1. Introduction
Recent years have seen frequent wildfires occurring around the globe. Transmission lines are a major component of the power system and a crucial channel for the transmission of electrical energy [
1]. However, the construction and layout of transmission lines often inevitably traverse forested areas, grasslands, and other regions where combustible materials are concentrated. Consequently, when a wildfire occurs, the transmission lines may be at risk of being engulfed or damaged by the fire source [
2]. The necessity of detecting wildfires on transmission lines becomes particularly important [
3]. Firstly, regular inspections for wildfires on transmission lines can be used to monitor and assess the risk of wildfires in power infrastructure areas and promptly discover and address fire sources to prevent fire incidents, thereby reducing the economic losses caused by fires and protecting the surrounding environment and ecosystems to avoid ecological crises caused by fires. This requires scientific methods and advanced technologies such as artificial intelligence, remote sensing technology, and drone inspections to improve the accuracy and efficiency of wildfire detection, so that we can respond to potential fire risks in a timely manner [
4].
Traditional wildfire detection based on sensors requires the fusion of multi-sensor data [
5], including temperature sensors, humidity sensors, and smoke sensors, among others, to integrate various sensor data and extract the fire source characteristics. The method of multi-sensor data fusion has certain advantages in fire source detection, but it has limitations in its monitoring range. The deployment cost is high, and it requires the handling of multiple data types, making the data processing and analysis procedure complex [
6]. With the continuous development of image processing technology, the use of images for forest fire detection has become the mainstream trend in forest fire monitoring. In recent years, computer vision-based wildfire detection has been widely applied [
7]. These methods have the advantages of less human interference, lower costs, a wider monitoring range, and real-time monitoring. Traditional machine learning methods include using SVM, decision trees, etc., which require manual feature extraction (such as hue, brightness, and texture, etc.) and the classification of features. This method is very dependent on the selected features and the performance of the classifier [
1]. Feature extraction is manually performed, and this has a significant impact on feature selection and model performance. If the selected features cannot effectively reflect the characteristics of the fire, it may lead to poor detection performance [
8]. At the same time, fire scenes have large variability, and fixed feature extraction methods may not be able to adapt to changes in various environmental factors [
5].
In recent years, deep learning-based methods have developed rapidly, allowing for more efficient wildfire detection [
9]. Currently, the most commonly used object detection algorithms include the region convolutional neural network (RCNN), single-shot multi-box detector (SSD) [
10], faster region convolutional neural network (Faster RCNN) [
11], and You Only Look Once (YOLO) [
12]. These methods, based on convolutional neural networks (CNNs), can automatically learn and extract image features, avoiding the problem of feature selection. The monitoring of wildfires requires the rapid detection and control of wildfires. Compared with other algorithms, the YOLO algorithm, as a single-stage algorithm, has better real-time performance [
13]. Moreover, YOLOv11 has been extensively used in wildfire detection due to its high accuracy and real-time performance, as demonstrated in several studies [
7,
14,
15]. These works show that YOLOv11 can effectively handle complex backgrounds and small-scale objects, making it well suited for wildfire monitoring. Therefore, this study is based on the use of YOLOv11 for wildfire object detection.
However, YOLOv11 requires a large number of labeled data for training, and actual wildfire images are often scarce, being insufficient for target detection tasks [
16]. To address the small sample problem in wildfire detection, some researchers have tried using meta-learning approaches [
17]. Wildfire images also have complex backgrounds with many distractions and significant scale differences [
18]. The original YOLO algorithm lacks the ability to fuse features across multiple scales, making it easily affected by complex backgrounds [
19]. To address these issues, this paper proposes a transmission line wildfire target detection model called MA-YOLO (where M refers to meta-learning and A refers to the attention module). This model is based on the convolutional neural network detector YOLOv11 [
12] and incorporates several improvements. The first is a meta-learning mechanism: to solve the problem of insufficient sample data for wildfire images, we propose a feature extractor based on meta-learning. During the feature extraction process, we use a meta-feature extractor and re-weighting module to improve the learning ability of the model in small-sample scenarios [
20]. The second is an adaptive feature fusion module: to reduce interference from complex backgrounds, we replace the first convolutional module in the feature extraction process with a spatial and channel reconstruction module (SCConv). We then adopt an adaptive feature fusion (AFF) module with pruning operations to dynamically adjust the fusion ratios between different feature layers and remove redundant channels, enhancing multi-scale feature fusion and reducing the computational overhead [
21]. Moreover, we include virtual data augmentation: we utilize the AirSim plugin from Unreal Engine to generate a large number of virtual wildfire image samples, constructing a support set to enhance the detection capabilities for small-sample wildfire data [
22]. Lastly, we apply a small target detection head: to enhance the network’s detection ability for small-scale wildfires, we add a specialized small target feature detection head to YOLOv11 [
15].
By incorporating these improvements, MA-YOLO addresses the limitations of existing wildfire detection models. Specifically, it enhances the model’s generalization abilities in small-sample conditions and its robustness against complex backgrounds through the introduction of meta-learning mechanisms and adaptive feature fusion techniques.
Our contributions are as follows.
- (1)
We designed a meta-learning-based target detection framework for small-sample wildfire detection and used a virtual engine to build a support set of wildfire image samples, thereby improving the detection accuracy of the target detection network in small-sample wildfire data.
- (2)
To further reduce the interference from complex backgrounds in wildfire detection, we constructed an adaptive feature fusion module with pruning operations, adaptively adjusting the fusion ratios between different feature layers and removing channels to enhance multi-scale feature fusion and reduce the computational overhead.
- (3)
To reduce the redundancy of CNN features in the support set feature extraction process, we performed spatial and channel reconstruction in the feature extraction process of the re-weighting module to reduce spatial redundancy and channel redundancy.
- (4)
We constructed a real wildfire image dataset and conducted extensive testing on the embedded device NUC13ANK i7000 in the inspection drone, thereby verifying the accuracy and detection speed of the method.
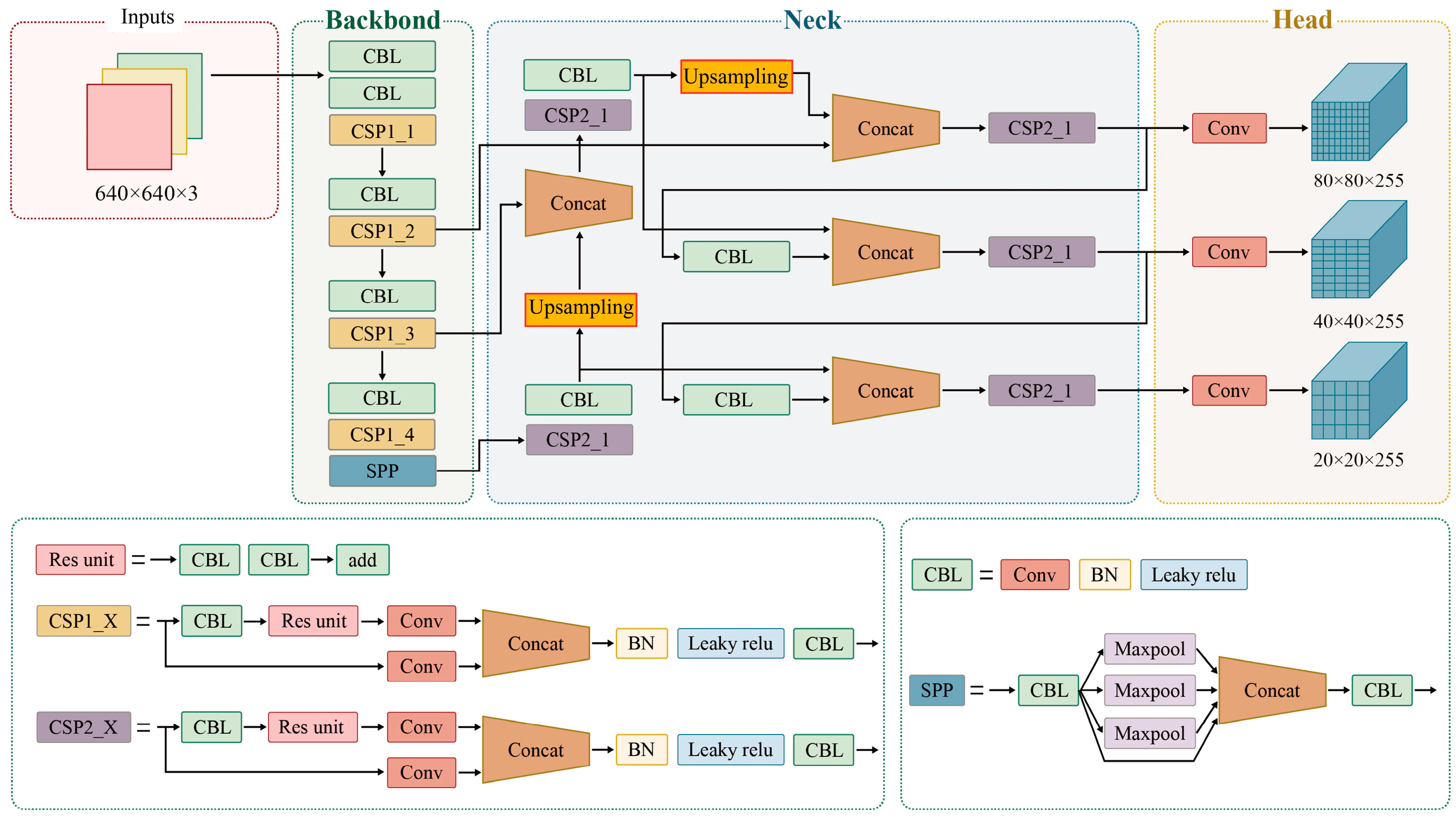
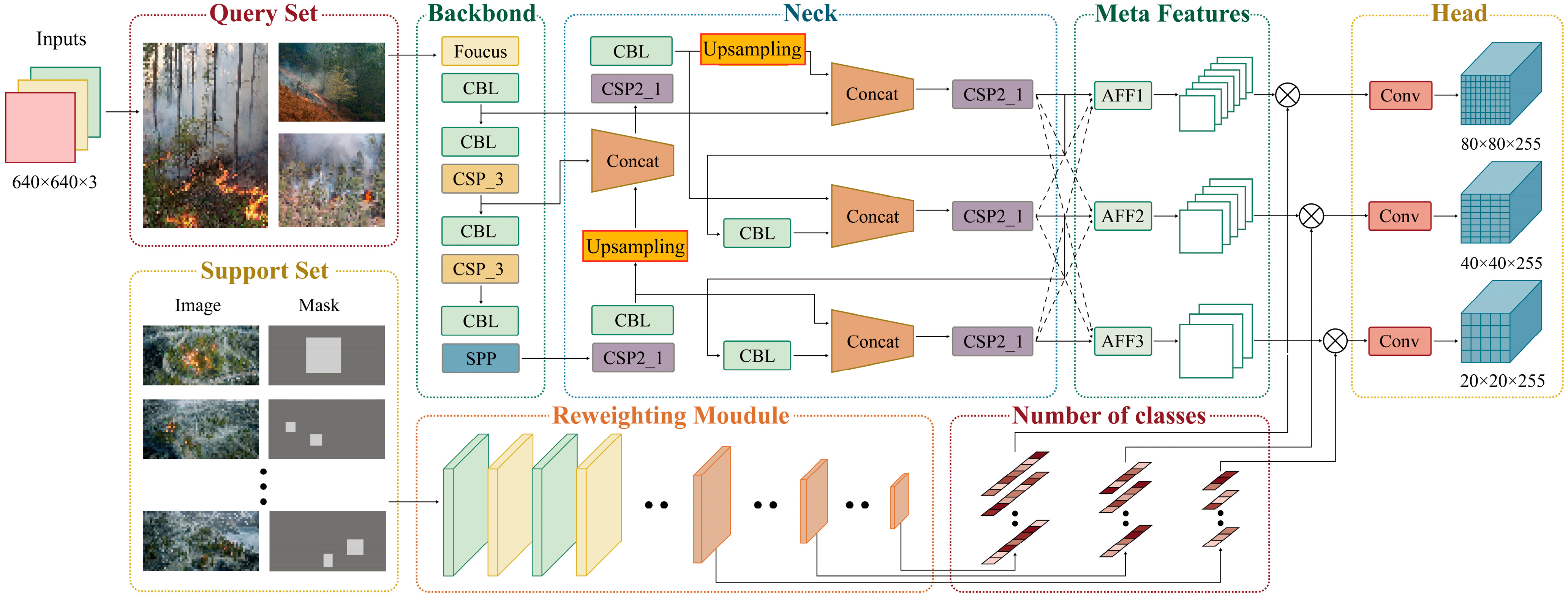
3. The MA-YOLO Network
Because of the small number of real image samples of hill fires, it is a challenging task to accurately recognize hill fire targets in small-sample scenarios. In this study, a meta-learning-based hill fire target detection network (MA-YOLO) is proposed for small-sample hill fire detection. The modeled network can perform target detection on images from the invisible class with only a small number of annotated samples. Two types of data are available for training, i.e., visible and invisible classes. For hill fire detection with small samples, a large number of annotated samples constructed from the virtual dataset are defined as the visible class, while real hill fire samples with only a small number of markers are defined as the invisible class. In this section, the network structure of MA-YOLO is described in detail. As shown in
Figure 2, the network is based on a modification of the YOLOv11 algorithm, and the backbone of the model consists of three parts: (1) meta-feature extractor: extracts meta-features of the hill fire target from the input query image; (2) re-weighting module: learns the supportive information to be embedded into the re-weighting vector and adjusts the contribution of each meta-feature of the query image accordingly; (3) detection head: hill fire target detection based on final characterization.
3.1. Meta-Feature Extractor
The meta-feature extractor network is designed to extract robust feature representations from the input query images. Due to the varying scales of wildfire targets in wildfire images, a multi-scale feature extraction network is used to better extract wildfire features for wildfire detection. The feature extractor proposed in this study is designed based on YOLOv11. For each input query image, the meta-feature extraction module generates meta-features at three different scales. Let
Iq ∈ Q (
q ∈ {1, 2, …,
Nq}) be one of the input query images; the meta-features generated by the meta-feature extractor can be represented by the following formula:
where
represents the feature encoding network with parameters
θ;
i represents the scale level,
i ∈ {1, 2, 3}; and
hi,
wi, and
mi represent the size of the feature map at scale
i. This study addresses the problem of poor small-object detection performance in the original YOLOv11 by removing the P5 (20 × 20) feature level and adding the P2 (160 × 160) feature level to improve the network’s detection ability for small wildfire targets. The final features extracted at the three scales are P2 (160 × 160), P3 (80 × 80), and P4 (40 × 40). The adaptive feature fusion module (AFF) [
28], as shown in
Figure 3a, is then used to adaptively fuse the features at the three scales, and channel pruning is introduced in the AFF module to reduce redundant features and improve the computational efficiency.
For example, in AFF-3, two rounds of upsampling are required to ensure that the results of P2 and P3 are the same size as those of P4. First, P2 and P3 need to be compressed to the same number of channels as P4 through 1 × 1 convolution, and then upsampling is performed by a factor of four and two to obtain the same dimensions as P4, resulting in corresponding feature maps
. After this, for each feature map
, the importance measure of each channel
j is calculated as follows:
The importance score
reflects the contribution of a specific channel to the overall detection performance. A larger value of
indicates that the corresponding channel plays a more significant role in identifying key features necessary for accurate object detection. Specifically, this importance is measured based on the activation levels across different channels; channels with higher activation levels are considered more important because they capture more relevant information about the objects being detected. This scoring mechanism helps in dynamically adjusting the fusion weights, thereby enhancing the model’s ability to focus on critical features while filtering out less relevant information [
29]. By defining importance in terms of the contribution to detection accuracy, we ensure that the model can prioritize essential features, improving its robustness and effectiveness, especially in challenging scenarios such as detecting small-scale wildfires or handling complex backgrounds.
Based on the results of the L1 norm, a pruning threshold
θ is set, and the channel index set
is selected. The larger the value of
, the greater the contribution of channel
j to the feature map, and the “more important” it is. The channels with
are selected, and their channel index sets
are chosen.
The feature map
is reconstructed based on the set
of channel indices:
Finally, the sum is taken;
,
, and
are the features of P2, P3, and P4, respectively. Then, the three features are multiplied by their respective parameters and summed to obtain the fused features after AFF-3. This process is shown in Equation (5):
where
represents the new feature map obtained through AFF. These parameters are the weight parameter of the three feature layers, and, through the Softmax function, it satisfies Equation (6):
and
are calculated via the following formulas:
where [·] represents the channel-wise concatenation along the cascade.
W1 and
W2 represent pointwise convolutions. BN stands for batch normalization [
30]. SiLU(·) and tanh(·) represent the Sigmoid linear unit (SiLU) and tanh activation functions, respectively.
The AFF module is integrated into the wildfire detection model in this study. It can improve the multi-scale feature fusion of wildfire targets and fully utilize the fine-grained features at the lower level and the semantic information of the high-level features. This enhances the model’s ability to represent wildfire target features in complex forest environments, suppresses the interference of invalid features in complex forest environments during wildfire detection, and improves the accuracy of MA-YOLO in detecting wildfire targets in complex forest environments.
3.2. Feature Re-Weighting Module
The re-weighting module M is designed as a lightweight CNN to improve the efficiency and simplify its learning. The feature re-weighting module extracts meta-knowledge from support images and guides wildfire detection in query images. The re-weighting module maps each support image to a set of re-weighting vectors, tailored to different detection heads. These re-weighting vectors are used to adjust the contributions of the meta-features, highlighting those that are meaningful for new object detection.
The support samples are from virtual wildfire images. Our feature re-weighting module receives input from virtual wildfire images and their annotations [
31]. The feature re-weighting module first uses a feature encoding network Gφ (with parameters φ) to extract features for each object, obtaining a representation vector of wildfire features, as shown in the following formula:
where
represent K support images and annotations corresponding to their bounding boxes, respectively.
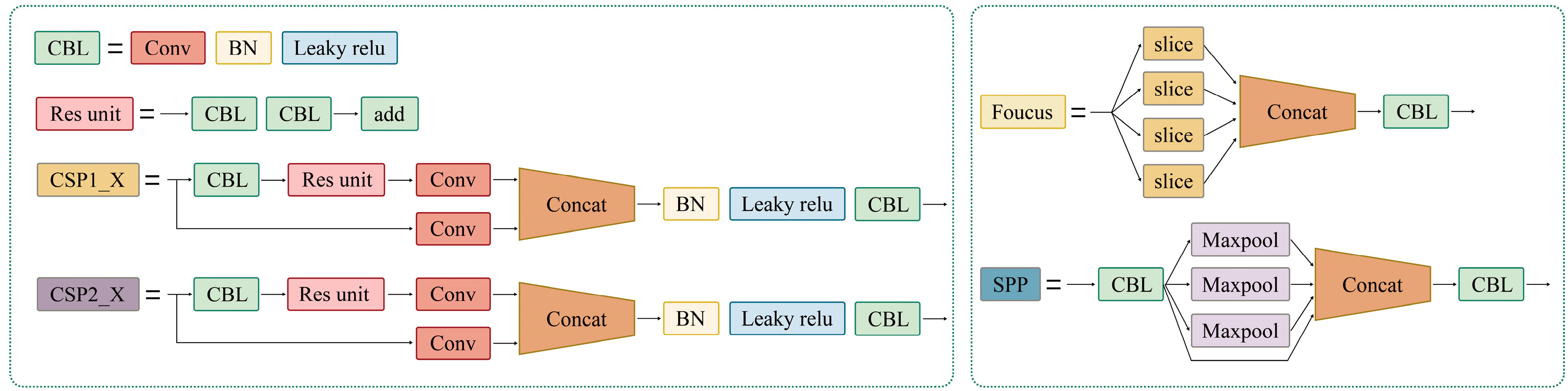
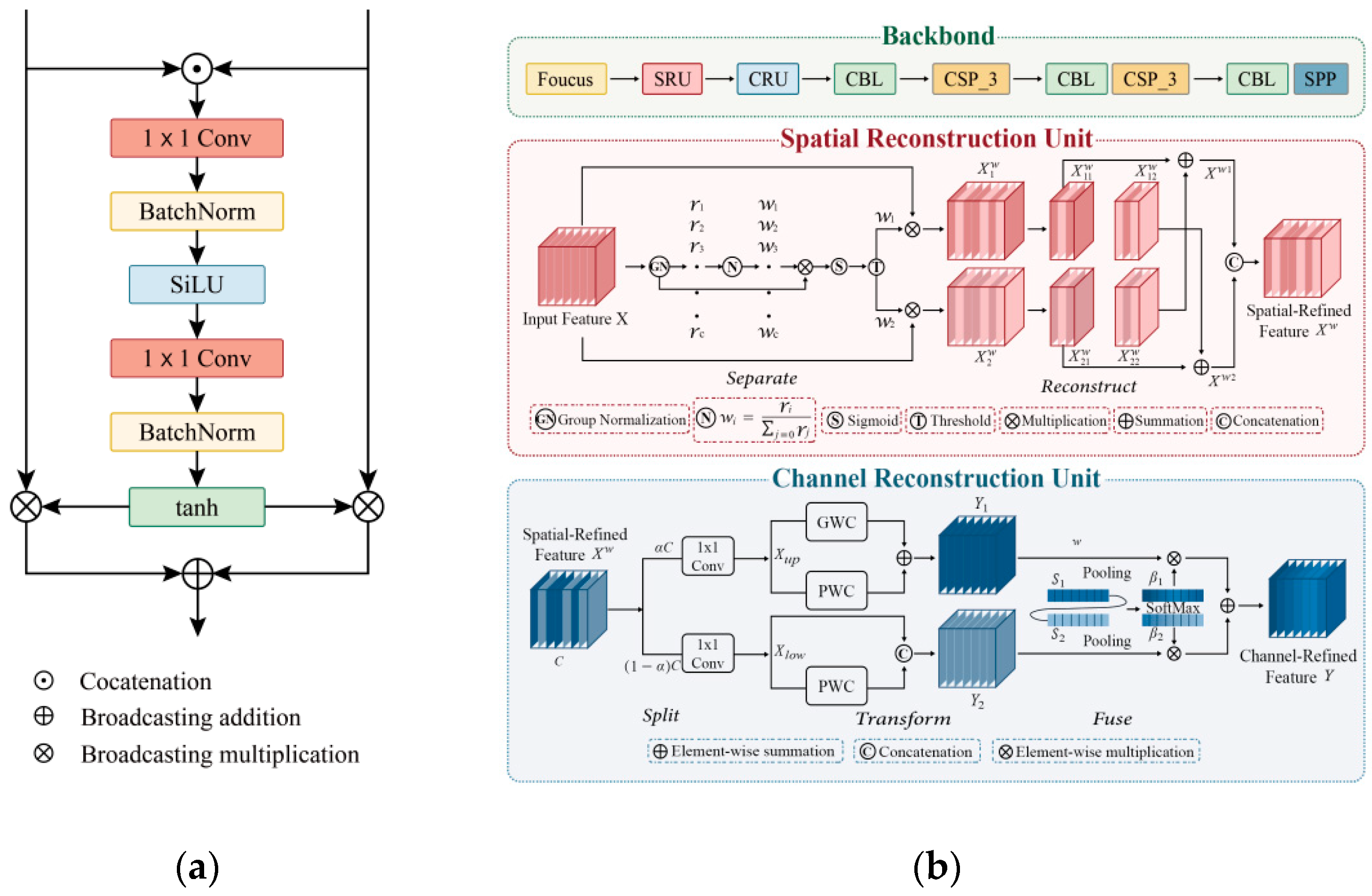
The re-weighting vectors V are used to re-weight the meta-features. The feature encoding module Gφ is shown in
Figure 3b, and it is improved from YOLOv11’s backbone. Between the first and second convolutional modules, a spatial and channel reconstruction module (SCConv) [
32] is added, which improves the performance of the re-weighting module’s feature extraction while reducing redundant features. The SCConv module utilizes two components: a spatial reconstruction unit (SRU) and a channel reconstruction unit (CRU). The SRU suppresses spatial redundancy through a separation–reconstruction method. The CRU reduces channel redundancy through a split–transform–fuse strategy. The SCConv module reduces the redundancy of features, speeds up the feature extraction of the re-weighting module, and improves the accuracy of the extraction of wildfire features. Finally, vectors with the same scale as the meta-features are generated.
After obtaining the re-weighting vector
, the generated meta-features
are multiplied by a 1 × 1 convolution implemented per channel, as the re-weighted vector
of the convolution kernel:
After channel multiplication, three sets of re-weighted features can be obtained, with each set corresponding to a scale. In each group, the feature re-weighting module produces the corresponding re-weighted feature vector. Finally, the features at the three scales are combined and used by the detection head to obtain the corresponding results of target recognition.
4. Experiment and Discussion
This study designed and implemented a drone-based wildfire inspection platform to verify the accuracy and effectiveness of MA-YOLOv11 in forest fire detection. As shown in
Figure 4, the drone platform is equipped with an embedded device, NUC13ANK i7000 from Intel Corporation (Santa Clara, CA, USA), Intel RealSense from Intel Corporation (Santa Clara, CA, USA), and Pixhawk6C flight control from Holybro (Hong Kong, China). Among them, the NUC13ANK i7000 is especially suitable for real-time image processing and complex algorithm execution due to its excellent computational performance and efficient energy management. The subsequent test experiments were all implemented on the NUC13ANK i7000 platform. This section describes in detail the experimental environment and settings, evaluation indices, performance analysis methods, effect verification process, comparative analysis between different models, ablation study, and comparison of the visualization results.
4.1. Dataset
The real wildfire dataset was derived from images of wildfires from Baidu and Google; images of wildfires collected by State Grid; and a forest fire dataset based on aerial images from FLAME [
33], which is provided by universities such as Northern Arizona University.
The virtual dataset is rendered by Unreal Engine. Unreal Engine can simulate and render realistic wildfire scenes and their characteristics, such as the size, shape, and color of the flames, the concentration and diffusion of smoke, and their interactions with the environment (such as mountains, trees, and weather). The wildfire images generated by Unreal Engine not only greatly enhance the scale of the training set but also cover various possible wildfire situations, satisfying the diversity requirement of meta-learning.
The model is trained on the dataset from Unreal Engine and then applied to detect real wildfire targets. The dataset from Unreal Engine consists of 1800 wildfire images in 6 different scenes [
34]. There are 150 images similar to wildfires (sunset, red light, etc.). Although the virtual dataset has obvious differences from real wildfire images, the large number of virtual wildfires results in a dataset that provides sufficient support for the model to ensure its performance. A total of 1830 images are used as the support set.
4.2. Experimental Setup
The hardware and software configurations of the experimentally deployed platform are shown in
Table 1. These were used to validate the accuracy and effectiveness of the improved YOLOv11 model in forest fire detection. The training phase of the platform was conducted on a PC equipped with a GeForce RTX 4070 graphics card and running the Windows 10 operating system. The Python 3.7 and PyTorch 1.8.1 deep learning frameworks were used for modeling and training in the training environment. After the training was completed, the weights of the model were deployed in the NUC13ANK i7000, an embedded device in the inspection UAV, for testing. With this platform, we were able to efficiently perform the real-time detection and prediction of hill fire images, providing an effective technical solution for forest fire monitoring in real applications. Considering the GPU memory size and time cost, we set the batch size of the model to 64, the momentum to 0.93, and the training process to 600 rounds using the Adam optimizer, with an initial value of 1 × 10
−4 for the learning rate and 0.001 for the weight decay.
4.3. Evaluation Metrics
In this experiment, multiple object detection networks were compared, and different evaluation metrics were used to assess the performance of the networks. The metrics used included the precision (P), mean average precision mAP95 (%), and mAP50 (%), which were used to evaluate the performance of the model in the small-sample wildfire detection task. P reflects the model’s ability to classify samples, while AP reflects the overall performance of the model in detecting and classifying targets. mAP represents the average value of the average precision of all categories. mAP95 (%) and mAP50 (%), respectively, represent the average mAP obtained by evaluating forest target detection models at an IoU threshold of 0.5 and 0.95. The calculation formulas are as follows (Formulas (10)–(13)):
4.4. Ablation Study
To verify the impact of each improvement on the network’s performance, we used YOLOv11 as a baseline and gradually added each improvement module to the model for an ablation study. The models with the best performance in the experiment were then used to validate the test set. The experimental results are shown in
Table 2.
It can be seen from
Table 2 that the improved MA-YOLO significantly improved the detection accuracy of forest fire targets; in particular, the mAP95 was improved by 9.8% compared to YOLOv11. At the same time, the FPS (test set containing images of different resolutions) slightly decreased, but it still reached 32.45, i.e., MA-YOLO could detect 38.21 forest fire images per second. Real-time monitoring videos usually have 25 to 30 frames per second, so the detection speed of MA-YOLO far exceeds the requirements of real-time detection.
4.5. Comparison Experiment with Different Networks
To further verify the effectiveness of the algorithm proposed in this paper, under the same training configuration and dataset conditions, the proposed network was compared with classic one-stage and two-stage target detection models, such as Faster R-CNN, SSD, YOLOX, and YOLOv11. The visualization results are shown in
Figure 5, which shows that the accuracy of the network proposed in this study in terms of fewer missed detections is higher. Relative to other methods, the number of undetected hill fire targets for MA-YOLO is smaller, and the detection frame is more accurate, which proves the superiority of MA-YOLO. The evaluation metrics used were the mAP95 (%), mAP50 (%), precision, and FPS, enabling a comprehensive comparison of the performance of each network. The detailed comparison results are shown in
Table 3.
As can be seen from
Table 3, compared with mainstream target detection algorithms, the algorithm proposed in this paper has obvious advantages. The model’s detection speed is the fastest among its peers, fully meeting the real-time requirements of the forest fire detection task. In addition, unless otherwise specified, the datasets and processing methods used in this paper were consistent with those used in the comparison experiments to ensure fairness and accuracy.
5. Conclusions
Based on YOLOv11, in this work, we first replaced the feature extraction module with a meta-feature extraction module and adjusted the detection head’s scale to detect smaller forest fire targets. To enhance the model’s ability to learn the target fire features from complex backgrounds, adaptive spatial feature fusion (adaptive feature fusion, AFF) was integrated into the feature extraction process of YOLOv11, improving the model’s ability to fuse features and filtering out unnecessary information, thus reducing interference from complex backgrounds. Subsequently, the re-weighting module was used to learn scale-specific fire feature re-weighting vectors from the support set samples, and we used them to recalibrate the mapping of the meta-features. The experimental results show that MA-YOLO’s accuracy was improved by 9.8% in a small-sample scenario. MA-YOLO misses fewer forest fire targets in different scenarios and is less affected by complex backgrounds. Despite the promising results achieved by MA-YOLO in enhancing wildfire detection, especially in small-sample scenarios, there are several limitations that need to be acknowledged. Firstly, while our model has shown significant improvements in accuracy and robustness against complex backgrounds, its performance heavily relies on the quality and representativeness of the virtual dataset. The synthetic data might not fully capture all of the nuances and variations present in real-world wildfire scenarios, which could limit the generalization ability of the model under diverse conditions.
Looking towards future work, one promising direction is the integration of Internet of Things (IoT) technologies to address wildfire problems more comprehensively. Additionally, further studies should investigate how to effectively combine AI-driven image analysis with IoT sensor data to create a more holistic wildfire monitoring system. This would involve developing algorithms capable of fusing multi-source data and dynamically adjusting their behavior based on the real-time environmental conditions.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}