
Coordinated Volt/VAR Control in Distribution Networks Considering Demand Response via Safe Deep Reinforcement Learning


Abstract
1. Introduction
2. Problem Formulation
2.1. Definition of Volt–VAR Control
2.2. Objective Function
2.3. Constraints
2.3.1. Power Balance Equations
2.3.2. PV System Constraints
2.3.3. SVC Constraints
2.3.4. Interruptible Load Constraints
2.3.5. Voltage Constraints
3. Data-Driven Method
3.1. Constrained Markov Decision Process
3.2. Constrained Soft Actor–Critic Algorithm
3.3. Training Process
| Algorithm 1: Constrained SAC Training Process | |
| 1: | Initialization: Initialize the policy network πθ\pi_\thetaπθ, critic networks Q1,ϕ and Q2,ϕ, constraint network Cψ, the Lagrange multiplier λ, and replay buffer D. |
| 2: | Interaction with the Environment: |
| 3: | For each step: |
| 4: | Observe the current state st, sample an action at∼πθ(at|st), and execute it. |
| 5: | Record the next state st+1, reward rt, cost ct, and store the transition (st, at, rt, ct, st+1) in D. |
| 6: | Parameter Updates: |
| 7: | Update Critic Networks Q1,ϕ and Q2,ϕ, according to (13) |
| 8: | Update Policy Network πθ, according to (15) |
| 9: | Update Constraint Network Cψ, according to (16) |
| 10: | Update Lagrange Multiplier λ, according to (19) |
| 11: | Repeat: |
| 12: | Continue iterating until the policy converges. |
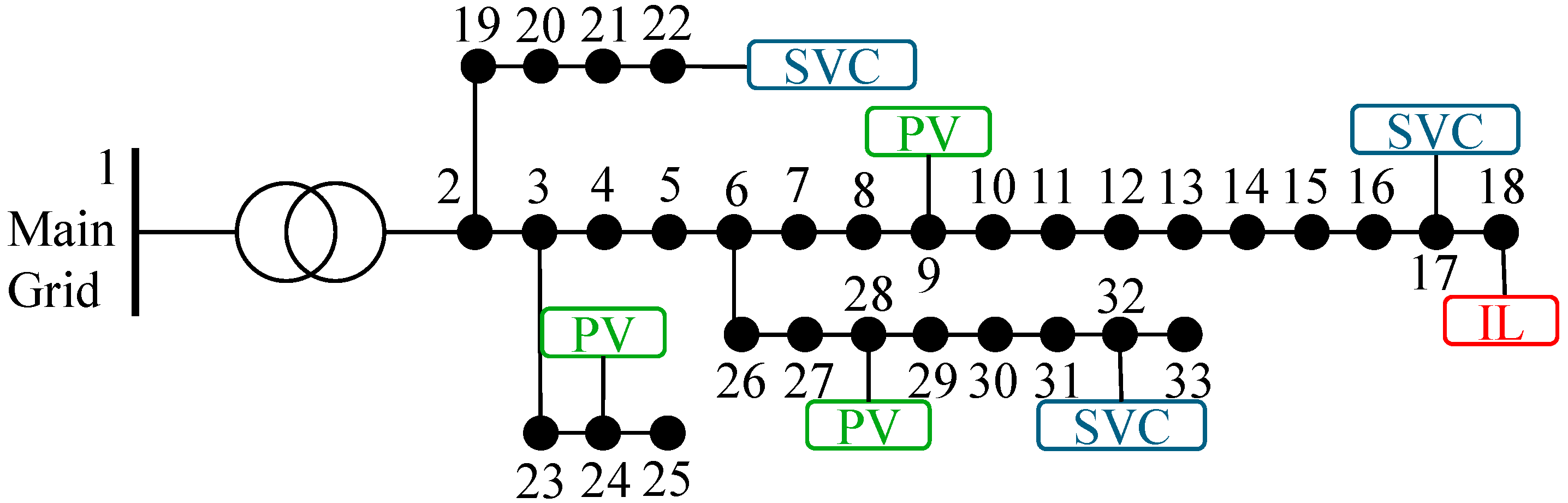
4. Case Study
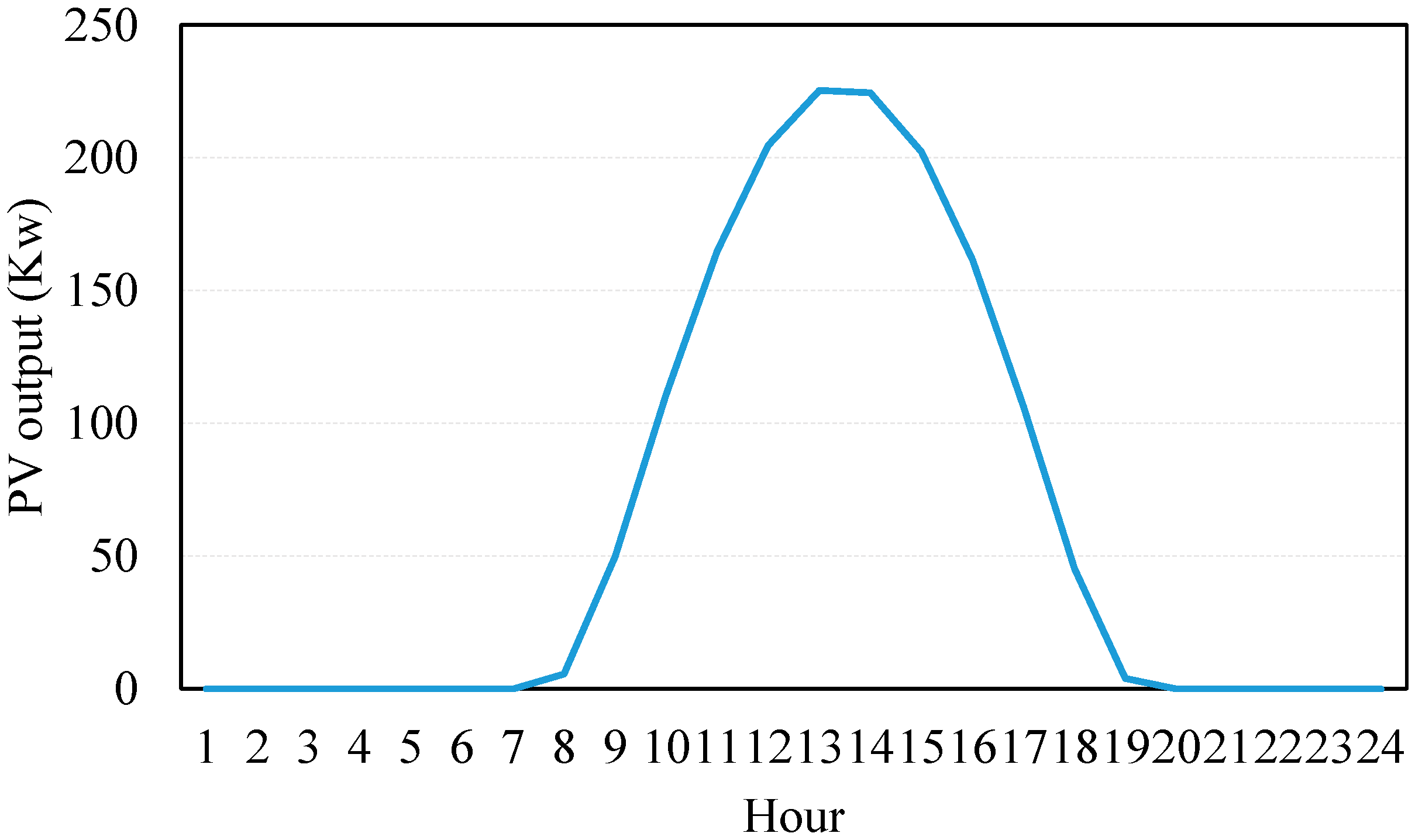
4.1. Offline Training
4.2. Test Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- de Mello, A.P.C.; Pfitscher, L.L.; Bernardon, D.P. Coordinated Volt/VAr control for real-time operation of smart distribution grids. Electr. Power Syst. Res. 2017, 151, 233–242. [Google Scholar] [CrossRef]
- Zhang, Z.; Hui, H.; Song, Y. Response Capacity Allocation of Air Conditioners for Peak-Valley Regulation Considering Interaction with Surrounding Microclimate. IEEE Trans. Smart Grid 2024. [Google Scholar] [CrossRef]
- Jia, X.; Dong, X.; Xu, B.; Qi, F.; Liu, Z.; Ma, Y.; Wang, Y. Static Voltage Stability Assessment Considering Impacts of Ambient Conditions on Overhead Transmission Lines. IEEE Trans. Ind. Appl. 2022, 58, 6981–6989. [Google Scholar] [CrossRef]
- Niknam, T.; Zare, M.; Aghaei, J. Scenario-based multiobjective volt/var control in distribution networks including renewable energy sources. IEEE Trans. Power Deliv. 2012, 27, 2004–2019. [Google Scholar] [CrossRef]
- Li, W.; Zou, Y.; Yang, H.; Fu, X.; Xiang, S.; Li, Z. Two stage stochastic Energy scheduling for multi energy rural microgrids with irrigation systems and biomass fermentation. IEEE Trans. Smart Grid 2024. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, S.; Gu, W.; Lu, S.; Chung, C.Y. Dynamic optimal energy flow of integrated electricity and gas systems in continuous space. Appl. Energy 2024, 375, 124052. [Google Scholar] [CrossRef]
- Samimi, A.; Kazemi, A. Coordinated Volt/Var control in distribution systems with distributed generations based on joint active and reactive powers dispatch. Appl. Sci. 2016, 6, 4. [Google Scholar] [CrossRef]
- Satsangi, S.; Kumbhar, G.B. Effect of load models on scheduling of VVC devices in a distribution network. IET Gener. Transm. Distrib. 2018, 12, 3993–4001. [Google Scholar] [CrossRef]
- Li, Z.; Wu, L.; Xu, Y. Risk-Averse Coordinated Operation of a Multi-Energy Microgrid Considering Voltage/Var Control and Thermal Flow: An Adaptive Stochastic Approach. IEEE Trans. Smart Grid 2021, 12, 3914–3927. [Google Scholar] [CrossRef]
- Gholami, K.; Azizivahed, A.; Arefi, A.; Li, L. Risk-averse Volt-VAr management scheme to coordinate distributed energy resources with demand response program. Int. J. Electr. Power Energy Syst. 2023, 146, 108761. [Google Scholar] [CrossRef]
- Li, P.; Ji, H.; Wang, C.; Zhao, J.; Song, G.; Ding, F.; Wu, J. Coordinated Control Method of Voltage and Reactive Power for Active Distribution Networks Based on Soft Open Point. IEEE Trans. Sustain. Energy 2017, 8, 1430–1442. [Google Scholar] [CrossRef]
- Feng, C.; Shao, L.; Wang, J.; Zhang, Y.; Wen, F. Short-term Load Forecasting of Distribution Transformer Supply Zones Based on Federated Model-Agnostic Meta Learning. IEEE Trans. Power Syst. 2024. [Google Scholar] [CrossRef]
- Huang, H.; Li, Z.; Sampath, L.P.M.I.; Yang, J.; Nguyen, H.D.; Gooi, H.B.; Liang, R.; Gong, D. Blockchain-enabled carbon and energy trading for network-constrained coal mines with uncertainties. IEEE Trans. Sustain. Energy 2023, 14, 1634–1647. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Feng, X. Hierarchical Coordination of Networked-Microgrids Toward Decentralized Operation: A Safe Deep Reinforcement Learning Method. IEEE Trans. Sustain. Energy 2024, 15, 1981–1993. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Wang, Y.; Yao, W.; Mondal, S.; Dasgupta, S.; Gupta, A.K.; Gupta, G.M. A Data-Driven Method for Online Gain Scheduling of Distributed Secondary Controller in Time-Delayed Microgrids. IEEE Trans. Power Syst. 2024, 39, 5036–5049. [Google Scholar] [CrossRef]
- Li, P.; Shen, J.; Wu, Z.; Yin, M.; Dong, Y.; Han, J. Optimal real-time Voltage/Var control for distribution network: Droop-control based multi-agent deep reinforcement learning. Int. J. Electr. Power Energy Syst. 2023, 153, 109370. [Google Scholar] [CrossRef]
- Xia, Y.; Xu, Y.; Wang, Y.; Mondal, S.; Dasgupta, S.; Gupta, A.K.; Gupta, G.M. A Safe Policy Learning-Based Method for Decentralized and Economic Frequency Control in Isolated Networked-Microgrid Systems. IEEE Trans. Sustain. Energy 2022, 13, 1982–1993. [Google Scholar] [CrossRef]
- Wang, W.; Yu, N.; Shi, J.; Gao, Y. Volt-VAR Control in Power Distribution Systems with Deep Reinforcement Learning. In Proceedings of the 2019 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Beijing, China, 21–23 October 2019; pp. 1–7. [Google Scholar]
- Hu, D.; Peng, Y.; Yang, J.; Deng, Q.; Cai, T. Deep Reinforcement Learning Based Coordinated Voltage Control in Smart Distribution Network. In Proceedings of the 2021 International Conference on Power System Technology (POWERCON), Haikou, China, 8–9 December 2021; pp. 1030–1034. [Google Scholar]
- Hossain, R.; Gautam, M.; Thapa, J.; Livani, H.; Benidris, M. Deep reinforcement learning assisted co-optimization of Volt-VAR grid service in distribution networks. Sustain. Energy Grids Netw. 2023, 35, 101086. [Google Scholar] [CrossRef]
- Gao, Y.; Yu, N. Model-augmented safe reinforcement learning for Volt-VAR control in power distribution networks. Appl. Energy 2022, 313, 118762. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, P.; Yu, L.; Li, N.; Qiu, J. Decoupled Volt/var Control with Safe Reinforcement Learning based on Approximate Bayesian Inference. IEEE Trans. Sustain. Energy 2024. [Google Scholar] [CrossRef]
- Liu, D.; Zeng, P.; Cui, S.; Song, C. Deep reinforcement learning for charging scheduling of electric vehicles considering distribution network voltage stability. Sensors 2023, 23, 1618. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Structure of actor network | 72 × 512 × 128 × 1 |
| Structure of critic network | 79 × 512×128 × 1 |
| Structure of constraint network | 79 × 512 × 128 × 1 |
| Actor learning rate | 1 × 10−4 |
| Critic learning rate | 1× 10−5 |
| Optimizer | Adam |
| Size of minibatch | 128 |
| Entropy weight | 0.12 |
| Method | Number of Voltage Violations | Standard Deviation of Voltage (p.u.) |
|---|---|---|
| SAC | 2 | 0.0305 |
| SAC with penalty | 2 | 0.0023 |
| The proposed method | 0 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hua, D.; Peng, F.; Liu, S.; Lin, Q.; Fan, J.; Li, Q. Coordinated Volt/VAR Control in Distribution Networks Considering Demand Response via Safe Deep Reinforcement Learning. Energies 2025, 18, 333. https://doi.org/10.3390/en18020333
Hua D, Peng F, Liu S, Lin Q, Fan J, Li Q. Coordinated Volt/VAR Control in Distribution Networks Considering Demand Response via Safe Deep Reinforcement Learning. Energies. 2025; 18(2):333. https://doi.org/10.3390/en18020333
Chicago/Turabian StyleHua, Dong, Fei Peng, Suisheng Liu, Qinglin Lin, Jiahui Fan, and Qian Li. 2025. "Coordinated Volt/VAR Control in Distribution Networks Considering Demand Response via Safe Deep Reinforcement Learning" Energies 18, no. 2: 333. https://doi.org/10.3390/en18020333
APA StyleHua, D., Peng, F., Liu, S., Lin, Q., Fan, J., & Li, Q. (2025). Coordinated Volt/VAR Control in Distribution Networks Considering Demand Response via Safe Deep Reinforcement Learning. Energies, 18(2), 333. https://doi.org/10.3390/en18020333