
Searchable Data Vault: Encrypted Queries in Secure Distributed Cloud Storage

 , ,
, ,
Abstract
:1. Introduction
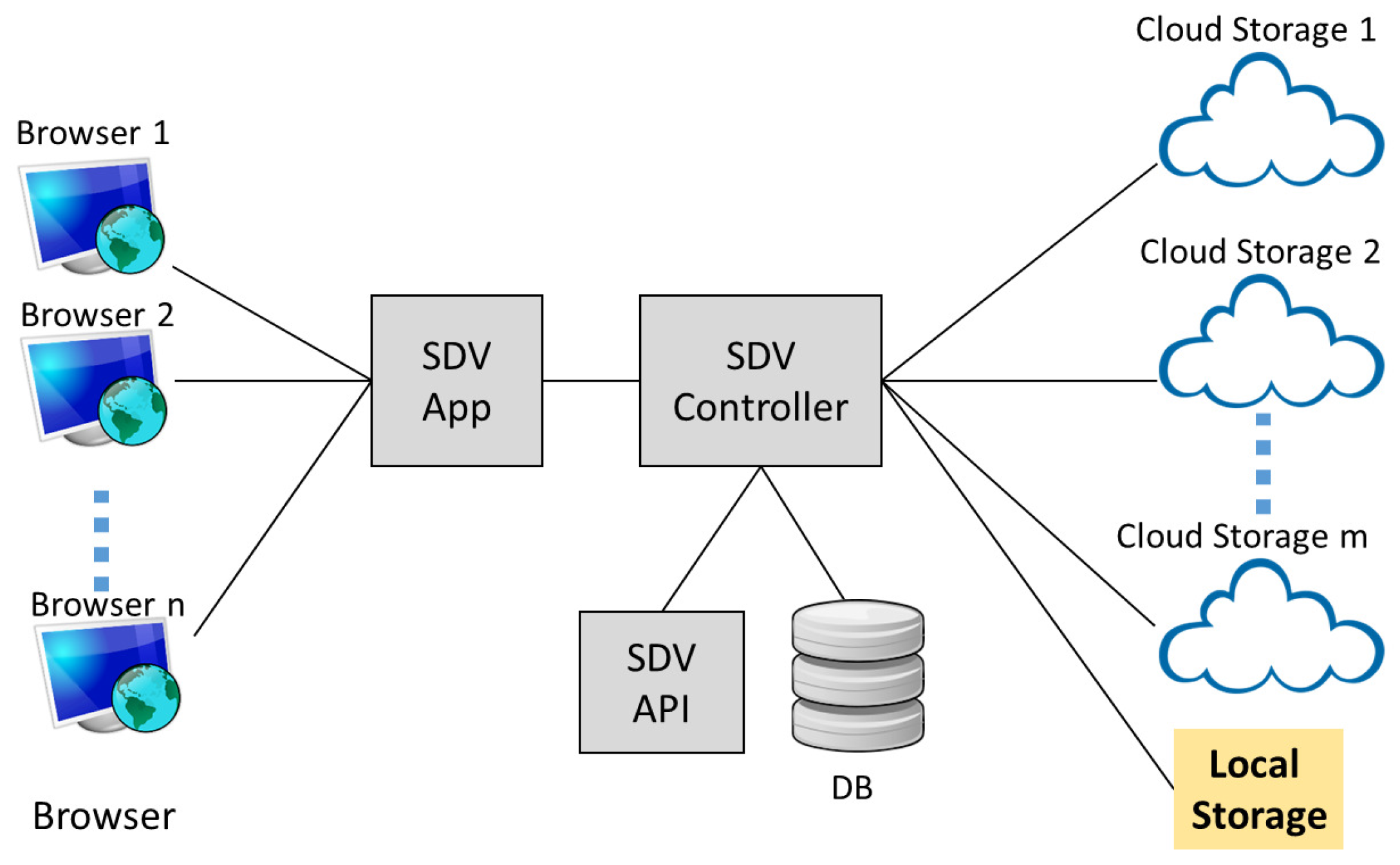
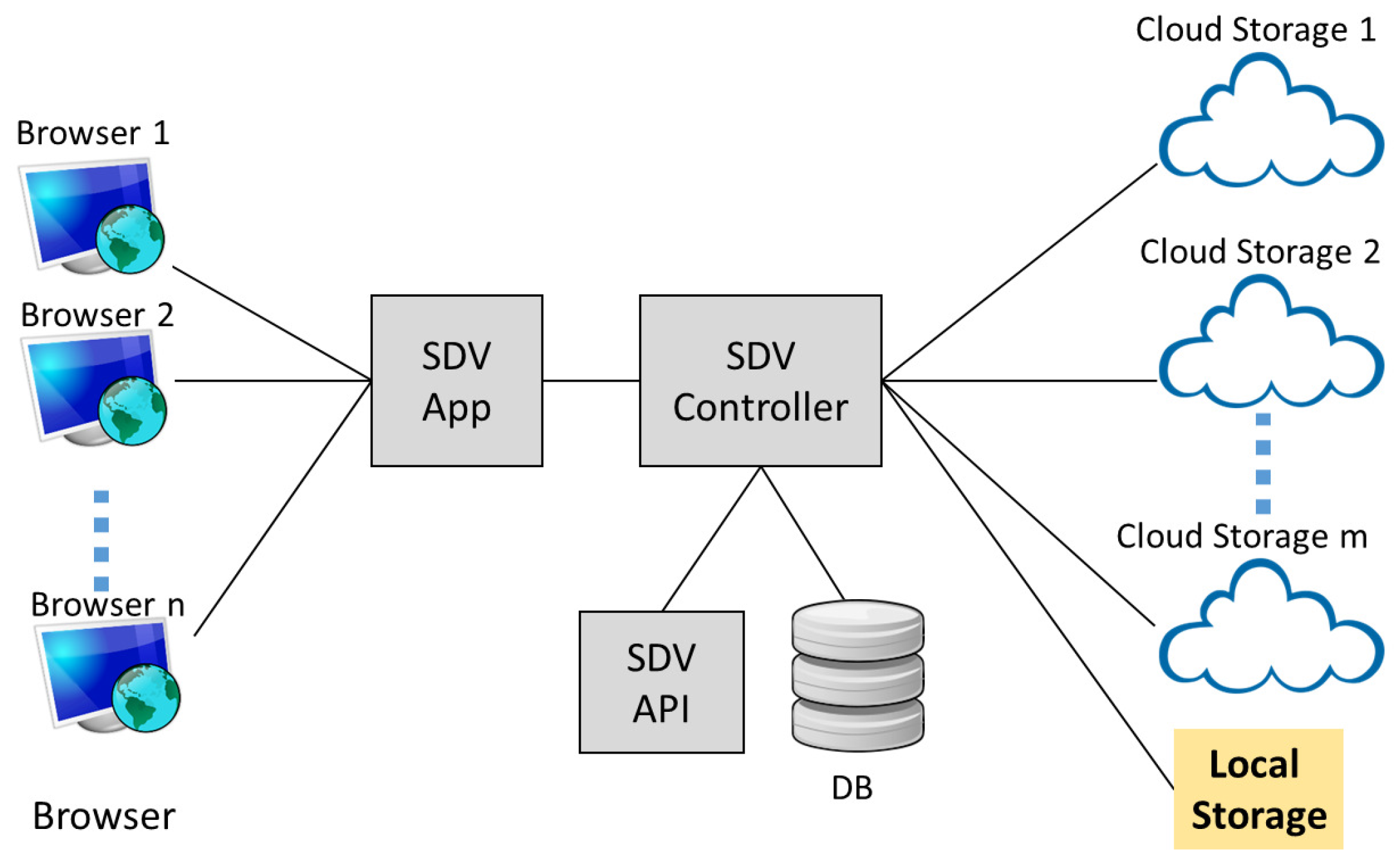
- SDV allows documents, or pieces of an encrypted document, called blocks, to be stored in different cloud storage services, in contrast to existing schemes and systems that focus on outsourcing to a single storage. It ensures with high probability that no single storage provider has a complete set of blocks, which it may use to learn additional information about the document. As far as we know, it is the first searchable encryption system that provides such a feature.
- A core component of SDV is a controller that manages query indexes, document submission, and retrieval. The controller is designed in such a way that the underlying searchable symmetric encryption (SSE) scheme, utilized for efficient search, is “pluggable”. It means existing schemes that cater for single storage provider can be adapted for use with our system. The controller may be implemented and placed in a query gateway. This is the case for our deployment.
- We further propose a multi-server SSE scheme, which is adapted from [3], with an implementation for SDV.
- The query index is designed to cater to a two-level dictionary structure, where the basic level is for a single-word query. An upper level can be included for future extension to more expressive queries (e.g., ranked, range, conjunctive).
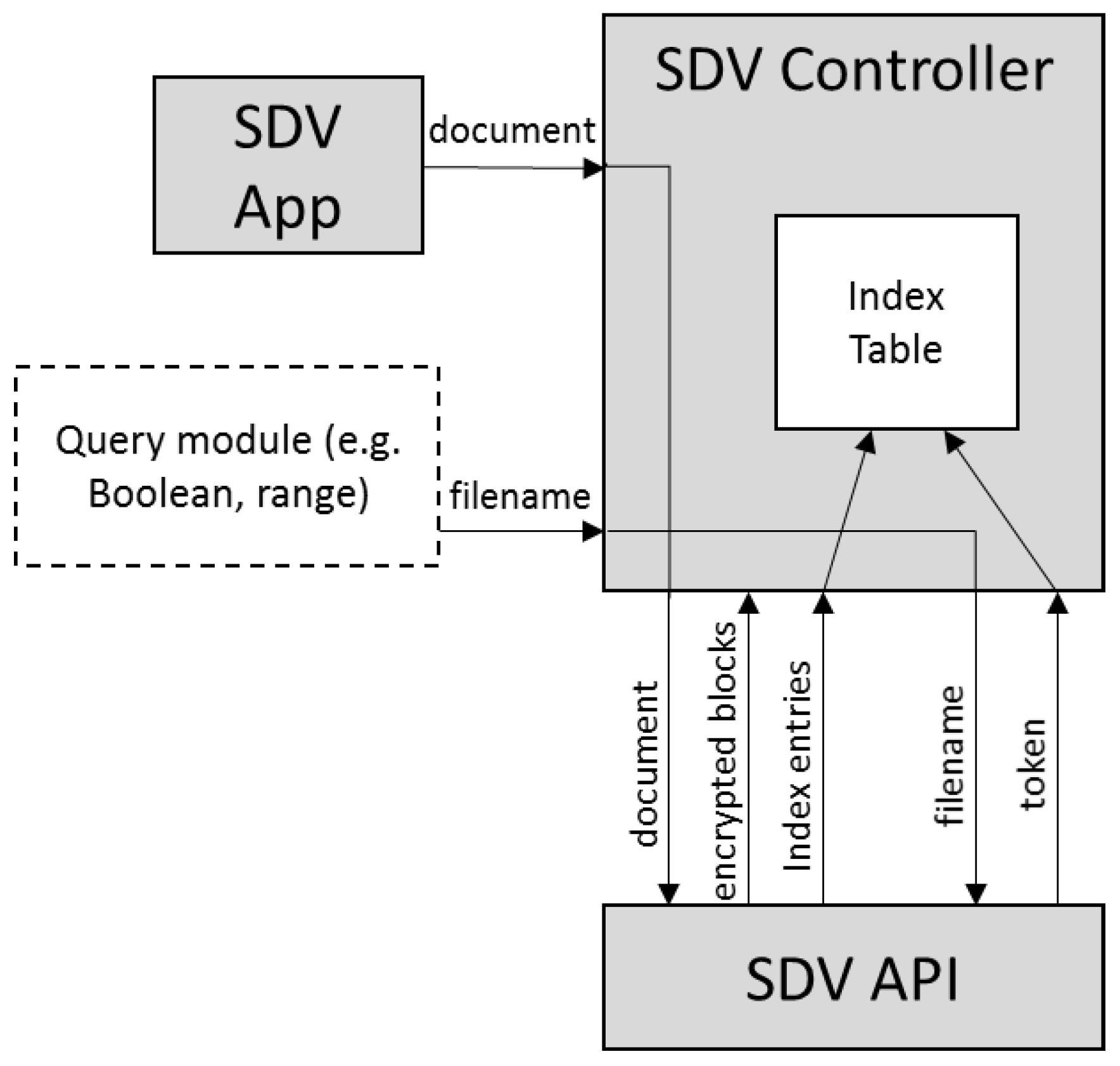
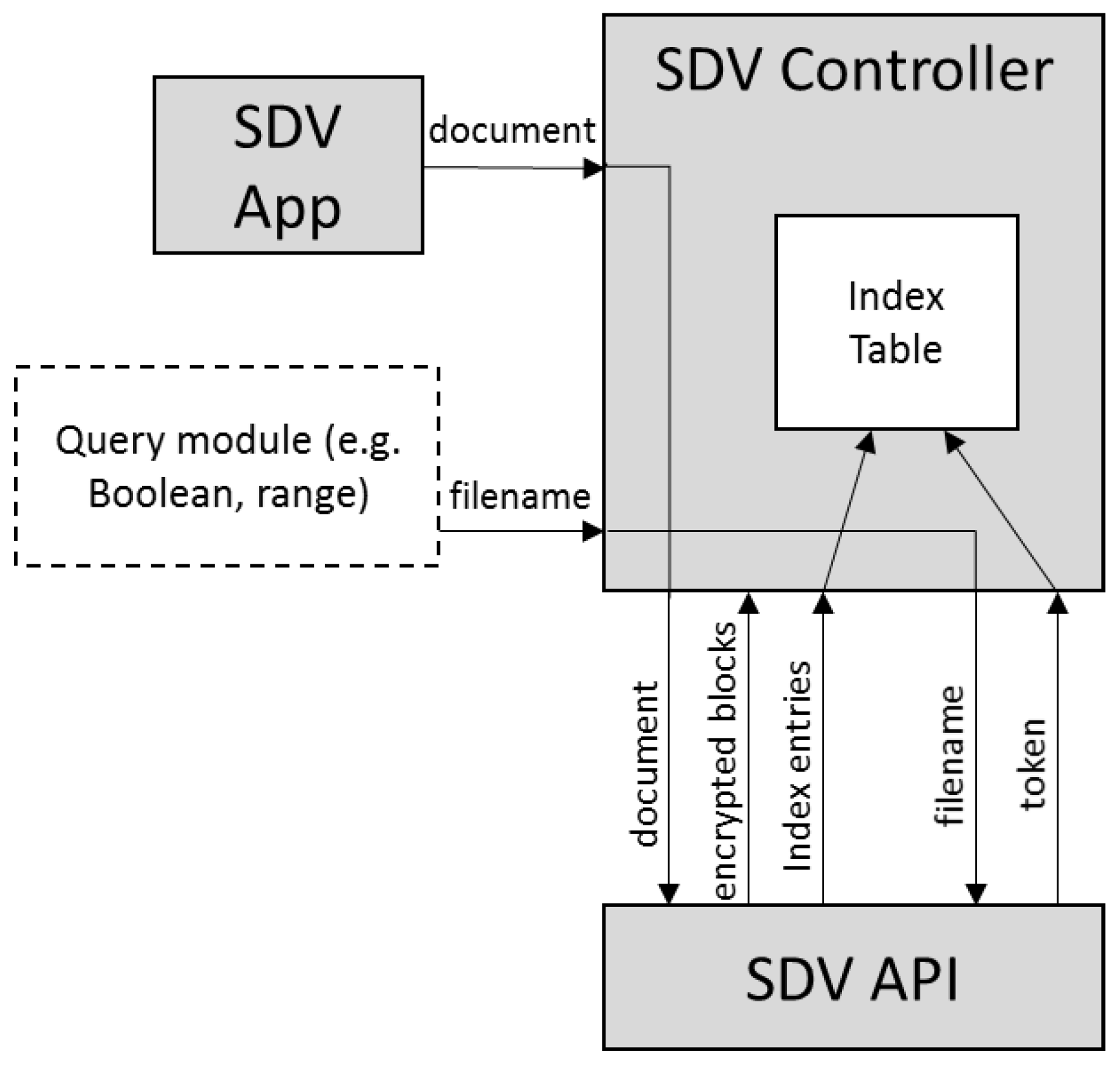
- SDV app: This module provides an interface for the SDV system to interact with the users for document upload and retrieval. In our deployment, it is also integrated with a unified authentication platform [4] for the purpose of user registration and authentication.
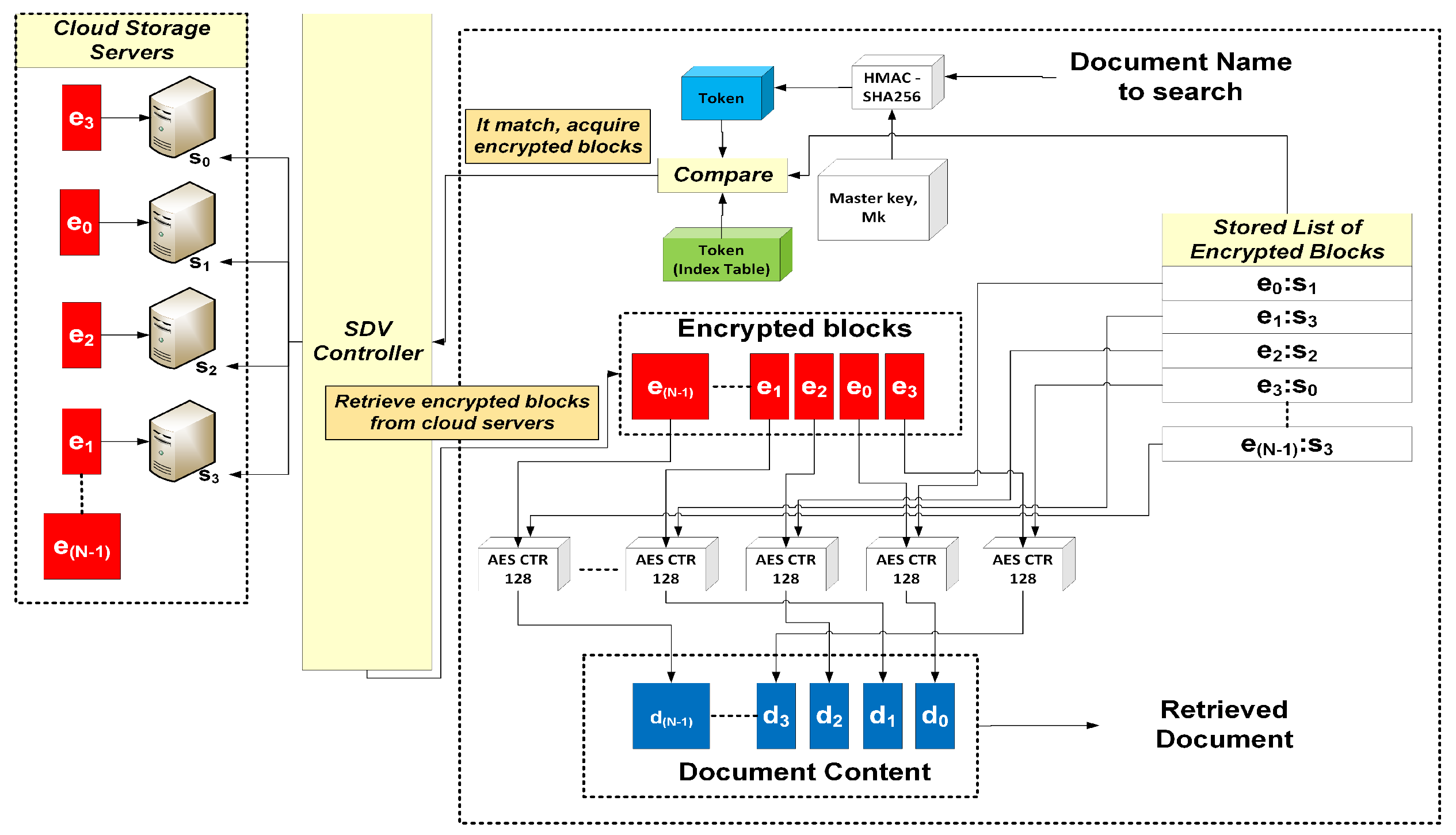
- SDV controller: This module maintains a database that contains credentials of users and cloud servers. It also creates a query index table, and manages the submission and retrieval of encrypted documents.
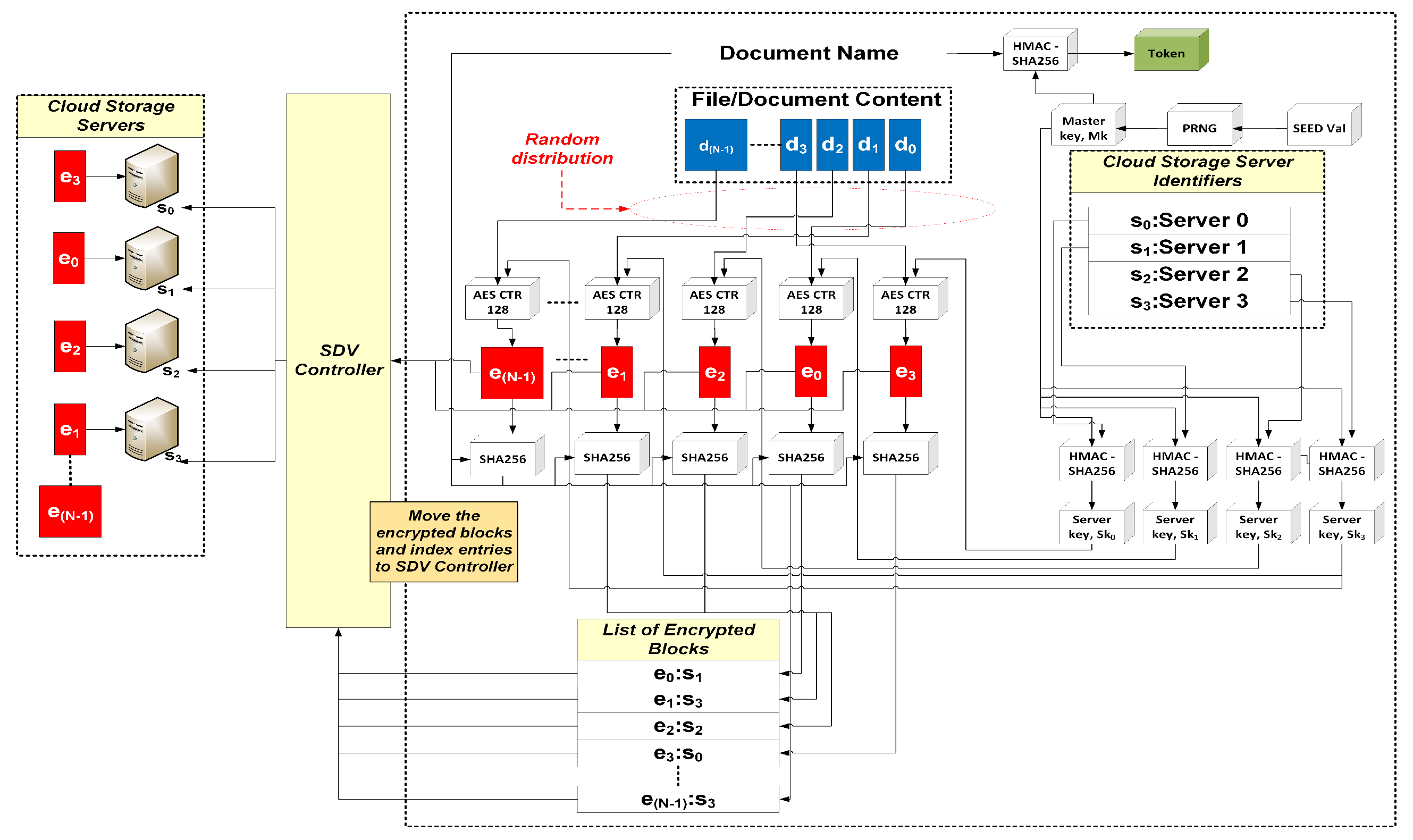
- SDV API: This module contains an implementation of our multi-server SSE scheme. The scheme divides and encrypts blocks of documents, and generates index entries for query purposes.
2. Related Work
2.1. Systems
2.2. Searchable Symmetric Encryption (SSE)
2.3. PEKS and General Mechanisms
3. Definition
3.1. Notations
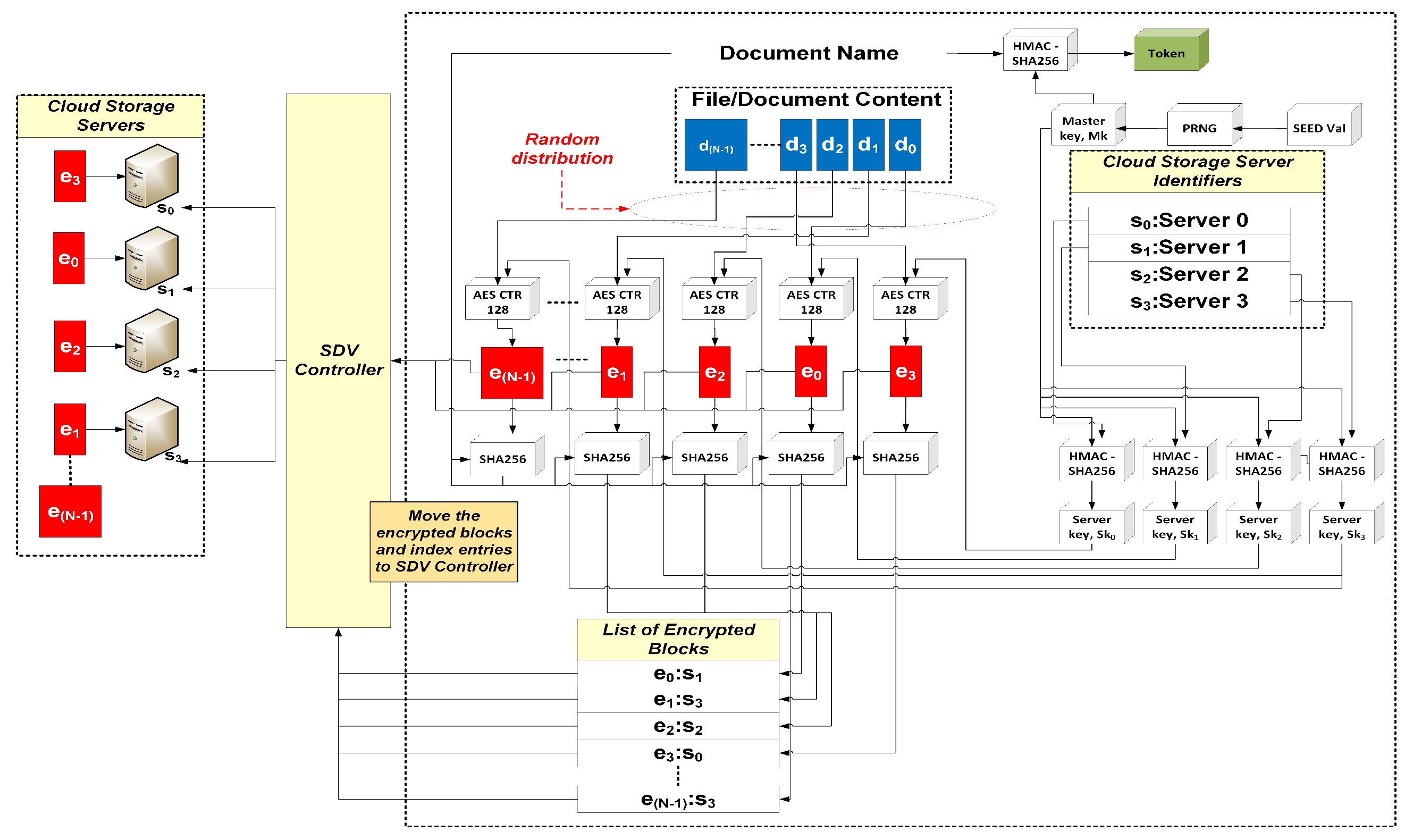
3.2. Multi-Server SSE Scheme
3.3. Security Model
4. A Multi-Server SSE Scheme
Security Analysis
5. Implementation
5.1. Cryptograhic Building Blocks
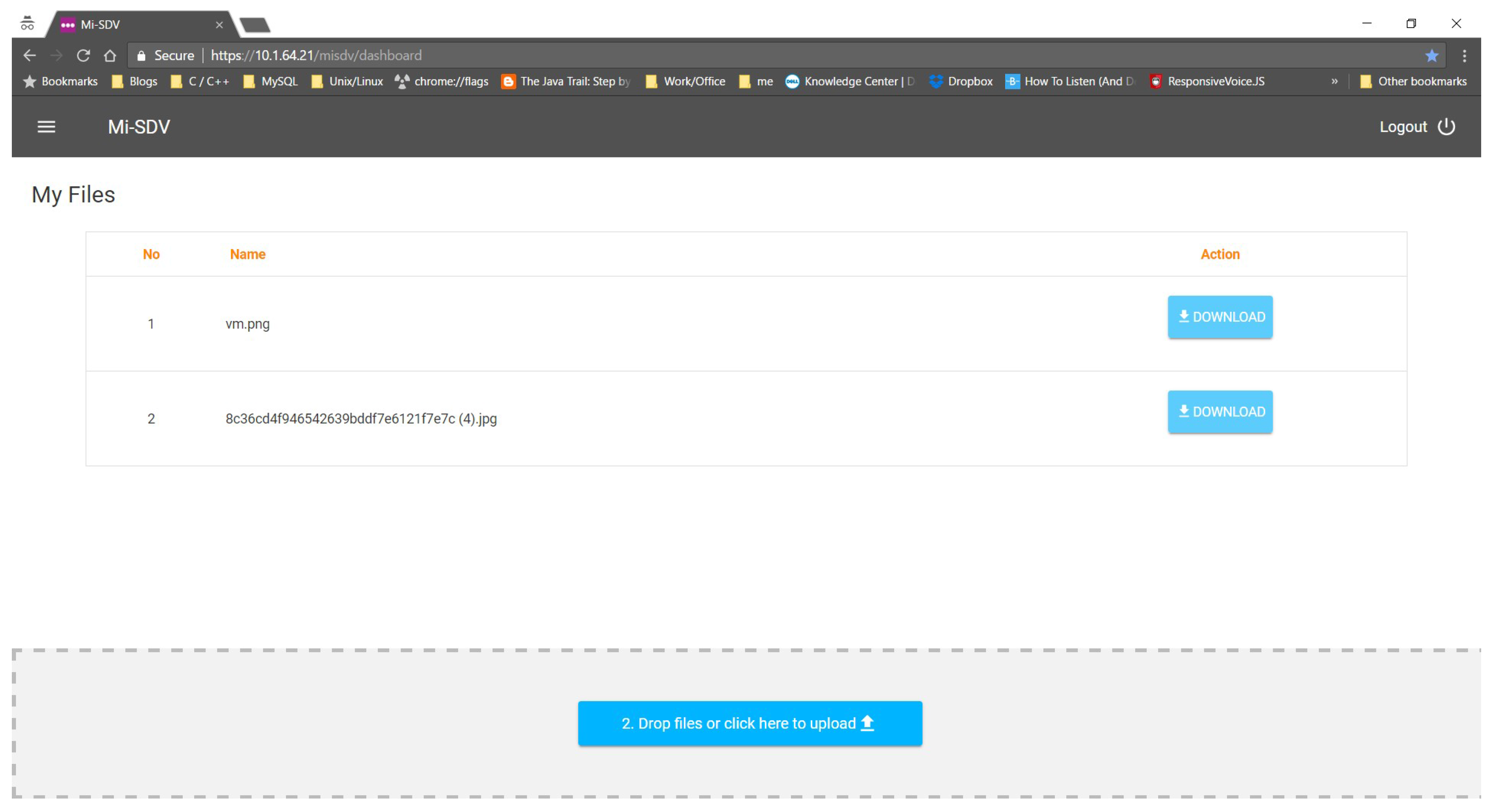
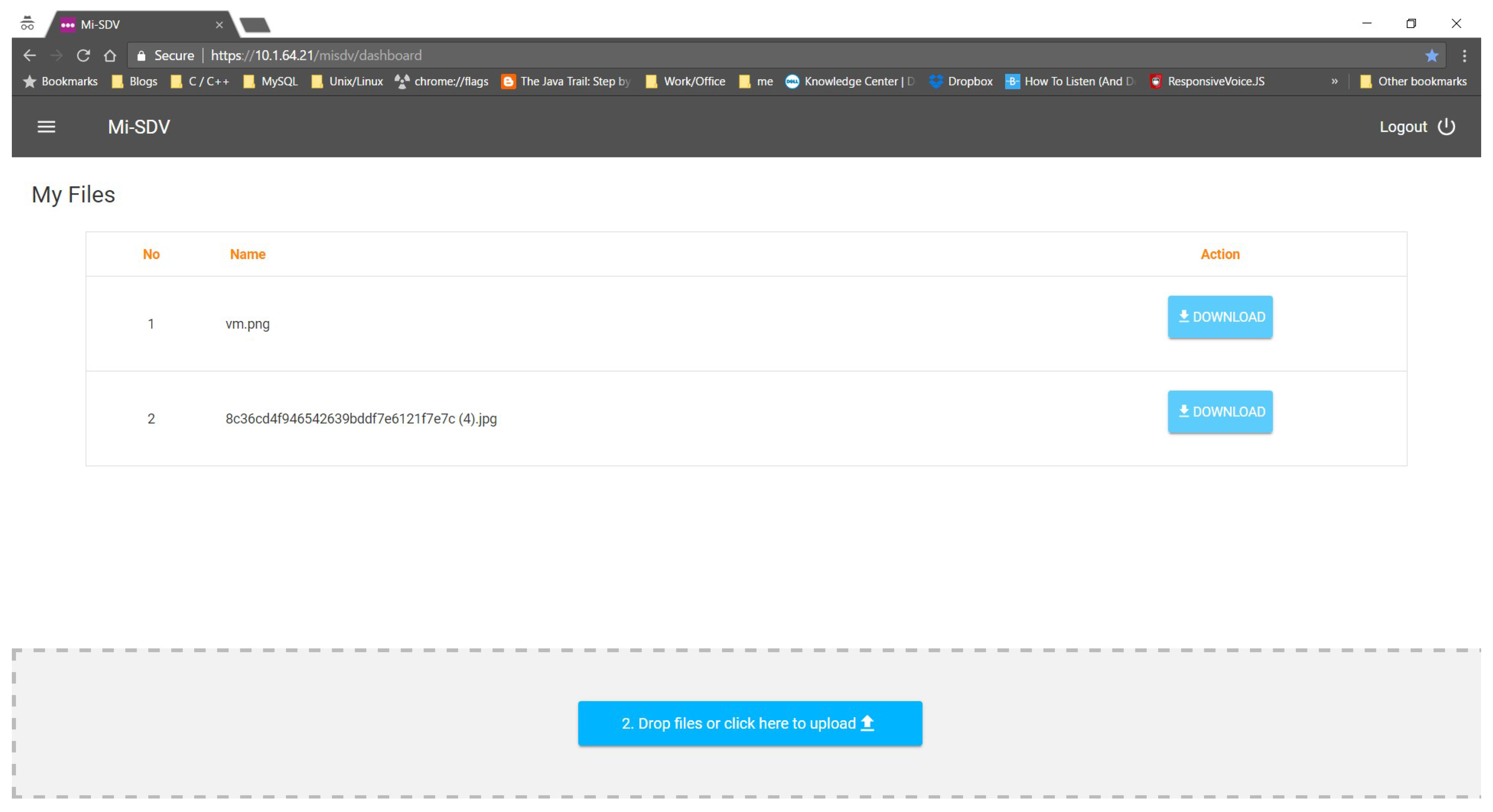
5.2. Main User Interface
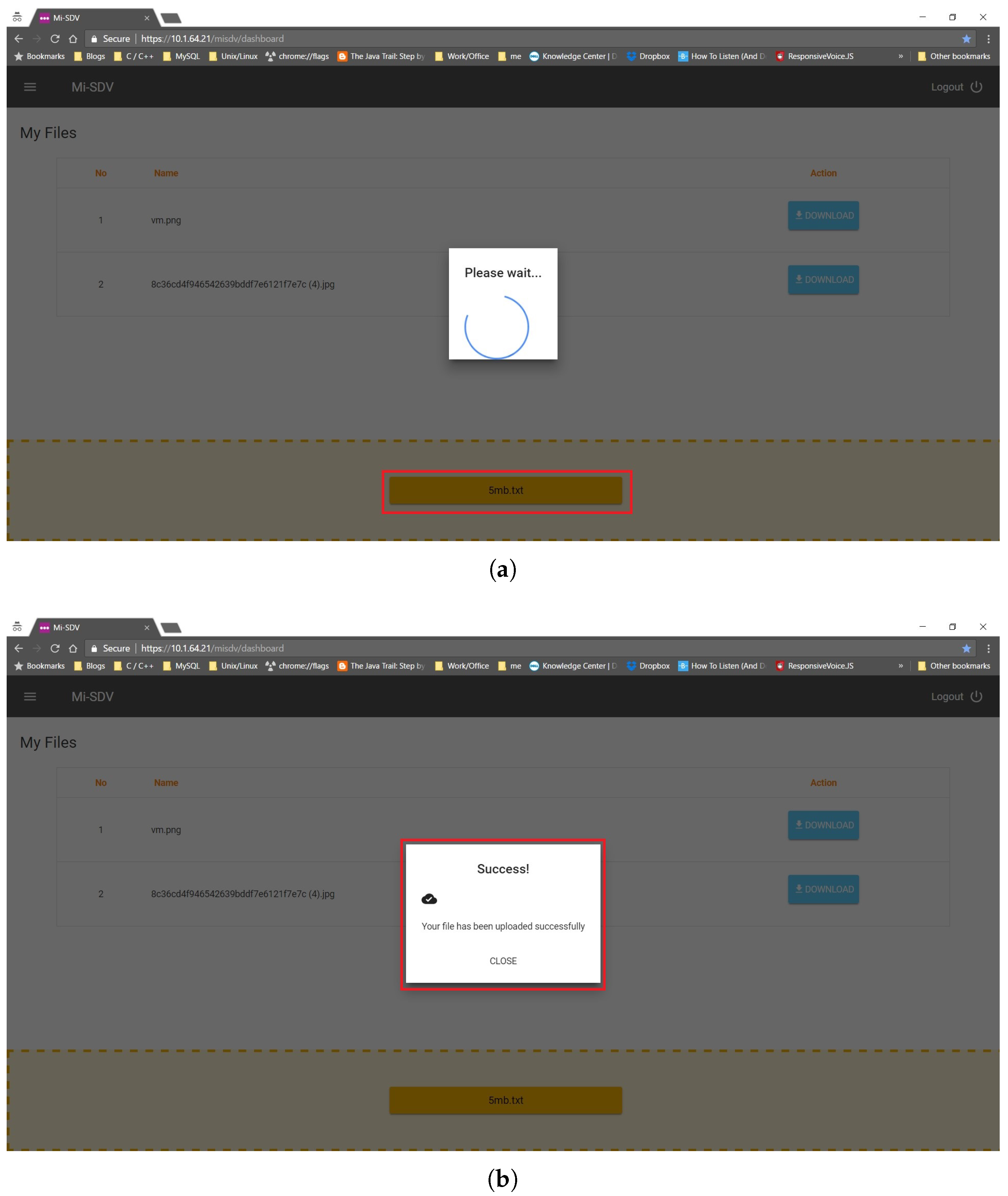
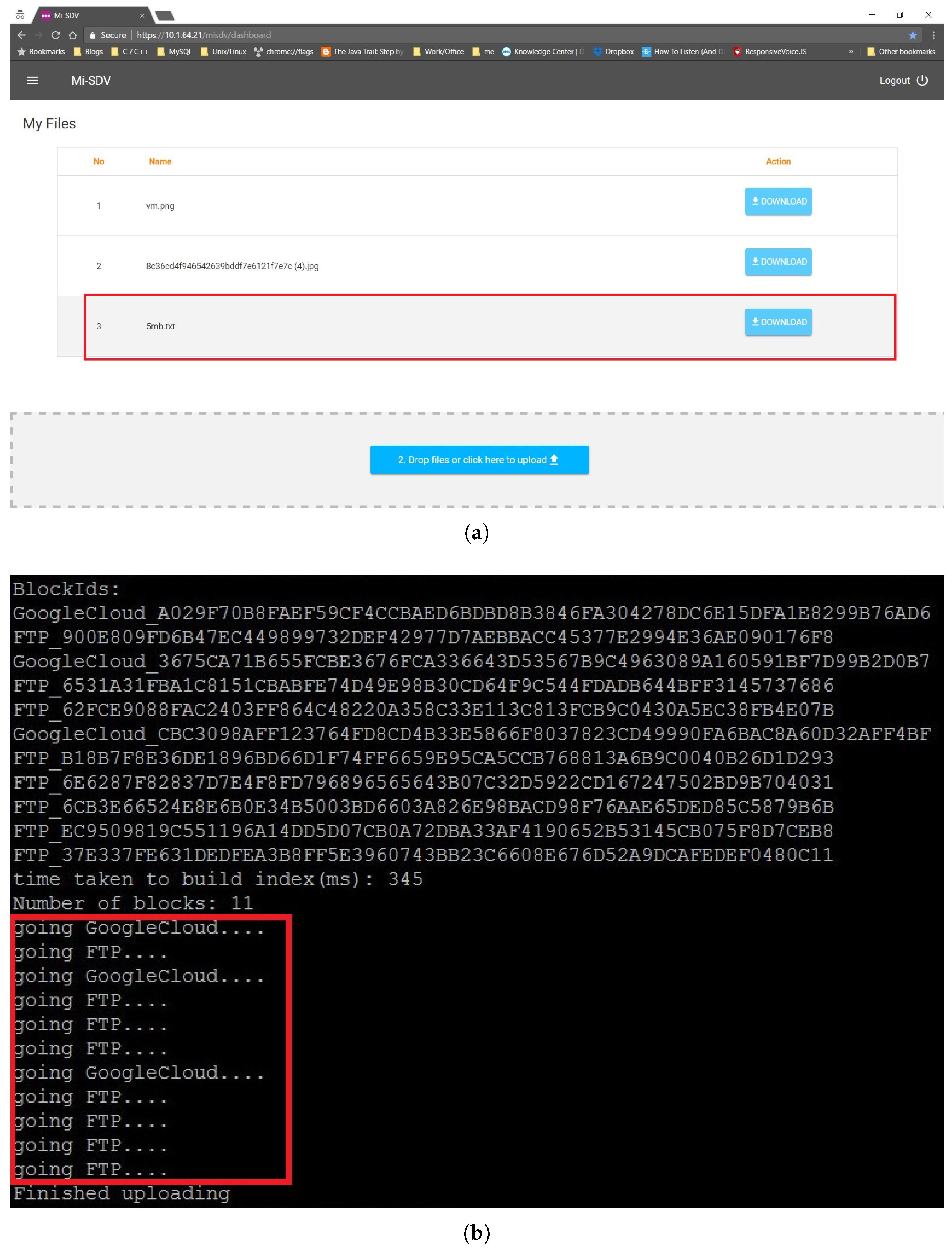
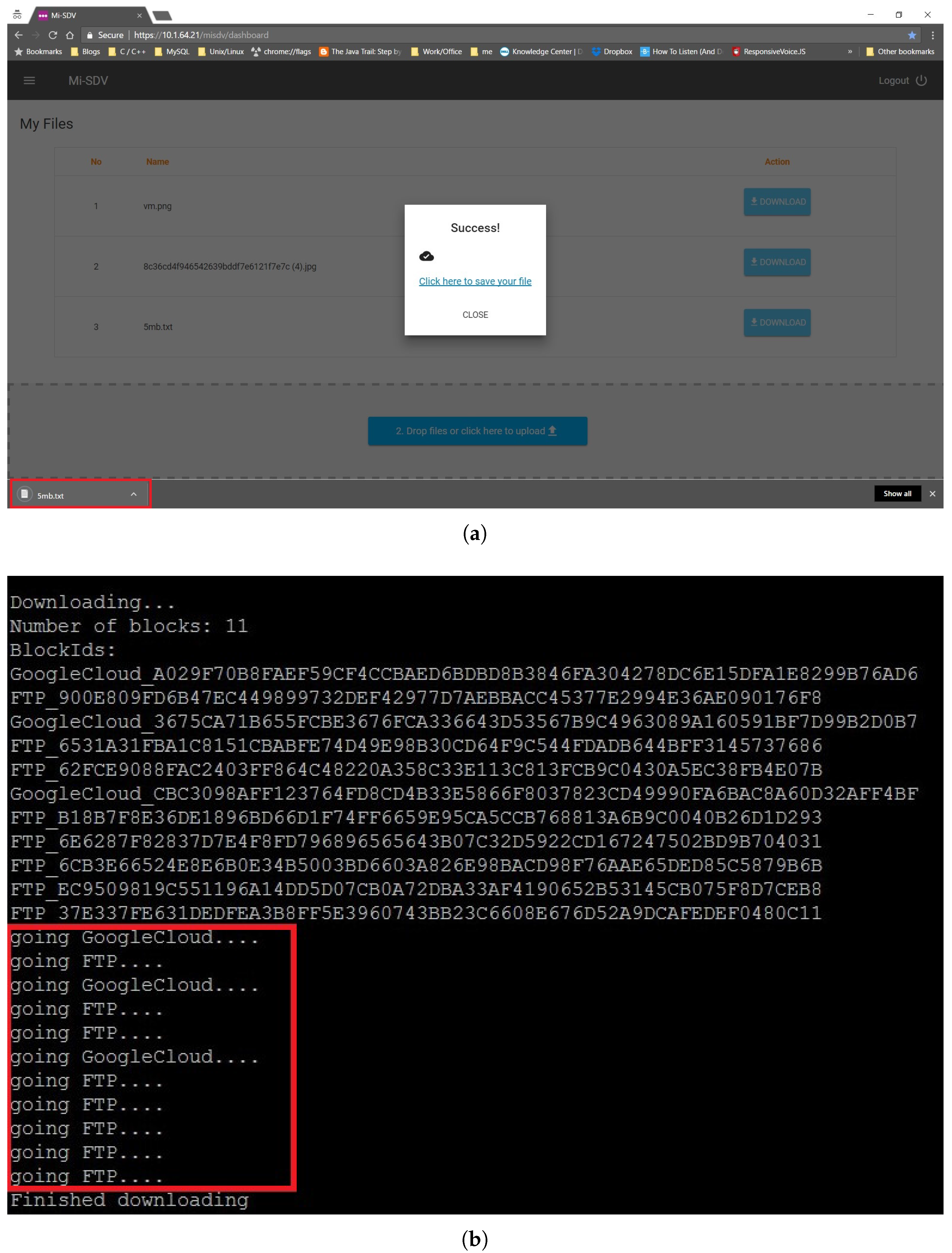
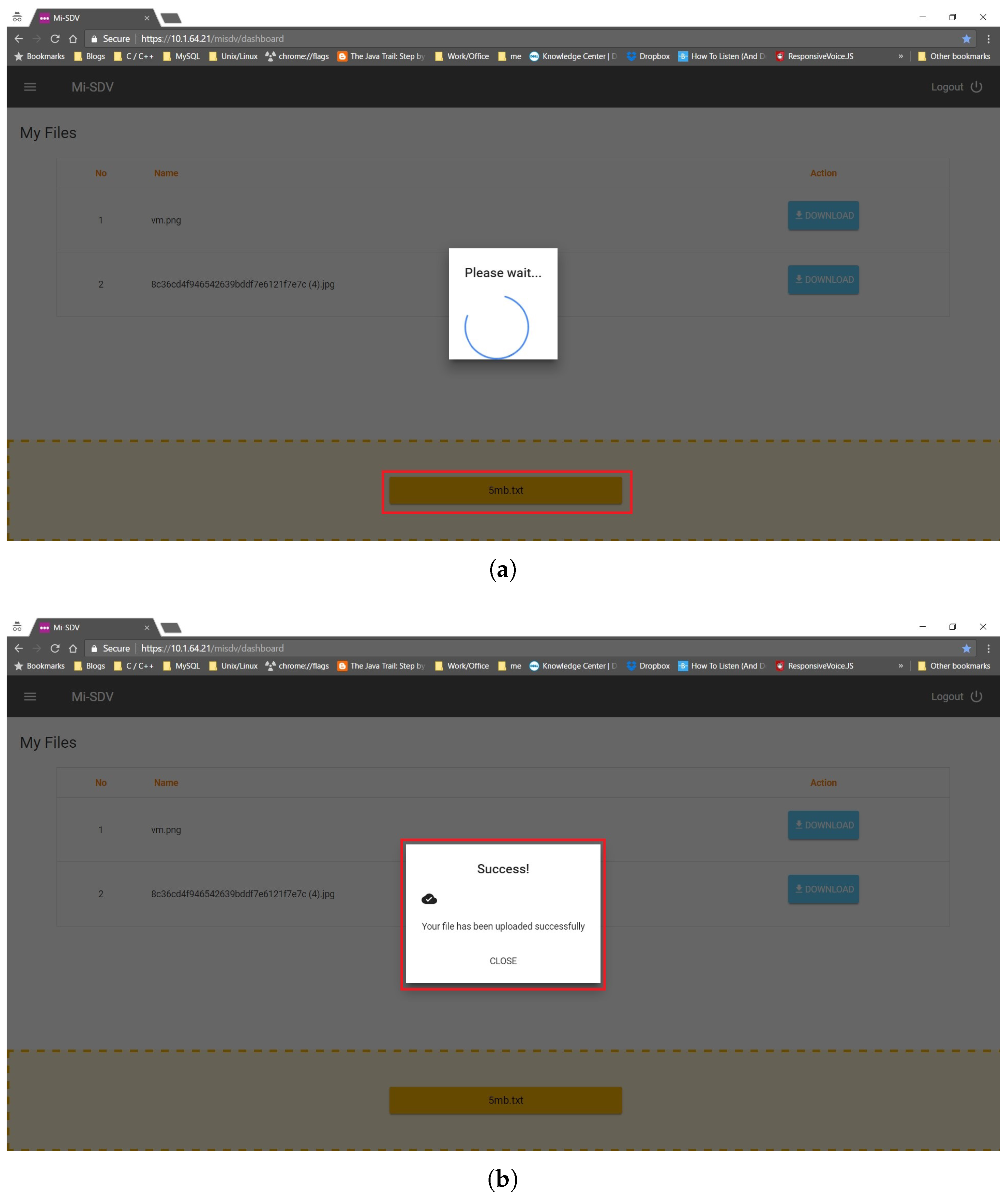
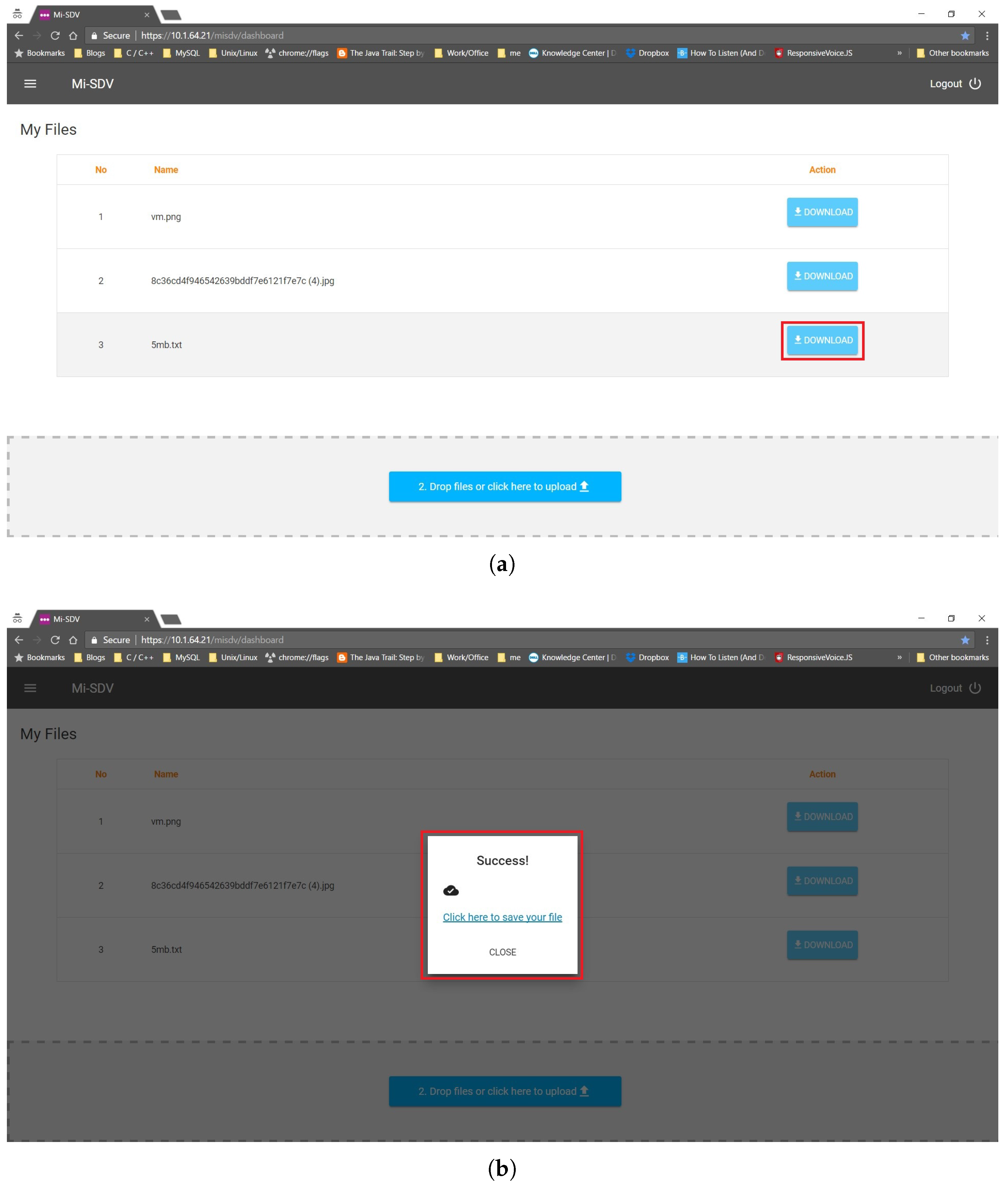
5.3. Submitting a Document
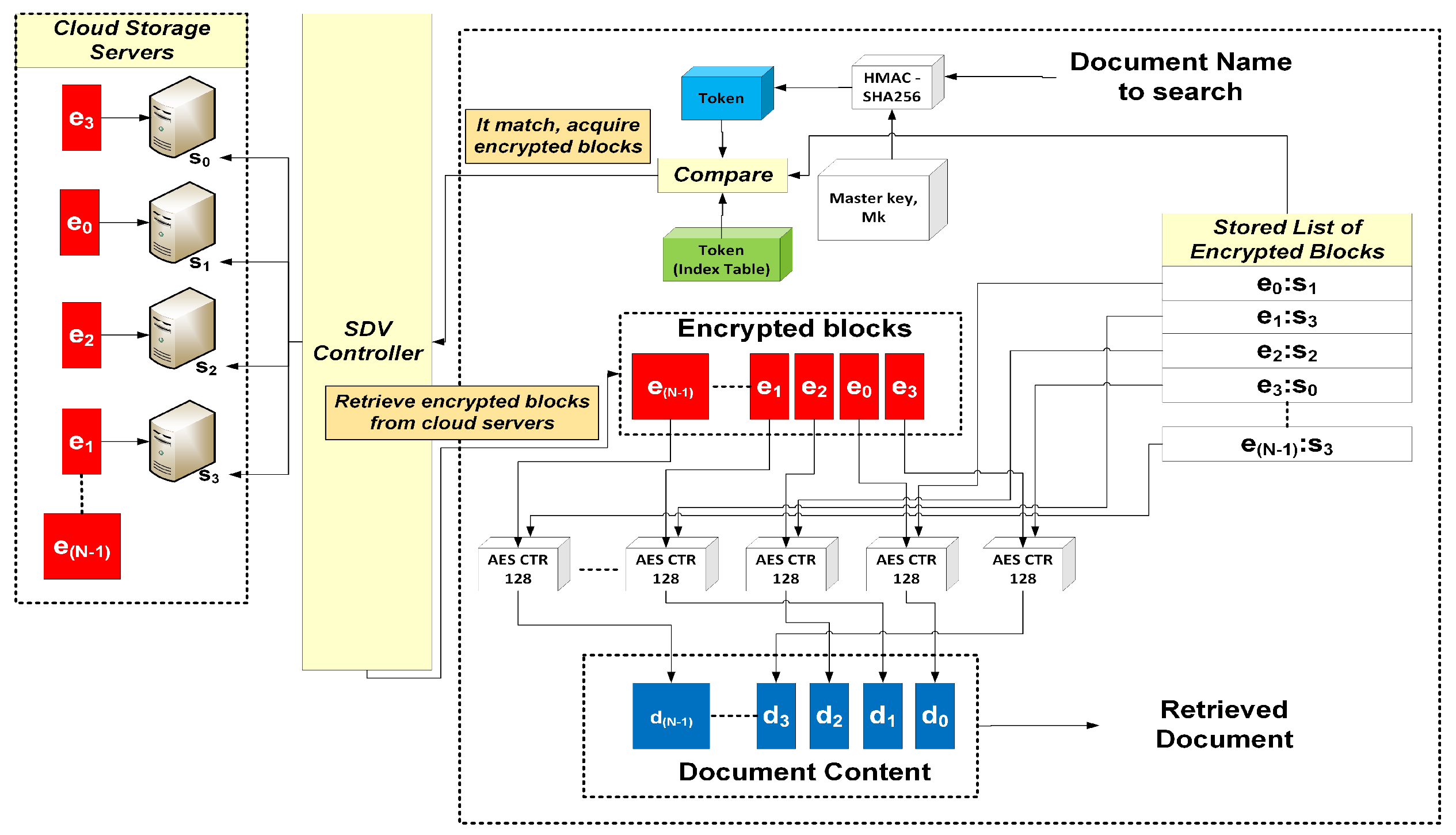
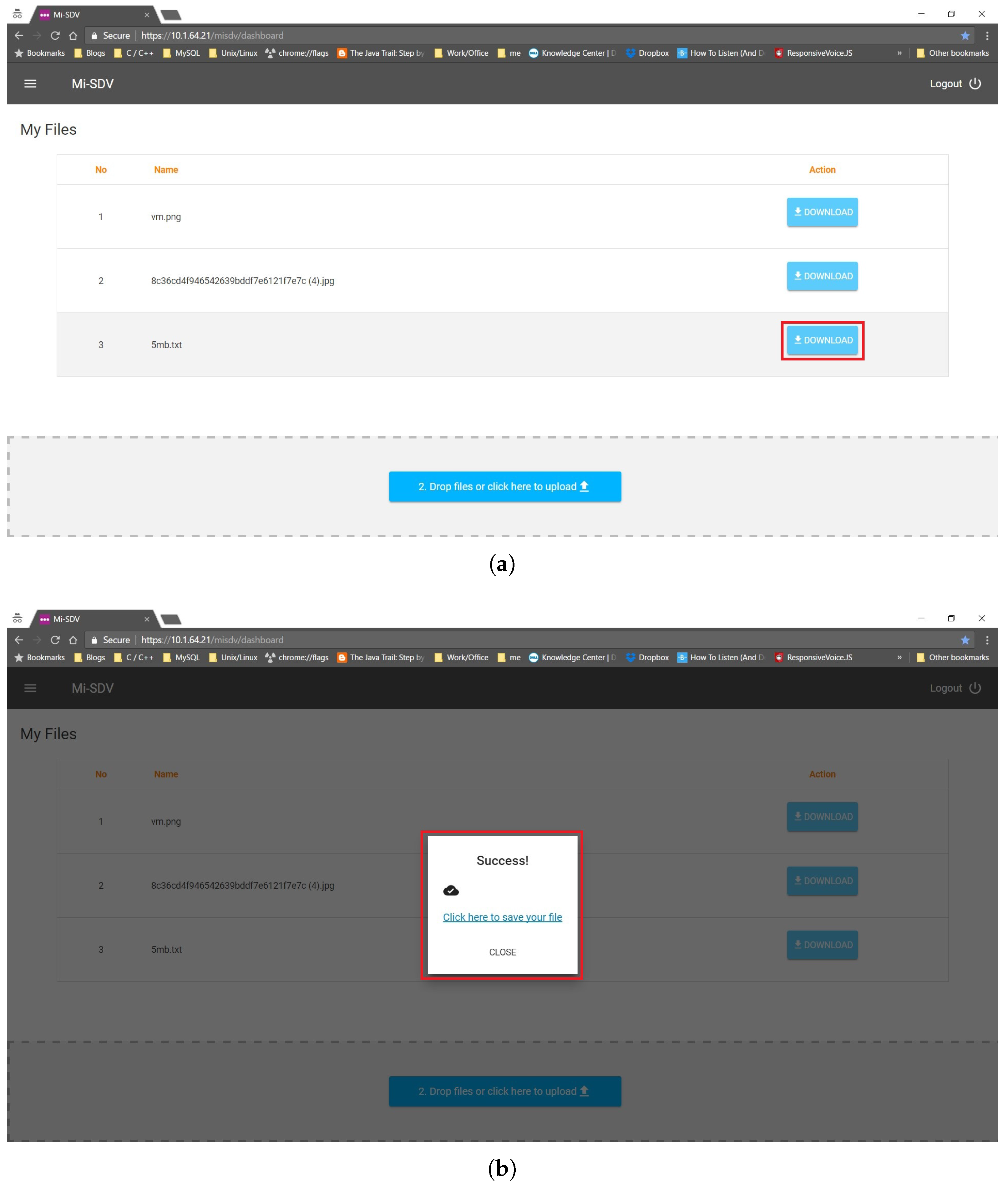
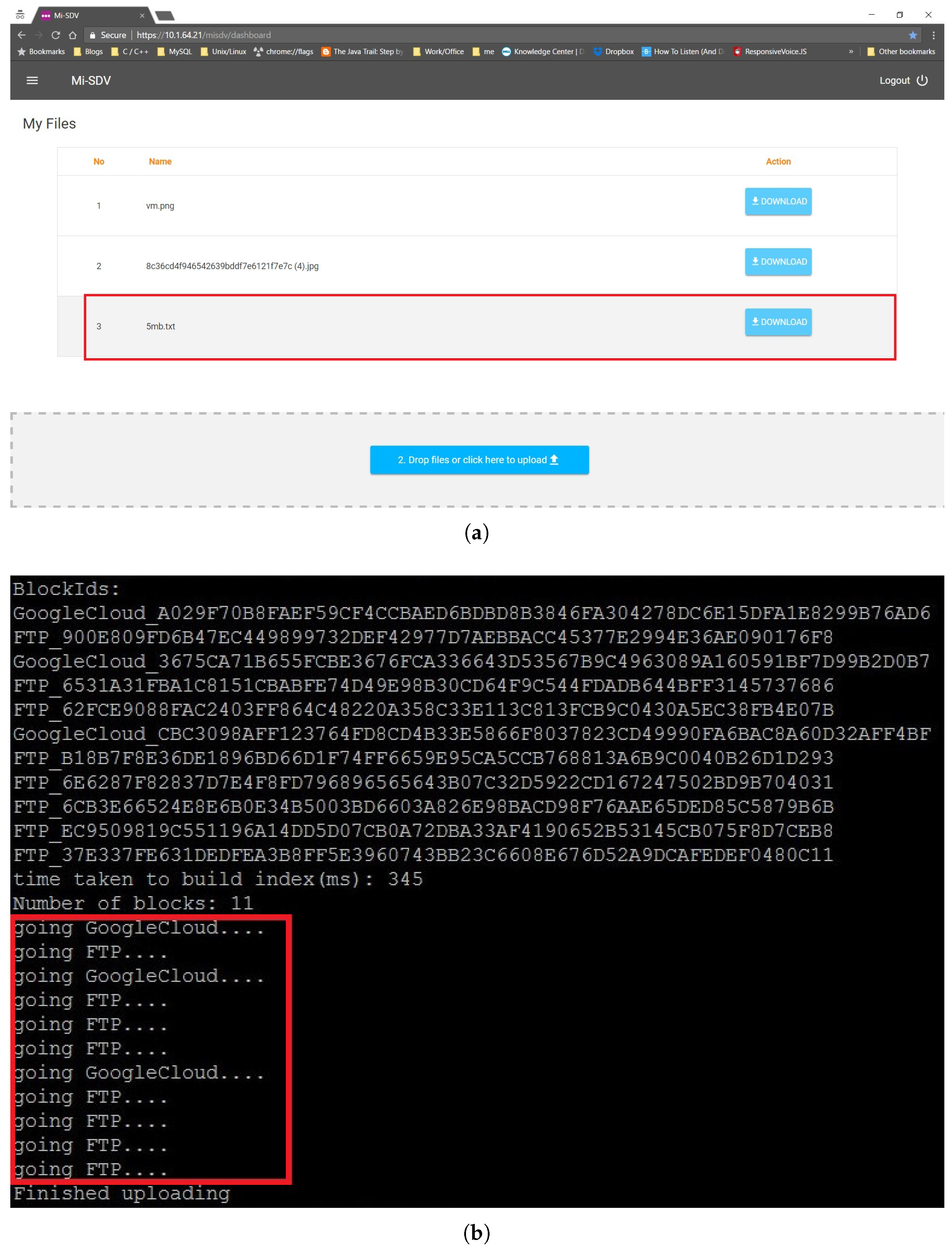
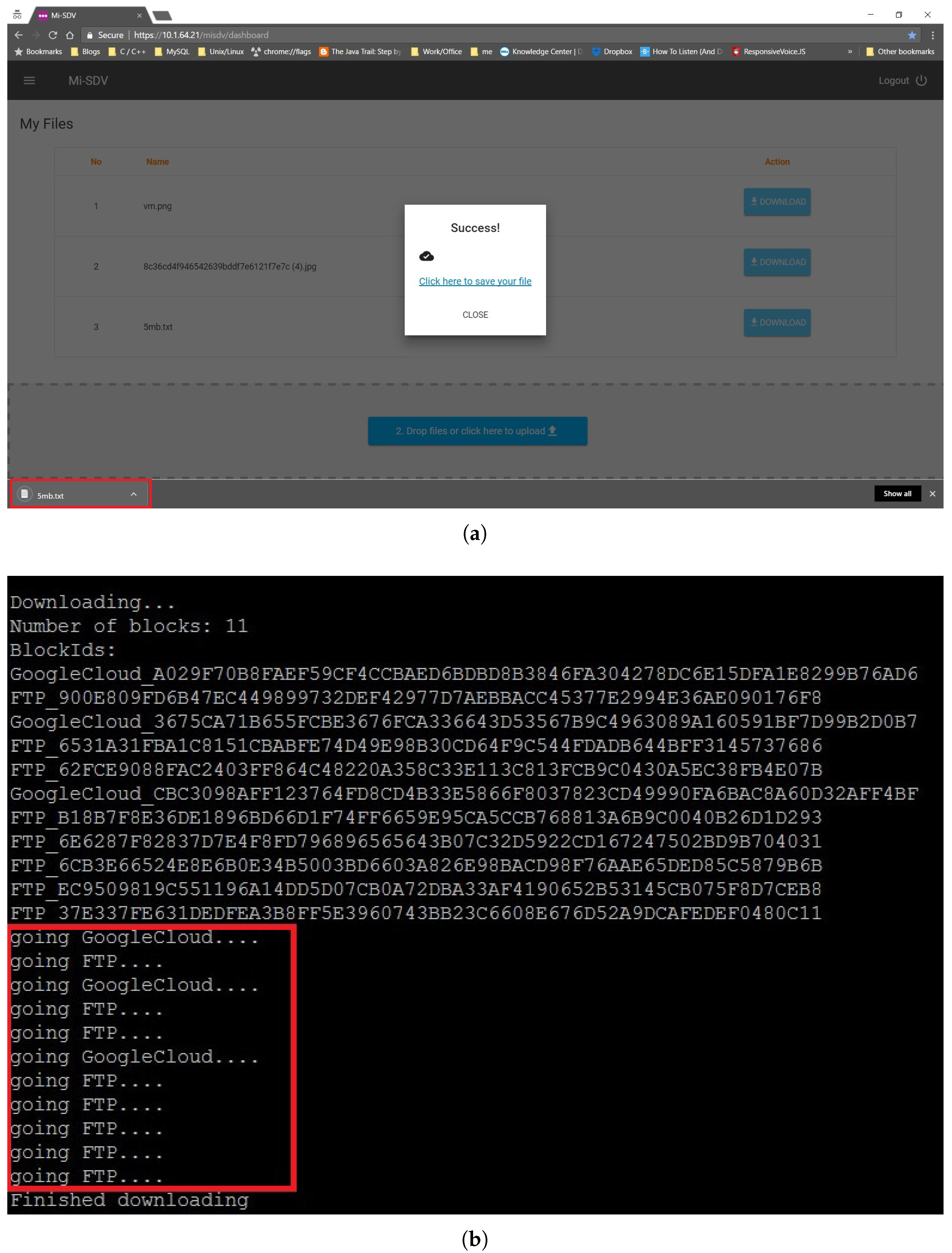
5.4. Searching and Retrieving a Document
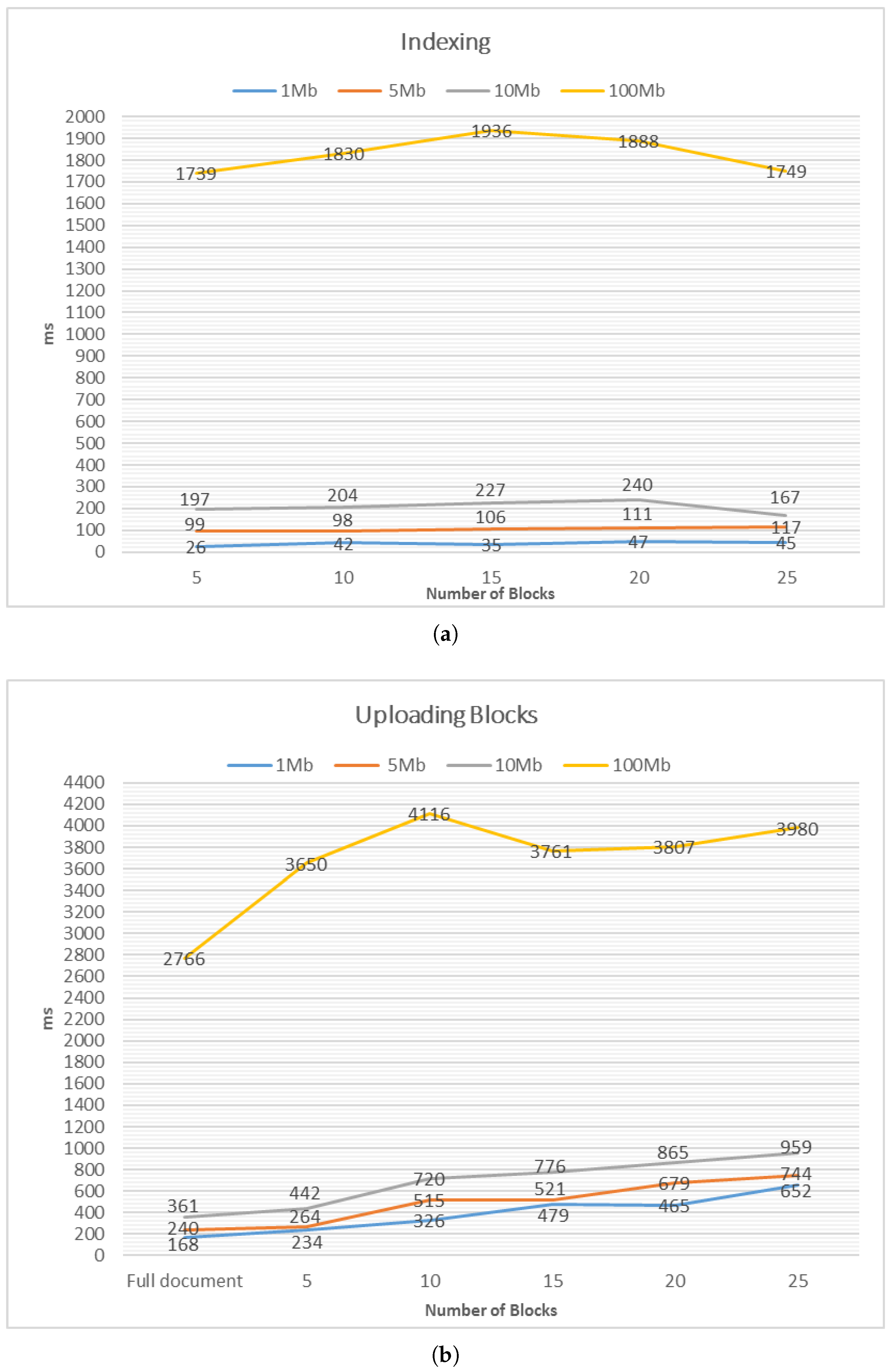
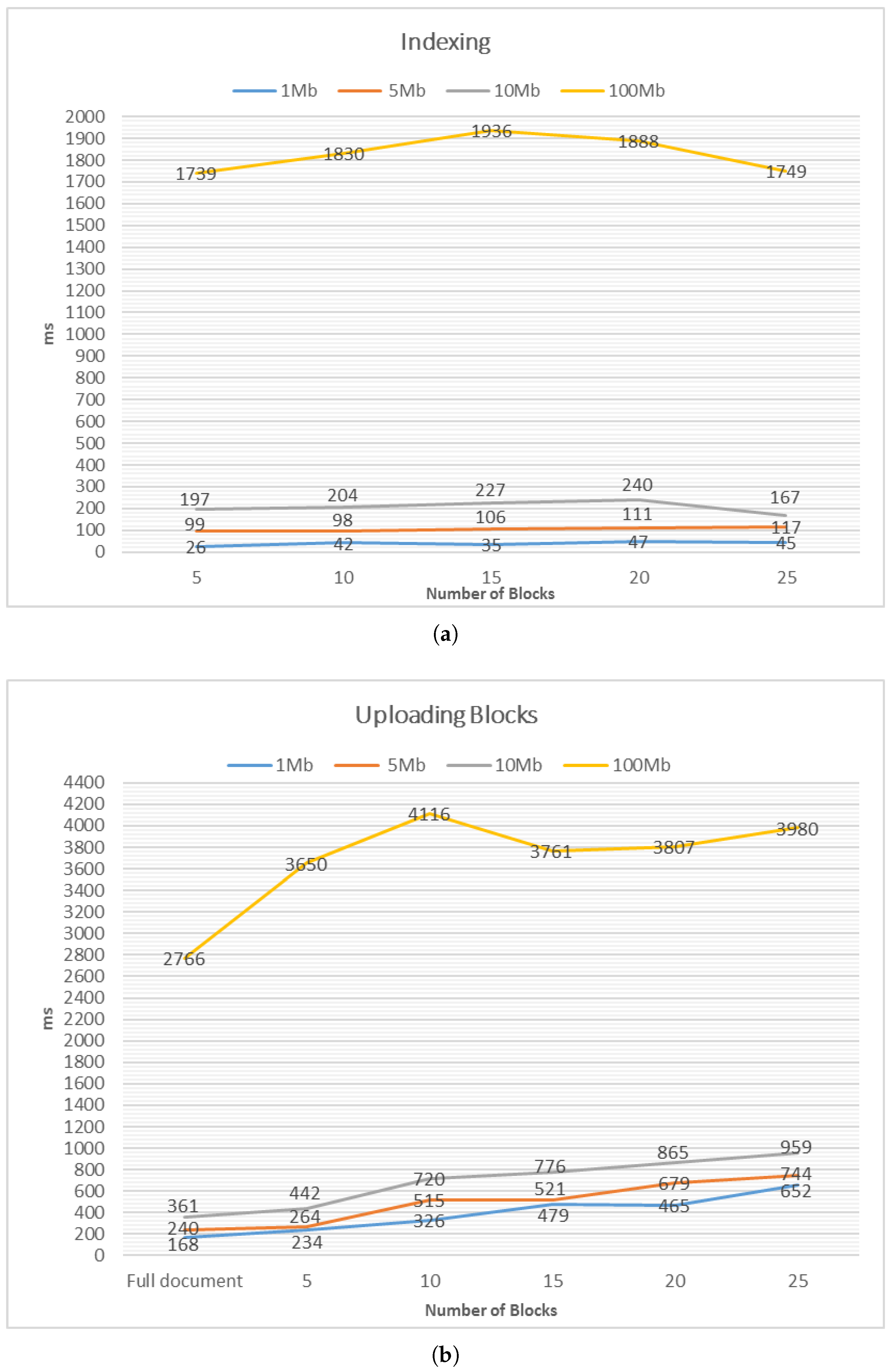
5.5. Performance
6. Discussions
6.1. Number of Servers
6.2. Generating Block Identifiers
6.3. Block Size
6.4. Limitation
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Netwrix. 2016 Cloud Security Report. 2016. Available online: https://www.netwrix.com/2016cloud_security_report.html (accessed on 6 May 2017).
- Cisco Systems, Inc. Cisco Global Cloud Index: Forecast and Methodology, 2015–2020; Cisco Systems, Inc.: San José, CA, USA, 2016. [Google Scholar]
- Poh, G.S.; Mohamad, M.S.; Chin, J.J. Searchable Symmetric Encryption over Multiple Servers. In Proceedings of the Arctic Crypt, Longyearbyen, Norway, 17–22 July 2016. [Google Scholar]
- Seak, S.C.; Siong, N.K.; Loon, W.H.; Haron, G.R. A Centralized Multimodal Unified Authentication Platform for Web-based Application. In Proceedings of the World Congress on Engineering and Computer Science (WCECS) 2014, San Francisco, CA, USA, 22–24 October 2014; pp. 157–172. [Google Scholar]
- Cash, D.; Jarecki, S.; Jutla, C.S.; Krawczyk, H.; Rosu, M.C.; Steiner, M. Highly-Scalable Searchable Symmetric Encryption with Support for Boolean Queries. In CRYPTO 2013; Canetti, R., Garay, J.A., Eds.; Springer: New York, NY, USA, 2013; Volume 8042, pp. 353–373. [Google Scholar]
- Cao, N.; Wang, C.; Li, M.; Ren, K.; Lou, W. Privacy-Preserving Multi-Keyword Ranked Search over Encrypted Cloud Data. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 222–233. [Google Scholar] [CrossRef]
- Popa, R.A.; Redfield, C.M.S.; Zeldovich, N.; Balakrishnan, H. CryptDB: Protecting confidentiality with encrypted query processing. In SOSP 2011; Wobber, T., Druschel, P., Eds.; ACM: New York, NY, USA, 2011; pp. 85–100. [Google Scholar]
- Song, D.X.; Wagner, D.; Perrig, A. Practical Techniques for Searches on Encrypted Data. In Proceedings of the IEEE Symposium on Security and Privacy (S&P 2000), Berkeley, CA, USA, 14–17 May 2000; p. 44. [Google Scholar]
- Lau, B.; Chung, S.P.; Song, C.; Jang, Y.; Lee, W.; Boldyreva, A. Mimesis Aegis: A Mimicry Privacy Shield-A System’s Approach to Data Privacy on Public Cloud. In Proceedings of the 23rd USENIX Security Symposium, San Diego, CA, USA, 20–22 August 2014; pp. 33–48. [Google Scholar]
- Pappas, V.; Krell, F.; Vo, B.; Kolesnikov, V.; Malkin, T.; Choi, S.G.; George, W.; Keromytis, A.D.; Bellovin, S. Blind Seer: A Scalable Private DBMS. In Proceedings of the IEEE Symposium on Security and Privacy (S&P 2014), San Jose, CA, USA, 18–21 May 2014; pp. 359–374. [Google Scholar]
- Fisch, B.A.; Vo, B.; Krell, F.; Kumarasubramanian, A.; Kolesnikov, V.; Malkin, T.; Bellovin, S.M. Malicious-Client Security in Blind Seer: A Scalable Private DBMS. In Proceedings of the IEEE Symposium on Security and Privacy (S&P 2015), San Jose, CA, USA, 17–21 May 2015; pp. 395–410. [Google Scholar]
- Popa, R.A.; Stark, E.; Valdez, S.; Helfer, J.; Zeldovich, N.; Balakrishnan, H. Building Web Applications on Top of Encrypted Data Using Mylar. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation, Seattle, WA, USA, 2–4 April 2014; pp. 157–172. [Google Scholar]
- Networks, S. Skyhigh Networks: Cloud Security Software. 2016. Available online: https://www.skyhighnetworks.com/ (accessed on 6 May 2016).
- CipherCloud. CipherCloud: Enterprise Cloud Security. 2016. Available online: https://www.ciphercloud.com/ (accessed on 6 May 2016).
- Bitglass. Bitglass: Cloud Access Security Broker. 2016. Available online: http://www.bitglass.com/ (accessed on 6 May 2016).
- Cash, D.; Grubbs, P.; Perry, J.; Ristenpart, T. Leakage-Abuse Attacks Against Searchable Encryption. In ACM CCS 2015; Ray, I., Li, N., Kruegel, C., Eds.; ACM: New York, NY, USA, 2015; pp. 668–679. [Google Scholar]
- Goh, E.J. Secure Indexes. IACR Cryptology ePrint Archive, Report 2003/216. 2003. Available online: http://eprint.iacr.org/2003/216/ (accessed on 6 May 2016).
- Chang, Y.C.; Mitzenmacher, M. Privacy Preserving Keyword Searches on Remote Encrypted Data. In ACNS 2005; Ioannidis, J., Keromytis, A.D., Yung, M., Eds.; Springer: New York, NY, USA, 2005; Volume 3531, pp. 442–455. [Google Scholar]
- Curtmola, R.; Garay, J.A.; Kamara, S.; Ostrovsky, R. Searchable Symmetric Encryption: Improved Definitions and Efficient Constructions. In ACM CCS 2006; Juels, A., Wright, R.N., di Vimercati, S.D.C., Eds.; ACM: New York, NY, USA, 2006; pp. 79–88. [Google Scholar]
- Chase, M.; Kamara, S. Structured Encryption and Controlled Disclosure. In ASIACRYPT 2010; Abe, M., Ed.; Springer: New York, NY, USA, 2010; Volume 6477, pp. 577–594. [Google Scholar]
- Kamara, S.; Papamanthou, C. Parallel and Dynamic Searchable Symmetric Encryption. In FC’13; Sadeghi, A.R., Ed.; Springer: New York, NY, USA, 2013; Volume 7859, pp. 258–274. [Google Scholar]
- Kamara, S.; Papamanthou, C.; Roeder, T. Dynamic Searchable Symmetric Encryption. In ACM CCS’12; Yu, T., Danezis, G., Gligor, V.D., Eds.; ACM: New York, NY, USA, 2012; pp. 965–976. [Google Scholar]
- Cash, D.; Jaeger, J.; Jarecki, S.; Jutla, C.S.; Krawczyk, H.; Rosu, M.C.; Steiner, M. Dynamic Searchable Encryption in Very Large Databases: Data Structures and Implementation. In Proceedings of the 2014 Network and Distributed System Security (NDSS) Symposium, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Kurosawa, K.; Ohtaki, Y. How to Construct UC-Secure Searchable Symmetric Encryption Scheme. 2015. Available online: https://pdfs.semanticscholar.org/bdbb/d27c0cda8f05419565cfc20b8ce953515047.pdf (accessed on 9 May 2017).
- Mohamad, M.S.; Poh, G.S. Verifiable Structured Encryption. In Inscrypt’12; Kutylowski, M., Yung, M., Eds.; Springer: New York, NY, USA, 2012; Volume 7763, pp. 137–156. [Google Scholar]
- Naveed, M.; Prabhakaran, M.; Gunter, C.A. Dynamic Searchable Encryption via Blind Storage. In Proceedings of the IEEE Symposium on Security and Privacy (S&P 2014), San Jose, CA, USA, 18–21 May 2014; pp. 639–654. [Google Scholar]
- Stefanov, E.; Papamanthou, C.; Shi, E. Practical Dynamic Searchable Encryption with Small Leakage. In Proceedings of the 2014 Network and Distributed System Security (NDSS) Symposium, San Diego, CA, USA, 23–26 February 2014. [Google Scholar]
- Bösch, C.; Peter, A.; Leenders, B.; Lim, H.W.; Tang, Q.; Wang, H.; Hartel, P.H.; Jonker, W. Distributed Searchable Symmetric Encryption. In Proceedings of the Twelfth Annual Conference on Privacy, Security and Trust (PST), Toronto, ON, Canada, 23–24 July 2014; pp. 330–337. [Google Scholar]
- Ishai, Y.; Kushilevitz, E.; Lu, S.; Ostrovsky, R. Private Large-Scale Databases with Distributed Searchable Symmetric Encryption. IACR Cryptol. ePrint Arch. 2015, 2015, 1190. [Google Scholar]
- Kuzu, M.; Islam, M.S.; Kantarcioglu, M. Distributed Search over Encrypted Big Data. In ACM CODASPY 2015; Park, J., Squicciarini, A.C., Eds.; ACM: New York, NY, USA, 2015; pp. 271–278. [Google Scholar]
- Boneh, D.; Crescenzo, G.D.; Ostrovsky, R.; Persiano, G. Public Key Encryption with Keyword Search. In EUROCRYPT 2004; Cachin, C., Camenisch, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3027, pp. 506–522. [Google Scholar]
- Gentry, C. A Fully Homomorphic Encryption Scheme. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2009. [Google Scholar]
- Goldreich, O.; Ostrovsky, R. Software Protection and Simulation on Oblivious RAMs. J. ACM 1996, 43, 431–473. [Google Scholar] [CrossRef]
- Stefanov, E.; Shi, E. ObliviStore: High Performance Oblivious Cloud Storage. In Proceedings of the IEEE Symposium on Security and Privacy (S&P 2013), San Francisco, CA, USA, 19–22 May 2013; pp. 253–267. [Google Scholar]
- Bösch, C.; Hartel, P.; Jonker, W.; Peter, A. A Survey of Provably Secure Searchable Encryption. ACM Comput. Surv. 2014, 47, 18. [Google Scholar] [CrossRef]
- Storage, I. Ceph. Available online: http://ceph.com/ (accessed on 6 May 2017).
| SSE = (Setup, Search, Update) |
| Setup |
| Input: A set of n documents , filenames of the documents (as keyword index), a list of s server identifiers . |
Output: A set of secret keys K, a set of encrypted blocks C and an index table I.
|
| Input: A keyword (). |
Output: A sequence of tuple (block identifier, server identifier) or false.
|
| Input: An operation op (add or remove), optionally an input object (a filename), the index table I and the set of server identifiers. |
Output: True with the updated index , or false (for unsuccessful addition or removal).
|

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| D | , is a set of n documents. |
| A document i. | |
| S | , is a set of s servers. |
| A server x. | |
| C | , is a set of lists of s encrypted blocks. |
| An identifier of an item x. | |
| K | A set of cryptographic keys. |
| I | A query index with a structure, in which given a , the is returned. |
| A keyword token. | |
| A temporary list to hold the identifiers of the encrypted blocks. | |
| A keyed pseudorandom function with key . This is used to generate keyword token. | |
| is a symmetric encryption scheme where Gen is the key generation function, Enc the encryption function and Dec the decryption function. | |
| op | The document addition or removal operation of the update algorithm in a SSE scheme, op Doc+, Doc-}. |
| in | The information submitted to the update algorithm. in can be a document for Doc+ or an identifier for Doc-. |
| A leakage profile that states information leakage of the l phase in a SSE scheme (i.e., document size, index size), where . | |
| A negligible function with security parameter . | |
| A simulator. | |
| An adversary. | |
| B, | List of blocks, and the number of blocks in the list. |
| b | Length (or size) of a block. |
| 1 MB | 5 MB | 10 MB | 100 MB | |
|---|---|---|---|---|
| [1 mb.txt] | [5 mb.txt] | [10 mb.txt] | [100 mb.txt] | |
| Indexing | 26 (45) | 99 (117) | 197 (167) | 1739 (1749) |
| Uploading blocks | 234 (465) | 264 (679) | 442 (865) | 3650 (3807) |
| Uploading full document | 168 | 240 | 361 | 2766 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poh, G.S.; Baskaran, V.M.; Chin, J.-J.; Mohamad, M.S.; Lee, K.; Maniam, D.; Z’aba, M.R. Searchable Data Vault: Encrypted Queries in Secure Distributed Cloud Storage. Algorithms 2017, 10, 52. https://doi.org/10.3390/a10020052
Poh GS, Baskaran VM, Chin J-J, Mohamad MS, Lee K, Maniam D, Z’aba MR. Searchable Data Vault: Encrypted Queries in Secure Distributed Cloud Storage. Algorithms. 2017; 10(2):52. https://doi.org/10.3390/a10020052
Chicago/Turabian StylePoh, Geong Sen, Vishnu Monn Baskaran, Ji-Jian Chin, Moesfa Soeheila Mohamad, Kay Win Lee, Dharmadharshni Maniam, and Muhammad Reza Z’aba. 2017. "Searchable Data Vault: Encrypted Queries in Secure Distributed Cloud Storage" Algorithms 10, no. 2: 52. https://doi.org/10.3390/a10020052
APA StylePoh, G. S., Baskaran, V. M., Chin, J.-J., Mohamad, M. S., Lee, K., Maniam, D., & Z’aba, M. R. (2017). Searchable Data Vault: Encrypted Queries in Secure Distributed Cloud Storage. Algorithms, 10(2), 52. https://doi.org/10.3390/a10020052