
Managing Climate Policy Information Facilitating Knowledge Transfer to Policy Makers



Abstract
:
1. Introduction
2. Background
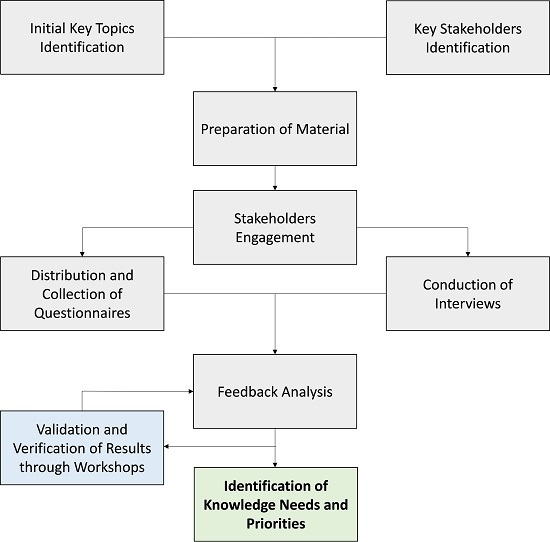
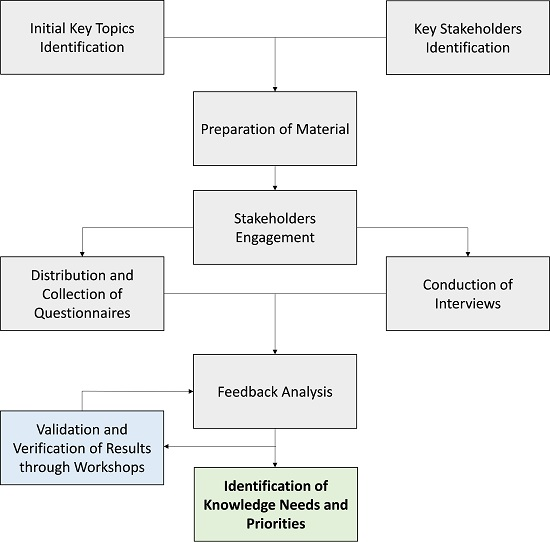
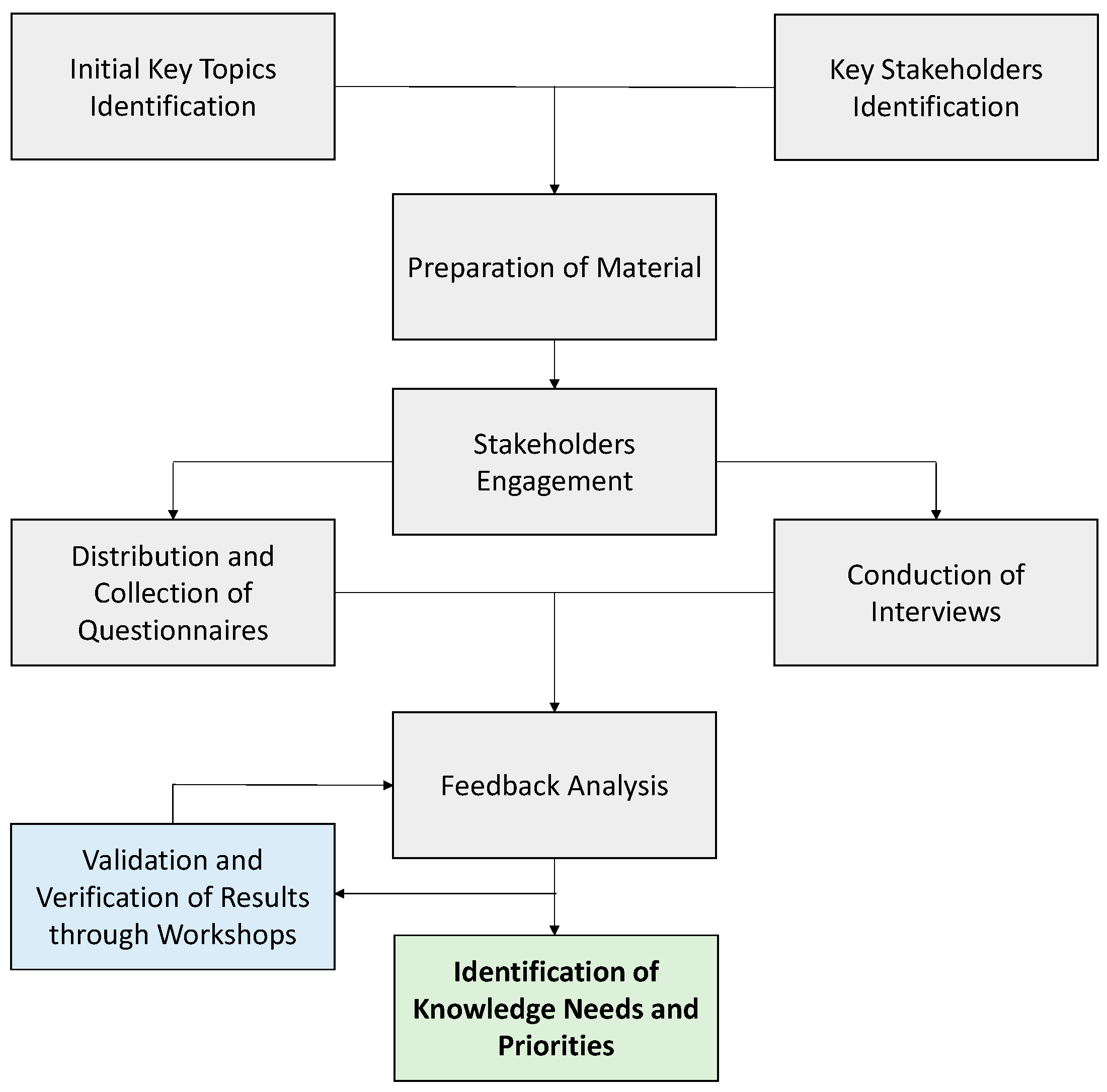
3. Methods
- Classify the resources under a hierarchical schema to facilitate search.
- Create a user centric database where users can search, view and extend the resources collected.
- Provide generic and custom views of the resources to the users of the database depending on selection criteria and tags.
- Support collaborative authoring of the available resources and their information, as well as versioning control over the changes performed in the data of the database.
- Support different schemas: There is no generally accepted schema or ontology for representing tags. Instead, there are several ones, which provide a structuration of the tagging processes on different levels.
- Tags are the first step in creating rich semantic knowledge bases. The database should support the future evolution of tags into rich semantic annotations. The tags should be extensible with additional metadata. This facility includes labels in different languages, relations between tags and other resources as well as relations between tags.
- Users should be able to annotate resources with tags, comments, notes and all possible other attributes.
- Additional filtering support: Filter performing an equality restriction to a certain value should be supported to facilitate search. Moreover, other filter types should be allowed, such as bound/unbound property of attributes, ranges of values on a facet as well as literal expressions.
- Status quo of climate policy negotiations and the EU climate policy discussion (including the climate and energy package 2020 and longer term decarbonisation and energy roadmaps).
- Identification of key trends and drivers, such as key economic, energy and demographic trends in EU and Rest of World, and trends in global land use.
- Possible international climate policy developments and scenarios based, among others, on progress in negotiation processes, observers’ opinions, papers, interviews, focusing especially on what the literature says about the social, economic and environmental impacts of climate policies and the resulting impact on their political acceptability by different stakeholders.
- Information about the way policies and measures proposed in international climate policy making might work in terms of direction, strength and expected effects in different EU stakeholder contexts.
4. Implementation
4.1. Information Setup and Resources
- EU Climate Policy
- International Climate Policy
- Renewable Energy
- Energy Efficiency
- Emissions Trading
- Adaptation
- Targets
- Policies
- Industry
- Transport
- Households
- Agriculture
- Background
- Scenarios
- Mechanisms
- Technology
- Finance
- Post 2020
- Implementation
- Costs & Benefits
- Reform
- Support systems/incentives
- Renewable energy
- Electricity market design
- Increasing farm efficiency
- Mainstreaming
- Land use
- International ETS
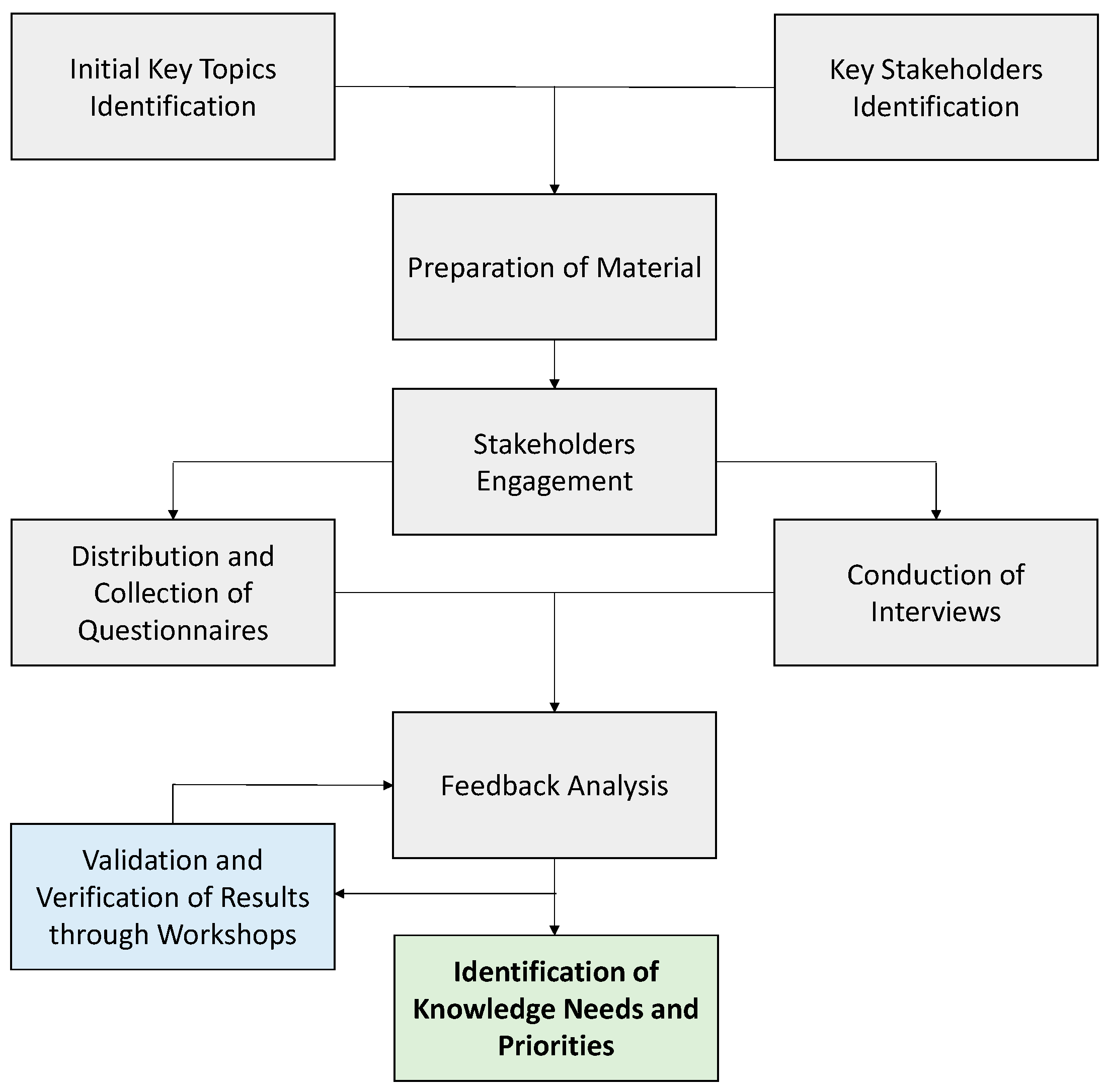
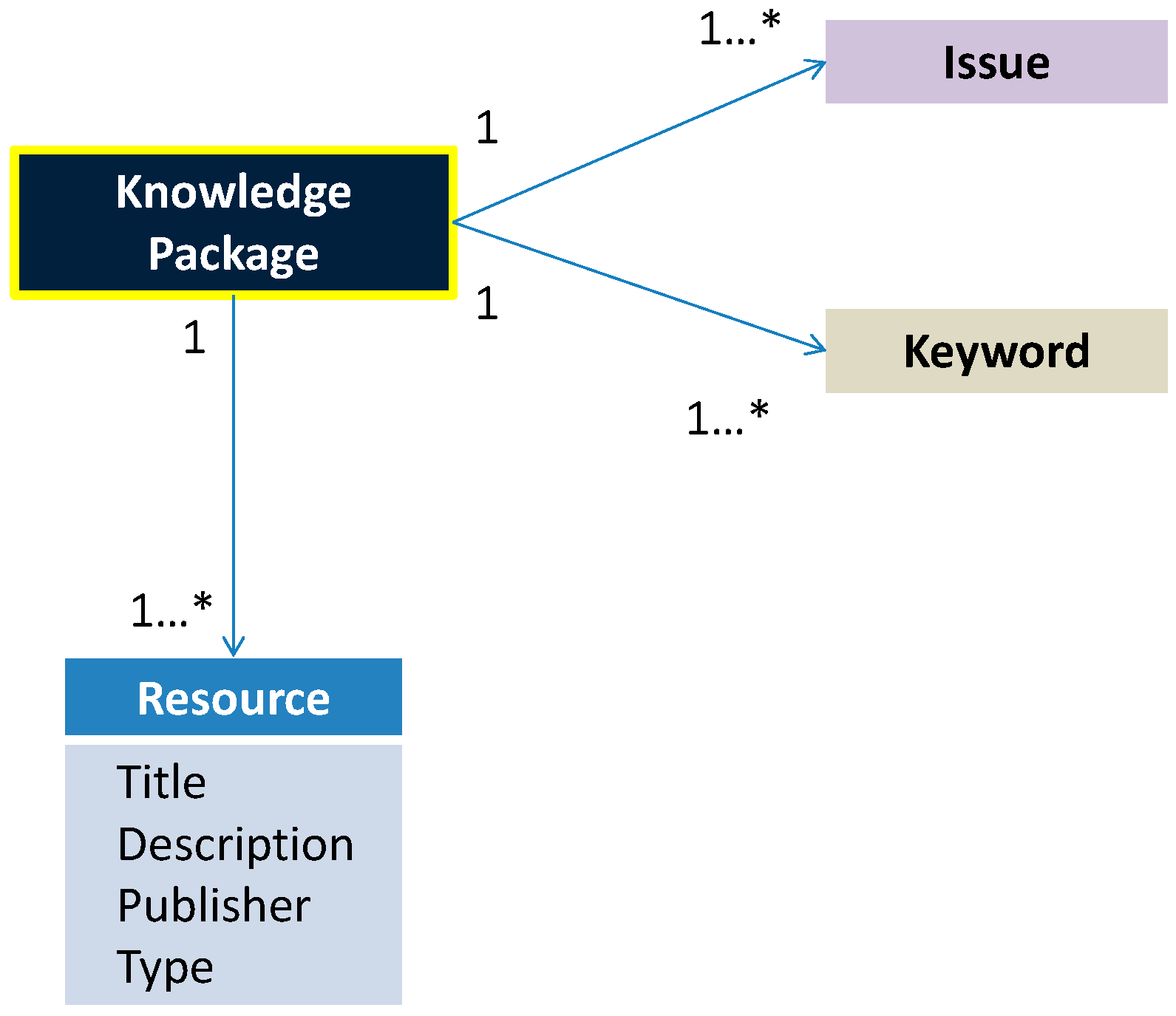
4.2. Climate Policy Ontology
4.3. Technological Choices
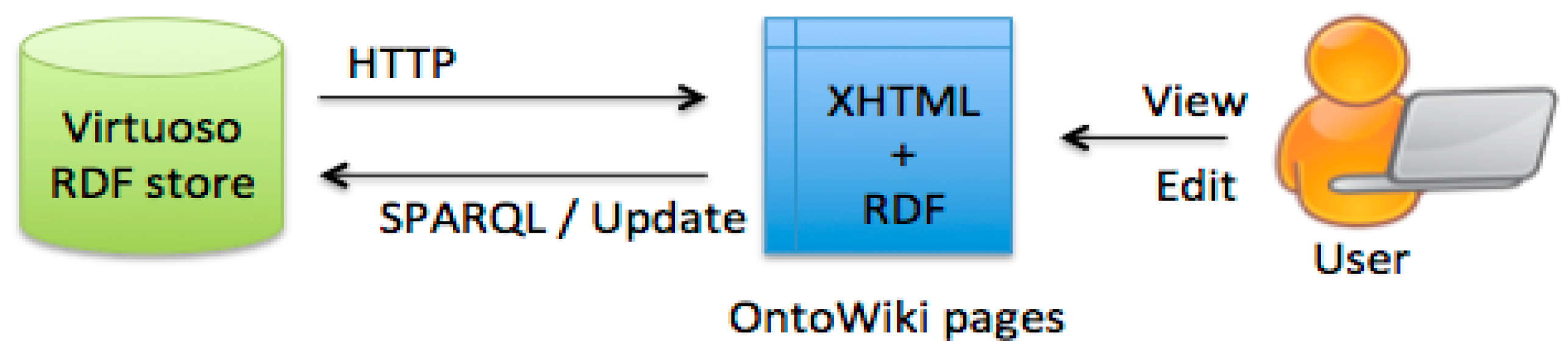
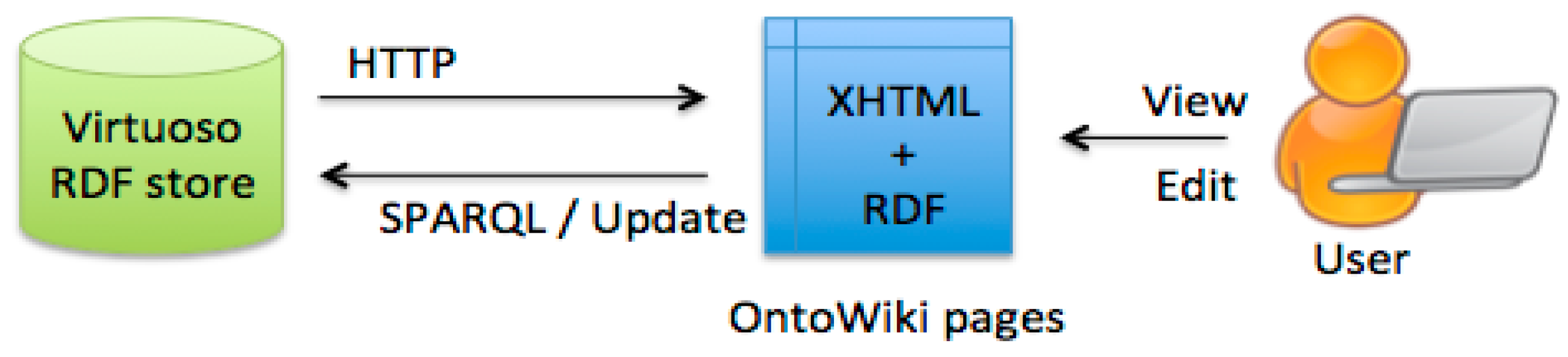
4.3.1. OpenLink Virtuoso: A Framework for Storing and Querying Data
4.3.2. OntoWiki
4.4. Climate Policy Database Setup
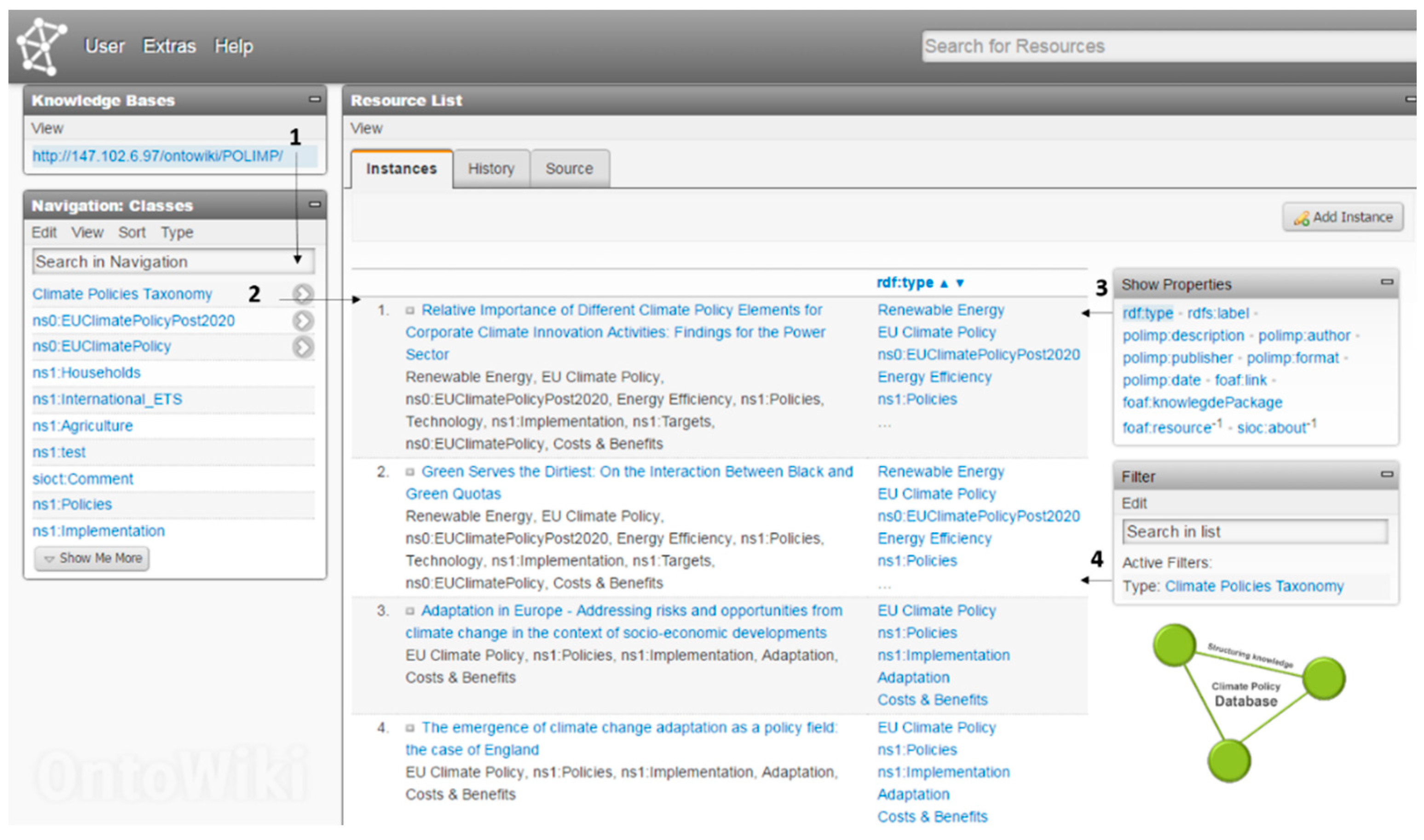
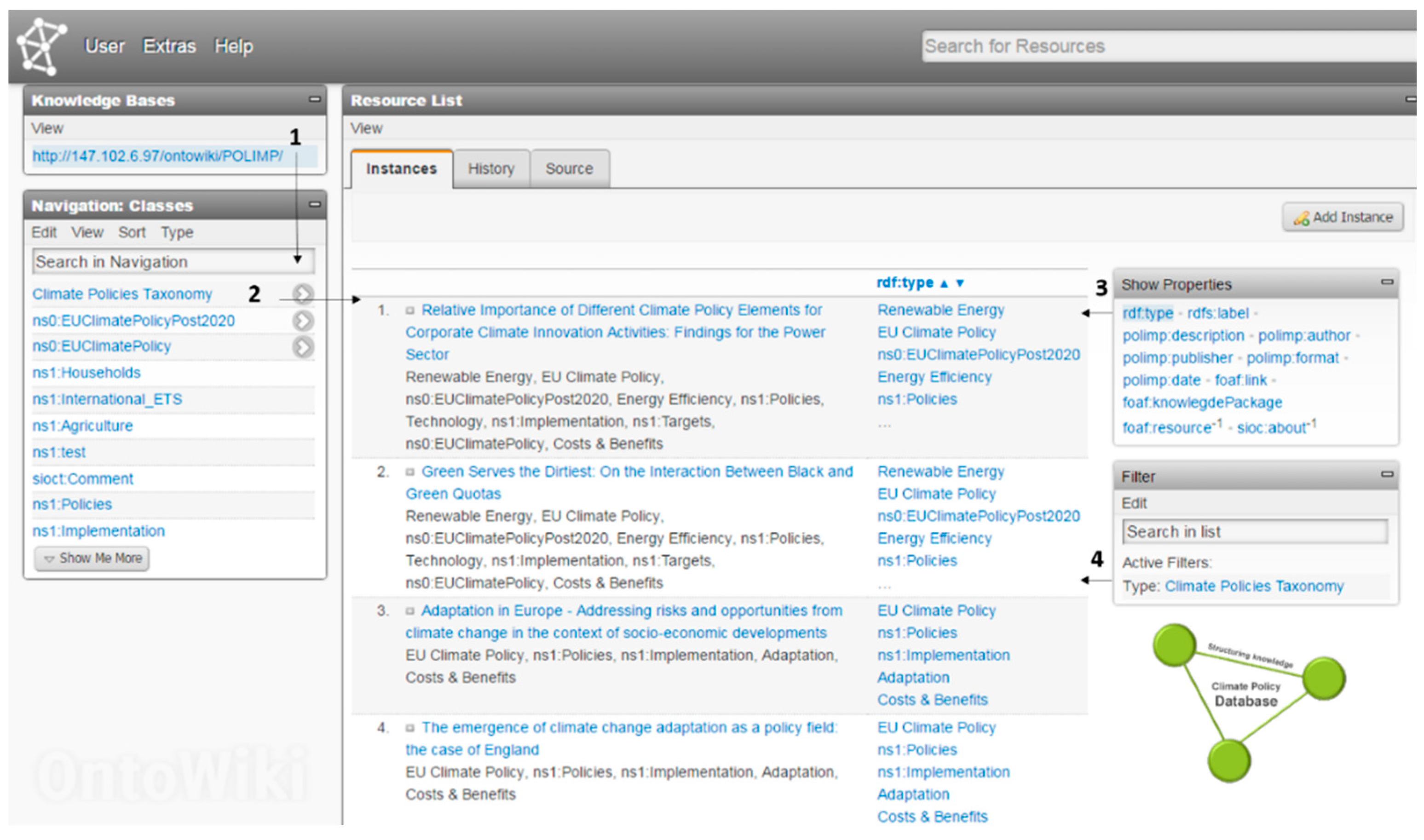
4.4.1. Main Building Blocks
- The knowledge bases—the knowledge bases provides a list of the available knowledge bases.
- The navigation component—the navigation component is a powerful OntoWiki extension that is able to extract the structure of knowledge bases and facilitate the navigability of datasets.
- The main window—in this area the resource list of chosen class is presented. Moreover, the main window serves as a form editing area when the user selects to edit a particular resource.
- The resource search field—the resource search field enables the user to perform searches on the resources based on keywords.
- Additional modules area—in this area additional helpful modules are displayed.
4.4.2. Extending the Climate Policy database—Creating a New Class and Instances
4.4.3. Browsing the Climate Policy database—Viewing the Instance List of a Class
4.4.4. Browsing the Climate Policy database—Viewing a Single Instance
4.4.5. Making changes to the Climate Policy Database—Modifying an Instance or a Class
4.4.6. Querying the Climate Policy Database—Applying Filters on the Resources
4.4.7. Community Features
4.4.8. Change Tracking and Versioning
5. Results and Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Dröge, S.; Spencer, T.; Deprez, A.; Gallagher, L.; Gradziuk, A.; Marcu, A.; Oberthür, S.; Sartor, O.; Waisman, H.; Wyns, T. The EU’s INDC and Its Contribution to a Successful Deal in Paris 2015; Working Paper FG 8, 2015/03; Division Global Issues, Stiftung Wissenschaft und Politik, German Institute for International and Security Affairs: Berlin, Germany, 2015. [Google Scholar]
- UNFCCC—United Nations Framework Convention on Climate Change. Adoption of the Paris Agreement, Proposal by the President, Draft decision -/CP.21 Conference of the Parties Twenty-First Session Paris. 12 December 2015; FCCC/CP/2015/L.9. [Google Scholar]
- WHO—World Health Organization. Climate Change and Human Health: Risks and Responses; McMichael, A.J., Campbell-Lendrum, D.H., Corvalán, C.F., Ebi, K.L., Githeko, A.K., Scheraga, J.D., Woodward, A., Eds.; World Health Organization: Geneva, Switzerland, 2002; ISBN 92-4-156248-X. [Google Scholar]
- Kaygusuz, K. Energy for sustainable development: A case of developing countries. Renew. Sustain. Energy Rev. 2012, 16, 1116–1126. [Google Scholar] [CrossRef]
- Ockwell, G.D.; Watson, J.; MacKerron, G.; Pal, P.; Yamin, F. Key Policy Considerations for Facilitating Low Carbon Technology Transfer to Developing Countries. Energy Policy 2008, 36, 4104–4115. [Google Scholar] [CrossRef]
- Schucht, S.; Colette, A.; Rao, S.; Holland, M.; Schöpp, W.; Kolp, P.; Klimont, Z.; Bessagnet, B.; Szopa, S.; Vautard, R.; et al. Moving towards Ambitious Climate Policies: Monetised Health Benefits from Improved Air Quality Could Offset Mitigation Costs in Europe. Environ. Sci. Policy 2015, 50, 252–269. [Google Scholar] [CrossRef]
- Wang, X.; Nathwani, J.; Wu, C. Visualization of International Energy Policy Research. Energies 2016, 9, 72. [Google Scholar] [CrossRef]
- Bassi, A.M. Evaluating the Use of an Integrated Approach to Support Energy and Climate Policy Formulation and Evaluation. Energies 2010, 3, 1604–1621. [Google Scholar] [CrossRef]
- Spyridaki, N.-A.; Ioannou, A.; Flamos, A. How Can the Context Affect Policy Decision-Making: The Case of Climate Change Mitigation Policies in the Greek Building Sector. Energies 2016, 9, 294. [Google Scholar] [CrossRef]
- Jänicke, M. Horizontal and Vertical Reinforcement in Global Climate Governance. Energies 2015, 8, 5782–5799. [Google Scholar] [CrossRef]
- Fujiwara, N. Status Quo of Climate Negotiations, Mobilizing and Transferring Knowledge on Post-2012 Climate Policy Implications (POLIMP) Project Report D3.1. Available online: http://www.polimp.eu/images/results/D3.1_-_Report_on_Status_Quo_of_Climate_Negotiations.pdf (accessed on 22 January 2014).
- Ecologic Institute 2014. Report on Knowledge Needs and Priorities, Mobilizing and Transferring Knowledge on Post-2012 Climate Policy Implications (POLIMP) Project Report D5.1. Available online: http://www.polimp.eu/images/results/D5.1_Report_on_knowledge_needs_and_priorities.pdf (accessed on 15 March 2014).
- Doukas, H.; Flamos, A.; Karakosta, C.; Psarras, J. Establishment of a European Energy Policy Think Tank Network: Necessity or Luxury? Int. J. Glob. Energy Issues (IJGEI) 2010, 33, 221–238. [Google Scholar] [CrossRef]
- Karakosta, C.; Doukas, H.; Psarras, J. Technology Transfer Challenges within the New Climate Regime. In Technology Transfer and Intellectual Property Issues; Braden, A.E., Nigel, L.T., Eds.; Nova Science Publishers, Inc.: Hauppauge, NY, USA, 2010; ISBN 978-1-60741-875-7. pp. 1–31. [Google Scholar]
- Karakosta, C.; Ioannou, A.; Flamos, A. Mobilizing and transferring knowledge on post-2012 climate policy. In Proceedings of the 7th International Scientific Conference on Energy and Climate Change, Athens, Greece, 8–10 October 2014.
- Hepp, M.; Bachlechner, D.; Siorpaes, K. OntoWiki: Community-driven Ontology Engineering and Ontology Usage based on Wikis. In Proceedings of the 2005 International Symposium on Wikis (WikiSym 2005), San Diego, CA, USA, 16–18 October 2005.
- Gruber, T.R. Toward, Principles for the Design of Ontologies Used for Knowledge Sharing. Int. J. Hum. Comput. Stud. 1995, 43, 907–928. [Google Scholar] [CrossRef]
- Guarino, N. Formal, Ontology in Information Systems. In Proceedings of the 1st International Conference (FOIS'98), Trento, Italy, 6–8 June 1998.
- De Graaf, K.A.; Liang, P.; Tang, A.; van Vliet, H. How organisation of architecture documentation affects architectural knowledge retrieval. Sci. Comput. Program. 2016, 121, 75–99. [Google Scholar] [CrossRef]
- Hong, T.; D’Oca, S.; Turner, W.J.N.; Taylor-Lange, S.C. An ontology to represent energy-related occupant behavior in buildings. Part I: Introduction to the DNAs framework. Build. Environ. 2015, 92, 764–777. [Google Scholar] [CrossRef]
- Hong, T.; D’Oca, S.; Turner, W.J.N.; Taylor-Lange, S.C.; Turner, W.J.N.; Chen, Y.; Corgnati, S.P. An ontology to represent energy-related occupant behavior in buildings. Part II: Implementation of the DNAS framework using an XML schema. Build. Environ. 2015, 94, 196–205. [Google Scholar] [CrossRef]
- Zhang, K.; Liao, P.-C. Ontology of ground source heat pump. Renew. Sustain. Energy Rev. 2015, 49, 51–59. [Google Scholar] [CrossRef]
- Küçük, D. A high-level electrical energy ontology with weighted attributes. Adv. Eng. Inf. 2015, 29, 513–522. [Google Scholar] [CrossRef]
- Corry, E.; Pauwels, P.; Hu, S.; Keane, M.; O’Donnell, J. A performance assessment ontology for the environmental and energy management of buildings. Autom. Constr. 2015, 57, 249–259. [Google Scholar] [CrossRef]
- Saba, D.; Laallam, F.Z.; Hadidi, A.E.; Berbaoui, B. Optimization of a Multi-Source System with Renewable Energy Based on Ontology. Energy Procedia 2015, 74, 608–615. [Google Scholar] [CrossRef]
- Lopez, G.; Custodio, V.; Moreno, J.I.; Sikora, M.; Moura, P.; Fernandez, N. Modeling Smart Grid neighborhoods with the ENERsip ontology. Comput. Ind. 2015, 70, 168–182. [Google Scholar] [CrossRef]
- Nardi, J.C.; de Almeida Falbo, R.; Almeida, J.P.A.; Guizzardi, G.; Pires, L.F.; van Sinderen, M.J.; Guarino, N.; Fonseca, C.M. A commitment-based reference ontology for services. Inf. Syst. 2015, 54, 263–288. [Google Scholar] [CrossRef]
- Abanda, F.H.; Tah, J.H.M.; Duce, D. PV-TONS: A photovoltaic technology ontology system for the design of PV-systems. Eng. Appl. Artif. Intell. 2013, 26, 1399–1412. [Google Scholar] [CrossRef]
- Solic, K.; Ocevcic, H. The information systems’ security level assessment model based on an ontology and evidential reasoning approach. Comput. Secur. 2015, 55, 100–112. [Google Scholar] [CrossRef]
- Kurilovas, E.; Juskeviciene, A. Creation of Web 2.0 tools ontology to improve learning. Comput. Hum. Behav. 2015, 51, 1380–1386. [Google Scholar] [CrossRef]
- Gil, R.; Virgili-Gomá, J.; García, R.; Mason, C. Emotions ontology for collaborative modelling and learning of emotional responses. Comput. Hum. Behav. 2015, 51, 610–617. [Google Scholar] [CrossRef]
- Levine, D.M.; Dutta, N.K.; Eckels, J.; Scanga, C.; Stein, C.; Mehra, S.; Kaushal, D.; Karakousis, P.C.; Salamon, H. A tuberculosis ontology for host systems biology. Tuberculosis 2015, 95, 570–574. [Google Scholar] [CrossRef] [PubMed]
- Lu, W.; Qin, Y.; Liu, X.; Huang, M.; Zhou, L.; Jiang, X. Enriching the semantics of variational geometric constraint data with ontology. Comput. Aided Des. 2015, 63, 72–85. [Google Scholar] [CrossRef]
- Kontopoulos, E.; Martinopoulos, G.; Lazarou, D.; Bassiliades, N. An ontology-based decision support tool for optimizing domestic solar hot water system selection. J. Clean. Prod. 2016, 112, 4636–4646. [Google Scholar] [CrossRef]
- Fox, M.S. The role of ontologies in publishing and analyzing city indicators. Comput. Environ. Urban Syst. 2015, 54, 266–279. [Google Scholar] [CrossRef]
- Bonacin, R.; Nabuco, O.F.; Junior, I.P. Ontology models of the impacts of agriculture and climate changes on water resources: Scenarios on interoperability and information recovery. Future Gener. Comput. Syst. 2016, 54, 423–434. [Google Scholar] [CrossRef]
- Ma, X.; Zheng, J.G.; Goldstein, J.C.; Zednik, S.; Fu, L.; Duggan, B.; Aulenbach, S.M.; West, P.; Tilmes, C.; Fox, P. Ontology engineering in provenance enablement for the National Climate Assessment. Environ. Model. Softw. 2014, 61, 191–205. [Google Scholar] [CrossRef]
- OpenLink Virtuoso Universal Server. Available online: http://virtuoso.openlinksw.com/ (accessed on 3 February 2015).
- Agile Knowledge Engineering and Semantic Web (AKSW). Available online: http://aksw.org (accessed on 10 February 2015).
- DBpedia. Available online: http://dbpedia.org (accessed on 11 February 2015).
- W3C Working Group Note. Available online: http://www.w3.org/TR/xhtml-rdfa-primer/ (accessed on 17 March 2015).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Title | Description | Language/Interface |
|---|---|---|
| An Ontology to represent energy-related occupant behavior in buildings. Part I: Introduction to the DNAs framework & Part II: Implementation of the DNAS framework using an Extensible Markup Language (XML) schema [20,21] |
| XML (eXtensible Markup Language) |
| Ontology of ground source heat pump [22] |
| Python, UCINET for visualization |
| A high-level electrical energy ontology with weighted attributes [23] |
| Protégé ontology editor |
| A performance assessment ontology for the environmental and energy management of buildings [24] |
| Data in Resource Description Framework (RDF), to convert them usage of three key ontologies: ifcOWL (OWL), SimModel (XML), and SSN |
| Optimization of a Multi-source System with Renewable Energy Based on Ontology [25] |
| Protege2000 software as the editing tool |
| Modeling Smart Grid neighborhoods with the ENERsip ontology [26] |
| OWL DL, Protégé as ontology development environment |
| PV-TONS: A photovoltaic technology ontology system for the design of PV-systems [27] |
| OWL, Semantic Web Rule Language (SWRL), Unified Modelling Language (UML) |
| Title | Description | Language/Interface |
|---|---|---|
| Ontology models of the impacts of agriculture and climate changes on water resources: Scenarios on interoperability and information recovery [36] |
| Web Ontology Language (OWL), SPARQL Query tab of Protégé 4.3 |
| Ontology engineering in provenance enablement for the National Climate Assessment [37] |
| RDF—Turtle (Terse RDF Triple Language), SPARQL queries, Dublin Core Metadata Initiative (DCMI) Types Vocabulary, Organization ontology (prefix: org), PROV-O ontology (prefix: prov), FOAF, SKOS (Simple Knowledge Organization System) |
| Prioritized Main Topics | Knowledge Needs |
|---|---|
| Renewable Energy | Cost-effectiveness of support schemes for renewable energy. |
| Costs development of renewable energy technologies. | |
| Harmonisation of support schemes for renewables within and across EU member states. | |
| Smart grids. | |
| Europe (EU) climate policy | Interaction of different climate policy instruments and different targets. |
| Cost-effectiveness of targets. | |
| Carbon-pricing instruments (emissions trading system (ETS), taxation). | |
| Actions in other parts of the world, compared to the European Union. | |
| International Climate Negotiations | Climate finance generating mechanisms, innovative climate finance schemes. |
| Types and timescales of climate change mitigation targets. | |
| Vertical integration between decision-making levels. | |
| Energy Policy | Electricity market design. |
| Energy price developments in different world regions, and its impacts. | |
| Energy efficiency | Effectiveness of existing energy efficiency policy. |
| Possible energy saving obligation schemes and financing options. | |
| Energy efficiency measures savings potential. | |
| Access to capital for energy efficiency measures. | |
| Emissions Trading | Further harmonization of emissions trading scheme implementation across the Europe (EU). |
| Price stabilisation mechanisms, backloading, changes to the linear reduction factor. | |
| Potential reform and impacts of links to other emissions trading schemes around the world. | |
| Financing | Incremental additional investment required in specific sectors. |
| Mobilisation of private financial flows. | |
| Innovative finance schemes in an international context. | |
| Adaptation | Institutional setup and organisation of mainstreaming of adaptation. |
| Methodologies for estimation of costs and benefits of adaptation measures. | |
| Effective tools and best practices for raising public awareness and public participation. | |
| Indicators for the evidence base for adaptation policy decisions. | |
| Agriculture & Forestry | Sustainability criteria for biomass. |
| Indirect land use and land use, land-use change and forestry (LULUCF) accounting. | |
| Carbon sequestration. | |
| Fertiliser, manure and livestock management. | |
| Industry | Competitiveness: carbon leakage impacts and related exemptions. |
| Sectoral innovation scope, reduction potential and costs. | |
| Transport | Increasing efficiency through intelligent transport systems. |
| Efficient integration of modal networks. |
| Main Classes | |||||
| EU Climate Policy | International Climate Policy | Renewable Energy | Energy Efficiency | Emissions Trading | Adaptation |
| Subclasses | |||||
| Background | Background | Background | Policies | Background | Background |
| Targets | Scenarios | Support Systems/Incentives | Background | Implementation | Mainstreaming |
| Policies | Targets | Costs & Benefits | Costs & Benefits | Costs & Benefits | |
| Post 2020 | Post 2020 Targets | Renewable Energy | Reform of the EU ETS | ||
| Industry | Land Use | Electricity market design | |||
| Transport | Mechanisms | ||||
| Households | Technology | ||||
| Agriculture | Finance | ||||
| Costs & Benefits | International ETS | ||||
| Increasing farm efficiency | |||||
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karakosta, C.; Flamos, A. Managing Climate Policy Information Facilitating Knowledge Transfer to Policy Makers. Energies 2016, 9, 454. https://doi.org/10.3390/en9060454
Karakosta C, Flamos A. Managing Climate Policy Information Facilitating Knowledge Transfer to Policy Makers. Energies. 2016; 9(6):454. https://doi.org/10.3390/en9060454
Chicago/Turabian StyleKarakosta, Charikleia, and Alexandros Flamos. 2016. "Managing Climate Policy Information Facilitating Knowledge Transfer to Policy Makers" Energies 9, no. 6: 454. https://doi.org/10.3390/en9060454
APA StyleKarakosta, C., & Flamos, A. (2016). Managing Climate Policy Information Facilitating Knowledge Transfer to Policy Makers. Energies, 9(6), 454. https://doi.org/10.3390/en9060454