1. Introduction
Contradiction is a kind of semantic relation between sentences. Contradiction occurs when sentences are unlikely to be correct at the same time [
1]. For example, the contradiction happens between the sentence pair “Some people and vehicles are on a crowded street” and “Some people and vehicles are on an empty street”. Contradiction detection aims to recognize the contrasting meanings between two sentences [
2]. Contradiction detection is helpful in many fields of natural language processing, such as information integration [
3], inconsistency discovery [
4,
5] and sarcasm detection [
6].
Contradiction detection can be regarded as a classification problem. Traditional approaches build classifiers and design effective features to improve classification accuracy. However, feature designing relies on professional knowledge and hardly captures latent semantic features. For the contradiction detection task, an effective feature learning approach is to learn the semantic relation representation from input texts.
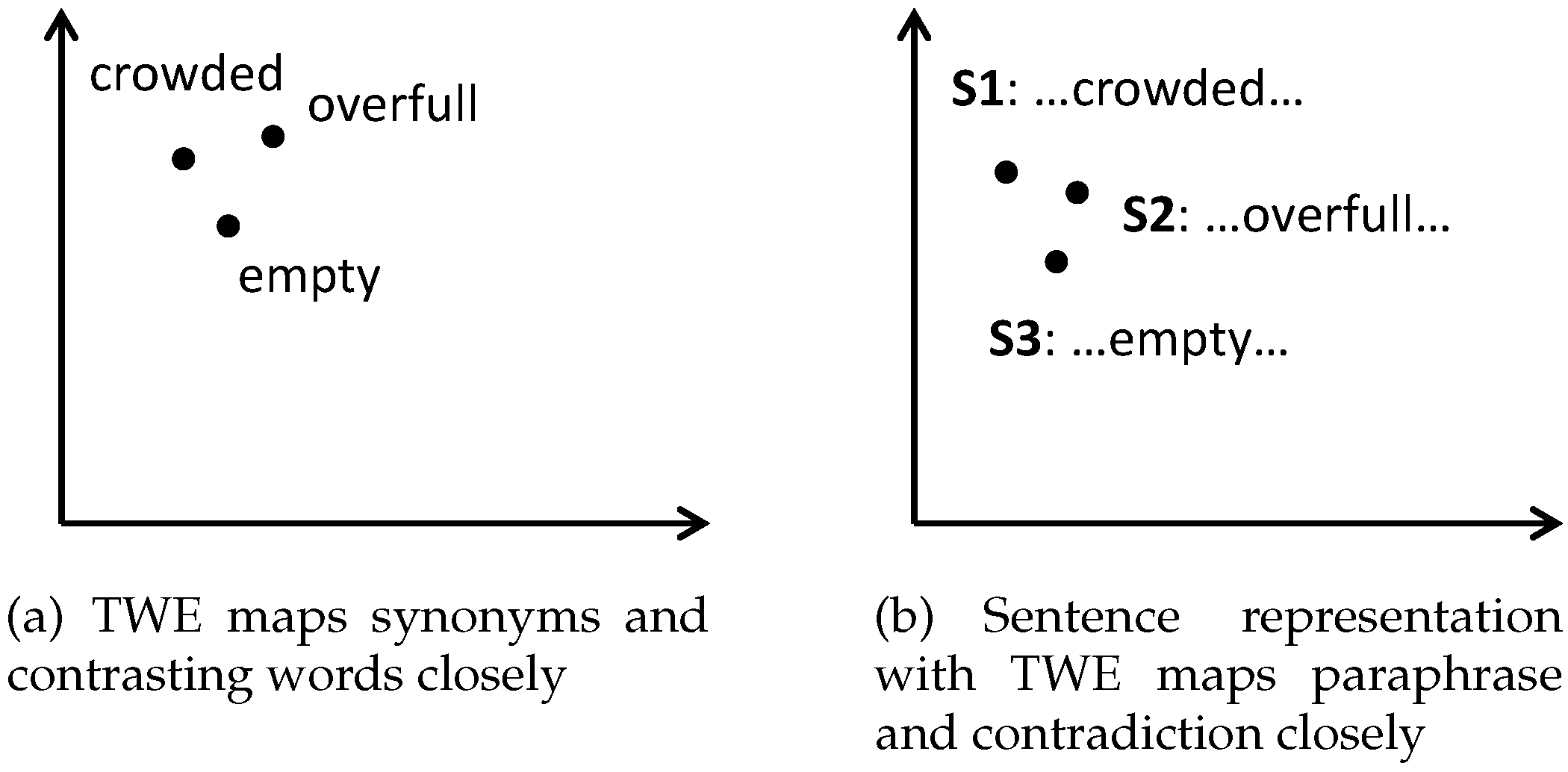
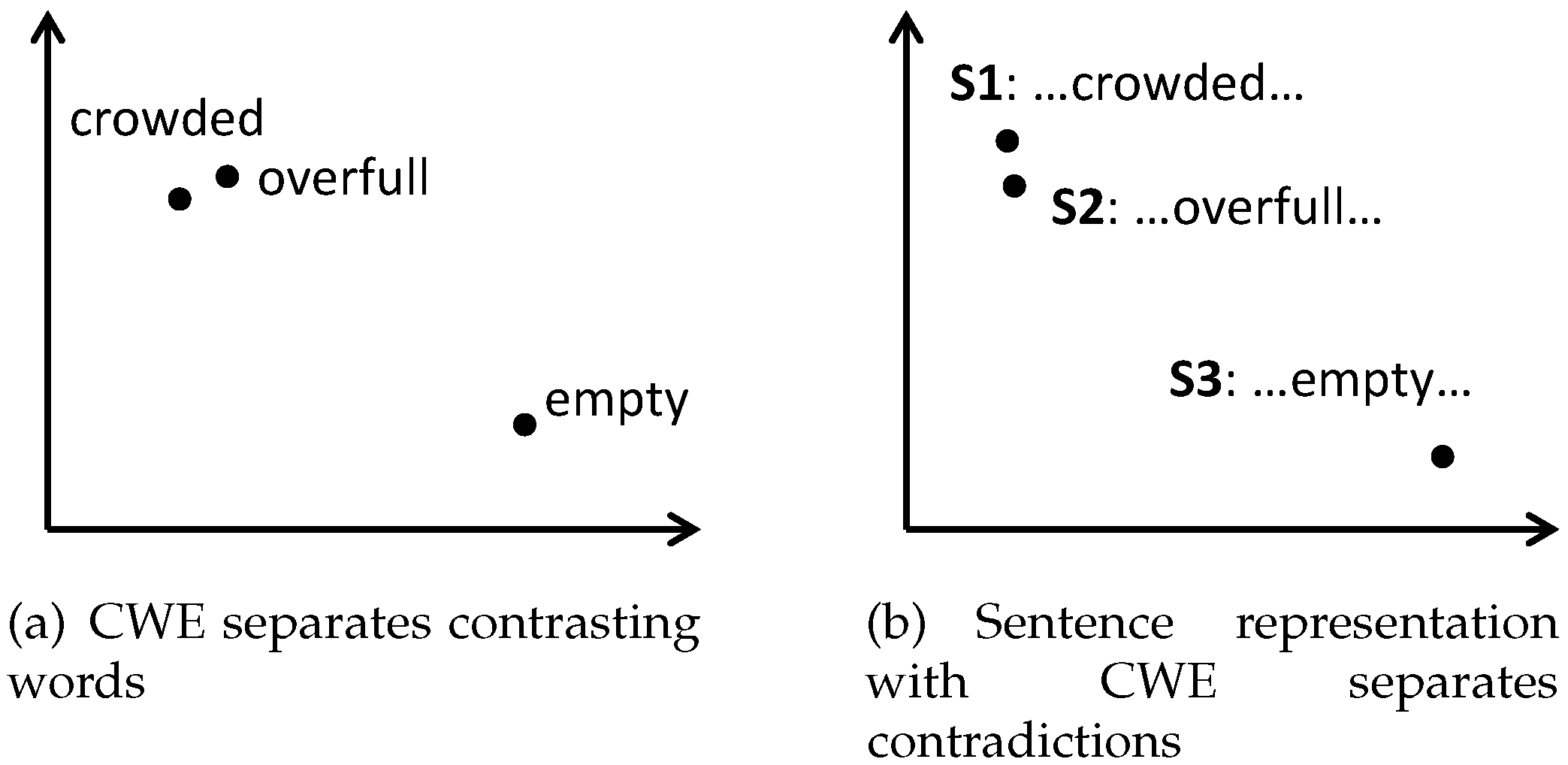
The representation learning of semantic relation is based on word embedding. However, word embedding is challenging to employ in contradiction detection because of the distributional semantics hypothesis. Traditional context-based word embedding learning algorithms typically map words with similar contexts into closed vectors. That means the words with contrasting meanings will be mapped into close vectors as long as they share a similar context [
7,
8], as shown in
Figure 1a. The close vectors of contrasting words will lead to similar representation of contradictory sentences, as shown in
Figure 1b. For a contradiction detection task, the ideal situation is that the vectors of contrasting words remain separate from each other, as shown in
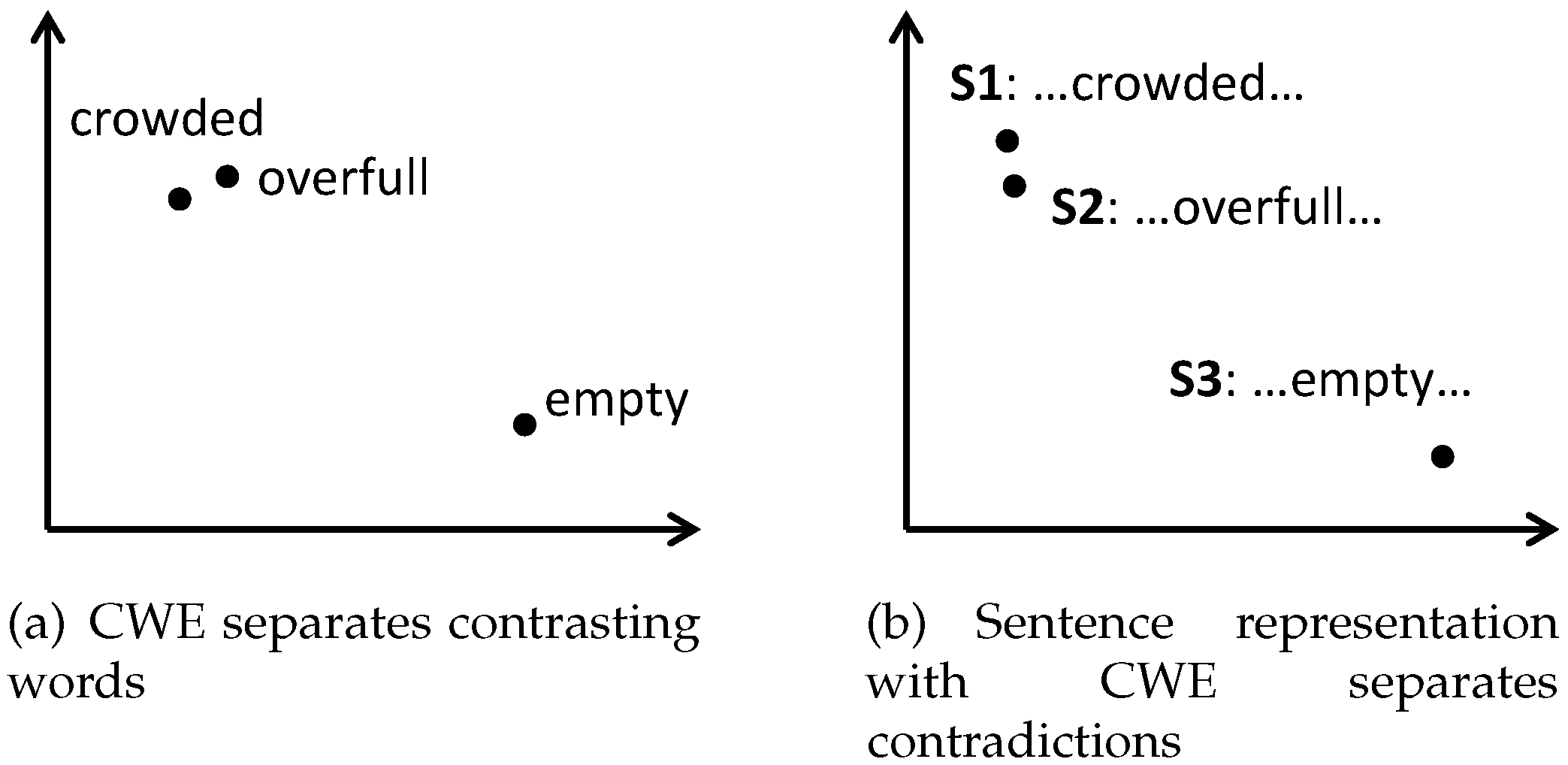
Figure 2a. The appropriate mapping of contrasting words will lead to a high discrimination of contradictory sentences, as shown in
Figure 2b.
To address the issue, there are some recent methods [
7,
8,
9,
10] currently being investigated. Mrksic et al. [
8] apply lexical knowledge such as WordNet [
11] and PPDB [
12] (Paraphrase Database) (
http://www.cis.upenn.edu/~ccb/ppdb/) to revise word embedding by using 12,802 antonym pairs and 31,828 synonymy pairs. The methods of Chen et al. [
7] and Liu et al. [
10] use WordNet and Thesaurus to get more antonym pairs and synonym pairs as the semantic constraints. These methods can get exact antonym pairs in these lexical resources; however, the number of antonym pairs is limited. In addition, antonym pairs are just part of contrasting word pairs, and many other contrasting word pairs such as “shelve” and “pass” can not be obtained from the lexical resources. Schwartz et al. [
9] use patterns such as “from X to Y” and “either X or Y” to extract antonyms from Wikipedia. However, the pattern based methods would meet the data sparsity problem. In the contradiction detection task, the pairs of sentences with contradiction relations always own contrasting words which are hardly discriminated by using antonym-based word embedding learning algorithms.
We present a method to construct a large corpus of contrasting pairs, including word pairs and phrase pairs. The large-scale corpus of contrasting pairs are generated from PPDB [
12] and WordNet [
11] automatically. Through our method, we obtain 1.9 million contrasting pairs and 1.6 million paraphrase pairs, that are one hundred times the size of the corpus Mrksic et al. [
8] used. Although the automatically-generated corpus contains noises, we argue that it is effective enough to be leveraged as task-specific supervisions to learn CWE. Based on the corpus, we develop a neural network to learn contradiction-specific word embedding (CWE). In the aim of separating contrasting words in an embedding space, CWE is learnt based on the pairs with paraphrase relation or contradiction relation. The model for learning CWE is optimized by minimizing the semantic gap between paraphrase pairs and maximizes the gap between contradiction pairs.
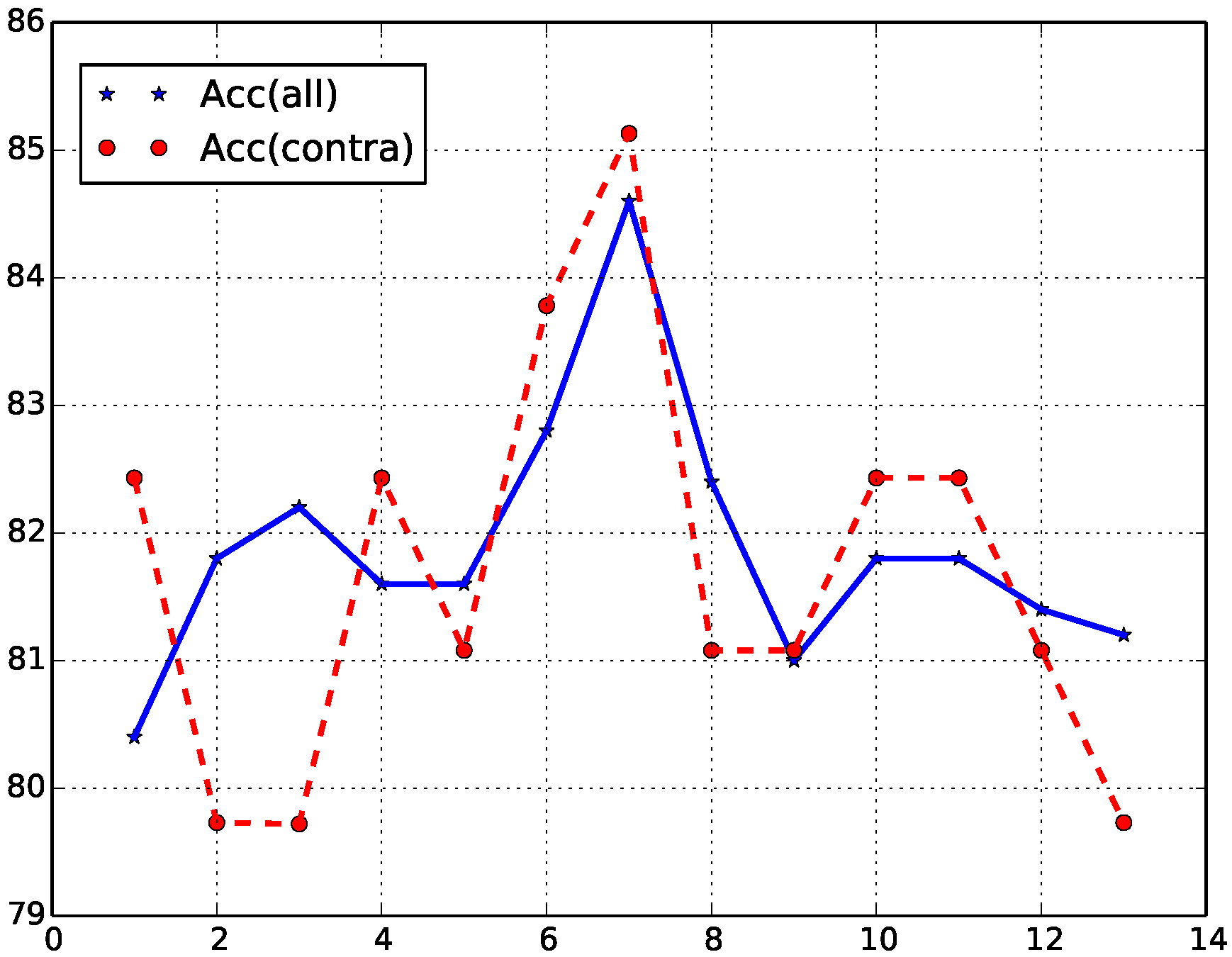
To detect contradiction relation from sentence pairs, we develop a semantic relation representation learning model, and incorporate CWE to detect contradiction. We run experiments on benchmark datasets from SemEval 2014 [
13]. The experiment results show that the proposed method with CWE performs comparably with top-performing systems in terms of overall classification accuracy. Specifically, it outperforms in terms of accuracy in the contradiction category.
The following statements present the major contributions of this work:
We present a data construction method to generate a large-scale corpus for training contradiction-specific word embedding. The corpus consists of millions of contrasting pairs, which bring more guidance than prior resources with tens of thousands of antonym pairs.
Based on the large-scale corpus with contrasting pairs, we develop a neural network tailored for learning contradiction-specific word embedding.
We apply contradiction-specific word embedding in a semantic relation representation learning model to detect contradiction, and the accuracy of contradiction category outperforms the state-of-the-art method on benchmark data set by 6.11%.
3. Contradiction Detection
Contradiction is a type of semantic relation. We present a neural network model to learn the semantic relation representation from each pair of sentences by using CWE. The semantic relation representation serves as features, which are generated automatically from the proposed model rather than from deep syntactic analysis and feature designing in the previous methods.
3.1. Neural Network Architecture
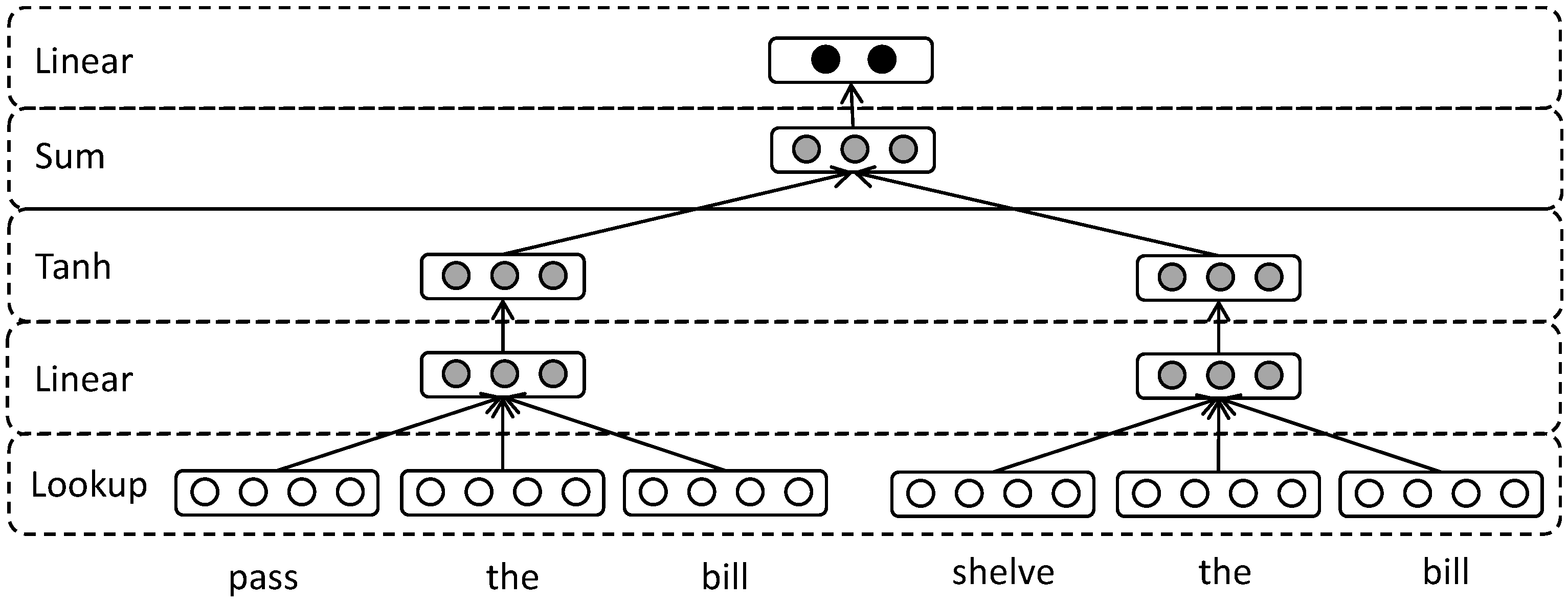
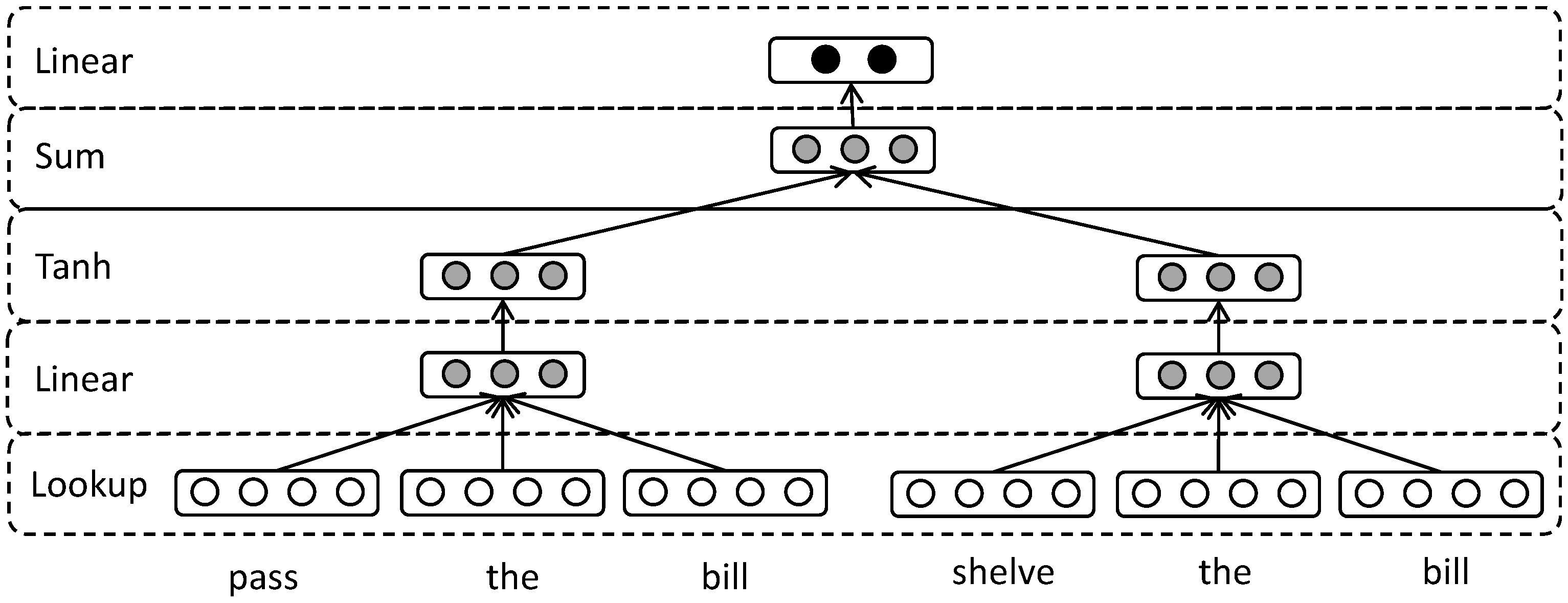
In detecting contradiction, the global semantic features and local semantic features are both important. The global features refer to the semantic meaning of the sentence which is relevant in terms of the word order. Two sentences which consist of similar words in different word orders may have different meanings. We use the representation of sentence-level semantic relation to capture global semantic features. The local features explore the semantic relation between unaligned phrases from the pair of sentences. The unaligned phrases always contain contrasting meanings in the contradictory sentences. For example, the phrases “passed” and “shelved” are unaligned phrases in the sentence pair (B) in
Figure 3.
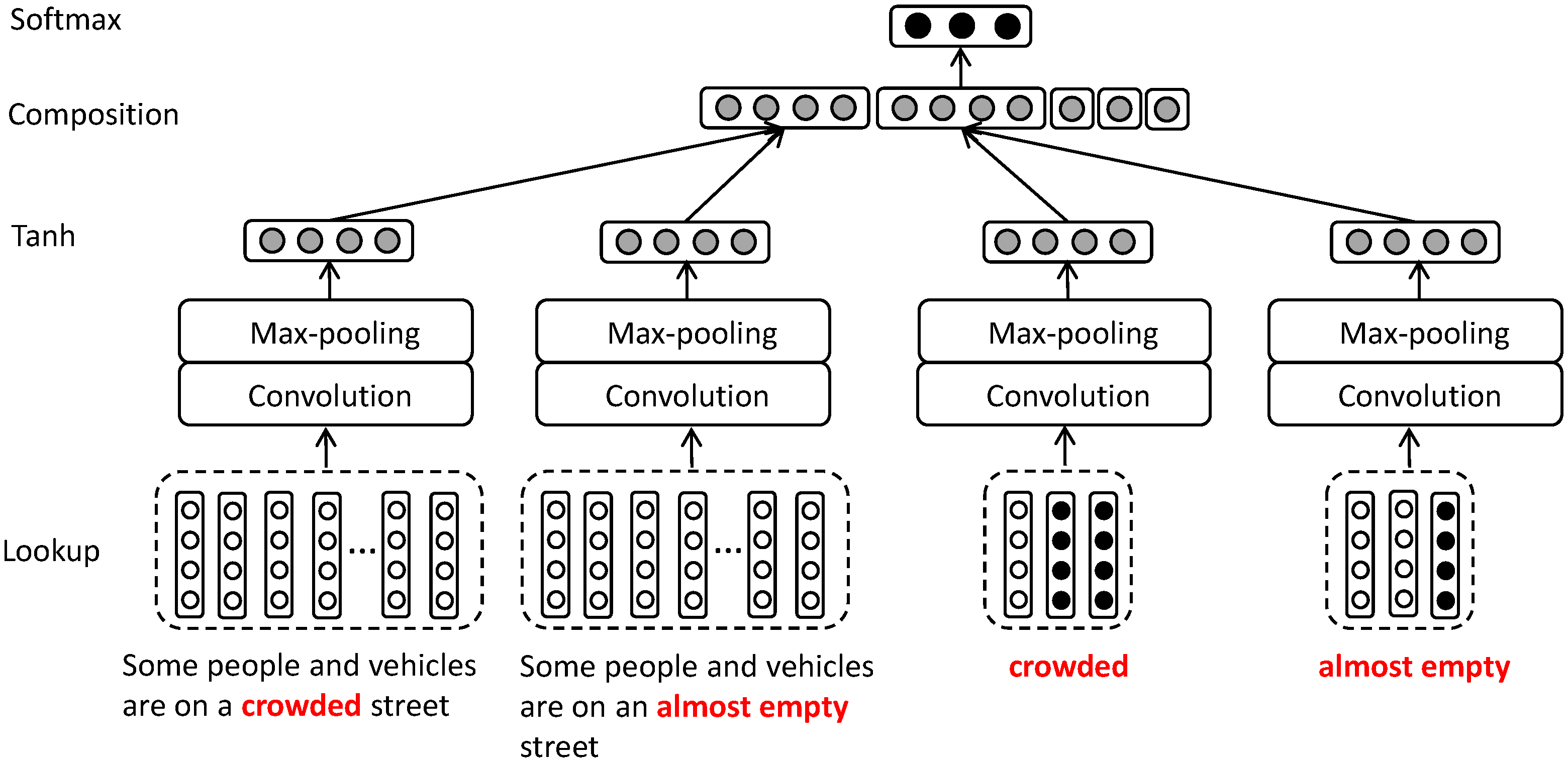
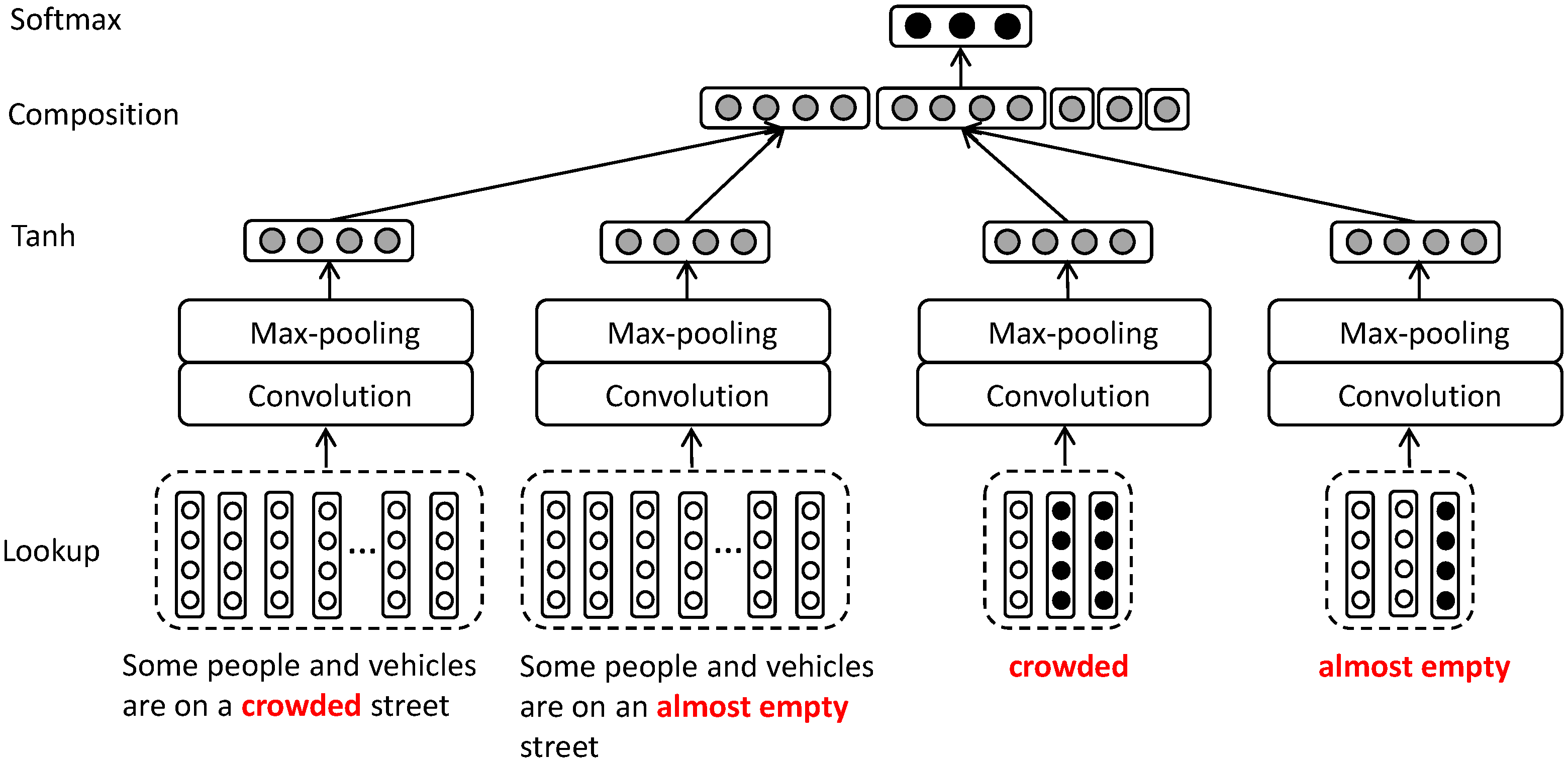
A CNN-based (Convolutional Neural Network) model is exploited to learn the global and local semantic relation from input sentences, as shown in
Figure 5. The architecture is extended from the model of learning CWE, and comprises six layers: lookup layer, convolutional layer, average-pooling layer, tanh layer, composition layer, and softmax layer. The pair of sentences and pair of unaligned phrases are the input of the model. Through the first four layers, sentences and phrases are all mapped into corresponding vectors in the same semantic space. Through the composition layer, the sentence-level and phrase-level semantic relation representations are generated and concatenated along with three shallow features. A softmax layer is adopted as a classifier.
Cross-entropy is used as a loss function. Given training data (T), the loss function to learn the classifier is expressed by Equation (
7), where
denotes the probability of the gold signal to the
kth sample in the data set.
3.2. Shallow Features
In order to enhance the capability of classification, we exploit three shallow features as summarized in
Table 2. By observing the training set, contradictory sentence pairs are mostly because of negations, except in the case of antonyms. If the number of negation words in the pair of sentences is odd, the semantic relation will have a high possibility of being contradiction.
The word order feature and unaligned word number feature help to recognize entailment relation between two sentences. A large value of the unaligned number roughly indicates that the relation is entailment. In the composition layer, three extra features are directly concatenated with the sentence-level and phrase-level semantic relation representations as the input of softmax layer.
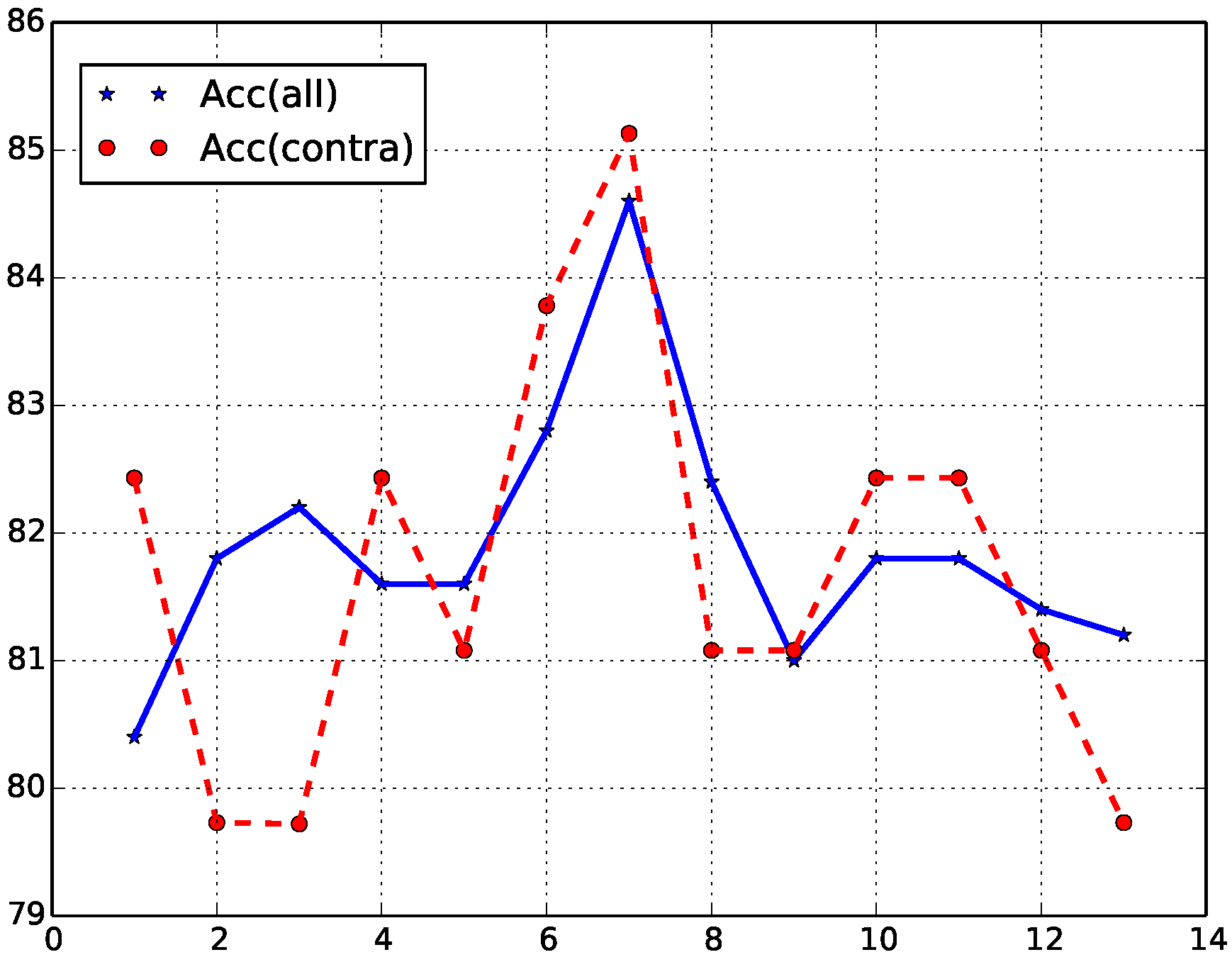
The parameters used in the contradiction detection experiment are set as follows. The lengths of embedding and the hidden layer vectors are both 50. The learning rate is 0.1. The window size is set to 7. The effect of the window size in the proposed method is experimentally studied. The result shows that the accuracy has a peak value when the window size is set to 7, which is applied in the experiment.
4. Experiments
We conduct experiments to show the effectiveness of CWE by incorporating it in a semantic relation learning model to detect contradiction. We make two comparison experiments. One is to evaluate the effectiveness of the proposed model for contradiction detection, and another is made between different embeddings for evaluating the effectiveness of CWE. We make an analysis of the corpus which is used to learn CWE.
4.1. Data Set for Contradiction Detection
Contradiction detection suffers from its lack of a gold standard dataset. In this study, we verify the effectiveness of CWE on the benchmark dataset of a textual entailment recognition task which consists of data with contradiction, entailment or neutral relation. The dataset is from task 1 in SemEval 2014 [
13]. The distribution of data is shown in
Table 3. The dataset is imbalanced, and the ratio among the contradiction, entailment, and neutral categories is roughly 1:2:4 not only in the training dataset but also in the trial and test datasets.
4.2. Baseline Methods
We compare our method with the following baseline methods:
Illinois-LH: This method is the top-performing system [
15] in Task 1 in SemEval 2014. It uses a MaxEnt model and makes deep semantic and syntactic analyses to manually gather features. The features are extracted based on the analysis of the distributional and denotational similarities, word alignment, negation, hypernym, hyponym, synonym, and antonym relations.
TreeRNN: The full name of the method is tree-structured recursive neural networks. The method uses syntax tree of the sentences as the structure of the recursive neural network. TreeRNN is applied to composite the representations of words or phrases layer by layer according to the syntax tree [
16].
TreeRNTN: The full name of the method is tree-structure recursive neural tensor networks. The struture of the method is syntax tree. The method uses a recursive neural tensor network to do the composition in each layer of the syntax tree of the sentences [
16]. This work is presented by Standford NLP group, which aims to verify the effectiveness of the tree-structure recursive neural network or tensor network in identifying logical relationships such as entailment and contradiction.
SVM (Support Vector Machine): As a good classifier in text classification problems, SVM is utilized to solve the classification problem with CWE and shallow features as a baseline method. CWE is applied to compose two semantic features, which are the semantic relation features between whole sentences and unaligned phrases. First, the representations of the sentences and phrases are computed by averaging the embedding of all words. Second, the semantic relation features are generated by a composition function between sentence representations or unaligned phrase representations.
LSTM-RNN: RNN (Recurrent Neural Network) can model the input sequences with time series. However, the error gradients vanish exponentially quickly with the size of the time lag in these methods [
17]. To solve the problem, Hochreiter first proposed Long Short-Term Memory (LSTM) to learn the representation of the data with long distance [
18]. Currently, as a popular neural network model, LSTM-RNN has been verified to be an effective or even the state-of-the-art method in many NLP tasks [
19,
20,
21,
22,
23].
4.3. Results and Analysis
We first compare different methods for contradiction detection task, then make a comparison among different embedding by incorporating in our model.
Given a pair of sentences, we aim to predict the correct semantic relation between them. The semantic relations include: entailment, contradiction and neutral. The ideal results are that the model can improve the accuracy of identifying the contradiction category on the premise that the three-category accuracy is at least comparable with the top-performing system.
We compare the proposed method with baseline methods on test data, and the results are shown in
Table 4. The comparison results show that our method gains the highest accuracy on the contradiction category. Illinois-LH system gains the best result on the average accuracy of three categories. Our method has a comparable result to the Illinois-LH system on the average accuracy of all categories. The state of the art method, Illinois-LH, applied feature engineering and a MaxEnt model to do the task. Specifically, it made deep semantic and syntactic analyses and recognized antonyms by lexical resources. However, most of contradictory words or phrases in the dataset are not antonyms and are hard to be recognized by lexical resources. Our method uses a neural network based model to learn the representation of the semantic relation between input sentences, and treat the representation as features in the classification. The model incorporates the contradiction-specific word embedding. The advantage of our method is the capability to recognize the contradictory meanings between input sentences. The model consists of two parts, which respectively represent the semantic relation between pairs of sentences and the semantic relation between pairs of unaligned phrases among the sentence pairs. The designing of the model also benefits the contradiction detection task.
TreeRNTN outperforms the LSTM-RNN models; however, it cannot beat other methods. The results of the SVM methods show that CWE is significantly beneficial, not only in detecting contradiction but also in the three-category classification. The LSTM-RNN model has a more than 90% accuracy on the training data and 76% in the test data. LSTM-RNN does not perform very well on the current dataset because of overfitting on the training data. LSTM-RNN has more parameters than other baseline methods and the proposed method, which needs a larger training dataset to avoid the overfitting problem.
Our proposed method is used by incorporating CWE and shallow features. The accuracy of the contradiction category is 80.28%, which is far higher than 75.97% of the Illinois-LH system. When we fine-tune CWE during training the proposed model, the average accuracy of all categories and the accuracy of the contradiction category both improve. The final accuracy on the contradiction category is 82.08%.
The effectiveness of CWE and three shallow features is analyzed in
Table 5. The accuracies clearly decrease when CWE is abandoned. This shows the effectiveness of CWE in representing semantic relations. When we abandon CWE, the model actually turns to be a softmax classifier with shallow features. Thus, the comparison between CWE and other features just show the effectiveness of the proposed model to learn semantic relation representation of the sentence pairs. Because the negation phenomenon has a high coverage in the whole dataset, the negation feature is also useful. The two features, which are the differences of the word order and the unaligned word number, are both helpful in three-category classification, but play a minor role in identifying contradiction category.
CWE and task-independent word embedding such as Glove are compared in the contradiction detection task on the test dataset, as shown in
Table 6. The proposed model is utilized by incorporating shallow features for comparison. We also use Mrksic’s embeddding [
8] to make a comparison with CWE in the same model. We aim to verify two things, which are: the necessity of learning a contradiction-specific word embedding for contradiction detection task and the advantage of our method in learning embedding. The results show that CWE performs better than Glove and Mrksic’s embedding in a contradiction detection task.
4.4. Effect of Window Size
The effect of the window size in the proposed method for the contradiction detection task is experimentally studied. In the task 1 of SemEval 2014, there is no development set. The systems participating in the task used trial data to tune parameters. Thus, we tune parameters of the proposed model on trial data. In
Figure 6, the accuracy is varied by different values of the window size. The result shows that the accuracy has a peak value when the window size is set to 7, which is applied in the experiment.
4.5. Effect of Composition Functions
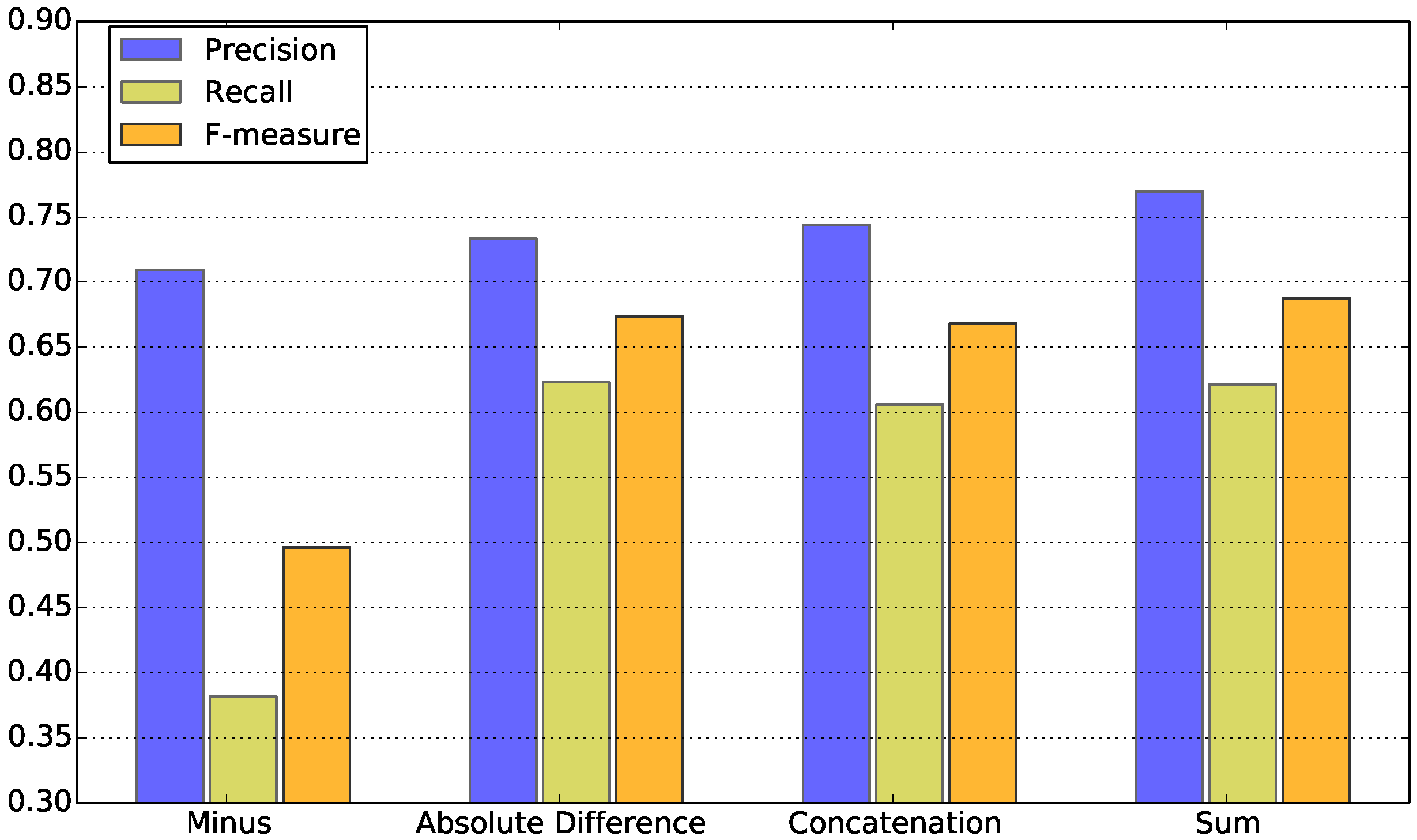
In the CWE learning model and the semantic relation representation learning model, the composition function is used to composite the vectors of input phrases or sentences. A comparison experiment of different composition functions is made on an antonym dataset. Because antonym is a special type of lexical-level contradiction relation, we gather 6335 word pairs from WordNet which are antonyms or synonyms. The dataset has a balanced ratio of positive and negative samples. The ratio of training data and test data is 2:1.
The semantic relation of each pair of words is represented by one of the composition functions in
Figure 7. The representation of the semantic relation can be used as features, and be incorporated in SVM.
Figure 7 shows the classification result. As we can see, the sum operation performed best, which is adopted in the contradiction detection experiment.
4.6. Analysis of the Corpus for Learning CWE
The corpus comprises about 1.9 million contradiction pairs and 1.6 million paraphrase pairs. The examples are shown in
Table 7. We can see some examples are indeed contrasting, such as “ingratitude” and “loyalty”, “inconsequence” and “rationality”, etc. Our automatically generating contradiction method can not only capture the nominal contrasting word pairs but can also generate contrasting words cross different POSs (Part of Speech), such as “inconspicuous” and “utter”. It is normal in the real world that an adjective and a verb share contrasting meanings. However, the contradiction relation between them is hard to be captured by lexicons. Because of the polysemy and the situation of individual words with multiple POSs, there are several examples without contrasting meanings. Nevertheless, the examples with opposite polarities are also meaningful for the research of contradiction detection, such as “meagerly” and “gratefully”. The same phenomena show in the examples of contrasting phrases in
Table 7.
To estimate the accuracy of generating contradiction corpus, we randomly choose a thousand samples and judge the correctness of each generated contradiction pair artificially by three persons. We use a voting method to annotate the labels of the samples based on the three personal judgments. When no less than two persons affirm the contradiction relation of a sample, the sample will be targeted as a correct sample (namely a real contradictory pair). Otherwise, it will be targeted as a wrong sample. Finally, the accuracy of constructing contradictory pairs is 71% in the randomly sampled subset.
5. Related Work
A brief review of related works is presented from two perspectives: contradiction detection and learning continuous representations for a specific task.
Contradiction Detection. A strict logical definition of contradiction is that two sentences are contradictory if they cannot both be true in any world. The definition is loosened to capture human intuitions of incompatibility and better fit applications of recognizing discrepancies of the same event [
1]. The looser definition of contradiction is that two sentences are contradictory when they are unlikely to be true at the same time. Contradiction detection aims to detect the semantic relation of contradiction among sentences. Condoravdi et al. first argued the importance of handling contradiction in text understanding [
2]. As a kind of relation in the entailment recognition problem, contradiction has been studied continually in Recognizing Textual Entailment Challenges [
13,
24,
25,
26,
27,
28,
29]. In previous years, researchers undertook the task by resolving some of the contradiction phenomena [
1,
30], like negation, antonyms, data/number mismatch and different structure. Ritter et al. utilized functional relations to recognize whether contradictions were apparent or actual [
31]. In recent years, some researchers have focussed on finding contradictory parts in a pair of sentences [
32,
33,
34,
35]; however, they could not capture the contradictory relation between whole sentences. Our method captures both the global and local semantic relations.
As a crucial part of contradiction analysis, antonyms detection has been gaining increasing attention from researchers [
7,
36]. Lin et al. used a few “incompatibility” patterns to acquire antonyms [
37]. Marneffe et al. expanded an antonym list for a word by adding words from the same synset in WordNet according to the direct antonym of the word [
1]. VerbOcean is also used as a lexical resource. However, employing lexical resources is limited by low coverage. Hashimoto et al. presented a kind of sematic orientation, namely, excitatory or inhibitory, such as the words “cause” and “ruin”. The authors argue that excitation is useful in extracting antonyms. However, the approach still cannot overcome the low coverage problem [
38]. A multi-relational latent semantic analysis presented by Chang et al. [
39] uses a three-way tensor to combine multiple relations between two words, in which one of the relations is antonymous. The authors use continuous space representations to capture lexical semantics through tensor decomposition techniques.
Word Representation Learning. Word representation is central to natural language processing (NLP). Harris states a distributional hypothesis that words in similar contexts have the same meanings [
40]. Based on the distributional hypothesis, many methods are context-based learning word representations [
41,
42]. Since the development of the neural language model [
43,
44,
45,
46,
47], it has become a popular approach to represent a word through a low-dimensionality continuous real-valued vector [
10,
48,
49,
50,
51].
Traditional representation learning methods aim to capture semantic and syntactic similarities between two words [
52]. A graph-based learning method is used for retrofitting word embedding by utilizing semantic lexicons [
53]. However, contrasting relation is also a semantic relation between words. With the aim to resolve the sentiment contrast, a sentiment-specific word embedding [
54] is learnt by weakly-supervised tweets collected by positive and negative emotions. Some neural network based models are proposed to revisit word embedding for lexical contrast [
7,
8,
9,
10]. There are two ways to get the contrasting pairs for learning embeddings. Chen et al. [
7] and Mrksic et al. [
8] both use lexical resources to get antonym pairs; however, this is the small part of contrasting pairs. Schwartz et al. [
9] apply patterns to get contrasting pairs from web text such as a Wikipedia page. This method also meet the low coverage problem, because the number of the contrasting pairs which can be described by “from X to Y” or “either X or Y” is limited.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}