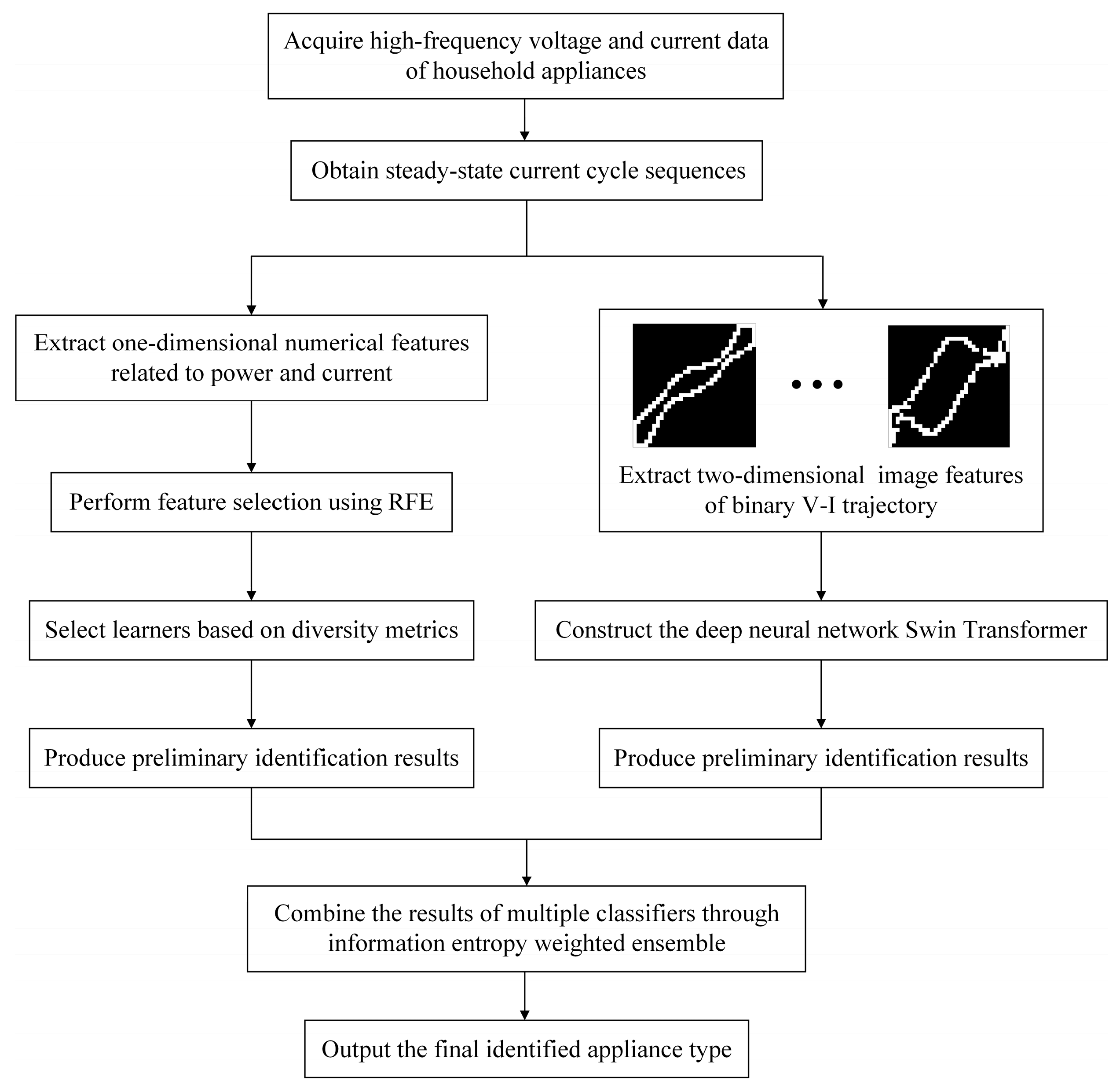
5.3.1. Results and Comparisons on the PLAID Dataset
Figure 9 illustrates the confusion matrices of the preliminary identification results for one-dimensional numerical features. In each confusion matrix, the rows represent the actual classes of the devices, while the columns denote the predicted classes. The diagonal entries indicate cases where the predicted class matches the actual class, signifying correct classification. Conversely, the off-diagonal entries represent misclassified instances.
The confusion matrices reveal that when using only LR for classification, the recall rates for fans, fridges, heaters, and washing machines are all below 80%, indicating that many samples of these appliances are not correctly identified. When employing only KNN, incandescent light bulbs, and microwaves are perfectly classified, while the recall rate for fridges drops to only 60%. With Adaboost alone, microwaves, and vacuum cleaners are completely distinguishable, but the precision for heaters is relatively low, suggesting that other appliances are frequently misclassified as heaters. GBDT demonstrates better classification performance, effectively identifying heaters, microwaves, and vacuum cleaners, though the recall rate for washing machines remains below 80%.
This suggests that appliances such as fridges and heaters, being multi-state devices [
42] with non-unique operating modes, are prone to misclassification. The classification outcomes vary across different learning algorithms for different appliances. It is expected that recognition accuracy can be further improved through effective ensemble methods.
As shown in
Figure 9e, the information entropy-weighted ensemble method combining these four learners achieves an overall accuracy of 98.77%, surpassing that of any individual learner. Except for fridges, nearly all appliances exhibit precision and recall rates close to or above 95%. This demonstrates that for one-dimensional numerical features, the proposed method effectively integrates multiple diverse learners to leverage their respective strengths, thereby enhancing classification performance.
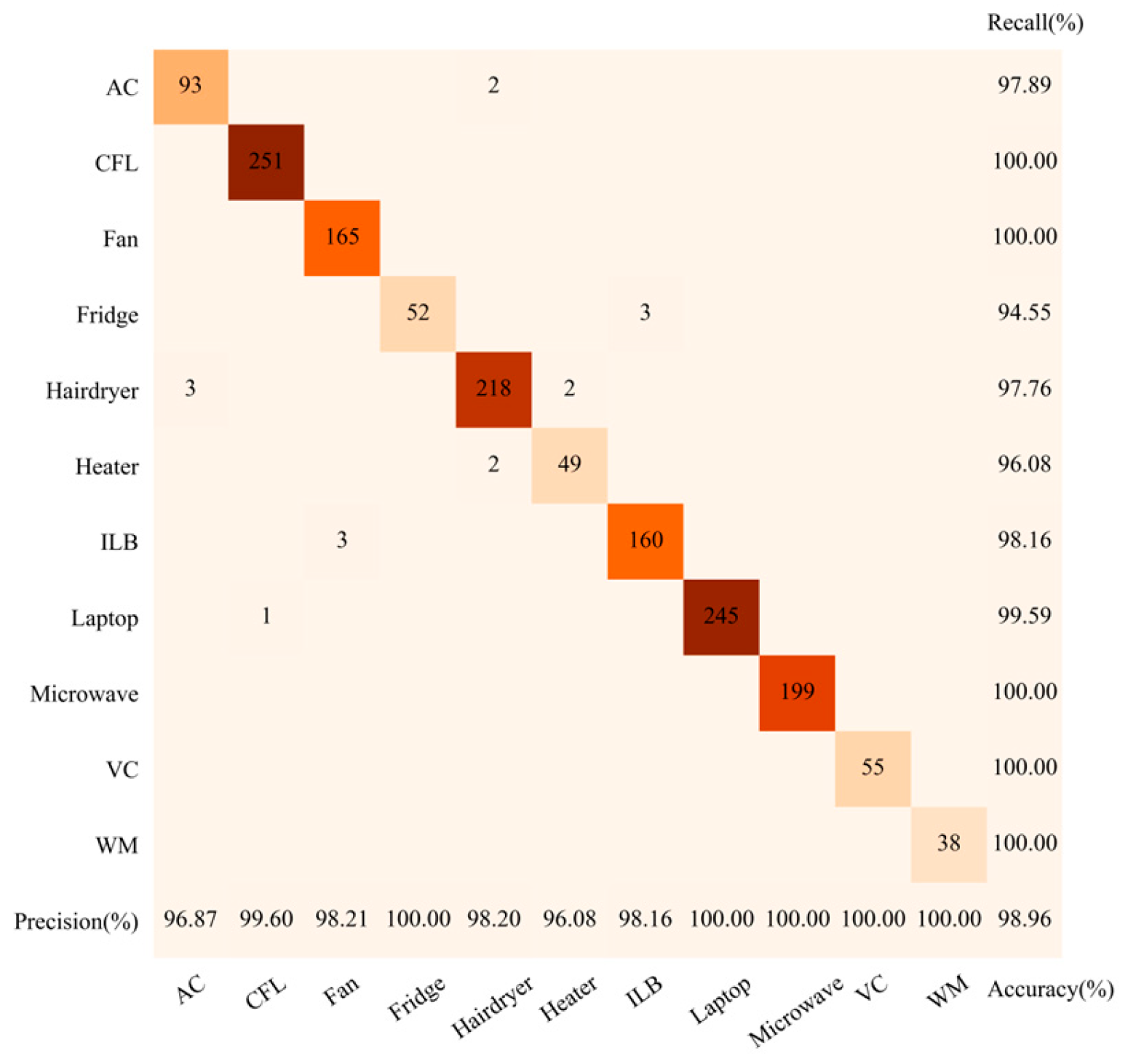
For two-dimensional image feature recognition, this paper adopts the Swin-Tiny (Swin-T) model, the variant with the lowest computational complexity within the Swin Transformer framework. The confusion matrix in
Figure 10 shows the overall accuracy of 98.96%. The precision and recall rates for microwaves, vacuum cleaners, and washing machines all reach 100%. However, misclassifications occur for air conditioners, fridges, hairdryers, heaters, incandescent light bulbs, and laptops. By examining the binary V-I trajectory images in
Figure 3, it can be observed that the fans, hairdryers, heaters, and incandescent light bulbs exhibit high trajectory similarity. Similarly, compact fluorescent lamps, and laptops also demonstrate close trajectory resemblance. Consequently, relying solely on two-dimensional binary V-I trajectory features proves insufficient for accurately distinguishing these appliances.
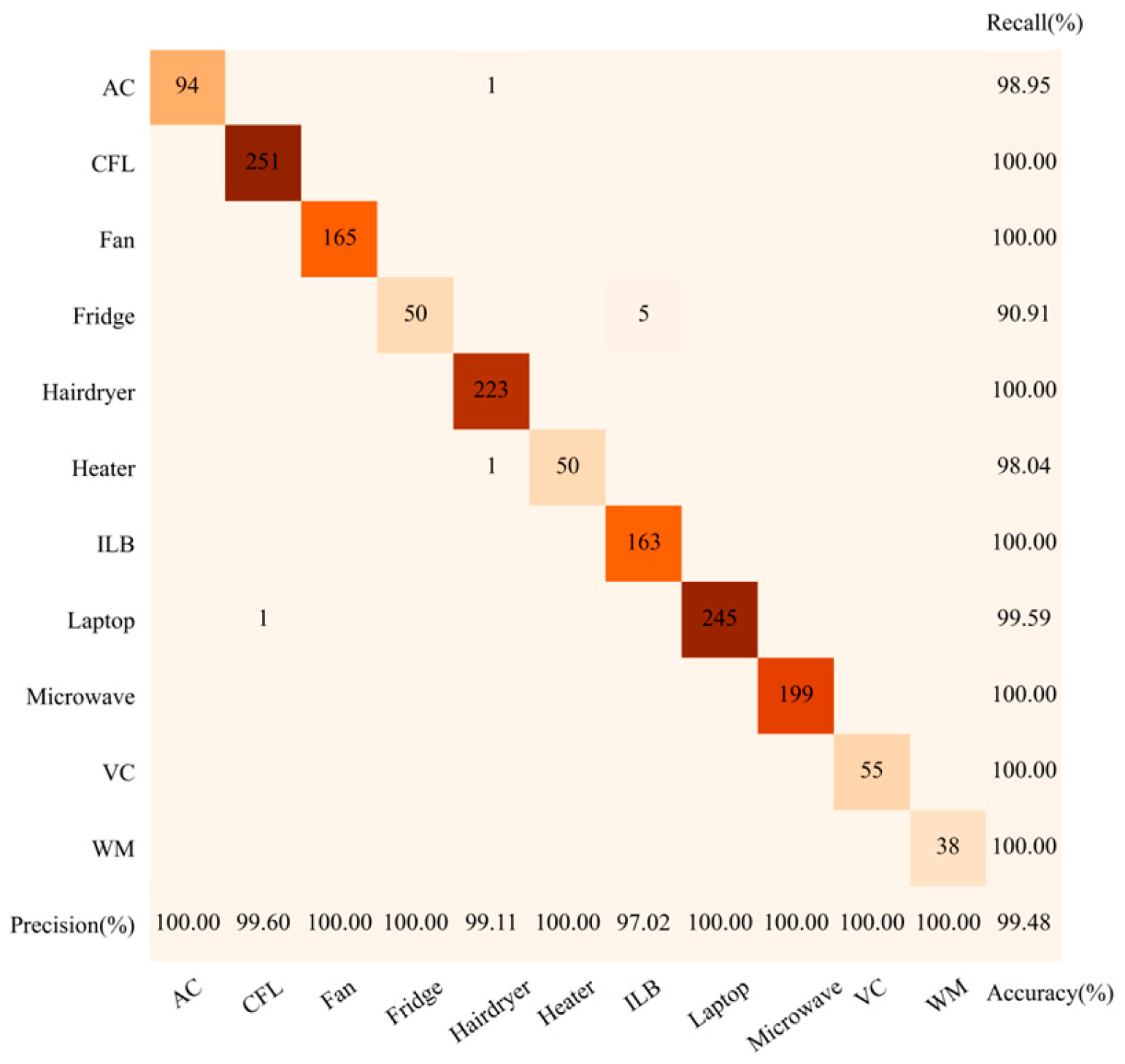
In
Figure 11, the proposed method achieves the identification accuracy of 99.48% by combining one-dimensional numerical features and two-dimensional image features, with the recall rate of 90.91% for the fridges and precision/recall rates exceeding 97% for all other appliances. Notably, microwaves, vacuum cleaners, and washing machines are classified perfectly. Moreover, the fans are now fully and correctly identified, which are always prone to misclassification. Only a minimal number of air conditioners, fridges, heaters, and laptops remain misclassified.
A comparison of
Figure 9e and
Figure 10 reveals clear complementarity between the features of two dimensions. For instance, the air conditioners misclassified as the fans using numerical features are correctly identified when using image features; the hairdryers misclassified as the heaters based on image features are accurately recognized using numerical features. It is proved that the proposed method effectively makes use of the complementarity between multivariate features and significantly enhances the identification capability for multi-state loads.
This paper employs an information entropy-weighted ensemble method to integrate individual learners, achieving the fusion of one-dimensional numerical features (e.g., power and current) and two-dimensional binary V-I trajectory image features. To further validate the effectiveness of feature fusion, a comparative analysis is conducted with existing feature fusion methods from prior research, where the classification algorithms are replaced with Swin-T models, as shown in
Table 5.
As shown in
Table 5, the method of reducing two-dimensional image features to one-dimensional numerical features through the neural network [
16] not only results in lower accuracy but also requires the longest computation time. Although the approaches that convert all one-dimensional numerical features into two-dimensional image features [
17,
18,
43] achieve some improvement in accuracy, their computation time remains higher than that of the method proposed in this paper due to the need for multiple operations on the image channels. Our method can more effectively leverage the quantitative statistical information of one-dimensional numerical features and the morphological information of two-dimensional image features without performing feature dimensionality transformation, making it more suitable for load identification scenarios involving feature fusion.
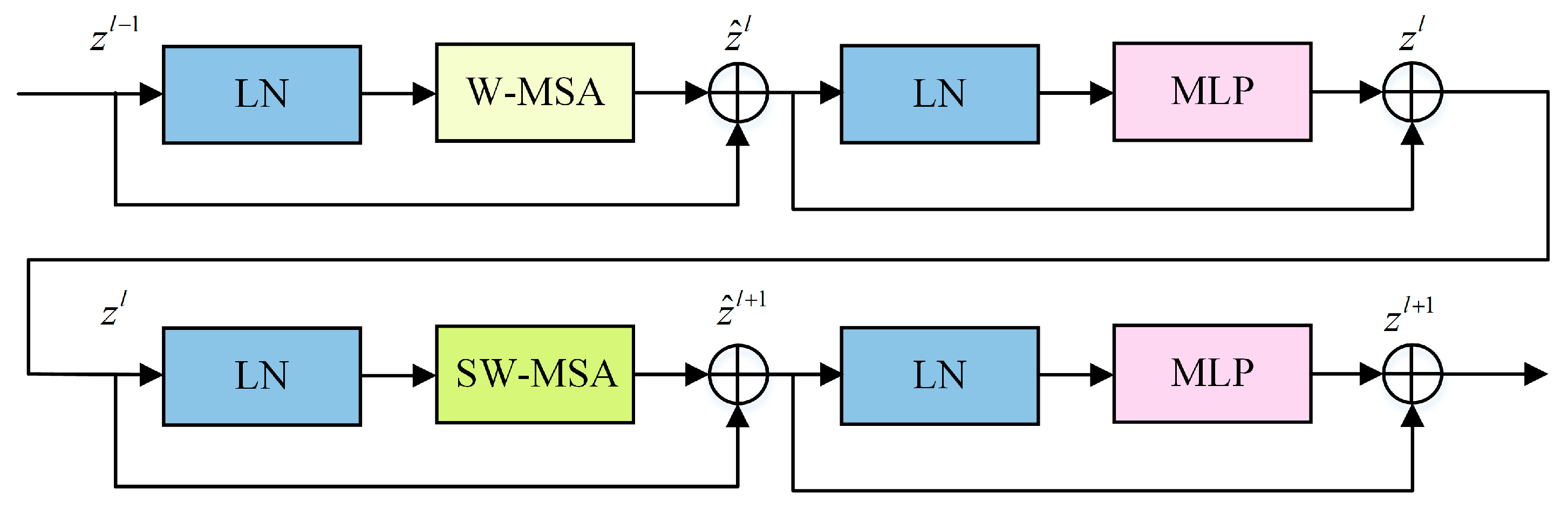
Table 6 presents a comparison of the final results obtained by information entropy-weighted integration with other commonly used image recognition algorithms. It can be observed that the LeNet-5 algorithm model has the simplest network structure and the fewest parameters, but its recognition capability is too low. Compared to the LeNet-5 model, the AlexNet model increases the number of convolutional layers and the number of kernels per layer, resulting in improved accuracy, yet it still fails to meet the requirements for high-precision recognition. The VGG-16 model replaces single large convolutional kernels with cascaded small-sized kernels, achieving extremely high accuracy. However, due to a significant increase in parameters, its training time is more than twice that of Swin-T. The GoogleNet model and ResNet-50 model incorporate the InceptionV1 module and residual module, respectively, deepening the network layers. Although their computation time is slightly lower than Swin-T, they cannot match the classification performance of Swin-T. The adopted Swin-T model utilizes shifted windows and a self-attention mechanism, confining computations to local windows while capturing long-range dependencies in images, thereby achieving a balance between efficiency and performance.
As demonstrated in
Table 7, the experimental results show the following performance ranking: Information entropy weighting > Simple average weighting > Ranking weighting = Bayesian model averaging > Accuracy-based weighting > Equal weighting, while the runtime difference is negligible. This is because the information entropy-weighted ensemble method proposed in this paper fully accounts for the varying recognition performance of each classifier across different input samples. By leveraging the more accurate posterior probability information from classifier outputs to calculate entropy values, it adaptively assigns more reasonable fusion weights to different samples. Therefore, the proposed entropy-weighted ensemble approach achieves superior classification performance compared to alternative weighting strategies.
5.3.2. Results on the WHITED Dataset
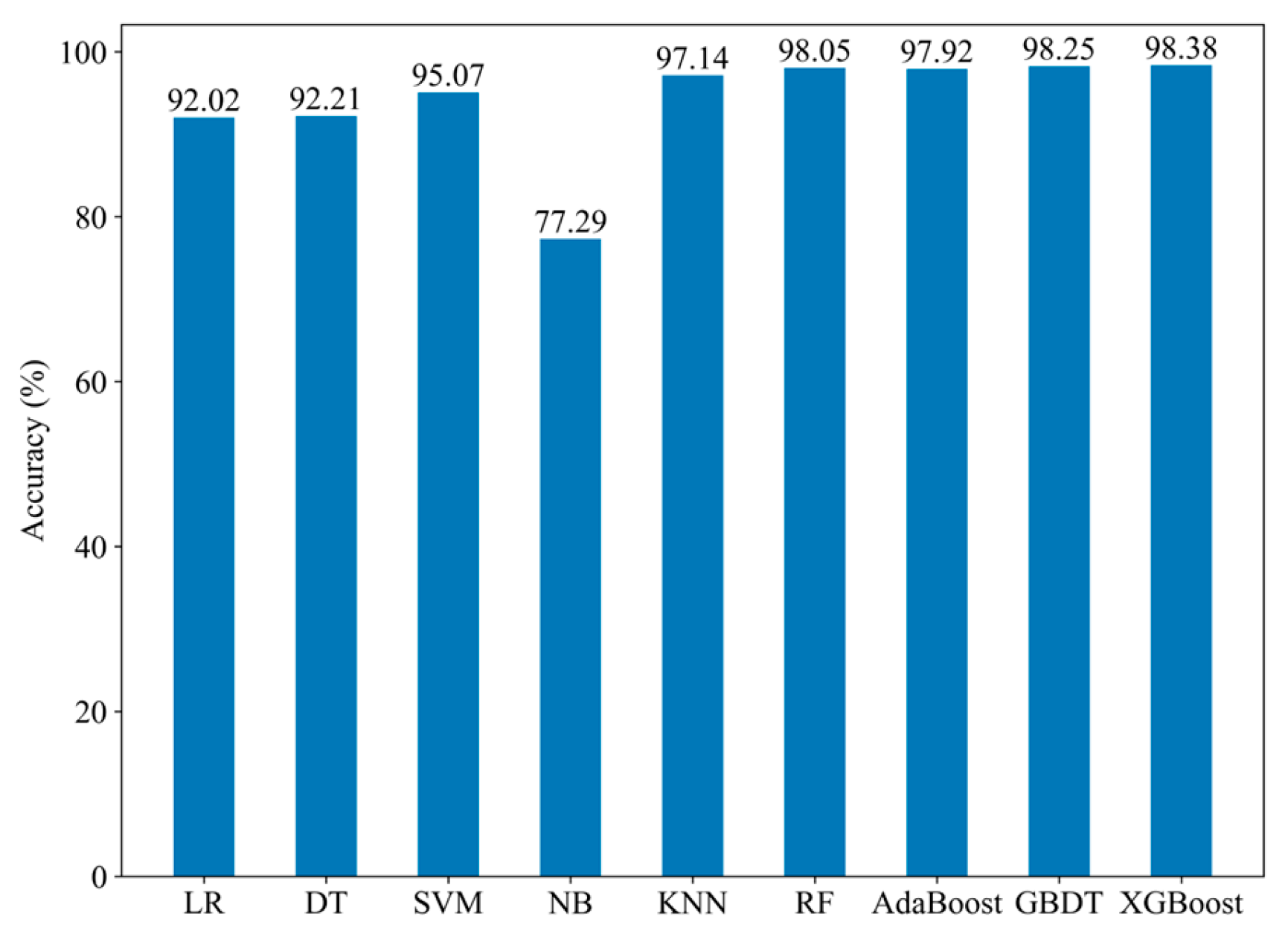
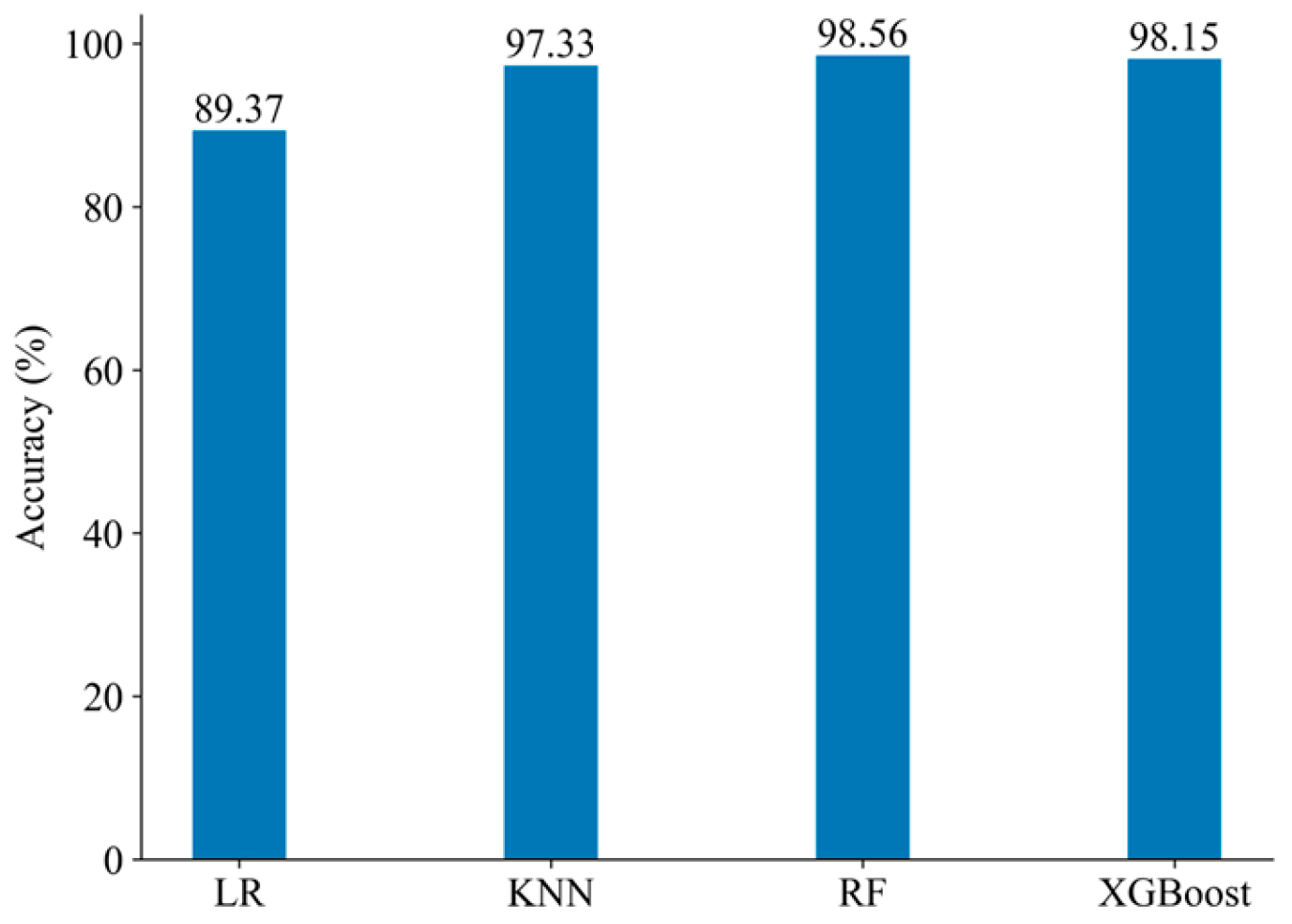
Following the same experimental procedure as that used with the PLAID dataset, the base learners selected for the WHITED dataset based on diversity metrics and accuracy indicators are LR, KNN, RF, and XGBoost. The accuracy of each base learner is shown in
Figure 12.
The classification results obtained by combining the four base learners using information entropy-weighted ensemble learning are shown in
Figure 12. The proposed load identification method, using one-dimensional numerical features, still performs well on the WHITED dataset. It achieves an overall accuracy of 98.82% and an F-score of 98.8%.
As shown in
Figure 13, the identification performance for laptops is relatively lower, primarily due to confusion with two other types of appliances: fans and fan heaters. The power characteristics of laptops exhibit significant fluctuations with changes of load. Similarly, fans experience power fluctuations due to speed adjustments or variations in natural airflow, while fan heaters exhibit intermittent on-off behavior as a result of temperature control regulation. These similar dynamic characteristics lead to overlapping steady states in one-dimensional numerical features. Therefore, it is necessary to incorporate higher-dimensional features to further enhance the ability to distinguish multi-state appliances.
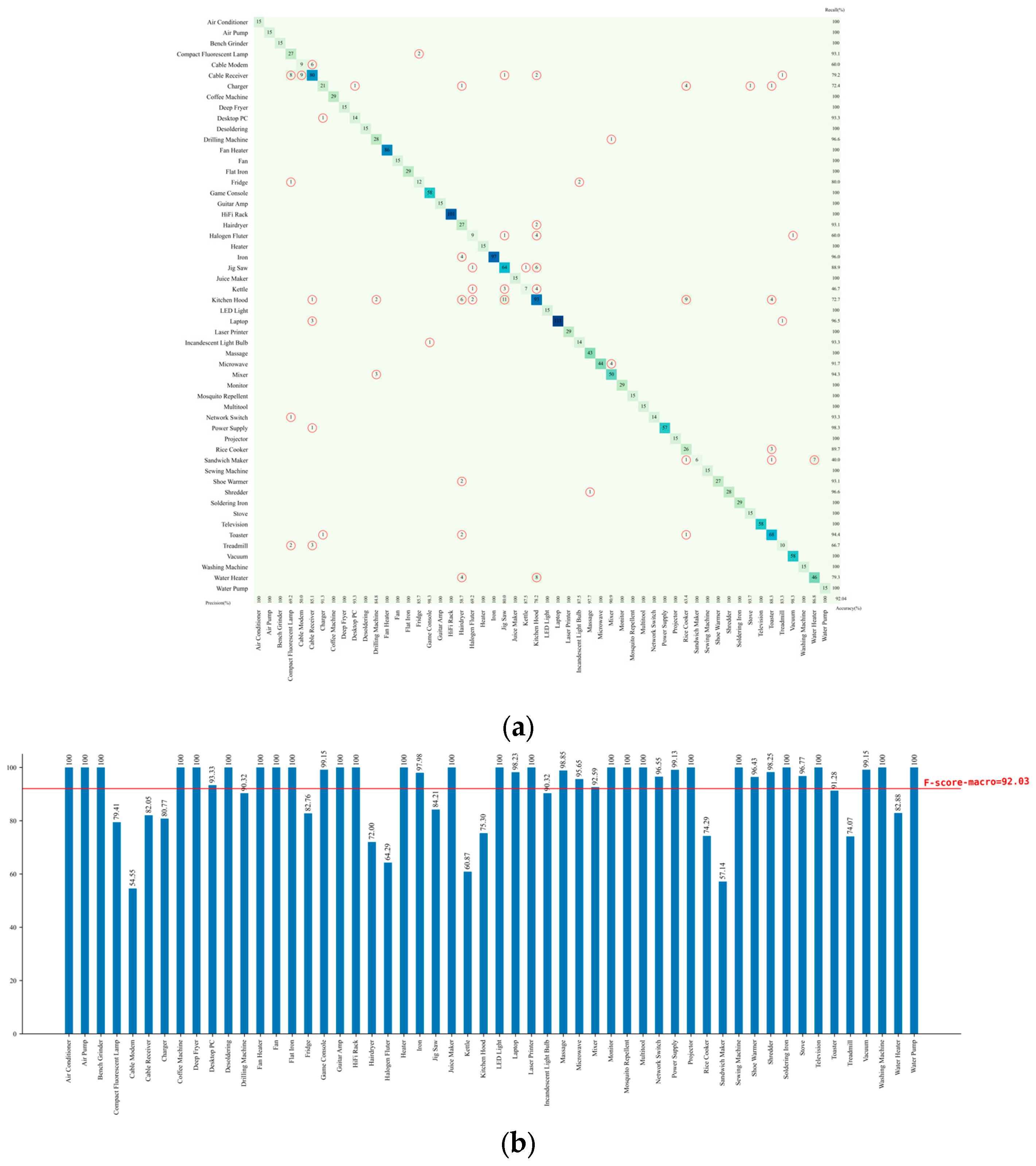
Figure 14 demonstrates the identification results of two-dimensional image features on the WHITED dataset using Swin-T. The model achieved an accuracy of 92.04% and an F-score of 92.03%. Appliances such as cable modems, halogen fluters, kettles, and sandwich makers exhibited significantly lower F-scores than the average, indicating that classification models based solely on two-dimensional binary V-I trajectory images still face certain limitations in accurately identifying these types of appliances.
The overall accuracy of identifying appliances using two-dimensional image features on the WHITED dataset is relatively lower compared to the PLAID dataset. This is because the PLAID dataset contains only 11 types of appliances, whereas the WHITED dataset includes a much richer set of 54 appliance types. As the number of appliance categories increases, the probability of different appliances exhibiting similar V-I trajectory shapes becomes higher, making it more difficult for deep neural networks to effectively capture subtle distinctions.
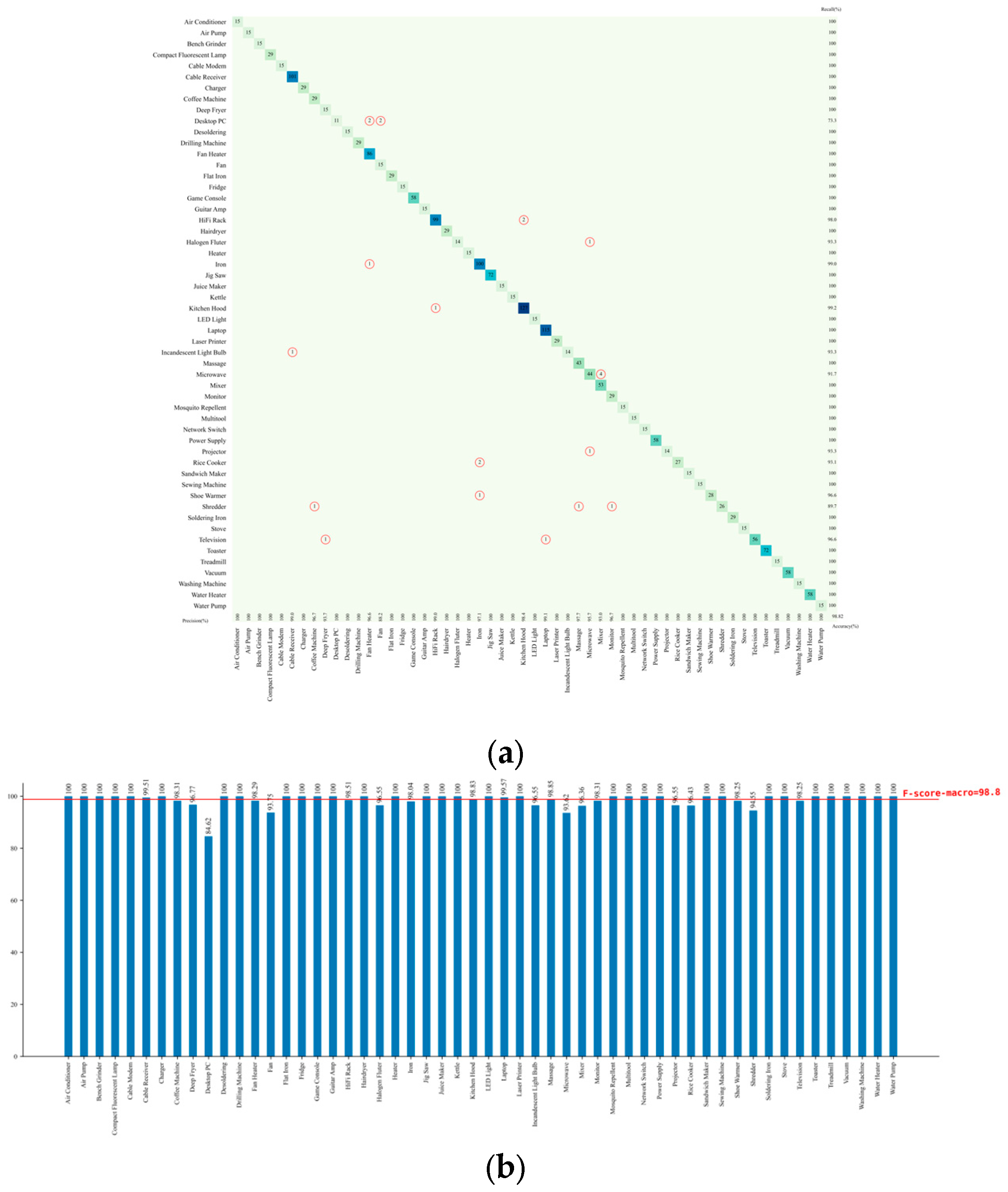
As illustrated in
Figure 15, the proposed load identification method based on multivariate features and information entropy-weighted ensemble also meets the high accuracy requirements on the WHITED dataset. The experimental results demonstrate that the overall accuracy and F-score on the WHITED dataset both reach 99.54%. Among the tested appliance categories, only a few misclassifications occurred for halogen fluters, kitchen hoods, microwaves, shoe warmers, and shredders, while the identification accuracy for all other appliances reached 100%. Compared to the method using only one-dimensional numerical features, the proposed method improves the accuracy and F-score by 0.72% and 0.74%, respectively. When compared to the method relying solely on two-dimensional image features, the improvements are even more significant, reaching 7.5% and 7.51%, respectively.
By comparing the classification results on the PLAID and WHITED datasets, it is observed that the proposed method demonstrates strong cross-dataset adaptability. In tests on both datasets, the F-scores for all appliance categories consistently remained above 94%, reflecting a high level of performance. These experimental results provide strong evidence that the proposed multivariate feature fusion strategy, based on the collaboration of multiple classifiers, offers significant advantages over traditional single-dimensional feature methods. It effectively addresses scenarios involving a large variety of appliance types and multiple brands within the same appliance category.
In summary, it can be observed that the appliances with remaining classification errors are mainly multi-state devices in both the PLAID and WHITED datasets. These devices typically operate cyclically or intermittently, and during different steady operating states, power values are similar while V-I trajectory shapes are also alike. Therefore, future research could consider incorporating transient features, such as startup current pulse amplitude, transient response time, and instantaneous power change rate. Fusing them with steady-state features may enhance the clarity of classifier decision boundaries.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}