1.1. Background
The reduction in conventional energy sources, skyrocketing prices of fossil fuels, along with the attendant effect on environmental degradation and pollution from the emission of greenhouse gases (GHG), as well as global warming, necessitates the use of renewable energy sources [
1,
2]. Amongst various forms of renewable energy sources, the wind is an efficient, affordable, pollution-free, renewable and abundant energy source [
3,
4]. Recently, wind energy generated in the world has increased to a 250-GW cumulative wind power capacity as of 2012, and it is projected to increase to 800 GW by 2021 according to world wind energy association (WWEA) [
3,
4]. Wind energy generation with many promising prospects, however, is faced with the challenge of the variability of the wind speed. The fluctuating, intermittent and stochastic nature of the wind makes predicting power generation a huge task [
5]. In addition, the non-linear, non-stationary characteristics of the wind speed temporal series make accurate forecasting of power generation difficult [
4]. Wind speed is the main wind information amongst others. Its predictability is essential for assessing wind energy exploitation purpose such as wind power generation. Hence, accurate wind speed prediction helps in maximising wind power generating facilities by reducing mistakes and economic cost involved in the planning and effective running of such facilities [
6].
Wind speed prediction methods for electrical energy exploitation purpose gained attention in recent research. Most literature lists different methods for wind speed/power forecasting some of which are the persistence, numerical, statistical and hybrid methods [
7,
8]. The statistical methods are seen as including the artificial intelligence (AI) methods, especially the artificial neural networks (ANN) method. ANN is a black-box statistical method and non-ANN methods are seen as grey-box statistical methods [
8]. Other authors, however, classify the AI methods as being non-statistical and broadly classify wind speed/power forecasting methods into conventional statistical methods and AI methods [
2,
4,
9]. Statistical methods are based on statistical time series using the previous history of wind data to forecast over the next short period, say, 1h. Models based on statistical methods are easy to use and develop. They adjust their parameters through the difference between their predicted and actual wind speed [
4]. AI methods, on the other hand, make use of machine learning (ML) models such as neural networks (NN) and gradient boosting machines (GBMs) [
2]. ML-based models make use of non-statistical approaches in knowing the relationship between input and output [
4,
10]. Statistical methods and ML methods, especially the NN methods, are both suited for short-term forecasting. The persistence method is used for very short-term predictions in the operation of wind turbines. The physical models make use of mathematical models of the atmosphere (such as numerical weather prediction (NWP)) and statistical distributions on physical quantities such as barometric pressure for forecasting. The hybrid models use a combination of any of these models especially the statistical models and machine learning models for forecasting [
4,
7].
Several forecasting techniques have been studied and further classified based on time scales and the type of model. While some authors used different time horizons in classifying forecast time scales into ultra short-term (few seconds or minutes), short-term (from minutes into hours), medium-term (hours and days) and long-term (weeks, month and year) [
2,
4], others classify forecasts ranging from hours to few days as short-term forecasting time horizon [
8,
9]. On the other hand, wind forecasting models are classified into deterministic and probabilistic forecasting models [
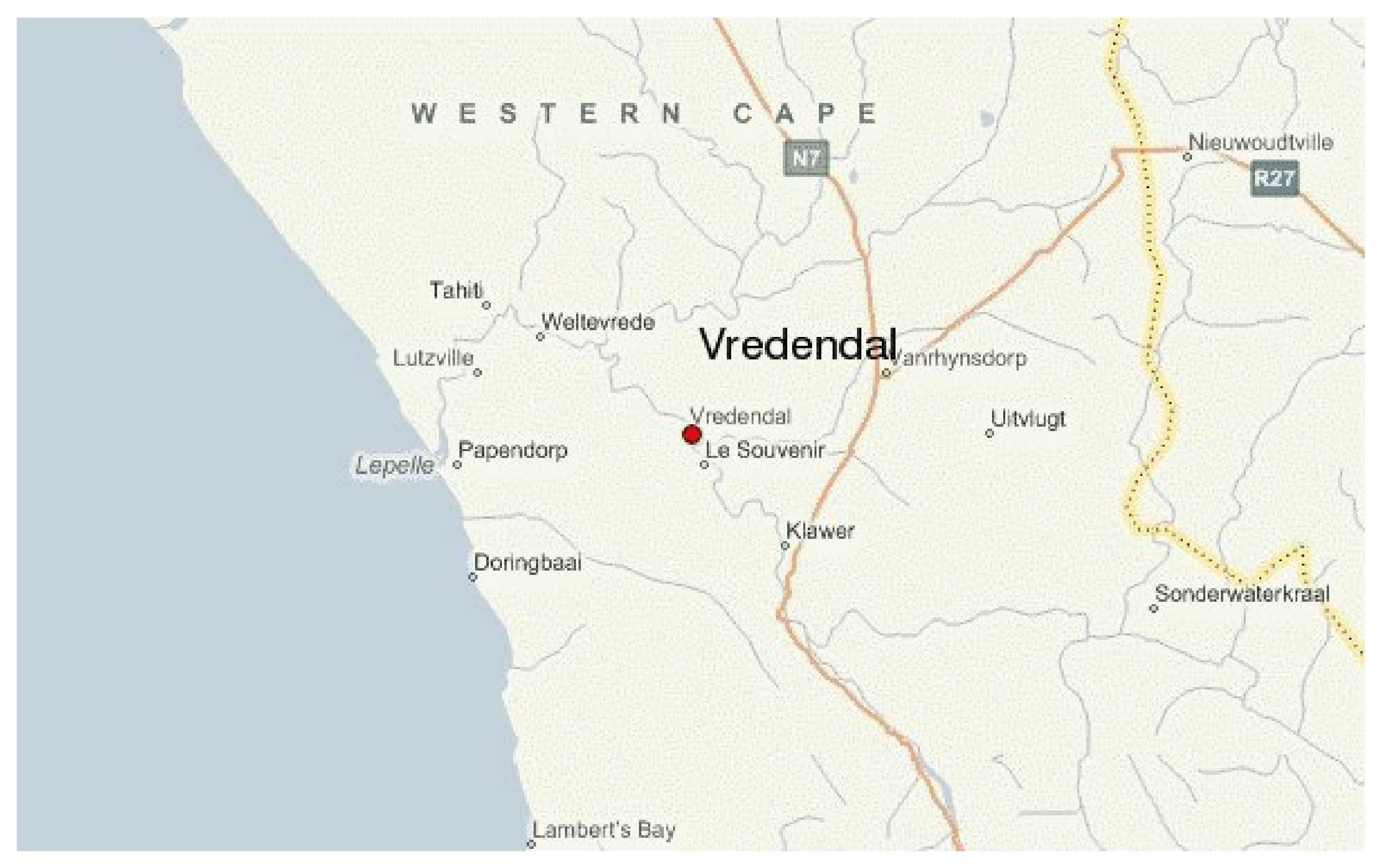
11]. Moreover, an investigation into techniques for forecasting wind speed useful for wind power generation is herein reported. Our approach involves two days ahead wind speed forecasting, using both deterministic and probabilistic approaches on a dataset containing wind meteorology data from a wind farm in Western Cape province, South Africa.
Statistical and ML methods are used for point and interval forecasting of wind speed. These methods are evaluated individually and combined to improve the forecasts. Statistical methods, such as statistical learning, make use of models such as autoregressive (AR), moving average (MA) or both (ARMA) and for non-stationary data makes use of autoregressive integrated moving average models (ARIMA). The conventional statistical learning techniques are the ARIMA models [
2]. Other statistical learning techniques involving generalised additive models (GAMs) can also be used for wind speed forecasting [
12]. Furthermore, a combination of forecasts from these methods, with the evaluated level of certainty using various point and interval forecasting metrics are discussed in this paper.
1.2. Review of Literature on Forecasting Techniques and Research Highlights
The approach employed in this paper only uses other covariates in a wind meteorology dataset to forecast wind speed and does not extend to wind power forecasting using the power curve and other methods, as discussed in [
8,
11]. In light of this, the authors present an account of forecasting techniques, the dataset used and conclusions based on the evaluation metrics used from relevant literature. The work of Chen and Folly [
2] has the same source of wind meteorology dataset used for this research, using the ARIMA model, ANN and the adaptive neuro-fuzzy inference systems (ANFIS). The results show that ANN and ANFIS performed better for the ultra-short-term, while the ARIMA model performed better for the short-term, 1 h ahead wind speed and wind power forecasting using RMSE and MAE. A comparison of four wind forecasting models was done by Barbosa de Alencar et al. [
4] involving ARIMA, hybrid ARIMA with a NN, ARIMA hybridised with two NNs and a NN on a SONDA dataset in all time scale forecast horizons. Using four evaluation metrics, the hybridised ARIMA with two neural networks outperformed the rest of the models.
In [
5], a wavelet-based NN forecast model, applicable to all seasons of the year, is used to predict the short-term wind power. Accurate forecasts using the normalised MAE (NMAE) and normalised RMSE (NRMSE) were recorded from the use of less historical data and a less complex model. A statistical approach to the wind power grid forecasting is discussed in [
13]. The authors used wind scale forecasting modelling technology involving correlation matrix of output power and forecast accuracy coefficients. RMSE and MAE were used to evaluate the accuracy of the forecasts. A short-term wind farm power output prediction model using fuzzy modelling derived from raw data of wind farm is presented in [
14]. This model was validated using the RMSE of the train set and the test set. The fuzzy model outperformed the NN model and was also able to provide an interpretable structure which reveals rules for the qualitative description of the prediction system. An investigation into accurate wind speed prediction using mathematical models is reported in [
6]. The mathematical models used were the Holt–Winters, ANN and hybrid time series models on SONDA and SEINFRA/CE data. Using MAE and RMSE for model evaluation, the hybrid model presented lesser errors amongst the other models.
An investigation comprising three types of backpropagation NN variants, Levenberg–Marquardt, Scaled conjugate gradient (SCG) and Bayesian regularisation, for a feed-forward multilayer perceptron was carried out by Baghirli [
15]. Using the statistical metrics of MAPE, SCG was found to outperform the rest. The Levenberg–Marquardt algorithm was used to train ANN ensembled with NWP to form a hybrid approach [
7]. This outperformed the benchmark quantile regression (QR) based probabilistic method for wind power forecasting evaluated using NNAE and NRMSE [
7]. The work of Mbuvha [
16] on the use of Bayesian regularisation backpropagation algorithm to short-term wind power forecasting was seen as a viable technique for reducing model over-fitting. Quantifying uncertainty in forecasts due to variability drives the work of Liu et al. [
17]. Quantile regression averaging (QRA) method for generating prediction intervals (PIs) from combined point load forecasts generated from regression models on a publicly available dataset from Global Energy Forecasting Competition 2014 (GEFC0m2014) was used. Pinball loss function and Wrinkler score were used to evaluate the performance of this model for a day ahead forecast and recorded better PIs than did the benchmark vanilla methods [
17].
Wang et al. [
18] combined probabilistic load forecasts using a constrained quantile regression averaging (CQRA) method, an ensemble, formulated as a linear programming (LP) problem. In this study, an ISO NE and CER dataset were used. The CQRA method outperformed the individual models [
18]. Nowotarski and Weron [
19] investigated interval forecasting using QRA to construct PIs on a dataset from GDF Suez website. The QRA method outperformed the 12 constituent models using PI coverage percentage (PICP) and PI width (PIW) in forecasting electricity spot prices. Using extreme learning machine, optimised with a two-step symmetric weighted objective function and particle swarm optimisation, a deterministic forecast with a quantifiable prediction uncertainty was used by Sun et al. [
20]. This was carried out on benchmark datasets and real-world by-product gas datasets. The results using PICP, prediction interval normalised average width (PINAW) and prediction interval normalised average deviation (PINAD) showed high-quality PIs constructed for by-product gas forecasting application.
Using wavelet neural networks (WNN), Shen et al. [
21] quantified the potential uncertainties of wind power forecasting via constructing prediction intervals using wind power data on an Alberta interconnected electric system. The prediction intervals constructed were evaluated using PICP and PI covered-normalised average width (PICAW). Indices such as coverage width-based criterion (CWC) and PI multi-objective criterion (PIMOC) including PINAW, PICAW and PICP were also used to evaluate their models. The PIs constructed from PIMOC were the most accurate compared to those based on the other prediction interval methods. The EKMOABC optimised WNN is the proposed method compared with WNN optimised with multi-objective particle swarm optimisation (MOPSO) and non-dominated sorting genetic algorithm II (NSGAII) [
21]. The need to quantify the uncertainty and risk associated with point forecasts through probabilistic forecasting drives the work of Abuella and Chowdhury [
22]. Using an ensemble learning tool, the random forest for combining individual models and hourly-ahead combined point forecasts were obtained. This was used for obtaining the ensemble based probabilistic solar power forecasts. The comparison carried out on one year of Australian year data showed that the ensemble-based and analogue ensemble-based probabilistic forecast have similar accuracy using the pinball loss function. For extensive reviews on probabilistic wind power forecasting, wind power generation and wind energy forecasting management and operational challenges, see [
3,
8,
23], respectively.
GAMs are suitable for exploring the dataset and visualising the relationship between the dependent and independent variables [
24]. Goude et al. [
25] used GAMs in modelling electricity demand for the French distribution network at both short- and medium-term time scales for more than 2200 substations. Drivers of the load consumption were modelled using GAM and compared with the operational one in [
26]. GAM is good for interpretability, regularisation, automation and flexibility [
24]. It finds a balance between the biased and yet interpretable algorithm, linear models and extremely flexible black-box learning algorithm composing the movement, seasonality and climate change variables. GAM was fitted on weekly load demand in [
27]. The existence of functional form trend between two variables and their shape whether linear or non-linear, should it exist, was examined using GAMs by Shadish et al. [
28].
Given the approaches used in existing literature for various kinds of forecasting, it is evident that the methods employed in this study have been used on different datasets around the world and evaluated, mostly using the same metrics we employ. The approach involves a comparative use of three such methods for point forecasting and two other methods for combining forecasts in which one of these two methods were used for interval forecasting using a dataset created and curated in South Africa. This was done to ascertain the viability of our methods for point forecasting of wind speed and interval forecasting. Another highlight in this paper is the use of GAMs for wind speed forecasting. We observe a dearth of GAM for wind speed forecasting in literature. To the best of our knowledge, we present the first-time use of GAM for wind speed forecasting. The rest of this paper is organised as follows.
Section 2 presents the various models employed.
Section 3 presents the results. A discussion of the results is presented in
Section 4. We conclude the paper in
Section 5.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








