Spectrum-Adapted Polynomial Approximation for Matrix Functions with Applications in Graph Signal Processing


Abstract
1. Introduction
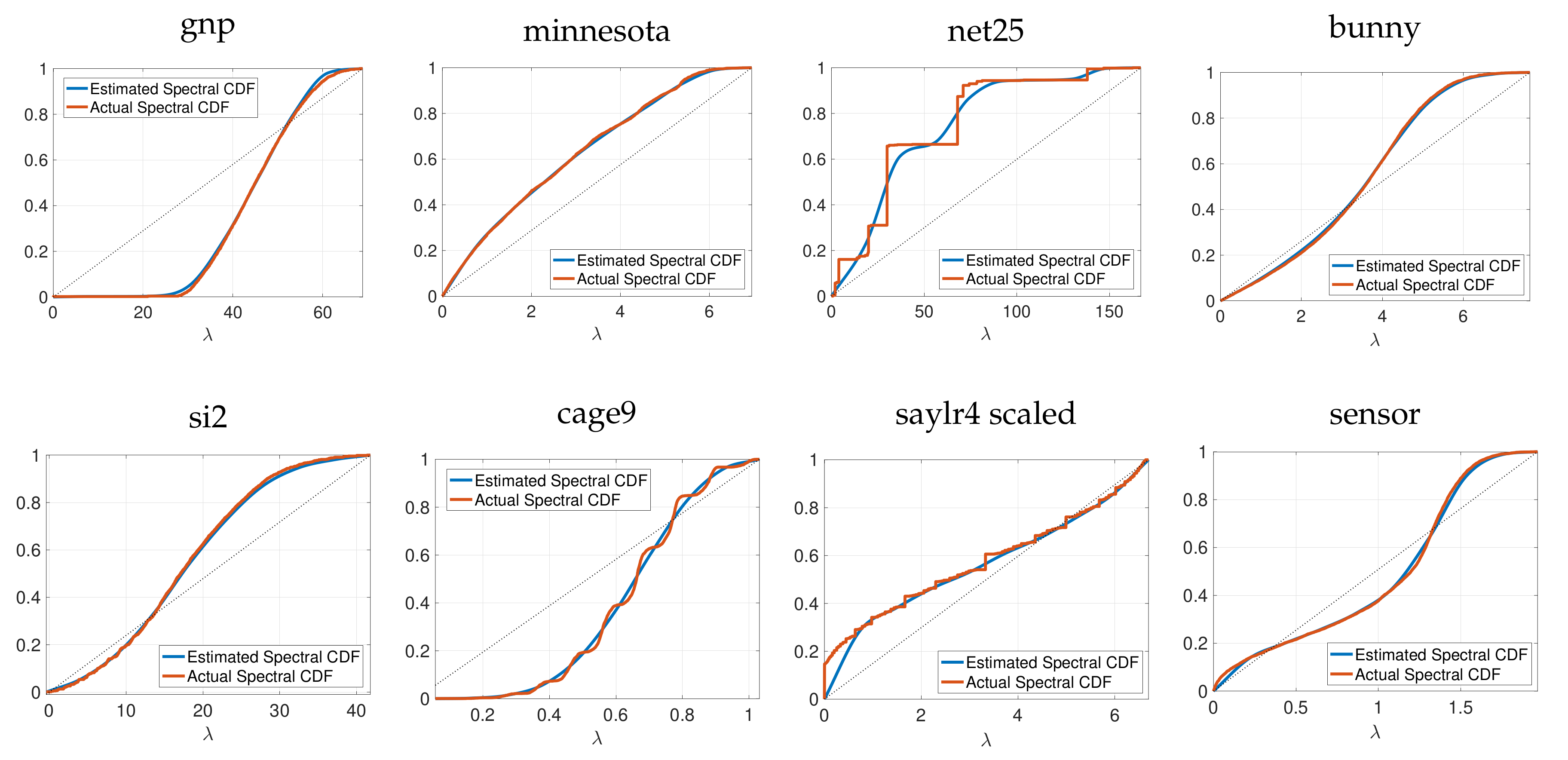
2. Spectral Density Estimation
3. Spectrum-Adapted Methods
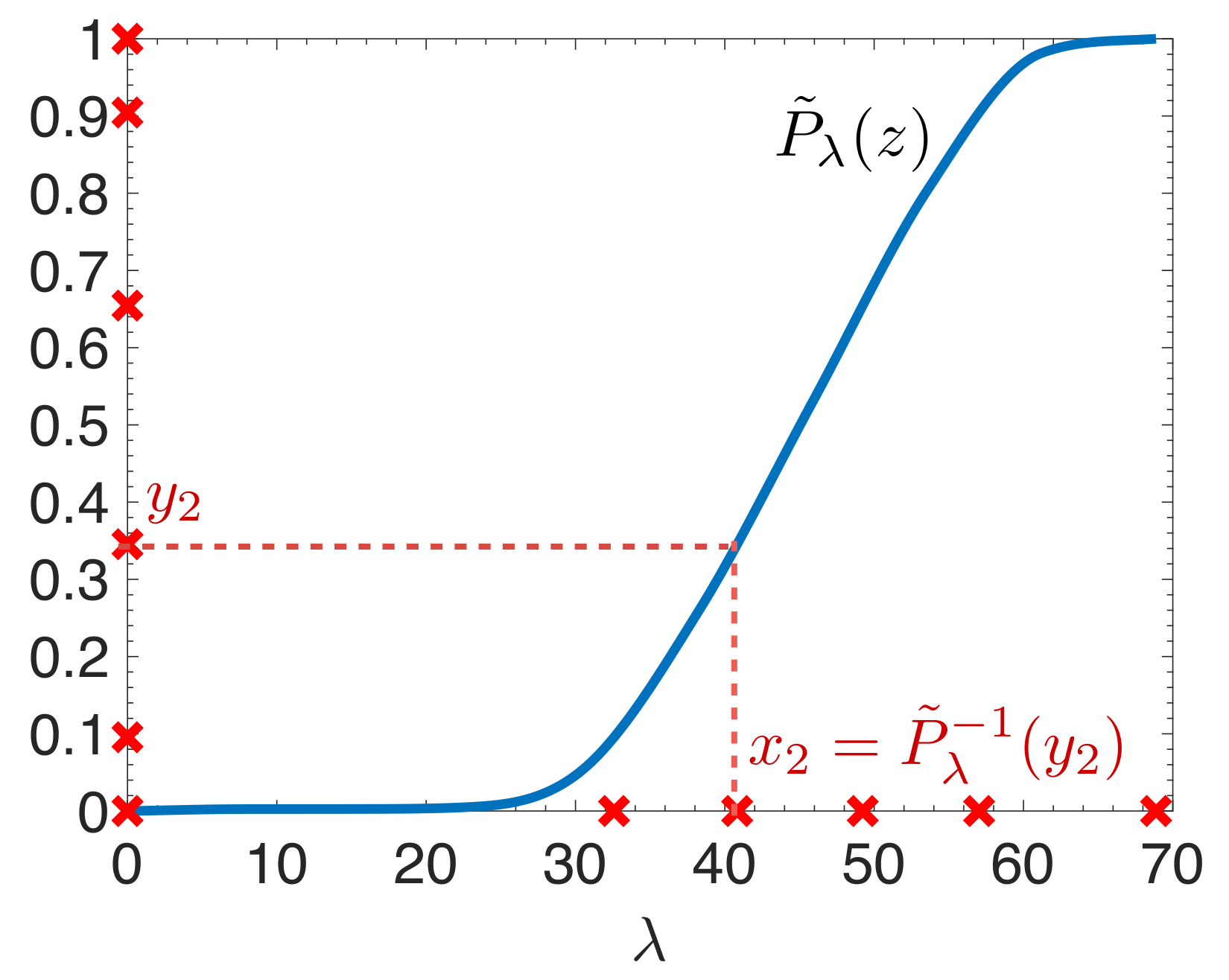
3.1. Spectrum-Adapted Polynomial Interpolation
| Algorithm 1 Spectrum-adapted polynomial interpolation. |
| Input Hermitian matrix , vector , function f, polynomial degree K |
| Output degree K approximation |
|
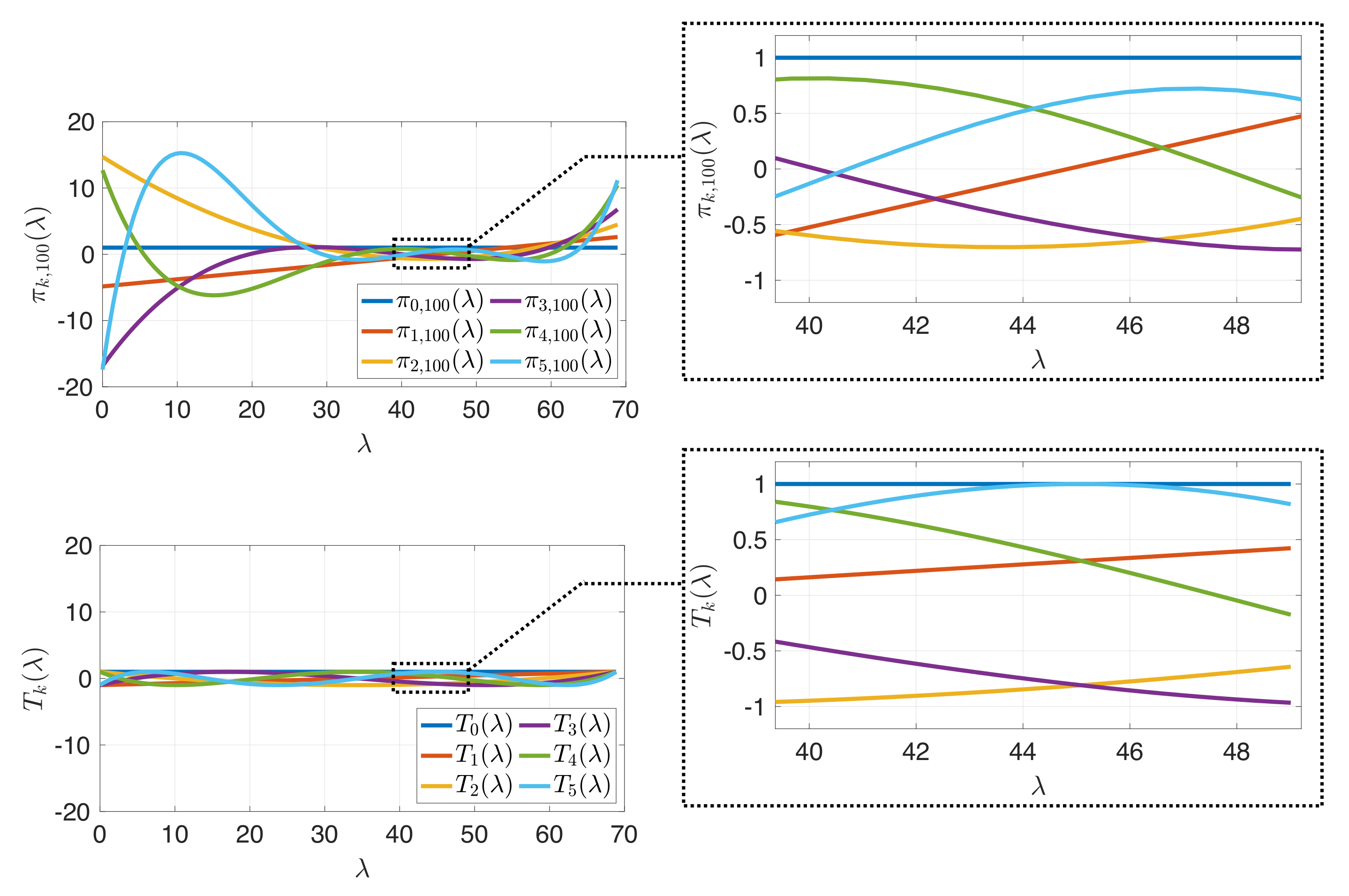
3.2. Spectrum-Adapted Polynomial Regression/Orthogonal Polynomial Expansion
| Algorithm 2 Spectrum-adapted polynomial regression. |
| Input Hermitian matrix , vector , function f, polynomial degree K, number of grid points M |
| Output degree K approximation |
|
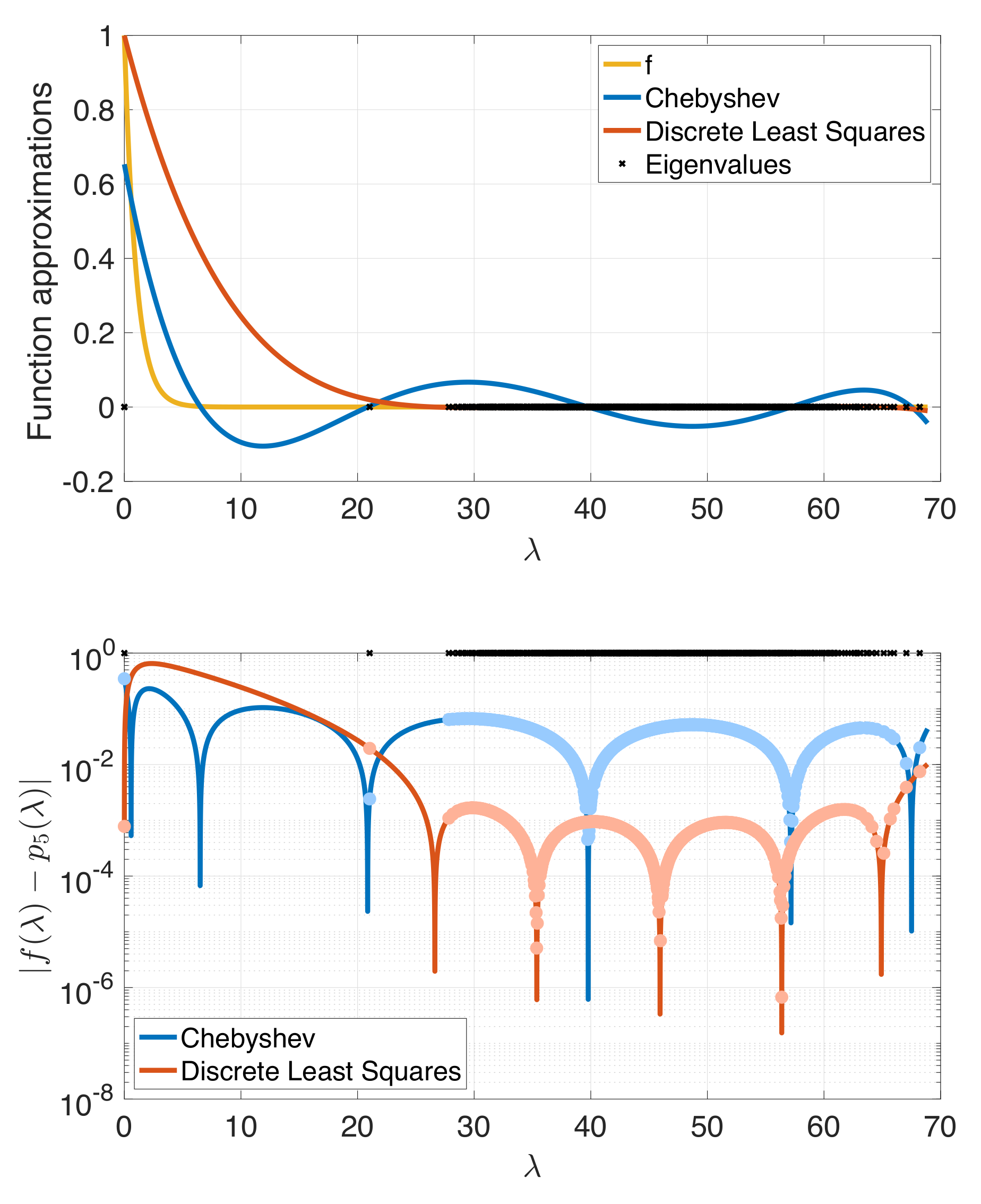
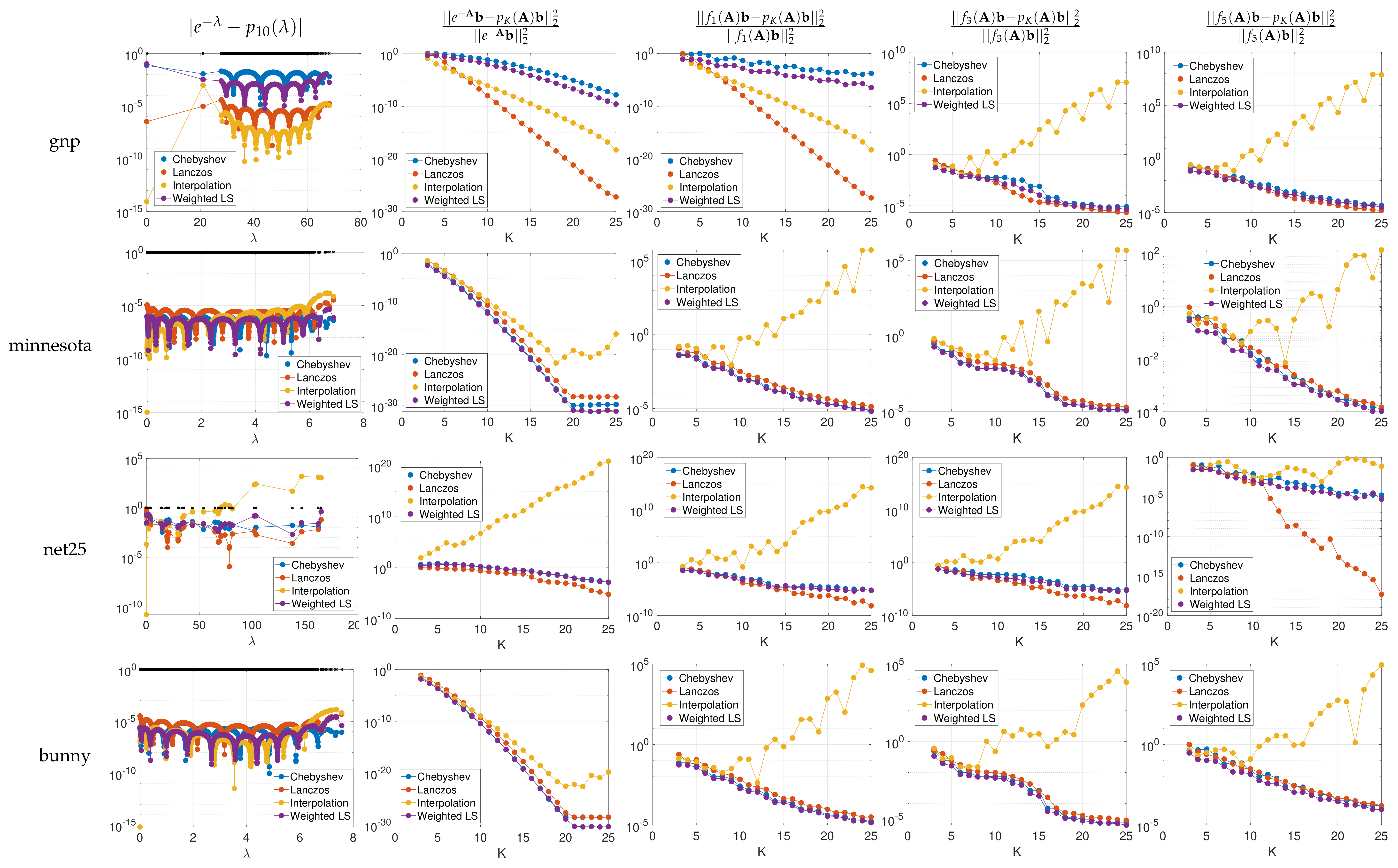
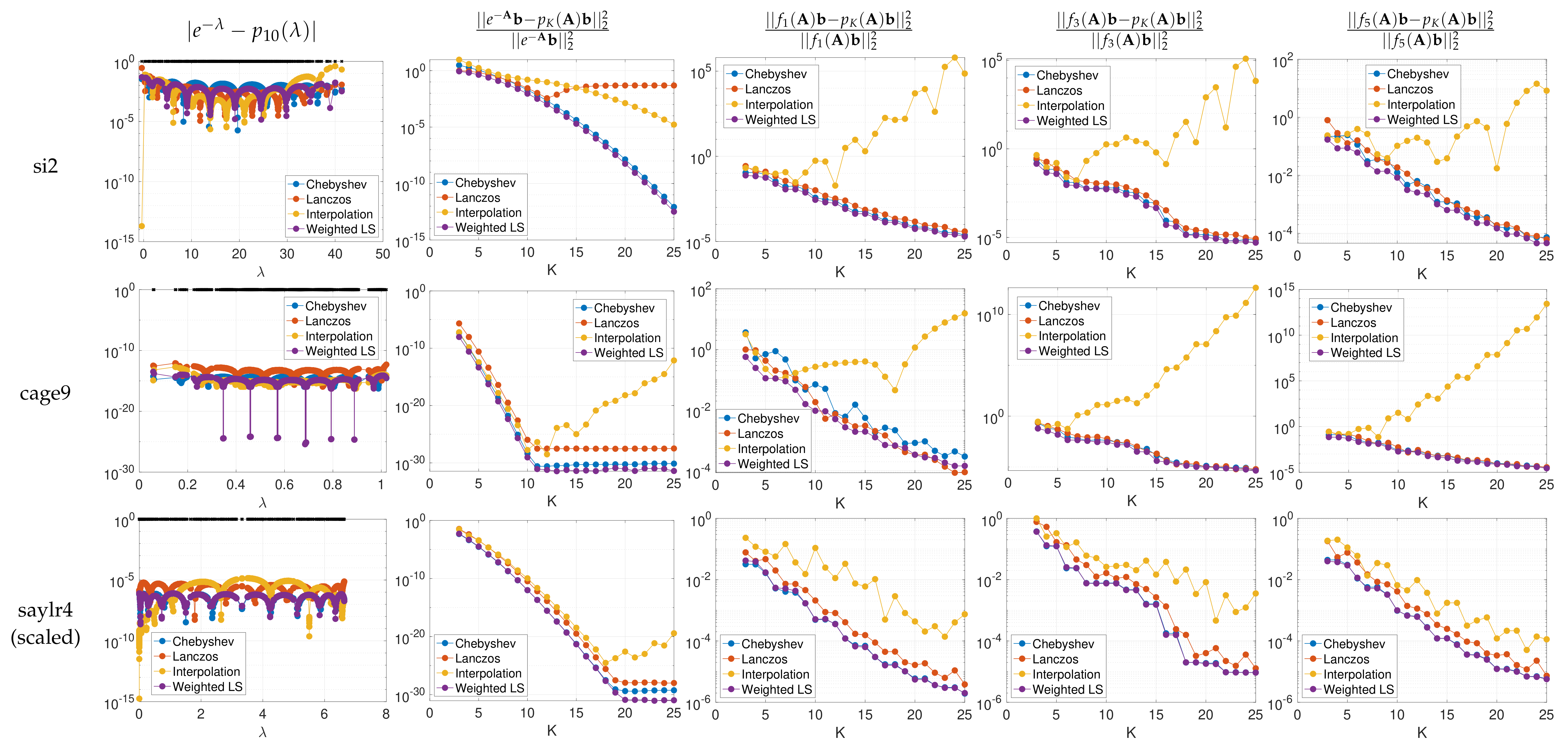
4. Numerical Examples and Discussion
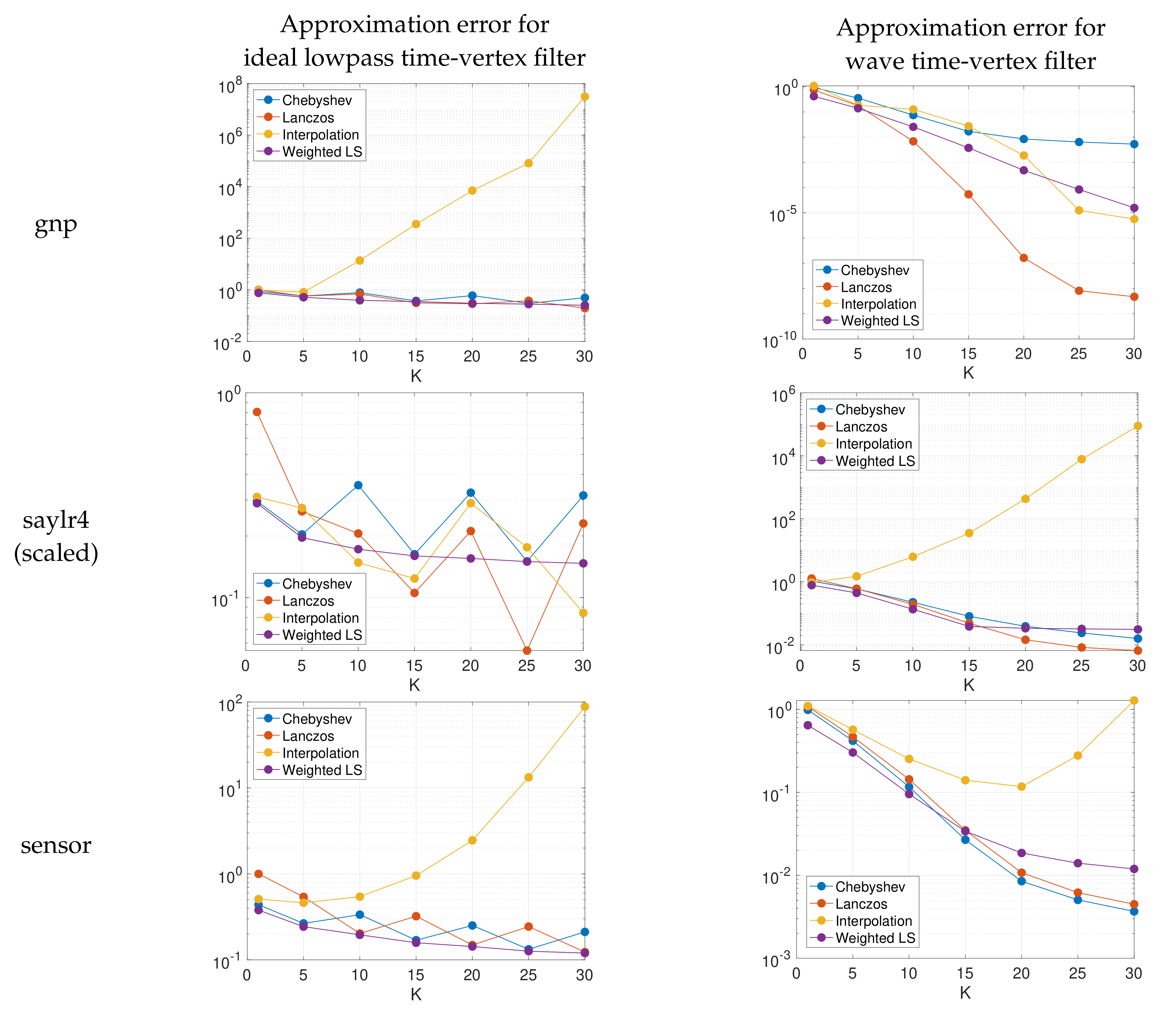
- The spectrum-adapted interpolation method often works well for low degree approximations (), but is not very stable at higher orders due to overfitting of the polynomial interpolant to the specific interpolation points (i.e., the interpolant is highly oscillatory).
- The proposed spectrum-adapted weighted least squares method tends to outperform the Lanczos method for matrices such as si2 and cage9 that have a large number of distinct interior eigenvalues.
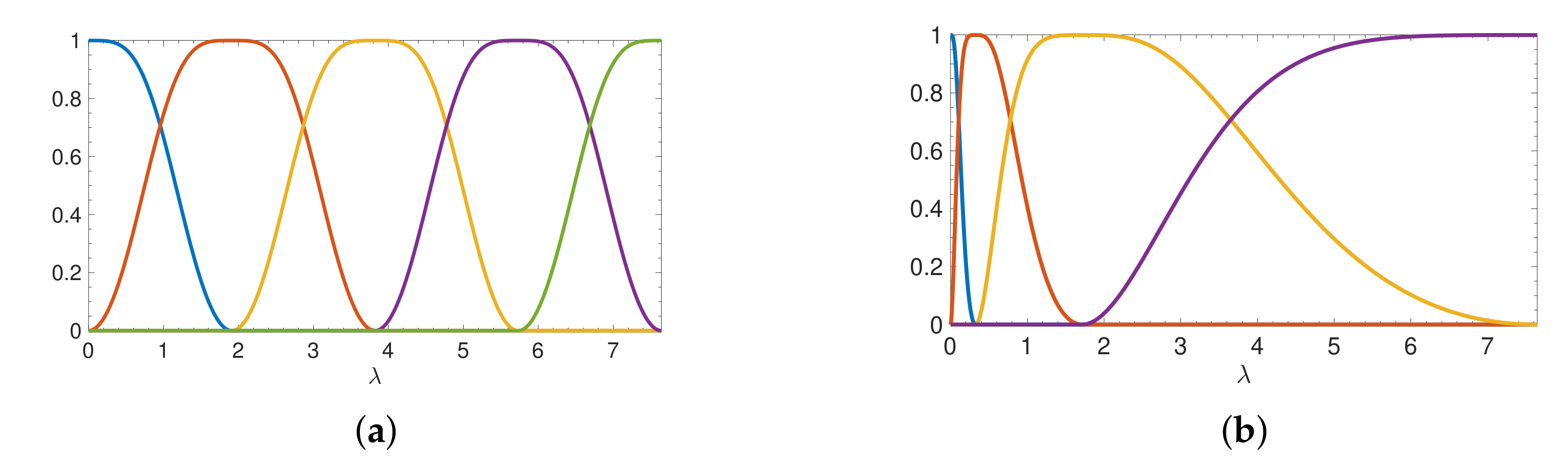
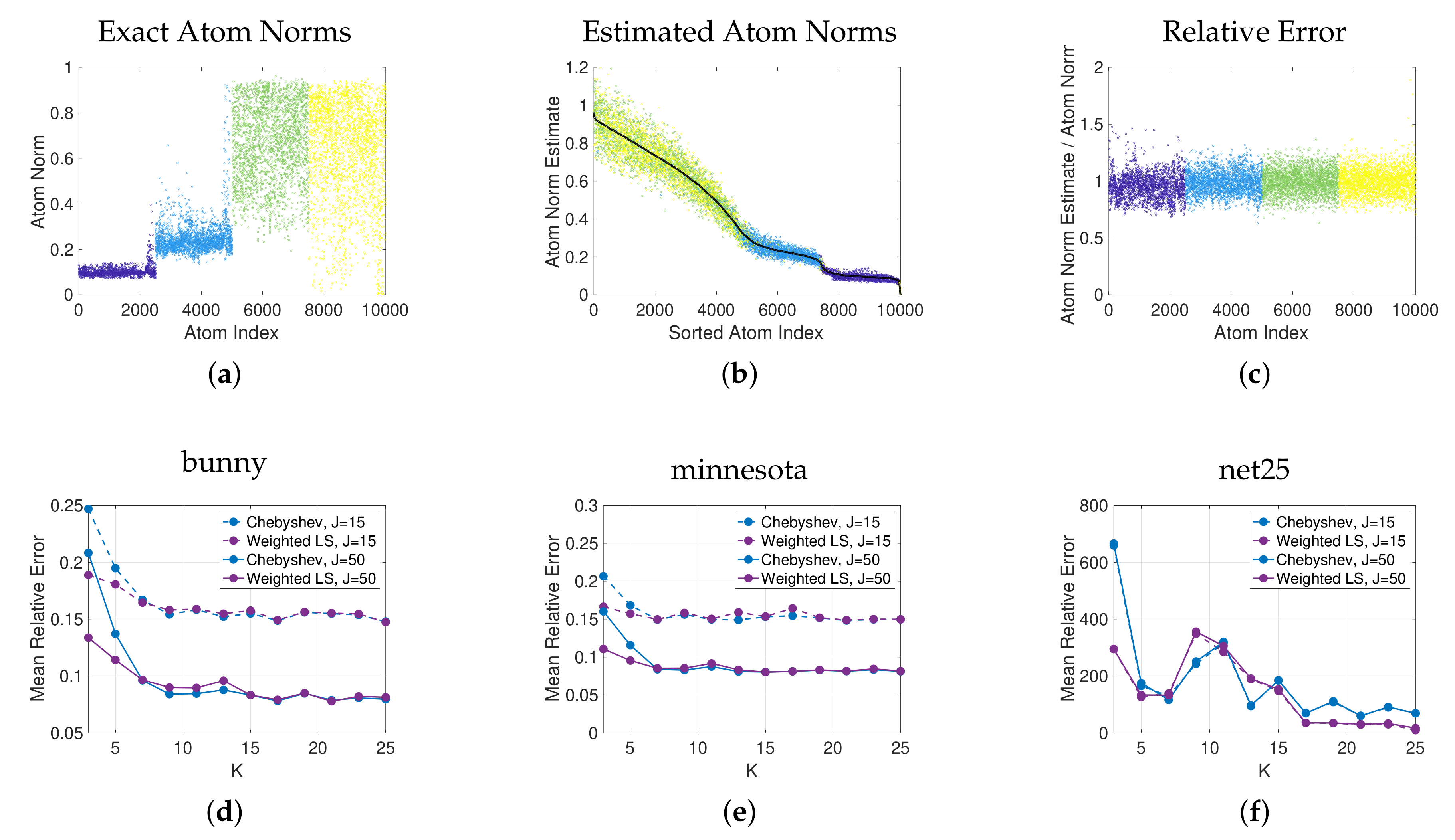
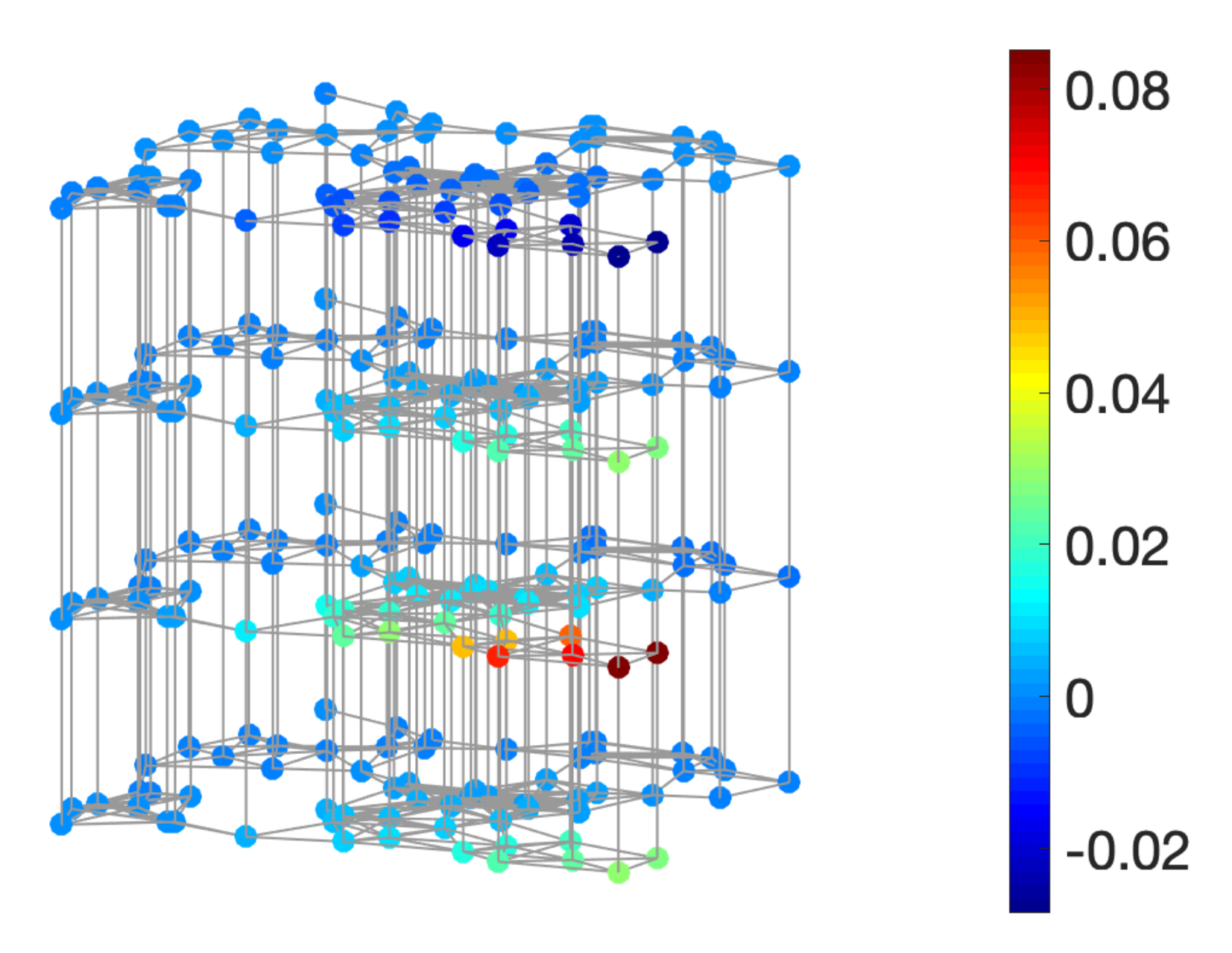
5. Application I: Estimation of the Norms of Localized Graph Spectral Filter Dictionary Atoms
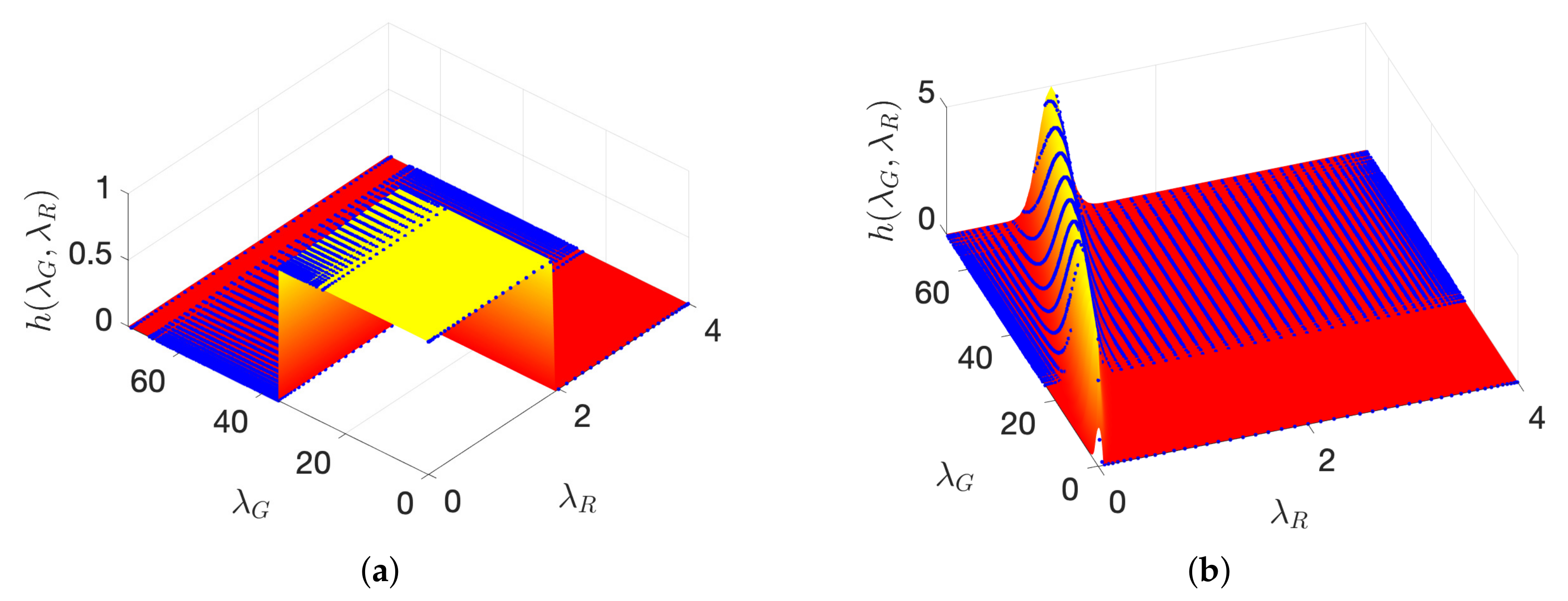
6. Application II: Fast Filtering of Time-Vertex Signals
6.1. Time-Vertex Signals
6.2. Time-Vertex Filtering
6.3. Spectrum-Adapted Approximation of Time-Vertex Filtering
| Algorithm 3 Spectrum-adapted approximate time-vertex filtering. |
| Input weighted undirected graph G with N vertices, time-vertex signal , filter h |
| Output time-vertex filtered signal |
|
6.4. Numerical Experiments
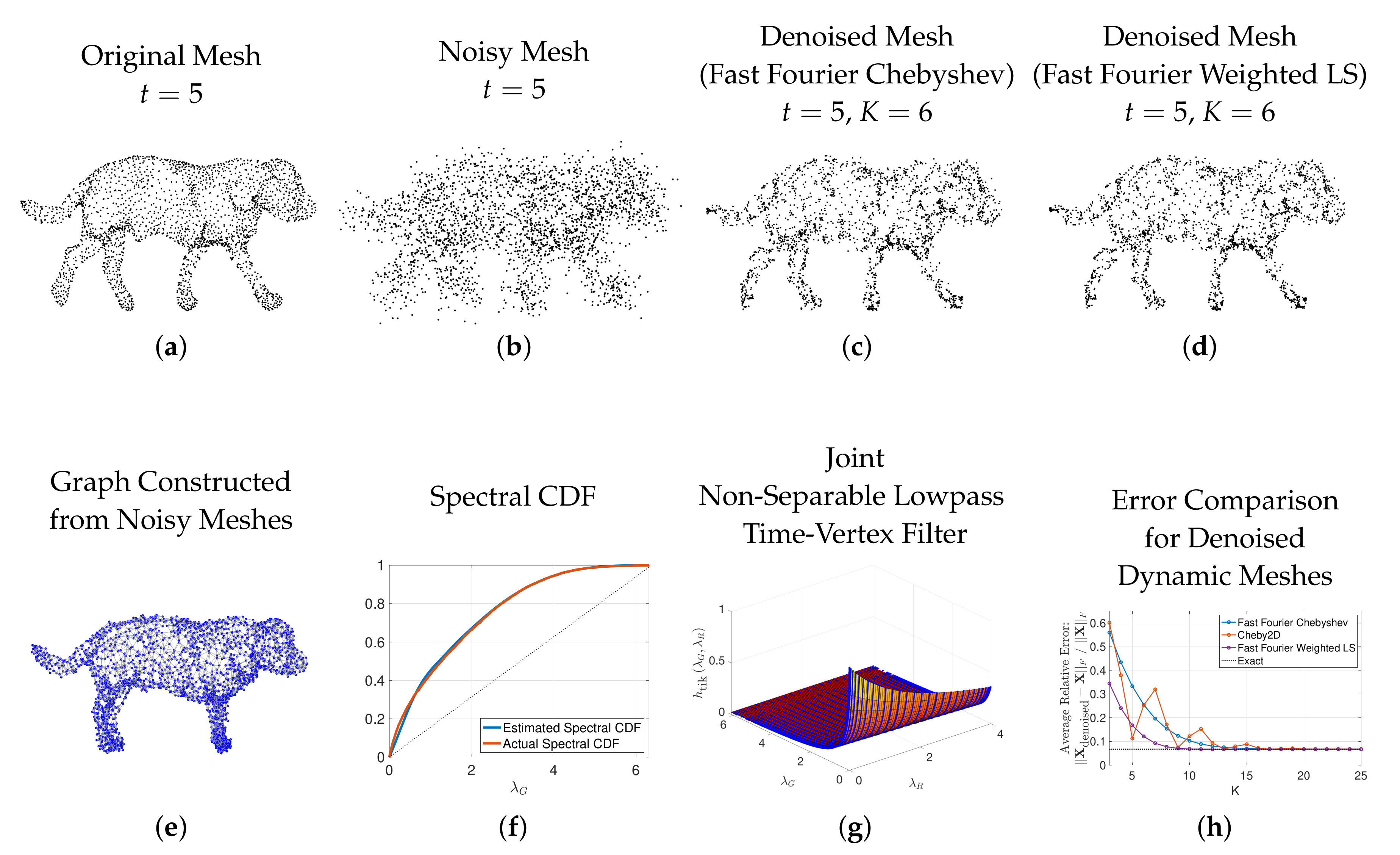
6.5. Dynamic Mesh Denoising
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Reproducible Research
References
- Smola, A.J.; Kondor, R. Kernels and Regularization on Graphs. In Learning Theory and Kernel Machines; Lecture Notes in Computer Science; Schölkopf, B., Warmuth, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 144–158. [Google Scholar]
- Belkin, M.; Matveeva, I.; Niyogi, P. Regularization and Semi-Supervised Learning on Large Graphs. In Learnning Theory; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2004; pp. 624–638. [Google Scholar]
- Zhou, D.; Bousquet, O.; Lal, T.N.; Weston, J.; Schölkopf, B. Learning with Local and Global Consistency; Advances Neural Information Processing Systems; Thrun, S., Saul, L., Schölkopf, B., Eds.; MIT Press: Cambridge, MA, USA, 2004; Volume 16, pp. 321–328. [Google Scholar]
- Shuman, D.I.; Narang, S.K.; Frossard, P.; Ortega, A.; Vandergheynst, P. The Emerging Field of Signal Processing on Graphs: Extending High-Dimensional Data Analysis to Networks and Other Irregular Domains. IEEE Signal Process. Mag. 2013, 30, 83–98. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering; Advances Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2016; pp. 3844–3852. [Google Scholar]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric Deep Learning: Going Beyond Euclidean Data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Tremblay, N.; Puy, G.; Gribonval, R.; Vandergheynst, P. Compressive Spectral Clustering. Proc. Int. Conf. Mach. Learn. 2016, 48, 1002–1011. [Google Scholar]
- Orecchia, L.; Sachdeva, S.; Vishnoi, N.K. Approximating the Exponential, the Lanczos Method and an Õ(m)-Time Spectral Algorithm for Balanced Separator. Proc. ACM Symp. Theory Comput. 2012, 1141–1160. [Google Scholar] [CrossRef]
- Lin, L.; Saad, Y.; Yang, C. Approximating Spectral Densities of Large Matrices. SIAM Rev. 2016, 58, 34–65. [Google Scholar] [CrossRef]
- Ubaru, S.; Saad, Y. Fast Methods for Estimating the Numerical Rank of Large Matrices. Proc. Int. Conf. Mach. Learn. 2016, 48, 468–477. [Google Scholar]
- Ubaru, S.; Saad, Y.; Seghouane, A.K. Fast Estimation of Approximate Matrix Ranks Using Spectral Densities. Neural Comput. 2017, 29, 1317–1351. [Google Scholar] [CrossRef]
- Ubaru, S.; Chen, J.; Saad, Y. Fast Estimation of tr(f(A)) Via Stochastic Lanczos Quadrature. SIAM J. Matrix Anal. Appl. 2017, 38, 1075–1099. [Google Scholar] [CrossRef]
- Han, I.; Malioutov, D.; Avron, H.; Shin, J. Approximating Spectral Sums of Large-Scale Matrices Using Stochastic Chebyshev Approximations. SIAM J. Sci. Comput. 2017, 39, A1558–A1585. [Google Scholar] [CrossRef]
- Arora, S.; Kale, S. A Combinatorial, Primal-Dual Approach to Semidefinite Programs. Proc. ACM Symp. Theory Comput. 2007, 227–236. [Google Scholar] [CrossRef]
- Sachdeva, S.; Vishnoi, N.K. Faster Algorithms Via Approximation Theory. Found. Trends Theor. Comput. Sci. 2014, 9, 125–210. [Google Scholar] [CrossRef]
- Hochbruck, M.; Lubich, C.; Selhofer, H. Exponential Integrators for Large Systems of Differential Equations. SIAM J. Sci. Comput. 1998, 19, 1552–1574. [Google Scholar] [CrossRef]
- Friesner, R.A.; Tuckerman, L.; Dornblaser, B.; Russo, T.V. A Method for Exponential Propagation of Large Systems of Stiff Nonlinear Differential Equations. J. Sci. Comput. 1989, 4, 327–354. [Google Scholar] [CrossRef]
- Gallopoulos, E.; Saad, Y. Efficient Solution of Parabolic Equations by Krylov Approximation Methods. SIAM J. Sci. Stat. Comput. 1992, 13, 1236–1264. [Google Scholar] [CrossRef]
- Higham, N.J. Functions of Matrices; SIAM: Philadelphia, PA, USA, 2008. [Google Scholar]
- Davies, P.I.; Higham, N.J. Computing f(A)b for Matrix Functions f. In QCD and Numerical Analysis III; Springer: Berlin/Heidelberg, Germany, 2005; pp. 15–24. [Google Scholar]
- Frommer, A.; Simoncini, V. Matrix Functions. In Model Order Reduction: Theory, Research Aspects and Applications; Springer: Berlin/Heidelberg, Germany, 2008; pp. 275–303. [Google Scholar]
- Moler, C.; Van Loan, C. Nineteen Dubious Ways to Compute the Exponential of a Matrix, Twenty-Five Years Later. SIAM Rev. 2003, 45, 3–49. [Google Scholar] [CrossRef]
- Druskin, V.L.; Knizhnerman, L.A. Two Polynomial Methods of Calculating Functions of Symmetric Matrices. USSR Comput. Maths. Math. Phys. 1989, 29, 112–121. [Google Scholar] [CrossRef]
- Saad, Y. Filtered Conjugate Residual-Type Algorithms with Applications. SIAM J. Matrix Anal. Appl. 2006, 28, 845–870. [Google Scholar] [CrossRef]
- Chen, J.; Anitescu, M.; Saad, Y. Computing f(A)b Via Least Squares Polynomial Approximations. SIAM J. Sci. Comp. 2011, 33, 195–222. [Google Scholar] [CrossRef]
- Druskin, V.; Knizhnerman, L. Extended Krylov Subspaces: Approximation of the Matrix Square Root and Related Functions. SIAM J. Matrix Anal. Appl. 1998, 19, 755–771. [Google Scholar] [CrossRef]
- Eiermann, M.; Ernst, O.G. A Restarted Krylov Subspace Method for the Evaluation of Matrix Functions. SIAM J. Numer. Anal. 2006, 44, 2481–2504. [Google Scholar] [CrossRef]
- Afanasjew, M.; Eiermann, M.; Ernst, O.G.; Güttel, S. Implementation of a Restarted Krylov Subspace Method for the Evaluation of Matrix Functions. Lin. Alg. Appl. 2008, 429, 2293–2314. [Google Scholar] [CrossRef]
- Frommer, A.; Lund, K.; Schweitzer, M.; Szyld, D.B. The Radau-Lanczos Method for Matrix Functions. SIAM J. Matrix Anal. Appl. 2017, 38, 710–732. [Google Scholar] [CrossRef]
- Golub, G.H.; Van Loan, C.F. Matrix Computations; Johns Hopkins University Press: Baltimore, MD, USA, 2013. [Google Scholar]
- Mason, J.C.; Handscomb, D.C. Chebyshev Polynomials; Chapman and Hall: London, UK, 2003. [Google Scholar]
- Trefethen, L.N. Approximation Theory and Approximation Practice; SIAM: Philadelphia, PA, USA, 2013. [Google Scholar]
- Shuman, D.I.; Vandergheynst, P.; Kressner, D.; Frossard, P. Distributed Signal Processing via Chebyshev Polynomial Approximation. IEEE Trans. Signal Inf. Process. Netw. 2018, 4, 736–751. [Google Scholar] [CrossRef]
- Hammond, D.K.; Vandergheynst, P.; Gribonval, R. Wavelets on Graphs Via Spectral Graph Theory. Appl. Comput. Harmon. Anal. 2011, 30, 129–150. [Google Scholar] [CrossRef]
- Segarra, S.; Marques, A.G.; Ribeiro, A. Optimal Graph-Filter Design and Applications to Distributed Linear Network Operators. IEEE Trans. Signal Process. 2017, 65, 4117–4131. [Google Scholar] [CrossRef]
- Van Mieghem, P. Graph Spectra for Complex Networks; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Tao, T. Topics in Random Matrix Theory; American Mathematical Society: Providence, RI, USA, 2012. [Google Scholar]
- Silver, R.N.; Röder, H. Densities of States of Mega-Dimensional Hamiltonian Matrices. Int. J. Mod. Phys. C 1994, 5, 735–753. [Google Scholar] [CrossRef]
- Silver, R.N.; Röder, H.; Voter, A.F.; Kress, J.D. Kernel Polynomial Approximations for Densities of States and Spectral Functions. J. Comput. Phys. 1996, 124, 115–130. [Google Scholar] [CrossRef]
- Wang, L.W. Calculating the Density of States and Optical-Absorption Spectra of Large Quantum Systems by the Plane-Wave Moments Method. Phy. Rev. B 1994, 49, 10154. [Google Scholar] [CrossRef]
- Li, S.; Jin, Y.; Shuman, D.I. Scalable M-channel critically sampled filter banks for graph signals. IEEE Trans. Signal Process. 2019, 67, 3954–3969. [Google Scholar] [CrossRef]
- Girard, D. Un Algorithme Simple et Rapide Pour la Validation Croisée Généralisée sur des Problèmes de Grande Taille; Technical Report; Université Grenoble Alpes: St Martin d’Hères, France, 1987. [Google Scholar]
- Girard, A. A fast ’Monte-Carlo cross-validation’procedure for large least squares problems with noisy data. Numer. Math. 1989, 56, 1–23. [Google Scholar] [CrossRef]
- Di Napoli, E.; Polizzi, E.; Saad, Y. Efficient Estimation of Eigenvalue Counts in an Interval. Numer. Linear Algebra Appl. 2016, 23, 674–692. [Google Scholar] [CrossRef]
- Puy, G.; Pérez, P. Structured Sampling and Fast Reconstruction of Smooth Graph Signals. Inf. Inference A J. IMA 2018, 7, 657–688. [Google Scholar] [CrossRef]
- Shuman, D.I.; Wiesmeyr, C.; Holighaus, N.; Vandergheynst, P. Spectrum-Adapted Tight Graph Wavelet and Vertex-Frequency Frames. IEEE Trans. Signal Process. 2015, 63, 4223–4235. [Google Scholar] [CrossRef]
- Fritsch, F.N.; Carlson, R.E. Monotone Piecewise Cubic Interpolation. SIAM J. Numer. Anal. 1980, 17, 238–246. [Google Scholar] [CrossRef]
- Gleich, D. The MatlabBGL Matlab Library. Available online: http://www.cs.purdue.edu/homes/dgleich/packages/matlab_bgl/index.html (accessed on 11 November 2020).
- Stanford University Computer Graphics Laboratory. The Stanford 3D Scanning Repository. Available online: http://graphics.stanford.edu/data/3Dscanrep/ (accessed on 11 November 2020).
- Grassi, F.; Loukas, A.; Perraudin, N.; Ricaud, B. A Time-Vertex Signal Processing Framework: Scalable Processing and Meaningful Representations for Time-Series on Graphs. IEEE Trans. Signal Process. 2018, 66, 817–829. [Google Scholar] [CrossRef]
- Davis, T.A.; Hu, Y. The University of Florida Sparse Matrix Collection. ACM Trans. Math. Softw. 2011, 38, 1:1–1:25. [Google Scholar] [CrossRef]
- Forsythe, G.E. Generation and Use of Orthogonal Polynomials for Data-Fitting with a Digital Computer. J. SIAM 1957, 5, 74–88. [Google Scholar] [CrossRef]
- Gautschi, W. Orthogonal Polynomials: Computation and Approximation; Oxford University Press: Oxford, UK, 2004. [Google Scholar]
- Gragg, W.B.; Harrod, W.J. The Numerically Stable Reconstruction of Jacobi Matrices from Spectral Data. Numer. Math. 1984, 44, 317–335. [Google Scholar] [CrossRef]
- Saad, Y. Analysis of Some Krylov Subspace Approximations to the Matrix Exponential Operator. SIAM J. Numer. Anal. 1992, 29, 209–228. [Google Scholar] [CrossRef]
- Golub, G.H.; Meurant, G. Matrices, Moments and Quadrature with Applications; Princeton University Press: Princeton, NJ, USA, 2010. [Google Scholar]
- Perraudin, N.; Paratte, J.; Shuman, D.I.; Kalofolias, V.; Vandergheynst, P.; Hammond, D.K. GSPBOX: A Toolbox for Signal Processing on Graphs. arXiv 2014, arXiv:1408.5781. Available online: https://epfl-lts2.github.io/gspbox-html/ (accessed on 11 November 2020).
- Shuman, D.I. Localized Spectral Graph Filter Frames: A Unifying Framework, Survey of Design Considerations, and Numerical Comparison. IEEE Signal Process. Mag. 2020, 37, 43–63. [Google Scholar] [CrossRef]
- Göbel, F.; Blanchard, G.; von Luxburg, U. Construction of tight frames on graphs and application to denoising. In Handbook of Big Data Analytics; Springer: Berlin/Heidelberg, Germany, 2018; pp. 503–522. [Google Scholar]
- de Loynes, B.; Navarro, F.; Olivier, B. Data-Driven Thresholding in Denoising with Spectral Graph Wavelet Transform. arXiv 2019, arXiv:1906.01882. [Google Scholar]
- Puy, G.; Tremblay, N.; Gribonval, R.; Vandergheynst, P. Random sampling of bandlimited signals on graphs. Appl. Comput. Harmon. Anal. 2018, 44, 446–475. [Google Scholar] [CrossRef]
- Benzi, M.; Boito, P. Quadrature Rule-Based Bounds for Functions of Adjacency Matrices. Lin. Alg. Appl. 2010, 433, 637–652. [Google Scholar] [CrossRef]
- Bekas, C.; Kokiopoulou, E.; Saad, Y. An Estimator for the Diagonal of a Matrix. Appl. Numer. Math. 2007, 57, 1214–1229. [Google Scholar] [CrossRef]
- Loukas, A.; Foucard, D. Frequency Analysis of Time-Varying Graph Signals. In Proceedings of the 2016 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Washington, DC, USA, 7–9 December 2016; pp. 346–350. [Google Scholar]
- Perraudin, N.; Loukas, A.; Grassi, F.; Vandergheynst, P. Towards Stationary Time-Vertex Signal Processing. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 3914–3918. [Google Scholar]
- Grady, L.J.; Polimeni, J.R. Discrete Calculus; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Isufi, E.; Loukas, A.; Simonetto, A.; Leus, G. Separable Autoregressive Moving Average Graph-Temporal Filters. In Proceedings of the 2016 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 200–204. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, T.; Shuman, D.I.; Ubaru, S.; Saad, Y. Spectrum-Adapted Polynomial Approximation for Matrix Functions with Applications in Graph Signal Processing. Algorithms 2020, 13, 295. https://doi.org/10.3390/a13110295
Fan T, Shuman DI, Ubaru S, Saad Y. Spectrum-Adapted Polynomial Approximation for Matrix Functions with Applications in Graph Signal Processing. Algorithms. 2020; 13(11):295. https://doi.org/10.3390/a13110295
Chicago/Turabian StyleFan, Tiffany, David I. Shuman, Shashanka Ubaru, and Yousef Saad. 2020. "Spectrum-Adapted Polynomial Approximation for Matrix Functions with Applications in Graph Signal Processing" Algorithms 13, no. 11: 295. https://doi.org/10.3390/a13110295
APA StyleFan, T., Shuman, D. I., Ubaru, S., & Saad, Y. (2020). Spectrum-Adapted Polynomial Approximation for Matrix Functions with Applications in Graph Signal Processing. Algorithms, 13(11), 295. https://doi.org/10.3390/a13110295