1. Introduction
Genetic algorithm (GA) is a probabilistic and heuristic search approach to investigate encoded solutions in an iterative manner, which was successfully applied in various practical applications, ranging from image processing [
1], general optimization problems [
2], biological sciences and bioinformatics [
3,
4], finance, economics and social sciences [
5,
6], speech processing [
7] to path planning [
8].
In case of evolutionary algorithms, a fitness function, determining the quality of each solution is used instead of a detailed formal description and analytical solution of the problem. The algorithm starts the search for the optimal solution with an initial generation encoding a set of randomly created solution candidates. Genetic algorithm in most common cases consists of three operations (selection, crossover and mutation) which are used repeatedly to create a new generation until reaching the solution with the designated threshold or stopping after a fixed number of generations. We produce a new generation by using the aforementioned fitness function to select a percentage of the best solutions from the current generation and then recombine them to yield new offspring (solution candidates). Before evaluating the new generation, we apply mutation inducing small changes in the solution candidates to maintain population diversity. Although some papers [
9] have used only mutation algorithm to create newer generations, combination of crossover and elitism usually increases convergence speed towards the optimal solution [
10].
Genetic algorithm as any other optimization algorithm could get stuck in a local optimum; a problem which can be solved by increasing the exploration rate. The Exploration-Exploitation dilemma is the most common trade-off problem between obtaining new knowledge and the necessity to use that knowledge to improve performance; a problem which can be found everywhere in nature [
11]. This problem manifests in genetic algorithm as well where applying solely mutation and randomly creating chromosomes increases the exploration rate to the utmost resembling random search which is time consuming and impractical in high-dimensional problems. On the other hand, selecting only the best solution and spreading it in the next population would increase the exploitation rate making the algorithm unrobust which will only lead to the first local optimum in the initial population. One would like to exploit moving toward the best solution, but also explore maintaining a diverse population; and delve in the best current solutions finding the optimal or sub-optimal solutions, but still avoid local optimum.
The most important factors affecting the accuracy of the final solution and the convergence of the algorithm are the format of the problem representation and the fitness function, which we need to assess the validity of each solution. These two factors will determine the space of all solution candidates. These elements are usually determined by heuristic approaches and are always problem dependent. Other factors, like different mutation and crossover methods, can be investigated more generally.
One of the most important and ubiquitous operation is mutation which has a large effect on the convergence of GAs [
12]. Throughout the literature, researchers have been using static or adaptive mutation [
13]. In the early implementations, static mutation probability was applied, where the mutation rate was optimized by heuristic approaches with trial and error. In these approaches, a single parameter was identified determining the rate of mutation and was applied in the same manner for each gene in each chromosome. Later, adaptive versions have appeared where mutation rate can be changed according to other state variables of the algorithm, like iteration number, quality of the selected solution candidates or average fitness of all the solutions.
One of the major hinder of most algorithms is parameter tuning where an appropriate parameter setting has to be chosen, but it can be a hard task due to parameters’ reliance on the representation of the optimization problem. Parameter tuning relies on experimenting many fixed parameters reaching the supposedly optimal parameter setting without taking into account the possible changes throughout the optimization process. Beside the problem of tedious time-consumption, another problem of parameter tuning is that the chosen parameters may only work well starting from a specific state of the search space. Another parameter scheme is dynamic parameter control which changes parameters adaptively, during execution. When first introduced, it relies on the state of the optimization process or on time [
14]. Parameter control later adopted self-correcting, self-adaptive, approach adjusting parameters while in progress relying on the feedback from the algorithm’s recent performance. Self-adaptation can be used as a strong, effective tool steering parameters with the help of some performance assistance e.g the fitness of a chromosome and the fitness of a population.
There is a huge focus recently in the machine learning community on gradient descent which can give you the optimal direction inside your local search space toward the local minimum or maximum. Using gradient descent with back propagation, which can tell you the optimal location for a change, solves the optimization problem faster by exploiting the neighbors of the current parameters. Although gradient descent seems like the perfect approach for any optimization problem, it is not applicable and ill-defined for non-differentiable objective functions and it is vulnerable against non-convex problems [
15]. Evolutionary Algorithms are good alternatives which can overcome the limitation of gradient descent and sometimes can be even faster than hill-climbing optimization [
16]. Evolutionary Algorithms can provide a solution; sometimes sub-optimal but still applicable in practice, without any deep knowledge of the system due to the random generation of a new population. Gradient based methods like stochastic gradient descent [
17] or ADAM optimizer [
18] have been the key for the recent advancements of deep learning which surpass any other optimization approach. Researchers started to integrate the two approaches striving for the optimal solution where evolutionary algorithms have been used for hyperparameter search [
19] and reinforcement learning [
20], which demonstrates the importance of GAs in machine learning as well.
Our method, called Locus mutation, extends the traditional approach of mutation where the probability of the alteration of a gene is uniformly distributed over each position of the genome in one sample. Locus mutation applies an additional probabilistic weight for each gene (i.e., location or dimension), thus, dimensions with higher probability will be selected more frequently, where an alteration could lead to a better solution with higher accuracy. Locus mutation resembles the traditional optimization approaches, back-propagation or gradient descent; where in case of a solution which is represented as a vector, our approach would point out the location which is recommended to be changed and keep satisfying segments intact.
In
Section 2 we will introduce Genetic Algorithms, in
Section 3 we will describe our alterations, describe our method and demonstrate results on the N-Queen problem, in
Section 4 we will show how our approach can be used on other problems as well, like the travelling salesman problem and in the last Section we will conclude our results.
2. Genetic Algorithm
Genetic algorithm is a heuristic approach, exploring the search space and exploiting local optima. A gene is a singular element, encoding one dimension of the problem and representing a fragment of a solution. Problem representation is an essential prerequisite which can heavily determine the result of the algorithm. Another essential prerequisite condition to any optimization approach is its fitness function F which depends on the problem itself. Most sophisticated optimization approaches only deal with differentiable loss functions, fitness functions, which do not always exist. In case of general problems, the loss function is not differentiable, but we still have estimation about the quality of a solution which can be used in evolutionary algorithm.
Since algorithm convergence is determined heavily by the selected heuristics, we will distinguish between two different problems. In case of many practical problems, the fitness function measures a deviation from the optimal solution where the value of the best possible solution is known (and usually is zero, like in case of the N-queen problem [
21]), meanwhile in other set of problems (like traveling salesman [
22] or knapsack problem [
23]) the fitness value of the optimal solution is unknown. Unlike the second set of problems, the first set of problems have a stopping criteria yielding a conceptual optimum. First we will demonstrate our solution using the first set of problems, but later we will present that it can be applied in case of the latter problems types as well.
The population will evolve exploiting the best solutions by selection then applying crossover operations amongst them. Ordering the chromosomes using the contrived fitness function then selecting a fixed percentage of the most fitted ones would help converging the population towards a better solution. Copying a small unchanged proportion of the fittest chromosomes into the next generation is called elitism which can steer the algorithm towards local optima. The new population consists of the selected elite chromosomes, combined chromosomes from the selected ones and new random chromosomes. Crossover exploits the best candidate solutions by combining them taking into account problem representation, creating only valid solution candidates. In addition to the randomly generated solutions, mutation has been used to increase the exploration rate searching for the optima. Intuitively, an adaptive mutation rate has been adopted where the mutation will be mitigated over time while converging to the optimal solution.
The traditional approach of genetic algorithm is presented in Algorithm 1 as a pseudo-code in forms of simple functions. Searching for the optimal solution
, we initialize the population
with random values. There is a trade-off problem between the size of the population
and the number of populations
which can be investigated with parameter tuning. Starting with an enormous
and small
could increase the exploration rate but yield a small exploitation rate. On the other hand, having small
and large
would limit the exploration of the search space. Our work focused on the mutation rate
which drives the mutation operation
. A fitness function
is used to select
the elite which is a small percentage of the fittest chromosomes. Crossover
is used after the selection process exploiting the elite. Lastly, we mutate
the current
with
probability. With a repetitive manner as many as the
and in chronological order, we apply the previously mentioned steps.
| Algorithm 1: Genetic algorithm main steps |
 |
Adaptive mutation can be divided into three categories: population level, individual level, and component level adaptation [
24]. Population level adaptation changes the mutation probability globally using feedback information from the previous population which means all the chromosomes have the same probabilistic chance for modification. At the individual level, each chromosome has its own adaptive operator which have been induced from the statistics of the previous generations. While the component level adaptation tries to combine the two previous methods by grouping the chromosomes and setting a different adaptive operator for each group.
However, it is important to note that none of the previously mentioned approaches utilize the statistic information inside the chromosome, which can be induced from the genes. To overcome this deficiency, we come up with the novel idea of locus mutation, where every gene has its own different adaptive operator and problematic genes have higher chance for change. Identifying the problematic genes is an important factor of our algorithm, and in our approach problematic means those genes which are mostly responsible for the high values in the error function (e.g., number of queens hitting each others in Case of the N-Queen problems).
3. Locus Adaptive Genetic Algorithm
All possible solutions in the initial population (
) are sampled randomly from the search space. The algorithm is iterated
times where at each step, the population is continuously changing and better samples are selected and recombined; this helps increasing the average fitness value of the population over time. Thus, the time dependency of the population can be noted by
which denotes the population at iteration
t. At each iteration within the population, each sample is usually referenced to as a chromosome. A chromosome is one possible solution; a solution candidate; and this can be referenced to as
where
chromosomes. A chromosome is a vector representing a solution, which can be further divided into individual elements (Like a position of a single queen on a chessboard) this is noted by a third index
where
genes. In the traditional approach, selection of a position for mutation is a random process and its major goal is the exploration of the high-dimensional search space without taking the current state of the chromosome into account. Optimal selection of the gene which will be modified requires a comprehensive knowledge of three different variables; the statistics of the inter and intra populations, the chromosomes as a function of time and the statistic of the genes’ competences. Scrutinizing the relation between this three variables and the fitness function will lead us to the optimal modification of every gene. Although seemingly the optimal solution can be attained from Equation (
1), it is not practical and both memory and time consuming because you need to keep track of all generations, chromosomes and genes throughout the algorithm.
calculates the probability of mutation for a given gene
j and
F is a function calculating the mutation rate of gene
j taking into account all previous generations (
q), chromosomes (
k) and genes (
l). A lot of attempts have been made to calculate an adaptive mutation operator using one of the aforementioned variables, but the authors are not aware of any method that has used the genes statistic to form a gene level mutation. Any mutation method can be rewritten as in Equation (
1) using constant parameters as we will see in the following paragraphs. Traditional Genetic algorithm uses static operators as defined in Equation (
2) which means that all chromosomes and genes throughout all generations would have the same mutation probability although some candidate solutions are closer to the optimal solution than others.
C is a constant value for every iteration, chromosome and gene. Static mutation is good until it gets stuck in a local minimum. After we reach a local minimum, we can walk back down the hill and try another angle craving for the optimal solution or try to jump from the local minima by increasing/decreasing the mutation rate or applying crossover. Parameter tuning is a manual, time consuming and unpleasant road which can be superseded with parameter control [
13]. Parameter control means to start from an initial value then tune it adaptively during execution as in the following approaches. With the presupposition of converging to the optimal solution over time, an adaptive mutation subjected to time as in Equation (
3) has been proposed.
F is a function of time which depends on
t but does not depend on the chromosome
i or the gene
j. Once the population is determined the probability of mutation is the same for every chromosome and gene (
) in that iteration. Dynamic mutation takes the number of the current iteration as an input and gives us the mutation rate as an output. The function used to calculate the mutation rate can be a linear function which relies on the fact that it is beneficial to have a high mutation rate at the beginning and lower mutation rate during convergence [
25], a gaussian function [
26] where the mutation rate is going to increase smoothly until reaching an apex then decrease steadily converging to zero, Lévy distribution [
27] or any arbitrary function. It is not the best approach having the same probability for each chromosome which could be very close to the optimal solution or far away from it.
Another approach with the same problem is population adaptive operator [
28,
29] as in Equation (
4) where each generation has a different mutation operator which is deduced from the generation statistics. In [
30], more than one mutation operators are used with an equal initial probability (1/the number of operators), but after each iteration the probabilities will increase/decrease according to the fitness values of each operator designated offspring. In general these approaches can be defined as:
F will determine how the mutation depends on all the fitness values in the current population for every
i and
j (chromosome and gene). Again once the population is determined, the probability of mutation is the same for every chromosome and gene (
). To solve this problem an individual adaptive mutation [
31,
32] was proposed as in Equation (
5) where each chromosome has its own different mutation operator that can be concluded from the statistic about the search space of each chromosome through the populations which is, the statistic, implicitly maintained by the algorithm. Mutation rate can change not only in different iterations, but also at the same generation where better candidates will have lower mutation rate, meanwhile worse candidates will have higher mutation rates. Each chromosome will have a different mutation rate which is proportional with comparison to the other chromosomes in the current population.
F is a function depending on the fitness function of the selected chromosome i, and the fitness of all the chromosomes k in the population. Even though chromosomes which are closer to the optimal solution has a smaller probability for mutation, their mutation most probably is going to diverge them from the optima. Thus, most of the genes are in a good position and any random modification is going to be mostly harmful. Hence uniformly distributed mutation over the genes is not the best option; assume we have an almost perfect solution (nine genes are perfect and one is bad), we have a 9/10 chance with uniform mutation to make this instance worse.
To tackle this problem, we have designated a different probability operator for each gene in a chromosome which can only be possible in partially solvable problems. To think about it, the mutation happens in gene level where we choose one or two genes randomly and then we change their values. Thus, a gene which is in a good position should be less prone to mutation. The simplest model for gene level mutation is locus mutation as in Equation (
6) where all generations and chromosomes have the same mutation rate but each gene has a different mutation rate which corresponds with the other genes.
F is a function depending on the fitness function of the selected gene
l. Once the mutation rate is set, the probability of mutation is the same for every chromosome at all time (
). To grasp the concept before diving into details, we can simply state that measuring the fitness of each gene in a partially solvable problem will deduce a unique customized distribution for each chromosome yielding a gene level mutation. As an advantage of our approach, we can combine locus mutation with any of the other proposed methods. Returning to the first and most generalized Equation (
1), we can use locus mutation with an adaptive individual level where each chromosome and each gene has an individual mutation rate which may give us a better result but certainly will make the whole process slower and resource consuming. We have only focused on the simplest version of our novel idea which is locus mutation.
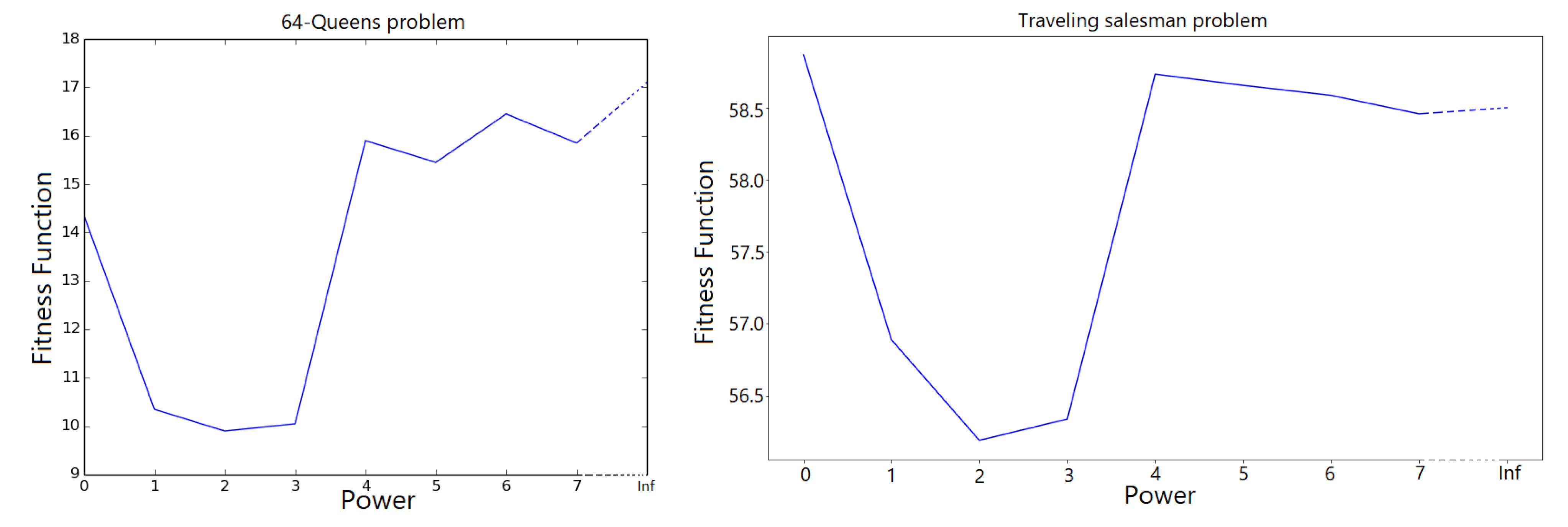
Algorithm 2 depicts GA with locus mutation. All parameters remain the same as in the original Algorithm 1 setting
parameter to one, but we do have a newly introduced gene level mutation (
) which depends on partial fitness (
). Although in our experiments we will always set
to one only focusing on the effect of locus mutation without taking into account
parameter, a detailed investigation
Section 5.4 will be conducted illustrating the advantage which can be garnered using
parameter.
| Algorithm 2: Genetic algorithm main steps |
 |
In a partially solvable problem, partial fitness can be calculated leading to mutation with probabilistic gene selection. In a problem representation, one could identify parts which are good, and parts which are bad. A good gene should be changed less frequently, a worse element should be changed more often exploring further regions away from local optima. To illustrate the importance of
in calculating the probabilistic mutation factor of each gene, we will discuss the partial solution of 8 queens problem as it has been depicted in
Figure 1. In 8 queens problem, the chromosome has eight genes which refer to the number of the row, while the index of each gene refers to the column. A chromosome with zero queens hitting each other is optimal. Intuitively, the fitness function calculates the number of hits. In the example depicted in
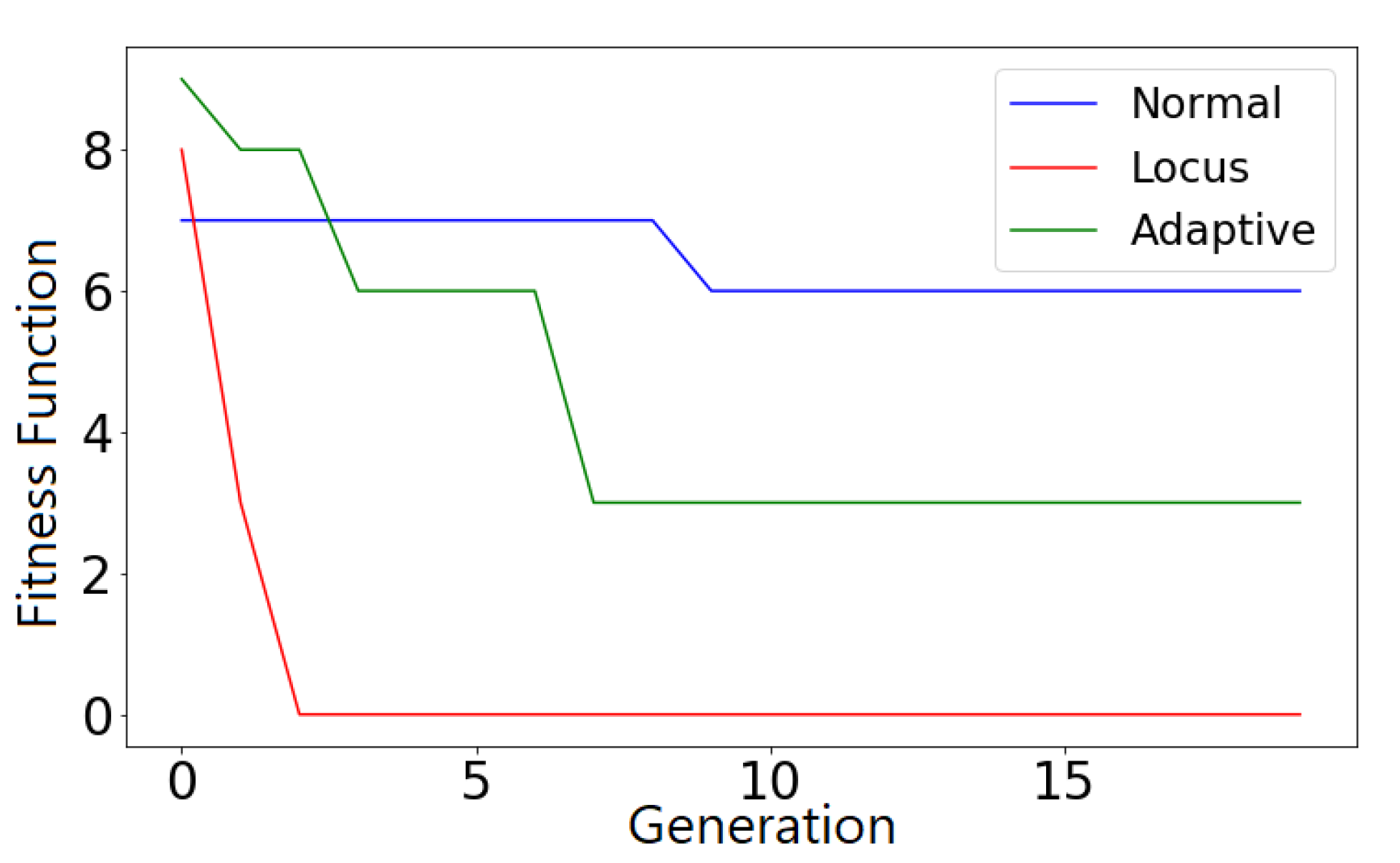
Figure 1, the loss is four (Calculating hitting pairs only once.) where queens 1, 2, 3, 4, 7, 8 are hitting 8, 3 and 4, 2 and 7, 2, 3, 1 respectively. On the other hand, partial fitness will give a different loss for each gene representing the number of queens hitting the current queen. In our example, partial values are [1 2 2 1 0 0 1 1] where for example queen number three is hitting two other queens (2 and 7) which means it is a bad queen and a high mutation rate should be assigned to it and likewise for queen number two. Whereas, queens five and six are not hitting any other queens, meaning that low mutation rates should be assigned to them.
Instead of using uniform distribution as in the traditional algorithm, we are using a probabilistic function conveying the information about the fitness of each gene. The mutating rate of each gene does not only depend on its partial value, but it is also proportional with other genes’ partial value, also every gene has a minimal mutation rate, this ensures that even a gene with zero hitting queens, will have a non-zero mutation probability.
4. Heuristically Partially Solvable Problems with Unknown Optimum
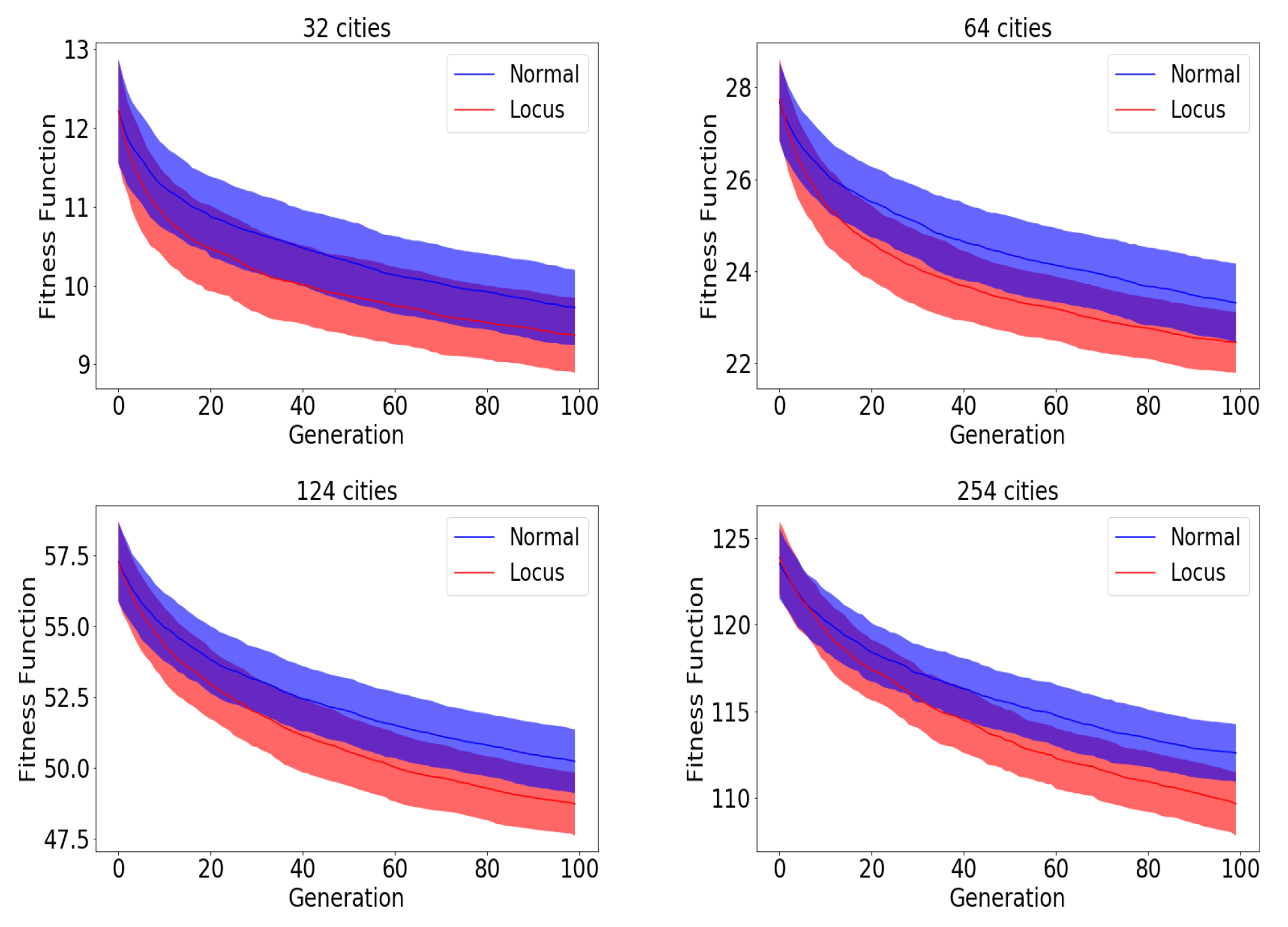
As we saw earlier, locus mutation works well with a partially solvable problem outperforming the traditional approach using gene level information. Although Locus mutation is only applicable for partially solvable problems e.g., N-Queens problem [
33], heuristic partial solution can be sufficient which can only be inferred with a comprehensive understanding of the problem. One of the most elusive problem is traveling salesmen problem (finding the shortest route to visit a set of cities), where the optimal solution is undefined making the optimization process interminable, and a heuristic threshold has to be used. In the N-Queens problem, calculating the partial solution was a straight forward process which is the number of queens hitting the current gene taking all the other genes into consideration. Having us doing so in the traveling salesman problem (TSP) [
34] requires a modification signifying the distance between the current gene (city) and the next gene with contrast to its distance with the other genes. Since traditionally the fitness of the entire chromosome relies solely on the distance between each gene and its next neighbor without taking into account any other genes, we came up with a new idea which we will call normalized comparative loss to calculate the partial fitness of each gene taking into consideration all other genes.
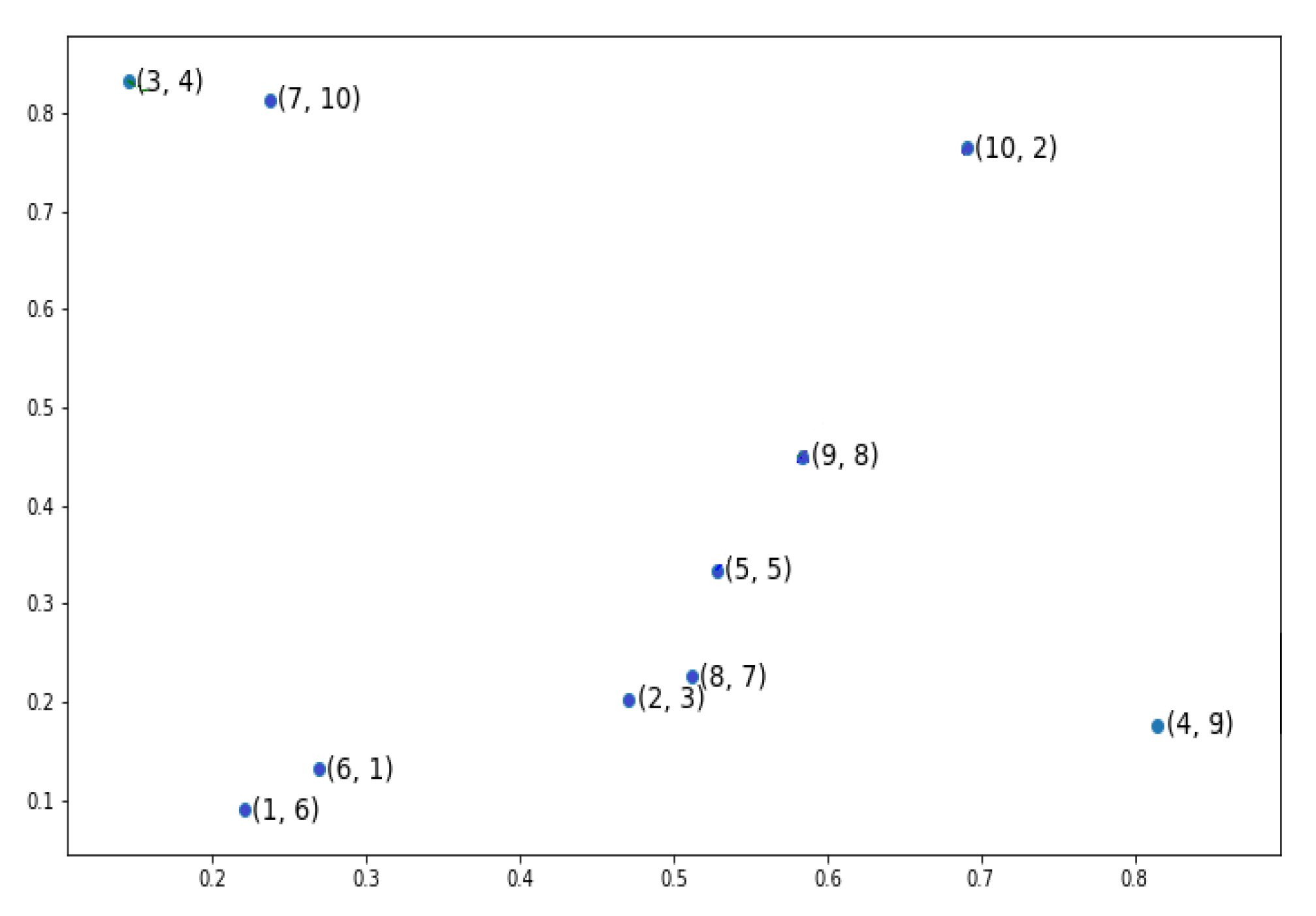
An example has been depicted in
Figure 2 showing a simple example of TSP problem with 10 cities. Each city has two indices, the first index indicates the order of the city in the candidate chromosome [6 3 4 9 5 1 10 7 8 2] and the second one refers to the actual label of the city e.g., the first gene in our chromosome has the label
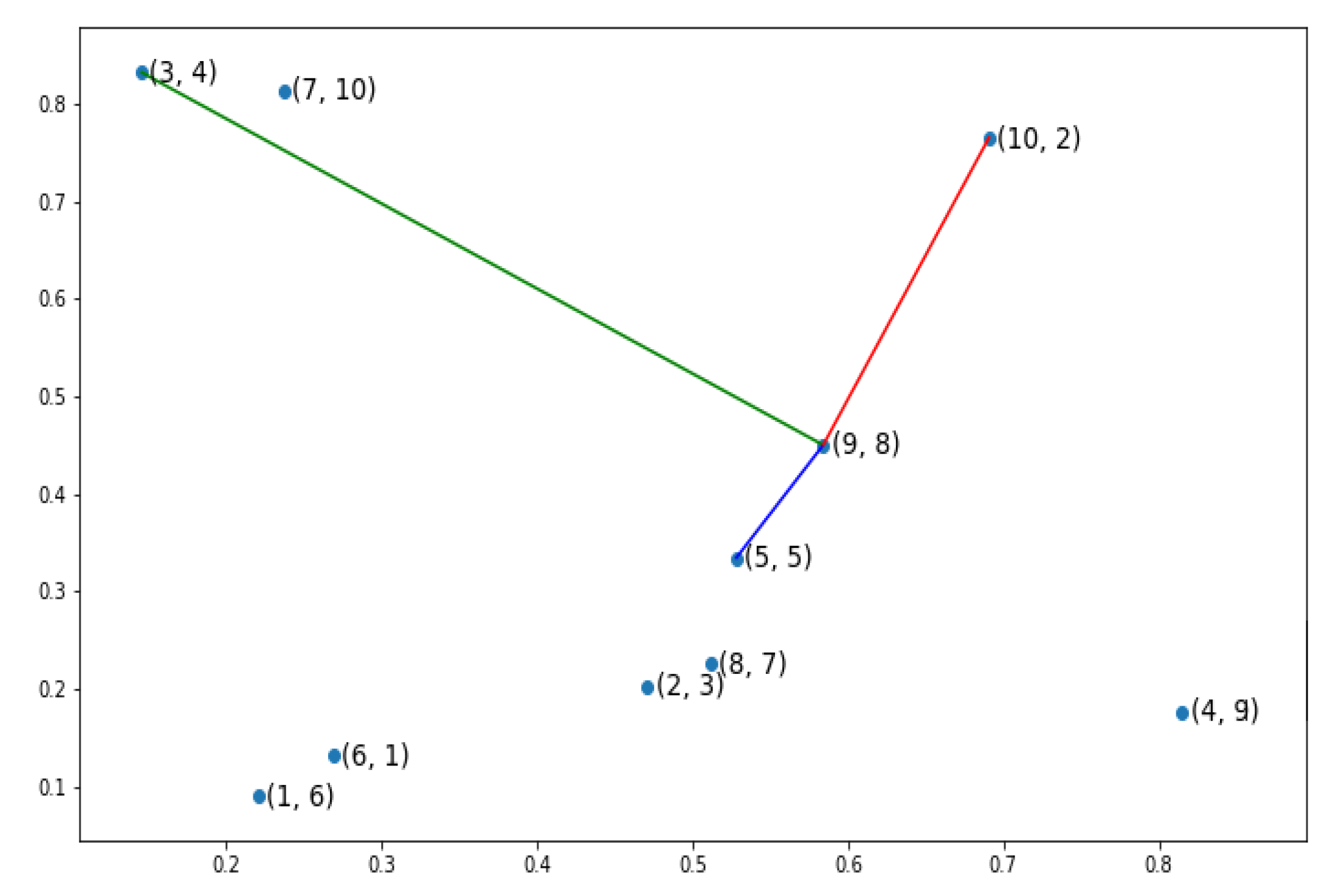
. To explain the partial fitness value of a gene, we have used the same candidate chromosome but focused on the penultimate gene, gene
, as in
Figure 3. This gene refers to the city number 8 which is located at the gene before the last gene in the candidate solution. The red line depicts the relevant connection between our gene and gene number two; the last gene in the current chromosome and the next neighboring gene. The gene which is the farthest away from our gene of interest has been linked to our gene with green line, while the blue line portrays the closest gene. Using the three previously mentioned distances;the pertinent distance between the current gene and next gene, the distance between the current gene and the gene which is farthest away from the current gene and the distance between the current gene and the gene which is closest to the current gene; we can calculate a heuristic partial fitness as in Equation (
7) where
i is the concerned gene while
and
give us respectively the minimum and the maximum distance between gene
i and the other genes.
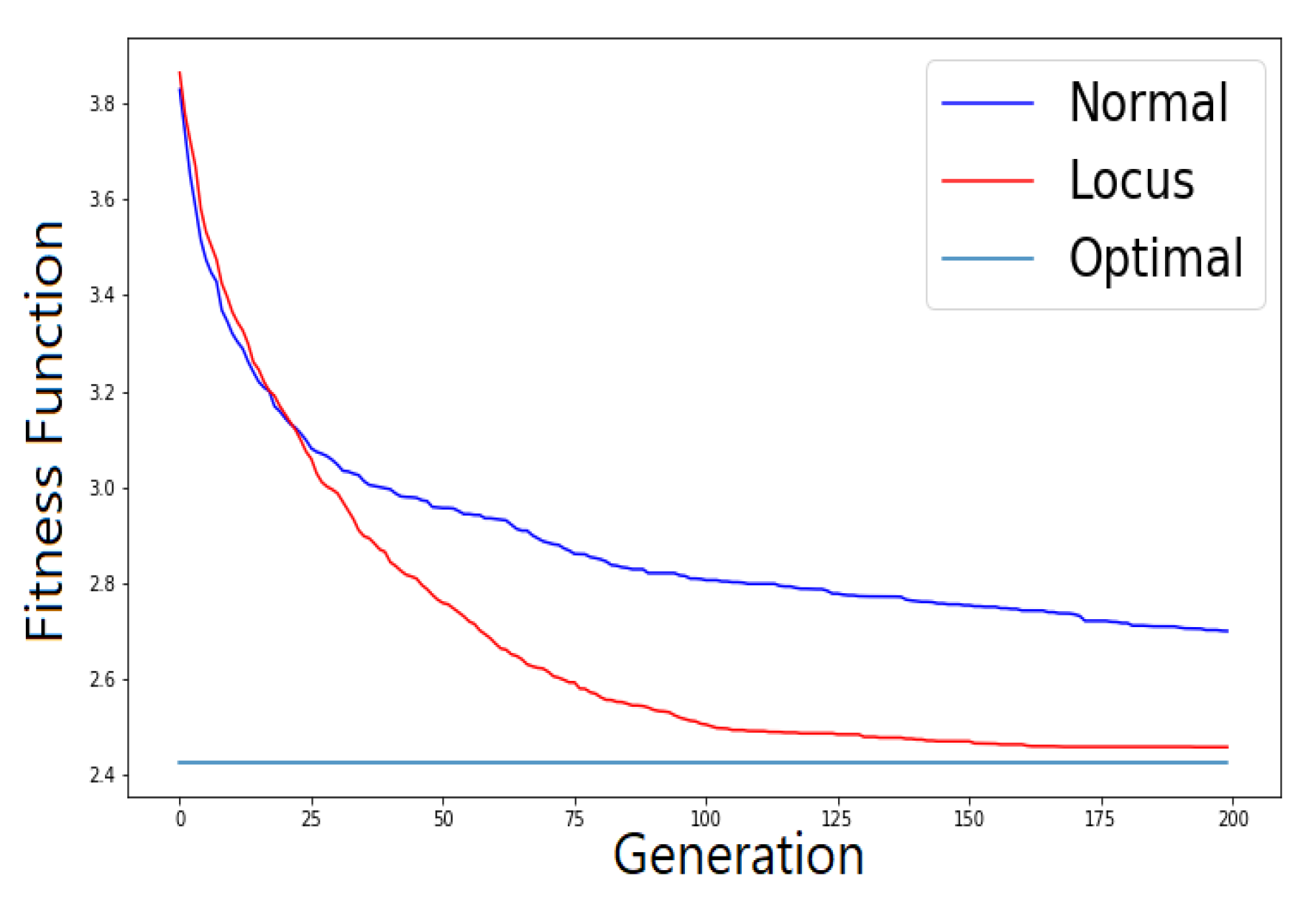
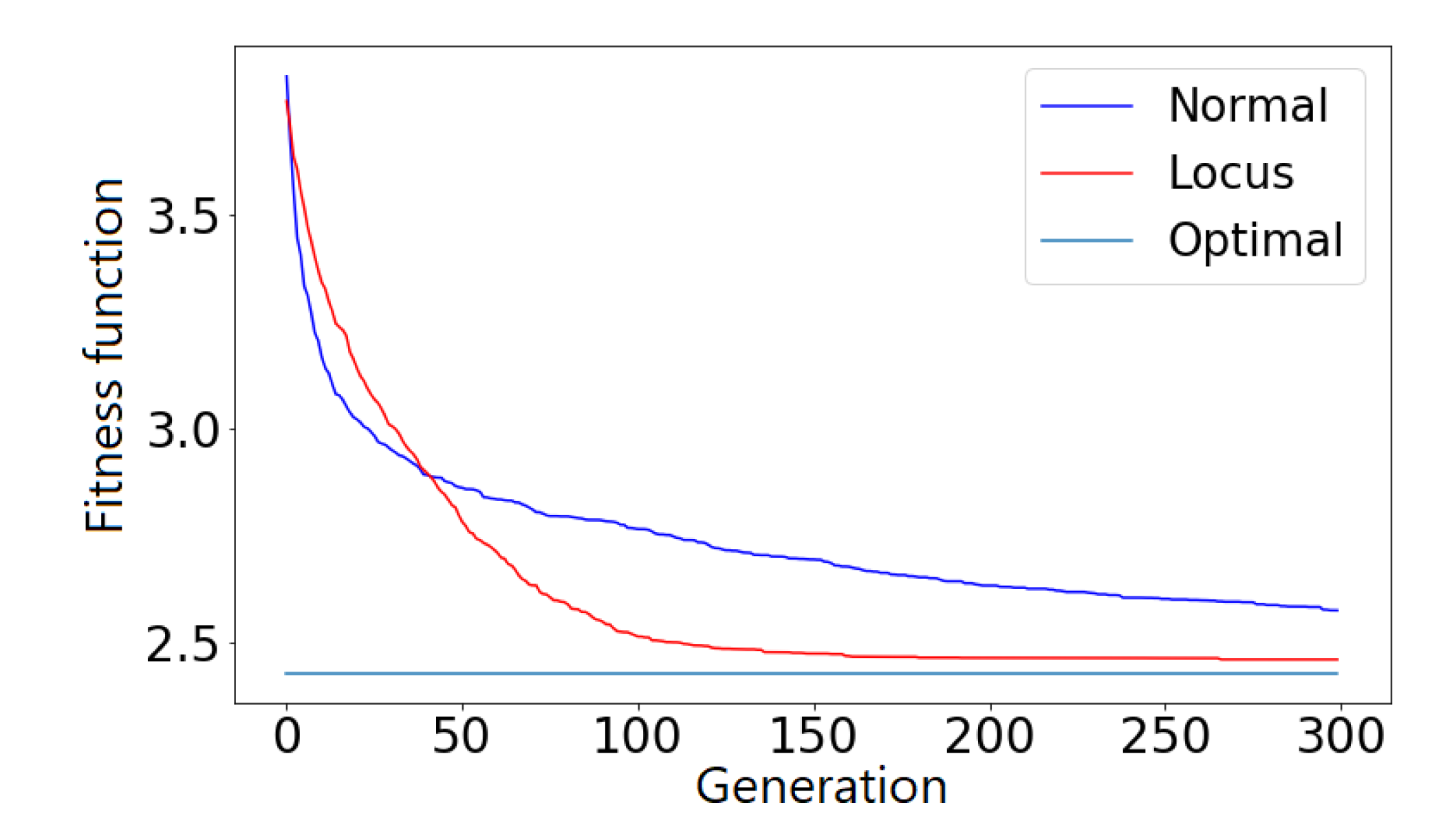
Before moving to the results section demonstrating the effectiveness of locus mutation, we will substantiate the advantage of using locus mutation by applying Wilcoxon test which is a non-parametric statistical test used to determine if two sets of distributions are different from each other in a statistically significant manner. We investigated a TSP instance with 48 cities, 1000 chromosomes, 20 generations. We used the same initial population for baseline and locus mutation then stored the evolved two populations after the 20th generation.
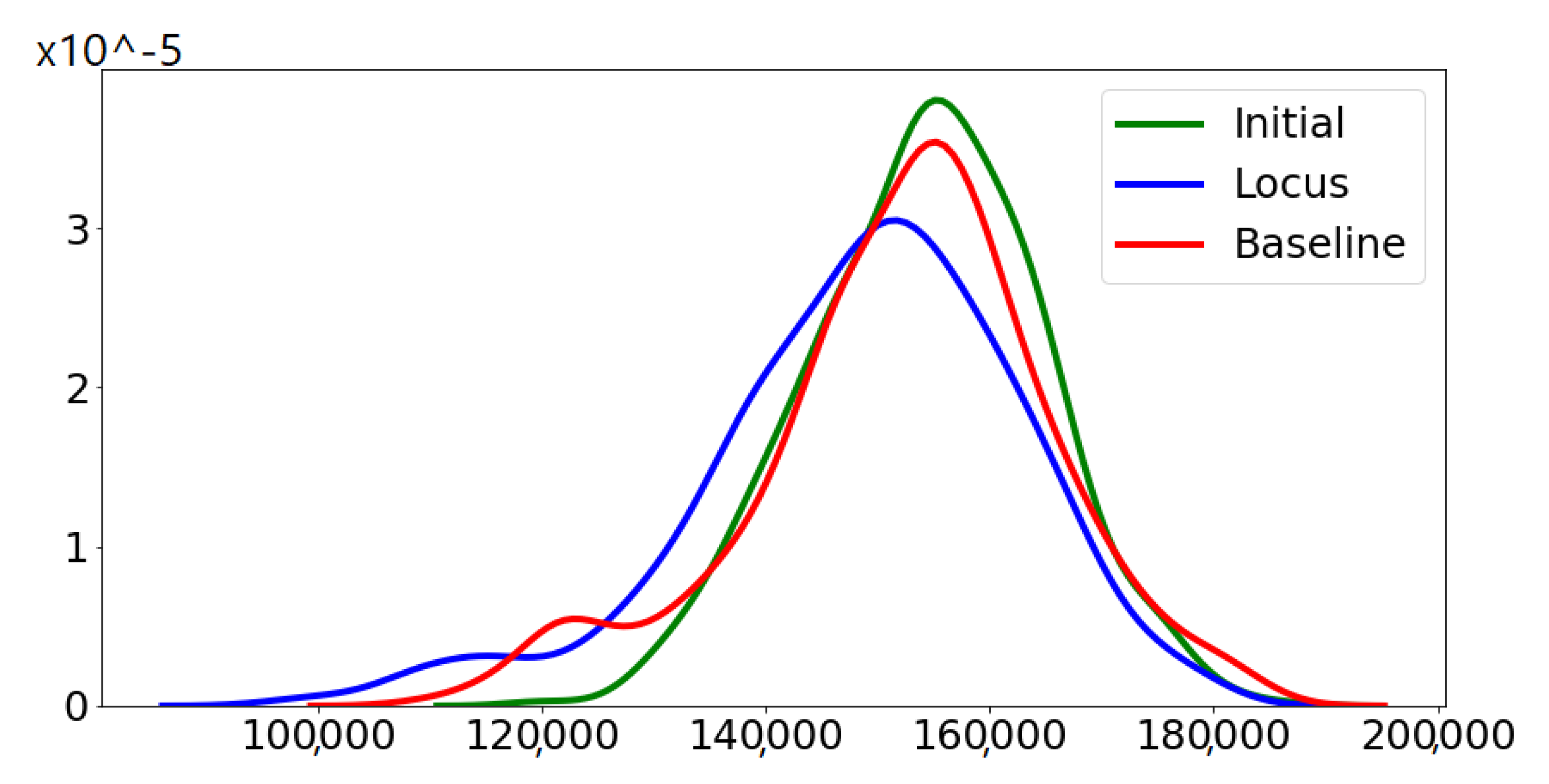
Figure 4 demonstrates the distribution of the fitness of the chromosomes for the initial population, the 20th baseline population and the 20th locus population.
Figure 4 illustrates visually the benefit of locus mutation where we can see that the distribution of the fitness of the 20th generation using locus mutation is closer to zero with smaller mean value. We applied Wilcoxon matched pairs test to the fitness of the evolved baseline and locus population obtaining a very small
p value,
. We can conclude from the minute
p value that the two distributions have different medians and reject the idea that the difference is due to chance.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}