1. Introduction
Object tracking is an important part of computer vision. Object tracking has various applications, such as video surveillance, human–computer interaction and traffic monitoring. Therefore, object tracking technology has rapidly advanced in recent years. There are two primary current trends in object tracking: deep learning and correlation filtering. Without the support of large-scale datasets, the potential of deep learning in object tracking has not been developed. Naiyan Wang proposed the DLT [
1] algorithm to introduce deep learning to this field for the first time. At that time, because there were no large-scale datasets dedicated to tracking, offline training of DLT was performed using the Tiny Images dataset [
2]. This was the first time the researchers observed the effectiveness of deep learning. With the advent of large-scale video sequence datasets, such as VOT (Visual Object Tracking Challenges) [
3] and OTB (Visual Tracking Benchmark) [
4], a large number of effective deep learning algorithms such as MDNet [
5] has emerged, and the use of deep learning in the field of tracking has grown explosively.
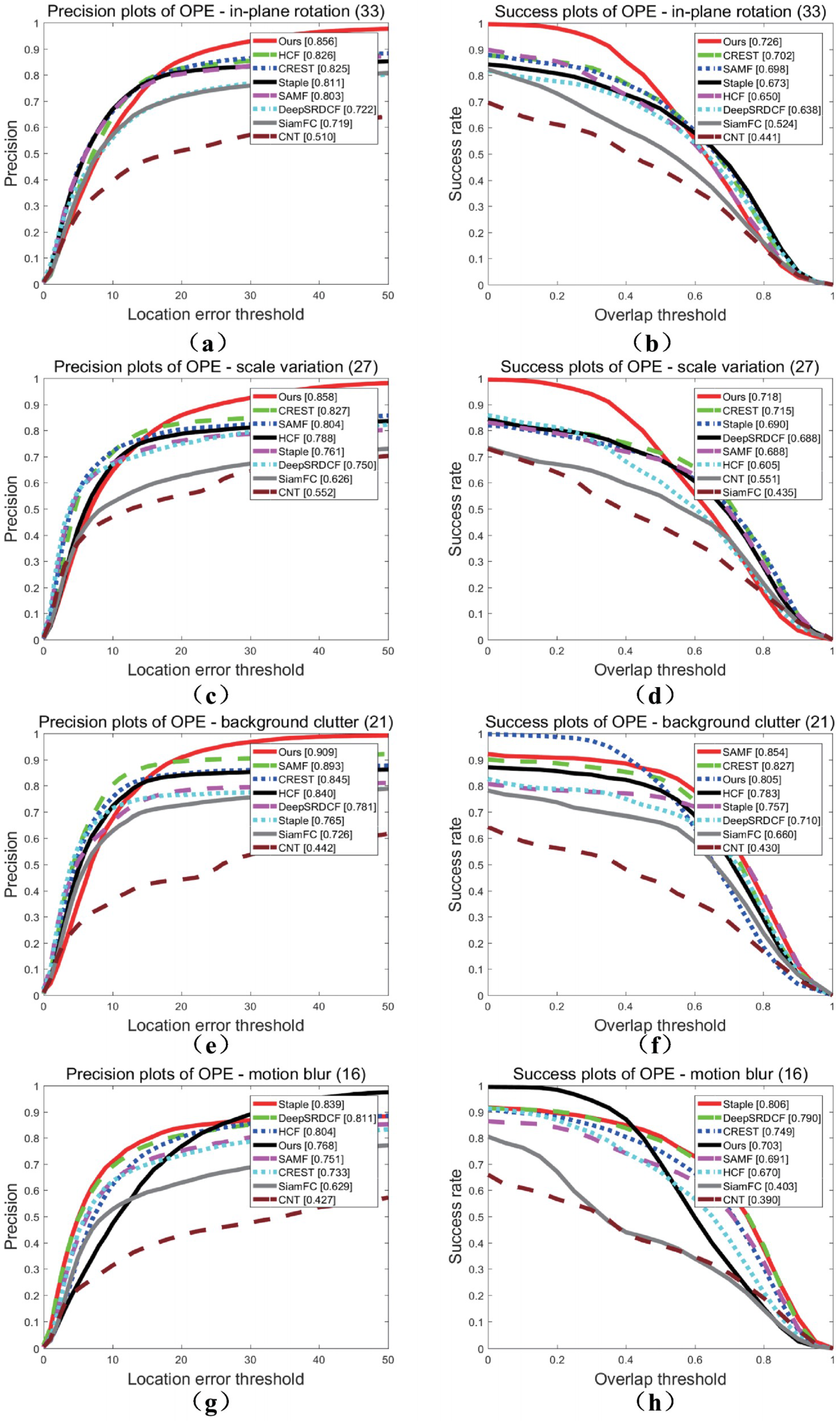
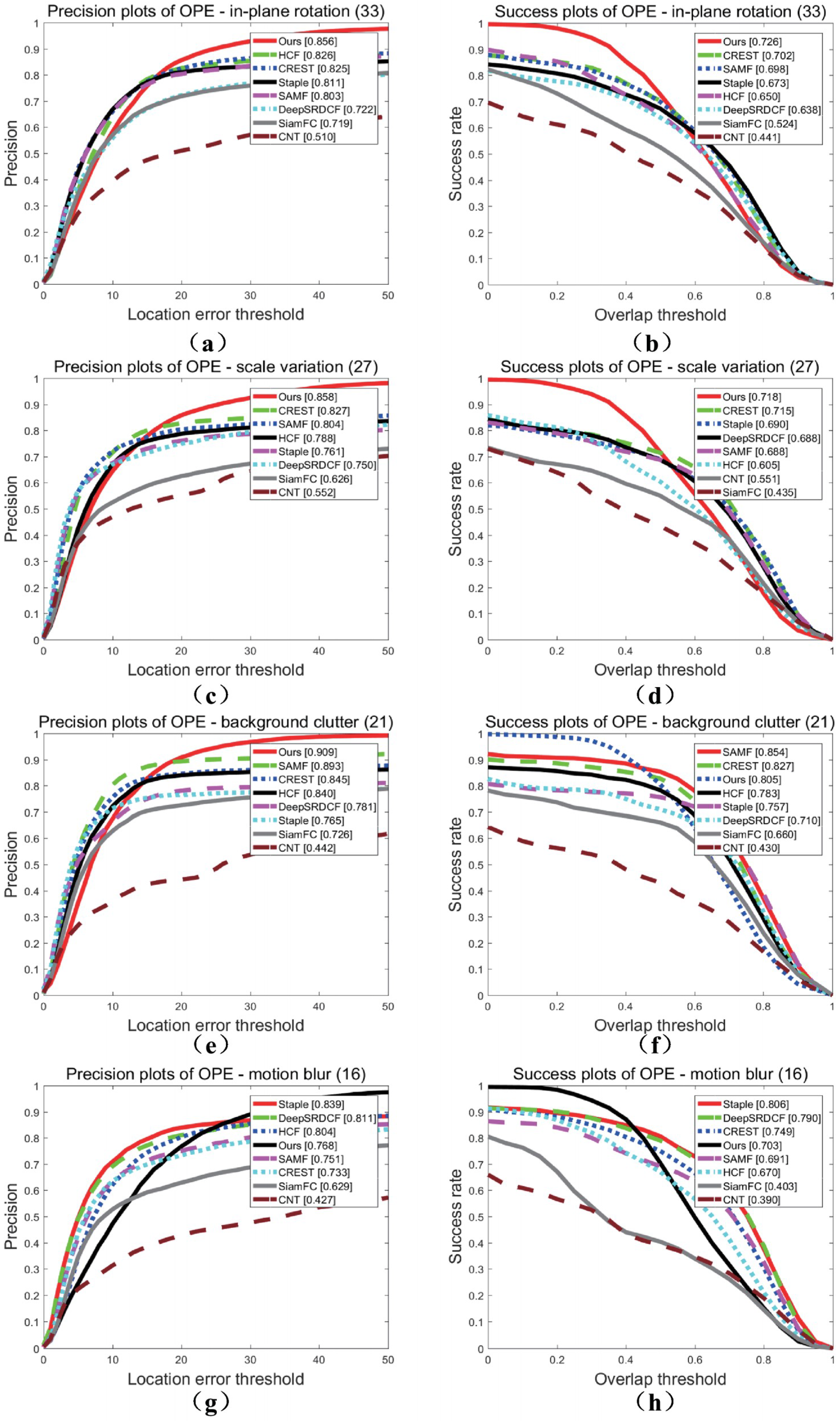
Object tracking is a difficult task because of several challenging factors, such as illumination variation (IV), scale variation (SV), occlusion (OCC), deformation (DEF), motion blur (MB), fast motion (FM), in-plane rotation (IPR), out-of-plane rotation (OPR), out-of-view (OV), background clutter (BC) and low resolution (LR) [
3]. Traditional object tracking algorithms mostly use artificial features. Artificial features, such as CN (Color Name) [
6] and HOG (Histogram of Oriented Gradient) [
7], cannot obtain deep semantic information of the object, are not sufficiently robust and are ineffective in overcoming challenges in object tracking. Certain correlation filtering trackers, such as C-COT [
8], also abandoned traditional artificial features and turned to deep features that better express the target semantic information. Certain algorithms, e.g., CFNet [
9] and DCFNet [
10], even entirely abandoned correlation filtering, using CNN’s convolution calculation instead of correlation calculations, and train a correlational deep network model to achieve tracking ability.
The deep convolutional neural network (CNN) has been widely used not only in target detection, such as YOLO [
11] but also recently in the field of object tracking. Compared to traditional features, a deep feature can express the semantic information of the target at a deeper level. Presently, deep learning object tracking algorithms primarily use offline training and online fine-tuning for network learning. However, due to the scarcity of computing resources, numerous network parameters and large computational complexity, most deep-learning target tracking algorithms are slow. Similarly, to the MDNet [
5] algorithm, most deep learning tracking algorithms use particle sampling mechanisms during the tracking phase to determine the maximum probability of a positive sample strategy for target tracking, undoubtedly increasing the amount of network computation. In the field of object tracking, in a broad sense, a positive sample is the object we need to track, and a negative sample is the background information surrounding the target. But different algorithms will have different positive and negative sample criteria.
The GOTURN [
12] algorithm only uses offline training. During the online tracking phase, the frozen network weights are not updated. The search area of the current frame and the target position of the previous frame are input into the network. The network learns to compare these areas to find the target object in the current frame; however, this algorithm can no longer retrieve the target once the target has been lost. At that point, the background will be falsely tracked. In terms of scaling, DSST [
13] requires not only a position filter but also a scalar filter. The training of multiple filters undoubtedly increases the complexity of the algorithm.
Inspired by the above observations, we propose a novel deep direction network for object tracking that classifies positive samples into 11 direction and scale categories: upper-left, left, lower-left, lower, lower-right, right, upper-right, upper, small-scale, large-scale and true-sample. We use end-to-end training, and the final output layer of the network has two branches. One branch classifies positive samples into 11 direction categories, and the other classifies positive and negative samples. To enable the network to learn the ability to describe the difference between target and background and to judge whether the target is lost in the tracking phase, the existence of the second branch is necessary. In the tracking phase, the network obtains the information on target direction according to the single sample extracted from the previous position and uses the sliding window operation to approach the target. Our algorithm uses a single-sample tracking strategy, thereby reducing the computational burden on the network and improving the tracking speed. Our algorithm cleverly classifies the target’s positive sample into 11 categories, uses the constraint box size to limit 11 classes, and uses a deep network to learn the differences between categories. Using a deep network can better describe the target and improve the robustness of tracking. Another interesting aspect of our algorithm is that we design a sliding window mechanism for direction classification network.
In summary, we make the following contributions:
We propose a network for the classification of target direction based on CNNs, and this network has a good adaptability to target tracking.
Our network successfully incorporates scale variation in a deep network that is robust to scale variation sequences.
In the online tracking stage, the network only calculates a single sample, which guarantees a low computational burden on the network.
The positive and negative sample redetection strategies can successfully ensure that the samples are not lost.
The rest of the paper is organized as follows.
Section 2 briefly summarizes our related studies.
Section 3 describes our direction network mechanism.
Section 4 illustrates our online tracking implementation.
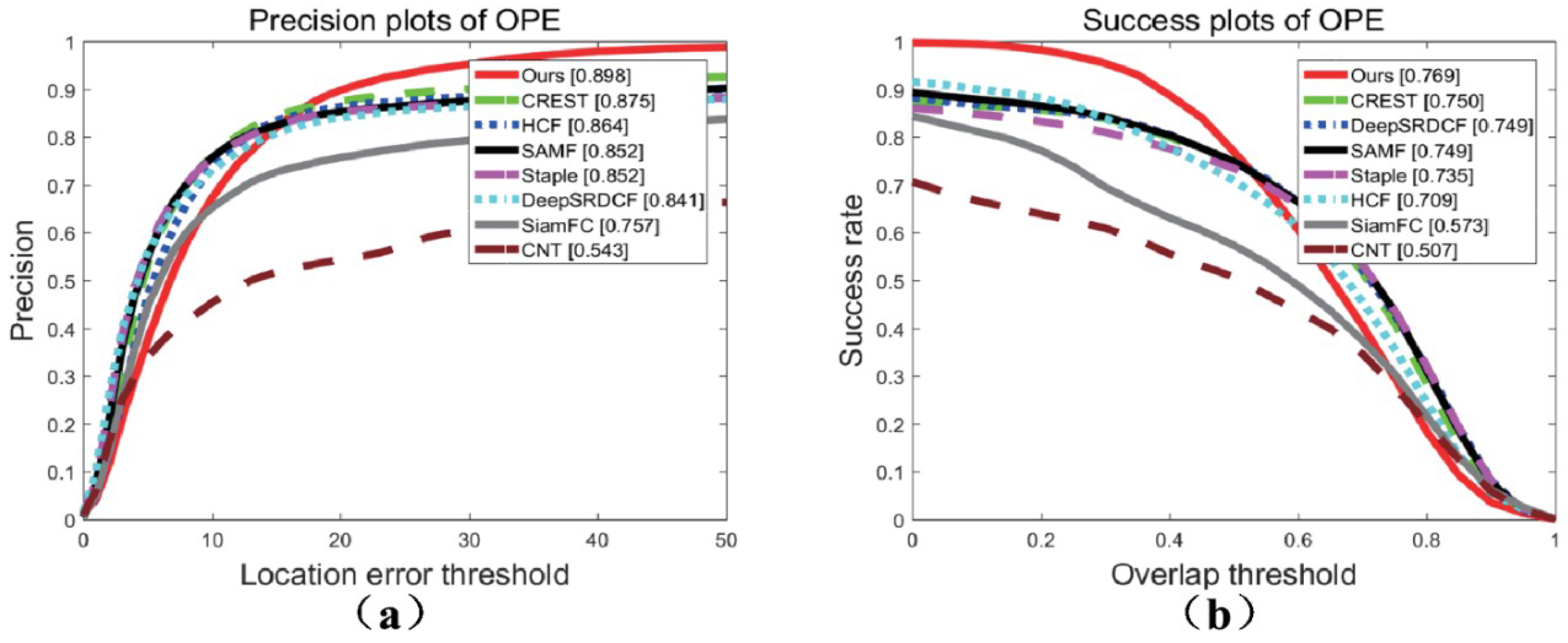
Section 5 demonstrates our experimental results with direction network in the Visual Tracker Benchmark.
3. Direction Deep Network Tracker
Deep networks have great learning potential. Most of the deep learning tracking algorithms extract the deep features of the target for classification and consider the positive sample, which is the most similar to the target as the tracking result. Many deep learning tracking algorithms do not fully utilize the large amount of information of the target sample, and the learning ability of deep networks has not been fully exploited. Therefore, we propose a novel direction deep network that uses directional information designed to classify positive samples more precisely, and according to the directional category of the sample, use the sliding window to find the target faster.
3.1. Overall Framework
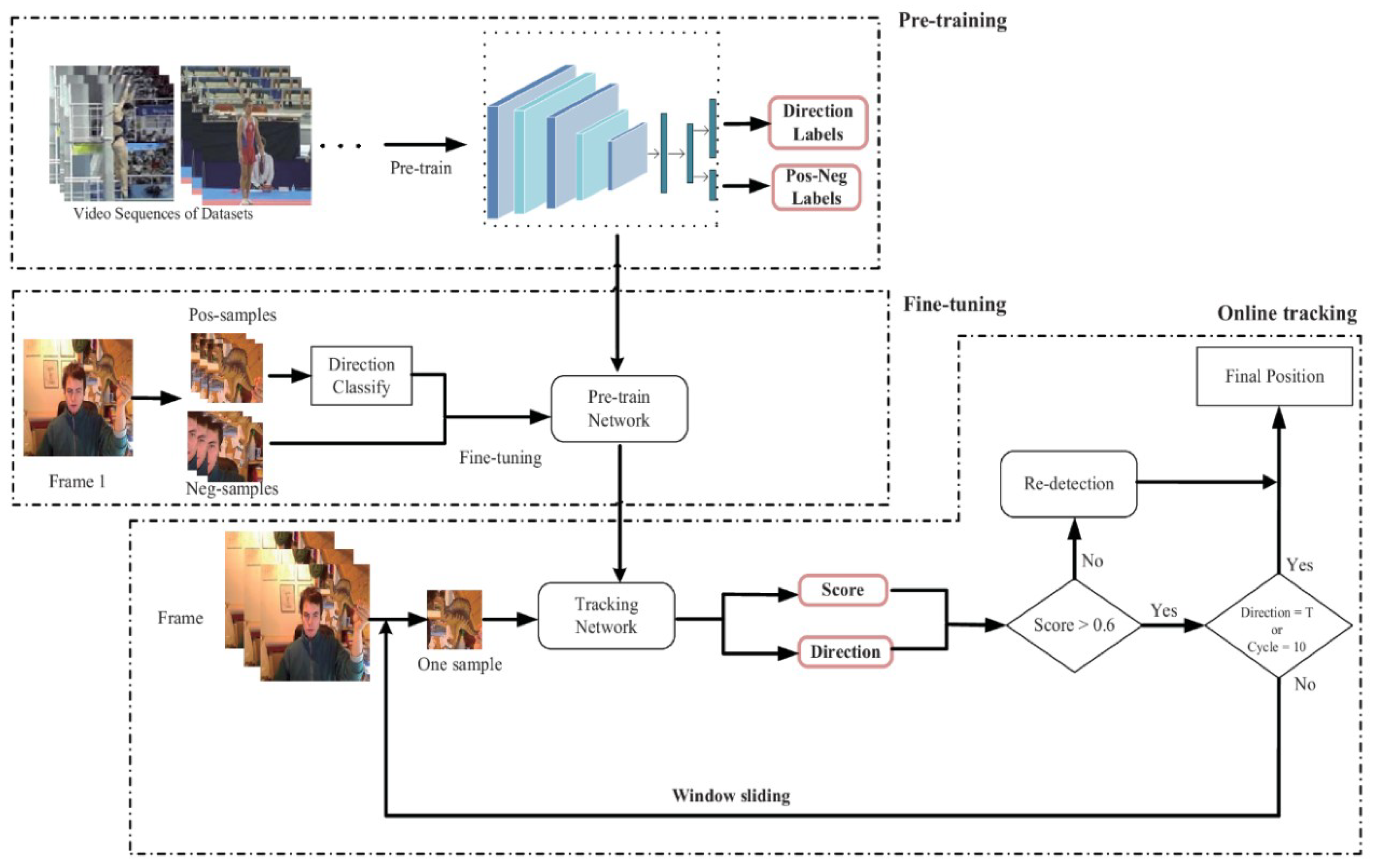
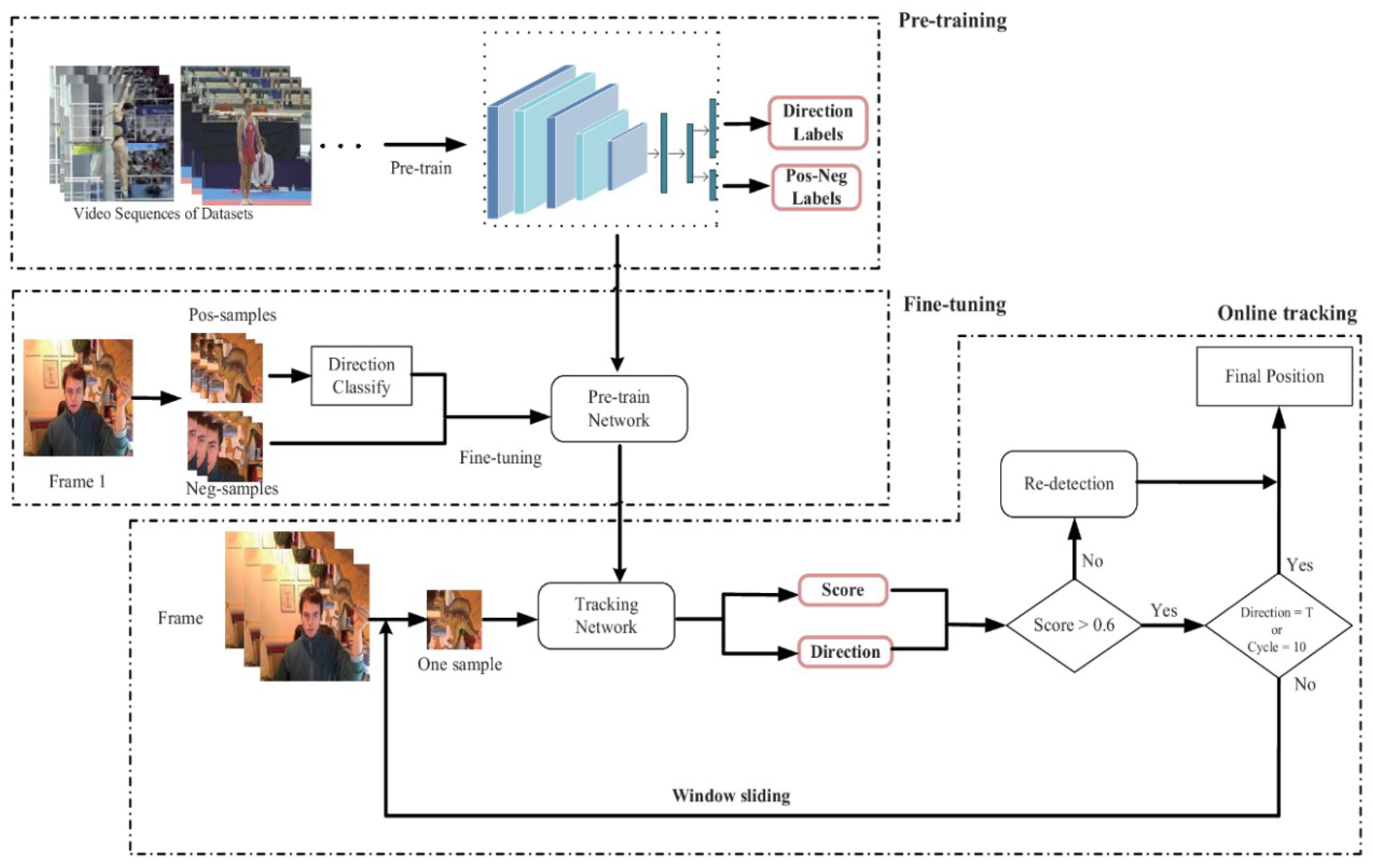
Figure 1 shows the overall flow chart of the tracking algorithm in this paper, including pretraining, fine-tuning and online tracking stages. At the top of the picture is the pretraining phase. The network is pretrained using the specific tracking datasets. Direction labels indicate the category labels for 11 direction categories, and Pos–Neg Labels denote the category labels for positive and negative samples. We obtain a pretrained network and then use the first frame to fine-tune the network. In the fine-tuning phase, we first extract the positive and negative samples. Then, we classify the positive samples into direction categories and fine-tune the network. In the tracking phase, we extract a sample at the previous frame and input the sample into the fine-tuned network to obtain a score and a direction. If the sample is negative, we use the redetection mechanism to determine the final target position. If it is a positive sample, we determine whether the direction class is T (true-sample). If direction class is T, then we obtain the final target position. If it is not, we will perform window sliding to continue sampling. If the number of sliding windows reaches ten, we stop the sliding window operation to determine the final target position.
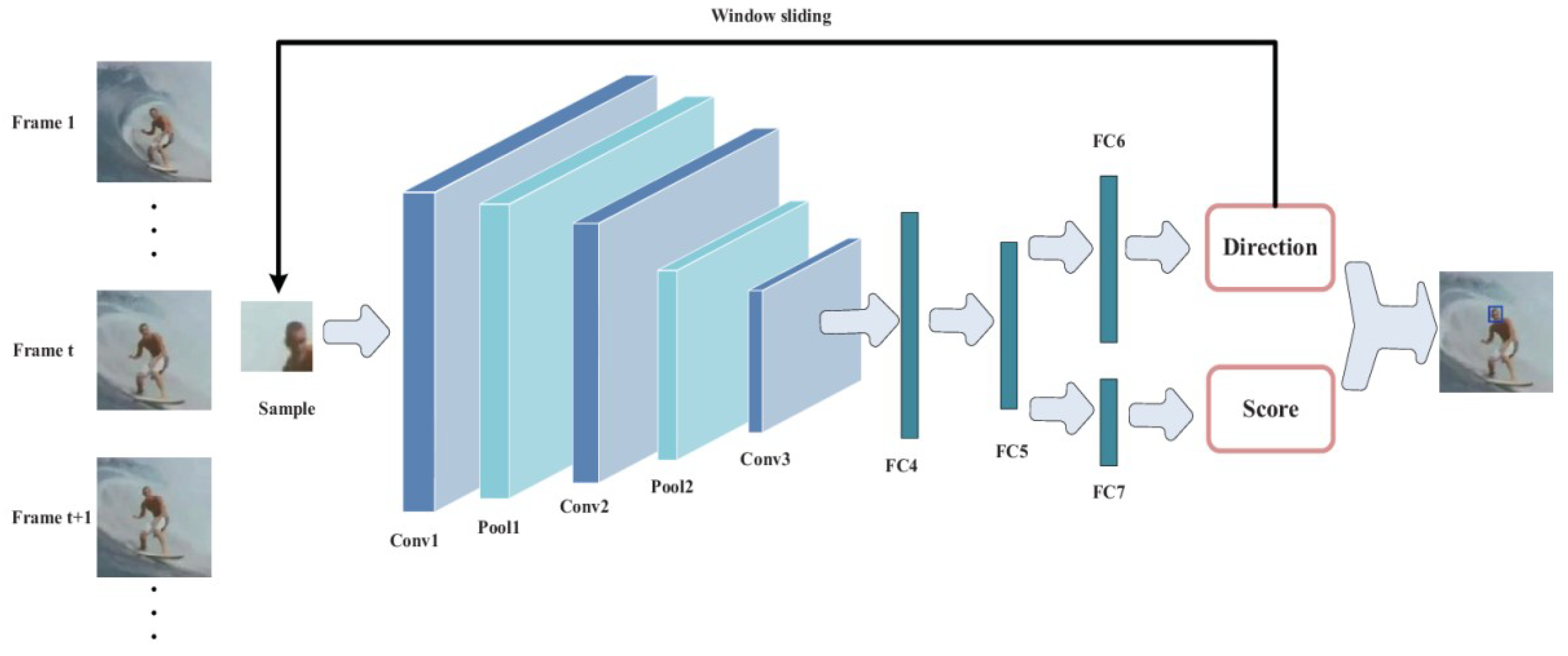
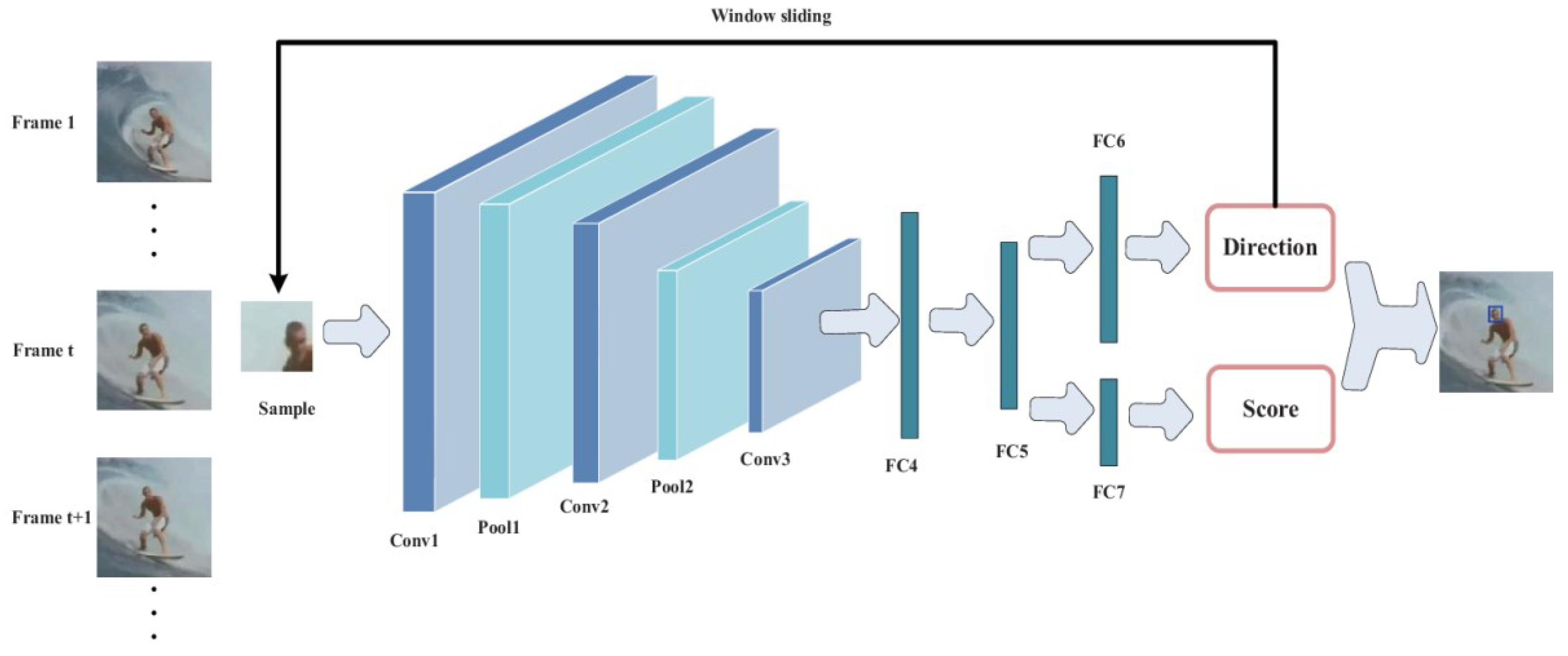
The architecture of the direction of the deep network for target tracking proposed in this paper is shown in
Figure 2. The architecture of the network mainly includes three convolutional layers (Conv1, Conv2 and Conv3) and three fully connected layers (FC4, FC5 and {FC6, FC7}). FC6 and FC7 are two independent branches of the same fully connected layer. They represent the direction classification layer and the pos–neg sample classification layers, respectively. There is a pooling layer behind layers conv1 and conv2, denoted Pool1 and Pool2, respectively. In the tracking phase, we extract a sample and then send it to the network to obtain the sample’s direction and score. Direction represents the sample direction category and score represents the pos-neg sample score of the sample. We perform the corresponding sliding window operation according to direction. We judge the final target position according to direction and score.
Table 1 shows the filter sizes and the numbers of each type of layer in the deep directional network. Our network uses three convolutional layers. Our original intention is to reduce computation amount of the network. Too many layers will inevitably increase the amount of computations and too few layers will be difficult to obtain the deep semantic features of the target. So we use three convolutional layers and three fully connected layers. We use the Relu activation function after each convolutional layer and fully connected layer, as shown in Equation (1).
3.2. Direction Classification Network
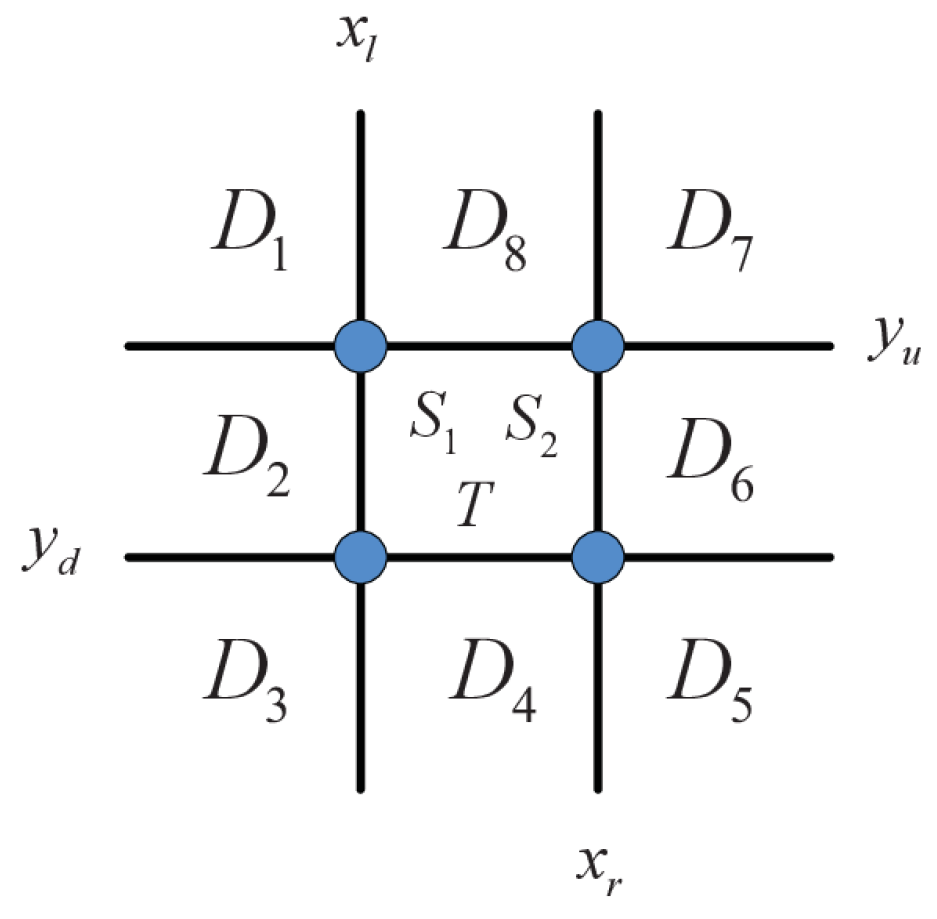
First, we classify positive samples into 11 categories based on direction information, as shown in
Figure 3. Specially, the positive samples are divided into upper-left (
), left (
), lower-left (
), lower (
), lower-right (
), right (
), upper-right (
), upper (
), small-scale (
), large-scale (
) and true-sample (T), namely, 11 classes of direction information.
In
Figure 3,
represents the left boundary, the right boundary, the upper boundary, and the lower boundary, respectively, of the direction division. The setting of the boundary is determined by the size of the original target of the sample, as shown in Equations (2) and (3). Assume that the ground truth of the current frame is represented by
, where
denotes the position of object along the x axis,
is the position of object along the y axis coordinate,
represents the width of the target along the x axis, and
is the height of the target along the y-axis.
In Equations (2) and (3),
is the scaling factor of the limited boundary; its specific value is described in the experimental section. The category of sample shown in
Figure 3 will be determined by the limited boundary in Equations (2) and (3).
Equation (4) describes a mechanism for determining the sample category, where
is the positional information of the sample, and
is the output result of the category the sample belongs to. In the paper,
is the discriminant function. We use the bounding box
and sample location information
to determine the direction category of the sample, and use
,
and the target’s true width and height
to determine the scale variation category of the sample.
The sampling rule will be introduced in
Section 3.4 and
Section 4. The sample category is determined according to the area corresponding to the sample horizontal and vertical coordinate values, as described in Equation (5). If the sample’s horizontal and vertical coordinates are in the area between the limited boundary, we will judge whether the target scale variation exists. A comparison of
of the sample and the original target truth value
is used to determine the category of scale variation as shown in Equation (6). The traditional scale processing mechanism primarily adopts samples of multiple scales, and the deep network determines which scale is the closest to the target [
14]. In contrast to the traditional mechanism, we integrate the scale variation into the sample classification and directly output the scale decision on the classification layer of the deep network, which significantly relies on the strong learning ability of the deep convolutional neural network. The premise of determining the sample scale variation is that the sample coordinates are in the middle of the limited boundary, which is
and
. The scale decision is primarily determined by Equation (6). The variables
and
represent the scale reduction factor and scale enlargement factor, respectively; the specific values will also be introduced in the experimental part. If the sample coordinates are in the bounding box, and there is no scale variation, we classify the sample as belonging to category
.
The specific directional information classification proposed in this paper is described above. The sample classification results subsequently determine the sliding trend of the sliding window network.
The final classification results of the sample are shown in
Figure 4. Two samples are extracted from each class. The original frame is shown in subfigure (a). The sample is from the birds2 video sequence of the VOT2015 [
25] dataset. The ground truth of the object is shown in subfigure (b). The category of the sample in subfigure (c) is shown underneath each image of (c).
Figure 4 shows that the gap between each sample is very small, almost a pixel-level change; however, each sample has a direction trend of the classification. The final result shows that a powerful neural network can fully learn the small changes in this strategy and classify positive samples accurately.
3.3. Sliding Window Model
Classifying the object sample by the classification network is not the final result of object tracking. When obtaining the sample direction information, a decision network is needed to determine how the sample slowly approaches the true position of the object. This paper uses a sliding window model to gradually approach the ground truth of the object. The sample of the current position is sent to the direction classification network to obtain the current direction class relative to the truth object. According to the direction information, the current sample window is correspondingly swept toward the target. This is the primary idea of the sliding window operation model in this paper.
The corresponding sliding window strategy for each direction category is described by Equation (7). The specific implementation measures are shown in Equation (7). In the equation, represents the pixel size of the sliding window operation. Variable indicates the next sample point to be sampled. When the sample of is classified as belonging to category , which is the closest to the target, the sliding window operation is stopped; finally, the object tracking result of the current frame is obtained.
3.4. Pretrained Direction Network
This paper uses a deep convolutional neural network, as shown in
Figure 2 and
Table 1. At the end of this network, a directional information classification layer is added to obtain the information on target direction. The previous three convolutional layers of the direction network use VGG-M [
26]. Numerous studies have proven that convolutional networks, such as VGG-Net, GoogLeNet [
27], etc., trained with large-scale datasets achieve good generalization performance and transfer learning capabilities. Our network uses the network weights that outstanding scholars have trained as the initialization of the direction network, and greatly improves the ability of tracking learning on the network.
The network framework finally adopts a dual-category network, whereby one classification network is trained to learn the direction information, and the other classification network is trained to learn the sample classification. As shown in
Figure 2, FC6 is a direction network that can classify eleven types of direction. FC7 is a sample classification network that is used to classify target and background information. We use the softmax cross-entropy loss function, stochastic gradient descent and backpropagation to update the network weights. The number of network pretraining cycles is 100, and the training dataset consists of 58 video sequences from the VOT2013, VOT2014 and VOT2015 datasets. Using video sequences for network pretraining is different from using large-scale classified data in the past. This method is more suitable for the tracking network.
The training samples were selected by the overlap rate strategy. To enable the network to learn more target orientation information during the training phase, the threshold value of the overlap rate is set to a smaller value of 0.6.
Positive and negative samples classification and threshold setting are shown in Equation (8), where represents the label of positive and negative samples, and denotes the calculation of the overlap rate. If the overlap rate of and is greater than 0.6, is judged to be positive; otherwise, it is negative. The number of samples per frame is set to 200 positive samples and 50 negative samples. The convolutional layer learning rate is 0.0001, and the fully connected layer learning rate is 0.001. The positive samples obtained by Equation (8) are classified as various direction categories according to the decision criterion in the Equation (4).
The direction network is trained by minimizing the multi-task loss function. The multi-task loss function is defined as Equation (9).
donates the batch size,
denotes the cross-entropy loss function.
and
represents the predicted direction and class respectively.
4. Online Tracking
After pretraining, we will obtain a deep network with updated weights. However, pretrained networks often cannot be used directly for new video sequences, and a strategy is needed, such as network initialization, online fine-tuning, tracking redetection mechanism, etc.
The pretrained network uses a large number of video sequences and has a good generalization performance. However, the network for specific video sequence tracking also requires fine-tuning. Therefore, in the first frame, the same strategy as pretraining is used to fine-tune the network weight so that the network applies to the video sequence. This algorithm selects 500 positive samples and 200 negative samples to initialize the network in the first frame. The overlap rate is set to 0.7.
The biggest challenge in target tracking is the deformation of the target. When the target moves for a period of time, the deformation will appear as an enlargement or reduction of size. In this case, the network trained by the feature information of the first frame cannot fully describe the target itself, so it is crucial to fine-tune the network online with the target feature of the new location. To solve the above problem, in the online tracking phase, the target is resampled after continuous tracking of 20 frame sequences. The number of samples is 200 positive samples and 50 negative samples, and the overlapping rate remains unchanged. In the online tracking phase, the training mechanism for resampling is similar to the pretraining phase. Our algorithm automatically selects positive and negative samples based on the threshold and the overlap rate as shown in Equation (8). Then, positive samples are automatically divided into 11 categories as shown in Equations (5) and (6). Our algorithm updates the network weights automatically using the resampled data. Fine-tuning the network can improve the network’s ability to deal with various deformations.
The dual-classification network is designed to deal with the loss of the tracking object. In
Figure 1, when the positive sample score is less than a certain threshold
, the positive sample is determined to have been lost, and the tracking result consists entirely of the background. The value of
will be given in the experimental section. At this time, the particle sampling strategy is adopted. The default target has only a small range of motion in adjacent frames. Then, the current frame is sampled using the Gaussian distribution rule at the previous frame target position, and the number of samples is set to 300. The samples are input into the network, and the sample with the highest score is selected from the positive and negative sample classification layer as the target position of the current frame.
The tracking sliding window strategy is performed at most 10 times per frame, and the loss mechanism is used if the target is not found during the sliding window operation. Experiments show that most frames can find the target after approximately 10 iterations of the sliding window operation. Because the sliding window mechanism makes it unnecessary to extract a large number of samples for each tracking, the computational burden of the deep network is reduced. As a result, the tracking speed of the network has been improved. Our proposed direction deep network tracker successfully tracked the target, as we had expected.
Figure 5 shows a schematic diagram of the sliding window. The video sequence is from the Bird2 sequence of the OTB-100 dataset. The first, second, third and fourth lines represent the tracking procedure diagrams of sliding windows for the 3rd, 25th, 37th and 73th frames, respectively. The label below each figure indicates the direction category of the current sample. We consider the first line as an example to describe the sliding window tracking procedure. The first picture of the first line represents the current frame. The second is the sample at the previous frame target position; we use the direction deep network to obtain the first sample category
. Then, we use the sliding window to obtain the second sample according to
, and we use the direction deep network to obtain the second sample category
, etc. When the sample output of the sixth sliding window is classified as category
, it is considered as the tracking result of this frame.
Figure 5 shows that the number of samples extracted in each frame of the proposed algorithm is close to 10.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}