1. Introduction
Heating, ventilation, and air conditioning (HVAC) systems represent a significant proportion of energy consumption in both commercial and residential buildings [
1,
2]. In the United States, HVAC systems account for approximately 50% of total building energy usage, while in countries with hot and humid climates, such as Singapore, this figure escalates to 60% [
3]. The chiller, a critical component of HVAC systems, plays a pivotal role in determining overall operational efficiency [
4]. Therefore, diagnosing chiller faults is essential for energy savings, enhancing chiller equipment efficiency and improving building comfort [
5].
Contemporary fault diagnosis methodologies can be broadly categorized into two primary approaches: model-based and data-driven. Model-based techniques have been successfully implemented across various domains, including active fault diagnosis in reconfigurable battery systems [
6], robotic systems [
7], cross-building energy systems [
8] and lithium-ion batteries [
9]. However, chiller data have significant non-linear as well as dynamic characteristics and these model-based approaches have been hampered in diagnosis accuracy. Most recent fault diagnosis is realized through the data-driven method. Prominent data-driven HVAC fault diagnosis techniques encompass principal component analysis (PCA) [
10,
11], neural networks [
12,
13,
14], Bayesian classifiers [
15] and extreme learning machines [
16].
A time series is classified as non-stationary when its statistical properties, such as mean and variance, fluctuate over time [
17]. While many data-driven methods for chiller fault diagnosis assume stationarity, the reality is that chiller data exhibit non-stationary behavior. This non-stationarity complicates the differentiation between normal operational changes and genuine dynamic anomalies, thereby significantly impacting fault diagnosis accuracy. So, the non-stationary property is the main factor leading to poor fault diagnosis accuracy. How to describe the relationship between non-stationary variables and isolate the fault variables during chiller non-stationary processes is a challenging problem, but this area has received limited research attention.
Recently, Zhao et al. [
18] applied the sparse reconstruction strategy to industrial non-stationary data, and it was well applied in the Tennessee Eastman process (TEP) fault diagnosis process. Their approach initially employs cointegration analysis (CA) to establish a model describing the long-run equilibrium relationship between non-stationary variables. Subsequently, to extract fault variables from the non-stationary process, they implement the least absolute shrinkage and selection operators (LASSO) strategy. Building upon these insights, this paper proposes a sparse cointegration analysis (SCA) method to elucidate the relationships between non-stationary chiller variables and isolate primary fault features, thereby enhancing fault diagnosis accuracy.
However, the propagation of unresolved faults among variables during chiller operation presents additional complexities [
19]. The more the fault variables are isolated, the greater the correlation between them becomes, which hampers the accurate identification of faults using the SCA method. Currently, graph neural network (GNN) based methods are achieving good results in dealing with correlated variables. In the realm of fault diagnosis, it has been successfully applied to complex industrial process fault diagnosis [
20], smart grid fault diagnosis [
21] and chiller fault diagnosis [
22]. Based on GNN, Fan et al. [
22] proposed a graph generation method to convert table-constructed operational data into correlation graphs. These graphs enable the application of graph convolution, which in turn provides valuable insights for chiller fault classification. Otherwise, few studies have explored the value of GNN in building equipment diagnosis of faults. The primary challenge in applying GNN to chiller diagnosis lies in the significant behavioral differences between the various parameters. For example, one variable represents the outlet water temperature, while another represents the inlet oil pressure and so on. However, a typical GNN uses the same model parameters to model each node, which diminishes the interpretability of the features by the GNN.
Deng et al. introduced a novel graph deviation network (GDN) model [
23] that effectively mitigates the adverse effects associated with GNN. By using embedding vectors, the GDN flexibly captures the unique features of each variable and learns to predict their future behaviors. This allows deviation to be identified and explained. Based on the above considerations, this paper further improves the traditional GDN model for data classification so that it shows good performance over other networks. GDN establishes a graph structure for the correlation variables by embedding vectors and applying it to chiller fault diagnosis, which perfectly models the relationship between different types of fault variables and successfully realizes fault classification.
However, in the early stages of fault generation, when the features of each fault are not prominent, the GDN-based fault diagnosis methods assume that all data are equally important in all cases. This approach fails to account for the necessity of attributing heightened attention to data that exert a more significant influence on classification outcomes. Consequently, this oversight inadvertently complicates the modeling process and adversely impacts the performance of the constructed model. Researchers have found that attention mechanism-based approaches offer significant efficiency improvements. The attention mechanism endows neural network models with the capability to selectively focus on distinct data subsets under varying circumstances, thereby facilitating rational and effective data utilization. Attention mechanism-based approaches have demonstrated considerable success in the domain of fault diagnosis. For example, Li et al. [
24] applied a multi-head attention mechanism for mechanical system fault diagnosis. Li et al. [
25] proposed an attention-based transfer model for fault diagnosis. Fahim et al. [
26] integrated a self-attention mechanism with a convolutional neural network to detect transmission line faults. These studies underscore the potential of incorporating an attention mechanism to significantly enhance the accuracy of chiller diagnosis.
In pursuit of improved fault diagnosis accuracy and reduced computational complexity, the convolutional block attention mechanism (CBAM) [
27] has gained wide attention in recent years for its lightweight and easy model insertion advantages. CBAM enables sequential evaluation of attention maps along two independent dimensions (temporal and spatial), followed by element-wise multiplication with input features for optimization. In the realm of fault diagnosis, Zhang et al. [
28] proposed a convolutional neural network based bearing fault diagnosis method incorporating an attention mechanism. Wu et al. [
29] proposed 1DCNN-BiLSTM with CBAM for aircraft engine fault diagnosis. Qin et al. [
30] proposed a rolling bearing fault diagnosis method based on CBAM_ResNet and ACON activation function. Inspired by these advancements, we posit that the integration of CBAM into our GDN model will yield an improved GDN (IGDN) with enhanced overall performance for chiller fault diagnosis.
In summary, this paper proposes an improved graph deviation network for chiller fault diagnosis by integrating the sparse cointegration analysis and the convolutional block attention mechanism (SCA-IGDN) for rapid and accurate diagnosis of chiller faults in non-stationary data environments. The primary contributions and novelties of this research are as follows:
- (1)
To describe the long-term equilibrium relationship between the non-stationary variables of the chiller and to obtain the sparse fault variables under non-stationary faults, this paper adopts the SCA method. The SCA method first extracts the non-stationary variables to build a cointegration model for them through CA in order to elucidate the long-run equilibrium relationship between different variables. Then, LASSO regression is further applied to separate the fault variables under a non-stationary faulty operation process, i.e., separation and sparsity of features are achieved;
- (2)
To address the issue of decreasing fault diagnosis accuracy caused by the correlation between fault variables, this paper further improves the GDN based on the fault features extracted by SCA. Firstly, the GDN classifier embeds vectors of the low-dimensional variables extracted from SCA to flexibly capture the unique features of each variable. Furthermore, the cosine similarity is computed on the embedded vectors, and the most relevant vectors are selected to build the inter-variable correlation graph structure. And finally, the message propagation is used to derive the deviation of each variable from its neighbors;
- (3)
To further augment the chiller’s fault diagnosis accuracy, we incorporated CBAM, based on the attention mechanism, into the improved GDN. This integration allowed for the application of variable attention levels to different fault data within the graph structure. CBAM processes the data by pooling operations as well as pays attention to the temporal and spatial dimensions, respectively, without adding almost any network overhead. At last, CBAM feeds its output to the fully-connected layers for fault diagnosis and classification, which strengthens the attention to the data and improves the ability of chiller fault diagnosis;
- (4)
This paper conducted comprehensive experiments and comparative analyses using the RP-1043 dataset from the ASHRAE program. The results demonstrate the superior ability of the SCA method in handling non-stationary chiller data and the excellent fault diagnosis performance of the proposed SCA-IGDN method, compared to alternative feature extraction and neural network algorithms.
The remainder of this paper is structured as follows:
Section 2 provides a detailed overview of the chiller system, typical seven faults and a primer on the CA methodology.
Section 3 details the application of the SCA method to chiller data.
Section 4 details the IGDN model for chiller fault diagnosis.
Section 5 gives the SCA-IGDN-based fault diagnosis strategy flow.
Section 6 comprises detailed experimental analyses and
Section 7 concludes the paper with final remarks and future research directions.
2. Chiller Analysis and Cointegration Analysis (CA) Methodology Primer
2.1. Introduction to Chiller
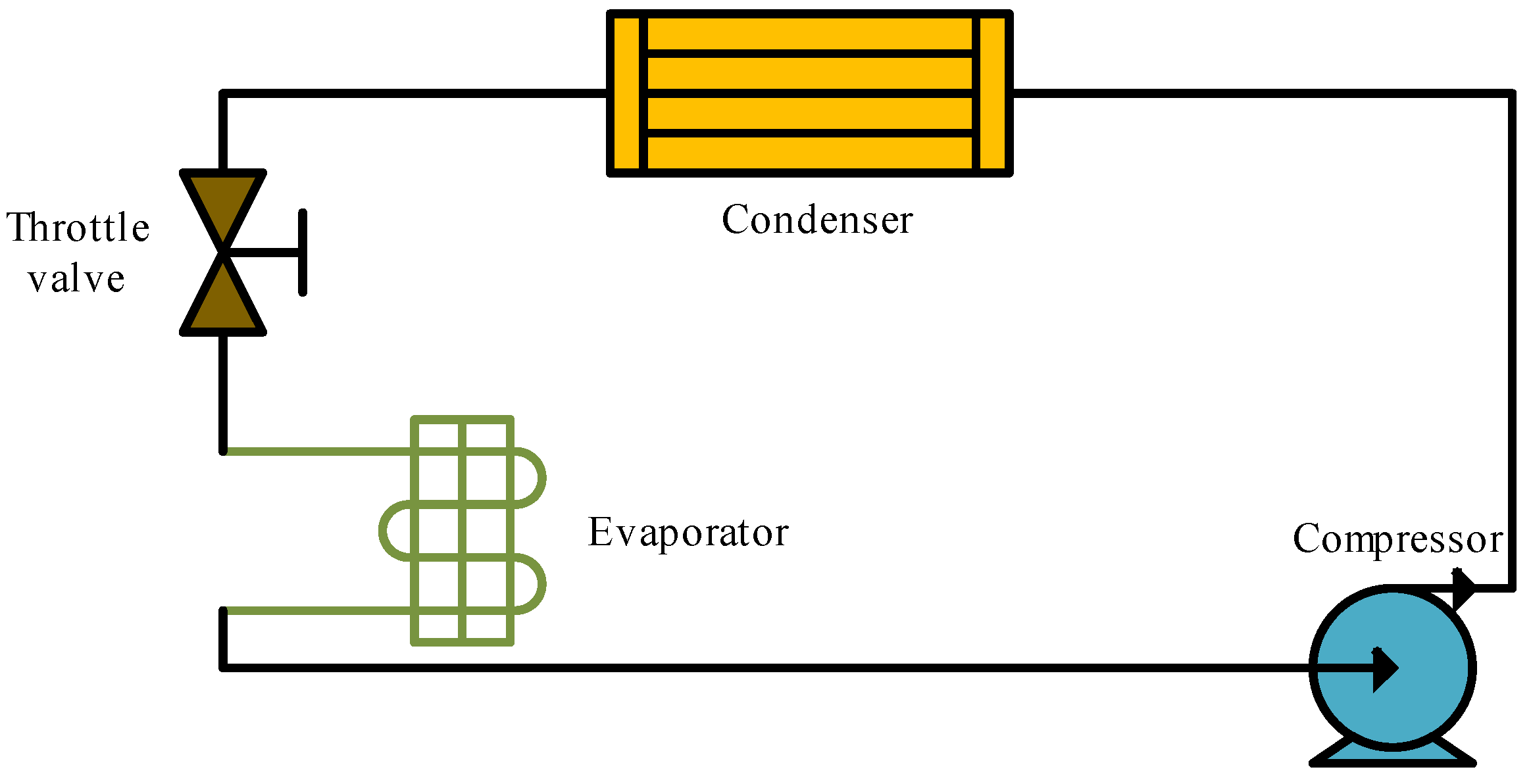
A chiller is a device used to provide cooling and is widely used in air conditioning systems, industrial refrigeration and data center cooling. Its main function is to remove heat through a refrigeration cycle and release it to the external environment through the cooling water system. The chiller typically includes key components such as a compressor, condenser, evaporator and expansion valve. The operation mechanism of the chiller based on the vapor compression refrigeration cycle is shown in
Figure 1, which consists of four main steps: Initially, the compressor changes the refrigerant into a vapor with high pressure and high temperature. Next, in the condenser, the refrigerant undergoes condensation into a high-pressure liquid through heat exchange with cooling water. The expansion valve then facilitates the transition of the high-pressure liquid refrigerant into a low-pressure, low-temperature mixture of liquid and gas. Finally, the low-pressure, low-temperature refrigerant absorbs heat from the cooling water or air in the evaporator, thereby completing the cooling process. This is how chillers use refrigerant to cool their surroundings.
2.2. The Introduction of Chiller’s Faults
There are a variety of faults that may be encountered during chiller operation. Understanding these typical fault patterns can aid in timely maintenance and repair, thereby preventing greater equipment damage and operational interruptions.
Chiller’s fault patterns are shown in
Table 1. Poor water quality leads to scale buildup and reduced condenser exchange efficiency produces condenser fouling (CF). Non-condensable gases in the refrigerant (NC) result in the degradation of the refrigerant quality. Various factors can cause different faults. For example, the quantity of refrigerant surpassing the standard value can lead to refrigerant overcharge (RO), while an excess of lubricant can result in excess oil (EO). A refrigerant charge below the standard value will lead to a refrigerant leak (RL). Another example is that improper pump selection, abnormal valve adjustment, or clogged pipes can result in reduced condenser water flow (FWC). This can also lead to reduced evaporator water flow (FEW).
To summarize, the chiller will produce a variety of faults in actual operation and long-term operation in a faulty state will lead to abnormal system operation, resulting in overload or inefficient operation. As a result, the fault may go undetected for an extended period, leading to increased maintenance costs and production downtime. Moreover, it is not difficult to see from the above arguments that chiller fault problems are related to each other. Xia et al. [
19] emphasized the gradual increase in the severity of faults during operation, which suggests that the fault variables have correlation characteristics over time. Therefore, timely and accurate diagnosis of faults is critical.
2.3. Non-Stationary of Chiller Data
Chiller fault diagnosis is a common classification issue. Current studies generally utilize data-driven solutions to tackle this issue. Most of the chiller data are non-stationary, which can reduce the accuracy of classification results. The main reasons for non-stationary chiller data include the following.
Changes in operating conditions. The chiller operates under different load conditions, resulting in changes in system parameters such as temperature, pressure and flow rate over time, showing non-stationary;
Influence of external environment. Factors such as variations in external temperature and humidity impact the chiller’s operating status, further exacerbating the non-stationary nature of the data;
Progressive development of faults. Faults may have a small effect in the initial stage, but the severity of the faults gradually increases over time, leading to non-stationary characteristics of the parameter variations.
In conclusion, a chiller in actual normal operation will have a variety of situation changes, which leads to non-stationary data. Therefore, in the context of fault diagnosis, it is crucial to extract key fault features from dynamic, time-varying, non-stationary data to effectively address the data’s non-stationary characteristics.
2.4. The Basic CA Algorithm
In order to elucidate the long-run equilibrium relationship between the non-stationary variables, this paper used the CA method.
If a non-stationary time series
becomes stationary after being differenced
d times, it is referred to as being integrated of order
d, denoted as
. Engel and Granger [
32] showed that if a group of non-stationary time series maintains a long-run equilibrium relationship, it can be represented as
, where
N is the count of non-stationary time series, and
U is the count of samples. The data from one sample point are taken and recorded as
there exists a vector
; these non-stationary series can be described as
where
is the sequence of residuals.
The purpose of CA is to solve for the cointegrating vector
. A vector autoregressive (VAR) model was used by Zhao et al. [
33] to find the cointegration vector and apply it to a collection of non-stationary variables, given the chiller dataset
where
N is the count of chiller non-stationary time series, and
M is the count of chiller samples. Data from a single sample point are collected and noted as
.
The VAR model of
can be described as
where
is the matrix of coefficients,
is the vector of white noise distributed as
,
is a constant, and
p is the order of the VAR model.
The vector error correction (VEC) model is derived by subtracting
from both sides of Equation (2).
where
,
Two full rank matrices,
and
, are obtained by decomposing
where
. This transformation converts Equations (3) and (4).
The residual sequence
is derived in accordance with Equation (4):
According to Zhao et al. [
18], the eigenvalue equation can be solved to determine the maximum likelihood estimates of
.
where
The coefficients and can be estimated by OLS. The N features are obtained from Equation (6) denoted as . The cointegration vector of the chiller is encapsulated within . The Johansen test yields R cointegrating vectors, from which the cointegration vector matrix can be derived. contains information on the characteristics between the variables and the idea of computing residuals will also be used for subsequent sparse processes.
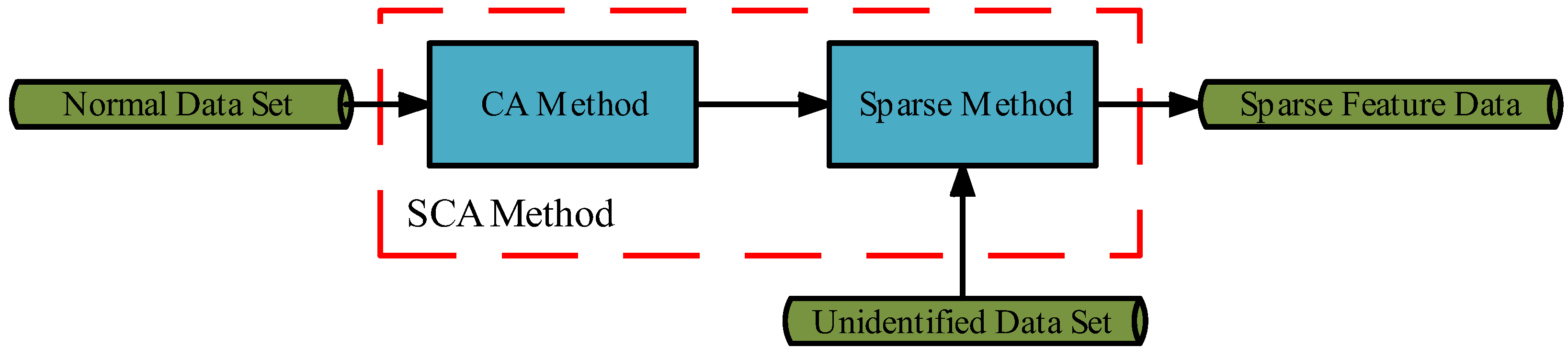
3. The Suggested Sparse Cointegration Analysis (SCA)
In fault data, not all variables contribute to the fault. Although feature extraction is possible using the CA method, it is not possible to obtain the determining sparse features. Therefore, based on the extracted features
in
Section 2.4, this paper proposes the SCA method to sparse the feature. As in
Figure 2, the SCA method first constructs a cointegration model using the non-stationary dataset obtained by the Augmented Dickey-Fuller (ADF) test [
34] strategy. Secondly SCA uses the LASSO method for isolation of the variables in the fault samples to obtain sparse features. The SCA method is described in detail below:
A new vector of fault samples to be recognized,
, can be factored as follows.
where
is the fault-free component,
is the standard orthogonal matrix containing the direction of the fault,
contains information about the fault magnitude,
denotes the fault magnitude, so
is the fault component.
Given that not all variables are related to the fault, the process of selecting fault variables can be formulated as the following optimization problem:
where
,
denote L1 paradigms and
is a constant,
, where
is the chiller data mentioned in
Section 2.4. In Equation (8),
represents the fault-free component,
is denoted as residuals after the removal of fault variables.
Equation (8)’s optimization can be framed as a LASSO regression problem, which relies on the principles of the regression model.
Perform the Cholesky decomposition on
where
is the lower triangular matrix.
Then, Equation (8) becomes:
Let , , then Equation (11) solves the LASSO regression problem. This constitutes the problem of variable selection grounded in sparse cointegration.
As stated in Equation (11), the regression coefficient is contingent upon the value of . As increases, more variables are identified as problematic, resulting in more non-zero elements in . Conversely, if is significantly low, many of the coefficients in may be set to zero.
Therefore, in this paper, the coordinate descent method is used to solve the LASSO regression problem, and the regression coefficients
can be accurately estimated by addressing the following optimization problem:
where
is the loss function of the LASSO regression, k is the number of iterations and Equation (12) is the case of solving for the minimum.
Transform Equations (12) and (13)
According to Equation (13), in order to obtain the optimal
, we need to find
, which is
. Let
. Let the canonical representation of column
be as follows:
and then obtain
Let
, then update the regression coefficients to
Finally, Equation (11) was calculated again based on the resulting . The model was repeatedly fitted for 100 different values of λ, and a 10-fold cross-validation was performed using the cross-validation function to choose the optimal penalty parameter λ. The output of the final algorithm is , i.e., sparse features.
Our main sparse fault variable steps are as follows:
- (1)
No variables were filtered, and a LASSO regression model was constructed for each fault sample point;
- (2)
A 10-fold cross-validation is performed using the cross-validation function to select the optimal penalty parameter λ;
- (3)
Calculate using the optimal λ, i.e., sparse the main features from the LASSO method. Here, since it is solving the smallest solution of Equation (11) it means that it can obtain all the sparse fault features, which is very effective in solving the problem of message propagation between fault variables.
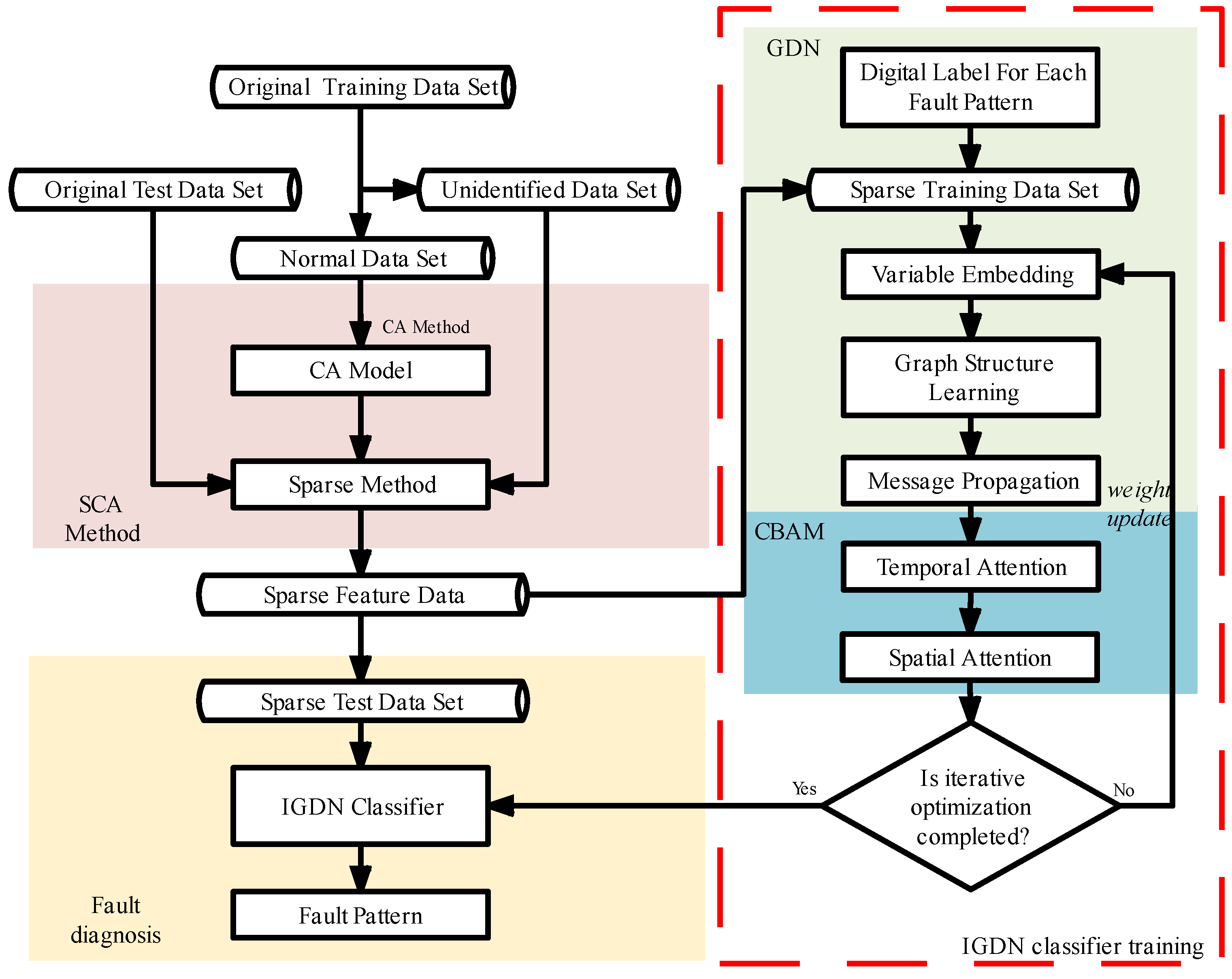
4. An Improved Graph Deviation Network (IGDN) Is Proposed
To address the issue of high correlation among different fault variables in the chiller and to further augment the model’s fault diagnosis capability, this paper adopts the SCA method to extract the features and then further proposes IGDN to classify the fault datasets. The traditional GDN assumes that all data are equally important after graph propagation, which invariably increases the difficulty of the modeling task. To address this issue, the GDN is improved by incorporating CBAM to increase attention on the data, and IGDN is finally proposed.
4.1. Graph Deviation Network (GDN)
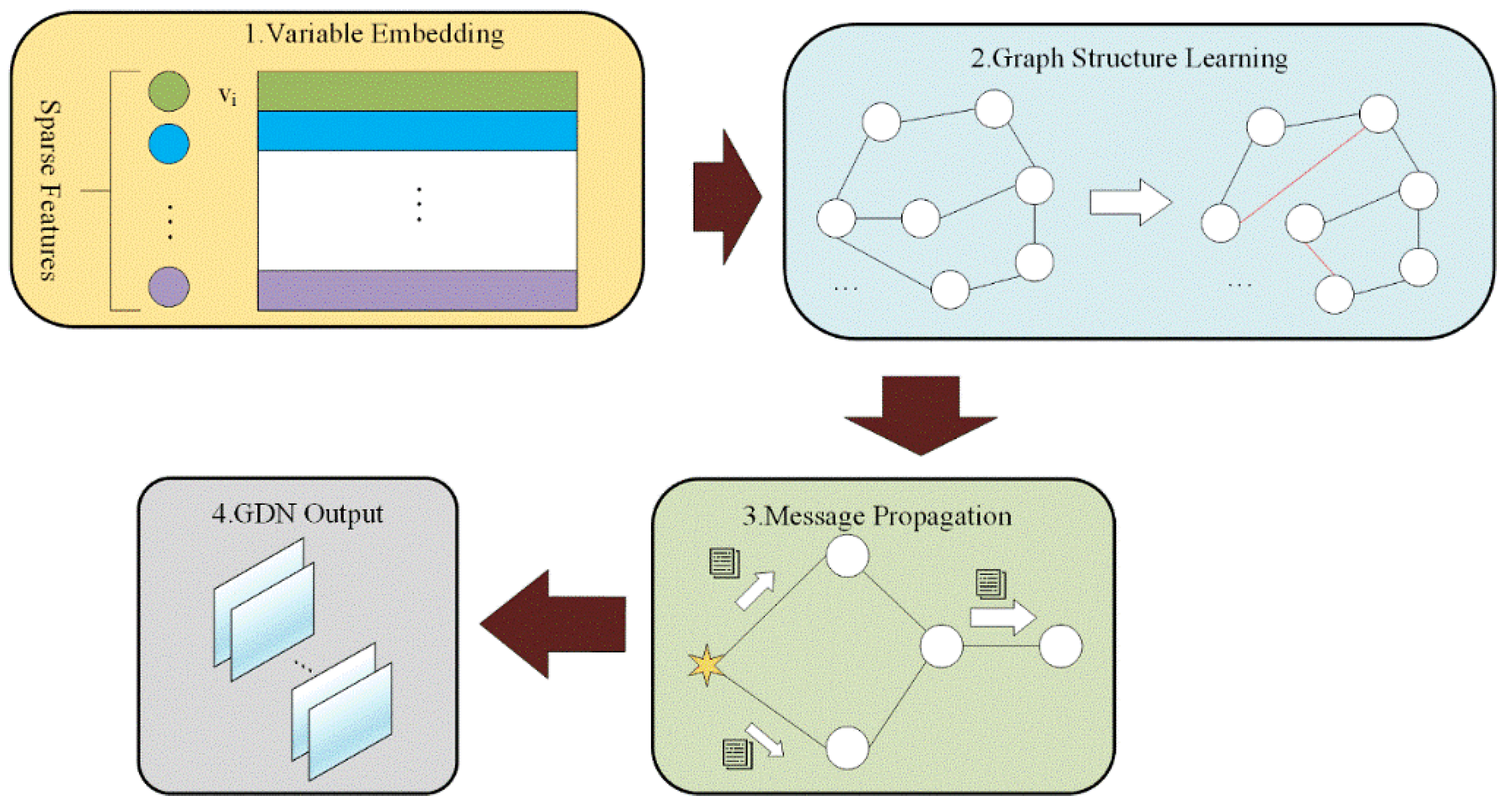
Over time, there is some correlation of features based on SCA after isolating. GDN flexibly captures the unique features of each variable and performs initial processing on the data. In order to flexibly represent the correlation between each different feature, an embedding vector is introduced for each variable to represent its features according to
Figure 3:
where
is the learnable embedding vector parameter,
N is the number of variables,
d is the embedding vector dimension, and the
ith row of the matrix
represents the embedding vector of variable
i, i.e.,
.
These embedding vectors are initially set randomly and then trained alongside the rest of the model.
To represent the relationship between fault variables, in the absence of a priori information, the candidate relationship for variable
i is the set of all variables other than itself
:
We compute the similarity between node
i’s embedding vector and the embeddings of its candidates
.
According to Equation (19), the graph structure of the obtained sparse features is constructed as.
where
denotes a directed edge that exists from variable
i to variable
j, TopK is the index of the top K values in similarity
, and K can depend on the number of sparse features.
That is, the GDN first computes the normalized dot product between the embedding vectors of each sparse variable and the candidate relations and index of the K normalized dot product are selected from the top. Based on this index, a graph structure is built up, which will be used for model post-processing.
For the sparse features obtained from SCA, i.e., the features in , retain their original data and set the data of the remaining features to zero. These are combined and denoted .
At moment
t, a sliding window of size
w is defined to process
and the model input
are obtained.
The output of the model is the data after processing each moment, denoted as .
In order to capture the relationship between the variables, message propagation is performed based on the information about the graph structure features of the learned nodes and the propagation representation is formulated as follows:
where
is denoted as the set of node neighbors obtained from the learned graph.
is the trainable weight matrix that is applied to the shared linear transformation at each variable. The coefficients are calculated as follows:
where
denotes the concatenation, thus
concatenates the vector
and the corresponding transformed feature
.
is a vector of coefficients.
The coefficients are computed using , which functions as a non-linear activation mechanism. This weight-initialized activation function mitigates the problem of vanishing gradients. Compared to the function, solves the neuron death problem of while inheriting the advantages of the function. After calculating the coefficients , the GDN uses the function to normalize the coefficients.
is element-wise multiplied with the corresponding embedding vector to obtain
:
where
denotes element-wise multiply.
The above is dimensionally transformed and denoted as , which is used as input to the subsequent CBAM for further feature attention.
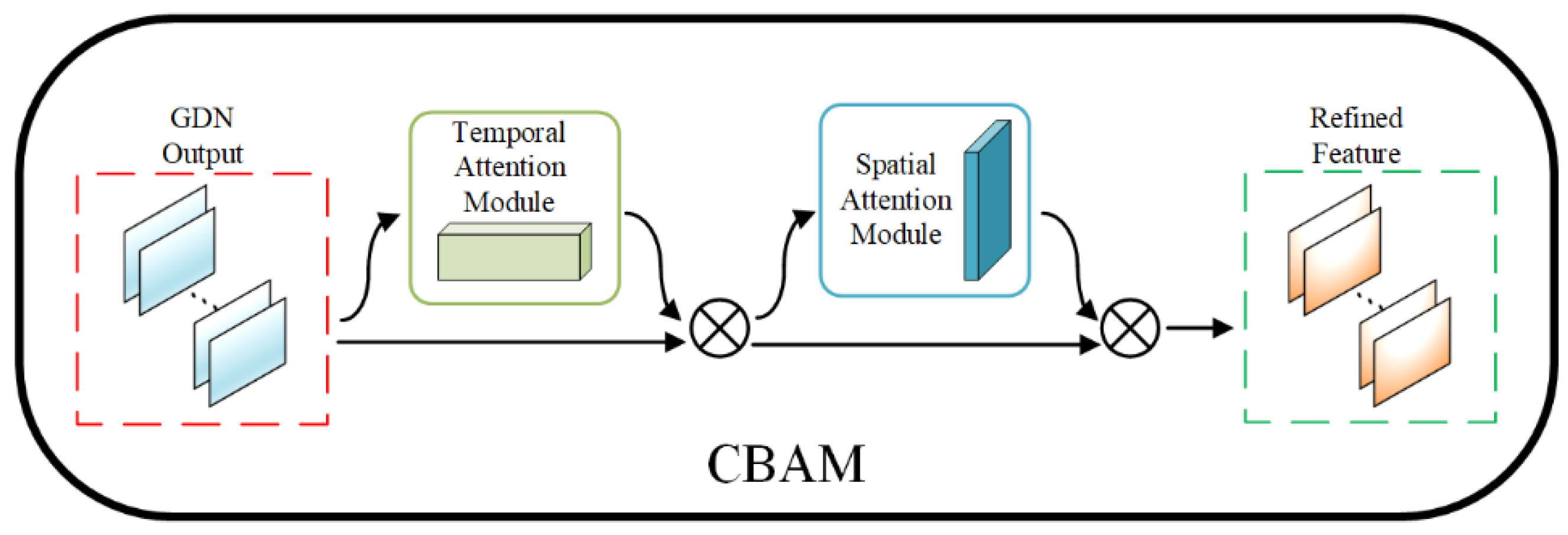
4.2. Convolutional Block Attention Mechanism (CBAM)
To augment the chiller fault diagnosis model’s ability to dynamically focus on fault data and improve its analysis accuracy, the CBAM is incorporated into the GDN model, forming a fault data attention mechanism.
CBAM has the ability to reduce redundant information in feature optimization by paying attention to the data twice to capture extremely subtle correlations within the data.
Figure 4 shows the overall process of CBAM.
As shown in
Figure 4, the output of the given GDN, i.e., the intermediate feature data
, is used as the input to CBAM. Where
C denotes the number of variables, and
H ×
W represents GDN preliminary processed data.
Temporal attention significantly enhances the network’s representation by integrating both average and maximum pooling features. These operations, referred to as
and
, are denoted as the average pooled features and maximum pooled features, respectively. These two descriptors are then processed through a multi-layer perceptron (MLP) with shared weights to generate two feature maps. The hidden layer activation size is set to
, and
r is the decay ratio. Finally, the temporal attention map is computed by element-by-element summation with a sigmoid function. The temporal attention is computed as:
where
denotes the sigmoid function,
,
.
The output of the temporal attention module is , which serves as the input to the spatial attention module.
Spatial attention was performed after temporal attention. It generates two two-dimensional feature maps by performing averaging and maximum pooling operations on the temporal dimension of the input feature maps of the chiller:
and
. These two feature maps are then processed through a convolutional layer to obtain the final spatial attention map using a sigmoid function.
where
denotes the sigmoid function,
denotes a convolution operation with a filter size of 7 × 7.
The final CBAM output is .
Given the GDN processed data, CBAM computes complementary attention through two attention modules, temporal and spatial, focusing on “what” and “where”, respectively. Eventually, the two modules are sequentially sorted, and temporal attention is prioritized for computation. Finally, the results of CBAM processing all variable data are fed into the fully connected layers to successfully achieve high-accuracy classification.
7. Conclusions
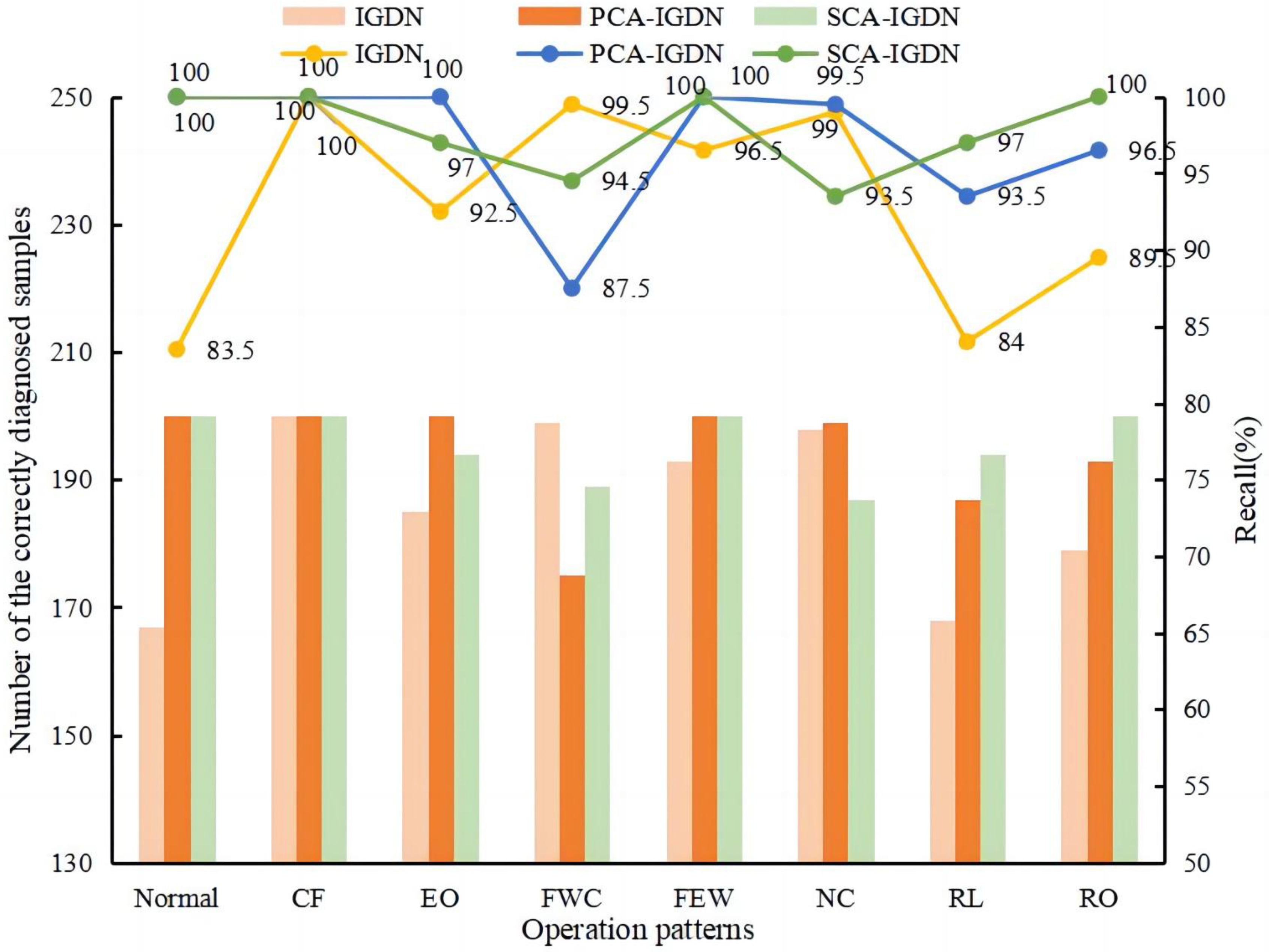
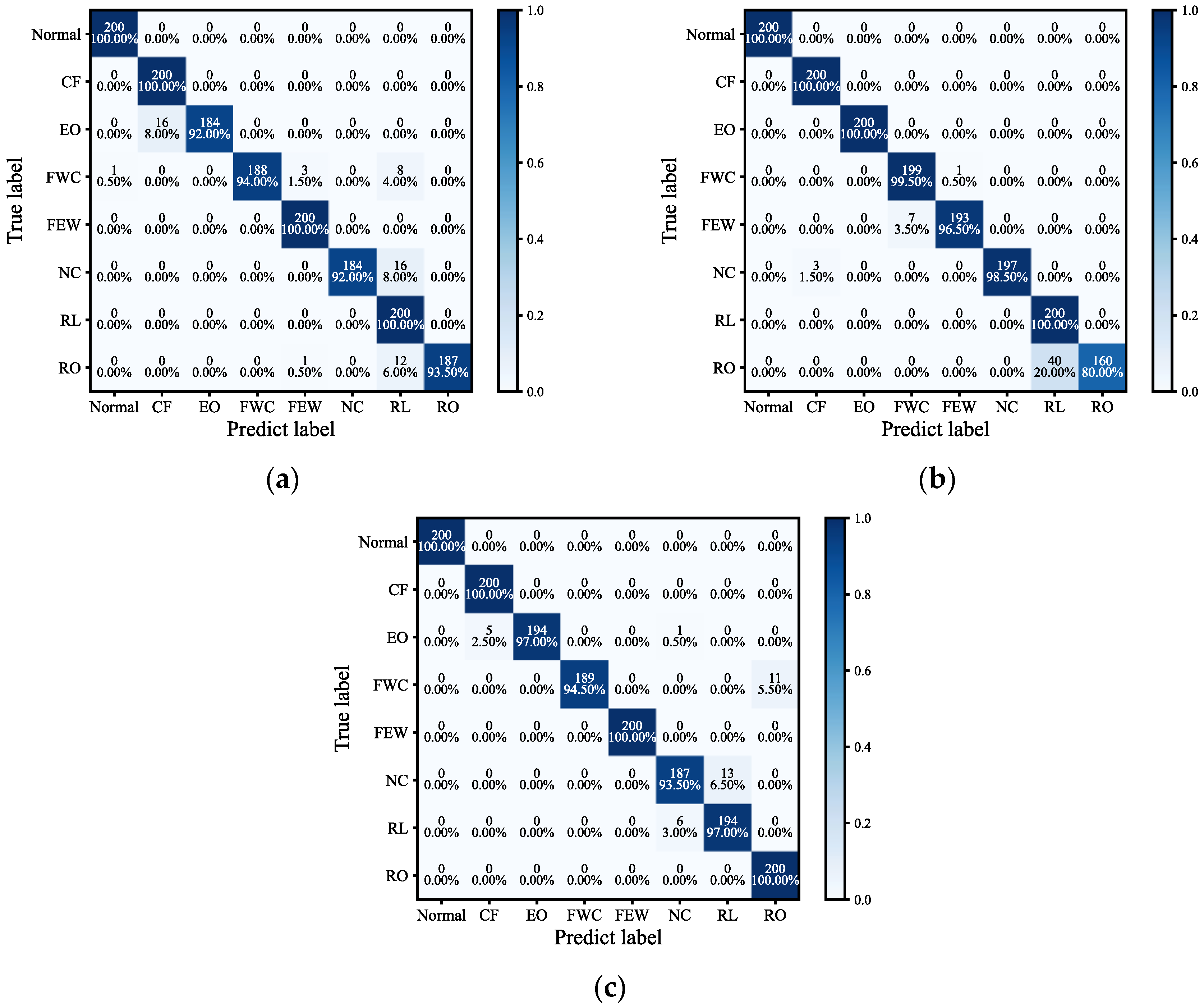
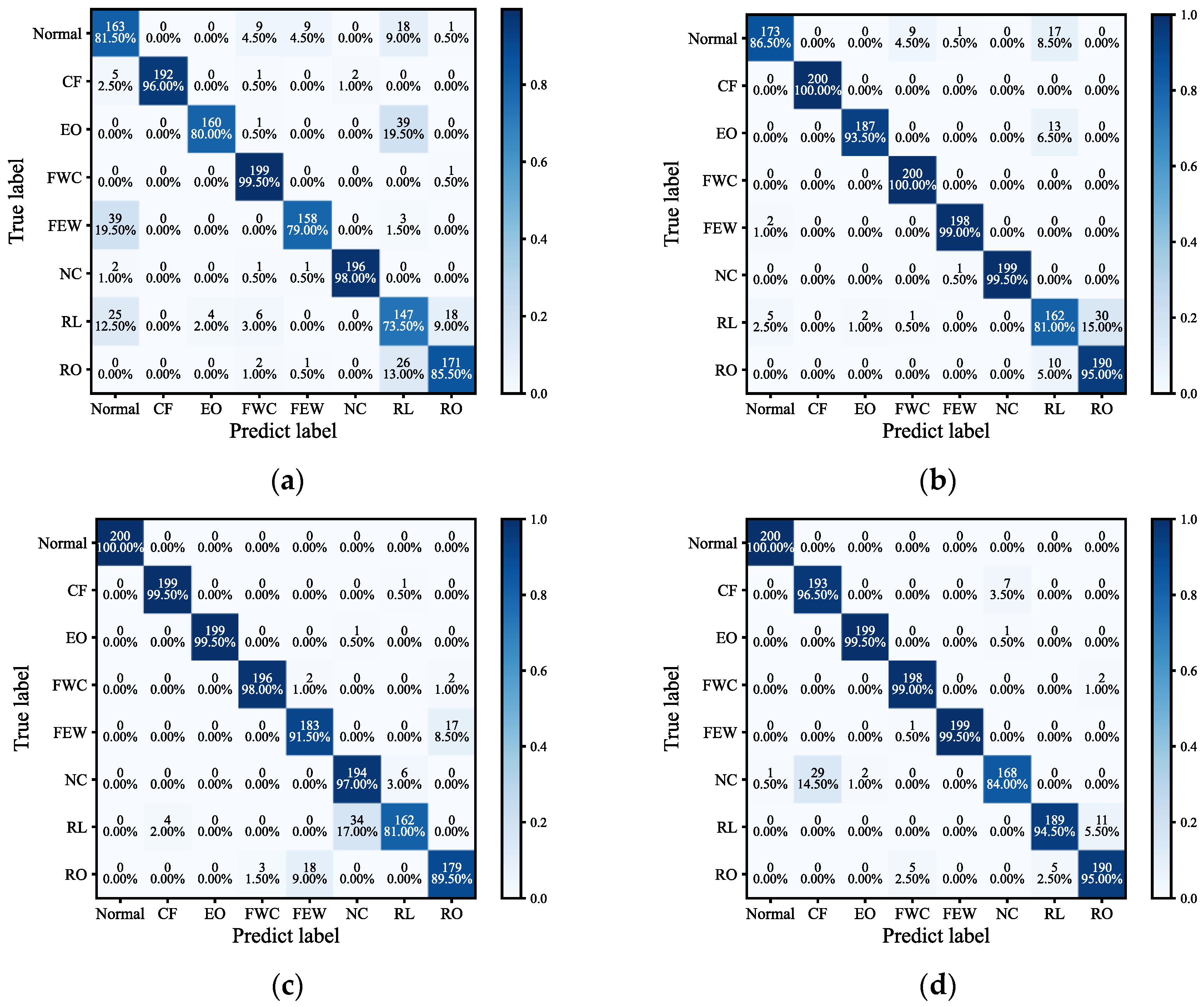
This study presents the SCA-IGDN method, a novel approach designed to enhance chiller fault diagnosis performance in non-stationary data environments. The SCA-IGDN method employs the developed SCA method, while the IGDN model is proposed in order to augment the diagnosis accuracy. SCA-IGDN demonstrates the capability to accurately extract sparse non-stationary features and derive fault decision features without relying on historical fault data. The feasibility and efficacy of SCA-IGDN are established through comprehensive comparative analyses against multiple models.
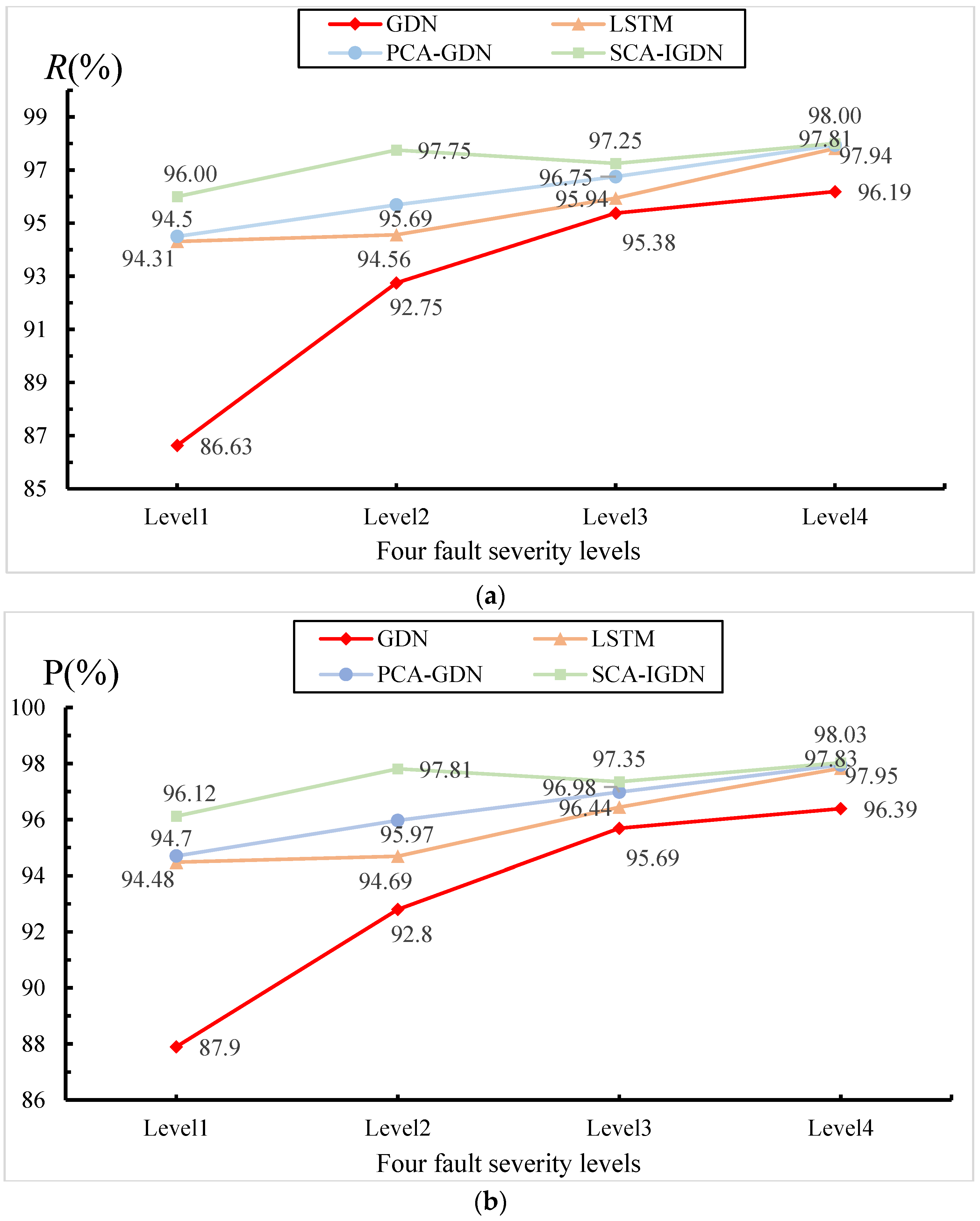
The primary contributions of this research are three-fold. Firstly, we capture the long-run equilibrium relationships between non-stationary variables and obtain sparse features. Secondly, a graph structure is created for the sparse correlation features. Finally, to increase the diagnosis accuracy, CBAM is incorporated into the GDN classifier to increase the attention to the data. On the ASHRAE 1043 dataset, by overall comparison with GDN, LSTM, and PCA-GDN methods, it is verified that the proposed SCA-IGDN method embodies excellent performance in chiller fault diagnosis based on non-stationary data. Specifically, the comparison with IGDN and PCA-IGDN demonstrates that the SCA method of the proposed SCA-IGDN model exhibits superior results in dealing with non-stationary data. In addition, compared with SCA-GDN and SCA-LSTM, it is demonstrated that the IGDN model exhibits superior performance in dealing with correlation features as well as enhancing data attention. To further demonstrate the feasibility of the proposed classifier after the SCA process, the paper concludes with detailed experiments on the propagation of faults across variable problems. The results reveal significant improvements in diagnostic R-value and p-value using the SCA-IGDN-based fault diagnosis method, thereby substantiating its accuracy.
It is noteworthy that the applicability of the proposed SCA-IGDN method extends beyond chiller fault diagnosis to other non-stationary operating systems, highlighting its versatility and potential for broader implementation. However, future research should focus on further reducing the computational complexity of the SCA-IGDN method to facilitate its practical application in real-world scenarios.
In addition, in the actual operation of the chiller, multiple faults may occur at the same time. Conventional fault diagnosis cannot recognize multiple faults. In future research, for this problem, advanced deep learning models can be utilized to capture the correlation features among different faults from complex high latitude data to achieve multiple fault diagnosis.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}