


Application of Machine Learning Techniques for Predicting Heating Coil Performance in Building Heating Ventilation and Air Conditioning Systems



Abstract
1. Introduction
1.1. Issue at Large
1.2. Industry Trends
2. Adoption of Data-Based Models to Predict Heating Coil Performance
2.1. Performance Prediction of the Heating Coil
2.2. Multiple Linear Regression Models (MLR)
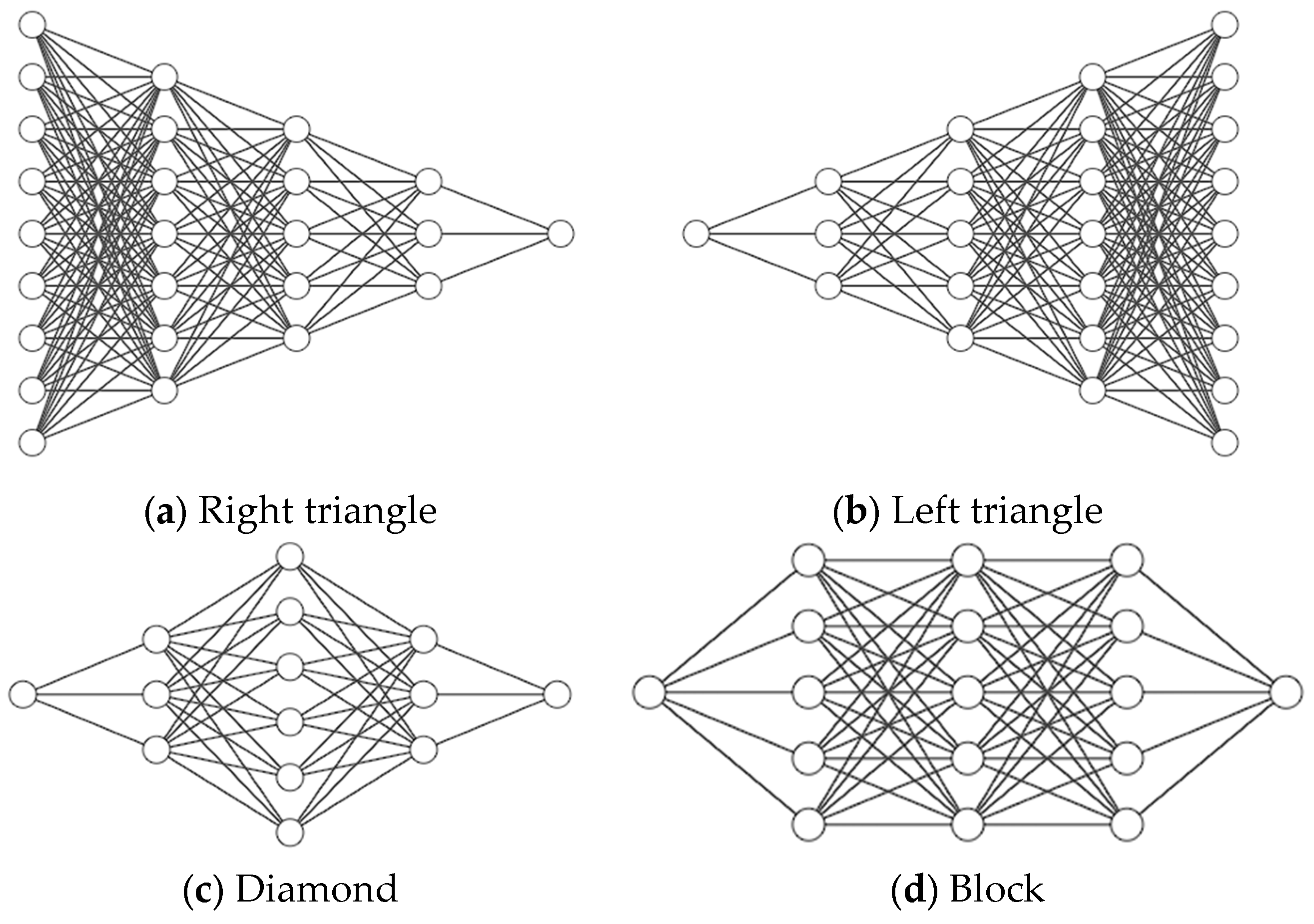
2.3. Neural Networks
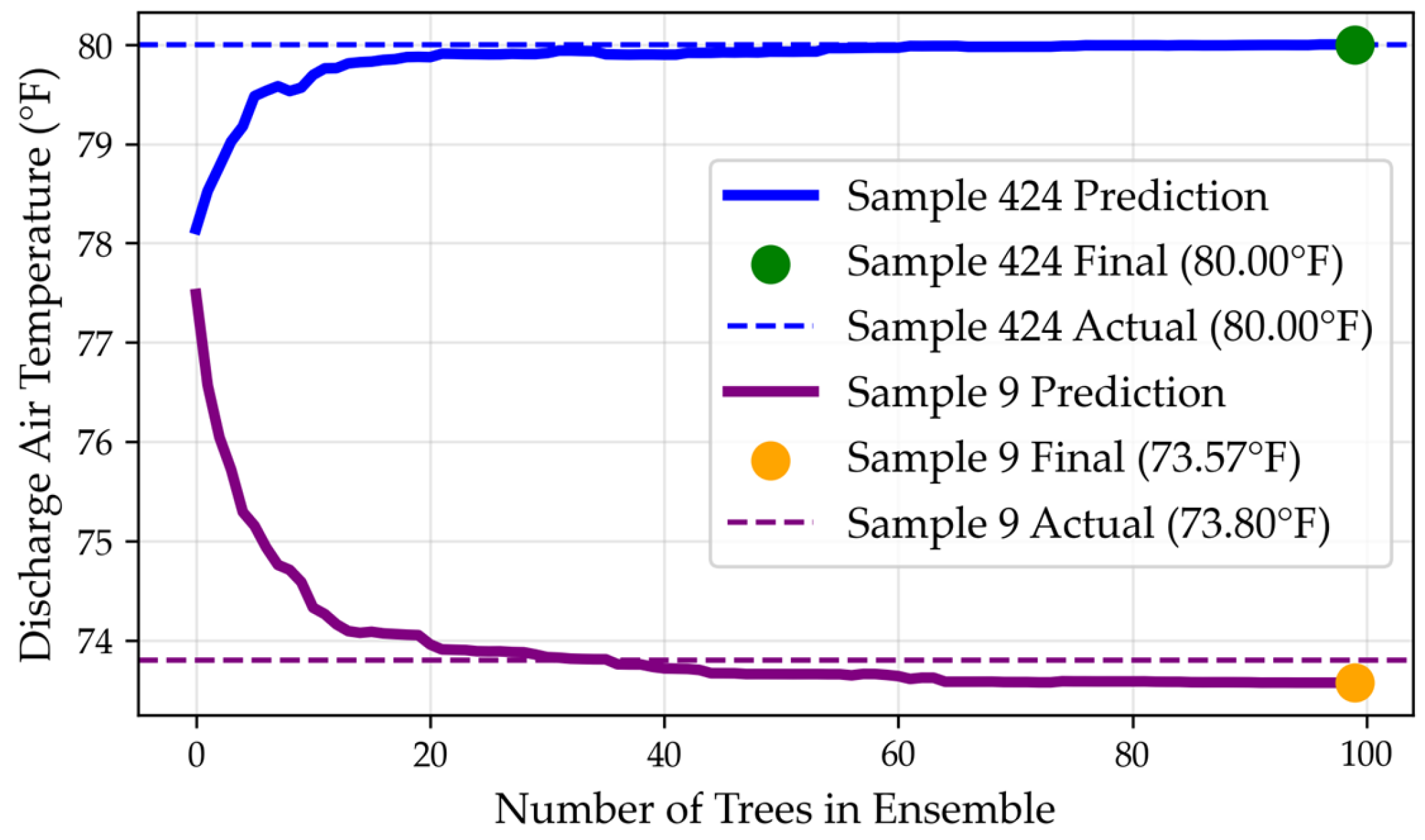
2.4. Bootstrap Aggregation (Bagging)
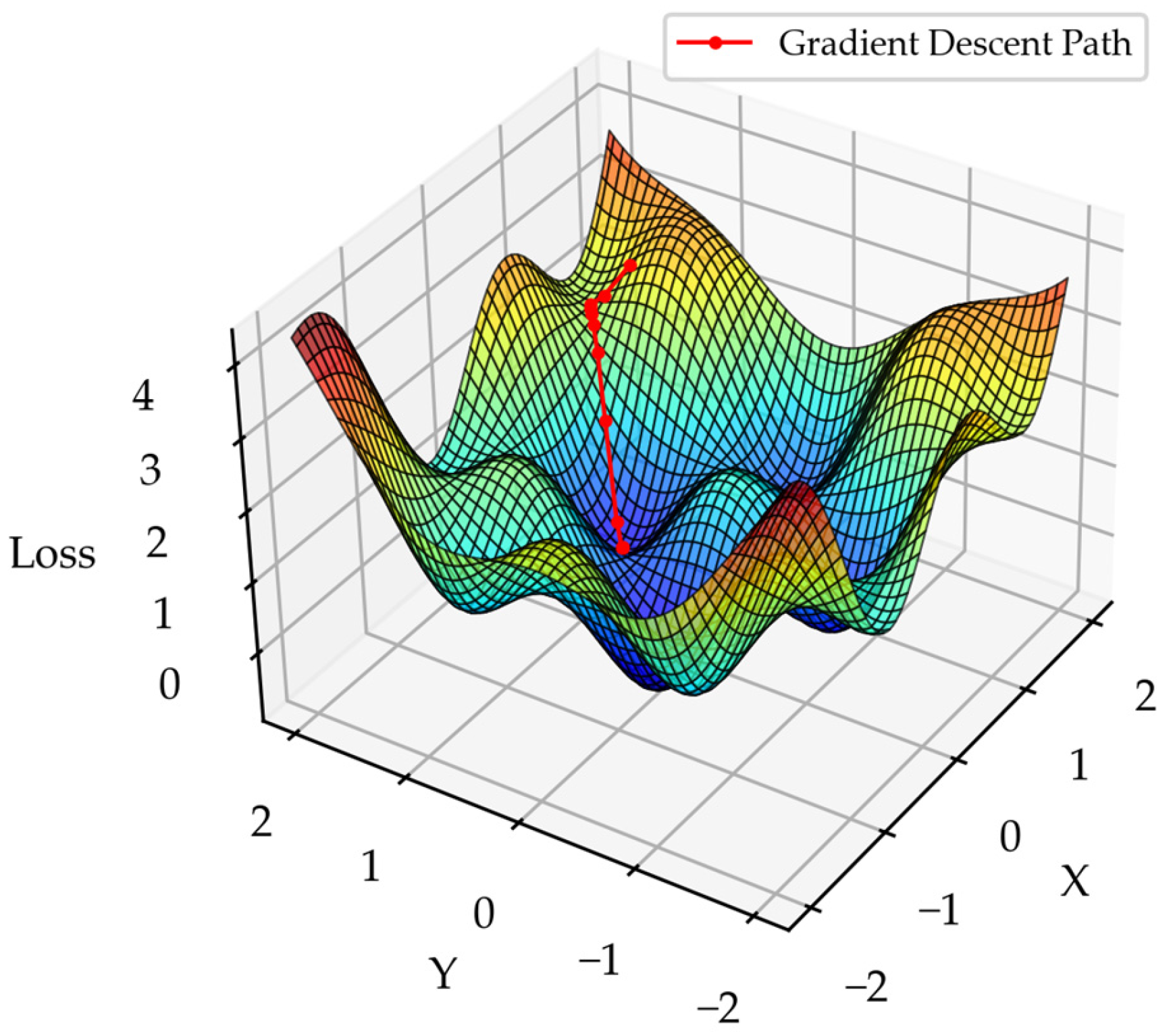
2.5. Gradient Boosting
2.6. Application of Advanced Data Analysis on Heating Coil Performance Prediction
3. Methodology
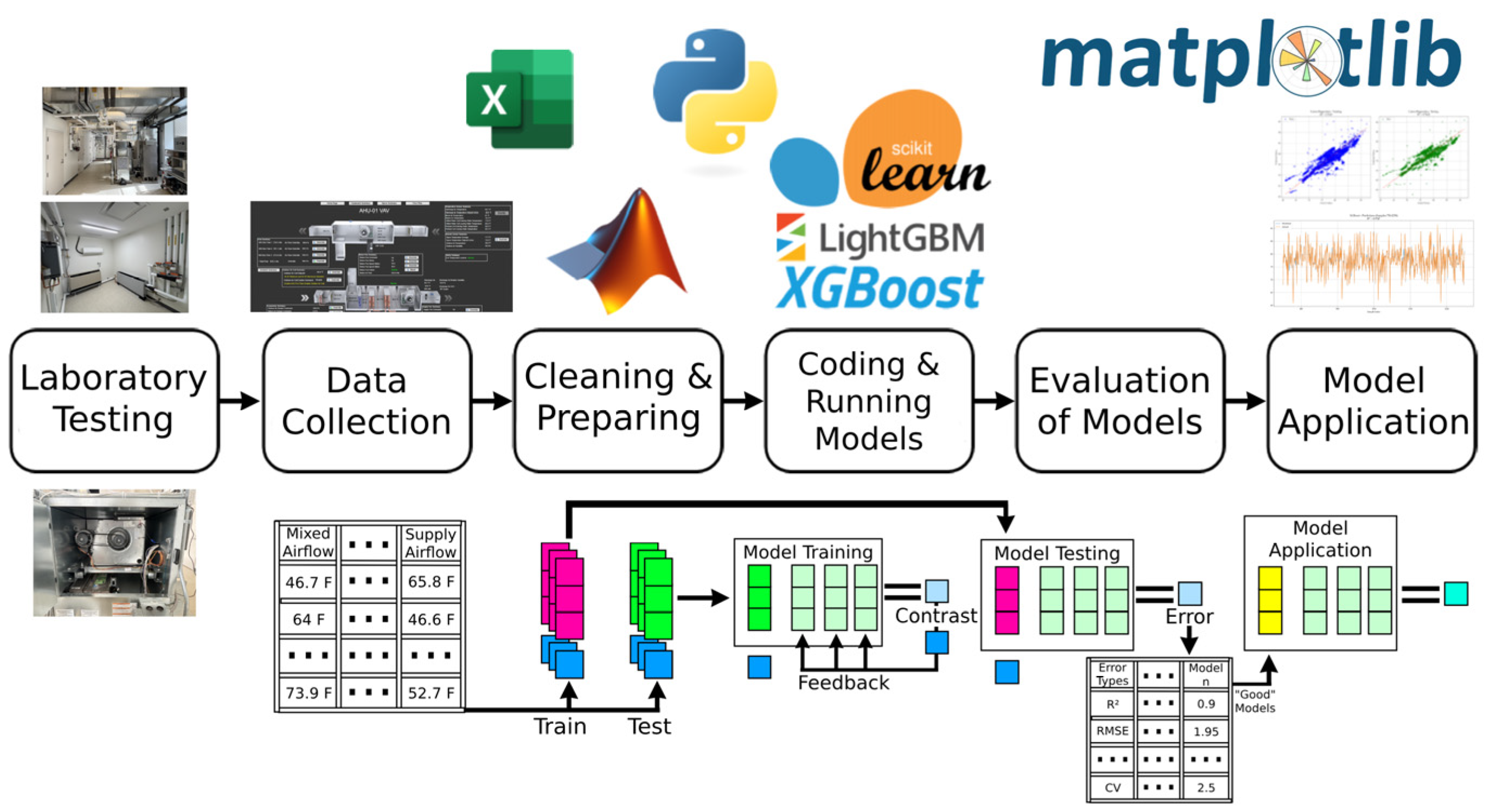
3.1. Overview of the Methodology
3.2. Laboratory Testing and Data Collection
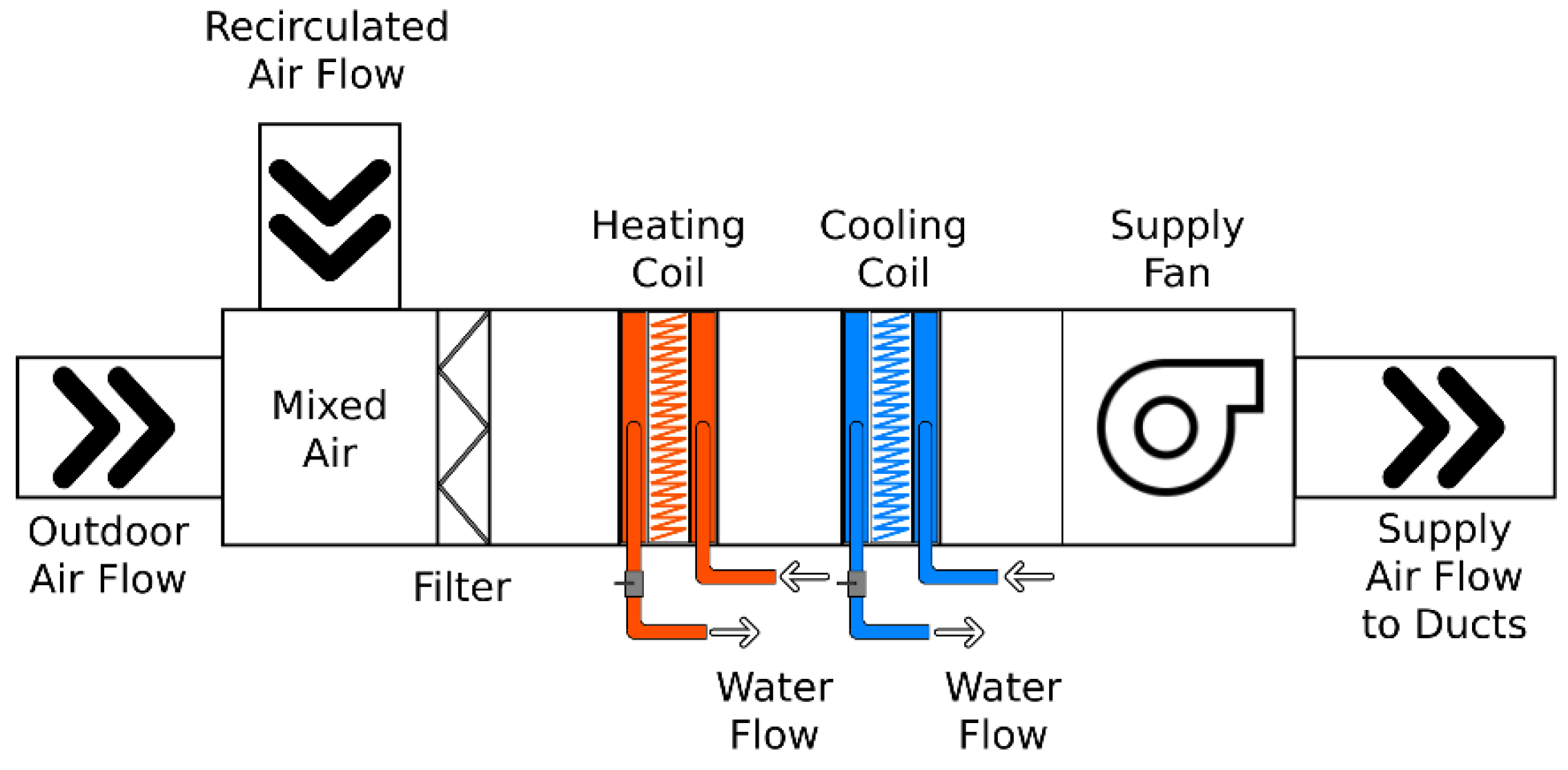
3.2.1. Overview of the Testing Facility
3.2.2. Laboratory Testing Procedure
3.2.3. Hot Water Loop and Airflow Control Conditions
3.3. Basis of Developing Predictive Models and Data Cleaning
3.3.1. Data Cleaning
- Mixed air temperature (°F);
- Supply water temperature of the heating coil (°F);
- Hot water flow rate through the heating coil (GPM);
- Total supply airflow (CFM).
- 5.
- Handling missing data: Any data entries with missing values, typically marked as “---”, were removed to prevent inconsistencies in the dataset.
- 6.
- Eliminating transition period data: Since data collection was continuous, readings captured during input transition periods were excluded to ensure only stabilized values influenced the analysis. To do this, any fluctuations of 0.5 GPM (0.00003 m3/s) or greater in water flow and any fluctuations of 250 cfm (424.8 m3/h) or greater in airflow were removed.
3.3.2. Development of Predictive Models
3.3.3. Splitting Data
3.3.4. Library Selection and Model Evaluation
3.4. Error Metrics Calculation
4. Results
4.1. Analysis of Models
4.2. Model Selection
4.3. Analysis and Discussion of the Selected Models
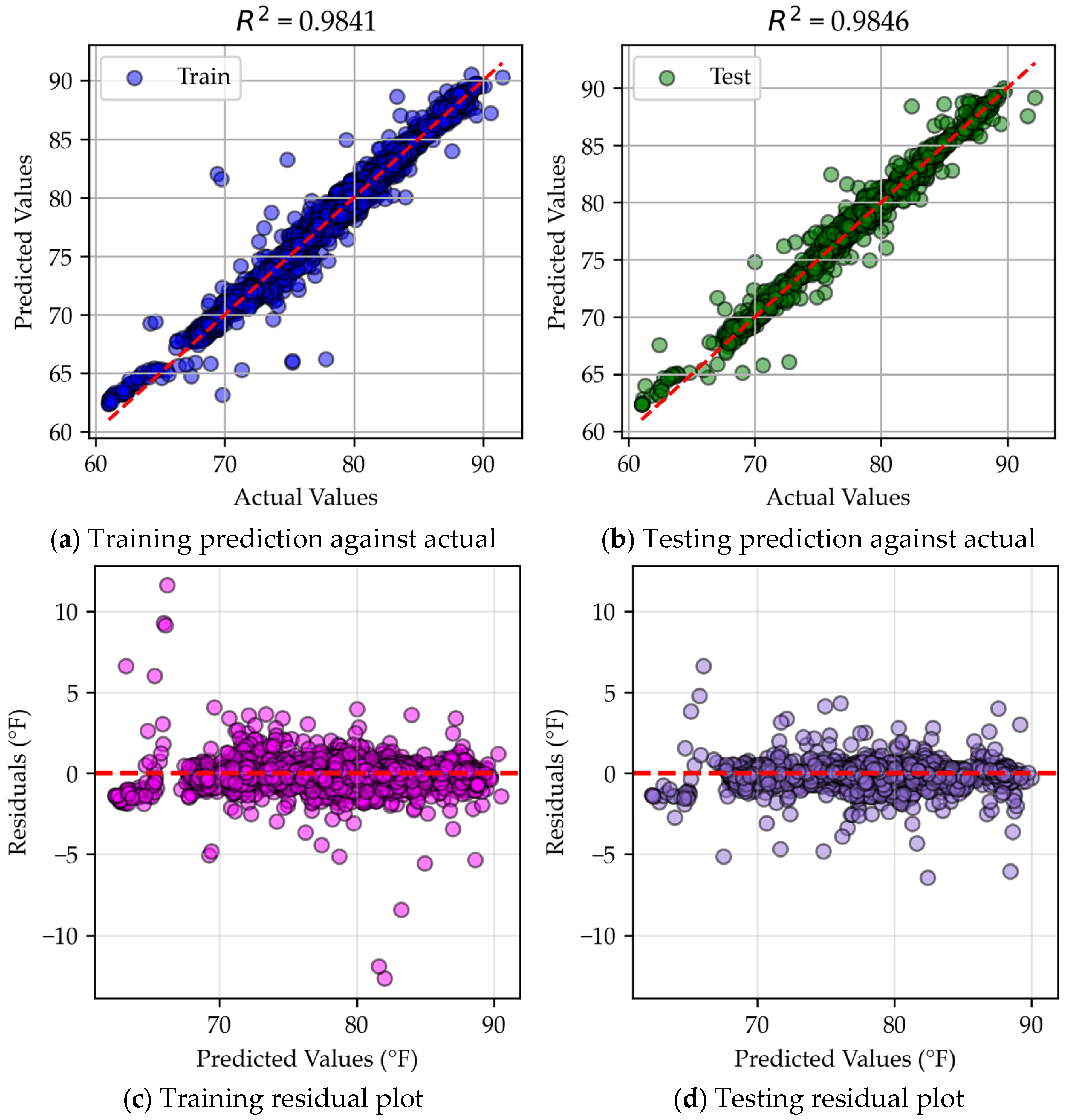
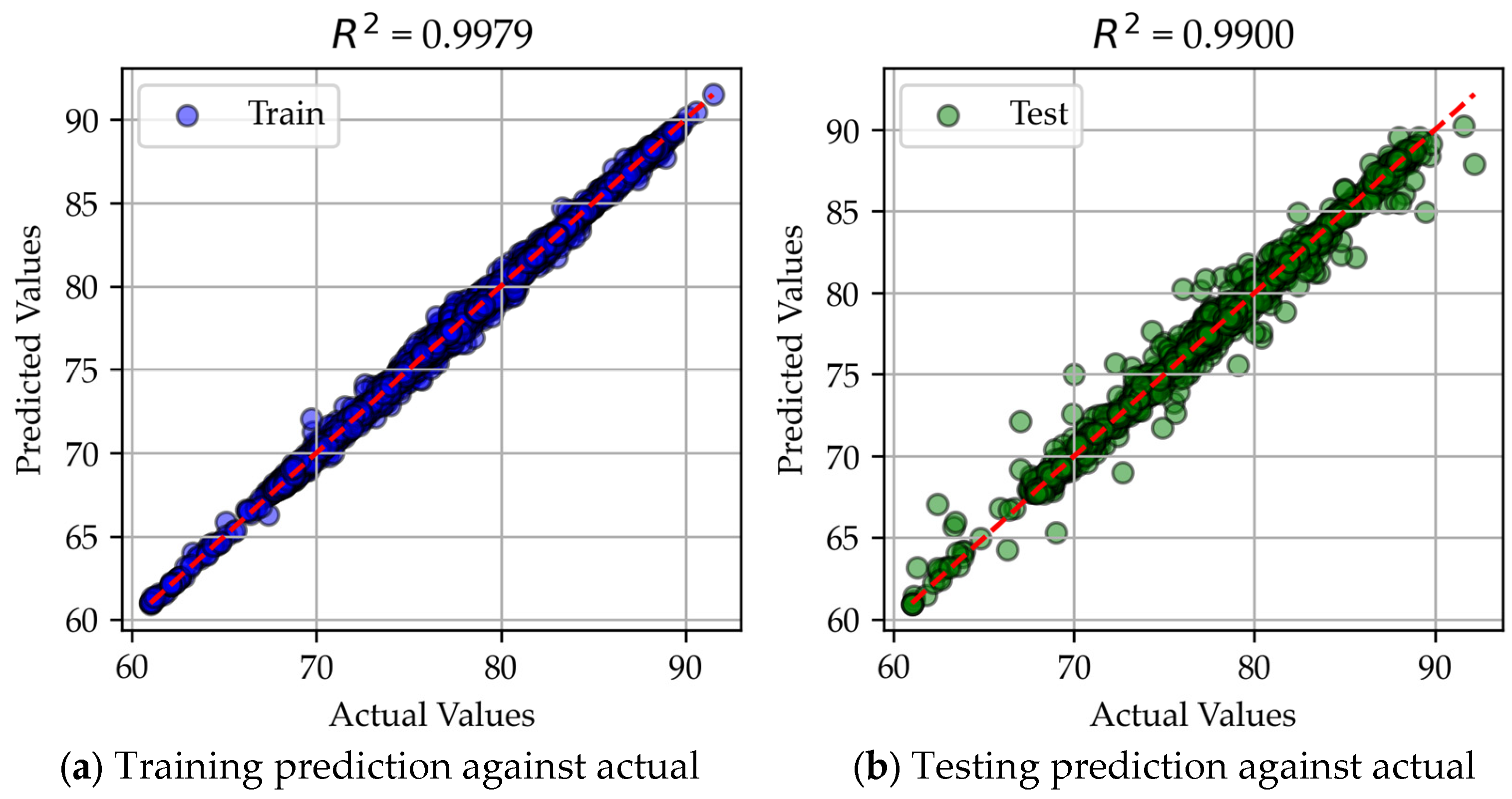
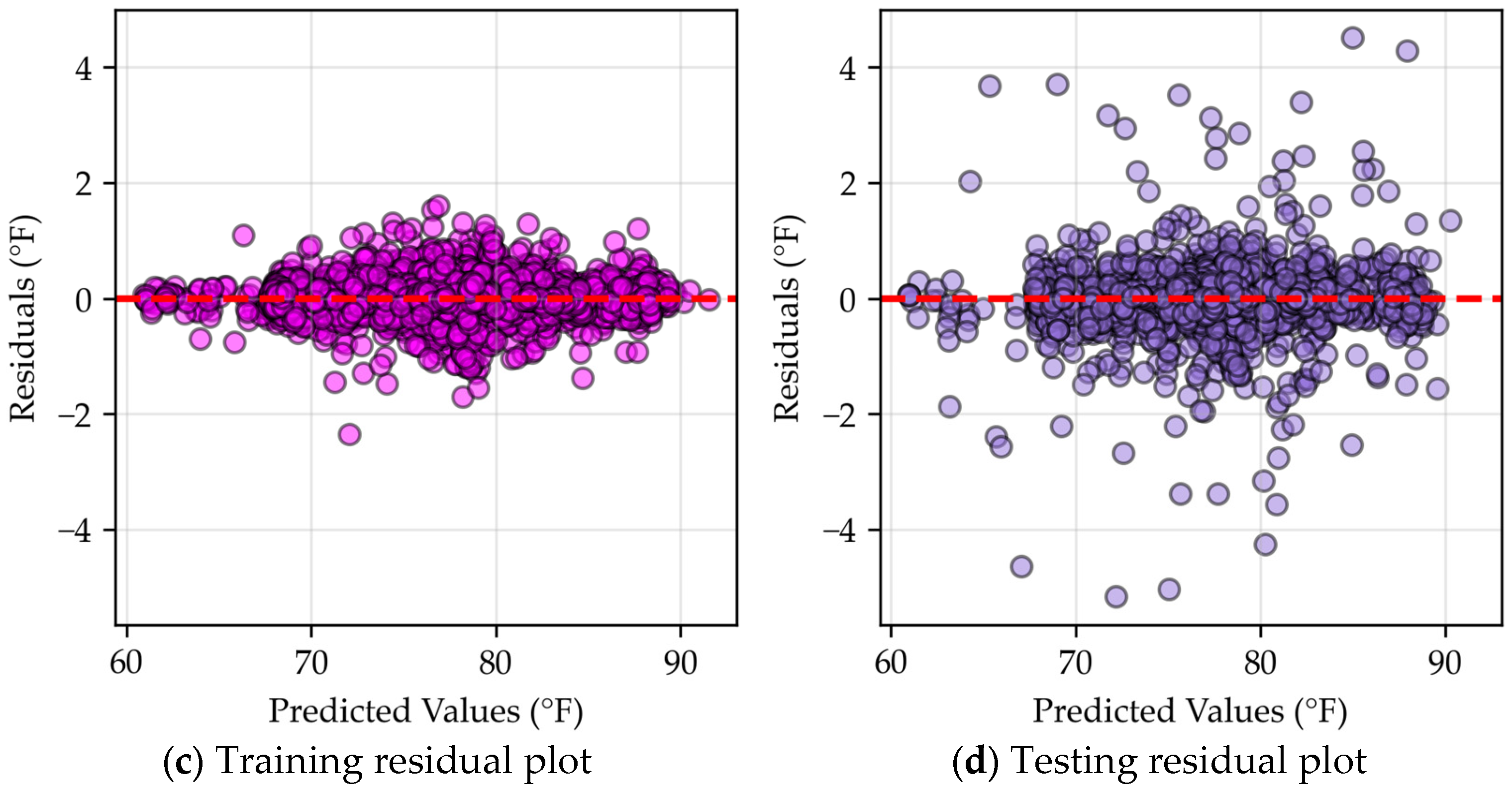
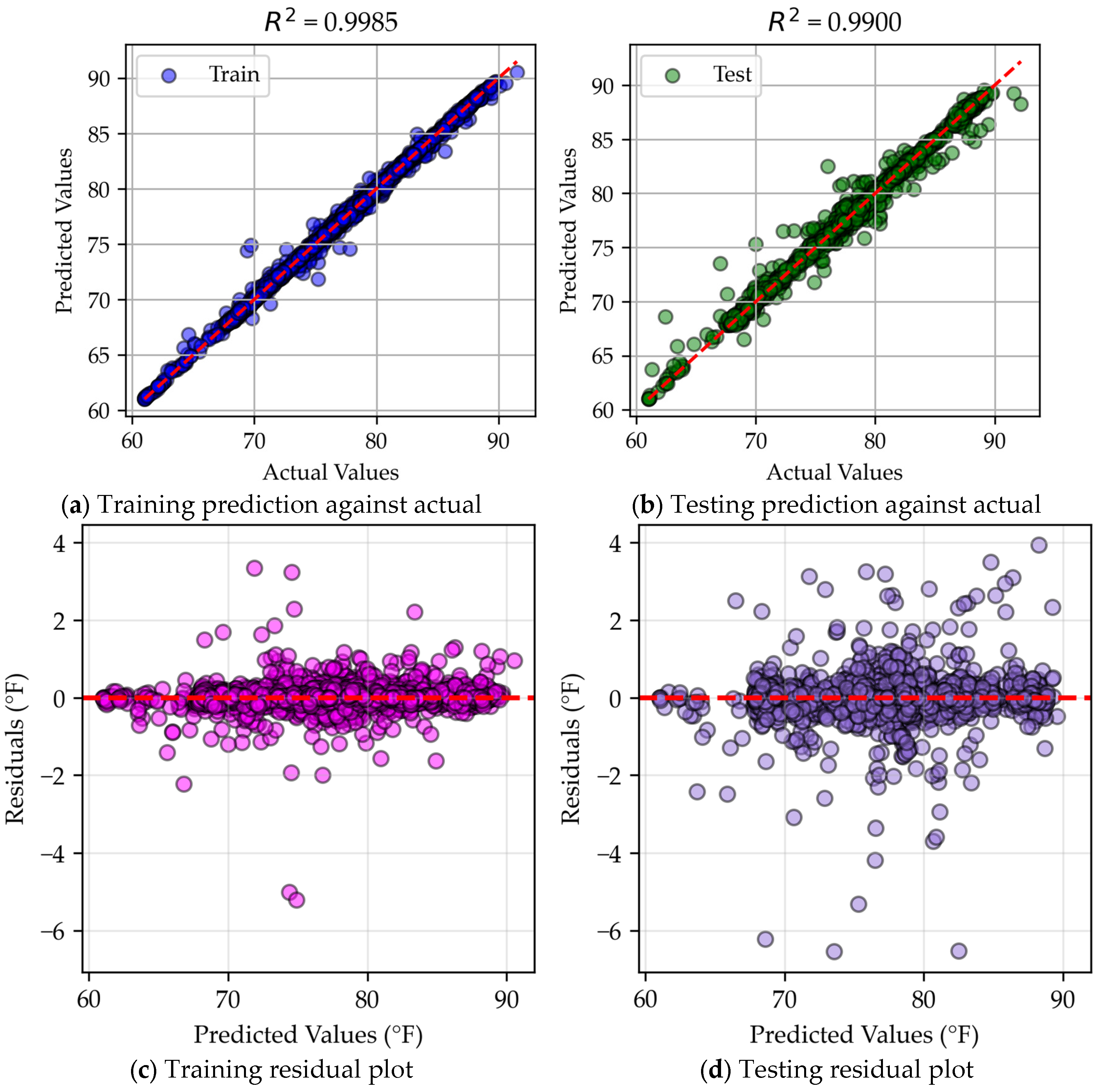
4.3.1. MLR
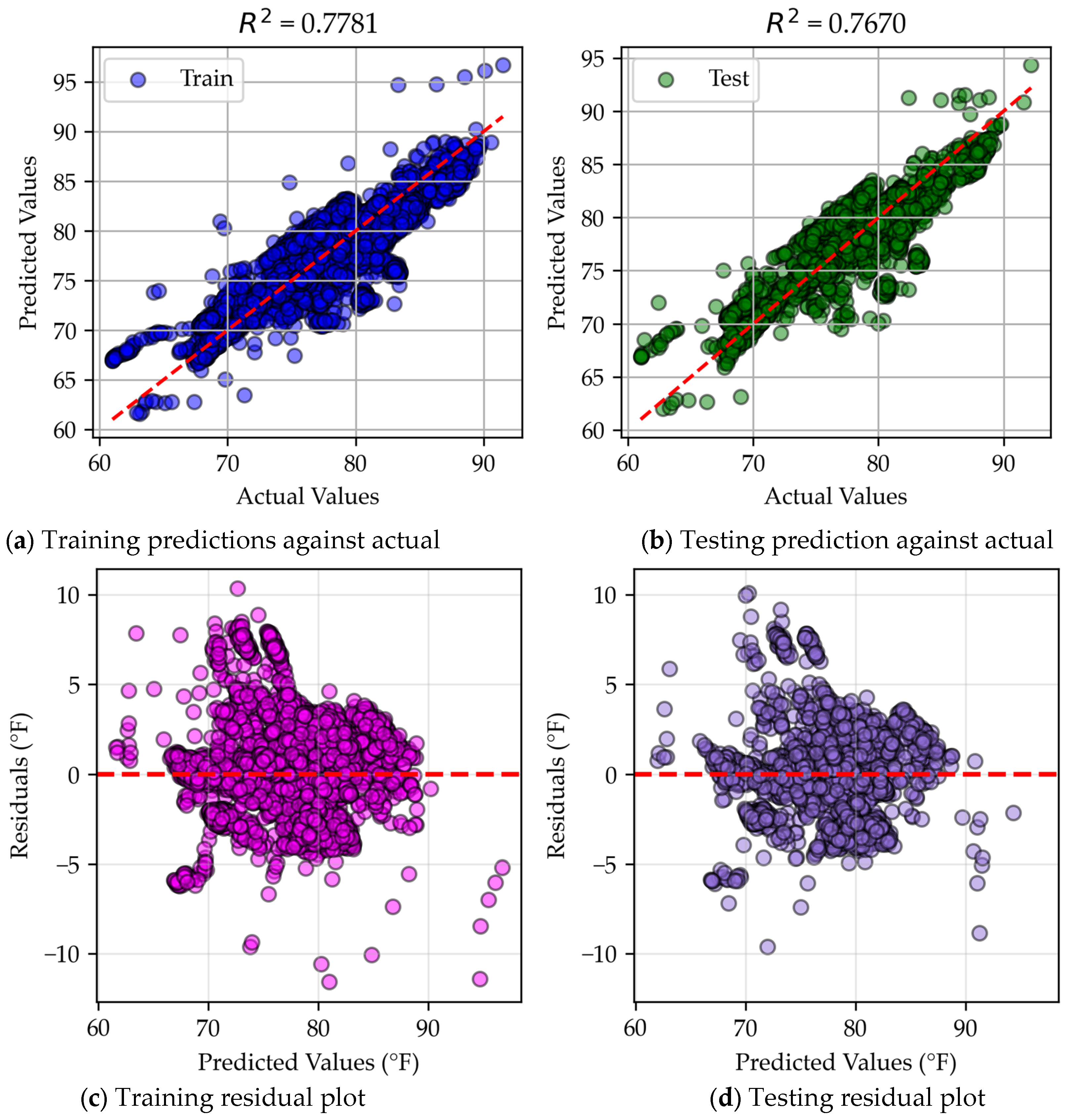
4.3.2. Neural Network
4.3.3. Gradient Boosting
4.3.4. Bagging
4.3.5. Analysis of Model Specialties
5. Practical Application
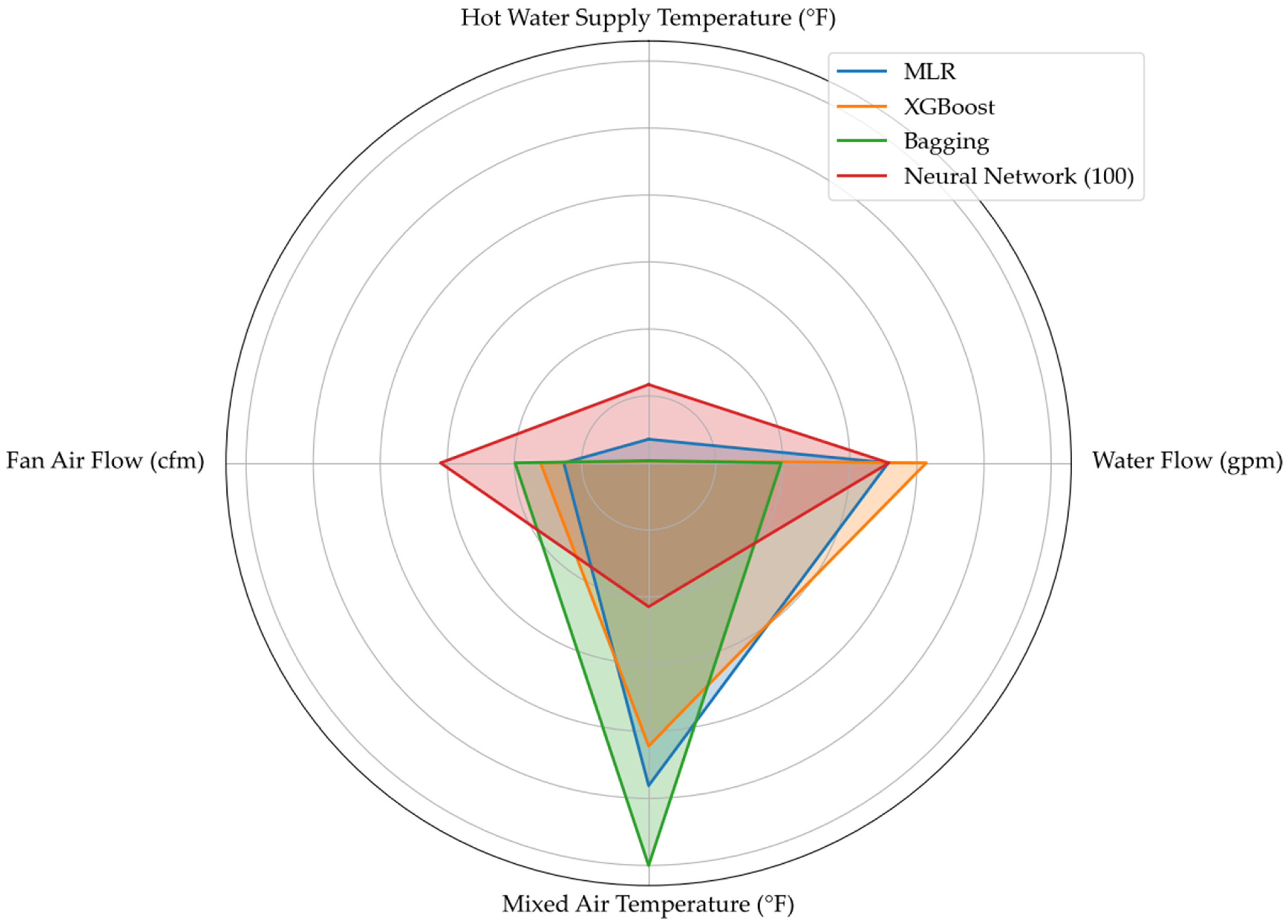
5.1. Input Significance
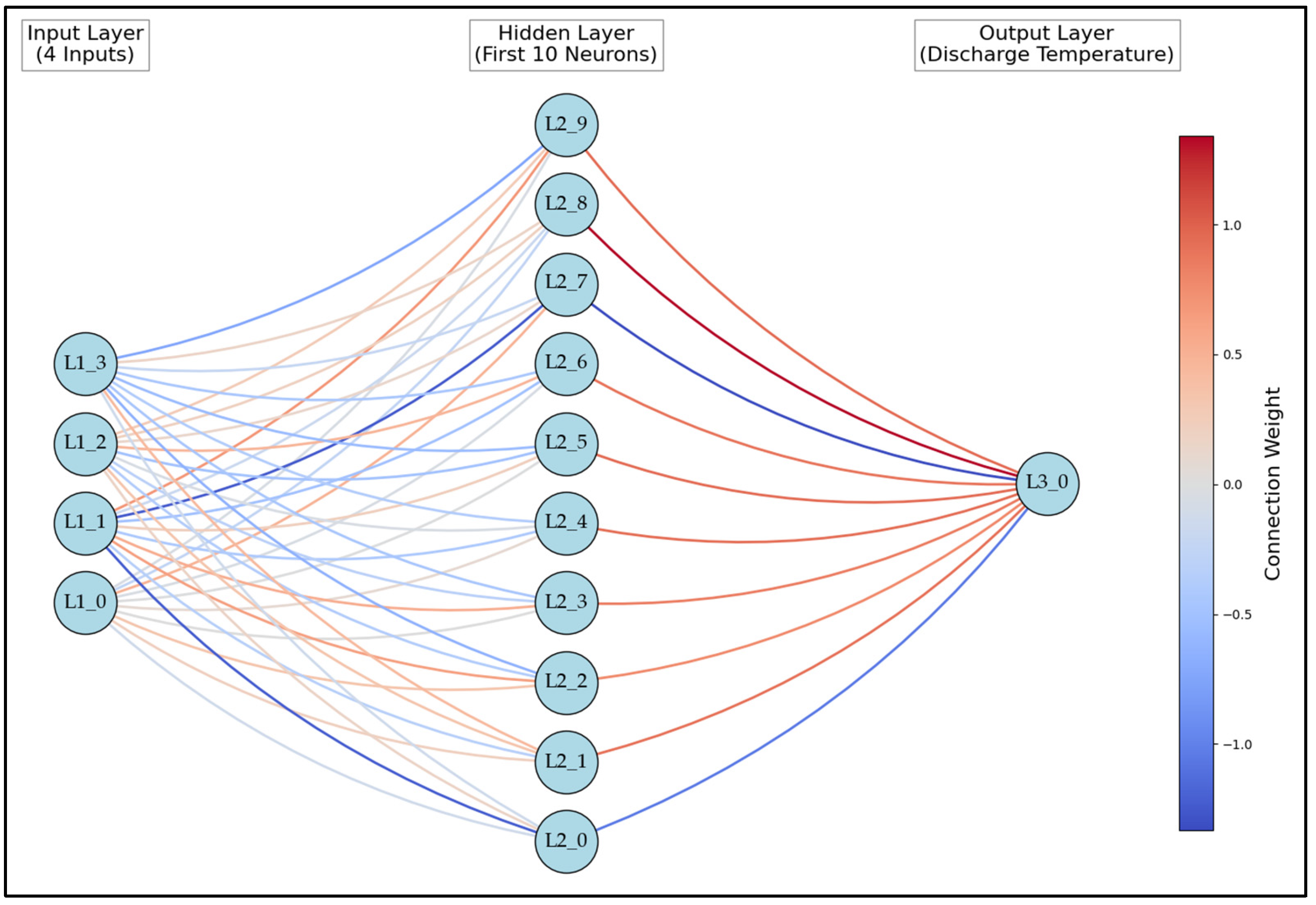
5.1.1. Model Input Weights
5.1.2. Input Weight Considerations
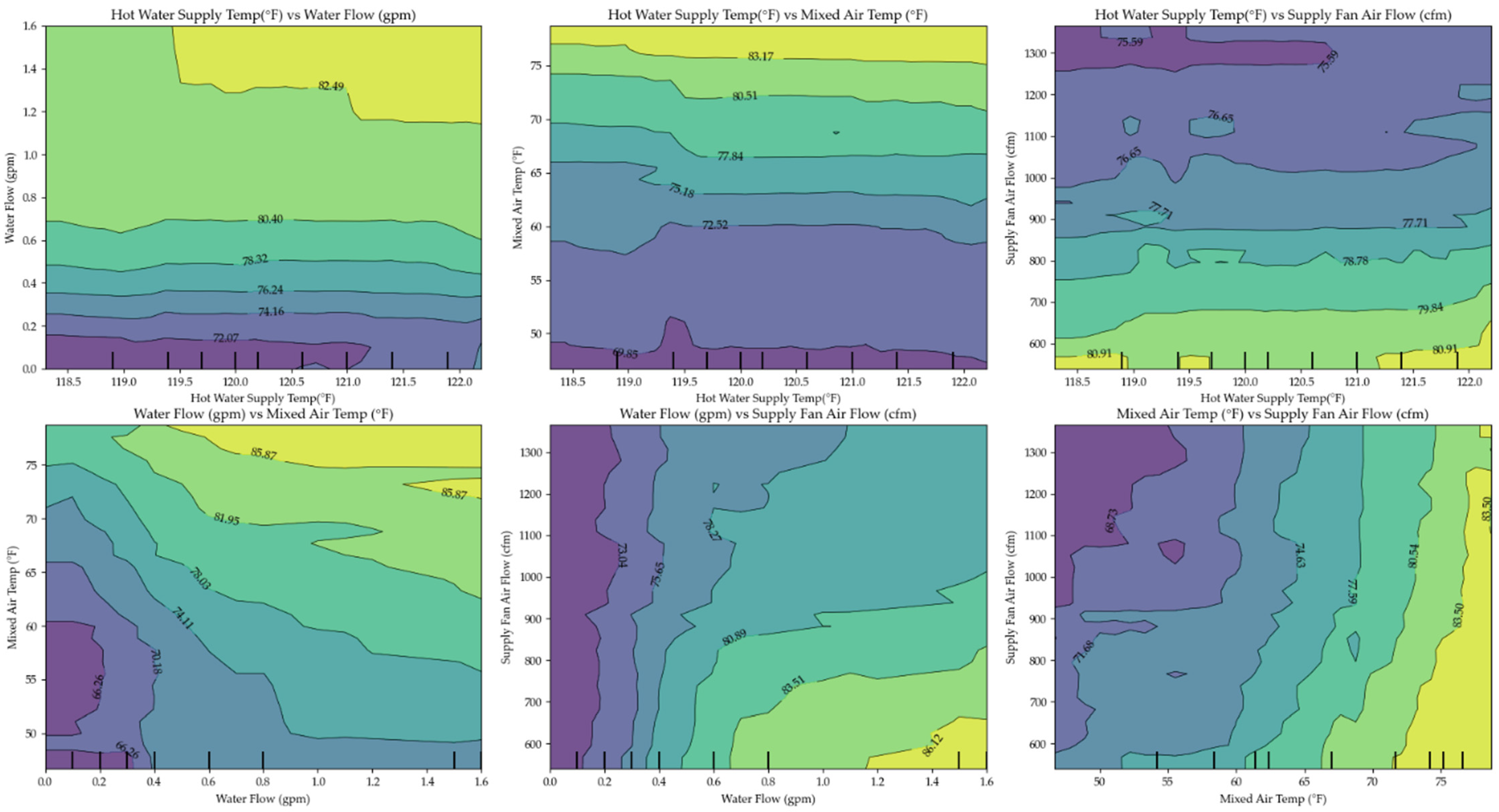
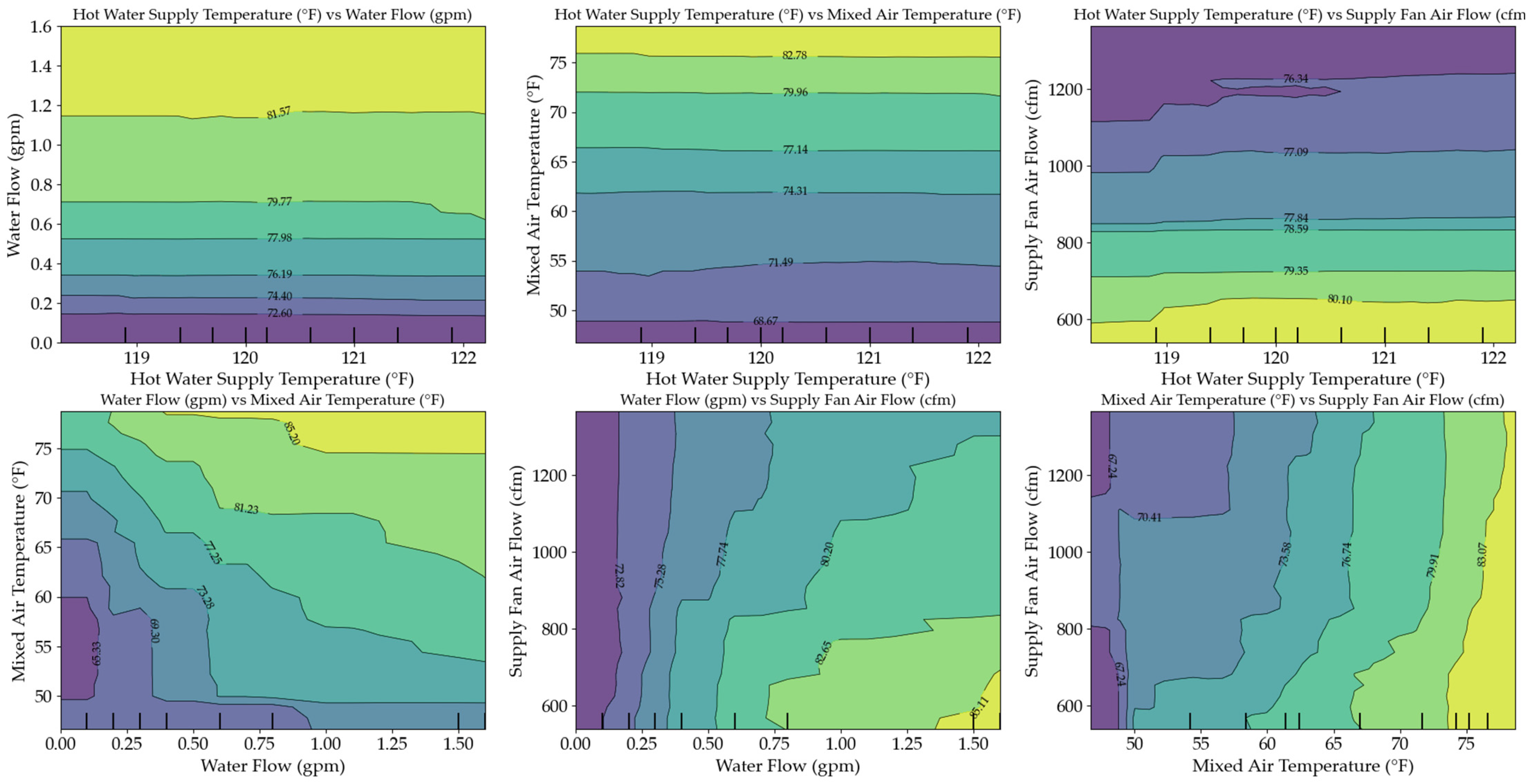
5.2. Model Applications
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AHU | Air Handling Unit |
| HVAC | Heating Ventilation and Air Conditioning |
| BEAST | Building Energy Assessments, Solutions, and Technologies |
| VAV | Variable Air Volume |
| BAS | Building Automation System |
| ASHRAE | American Society of Heating Refrigerating and Air-Conditioning Engineers |
| MLR | Multiple Linear Regression |
| XGBoost | Extreme Gradient Boosting |
| R2 | Coefficient of determination |
| CV | Coefficient of Variance |
| RMSE | Root Mean Square Error |
| MSE | Mean Squared Error |
| MAE | Mean Absolute Error |
| SHAP | Shapley Additive Explanations |
| ReLU | Rectified Linear Unit |
Appendix A. R2 and Residual Errors
Appendix A.1. R2 Values

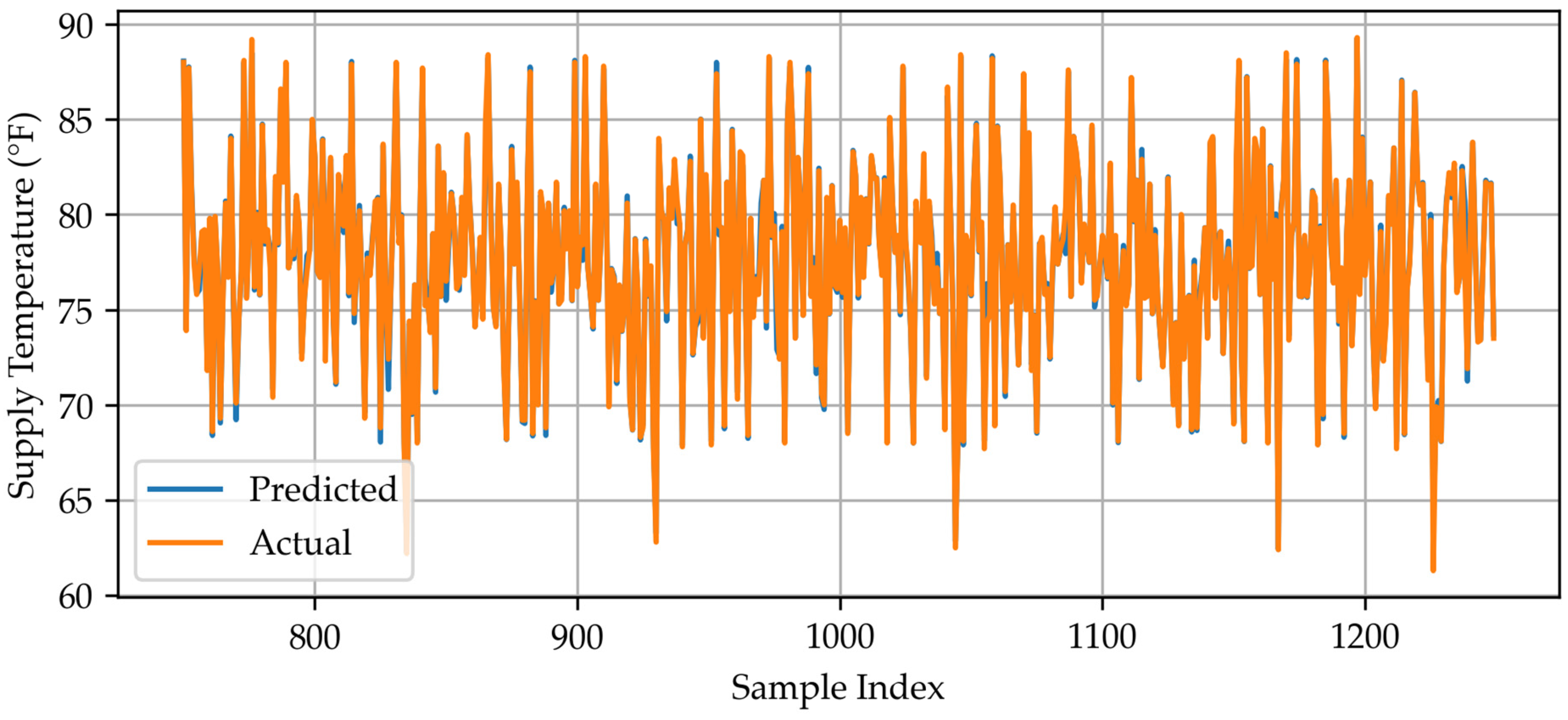
Appendix A.2. MLR Predicted vs. Actual Data
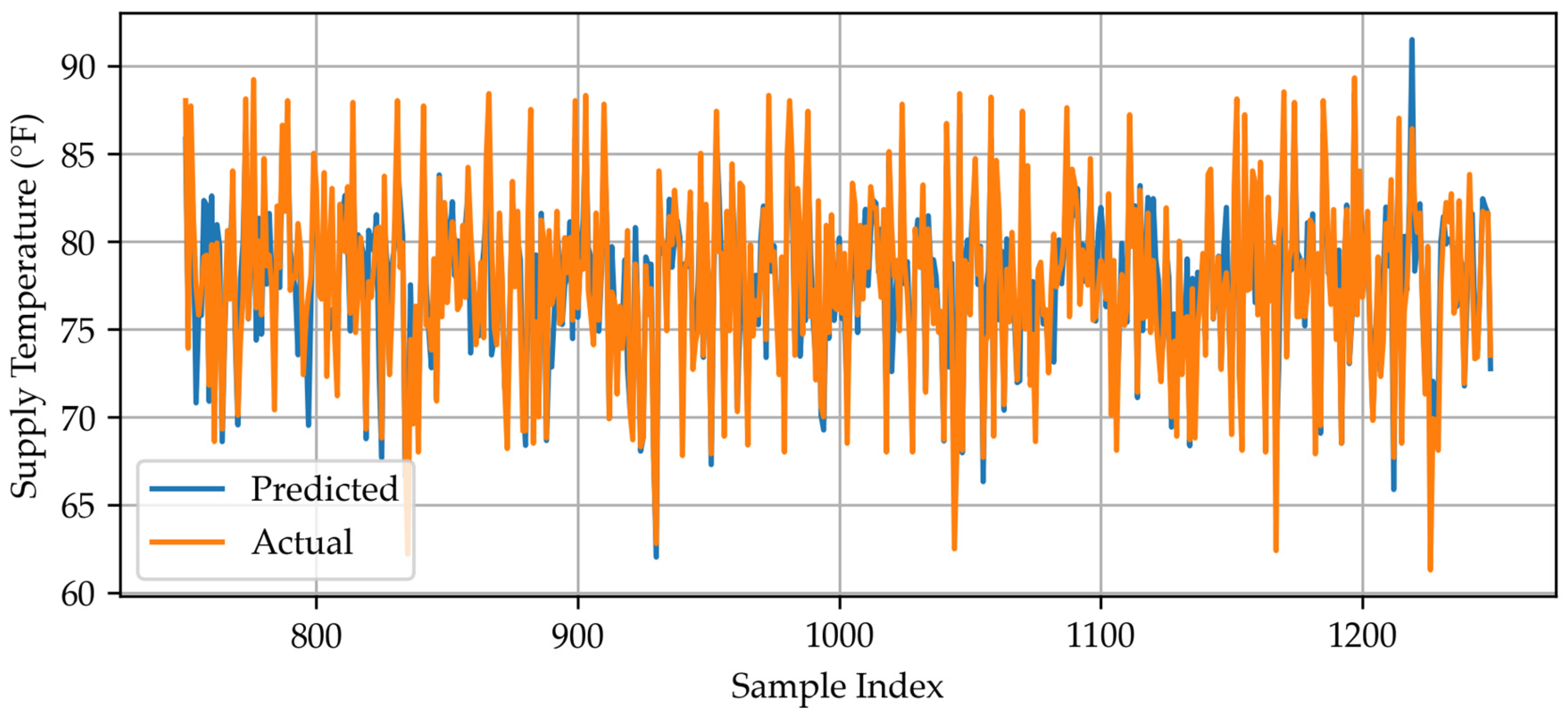
Appendix A.3. Neural Network Predicted vs. Actual Data
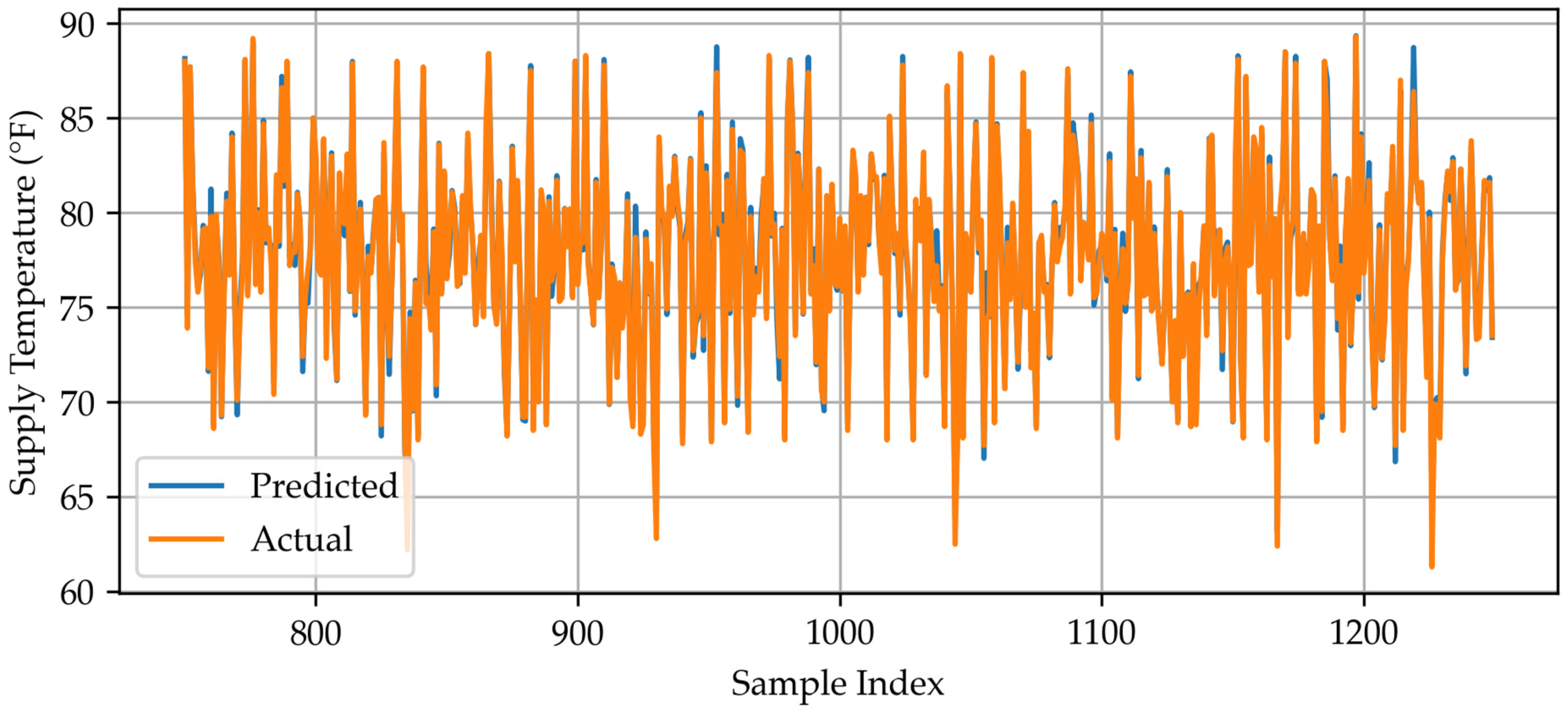
Appendix A.4. XGBoost Predicted vs. Actual Data
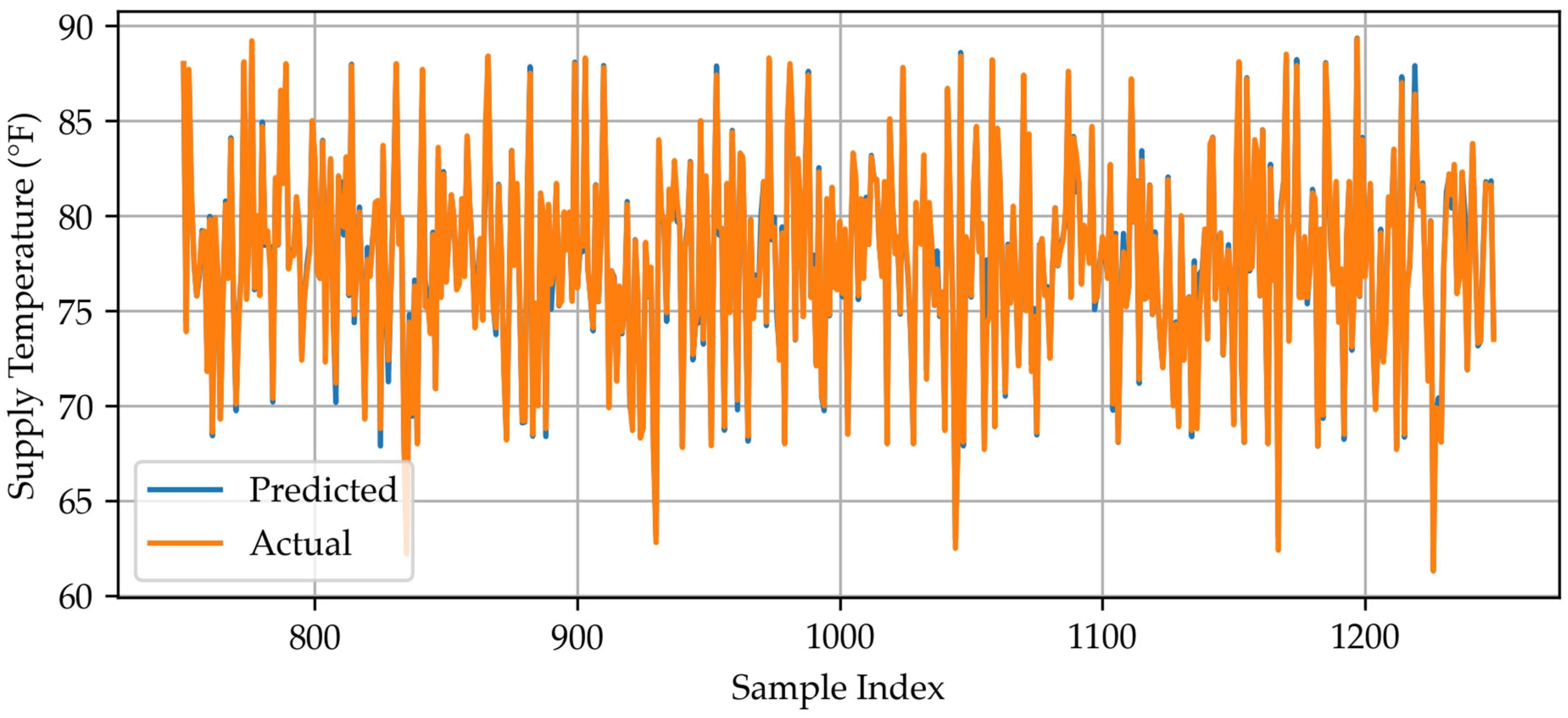
Appendix A.5. Bagging Predicted vs. Actual Data
Appendix B. Shapley Additive Explanations (SHAP) Values
Appendix B.1. MLR SHAP Chart

Appendix B.2. Neural Network SHAP Chart
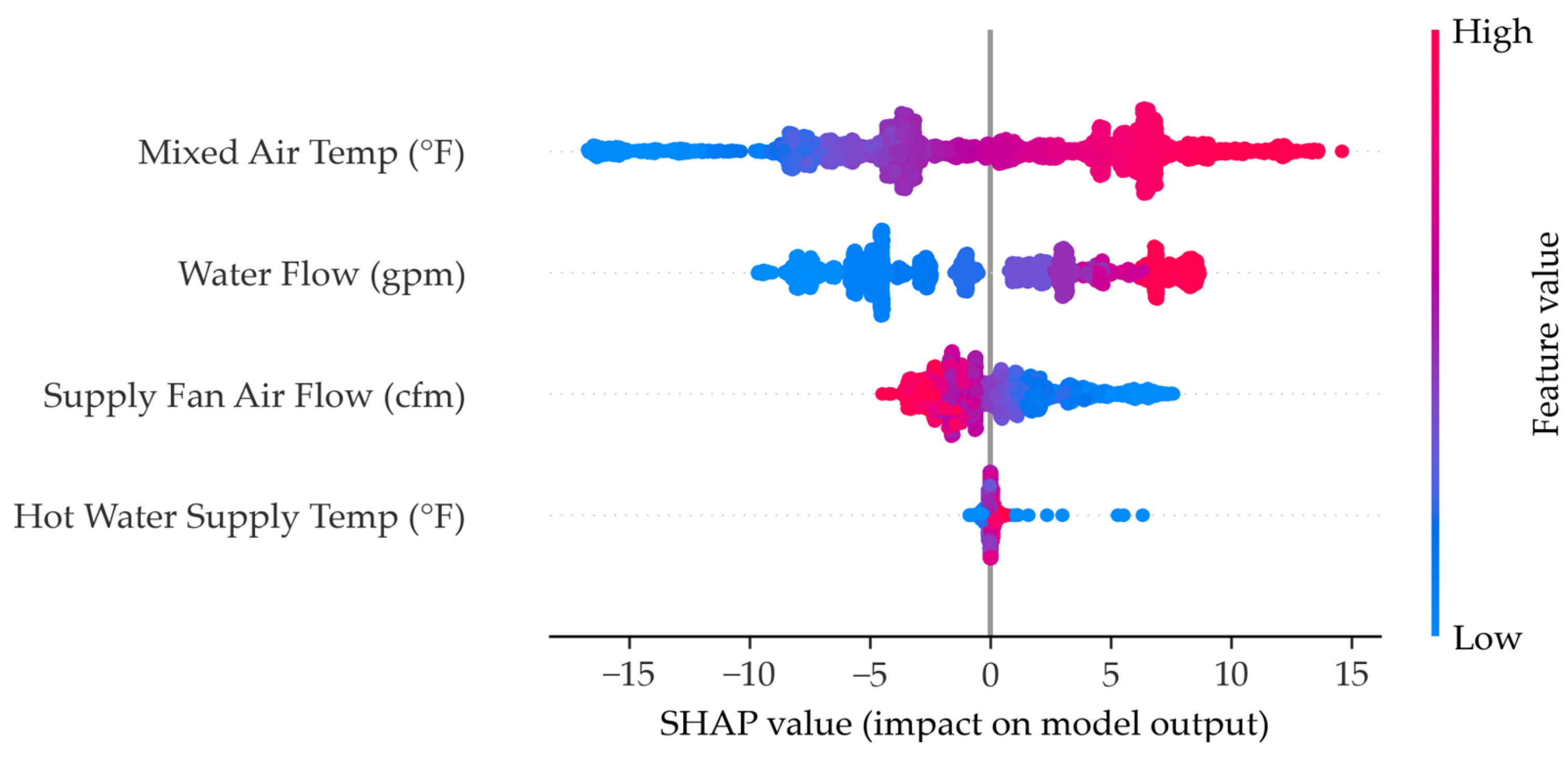
Appendix B.3. XGBoost SHAPSHAP Chart
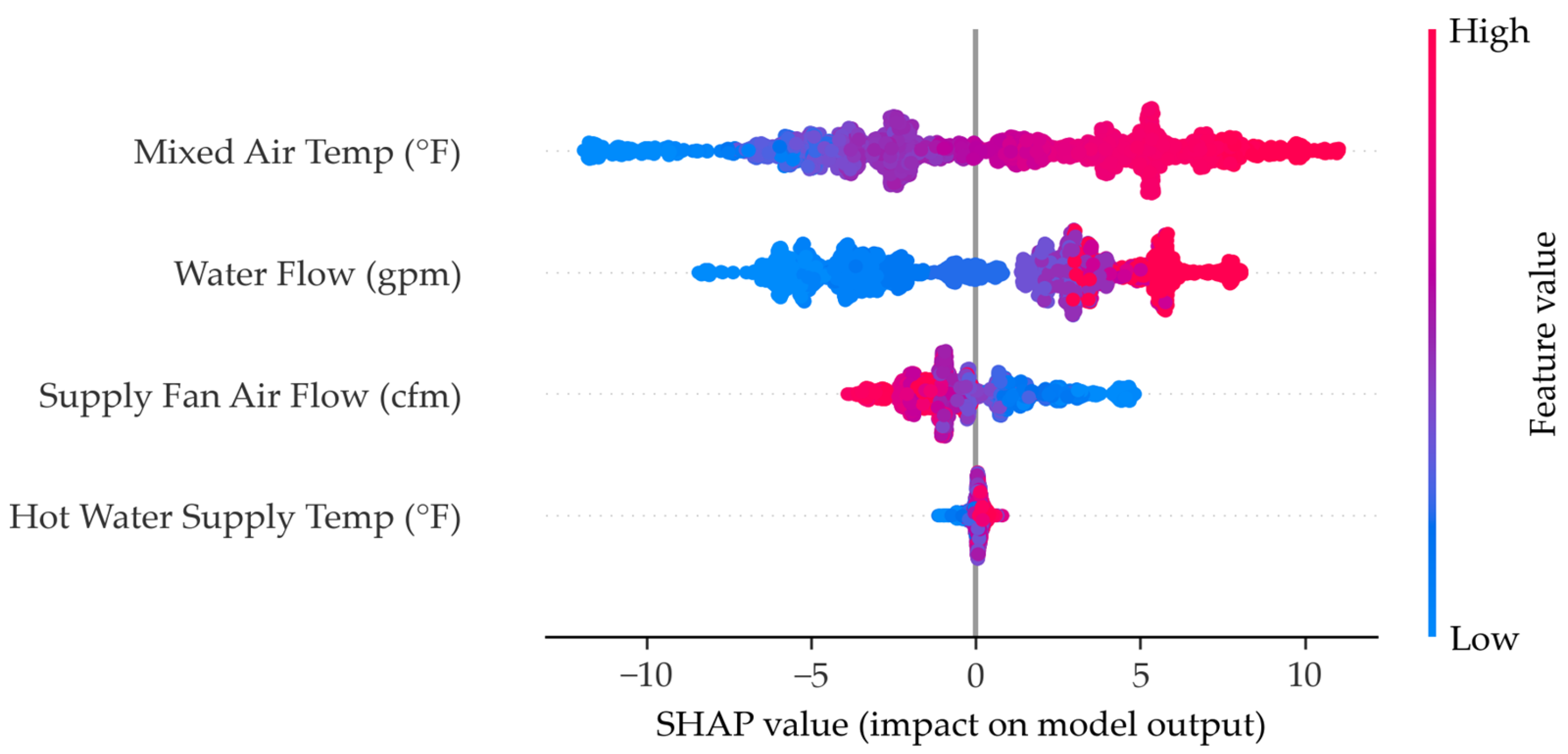
Appendix B.4. Bagging SHAP Chart

References
- Paul, W.L.; Taylor, P.A. A Comparison of Occupant Comfort and Satisfaction between a Green Building and a Conventional Building. Build. Environ. 2008, 43, 1858–1870. [Google Scholar] [CrossRef]
- Dharmasena, P.M.; Meddage, D.P.P.; Mendis, A.S.M. Investigating Applicability of Sawdust and Retro-Reflective Materials as External Wall Insulation under Tropical Climatic Conditions. Asian J. Civ. Eng. 2022, 23, 531–549. [Google Scholar] [CrossRef]
- Solano, J.C.; Caamaño-Martín, E.; Olivieri, L.; Almeida-Galárraga, D. HVAC Systems and Thermal Comfort in Buildings Climate Control: An Experimental Case Study. Energy Rep. 2021, 7, 269–277. [Google Scholar] [CrossRef]
- Dharmasena, P.; Nassif, N. Development and Optimization of a Novel Damper Control Strategy Integrating DCV and Duct Static Pressure Setpoint Reset for Energy-Efficient VAV Systems. Buildings 2025, 15, 518. [Google Scholar] [CrossRef]
- Westphalen, D.; Koszalinski, S. Energy Consumption Characteristics of Commercial Building HVAC Systems Volume I: Chillers, Refrigerant Compressors, and Heating Systems; Arthur D. Little, Inc.: Boston, MA, USA, 2001. [Google Scholar]
- American Socitey of Heating Ventilation and Air-Conditioning Systems and Equipment. 2020—ASHRAE Handbook—HVAC Systems and Equipment; ASHRAE: Peachtree Corners, GA, USA, 2020; ISBN 978-1-947192-52-2. [Google Scholar]
- U.S. Energy Information Administration (EIA). Use of Energy in Commercial Buildings. Available online: https://www.eia.gov/energyexplained/use-of-energy/commercial-buildings.php (accessed on 7 March 2025).
- Peters, G.P.; Andrew, R.M.; Canadell, J.G.; Friedlingstein, P.; Jackson, R.B.; Korsbakken, J.I.; Le Quéré, C.; Peregon, A. Carbon Dioxide Emissions Continue to Grow amidst Slowly Emerging Climate Policies. Nat. Clim. Change 2020, 10, 3–6. [Google Scholar] [CrossRef]
- Wang, Y.-W.; Cai, W.-J.; Soh, Y.-C.; Li, S.-J.; Lu, L.; Xie, L. A Simplified Modeling of Cooling Coils for Control and Optimization of HVAC Systems. Energy Convers. Manag. 2004, 45, 2915–2930. [Google Scholar] [CrossRef]
- Ebrahimi, P.; Ridwana, I.; Nassif, N. Solutions to Achieve High-Efficient and Clean Building HVAC Systems. Buildings 2023, 13, 1211. [Google Scholar] [CrossRef]
- Yu, B.; Kim, D.; Koh, J.; Kim, J.; Cho, H. Electrification and Decarbonization Using Heat Recovery Heat Pump Technology for Building Space and Water Heating. In Proceedings of the ASME 2023 17th International Conference on Energy Sustainability Collocated with the ASME 2023 Heat Transfer Summer Conference, Washington, DC, USA, 10–12 July 2023. [Google Scholar]
- Deason, J.; Borgeson, M. Electrification of Buildings: Potential, Challenges, and Outlook. Curr. Sustain. Renew. Energy Rep. 2019, 6, 131–139. [Google Scholar] [CrossRef]
- Yayla, A.; Świerczewska, K.S.; Kaya, M.; Karaca, B.; Arayici, Y.; Ayözen, Y.E.; Tokdemir, O.B. Artificial Intelligence (AI)-Based Occupant-Centric Heating Ventilation and Air Conditioning (HVAC) Control System for Multi-Zone Commercial Buildings. Sustainability 2022, 14, 16107. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, T.; Zhang, X.; Zhang, C. Artificial Intelligence-Based Fault Detection and Diagnosis Methods for Building Energy Systems: Advantages, Challenges and the Future. Renew. Sustain. Energy Rev. 2019, 109, 85–101. [Google Scholar] [CrossRef]
- Babadi Soultanzadeh, M.; Ouf, M.M.; Nik-Bakht, M.; Paquette, P.; Lupien, S. Fault Detection and Diagnosis in Light Commercial Buildings’ HVAC Systems: A Comprehensive Framework, Application, and Performance Evaluation. Energy Build. 2024, 316, 114341. [Google Scholar] [CrossRef]
- ANSI/ASHRAE/IES Standard 90.1-2022; Energy Standard for Sites and Buildings Except Low-Rise Residential Buildings. American Socitey of Heating Ventilation and Air-Conditioning Systems and Equipment (ASHRAE): Peachtree Corners, GA, USA, 2022.
- International Code Council, Inc. (ICC). 2021 International Energy Conservation Code (IECC); ICC: Country Club Hills, IL, USA, 2021. [Google Scholar]
- The Paris Agreement|UNFCCC. Available online: https://unfccc.int/process-and-meetings/the-paris-agreement (accessed on 12 March 2025).
- Barney, G.C.; Florez, J. Temperature Prediction Models and Their Application to the Control of Heating Systems. IFAC Proc. Vol. 1985, 18, 1847–1852. [Google Scholar] [CrossRef]
- Asamoah, P.B.; Shittu, E. Evaluating the Performance of Machine Learning Models for Energy Load Prediction in Residential HVAC Systems. Energy Build. 2025, 334, 115517. [Google Scholar] [CrossRef]
- Lu, S.; Zhou, S.; Ding, Y.; Kim, M.K.; Yang, B.; Tian, Z.; Liu, J. Exploring the Comprehensive Integration of Artificial Intelligence in Optimizing HVAC System Operations: A Review and Future Outlook. Results Eng. 2025, 25, 103765. [Google Scholar] [CrossRef]
- Gao, Z.; Yu, J.; Zhao, A.; Hu, Q.; Yang, S. A Hybrid Method of Cooling Load Forecasting for Large Commercial Building Based on Extreme Learning Machine. Energy 2022, 238, 122073. [Google Scholar] [CrossRef]
- Norouzi, P.; Maalej, S.; Mora, R. Applicability of Deep Learning Algorithms for Predicting Indoor Temperatures: Towards the Development of Digital Twin HVAC Systems. Buildings 2023, 13, 1542. [Google Scholar] [CrossRef]
- Maddalena, E.T.; Lian, Y.; Jones, C.N. Data-Driven Methods for Building Control—A Review and Promising Future Directions. Control Eng. Pract. 2020, 95, 104211. [Google Scholar] [CrossRef]
- Halhoul Merabet, G.; Essaaidi, M.; Ben Haddou, M.; Qolomany, B.; Qadir, J.; Anan, M.; Al-Fuqaha, A.; Abid, M.R.; Benhaddou, D. Intelligent Building Control Systems for Thermal Comfort and Energy-Efficiency: A Systematic Review of Artificial Intelligence-Assisted Techniques. Renew. Sustain. Energy Rev. 2021, 144, 110969. [Google Scholar] [CrossRef]
- Platt, G.; Li, J.; Li, R.; Poulton, G.; James, G.; Wall, J. Adaptive HVAC Zone Modeling for Sustainable Buildings. Energy Build. 2010, 42, 412–421. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, Y.; Fan, C.; Li, T.; Zhang, X.; Li, J. A Generic Prediction Interval Estimation Method for Quantifying the Uncertainties in Ultra-Short-Term Building Cooling Load Prediction. Appl. Therm. Eng. 2020, 173, 115261. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Q.; Wang, Z.; Liu, M.; He, Q. A Simplified Model of Dynamic Interior Cooling Load Evaluation for Office Buildings. Appl. Therm. Eng. 2016, 108, 1190–1199. [Google Scholar] [CrossRef]
- Lin, X.; Tian, Z.; Lu, Y.; Zhang, H.; Niu, J. Short-Term Forecast Model of Cooling Load Using Load Component Disaggregation. Appl. Therm. Eng. 2019, 157, 113630. [Google Scholar] [CrossRef]
- Dharmasena, P.; Nassif, N. Testing, Validation, and Simulation of a Novel Economizer Damper Control Strategy to Enhance HVAC System Efficiency. Buildings 2024, 14, 2937. [Google Scholar] [CrossRef]
- Wahba, N.; Rismanchi, B.; Pu, Y.; Aye, L. Efficient HVAC System Identification Using Koopman Operator and Machine Learning for Thermal Comfort Optimisation. Build. Environ. 2023, 242, 110567. [Google Scholar] [CrossRef]
- Babadi Soultanzadeh, M.; Nik-Bakht, M.; Ouf, M.M.; Paquette, P.; Lupien, S. Unsupervised Automated Fault Detection and Diagnosis for Light Commercial Buildings’ HVAC Systems. Build. Environ. 2025, 267, 112312. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, P.; Feng, F.; Qiao, Y.; Luo, W. Data Mining Algorithm and Framework for Identifying HVAC Control Strategies in Large Commercial Buildings. Build. Simul. 2021, 14, 63–74. [Google Scholar] [CrossRef]
- Khanuja, A.; Webb, A.L. What We Talk about When We Talk about EEMs: Using Text Mining and Topic Modeling to Understand Building Energy Efficiency Measures (1836-RP). Sci. Technol. Built Environ. 2023, 29, 4–18. [Google Scholar] [CrossRef]
- Ajifowowe, I.; Chang, H.; Lee, C.S.; Chang, S. Prospects and Challenges of Reinforcement Learning-Based HVAC Control. J. Build. Eng. 2024, 98, 111080. [Google Scholar] [CrossRef]
- Jiang, M.L.; Wu, J.Y.; Xu, Y.X.; Wang, R.Z. Transient Characteristics and Performance Analysis of a Vapor Compression Air Conditioning System with Condensing Heat Recovery. Energy Build. 2010, 42, 2251–2257. [Google Scholar] [CrossRef]
- Wang, S.; Ma, Z. Supervisory and Optimal Control of Building HVAC Systems: A Review. Hvac&R Res. 2008, 14, 3–32. [Google Scholar] [CrossRef]
- Belany, P.; Hrabovsky, P.; Sedivy, S.; Cajova Kantova, N.; Florkova, Z. A Comparative Analysis of Polynomial Regression and Artificial Neural Networks for Prediction of Lighting Consumption. Buildings 2024, 14, 1712. [Google Scholar] [CrossRef]
- Fumo, N.; Rafe Biswas, M.A. Regression Analysis for Prediction of Residential Energy Consumption. Renew. Sustain. Energy Rev. 2015, 47, 332–343. [Google Scholar] [CrossRef]
- 6.1—MLR Model Assumptions|STAT 462. Available online: https://online.stat.psu.edu/stat462/node/145/ (accessed on 19 March 2025).
- Lee, C.-W.; Fu, M.-W.; Wang, C.-C.; Azis, M.I. Evaluating Machine Learning Algorithms for Financial Fraud Detection: Insights from Indonesia. Mathematics 2025, 13, 600. [Google Scholar] [CrossRef]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-Art in Artificial Neural Network Applications: A Survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Han, S.-H.; Kim, K.W.; Kim, S.; Youn, Y.C. Artificial Neural Network: Understanding the Basic Concepts Without Mathematics. Dement. Neurocogn Disord. 2018, 17, 83–89. [Google Scholar] [CrossRef]
- 1.17.Neural Network Models (Supervised). Available online: https://scikit-learn.org/stable/modules/neural_networks_supervised.html (accessed on 19 March 2025).
- Abdolrasol, M.G.M.; Hussain, S.M.S.; Ustun, T.S.; Sarker, M.R.; Hannan, M.A.; Mohamed, R.; Ali, J.A.; Mekhilef, S.; Milad, A. Artificial Neural Networks Based Optimization Techniques: A Review. Electronics 2021, 10, 2689. [Google Scholar] [CrossRef]
- Engelbrecht, A.P.; Cloete, I.; Zurada, J.M. Determining the Significance of Input Parameters Using Sensitivity Analysis. In Proceedings of the From Natural to Artificial Neural Computation, Torremolinos, Spain, 7–9 June 1995; Mira, J., Sandoval, F., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 382–388. [Google Scholar]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Dietterich, T.G. Machine-Learning Research. AI Mag. 1997, 18, 97–136. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Nogales, A.G. On Consistency of the Bayes Estimator of the Density. Mathematics 2022, 10, 636. [Google Scholar] [CrossRef]
- Gu, M.; Kang, S.; Xu, Z.; Lin, L.; Zhang, Z. AE-XGBoost: A Novel Approach for Machine Tool Machining Size Prediction Combining XGBoost, AE and SHAP. Mathematics 2025, 13, 835. [Google Scholar] [CrossRef]
- Scikit-Learn: Machine Learning in Python—Scikit-Learn 1.6.1 Documentation. Available online: https://scikit-learn.org/stable/ (accessed on 12 March 2025).
- Pandas—Python Data Analysis Library. Available online: https://pandas.pydata.org/ (accessed on 12 March 2025).
- NumPy. Available online: https://numpy.org/ (accessed on 12 March 2025).
- Li, X.; Shen, Y.; Meng, Q.; Xing, M.; Zhang, Q.; Yang, H. Single-Model Self-Recovering Fringe Projection Profilometry Absolute Phase Recovery Method Based on Deep Learning. Sensors 2025, 25, 1532. [Google Scholar] [CrossRef]
- Jakubec, M.; Cingel, M.; Lieskovská, E.; Drliciak, M. Integrating Neural Networks for Automated Video Analysis of Traffic Flow Routing and Composition at Intersections. Sustainability 2025, 17, 2150. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Applications in R; Springer Texts in Statistics; Springer: New York, NY, USA, 2021; ISBN 978-1-0716-1417-4. [Google Scholar]
- Qavidelfardi, Z.; Tahsildoost, M.; Zomorodian, Z.S. Using an Ensemble Learning Framework to Predict Residential Energy Consumption in the Hot and Humid Climate of Iran. Energy Rep. 2022, 8, 12327–12347. [Google Scholar] [CrossRef]
- Wang, J.; Yuan, Z.; He, Z.; Zhou, F.; Wu, Z. Critical Factors Affecting Team Work Efficiency in BIM-Based Collaborative Design: An Empirical Study in China. Buildings 2021, 11, 486. [Google Scholar] [CrossRef]
- Neter, J.; Wasserman, W.; Kutner, M.H. Applied Linear Regression Models; Richard D. Irwin, Inc.: Homewood, IL, USA, 1983; ISBN 0-256-02547-9. [Google Scholar]
- Lian, J.; Jiang, J.; Dong, X.; Wang, H.; Zhou, H.; Wang, P. Coupled Motion Characteristics of Offshore Wind Turbines During the Integrated Transportation Process. Energies 2019, 12, 2023. [Google Scholar] [CrossRef]
- Liu, J.; Wu, Q.; Sui, X.; Chen, Q.; Gu, G.; Wang, L.; Li, S. Research Progress in Optical Neural Networks: Theory, Applications and Developments. PhotoniX 2021, 2, 5. [Google Scholar] [CrossRef]
- Babatunde, D.E.; Anozie, A.; Omoleye, J. Artificial Neural Network and Its Applications in the Energy Sector—An Overview. Int. J. Energy Econ. Policy 2020, 10, 250–264. [Google Scholar] [CrossRef]
- XGBoost Documentation—Xgboost 3.0.0 Documentation. Available online: https://xgboost.readthedocs.io/en/stable/ (accessed on 25 March 2025).
- Chen, T.; Guestrin, C. XGBoost: Reliable Large-Scale Tree Boosting System. In Proceedings of the 22nd SIGKDD Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Sehrawat, N.; Vashisht, S.; Singh, A. Solar Irradiance Forecasting Models Using Machine Learning Techniques and Digital Twin: A Case Study with Comparison. Int. J. Intell. Netw. 2023, 4, 90–102. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Values | ||||||
|---|---|---|---|---|---|---|
| Models | R2 Train | R2 Test | RMSE | MAE | MSE | CV |
| Bagging | 0.997854 | 0.977027 | 0.761906 | 0.291603 | 0.580500 | 0.980804 |
| Random Forest | 0.997867 | 0.976929 | 0.763534 | 0.291076 | 0.582985 | 0.982900 |
| Voting Regressor | 0.994969 | 0.976603 | 0.768907 | 0.321640 | 0.591218 | 0.989816 |
| XGBoost | 0.997564 | 0.974697 | 0.799610 | 0.327223 | 0.639376 | 1.029341 |
| Models | ||||
|---|---|---|---|---|
| Input Values | MLR | Neural Network (100) | Bagging | XGBoost |
| Hot Water Supply Temperature (°F) | 0.035 | 0.117 | 0.003 | 0.003 |
| Water Flow (gpm) | 0.357 | 0.358 | 0.197 | 0.414 |
| Mixed Air Temperature (°F) | 0.481 | 0.215 | 0.600 | 0.422 |
| Supply Fan Air Flow (cfm) | 0.126 | 0.310 | 0.199 | 0.161 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nassif, A.; Dharmasena, P.; Nassif, N. Application of Machine Learning Techniques for Predicting Heating Coil Performance in Building Heating Ventilation and Air Conditioning Systems. Energies 2025, 18, 2314. https://doi.org/10.3390/en18092314
Nassif A, Dharmasena P, Nassif N. Application of Machine Learning Techniques for Predicting Heating Coil Performance in Building Heating Ventilation and Air Conditioning Systems. Energies. 2025; 18(9):2314. https://doi.org/10.3390/en18092314
Chicago/Turabian StyleNassif, Adam, Pasidu Dharmasena, and Nabil Nassif. 2025. "Application of Machine Learning Techniques for Predicting Heating Coil Performance in Building Heating Ventilation and Air Conditioning Systems" Energies 18, no. 9: 2314. https://doi.org/10.3390/en18092314
APA StyleNassif, A., Dharmasena, P., & Nassif, N. (2025). Application of Machine Learning Techniques for Predicting Heating Coil Performance in Building Heating Ventilation and Air Conditioning Systems. Energies, 18(9), 2314. https://doi.org/10.3390/en18092314