1. Introduction
With the rapid growth of positioning technology, locations can be acquired by many devices such as mobile phones and global position system (GPS)-based equipment. Location prediction is of great significance in many location-based services. For example, while a package is being delivered, customers are eager to know where the courier is and which place he would visit next, in order to estimate the arrival time of the package. The same scenario applies to food delivery. Moreover, in public transportation systems, passengers are curious about where the nearest taxi or bus will go so as to estimate their waiting time. In real-time advertising systems, places where customers will go are important because they determine which kinds of ads to be posted. Location prediction can be determined in the following way: given a series of locations, pre-collected or real-time-dependent, location prediction techniques will infer the next location where the object is most likely to go.
Due to the continuity of space and time, trajectory is not suitable to be directly imported to a prediction model. Before using prediction models, each of the points in a trajectory is first preprocessed in order to convert the real continuous values associated to the geospatial coordinates of latitude and longitude, into discrete codes associated to specific regions. Traditional prediction methods usually start with clustering trajectories into frequent regions or stay points, or simply partition trajectories into cells. Trajectories are transformed into clusters or grids with discrete codes, then pattern mining or model building techniques are utilized to find frequent patterns along the clusters. For example, the historical trajectories of a person show that he always go to the restaurant after the gym. If the person is now in the gym, it is a distinct possibility that the next place he will visit is the restaurant.
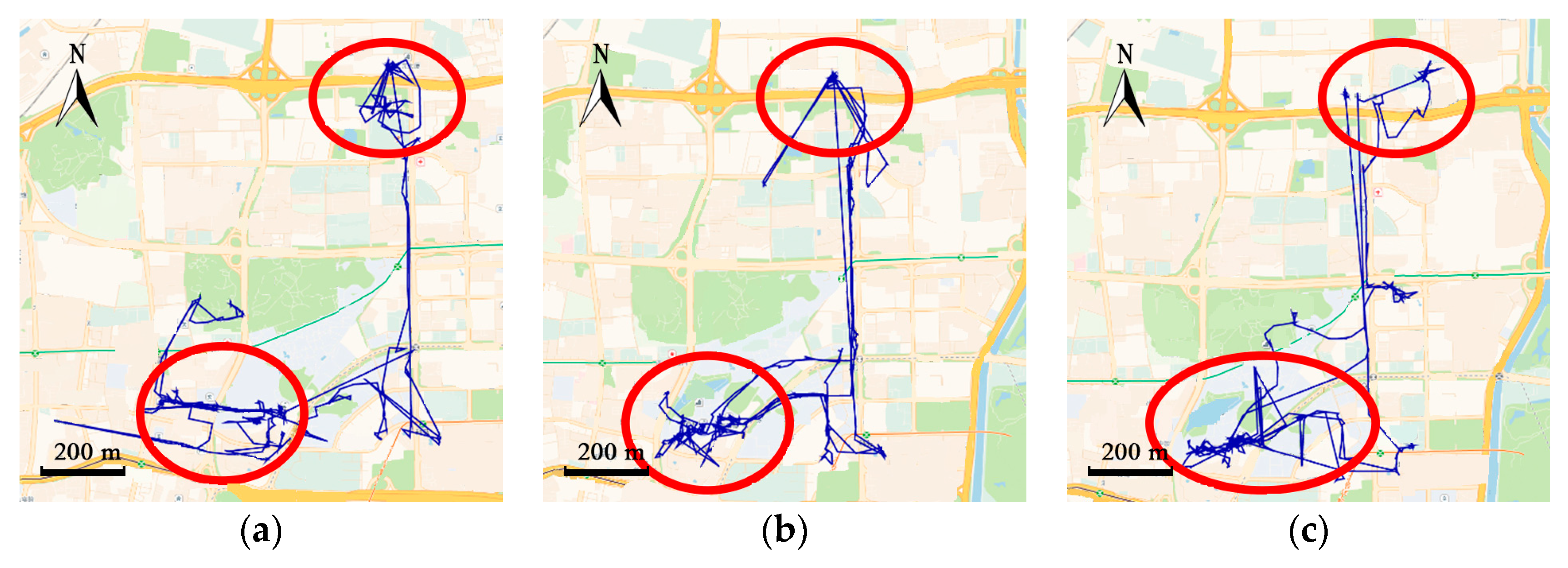
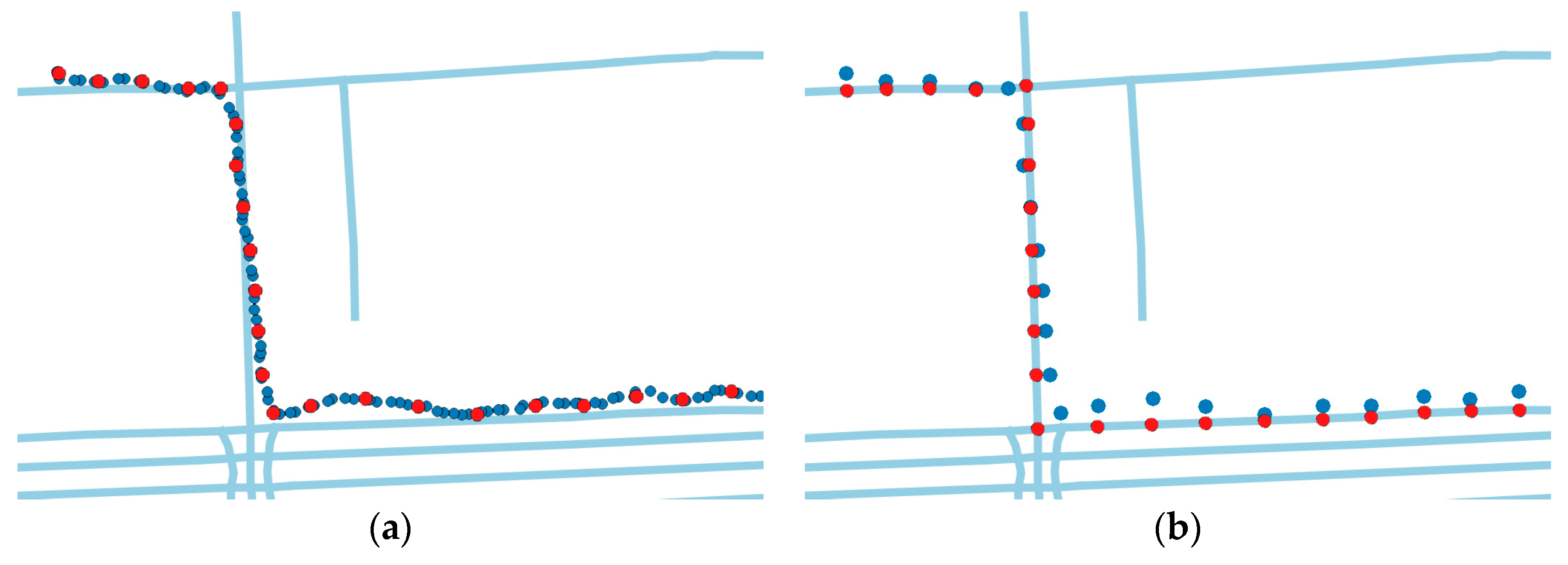
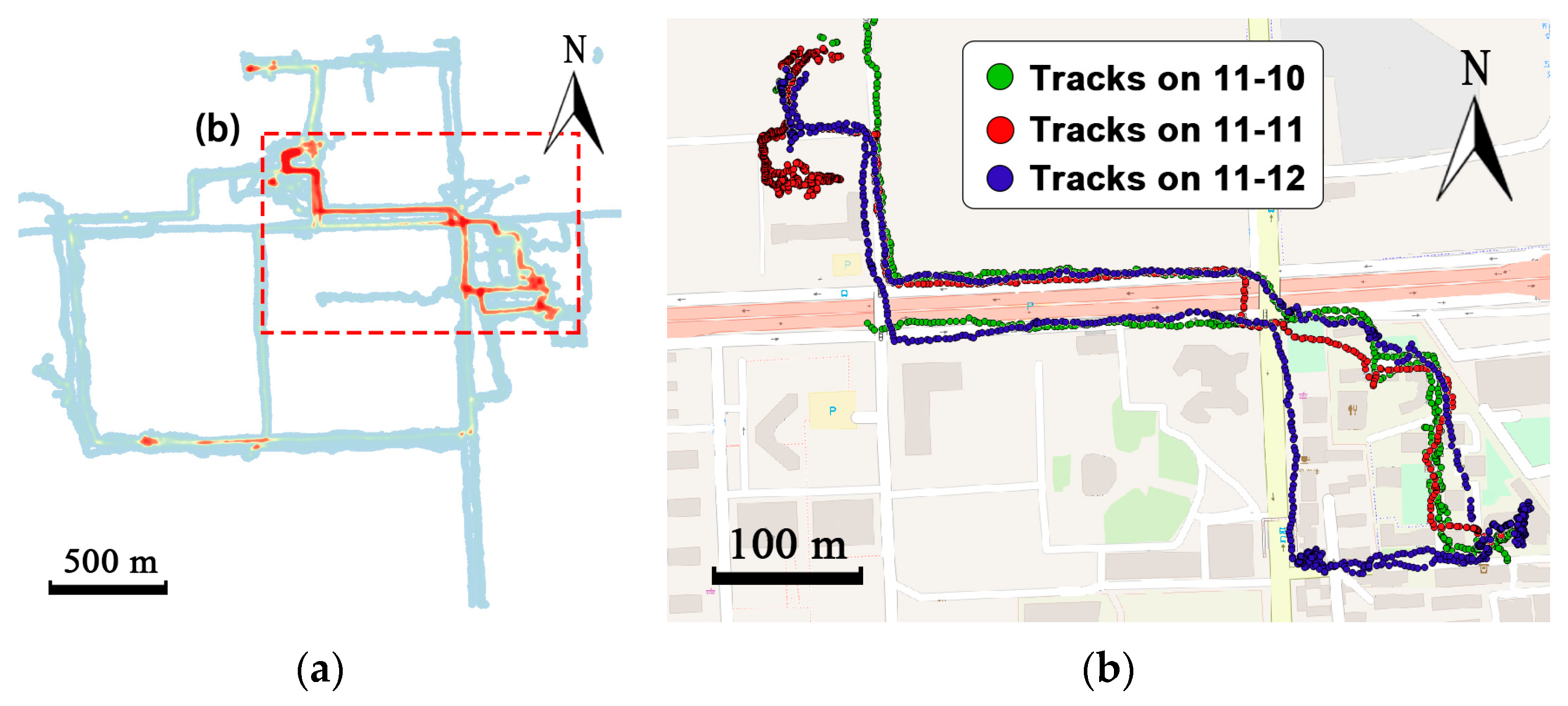
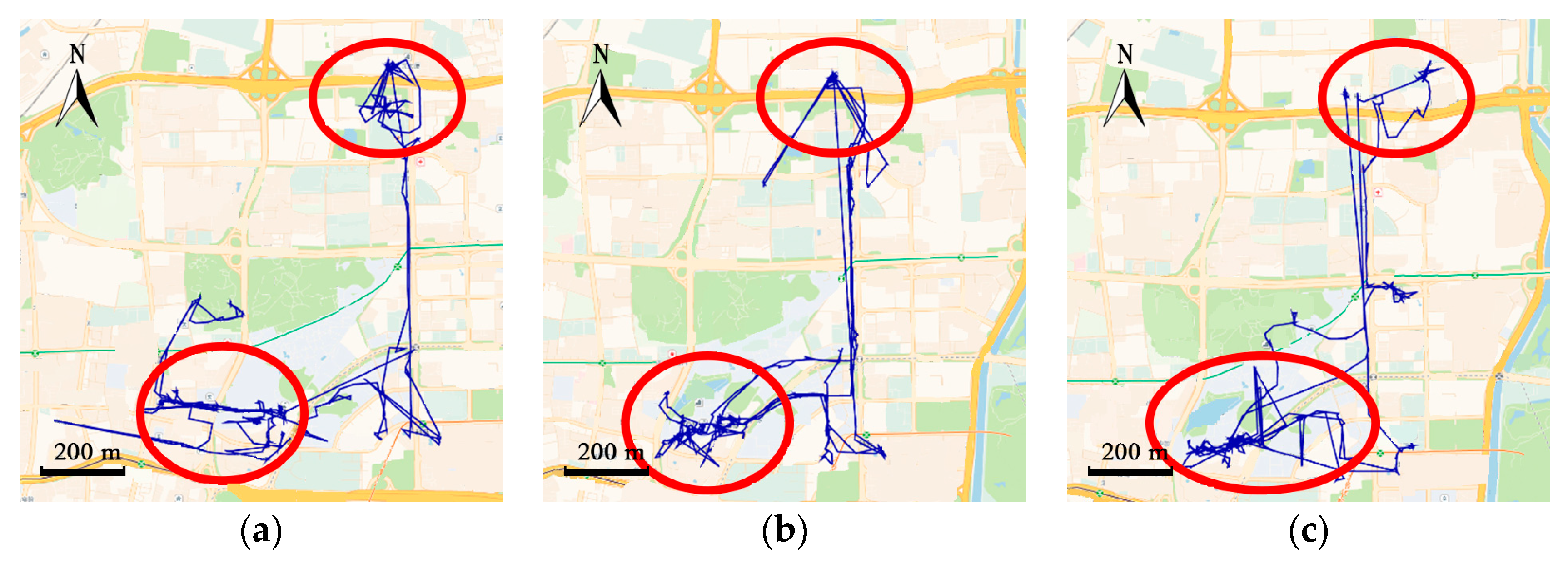
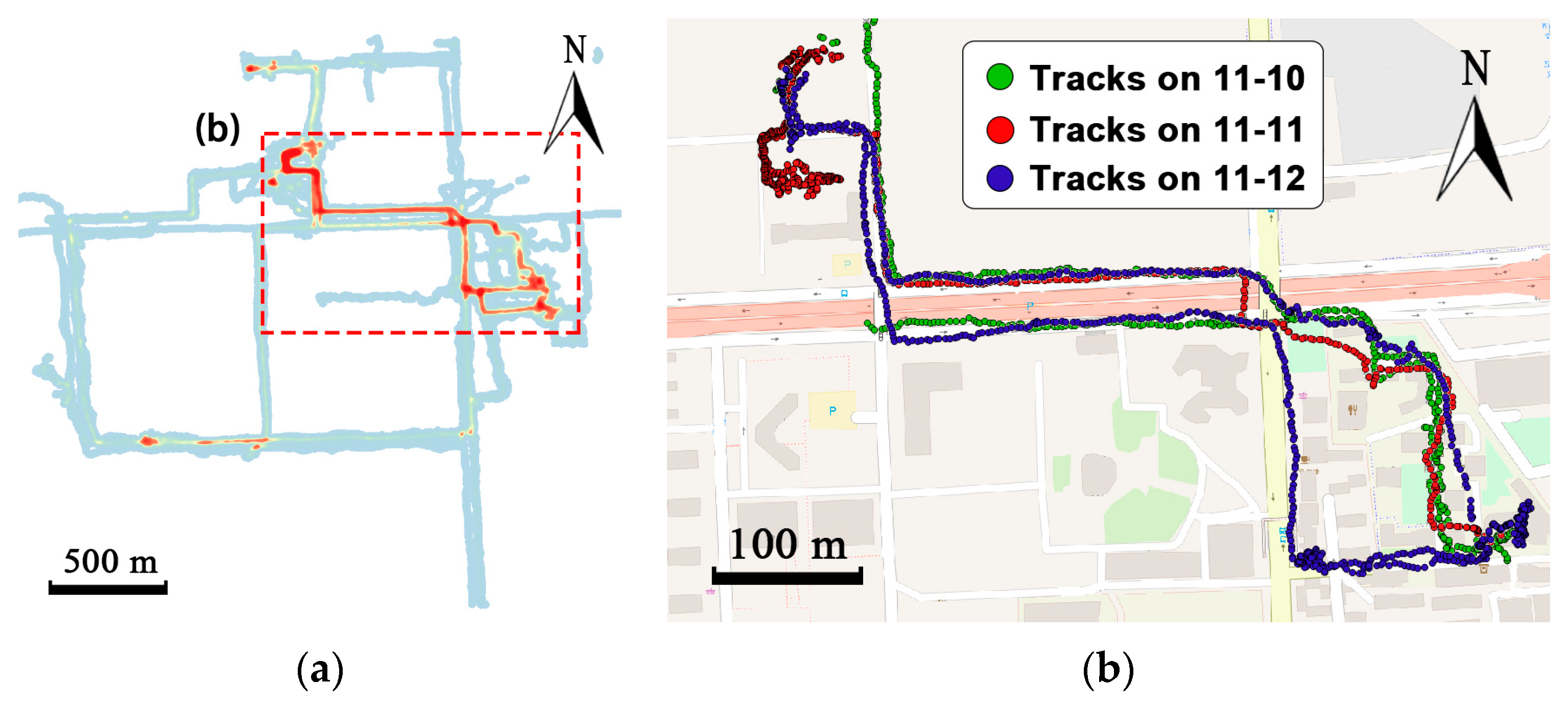
However, traditional cluster-based or cell-based methods ignore trajectories between the clusters, which may contain critical information for specific applications. For example, trajectories in
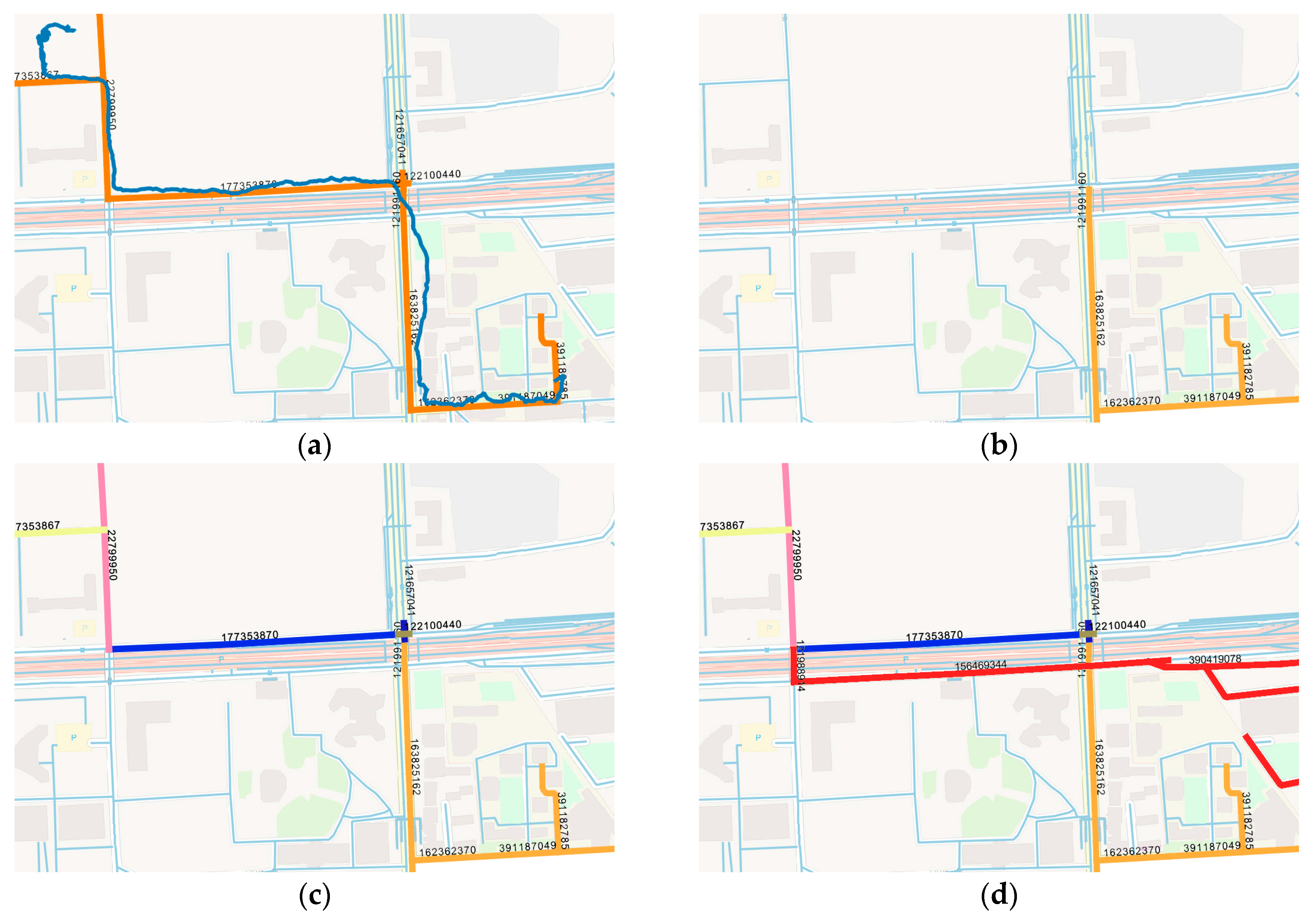
Figure 1a contain 350 track points and only two frequent regions are grouped. Traditional methods can infer region 2 from region 1, but fail to predict where the courier is between the two regions. Many location-based services such as delivery-pickup system and transportation system pay significant attention to predicting where the objects exactly are along the road.
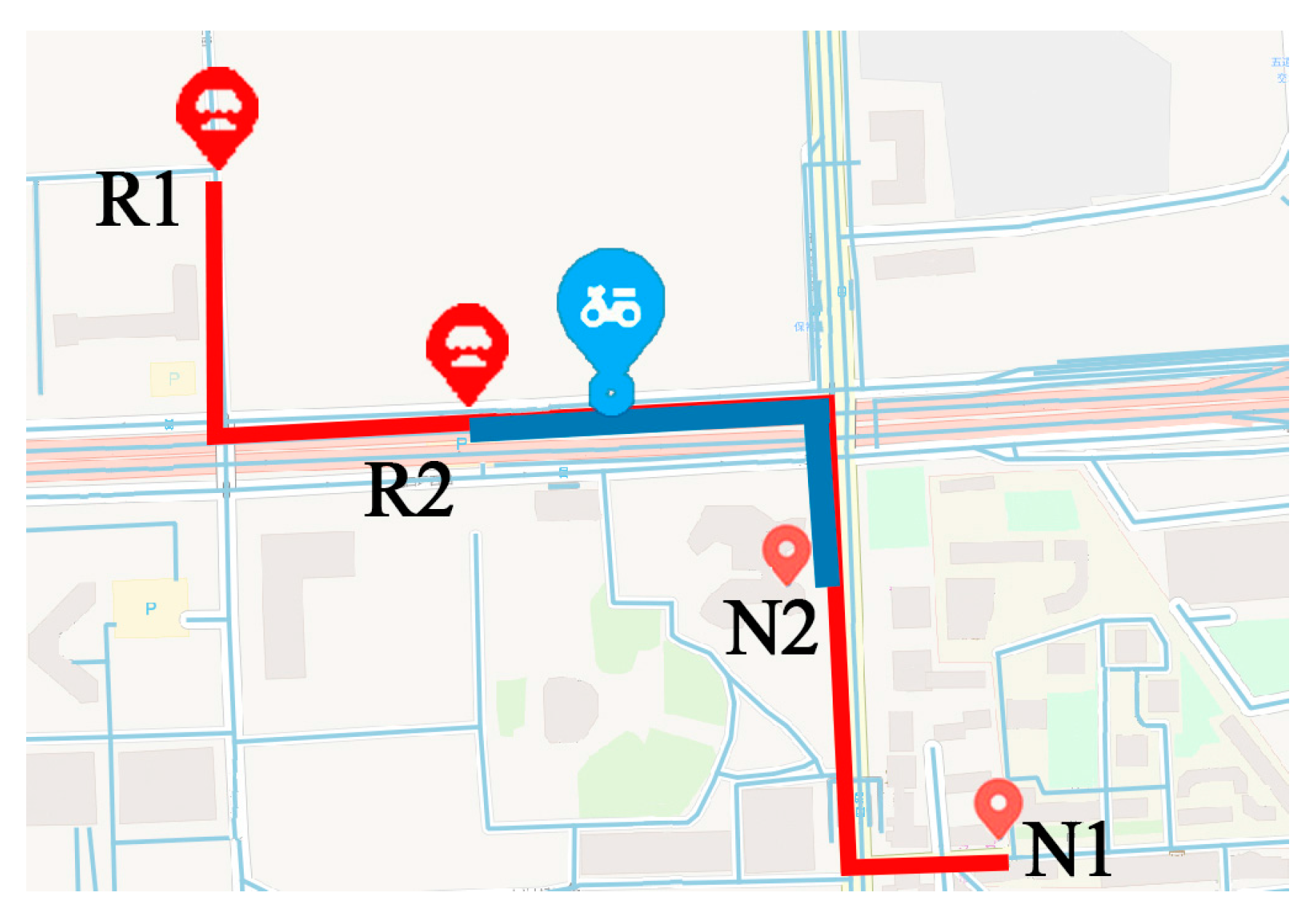
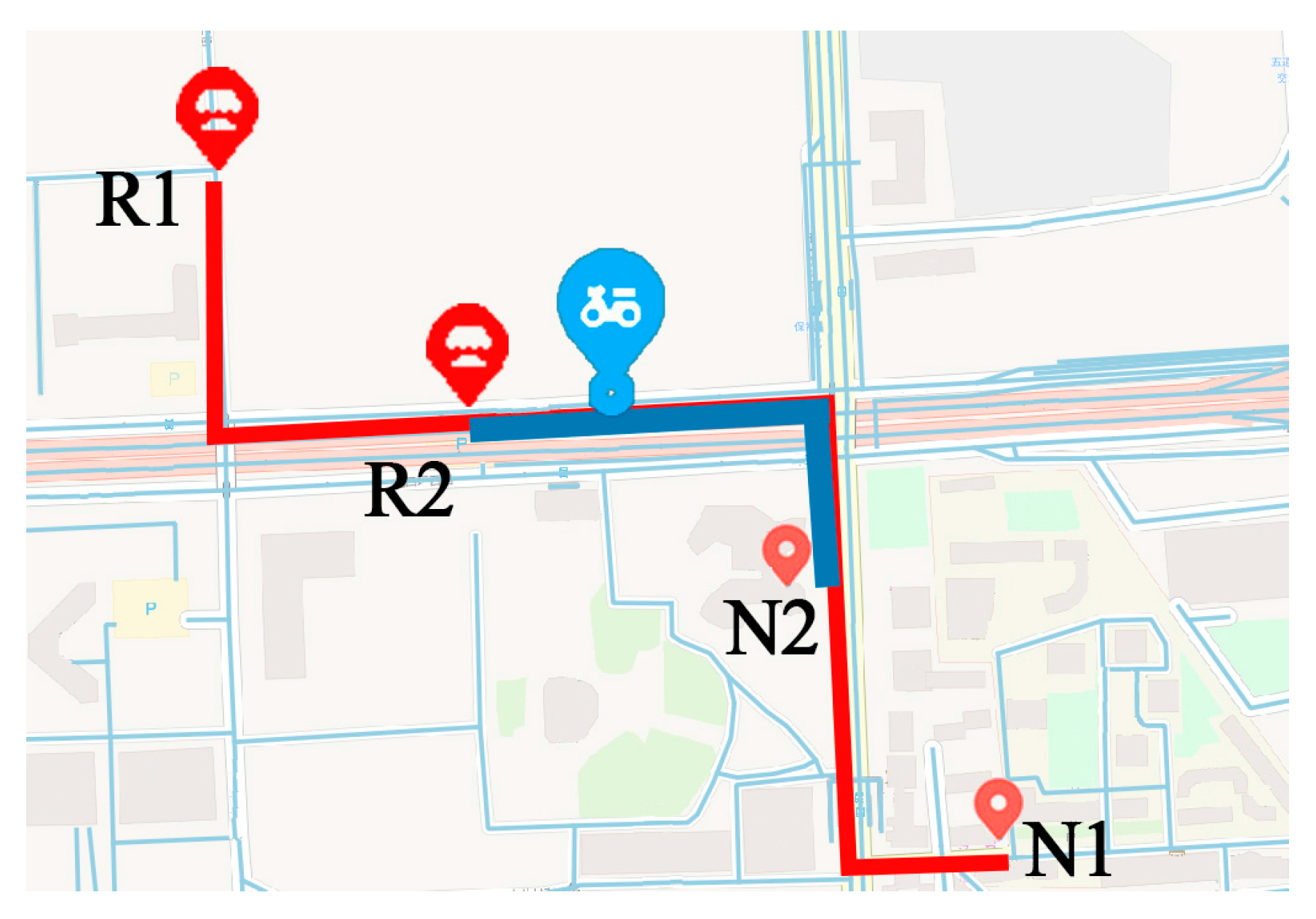
Moreover, frequent patterns or location sequences generated by clustering method are relatively short. Traditional models, such as the hidden Markov model (HMM) and the recurrent neural networks (RNN), are good at handling short sequences. However, when considering points along the road, the length of location sequences generated from raw trajectories become longer. Performance of traditional models may decline with long sequences. For example, as shown in
Figure 2, the courier has two frequent patterns. He always goes to Neighborhood 1 from Restaurant 1 by the route in red, and goes to Neighborhood 2 from Restaurant 2 by the route in blue. One day he started from Restaurant 1 and traveled at the blue spot. Traditional models that deal with short sequences may suggest that the courier started from Restaurant 2, because it is not far away from the courier. Then the model will predict that the next location of the courier is Neighborhood 2 according to the historical patterns. However, the courier is actually going to Neighborhood 1.
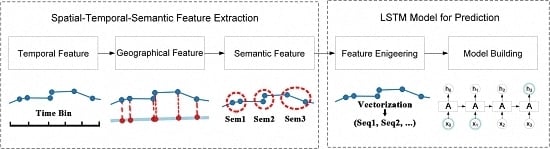
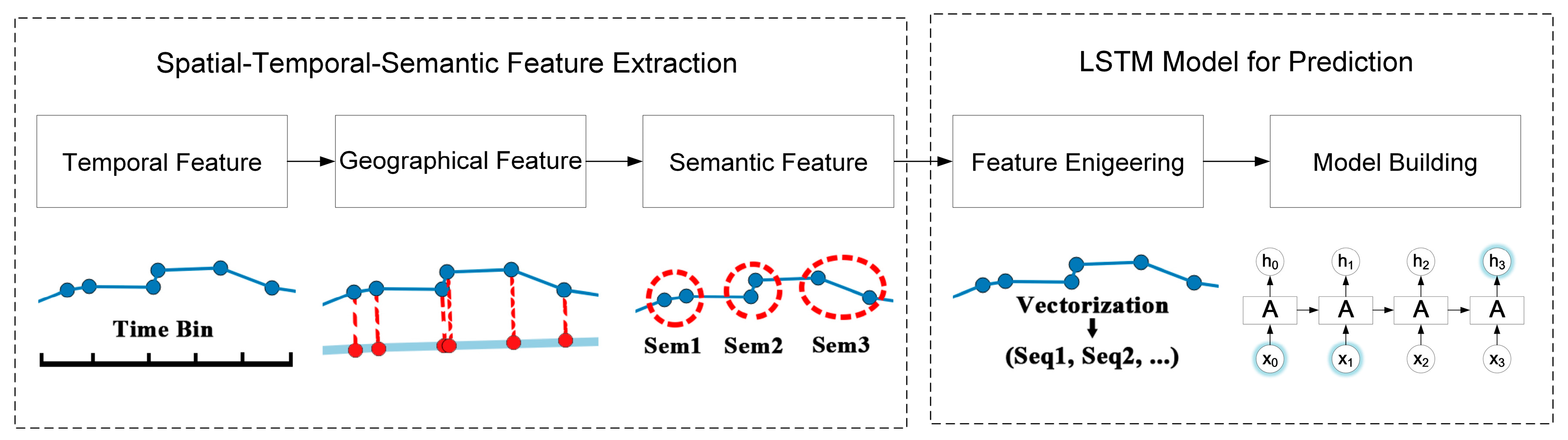
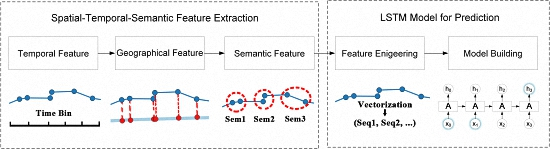
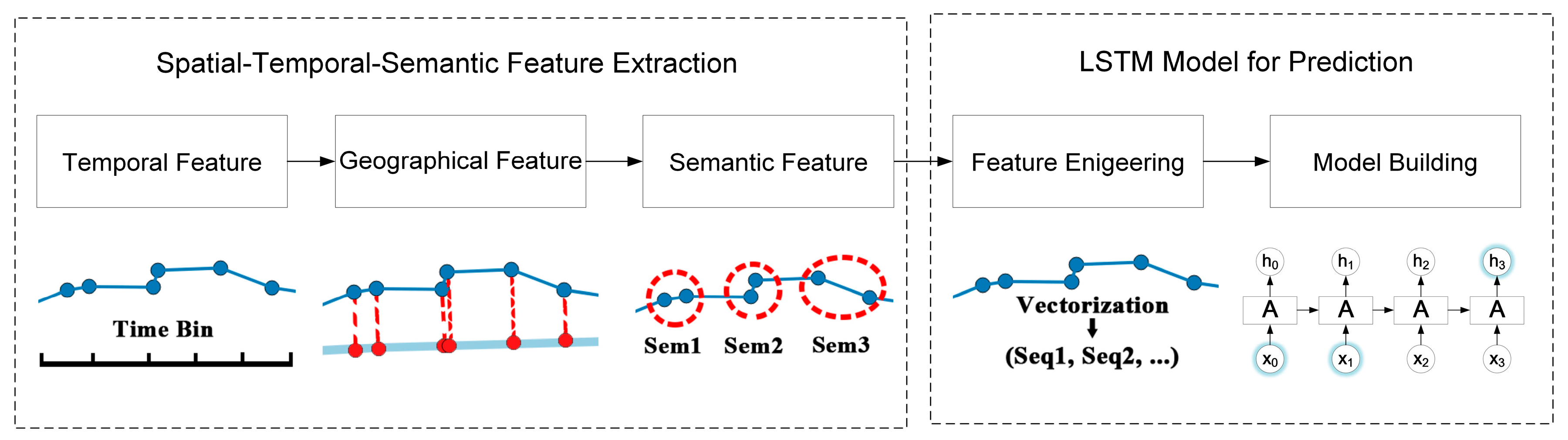
To overcome the above limitations, a spatial-temporal-semantic neural network algorithm for location prediction (STS-LSTM) is proposed in this paper. First, a spatial-temporal-semantic (STS) feature extraction algorithm is put forward to transform the whole trajectory into discrete location sequences with fixed code that are friendly to the prediction model, and will maintain points along the road; Second, a long short-term memory (LSTM)-based neural network model is proposed. The location sequences are partitioned into multiple sequences with fixed length by a sliding window. The next locations are used as labels for classification. Then, both the historical and the current trajectories are used to train the model and to make predictions. The algorithm is evaluated on two real-world datasets and compared with several classic algorithms from the aspects of both feature extraction and model building. The main novelties of the proposed algorithm and contributions of this paper are listed as follows:
Traditional clustering-based prediction algorithms ignore trajectories between the clusters such as points along the road. The proposed STS feature extraction algorithm transforms the trajectory into location sequences with fixed and discrete road IDs. The method can take points along the road into account, which can meet the demand of specific applications. Moreover, the generated location sequences can be better used in the prediction model, which can achieve better prediction results.
The location sequences generated by the STS feature extraction algorithm might be very long. Traditional sequential models such as HMM and RNN may not perform well with long sequences. The LSTM-based prediction model is proposed to solve the problem. The model can take advantage of location sequences over a long period of time, which can make better predictions. Evaluation results prove that both the STS feature extraction algorithm and the LSTM based prediction model outperform traditional methods.
2. Related Work
Studies on location prediction have gained increasing popularity. The most direct manner is to derive the next location by speed and direction according to the past locations. This may not be an accurate method, because the next location is affected by various factors such as traffic condition, weather, and the behaviors of the objects. In recent years, many location prediction methods focus on mining historical track data. The movements of individuals may show regularity. For example, in
Figure 1, couriers deliver the packages from one neighborhood to another, following the same routes and visiting orders every day. Buses travel along the same routes every day. The combination of historical movements and the latest few locations of the objects can provide accurate prediction result.
In addition to trajectory data, location prediction methods based on other spatial-temporal data such as check in data and event-triggered data are also valuable as references. Related works in the area of location prediction are summarized in
Table 1.
The next location is highly related to the interest and intentions of an object. Recommendation algorithms are used to find the most possible place the user is interested in visiting. The matrix factorization-based method by Koren [
1] factorizes a user-item rating matrix considering multiple features including the geo-location. Xiong [
2] extended it as tensor factorization (TF) to be time-aware, by treating time bins as another dimension when factorizing. Zheng [
3] modeled spatial information into factorization models. Moreover, Bahadori [
4] included both temporal and spatial aspects in TF as two separated dimensions and make location more predictable. Zhuang [
5] proposed a recommender that leverages rich context signals from mobile device such as geo-location and time. However, it is hard for factorization-based models to generate movements that have never or seldom appeared in the training data. Monereale [
6] proposed a hybrid method considering both the user’s own data and crowds that have similar behaviors. Recommendation-based algorithms do not consider current locations of users and the order of the movements, which may lead to a low precision of prediction.
Movement pattern mining techniques find the regularity of movements of objects and combine current movements with historical data for prediction. By transforming trajectories into cells, Jiang [
7] studied trajectories of taxis and found they move in flight behaviors. Jeung [
8] forecasted the future locations of a user by predefined motion functions and linear or nonlinear models, then movement patterns are extracted by an a priori algorithm. Yavas [
9] utilized an improved a priori algorithm to find association rules with support and confidence. These frequent patterns reveal the co-occurrences of locations. Morzy [
10] developed a modified PrefixSpan algorithm to discover both the relevance of locations and the order of location sequences. Moreover, sequential pattern methods can be improved by adding temporal information. Giannotti [
11] extended travel time to location sequences and generated spatial-temporal patterns. Li [
12,
13] proposed two kinds of trajectory patterns: the periodic behavior pattern and the swarm pattern. Trajectories are first clustered into reference spots and a Fourier-based algorithm is utilized to detect period. Then periodic patterns are mined by hierarchical clustering. The core step of pattern-based prediction methods is to cluster frequent places. However, due to the limitation of positioning devices, track points will be lost when the satellite signal is low. For example, when buses travel into tunnels or regions covered with tall buildings, the GPS signal is blocked and no points will be collected during that time, which causes the data sparsity problem during clustering. As shown in
Figure 1, the courier also frequently visited the place at the bottom-right section of the map, which is not clustered. Only two frequent areas are gathered and trajectories between the frequent regions are abandoned. Clustering-based algorithms may lose a lot of information, leading to low coverage of prediction.
After extracting the frequent regions from raw trajectories, various kinds of models can be used to make prediction. Lathia [
14] proposed a time-aware neighborhood-based model paying more attention to recent locations and less to the past. Cheng [
15] proposed a multi-center Gaussian model to calculate the distance between patterns. However, neighborhood-based methods do not consider the sequential factors in user’s behaviors. The Markov chain (MC) model can take sequential features into consideration. Rendle [
16] extended the MC with factorization of the transition matrix and calculated the probability of each behavior based on the past behaviors. Mathew [
17] proposed a hybrid hidden Markov model (HMM) to transform the trajectory into clusters and train the HMM with them. Jeung [
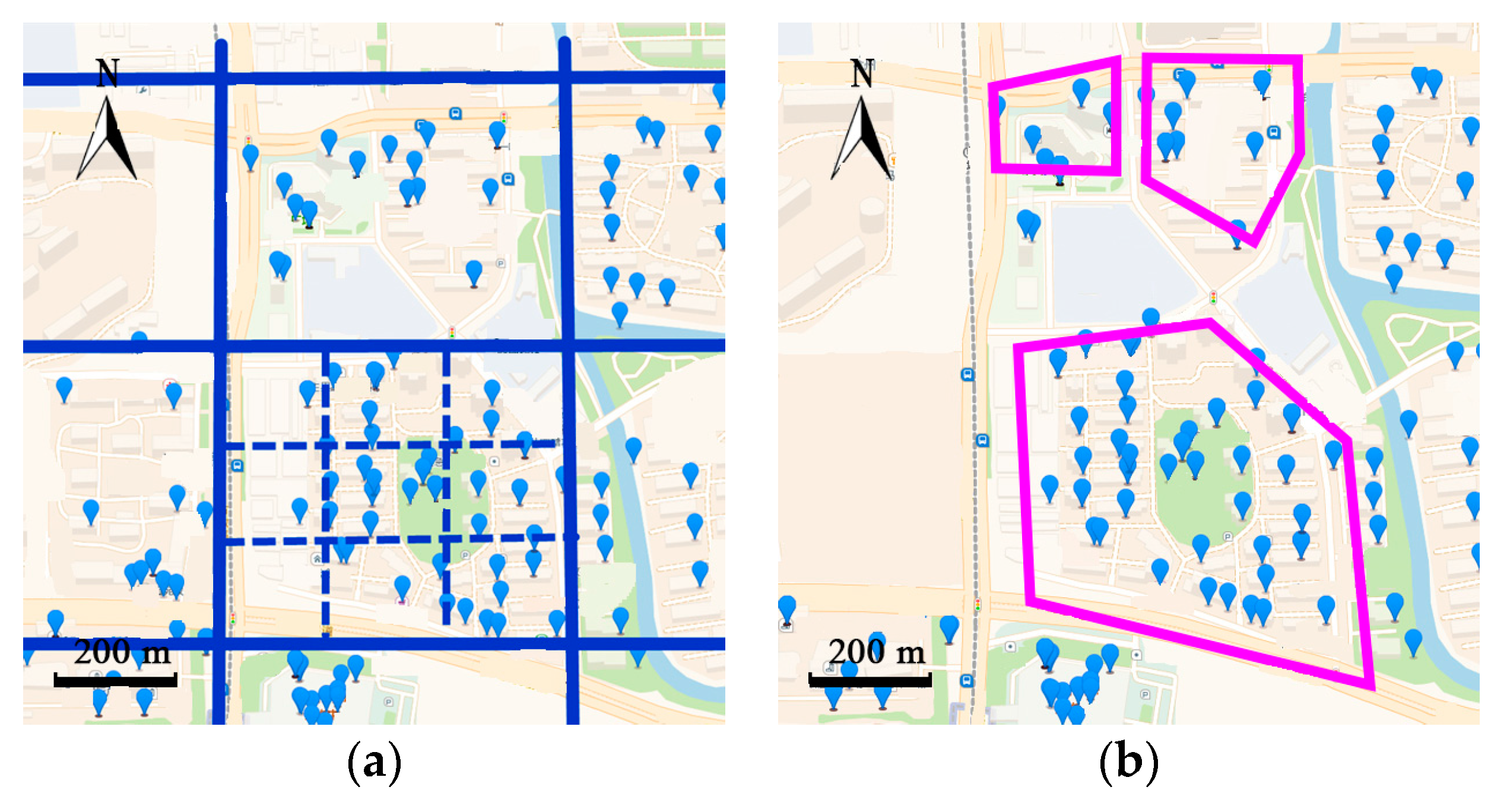
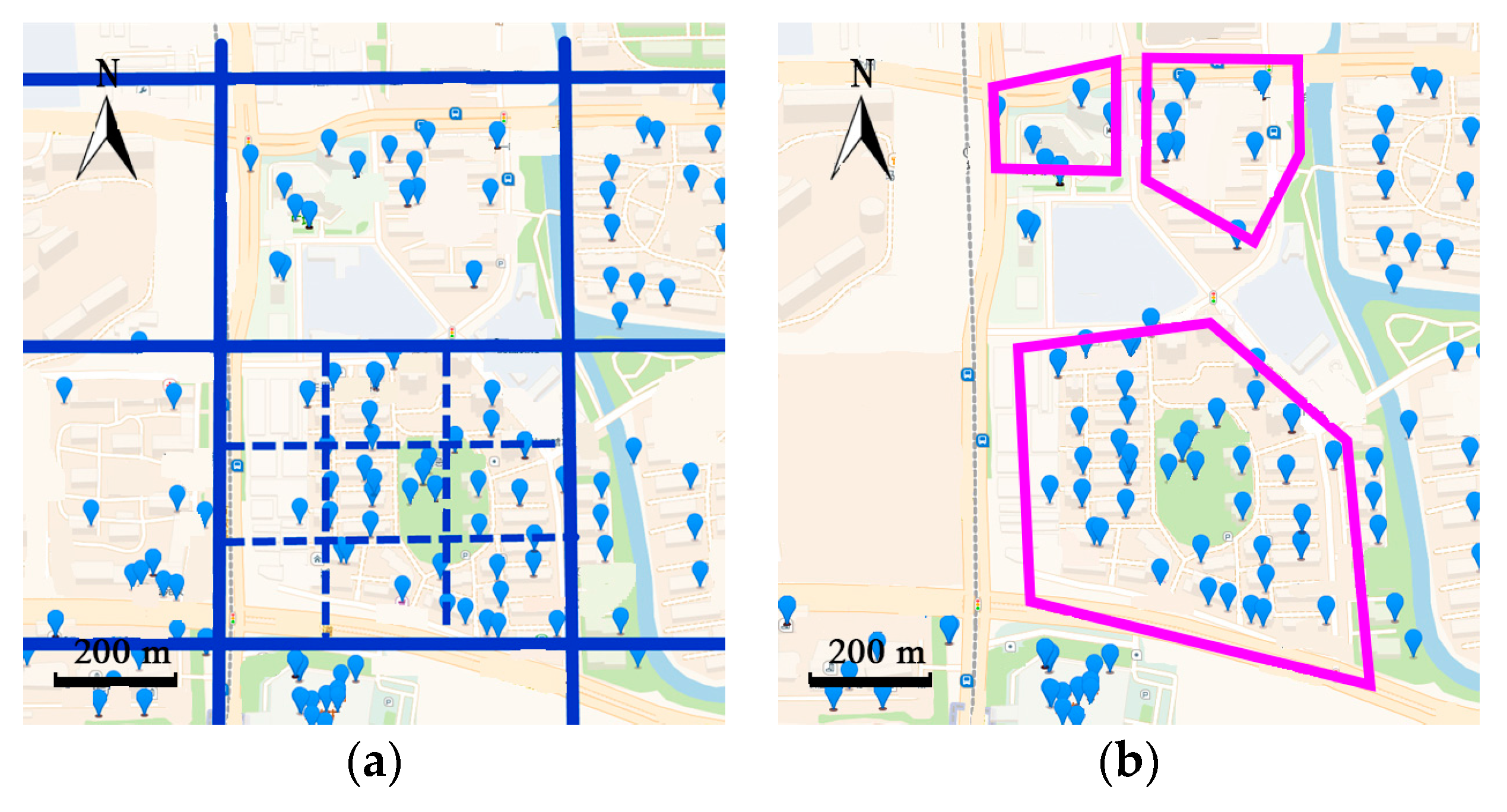
18] transferred trajectories into frequent regions by a cell partition algorithm, treating them as hidden states and observable states of the HMM. Accuracy of the prediction depends highly on the level of granularity of the cells. For example, in
Figure 3, partition by large cells is more precise and the clusters are closed to the actual boundaries of the neighborhoods. However, partition by the smaller cell loses the geo-information of the neighborhoods.
Semantically-based prediction methods claim that many behaviors of users are semantically-triggered. Alvares [
19] discovered stops from trajectories and map these stops to semantic landmarks. Then a sequential pattern mining algorithm is used to achieve frequent semantic patterns. Bogorny [
20] utilized a hierarchical method to obtain geographic and semantic features from trajectories. Ying [
21] proposed a geographic-temporal-semantic pattern mining method for prediction, which also transforms trajectory into stay points. Then trajectory patterns are clustered to build the frequent pattern tree for detecting future movements. Semantically-based methods mainly focus on mining the stay points. The trajectories along the road are abandoned.
Recently, recurrent neural networks (RNNs) have gained a breakthrough in sequence mining. Mikolov [
23] developed RNNs in word embedding for sentence modeling. Multiple hidden layers in RNN can adjust dynamically with the input of behavioral history, therefore, an RNN is suitable for modeling temporal sequence. Liu [
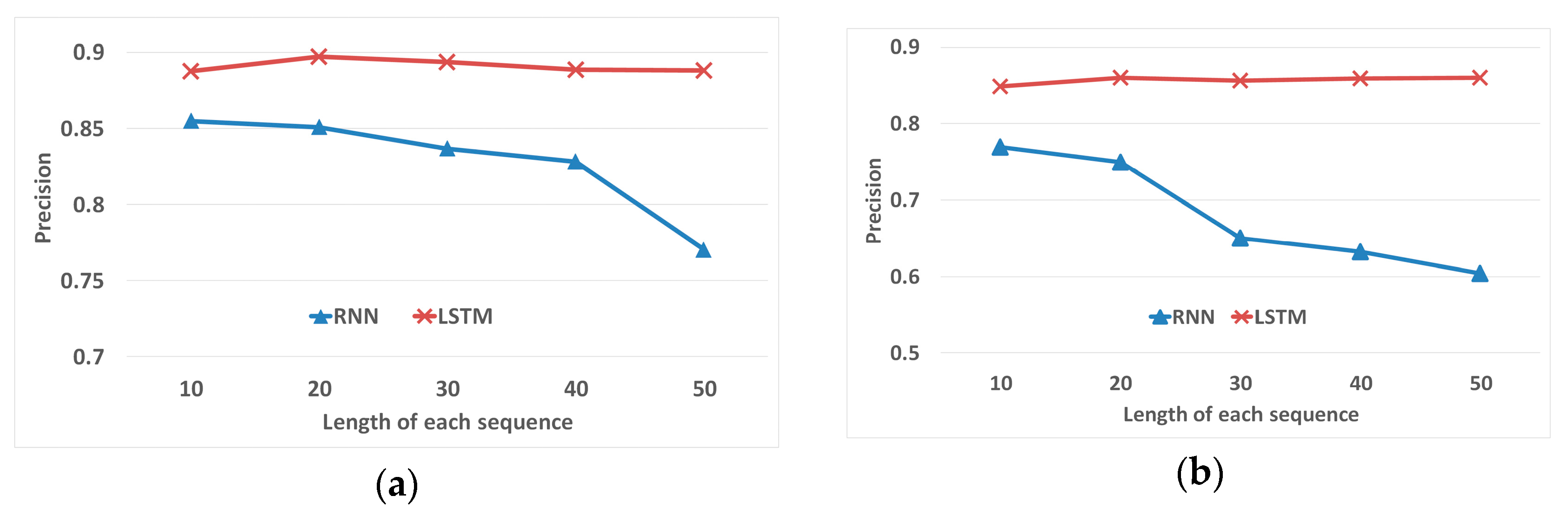
22] extended traditional RNN with geographical and temporal contexts to handle prediction problem of spatial-temporal data. An RNN performs well with short location sequences, such as clusters and stay points. However, when considering the whole trajectory, the location sequences become longer and the precision of prediction of RNN may decline.
In conclusion, in order to utilize machine learning models, the trajectory should be transformed to be model-friendly. Existing location prediction algorithms usually cluster trajectory into cells, regions, or stay points. Track points along the road are abandoned, but these points can be important to specific applications. To solve this problem, a spatial-temporal-semantic neural network algorithm for location prediction is proposed in this paper. First, in order to transform the whole trajectory into location sequences friendly to the prediction model, STS feature extraction is utilized to map trajectory to the reference points and maintain as much information as possible; Second, the LSTM model is built to handle the long sequences generated before, and to make further prediction.
3. Methodology
The core idea of location prediction algorithms is to model regular patterns hidden in historical data and find the most possible movements based on current observations. Due to the continuity of space and time, trajectory is not suitable to be directly imported to a prediction model. As shown in
Figure 4, the courier travels along the same road every day, but the trajectories are not exactly the same. Simply representing a location by continuous coordinates may lead to high computational cost and may not achieve a better prediction result. Before using prediction models, each of the points in a trajectory is first preprocessed in order to convert the real continuous values associated to the geospatial coordinates of latitude and longitude, into discrete codes associated to specific regions. Existing methods use clustering-based algorithms to transform trajectory into discrete cells, clusters and stay points. However, the density of points on the road may be relatively low compared to frequent regions, making it hard for clustering algorithm to identify. Additionally, they cannot deal with points along the road.
In
Section 3.1, a spatial-temporal-semantic feature extraction algorithm is proposed to overcome the difficulties and to discretize trajectory into location sequences, namely,
. As shown in Equation (1), given an object
and current time
, the problem of location prediction can be formulated as estimating the probability of the next location
based on the current locations
:
Then location prediction with discrete locations is like the classification problem. During the model building process, location sequence
is used as features and
is the label. However,
generated by the first step might be very long and the performance of traditional models, such as HMM and RNN, will decline. In
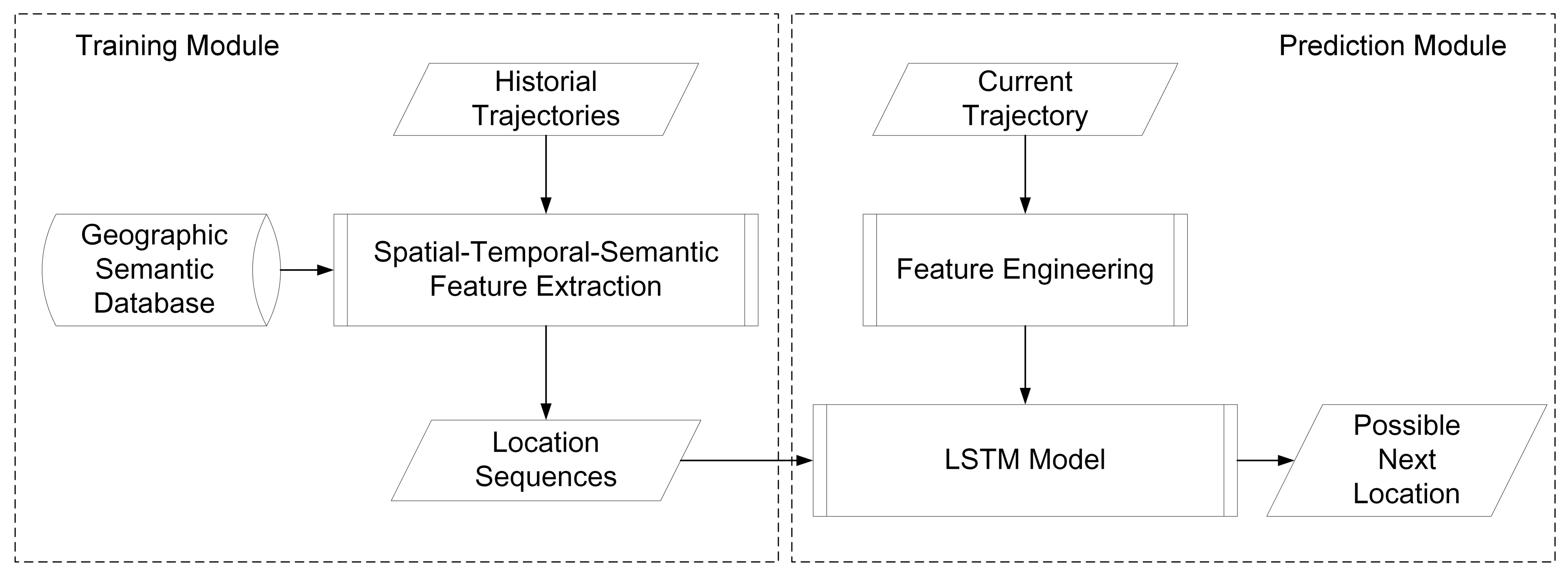
Section 3.2, a LSTM-based prediction model is proposed to handle long sequences. The flowchart of the STS-LSTM is illustrated in
Figure 5.
3.1. Spatial-Temporal-Semantic Feature Extraction
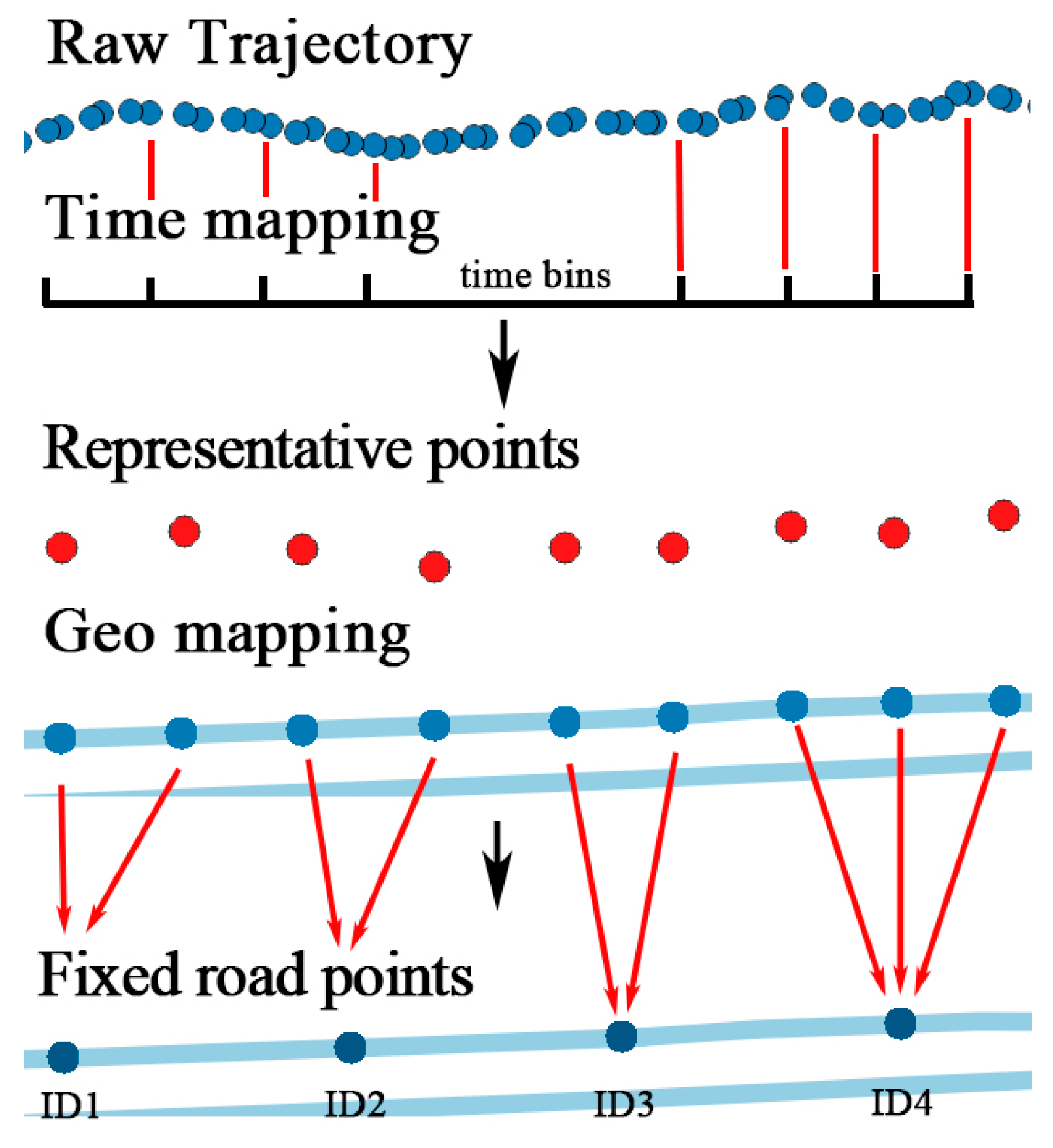
A trajectory is composed of a series of track points, expressed as , where N is the number of track points. Each track point is composed of spatial information such as longitude, latitude and time stamp, expressed as , which is continuous in space and time. To discretize the trajectory, both spatial and temporal factors should be added into the model. The feature extraction method introduced in this section aims to transform the trajectory to fixed, discrete location sequences without losing much information.
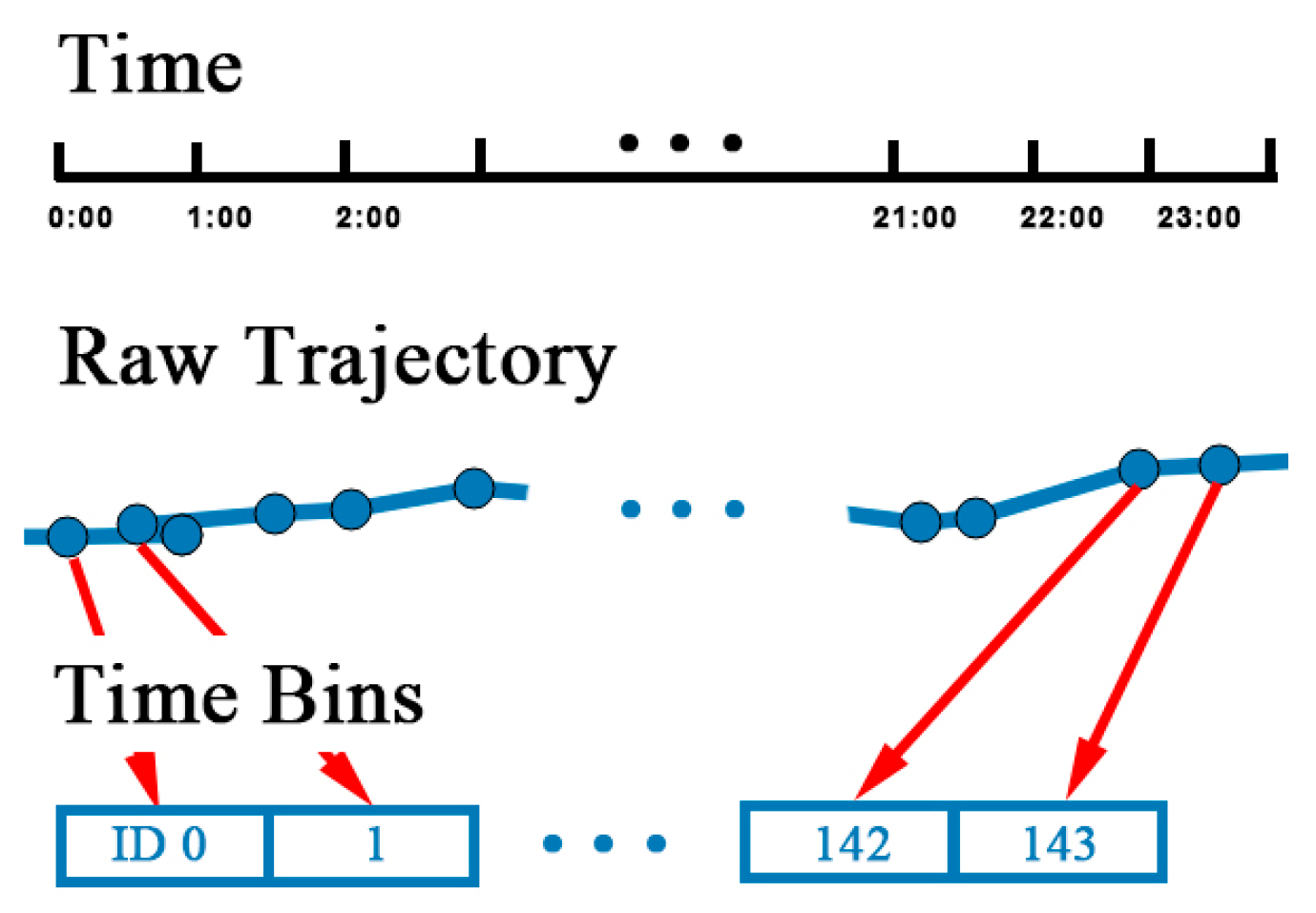
3.1.1. Temporal Feature Matching
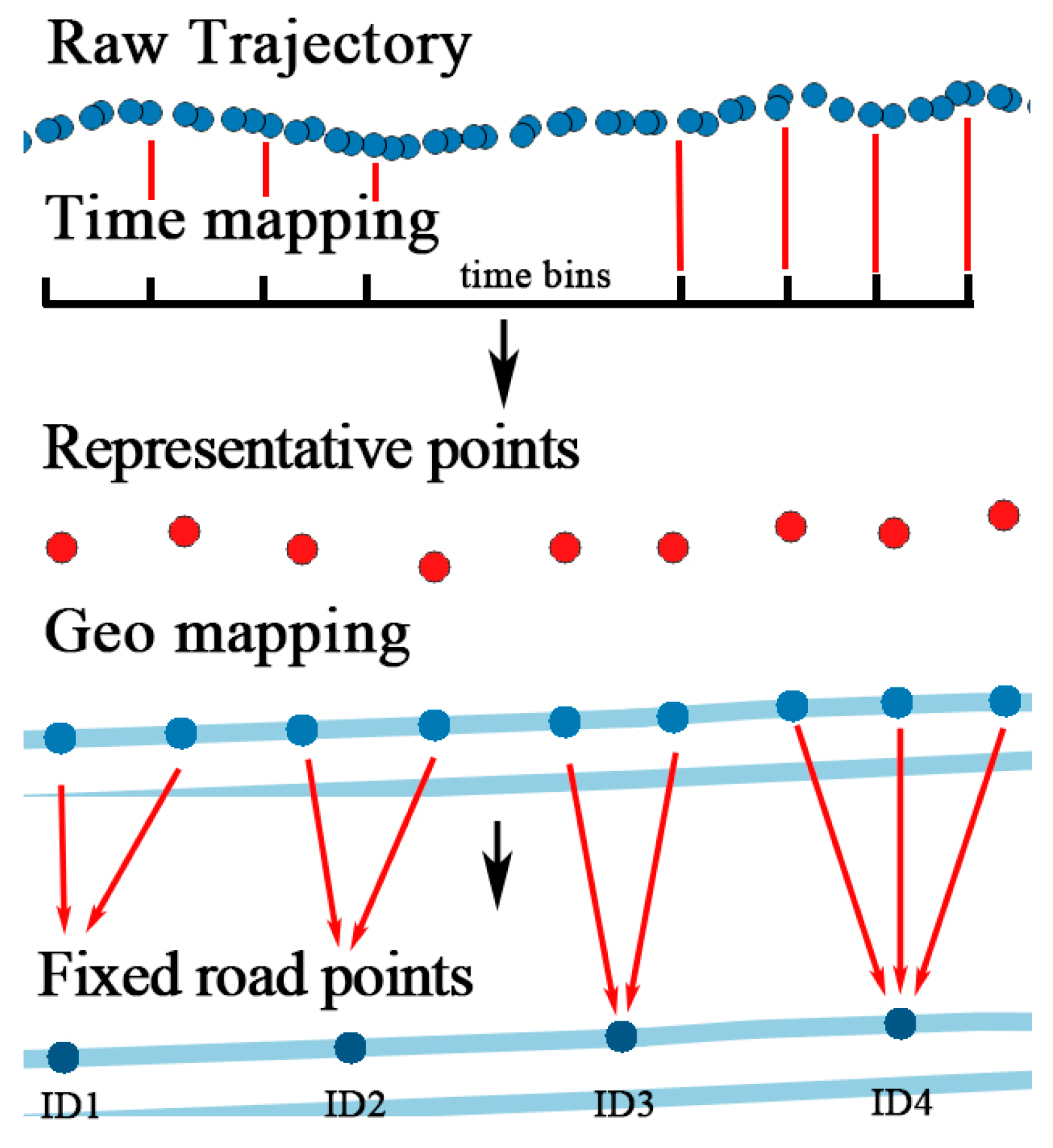
To transform continuous temporal information into discrete time, a proper time interval should be selected. Positioning devices such as the GPS module inside the mobile phone collect track points at a fixed sampling rate, usually one every second. However, due to the cost of network transmission and storage problems, points collected are not completely uploaded to the server. For example, the locations of couriers are sent to the server every five seconds and it changes to 30 s in the applications of taxi or bus. The precision of location prediction is affected by the sampling rate. If the time interval between each location is five minutes, the model will predict the next location five minutes from the current one. The time interval is determined by the demand of specific services. Generally, the time interval should be larger than the average sample rate.
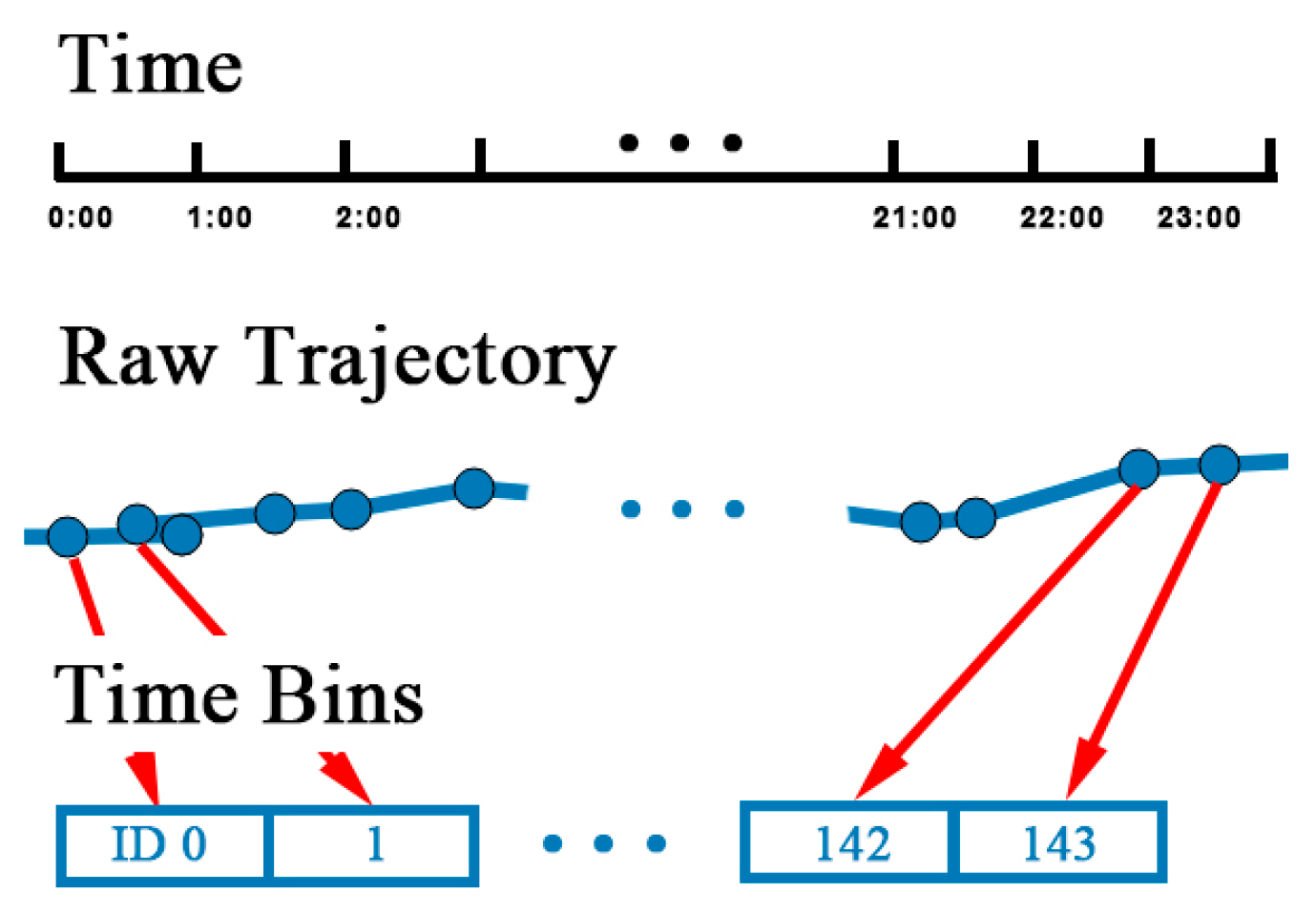
Trajectories are usually stored and segmented by natural day. However, the record of tracks may be interrupted because of the GPS blocking problem. First, each trajectory is divided into segments if the time interval between two track points is over 30 min. Intervals under 30 min can be regarded as blocking, which does not affect the continuity of trajectory. After segmentation, track points are allocated to
timebins. Time of a day is divided into multiple time bins by the size the time bin. For example, if the size of time bin is 15 min, there is four time bins in an hour and 144 time bins in a day, identified from 0 to 143. Next, time of each track points is mapped to a time bin by Equation (2), where
is the time of
.
is the zero time of a day and
is the integral function:
The temporal mapping process is illustrated in
Figure 6. After mapping, there might be several points in the same time bin. A representative point is selected by calculating the linear center of the points with the average longitude and latitude.
Trajectory is transformed into , where is the representative point in each time bin. The sequence of representative points is sorted in ascending order of the time bin ID. After time matching, temporal information is fixed and discretized.
3.1.2. Geographical Feature Matching
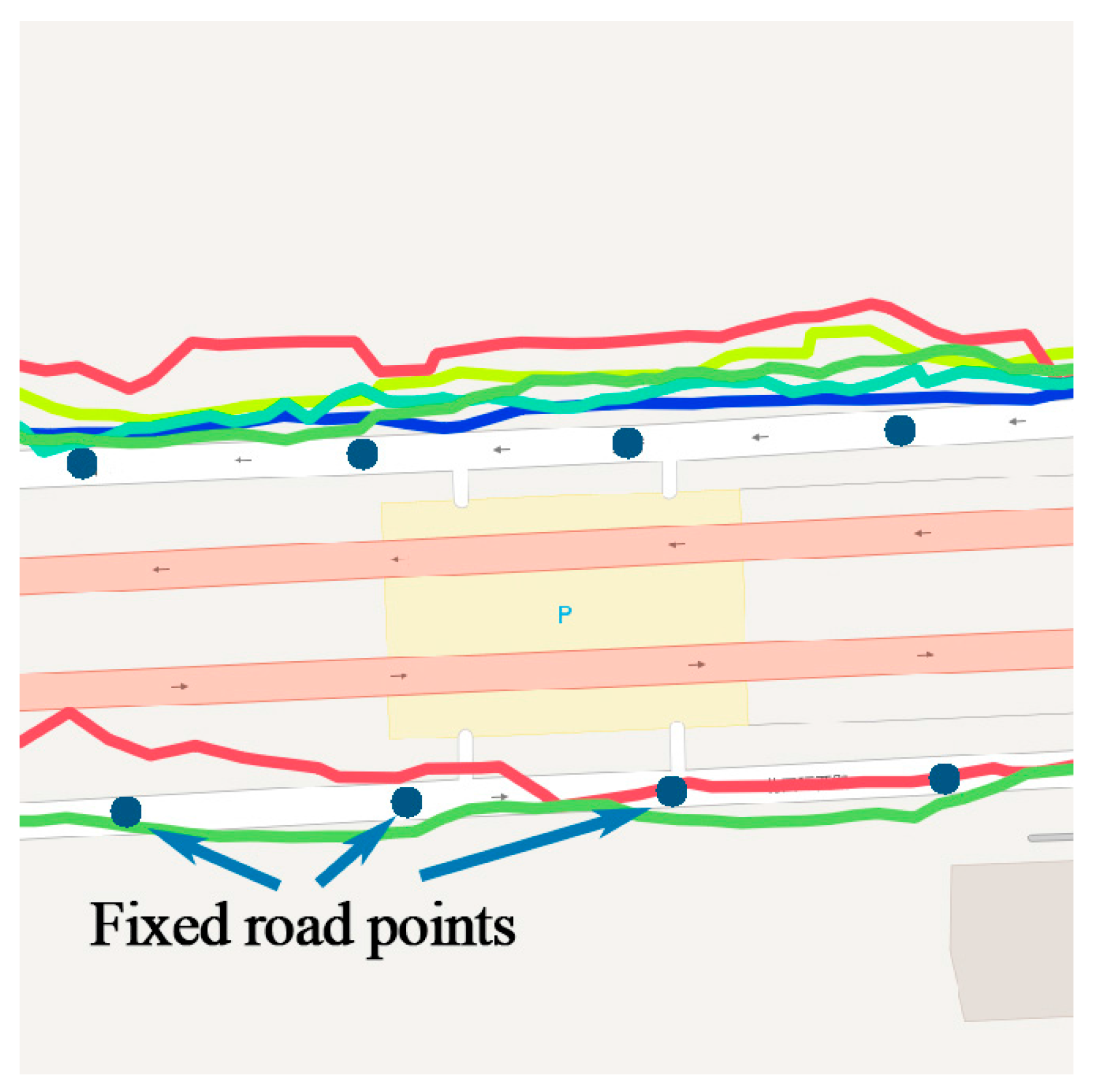
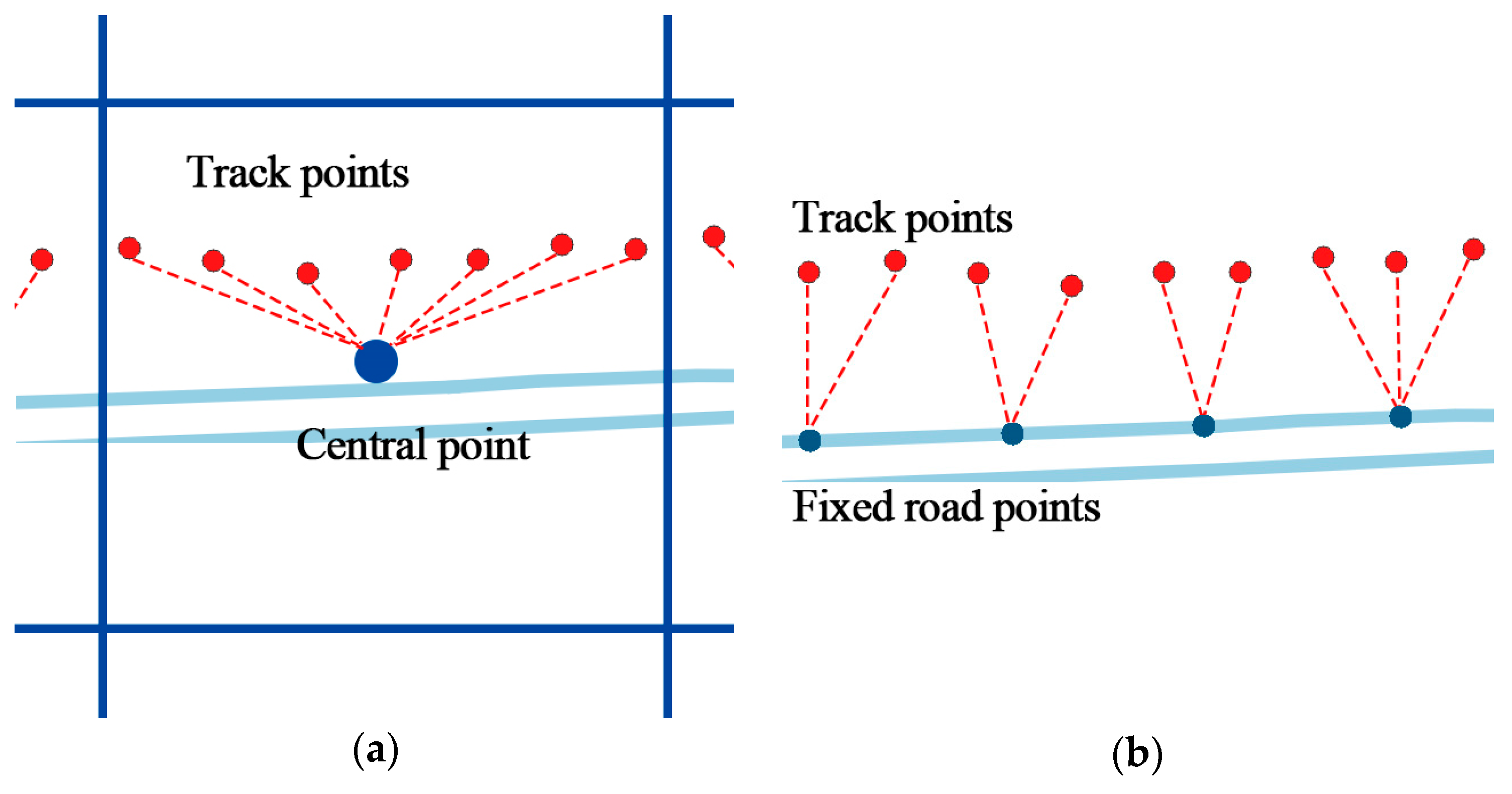
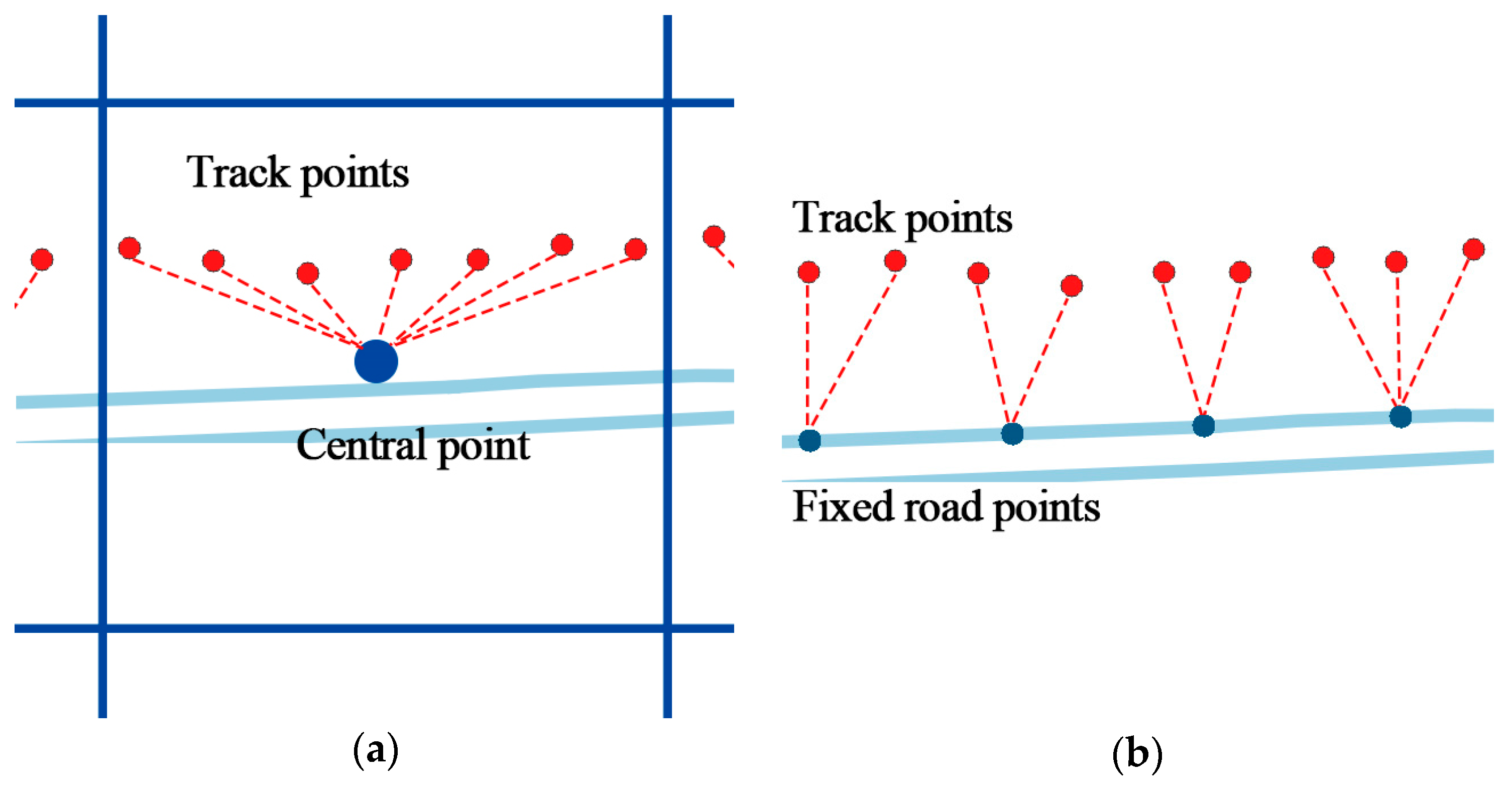
Same as time factor, the geographical information of trajectory such as coordinate is continuous in space, which is difficult to use in a model. Trajectory should be converted to fixed reference points. Existing methods utilizing cell-based partitioning, clustering, and stop point detection cannot handle points on the road. Therefore, a new geographical feature mapping method is proposed to transform all the points in a trajectory. Objects always travel along the road in the city, therefore, the city road networks are selected as reference points. Open Street Map (OSM) is a project that creates and distributes free geographic data for the world [
24]. Map data from OSM is in
format. It contains all elements including points of interest, roads, and regions, as shown in
Figure 7.
Each road can be represented as a line
, with a start node
and an end node
. First, for each track point
, find the nearest line
by sorting the distance from
to all lines in the network. The searching could be time consuming when the network is very large. However, with the indexing technology used in geo-database such as PostgreSQL, the process could be executed in milliseconds. The projection point
of
on
is calculated by Equation (3), shown as the red points in
Figure 8a, where
is the slope of
:
The projection point could be anywhere on the line, which is not discrete. Several fixed points on the line are set by the distance parameter
. According to the precision required by different applications,
could be 5 m, 10 m, or 15 m, smaller than the length of the road. The length of road
is calculated by Equation (4), where
is the radian of
,
is the radian of
,
is the radian of
, and
is the radian of
.
is the radius of the earth, which depends on the mapping implementation, and a good choice for the radius is the mean earth radius,
(for the WGS84 ellipsoid). Then, the line is divided into
segments. The fixed points in line
can be calculated by
,
, and
, as shown in
Figure 8b. Finally, each projection point is mapped to the nearest fixed points, so do the original track points, as shown in
Figure 8c.
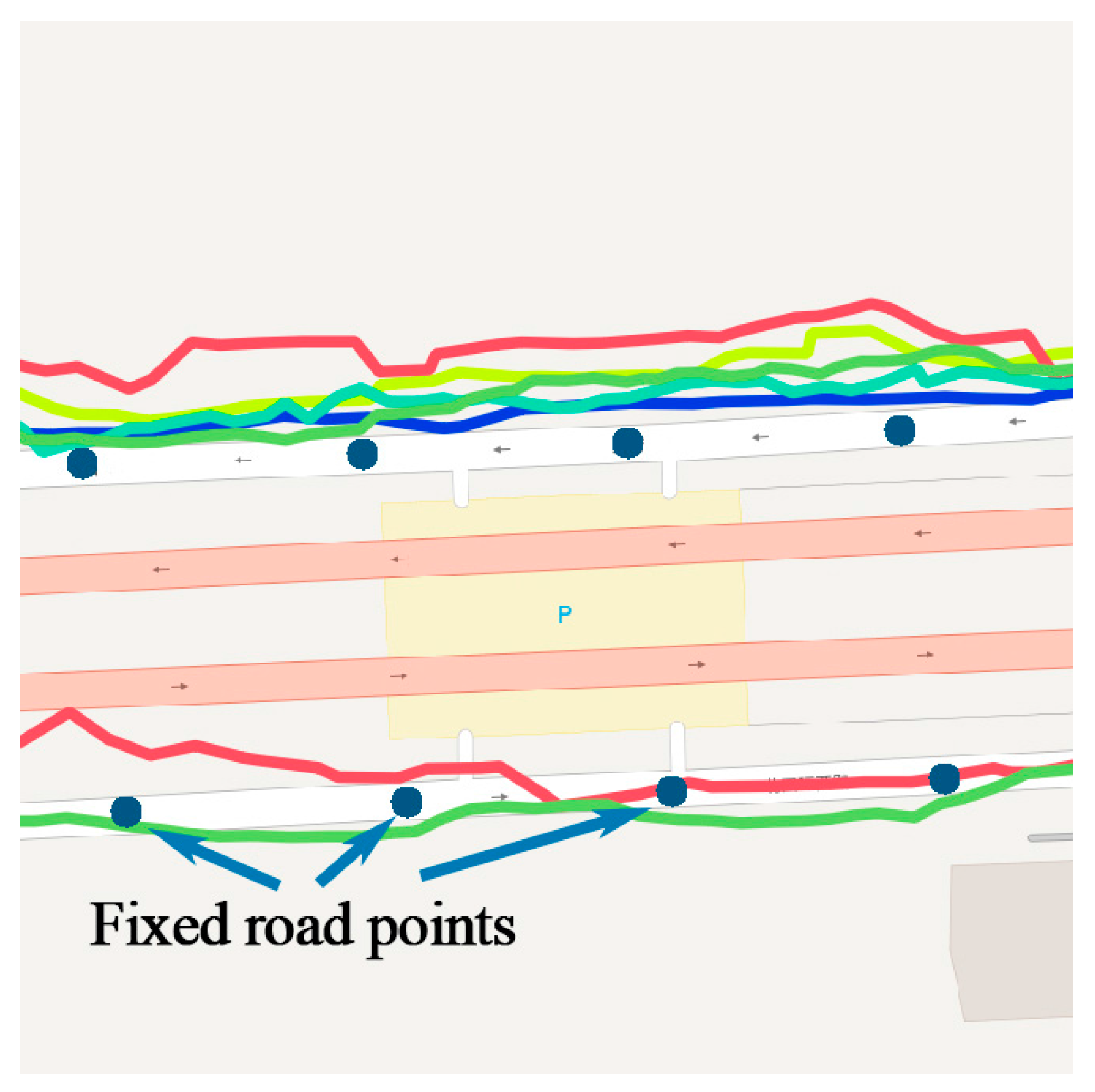
After the mapping of temporal and geographic features, the original trajectory is transformed into , represented by a series of lines in the road network, and each line consists of several fixed points .
3.1.3. Semantic Feature Matching
Fixed points in the line should be represented in a way that the model can recognize. The OSM map data stores the semantic tags of each road in the network, as shown in
Table 2. The unique ID of the road could be used to represent the line. Semantic tags of the fixed points are assigned by the ID of the road,
.
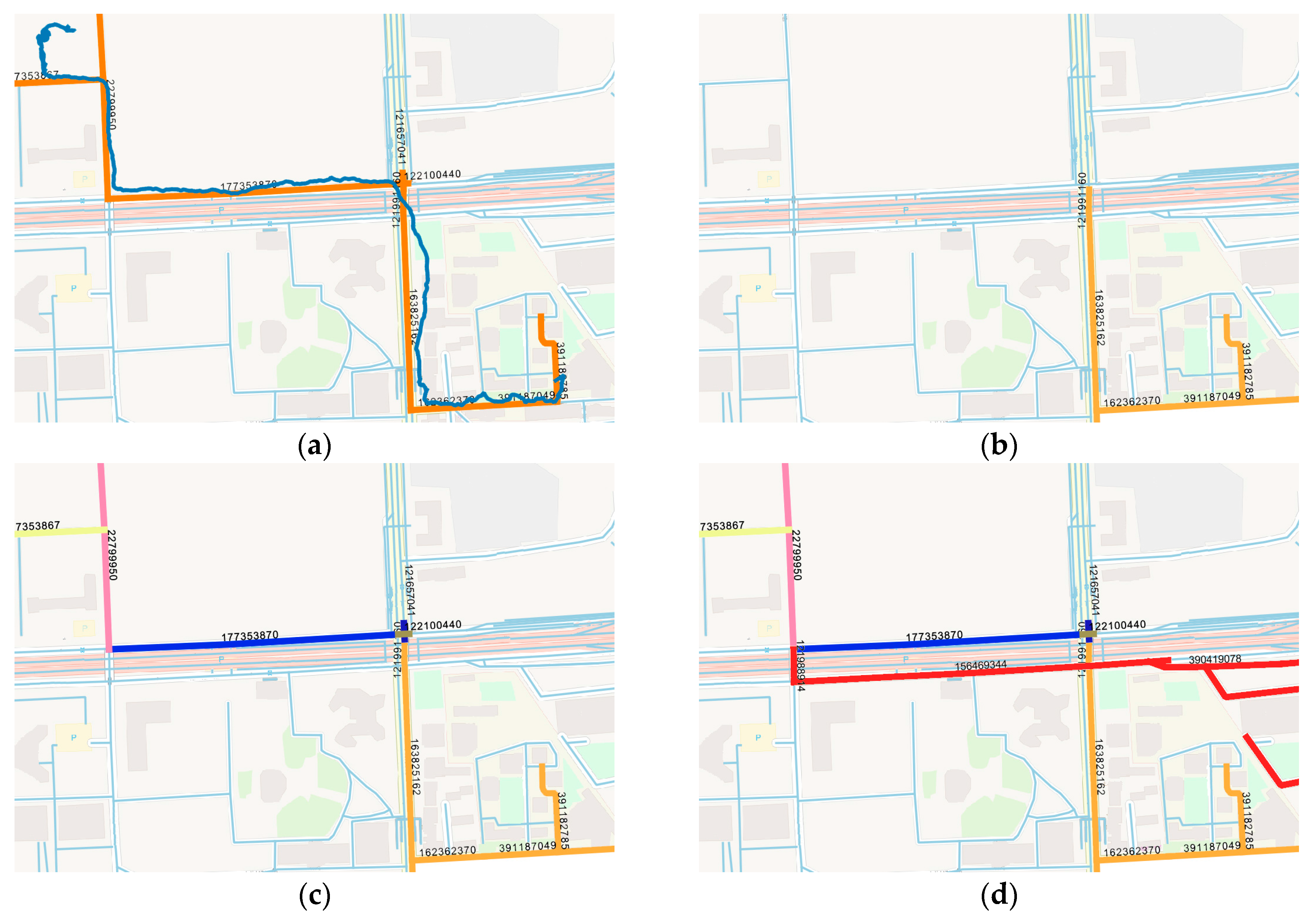
After the spatial-temporal-semantic feature extraction, the trajectory is transformed into a location sequence represented by the road ID,
. A running example is shown in
Figure 9. A trajectory from a courier in Beijing, China is used to illustrate the process. The result of STS feature extraction is similar to the result of map matching algorithms [
25,
26]. However, map matching only focuses on projecting the track points to the nearest road and the STS transfers trajectory into location sequence that prediction models can recognize.
3.2. Long Short-Term Memory Network Model for Location Prediction
3.2.1. Model Description
The recurrent neural networks can handle sequential data and have become a hot spot in the fields of machine learning [
22,
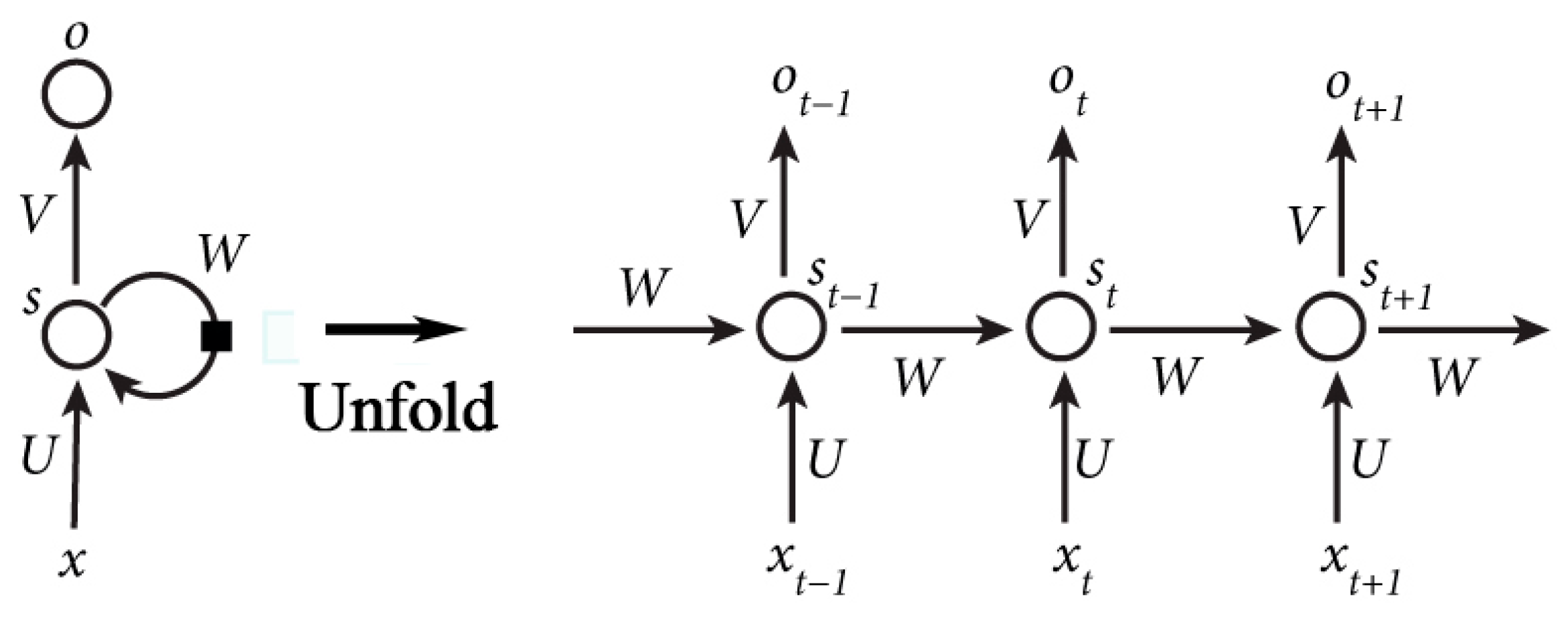
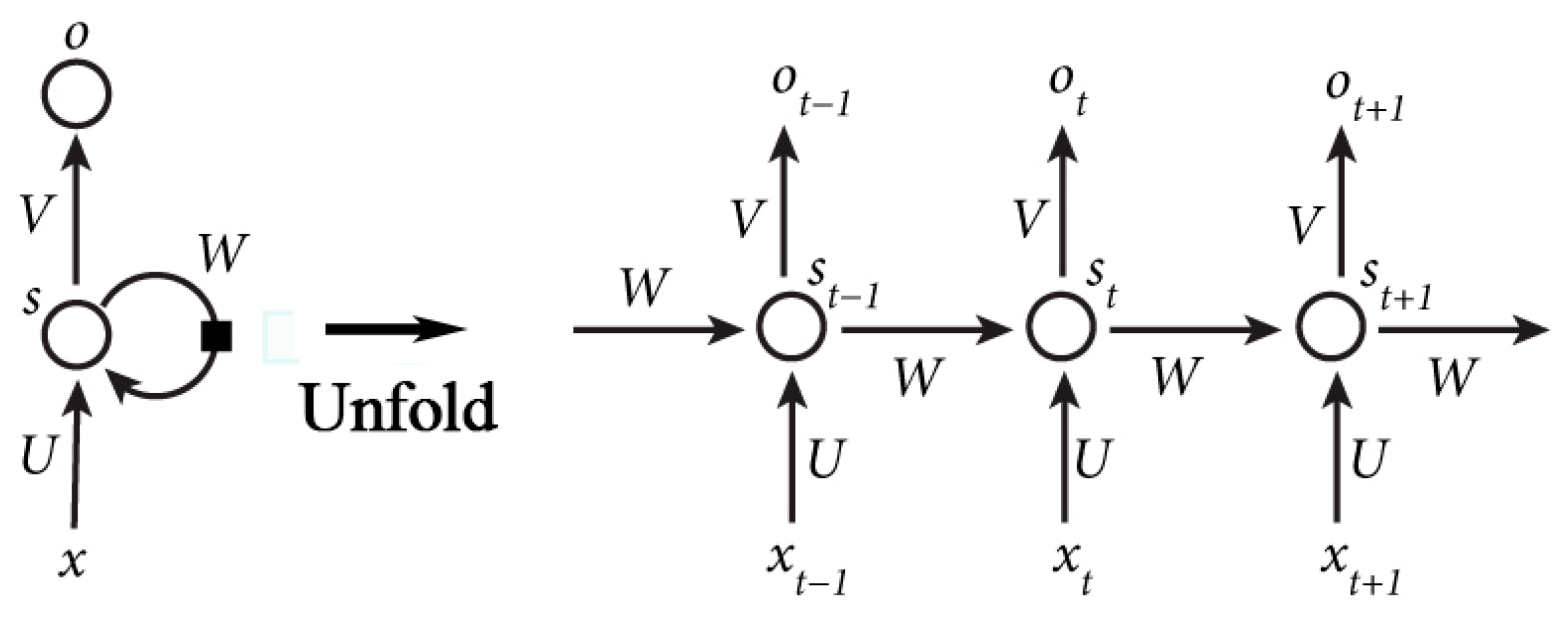
27]. They are networks with loops of several hidden layers that can change monotonously along with the position in a sequence, as shown in
Figure 10a. It enables RNN to learn sequential data and Liu [
23] has utilized RNN in location prediction with check-in data.
Figure 10 shows the structure of RNN.
is the vector of the value of the input layer.
represents the value of the hidden layer and
is the value of the output layer.
,
are the weight matrix between
and
,
and
.
is the weight matrix between the value of the hidden layer at time
and time
.
The RNN can be expressed as Equations (5) and (6), where
and
are the activation functions. The output of the RNN, namely
, is affected by the input
. This is the reason why the RNN can take advantage of historical sequential data. Moreover, parameters in the RNN can be further learned with the back propagation through time (BPTT) algorithm [
28]. The error term
during the weight gradient computing has the property shown in Equation (7), where
is the time interval between the current time and historical time. Other parameters is introduced in [
29]. When
is large (locations that are long time ago), the value of
will grows or shrinks very quickly (depending on
greater or less than 1). This may cause the learning problems described in [
29].
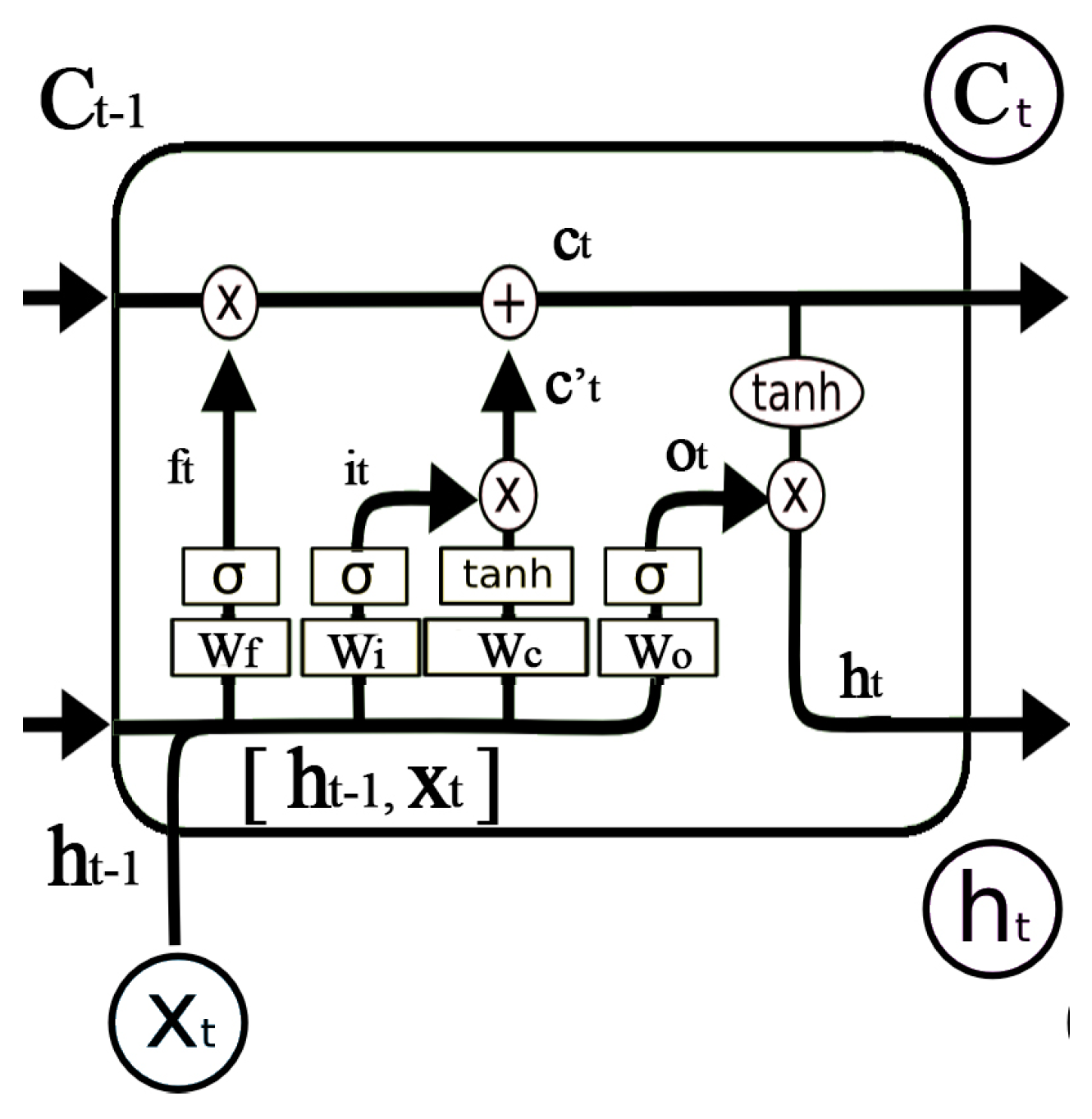
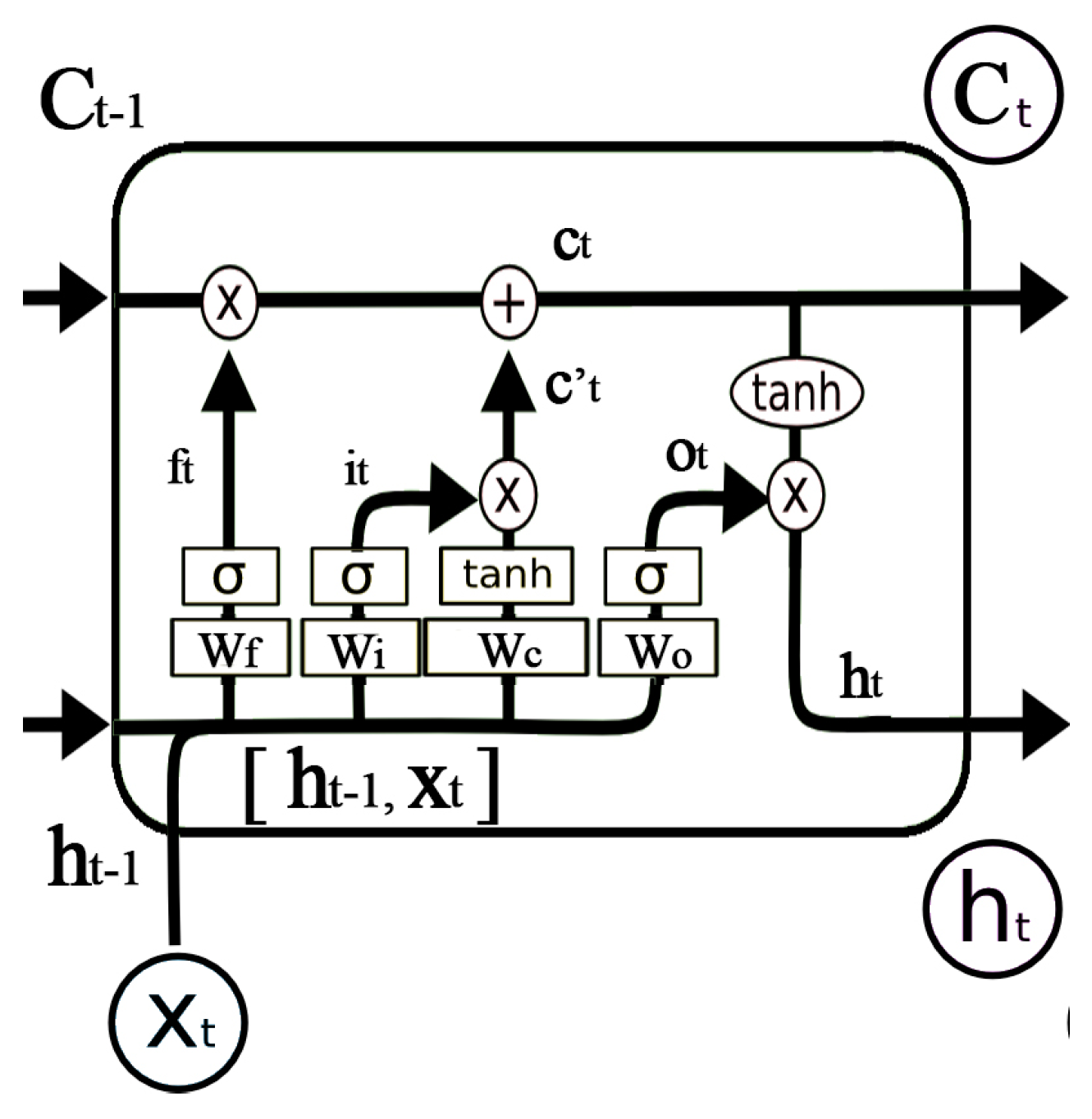
However, location sequences generated by the STS feature extraction could be very long. The RNN may not perform with long sequences. Long short-term memory networks (LSTMs) are a special kind of RNN, capable of learning information for long periods of time [
30]. Instead of the simple
hidden layer in RNN, LSTM has a more complicated repeating module, as shown in
Figure 11. The LSTM uses gates to control the cell states passed from long time ago. The gate is a full connection layer expressed as
, where
is the weight vector and
is the bias.
is the sigmoid function so that the output of the gate is 0 to 1.
LSTM utilizes two gates to control the cell state. The forget gate decides how much information of the last cell state
will keep to the current time
. The other is the input gate, which decides how much information of the input of the current networks
will keep to cell state
. LSTM uses the output gate to control how much information of the cell state
will output to
. The expression of the forget gate is shown in Equation (8), where
is the weight matrix and
is the bias of the forget gate. Similar calculations can be used in the input gate and output gate, as shown in Equations (9) and (12). The cell state of the current input
is calculated by the last output and the current input, as shown in Equation (10). As shown in
Figure 11, the current cell state
is calculated by Equation (11). The output of LSTM
, as shown in Equation (13), is decided by
and
. The training and parameter derivation process can be found in [
30]. In conclusion, the conveyor belt-like structure allows LSTM to remove or add information from the very beginning to the current state. Therefore, LSTM is expected to perform well with long sequences.
3.2.2. Model Training and Predicting
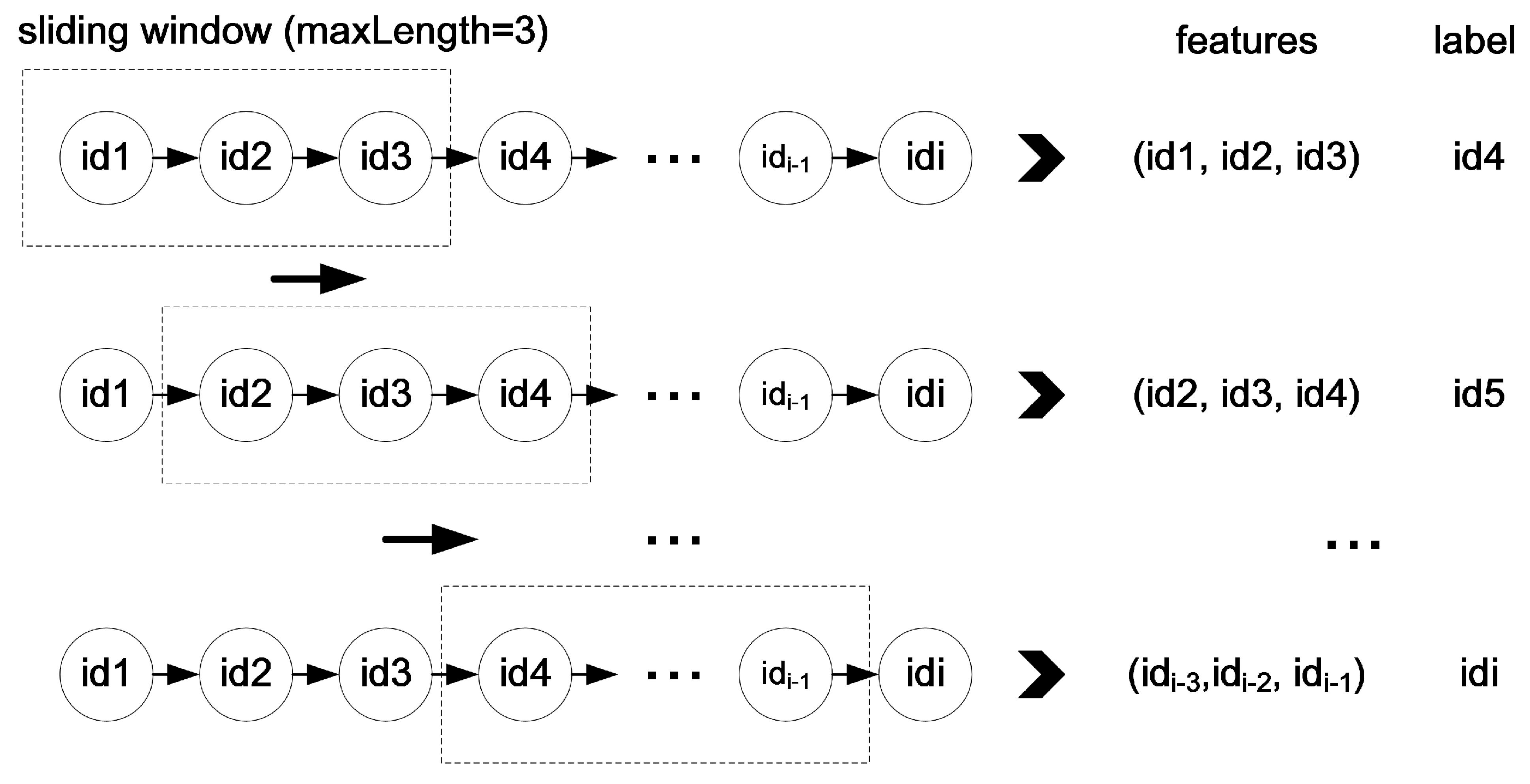
The training process. After the STS feature extraction, trajectories are transformed into fixed and discrete sequences with road IDs, expressed as
. However, the sequences cannot be directly put into the LSTM model. Each sequence should be divided into segments with fixed length. The length of each segment is determined by specific applications. For example, in the bus system, traces of the past 15 min are used to predict the next location. There are 30 locations collected in 15 min so the length is 30. The length of location segment is defined as
. Each location sequence is scanned by a sliding window with fixed width equals to
. The window moves forward by one location until it reaches the end of each sequence. Locations in the window are gathered as training features. The next location outside the window is used as label. The process is called feature engineering and is illustrated in
Figure 12. Then, each location sequence with features and a label is used to train the LSTM model.
The predicting process. When a new track point is collected, a prediction is not made until all points in a time bin are gathered. Then a representative point is selected from each time bin by the time matching process. Each representative point is mapped to the nearest road in the city road networks. The mapping point is then classified to the nearest fixed road point along the road. The fixed road points are predefined with the distance threshold, which depends on different applications. Each fixed road point has a unique ID. Thus, the new trajectories is transformed into a location sequence represented by road IDs. Then, those IDs are used as the import of the LSTM model for prediction. The predicting process is shown in
Figure 13. The model will be re-trained each day during the free time with the trajectories collected in that day to learn the new movement patterns.
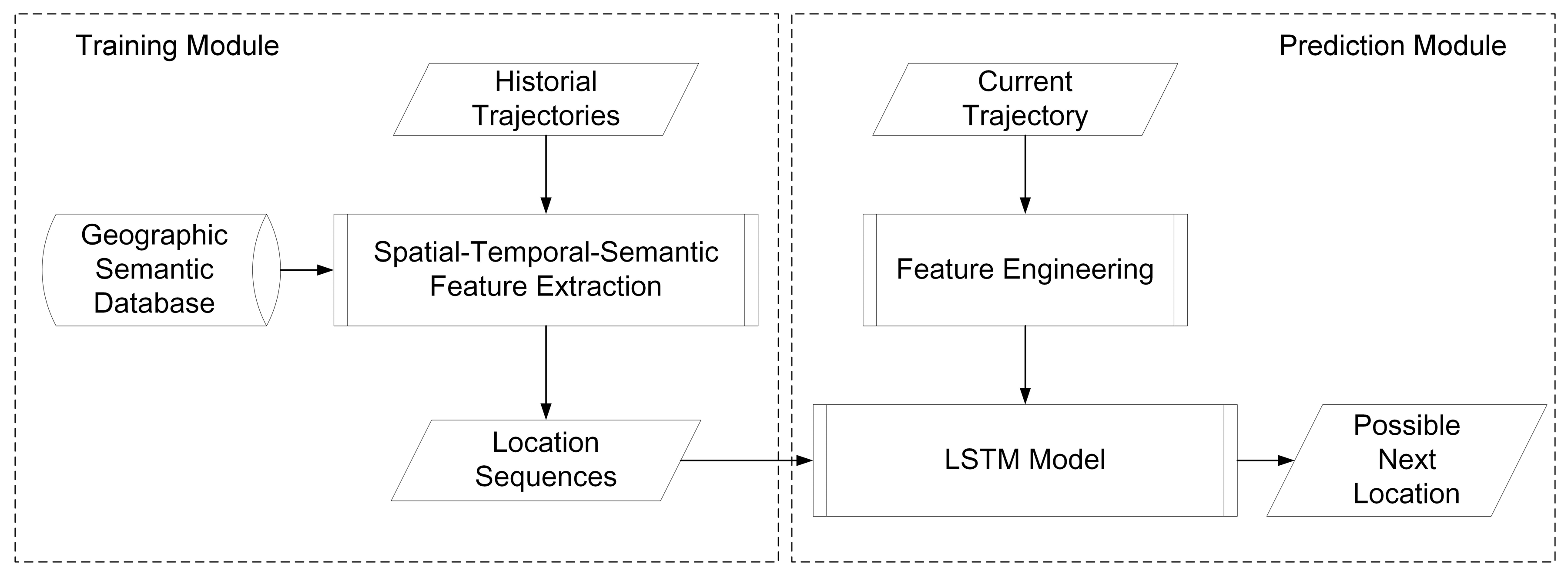
The whole training and predicting processes are shown in
Figure 14.
5. Conclusions
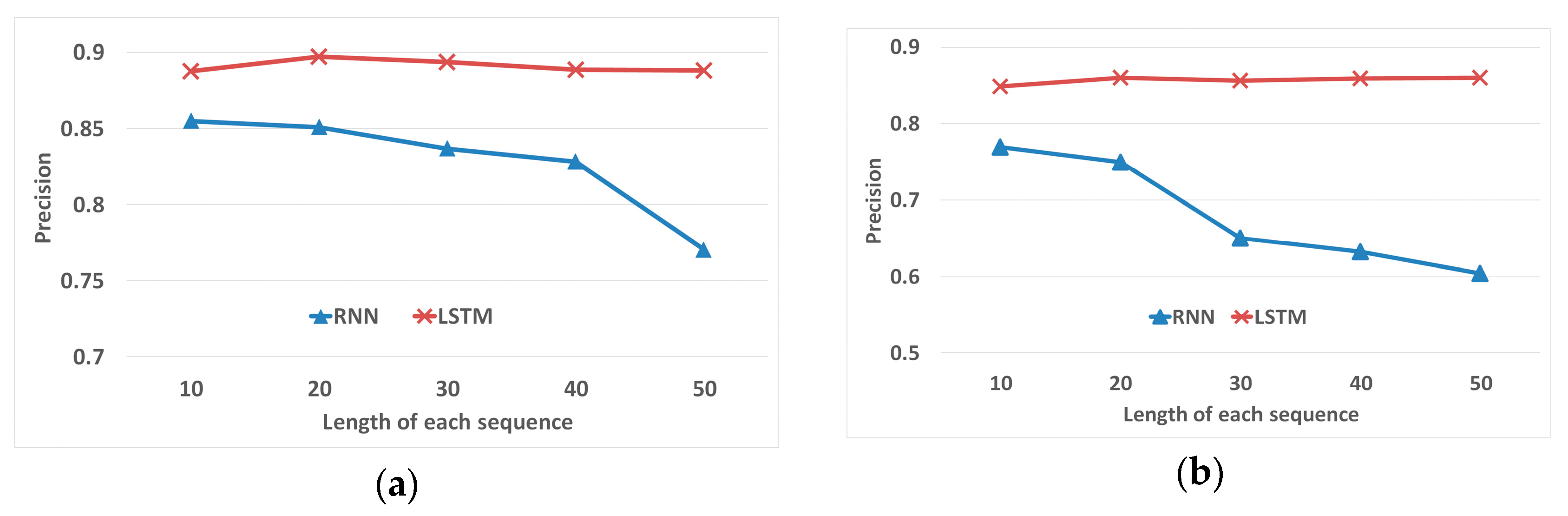
In this paper, a spatial-temporal-semantic neural network algorithm for location prediction is proposed. The algorithm consists of two steps, the spatial-temporal-semantic (STS) feature extraction and the LSTM-based model building. Aiming at solving the problem that traditional methods based on cell partitioning or clustering ignore a large amount of information about points along the road, the STS feature extraction algorithm is proposed. The method transforms the trajectory into location sequences by mapping track points to fixed and discrete points in the road networks. The STS can take advantage of points along the road, which meets the demand of services like delivering systems and transportation systems. After feature extraction, trajectories are transformed into long location sequences. Traditional models cannot perform well with long sequential data; therefore, an LSTM-based model is proposed to overcome the difficulty. The model can better deal with long location sequences to gain better prediction results. Experiments on two real-world datasets show that the proposed STS feature extraction algorithm has lower deviation distance. The location sequences generated by the STS can improve the prediction precision by 27%. Moreover, the proposed LSTM-based model can improve the precision of 25% compared with traditional classification models. The STS-LSTM algorithm has stable and better performance on both datasets.
There are several potential extensions of this paper. Aiming at solving practical problems, the algorithm should be robust to trajectory of poor quality. More data preprocessing works, such as data compression, noise filtering, and data filling could be done in the future. Moreover, the LSTM-based model could be further modified to accept more features and dimensions, such as temporal features like month, week, and day, and semantic features, like stay points. Moreover, LSTM could be combined and intercepted into other classification models, or replaced by a similar but simpler structure called the gated recurrent unit (GRU) [
37].





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}