
Research on Grid Multi-Source Survey Data Sharing Algorithm for Cross-Professional and Cross-Departmental Operations Collaboration


Abstract
1. Introduction
- (1)
- Addressing the security of cross-professional inter-survey data sharing, we propose a novel method that integrates differential privacy with a generative adversarial network (GAN). Specifically, our approach extends the discriminator in the original GAN to multiple discriminators. Furthermore, a dynamic noise adjustment algorithm is designed to mitigate the impact of differential privacy noise on the utility of the shared data. Empirical results demonstrate that the proposed method effectively facilitates the sharing of surveying data while maintaining high data utility.
- (2)
- Addressing the problem of excessive computational and communication overheads due to dynamic changes in cross-departmental permissions, we introduce an attribute-based encryption (ABE) method for managing permission alterations. Within the ciphertext-policy ABE framework, the flexibility of managing user permissions is achieved through the updating of user private keys, thereby resolving the issue of excessive computational and communicational costs associated with dynamic user access permissions in the secure sharing of surveying data.
2. Grid Engineering Survey Data and Its Characteristics
- (1)
- Diversity in Expressed Content: The data from power grid surveying encompasses a wide array of information from various domains such as geography, geology, environment, land, and resources. It includes not only the alignment of transmission lines, precise coordinates of tower bases, and accurate elevations of the terrain, which are critical factors, but also data from geological exploration points.
- (2)
- Data Format Complexity: The surveying data for power grid engineering comprise a multitude of data formats, originating from various surveying methods and technologies. For instance, remote sensing imagery data is often stored in formats such as TIFF, PNG, JPG, GeoTIFF, IMG, GIF, and BMP. In contrast, geotechnical data may utilize formats like XML, HTML, JSON, YAML, and CSV. Furthermore, structured data, including sensor data and fundamental control survey information, might be present in formats such as TXT, DAT, BRN, CSV, or structured formats like XML, HTML, JSON, and YAML. Unstructured data, such as three-dimensional model data, could be in formats like CGR, DWG, DXF, DWF, DGNPLN, and RVT.
- (3)
- Multi-scale and Multi-resolution: From the perspective of data resolution, at the macro scale, data typically exhibit lower resolution, which is suitable for large-scale power grid layout and planning. For example, satellite remote sensing data is utilized to assess the topography and land use over vast areas. At the meso scale, data with higher resolution can display more detailed geographical features and environmental elements, which is applicable for the specific route selection and preliminary design of power grid lines. The micro scale, on the other hand, provides data with the highest resolution, such as high-precision topographic data obtained through ground surveys and LiDAR scanning, which aids in the precise positioning, design, and determination of construction details for tower bases.
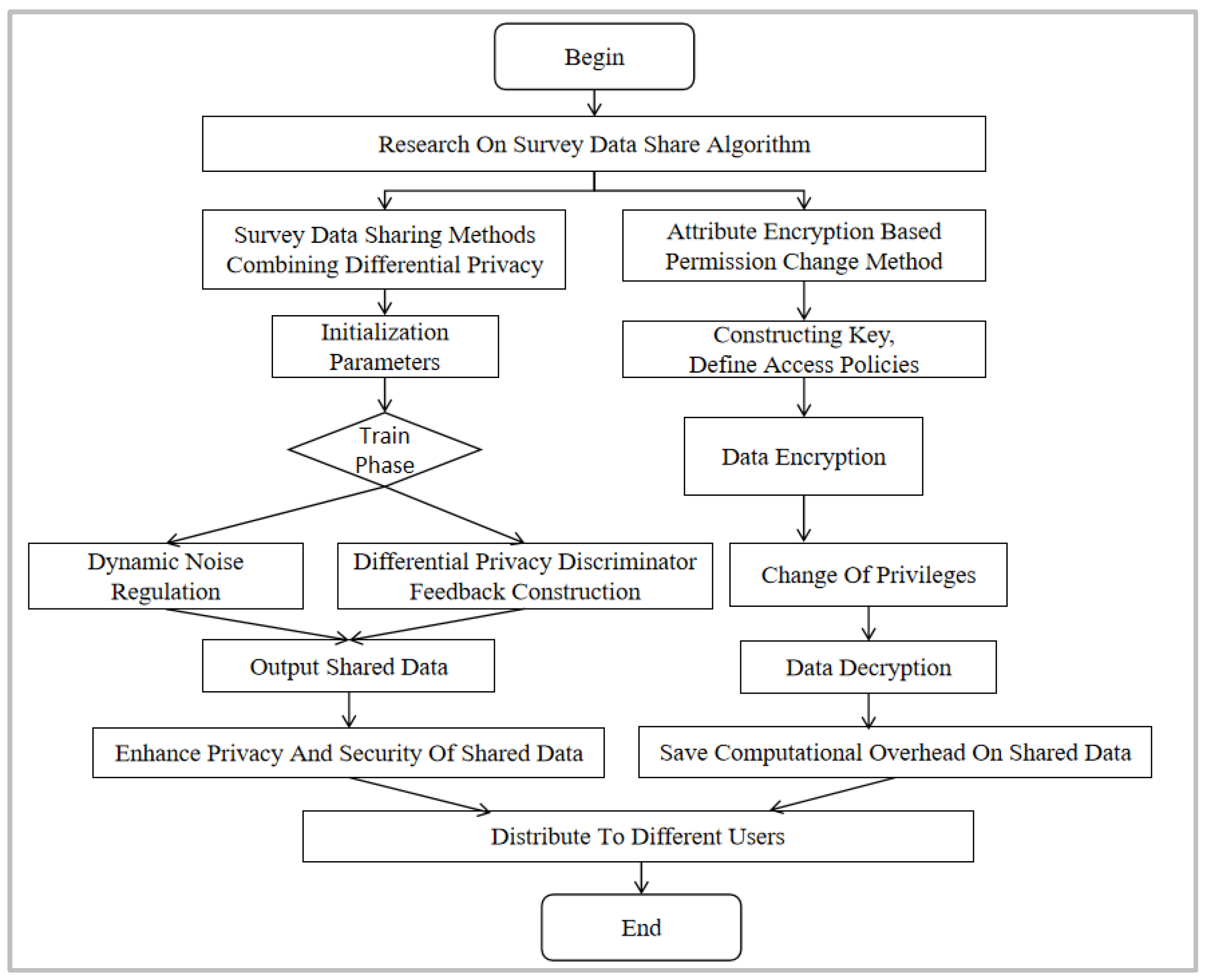
3. Research on Grid Survey Data Sharing Algorithm
3.1. Survey Data Sharing Methods Combining Differential Privacy
3.1.1. Overview of the Methodology
3.1.2. Discriminator Feedback Construction Combining Differential Privacy
| Algorithm 1. Discriminator Weight Updates Combined with Differential Privacy |
| Inputs: discriminator weight TD, discriminator loss function LD, survey data data_x, generator synthesized shared data data_g, learning rate l_r, Privacy budget for differential privacy ep, Differential privacy sensitivity delta, first-order momentum estimation m, second-order momentum estimation v, threshold C, and Gaussian noise standard deviation S. Initialization: m = 0 v = 0 sigma = sqrt (delta/(2×ep)) for each iteration in training://Each iterative step in the training process //Calculate the loss for real and generated data loss_real = LD(data_x,TD) loss_fake = LD(data_g,TD) //Gradient calculation, the gradient function is used to calculate the gradient of the loss function with respect to the model parameters grad_real = gradient(loss_real, TD) grad_fake = gradient(loss_fake, TD) //Merge the gradients and compute the average gradient grad = (grad_real + grad_fake)/2 //Updating the first- and second-order momentum estimates, beta1 and beta2 are the first- and second-order momentum parameters of Adam’s optimizer. m = beta1*m + (1−beta1)×grad v = beta2*v + (1-beta2)×(grad2) //Calculate the adaptive learning rate, t denotes the current number of iterations adaptive_lr = l_r×(sqrt(v/(1−beta2t))) //Noise is added according to differential privacy requirements, and the normal_noise function generates noise based on a Gaussian distribution Noise = normal_noise(mean = 0, std = S) //Updating discriminator weights while considering privacy-preserving noise TD = TD−adaptive_lr×(m + noise) //Updating the privacy budget ep = ep−delta //Stop updating if the privacy budget is depleted or less than the threshold C if epsilon < 0 or epsilon < C: break return TD |
3.1.3. Dynamic Noise Regulation
| Algorithm 2. Dynamic Noise Conditioning Algorithm |
| Input: Attenuation rate , Initial noise size , Survey data data_sources. Initialization: noise_scales = {source: for source in data_sources} for source in data_sources://Iterate through each data source //Sample data from the current data source batch_data = sample_data(source) //Calculate the loss and gradient of the model on the current data loss = calculate_loss(model, batch_data) grad = calculate_gradient(loss, model.params) //Dynamically adjust the noise scale of the current data source according to the attenuation rate noise_scales [source] = noise_scales [source] × //Adding noise for differential privacy noise = normal_noise(mean = 0, std = noise_scales [source]) noisy_grad = grad + noise return noisy_grad//Gradient after output adaptive perturbation |
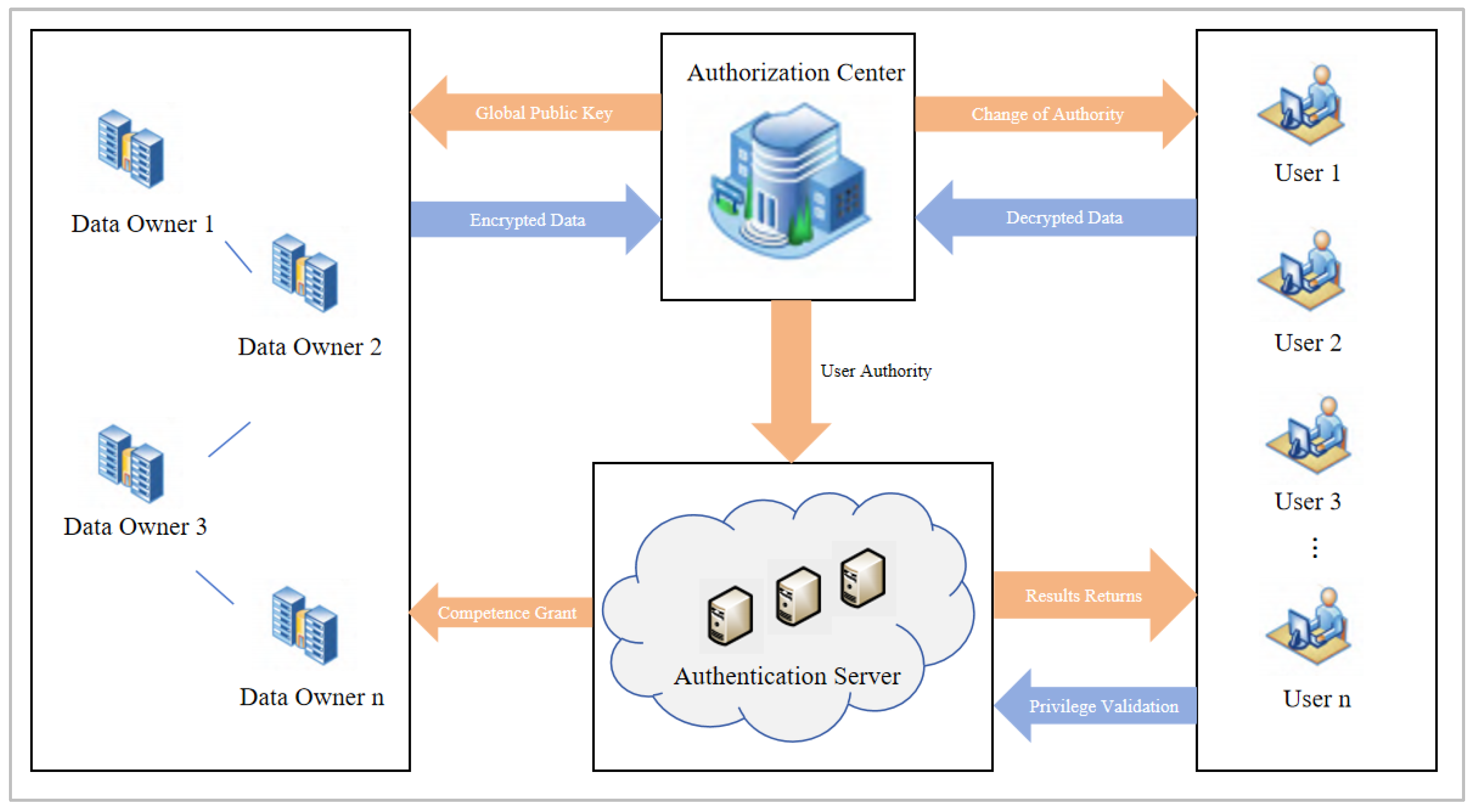
3.2. Attribute Encryption Based Permission Change Method
- (1)
- System initialization phase: (PK,MSK)←Initialize(ɑ).
- (2)
- User key generation phase: USK←KeyGen (MSK,U).
- (3)
- Data encryption phase: ct←Encrypt (PK,M,Σ).
- (4)
- Permission change phase: USK1←KeyGen (MSK,U1).
- (5)
- User authentication phase: Auth←Verify (ID,U or U1).
- (6)
- Data decryption phase: M1←Decrypt (USK or USK1,ct).
4. Experiment
4.1. Experimental Configuration and Data Sources
4.2. Experimental Situation
4.2.1. Parameter Settings
4.2.2. Evaluation Index
4.2.3. Experimental Results against Survey Data Sharing Methods Combining Differential Privacy
Comparison of Algorithm Performance under Sharing between Different Professionals
Comparison of Algorithm Performance under Sharing between Different Departments
4.2.4. Experimental Results of Attribute Encryption Based Permission Change Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, M.; Rui, L.; Xu, S.; Gao, Z.; Liu, H.; Guo, S. A multi-keyword searchable encryption sensitive data trusted sharing scheme in multi-user scenario. Comput. Netw. 2023, 237, 110045. [Google Scholar] [CrossRef]
- Liu, Z.; Li, T.; Li, P.; Jia, C.; Li, J. Verifiable searchable encryption with aggregate keys for data sharing system. Futur. Gener. Comput. Syst. 2018, 78, 778–788. [Google Scholar] [CrossRef]
- Niu, S.; Yang, P.; Xie, Y.; Du, X. Cloud-assisted ciphertext policy attribute-based data sharing encryption scheme on blockchain. J. Electron. Inf. 2021, 43, 1864–1871. [Google Scholar]
- Jiang, L.; Qin, Z. An efficient decentralized mobile groupwise data sharing scheme based on attribute hiding. J. Univ. Electron. Sci. Technol. 2023, 52, 915–924. [Google Scholar]
- Tian, G.; Hu, Y.; Wei, J.; Liu, Z.; Huang, X.; Chen, X.; Susilo, W. Blockchain-based secure deduplication and shared auditing in decentralized storage. IEEE Trans. Dependable Secur. Comput. 2021, 19, 3941–3954. [Google Scholar] [CrossRef]
- Xu, Y.; Mao, Y.; Li, S.; Li, J.; Chen, X. Privacy-Preserving Federal Learning Chain for Internet of Things. IEEE Internet Things J. 2023, 10, 18364–18374. [Google Scholar] [CrossRef]
- Yin, L.; Feng, J.; Xun, H.; Sun, Z.; Cheng, X. A privacy-preserving federated learning for multiparty data sharing in social IoTs. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2706–2718. [Google Scholar] [CrossRef]
- Huang, L.; Yi, W.; Wang, Y.; Cha, D. Research on secure data sharing method for sea-rail transportation based on federated learning and multi-party secure computing. Railw. Transp. Econ. 2024, 46, 58–67. [Google Scholar] [CrossRef]
- Chen, J.; Peng, C.; Tan, W. A design scheme for user profiling based on federated learning with multi-source data. J. Nanjing Univ. Posts Telecommun. (Nat. Sci. Ed.) 2023, 43, 83–91. [Google Scholar] [CrossRef]
- Chen, L.; Xiao, D.; Yu, Z.; Huang, H.; Li, M. Efficient federated learning for communication based on secret sharing and compressed sensing. Comput. Res. Dev. 2022, 59, 2395–2407. [Google Scholar]
- Ren, Z.; Yan, E.; Chen, T.; Yu, Y. Blockchain-based CP-ABE data sharing and privacy-preserving scheme using distributed KMS and zero-knowledge proof. J. King Saud Univ.—Comput. Inf. Sci. 2024, 36, 101969. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, Y.; Fu, J.; Xie, H. Policy-hiding efficient multi-authorized organization CP-ABE data sharing scheme for Internet of Things. Comput. Res. Dev. 2023, 60, 2193–2202. [Google Scholar]
- Zhao, K.; Kang, P.; Liu, B.; Guo, Z.; Feng, C.; Qing, Y. A CP-ABE scheme supporting cloud proxy re-encryption. J. Electron. 2023, 51, 728–735. [Google Scholar]
- Liu, C.; Zhang, Q.; Li, Y.; Zhang, H. Efficient storage and sharing algorithm for power information based on fog computing. J. Shenyang Univ. Technol. 2024, 46, 1–6. [Google Scholar]
- Guo, F.; Liu, S.; Wu, X.; Chen, B.; Zhang, W.; Ge, Q. Fault diagnosis of power transformer with unbalanced sample data based on federated learning. Power Syst. Autom. 2023, 47, 145–152. [Google Scholar]
- Qin, S.; Dai, W.; Zeng, H.; Gu, X. Research on secure data sharing of electric power application based on blockchain. Inf. Netw. Secur. 2023, 23, 52–65. [Google Scholar]
- Deng, S.; Hu, Q.; Wu, D.; He, Y. BCTC-KSM: A blockchain-assisted threshold cryptography for key security management in power IoT data sharing. Comput. Electr. Eng. 2023, 108, 108666. [Google Scholar] [CrossRef]
- Yang, X.; Liao, Z.; Liu, L.; Wang, C. Power data sharing scheme based on blockchain and attribute-based encryption. Power Syst. Prot. Control 2023, 51, 169–176. [Google Scholar] [CrossRef]
- Zhang, H.; Ding, P.; Peng, Y.; Sun, C. State Grid Electricity Data Sharing Program Based on CKKS and CP-ABE. Inf. Secur. Res. 2023, 9, 262–270. [Google Scholar]
- Xiang, Y.; Yang, L.; Chen, B.; Li, G. Research on power line loss data sharing based on differential privacy protection. Comput. Appl. Softw. 2023, 40, 333–336+341. [Google Scholar]
- Wang, B.; Guo, Q.; Yu, Y. Mechanism design for data sharing: An electricity retail perspective. Appl. Energy 2022, 314, 118871. [Google Scholar] [CrossRef]
- Song, J.; Yang, Y.; Mei, J.; Zhou, G.; Qiu, W.; Wang, Y.; Xu, L.; Liu, Y.; Jiang, J.; Chu, Z.; et al. Proxy re-encryption-based traceability and sharing mechanism of the power material data in blockchain environment. Energies 2022, 15, 2570. [Google Scholar] [CrossRef]
- Erlingsson, Ú.; Pihur, V.; Korolova, A. Rappor: Randomized aggregatable privacy-preserving ordinal response. In Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security, Scottsdale, AR, USA, 3–7 November 2014; pp. 1054–1067. [Google Scholar]
- Jiang, W.; Chen, Y.; Han, Y.; Wu, Y.; Zhou, W.; Wang, H. A privacy-preserving approach for mix-and-shuffle differentials during K-Modes clustering data collection and distribution. J. Commun. 2024, 45, 201–213. [Google Scholar]
- Fan, H.; Xu, W.; Fan, X.; Wang, Y. Analysis and outlook of the application of privacy computing in new power systems. Power Syst. Autom. 2023, 47, 187–199. [Google Scholar]
- Yu, H.; Liang, Y.; Song, J.; Li, h.; Xi, X.; Yuan, J. Overview of the development of data security sharing technology and its application in the field of energy and electric power. Inf. Secur. Res. 2023, 9, 208–219. [Google Scholar]
- Sadeghi, P.; Korki, M. Offset-symmetric Gaussians for differential privacy. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2394–2409. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. In Advances in Neural Information Processing Systems; NeurIPS: La Jolla, CA, USA, 2017; p. 30. [Google Scholar]
- Wang, Y.; Ren, T.; Fan, Z. UAV air combat maneuver decision making based on bootstrap Minimax-DDQN. Comput. Appl. 2023, 43, 2636–2643. [Google Scholar]
- Zhao, Y.; Yang, M. A review of progress in differential privacy research. Comput. Sci. 2023, 50, 65–276. [Google Scholar]
- Xie, L.; Lin, K.; Wang, S.; Wang, F.; Zhou, J. Differentially private generative adversarial network. arXiv 2018, arXiv:1802.06739. [Google Scholar]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular data using Conditional GAN. arXiv 2019, arXiv:1907.00503. [Google Scholar]
- Wang, Z.; Cheng, X.; Su, S.; Liang, J.; Yang, H. ATLAS: GAN-Based Differentially Private Multi-Party Data Sharing. IEEE Trans. Big Data 2023, 9, 1225–1237. [Google Scholar] [CrossRef]
- Wang, Z.; Cheng, X.; Su, S.; Wang, G. Differentially private generative decomposed adversarial network for vertically partitioned data sharing. Inf. Sci. 2023, 619, 722–744. [Google Scholar] [CrossRef]
- Sun, C.; van Soest, J.; Dumontier, M. Generating synthetic personal health data using conditional generative adversarial networks combining with differential privacy. J. Biomed. Inform. 2023, 143, 104404. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Content | Format | Structured vs. Unstructured | Real-Time vs. Non-Real-Time |
|---|---|---|---|---|
| Image data | Including remote sensing data, aerial data, laser point cloud data, etc. | TIFF, PNG, JPG, GeoTiff, IMG, GIF, BMP | Unstructured/ | real-time |
| Sensors data | Includes pressure sensor data, radar sensor data, humidity sensor data, etc. | TXT, DAT, BRN, CSV | Structured, unstructured | real-time |
| Basic control measurement data | Basic control measurement information element attribute information | XML, HTML, JSON, YAML, CSV | Structured | real-time |
| Geotechnical data | Attribute information of exploration data elements of exploration points, etc. | XML, HTML, JSON, YAML, CSV | Structured | real-time |
| 3D modeling data | Three-dimensional modeling data of power grid engineering facilities and the surrounding environment | CGR, DWG, DXF, DWF, DGNPLN, RVT | Unstructured | non-real-time |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; He, B.; Lv, J.; Zhao, C.; Yu, G.; Liu, D. Research on Grid Multi-Source Survey Data Sharing Algorithm for Cross-Professional and Cross-Departmental Operations Collaboration. Energies 2024, 17, 4380. https://doi.org/10.3390/en17174380
Zhang J, He B, Lv J, Zhao C, Yu G, Liu D. Research on Grid Multi-Source Survey Data Sharing Algorithm for Cross-Professional and Cross-Departmental Operations Collaboration. Energies. 2024; 17(17):4380. https://doi.org/10.3390/en17174380
Chicago/Turabian StyleZhang, Jiyong, Bangzheng He, Jingguo Lv, Chunhui Zhao, Gao Yu, and Donghui Liu. 2024. "Research on Grid Multi-Source Survey Data Sharing Algorithm for Cross-Professional and Cross-Departmental Operations Collaboration" Energies 17, no. 17: 4380. https://doi.org/10.3390/en17174380
APA StyleZhang, J., He, B., Lv, J., Zhao, C., Yu, G., & Liu, D. (2024). Research on Grid Multi-Source Survey Data Sharing Algorithm for Cross-Professional and Cross-Departmental Operations Collaboration. Energies, 17(17), 4380. https://doi.org/10.3390/en17174380