1. Introduction
As the impact of global climate change intensifies and the emphasis on sustainable development goals escalates, the management and mitigation of carbon emissions have risen to prominence within the international agenda. Governments worldwide acknowledge the critical need to curtail carbon emissions and are actively devising policies that foster carbon reduction initiatives. The 1997 Kyoto Protocol specified the targets for reducing greenhouse gases for industrialized countries from 2005 to 2020 and pro-posed three mechanisms for emission reduction: carbon emissions trading, joint fulfillment, and the Clean Development Mechanism [
1]. Among these, the carbon-trading mechanism serves as an effective market-based tool aimed at incentivizing reduction behaviors through the pricing of carbon emissions, incentivizing reduction efforts through the monetization of carbon emissions and serving as a fundamental strategy to meet greenhouse gas reduction targets [
2]. In 2020, China announced its dual carbon goals, underscoring the necessity to establish and refine market mechanisms and to harness the role of the national carbon emission trading market. Presently, China has operational carbon-trading markets in multiple cities including Beijing, Shanghai, and Guangzhou, with the cumulative transaction volume reaching 440 million tons and a transaction value of CNY 24.9 billion by the end of 2023, reflecting a dynamically evolving carbon market [
3].
The carbon market plays a crucial role in achieving global and regional climate goals. By pricing carbon emissions, it creates financial incentives for businesses and industrial sectors to reduce their carbon footprints [
4]. Carbon trading is categorized into two systems: cap-and-trade markets and voluntary markets. Cap-and-trade markets involve the allocation of carbon quotas by governments, usually distributed to businesses through auctions or free allocations and subsequently traded in the market. These quotas, often based on historical emissions and industry benchmarks, enable enterprises to actively participate in buying and selling [
5]. This mechanism is mandatory in regions like the European Union, the United States’ California, and China [
6]. Conversely, voluntary markets allow enterprises to engage in the trading of carbon credits voluntarily, often through participation in certified emission reduction projects, which are active in countries such as Canada and Australia [
7]. This market-driven approach encourages innovation and investment in clean technologies, promoting the transition to a low-carbon economy. These systems not only ensure the achievement of emission reduction targets but also provide businesses with the flexibility to comply in a cost-effective manner. By integrating various market products such as low-carbon investment funds and carbon credit futures, the carbon market offers multiple pathways for investors to support emission reduction efforts.
The carbon price, a pivotal element in the carbon market, is subject to influences from policy shifts, economic activity, energy price fluctuations, and climatic extremes. This complexity renders carbon price forecasting a formidable task. Accurate carbon price pre-dictions are vital for establishing a robust price discovery mechanism and for guiding decisions in production, management, and investment. The nonlinear, non-stationary, and multifaceted nature of carbon prices, coupled with the intrinsic risks distinct from traditional financial assets like stocks, necessitates a sophisticated approach to forecasting [
8,
9,
10].
Practically, precise carbon price forecasting is essential for enabling businesses and policymakers to make informed decisions. For businesses, it improves risk management, optimizes investment strategies, and facilitates efficient resource allocation. For governments, understanding carbon price dynamics helps in formulating more effective environmental policies, driving emission reductions, and advancing global climate objectives. Thus, the forecasting model presented in this paper is not only a theoretical innovation but also holds considerable potential for practical application, contributing significantly to the advancement of global sustainable development.
Accurate forecasting of carbon prices is imperative for informed decision-making by governments. The pricing mechanism serves as a pivotal component within the intricate carbon market system, significantly influenced by diverse factors such as energy prices, abnormal weather patterns, and political decisions [
11]. Early studies of the carbon market predominantly focused on elucidating the operational mechanisms of carbon trading, garnering substantial scholarly attention. For instance, Jesper and Rasmussen utilized a general equilibrium model to explore various methods of allocating tradable carbon emission rights, highlighting the potential compensatory benefits of emission rights [
12]. Similarly, Benz and Truck simulated different approaches to EU emission allowance returns, uncovering fluctuations in the demand for CO
2 quotas under distinct trading mechanisms [
13]. Tavoni et al. employed a comprehensive model to quantify the impacts of carbon-trading mechanisms on different regions, showcasing the efficiency and equity of the carbon market in promoting clean energy investments [
14]. Meanwhile, Daskalakis assessed the market efficiency of EU carbon futures, observing a gradual maturation of the EU ETS [
15]. These studies laid the theoretical foundation for the carbon market, emphasizing the important role of carbon-trading mechanisms in emission reduction and economic benefits. However, there remains a significant gap in the area of carbon price forecasting.
While acknowledging the carbon-trading market’s evolution towards resembling a financial market, recent research has delved into forecasting carbon prices to maintain market stability and inform investor strategies [
16]. This shift has seen the emergence of various forecasting methodologies, including traditional econometric models, emerging machine learning algorithms, and composite models. Chevallier pioneered the application of non-parametric models in carbon price forecasting, highlighting the nonlinear nature of carbon spot price data and their effectiveness through empirical evidence [
17]. Conversely, Koop and Tole utilized Dynamic Moving Average (DMA) to describe the characteristics of carbon prices, providing policy and statistical insights by flexibly capturing the dynamic changes in time series data [
18]. Byun and Cho used the GARCH model to handle the volatility in time series data and identified significant predictors of carbon prices, emphasizing the roles of electricity, coal, and Brent crude oil prices [
19]. Additionally, Han et al. used a Distributed Lag Model to forecast EU carbon prices, demonstrating the effectiveness of the GA-ridge algorithm in selecting predictive variables [
20].
The advent of machine learning has further revolutionized carbon price forecasting, utilizing powerful data analysis capabilities to capture nonlinear data characteristics. Atsalakis proposed computational intelligence techniques such as the hybrid neuro-fuzzy controller (PATSOS), artificial neural networks (ANN), and adaptive neuro-fuzzy inference system (ANFIS), which combine neural networks and fuzzy logic to capture the complex nonlinear features in carbon price data. Among these, PATSOS demonstrated the highest prediction accuracy [
21]. Abdi and Taghipour constructed a probabilistic model based on Bayesian neural networks (BNN), incorporating energy prices, economic growth, and weather conditions. Using Bayesian statistics to handle uncertainty and prior information, they improved the robustness and accuracy of carbon price predictions in the Western Climate Initiative market [
22]. Simultaneously, Jaramillo-Morán and García-García developed a multi-layer perceptron neural network (MLP) model, which processes complex nonlinear relationships through a multi-layer network structure to forecast carbon quota prices and examine the spatiotemporal relationships between electricity, steel, and carbon prices [
23]. Yahşi et al. explored various forecasting models and found that the Random Forest algorithm performed excellently in predicting EU carbon prices. The Random Forest approach constructs multiple decision trees and integrates the results of various models, enhancing the stability and accuracy of predictions [
24]. Additionally, Adekoya compared forecasting models using the Feasible Generalized Least Squares (FQGLS) estimation, which addressed heteroscedasticity and autocorrelation issues, highlighting the effectiveness of asymmetric models and the significance of energy prices in carbon price forecasting [
25].
In this context, this paper considers the impacts of policy, market, technology, and climate on the carbon market. By integrating traditional algorithms such as LASSO, LSTM, and RFR with a dynamic weighting hybrid strategy, and using Python 3.8 software, a superior carbon price forecasting algorithm is developed. The primary goal is to enhance the accuracy and robustness of carbon price predictions. By providing more accurate and reliable carbon price data, this model helps reduce market uncertainty and improve the scientific and effective nature of the decision-making process. This not only helps businesses remain competitive in a complex and volatile market environment but also assists policymakers in formulating more flexible and precise carbon emission policies, thus advancing global and regional climate goals. For businesses, accurate carbon price forecasts can optimize investment decisions, improve risk management, and facilitate efficient resource allocation. Policymakers can use carbon price forecasting models to create more targeted environmental policies, effectively promoting emission reduction goals. Investors can conduct more precise market analyses using the model, making more informed low-carbon investment choices. Additionally, regulatory bodies can use this model to monitor market dynamics, ensuring the stability and transparency of the carbon market, thereby enhancing market trust and participation.
The structure of this paper is as follows:
Section 2 details the materials and methods used, including data preprocessing and the hybrid forecasting model.
Section 3 presents the results and their analysis.
Section 4 compares the performance of various models. Finally,
Section 5 discusses the conclusions and future work directions.
3. Results
3.1. Example Selection
This study primarily utilizes carbon price data from the National Carbon Market (China). Predicting carbon prices is a complex process influenced by various factors. To more accurately predict carbon prices, we need to consider a series of relevant market indicators. Given that changes in carbon prices are closely related to the energy and financial markets, we must take these into account. The supply–demand relationship and price fluctuations in the energy market directly impact the demand for carbon emissions rights and investment decisions, thereby affecting carbon prices. Simultaneously, the financial market significantly influences carbon prices through financial innovation, capital flows, and policy and regulatory measures. Therefore, when predicting and analyzing carbon prices (), it is essential to comprehensively consider various factors from both markets.
The financial market indicators include the Shanghai Stock Exchange Composite Index (
), the midpoints of the USD to CNY (
) and EUR to CNY (
) exchange rates, and the China Enterprise Commodity Price Index (
). These indicators reflect the performance of the domestic stock market, exchange rate changes, and commodity price fluctuations, which impact the carbon market’s capital flows, investor sentiment, and supply–demand relationship. The energy market indicators include the closing price of crude oil futures (
), the price of liquefied natural gas (
), the price of industrial natural gas (
), and the Bohai Rim Steam Coal Price Index (
). The fluctuations in these energy prices directly or indirectly affect the supply–demand relationship and pricing in the carbon market, as shown in
Table 1.
In carbon price forecasting, the theoretical output results typically manifest as predicted carbon prices at a future point in time (such as the next day), and the model’s training process aims to align these predictions as closely as possible with actual observed values. The form of the output results can be flexible, either as a single day’s forecast or as a series of predicted values for future points in time, depending on the design of the model and specific requirements of the task. The expected accuracy of the forecasts is influenced by several factors, including the chosen model, the volume of training, data quality, and the complexity of the problem. Common metrics used to measure model performance include Root Mean Square Error (RMSE), Mean Absolute Error (MAE), Symmetric Mean Absolute Percentage Error (SMAPE), and accuracy. A comprehensive consideration of these indicators helps to assess the overall performance of the model and improve the accuracy of future carbon price changes.
The model and related procedures defined in this study allow for the training and prediction time series length to be set according to real-world conditions. For simplicity, this study selected an example using 5 days’ worth of data (a working week) as input, aimed at predicting the carbon price for the next day. The input data include carbon price data from the past 5 days, as well as other energy and financial market indicator factors. Regarding the output data, this report predicts the carbon price for the next day. The selection of this example is well justified. Firstly, using a shorter range of data can more sensitively reflect the short-term fluctuations in carbon prices, thus testing the model’s ability to capture market dynamics. Secondly, predicting the carbon price for the next day is a common task in practical scenarios and a focus of interest for investors and decision-makers; thus, it is representative of practical applications. Finally, the example includes multiple influencing factors, allowing the model to make predictions in more complex situations and verifying its robustness under the influence of multiple factors.
The object of the trial calculation’s verification is to compare the model’s predicted carbon price for the next day with the actual observed data. By comparing with actual data, the accuracy and reliability of the model in this short-term prediction task can be assessed. This verification object directly relates to the algorithm’s effectiveness in real-market applications, providing strong support for the model’s practicality. By choosing this example, this study aims to demonstrate the application effect of the carbon price prediction algorithm in real scenarios and provide a solid basis for validating the model’s performance.
Furthermore, to more comprehensively demonstrate the advantages of the proposed forecasting model, this study selected a complete dataset spanning from 4 January 2022 to 30 December 2023 for step-by-step prediction validation. The choice of such an extended time span aims to thoroughly evaluate the model’s adaptability to different seasons, cycles, and external factors, verifying its stability and robustness in long-term forecasting tasks. Through step-by-step prediction validation using the full-year data, this study can more comprehensively assess the model’s ability to capture carbon price fluctuations, further validating its feasibility and practicality in real market environments. This also helps reveal the model’s performance in long-term forecasting, providing decision-makers with more reliable market trend references.
To determine the optimal exogenous parameter settings in the proposed model, this study employed the GridSearchCV method, which optimizes model parameters by traversing a given parameter grid, in conjunction with cross-validation to identify the best parameter combinations. Specifically, we set a fine parameter grid ranging from 0 to 1 with an interval of 0.01 for the key parameter (regularization parameter) of the LASSO model. For the LSTM model, detailed parameter grids were set for the training batch size ([32, 64, 128]), the number of network layers ([1, 2, 3, 4]), and the number of neurons ([20, 40, 60, 80, 100, 120]). For the Random Forest model, we meticulously set parameter grids for the number of decision trees ([100, 200, 300]) and the maximum depth of each tree ([None, 10, 20, 30]).
Ultimately, through rigorous cross-validation, we selected the best-performing parameter combinations: the regularization parameter for the LASSO model was set at 0.1; the LSTM network structure was determined to be 3 layers with 100 hidden layer neurons; and the Random Forest model was set with 100 decision trees, each with a depth of 20. These key exogenous parameter settings provide strong support for the accuracy and reliability of the model in this study.
3.2. Results Analysis
To verify the predictive accuracy of the trial calculation example and to assess whether the hybrid algorithm offers an advantage, we can calculate four predictive accuracy indicators (RMSE, MAE, SMAPE, Accuracy) and make comparisons, as shown in
Figure 1.
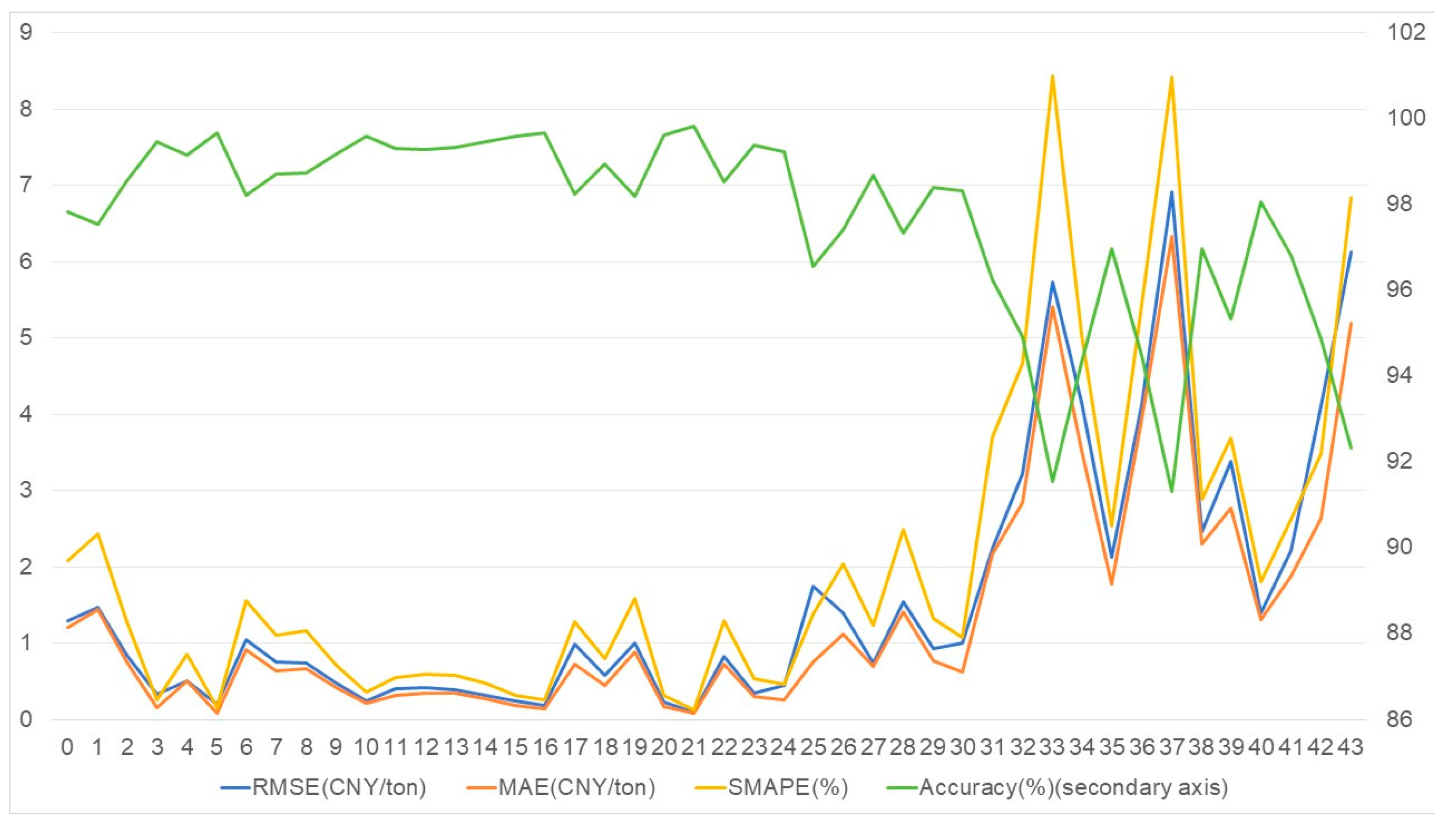
Figure 1 presents four evaluation metrics of the hybrid algorithm in carbon price prediction: RMSE, MAE, SMAPE, and Accuracy. The blue line represents RMSE, the orange line represents MAE, the yellow line represents SMAPE, and the green line represents Accuracy (right
Y-axis). As shown in the figure, the maximum values of RMSE and MAE are 6.1242 CNY/ton and 5.1882 CNY/ton, respectively. For most of the time, they remain below 1, with minimum values reaching 0.2352 CNY/ton and 0.2071 CNY/ton, indicating that the prediction error of the model is relatively small. The maximum value of SMAPE is 6.8337%, but it stays below 2 for most of the time, also indicating a relatively small error. The minimum value of Accuracy is 92.33%, and it remains above 95% for most of the time, indicating a high prediction accuracy of the model. Overall, these metrics demonstrate the effectiveness and reliability of the proposed hybrid algorithm in carbon price prediction.
Before proceeding with the comparative analysis, it is necessary to understand the range or standards of the indicators predetermined by the research objectives. Generally, lower values of RMSE, MAE, and SMAPE, along with a higher Accuracy value, indicate better predictive accuracy. We can initially compare the performance of the hybrid algorithm against three separate algorithms on these indicators to verify whether the hybrid algorithm has advantages across multiple metrics. The comparison between the prediction results and the original data is shown in
Figure 2.
Figure 2 shows the comparison between actual carbon prices and predicted carbon prices. The blue line represents actual carbon prices (CNY/ton), and the orange line represents the carbon prices predicted by the proposed algorithm (CNY/ton). The actual carbon prices underwent several significant phases from January 2022 to December 2023: slight fluctuations in early 2022, but generally stable between 55 and 60 CNY/ton; relatively stable from mid-2022 to early 2023, maintaining the same range of 55–60 CNY/ton; an upward trend from early 2023 to mid-2023, peaking at over 80 CNY/ton in mid-2023; and significant volatility from mid-2023 to the end of 2023, with a sharp decline followed by a recovery, stabilizing between 70 and 80 CNY/ton. The predicted carbon prices closely align with the actual prices. Overall, the proposed algorithm performs well in predicting carbon prices. Although there are slight delays or deviations in some periods, the overall trend is consistent with the actual prices. Especially in early 2022 and early 2023, the prediction results closely match the actual results. During periods of significant price volatility, the predictions still accurately reflect the actual price trends, demonstrating the model’s effectiveness and high prediction accuracy.
This study’s predictions perform generally well as the model successfully captures the overall fluctuation trend of carbon prices and achieves satisfactory predictive accuracy on many dates. Facing various complex market scenarios, the model demonstrates strong adaptability and successfully predicts changes in carbon prices. These results indicate that the hybrid forecasting algorithm in this study possesses high accuracy and robustness in predicting carbon prices, meeting the predetermined indicators of the research objectives and providing reliable decision support for handling uncertainties in the carbon market.
Despite significant progress in carbon price prediction, we must acknowledge the presence of some anomalies that were not predicted. These anomalies may be influenced by various unexpected events, policy adjustments, or other unpredictable factors, contributing to market volatility uncertainties. While adjusting model parameters can increase sensitivity to outliers, this often comes at the expense of overall predictive accuracy. Tuning the model to better capture outliers might make it more sensitive to noise or short-term fluctuations, thereby reducing its ability to accurately capture overall trends. When balancing the model’s sensitivity and stability, we need to weigh the response to outliers against the grasp of overall market trends.
Although the presence of unpredicted outliers does not affect the model’s reliability in general situations, we recommend integrating the model’s outputs with other market analysis tools in practical applications to fully understand the dynamics of the carbon market. Additionally, regularly monitoring model performance and making necessary adjustments based on market changes are key to maintaining the model’s accuracy and robustness.
Overall, the hybrid forecasting algorithm in this study demonstrates a relatively high level of accuracy and robustness in predicting carbon prices, providing decision-makers with a reliable decision support tool. However, we must remain cautious in using the model, recognize the presence of outliers, and adjust the model flexibly to adapt to dynamic market changes.
4. Comparison of Algorithmic Advantages
4.1. Logical Advantages
The carbon price forecasting algorithm developed in this study demonstrates several advantages in its logical design. First, it adopts a comprehensive algorithmic architecture that integrates various mature forecasting algorithms such as Lasso, LSTM, and RFR, making full use of their strengths in time series data analysis, feature capture, and nonlinear relationship modeling. Secondly, by introducing a dynamic weight mixing strategy, it flexibly adjusts the weights of each algorithm, thus better adapting to the dynamic changes in the carbon market. Most notably, the use of a dual sliding window enhances the model’s sensitivity to changes in carbon prices, enabling it to better adapt to the instantaneous fluctuations and long-term trends of the market.
4.2. Performance Advantages
In our comparative analysis, we conducted a comprehensive evaluation of the independent applications of the Lasso, LSTM, and RFR algorithms against the dynamic weight mixing forecast model proposed in this paper. The results from
Table 2 clearly show that the dynamic weight mixing forecast model in this study significantly outperforms the other forecasting algorithms when applied independently in terms of various evaluation metrics and overall accuracy.
Specifically, the Lasso algorithm’s RMSE (3.3767), MAE (1.983), and SMAPE (3.00855) values are relatively high, with an accuracy of only 91.94%. In contrast, the LSTM algorithm and RFR algorithm perform better on these metrics, but still not as well as the hybrid model developed in this study. The Autoregressive Integrated Moving Average (ARIMA) model and Exponential Smoothing algorithm perform even worse on these metrics, as shown in
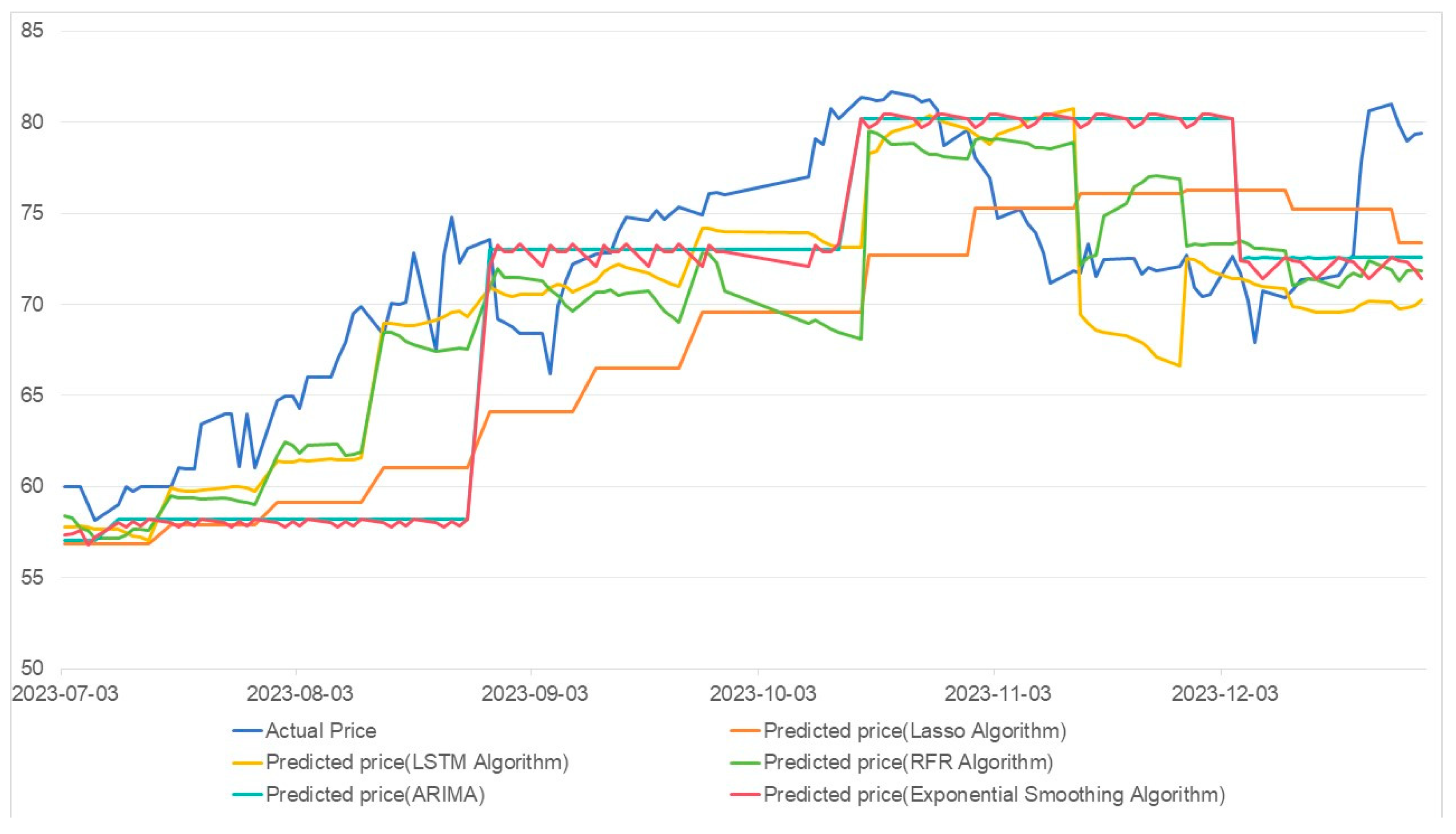
Figure 3.
The LSTM algorithm shows shortcomings in handling sudden changes in carbon prices, as evidenced by its poor performance during the sudden price drop in November 2023 and the sudden price rise in December 2023. The Lasso algorithm also lacks in capturing price volatility. The RFR algorithm sometimes fails to accurately capture changes in carbon prices; for example, when actual prices were rising in October 2023, the algorithm predicted a downward trend. Both the ARIMA model and the Exponential Smoothing algorithm can capture overall trends in carbon prices, but they fall short in addressing short-term price fluctuations.
The dynamic weighted hybrid prediction model proposed in this paper achieves RMSE, MAE, and SMAPE values of 1.5882, 1.35423, and 2.049, respectively, with an accuracy of 97.64%. This indicates that our model significantly surpasses traditional algorithms in terms of accuracy and robustness in carbon price prediction. By leveraging the strengths of the Lasso, LSTM, and RFR algorithms through a dynamic weighting strategy, our model provides more realistic predictions, offering more reliable decision support for carbon market participants. This significant performance improvement demonstrates the effectiveness and superiority of the hybrid prediction strategy adopted in this study.
In order to more comprehensively evaluate the performance of the model, we used a method of gradually eliminating indicators and carefully observed the changes in the prediction results of indicators such as mean absolute error (MAE), root mean square error (RMSE), symmetrical mean absolute percentage error (SMAPE), and accuracy. This allowed us to more accurately grasp the impact of each indicator on the prediction results.
In
Table 2, we learn that the algorithm model proposed in this article has scores of 1.5882, 1.35423, 2.049, and 97.64% in terms of RMSE, MAE, SMAPE, and accuracy, respectively. In
Table 3, we show the changes in the model’s RMSE after removing each metric. The “−” sign indicates a decrease in the corresponding value compared to the above scores, while the “+” sign indicates an increase in the corresponding value compared to the above scores.
From the analysis results of
Table 3, it is evident that price indicators have significant economic and managerial implications for the carbon market. Specifically, the price of liquefied natural gas (
) has the greatest impact on carbon price changes, as indicated by an increase in RMSE by 0.062752, in MAE by 0.063991, and in SMAPE by 0.111424, and a decrease in accuracy by 0.110185. This suggests that the price of liquefied natural gas is one of the most critical variables in carbon market pricing. Managers should closely monitor the fluctuations in the liquefied natural gas market and its impact on carbon prices, and develop corresponding risk management strategies. Conversely, the USD to CNY exchange rate midpoints (
) have the least impact, with RMSE increasing by only 0.00529, MAE by 0.004948, and SMAPE by 0.026189, and accuracy decreasing by 0.01317. This indicates that exchange rate fluctuations have a relatively minor impact on carbon market prices. When formulating carbon market policies and conducting market forecasts, less attention can be given to exchange rate changes, allowing more resources to be allocated to monitoring and analyzing energy prices, especially the price of liquefied natural gas, to improve the accuracy of prediction models and the effectiveness of management decisions.
4.3. Other Advantages
Beyond performance improvements, the algorithms in this study also possess other significant advantages. First, the algorithm fully utilizes information from different algorithms during the training phase and effectively avoids the limitations of a single algorithm under specific conditions through dynamic weight mixing. Secondly, detailed analysis of influencing factors and data preprocessing enable the algorithm to better adapt to the complexities of the carbon market, enhancing the adaptability of the model. Overall, the advantages of the algorithms in this study lie not only in their outstanding performance but also in their comprehensive consideration of multiple factors in their design, making them more practical and reliable. This provides decision-makers with a more comprehensive reference for carbon market trends, holding significant value for practical applications.




{kind=link}
{kind=link}
{kind=link}