A Study on Faster R-CNN-Based Subway Pedestrian Detection with ACE Enhancement

Abstract
1. Introduction
2. The Methods of Sample Processing
2.1. Reducing Sample Categories
2.2. Automatic Color Enhancement
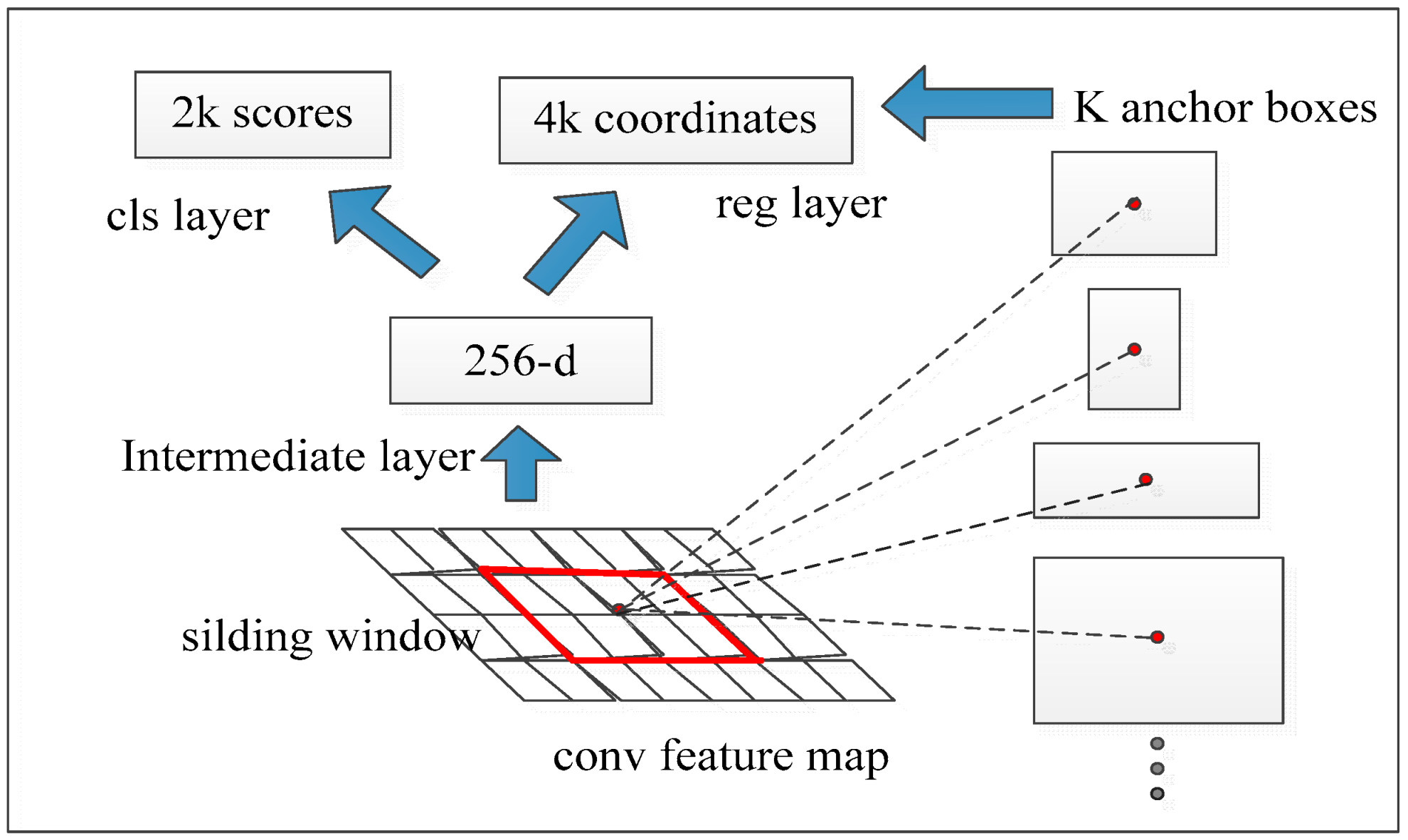
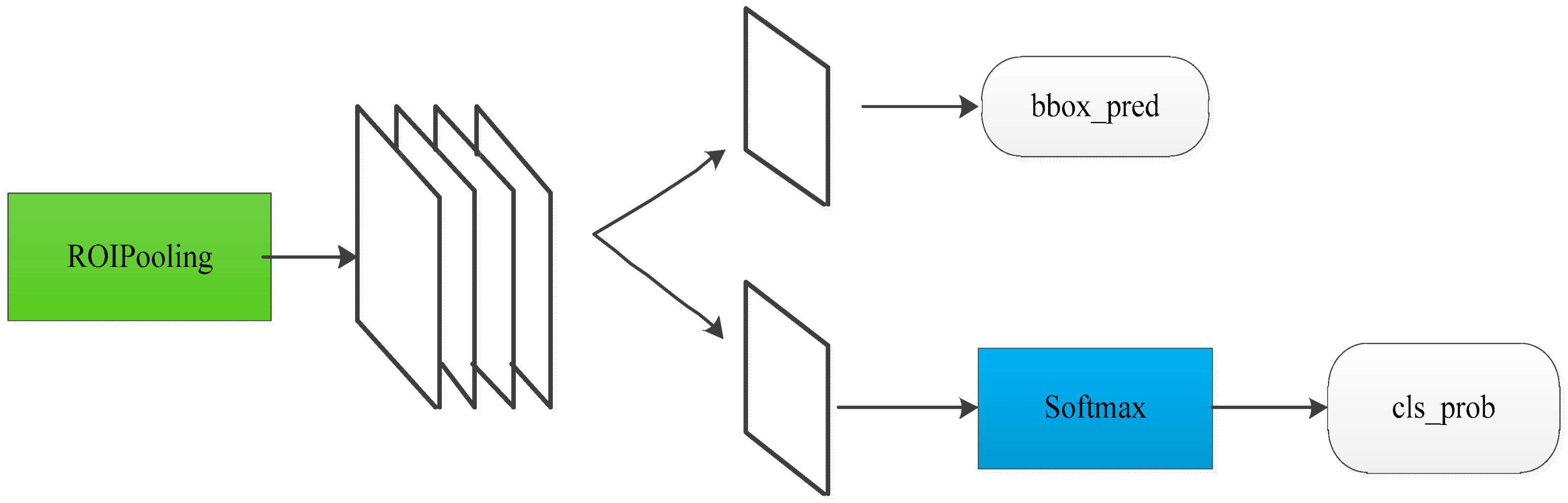
3. The Introduction of Faster R-CNN
4. The Experiments on Different Calibration Method and Using Image Enhancement to Process Samples
4.1. The Description of Dataset
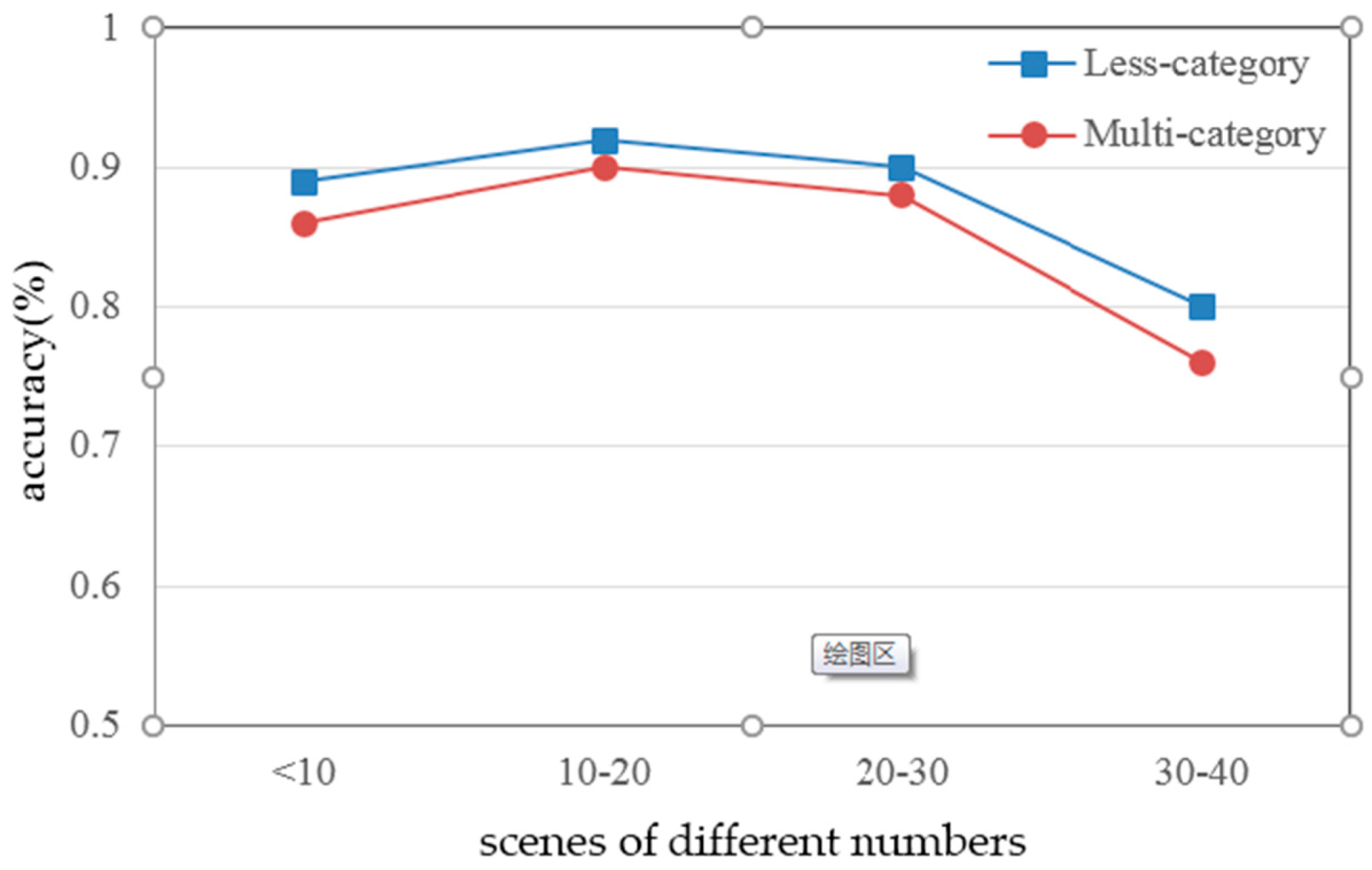
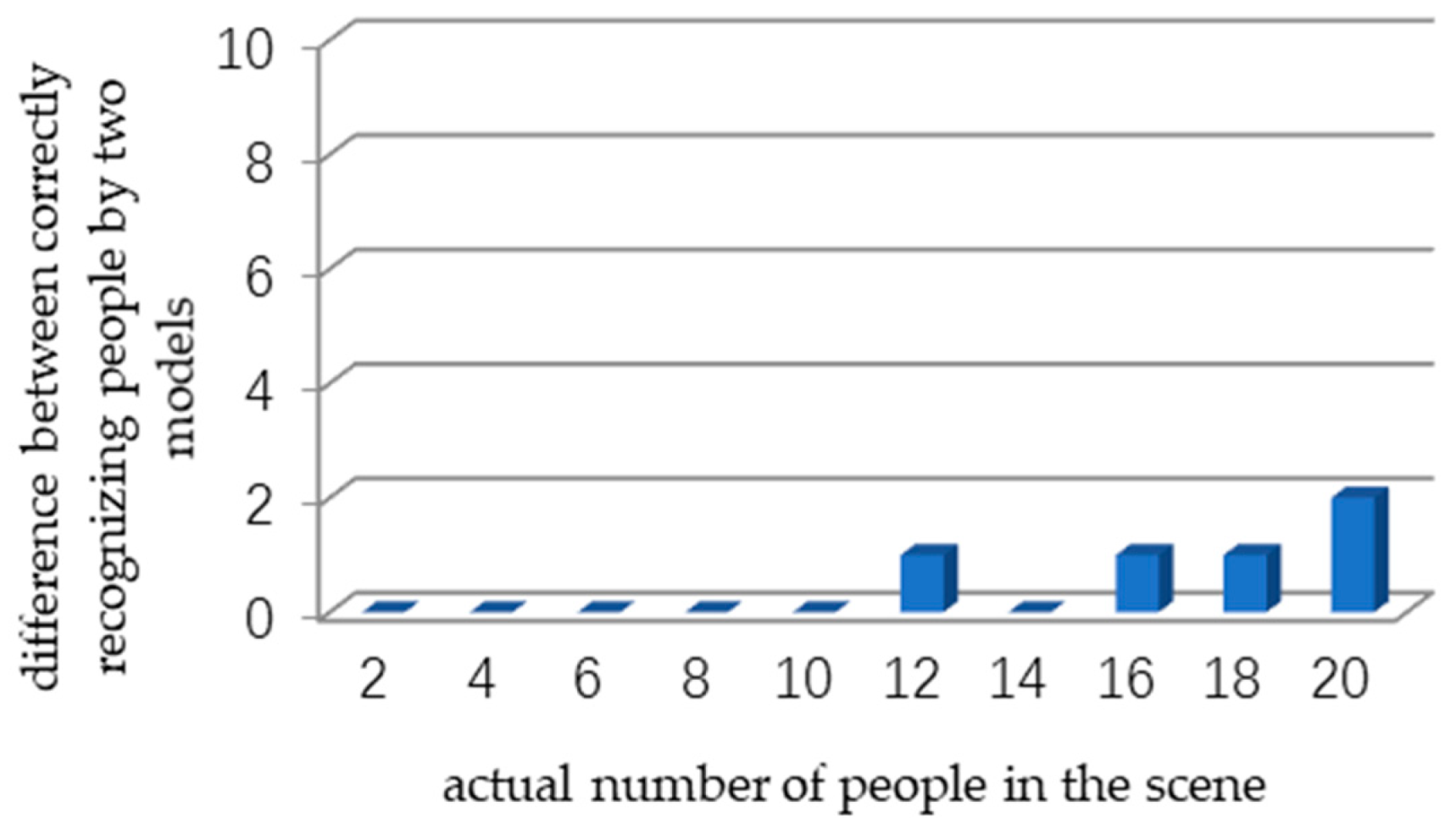
4.2. The Performance of the Calibration Method
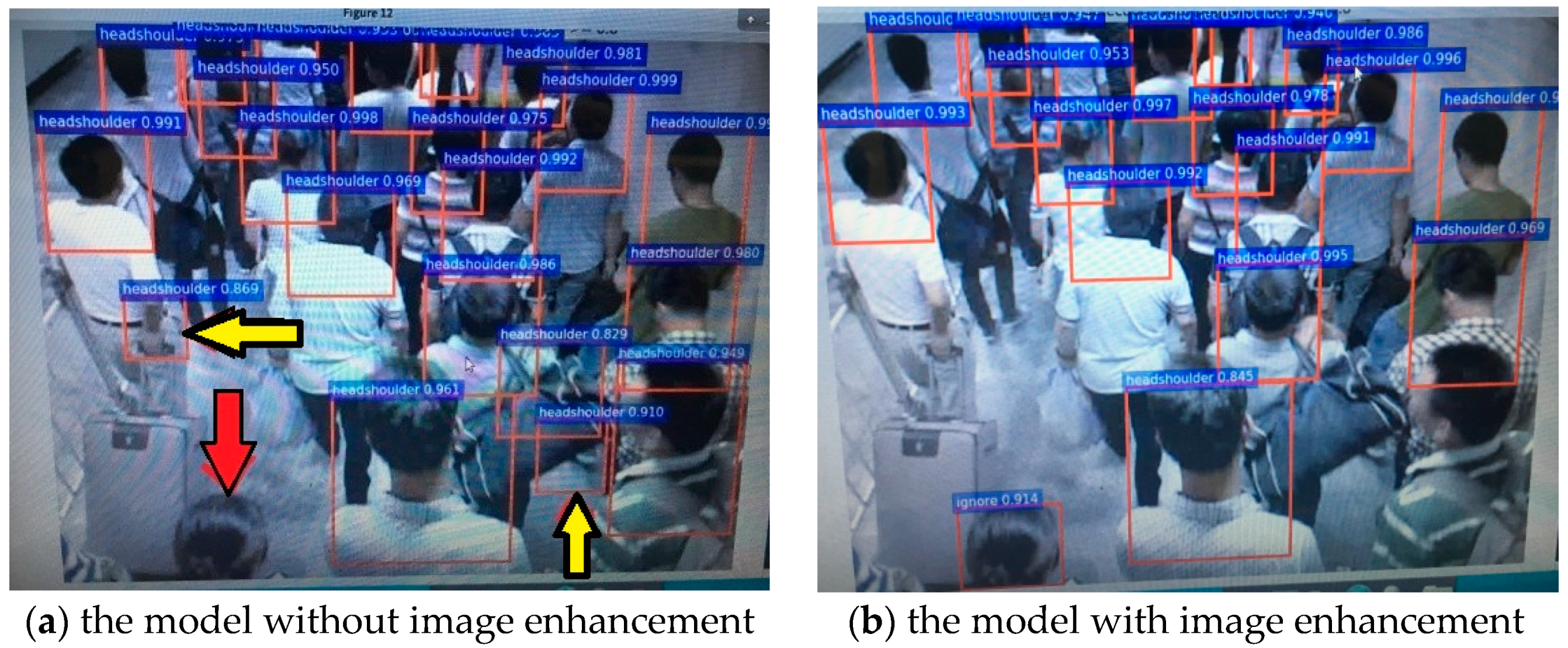
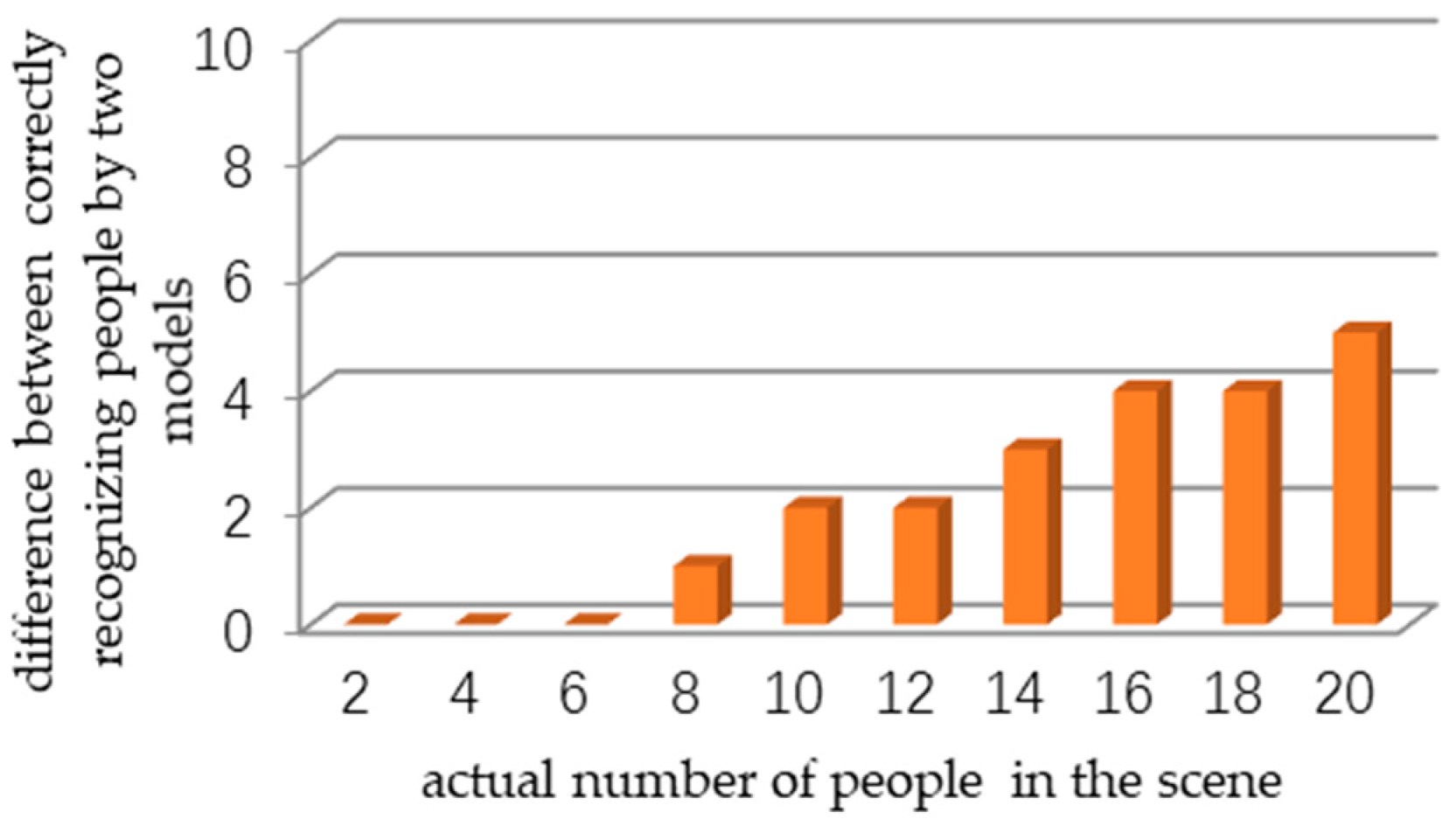
4.3. Performance Analysis with Image Enhancement on Pedestrian Datasets
4.4. Performing Experiments on Other Datasets and Comparing with Other State-Of-The-Art Approaches on Other Public Datasets
4.4.1. The Summary of Public Pedestrian Datasets
4.4.2. The Experiment on Public Pedestrian Dataset
4.4.3. The Comparison of State-Of-The-Art Methods
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Zhang, L. Safety Problems and Countermeasures of Subway Peak Passenger Flow; Urban Rail Transit Key Technology: Beijing, China, 2006. [Google Scholar]
- Zhang, B.; Xu, Z.S.; Zhao, Q.W.; Liu, Y.Y. A Study on Theoretical Calculation Method of Subway Safety Evacuation. Procedia Eng. 2014, 71, 597–604. [Google Scholar] [CrossRef]
- Zhou, X.J.; Yu, X.Y. Study on safety evacuation time for passengers in subway station and its application. Adv. Mater. Res. 2013, 671–674, 2965–2969. [Google Scholar] [CrossRef]
- Zhang, Y. Automatic detection technology of passenger density in Beijing Metro. China Railw. 2017, 4, 96–100. [Google Scholar]
- Chen, Y.Y.; Chen, N.; Zhou, Y.Y.; Lai, J.H.; Zhang, W.W. A Method of Automatic Pedestrian Counting in Metro Station Based on Machine Vision. J. Highw. Transp. Res. Dev. 2013, 30, 122–133. [Google Scholar]
- Han, N.; Chen, D.-W.; Zhong, Z.-C. Comparative Research on Algorithm of Passenger Flow Statistics System Based on Intelligent Video Technology. Information Technology 2016, 6, 45–48. (In Chinese) [Google Scholar]
- Zhang, M.; Chen, X.; Zhang, T. Human body detection model based on haar-HOG algorithm. Revista de la Facultad de Ingenieria 2017, 32, 76–82. [Google Scholar]
- Yi, Z.; Xue, J. Improving Hog descriptor accuracy using non-linear multi-scale space in people detection. In Proceedings of the 2014 ACM Southeast Regional Conference, ACM SE 2014, Kennesaw, GA, USA, 28–29 March 2014. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Huo, Z.; Xia, Y.; Zhang, B. Vehicle type classification and attribute prediction using multi-task RCNN. In Proceedings of the BioMedical Engineering and Informatics, CISP-BMEI 2016, Datong, China, 15–17 October 2016; pp. 564–569. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Washington, DC, USA, 7–13 December 2015. [Google Scholar]
- Jiang, H.; Learned-Miller, E. Face Detection with the Faster R-CNN. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 650–657. [Google Scholar]
- Byeon, Y.H.; Kwak, K.C. A Performance Comparison of Pedestrian Detection Using Faster RCNN and ACF. In Proceedings of the 2017 6th IIAI International Congress on Advanced Applied Informatics, IIAI-AAI 2017, Hamamatsu, Japan, 9–13 July 2017; pp. 858–863. [Google Scholar]
- Zhao, X.; Li, W.; Zhang, Y.; Gulliver, T.A.; Chang, S.; Feng, Z. A faster RCNN-based pedestrian detection system. In Proceedings of the IEEE Vehicular Technology Conference, Montreal, QC, Canada, 18–21 September 2016. [Google Scholar]
- Roh, M.C.; Lee, J.Y. Refining faster-RCNN for accurate object detection. In Proceedings of the 15th IAPR International Conference on Machine Vision Applications, MVA 2017, Nagoya, Japan, 8–12 May 2017; pp. 514–517. [Google Scholar]
- Lokanath, M.; Kumar, K.S.; Keerthi, E.S. Accurate object classification and detection by faster-RCNN. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2017; Volume 263. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive Histogram Equalization and Its Variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Zeng, Y.-C. Automatic local contrast enhancement using adaptive histogram adjustment. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, ICME 2009, Hilton Cancun, Mexico, 28 June–3 July 2009; pp. 1318–1321. [Google Scholar]
- Gillespy, T., III. Optimized algorithm for adaptive histogram adjustment. Proc. SPIE Int. Soc. Opt. Eng. 1998, 3338, 1052–1055. [Google Scholar]
- Hummel, R. Image enhancement by histogram transformation. Comput. Graph. Image Process. 1977, 6, 184–185. [Google Scholar] [CrossRef]
- Gatta, C.; Rizzi, A.; Marini, D. ACE: An Automatic Color Equalization Algorithm. In Proceedings of the Conference on Color in Graphics, Imaging, and Vision, CGIV 2002 Final Program and Proceedings, Poitiers, France, 2–5 April 2002; pp. 316–320. [Google Scholar]
- Korpi-Anttila, J. Automatic color enhancement and scene change detection of moving pictures. In Proceedings of the Final Program and Proceedings—IS and T/SID Color Imaging Conference, Scottsdale, AZ, USA, 1 January 1999; pp. 243–246. [Google Scholar]
- Choudhury, A.; Medioni, G. Perceptually motivated automatic color contrast enhancement. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1893–1900. [Google Scholar]
- Getreuer, P. Automatic Color Enhancement (ACE) and its Fast Implementation. Image Process. Line 2012, 2, 266–277. [Google Scholar] [CrossRef]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast Feature Pyramids for Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Xu, D.; Ouyang, W.; Ricci, E.; Wang, X.; Sebe, N. Learning Cross-Modal Deep Representations for Robust Pedestrian Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ouyang, W.; Zhou, H.; Li, H.; Li, Q.; Yan, J.; Wang, X. Jointly learning deep features, deformable parts, occlusion and classification for pedestrian detection. IEEE Trans. Pattern Anal. Mach. Intell. PAMI 2017, accepted. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, W.; Zeng, X.; Wang, X. Partial Occlusion Handling in Pedestrian Detection with a Deep Model. IEEE Trans. Circuits Syst. Video Technol. TCSVT 2015, accepted. [Google Scholar] [CrossRef]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Calibration Method | Mean Average Precision |
|---|---|
| Multi-category | 58% |
| Less-category | 85% |
| Method | Mean Average Precision | Time Taken/s |
|---|---|---|
| Unenhanced model | 87.3% | 37,740 |
| Enhanced model | 90.5% | 37,110 |
| Dataset | Scenario | Number of Pedestrians | Number of Images | Image Resolution |
|---|---|---|---|---|
| MIT | street | 924 | 924 | 64 × 128 |
| INRIA | street/park | 3542 | 902 | 640 × 480 |
| Caltech | road | 2300 | 250,000 | 640 × 480 |
| TUD | street | 1776 | 1092 | 720 × 576 |
| CVC | road | 1000 | 7175 | 640 × 480 |
| NICTA | street | 25,551 | 25,551 | 32 × 80 |
| USC | street | 313 | 250 | 640 × 480 |
| Method | Mean Average Precision |
|---|---|
| Unenhanced model | 82.59% |
| Enhanced model | 83.34% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qu, H.; Wang, M.; Zhang, C.; Wei, Y. A Study on Faster R-CNN-Based Subway Pedestrian Detection with ACE Enhancement. Algorithms 2018, 11, 192. https://doi.org/10.3390/a11120192
Qu H, Wang M, Zhang C, Wei Y. A Study on Faster R-CNN-Based Subway Pedestrian Detection with ACE Enhancement. Algorithms. 2018; 11(12):192. https://doi.org/10.3390/a11120192
Chicago/Turabian StyleQu, Hongquan, Meihan Wang, Changnian Zhang, and Yun Wei. 2018. "A Study on Faster R-CNN-Based Subway Pedestrian Detection with ACE Enhancement" Algorithms 11, no. 12: 192. https://doi.org/10.3390/a11120192
APA StyleQu, H., Wang, M., Zhang, C., & Wei, Y. (2018). A Study on Faster R-CNN-Based Subway Pedestrian Detection with ACE Enhancement. Algorithms, 11(12), 192. https://doi.org/10.3390/a11120192