1. Introduction
With the rise in worldwide energy consumption and the growing prominence of environmental concerns, governments and research institutions worldwide are paying more attention to developing renewable energy technologies. This trend aims to modify the energy structure and foster the sustainable advancement of society. Renewable energy sources, such as solar, wind, geothermal, and biomass, act as alternatives to conventional fossil fuels and can significantly reduce carbon emissions. Distributed generation technologies based on these energy sources are receiving high academic attention [
1,
2,
3,
4].
In simple terms, a microgrid is a small-scale power system that can operate independently of the traditional grid or be interconnected with it. Microgrids typically include various renewable energy sources, such as solar and wind power, energy storage devices, conventional generators, and loads [
5,
6,
7]. As an innovative way of supplying energy, microgrids can integrate multiple energy sources to achieve a more efficient, stable, and sustainable power supply. The core value of microgrids lies in their ability to integrate and optimally configure various energy sources [
8]. However, the high complexity and uncertainty of microgrids make their scheduling and management a significant challenge. Compared to traditional microgrids, microgrids have greater flexibility and response speeds, allowing them to react quickly to emergencies and load changes. However, this flexibility also brings more uncertainty, especially considering the weather dependency of renewable energy sources [
9,
10].
Various methods for controlling microgrid scheduling have emerged with the prevalence of microgrids. One of the earliest methods is rule-based scheduling, which defines how to schedule different resources under specific circumstances. In the work of Dimeas and Hatziargyriou [
11], they proposed a microgrid control method based on multi-agent systems and algorithms for the fair allocation problem, achieving optimal energy exchange between production units, local loads, and the main grid in the microgrid. Logenthiran et al. [
12] proposed the exploration of multi-agent coordination of Distributed Energy Resources (DERs) in microgrids, emphasizing the importance of defining clear operating rules based on the real-time status of the microgrid, such as load demand, renewable energy output, and the state of energy storage devices. In their research, Li et al. [
13] focused on the application field of smart home control, using rule-based methods for scheduling and managing devices. Lasseter and Paigi [
14] delved into the characteristics of microgrids as a conceptual solution. They discussed how microgrids can operate autonomously, interact with the traditional grid, or operate independently during a power outage through predefined rules and strategies.
The core advantage of Model Predictive Control (MPC) lies in its ability to self-correct uncertain predictions of the model and adaptively adjust the control sequence [
15]. It continuously optimizes its predictive model within a rolling time window. Many successful examples demonstrate the effectiveness of MPC in the energy management of microgrids. Molderink et al. [
16] studied the management and control of smart grid technology for households, adopting an MPC strategy to implement a three-step control method, including local forecasting, global planning, and real-time local control to schedule different household devices for more efficient energy use. Parisio et al. [
17] proposed a method based on MPC to optimize the operation of microgrids, conducting an in-depth exploration of different energy assets within the microgrid, aiming to maximize economic benefits and ensure stable operation. Garcia-Torres et al. [
18] published an article on the MPC of microgrid functionalities, discussing the applications and advantages of MPC in microgrids, summarizing the prospects of its application, and proposing future issues and challenges that need to be addressed. While the above methods have achieved certain success in the control of microgrids, they all have their drawbacks. Rule-based scheduling methods need more flexibility and adaptability, and MPC methods rely on accurate mathematical models of the system.
Reinforcement learning (RL) [
19] is an adaptive learning method that operates through a “trial-and-error” approach. RL algorithms continuously interact with the environment, perceiving the state of the environment and implementing corresponding control strategies to alter that state [
20]. Subsequently, based on the rewards received, the agent updates model parameters to maximize cumulative reward returns. Through this cycle of perception, action, evaluation, and learning, the agent progressively refines its strategy to adapt to changes in the environment and identifies the optimal strategy. RL has been widely applied in various fields, including autonomous driving [
21,
22], robotic control [
23], and gaming [
24]. Using RL for microgrid scheduling has the advantage of improving the efficiency of the microgrid and enhancing its adaptability to environmental and market changes. Many papers have demonstrated the feasibility of using RL for energy management in microgrids. Bui et al. [
25] proposed a new approach that combines centralized and decentralized energy management systems and applied Q-learning to the operational strategy of Community-Based Energy Storage Systems in microgrid systems. This approach can enhance the efficiency and dependability of microgrid systems while reducing learning time and improving operational outcomes. The research in the paper has important theoretical and practical significance for intelligent energy management in microgrid systems. Alabdullah and Abido [
26] proposed a method based on deep RL for solving the energy management problem of microgrids. By implementing an efficient deep Q-network algorithm, this method can schedule diverse energy resources within the microgrid in real time and implement cost-effective measures under uncertain conditions. The research results show that the proposed method is close to optimal operating cost results and has a short computation time, demonstrating the potential for real-time implementation. Mu et al. [
27] proposed using a multi-objective interval optimization scheduling model and an improved DRL algorithm called TCSAC to optimize microgrids’ economic cost, network loss, and branch stability index. The effectiveness of the proposed method was verified through simulation results, rendering it a significant asset for scholars and practitioners in the domain of smart grid technology.
RL offers significant advantages in multi-objective optimization and real-time decision-making in microgrid scheduling. By using RL, microgrid energy management systems can achieve adaptive regulation, enhance system flexibility and robustness, optimize energy usage efficiency, reduce operational costs, and improve adaptability to external changes such as weather variations and market price fluctuations. However, there are notable drawbacks, such as the requirement for extensive training data and a lack of capability to rapidly adapt to new environments.
With the development of artificial intelligence and machine learning technology, meta-learning has become an essential branch of machine learning, attracting much attention due to its many advantages, such as fast adaptation to new tasks and low data requirements [
28,
29,
30]. The goal of meta-learning is to enable models to accumulate experience during the learning process and utilize this experience to quickly adapt to new tasks or environments, thereby reducing dependence on extensive labeled data and enhancing learning efficiency. The essence of meta-learning lies in enabling models to learn general knowledge across a series of related tasks, allowing them to rapidly adjust parameters with minimal data during iterations when encountering new tasks. Meta-learning has been widely applied across multiple fields. In natural language processing, meta-learning can help models quickly adapt to new languages, dialects, or specific domain texts, improving the model’s performance in few-shot learning and cross-lingual transfer learning [
31]. In image recognition, meta-learning is used to train efficient classifiers with only a few labeled samples [
32]. Meta-learning is particularly important for medical image analysis and biometric recognition, where obtaining a large amount of labeled data is often difficult or expensive. In fields such as autonomous driving and weather forecasting, meta-learning can be used to quickly adjust model parameters under different environments or conditions, ensuring the stability and accuracy of the model [
33].
The generalization ability of meta-learning, which allows for quick learning from past experiences and adaptation to new tasks, can effectively compensate for the deficiencies of RL in microgrid scheduling. Consequently, this paper proposes a method for real-time microgrid scheduling that combines meta-learning with RL. The contributions of this article to the research field are shown below.
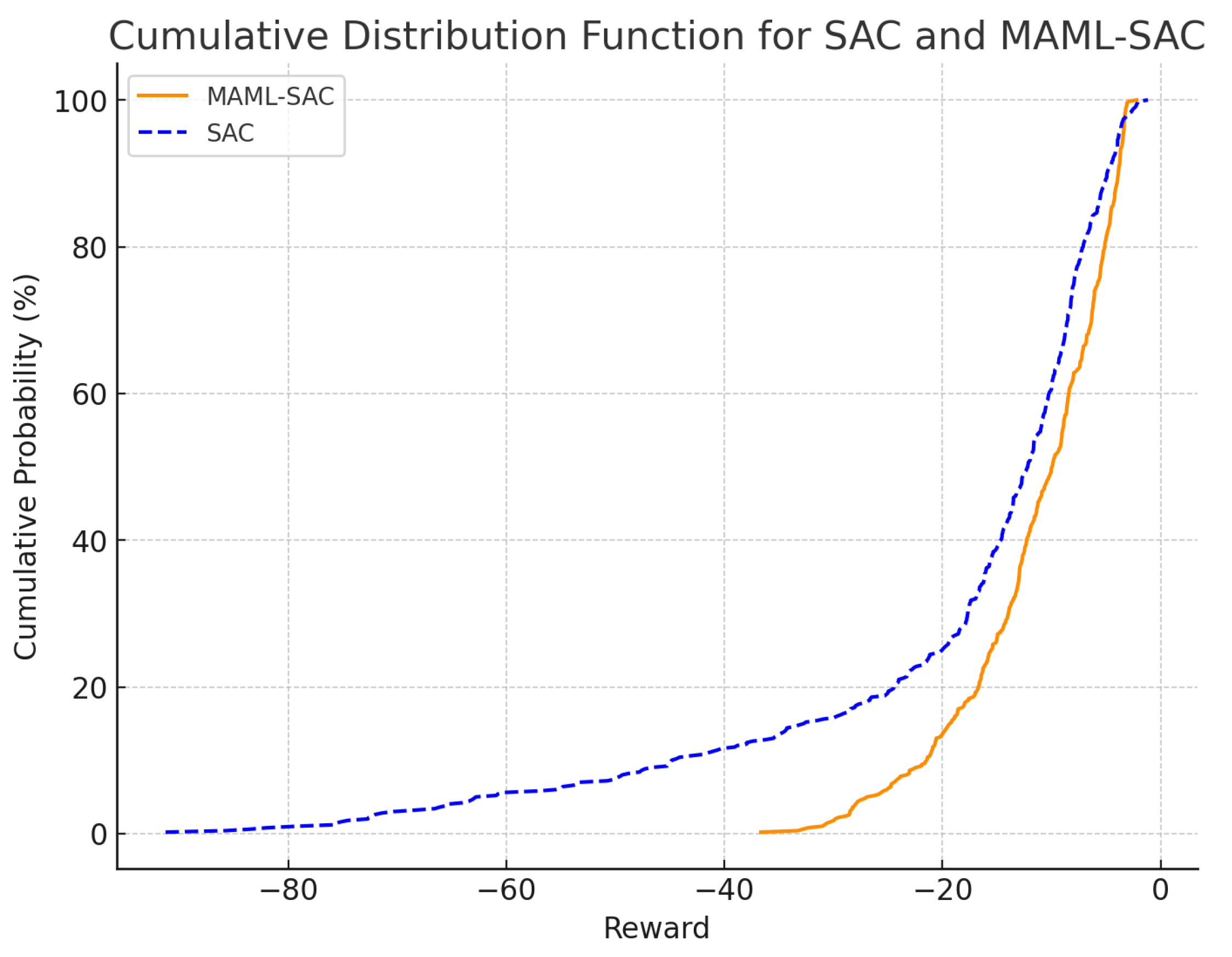
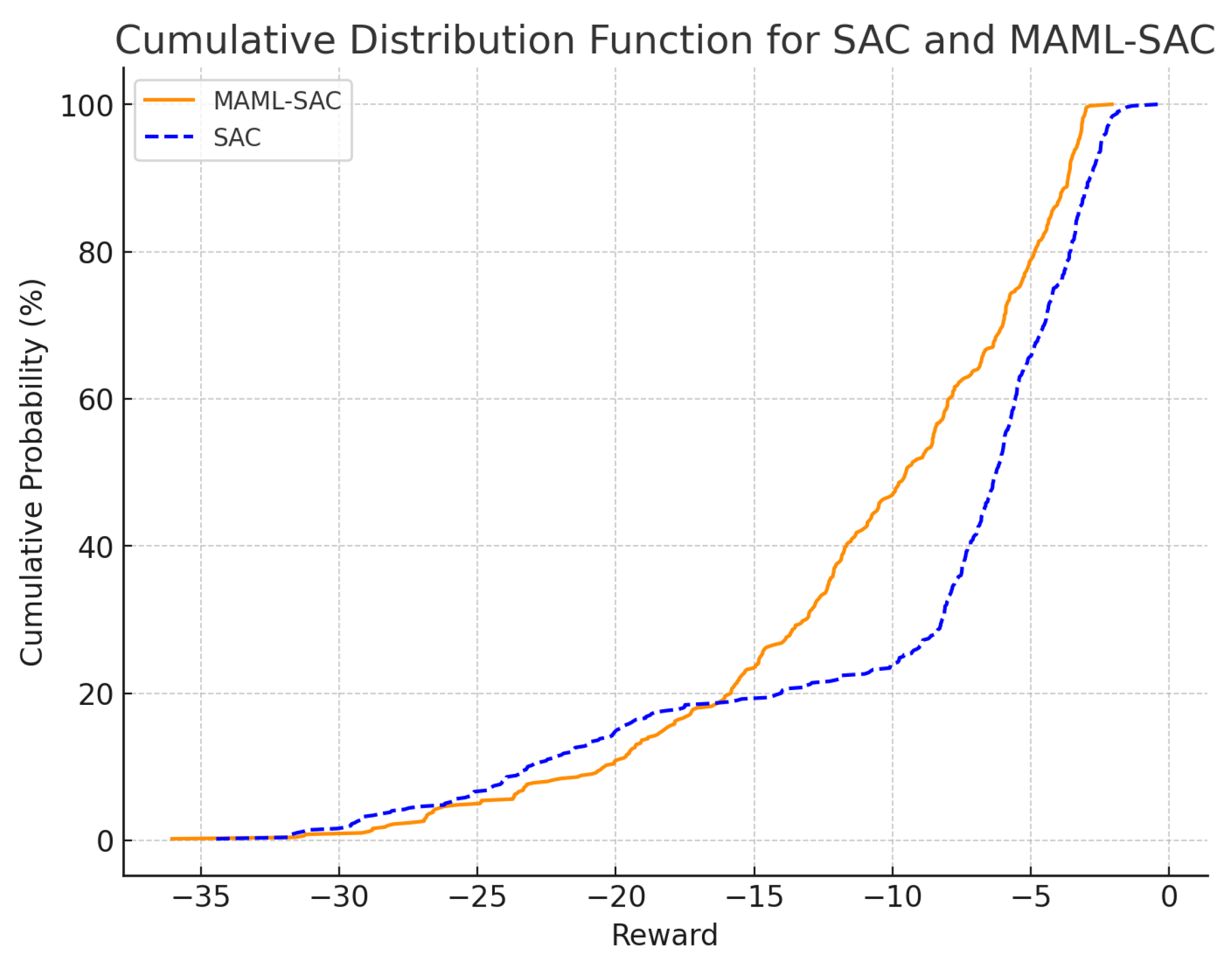
1. This paper proposes a novel algorithm based on Model-Agnostic Meta-Learning (MAML) and Soft Actor–Critic (SAC), Model-Agnostic Meta-Learning for Soft Actor–Critic (MAML-SAC), which is able to quickly adapt to new microgrid environments with a small amount of training data. Compared to the Soft Actor–Critic algorithm, the algorithm proposed in this paper makes better decisions in the early stage of microgrid operation with scarce data.
2. This paper provides new ideas for the real-time scheduling of microgrids. The algorithm of meta-reinforcement learning is used for decision-making at the beginning of microgrid operation when data is scarce. As the amount of data increases, RL is applied at appropriate times for training and decision-making.
3. In the proposed meta-reinforcement learning framework, we introduce a dynamic learning rate adjustment mechanism and residual connection technology to promote the effective flow of information and the efficient propagation of gradients. Integrating these techniques enables the algorithm to adapt quickly to new environments, improving learning efficiency and generalization ability.
4. RL methods typically require a large amount of training data from the current environment for prolonged training. In contrast, the meta-reinforcement learning method proposed in this paper achieves microgrid optimization scheduling in a short time by pre-training and fine-tuning.
The rest of the paper is organized as follows:
Section 2 introduces the components of a microgrid and describes the problem in mathematical terms.
Section 3 presents our proposed MAML-SAC model.
Section 4 presents the experimental setup and experimental results. Finally, we give conclusions and summarize in
Section 5.
3. The Framework of the Proposed Method
3.1. Markov Decision Process (MDP)
A Markov process is a stochastic process in which the probability distribution of future states is solely contingent upon the present state and not on the sequence of preceding states. This property is called “memorylessness” or “Markov property”. The problem described in the previous chapter can be formulated as a Markov process and modeled as a quintuple . S represents the set of system states. A represents the set of actions. P represents the state transition probabilities, where denotes the probability of transitioning from state s to state s′ under action a. R represents the reward function, where R(s, a) denotes the reward received after taking action an in-state s. is the discount factor, ranging from 0 to 1. A larger value of places more emphasis on long-term accumulated rewards. This Markov process formulation is frequently employed in RL to model decision-making scenarios in which an agent engages with an environment to maximize cumulative reward.
3.2. MDP Modeling of Microgrid Environments
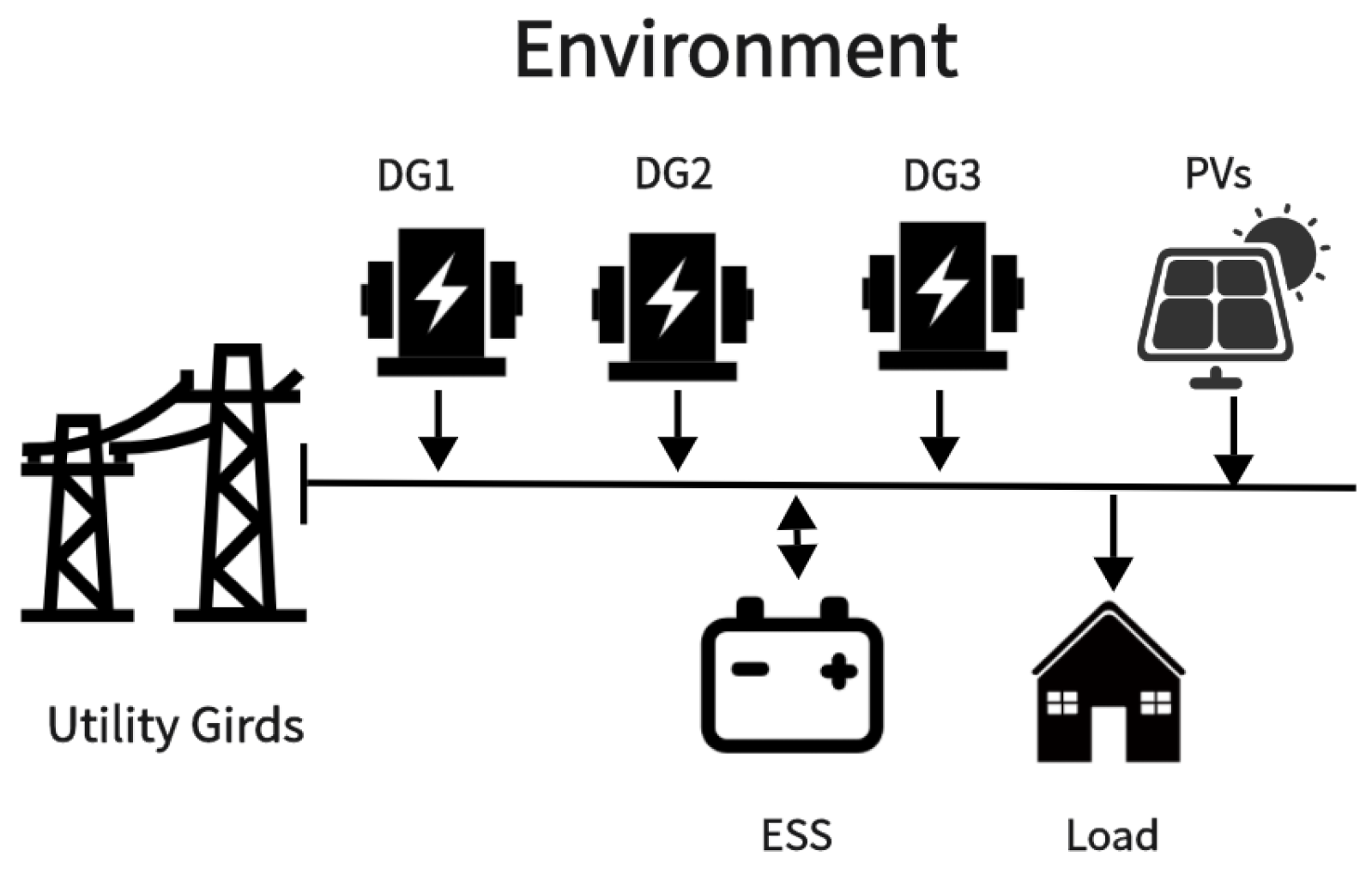
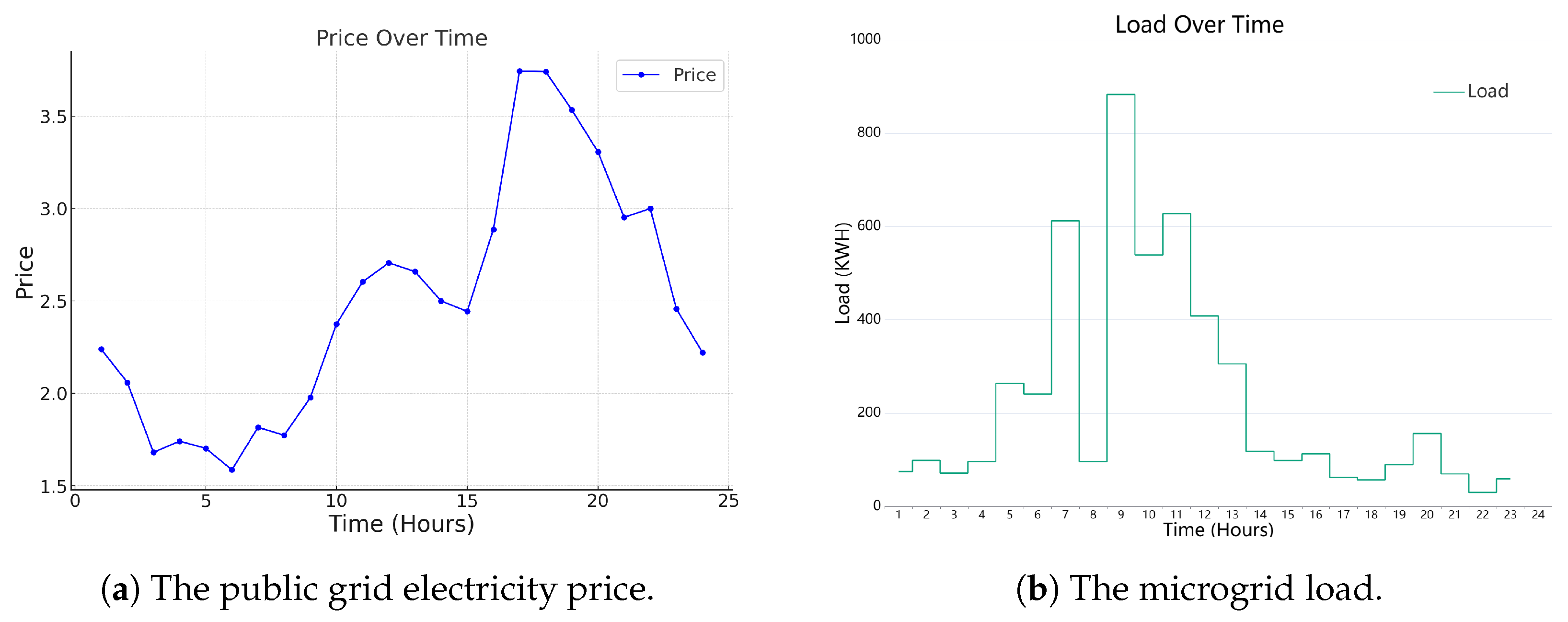
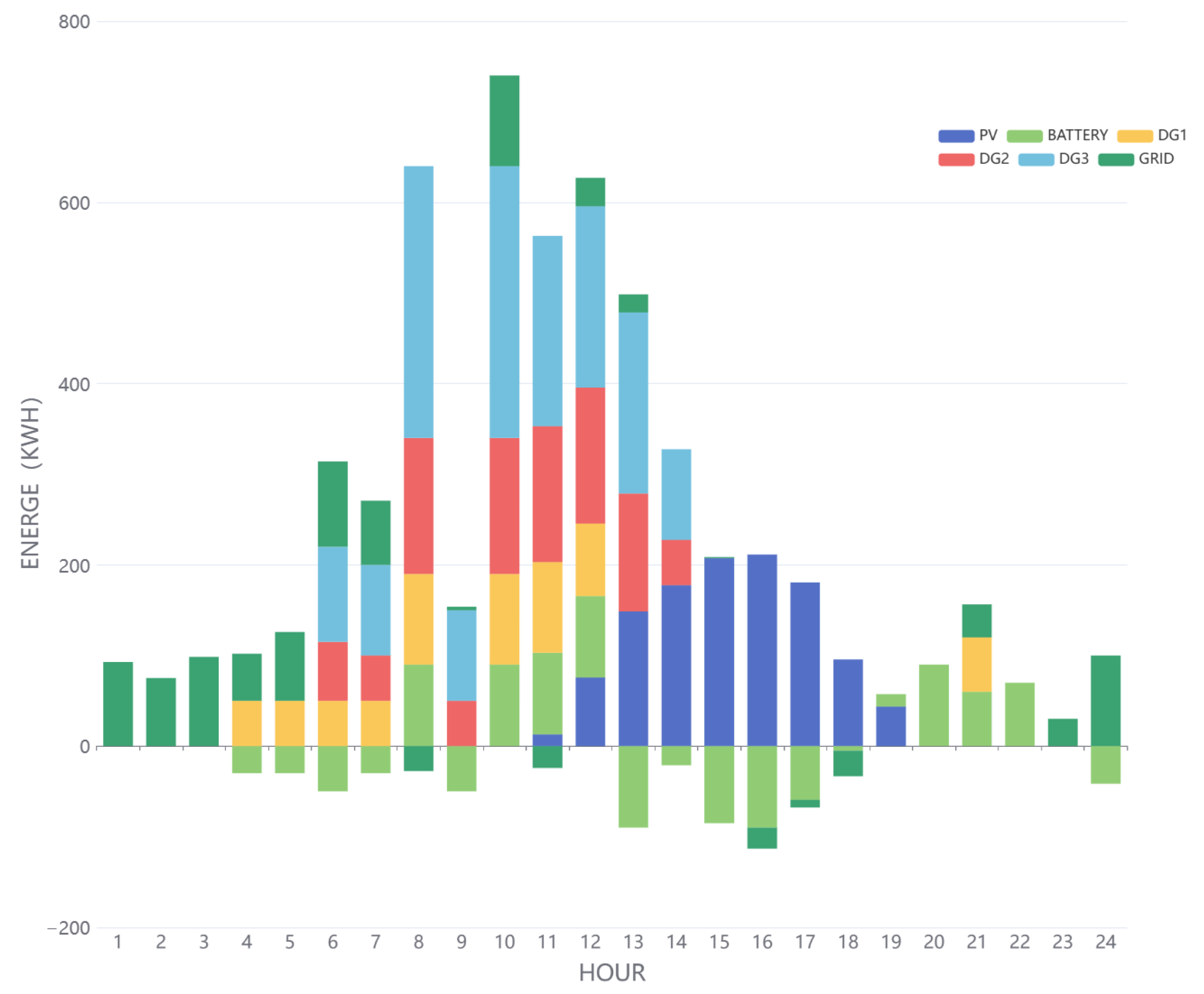
In the Markov process, the RL agent controls energy scheduling, and the state information serves as a crucial foundation for the agent. We define the state space as follows: , where t is the timestamp, p is the electricity price of the main grid, soc is the remaining energy of the ESS, is the current load, and is the power generation of the generator. The action space for the agent to control energy scheduling is , where is the charging/discharging power of the ESS, and is the status of the generator. The agent cannot control the exchange power between the microgrid and the main grid. After taking action, the main grid balances the load by inputting/outputting electrical energy, and there is a maximum power limit for input and output.
In time
t, given the state
and action
, the probability of the system transitioning to the next state
is denoted by the state transition probability:
In RL, the reward r is provided by the environment and guides the direction of policy updates. In the microgrid optimization scheduling problem discussed in this paper, the reward function should direct the agent to take actions that reduce operating costs.
In the microgrid optimization problem context, the cost
C(
t), i.e.,
C(
t) in (
14), represents the expenses associated with purchasing electricity from the main grid and the operation of generators. The term
represents the imbalance at time t, which could be due to a shortage or surplus of electricity. The parameters
and
balance the trade-off between minimizing costs and penalizing power imbalances. The RL algorithm aims to find an optimal scheduling policy that maximizes the total expected discounted reward over the defined MDP. This involves making decisions that minimize costs and balance supply and demand in the microgrid.
3.3. MAML-SAC
Based on RL, the Soft Actor–Critic (SAC) algorithm has advantages in microgrid applications, such as real-time decision-making and control, multi-objective optimization, strong robustness, and efficient energy management. However, RL methods still face challenges, such as low sample efficiency and the need for accurate environmental models.
A combined approach of Model-Agnostic Meta-Learning (MAML) and SAC, called MAML-SAC, has been proposed to tackle these challenges. MAML is a meta-learning method that enables fast adaptation to new tasks with a small amount of data, which can help improve sample efficiency. By integrating MAML with SAC, the MAML-SAC method can leverage the strengths of both approaches, enabling more efficient and effective learning and decision-making in microgrid energy management.
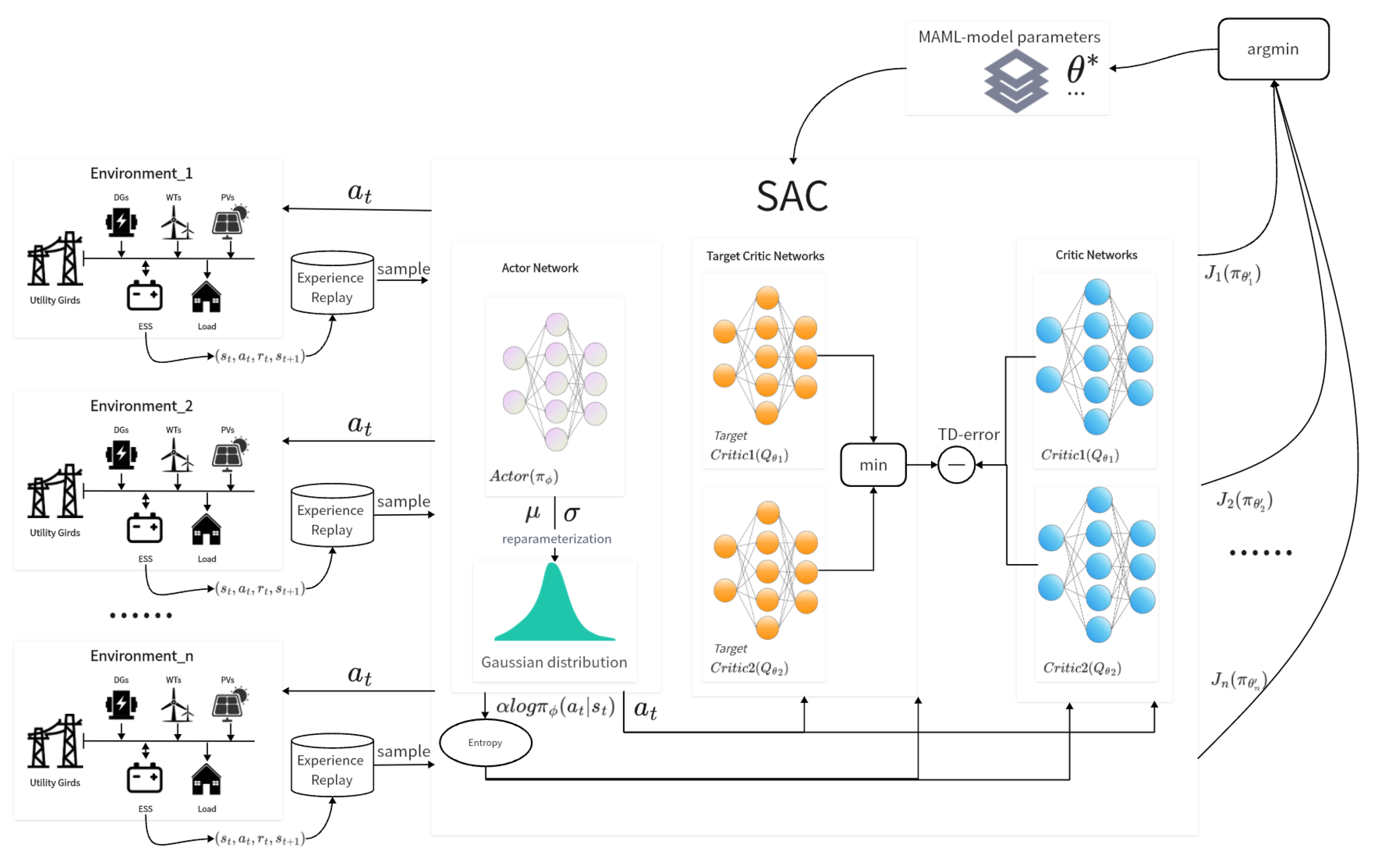
Figure 1 shows the training process of the MAML-SAC model. The first step in the MAML-SAC approach for microgrid control is task sampling. This step randomly sampled a series of microgrid tasks from the task distribution. These tasks can vary based on different factors such as time, internal conditions of the microgrid, and other variables that represent different operating scenarios. This sampling process is crucial for ensuring that the model is subjected to a wide array of scenarios, which helps in learning a generalizable set of initial parameters that can quickly adapt to new tasks.
The next step is model initialization. This step selects an RL model suitable for the microgrid optimization problem. For the MAML-SAC approach, the SAC architecture is chosen due to its ability to handle continuous action spaces and its balance between exploration and exploitation. The model parameters, including those of the policy network and the Q-network, are then initialized. These initial parameters serve as the subsequent steps’ starting point for the adaptation process. The goal is to learn a set of initial parameters that can be quickly fine-tuned to perform well on new tasks with minimal additional training.
The training process in the MAML-SAC approach for microgrid control is divided into two main loops: the inner loop (fast adaptation) and the outer loop (meta-learning update). The inner loop of the MAML-SAC approach involves the following steps for each sampled task: (1) exploration and data collection: The current policy is executed to interact with the microgrid environment, collecting data on states, actions, rewards, and the next states. This step is crucial for gathering the experience necessary to adapt the policy to the specific task. (2) Gradient update: Based on the collected data, the gradient of the policy is computed and the model parameters are updated. The number of updates is usually kept small to enable quick adaptation to the task. In the case of SAC, this involves updating both the policy network and the Q-network. (3) Policy evaluation: The adapted policy is tested on different instances of the same task to evaluate the model’s adaptability. This step assesses how well the model has adapted to the task with the limited updates performed in the previous step. These steps are repeated for each task in the batch, allowing the model to adapt to various microgrid operating scenarios. The goal is to learn initial parameters that can be quickly fine-tuned for effective performance on new tasks.
After completing the inner loop, the model’s performance across multiple tasks adjusts the meta-learning parameters. This typically involves the following steps: (1) loss function aggregation: The average loss across multiple tasks is aggregated, which reflects how well the model adapts to new tasks. This aggregated loss is used to guide the meta-update. (2) Meta-update: Gradient descent is used to update the meta-parameters. This step aims to improve the model’s ability to quickly adapt to new tasks. The meta-parameters are updated in a direction that reduces the aggregated loss, which indicates better adaptability. The process of repeating the inner and outer loop continues until the agent’s performance reaches a satisfactory level. Through this iterative process, the model learns a set of initial parameters that can be effectively fine-tuned to perform well on various microgrid operating scenarios, enhancing the flexibility and efficiency of the microgrid control system.
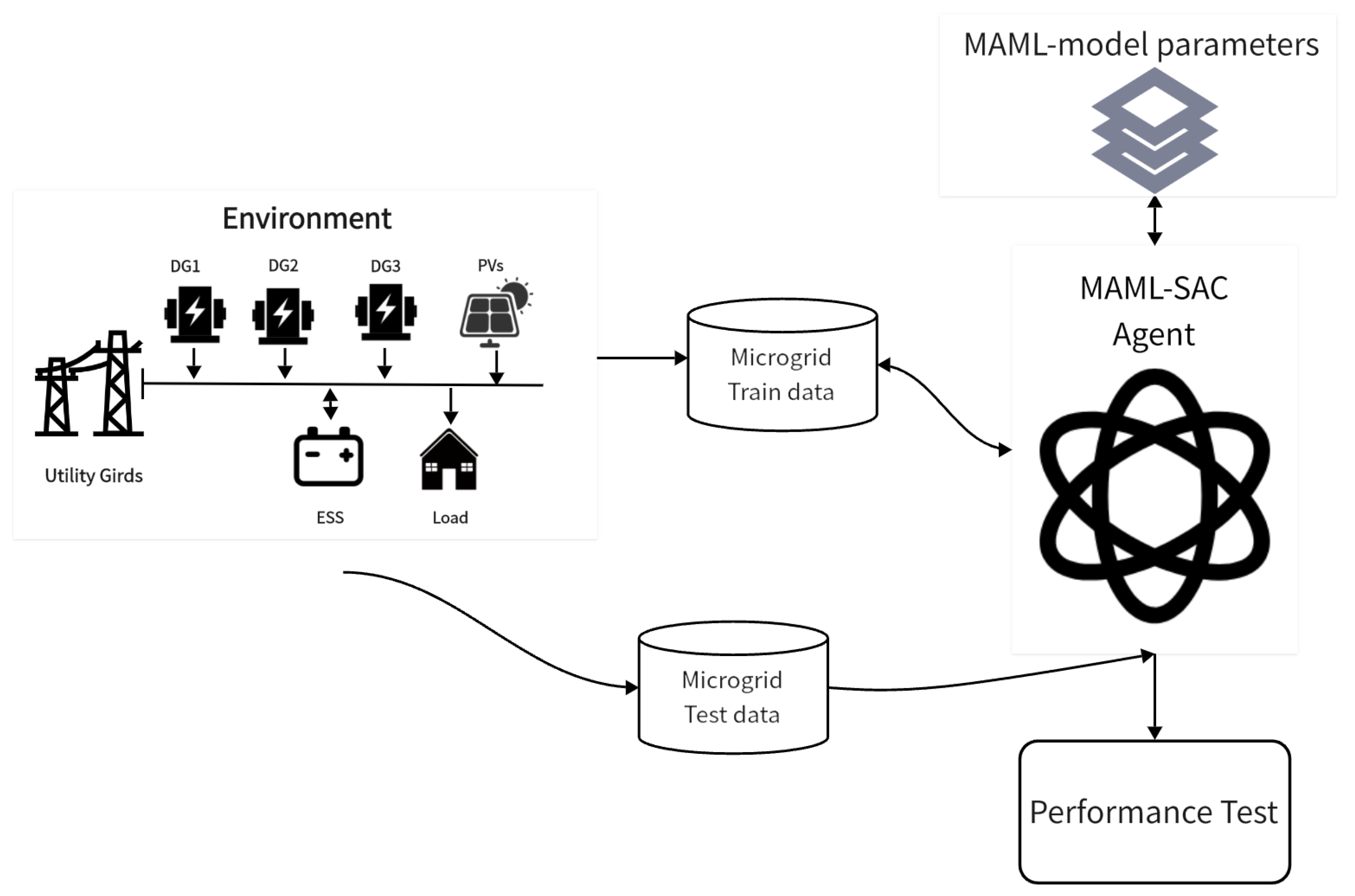
Figure 2 shows the task adaptation phase of the MAML-SAC model. When facing a new microgrid optimization task, the model trained during the meta-learning phase is a starting point for rapid adaptation. By interacting with the new task environment, the model continues to collect data, and these data are used to further fine-tune the model parameters, enabling the model to maximize its adaptability to the specific microgrid configuration. After adapting to the new task, the model’s performance is tested. Based on the test results, the model can be deployed to optimize the operation of the microgrid.
When combining MAML and SAC, the goal is to train a microgrid control policy that can quickly adapt to different operating conditions. The objective function for this approach can be defined as follows:
In the context of the MAML-SAC objective function,
N represents the number of tasks, and each task
corresponds to a specific microgrid operating scenario. The objective function
for task
using the SAC algorithm can be defined as:
where
r(
s,
a) is the immediate reward obtained by taking action a in state
s.
represents the expected value of the value function
for the next state
s′, where
p is the state transition probability.
is the entropy regularization term, which encourages exploration in the policy, and
is the temperature parameter.
For each task
, the policy and value networks are updated through gradient descent. The updated equations can be expressed as follows:
where
and
are the learning rates for the policy network and the value network, which controls the step size of the gradient descent update for the policy parameters
and the value network parameters
.
By applying MAML, the model learns parameters and , which enable the policy and value networks to quickly adapt to new microgrid operating tasks with just a few gradient updates. This allows the microgrid control system to efficiently manage and optimize energy resources when faced with different operating conditions and demands.
3.4. Dynamic Learning Rate and Residual Connection
A dynamic learning rate can automatically adjust the learning speed based on the characteristics of different tasks, adopting different learning strategies at different stages and enabling the model to adapt more quickly to new tasks. This is particularly important for rapid adaptability in meta-reinforcement learning. In the later stages of training, reducing the learning rate can reduce the model’s overfitting to training data, thereby improving the model’s generalization ability on new tasks. More importantly, in meta-reinforcement learning, where the model needs to switch between multiple tasks, dynamically adjusting the learning rate can prevent training oscillations caused by excessively large learning rates, maintaining the stability of the training process.
Incorporating residual connections into the meta-reinforcement learning model can help information propagate more effectively through the network, reducing the problem of vanishing gradients during training and accelerating the learning process. This is particularly important in meta-reinforcement learning, as rapid adaptation to new tasks is one of the core goals of meta-learning. Residual connections can also enhance the model’s generalization ability and capacity to represent complex functions, leading to better performance when facing new tasks. This is because residual connections help retain the original input information, allowing the model to better adapt to new environments and tasks. By preserving the input information through the network layers, the model can learn more complex mappings between inputs and outputs, making it more versatile and effective in various microgrid optimization scenarios.
In summary, incorporating residual connections and dynamic learning rates in meta-reinforcement learning can offer several advantages, including accelerating the learning process, improving generalization ability, and preventing training oscillations. These enhancements can make the meta-learning model more effective and efficient in adapting to new tasks and environments, which is crucial for optimizing microgrid operations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}