
Automated Detection Method for Bolt Detachment of Wind Turbines in Low-Light Scenarios

 , and
, and
Abstract
1. Introduction
2. Methods
2.1. Overview
- (1)
- Dataset preparation phase: Acquire the bolt image dataset through multiple channels. Construct and train a deep convolutional generative adversarial network to deeply expand and augment the bolt images. The unlabeled images after deep expansion serve as dataset 1, while the labeled images are added as dataset 2. Both types are utilized in the subsequent network training process.
- (2)
- Model training stage: Firstly, construct the low-light enhancement model Zero-DCE++ and train it using dataset 1. Secondly, build the bolt defect detection model and train it with dataset 2.
- (3)
- Disease identification phase: Based on the YUV color space method, separate the brightness (Y) and chrominance (UV) features of the collected image awaiting detection. Calculate the feature value of the brightness component to categorize the image into low-light and normal-light types. For low-light images, conduct image brightness enhancement processing first, and then input them along with normal-light images into the bolt detachment defect model to accomplish the automated detection of bolt defect.
- (4)
- Method effectiveness analysis: Verify the effectiveness of the proposed method via experiments (in Changsha, Hunan Province, China). Analyze the impact of the shooting angle, distance, and light intensity on model performance by altering different imaging conditions.
2.2. Data Generation Augmentation and Evaluation
2.2.1. Deep Convolutional Generative Adversarial Network (DCGAN)
2.2.2. Image Similarity Evaluation Metrics
2.3. Low-Light Image Enhancement Algorithm Based on Zero-DCE++
2.3.1. Light-Enhancement Curve (LE-Curve)
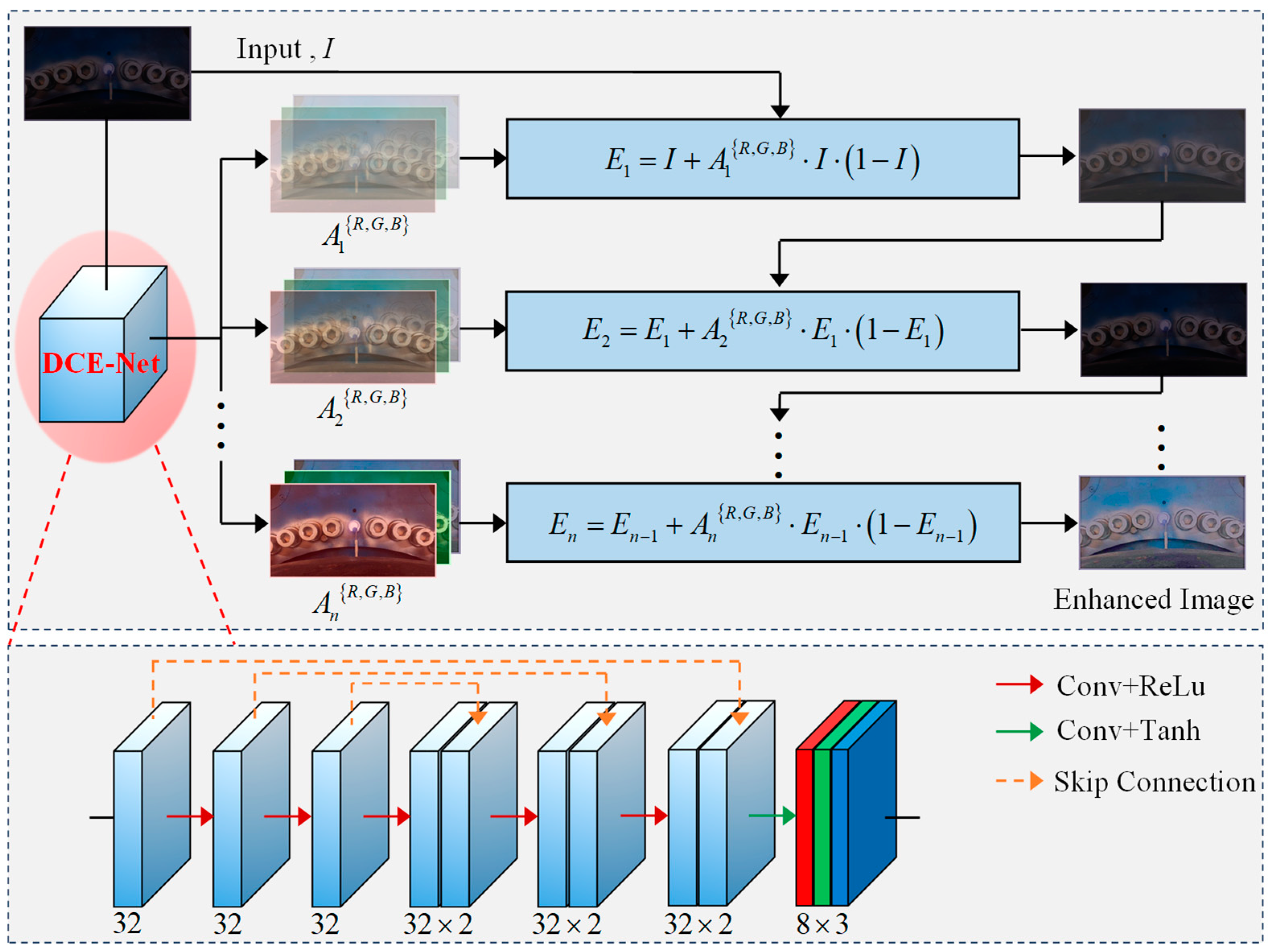
2.3.2. Deep Curve Estimation Network (DCE-Net)
2.3.3. Loss Function
2.4. Bolt Detachment Defect Detection Algorithm
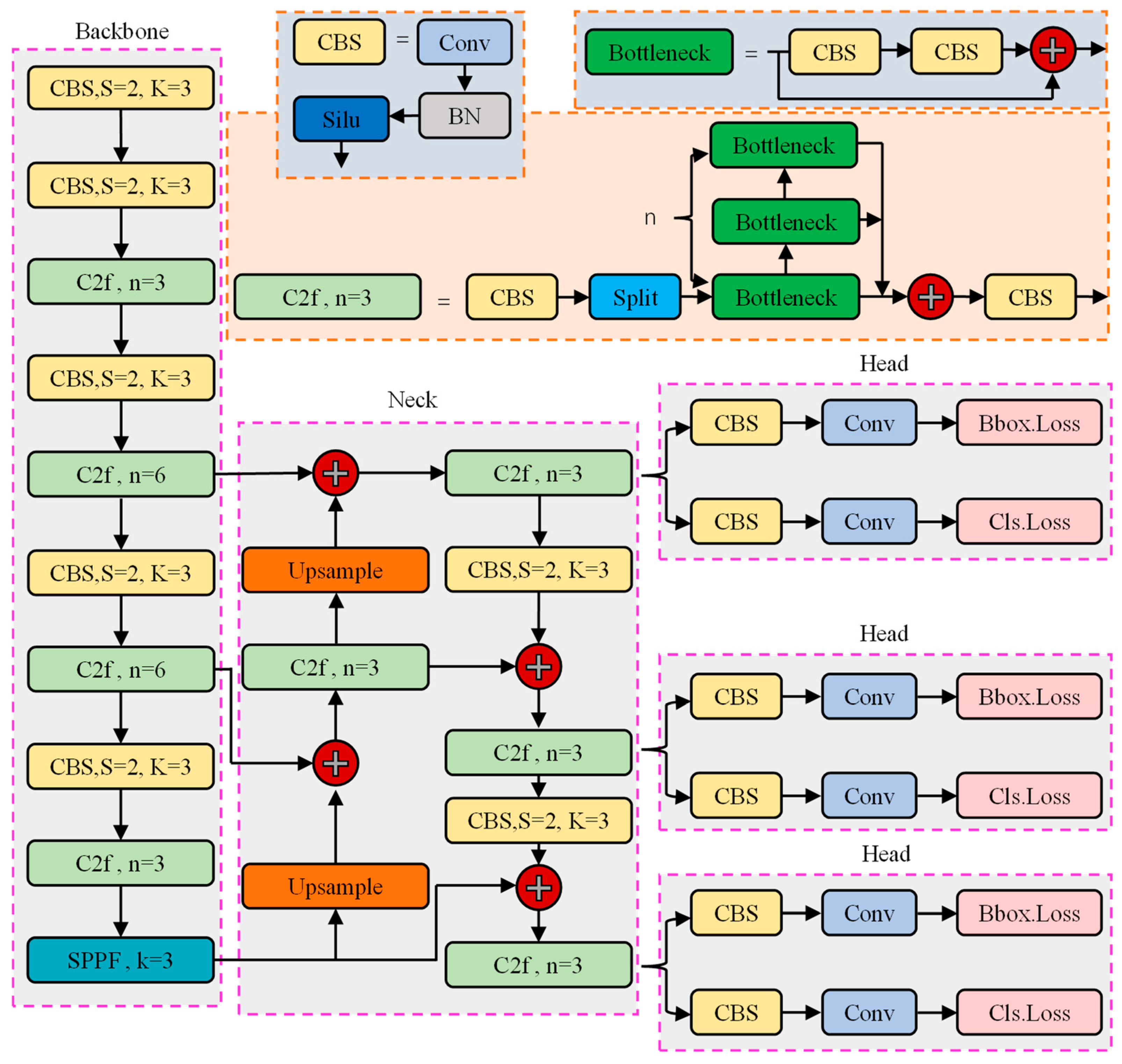
2.4.1. Target Detection Algorithm
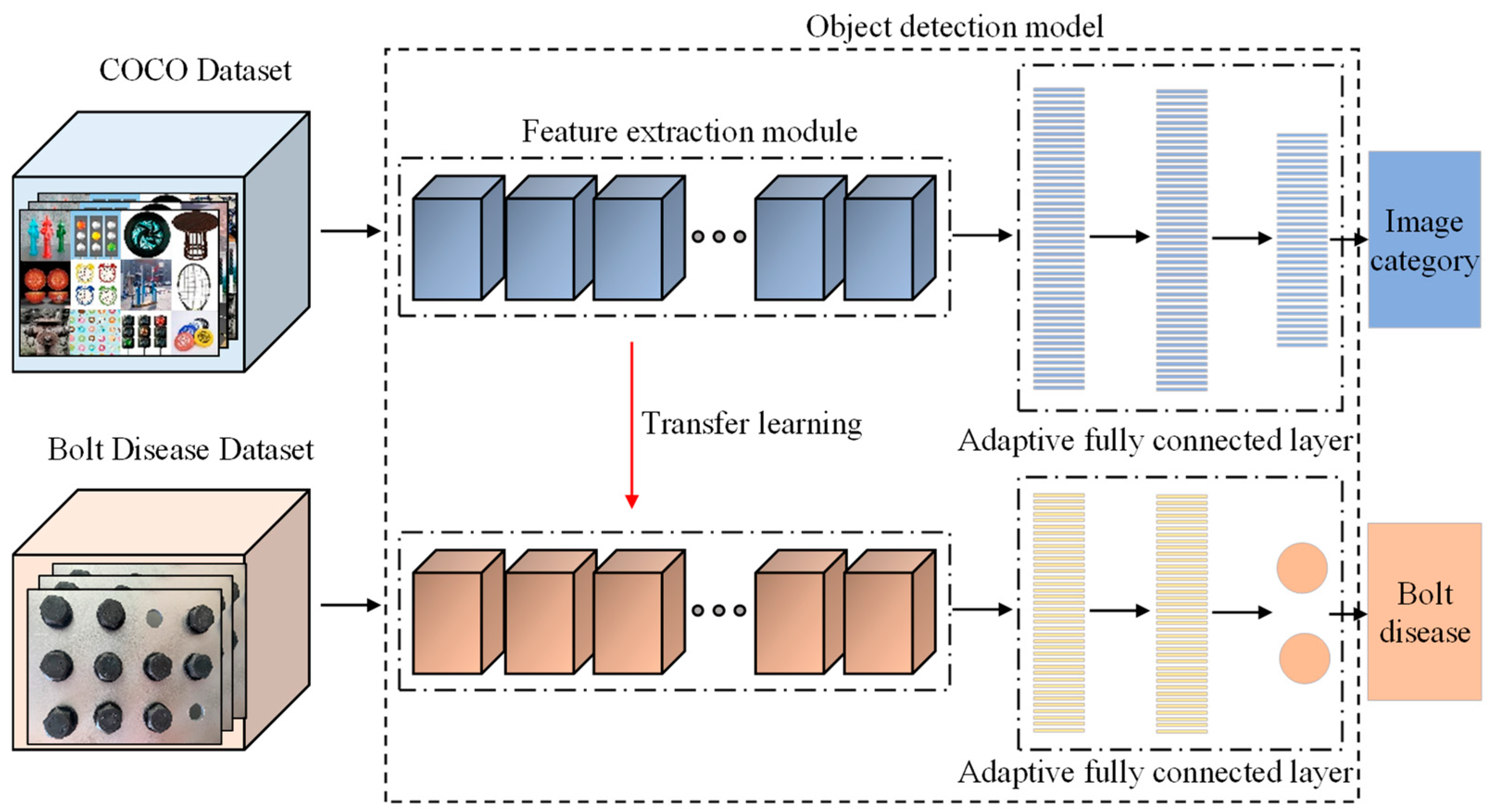
2.4.2. Transfer Learning
3. Experiments and Results
3.1. Preparation of Image Dataset
3.2. Augmentation of Image Dataset
3.2.1. Training of DCGAN
3.2.2. Image-Generation Results
3.2.3. Evaluation of Image Generation Quality
3.3. Training of Zero-DCE++
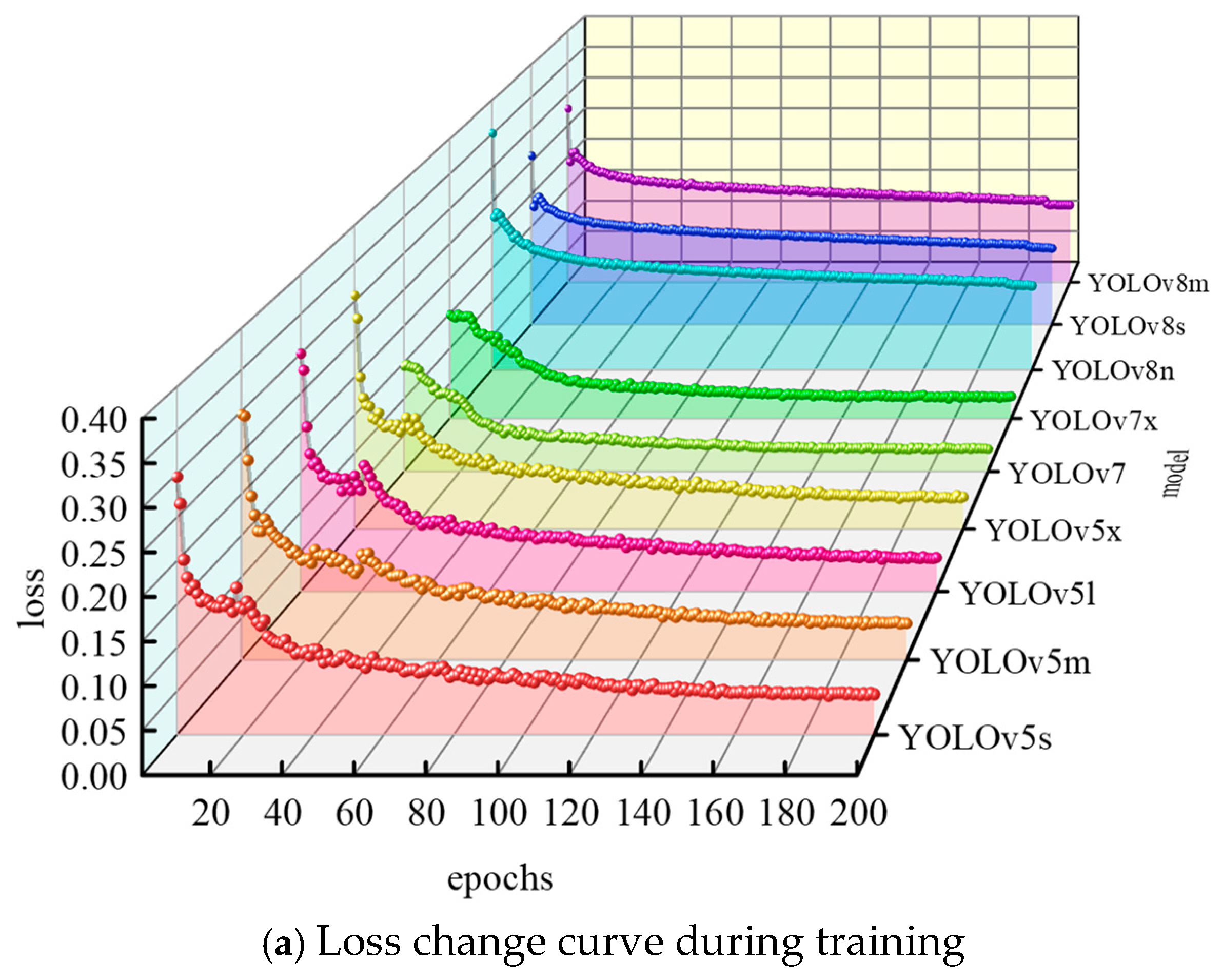
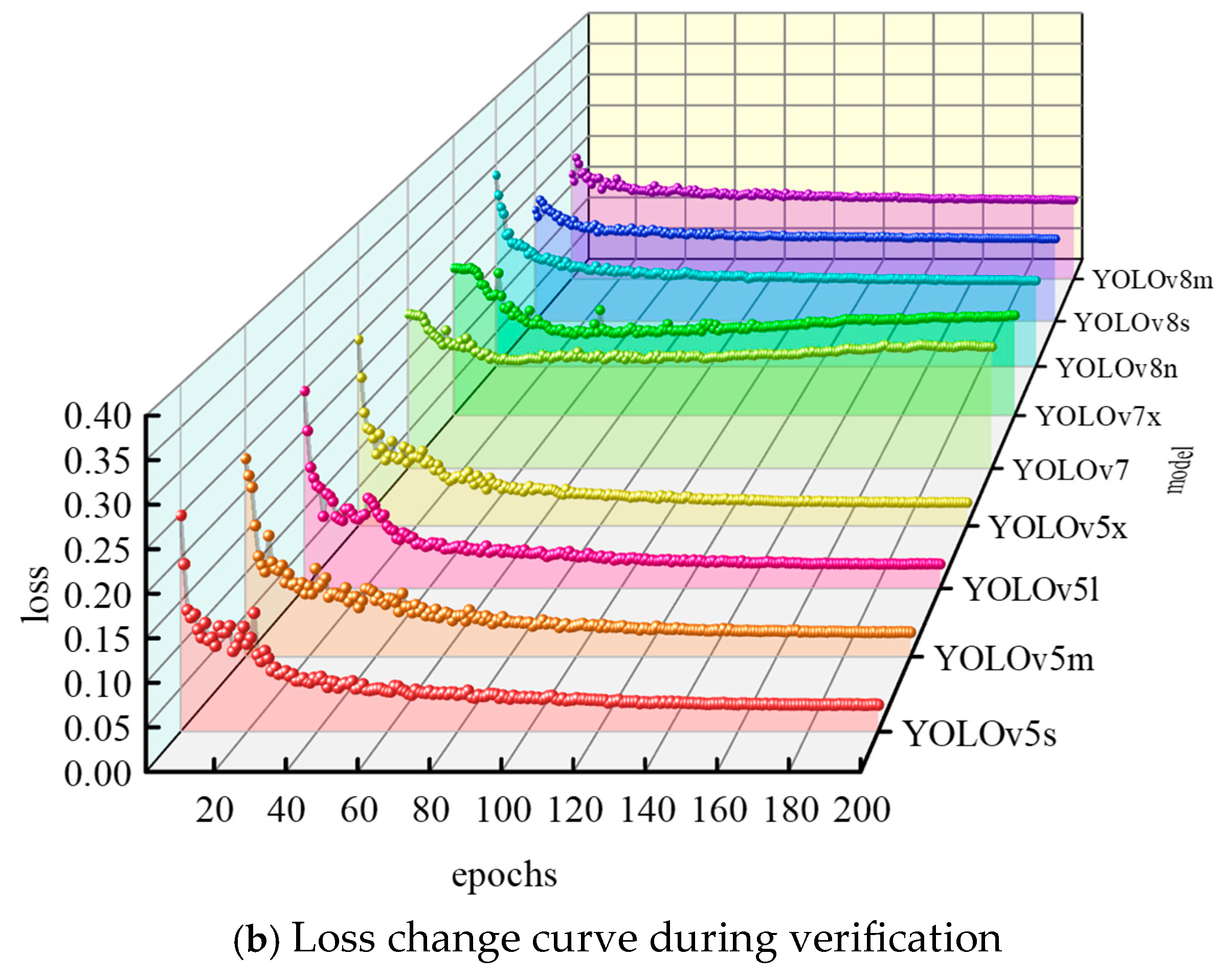
3.4. Training of Target Detection Model
3.5. Bolt Detachment Defect Detection Results
3.6. Validation
4. Conclusions
- (1)
- The deep convolutional generative adversarial network (DCGAN) is demonstrated as an effective approach to augmenting image datasets by generating realistic bolt images, thereby enhancing both the quantity and quality of training data while diversifying feature distributions. This methodology provides a viable solution for few-shot learning scenarios, where limited annotated data are available.
- (2)
- To optimize the detection performance, nine model variants—including YOLOv5, YOLOv7, and YOLOv8—are rigorously evaluated. After comprehensively balancing detection accuracy and computational efficiency, the YOLOv8n model is selected for bolt detachment defect detection. The model achieves a detection speed of 424 frames per second (FPSs) and a mean average precision (mAP@0.5:0.95) of 93.97%, enabling the high-precision real-time online monitoring of bolt defects in wind turbines.
- (3)
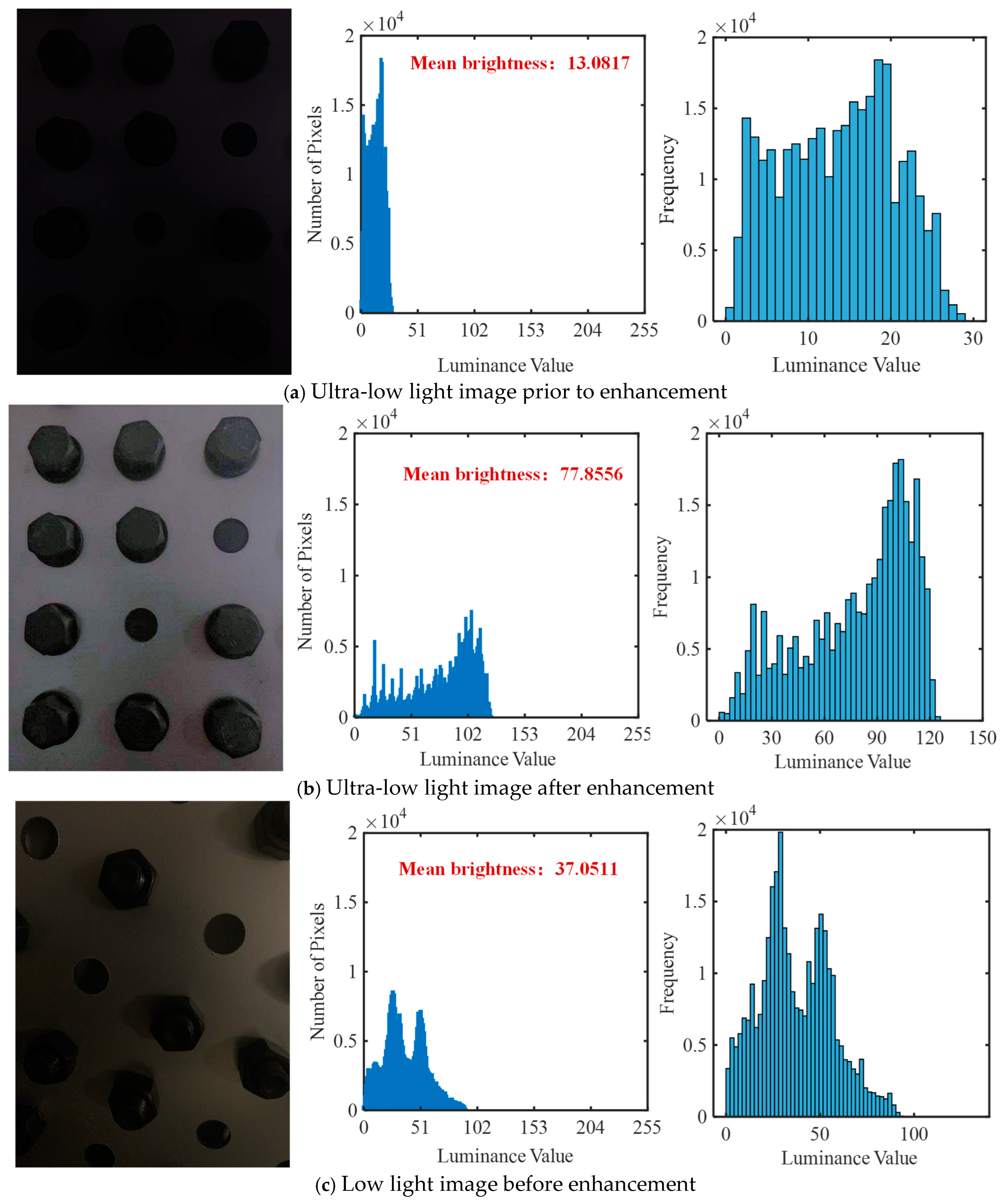
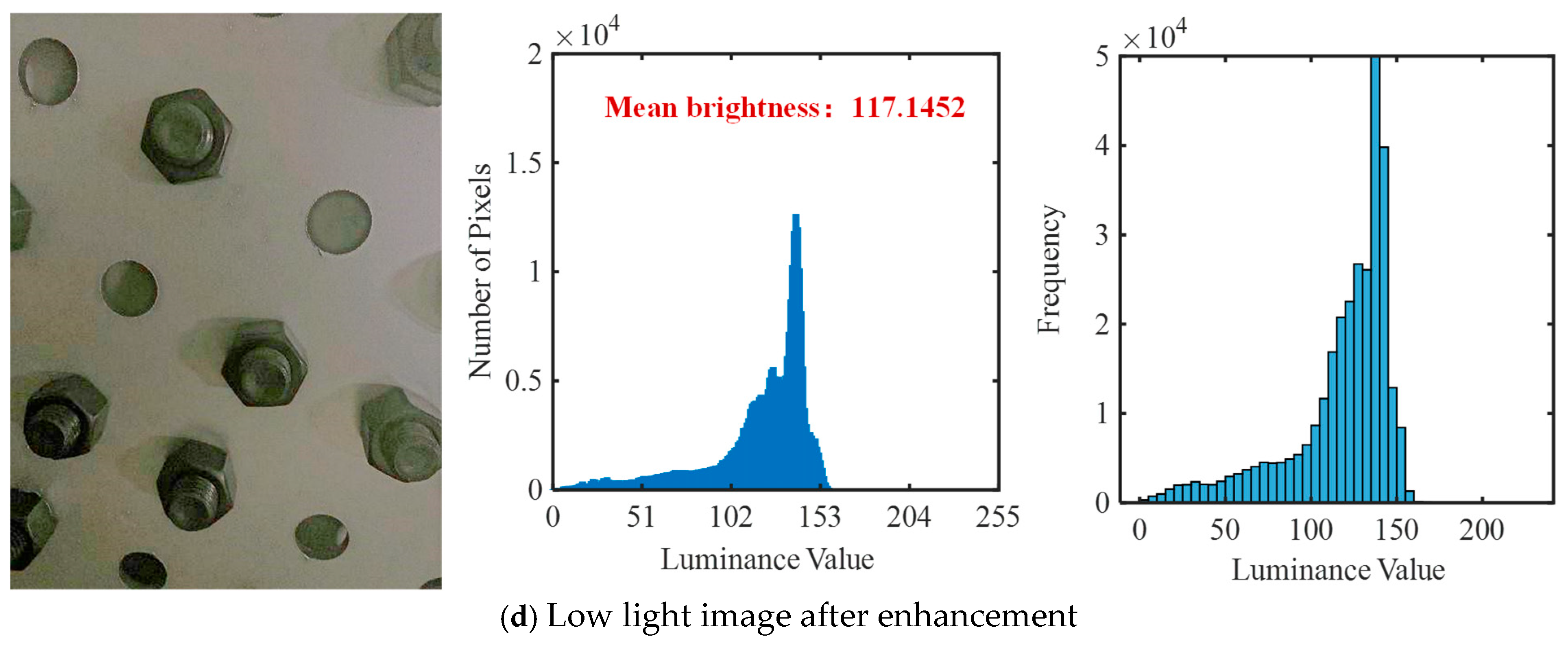
- After bolt images under different imaging conditions are enhanced by the Zero-DCE++ algorithm, the Mb of bolt images is significantly increased. Moreover, after image enhancement, the bolt detachment detection error rate is reduced from 31.08% to 2.36%, and the bolt detachment detection accuracy is improved. However, changes in shooting distance and angle can affect the model’s detection performance. Controlling the shooting distance within 1.6 m and the shooting angle within 20° can greatly enhance the reliability of the model’s detection results. At this point, zero false detection and missed detection can be achieved.
- (4)
- For offshore applications, our method requires IP68-rated cameras mounted on inspection drones or robotic arms, paired with edge computing devices (e.g., NVIDIA Jetson AGX). Data transmission via 5G modules ensures real-time monitoring. Field deployment should prioritize anti-corrosion hardware and periodic model retraining using marine-environment datasets.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cheng, L.; Yang, F.; Seidel, M.; Veljkovic, M. FE-assisted investigation for mechanical behaviour of connections in offshore wind turbine towers. Eng. Struct. 2023, 285, 116039. [Google Scholar] [CrossRef]
- Tran, T.-T.; Lee, D. Understanding the behavior of l-type flange joint in wind turbine towers: Proposed mechanisms. Eng. Fail. Anal. 2022, 142, 106750. [Google Scholar] [CrossRef]
- Mar, A.M.; José, M.A.; Felipe, P.Á.R.; Juan, J.D.C.D. Wind turbine tower collapse due to flange failure: FEM and DOE analyses. Eng. Fail. Anal. 2019, 104, 932–949. [Google Scholar]
- Du, J.; Qiu, Y.; Wang, Z.; Li, J.; Wang, H.; Wang, Z.; Zhang, J. A Three-Stage Criterion to Reveal the Bolt Self-Loosening Mechanism Under Random Vibration by Strain Detection. Eng. Fail. Anal. 2022, 133, 105954. [Google Scholar] [CrossRef]
- Ma, T.; Feng, Q.; Tan, Z.; Ou, J. Optical phase mode analysis method for pipeline bolt looseness identification using distributed optical fiber acoustic sensing. Struct. Health Monit. 2024, 23, 1547–1559. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, W.; Wu, J.; Wang, J.; Li, W. Experimental Evaluation of Wearable Piezo Ring for Bolted Connection Monitoring Using the Active Sensing Approach. IEEE Sens. J. 2023, 23, 4430–4437. [Google Scholar] [CrossRef]
- Qin, X.; Peng, C.; Zhao, G.; Ju, Z.; Lv, S.; Jiang, M.; Sui, Q.; Jia, L. Full life-cycle monitoring and earlier warning for bolt joint loosening using modified vibro-acoustic modulation. Mech. Syst. Signal Process 2022, 162, 108054. [Google Scholar] [CrossRef]
- Zhou, L.; Chen, S.-X.; Ni, Y.-Q.; Choy, A.W.-H. EMI-GCN: A hybrid model for real-time monitoring of multiple bolt looseness using electromechanical impedance and graph convolutional networks. Smart Mater. Struct. 2021, 30, 035032. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, S.; Zhou, M.; Chen, H.; Yuan, C.; Kong, Q. Percussion-based bolt looseness identification using vibration-guided sound reconstruction. Struct. Control Health Monit. 2022, 29, e2876. [Google Scholar] [CrossRef]
- Han, C.; Wang, S.; Madan, A.; Zhao, C.; Mohanty, L.; Fu, Y.; Shen, W.; Liang, R.; Huang, E.S.; Zheng, T.; et al. Intelligent detection of loose fasteners in railway tracks using distributed acoustic sensing and machine learning. Eng. Appl. Artif. Intell. 2024, 134, 108684. [Google Scholar] [CrossRef]
- Wang, F.; Chen, Z.; Song, G. Monitoring of multi-bolt connection looseness using entropy-based active sensing and genetic algorithm-based least square support vector machine. Mech. Syst. Signal Process 2020, 136, 106507. [Google Scholar] [CrossRef]
- Luo, J.; Zhao, J.; Sun, Y.; Liu, X.; Yan, Z. Bolt-loosening detection using vision technique based on a gray gradient enhancement method. Adv. Struct. Eng. 2023, 26, 668–678. [Google Scholar] [CrossRef]
- Han, Q.; Wang, S.; Fang, Y.; Wang, L.; Du, X.; Li, H.; He, Q.; Feng, Q. A Rail Fastener Tightness Detection Approach Using Multi-source Visual Sensor. Sensors 2020, 20, 1367. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Wang, N.; Ho, S.-C.; Chen, X.; Song, G.; Ho, M. Design of a New Vision-Based Method for the Bolts Looseness Detection in Flange Connections. IEEE Trans. Ind. Electron. 2020, 67, 1366–1375. [Google Scholar] [CrossRef]
- Ta, Q.-B.; Kim, J.-T. Monitoring of Corroded and Loosened Bolts in Steel Structures via Deep Learning and Hough Transforms. Sensors 2020, 20, 6888. [Google Scholar] [CrossRef]
- Wang, Q.; Zhang, H.; Lin, C.; Yang, Y. A New Bolts-Loosening Detection Method in High-Voltage Tower Based on Binocular Vision. In Proceedings of the 2023 29th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Queenstown, New Zealand, 21–24 November 2023; pp. 90–99. [Google Scholar]
- Huynh, T.-C. Vision-based Autonomous Bolt-Looseness Detection Method for Splice Connections: Design, Lab-Scale Evaluation, and Field Application. Autom. Constr. 2021, 124, 103591. [Google Scholar] [CrossRef]
- Yuan, C.; Chen, W.; Hao, H.; Kong, Q. Near real-time bolt-loosening detection using mask and region-based convolutional neural network. Struct. Control Health Monit. 2021, 28. [Google Scholar] [CrossRef]
- Wu, Y.; Qin, Y.; Qian, Y.; Guo, F. Automatic Detection of Arbitrarily Oriented Fastener Defect in High-Speed Railway. Autom. Constr. 2021, 131, 103913. [Google Scholar] [CrossRef]
- Mushtaq, F.; Ramesh, K.; Deshmukh, S.; Ray, T.; Parimi, C.; Tandon, P.; Jha, P.K. Nuts&bolts: YOLO-v5 and image processing based component identification system. Eng. Appl. Artif. Intell. 2023, 118, 105665. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, X.; Liu, P.; He, B.; Li, W.; Song, T. Automated detection and segmentation of tunnel defects and objects using YOLOv8-CM. Tunn. Undergr. Space Technol. 2024, 150, 105857. [Google Scholar] [CrossRef]
- Lu, Q.; Jing, Y.; Zhao, X. Bolt Loosening Detection Using Key-Point Detection Enhanced by Synthetic Datasets. Appl. Sci. 2023, 13, 2020. [Google Scholar] [CrossRef]
- Bolton, T.; Bass, J.; Gaber, T.; Mansouri, T. Comparing Object Recognition Models and Studying Hyperparameter Selection for the Detection of Bolts. In NLDB, 2023; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2023; Volume 13913, pp. 186–200. [Google Scholar]
- Yu, Y.; Liu, Y.; Chen, J.; Jiang, D.; Zhuang, Z.; Wu, X. Detection Method for Bolted Connection Looseness at Small Angles of Timber Structures based on Deep Learning. Sensors 2021, 21, 3106. [Google Scholar] [CrossRef] [PubMed]
- Ian, J.G.; Jean, P.-A.; Mehdi, M.; Xu, B.; David, W.-F.; Sherjil, O.; Aaron, C.; Yoshua, B. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- Connor, S.; Taghi, M.K. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar]
- Zhou, Y.; Wang, B.; He, X.; Cui, S.; Shao, L. DR-GAN: Conditional Generative Adversarial Network for Fine-Grained Lesion Synthesis on Diabetic Retinopathy Images. IEEE J. Biomed. Health Inform. 2022, 26, 56–66. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, P.; Yu, Y.; Li, X.; Biancardo, S.A.; Zhang, J. Missing Data Repairs for Traffic Flow With Self-Attention Generative Adversarial Imputation Net. IEEE Trans. Intell. Transp. Syst. 2022, 23, 7919–7930. [Google Scholar] [CrossRef]
- Li, J.; Chen, Z.; Cheng, L.; Liu, X. Energy data generation with Wasserstein Deep Convolutional Generative Adversarial Networks. Energy 2022, 257, 124694. [Google Scholar] [CrossRef]
- Lu, Y.; Chen, D.; Olaniyi, E.; Huang, Y. Generative Adversarial Networks (GANs) for Image Augmentation in Agriculture: A Systematic Review. Comput. Electron. Agric. 2022, 200, 107208. [Google Scholar] [CrossRef]
- Pan, X.; Tavasoli, S.; Yang, T.Y. Autonomous 3D Vision-Based Bolt Loosening Assessment Using Micro Aerial Vehicles. Comput. Civ. Infrastruct. Eng. 2023, 38, 2443–2454. [Google Scholar] [CrossRef]
- Du, F.; Wu, S.; Xu, C.; Yang, Z.; Su, Z. Electromechanical Impedance Temperature Compensation and Bolt Loosening Monitoring Based on Modified Unet and Multitask Learning. IEEE Sens. J. 2023, 23, 4556–4567. [Google Scholar] [CrossRef]
- Luo, P.; Wang, B.; Wang, H.; Ma, F.; Ma, H.; Wang, L. An Ultrasmall Bolt Defect Detection Method for Transmission Line Inspection. IEEE Trans. Instrum. Meas. 2023, 72, 5006512. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A Convolutional Neural Network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the Darkness: A Practical Low-light Image Enhancer. In Proceedings of the 27th ACM International Conference on Multimedia (MM’19), Nice, France, 21–25 October 2019. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond Brightening Low-light Images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhancement Without Paired Supervision. IEEE Trans. Image Process 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward Fast, Flexible, and Robust Low-Light Image Enhancement. IEEE Conf. Comput. Vis. Pattern Recognit. 2022, 2022, 5627–5636. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Chen, C.L.; Hou, J.; Sam, K. Zero-Reference Deep Curve Estimation for Low-Light Image Enhancement. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1777–1786. [Google Scholar]
- Li, C.; Guo, C.; Chen, C.L. Learning to Enhance Low-Light Image via Zero-Reference Deep Curve Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4225–4238. [Google Scholar] [CrossRef]
- Gao, F.; Qian, C.; Xu, L.; Liu, J.; Zhang, H. An experimental study on the identification of the root bolts’ state of wind turbine blades using blade sensors. Wind. Energy 2024, 27, 363–381. [Google Scholar] [CrossRef]
- Sethi, M.R.; Subba, A.B.; Faisal, M.; Sahoo, S.; Raju, D.K. Fault diagnosis of wind turbine blades with continuous wavelet transform based deep learning model using vibration signal. Eng. Appl. Artif. Intell. 2024, 138, 109372. [Google Scholar] [CrossRef]
- Guan, Y.; Meng, Z.; Gu, F.; Cao, Y.; Li, D.; Miao, X.; Ball, A.D. Fault diagnosis of wind turbine structures with a triaxial vibration dual-branch feature fusion network. Reliab. Eng. Syst. Saf. 2025, 256, 110746. [Google Scholar] [CrossRef]
- Liu, P.; Wang, X.; Wang, Y.; Zhu, J.; Ji, X. Research on percussion-based bolt looseness monitoring under noise interference and insufficient samples. Mech. Syst. Signal Process 2024, 208, 111013. [Google Scholar] [CrossRef]
- Wang, X.; Yue, Q.; Liu, X. Bolted lap joint loosening monitoring and damage identification based on acoustic emission and machine learning. Mech. Syst. Signal Process 2024, 220, 111690. [Google Scholar] [CrossRef]
- Fu, W.; Zhou, R.; Guo, Z. Automatic bolt tightness detection using acoustic emission and deep learning. Structures 2023, 55, 1774–1782. [Google Scholar] [CrossRef]
- Li, D.; Nie, J.-H.; Wang, H.; Ren, W.-X. Loading condition monitoring of high-strength bolt connections based on physics-guided deep learning of acoustic emission data. Mech. Syst. Signal Process 2024, 206, 110908. [Google Scholar] [CrossRef]
- Yang, X.; Gao, Y.; Fang, C.; Zheng, Y.; Wang, W. Deep learning-based bolt loosening detection for wind turbine towers. Struct. Control Health Monit. 2022, 29, e2943. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, Y.; Wang, J.; Yue, Q.; Chen, H. Comparison of non-destructive testing methods of bolted joint status in steel structures. Measurement 2025, 242, 116318. [Google Scholar] [CrossRef]
- Alec, R.; Luke, M.; Soumith, C. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- Sara, U.; Akter, M.; Uddin, M.S. Image Quality Assessment Through FSIM, SSIM, MSE and PSNR—A Comparative Study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Zhou, W.; Conrad, A.B.; Rahim, H.S.; Eero, S. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2019, 111, 257–276. [Google Scholar] [CrossRef]
- Regin, V.; Sambath, M. YOLOv8: A Novel Object Detection Algorithm with Enhanced Performance and Robustness. In Proceedings of the 2024 International Conference on Advances in Data Engineering and Intelligent Computing Systems (ADICS), Chennai, India, 18–19 April 2024; pp. 1–6. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Zhuang, L.; Qi, H.; Wang, T.; Zhang, Z. A Deep-Learning-Powered Near-Real-Time Detection of Railway Track Major Components: A Two-Stage Computer-Vision-Based Method. IEEE Internet Things J. 2022, 9, 18806–18816. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Type of Network | Network Layer | Network Composition | Kernel Size | Stride | N_Out |
|---|---|---|---|---|---|
| Generator | G1 | DeConv2d + BN + ReLU | 4 | 1 | 512 |
| G2 | DeConv2d + BN + ReLU | 3 | 2 | 256 | |
| G3 | DeConv2d + BN + ReLU | 3 | 3 | 128 | |
| G4 | DeConv2d + BN + ReLU | 4 | 4 | 64 | |
| G5 | DeConv2d + BN + Tanh | 6 | 4 | 64 | |
| Discriminator | D1 | Conv2d + IN + LeakyReLU | 6 | 4 | 64 |
| D2 | Conv2d + IN + LeakyReLU | 4 | 4 | 64 | |
| D3 | Conv2d + IN + LeakyReLU | 3 | 3 | 128 | |
| D4 | Conv2d + IN + LeakyReLU | 3 | 2 | 256 | |
| D5 | Conv2d | 4 | 1 | 512 |
| Generate Images | Number of Images | Image Pixels | MSE (↓) | PSNR (↑) | SSIM (↑) |
|---|---|---|---|---|---|
| Bolt cap | 200 | 32 × 32 | 24.18 | 15.16 | 0.48 |
| 200 | 64 × 64 | 29.28 | 14.27 | 0.34 | |
| 200 | 96 × 96 | 23.07 | 15.32 | 0.39 | |
| Nut | 200 | 32 × 32 | 12.13 | 17.45 | 0.49 |
| 200 | 64 × 64 | 11.20 | 18.02 | 0.38 | |
| 200 | 96 × 96 | 9.11 | 18.81 | 0.49 | |
| Detachment | 200 | 32 × 32 | 18.58 | 16.47 | 0.60 |
| 200 | 64 × 64 | 16.14 | 16.99 | 0.58 | |
| 200 | 96 × 96 | 16.96 | 16.79 | 0.59 |
| Model | p (%) | r (%) | F1 (%) | mAP_0.5:0.95 | Param (M) | Weight_Size (MB) | FPS (GPU) |
|---|---|---|---|---|---|---|---|
| YOLOv5s | 96.48 | 97.69 | 97.08 | 84.69 | 7.0 | 14.5 | 476 |
| YOLOv5m | 96.30 | 97.70 | 96.99 | 83.92 | 20.9 | 42.3 | 371 |
| YOLOv5l | 96.85 | 97.67 | 97.26 | 86.39 | 46.2 | 92.9 | 244 |
| YOLOv5x | 97.16 | 97.72 | 97.44 | 86.40 | 86.2 | 173.2 | 154 |
| YOLOv7 | 94.09 | 93.84 | 93.69 | 81.66 | 37.2 | 74.9 | 205 |
| YOLOv7x | 93.69 | 95.97 | 94.82 | 79.98 | 70.9 | 142.2 | 147 |
| YOLOv8n | 98.98 | 99.05 | 99.01 | 93.97 | 3.1 | 6.3 | 424 |
| YOLOv8s | 99.16 | 99.19 | 99.17 | 94.88 | 11.1 | 22.5 | 449 |
| YOLOv8m | 99.08 | 99.18 | 99.13 | 95.08 | 25.9 | 52.1 | 307 |
| Working Conditions | Mb (10–50) | d (1.0–2 m) | (0°–40°) |
|---|---|---|---|
| I1–I4 | 10–20, 20–30, 30–40, 40–50 | 1.0 m | 0° |
| I5–I8 | 20–30 | 1.0 m, 1.3 m, 1.6 m, 2.0 m | 0° |
| I9–I12 | 20–30 | 1.0 m | 10°, 20°, 30°, 40° |
| Conditions | Without Zero-dce++ | With Zero-dce++ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 7 | 10 | 18 | 19 | 23 | FMR | 4 | 7 | 10 | 18 | 19 | 23 | FMR | |
| I1 | 0.45 | 0.85 | 0.60 | 0.91 | 0.93 | 0.86 | 45.83% | 0.93 | 0.95 | 0.91 | 0.95 | 0.94 | 0.95 | 0.00% |
| I2 | 0.76 | 0.91 | 0.65 | 0.91 | 0.91 | 0.89 | 33.33% | 0.96 | 0.96 | 0.94 | 0.95 | 0.95 | 0.95 | 0.00% |
| I3 | 0.84 | 0.91 | 0.61 | 0.91 | 0.91 | 0.89 | 25.00% | 0.96 | 0.95 | 0.93 | 0.94 | 0.96 | 0.95 | 0.00% |
| I4 | 0.88 | 0.91 | 0.63 | 0.91 | 0.91 | 0.90 | 20.83% | 0.96 | 0.96 | 0.92 | 0.94 | 0.95 | 0.95 | 0.00% |
| I5 | 0.84 | 0.90 | 0.64 | 0.82 | 0.84 | 0.83 | 29.17% | 0.95 | 0.94 | 0.93 | 0.95 | 0.96 | 0.94 | 0.00% |
| I6 | 0.76 | 0.85 | / | 0.85 | 0.87 | 0.83 | 33.33% | 0.89 | 0.94 | 0.92 | 0.91 | 0.95 | 0.94 | 0.00% |
| I7 | 0.6 | 0.91 | 0.66 | 0.78 | 0.85 | 0.76 | 33.33% | 0.9 | 0.96 | 0.95 | 0.88 | 0.92 | 0.80 | 4.17% |
| I8 | / | 0.89 | 0.62 | 0.61 | 0.79 | 0.76 | 50.00% | 0.83 | 0.95 | 0.94 | 0.83 | 0.88 | 0.87 | 8.33% |
| I9 | 0.86 | 0.87 | 0.64 | 0.89 | 0.89 | 0.87 | 30.77% | 0.92 | 0.96 | 0.95 | 0.95 | 0.95 | 0.89 | 0.00% |
| I10 | 0.6 | 0.85 | / | 0.91 | 0.89 | 0.89 | 19.23% | 0.91 | 0.95 | 0.94 | 0.95 | 0.96 | 0.93 | 3.85% |
| I11 | 0.84 | 0.83 | 0.46 | 0.55 | 0.75 | 0.72 | 23.08% | 0.94 | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 | 3.85% |
| I12 | 0.46 | 0.53 | 0.41 | / | 0.73 | 0.53 | 30.77% | 0.91 | 0.66 | 0.91 | 0.89 | 0.93 | 0.92 | 7.69% |
| global FMR | 31.08% | 2.36% | ||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, J.; Yao, Y.; Rao, M.; Yang, Y.; Luo, C.; Li, Z.; Hua, X.; Chen, B. Automated Detection Method for Bolt Detachment of Wind Turbines in Low-Light Scenarios. Energies 2025, 18, 2197. https://doi.org/10.3390/en18092197
Deng J, Yao Y, Rao M, Yang Y, Luo C, Li Z, Hua X, Chen B. Automated Detection Method for Bolt Detachment of Wind Turbines in Low-Light Scenarios. Energies. 2025; 18(9):2197. https://doi.org/10.3390/en18092197
Chicago/Turabian StyleDeng, Jiayi, Yong Yao, Mumin Rao, Yi Yang, Chunkun Luo, Zhenyan Li, Xugang Hua, and Bei Chen. 2025. "Automated Detection Method for Bolt Detachment of Wind Turbines in Low-Light Scenarios" Energies 18, no. 9: 2197. https://doi.org/10.3390/en18092197
APA StyleDeng, J., Yao, Y., Rao, M., Yang, Y., Luo, C., Li, Z., Hua, X., & Chen, B. (2025). Automated Detection Method for Bolt Detachment of Wind Turbines in Low-Light Scenarios. Energies, 18(9), 2197. https://doi.org/10.3390/en18092197