A Hybrid Algorithm for Optimal Wireless Sensor Network Deployment with the Minimum Number of Sensor Nodes


Abstract
:1. Introduction
- A Hybrid algorithm based on the gradient and the SA algorithm is demonstrated for the sensor deployment problem, with the selection of the minimal number of nodes.
- Simulation results are shown to prove the efficiency of the proposed technique.
- A comparison with other approaches is concluded in order to evaluate the efficiency of the proposed algorithm.
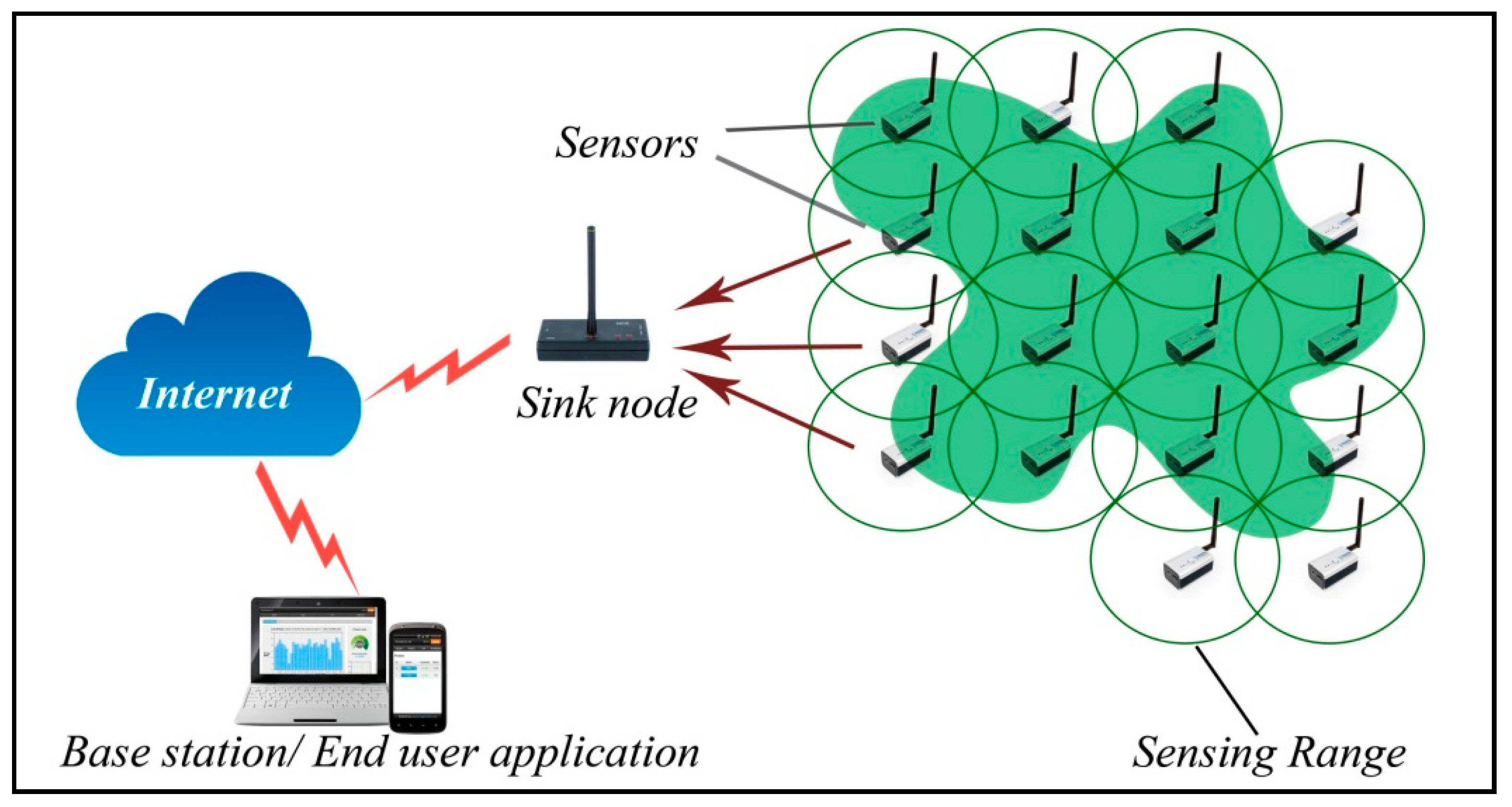
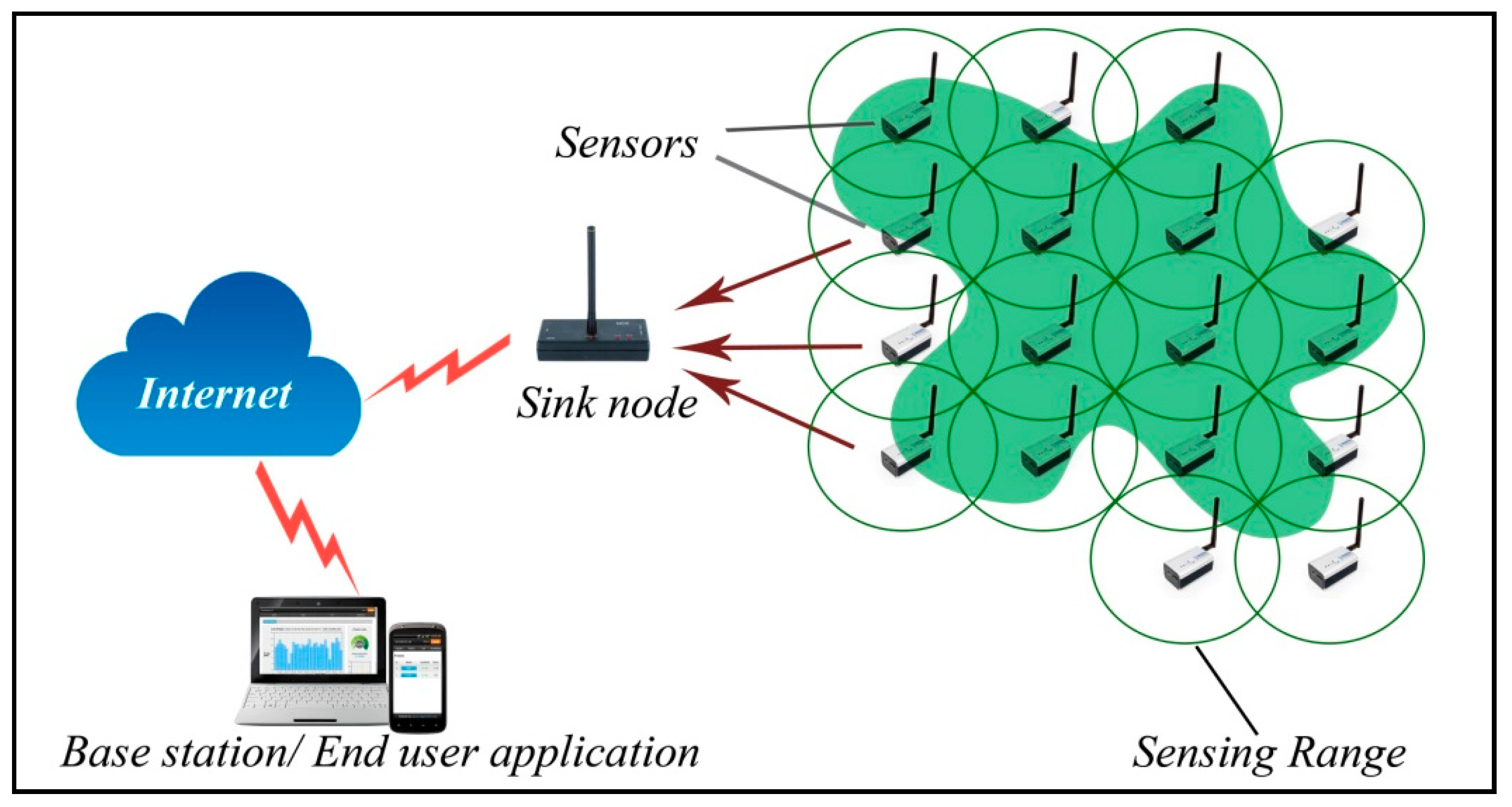
2. WSN Basic Concepts and Preliminaries
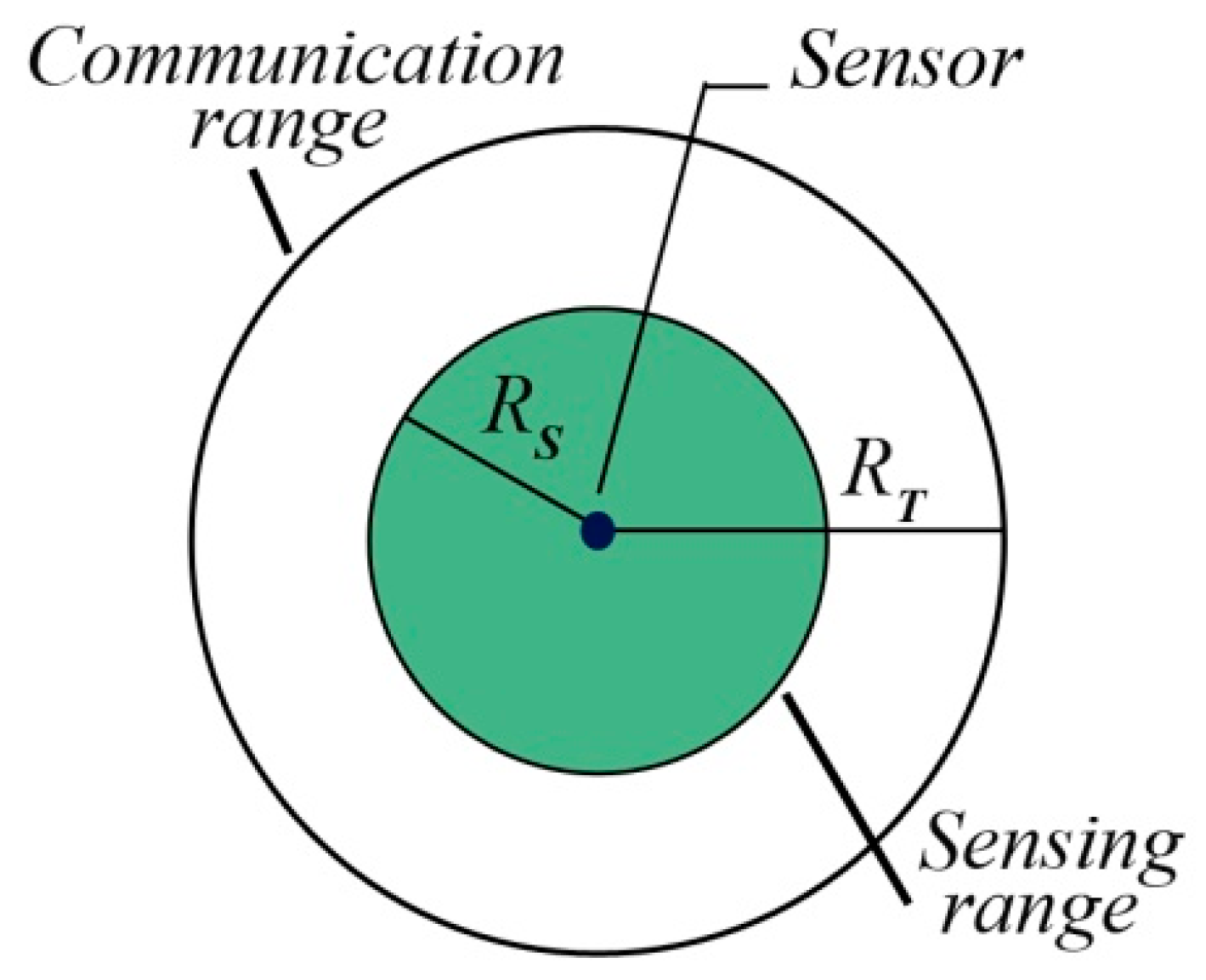
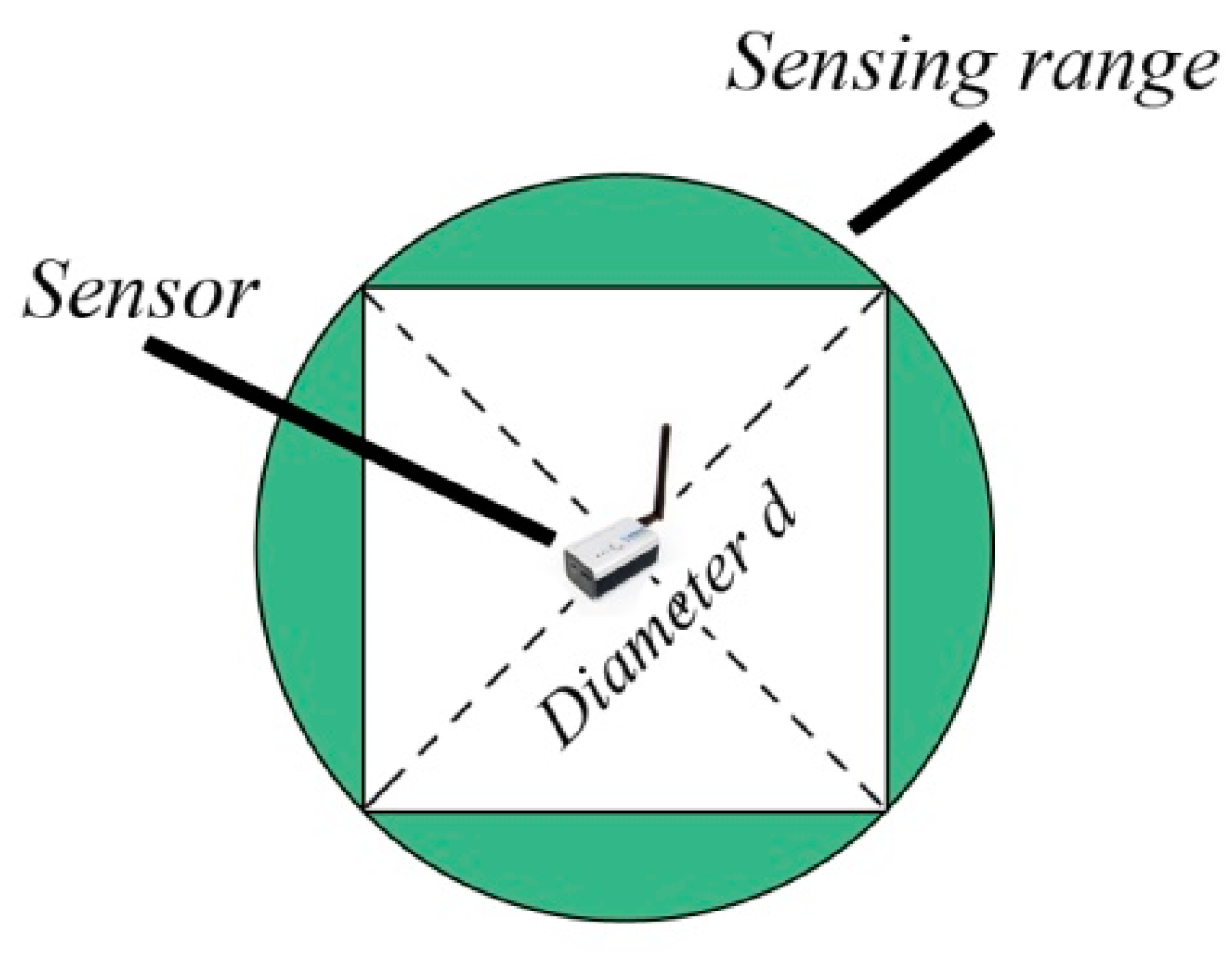
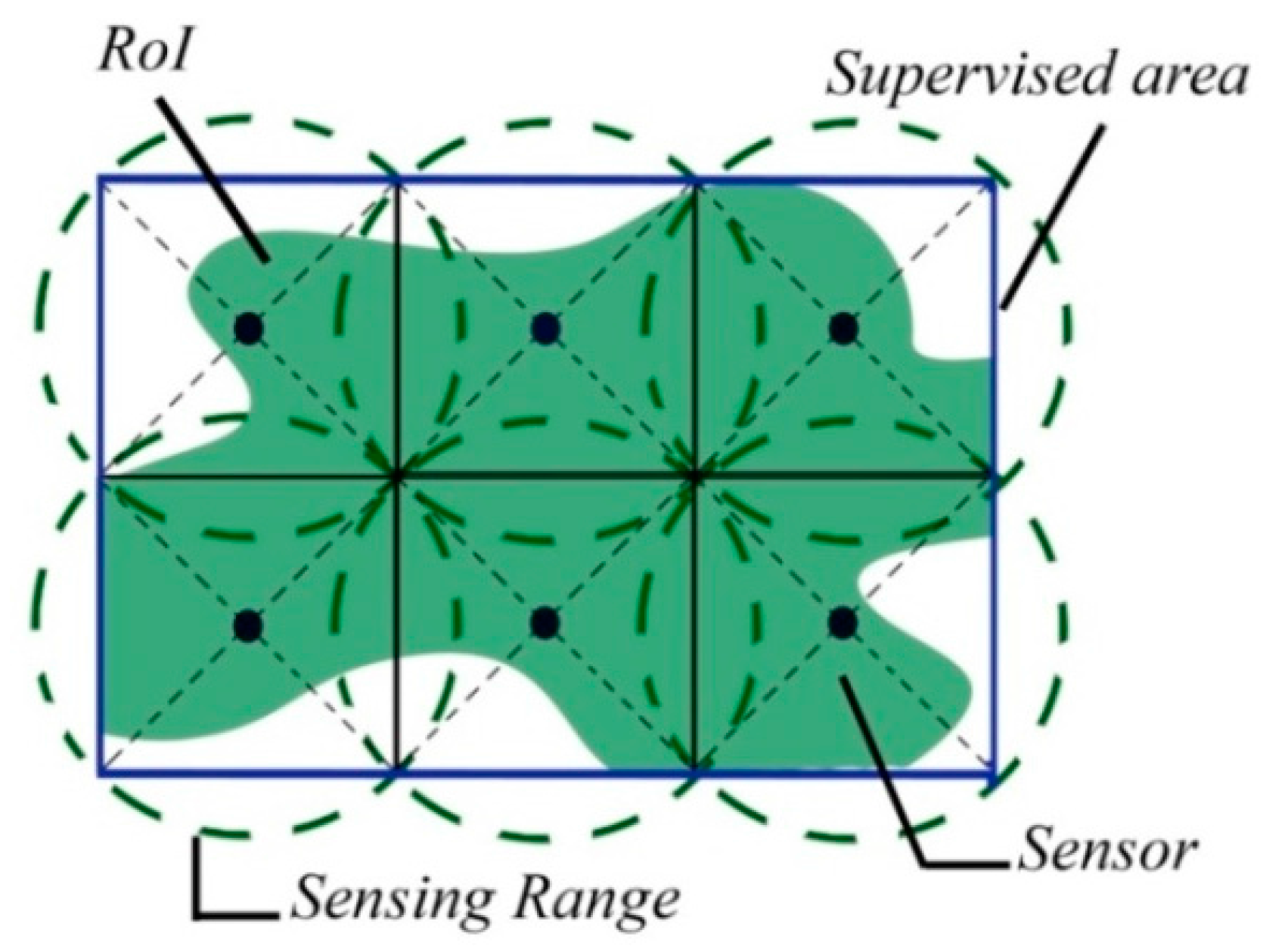
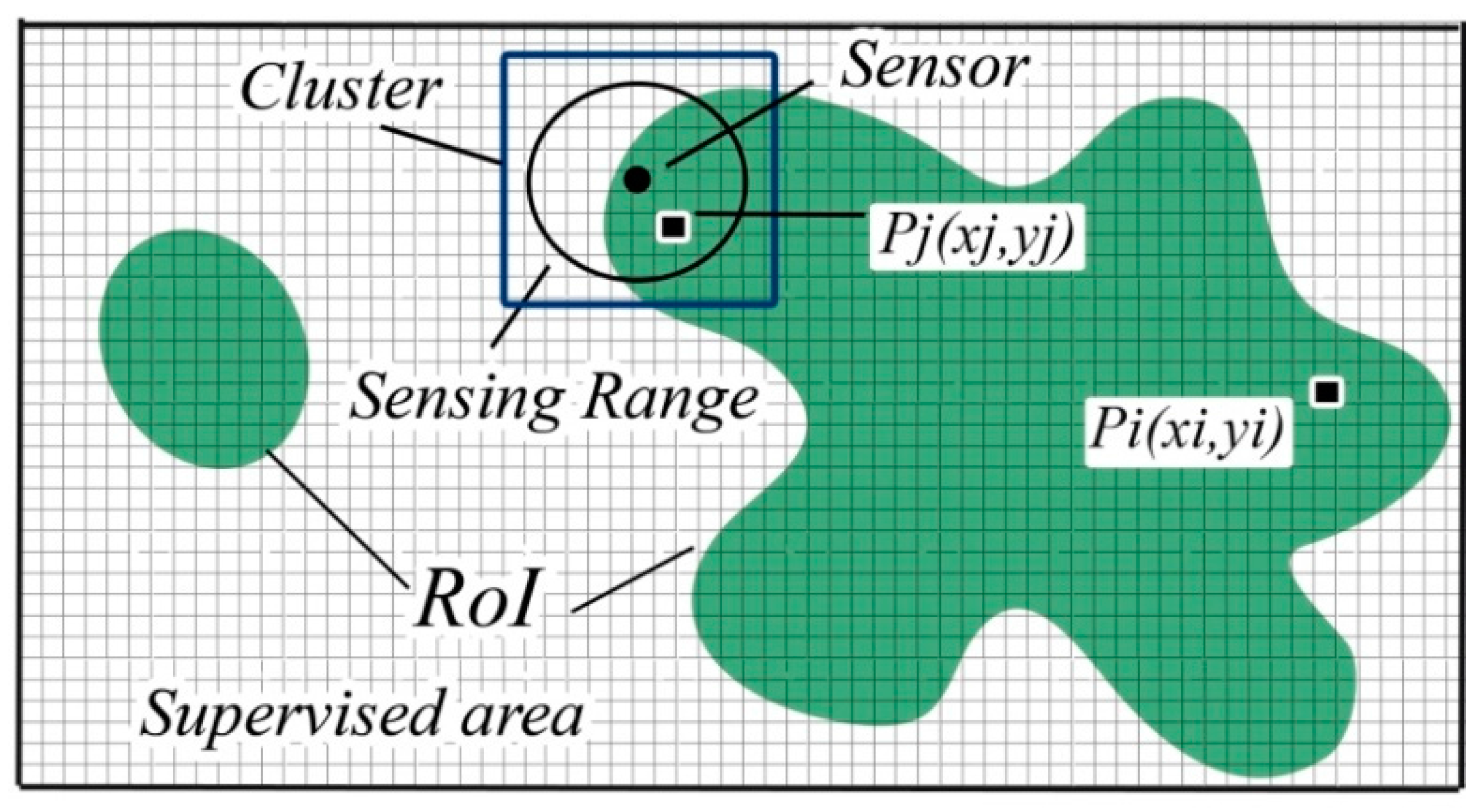
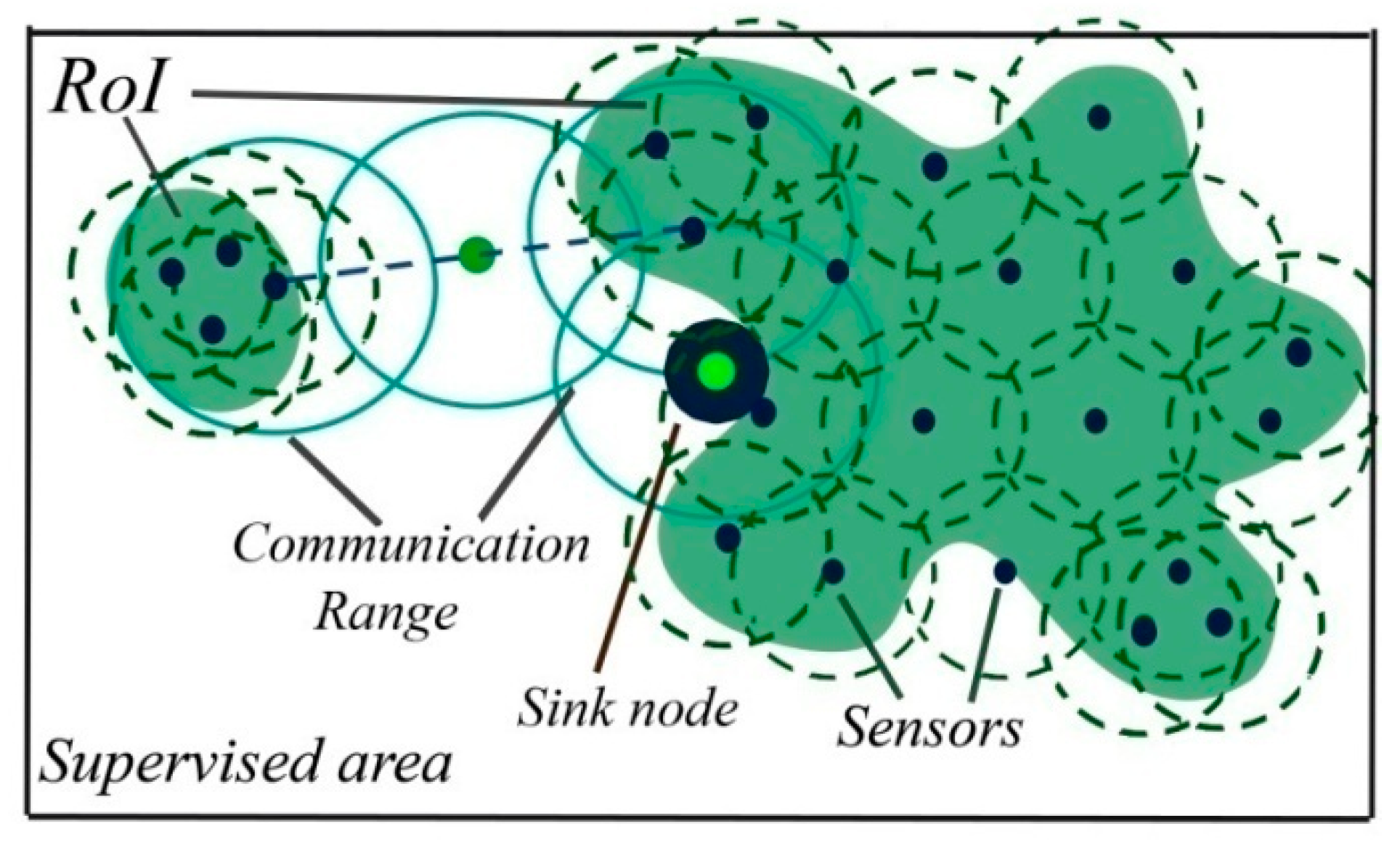
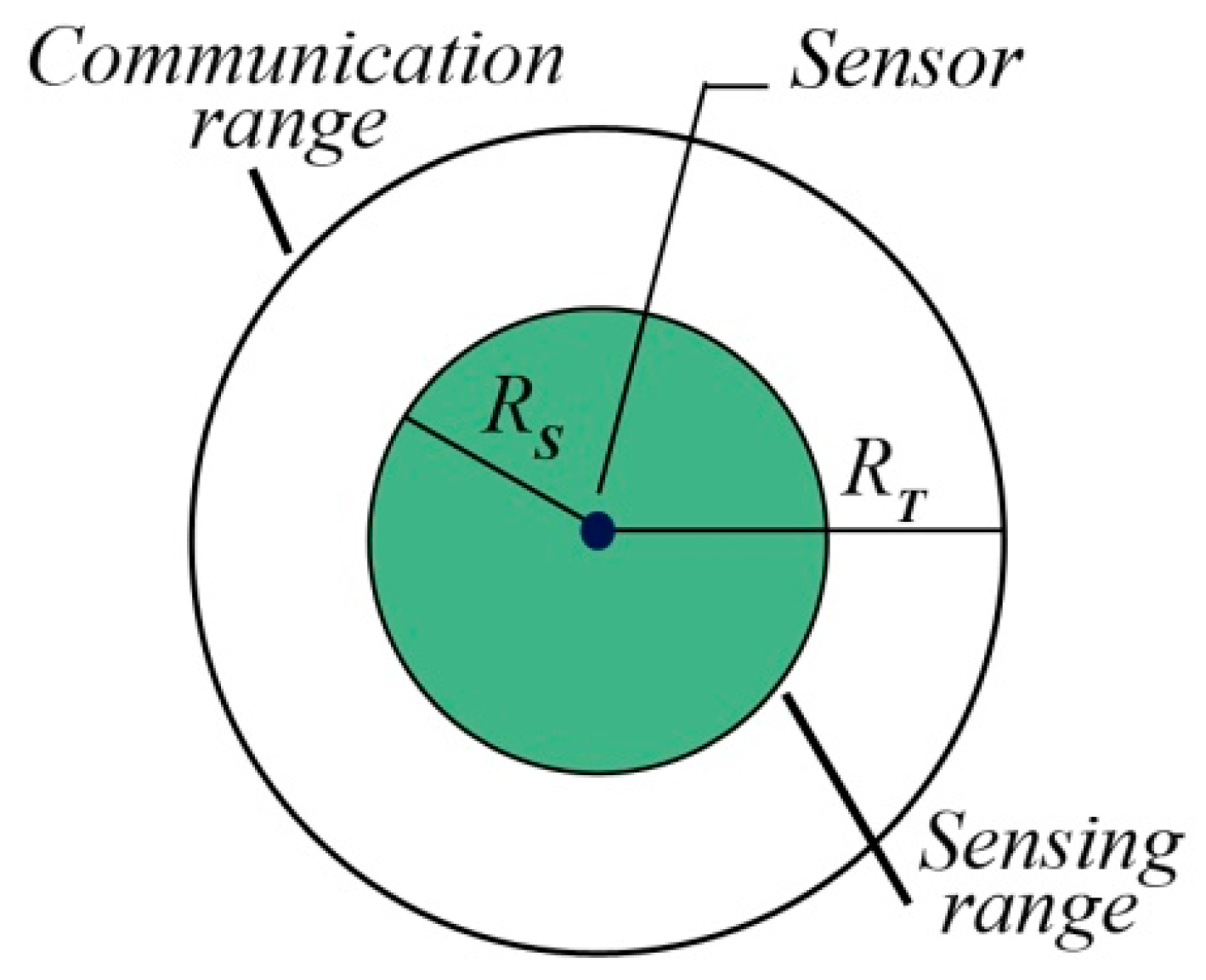
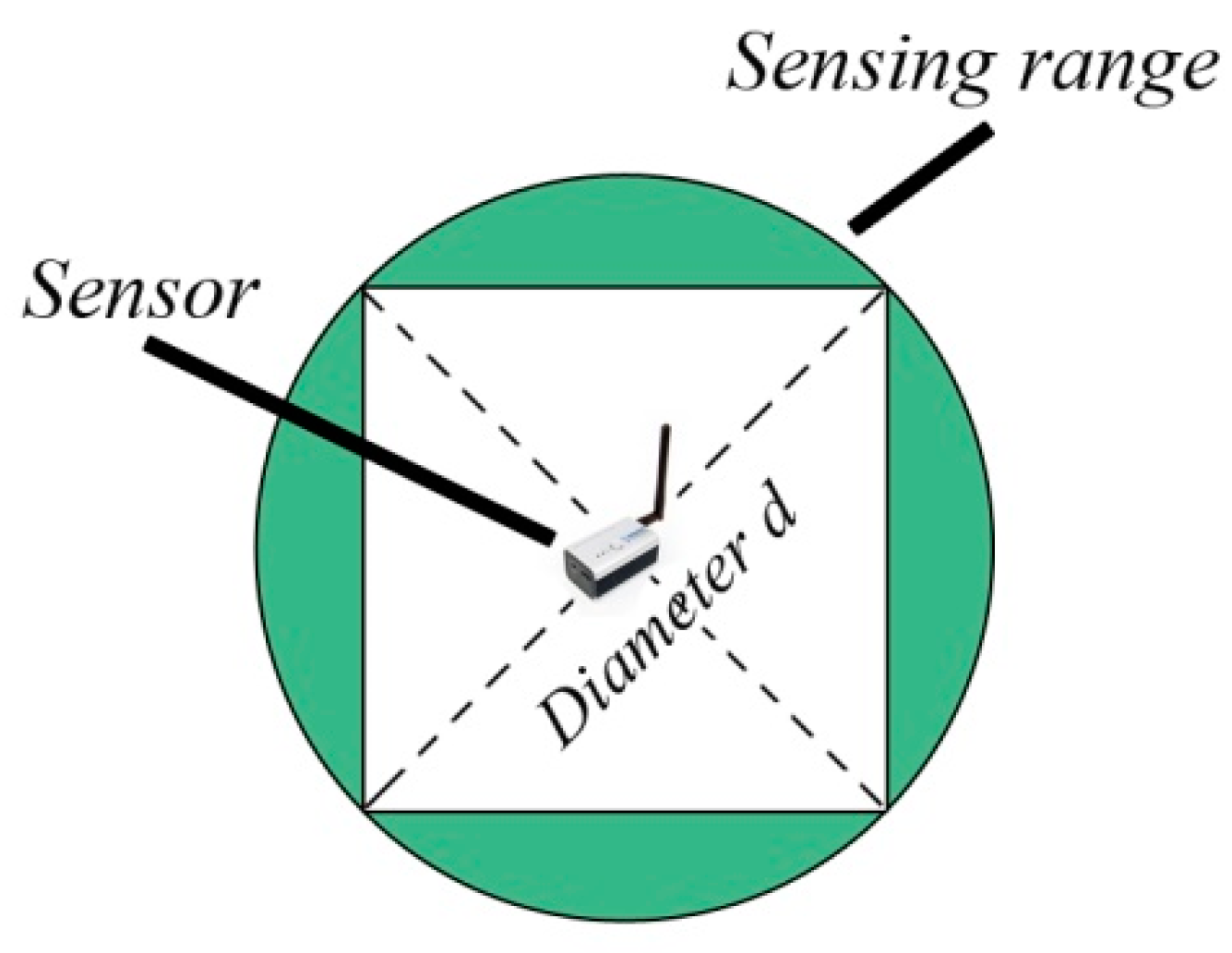
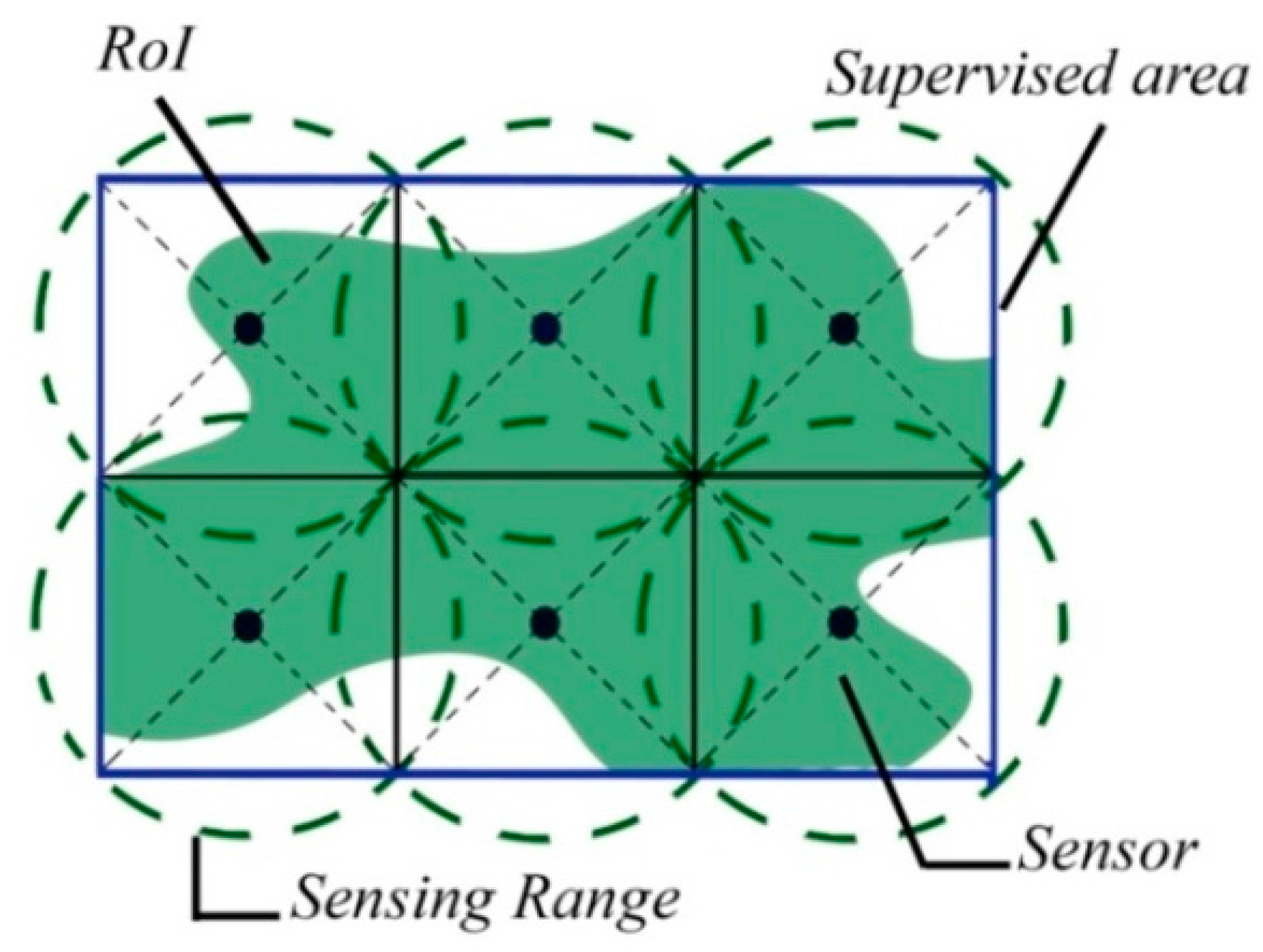
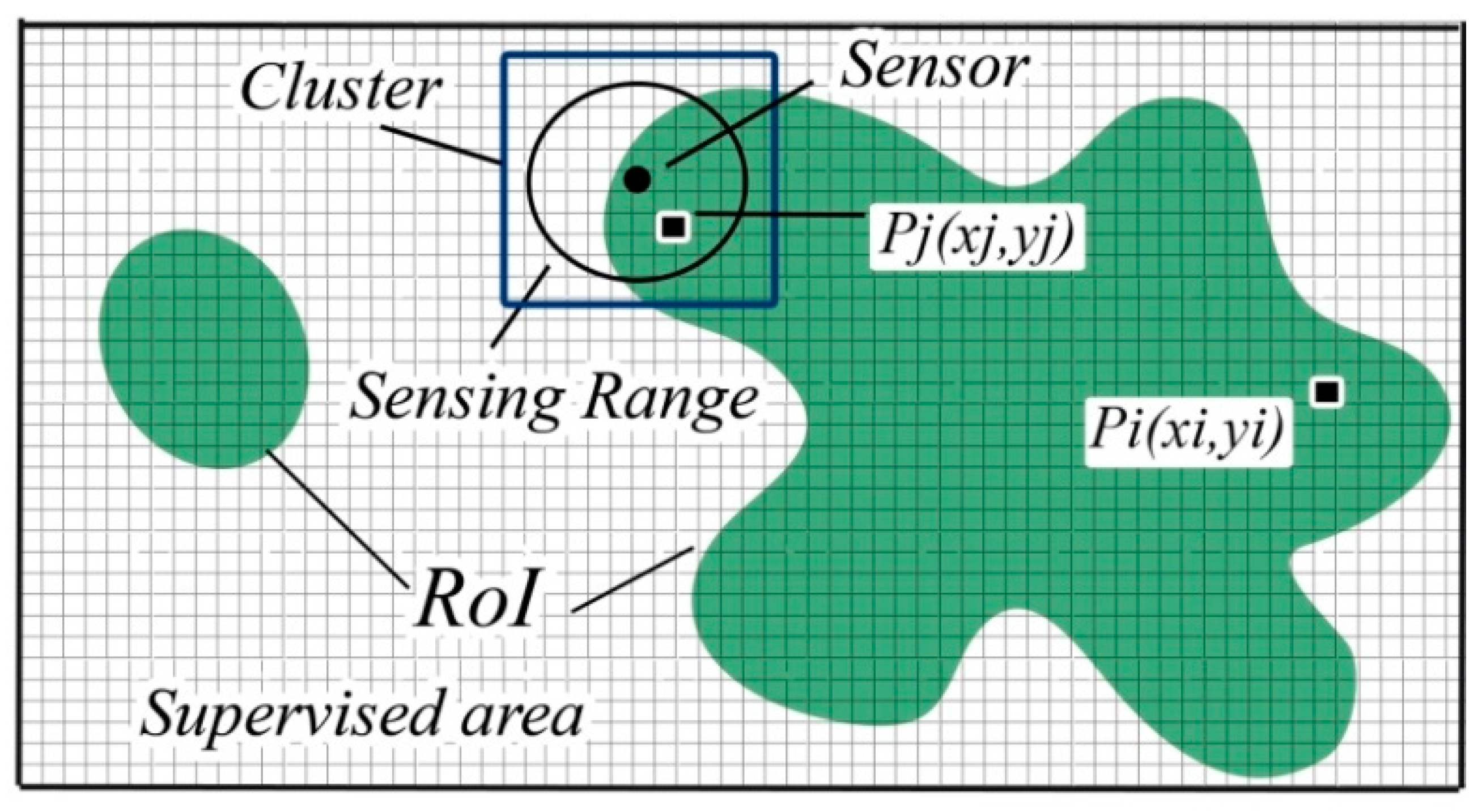
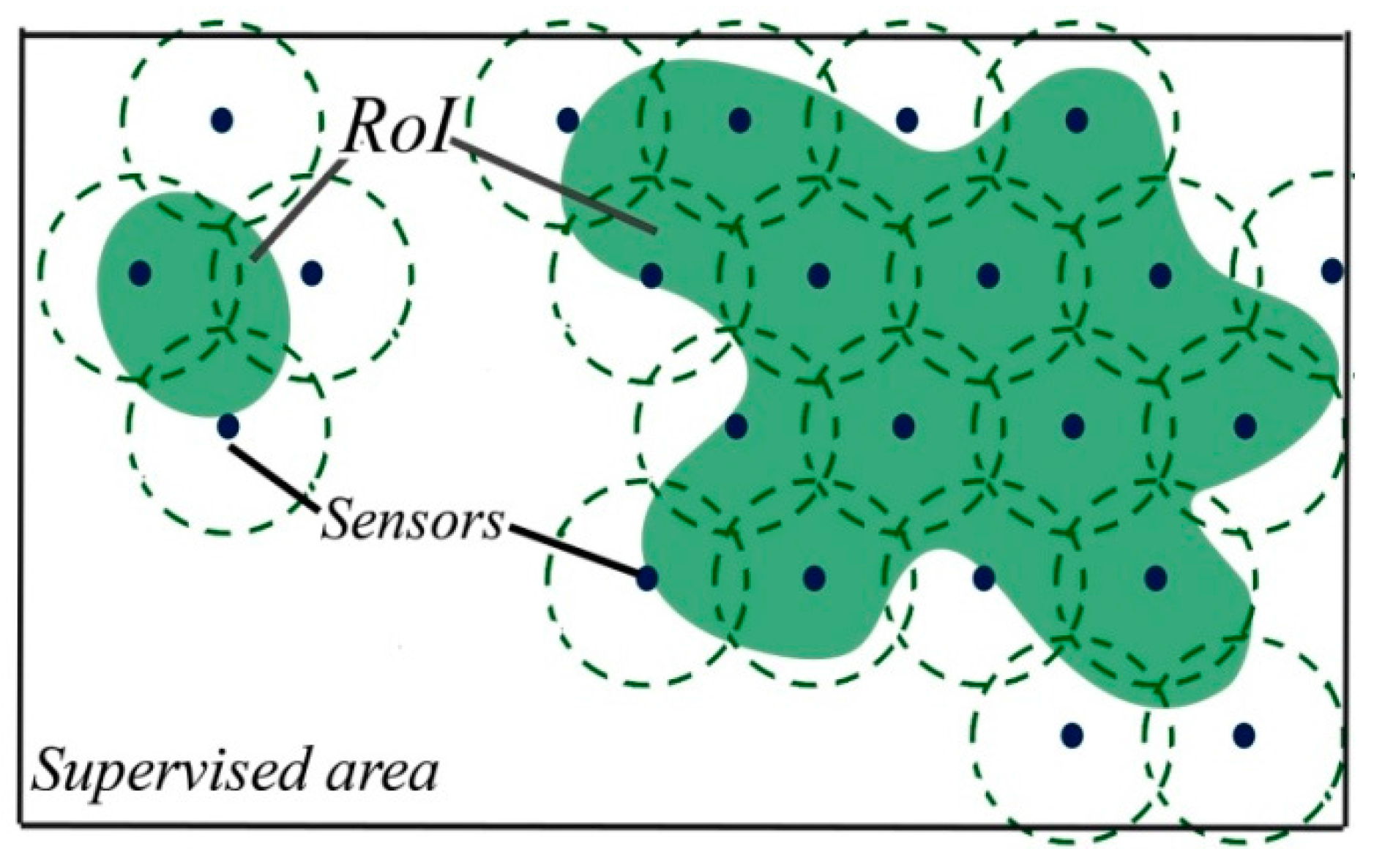
2.1. Preliminary Definitions
- A random-uniform deployment, where sensor nodes are uniformly distributed;
- Engineered-uniform deployment strategy where the sensor nodes are distributed in an engineered-uniform fashion;
- Random-Gaussian deployment strategy considers an incremental deployment model such that the number of sensor nodes keeps on increasing near the sink vicinity.
- Engineered Gaussian deployment strategy, where the density of sensor nodes in the first corona is higher than the other coronas, treats the energy hole problem;
- In the second Engineered corona-based sensor node deployment strategy, the sensor node distribution should achieve the maximum coverage using the minimum number of sensor nodes;
- For optimized, balanced energy consumption, the third and the fourth categories use, respectively, arithmetic/geometric proportion, to find the optimum number of nodes in Corona;
- Finally, the engineered corona-based sensor nodes deployment strategy, using relay nodes for transmission that aim to reduce redundant data transmission.
2.2. WSN Basic Concepts
3. Related Work
4. WSN Deployment Approaches Based on the SA Algorithm
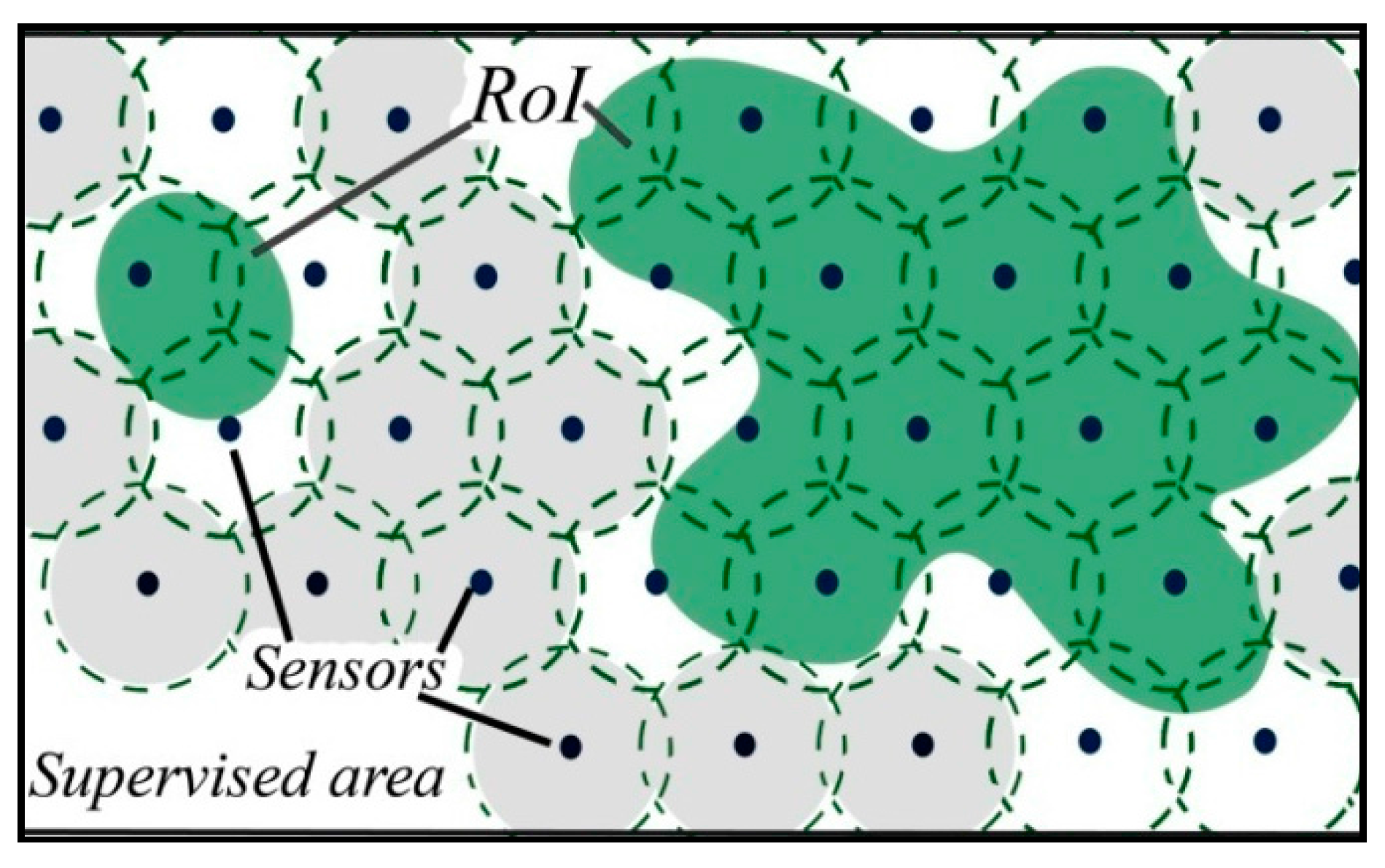
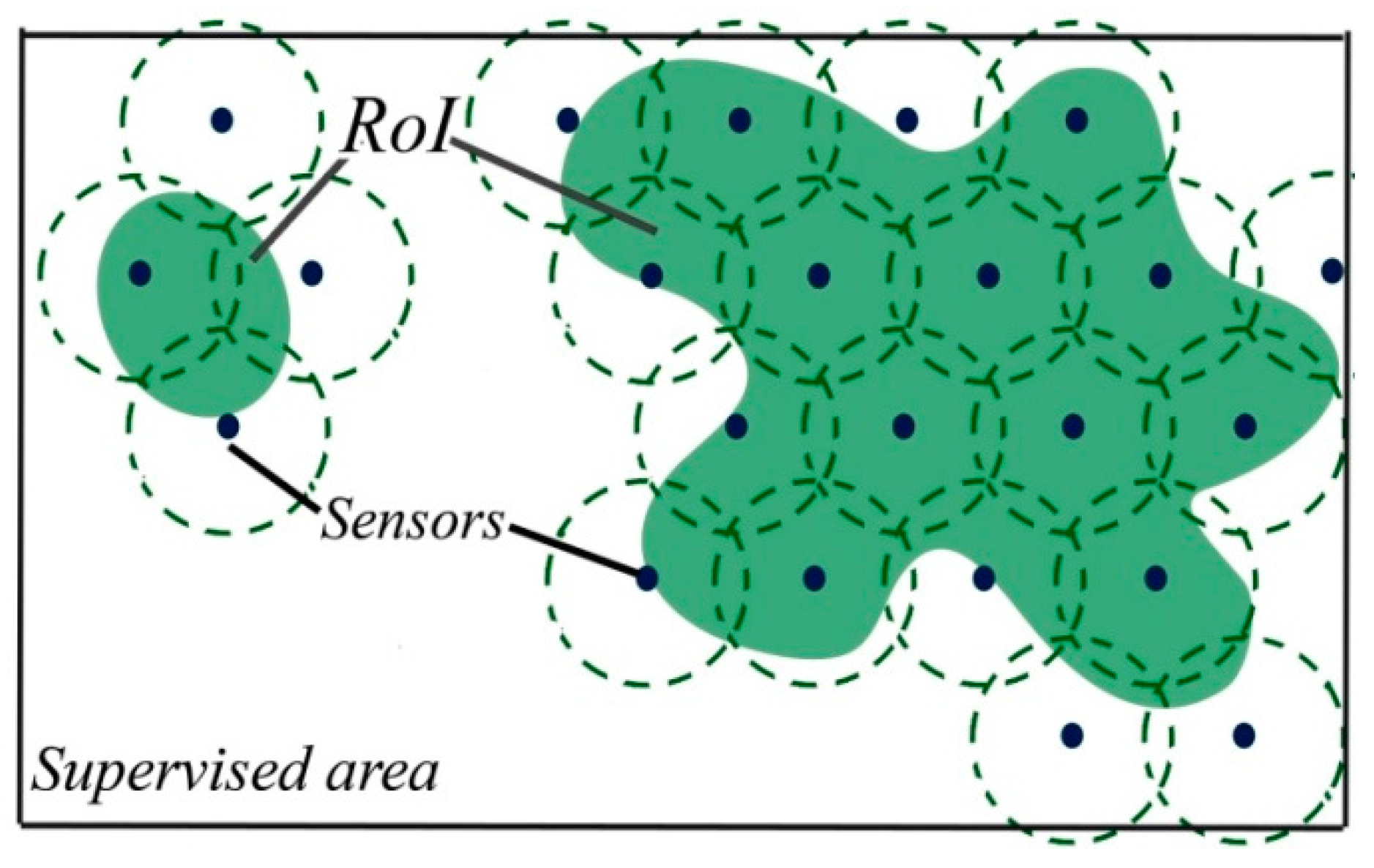
5. Model Formulation and Description
5.1. Model Formulation
| Algorithm 1: Gradient—SA Hybrid Algorithm for Sensor Deployment |
| 1. T = T0, is the initial temperature and d = the initial distance of deployment. ν and µ denote respectively the added value to the actual distance of deployment d and the transition value for nodes at the boundary. 2. Let compute the initial number of nodes, = {x1, x2,…, xN0 } (i) corresponds to the index of the current node. Initial interest function value is = 0 and. 3. While T > 0 \\Let distribute nodes line by line and save those with a collected interest value Si ≥ 0, then compute. The first position is chosen randomly. 3.1 While k < sensor nodes on x-axis, 3.1.1 While j < sensor nodes on y-axis 3.1.1.1 Define the cluster 3.1.1.2 Calculate the collected interest Si per node then the joint interest. 3.1.1.3 If Si > 0 then xi ϵ (X); End 3.1.1.4 Shift the sensor position horizontally by ν; 3.1.1.5 Update j 3.1.1.6 end 3.1.2 Shift the sensor position vertically by ν; 3.1.3 Update k 3.1.4 End \\Let search for sensors on the RoI boundary, shift their positions and calculate the sum of collected interest of sensor nodes. 3.2 t =, is the number of iterations needed for a node to move from its position on the Roi boundary until approximating its neighbour by Rs/4. 3.3 While t > 0 3.3.1 While I < N sensor 3.3.1.1 Detect sensors on the RoI boundary 3.3.1.2 Shift positions by µ using 3.3.1.3 Define the cluster then calculate the collected interest 3.3.1.4 End 3.3.2 Calculate the joint interest; 3.3.3 t = tγ 3.3.4 End 3.4 If (X0 −(X) ≤ Q then (X0) = (X) End; \\Q is the accepted tolerance: For 100% coverage Q = 0 3.5 Let detect unconnected nodes, and add nodes by using . 3.6 Upgrade the values of the functions and 3.7 T = Tδ. 3.8 End |
5.2. Model Description
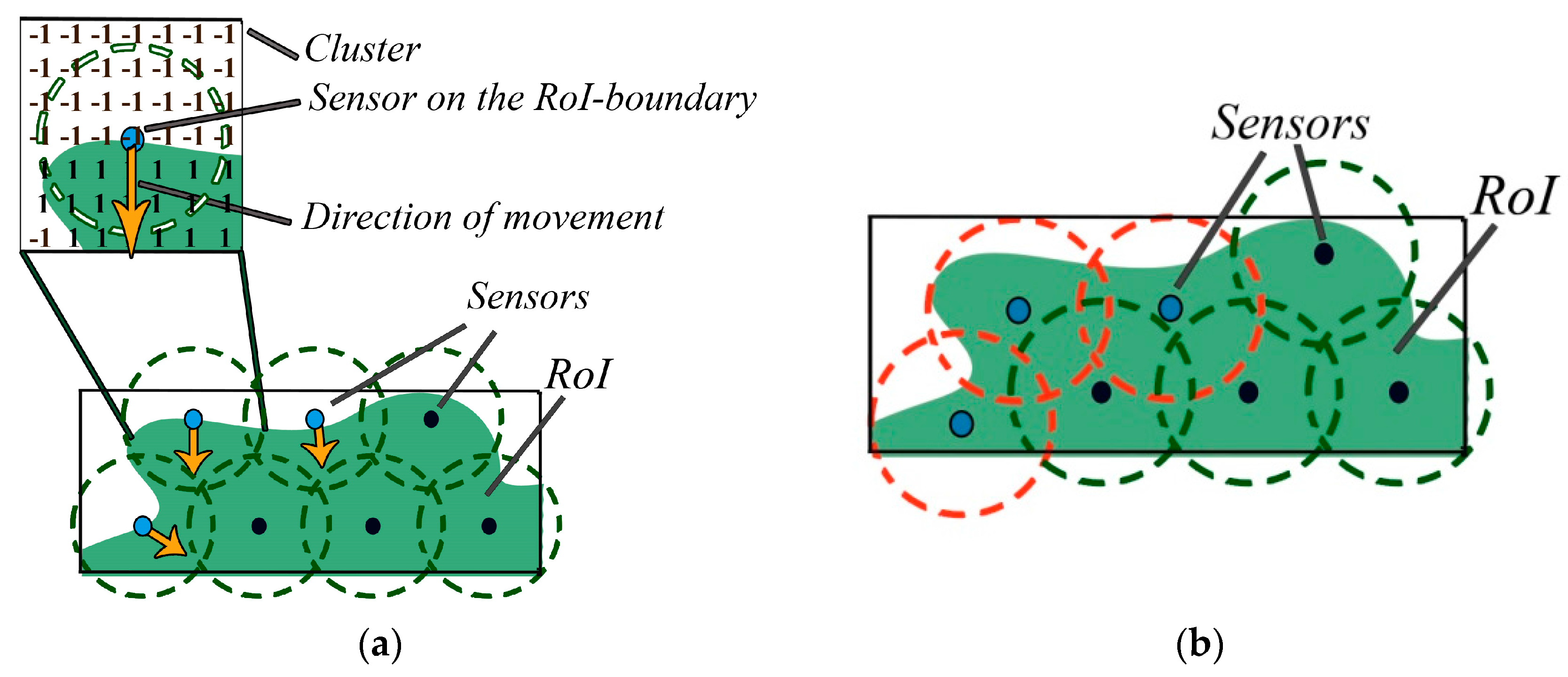
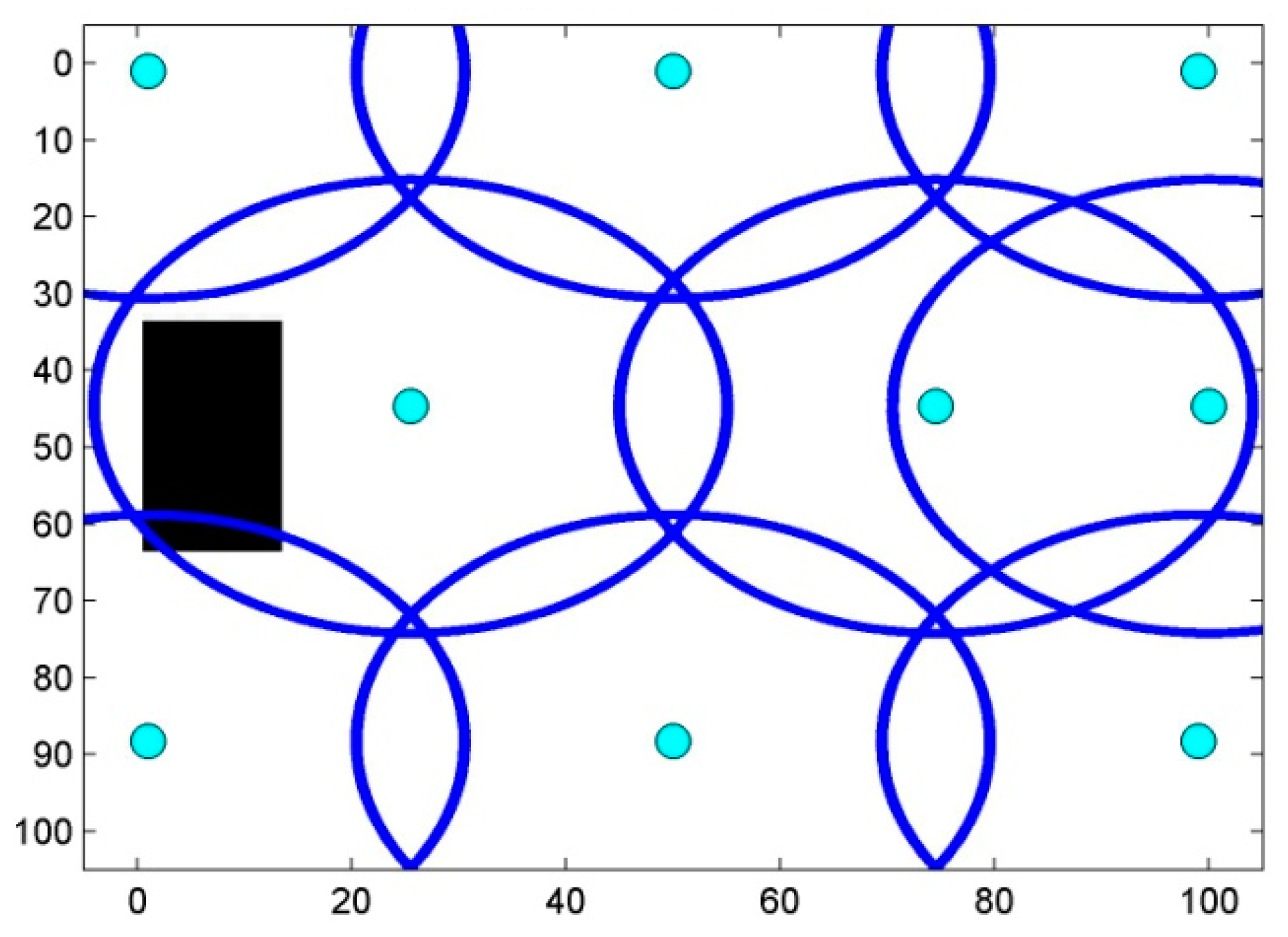
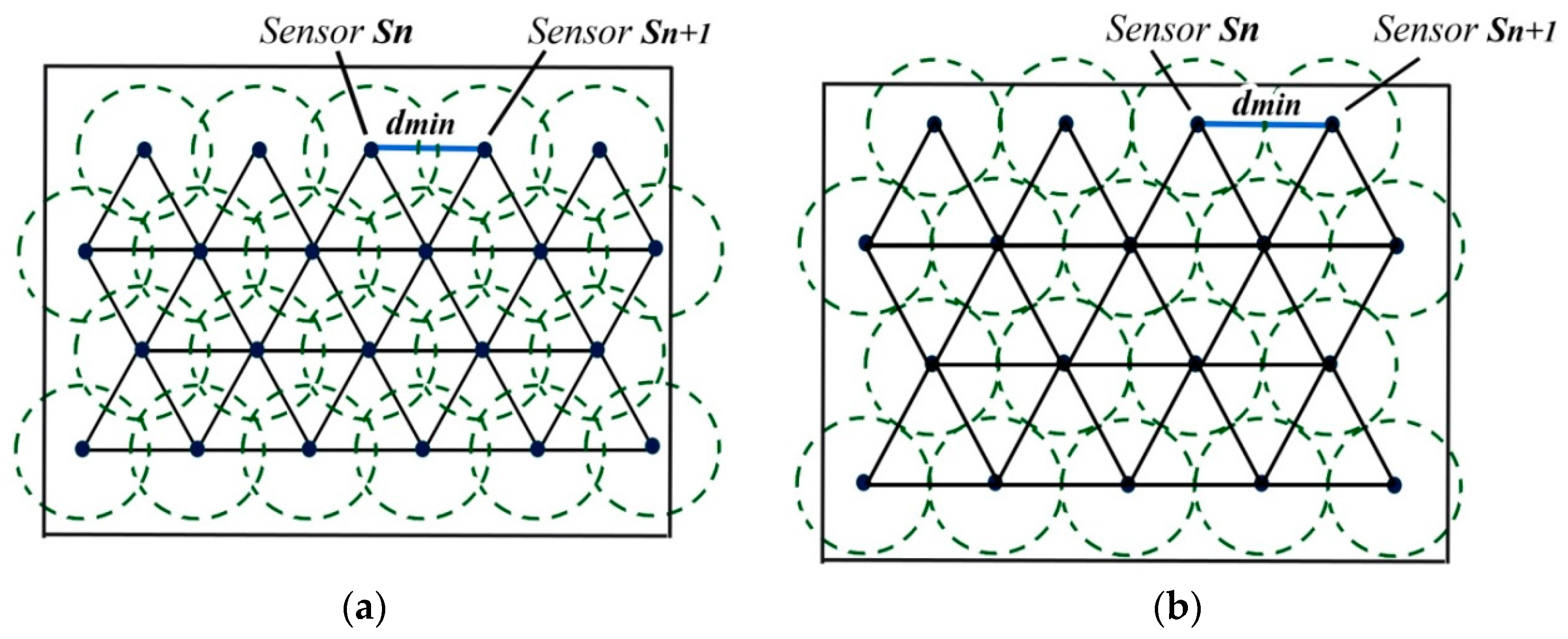
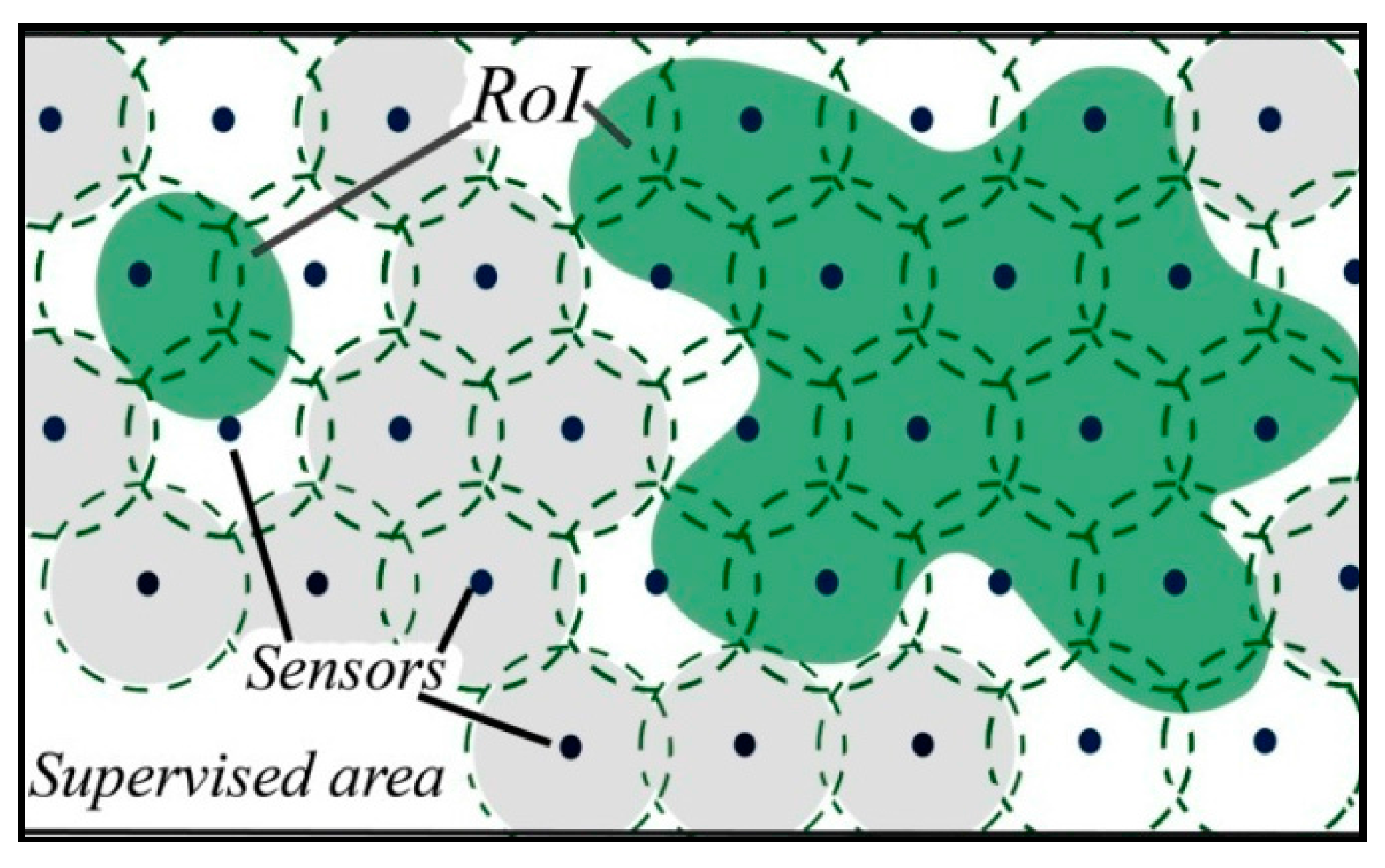
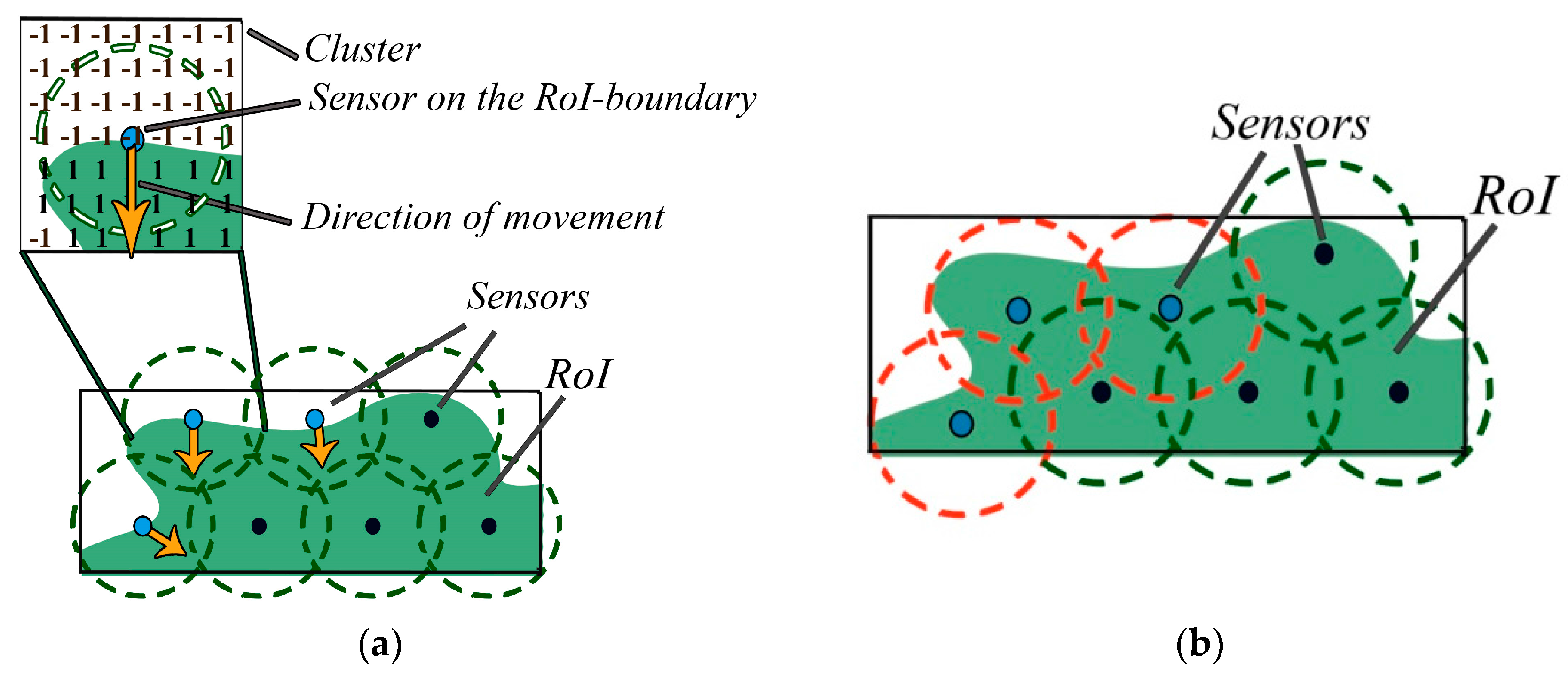
5.2.1. Step One: Searching for Interest
5.2.2. Step Two: RoI-Boundary Sensor Optimization
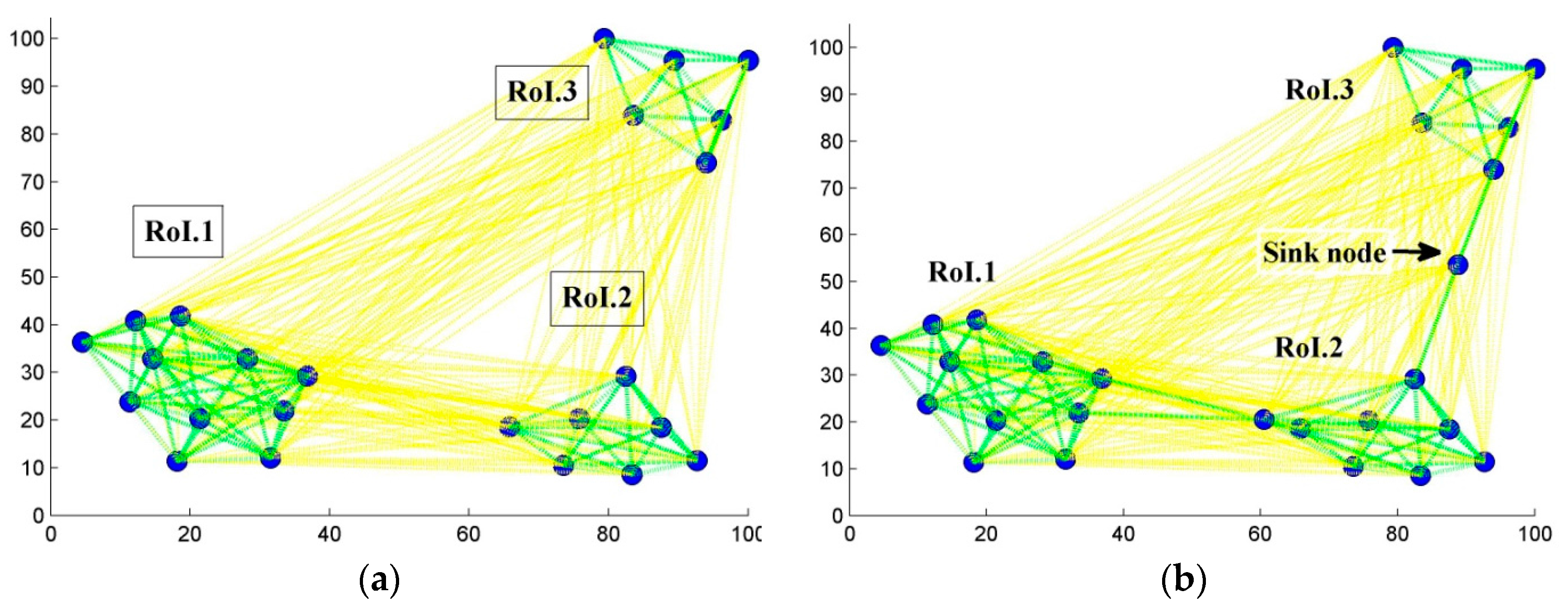
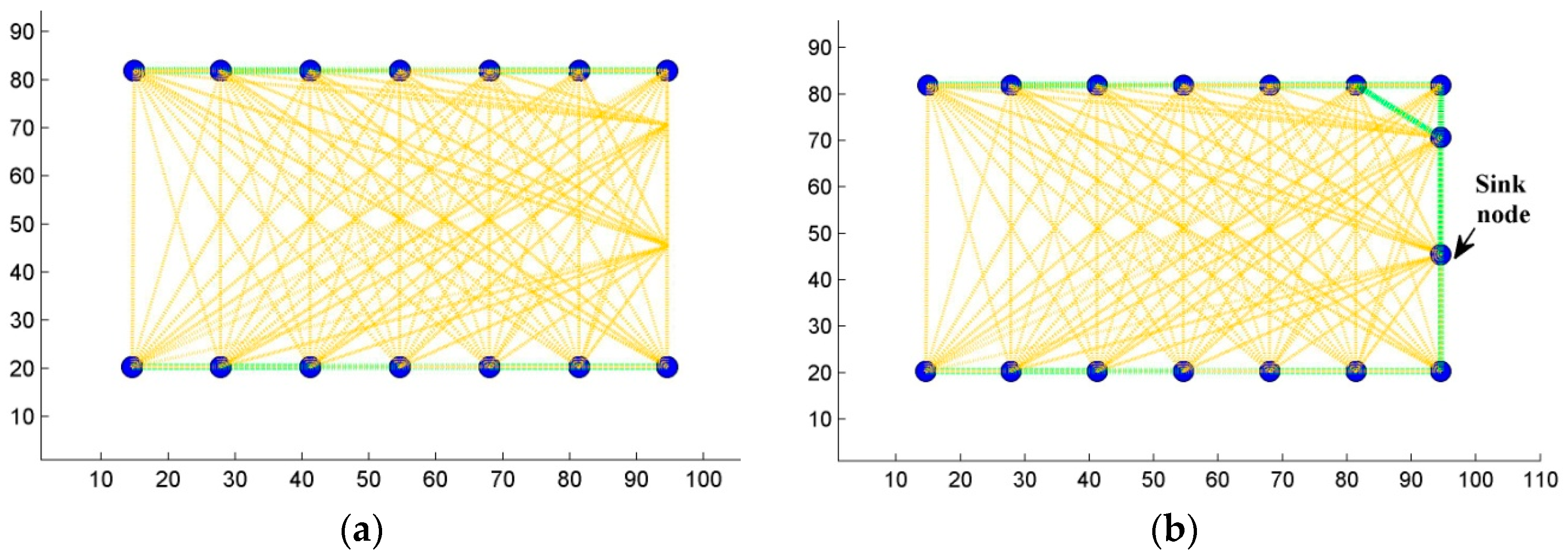
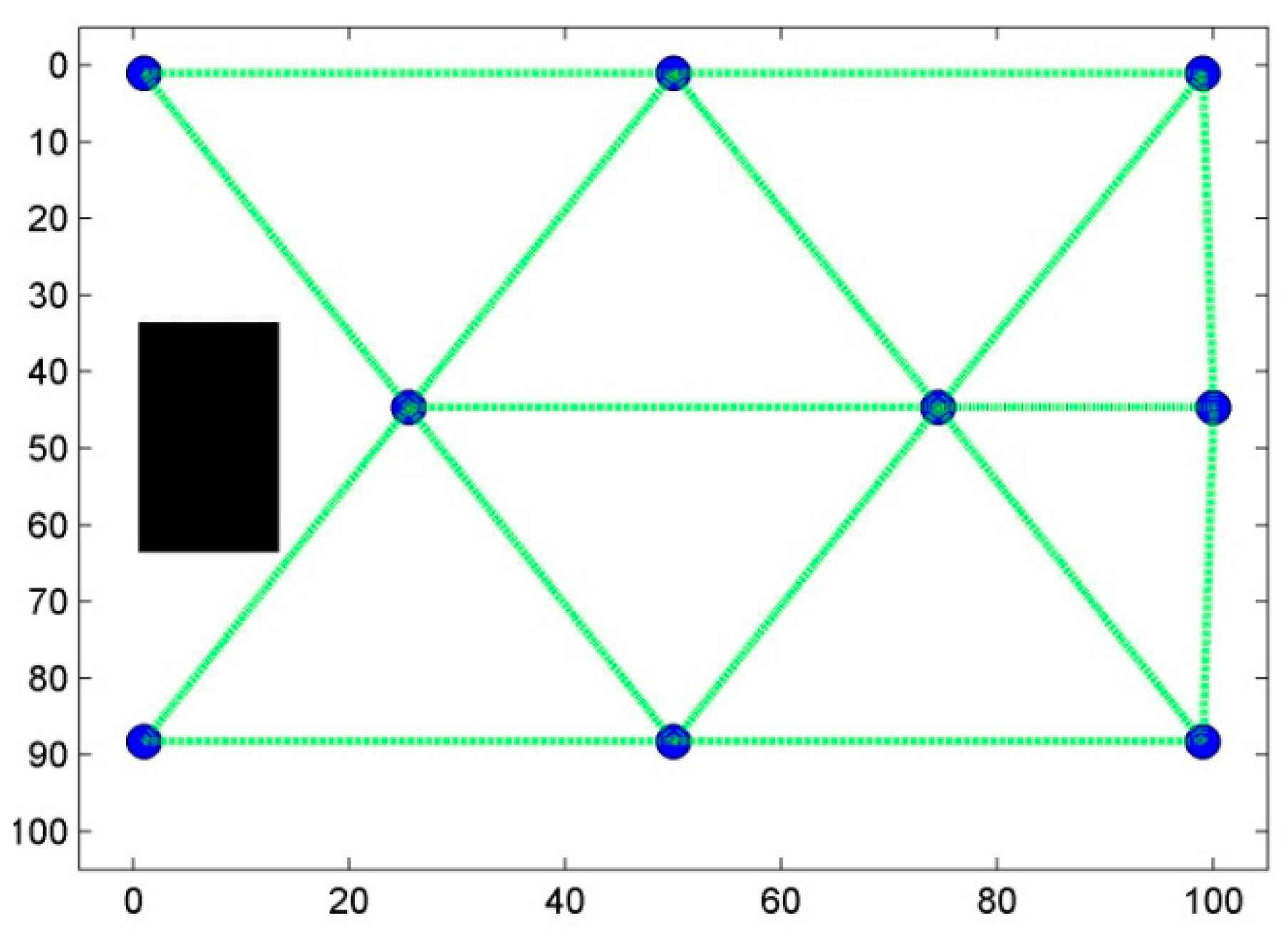
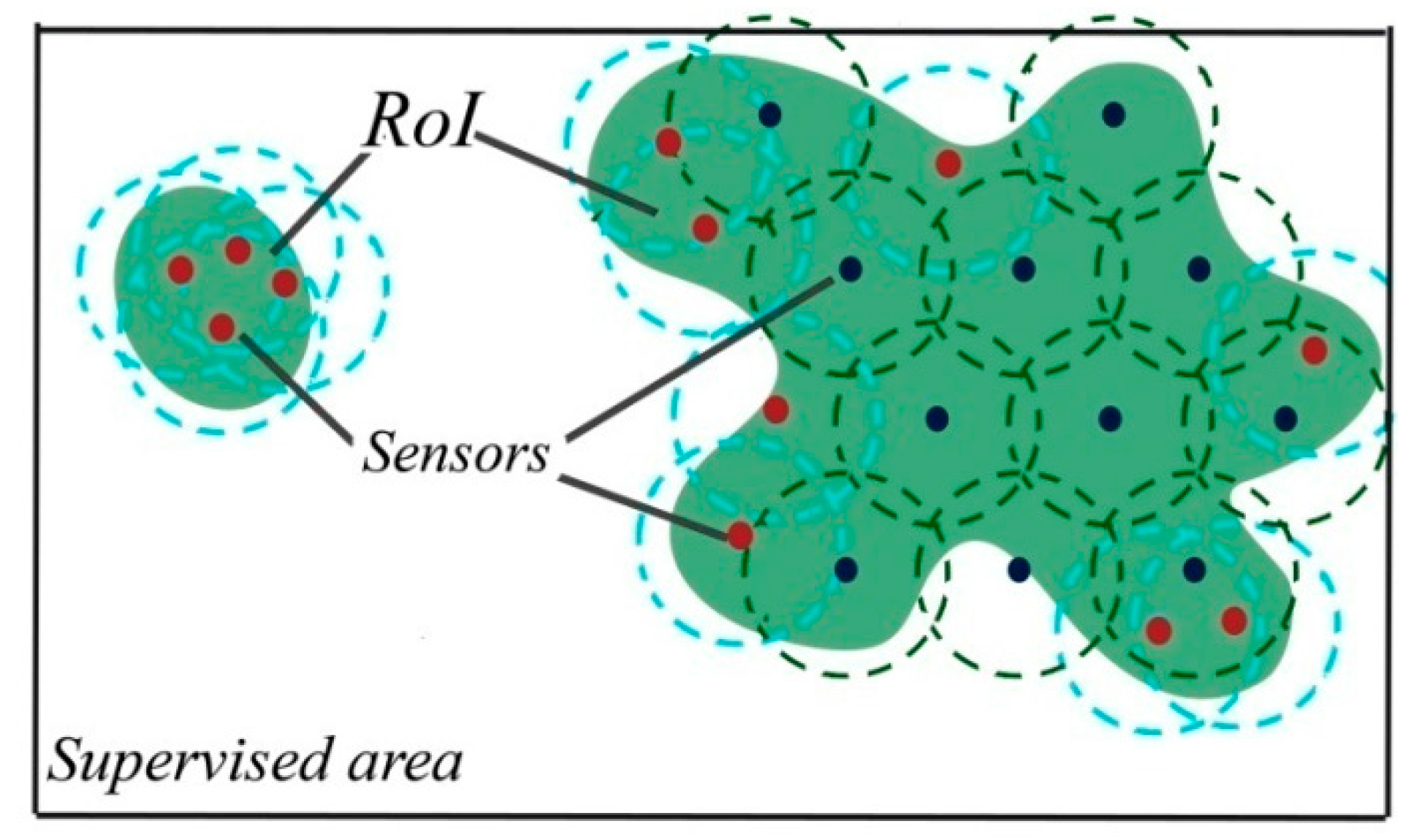
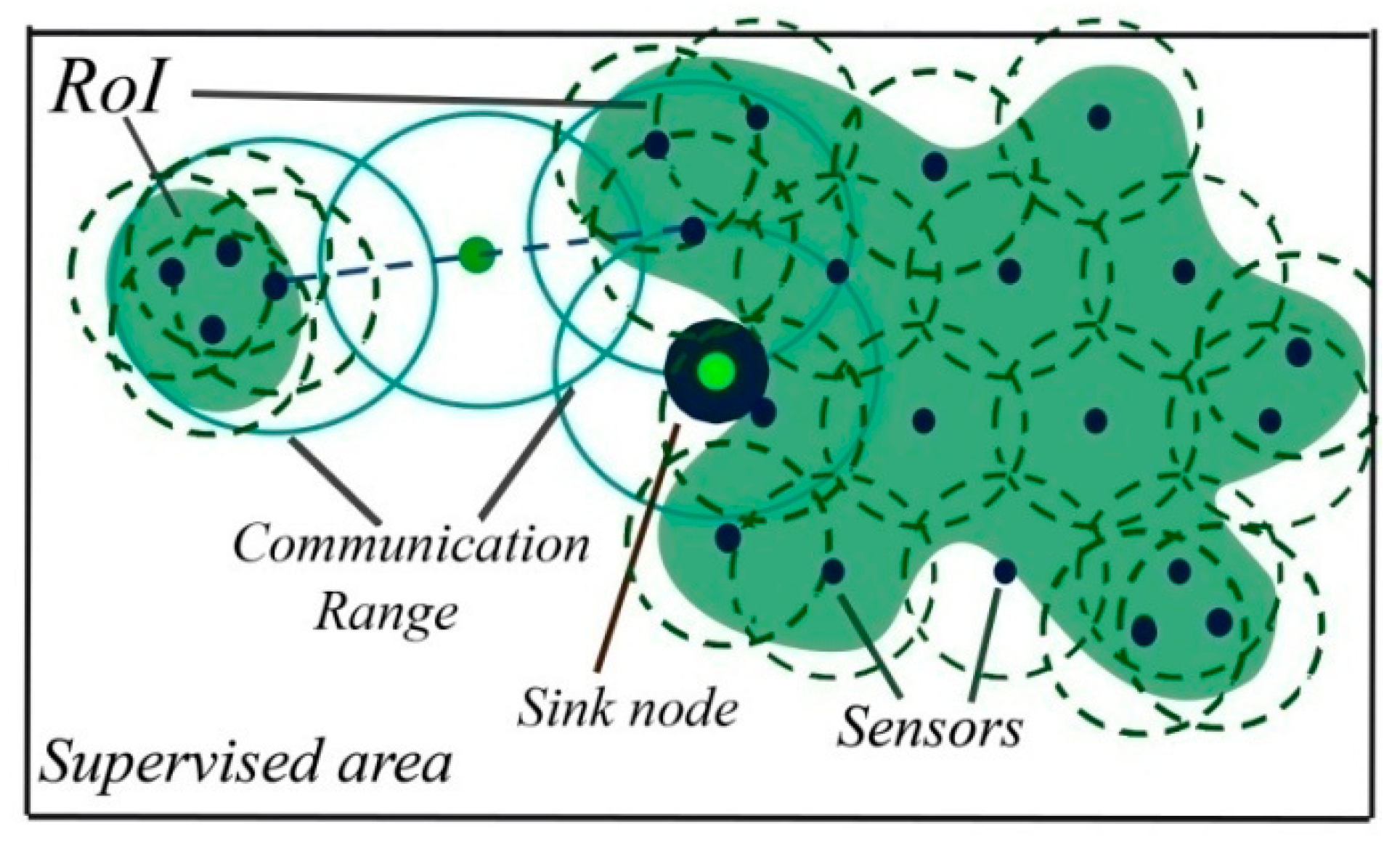
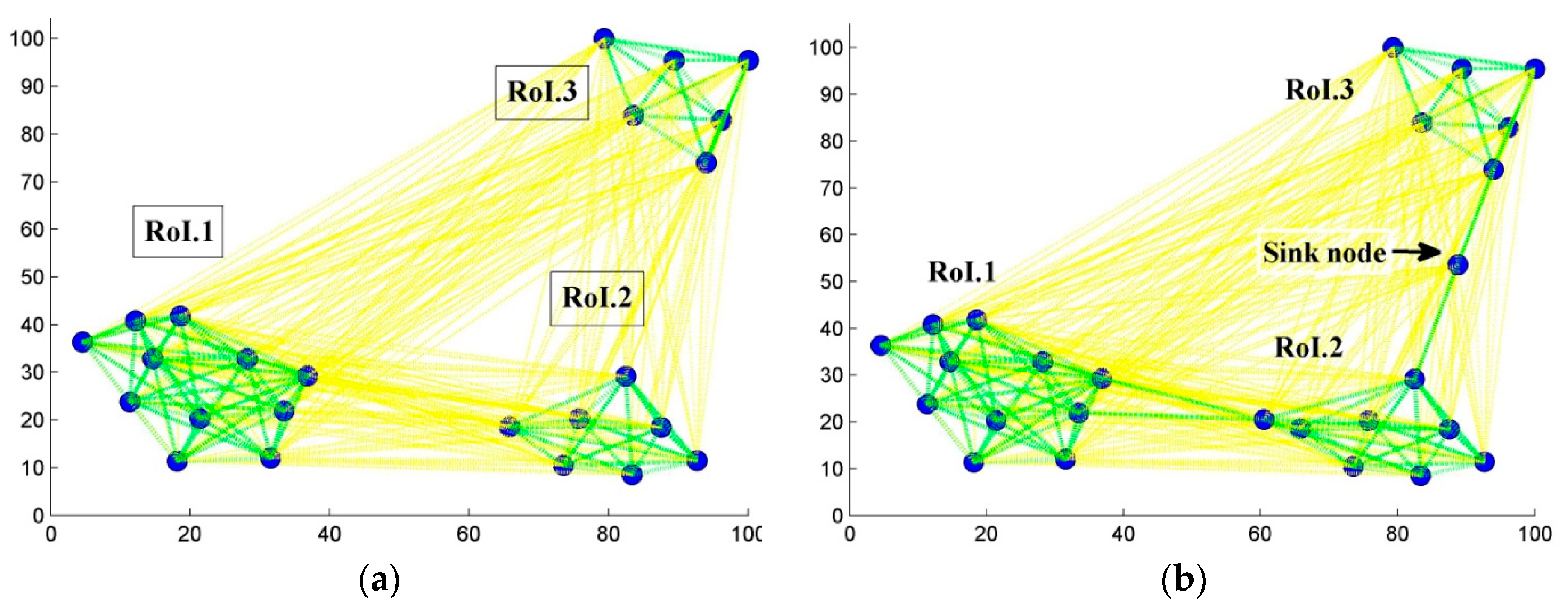
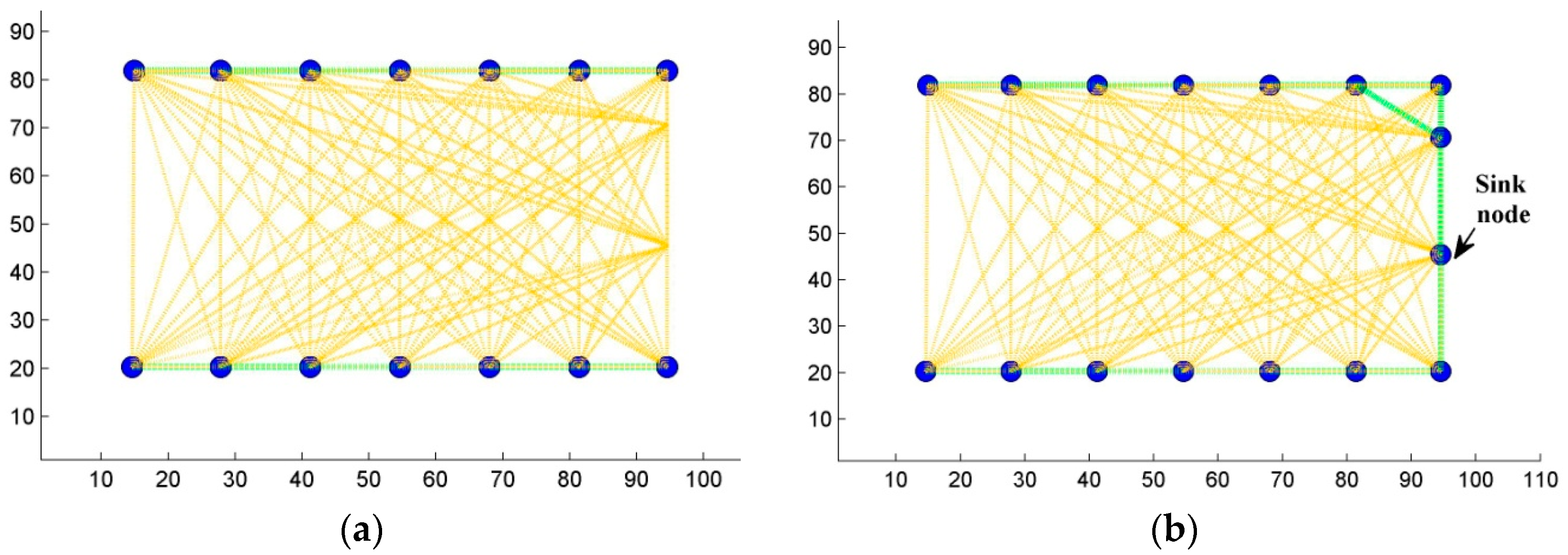
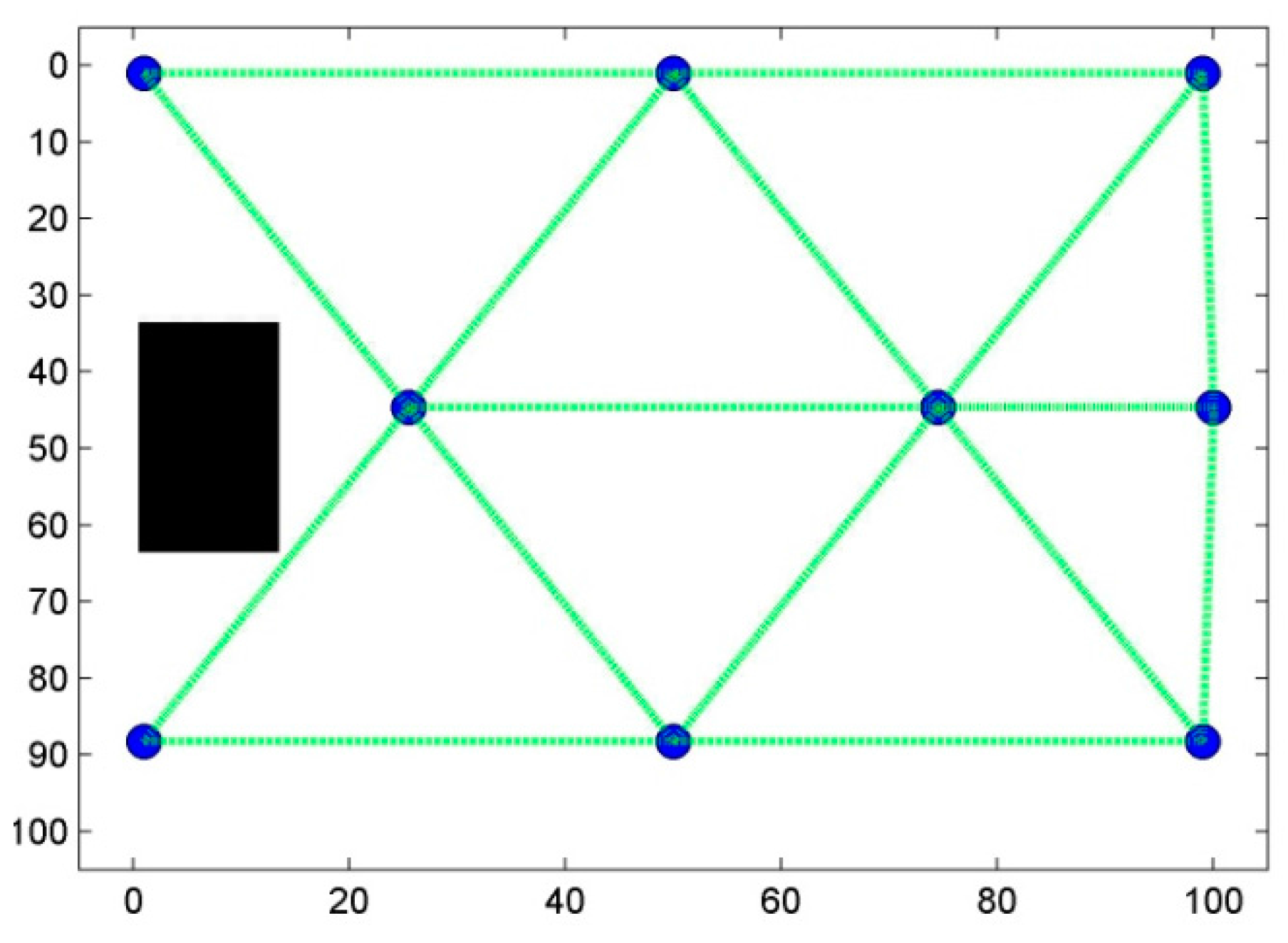
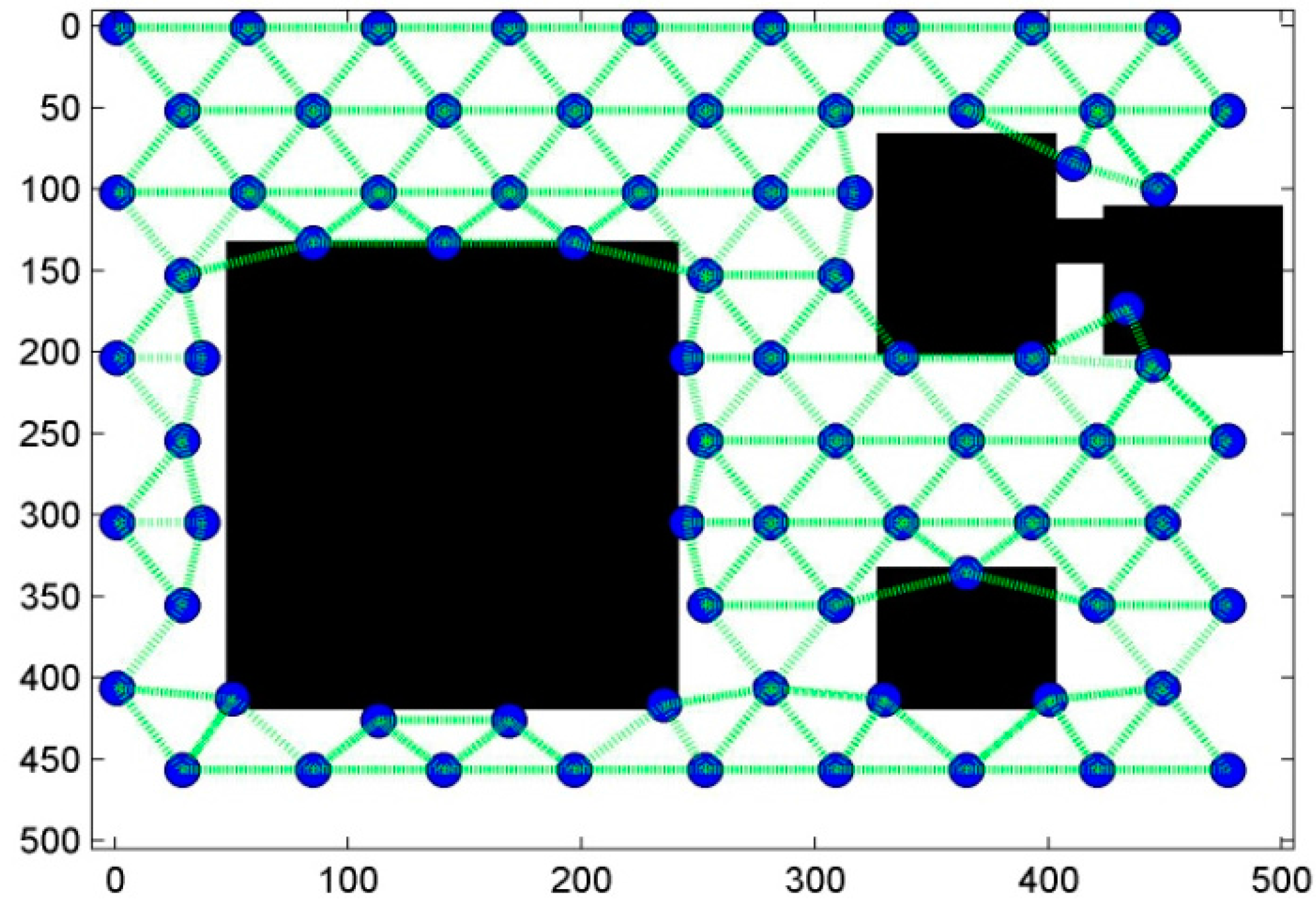
5.2.3. Step Three: Ensuring Connectivity
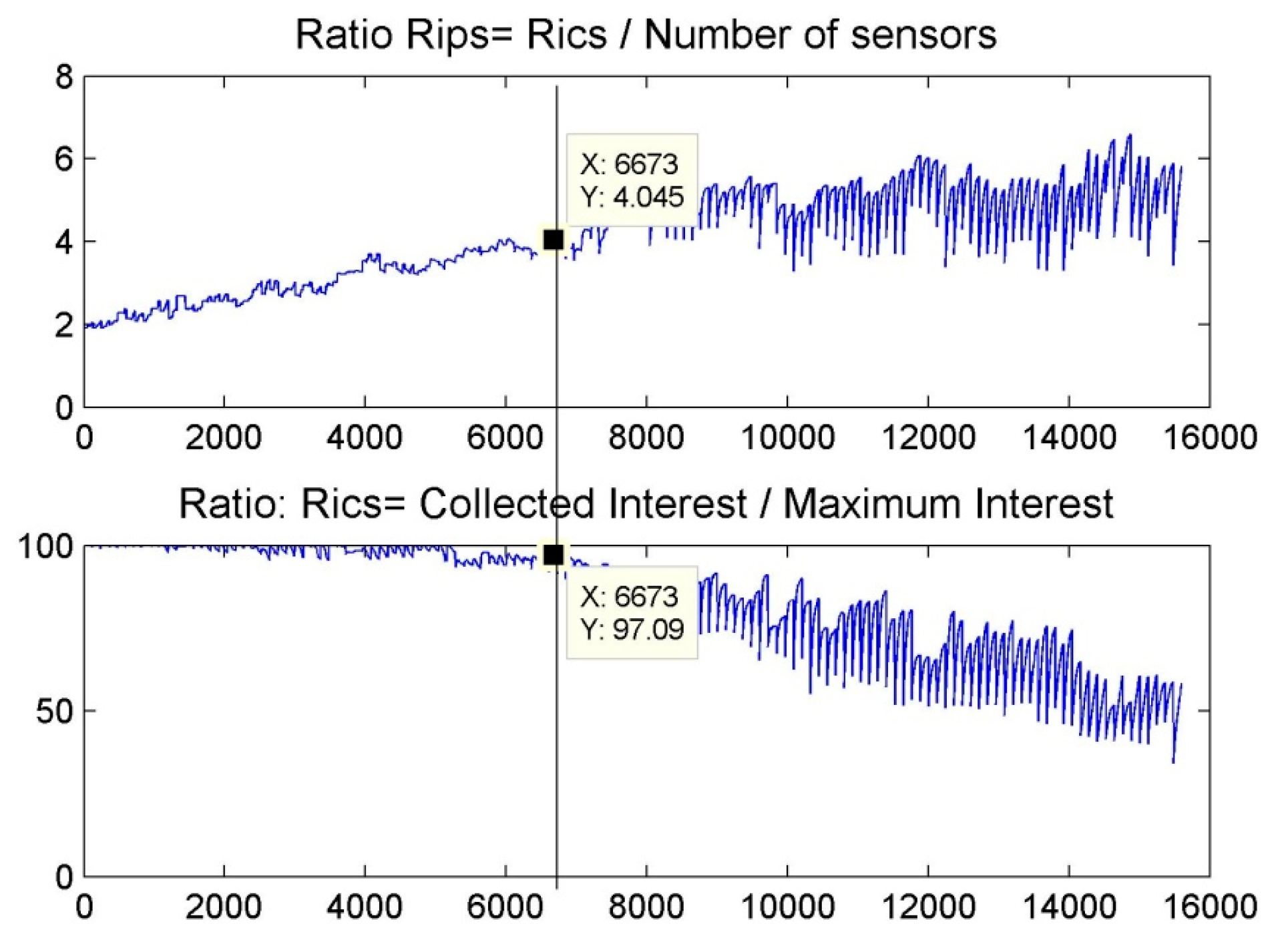
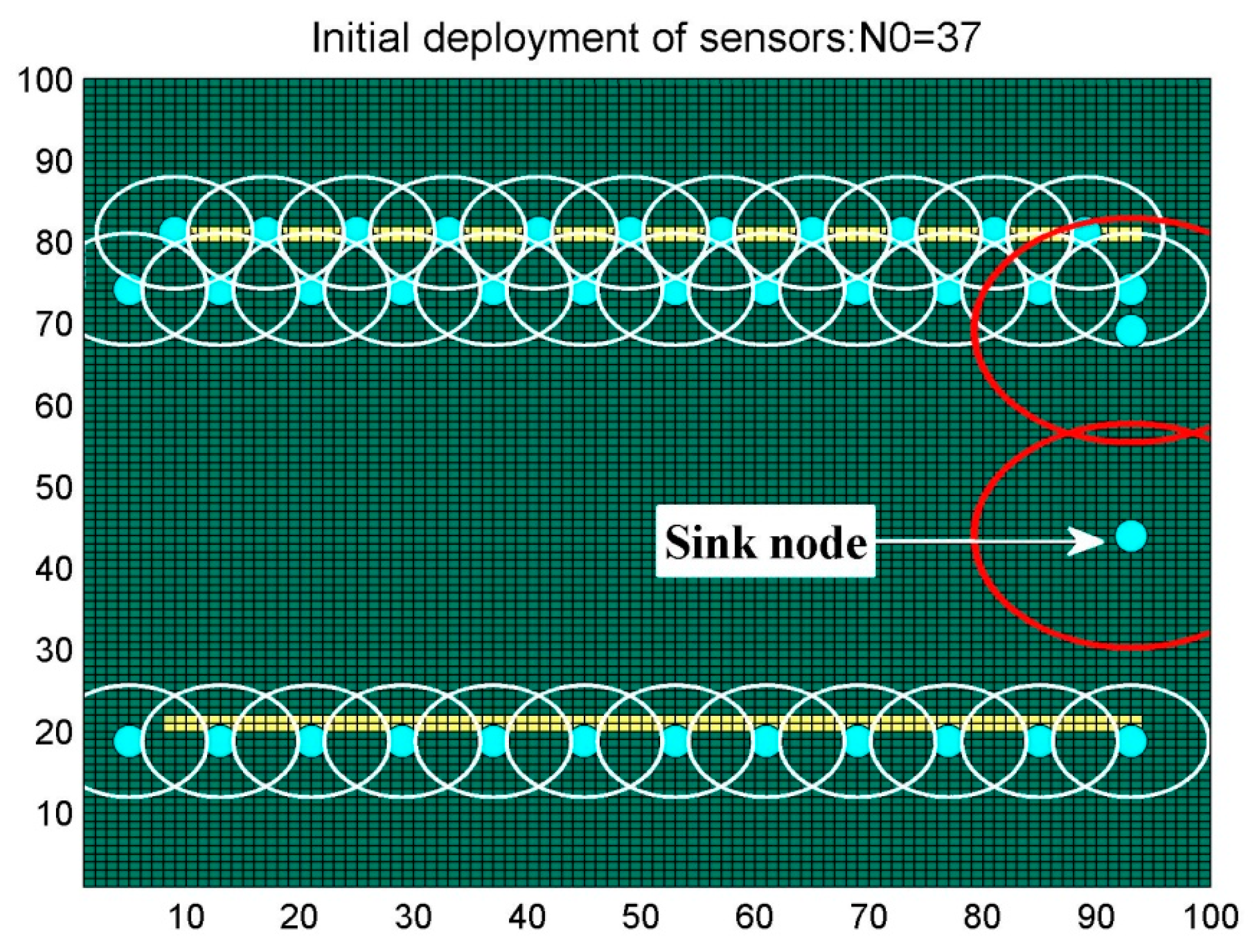
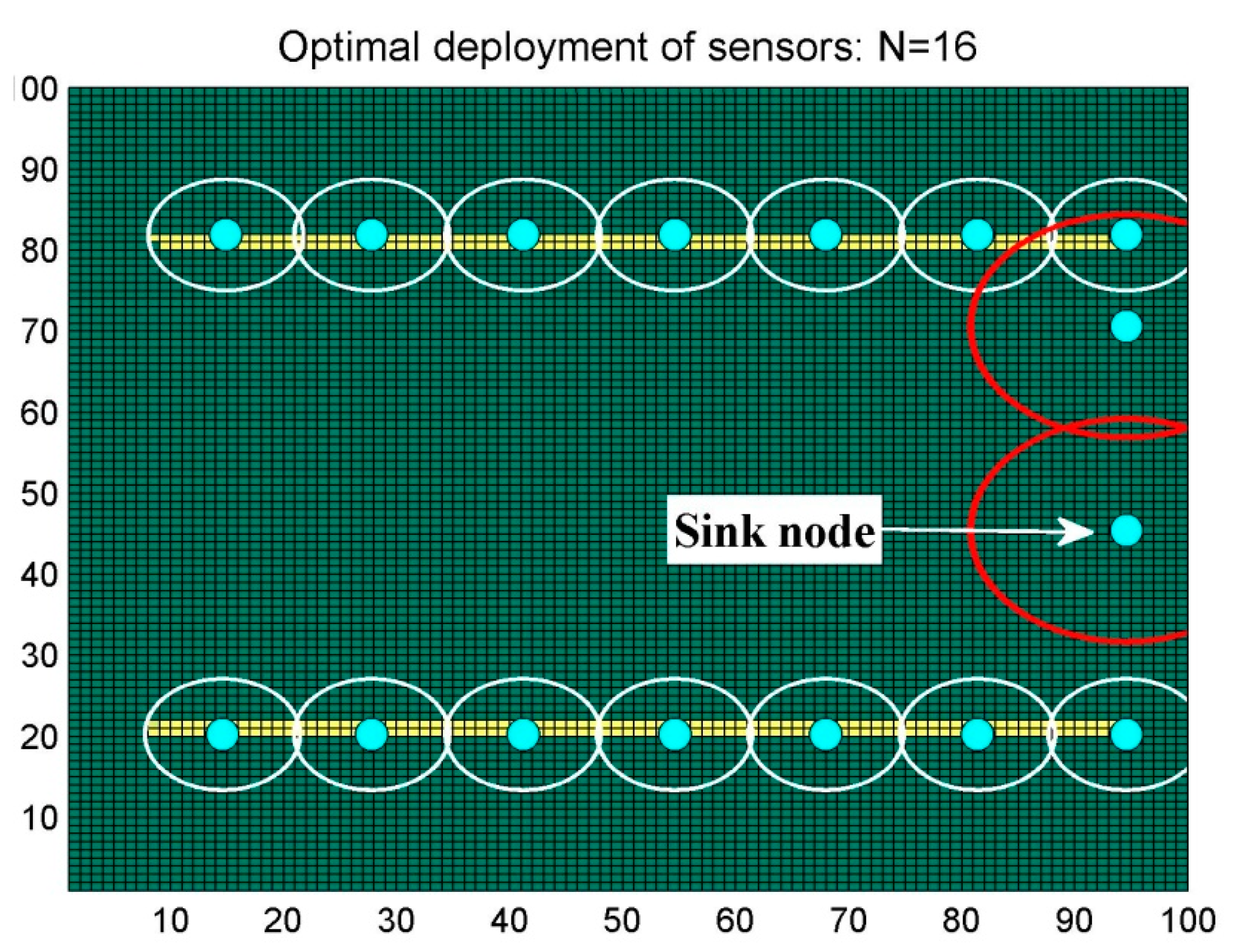
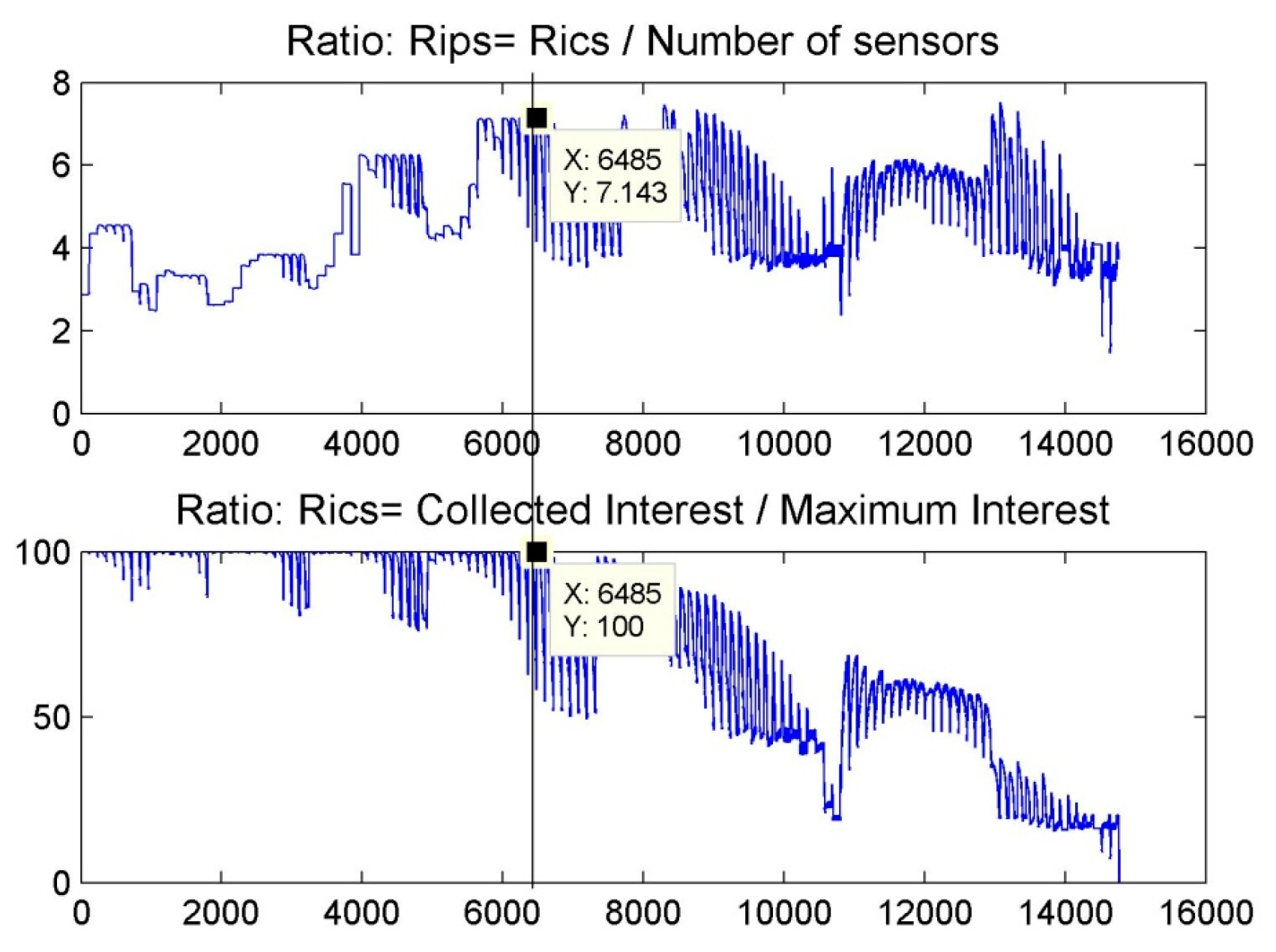
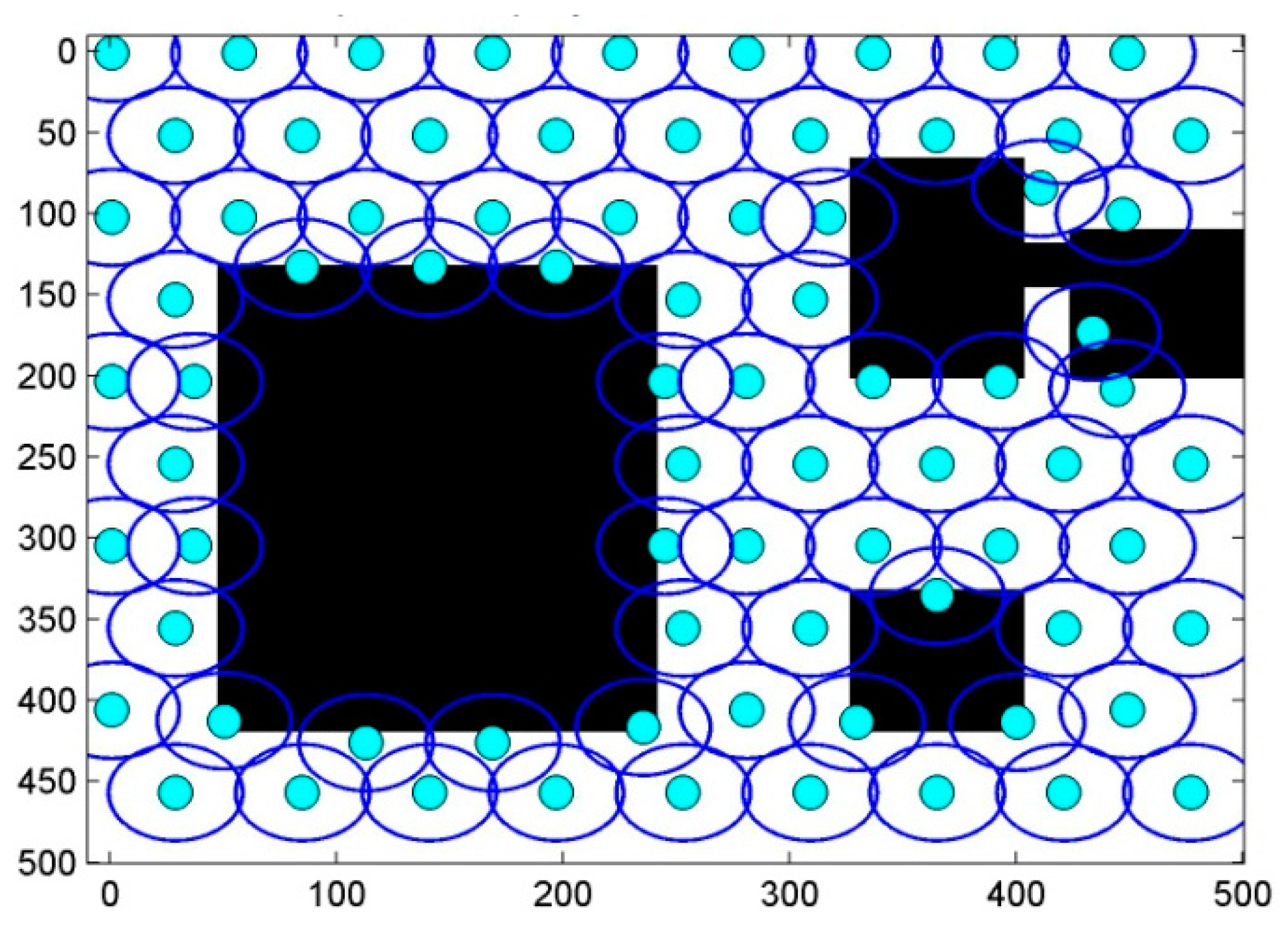
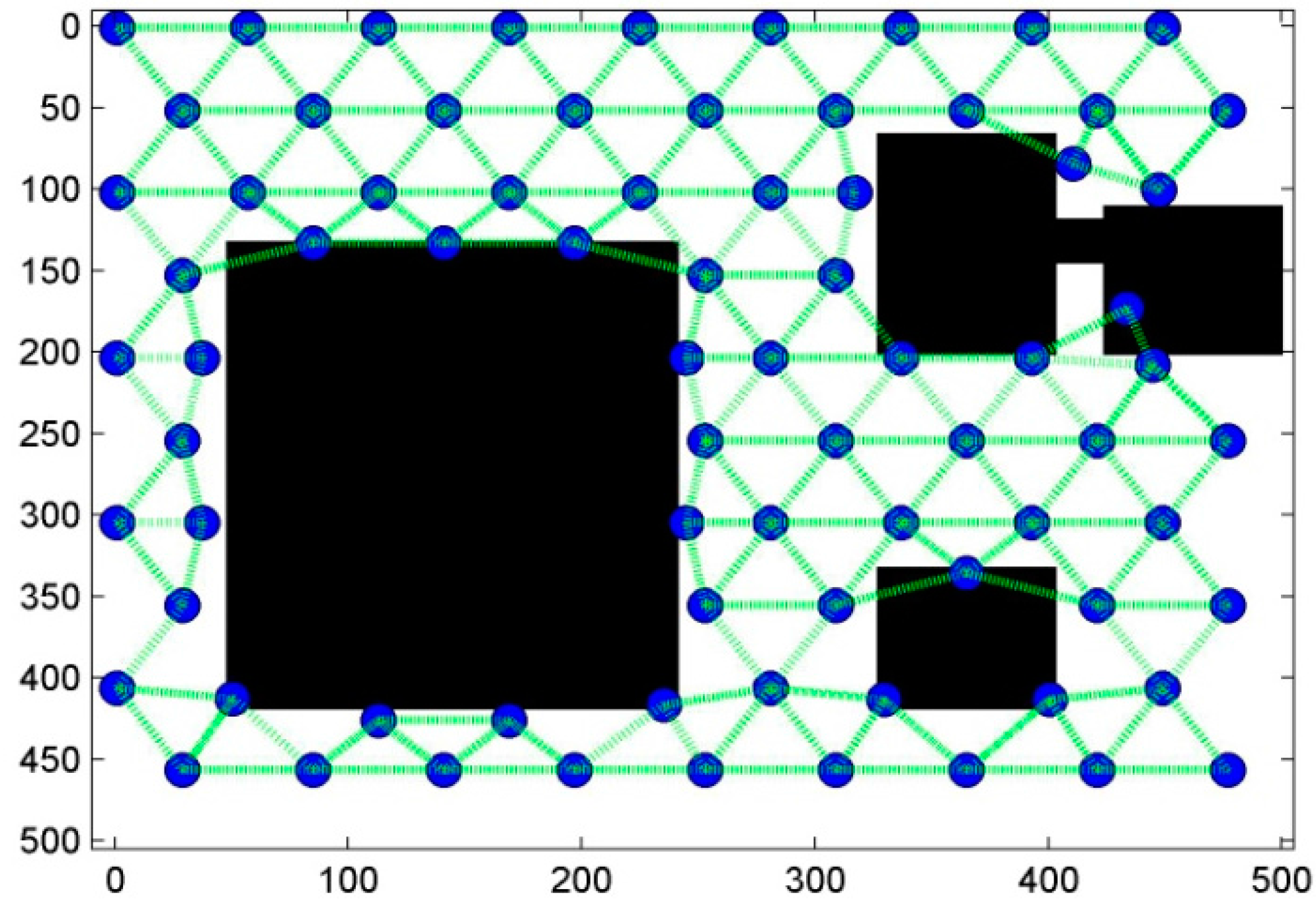
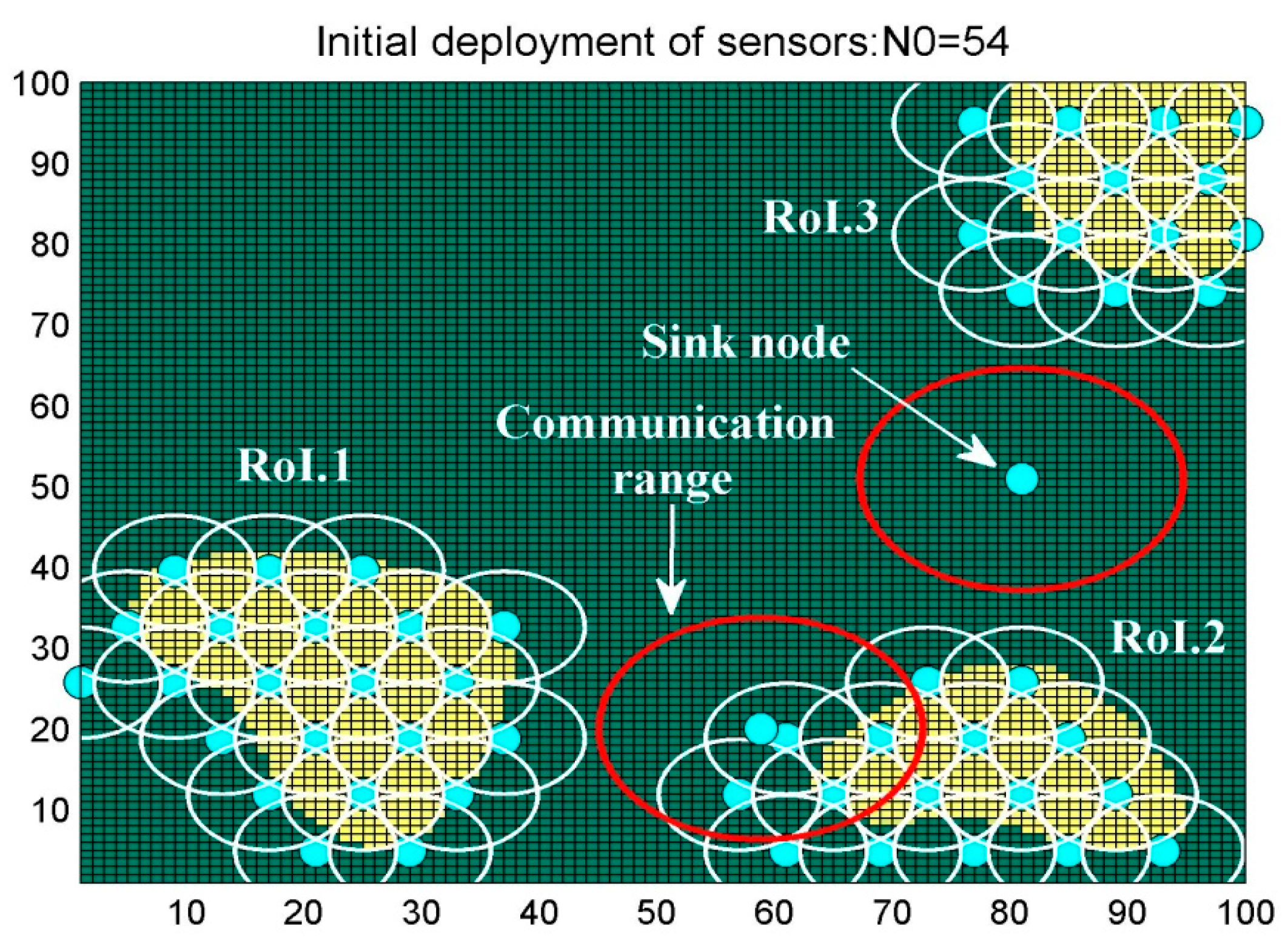
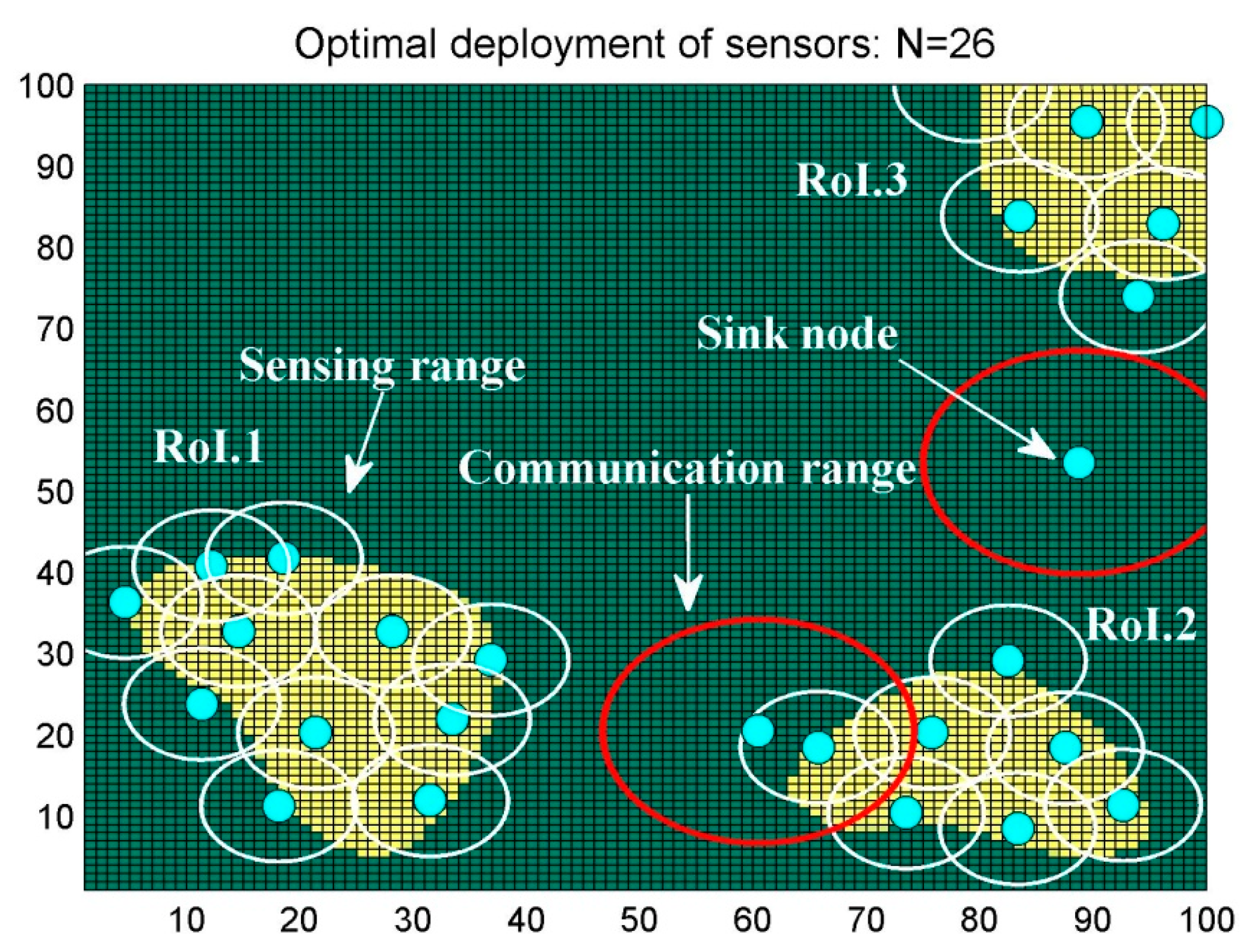
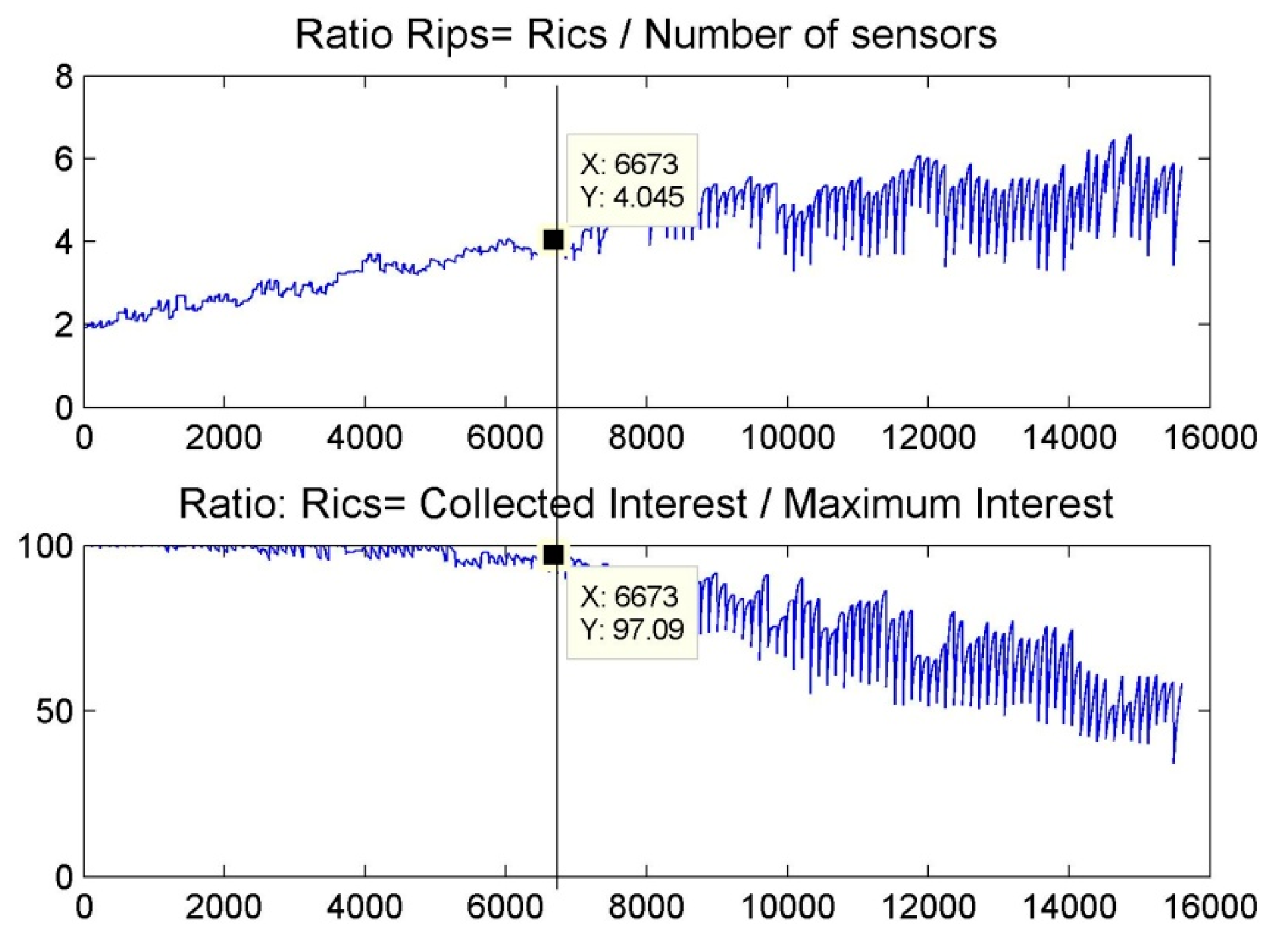
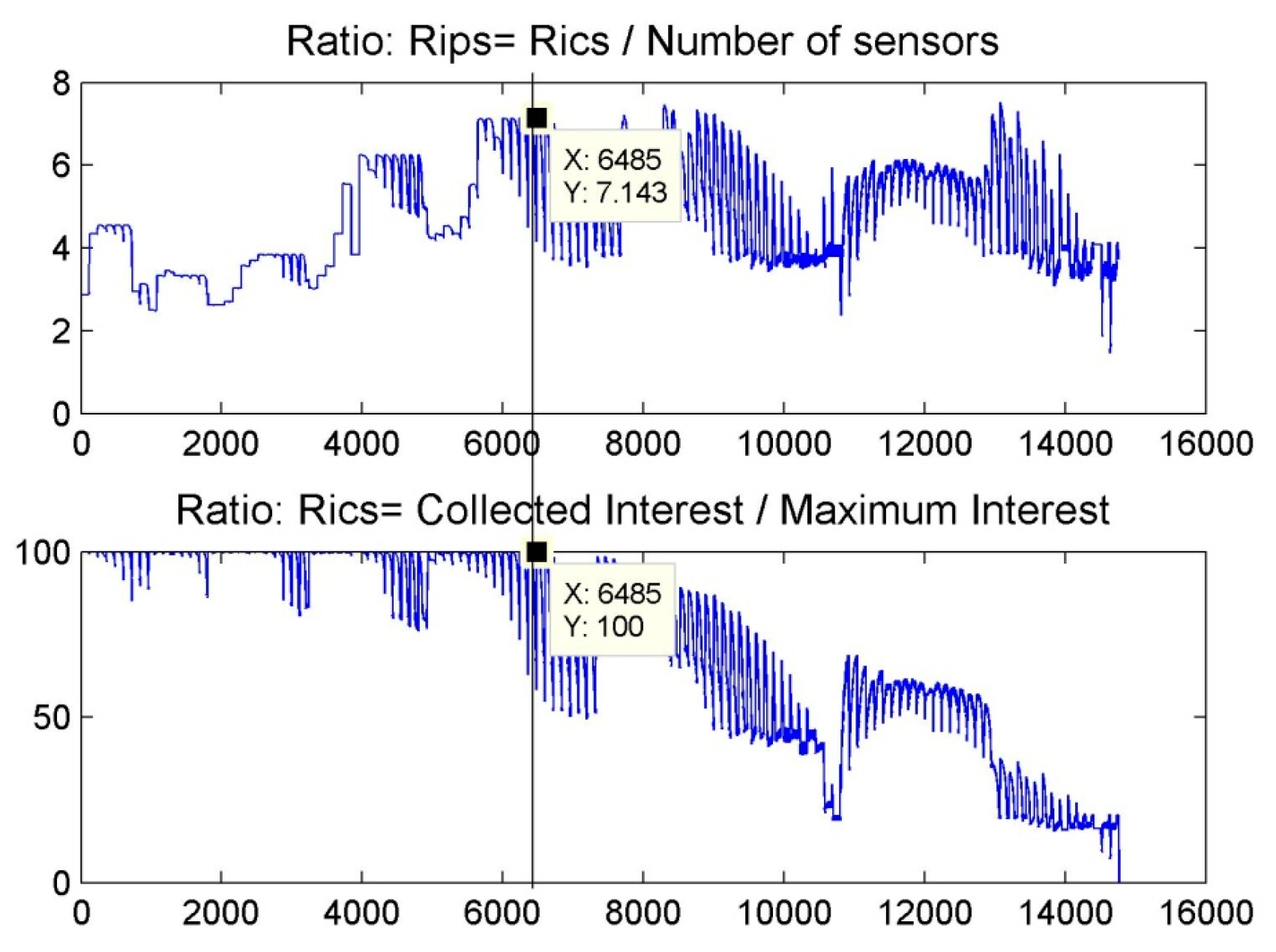
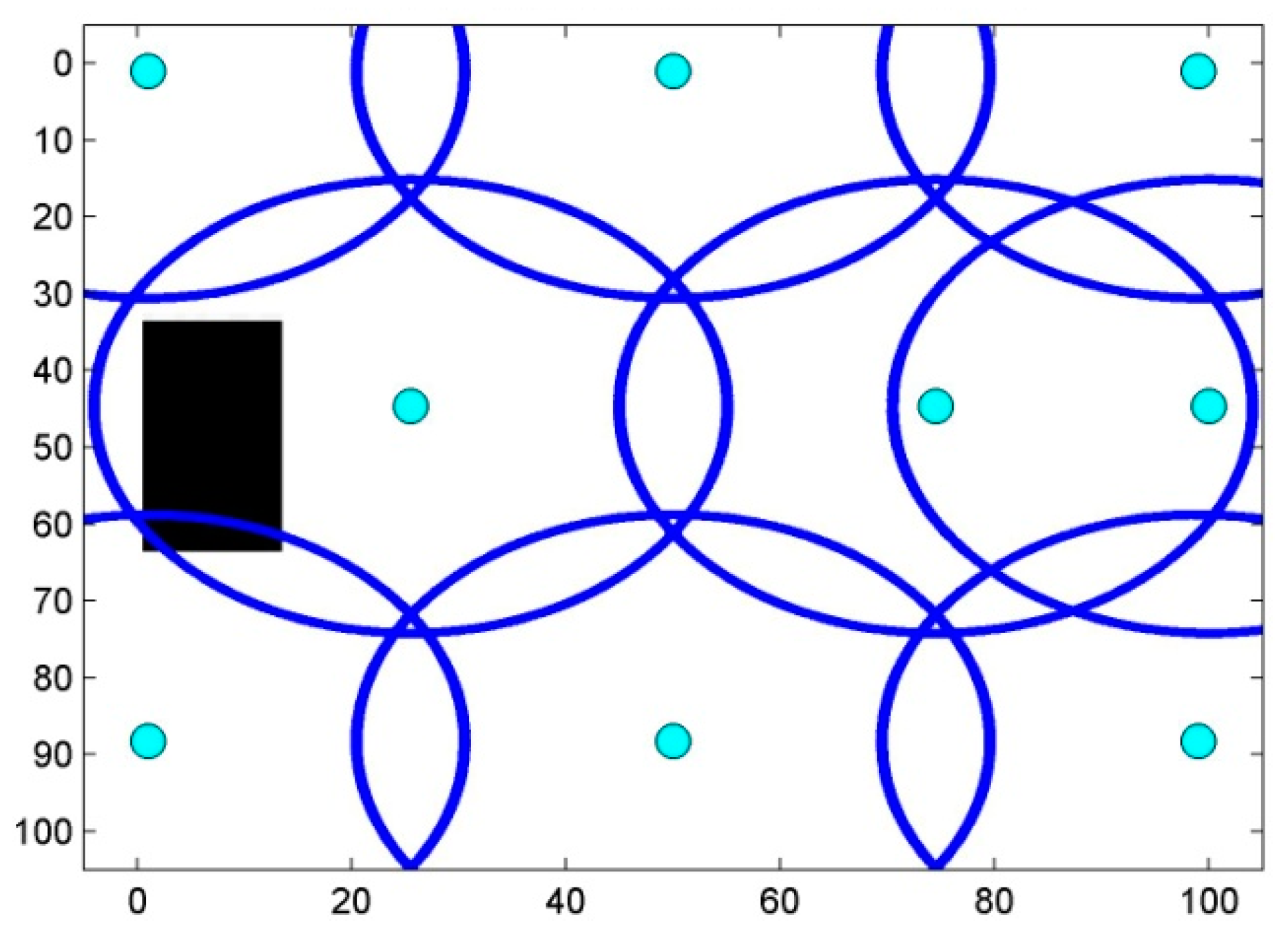
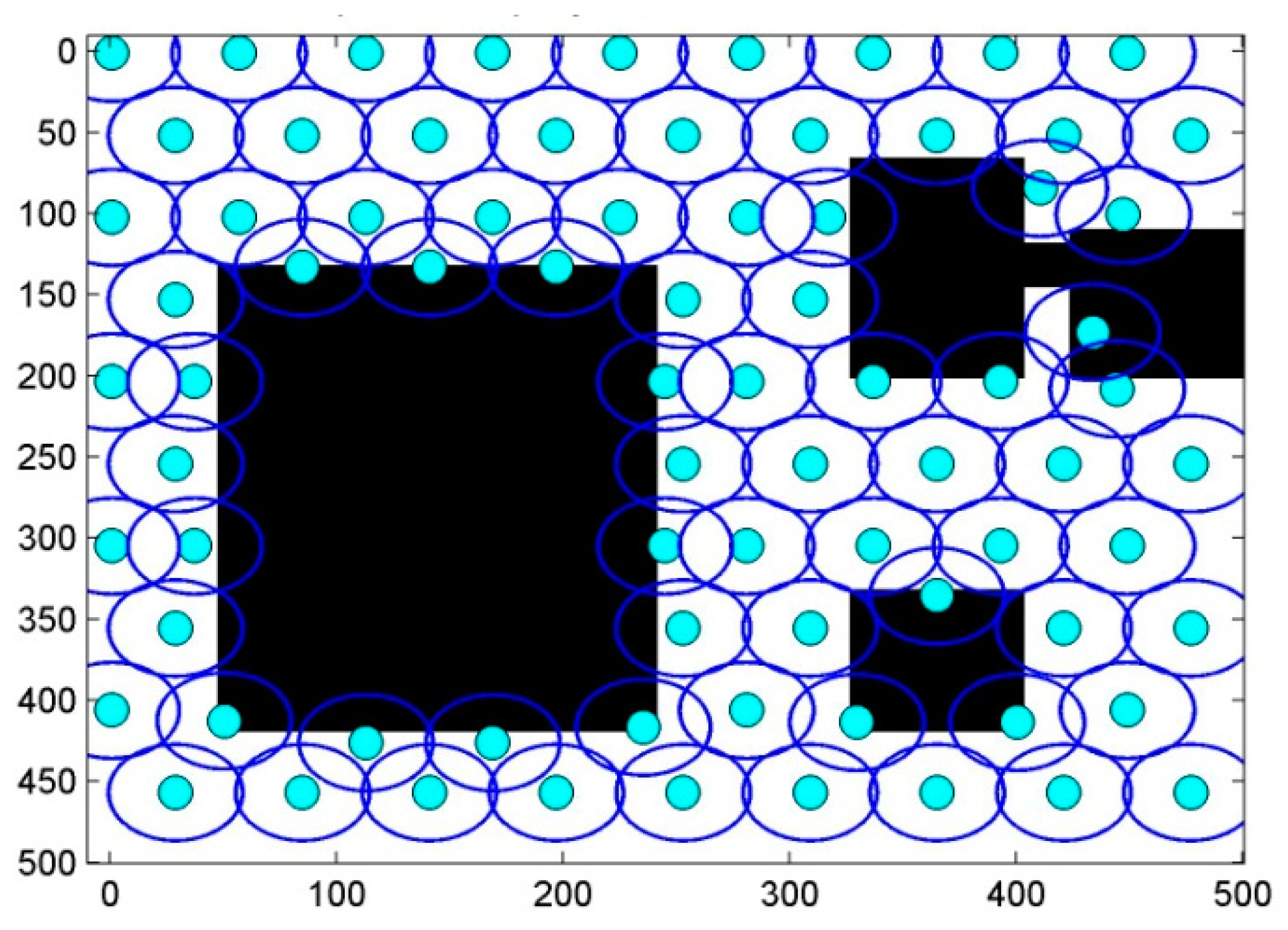
6. Results and Discussion
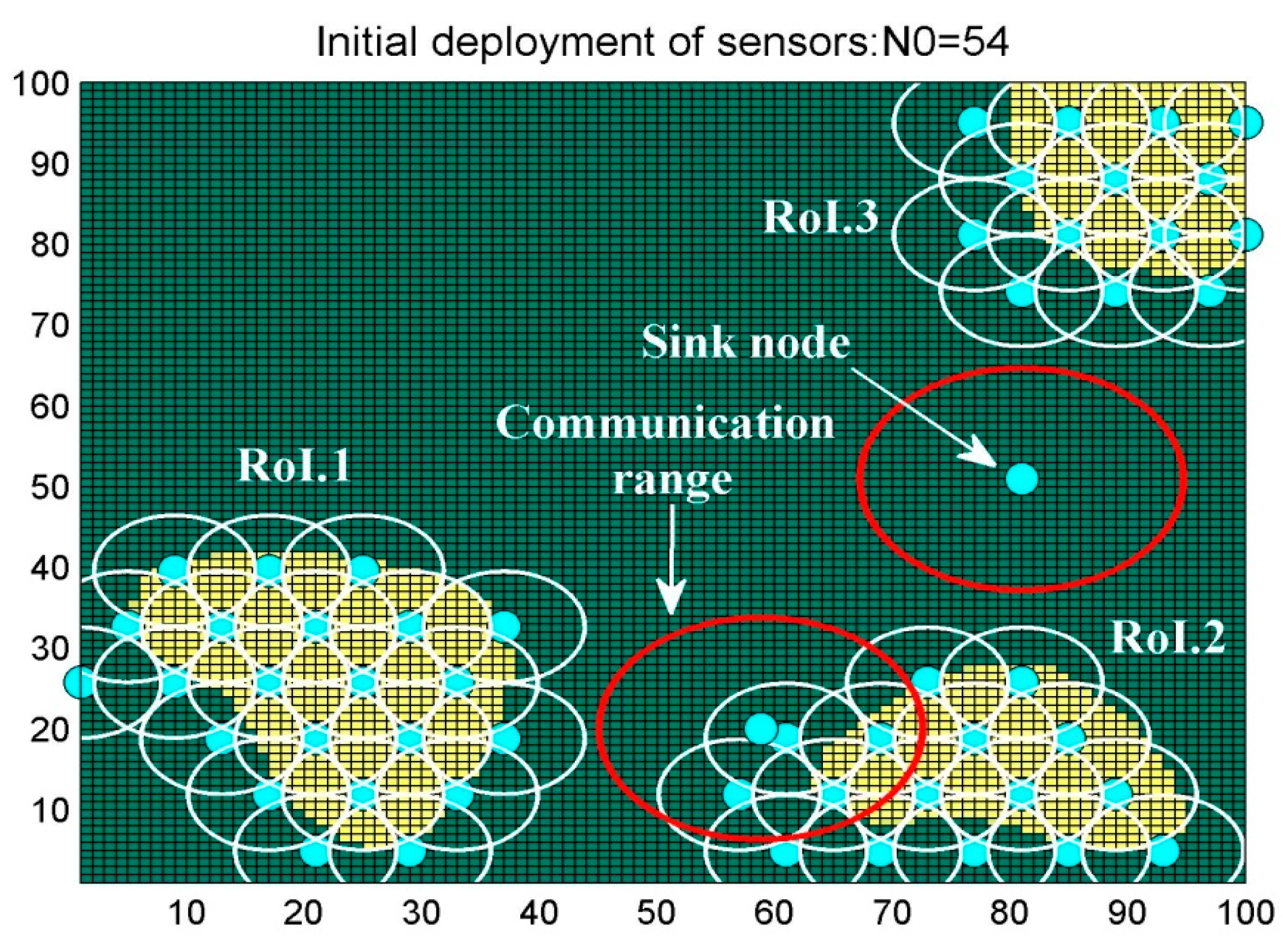
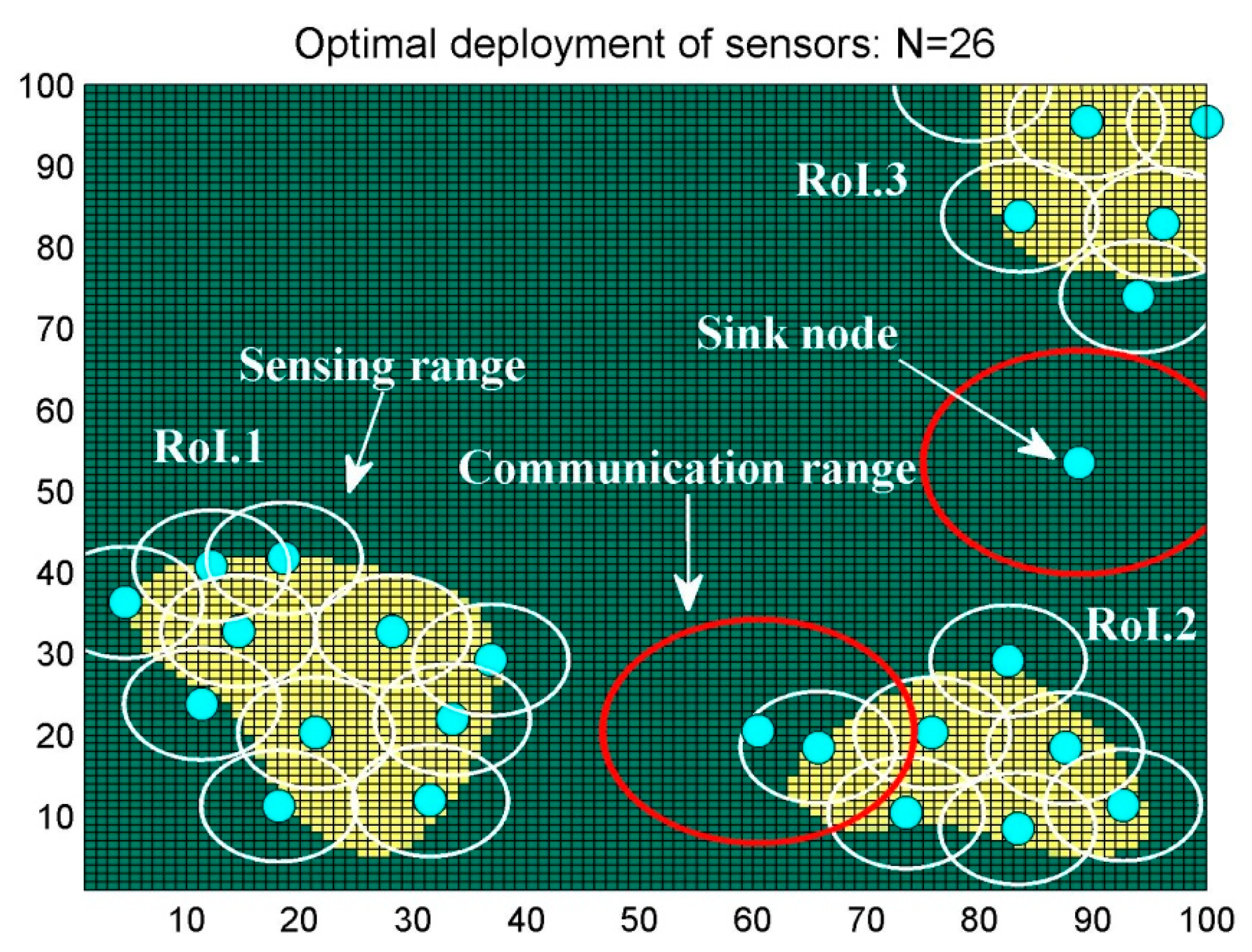
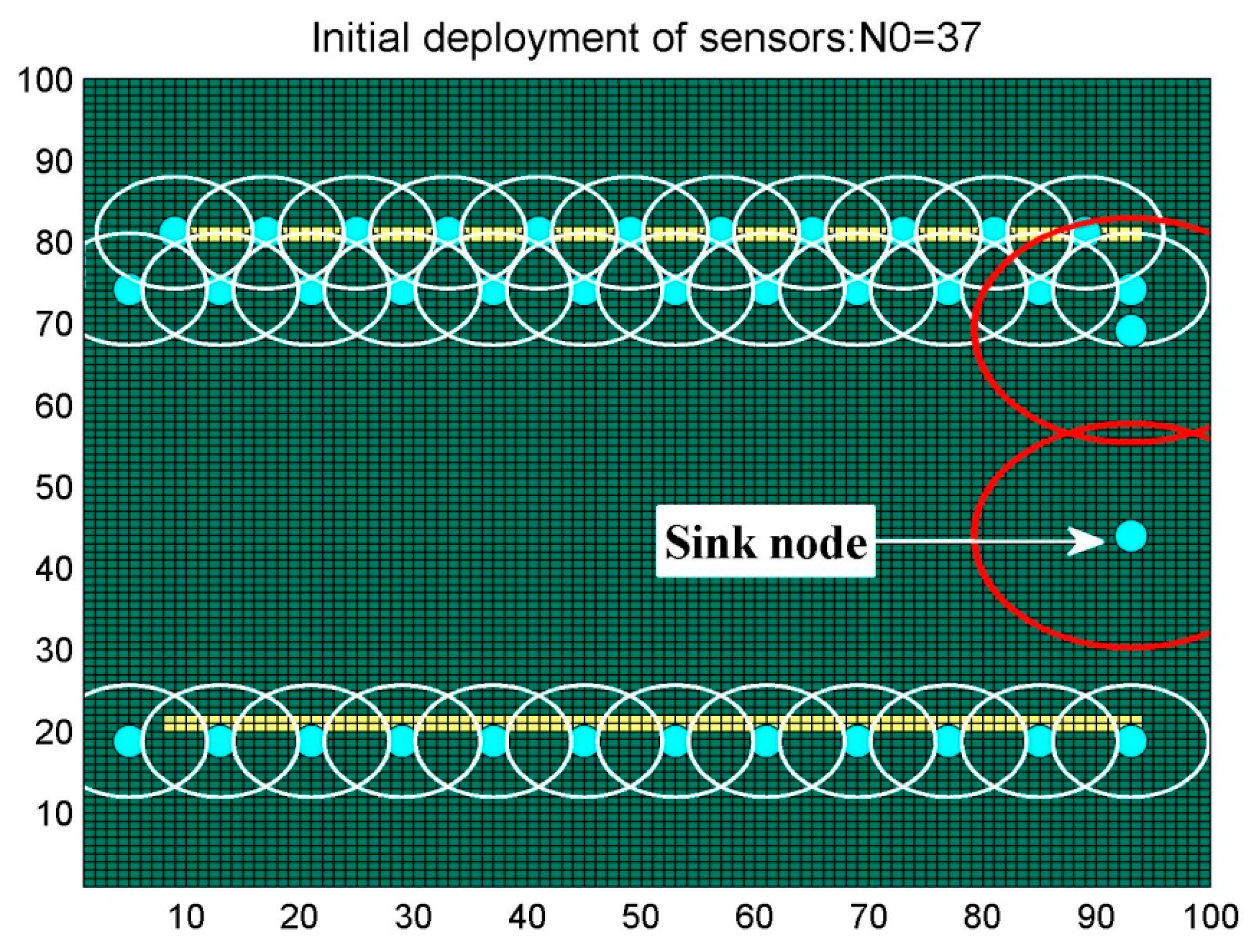
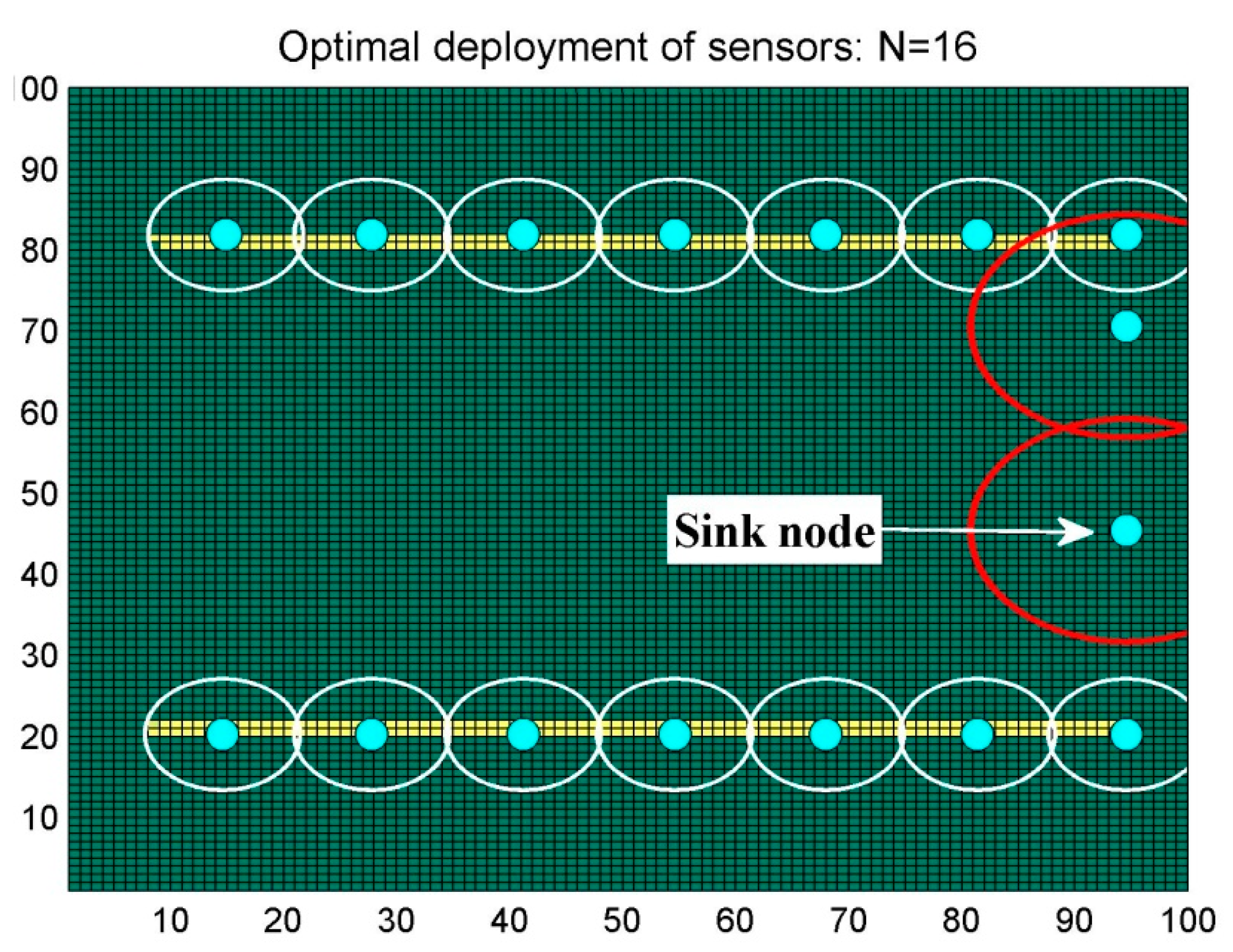
6.1. Scenario 1: Area Coverage with RoI.1/2/3
6.2. Scenario 2: Barrier Coverage
6.3. Comparisons
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Xu, G.; Shen, W.; Wang, X. Applications of Wireless Sensor Networks in Marine Environment Monitoring: A Survey. Sensors 2014, 14, 16932–16954. [Google Scholar] [CrossRef] [PubMed]
- Wu, C.-I.; Kung, H.-Y.; Chen, C.-H.; Kuo, L.-C. An intelligent slope disaster prediction and monitoring system based on WSN and ANP. Expert Syst. Appl. 2014, 41, 4554–4562. [Google Scholar] [CrossRef]
- Nellore, K.; Hancke, G.P. A Survey on Urban Traffic Management System Using Wireless Sensor Networks. Sensors 2016, 16, 157. [Google Scholar] [CrossRef] [PubMed]
- Ameen, M.A.; Liu, J.; Kwak, K. Security and privacy issues in wireless sensor networks for healthcare applications. J. Med. Syst. 2012, 36, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Sharma, U.; Reddy, S. Design of home/office automation using wireless sensor network. Int. J. Comput. Appl. 2012, 43. [Google Scholar] [CrossRef]
- Abdollahzadeh, S.; Navimipour, N.J. Deployment strategies in the wireless sensor network: A comprehensive review. Comput. Commun. 2016, 91–92, 1–16. [Google Scholar] [CrossRef]
- Jung, C.; Lee, S.J.; Bhuse, V. The Minimum Scheduling Time for Convergecast in Wireless Sensor Networks. Algorithms 2014, 7, 145–165. [Google Scholar] [CrossRef]
- Akbarzadeh, V.; Lévesque, J.-C.; Gagné, C.; Parizeau, M. Efficient sensor placement optimization using gradient descent and probabilistic coverage. Sensors 2014, 14, 15525–15552. [Google Scholar] [CrossRef] [PubMed]
- Aznoli, F.; Navimipour, N.J. Deployment Strategies in the Wireless Sensor Networks: Systematic Literature Review, Classification, and Current Trends. Wirel. Pers. Commun. 2016. [Google Scholar] [CrossRef]
- Rahman, A.U.; Alharby, A.; Hasbullah, H.; Almuzaini, K. Corona based deployment strategies in wireless sensor network: A survey. J. Netw. Comput. Appl. 2016, 64, 176–193. [Google Scholar] [CrossRef]
- Fan, T.; Teng, G.; Huo, L. A Pre-Determined Nodes Deployment Strategy of Two-Tiered Wireless Sensor Networks Based on Minimizing Cost. Int. J. Wirel. Inf. Netw. 2016, 21, 114. [Google Scholar] [CrossRef]
- Azami, M.; Ranjbar, M.; Shokouhirostami, A.; Amiri, A.J. Increasing the network life time by simulated annealing algorithm in WSN with point coverage. Int. J. Sens. Ubiq. Comput. 2013, 4, 31–45. [Google Scholar]
- Vales-Alonso, J.; Costas-Rodríguez, S.; Bueno-Delgado, M.V.; Egea-López, E.; Gil-Castiñeira, F.; Rodríguez- Hernández, P.S.; García-Haro, J.; González-Castaño, F.J. An Analytical Approach to the Optimal Deployment of Wireless Sensor Networks. Comput. Intell. Remote Sens. 2008, 133, 145–161. [Google Scholar]
- Tahiri, A.; Egea-López, E.; Vales-Alonso, J.; García-Haro, J.; Essaaidi, M. A novel approach for optimal wireless sensor network deployment. Symp. Progress Inf. Commun. Technol. 2009, 40–45. [Google Scholar]
- Habib, S.J.; Marimuthu, P.N. Restoring coverage area for WSN through simulated annealing. Int. J. Perv. Comput. Commun. 2011, 7, 205–219. [Google Scholar] [CrossRef]
- Krishnan, M.; Rajagopal, V.; Rathinasamy, S. Performance evaluation of sensor deployment using optimization techniques and scheduling approach for K-coverage in WSNs. Wirel. Netw. 2016. [Google Scholar] [CrossRef]
- Kumar Sahoo, P.; Chiang, M.-J.; Wu, S.-L. An Efficient Distributed Coverage Hole Detection Protocol for Wireless Sensor Networks. Sensors 2016, 16, 386. [Google Scholar] [CrossRef] [PubMed]
- Hu, C.; Li, M.; Zeng, D.; Guo, S. A survey on sensor placement for contamination detection in water distribution systems. Wirel. Netw. 2016. [Google Scholar] [CrossRef]
- Deif, D.S.; Gadallah, Y. Classification of wireless sensor networks deployment techniques. IEEE Commun. Surv. Tutor. 2013, 16, 834–855. [Google Scholar] [CrossRef]
- Wang, G.; Guo, L.; Duan, H.; Liu, L.; Wang, H. Dynamic Deployment of Wireless Sensor Networks by Biogeography Based Optimization Algorithm. J. Sens. Actuator Netw. 2012, 1, 86–96. [Google Scholar] [CrossRef]
- Bar-Noy, A.; Brown, T.; Shamoun, S. Sensor allocation in diverse environments. Wirel. Netw. 2012, 18, 697–711. [Google Scholar] [CrossRef]
- Hefeeda, M.; Ahmadi, H. Energy Efficient Protocol for Deterministic and Probabilistic Coverage in Sensor Networks. IEEE Trans. Parallel Distrib. Syst. 2009, 99, 579–593. [Google Scholar] [CrossRef]
- Zhou, G.D.; Yi, T.H.; Li, H.N. Wireless sensor placement for bridge health monitoring using a generalized genetic algorithm. Int. J. Struct. Stab. Dyn. 2014, 14. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Ermis, M.; Sifyan, M. Positioning and utilizing sensors on a 3-D terrain part ii; solving with a hybrid evolutionary algorithm. IEEE Trans. Syst. Man Cybern. 2011, 41, 470–480. [Google Scholar] [CrossRef]
- Liao, W.H.; Kao, Y.C.; Li, Y.S. Sensor deployment approach using glowworm swarm optimization algorithm in wireless sensor networks. Expert Syst. Appl. 2011, 38, 12180–12188. [Google Scholar] [CrossRef]
- Li, J.; Zhang, B.; Cui, L.; Chai, S. An Extended Virtual Force-Based Approach to Distributed Self-Deployment in Mobile Sensor Networks. Int. J. Distrib. Sens. Netw. 2012, 8, 417307. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Ma, J.-J. An Improved Co-evolutionary Particle Swarm Optimization for Wireless Sensor Networks with Dynamic Deployment. Sensors 2007, 7, 354–370. [Google Scholar] [CrossRef]
- Rahman, A.U.; Hasbullah, H.; Sama, N.U. Efficient Energy Utilization through Optimum Number of Sensor Node Distribution in Engineered Corona-Based (ONSD-EC) Wireless Sensor Network. Wirel. Pers. Commun. 2013, 73, 1227. [Google Scholar] [CrossRef]
- Mohanty, P.; Mohapatra, P. Maximum Coverage in WSN using Optimal Deployment Technique. IJCA Special Issue on 2nd National Conference-Computing. Commun. Sens. Netw. 2011, 4, 39–45. [Google Scholar]
- Kim, Y.; Yeo, M.; Kim, D.; Chung, K. A Node Deployment Strategy Considering Environmental Factors and the Number of Nodes in Surveillance and Reconnaissance Sensor Networks. Int. J. Distrib. Sens. Netw. 2012, 8. [Google Scholar] [CrossRef]
- Yick, J.; Mukherjee, B.; Ghosal, D. Wireless sensor network survey. Comput. Netw. 2008, 52, 2292–2330. [Google Scholar] [CrossRef]
- Dâmaso, A.; Freitas, D.; Rosa, N.; Silva, B.; Maciel, P. Evaluating the Power Consumption of Wireless Sensor Network Applications using models. Sensors 2013, 13, 3473–3500. [Google Scholar] [CrossRef] [PubMed]
- Shan, A.; Xu, X.; Cheng, Z. Target Coverage in Wireless Sensor Networks with Probabilistic sensors. Sensors 2016, 16, 1372. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensors | ------- | |||||
|---|---|---|---|---|---|---|
| ------- | ||||||
| ------- | ||||||
| ------- | --------- | ------- | ------- | |||
| Method | Method’s Properties | Map1 UL-A | Map2 UL-B |
|---|---|---|---|
| The proposed algorithm | Number of sensors | 9 | 78 |
| Average | 100% | 89.48% | |
| CPU Time | 6 m 42 s | 5.2 h | |
| GD Algorithm | Number of sensors | 12 | 60 |
| Average | 91.38% | 83.17% | |
| CPU Time | 72 s | 22.2 m | |
| CMA-ES Algorithm | Number of sensors | 12 | 60 |
| Average | 90.44% | 87.63% | |
| CPU Time | 15.9 m | 11.1 h |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
El Khamlichi, Y.; Tahiri, A.; Abtoy, A.; Medina-Bulo, I.; Palomo-Lozano, F. A Hybrid Algorithm for Optimal Wireless Sensor Network Deployment with the Minimum Number of Sensor Nodes. Algorithms 2017, 10, 80. https://doi.org/10.3390/a10030080
El Khamlichi Y, Tahiri A, Abtoy A, Medina-Bulo I, Palomo-Lozano F. A Hybrid Algorithm for Optimal Wireless Sensor Network Deployment with the Minimum Number of Sensor Nodes. Algorithms. 2017; 10(3):80. https://doi.org/10.3390/a10030080
Chicago/Turabian StyleEl Khamlichi, Yasser, Abderrahim Tahiri, Anouar Abtoy, Inmaculada Medina-Bulo, and Francisco Palomo-Lozano. 2017. "A Hybrid Algorithm for Optimal Wireless Sensor Network Deployment with the Minimum Number of Sensor Nodes" Algorithms 10, no. 3: 80. https://doi.org/10.3390/a10030080
APA StyleEl Khamlichi, Y., Tahiri, A., Abtoy, A., Medina-Bulo, I., & Palomo-Lozano, F. (2017). A Hybrid Algorithm for Optimal Wireless Sensor Network Deployment with the Minimum Number of Sensor Nodes. Algorithms, 10(3), 80. https://doi.org/10.3390/a10030080