1. Introduction
Since renewable energy resources are environment-friendly and economical, global energy resources are totally transforming towards renewable energy resources. Most of the energy resources will be shifted towards renewables by 2050, according to a report from the International Energy Agency (IRENA) [
1]. This will reduce the overall CO
2 production by 27 percent, reducing global warming. Solar power is one of the most used and easy-to-install renewable resources. However, like most other renewable energy sources, solar power is also intermittent, making it challenging to supply reliable and uninterruptible power [
2]. Therefore, one of the best and most economical strategies to overcome these intermittencies is to predict the power output before. Accurate forecasting can provide multiple benefits [
3]. For instance, an efficient power trading strategy can be planned with accurate day-ahead forecasting; penalties can be avoided with correct forecasting. In addition, accurate forecasting also helps in balancing generation and demand, improving system stability, and providing ancillary services [
4]. Solar power forecasting can be categorized into physical, statistical, and machine learning (ML) models [
5]. Physical methods are accurate but computationally expensive. Statistical methods are based on traditional predefined mathematical modeling, which either map linearly or cannot capture the underlying non-linear relationship between input features and target output [
6]. ML models can overcome these challenges by capturing non-linear relations between input features and target output power. These models are trained to build a mapping using a dataset of input features and corresponding output values, resulting in a black-box model. Different machine learning models have been used for solar power forecasting. For instance, the Support Vector machine model (SVM) based on various weather information, such as cloud, sun duration, etc., has been used to forecast solar power in [
7]. Ensemble models are proposed as state-of-the-art machine learning models in [
8]. Ensemble models include random forest regression (RFR) and extreme gradient boosting (XGBoost), which are other types of ensemble models. Other machine learning models are Recurrent Neural Networks (RNN) [
9] based suitable for time series problems.
As mentioned before, ML models are trained in a supervised learning manner to generate black-box models. These are called black box models because of the lack of understanding of the inner working mechanism. Utility engineers are hesitant to deploy AI-based models due to a lack of insight and explanation, which can help in understanding the dynamic decision-making mechanism. Explainable AI (XAI) can address these challenges by explaining, interpreting, and increasing the transparency of AI-based so-called black box models. A detailed review of XAI has been done in [
10], which reviews concepts, taxonomies, opportunities, challenges, and adopting XAI tools. An XAI project is introduced in [
11] to deliver AI techniques with more explainable models to understand, trust, and adequately deal with rising AI applications.
The following are the main motivations for applying XAI in solar power forecasting. Adaptation of solar photovoltaic (PV) has remarkably increased since the last decade; for instance, in the US, more than 1 million installations totaling 71.4 GW capacity [
12]. This increase in installations has led to different AI-based forecasting approaches, which require explanation and interpretation. In the literature, not many studies have been carried out on the detailed application of XAI techniques in solar power forecasting. Furthermore, in the energy market, with the inclusion of distributed resources and electric vehicles, explainable and trustable models are essential.
In the literature, some XAI-based models are proposed for smart grid applications as in [
13]; a short-term load is forecasted with generalized additive models to integrate a regressive part with explanatory variables such as weather, time, and trends. An agent-based deep reinforcement learning algorithm using XAI is proposed in [
14] to manage an energy storage system. These models built an efficient dispatch algorithm for the energy storage device under variable tariff structures. XAI is applied to explain demand forecasting out of the gradient boosting algorithm in [
15]. The analysis was done using Shapley Additive exPlanations) SHAP. This paper only used SHAPE and ELI5 XAI tools. However, other more sophisticated XAI tools are available and applied in different fields. Further, these works do not clearly demonstrate the impact of varying input features on the output, such as solar radiation, pressure, temperature, snow depth, and humidity.
Federated Learning (FL) is a distributed ML methodology that trains models across multiple nodes, allowing each node to preserve its data while handling the issues of privacy, security, and data locality [
16]. FL methodologies are particularly applicable in the healthcare, finance, and smart grid industries, where data privacy is of utmost importance. Vanilla FL addresses a practical distributed learning situation wherein (1) the centralized server is restricted from accessing any user data and (2) the data distribution among different users is non-IID, a realistic premise in actual applications [
17]. The central server monitors the learning process by averaging local model updates instead of utilizing their raw data, hence considerably mitigating data exposure hazards. Consequently, this methodology depends on a singular global model as the central entity for aggregating user input parameters. To overcome these limitations, we propose an explainable clustered federated learning (XCFL) framework that incorporates a cluster-wise training approach, where clients are grouped based on data similarity using Mean Shift clustering. Within each cluster, local models are trained independently, and their predictions are aggregated using a weighted averaging mechanism. The stochastic gradient descent (SGD) [
16] for single-center aggregation is typically formulated for IID data, encountering obstacles such as data heterogeneity, data imbalance, time-variant preferences, and variations in data quality among nodes.
Clustering is a data analysis method that systematically groups clients or organizations with similar attributes and features into coherent clusters. This method utilizes sophisticated algorithms to identify underlying patterns within complex datasets, facilitating the generation of clusters that optimize intra-group similarities and highlight inter-group disparities. Clustering groups clients by shared features, enabling a detailed comprehension of data structures and offering significant insights for targeted strategies and decision-making across various industries. It can assist in classifying unlabeled data into several categories with little to no supervision [
18]. The grouping is structured such that items within the same category display similar characteristics and are differentiated from those in other categories [
19]. Acquiring knowledge from the dataset without accounting for pertinent characteristics results in a biased prediction, particularly when imbalanced features and known labels are integrated [
20].
The proposed XCFL explicitly addresses data heterogeneity by allowing each cluster to train localized models that adapt to unique climatic, geographic, or sensor conditions, thus outperforming uniform global models in heterogeneous settings. In other words, the XCFL is designed in a way that considers scalability, particularly through its use of mean shift clustering, which groups similar data distributions before model training. This reduces the number of communication rounds required compared to traditional FedAvg. The modular architecture of XCFL also makes it suitable for deployment across large-scale solar power networks, where each cluster can represent a plant, region, or sensor group. The main contributions of this paper are summarized as follows:
Introduces a systematic methodology that integrates explainability into federated clustering, hence enhancing transparency in decision-making through the incorporation of weighted aggregation at both the cluster-specific and global model aggregation.
Suggests the application of XCFL to encompass dynamic and real-time clustering contexts, seeking wider applicability in heterogeneous and distributed learning contexts.
Our proposed XCFL outperforms the conventional FedAvg algorithm, achieving better model performance by leveraging feature-based explainability. Provides insights into the impact of specific attributes on clustering and model refinement.
In XCFL, the aggregation weights are derived either from the size of the local training data or model performance metrics such as the R
2 score. This ensures that more reliable or data-rich clusters contribute proportionally more to the final prediction, thereby improving robustness and generalization in heterogeneous settings. This strategy ensures that the aggregation process is sensitive to both data volume and prediction quality rather than relying on equal contributions from all nodes. Regarding long-term performance, the XCFL framework can incorporate temporal clustering or retrain clusters periodically to adapt to seasonal variability or evolving energy patterns. The list of symbols used in this paper is summarized in
Table 1.
The rest of the paper is structured as follows:
Section 2 discusses the literature review of both domains, FL and XAI.
Section 3 provides the system model and elaborates on the algorithms used in this work.
Section 4 presents XAI tools and the proposed explainable clustered federated learning.
Section 5 elaborates on the experiment setup and the results, and finally,
Section 6 concludes the work and discusses the prospects of future XAI applications in other real-world domains.
2. Background
Federated Learning and Explainable AI are transforming energy with secure, decentralized, and interpretable data-driven solutions [
21,
22]. FL enables collaborative model training across multiple sites while maintaining privacy by keeping raw data locally, which is crucial in smart grid and distributed photovoltaic systems. In contrast, XAI presents transparency in AI decision-making, enabling stakeholders to understand the contributions of characteristics in processes such as solar energy forecasts [
23]. Over the past decade, machine learning has successfully enabled building energy management in several common applications, such as load/power forecasting, failure detection and diagnosis (FDD), and occupancy-related applications [
24]. Load prediction is the estimation of projected cooling, heating, and energy demand in the next hours or days. Power prediction, on the other hand, is the estimation of power generation from equipment like photovoltaic (PV) panels and wind turbines. Ensuring precise load/power forecasting is crucial for enhancing building energy efficiency and adaptability [
25]. Model predictive control and demand-side management are the two primary applications of load/power prediction models [
26]. The objective of model predictive control is to minimize cost or energy consumption by optimizing building energy systems while considering restrictions such as thermal comfort and setpoint boundaries [
27]. In contrast to physics-based load/power prediction, machine learning methods rely on historical data rather than intricate physical knowledge and thermal balance calculations, therefore simplifying their development and deployment. Many machine learning algorithms, including autoregressive approaches, tree-based methods, artificial neural networks (ANN), and deep neural networks (DNN), have been extensively studied and shown to have excellent performance in load/power prediction over the last few decades [
26].
The growing implementation of artificial intelligence across diverse domains requires precise and interpretable models. Explainable AI fulfills this requirement by rendering AI judgments transparent, thereby cultivating user confidence and ensuring adherence to ethical standards. Simultaneously, Federated Learning has emerged as a method for training models using decentralized data sources, maintaining data privacy by localizing data [
22]. Nevertheless, the amalgamation of FL’s decentralized characteristics and intricate model structures presents considerable obstacles to attaining explainability. The concept of FED-XAI, introduced by [
21], proposes the federated learning of XAI models for AI-pervasive 6G networks, together with an a posteriori XAI architecture. The objective is to optimize the efficiency, intelligence, and reliability of automated vehicle networking, therefore enhancing user experience and ensuring the safety of end-users in network AI operations. The opaque characteristics of numerous AI models, particularly deep learning frameworks, sometimes engender distrust and hesitance in their implementation, especially in vital sectors such as healthcare and finance. XAI aims to elucidate these models by providing insights into their decision-making processes, thereby enhancing user confidence and facilitating regulatory compliance [
28]. In medical diagnostics, understanding the rationale behind a model’s prediction is crucial for doctors to trust and effectively utilize AI solutions. In finance, explainable models are crucial for maintaining transparency and equity in decision-making processes.
Federated Learning facilitates collaborative model training while maintaining privacy by eliminating the necessity to exchange raw data. This decentralized method, however, presents issues in attaining model explainability [
16]. The variability of data among many nodes and the intricacy of consolidating models trained on disparate datasets hinder the understanding of the global model’s performance. Confronting these obstacles is crucial for implementing federated learning in sensitive applications where comprehending model decisions is imperative. Recent studies have explored various approaches to enhance the interpretability of FL models [
29]. The proposal of explainable fuzzy regression models aims to reconcile performance and interpretability within a federated framework. The notion of Federated Explainable AI models (Fed-XAI) has been presented to safeguard data privacy and maintain a degree of explainability concurrently [
30]. Recent advancements show the increasing potential of Large Language Models (LLMs) to enhance interpretability and prediction accuracy in power systems, more specifically, time series forecasting. This has been demonstrated by the integration of market sentiment and bidding behaviors into electricity price forecasting models [
31] and the utilization of event analysis through reflective reasoning mechanisms to enhance forecasting outcomes [
32], highlighting promising opportunities for employing similar methods in solar energy forecasting.
Despite the progress in XAI and FL, numerous difficulties still persist. The challenge of balancing model accuracy with interpretability persists, as more complex models generally provide enhanced performance but are harder to understand. Intelligent approaches such as Fed-BN [
33] enhance personalization through local batch normalization layers, whereas Hierarchical FL [
18] performs multi-level aggregation. However, none of these approaches incorporates feature attribution directly into their aggregation process like XCFL does. The integration of interpretability metrics across federated learning nodes can produce generalized global insights. However, it may obscure node-specific features. Addressing these issues is crucial for establishing confidence in federated AI systems and for their widespread implementation in critical areas [
34]. Recent developments highlight hybrid methodologies that integrate physics-based modeling with symbolic regression to improve interpretability and generalization with limited data. This is exemplified in [
35], where a gray box model that employs symbolic regression to create precise and interpretable models for air conditioning systems effectively resolves the complexities of white box models and the obscurities of black box models. Furthermore, ref. [
36] emphasizes the significance of systematic feature selection in augmenting model interpretability and predictive accuracy. They employed Elastic Net and Artificial Neural Networks for the essential selection of input features in air conditioning equipment modeling, illustrating that meticulous selection of impactful input features markedly enhances the performance and elucidation of predictive models in energy-related contexts.
Motivation
Most FL setups apply explainability to centralized models, focusing on global interpretability without considering local model subtleties. Explainability methods like SHAP and LIME are generally constrained to centralized or local models without federated learning [
10]. Currently, in centralized or federated models with explainability, privacy issues may arise as client data can still be indirectly revealed through aggregated models or shared updates. Conventional federated learning frameworks do not emphasize explainability, particularly with local models, due to privacy limitations [
37]. Authors in [
38] employ model aggregation methodologies that consider data heterogeneity among clusters, like weight-based aggregation or personalized federated learning (FedProx). Implementing explainability approaches within a privacy-preserving federated learning framework guarantees the generation of insights without disclosing raw client data. This is vital in domains such as energy forecasting, where sensitive data such as energy usage and local meteorological conditions are used. Integrating CFL with explainability mitigates various deficiencies of conventional approaches, especially regarding data heterogeneity, privacy assurance, and the provision of explainable insights at both local and global scales.
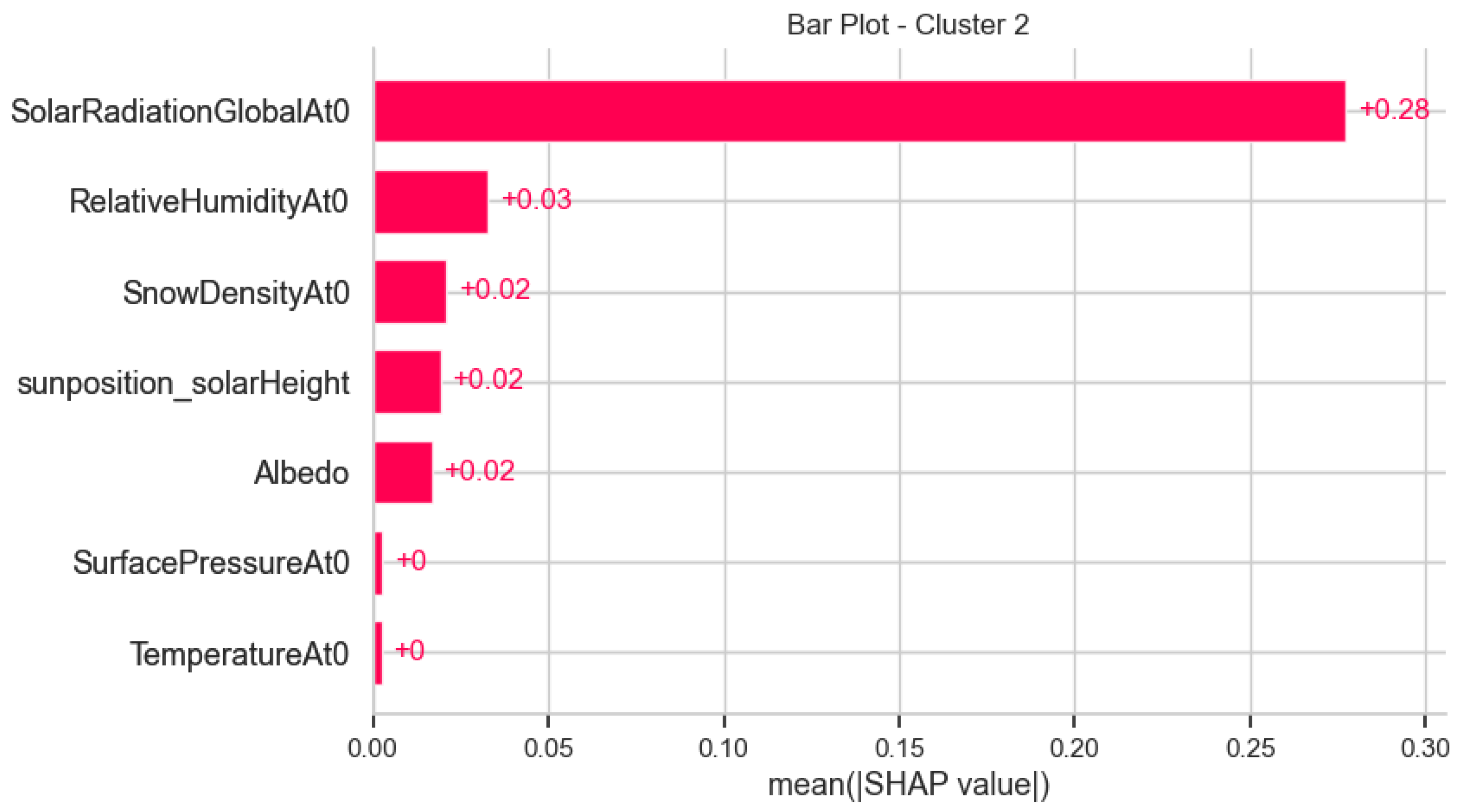
In contrast, the proposed XCFL enhances federated learning by ensuring that model enhancements and decisions are informed by domain-specific insights. In smart grid and solar forecasting applications, as well as in time-series forecasting across distributed clients, this results in practical benefits: energy operators receive more precise predictions customized for various grid segments, and they learn insights into the explanations for variations in the predictions as in our proposed XCFL approach, the forecast is most contributed by the “SolarRadiationGlobalAT0” feature in the cluster. It reduces the challenges of data heterogeneity by clustering, offers some level of personalization, preserves privacy via federated training, and ensures model interpretability through integrated XAI, achieving a balance that existing approaches addressed as separate issues [
11,
16,
17]. This ensures that the collaborative models are robust, customized to their data niches, and understandable at local, cluster, and global levels. It demonstrates a significant improvement over the current state-of-the-art FedAvg [
39], clustered FL [
40], or XAI tools [
30] in FL by providing a comprehensive framework that allows stakeholders to evaluate and validate each model’s behavior. It is especially critical in areas like renewable energy forecasts, where model-aware tasks such as grid management or energy trading require both accuracy and trustworthiness.
4. Explainable Clustered Federated Learning
Currently, AI has been applied to numerous industries, but its full adoption is constrained by the opaque internal processes of AI systems [
41]. Both academics and industries have developed numerous strategies and XAI technologies to make AI systems transparent. LIME (Local Interpretable Model-Agnostic Explanations) [
42], SHAP (Shapley Additive exPlanations) [
43], ELI5, MLxtend (machine learning extensions) [
44], Interpret ML [
45], TreeInterpreter [
15], Alibi [
46], yellowbrick, CEM (Contrastive Explanation Method), and others are a few of these methods and tools. In this paper, we focus on the SHAP, which is widely used in the PV power prediction model by developers and researchers these days. The interpretation of the Random Forest and XGboost models involves an analysis by calculating the average change in model predictions resulting from variations in input features. It’s important to note that all the methods mentioned above only provide insights into the global behavior of the ML model. In contrast, the SHAP method explores both local and global behavior, utilizing game theory-based SHapley values to overcome these limitations [
47]. Additionally, SHAP’s feature attribution values are additive, meaning their sum equals the model’s prediction, rendering SHAP more intuitive [
43].
4.1. SHAP
SHAP (SHapley Additive exPlanations) operates on the principle of cooperative game theory, aiming to explain the contribution of each input feature to individual predictions [
43]. It calculates the average change in predictions when a particular feature is included across all possible feature combinations [
48]. These calculations yield SHAP values, which ensure that the sum of feature contributions equals the model’s prediction. By creating a baseline, perturbing input features, and constructing a weighted linear model, SHAP provides a transparent approximation of complex models’ behavior. The incorporation of SHAP-based feature importance enhances interpretability and enables more informed aggregation within XCFL, it does introduce a degree of computational overhead at the client or cluster level. To maintain overall efficiency, XCFL is designed with a clustering mechanism applied prior to federated training. This clustering significantly reduces both the number of communication rounds and the volume of model updates transmitted between clients and the central server. By performing aggregation at the cluster level instead of the individual client level, XCFL effectively mitigates the additional cost introduced by SHAP computations. While this work does not explicitly quantify the SHAP-related overhead, the overall architecture of XCFL achieves a favorable trade-off, balancing predictive performance with scalability and communication efficiency. This approach enables both global and local interpretations, making it a robust tool for understanding feature importance and interactions within a model’s decision-making process [
49]. The SHAP values are calculated as
is the combination matrix,
is explaining the model by using
which is the contribution feature in particular
the baseline prediction value,
the SHAP characteristic values and
is the coalition vector indicating whether a feature is included (11) or not (0). In the proposed XCFL framework, SHAP values serve not only as global feature importance metrics but also as local and cluster-level feature-dependent attributions that drive the weighting of model updates. This feature-level weighting mitigates variability by allowing cluster-specific prioritization of predictive features. To reduce such unfairness, our approach standardizes SHAP contributions among clients within each cluster, ensuring that no individual client’s feature predominates due to localized false correlations. In addition, by aggregating normalized SHAP values at the cluster level and not relying exclusively on client-specific distributions, we enhance the fair representation of diverse configurations. Regarding overfitting, using SHAP for weighting mitigates the impact of irrelevant or weakly correlated features, thus effectively normalizing the model updates.
4.2. Interpretation of CFL Using XAI Tools
The growing adoption of artificial intelligence has highlighted its complexity, including issues related to ethics, privacy, security, and intellectual property rights, commonly referred to as copyright. These concerns are being addressed through innovative methodologies, such as explainable AI, trusted AI, and distributed learning frameworks like federated learning (FL). Analyzing CFL with Explainable AI can help build trust and provide transparency in decentralized machine learning models, particularly in critical infrastructures such as energy demand forecasting. We propose Explainable Clustered Federated Learning, which aims to provide enhanced interpretability and performance by organizing clients with heterogeneous data distributions into clusters, facilitating personalized models for each clustering group. FL models, similar to conventional machine learning models, often function as “black boxes”, which complicates the client’s comprehension of the bias behind predictions. Integrating XAI techniques, such as SHAP, LIME, and permutation, is important as it renders CFL models interpretable at both local (client or cluster) and global levels. This facilitates a comprehensive understanding of how various input factors, such as meteorological conditions or solar radiation, impact forecasts across different geographies, providing actionable insights while preserving data privacy. Federated learning inherently incurs communication overhead, which can become a significant challenge in real-world scenarios characterized by limited bandwidth or high-latency networks. The XCFL mitigates this issue by performing aggregation at the cluster level, rather than the individual client level, thereby reducing the frequency of communication rounds. However, its performance may still be influenced by unstable network conditions or resource limitations.
The integration of CFL and XAI improves model efficacy and reliability, rendering it more appropriate for real-world applications where transparency in decision-making is essential. Clustering in the federated approach for solar farms is essential because of the varying weather patterns and environmental circumstances across different geographical regions, which can influence solar power generation in diverse ways [
50]. The imperative for output forecaster interpretability through XAI stems from the requirement to comprehend the impact of local variables, such as solar radiation, temperature, and cloud cover, on power predictions, thereby facilitating more reliable and transparent decision-making in energy management across various regions.
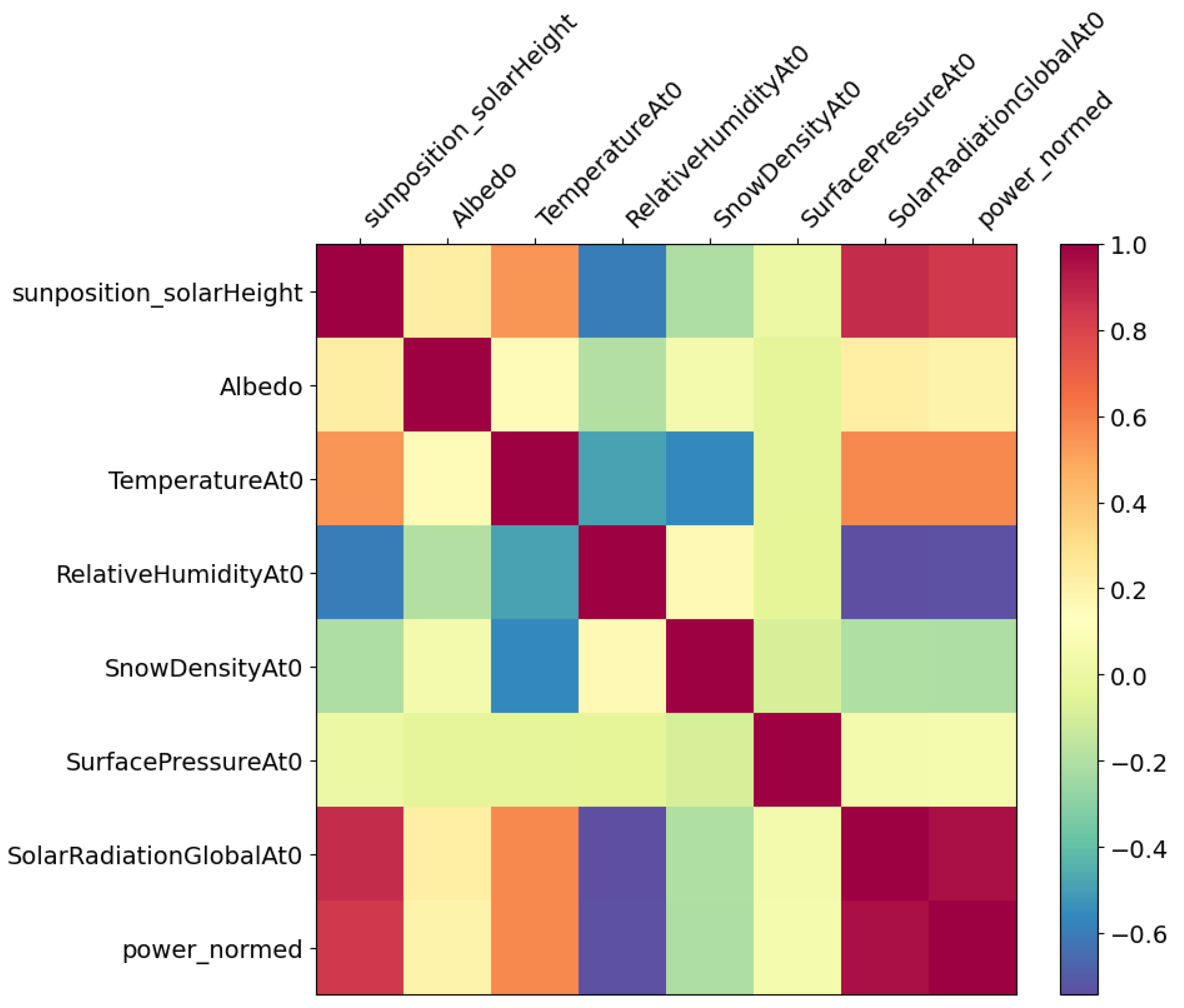
The distributed photovoltaic (PV) panels in various geographical regions demonstrate considerable variations in weather and meteorological conditions. To tackle this heterogeneity, we first find out the most significant features by Pearson correlation analysis, as shown in
Figure 1. The Pearson correlation has been selected for its increased efficiency in identifying important linear relationships within the dataset relative to other approaches. Its computational efficiency and efficacy make it a suitable choice for feature selection in solar PV analysis.
Figure 1 illustrates the linear relationships between input features and the target variable power_normed. It helps identify inter-feature correlations, which can be leveraged to avoid feature redundancy and improve model generalization. These insights not only validate the input selection but also inform strategies for data collection and model simplification in practical deployments. Data heterogeneity is a core challenge in distributed solar forecasting systems. Although XCFL addresses this by applying Mean Shift clustering to group clients with similar data patterns, the effectiveness of this strategy depends on the ability to form well-defined clusters. In practical scenarios involving high noise levels, sparse measurements, or significant variability, the clustering process may become less reliable. As a result, the global model may struggle to accurately represent localized behaviors. Using Mean-Shift clustering ensures that photovoltaic panels are clustered according to the underlying data distribution, thereby enhancing the effectiveness of federated learning by assuring that localized models are developed on more homogeneous datasets. Clients execute localized training within their cluster, utilizing the feature set particular to that cluster. Utilizing XAI tools, the most contributing features for the localized models in each cluster are analyzed, and the models, together with their corresponding feature importance weights, are shared with the server as
where
m is the cluster index,
k is the clients in cluster
,
is the important features score contributing the model in the training and
are the weights assigned to each feature based on their contribution scores, using the XAI tools to be shared with the server for cluster-specific aggregation purposes. Furthermore, XCFL explicitly addresses data heterogeneity by allowing each cluster to train localized models that adapt to unique climatic, geographic, or sensor conditions, thus outperforming uniform global models in heterogeneous settings. The server then executes weighted aggregation based on feature significance values to provide cluster-specific models and subsequently performs global aggregation. This technique is repetitively executed for each round. The XAI approaches enable the elucidation of feature contributions, which are crucial for effective cluster-specific model aggregation and improving the overall training process as in Equation (
3).
where
m is the index of cluster,
k (1, 2, 3, …, K) is the clients in cluster
,
is contribution of the features by
k client. Equations (
2) and (
3) present the hierarchical weighted aggregation process used in XCFL. In contrast to conventional FedAvg, where all client contributions are treated equally, XCFL leverages feature importance scores (extracted using XAI tools) and inter-feature redundancy penalties to compute client-specific and cluster-specific weights. This enables the aggregation to be performance-aware and semantically informed, ensuring that models trained on more informative or diverse features contribute more significantly to the global model. The normalization terms ensure fair comparison across clients and clusters, while the redundancy term
reduces the influence of overlapping or less distinctive features. This mechanism enhances the robustness and generalization capability of the global model, particularly under non-IID and heterogeneous data distributions. The working flow of the XCFL algorithm is explained in Algorithm 1. In line 3, the server is initializing the initial model, computing the person coefficient, and assigning the initial clustering. The local model training is done in lines 7 and 8, whereas in line 9, the SHAP values are computed for each feature from the dataset, and then the process of weight assignment for weighted aggregation is calculated in line 10. In line 13, the server aggregates models from all clusters using cluster-level SHAP contributions and finally returns the cluster-specific model in line 15.
| Algorithm 1 Explainable Clustered Federated Learning (XCFL). |
- 1:
Input: , C, T, epochs e, , F, - 2:
Output: Cluster-specific explainable models - 3:
Server Initialization: Compute P.C for F assign clients into clusters - 4:
for
do - 5:
for do - 6:
for (parallel) do - 7:
Set local model: - 8:
- 9:
Compute normalized weights for clients using SHAP values: - 10:
Weighted aggregation to update cluster-specific model: - 11:
Aggregate SHAP values at cluster-level: - 12:
Share and to server - 13:
- 14:
- 15:
return
|







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}