1. Introduction
A typical situation in numerical simulations based on differential equations is that one is not interested in the solution per se but in a
Quantity of Interest (QoI) that is given as a functional of the solution. When designing an airplane, the QoI would be the lift coefficient divided by the drag coefficient. In simulations of the Greenland ice sheet, it could be the net amount of ice loss over a year [
1]. For wind turbine design, the amount of energy produced during a certain time period is more important than the actual flow solution. Other examples are in optimization with ODEs or PDEs as constraints. In the turbine example, one may want to optimize blade shape [
2] or determine optimal placement of, for example, tidal turbines [
3], for maximal energy output.
In this article, we consider time-dependent problems with a QoI as follows:
The goal is to find an adaptive time discretization to reduce computational costs. An
adaptive method consists of a
time-integration scheme for Equation (
1), an
error estimator, a
timestep controller and a discretization scheme for Equation (2). The input for an adaptive method is a tolerance
and initial timestep
. The output is an approximation to the solution, this can be a discrete solution
, or
.
Definition 1. An adaptive method for Equation (1) is called convergent, ifwhere. An adaptive method for Equations (1) and (2) is called convergent in the QoI, if The standard approach for goal oriented adaptivity is the dual weighted residual (DWR) method [
4,
5]. It is most commonly used in the context of space-adaptivity for PDEs, but there is also work specifically on time-adaptivity [
6,
7,
8]. DWR uses the adjoint (dual) problem to perform a posteriori adaptivity and get error bounds for the QoI.
In the time dependent case, the adjoint problem is a terminal value problem, i.e., an IVP backwards in time. The method yields global error estimates (bounds for linear problems). These error estimates are obtained by subsequently integrating forward and backward in time, storing both solutions. The estimates contain local information used to refine the discretization. This iterative process is repeated until a discretization is found with an error estimate
that fulfills
The resulting grids are typically of higher quality than those of local error based adaptive methods, particularly for advection dominated PDEs with spatially local QoIs.
The major drawback of this method is its cost, both in implementation and computation. To reduce computational effort, [
9] suggested to apply the approach in a block-wise manner, thus making it more local. The method requires a variational formulation and is thus typically used in the context of Galerkin type schemes but can also be used, for example, for linear multistep methods [
10].
Alternatives are classical adaptive methods for IVPs (Equation (
1)) based on local error estimation. Convergence results are well established and described in standard textbooks [
11,
12]. They do not yield global error bounds. However, the error estimate is cheap and works very well for stiff problems, which typically have a dissipation mechanism to a base solution. We aim to extend these methods to problems like in Equations (
1) and (2).
One way to include the QoI [
13] is to reformulate Equations (
1) and (2) as
We then have
. Solving Equation (
3) using an adaptive method based on the norm of the local error, the additional term coming from the added equation acts as a quadrature error estimate. In our numerical tests, this additional term is negligible in comparison to the local error in
, and thus there is no benefit compared to the classic method. Here,
is discretized using the quadrature scheme defined by time-integration. This choice has an impact on performance, but we do not have conclusive results when it is beneficial or detrimental.
A different approach is to combine the classic adaptive method with an error estimate that uses local errors in the QoI only [
14]. This way, the hope is to be more efficient than either DWR or the classic approach by having a cheap error estimate, focusing on direct error contributions to the QoI. One only requires additional evaluations of
to compute the error estimate. This makes it notably less intrusive to implement compared to DWR and suitable for partitioned approaches to coupled systems, since it only requires a local error estimate.
Methods in this spirit have been proposed before. John and Rang conceptualize this idea for drag and lift coefficients in incompressible flows [
15]. Turek predicts “catastrophical results” [
16] for a problem with an alternating lift coefficient due to vanishing error estimates. As a remedy, Turek proposes the usage of multiple QoIs for error estimation and does so using pressure, velocity, lift and drag. Wick et al. use a point-wise evaluation of the displacement field in fluid-structure interaction [
17,
18]. The authors get good results in two test cases, in one of which they observe slightly larger errors for too large tolerances. However, in all of the above cases, usage of this approach is heuristic and no analysis is presented.
Thus the question arises if these reports can be explained and could have been expected. The purpose of this article is to present a formal derivation and analysis of such a goal oriented adaptive method based on local error estimates, allowing us to answer this question in detail. To this end, we estimate the contribution per timestep to the error in the QoI. It consists of both quadrature and time-integration errors. We then derive local error estimates for these and use them in a deadbeat controller.
For the new adaptive method, we show convergence in the solution under a controllability condition with additional requirements on the timesteps. To obtain tolerance proportionality, i.e., (we define , iff ), for the error in the QoI when using higher order (>2) time-integration schemes, one needs solutions of sufficiently high order in intermediate points.
We do our analysis for embedded RK schemes [
11] and a deadbeat timestep controller. The structure of our proof allows for simple convergence proofs of other controllers, for example, PID controllers [
19], based on similarity to the deadbeat controller. To make statements on the performance of the goal oriented adaptive method, we analyze the impact of error dynamics on the error in the QoI.
We use numerical tests with widely different global error behaviors with respect to the QoI. For these, we confirm the convergence results and are able to explain the performance results. Our results show that the local error based methods are much more efficient than the DWR method for dissipative problems. It turns out to be relatively easy to predict bad performance, but harder to predict performance improvements. The goal oriented adaptive method shows good performance in most cases and significant speedups in some.
The structure of the article is as follows: We first review current adaptive methods in
Section 2 and
Section 3, then we explain and analyze our approach in
Section 4. Numerical results are presented in
Section 5.
3. Time Adaptivity Based on Local Error Estimates
The second adaptive method is the standard in ODE solvers. This method uses local error estimates and does not yield global error bounds or near optimal grids, but works very well in practice and is computationally cheap. It is convergent under a smoothness assumption.
The results from this section for one-step methods and the deadbeat controller (Equation (
10)) are in principal classic [
23]. Here, we present a new convergence proof, following the same principle techniques as in [
23], but separating requirements on the error estimate, timesteps, and
, for generic one-step methods. This prepares convergence proofs for general controllers and estimates, and we use it to show convergence in the QoI for the goal oriented adaptive method in
Section 4. We first introduce the relevant notation.
Definition 2. The flow [24] of an IVP (Equation (1)) is the mapwhereandfor. The flow is the solution operator for
. To numerically solve an IVP means to approximate the flow by a
numerical flow map defined by some numerical scheme. The solution after a timestep can be written in the form
We generally assume Problem (
1) to have the unique solution
guaranteeing existence of the flow map
. We define the
global error by
The dynamics of global error propagation is usually not known. The global error increments, however, have a known structure. Given a sufficiently smooth right-hand side
for Equation (
1), the
local error of a scheme
of order
p is
with the
principal error function [
11].
3.1. Error Estimation and Timestep Controller
We now derive an estimate for the local error using two solutions of different order. We approximate the local error behavior by a simplified model, focusing on the leading terms. Aiming to keep the norm of the local error equal to a desired tolerance, this becomes a timestep controller yielding based on timestep , the local error estimate and a tolerance .
Assume two schemes
with orders
and corresponding principal error functions
. We estimate
This error estimate is
asymptotically correct, i.e., the leading term of
, characterized by the principal error function
, matches the leading term of
. We model the local error
via
Assuming
to be slowly changing, the next step of this model yields
Aiming for
gives the well-known deadbeat controller
This controller is based on asymptotically correct estimates of the local error for
, we propagate the solution using
for its higher order. This is known as
local extrapolation [
23].
3.2. Convergence in the Solution
We first relate global errors to variable, non-adaptive timesteps and then consider the adaptive case. The basis is the following Lemma ([
25], p. 68):
Lemma 1. Consider Problem (1) and a schemeof order p. Assume a gridwith timestepsgiven by a step-size function,such that for a given base step size Then, the global error (Equation (7)) fulfills. Assuming
we can define reference timesteps
by a step-size function
and a
as follows
These variable, non-adaptive timesteps meet the requirements of Lemma 1, yielding
. Now, one can observe that Lemma 1 still holds for a grid perturbed by
see [
23]. This is straight forward to show using the scaling ansatz
with
. To prove convergence for the adaptive method with the controller in Equation (
10), it thus suffices to show that these adaptive steps are a sufficiently small perturbation of the reference steps
.
Theorem 1. Consider Problem (1) and an adaptive method consisting of: A pair of schemeswith orders p,, with, error estimator Equation (8), deadbeat controller Equation (10), and,. If the principal error function to
fulfillsthen the adaptive method is convergent with . Proof. We show by induction over
n that the adaptive timesteps fulfill
by definition of
. Choosing
for
, the
induction base is met. The timesteps given by the controller in Equation (
10) are
In the denominator we expand
in
, which gives an
term. Since
is based on the steps
, which fulfill Equation (
13), we get
from Lemma 1. This term is smaller than the
term already in the denominator in Equation (
14). Further expansions to separate the
term yield
For the
term we have
by definition and
from the induction hypothesis Equation (
13). This completes the induction step, and the adaptive timesteps fulfill Equation (
11) for
, which yields
. □
Thus, we established convergence for the adaptive method. Further, we built a structure with which one can prove similar results for different controllers, for example, PID controllers [
19]. To prove convergence, it is sufficient to show
.
Remark 1. Assumption (12) prevents vanishing error estimates in Equation (10), which would result in extremely large timesteps. In practice, one often enforces a maximal timestepconst. manually. To preserveone needs to scaleappropriately with τ. 4. Goal Oriented Adaptivity Using Local Error Estimates
Consider Problem (
1) and (2). We approximate
using quadrature and
by
such that
Here , are the quadrature nodes and weights, and . We first show convergence in the QoI based on convergence in the solution with the following theorem.
Theorem 2. Consider Problem (1) and (2) with j sufficiently smooth, a gridwith timesteps, and an approximation, see Equation (15) by a quadrature scheme of order r. For an approximationwiththe error in the QoI fulfills. Proof. By splitting the error, we obtain
and address the two errors separately. An estimate for general quadrature schemes gives
For the time-integration error we linearise
about
and use Equation (
16) to get
Using this for the time-integration error gives
Summing up quadrature and time-integration error results in
□
Remark 2. Using linear interpolation to compute solutions at, one gets at most. Higher orders are achievable using, for example, dense output ([11], p. 188). Our idea is to use a goal oriented local error estimate to obtain step-sizes more suitable to address the error in the QoI. We first derive our error estimate and controller, for the resulting goal oriented adaptive method we show convergence in the QoI with Theorem 3. We make an analysis to predict performance in
Section 4.3.
4.1. Goal Oriented Error Estimates
In the proof of Theorem 2, we see two error sources—time-integration and quadrature, see (
17). We estimate these errors separately.
4.1.1. Time-Integration Error Estimate
Estimating the time-integration error in Equation (
18) would require error estimates for all evaluation points of the quadrature formula. Instead, we consider the following quadrature independent estimate:
Again, the global error propagation dynamics are unknown, but we can estimate and control the global error increment. Using the same principle technique as in
Section 3.2, we estimate the global error increment in Equation (20) by
4.1.2. Quadrature Error Estimate
We now consider the quadrature error
For a time-interval
we use the notation
for an
r-th order quadrature scheme. We denote quadrature for the numerical solution by
and assume there is a discrete solution available in all relevant points or given by interpolation. Given sufficient smoothness of
j and
, the quadrature error in one timestep is
Analogous to time-integration,
is the
principal error function. Following the previous approach from time-integration, we employ an additional scheme of order
to estimate
For a practical error estimate we, however, need to use the numerical solution
. By expanding
in
, we get
assuming
, where
, i.e., sufficiently high order solutions in all quadrature evaluation points. We then have
4.1.3. Timestep Controller
Now, we want to choose timesteps as to keep the sum of the error estimates of Equations (
21) and (
24) at a given tolerance. For this we need to model the temporal evolution of the estimated errors. We linearise the second term in Equation (
21) about
and get
Assuming
, we choose the leading terms of Equations (
25) and (
23) to define our model by
using the previous Model (
9) for
. Assuming both principal error functions and the derivative term be to slowly changing, the error in the next step is
Aiming for
we get the deadbeat-type goal oriented controller
We thus constructed a timestep controller to control the local error contributions to the QoI, see Equation (2), based on the splitting in Equation (
17).
Remark 3. One can, likewise, construct controllers using only the quadrature or time-integration error estimate by settingresp.equal to zero.
4.2. Convergence in the QoI
We show convergence in the QoI for the adaptive timesteps (Equation (
26)) following the structure of
Section 3.2 for showing convergence in the solution for the timesteps of Equation (
10). With
we define non-adaptive reference timesteps
as follows:
We now show that our adaptive timesteps (Equation (
26)) are a sufficiently small perturbation (Equation (
11)) of the above reference steps. This yields convergence in the solution by Lemma 1 and then convergence in the QoI by Theorem 2.
Theorem 3. Consider Problem (1) and (2) and assume j to be sufficiently smooth. Assume an adaptive method consisting of: Time-integration schemes,with orders p,,, quadrature schemes of order r,, and, a schemeto obtain solutions of orderfor intermediate points, the error estimator in Equation (21), controller in Equation (26), and,. If the principle error functions corresponding to the lower order schemes fulfill Equation (27), then. Proof. We first show convergence in the solution by showing
via induction over
n. The induction base is met by choosing
for
. For the steps in Equation (
26), we address the denominator terms separately. For the local error estimate we have
Using the same expansions as in the proof for Theorem 1 we have
The steps
leading up to
fulfill the induction hypothesis in Equation (
28) and thus are a perturbation of
fulfilling Equation (
11). Thus, Lemma 1 holds, which gives
. Thus, we obtain
For the quadrature estimate we use Equation (
24). Summing up Equations (
29) and (
24) gives
since we have
by the induction hypothesis. Inserting the above term into the controller in Equation (
26), separating the resulting
term from the denominator gives
This concludes the induction step. Consequently, we can use Lemma 1 for the steps in Equation (
26), since they fulfill Equation (
11), which gives convergence in the solution.
The statement now follows from Theorem 2 provided that Condition (
16) holds. A single step of size
from
to
, with the scheme
, gives the error
Here we have
⇒
. Thus, Equation (
16) holds for
, which gives us convergence in the QoI with
by Theorem 2. □
Remark 4. The assumption of Equation (27) is a requirement of controllability in the asymptotic regime, ensuring non-zero error estimates. Using both the quadrature and time-integration error estimate makes a scheme more robust, aswould require a common zero in both principle error functions. Remark 1 likewise applies here. Example 1. In [16] Turek describes using the lift-coefficient of the flow around a cylinder as QoI. Thisis oscillating in time, changing signs. Attaining very small absolute values would thus lead to very large timesteps and “catastrophical results” [16]. This is a prime example of Criterion (27) not being fulfilled and thus not guaranteeing convergence in the QoI. In such scenarios, Turek proposes using multiple quantities for error estimation, for example, drag and lift, combined with global norms of pressure and velocity. The authors of [18] present a numerical experiment with an oscillating beam andbeing the displacement in the x-direction. This likewise implies vanishing error estimates, but the author obtains good results. This is likely due to their strict limits on step-size changes, cf. Equation (32), and enforcing a maximal timestep. 4.3. The Zero Set of the Density Function and Global Error Propagation
Now, we analyze global error dynamics to make a qualitative statement about the obtained grid. We establish guidelines to predict grid quality and thus the performance of the goal-oriented adaptive method.
Assume a QoI with a density function that is linear in
,
Global error propagation only appears in the time-integration part of Equation (
17), given by
We define a weighted seminorm
by
for which we assume
for some indices
i, yielding a non-trivial zero set. Using Equation (
30) we get
and are thus interested in
, resp.
. The global error propagation form for this is
compare Equations (
19) and (20). Using this, we now consider grid efficiency (number of step vs. global error for a fixed error or number of steps) and how global error dynamics affect the error in the QoI.
Assume the local error estimate
, see Equation (
8), to be of comparable size in both
and
, i.e.,
. This means both the classical (Equation (
10)) and the goal oriented controller in Equation (
26), neglecting the quadrature estimate (cf. Remark 3), yield similar step sizes. The question of grid efficiency becomes one of global error dynamics.
Now, if we also have , the resulting global errors and grid efficiency are similar. Examples are QoIs capturing the main dynamics, and thus largest errors, of a system. On the other hand, assume . This results in a smaller error in the QoI and a higher grid efficiency. Examples for this are convection dominated PDEs where shifts global errors to the zero set of .
In the following, we consider only the errors obtained by the goal oriented method. We instead assume , i.e., parts of the local error estimate to be in the zero set of , resulting in larger timesteps for the goal oriented method.
If remains small despite larger timesteps compared to the classical method, grid efficiency is better. Examples are flows such that , despite an increasing norm, largely remains in the zero set of or when the main dynamics of a system have a negligible effect on the error in the QoI. Another example is a flow such that remains small in the first place due to, for example, strong dampening.
An example with a low grid efficiency is obtained if global errors grow in the zero set of
and are later shifted into its image. This can occur if the timesteps of the goal oriented method leaves dynamics in the zero set of
insufficiently resolved, leading to
large in norm. Such error shifts can be caused, for example, by convection in PDEs. We experimentally demonstrate this in
Section 5.2.
Example 2. We again consider [18], and compare Example 1. For timestep control based on this QoI, there is a time delay from flow build-up to displacement. This leads to too large timesteps when the displacement is just starting to grow, leaving the initial flow pattern under-resolved. The author observes the maximal timestep being attained for large tolerances and significant error reductions for smaller tolerances, which is likely the point at which the inflow is sufficiently resolved.
5. Numerical Results
We now test the results of Theorem 2 numerically. Further, we compare the performance of the DWR method and the local error based adaptive methods. The tests were run on an Intel i5-2500K 3.30 GHz CPU with Python 3.6 using FEniCS v. 2018.1.0 [
26]. See [
27] for the code.
The following specifications are common to all tests. For local error based methods using controllers, we bound the stepsize ratio by
Here,
for Equation (
10) resp.
for Equation (
26). This provides more computational stability by preventing too large timestep changes ([
11], p.168). We use
and
and do not reject timesteps. Unless specified otherwise, we use
.
For the DWR method, we use an initial grid with 10 equidistant timesteps. As a refinement strategy, we use fixed-rate refinement [
20], refining those 80% with the largest errors. We consider no coarsening. Refinement means to replace a timestep by two steps of half the size. To approximate
, we use a finer grid, dividing all time-intervals in half. While this is expensive, it is also highly accurate. We only consider linear problems and thus do not need to compute
to construct the adjoint problem for the finer resolution. Thus, for this refinement strategy, the costs are significantly higher in the nonlinear case. In the nonlinear case, the dual problem is still linear.
We refer to the adaptive method from
Section 3 as “Classical” and denote it by “Norm” in figures. For the goal oriented case in Equation (
26), we consider the controllers using only quadrature or time-integration estimates, or both; they are denoted by “Goal Q”, “Goal T” and “Goal T+Q” in figures. Using the DWR method we get both the error estimate
, which we denote by “DWR Est” and the actual error “DWR Err”, based on a reference solution.
Unless stated otherwise, we use the trapezoidal rule for quadrature. We verified the correctness of all associated solvers using suitable test problems with exact solutions and visualizations.
5.1. Test Problem
As a simple test problem with known global error dynamics, we consider
This test case has a one-sided coupling, which makes it a good candidate for testing some of the cases from
Section 4.3. For this, we additionally vary the stiffness of the problem by
.
5.1.1. DWR Estimate
The exact solution is
. We get the weak formulation
We use the FE space
denoting the space of continuous piece-wise
q-th order polynomials
. Let
be the exact adjoint solution for a given
and
its FE approximation, we get
. We approximate
by
to get
Defining
and
, we get the final error estimate
using the composite trapezoidal rule
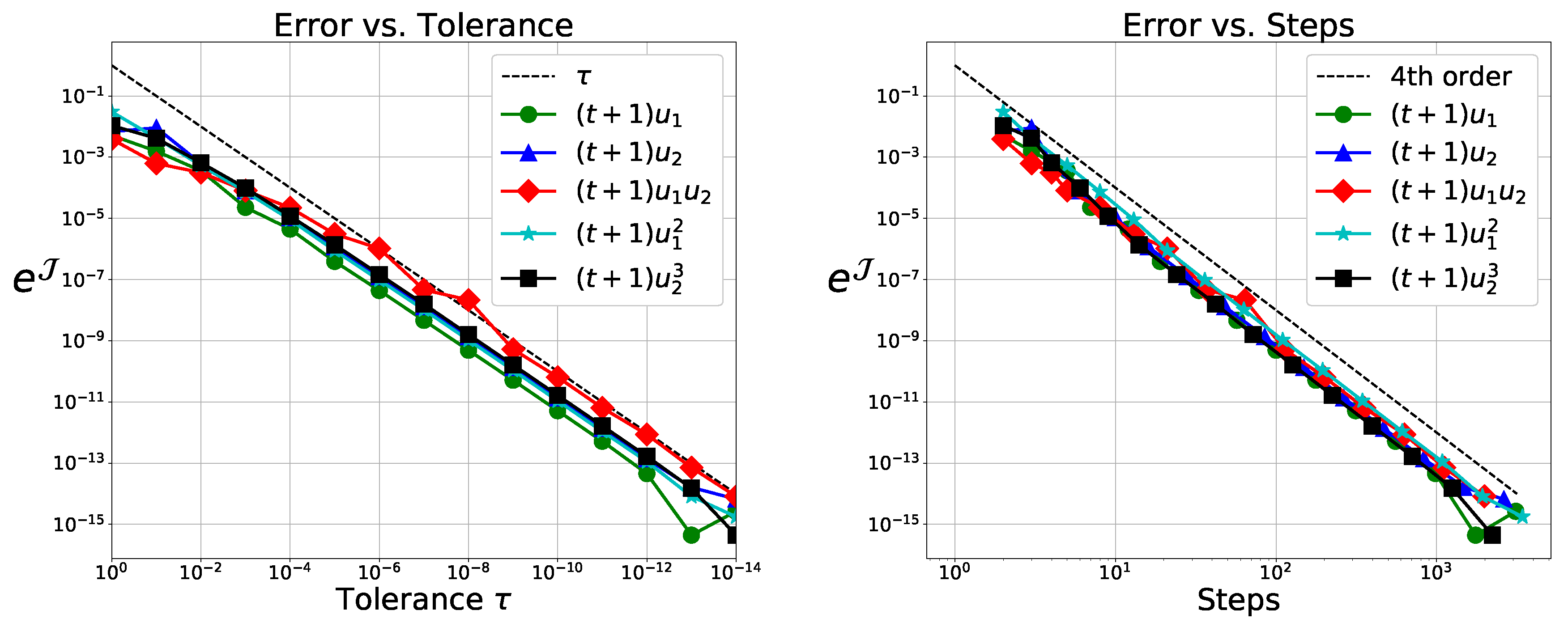
5.1.2. Numerical Verification of Theorem 2
We first verify Theorem 2 using Simpson’s rule for quadrature and the classical RK scheme to get
. As embedded scheme we use the weights
, yielding a third order solution for autonomous systems. We get the local fourth order solution at
using the weights
. We expect to get
from Theorem 2. This is observed in
Figure 1.
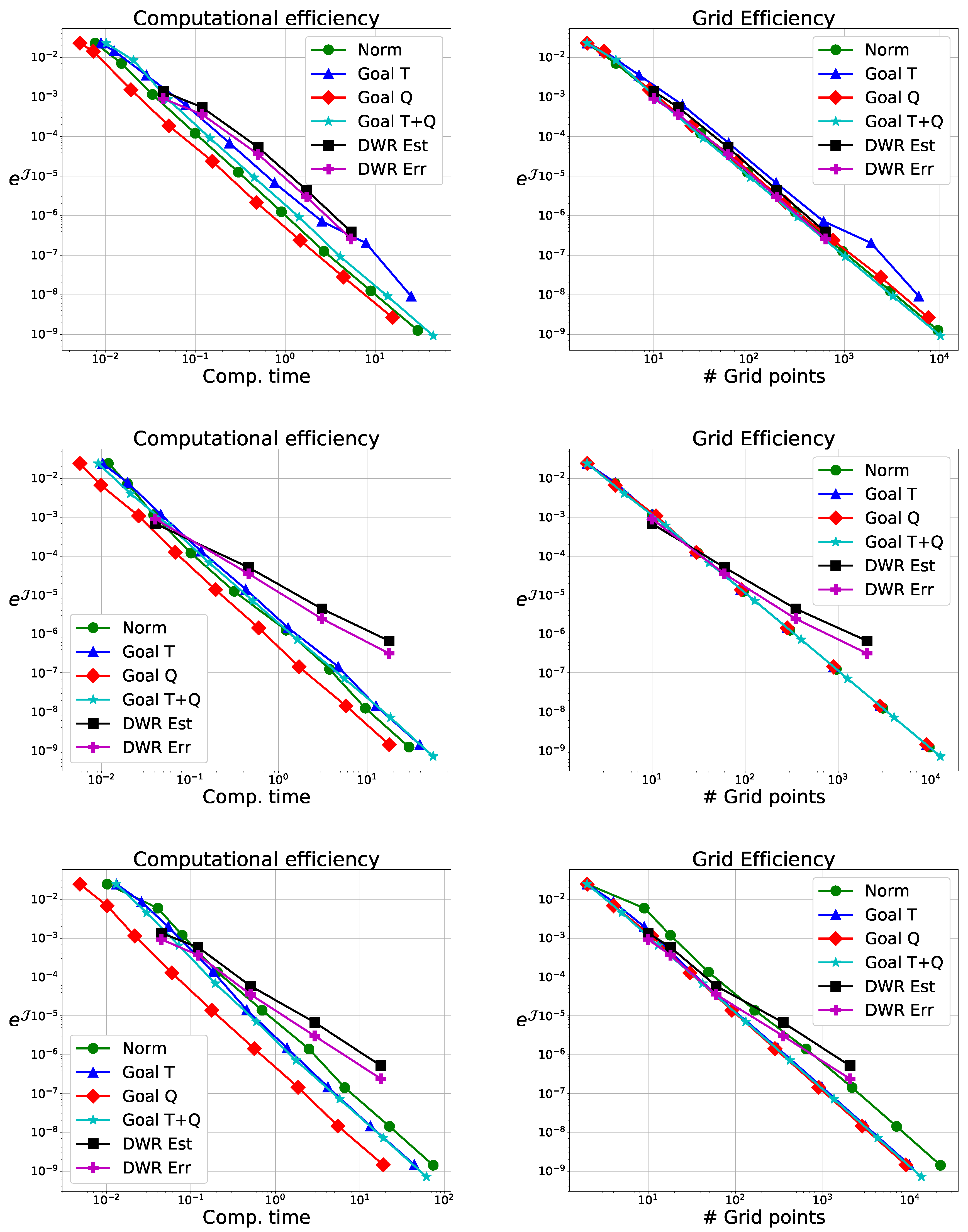
5.1.3. Method Comparison and Performance Tests
To compare DWR with the local error based methods, we use the Crank–Nicolson scheme and estimate local errors with Implicit Euler. Comparison is done in terms of computational efficiency (error vs. (wall-clock) runtime) and grid quality (error vs. number of timesteps). We consider
for
and
for
. Results are shown in
Figure 2.
5.1.4. Discussion
Considering the global errors, we see DWR does not yield notably better grids, but it is significantly slower for small tolerances as it needs to solve adjoint problems.
In the case of and , we have comparable timesteps for all local error based methods, since the local error in the second component is dominant. These methods have grids of nearly identical quality and require the same computational effort.
For
, we get larger timesteps using the goal oriented method, particularly for
. Due to the off-diagonal term in
, the flow map shifts errors from the second component, the zero set of
j, to the first component. This leads to comparable performance for
and a performance gain for
. While not immediately evident, for
, we have
and do not fulfill Equation (
27), which is needed for convergence in the QoI. This does, however, not cause computational problems here, but we see notably worse performance when using only the time-integration error estimate.
Comparing the computational efficiency with the grid qualities, we see the goal oriented method using only the quadrature estimate has better performance results than other methods with the same grid quality. This is because we reuse values computed for .
5.2. Convection–Diffusion Equation
As a problem with a spatial component, we look at a linear convection-diffusion problem given by
We want to model the case of having error build-up in the zero set of
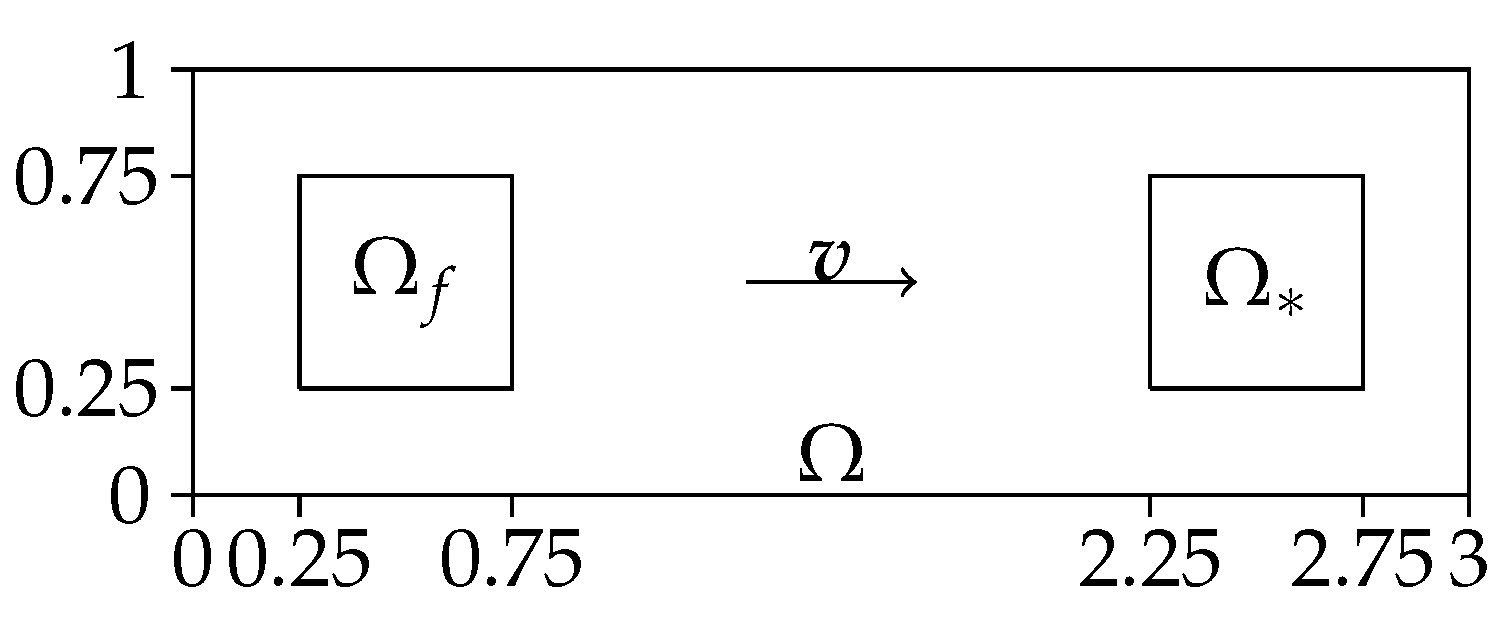
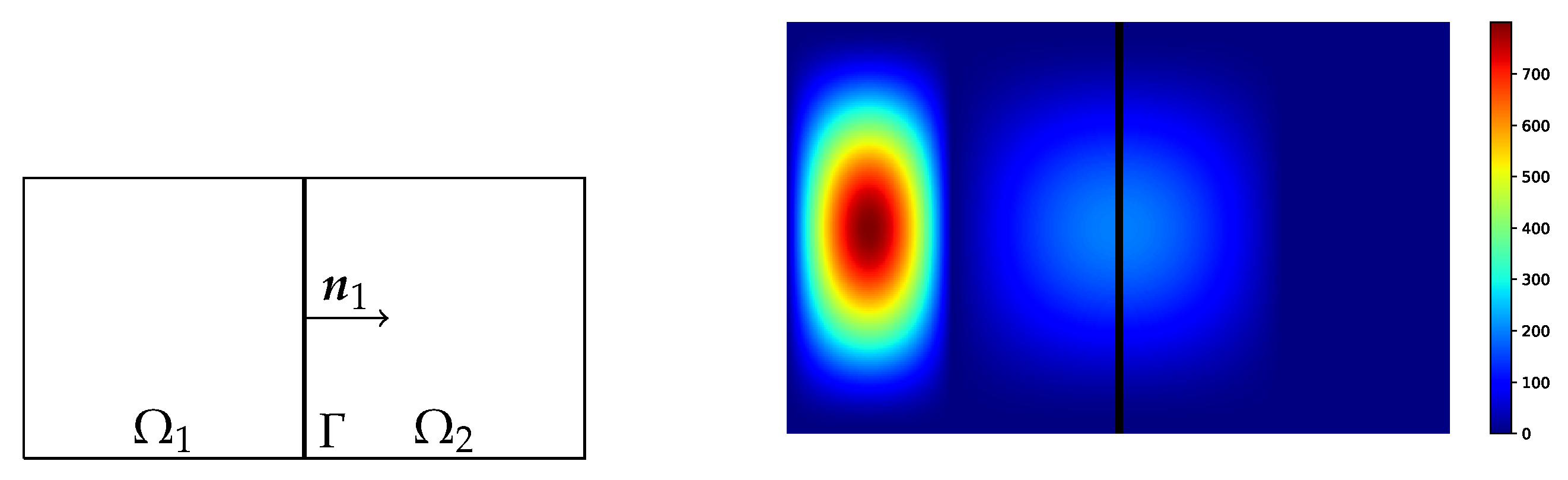
, which is transported into its image. For this, we consider the domain
. We choose a source term
f with support
and a spatially local QoI sufficiently far away in the downwind direction at
. For a visualization of the spatial domain, see
Figure 3, for the time-domain we use
.
The QoI we consider is
i.e., the average value, time and space, in
. We use the source term
providing a spike-shaped build-up around
. The remaining parameters are
,
,
,
, and
. We use as reference solution the result from the classic adaptive method with
.
5.2.1. Discretization
For our convection–diffusion problem we have a weak solution in the space
see [
28]. We get the variational formulation
By some standard reformulation we get the weak form
We discretize time along the points
with
and space by
regular triangular cells
K defining the finite element mesh. We define the global finite element space by
where
is the space of polynomials on
of degree up to
q and
the space of polynomials on
K with partial degrees up to 1. The adjoint problem to Equations (
34) and (
35) is
5.2.2. DWR Estimate
We have the error in the QoI given by
where we approximate
by a finer grid in time. Splitting this by timesteps gives
We use the composite trapezoidal rule to get the error estimate
using linear interpolation for
and
in computing
.
5.2.3. Method Comparison and Performance Tests
We use the same time-integration as in
Section 5.1.3. The source term is in the zero set of
and due to convection
shifts build-up from
to
. Thus, we expect the goal oriented method to perform poorly due to a huge error growth in the zero-set, which later becomes part of the error in the QoI.
5.2.4. Discussion
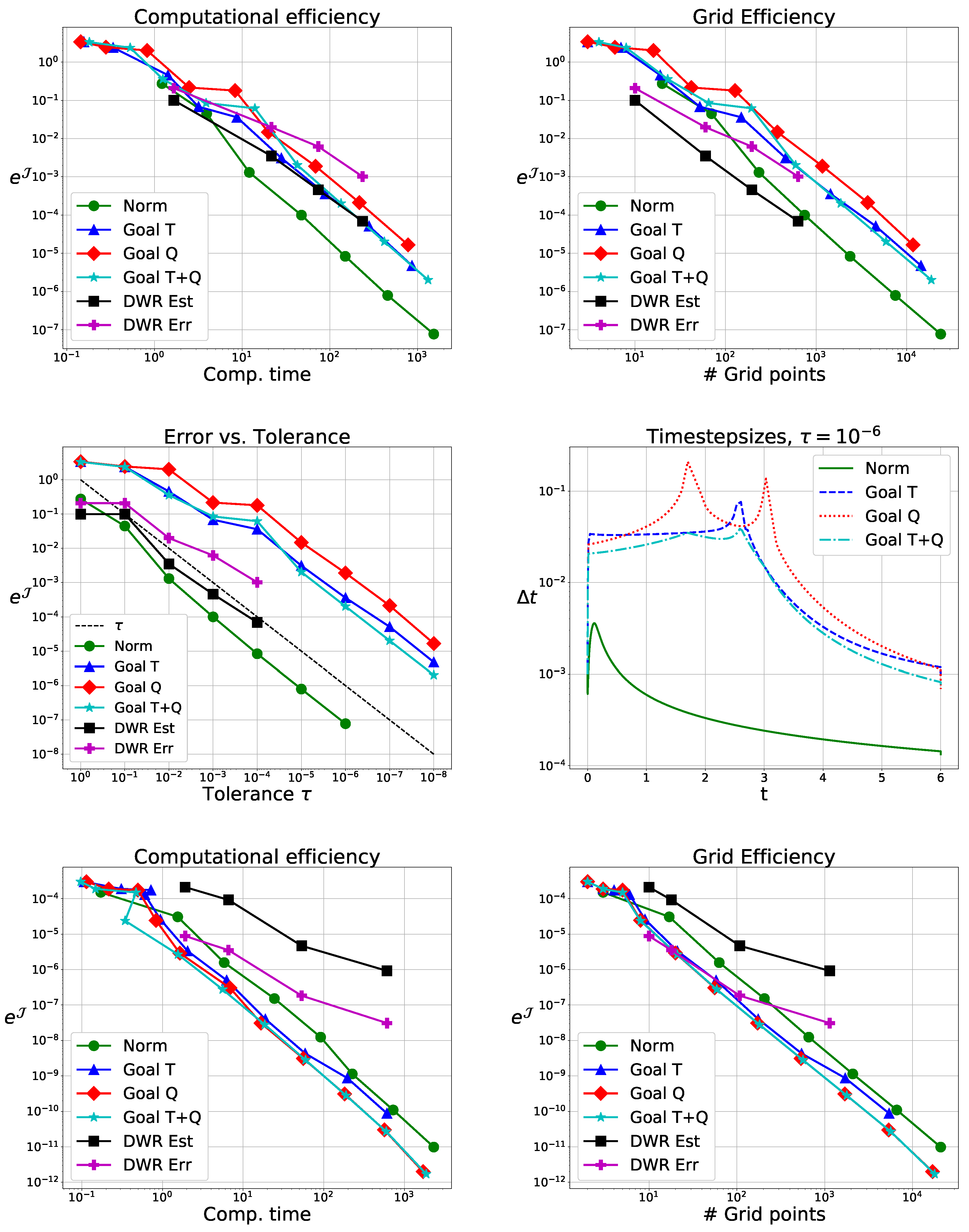
In
Figure 4 (top), we observe the classical adaptive method performs well and the goal oriented adaptive methods, as expected, perform worse. There, timesteps are clearly too big for the given source term. Nevertheless, convergence in the QoI with
is observed, as predicted by Theorem 2. The DWR method is expensive but gives high quality grids. Here, we used it to only adapt in time.
Changing the sign of the convection term, we expect good results for the goal oriented method, as the source term can be neglected. This is observed in
Figure 4; bottom (reference solution with
). The goal oriented methods perform better than the classical one. The DWR method performs notably worse than in the previous examples.
5.3. Thermal Fluid Structure Interaction
The previous examples were of academic nature, to demonstrate strength and weaknesses of the method, as predicted in
Section 4.3. As a third test problem, we consider the coupling of two heat equations with different thermal conductivities and diffusivities. This models, for example, steel cooling with pressurized air. Furthermore, this example will show how the proposed method can be applied seamlessly in a partitioned approach. The model equations for this problem are
Our QoI is the time-averaged heat transfer over the interface
and given by
which in the discrete case is given by the finite difference
where
and
.
We consider the spatial domains
,
,
, and
. We use the initial conditions
see
Figure 5, which also shows the geometry.
For time-integration we use SDIRK2, which is implicit with
. To solve the problem arising from the so called
transmission conditions (Equation (
36)) on the interface
, we use the Dirichlet–Neumann iteration for each stage derivative of SDIRK2 [
29]. We choose the parameters
and
. Based on the results of [
30], this gives us a convergence rate of approximately
for the Dirichlet–Neumann iteration for
.
Standard linear FE are used in space for both domains with identical triangular meshes for
. Details of the implementation of the discretization and methods can be found in [
31].
For this problem, we use . The reference solution is computed using the classical scheme with and an absolute tolerance of in the Dirichlet–Neumann iteration, where the numerical tests use an absolute tolerance of .
5.3.1. Method Comparison and Performance Tests
Based on the results from the previous problems, we no longer consider the DWR method. While we specifically considered both grid quality and computational efficiency because of the DWR method, we now look only at grid quality, as these two performance measures are essentially identical here.
We chose and such that there is notable initial heat in the domain , but it has little relevance to the heat flux over the interface .
5.3.2. Discussion
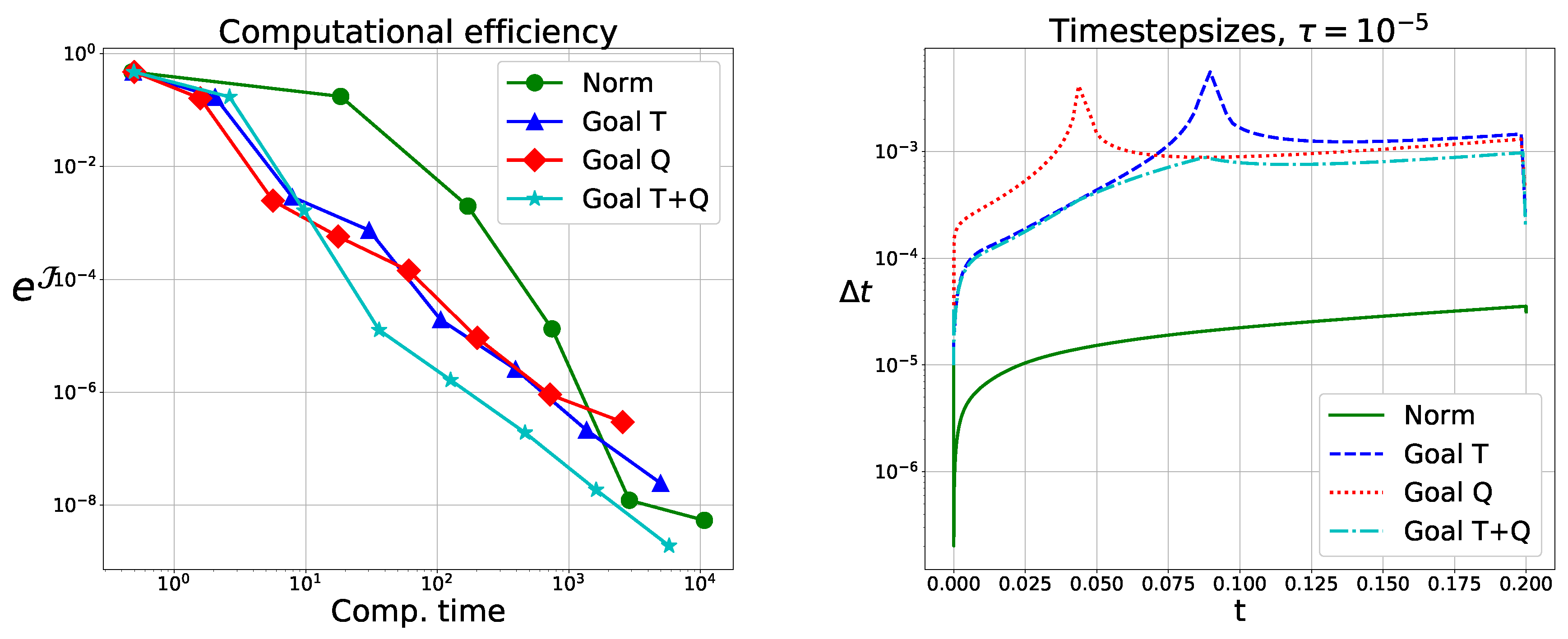
As a result, the classical method will choose small timesteps to correctly resolve the diffusion process on the whole domain, effectively over-resolving the time-domain with respect to the error in the QoI. We expect larger timesteps for the goal-oriented methods with a higher computational efficiency. As seen in
Figure 6, we have a gain in efficiency for larger tolerances by a factor larger than 10. For smaller tolerances, this factor is smaller.
Furthermore,
Figure 6 shows the timesteps for
. There, we see upward cusps for the goal-oriented method when using only one error estimate, which are due to sign changes in the heat flux. These violate the controllability requirement (Equation (
27)). For both the quadrature and time-integration error, there is no common zero. This guarantees convergence for
and gives significantly better performance results.
6. Conclusions
Similar to previously proposed methods, we derived a simple and easy to implement goal oriented local error estimator. Implementation comes with little to no extra work and is well-suited for partitioned approaches for coupled systems.
For the resulting goal oriented adaptive method, we show convergence for the first time and its rates with respect to the error in the QoI. To obtain tolerance proportionality, sufficiently high order solutions in all quadrature evaluation points are needed. The proof is constructive and gives rise to a principle to formally show convergence for closely related stepsize controllers.
Performance of the goal oriented method deteriorates when local errors of underresolved processes accumulate in the zero set of the density function that later shift into its image. This can be the case for convection dominated problems, and one should then consider using the standard local error estimate. It is less problematic for dissipative problems, where slow and global processes dominate the error.
Numerical experiments designed to test these guidelines show them to work well, as well as confirming the results on convergence rates. The tests show that bad performance of the goal oriented method can be predicted and thus avoided. For dissipative test cases, the DWR method is notably more expensive and outperformed by the local error based method. The goal oriented adaptive method shows good performance in most cases and significant speedups in some.
Future Work
It would be interesting to test the proposed goal oriented method in the context of PDE-constrained optimization. There, one has to repeatedly solve a given PDE for varying parameters. This would be particularly interesting for non-gradient based optimization algorithms, where the proposed method could lead to considerable speedups for the optimization process as a whole.
Our analysis is based on a specific type of QoI. It is natural to try to extend our results to more general QoIs, for example, point-wise evaluations in time.
One could further generalize this work by using a density function in error estimation, that is not the density function j from the QoI. This adds a degree of freedom in constructing the goal oriented method and can be used to overcome possible weaknesses, such as vanishing error estimates. This requires further testing and gives rise to the question on how to optimally choose .


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





