On Finding and Enumerating Maximal and Maximum k-Partite Cliques in k-Partite Graphs

 , , and
, , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. The MMCE Algorithm
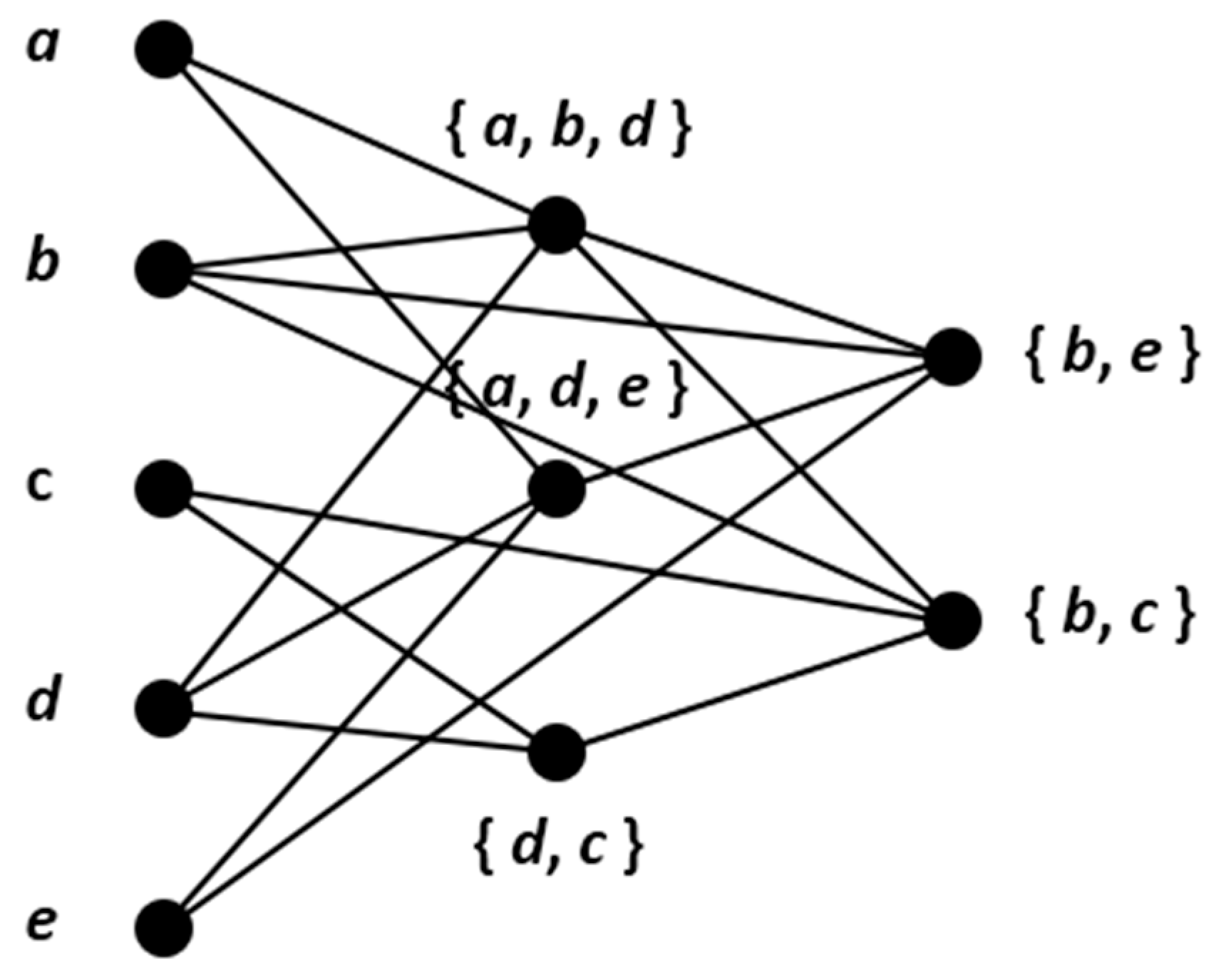
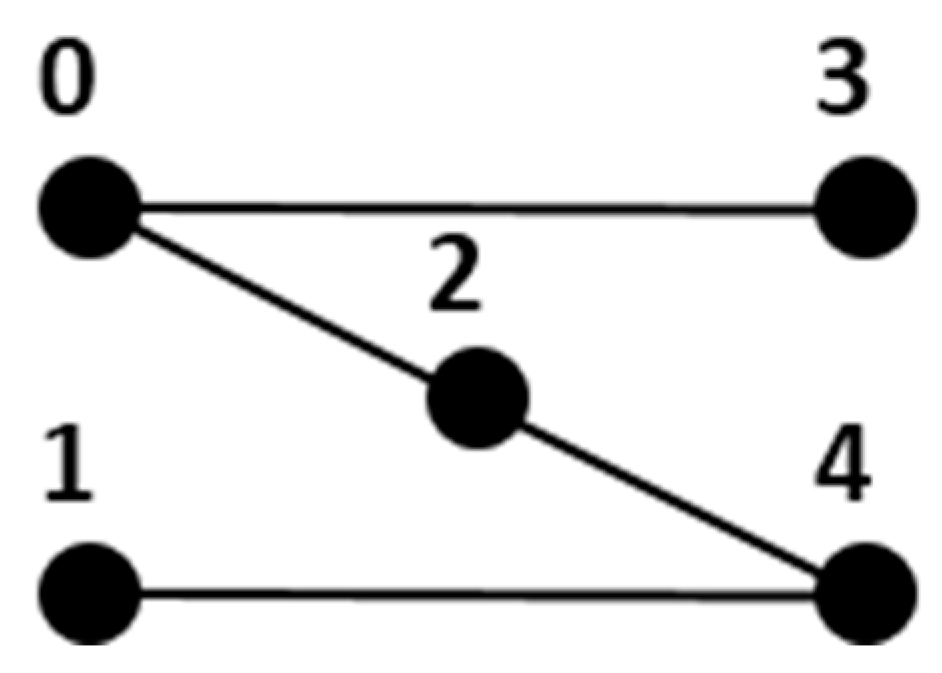
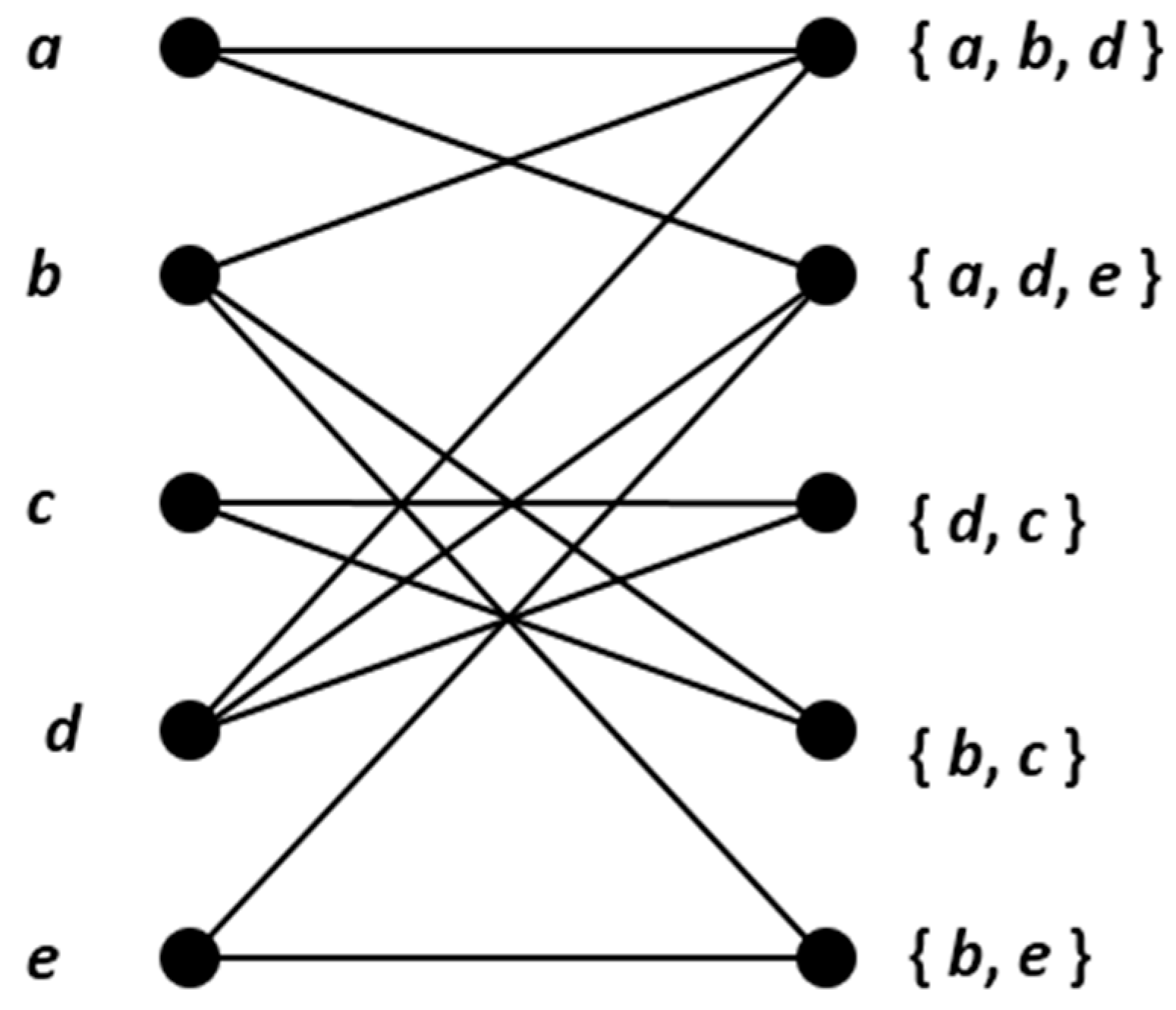
2.1. Multipartite Graphs
2.2. Algorithm Synthesis
| Algorithm 1. MMCE |
| 1 input: a k-partite graph G = (V, E), with partite sets V1, V2, …, Vk; |
| 2 output: all maximal k-partite cliques in G; |
| 3 add all possible intrapartite edges to G; |
| 4 R ← ∅; P ← V; X ← ∅; |
| 5 ENUMERATE (G, R, P, X); |
| 6 end MMCE |
| Subroutine ENUMERATE (G, R, P, X) |
| 1 input: a graph G = (V, E), with vertex partition V1, V2, …, Vk, a clique R that covers this partition, and two disjoint subsets P and X such that P ∪ X = { v ∊ V; R ⊆ N(v)}; |
| 2 output: all maximal cliques covering this partition that extend R with vertices in P; |
| 3 if P = ∅ and X = ∅ |
| 4 then if R covers the partition V1, V2, …, Vk |
| 5 then report R as a maximal k-partite clique; |
| 6 return; |
| 7 choose a pivot vertex u in P ∪ X that maximizes |P ∩ N(u)|; |
| 8 for each vertex v in P \ N(u) |
| 9 ENUMERATE (G, R ∪ v, P ∩ N(v), X ∩ N(v)); |
| 10 P ← P \ v; |
| 11 X ← X ∪ v; |
| 12 end ENUMERATE |
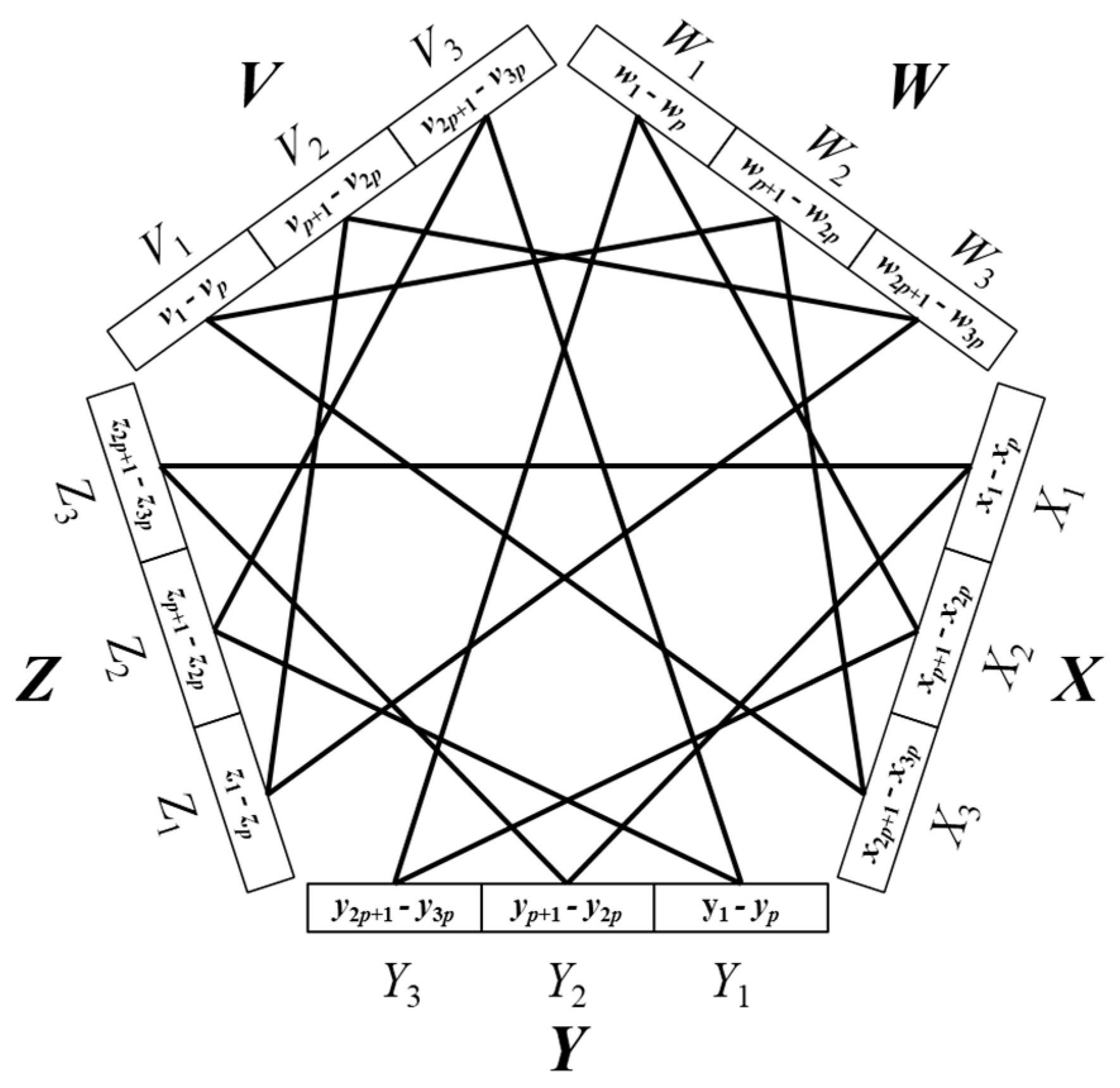
3. The Asymptotic Optimality of MMCE
4. Complexity-Theoretic Issues
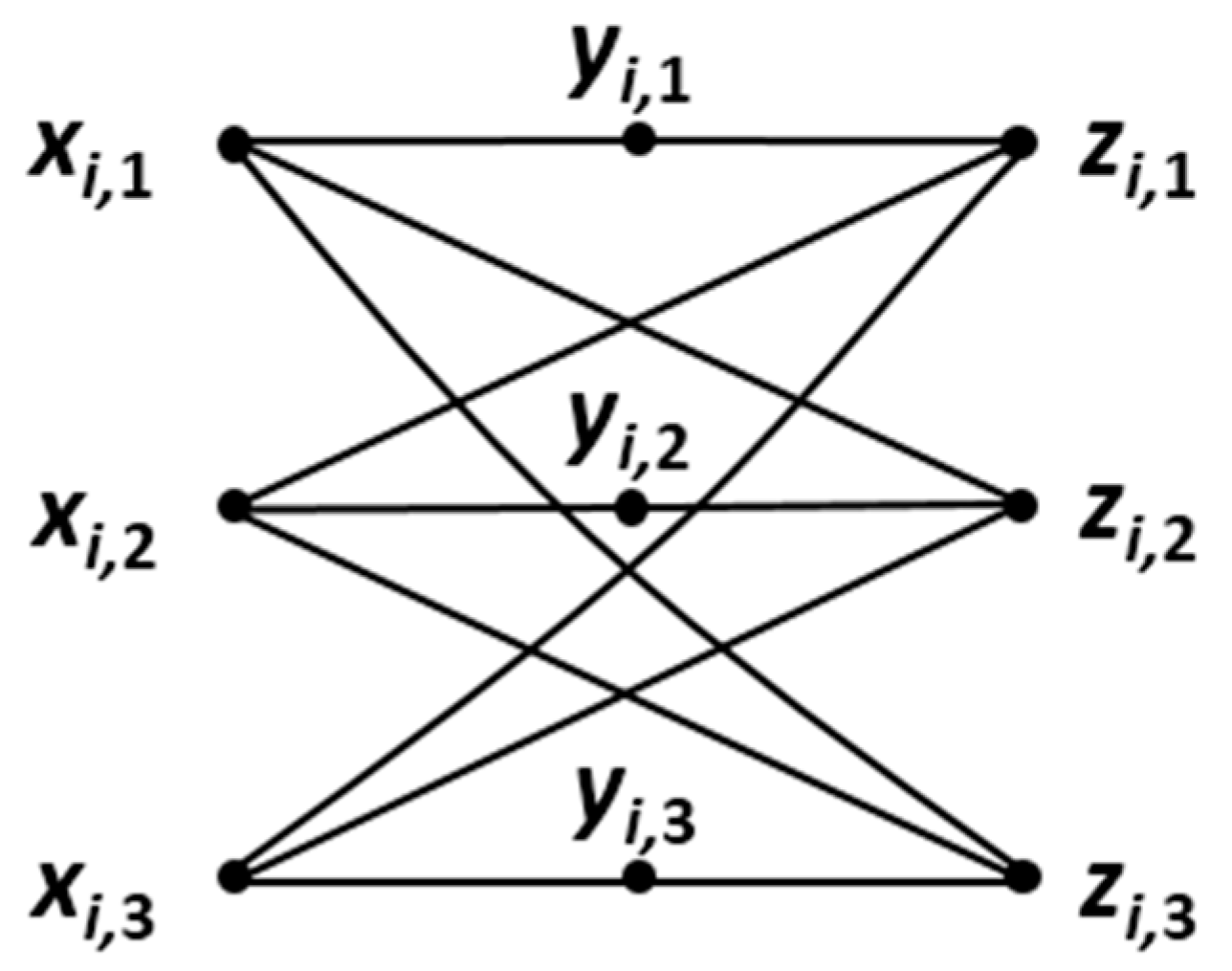
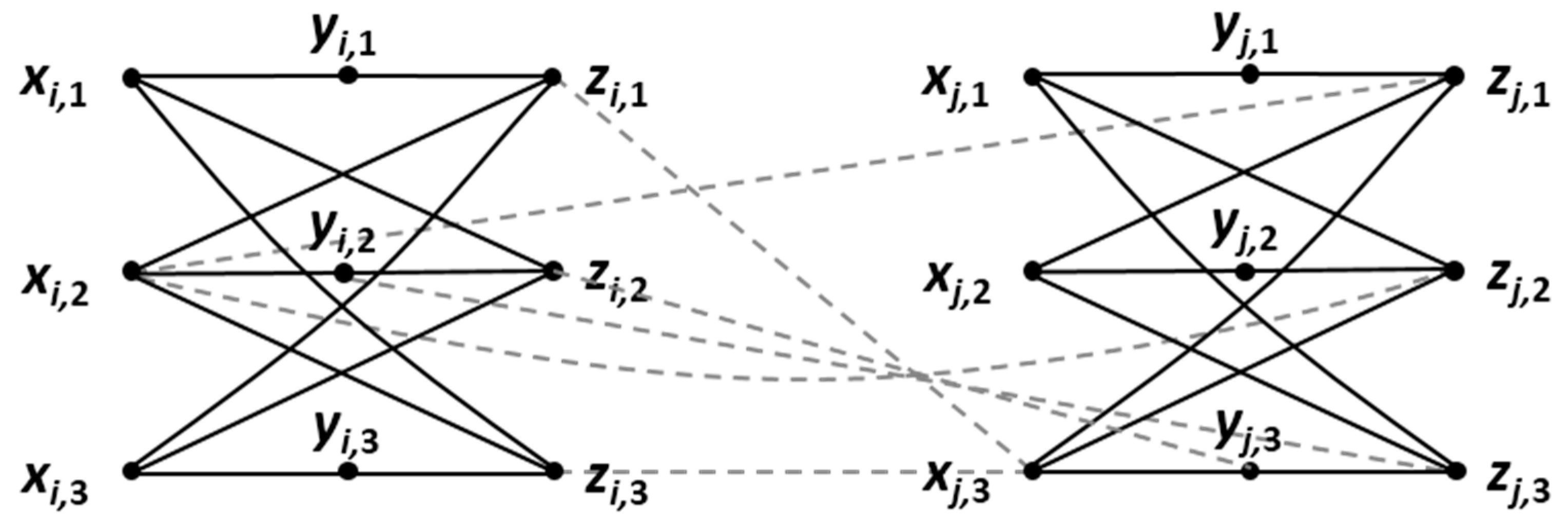
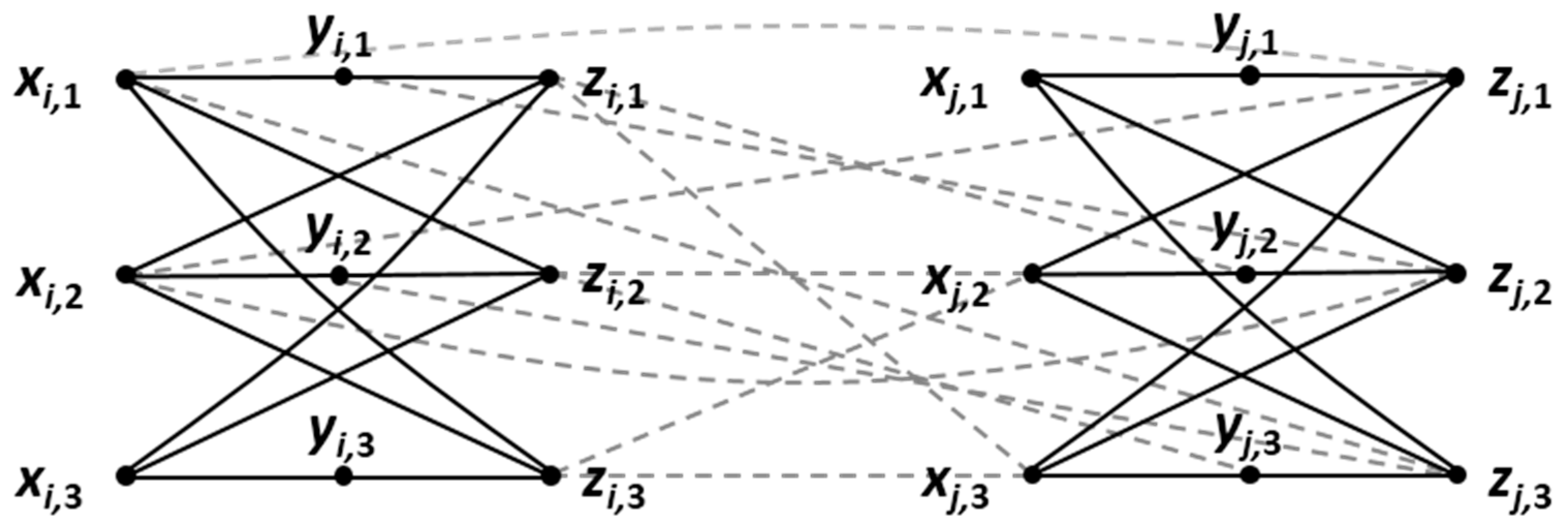
5. A Special Class of Multipartite Graphs
| Algorithm 2. MMCE-SI |
| 1 input: a k-partite set intersection graph G = (V, E), with partite sets V1, V2, …, Vk; |
| 2 output: all maximal k-partite cliques in G; |
| 3 compute the bipartite graph Gb; |
| 4 invoke MBEA on Gb; |
| 5 for each maximal biclique B returned by MBEA |
| 6 if every partite set of G contains at least one ui for which vi ∊ B |
| 7 then report {ui|vi ∊ B} as a maximal k-partite clique; |
| 8 end MMCE-SI |
| Algorithm 3. MSIGR |
| 1 input: a k-partite graph G = (V,E), with partite sets V1, V2, …, Vk; |
| 2 ouput: “yes” or “no,” depending on whether G is a k-partite set intersection graph; |
| 3 for each partite set P of G |
| 4 flag ← true; |
| 5 for every u and v in different partite sets, neither of which is P |
| 6 if u and v are adjacent but have no common neighbor in P |
| 7 then flag ← false and break for loop; |
| 8 if u and v are nonadjacent but have a common neighbor in P |
| 9 then flag ← false and break for loop; |
| 10 if flag then report “yes” and halt; |
| 11 report “no”; |
| 12 end MSIGR |
6. Summary and Directions for Future Research
Author Contributions
Funding
Conflicts of Interest
Appendix A
- (∗)
- Observe that .
- (∗∗)
- To see that , we expand the summationsand exploit the symmetry given by . In Equation (A1) or (A2), we can substitute for , for , for , …, and for to yield the other equation.
- (∗∗∗)
- By the binomial theorem, .
Appendix B
Appendix C
References
- Grünert, T.; Irnich, S.; Zimmermann, H.; Schneider, S.M.; Wulfhorst, B. Finding all k-cliques in k-partite graphs, an application in textile engineering. Comput. Oper. Res. 2001, 29, 13–31. [Google Scholar] [CrossRef]
- Zaki, M.J.; Peters, M.; Assent, I.; Seidl, T. Clicks: An effective algorithm for mining subspace clusters in categorical datasets. Data Knowl. Eng. 2007, 60, 51–70. [Google Scholar] [CrossRef]
- Phillips, C.A.; Wang, K.; Bubier, J.; Baker, E.J.; Chesler, E.J.; Langston, M.A. Scalable Multipartite Subgraph Enumeration for Integrative Analysis of Heterogeneous Experimental Functional Genomics Data. In Proceedings of the 6th ACM Conference on Bioinformatics, Computational Biology and Health Informatics, Atlanta, Georgia, 9–12 September 2015; pp. 626–633. [Google Scholar]
- Liu, Q.; Chen, Y.P.; Li, J. k-Partite Cliques of Protein Interactions: A Novel Subgraph Topology for Functional Coherence Analysis on PPI Networks. J. Theor. Biol. 2014, 340, 146–154. [Google Scholar] [CrossRef] [PubMed]
- Turán, P. On an Extremal Problem in Graph Theory. Matematikai és Fizikai Lapok 1941, 48, 436–452. [Google Scholar]
- Aigner, M. Turán’s Graph Theorem. Am. Math. Mon. 1995, 102, 808–816. [Google Scholar]
- Karp, R. Reducibility among combinatorial problems. In Complexity of Computer Computations; Miller, R., Thatcher, J., Eds.; Plenum Press: New York, NY, USA, 1972; pp. 85–103. [Google Scholar]
- Bron, C.; Kerbosch, J. Algorithm 457: Finding All Cliques of an Undirected Graph. Commun. ACM 1973, 16, 575–577. [Google Scholar] [CrossRef]
- Tomita, E.; Tanaka, A.; Takahashi, H. The Worst-Case Time Complexity for Generating all Maximal Cliques and Computational Experiments. Theor. Comput. Sci. 2006, 363, 28–42. [Google Scholar] [CrossRef]
- Eppstein, D.; Löffler, M.; Strash, D. Listing All Maximal Cliques in Large Sparse Real-World Graphs. J. Exp. Algorithm. 2013, 18, 3.1–3.21. [Google Scholar] [CrossRef]
- Zhang, Y.; Abu-Khzam, F.N.; Baldwin, N.E.; Chesler, E.J.; Langston, M.A.; Samatova, N.F. Genome-Scale Computational Approaches to Memory-Intensive Applications in Systems Biology. In Proceedings of the Supercomputing, Seattle, WA, USA, 12–18 November 2005. [Google Scholar]
- Kose, F.; Weckwerth, W.; Linke, T.; Fiehn, O. Visualizing plant metabolomic correlation networks using clique–metabolite matrices. Bioinformatics 2001, 17, 1198–1208. [Google Scholar] [CrossRef]
- Abu-Khzam, F.N.; Baldwin, N.E.; Langston, M.A.; Samatova, N.F. On the Relative Efficiency of Maximal Clique Enumeration Algorithms, with Application to High-Throughput Computational Biology. In Proceedings of the Proceedings, International Conference on Research Trends in Science and Technology, Beirut, Lebanon, 7–9 March 2005. [Google Scholar]
- Li, J.; Li, H.; Soh, D.; Wong, L. A Correspondence Between Maximal Complete Bipartite Subgraphs and Closed Patterns. In Knowledge Discovery in Databases: PKDD 2005; Jorge, A., Torgo, L., Brazdil, P., Camacho, R., Gama, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3721, pp. 146–156. [Google Scholar]
- Zhang, Y.; Phillips, C.A.; Rogers, G.L.; Baker, E.J.; Chesler, E.J.; Langston, M.A. On Finding Bicliques in Bipartite Graphs: A Novel Algorithm and Its Application to the Integration of Diverse Biological Data Types. BMC Bioinform. 2014, 15, 110. [Google Scholar] [CrossRef]
- Baker, E.J.; Jay, J.J.; Bubier, J.A.; Langston, M.A.; Chesler, E.J. GeneWeaver: A Web-based System for Integrative Functional Genomics. Nucleic Acids Res. 2012, 40, D1067–D1076. [Google Scholar] [CrossRef] [PubMed]
- Mirghorbani, M.; Krokhmal, P. On Finding k-cliques in k-partite Graphs. Optim. Lett. 2013, 7, 1155–1165. [Google Scholar] [CrossRef]
- Makino, K.; Uno, T. New Algorithms for Enumerating All Maximal Cliques. In Algorithm Theory—SWAT 2004, Proceedings of the Scandinavian Workshop on Algorithm Theory, Humlebaek, Denmark, 8–10 July 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 260–272. [Google Scholar]
- Miller, R.E.; Muller, D.E. A Problem of Maximum Consistent Subsets; IBM Research Report RC-240; Watson Research Center: Yorktown Heights, NY, USA, 1960. [Google Scholar]
- Moon, J.W.; Moser, L. On Cliques in Graphs. Isr. J. Math. 1965, 3, 23–28. [Google Scholar] [CrossRef]
- Gaspers, S.; Kratsch, D.; Liedloff, M. On Independent Sets and Bicliques in Graphs. Algorithmica 2012, 62, 637–658. [Google Scholar] [CrossRef]
- Prisner, E. Bicliques in Graphs, I. Bounds on Their Number. Combinatorica 2000, 20, 109–117. [Google Scholar] [CrossRef]
- Garey, M.R.; Johnson, D.S. Computers and Intractability: A Guide to the Theory of NP-Completeness; W. H. Freeman and Company: New York, NY, USA, 1979. [Google Scholar]
- Peeters, R. The maximum edge biclique is NP-complete. Discret. Appl. Math. 2003, 131, 651–654. [Google Scholar] [CrossRef]
- Manurangsi, P. Inapproximability of Maximum Biclique Problems, Minimum k-Cut and Densest At-Least-k-Subgraph from the Small Set Expansion Hypothesis. Algorithms 2018, 11, 10. [Google Scholar] [CrossRef]
- Feige, U. Approximating Maximum Clique by Removing Subgraphs. SIAM J. Discret. Math. 2004, 18, 219–225. [Google Scholar] [CrossRef]
- Håstad, J. Clique is Hard to Approximate Within n^(1-є). Acta Math. 1999, 182, 105–142. [Google Scholar] [CrossRef]
- Clementi, A.F.; Crescenzi, P.; Rossi, G. On the Complexity of Approximating Colored-Graph Problems. In Computing and Combinatorics; Asano, T., Imai, H., Lee, D.T., Nakano, S.-I., Tokuyama, T., Eds.; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1627, pp. 281–290. [Google Scholar]
- Schaefer, T.J. The Complexity of Satisfiability Problems. In Proceedings of the Tenth Annual ACM Symposium on Theory of Computing, San Diego, CA, USA, 1–3 May 1978; pp. 216–226. [Google Scholar]
- Gupta, M.; Li, R.; Yin, Z.; Han, J. An Overview of Social Tagging and Applications. In Social Network Data Analytics; Aggarwal, C.C., Ed.; Springer: Berlin, Germany, 2011; pp. 447–497. [Google Scholar]
- Baker, E.; Bubier, J.A.; Reynolds, T.; Langston, M.A.; Chesler, E.J. GeneWeaver: Data Driven Alignment of Cross-Species Genomics in Biology and Disease. Nucleic Acids Res. 2016, 44, D555–D559. [Google Scholar] [CrossRef]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [PubMed]
- Smith, C.L.; Eppig, J.T. The Mammalian Phenotype Ontology: Enabling Robust Annotation and Comparative Analysis. Wiley Interdiscip. Rev. 2009, 1, 390–399. [Google Scholar] [CrossRef] [PubMed]
- Pardalos, P.; Vavasis, S. Quadratic Programming with One Negative Eigenvalue is NP-hard. J. Glob. Optim. 1991, 1, 15–22. [Google Scholar] [CrossRef]
- Zwick, U. Approximation Algorithms for Constraint Satisfaction Problems Involving at Most Three Variables per Constraint. In Proceedings of the ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 25–27 January 1998; pp. 201–210. [Google Scholar]








© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phillips, C.A.; Wang, K.; Baker, E.J.; Bubier, J.A.; Chesler, E.J.; Langston, M.A. On Finding and Enumerating Maximal and Maximum k-Partite Cliques in k-Partite Graphs. Algorithms 2019, 12, 23. https://doi.org/10.3390/a12010023
Phillips CA, Wang K, Baker EJ, Bubier JA, Chesler EJ, Langston MA. On Finding and Enumerating Maximal and Maximum k-Partite Cliques in k-Partite Graphs. Algorithms. 2019; 12(1):23. https://doi.org/10.3390/a12010023
Chicago/Turabian StylePhillips, Charles A., Kai Wang, Erich J. Baker, Jason A. Bubier, Elissa J. Chesler, and Michael A. Langston. 2019. "On Finding and Enumerating Maximal and Maximum k-Partite Cliques in k-Partite Graphs" Algorithms 12, no. 1: 23. https://doi.org/10.3390/a12010023
APA StylePhillips, C. A., Wang, K., Baker, E. J., Bubier, J. A., Chesler, E. J., & Langston, M. A. (2019). On Finding and Enumerating Maximal and Maximum k-Partite Cliques in k-Partite Graphs. Algorithms, 12(1), 23. https://doi.org/10.3390/a12010023