1. Introduction
The concept of edit distance and its variants has applications in many areas such as computational linguistics [
1], bioinformatics [
2], and synchronization error detection in data communications [
3]. The edit distance of a language
L with at least two words—also referred to as
inner edit distance of
L—is the minimum edit distance between any two different words in
L. In [
4], the author considers the problem of computing the edit distance of a regular language, which is given via a Nondeterministic Finite Automaton (NFA), or a Deterministic Finite Automaton (DFA). For a given automaton
with
n transitions and an alphabet of
r symbols, the algorithm proposed in [
4] has worst-case time complexity
where
q is either the number of states in
(if
is a DFA), or the square of the number of states in
(if
is an NFA). If the size of the alphabet is ignored and the automaton in question has only states that can be reached from the start state, then the number of states is
and the worst-case time complexity shown in Label (
1) can be written as
In this paper, we present two efficient algorithms to compute the inner edit distance of a regular language given via an NFA with
n transitions—see Theorems 1 and 3. Both algorithms, which are called
DistErrDetect and
DistInpAlter, have the same worst-case time complexity
where
d is the computed distance, which is a significant improvement over the original algorithm in [
4].
Our first algorithm,
DistErrDetect, is based on the general method of [
5] for computing distances via the error-detection property. Now, however, we have an efficient way of realizing algorithmically that general method using an incremental construction of a (nondeterministic) transducer and the test of [
6] for partial identity for transducers. In our second algorithm,
DistInpAlter, the idea is to model the edit operations of the desired distance using an efficient, in terms of size, input-altering transducer (a transducer whose output is always different from the input used). Please see subsequent sections for definitions of terms. For clarity of presentation, we give in detail not only the new algorithms, but also their preliminary versions
PrelimDistErrDetect and
PrelimDistInpAlter that could possibly be applied to other types of distances. We have implemented the preliminary and final versions of the second algorithm (
PrelimDistInpAlter and
DistInpAlter) in Python using the well maintained, open source package FAdo for automata [
7]. We have also tested our implementation experimentally, and we present in this paper the outcomes of the tests.
We note that some related problems involving distances between words and languages can be found in [
8,
9] (edit distance between a word and a language), and in [
10,
11,
12,
13,
14] (various distances between two languages). Also in [
15], the newer concept of edit distance with moves is investigated. The problem considered here is technically different, however, as the desired distance involves
different words within the
same language. More specifically, if we used directly the tools of [
10,
11], for instance, to compute an edit string with minimal number of errors between the given language and itself, then that string would simply be an edit string of zero errors, as the edit distance between any word and itself is zero. We also note that the inner prefix distance of a regular language, which is quite different from the inner edit distance, is considered in [
16] and computed in time
.
The paper is organized as follows. The next section contains basic notions on languages, word relations, finite-state machines and edit-strings.
Section 3 describes the approach of computing the desired edit distance via the concept of error-detection and presents the preliminary version
PrelimDistErrDetect of the first algorithm. Then,
Section 4 explains the improved and final version
DistErrDetect of the first algorithm. In
Section 5, it is shown that the edit distance is definable via an efficient input-altering transducer—see Theorem 2—and then the second algorithm
DistInpAlter is presented.
Section 6 discusses the implementation and testing of the second algorithm and its preliminary version. The last section contains a few concluding remarks. The
appendix contains the proofs of two technical lemmata.
2. Notation, Background and Preliminary Results
This section contains basic terminology about formal languages, automata, transducers, and edit strings. Most of the basic notions presented here can be found in various texts such as [
17,
18,
19,
20,
21].
2.1. Sets, Words, Languages, Channels
The set of positive integers is denoted by
. Then,
. If
S is any set, the expression
denotes the cardinality of
S. We use standard basic notation and terminology for alphabets, words and languages—see [
22], for instance. For example,
denotes an alphabet,
the set of nonempty words,
the empty word,
,
the length of the word
w. We write
to indicate that the word
u is a
prefix of
w, that is,
for some word
v. Then,
means that
u is a
proper prefix, that is,
and
. We use the concepts of (formal) language and concatenation between words, or languages, in the usual way. We say that
w is an
L-
word if
and
L is a language.
A binary word relation on is any subset of . The domain of is . A channel is a binary relation on that is input-preserving; that is, and for all words w in the domain of . When , we say that u can be received as v via the channel , or v is a possible output of when u is used as input. If , then we say that u can be received (via ) with errors. Here, we only consider the channel , for some , such that if and only if v can be obtained by applying at most k errors in u, where an error could be a deletion of a symbol in u, a substitution of a symbol in u with another symbol, or an insertion of a symbol in u—see further below for a more rigorous definition via edit-strings.
2.2. NFAs and Transducers
A Nondeterministic Finite Automaton with empty transitions,
λ-NFA for short, or just
automaton, is a quintuple
such that
Q is the finite set of states,
is the alphabet,
is the start (or initial) state,
is the set of final states, and
is the finite set of transitions or edges. Let
be a transition of
. Then,
x is called the
label of the transition, and we say that the transition
goes out of
p. We also use the notation
for a transition
. The
-NFA
is called an
NFA, if no transition label is empty, that is,
. A
Deterministic Finite Automaton,
DFA for short, is a special type of NFA in which, for each state
p, there are no two transitions with equal labels going out of
p.
A
path of
is a finite sequence of consecutive transitions:
for some nonnegative integer
ℓ, where we use concatenation of these transitions to denote the path. Then, if
and
are two paths such that the last state of
is equal to the first state of
,
denotes the path resulting by concatenating the transitions of and .
The word
is called the
label of the path in Label (
4). We write
to indicate that there is a path with label
x from
to
. A path as above is called a
computation of
if
is the start state. It is called an
accepting path/computation if
is the start state and
is a final state. The
language accepted by
, denoted as
, is the set of labels of all the accepting paths of
. The automaton
is called
trim, if every state appears in some accepting path of
.
A (finite nondeterministic)
transducer [
17,
20] is a quintuple (In the literature, a transducer also has an output alphabet
, but we consider here that
is the same as the input alphabet
. Without further mention all transducers considered here are nondeterministic.)
such that
are exactly the same as those in
-NFAs,
is the alphabet, and
is the finite set of transitions or edges. We write
, or
for a transition—the
label here is
, with
x being the
input and
y being the
output label of the transition. The concepts of path, computation, accepting path, and trim transducer are similar to those in
-NFAs. However, the label of a transducer path
is the pair
of the two words consisting of the concatenations of the input and output labels in the path, respectively. The
relation realized by the transducer
, denoted by
, is the set of labels in all the accepting paths of
. We write
for the
set of possible outputs of
on input
u, that is,
The transducer is called functional, if the relation is a function, that is, consists of at most one word, for all input words u. We say that realizes a partial identity, if implies that .
If
is an automaton or a transducer, then the
size of
, denoted by
, is the number of states plus the number of transitions in
. We shall write
If
is trim then
; thus,
We recall that making an automaton or transducer trim can be done in linear time .
2.3. Edit Strings and Edit Distance
The alphabet
of the
(basic) edit operations, which depends on the alphabet
of ordinary symbols, consists of all symbols
such that
and at least one of
x and
y is in
. If
and
x is not equal to
y, then
is called an
error [
23]. The edit operations
,
,
, where
and
, are called
substitution, insertion, deletion, respectively. We write
for the empty word over the alphabet
. We note that
is used as a formal symbol in the elements of
. For example, if
, then
. The elements of
are called
edit strings. The
weight of an edit string
h, denoted by
, is the number of errors occurring in
h. For example, for
. The
input and
output parts of an edit string
are the words (over
)
and
, respectively. We write
for the input part and
for the output part of
h. For example, for the
g shown above,
and
. The
inverse of an edit string h is the edit string resulting by inverting the order of the input and output parts in every edit operation in
h. For example, the inverse of
g shown above is
The channel
can be defined more rigorously via edit strings:
The
edit (or Levenshtein) distance [
24] between two words
u and
v, denoted by
, is the smallest number of errors (substitutions, insertions and deletions) that can be used to transform
u to
v. More formally,
We say that an edit string
h realizes the edit distance between two words u and
v, if
and, either
and
, or
and
. For example, for
, we have that
and the edit string
realizes
. Note that several edit strings can realize the distance
. If
L is a language containing at least two words, then the edit distance of
L is
Testing whether a given NFA accepts at least two words is not a concern in this paper, but we note that this can be done efficiently (in linear time via a breadth first search type algorithm) [
25].
The next lemma comes from [
4]. The bound
is always less than or equal to the number of states in the NFA
. Moreover, there are NFAs for which this bound is tight—see
Section 6.
Lemma 1. For every NFA accepting at least two words, we have thatwhere is the number of states in the longest path in from the start state having no repeated state. However, the bound
is of no use in our context, as the problem of determining the length of a longest path in a given automaton, or a graph in general, is NP-complete since an algorithm solving this problem can be used to decide the existence of a Hamiltonian path; see for example [
26]. There are many ways to obtain an efficiently computable upper bound on the edit distance of
that is always at most equal to the number of states in
. For example, that distance is always less than or equal to the distance of the two shortest accepted words. We agree to use this as a working upper bound:
Lemma 2. For every NFA accepting at least two words, we have thatwhere is the edit distance of two shortest words in . 3. Edit Distance via Error-Detection
In [
5], the authors discuss a conceptual method for computing integral distances of regular languages—integral means that all distance values are nonnegative integers—via the property of error-detection. In this section, we review that method and produce a
concrete preliminary algorithm for computing the edit distance of a regular language.
A language
L is
error-detecting for a channel
, [
27], if no
L-word can be received as a different
L-word via
; that is (The definition of error-detection in [
27] uses
instead of
L in Formula
6. This slight change makes the presentation here simpler and has no bearing on any existing results regarding error-detecting languages.), for any words
u and
v,
Remark 1. The error-detection method of [5] for computing inner distances of regular languages is based on the following observations, where is an NFA and is an input-preserving transducer. - 1.
A language L is error-detecting for , if and only if .
- 2.
is equal to the positive integer k such that L is error-detecting for and L is not error-detecting for .
- 3.
We have the following facts from [27]. A language L is error-detecting for a channel γ if and only if the following relation is a function Moreover, if accepts L and realizes γ, then a transducer realizing can be constructed in time and, analogously, a transducer realizing can be constructed in time . Both constructions are cross-product constructions. In each case, the resulting transducer has states and transitions. Thus, the transducerrealizes relation (7) and can be constructed in time . - 4.
There is an time algorithm that decides whether a given transducer is functional [6,28], where r is the size of the alphabet.
Using the above observations, we present first a preliminary error-detection-based algorithm for computing the desired edit distance.
Algorithm PrelimDistErrDetect
- 0.
Input: NFA
- 1.
Let be the edit distance bound in Lemma 2
- 2.
Let and
Perform binary search to find the largest k in
for which is error-detecting for as follows:
while ()
- a)
Let
- b)
Construct transducer
realizing the channel
—see
Figure 1- c)
Construct the transducer
- d)
If is error-detecting for , let
Else let
- 4.
return min
Remark 2. Step (3d) of the above algorithm can be computed using the transducer functionality algorithm on , which leads again to a polynomial but expensive algorithm. It turns out, however, using standard logical arguments, thatwhen realizes γ—in the above algorithm, is . Moreover, [6], there is antime algorithm that tests whether a given transducer realizes a partial identity, where r is the size of the alphabet. Corollary 1. Consider the algorithm PrelimDistErrDetect. Using the partial identity test for in step 3d, the algorithm computes the edit distance of a language given via a trim NFA in timewhere r is the cardinality of the alphabet used in , and . Proof. The correctness of the algorithm follows from Remarks 1 and 2. For the time complexity, the whole loop will perform
iterations. In each iteration, the value
k is used to construct the transducer
shown in
Figure 1 with alphabet being the set of alphabet symbols appearing in the definition of
. Then, the transducer
is constructed having
states and
transitions. Then, the partial identity of
is tested in time
. As
, it follows that the total time complexity is as required. □
We note that, in the worst case,
is of order
and, assuming a fixed alphabet, the above algorithm operates in time
which is asymptotically better than the time complexity of the algorithm in [
4], even when the given automaton is a DFA.
4. An Algorithm for Edit Distance via Error-Detection
In this section, we observe that the algorithm of the previous section repeats a lot of computations, and we eliminate those repeated computations to arrive at an improved algorithm that computes the edit distance d of a trim NFA in time , where r is the cardinality of the alphabet used in , and . The improved algorithm is based on the following two observations:
The previous algorithm starts the binary search loop by constructing the transducer , but the edit distance might be much smaller than . It turns out that it is more efficient in the end to construct in turn until the first that does not realize a partial identity.
If is constructed and tested that does not realize a partial identity, then the transducer is constructed from scratch and the partial identity test is repeated for the part of that corresponds to . We shall define the transducer to be the part that is added to in order to obtain , plus some initial state. Moreover, we shall show that, if realizes a partial identity, then realizes a partial identity if and only if does so. Thus, the partial identity test in each step will apply only to the new part that is added to the transducer of the previous step.
We proceed with details based on the above observations.
Product construction of trim , given transducer and NFA . As usual in cross product constructions, the states of are triples of the form , where is a state of , and q, are states of . The initial state of is , where is the initial state of and is the initial state of . The construction is incremental, starting with the creation of ; then:
If state
has been created, and there are transitions
of
,
and
, respectively, then the transition
is added in
. Here,
is the
-NFA that results if we add in
the loop transitions
to all states
q of
.
The final states of are those constructed triples consisting of final states in and . In the end, we also make trim.
Optimized construction of and from the trim . Suppose that
has been constructed, where initially
. Constructing
using
will be done again incrementally. The
first phase of the incremental construction is to add the new transitions
where
is an error and
are transitions in
. There will be no new transitions of the form
for
, because the transducer
has no transitions from any state
with
to state
. Note that the numbers of new transitions and new states created as in (
8) are
and
, respectively.
After the first phase, the incremental construction proceeds from the new states
in (
8). Any new transition must be of the form
where
. This is because the transducer
has only transitions of the form
going out of the state
. The process ends when no new states are created. The transitions and final states of the transducer
are those in
plus the newly created ones, after removing any new states that cannot reach a final state (thus, also
is trim). The transducer
has as transitions and final states only the newly created ones, and has as initial state a new state
with transitions
, for all states of the form
. □
Lemma 3. Suppose the trim transducer realizes a partial identity.
If is a computation of ending at a state of the form then the label of is of the form .
realizes a partial identity if and only if does so.
Proof. For the first statement, consider any computation of having some label and ending at a state of the form . We show that . If the state is final, then is an accepting computation, which implies , as realizes a partial identity. If is not a final state, then, as is trim, there is a path from to a final state of , where all states of that path are of the form and all labels of that path are of the form —this is because any transition of from state can only go to state and can only have a label of the form . Thus, there is an accepting path of of the form with label for some nonempty word z. Then, as realizes a partial identity, we have that , which implies , as required.
For the ‘only if’ part of the second statement, assume that realizes a partial identity. Consider any accepting computation of with some label . We show that . Let be the first transition of . Let be the path that results when we remove the first transition of . By the construction of , there is a computation of that ends at state . Let be the label of . Then, is an accepting computation of with label . As realizes a partial identity, , which implies , as required.
For the ‘if’ part of the second statement, assume that
realizes a partial identity. Consider any accepting computation
C of
. We show that the label of
C must be of the form
. If
C is already a computation of
, then this holds, as
realizes a partial identity. Now suppose that
such that
is a computation of
and
is a path in
that starts with a transition as in (
8) and then uses transitions as in (
9). Let
be the last state of
, which is also the first state of
. Then,
has some label
. In addition, the path
is an accepting computation of
, which implies that it has some label
. Hence, the label of
C is
and, therefore,
realizes a partial identity.
The improved algorithm is shown next:
Algorithm DistErrDetect
- 0.
Input: NFA
- 1.
Construct the transducer
realizing the channel
—see
Figure 1- 2.
Construct the trim transducer
- 3.
Let
- 4.
Let
- 5.
while ( realizes a partial identity)
- a)
Construct and from using the optimized construction
- b)
Let
- c)
Let
- 6.
returnk
Theorem 1. Algorithm DistErrDetect computes the edit distance of a language given via a trim NFA in timewhere d is the computed edit distance, , and r is the cardinality of the alphabet used in . Proof. The correctness of the algorithm follows from the optimized construction and the above lemma. For the time complexity of the algorithm, we note the following. First, is constructed in time . Then, are constructed according to the optimized construction. Each of these is constructed in time and has states and transitions. In addition, each is tested for partial identity in time , which is .
5. An Algorithm for Edit Distance via Input-Altering Transducers
In this section, we present another algorithm for computing the desired edit distance via input-altering transducers—see Theorem 3 and the associated algorithm. A transducer
is called
input-altering, if
that is, the output of
is never equal to the input used.
We explain now how input-altering transducers are related to edit-distance and error-detection. Let
be a transducer. A language
L is
-independent,
29,
30], if
Of course, when
is input-preserving, then
-independence is the same as error-detection for the channel
, and condition (
10) can be tested as explained in Remark 2. On the other hand, if the transducer
is input-altering, then [
30], condition (
10) is equivalent to
If
L is accepted by some NFA
, then the above condition can be tested using two product constructions: first, construct an NFA
accepting
, then construct an NFA
by intersecting
with
, and then test whether there is a path from the start to a final state of
. Thus, condition (
11) can be tested in time
Certain types of input-altering transducers are useful in constructing maximal
-independent languages [
30]. In Theorem 2, we show how an input-altering transducer can be used to model the edit operations used in the definition of the edit distance.
5.1. An Input-Altering Transducer for Edit-Distance
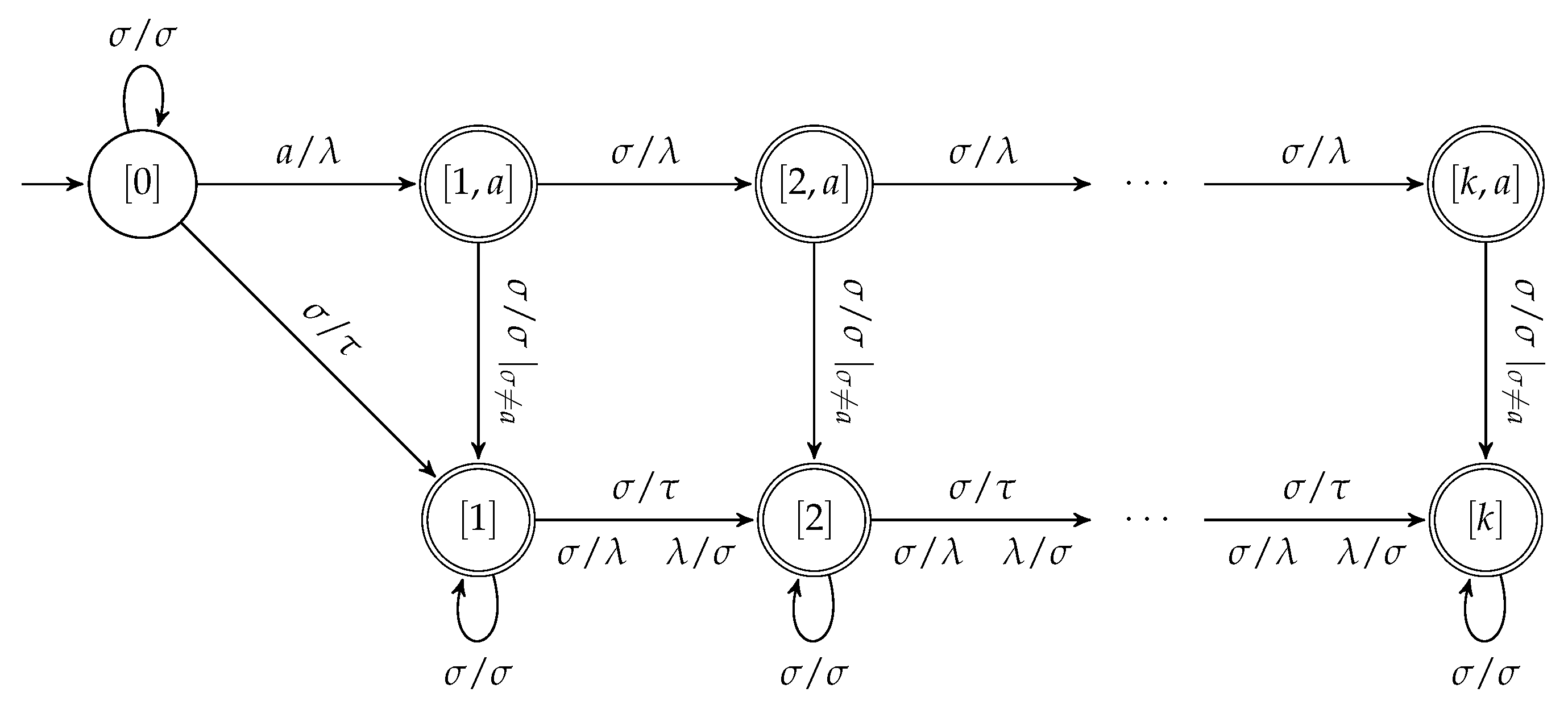
We shall define the input-altering transducer
, which is partially shown in
Figure 2. The value
i in a state
or
is called the
error counter, meaning that any path from
to a state with error counter
i has to be labeled
such that
. More precisely, we will define the edges such that a state
can be reached from
via a path with label
if and only if
for some word
x and
, thus,
v is a proper prefix of
u and state
remembers the left-most letter of
u that occurs after its prefix
v. A state
with
can only be reached via a path labeled
from
if
, thus,
. Furthermore, we make sure that for
such that neither
nor
there is a path from
to
which is labeled by
or
.
Definition 1. The transduceris defined as follows. The set of states iswith all but the initial state being final states: The transitions in can be divided into the four sets of edges . The transitions from do not introduce any error, edges from the other sets model one substitution (), insertion (), or deletion (): Terminology. If
is a transducer in standard form, then, we write
for the NFA
over the edit alphabet
, where the labels of the transitions in
are viewed as elements of
. Note that, the label of a path
P in
is a pair of words
, whereas the label of the corresponding path in
, which we denote as
, is an edit string
h such that
and
. This type of NFA is called an eNFA in [
23].
Definition 2. An edit string h of nonzero weight is calledreduced, if (a) the first error in h is not an insertion, and (b) if the first error in h is a deletion of the form , then the first non-deletion edit operation that follows in h (if any) is of the form with .
Example. The edit string is reduced as its first error is a substitution. The edit string is reduced as well. The edit string is not reduced as it starts with an insertion, and the edit string is not reduced either.
The proofs of the next two lemmata are given in the
appendix.
Lemma 4. Let be words. The following statements hold true:
- 1.
.
- 2.
If then .
- 3.
If , then there is a reduced edit string h realizing .
Lemma 5. Let and let be words. The following statements hold true with respect to the transducer .
- 1.
In , every path from the start state to any state or has as label a reduced edit string whose weight is equal to i.
- 2.
If and h is a reduced edit string realizing , then h is accepted by .
- 3.
If , then .
Theorem 2. For each , the transducer is input-altering and of size , where r is the cardinality of the alphabet, and satisfies the following condition, for any language L containing at least two words Proof. By construction, it follows that
is trim and has
states and
transitions. Hence, it is indeed of size
. The third statement of Lemma 5 implies that the transducer is input-altering. Next, we show that (
20) is true for all languages
L containing at least two words.
First, for the ‘if’ part, assume
and consider any words
. We need to prove
. If
, then this holds as
is input-altering. Else, it follows from the third statement of Lemma 5. Now, for the ‘only if’ part, assume
but, for the sake of contradiction, suppose there are different words
such that
. Let
h be a reduced edit string realizing
. By the second statement of Lemma 5,
h is accepted by
via some path
and, therefore, either of
and
is the label of the path
P of
, that is, we have
or
, which contradicts (
21). □
Corollary 2. For each NFA accepting at least two words and for each transducer , with , the following condition is satisfied: Proof. The statement follows from the above theorem and the fact (based on standard logic arguments) that is equivalent to . □
The reason why condition is preferred to the equivalent one in Theorem 2 is explained further below in the remark that follows Theorem 3.
5.2. The Second Algorithm for Edit Distance
Here, we use the results of the previous subsection to arrive at the second algorithm for computing the desired edit distance. Corollary 2 implies that the preliminary algorithm PrelimDistInpAlter shown below correctly computes the desired edit distance. Moreover, by reasoning as in the proof of Corollary 1, it follows that this algorithm also executes in time , where r is the cardinality of the alphabet used in , and .
Algorithm PrelimDistInpAlter
- 0.
Input: NFA
- 1.
Let be the bound in Lemma 2
- 2.
Let and
- 3.
Perform binary search to find the largest k in
for which is error-detecting for as follows:
while ()
- a)
Let
- b)
Construct the transducer
(see
Figure 2)
- c)
Construct the transducer
- d)
If let
Else let
- 4.
return min
We discuss now how to improve the above algorithm. The two observations we made at the beginning of
Section 4 apply here as well if, instead of partial identity of
, we talk about the emptiness of
. Thus, we want the improved algorithm to construct in turn
until the first
with
. Moreover, when
has been constructed and realizes ∅, we continue in the next step with new transitions added to
in order to get
.
Optimized construction of from the trim . Suppose that the trim
has been constructed, where initially
. Constructing
using
will be done again incrementally. The
first phase of the incremental construction is to add two sets of new transitions: the new transitions
where
is an error and
are transitions in
; and the new transitions
where
, and
are transitions in
. Note that the total numbers of new transitions and states created in the first phase are
and
, respectively.
After the first phase, the incremental construction proceeds from the new states
and
. Any new transition must be of the form
where
and, in the second case above,
. This is because the transducer
has only transitions of the form
and
, with
, going out of the state
. The incremental process ends when no new states are created. The transitions and final states of the transducer
are those in
plus the newly created ones, after removing any new states that cannot reach a final state (thus, also
is trim). □
Remark 3. If the trim transducer has no final states, then has no final states if and only if none of the new created states in the optimized construction is a final state.
Algorithm DistInpAlter
- 0.
Input: NFA
- 1.
Construct the transducer
—see
Figure 2- 2.
Construct the trim transducer
- 3.
Let
- 4.
Let the set of states of
- 5.
while ( contains no final states)
- a)
Construct from using the optimized construction
- b)
Let be the set of new states in the optimized construction
- c)
Let
- 6.
returnk
Theorem 3. Algorithm DistInpAlter computes the edit distance of the language given via a trim NFA in timewhere d is the computed edit distance, , and r is the cardinality of the alphabet used in . Proof. The correctness of the algorithm follows from the above optimized construction and Corollary 2. For the time complexity of the algorithm, we note the following: first, is constructed in time . Then, are constructed according to the optimized construction. Each of these is constructed in time and has states and transitions. In addition, each is tested for final states in linear time. □
Remark 4. When a final state f, say, of is created, then we know that there is an accepting path of ending at f. The label of that path is a word pair such that . Thus, the above algorithm can be modified to return not only the edit distance of , but also a witness pair for that distance.
6. Implementation and Testing
As both algorithms
DistErrDetect and
DistInpAlter have the same theoretical complexity, we chose to implement one of the two. We chose to implement
DistInpAlter because it requires a simpler test for each constructed transducer (although
is slightly more complex than
, the test for partial identity, [
6], is more sophisticated than testing merely for existence of final states). We have also implemented the preliminary algorithm
PrelimDistInpAlter.
Our implementation uses the FAdo package for automata, version 1.3.5.1, [
7], which is well maintained and provides several useful tools for manipulating automata. We have performed several tests (All tests were performed on a laptop with the following specification. Make: Apple, Model: MacBook Pro, Processor 2.5 GHz Intel Core i7, Memory (RAM): 16.00 GB, Operating System: macOS High Sierra Version 10.13.6.) for the correctness of these algorithms, as well as two sets of tests for the time complexity, which confirm the theoretical result that
DistInpAlter is indeed faster than
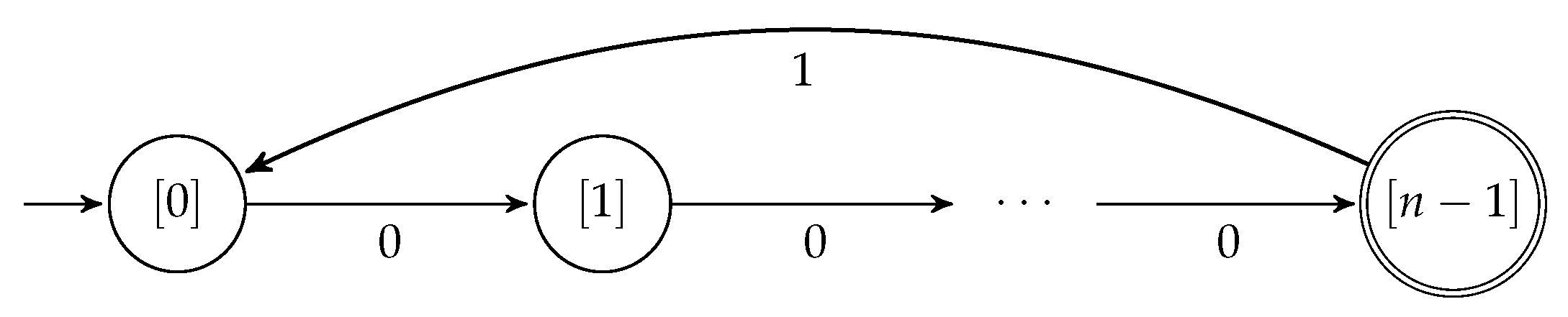
PrelimDistInpAlter. The two sets of tests correspond to two lists of DFAs,
and
, shown in
Figure 3 and
Figure 4. The first test set is such that the desired distance is equal to
n, for each DFA
, that is, the distance grows with
n and, in fact, it is a worst-case scenario where the distance is equal to the number of states of the automaton. The second test set is such that the desired distance is fixed, equal to 2, for all
n.
Table 1 shows the actual running times (in seconds) of the two algorithms on the DFAs
. The number in parentheses next to each
indicates the number of transitions in
. The column
d shows the computed edit distance, and the column
shows the computed upper bound on the edit distance (used in algorithm
PrelimDistInpAlter).
Table 2 shows the actual running times (in seconds) of the two algorithms on the DFAs
. Again, the number in parentheses next to each
indicates the number of transitions in
.
In both test sets, the empirical outcomes confirm the asymptotic outcome that the improved algorithm based on the optimized construction is faster than the preliminary one.

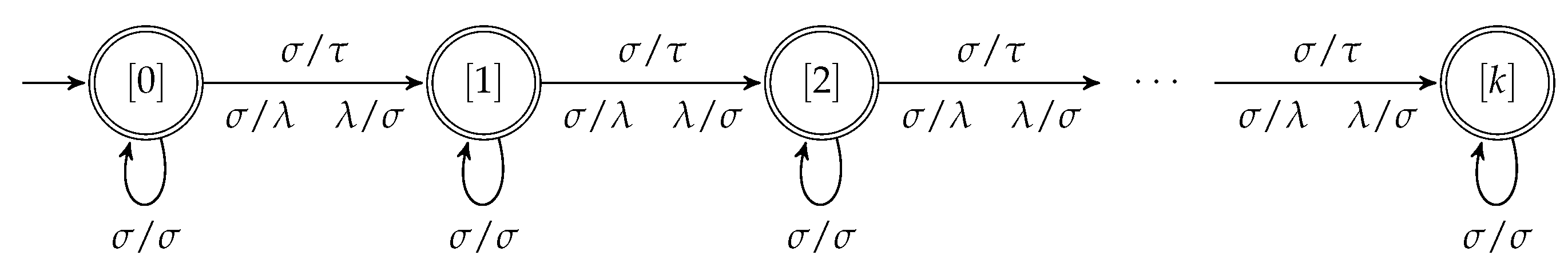


{kind=link}
{kind=link}
{kind=link}
{kind=link}