Can People Really Do Nothing? Handling Annotation Gaps in ADL Sensor Data



Abstract
1. Introduction
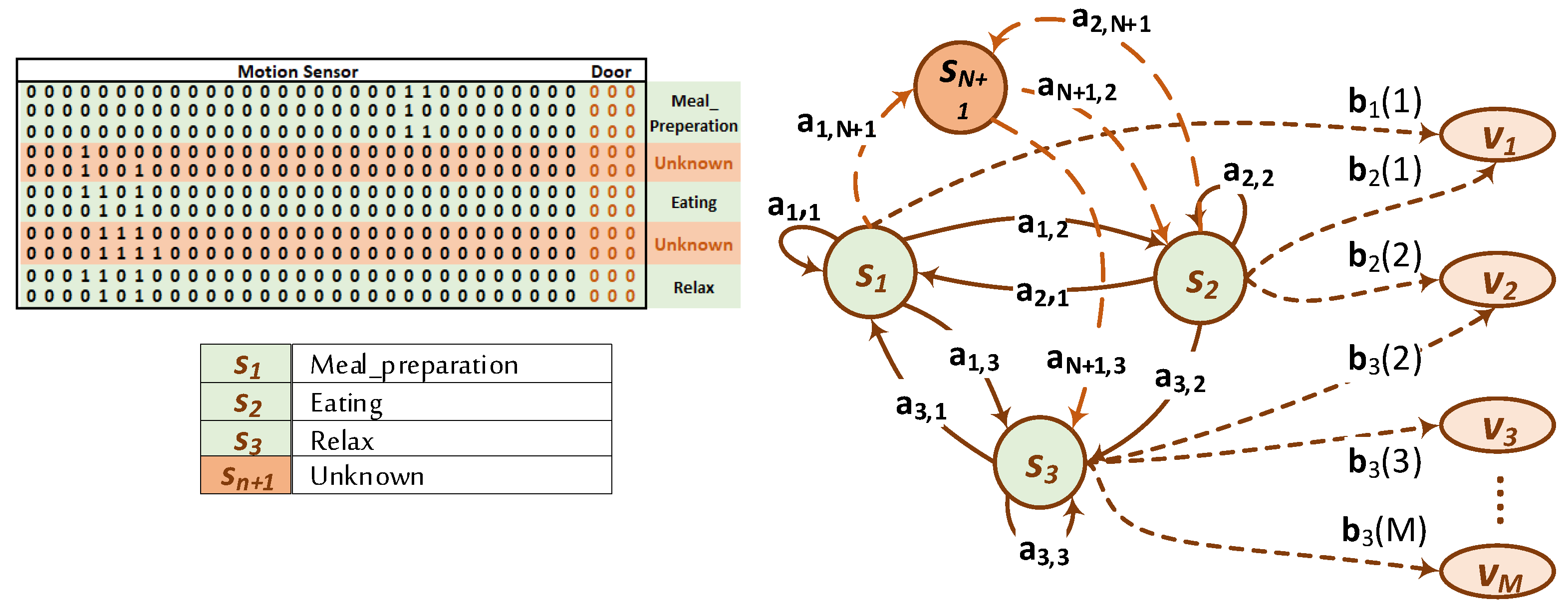
2. Hidden Markov Modeling of Activity Recognition
- is the set of the hidden states, N is the number of the states. The active state at a time instant, t, is . In the activity recognition model considered herein, the states represent the conducted activity in this specific instant, t;
- is the set of observable events and M is the number of observation events. The observable events in our case are the sensor readings;
- is the state transition probability distribution, where ;
- is the observation event probability distribution for state where ;
- is the set of initial state probability distribution where .
3. Annotation Gaps
- There is a usual delay between acquisition and annotation. This results in missing specific labels of some activities.
- By nature, many activities lack clear in-between boundaries determining their beginnings and their ends.
- A household himself/herself is often the annotator. He/She usually gives labels to activities on fuzzy basis depending on his/her memory of the starts and the ends of the activities. Supported by the aforementioned annotation delay, this leads to consequent annotation inaccuracy.
4. Gap Handling Paradigms
4.1. Gap Removal
4.2. A Unique Label for Gaps
4.3. Distinct Interactivity Labels
5. Experimental Setup
5.1. Dataset
5.2. Evaluation Procedures and Metrics
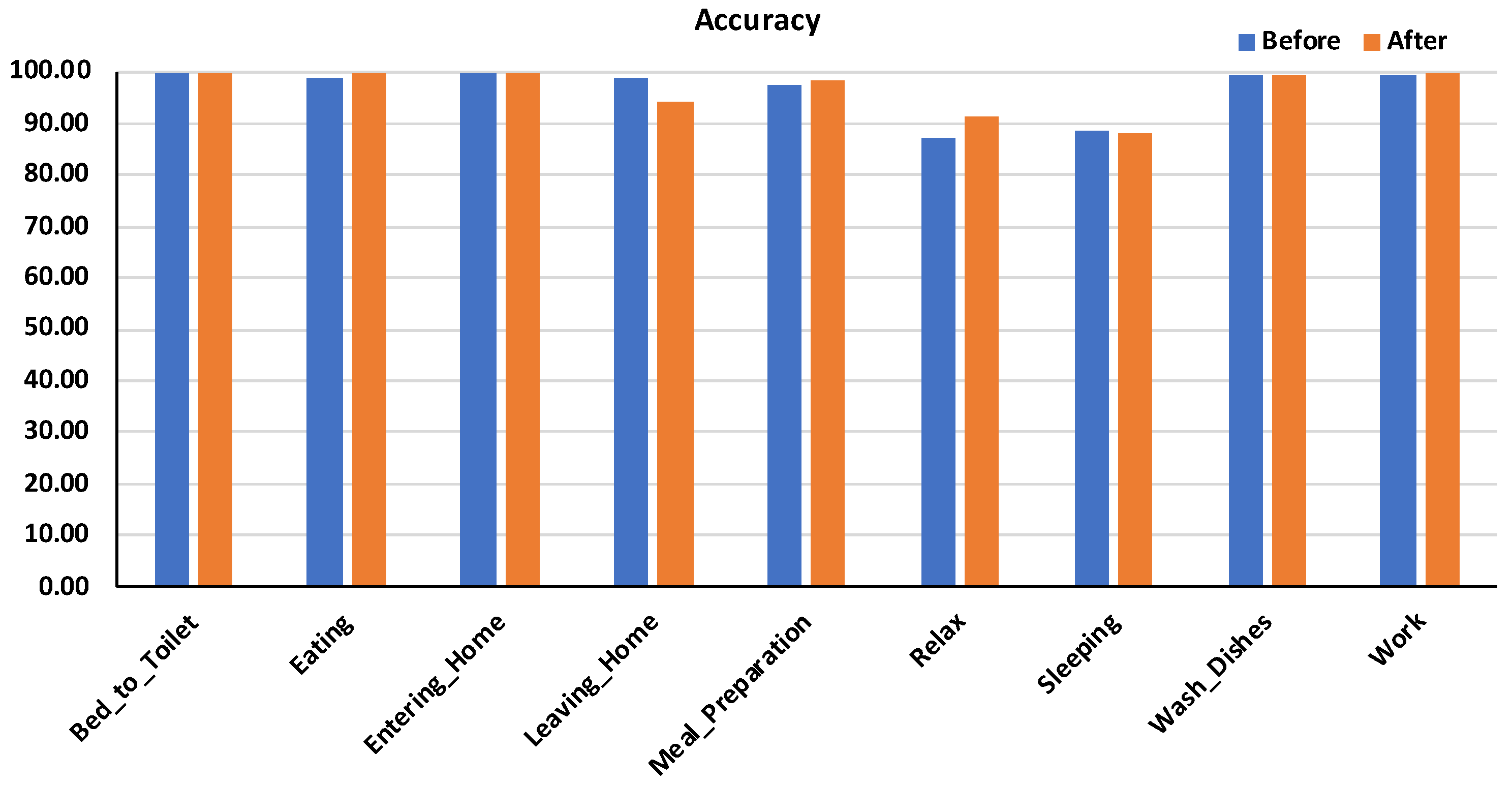
6. Results and Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| ADL | Activities of Daily Living |
| SOM | Self-Organizing Map |
| EM | Expectation Maximization |
| ANN | Artificial Neural Networks |
| GFMM | General Fuzzy Min-Max |
| CANN | Capacitance Artificial Neural Network |
| HMM | Hidden Markov Model |
| TNR | True Negative Rate |
References
- Li, Y.F.; Zhou, Z.H. Towards making unlabeled data never hurt. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 175–188. [Google Scholar] [CrossRef] [PubMed]
- Weber, N. Unsupervised Learning in Human Activity Recognition: A First Foray into Clustering Data Gathered from Wearable Sensors. Ph.D. Thesis, Radboud University, Nijmegen, The Netherlands, 2017. [Google Scholar]
- Trabelsi, D.; Mohammed, S.; Chamroukhi, F.; Oukhellou, L.; Amirat, Y. An unsupervised approach for automatic activity recognition based on Hidden Markov Model regression. IEEE Trans. Autom. Sci. Eng. 2013, 10, 829–835. [Google Scholar] [CrossRef]
- Toda, T.; Inoue, S.; Tanaka, S.; Ueda, N. Training Human Activity Recognition for Labels with Inaccurate Time Stamps. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, WA, USA, 13–17 September 2014; pp. 863–872. [Google Scholar]
- Yoon, J.W.; Cho, S.B. Global/Local Hybrid Learning of Mixture-of-Experts from Labeled and Unlabeled Data. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Wroclaw, Poland, 23–25 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 452–459. [Google Scholar]
- Tan, Q.; Yu, Y.; Yu, G.; Wang, J. Semi-supervised multi-label classification using incomplete label information. Neurocomputing 2017, 260, 192–202. [Google Scholar] [CrossRef]
- Dara, R.; Kremer, S.; Stacey, D. Clustering unlabeled data with SOMs improves classification of labeled real-world data. In Proceedings of the 2002 International Joint Conference on Neural Networks, Honolulu, HI, USA, 12–17 May 2002; Volume 3, pp. 2237–2242. [Google Scholar]
- Lee, Y.S.; Cho, S.B. Activity recognition with android phone using mixture-of-experts co-trained with labeled and unlabeled data. Neurocomputing 2014, 126, 106–115. [Google Scholar] [CrossRef]
- Pentina, A.; Lampert, C.H. Multi-Task Learning with Labeled and Unlabeled Tasks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 2807–2816. [Google Scholar]
- Chawla, N.V.; Karakoulas, G. Learning from labeled and unlabeled data: An empirical study across techniques and domains. J. Artif. Intell. Res. 2005, 23, 331–366. [Google Scholar] [CrossRef]
- Gabrys, B.; Bargiela, A. General fuzzy min-max neural network for clustering and classification. IEEE Trans. Neural Netw. 2000, 11, 769–783. [Google Scholar] [CrossRef] [PubMed]
- Cohn, D.; Caruana, R.; McCallum, A. Semi-supervised Clustering with User Feedback. Constrained Clust. Adv. Algorithms Theory Appl. 2003, 4, 17–32. [Google Scholar]
- Kowsari, K.; Brown, D.E.; Heidarysafa, M.; Meimandi, K.J.; Gerber, M.S.; Barnes, L.E. HDLTex: Hierarchical Deep Learning for Text Classification. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017. [Google Scholar]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A Review of Human Activity Recognition Methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef]
- Szilágyi, L.; Medvés, L.; Szilágyi, S.M. A modified Markov clustering approach to unsupervised classification of protein sequences. Neurocomputing 2010, 73, 2332–2345. [Google Scholar] [CrossRef]
- Goutte, C.; Déjean, H.; Gaussier, E.; Cancedda, N.; Renders, J.M. Combining labelled and unlabelled data: A case study on fisher kernels and transductive inference for biological entity recognition. In Proceedings of the 6th Conference on Natural Language Learning, Taipei, Taiwan, 31 August–1 September 2002. [Google Scholar]
- Goldman, S.A.; Zhou, Y. Enhancing Supervised Learning with Unlabeled Data. In Proceedings of the 17th International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; Volume 3, pp. 327–334. [Google Scholar]
- Seeger, M. Learning with labeled and unlabeled data. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2001. [Google Scholar]
- Cozman, F.G.; Brazil, S.P.; Cohen, I. Unlabeled Data Can Degrade Classification Performance of Generative Classifiers. In Proceedings of the Fifteenth International Florida Artificial Intelligence Research Society Conference, Pensacola, FL, USA, 14–16 May 2002; pp. 327–331. [Google Scholar]
- Wu, X. Incorporating large unlabeled data to enhance em classification. J. Intell. Inf. Syst. 2006, 26, 211–226. [Google Scholar] [CrossRef]
- Liisberg, J.; Møller, J.K.; Bloem, H.; Cipriano, J.; Mor, G.; Madsen, H. Hidden Markov Models for indirect classification of occupant behaviour. Sustain. Cities Soc. 2016, 27, 83–98. [Google Scholar] [CrossRef]
- Oliver, N.; Horvitz, E. A Comparison of HMMs and Dynamic Bayesian Networks for Recognizing Office Activities. In Proceedings of the International Conference on User Modeling, Edinburgh, UK, 24–29 July 2005; pp. 199–209. [Google Scholar]
- Banerjee, T.; Keller, J.M.; Skubie, M. Building a framework for recognition of activities of daily living from depth images using fuzzy logic. In Proceedings of the 2014 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), Beijing, China, 6–11 July 2014; pp. 540–547. [Google Scholar]
- Bourobou, S.; Yoo, Y. User Activity Recognition in Smart Homes Using Pattern Clustering Applied to Temporal ANN Algorithm. Sensors 2015, 15, 11953–11971. [Google Scholar] [CrossRef] [PubMed]
- Rabiner, L.R. A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Aggarwal, J.; Ryoo, M. Human activity analysis: A review. ACM Comput. Surv. 2011, 43, 16:1–16:43. [Google Scholar] [CrossRef]
- Abdel-Hakim, A.E.; Deabes, W.A. Impact of sensor data glut on activity recognition in smart environments. In Proceedings of the 2017 IEEE 17th International Conference on Ubiquitous Wireless Broadband (ICUWB), Salamanca, Spain, 12–15 September 2017. [Google Scholar]
- Datasets from WSU CASAS Smart Home Project. Available online: http://ailab.wsu.edu/casas/datasets/ (accessed on 20 March 2017).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sleeping | Bed_To_Toilet | |||||
|---|---|---|---|---|---|---|
| Binary | Hex | Binary | Hex | |||
| 0000000000000000000000000000000001 | 0x000000001 | Unknown | 0000000000000000000010111110100000 | 0x000002FA0 | Unknown | |
| 0000000000000000000010100100101101 | 0x00000292D | 0000000000000000000000000000000001 | 0x000000001 | |||
| 0000000000000000000000000000000001 | 0x000000001 | Sleeping | ||||
| 0000000000000000000010100100101101 | 0x00000292D | |||||
| 0000000000000000000010100100101101 | 0x00000292D | Bed_To_Toilet | ||||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000010111110100000 | 0x000002FA0 | Unknown | ||
| Bed_To_Toilet | 0000000000000000000000000000000001 | 0x000000001 | ||||
| Sleeping | ||||||
| Sleeping | ||||||
| 0000000000000000000000000000000001 | 0x000000001 | Unknown | Bed_To_Toilet | |||
| 0000000000000000000010100100101101 | 0x00000292D | 0000000000000000000000000000000001 | 0x000000001 | Unknown | ||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000010111110100000 | 0x000002FA0 | |||
| Bed_To_Toilet | 0000000000000000000010111110100000 | 0x000002FA0 | ||||
| Sleeping | ||||||
| Sleeping | ||||||
| 0000000000000000000000000000000001 | 0x000000001 | Unknown | Bed_To_Toilet | |||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000011010001011001 | 0x000003459 | Unknown | ||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000011010001011001 | 0x000003459 | |||
| 0000000000000000000010100100101101 | 0x00000292D | Sleeping | ||||
| 0000000000000000000000000000000001 | 0x000000001 | |||||
| 0000000000000000000010111110100000 | 0x000002FA0 | Bed_To_Toilet | ||||
| Bed_To_Toilet | 0000000000000000000011010001011001 | 0x000003459 | Unknown | |||
| 0000000000000000000000000000000001 | 0x000000001 | |||||
| Sleeping | Sleeping | |||||
| 0000000000000000000010100100101101 | 0x00000292D | Unknown | ||||
| 0000000000000000000010100100101101 | 0x00000292D | Bed_To_Toilet | ||||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000000000000000001 | 0x000000001 | Unknown | ||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000000000000000001 | 0x000000001 | |||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000011010001011001 | 0x000003459 | |||
| 0000000000000000000000000000000001 | 0x000000001 | 0000000000000000000000000000000001 | 0x000000001 | |||
| Bed_To_Toilet | Sleeping | |||||
| Motion Sensor | Door | |||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | |
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | |
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | |
| 0 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdel Hakim, A.E.; Deabes, W. Can People Really Do Nothing? Handling Annotation Gaps in ADL Sensor Data. Algorithms 2019, 12, 217. https://doi.org/10.3390/a12100217
Abdel Hakim AE, Deabes W. Can People Really Do Nothing? Handling Annotation Gaps in ADL Sensor Data. Algorithms. 2019; 12(10):217. https://doi.org/10.3390/a12100217
Chicago/Turabian StyleAbdel Hakim, Alaa E., and Wael Deabes. 2019. "Can People Really Do Nothing? Handling Annotation Gaps in ADL Sensor Data" Algorithms 12, no. 10: 217. https://doi.org/10.3390/a12100217
APA StyleAbdel Hakim, A. E., & Deabes, W. (2019). Can People Really Do Nothing? Handling Annotation Gaps in ADL Sensor Data. Algorithms, 12(10), 217. https://doi.org/10.3390/a12100217