochastic matrix and a family of measures must be specified, according to (15). For simplicity, we suppose that the state comprises two regimes and that an indirect information is observed within the interval , after appropriate transformation. For instance, could measure a percentage of rainy days over a pre-specified sliding window over a past period. Alternatively, may stand for a specific quantity (average temperature) with distribution function typical for this quantity in the normal regime, applied on its recording. With this assumption, we consider as a regular regime, under which the observations follow a beta distribution with specific parameters defined for the state , whereas in the presence of environmental hazards, in the regime , the observation follows a beta distribution with other parameters typical for . Finally, let us suppose that the regime change matrix
describes a situation where the regular regime is more stable . The following code illustrates a simulation of such observations and the corresponding filtered information with results of filtering procedure depicted in Figure 2.

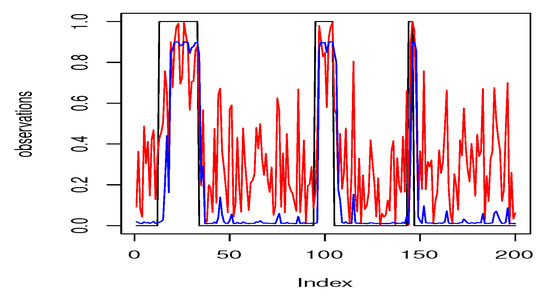
Figure 2.
Believe state evolution: Observations depicted by red line, the probability that the system is in the regime 2 by black (true state) and blue (filtered believe) line.
Let us address an implementation of the Algorithm 1. Having defined the appropriate operators

 we introduce arrays as data containers
we introduce arrays as data containers
 these containers are filled with appropriate quantities:
these containers are filled with appropriate quantities:


we introduce arrays as data containers
these containers are filled with appropriate quantities:
After such initialization, the backward induction is run:

The Figure 3 depicts the value function for the state depending on the believe state, such that the x- axes is interpreted as the conditioned probability that the system is in the deterministic growth regime. That is, the end points of the graph represent values of the expected return of the optimal strategy under the condition that it is known with certainty that the system starts in random growth (left end) or in deterministic growth (right end). Observe that those values are close to 2660.412 and 3012.010 obtained in the classical Markov decision setting. Naturally, the uncertainty about the current regime yields intermediate values, connected by a convex line.
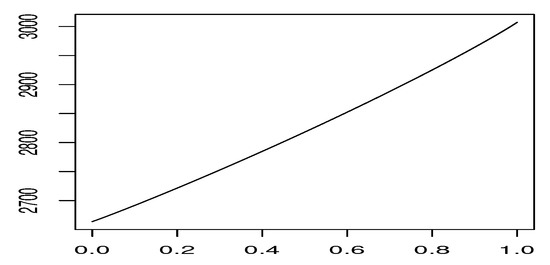
Figure 3.
Value function for the state 2 depending on believe probability.
The Figure 4 illustrates the choice of the optimal action for the state depending on the believe state depicted in the same way as in Figure 3. Again the end points of the graph represent optimal actions conditioned on certainty about the current regime. As expected, the optimal decision switches from (act) to (be idle) at some believe probability of approximately .
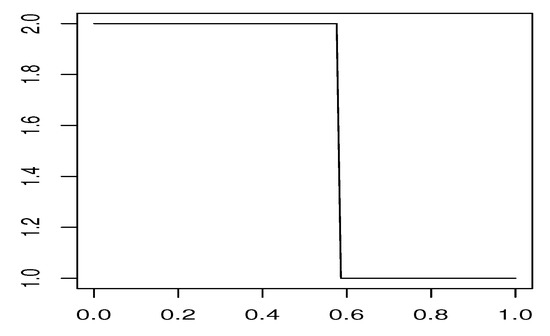
Figure 4.
Optimal action for the state 3 depending on believe probability.
7. Conclusions
Having utilized a number of specific features of our problem class, we suggest a simple, reliable, and easy-to-implement algorithm that can provide a basis for rational sequential decision-making under uncertainty. Our results can be useful if there are no historical data about what could go wrong, or when high requirements on risk assessment are proposed. In such situations, we suggest encoding all relevant worst-case scenarios as potential regime changes, making conservative a priori assumptions on regime change probabilities. Using our algorithm, all optimal strategies can be efficiently examined in such a context, giving useful insights about parameter sensitivity and model risk associated with this sensitivity. The author believes that the suggested algorithm can help gaining a better understanding of risks and opportunities in such context.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The author declares no conflict of interest.
References
- Puterman, M. Markov Decision Processes: Discrete Stochastic Dynamic Programming; Wiley: New York, NY, USA, 1994. [Google Scholar]
- Smallwood, R.D.; Sondik, E.J. The Optimal Control of Partially Observable Markov Processes over a Finite Horizon. Oper. Res. 1973, 21, 1071–1088. [Google Scholar] [CrossRef]
- Hinz, J.; Tarnopolskaya, T.; Yee, T. Efficient algorithms of pathwise dynamic programming for decision optimization in mining operations. Ann. Oper. Res. 2020, 286, 583–615. [Google Scholar] [CrossRef]
- Tsiropoulou, E.E.; Kastrinogiannis, T.; Symeon, P. Uplink Power Control in QoS-aware Multi-Service CDMA Wireless Networks. J. Commun. 2009, 4. [Google Scholar] [CrossRef]
- Huang, X.; Hu, F.; Ma, X.; Krikidis, I.; Vukobratovic, D. Machine Learning for Communication Performance Enhancement. Wirel. Commun. Mob. Comput. 2018, 2018, 3018105:1–3018105:2. [Google Scholar] [CrossRef]
- Bäuerle, N.; Rieder, U. Markov Decision Processes with Applications to Finance; Springer: Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Powell, W.B. Approximate Dynamic Programming: Solving the Curses of Dimensionality; Wiley: Hoboken, NJ, USA, 2007. [Google Scholar]
- Belomestny, N.; Kolodko, A.; Schoenmakers, J. Regression methods for stochastic control problems and their convergence analysis. SIAM J. Control Optim. 2010, 48, 3562–3588. [Google Scholar] [CrossRef][Green Version]
- Carriere, J.F. Valuation of the Early-Exercise Price for Options Using Simulations and Nonparametric Regression. Insur. Math. Econ. 1996, 19, 19–30. [Google Scholar] [CrossRef]
- Egloff, D.; Kohler, M.; Todorovic, N. A dynamic look-ahead Monte Carlo algorithm. Ann. Appl. Probab. 2007, 17, 1138–1171. [Google Scholar] [CrossRef]
- Tsitsiklis, J.N.; Van Roy, B. Regression Methods for Pricing Complex American-Style Options. IEEE Trans. Neural Netw. 2001, 12, 694–703. [Google Scholar] [CrossRef]
- Tsitsiklis, J.; Roy, B.V. Optimal Stopping of Markov Processes: Hilbert Space, Theory, Approximation Algorithms, and an Application to Pricing High-Dimensional Financial Derivatives. IEEE Trans. Automat. Contr. 1999, 44, 1840–1851. [Google Scholar] [CrossRef]
- Longstaff, F.; Schwartz, E. Valuing American options by simulation: A simple least-squares approach. Rev. Financ. Stud. 2001, 14, 113–147. [Google Scholar] [CrossRef]
- Ormoneit, D.; Glynn, P. Kernel-Based Reinforcement Learning. Mach. Learn. 2002, 49, 161–178. [Google Scholar] [CrossRef]
- Ormoneit, D.; Glynn, P. Kernel-Based Reinforcement Learning in Average-Cost Problems. IEEE Trans. Automat. Contr. 2002, 47, 1624–1636. [Google Scholar] [CrossRef]
- Fan, J.; Gijbels, I. Local Polynomial Modelling and Its Applications; Chapman and Hall: London, UK, 1996. [Google Scholar]
- Bertsekas, D.P.; Tsitsiklis, J.N. Neuro-Dynamic Programming; Athena Scientific: Nashua, NH, USA, 1996. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Cassandra, A.R. Planning and acting in partially observable stochastic domains. Artific. Intell. 1998, 101, 99–134. [Google Scholar] [CrossRef]
- Lovejoy, W.S. Computationally Feasible Bounds for Partially Observed Markov Decision Processes. Operat. Res. 1991, 39, 162–175. [Google Scholar] [CrossRef]
- Shani, G.; Pineau, J.; Kaplow, R. A survey of point-based POMDP solvers. Autonom. Agents Multi-Agent Syst. 2013, 27, 1–51. [Google Scholar] [CrossRef]
- Pineau, J.; Gordon, G.; Thrun, S. Point-based value iteration: An anytime algorithm for POMDPs. In Proceedings of the 18th International IJCAI’03: Joint Conference on Artificial Intelligence, Acapulco, Mexico, 9–15 August 2003; pp. 1025–1032. [Google Scholar]
- Hinz, J. Optimal stochastic switching under convexity assumptions. SIAM J. Contr. Optim. 2014, 52, 164–188. [Google Scholar] [CrossRef]
- Hinz, J.; Yap, N. Algorithms for optimal control of stochastic switching systems. Theor. Prob. Appl. 2015, 60, 770–800. [Google Scholar] [CrossRef]
- Hinz, J.; Yee, J. Optimal forward trading and battery control under renewable electricity generation. J. Bank. Financ. 2017. [Google Scholar] [CrossRef]
- Hinz, J.; Yee, J. Stochastic switching for partially observable dynamics and optimal asset allocation. Int. J. Contr. 2017, 90, 553–565. [Google Scholar] [CrossRef]
- Hinz, J.; Yee, J. Rcss: R package for optimal convex stochastic switching. R J. 2018. [Google Scholar] [CrossRef]
- Hinz, J.; Yee, J. Algorithmic Solutions for Optimal Switching Problems. In Proceedings of the 2016 Second International Symposium on Stochastic Models in Reliability Engineering, Life Science and Operations Management (SMRLO), Beer Sheva, Israel, 15–18 February 2016; pp. 586–590. [Google Scholar] [CrossRef]
- Buongiorno, J. Generalization of Faustmann’s Formula for Stochastic Forest Growth and Prices with Markov Decision Process Models. For. Sci. 2001, 47, 466–474. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).