
A Time Series Forecasting Approach Based on Meta-Learning for Petroleum Production under Few-Shot Samples

Abstract
1. Introduction
2. Proposed Methodology
2.1. Meta-Learning
2.2. Basic Forecasting Models
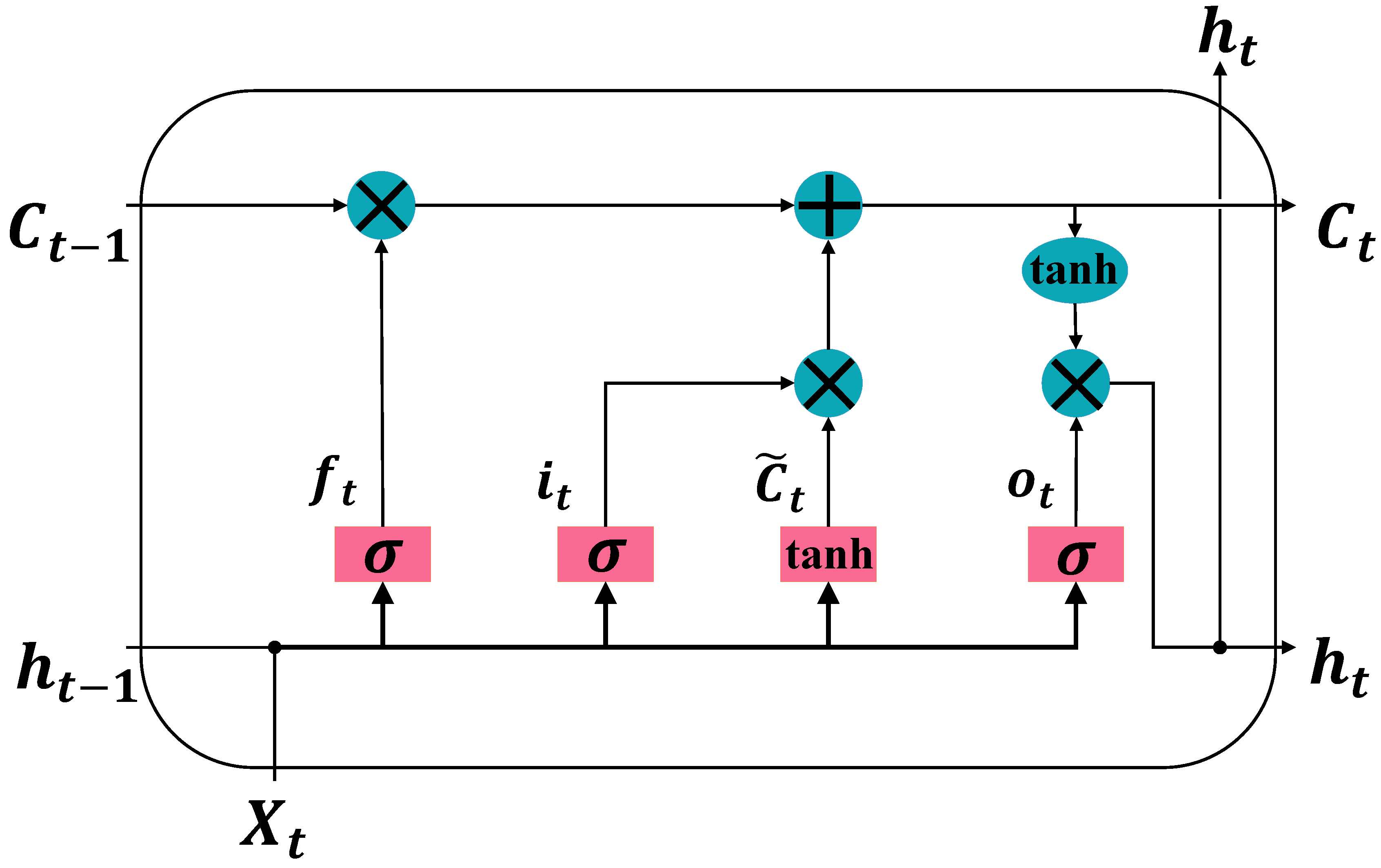
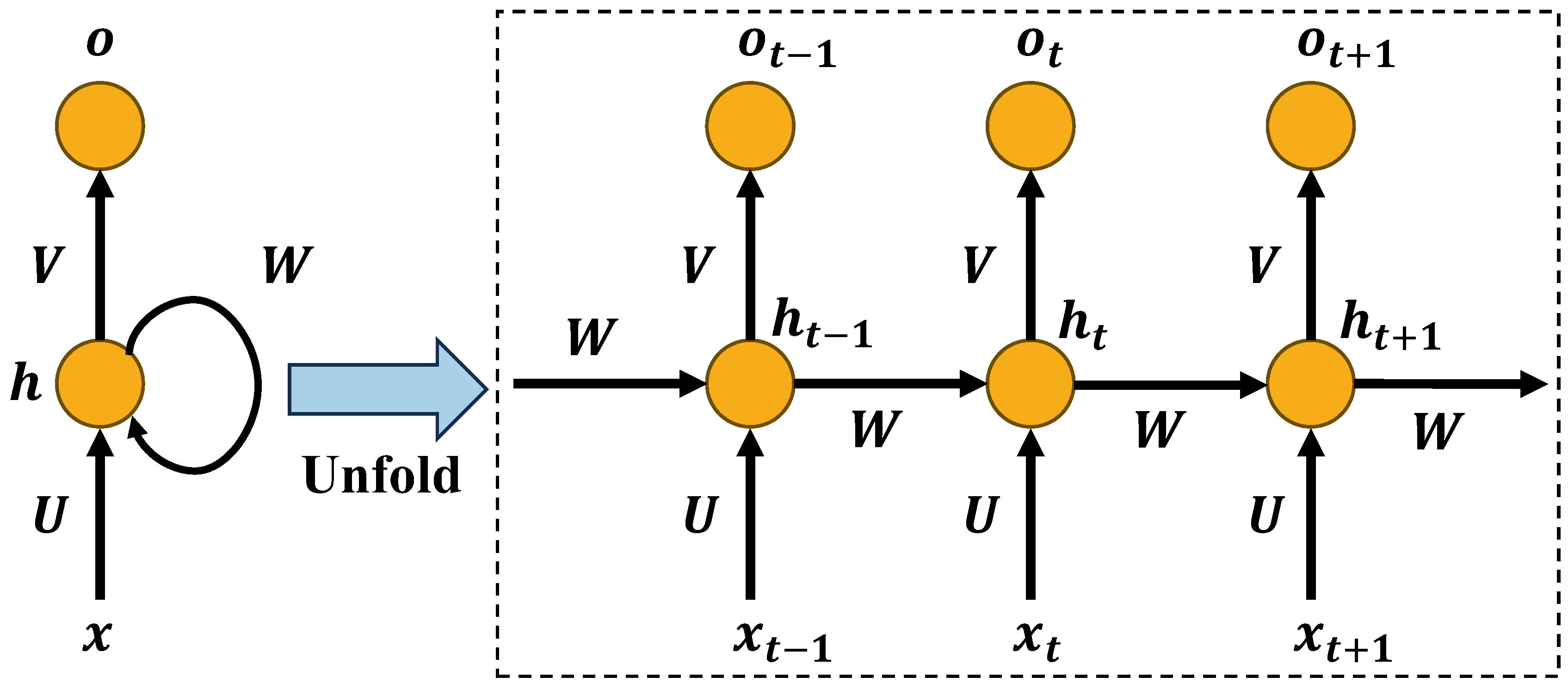
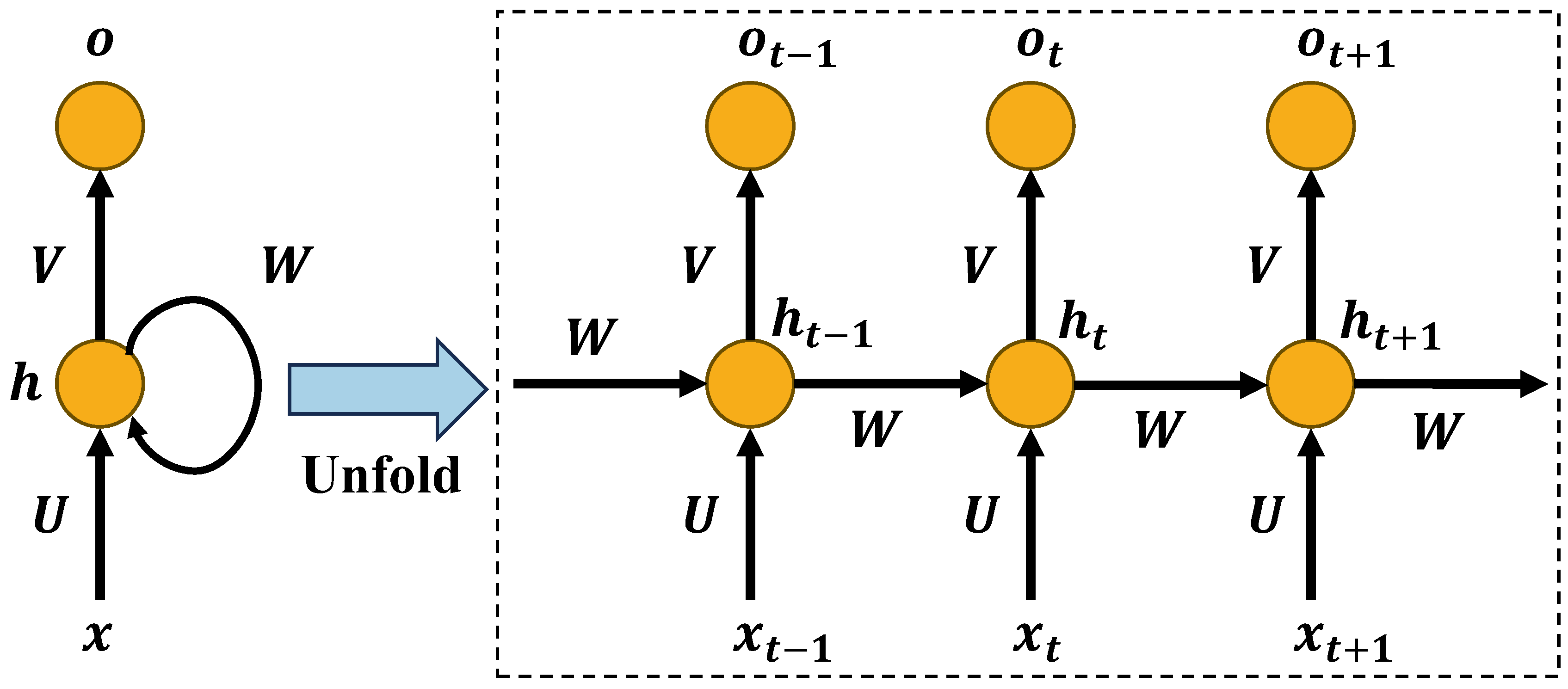
2.2.1. LSTM
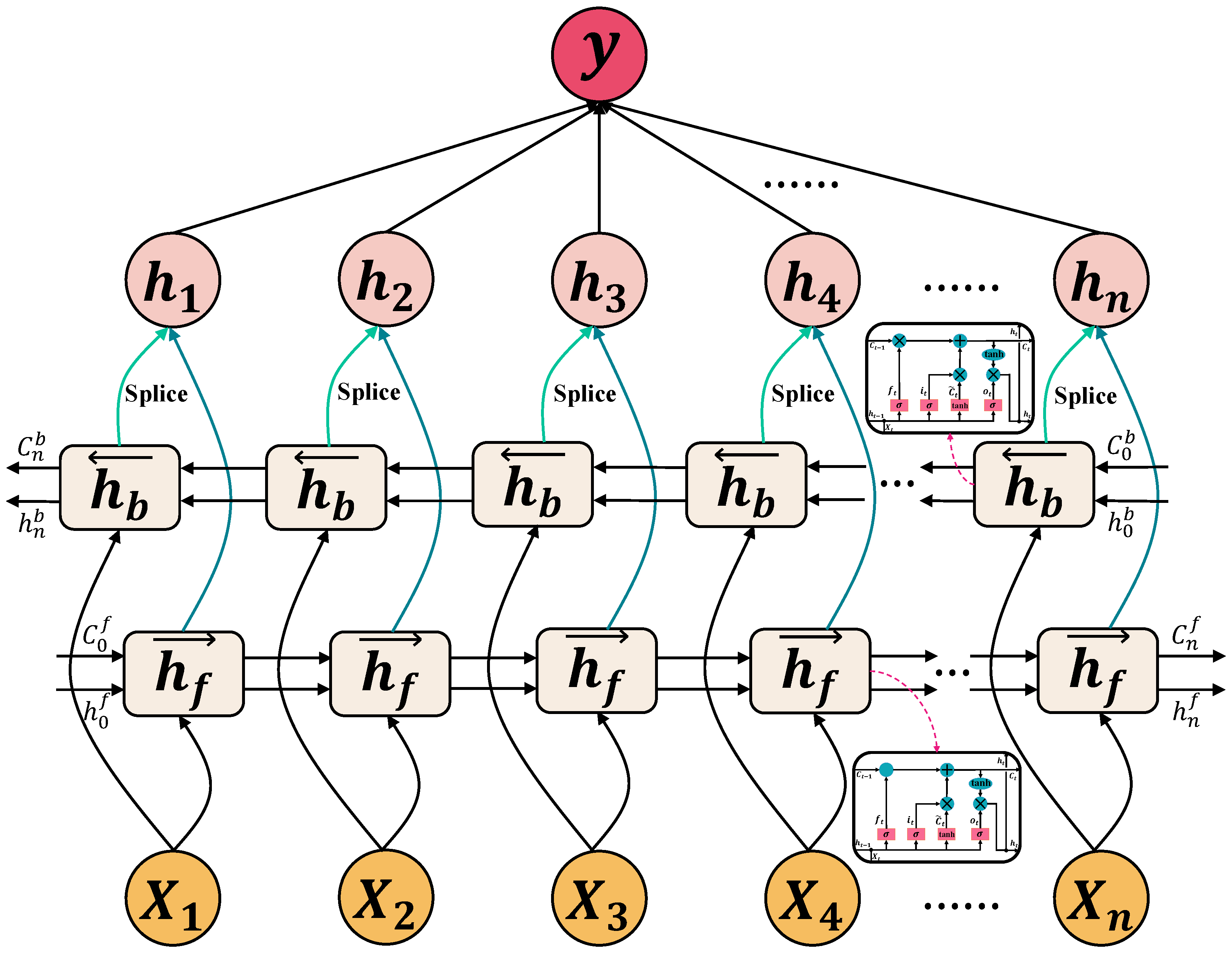
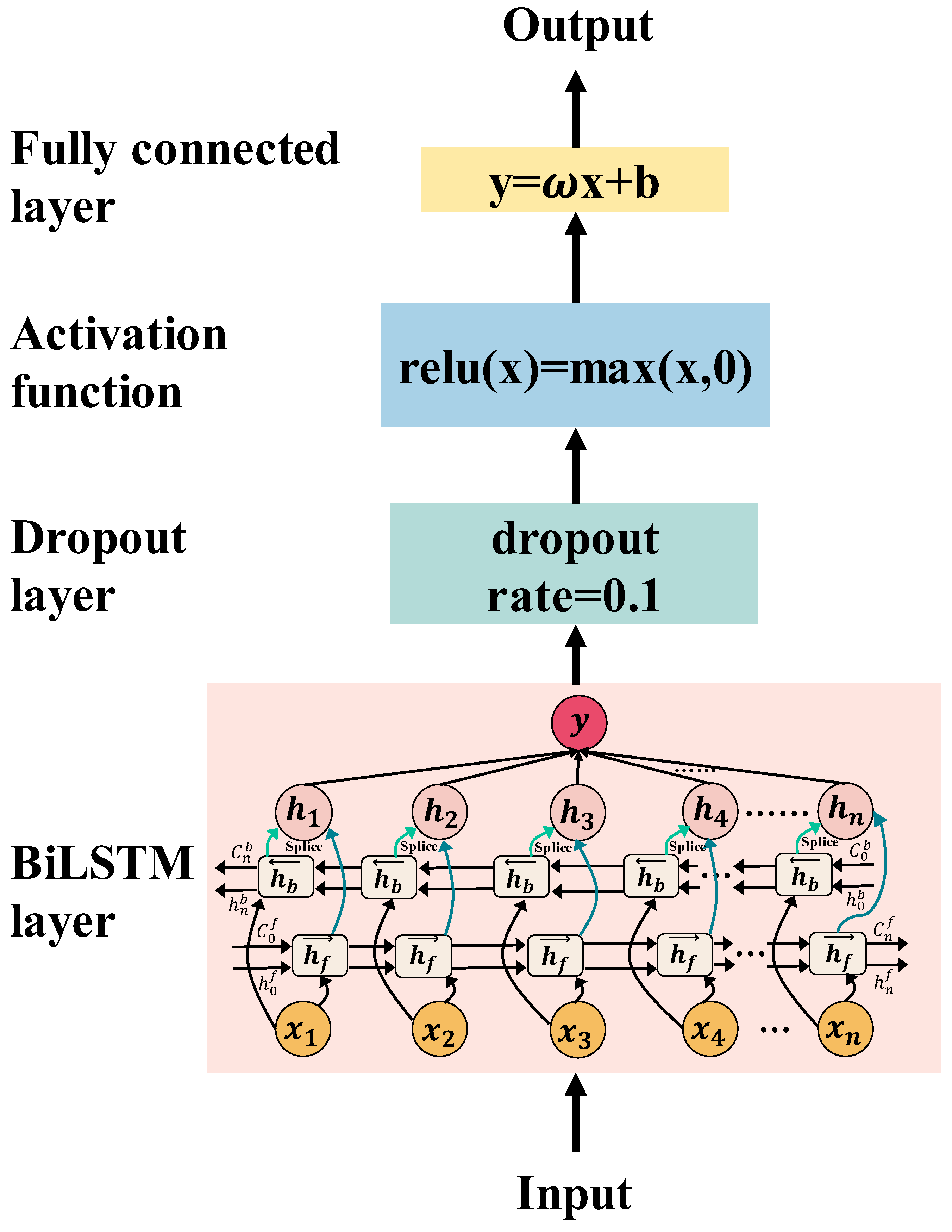
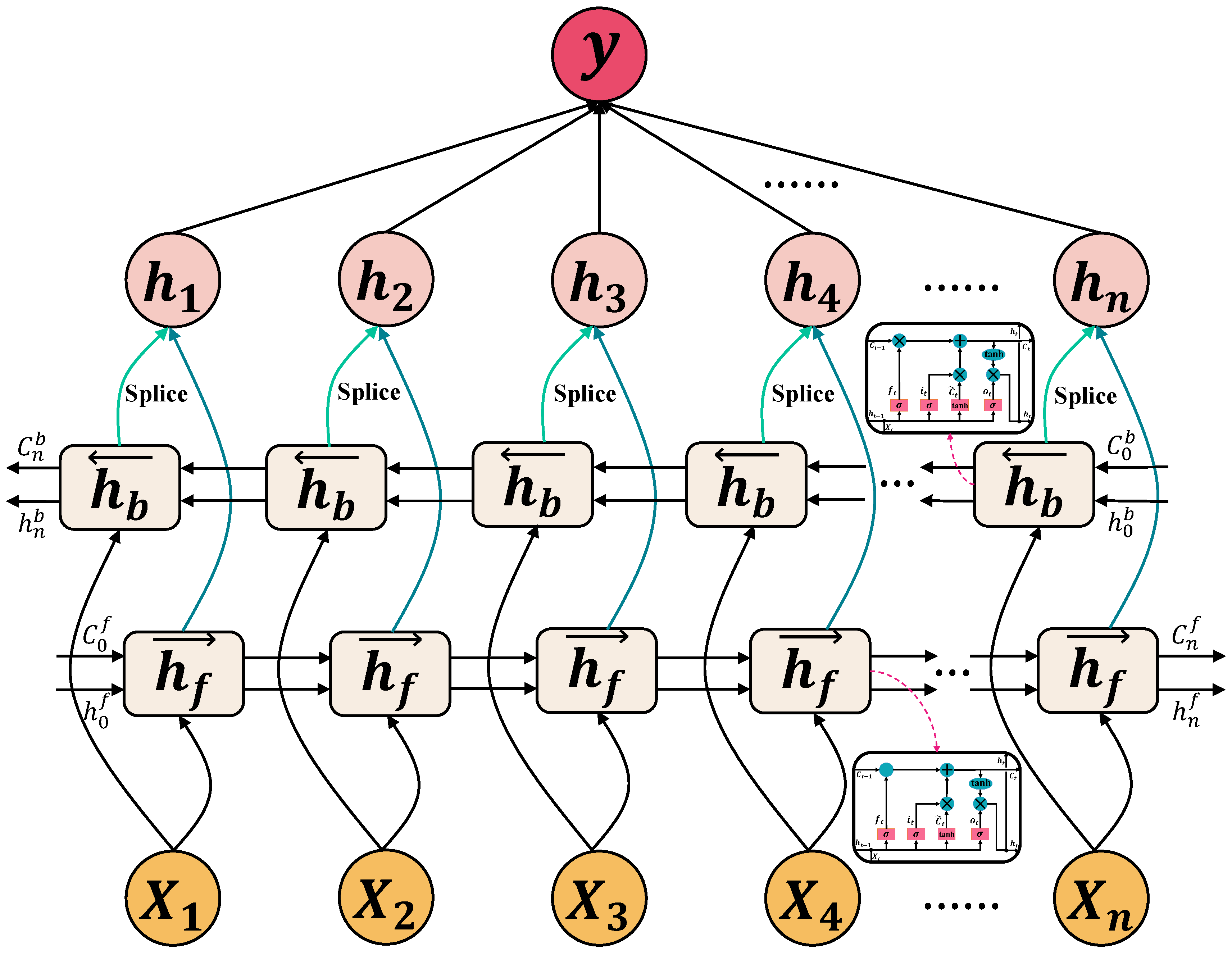
2.2.2. Bidirectional LSTM
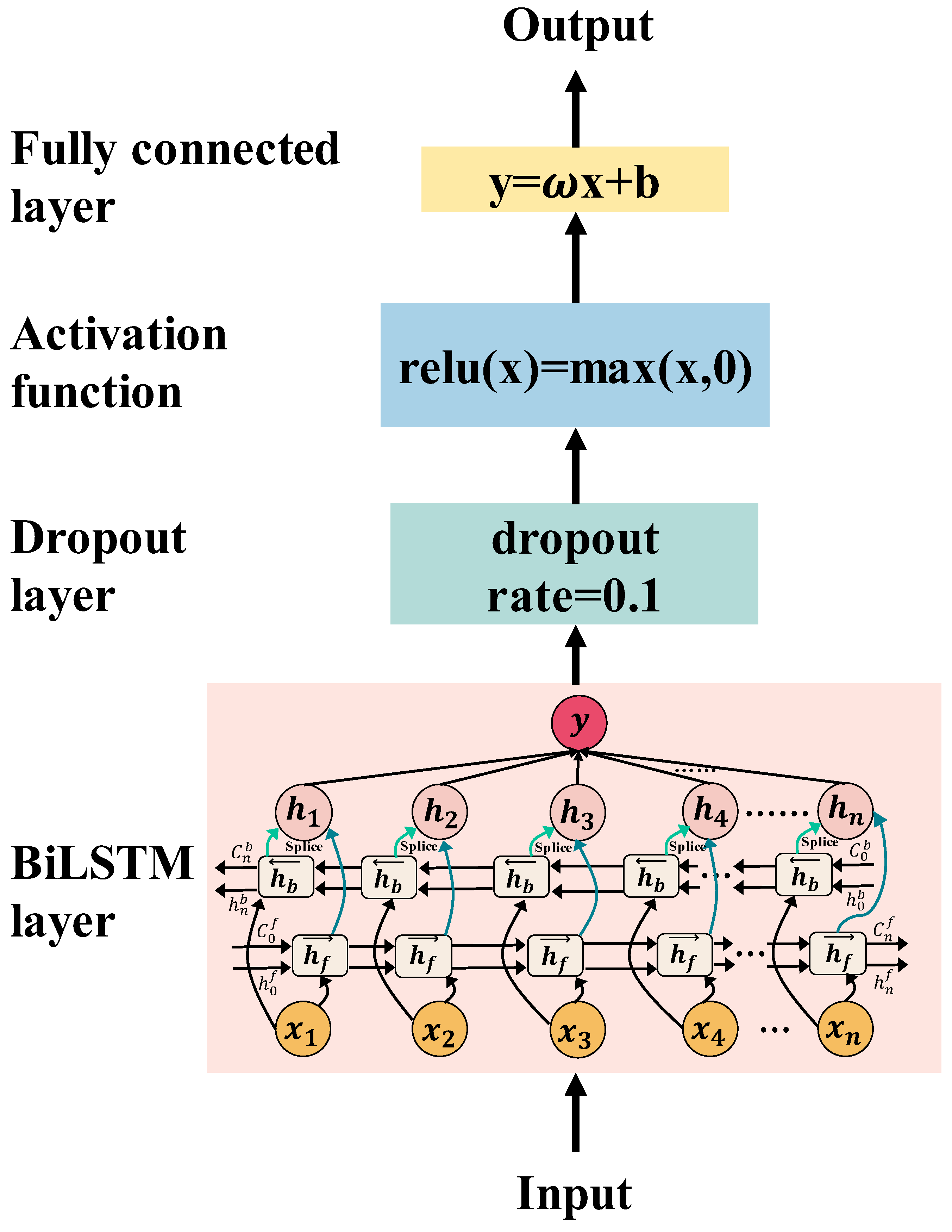
2.3. Proposed Model
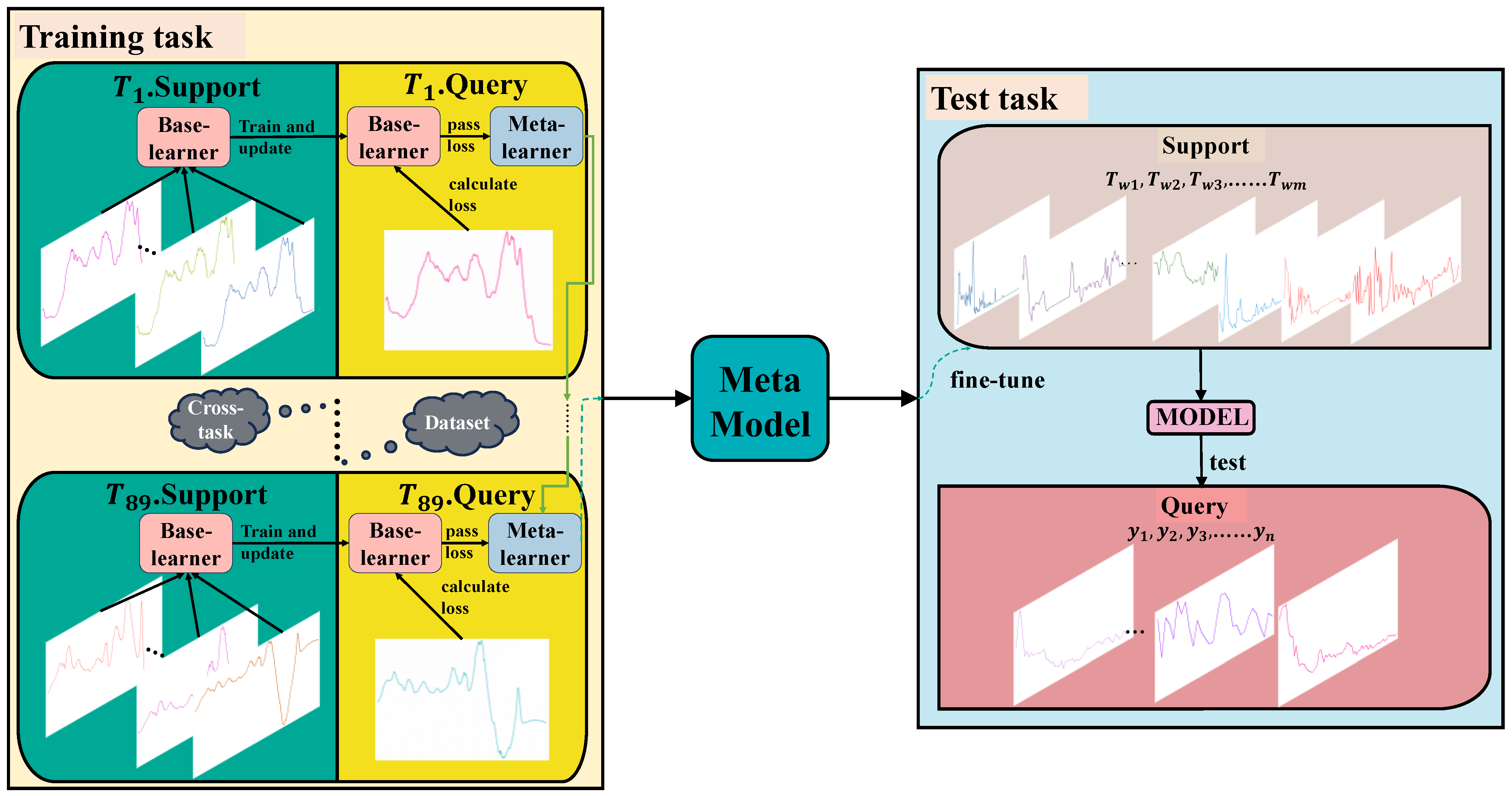
2.3.1. Framework Overview
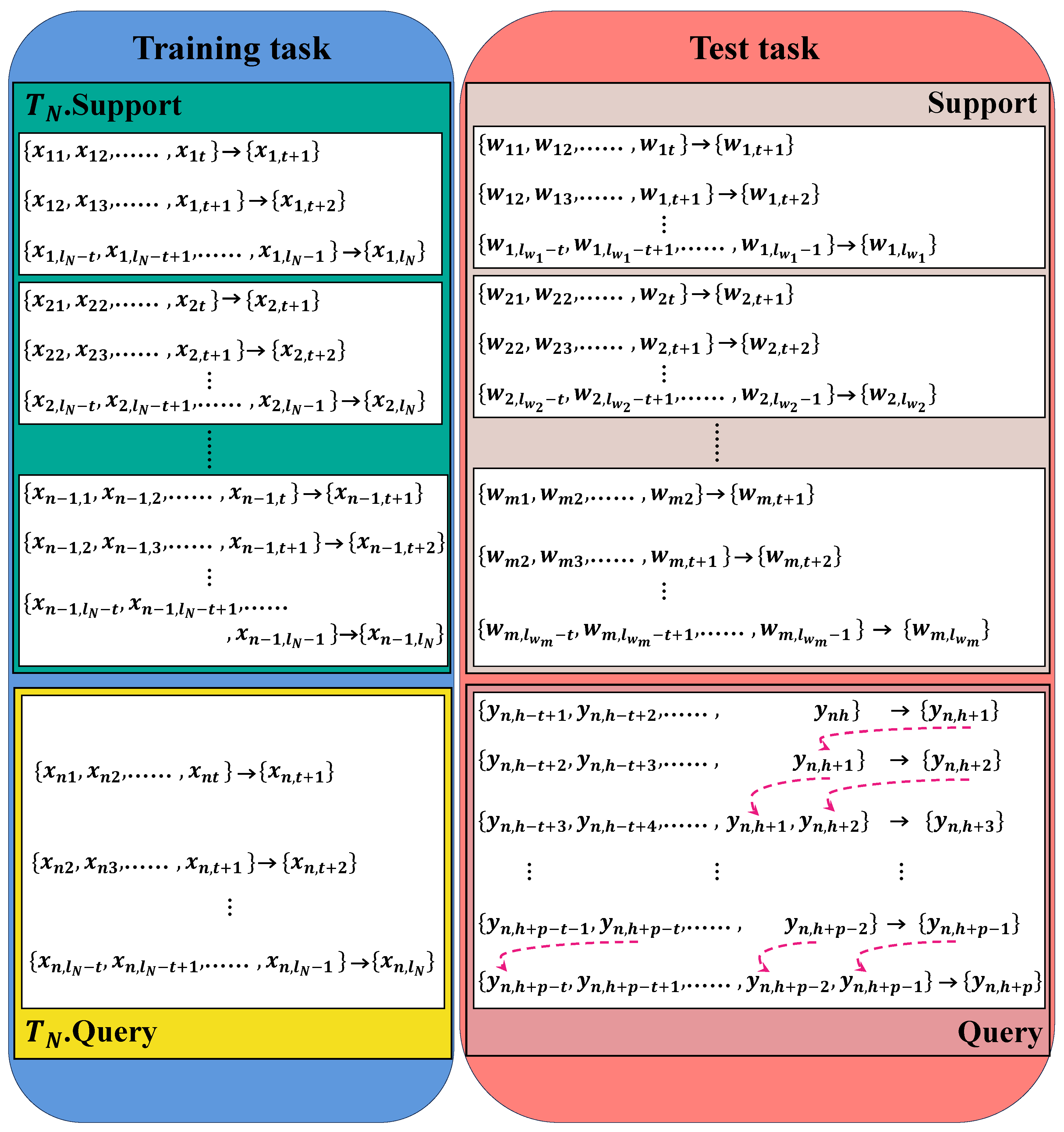
2.3.2. Support Set and Query Set
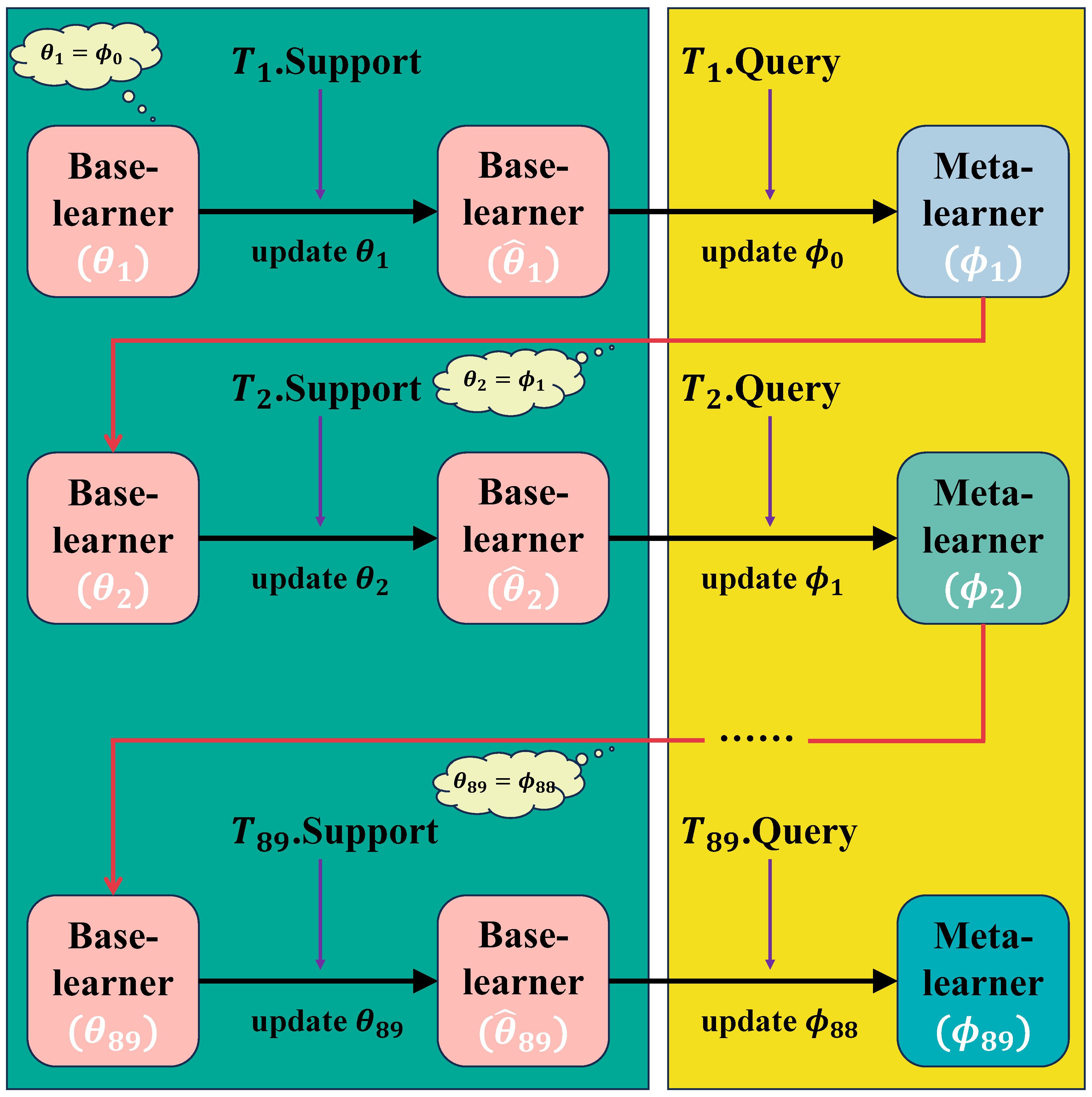
2.3.3. Base-Learner, Meta-Learner, and Training of Learners
2.3.4. Test
2.4. Reference Models
3. Data Preprocessing
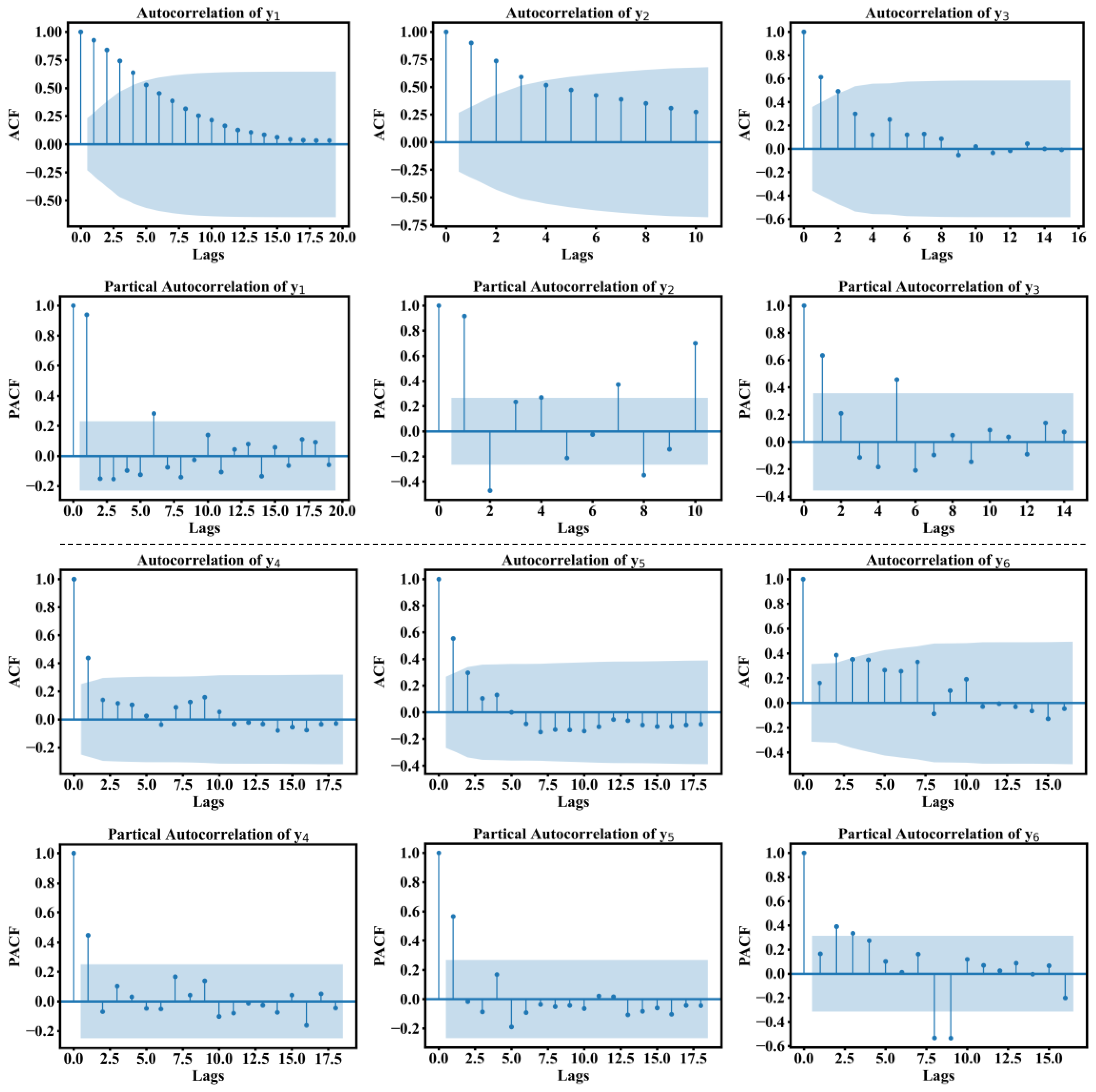
3.1. Data
3.2. Experimental Setting
3.3. Evaluation Indicators
4. Results and Discussion
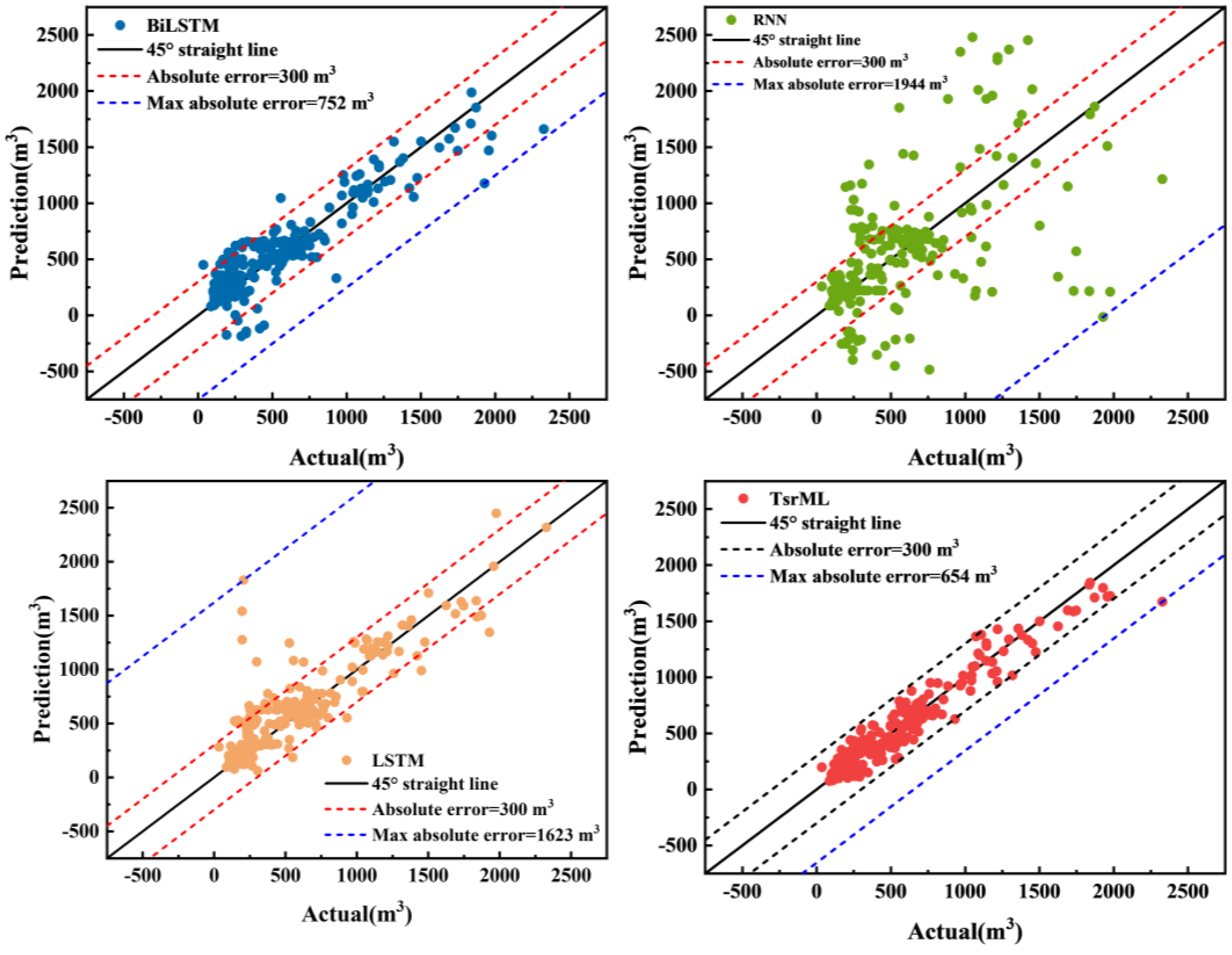
4.1. Results of Comparison
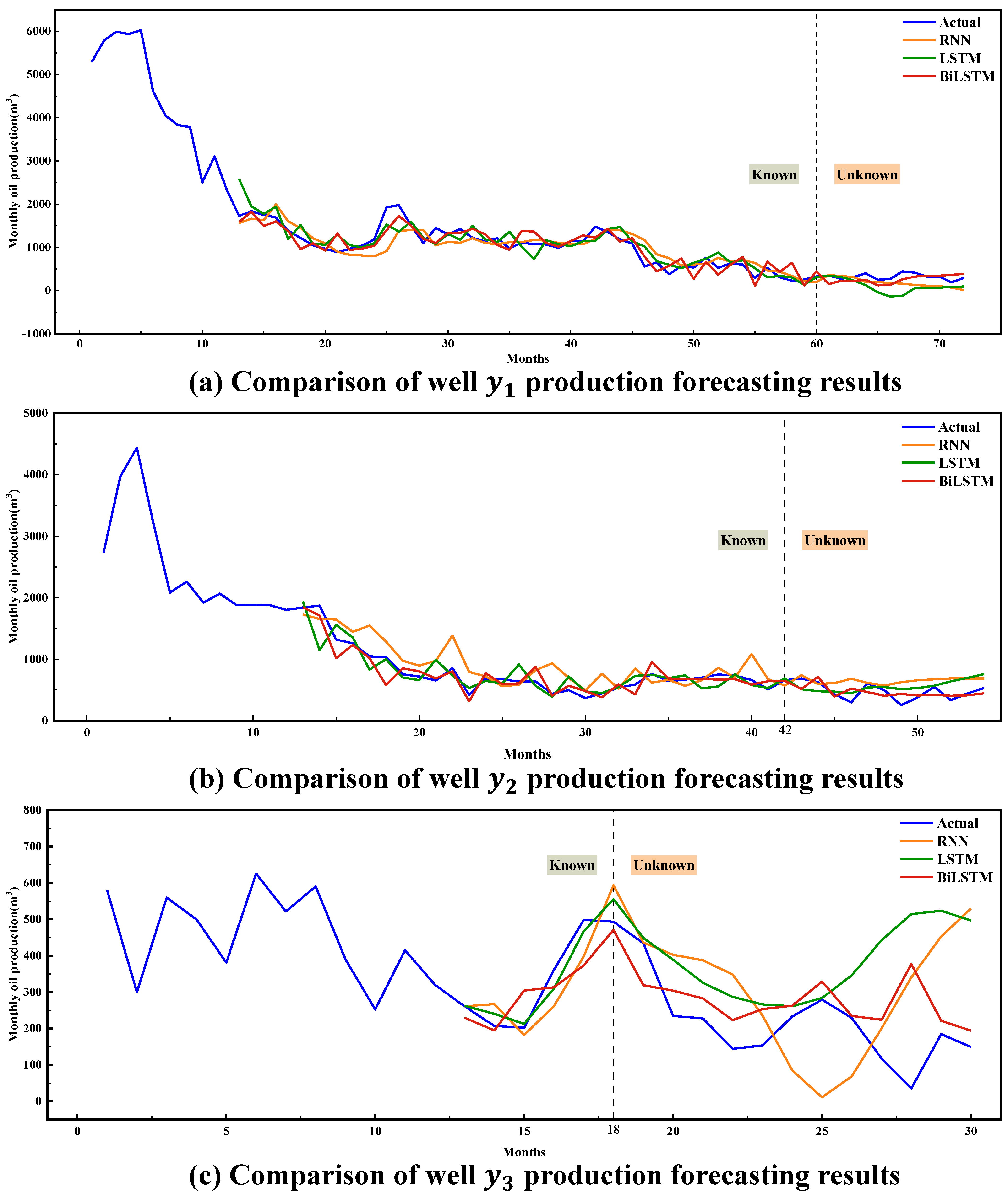
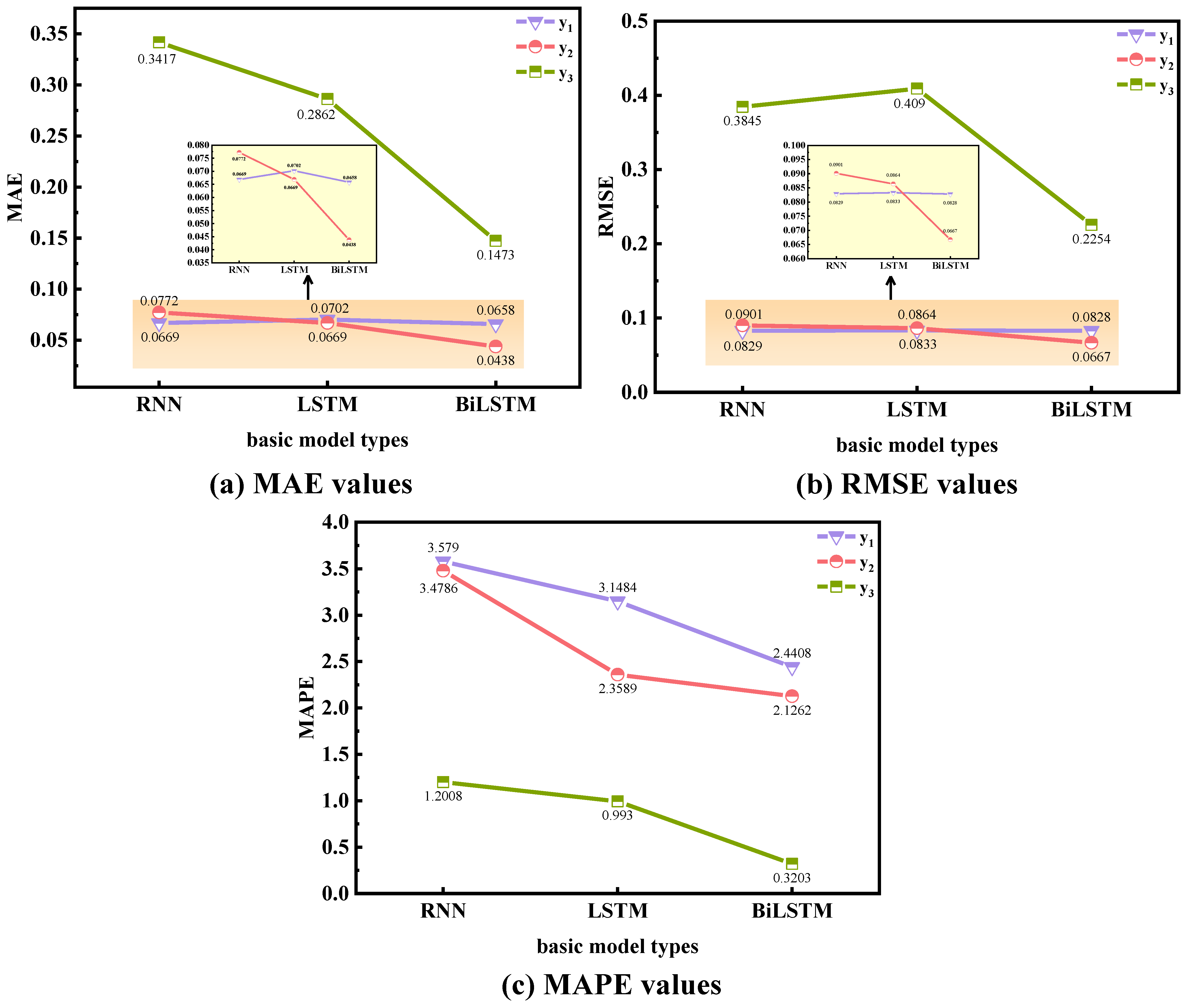
4.1.1. Case Study 1: Using Different Basic Models in the Proposed Methodology
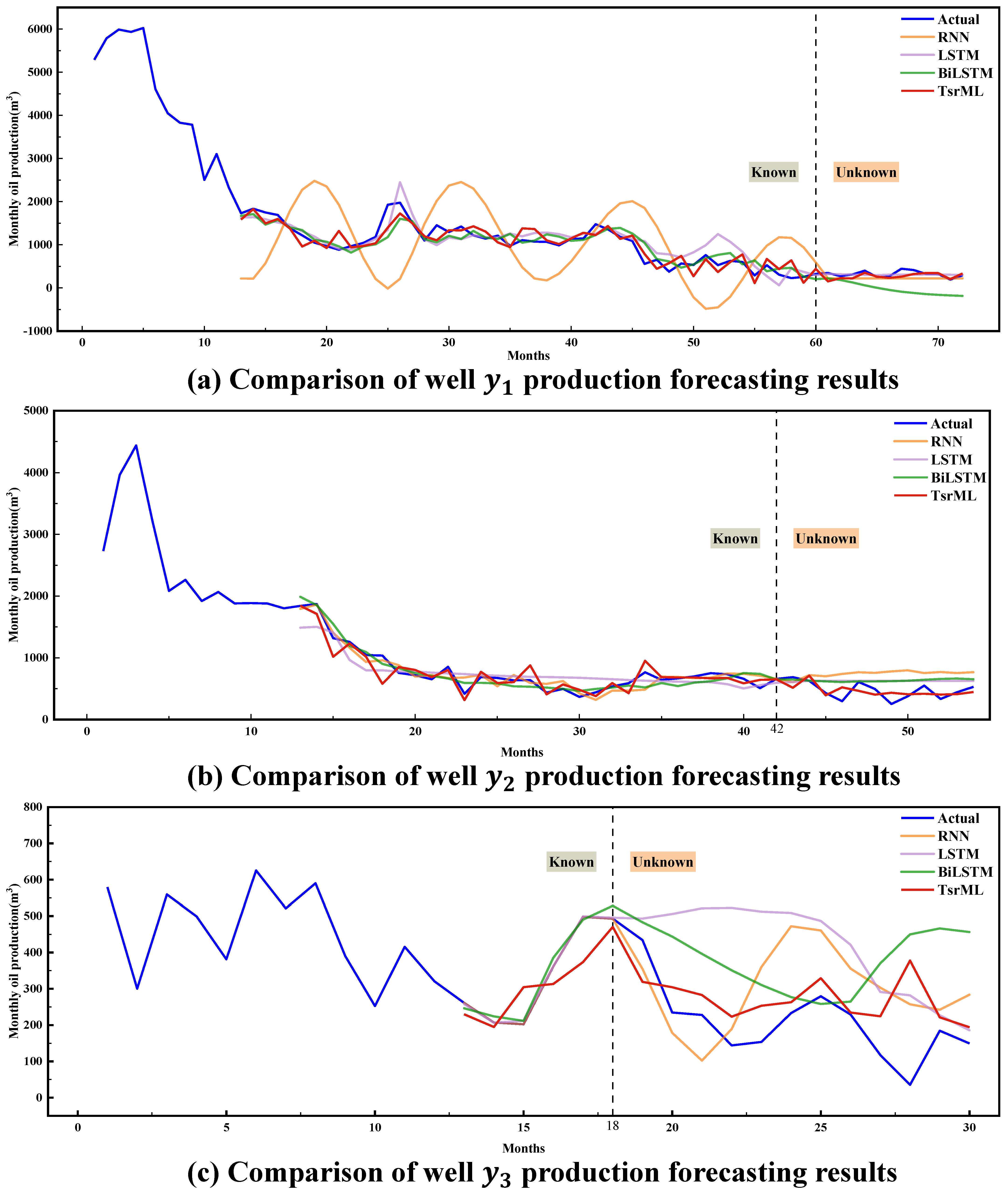
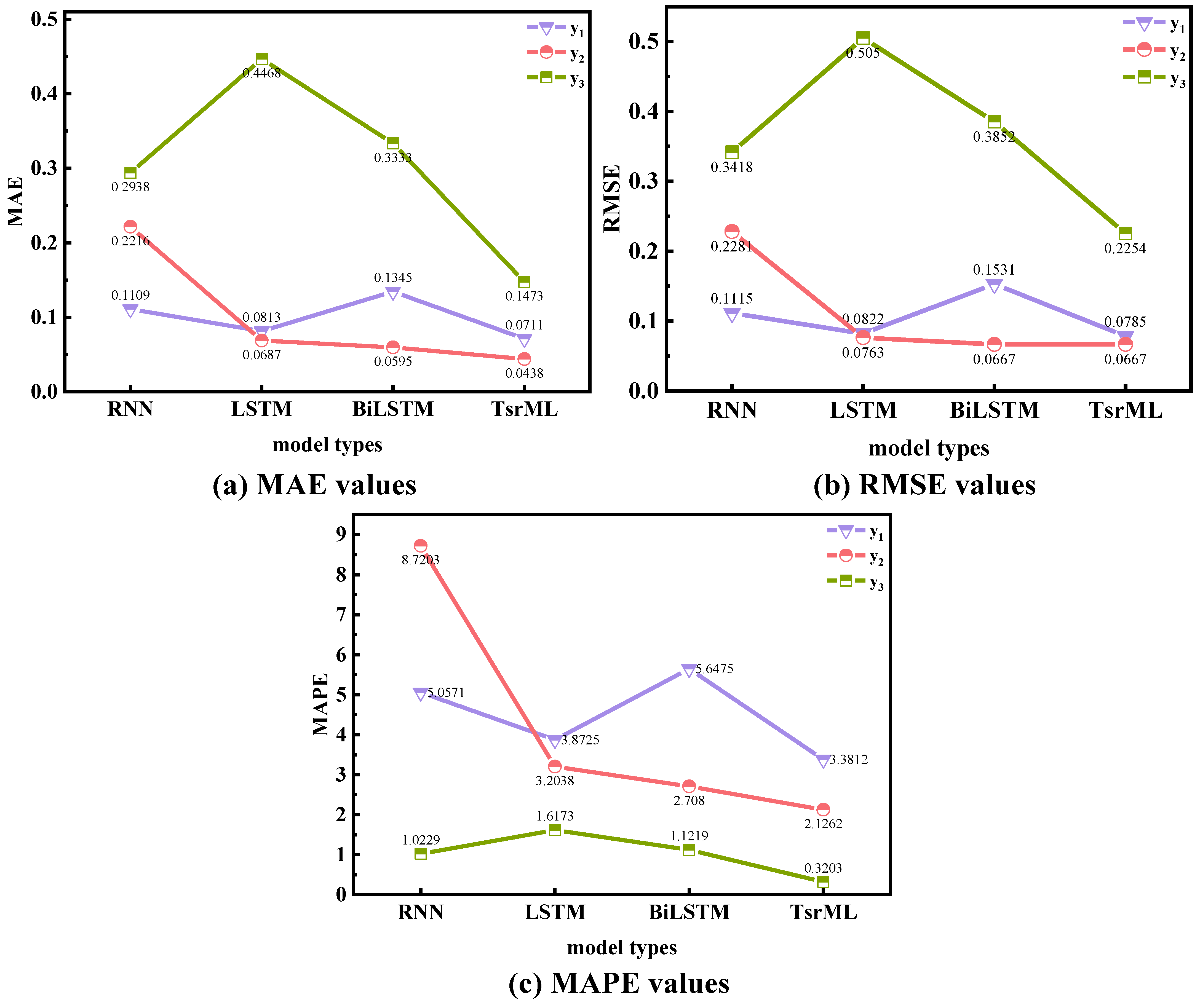
4.1.2. Case Study 2: Comparison of Our Model with Traditional Deep Learning Methods
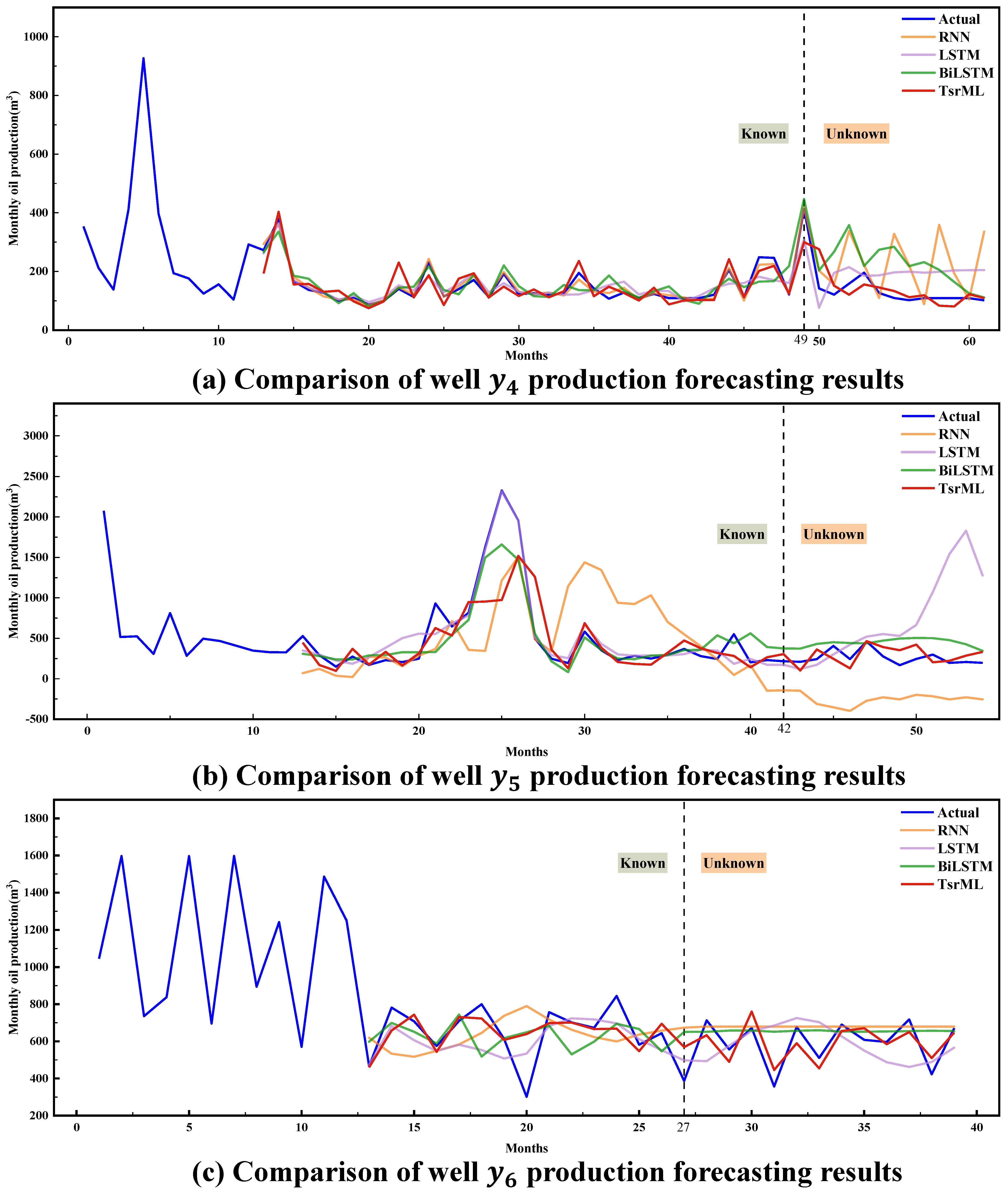
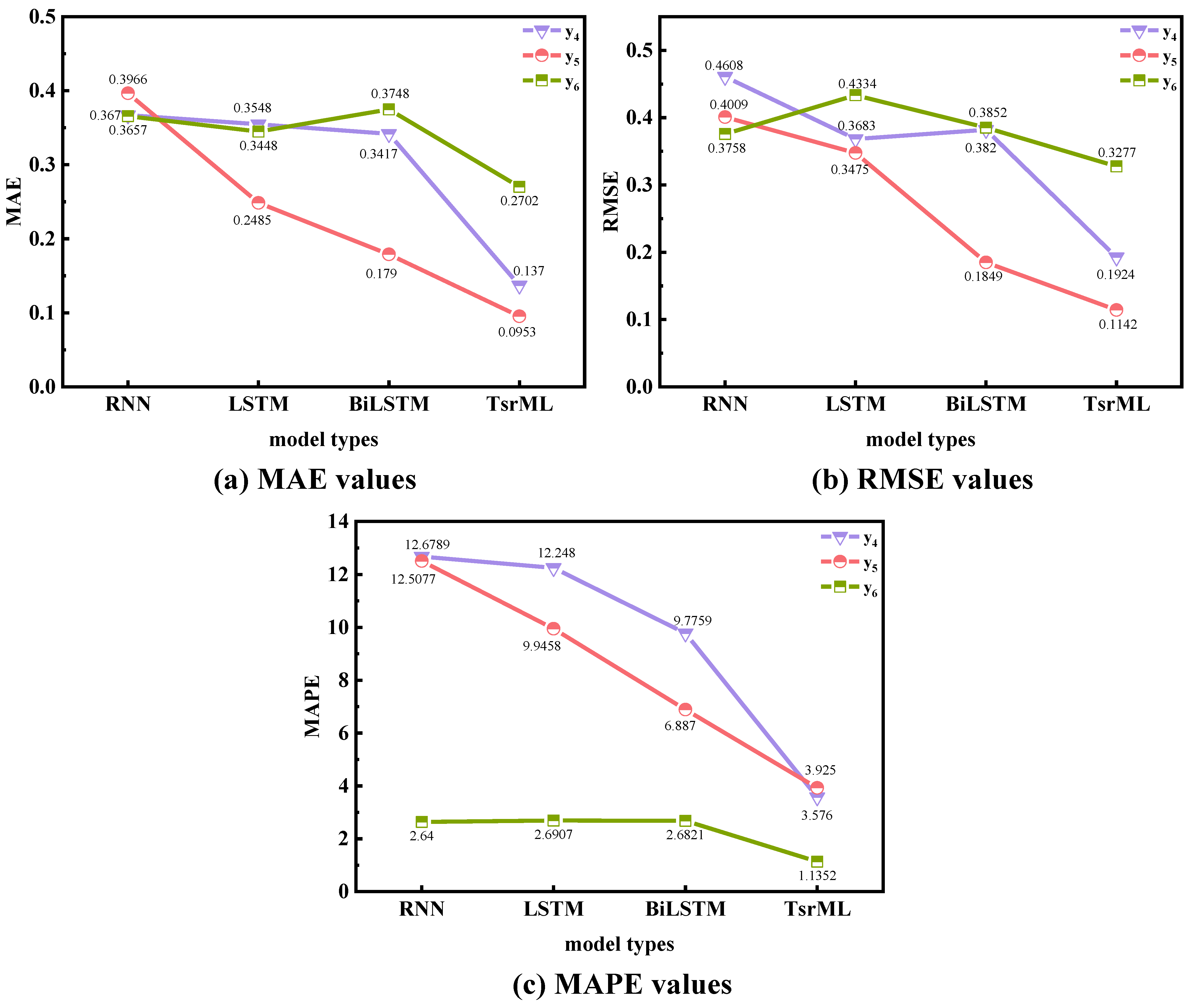
4.1.3. Case Study 3: Testing the Generalization of the Proposed Meta-Method
4.2. Results Analysis and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
| Algorithm A1. Time Series-Related Meta-Learning |
| Require: Time series dataset , dataset of wells |
| Ensure: Trained base-model parameters , trained meta-model parameters |
| index of loop |
| Randomly initialize |
| for in , do |
| for in , do |
| if then |
| end if |
| Output the value by the step. |
| Compute adapted parameters with gradient descent by Adam: |
| Update (Equations (13)–(18)) |
| end for |
| for in , do |
| Output the value by the step. |
| Compute and record loss: |
| end for |
| Update |
| end for |
| for in , do |
| for in , do |
| Output the value by the step. |
| Compute adapted parameters with gradient descent by Adam: |
| Update (Equations (13)–(18)) |
| end for |
| end for |
References
- Lu, H.; Huang, K.; Azimi, M.; Guo, L. Blockchain Technology in the Oil and Gas Industry: A Review of Applications, Opportunities, Challenges, and Risks. IEEE Access 2019, 7, 41426–41444. [Google Scholar] [CrossRef]
- Pan, S.; Yang, B.; Wang, S.; Guo, Z.; Wang, L.; Liu, J.; Wu, S. Oil well production prediction based on CNN-LSTM model with self-attention mechanism. Energy 2023, 284, 128701. [Google Scholar] [CrossRef]
- Karevan, Z.; Suykens, J.A. Transductive LSTM for time-series prediction: An application to weather forecasting. Neural Netw. 2020, 125, 1–9. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]
- Yang, H.; Huang, K.; King, I.; Lyu, M.R. Localized support vector regression for time series prediction. Neurocomputing 2009, 72, 2659–2669. [Google Scholar] [CrossRef]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef]
- McCoy, T.H.; Pellegrini, A.M.; Perlis, R.H. Assessment of Time-Series Machine Learning Methods for Forecasting Hospital Discharge Volume. JAMA Netw. Open 2018, 1, e184087. [Google Scholar] [CrossRef]
- Abbasimehr, H.; Shabani, M.; Yousefi, M. An optimized model using LSTM network for demand forecasting. Comput. Ind. Eng. 2020, 143, 106435. [Google Scholar] [CrossRef]
- Nguyen, H.; Tran, K.P.; Thomassey, S.; Hamad, M. Forecasting and Anomaly Detection approaches using LSTM and LSTM Autoencoder techniques with the applications in supply chain management. Int. J. Inf. Manag. 2021, 57, 102282. [Google Scholar] [CrossRef]
- Sun, J.; Di, L.P.; Sun, Z.H.; Shen, Y.L.; Lai, Z.L. County-Level Soybean Yield Prediction Using Deep CNN-LSTM Model. Sensors 2019, 19, 4363. [Google Scholar] [CrossRef]
- Gasparin, A.; Lukovic, S.; Alippi, C. Deep learning for time series forecasting: The electric load case. Caai Trans. Intell. Technol. 2022, 7, 1–25. [Google Scholar] [CrossRef]
- Chen, J.; Zeng, G.-Q.; Zhou, W.; Du, W.; Lu, K.-D. Wind speed forecasting using nonlinear-learning ensemble of deep learning time series prediction and extremal optimization. Energy Convers. Manag. 2018, 165, 681–695. [Google Scholar] [CrossRef]
- Lu, X.; Lin, P.; Cheng, S.; Lin, Y.; Chen, Z.; Wu, L.; Zheng, Q. Fault diagnosis for photovoltaic array based on convolutional neural network and electrical time series graph. Energy Convers. Manag. 2019, 196, 950–965. [Google Scholar] [CrossRef]
- Vida, G.; Shahab, M.D.; Mohammad, M. Smart Proxy Modeling of SACROC CO2-EOR. Fluids 2019, 4, 85. [Google Scholar] [CrossRef]
- Chen, G.; Tian, H.; Xiao, T.; Xu, T.; Lei, H. Time series forecasting of oil production in Enhanced Oil Recovery system based on a novel CNN-GRU neural network. Geoenergy Sci. Eng. 2024, 233, 212528. [Google Scholar] [CrossRef]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Bollapragada, R.; Mankude, A.; Udayabhanu, V. Forecasting the price of crude oil. Decision 2021, 48, 207–231. [Google Scholar] [CrossRef]
- Ma, X.; Liu, Z. Predicting the oil production using the novel multivariate nonlinear model based on Arps decline model and kernel method. Neural Comput. Appl. 2018, 29, 579–591. [Google Scholar] [CrossRef]
- Chithra Chakra, N.; Song, K.-Y.; Gupta, M.M.; Saraf, D.N. An innovative neural forecast of cumulative oil production from a petroleum reservoir employing higher-order neural networks (HONNs). J. Pet. Sci. Eng. 2013, 106, 18–33. [Google Scholar] [CrossRef]
- Fan, D.Y.; Sun, H.; Yao, J.; Zhang, K.; Yan, X.; Sun, Z.X. Well production forecasting based on ARIMA-LSTM model considering manual operations. Energy 2021, 220, 119708. [Google Scholar] [CrossRef]
- Abdullayeva, F.; Imamverdiyev, Y. Development of oil production forecasting method based on deep learning. Stat. Optim. Inf. Comput. 2019, 7, 826–839. [Google Scholar] [CrossRef]
- Aizenberg, I.; Sheremetov, L.; Villa-Vargas, L.; Martinez-Muñoz, J. Multilayer neural network with multi-valued neurons in time series forecasting of oil production. Neurocomputing 2016, 175, 980–989. [Google Scholar] [CrossRef]
- Shin, H.; Hou, T.; Park, K.; Park, C.-K.; Choi, S. Prediction of movement direction in crude oil prices based on semi-supervised learning. Decis. Support Syst. 2013, 55, 348–358. [Google Scholar] [CrossRef]
- Song, X.; Liu, Y.; Xue, L.; Wang, J.; Zhang, J.; Wang, J.; Jiang, L.; Cheng, Z. Time-series well performance prediction based on Long Short-Term Memory (LSTM) neural network model. J. Pet. Sci. Eng. 2020, 186, 106682. [Google Scholar] [CrossRef]
- Schmidhuber, J. A neural network that embeds its own meta-levels. In Proceedings of the IEEE International Conference on Neural Networks, San Francisco, CA, USA, 28 March–1 April 1993; pp. 407–412. [Google Scholar]
- Thrun, S. Lifelong Learning Algorithms. In Learning to Learn; Thrun, S., Pratt, L., Eds.; Springer: Boston, MA, USA, 1998; pp. 181–209. [Google Scholar] [CrossRef]
- Jamal, M.A.; Qi, G.-J. Task agnostic meta-learning for few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11719–11727. [Google Scholar]
- Prudêncio, R.B.; Ludermir, T.B. Meta-learning approaches to selecting time series models. Neurocomputing 2004, 61, 121–137. [Google Scholar] [CrossRef]
- Schweighofer, N.; Doya, K. Meta-learning in reinforcement learning. Neural Netw. 2003, 16, 5–9. [Google Scholar] [CrossRef] [PubMed]
- Widmer, G. Tracking context changes through meta-learning. Mach. Learn. 1997, 27, 259–286. [Google Scholar] [CrossRef]
- Hu, J.; Heng, J.; Tang, J.; Guo, M. Research and application of a hybrid model based on Meta learning strategy for wind power deterministic and probabilistic forecasting. Energy Convers. Manag. 2018, 173, 197–209. [Google Scholar] [CrossRef]
- Van Engelen, J.E.; Hoos, H.H. A survey on semi-supervised learning. Mach. Learn. 2020, 109, 373–440. [Google Scholar] [CrossRef]
- Gupta, G.; Yadav, K.; Paull, L. Look-ahead meta learning for continual learning. Adv. Neural Inf. Process. Syst. 2020, 33, 11588–11598. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-Learning in Neural Networks: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 5149–5169. [Google Scholar] [CrossRef] [PubMed]
- Li, X.C.; Ma, X.F.; Xiao, F.C.; Xiao, C.; Wang, F.; Zhang, S.C. Small-Sample Production Prediction of Fractured Wells Using Multitask Learning. SPE J. 2022, 27, 1504–1519. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, C.; Hou, J.; Chu, S.; Zhang, Y.; Zhu, Y. ARIMA model and few-shot learning for vehicle speed time series analysis and prediction. Comput. Intell. Neurosci. 2022, 2022, 252682. [Google Scholar] [CrossRef]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Xu, Z.; Chen, X.; Tang, W.; Lai, J.; Cao, L. Meta weight learning via model-agnostic meta-learning. Neurocomputing 2021, 432, 124–132. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the 2017 International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Munkhdalai, T.; Yu, H. Meta networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2554–2563. [Google Scholar]
- Xu, H.; Wang, J.; Li, H.; Ouyang, D.; Shao, J. Unsupervised meta-learning for few-shot learning. Pattern Recognit. 2021, 116, 107951. [Google Scholar] [CrossRef]
- Li, X.; Sun, Z.; Xue, J.-H.; Ma, Z. A concise review of recent few-shot meta-learning methods. Neurocomputing 2021, 456, 463–468. [Google Scholar] [CrossRef]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Wang, J.X. Meta-learning in natural and artificial intelligence. Curr. Opin. Behav. Sci. 2021, 38, 90–95. [Google Scholar] [CrossRef]
- Nichol, A.; Achiam, J.; Schulman, J. On First-Order Meta-Learning Algorithms. arXiv, 2018; arXiv:1803.02999. [Google Scholar] [CrossRef]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. Adv. Neural Inf. Process. Syst. 2016, 29, 3637–3645. [Google Scholar]
- Antoniou, A.; Edwards, H.; Storkey, A. How to train your MAML. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Sabzipour, B.; Arsenault, R.; Troin, M.; Martel, J.-L.; Brissette, F.; Brunet, F.; Mai, J. Comparing a long short-term memory (LSTM) neural network with a physically-based hydrological model for streamflow forecasting over a Canadian catchment. J. Hydrol. 2023, 627, 130380. [Google Scholar] [CrossRef]
- Song, B.; Liu, Y.; Fang, J.; Liu, W.; Zhong, M.; Liu, X. An optimized CNN-BiLSTM network for bearing fault diagnosis under multiple working conditions with limited training samples. Neurocomputing 2024, 574, 127284. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef] [PubMed]
- Sharfuddin, A.A.; Tihami, M.N.; Islam, M.S. A Deep Recurrent Neural Network with BiLSTM model for Sentiment Classification. In Proceedings of the 2018 International Conference on Bangla Speech and Language Processing (ICBSLP), Sylhet, Bangladesh, 21–22 September 2018; pp. 1–4. [Google Scholar]
- da Silva, D.G.; Meneses, A.A.d.M. Comparing Long Short-Term Memory (LSTM) and bidirectional LSTM deep neural networks for power consumption prediction. Energy Rep. 2023, 10, 3315–3334. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar] [CrossRef]
- Shan, F.; He, X.; Armaghani, D.J.; Sheng, D. Effects of data smoothing and recurrent neural network (RNN) algorithms for real-time forecasting of tunnel boring machine (TBM) performance. J. Rock Mech. Geotech. Eng. 2023. [Google Scholar] [CrossRef]
- Dau, H.A.; Bagnall, A.; Kamgar, K.; Yeh, C.-C.M.; Zhu, Y.; Gharghabi, S.; Ratanamahatana, C.A.; Keogh, E. The UCR time series archive. IEEE/CAA J. Autom. Sin. 2019, 6, 1293–1305. [Google Scholar] [CrossRef]
- Linear. Available online: https://pytorch.org/docs/stable/generated/torch.ao.nn.quantized.Linear.html (accessed on 9 March 2024).
- Hyndman, R.J. Measuring forecast accuracy. In Business Forecasting: Practical Problems and Solutions; Gilliland, M., Tashman, L., Sglavo, U., Eds.; John Wiley & Sons: Hoboken, NJ, USA, 2016; pp. 177–184. [Google Scholar]
- Siami-Namini, S.; Tavakoli, N.; Namin, A.S. The performance of LSTM and BiLSTM in forecasting time series. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3285–3292. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Optimizer | Time Step | No. of Layers | Learning Rate | Hidden Size |
|---|---|---|---|---|---|
| RNN | Adam | 12 | 3 | 10−3 | 32 |
| LSTM | Adam | 12 | 3 | 10−3 | 32 |
| BiLSTM | Adam | 12 | 1 | 10−3 |
| Dataset | Maximum No. of Rows | Minimum No. of Rows | Maximum No. of Columns | Minimum No. of Columns | No. of Series |
|---|---|---|---|---|---|
| Train | 3636 | 16 | 2709 | 128 | 33,531 |
| Test | 3840 | 20 | 2709 | 128 | 90,431 |
| Oil Field | Well | Count | Mean (m3/Month) | Max (m3/Month) | Min (m3/Month) | Standard Derivation |
|---|---|---|---|---|---|---|
| 268 | 1258.8 | 7770.9 | 21.2 | 1434.7 | ||
| 257 | 1081.5 | 7025.4 | 146.8 | 1086.0 | ||
| 224 | 378.1 | 1325.7 | 76.3 | 198.7 | ||
| 250 | 369.9 | 2905.6 | 18.3 | 248.5 | ||
| 125 | 237.2 | 1703.2 | 8.0 | 257.7 | ||
| 198 | 624.9 | 2647.5 | 8.1 | 391.6 | ||
| 203 | 327.9 | 982.2 | 10.2 | 165.3 | ||
| 139 | 720.4 | 2987.7 | 83.8 | 607.5 | ||
| 72 | 1482.3 | 6024.5 | 191.9 | 1496.7 | ||
| 54 | 1094.7 | 4437.0 | 251.8 | 909.8 | ||
| 30 | 329.4 | 625.4 | 35.4 | 158.3 | ||
| 61 | 176.5 | 926.8 | 86.9 | 126.7 | ||
| 54 | 471.9 | 2327.8 | 149.9 | 468.4 | ||
| 39 | 776.5 | 1597.3 | 301.0 | 330.6 |
| Dataset | Error | Dataset | Error |
|---|---|---|---|
| ACSF1 | 0.409 | Lightning2 | 0.024 |
| Adiac | 0.005 | Lightning7 | 0.041 |
| ArrowHead | 0.008 | Mallat | 0.005 |
| Beef | 0.006 | Meat | 0.003 |
| BirdChicken | 0.005 | MixedShapesRegularTrain | 0.003 |
| BME | 0.024 | MixedShapesSmallTrain | 0.003 |
| Car | 0.003 | NonInvasiveFetalECGThorax1 | 0.002 |
| CBF | 0.135 | NonInvasiveFetalECGThorax2 | 0.001 |
| ChlorineConcentration | 0.091 | OliveOil | 0.007 |
| CinCECGTorso | 0.004 | OSULeaf | 0.007 |
| Coffee | 0.011 | Phoneme | 0.040 |
| Computers | 0.060 | PigAirwayPressure | 0.013 |
| CricketX | 0.031 | PigArtPressure | 0.006 |
| CricketY | 0.031 | PigCVP | 0.018 |
| CricketZ | 0.032 | Plane | 0.019 |
| DiatomSizeReduction | 0.003 | PowerCons | 0.052 |
| Earthquakes | 0.197 | RefrigerationDevices | 0.108 |
| ECG5000 | 0.021 | ScreenType | 0.044 |
| ECGFiveDays | 0.009 | SemgHandGenderCh2 | 0.090 |
| EOGHorizontalSignal | 0.005 | SemgHandMovementCh2 | 0.089 |
| EOGVerticalSignal | 0.005 | SemgHandSubjectCh2 | 0.087 |
| EthanolLevel | 0.006 | ShapeletSim | 0.329 |
| FaceAll | 0.050 | ShapesAll | 0.005 |
| FaceFour | 0.042 | SmallKitchenAppliances | 0.023 |
| FacesUCR | 0.075 | StarLightCurves | 0.004 |
| FiftyWords | 0.007 | Strawberry | 0.005 |
| Fish | 0.002 | SwedishLeaf | 0.023 |
| FordA | 0.027 | Symbols | 0.003 |
| FordB | 0.025 | ToeSegmentation1 | 0.025 |
| FreezerRegularTrain | 0.012 | ToeSegmentation2 | 0.014 |
| FreezerSmallTrain | 0.012 | Trace | 0.018 |
| Fungi | 0.013 | TwoPatterns | 0.118 |
| GunPointAgeSpan | 0.006 | UMD | 0.021 |
| GunPointMaleVersusFemale | 0.006 | UWaveGestureLibraryAll | 0.008 |
| GunPointOldVersusYoung | 0.007 | UWaveGestureLibraryX | 0.005 |
| GunPoint | 0.006 | UWaveGestureLibraryY | 0.005 |
| Ham | 0.016 | UWaveGestureLibraryZ | 0.005 |
| HandOutlines | 0.002 | Wafer | 0.015 |
| Haptics | 0.005 | Wine | 0.003 |
| Herring | 0.003 | WordSynonyms | 0.007 |
| HouseTwenty | 0.027 | WormsTwoClass | 0.011 |
| InlineSkate | 0.004 | Worms | 0.011 |
| InsectEPGRegularTrain | 0.026 | Yoga | 0.003 |
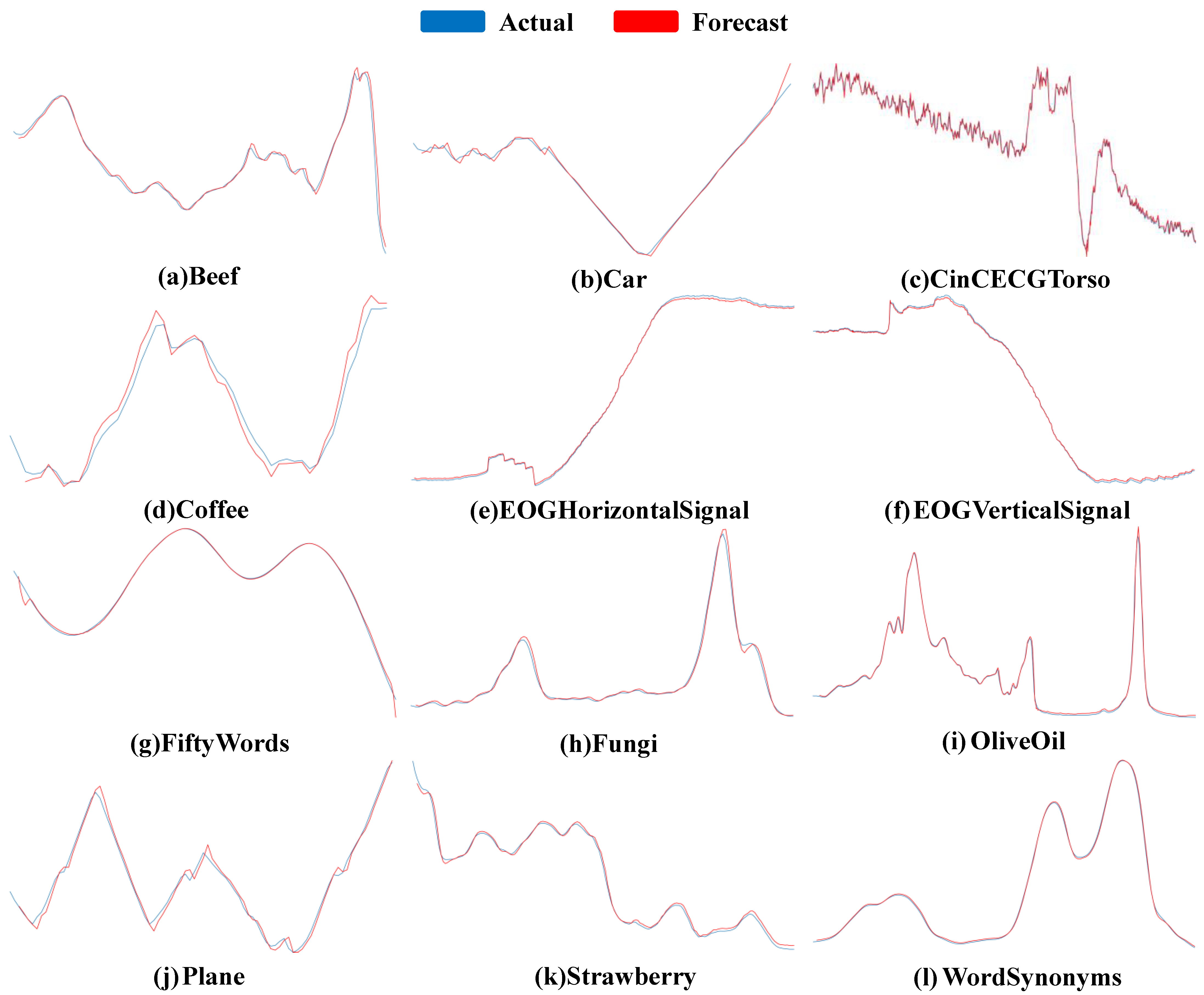
| InsectEPGSmallTrain | 0.026 | Average | 0.031 |
| Well | Basic Model | MAE | MSE | RMSE | MAPE(%) |
|---|---|---|---|---|---|
| RNN | 0.0669 | 0.0069 | 0.0829 | 3.5790 | |
| LSTM | 0.0702 | 0.0070 | 0.0833 | 3.1484 | |
| BiLSTM | 0.0658 | 0.0068 | 0.0828 | 2.4408 | |
| RNN | 0.0772 | 0.0081 | 0.0901 | 3.4786 | |
| LSTM | 0.0669 | 0.0075 | 0.0864 | 2.3589 | |
| BiLSTM | 0.0438 | 0.0044 | 0.0667 | 2.1262 | |
| RNN | 0.3417 | 0.1479 | 0.3845 | 1.2008 | |
| LSTM | 0.2862 | 0.1673 | 0.4090 | 0.9930 | |
| BiLSTM | 0.1473 | 0.0508 | 0.2254 | 0.3203 |
| Basic Model | Training Time |
|---|---|
| RNN | 4 h’19 min |
| LSTM | 4 h’21 min |
| BiLSTM | 4 h’38 min |
| Model | Well | No. of Epochs | Train | Test |
|---|---|---|---|---|
| RNN | 100 | 0.1370 | 0.3067 | |
| 150 | 0.1218 | 0.2163 | ||
| 200 | 0.1140 | 0.2452 | ||
| 100 | 0.1932 | 0.3423 | ||
| 150 | 0.1281 | 0.2281 | ||
| 200 | 0.1278 | 0.2610 | ||
| 50 | 0.0771 | 0.3646 | ||
| 200 | 0.0225 | 0.3418 | ||
| 300 | 0.0149 | 0.3417 | ||
| LSTM | 50 | 0.0642 | 0.0544 | |
| 200 | 0.0330 | 0.0180 | ||
| 300 | 0.0411 | 0.0430 | ||
| 50 | 0.0815 | 0.0581 | ||
| 200 | 0.0621 | 0.0578 | ||
| 300 | 0.0603 | 0.0554 | ||
| 50 | 0.2012 | 0.5859 | ||
| 100 | 0.1435 | 0.5049 | ||
| 150 | 0.1211 | 0.6078 | ||
| BiLSTM | 50 | 0.0720 | 0.2176 | |
| 150 | 0.0321 | 0.0956 | ||
| 250 | 0.0295 | 0.0992 | ||
| 50 | 0.0830 | 0.2341 | ||
| 150 | 0.0489 | 0.0564 | ||
| 250 | 0.0295 | 0.0570 | ||
| 50 | 0.0034 | 0.3544 | ||
| 100 | 0.0011 | 0.3852 | ||
| 150 | 0.0004 | 0.4042 |
| Well | Model | MAE | MSE | RMSE | MAPE(%) |
|---|---|---|---|---|---|
| RNN | 0.1109 | 0.0124 | 0.1115 | 5.0571 | |
| LSTM | 0.0813 | 0.0068 | 0.0822 | 3.8725 | |
| BiLSTM | 0.1345 | 0.0234 | 0.1531 | 5.6475 | |
| TsrML | 0.0711 | 0.0061 | 0.0785 | 3.3812 | |
| RNN | 0.2216 | 0.0520 | 0.2281 | 8.7203 | |
| LSTM | 0.0687 | 0.0058 | 0.0763 | 3.2038 | |
| BiLSTM | 0.0595 | 0.0044 | 0.0667 | 2.7080 | |
| TsrML | 0.0438 | 0.0044 | 0.0667 | 2.1262 | |
| RNN | 0.2938 | 0.1168 | 0.3418 | 1.0229 | |
| LSTM | 0.4468 | 0.2550 | 0.5050 | 1.6173 | |
| BiLSTM | 0.3333 | 0.1484 | 0.3852 | 1.1219 | |
| TsrML | 0.1473 | 0.0508 | 0.2254 | 0.3203 |
| Well | Model | MAE | MSE | RMSE | MAPE(%) |
|---|---|---|---|---|---|
| RNN | 0.3670 | 0.2123 | 0.4608 | 12.6789 | |
| LSTM | 0.3548 | 0.1356 | 0.3683 | 12.2480 | |
| BiLSTM | 0.3417 | 0.1459 | 0.3820 | 9.7759 | |
| TsrML | 0.1370 | 0.0370 | 0.1924 | 3.5760 | |
| RNN | 0.3966 | 0.1607 | 0.4009 | 12.5077 | |
| LSTM | 0.2485 | 0.1207 | 0.3475 | 9.9458 | |
| BiLSTM | 0.1790 | 0.0342 | 0.1849 | 6.8870 | |
| TsrML | 0.0953 | 0.0131 | 0.1142 | 3.9250 | |
| RNN | 0.3657 | 0.1413 | 0.3758 | 2.6400 | |
| LSTM | 0.3448 | 0.1879 | 0.4334 | 2.6907 | |
| BiLSTM | 0.3748 | 0.1484 | 0.3852 | 2.6821 | |
| TsrML | 0.2702 | 0.1074 | 0.3277 | 1.1352 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, Z.; Yu, G. A Time Series Forecasting Approach Based on Meta-Learning for Petroleum Production under Few-Shot Samples. Energies 2024, 17, 1947. https://doi.org/10.3390/en17081947
Xu Z, Yu G. A Time Series Forecasting Approach Based on Meta-Learning for Petroleum Production under Few-Shot Samples. Energies. 2024; 17(8):1947. https://doi.org/10.3390/en17081947
Chicago/Turabian StyleXu, Zhichao, and Gaoming Yu. 2024. "A Time Series Forecasting Approach Based on Meta-Learning for Petroleum Production under Few-Shot Samples" Energies 17, no. 8: 1947. https://doi.org/10.3390/en17081947
APA StyleXu, Z., & Yu, G. (2024). A Time Series Forecasting Approach Based on Meta-Learning for Petroleum Production under Few-Shot Samples. Energies, 17(8), 1947. https://doi.org/10.3390/en17081947