The proposed approach has been applied to the Italian electricity market, which is divided into seven market regions or zones, as shown in
Figure 2. The Italian electricity market comprises a network of seven distinct market regions or zones, each characterised by its unique set of attributes and operational dynamics. These zones exhibit notable variations across multiple dimensions, including demographic composition, industrial infrastructure, energy consumption patterns, geographical features, and climatic conditions [
39]. For instance, certain regions may be densely populated urban centres with high industrial activity, leading to pronounced peaks in energy demand during specific hours of the day. In contrast, other zones might encompass rural areas characterised by agrarian economies, where energy usage patterns differ significantly due to factors such as agricultural operations and seasonal variations. Additionally, geographical considerations, such as proximity to renewable energy sources like hydroelectric or solar power plants, play a pivotal role in shaping the energy generation mix and overall market dynamics within each zone. Furthermore, climatic variations across different regions influence factors such as solar availability, further contributing to the heterogeneity observed in energy production patterns. As delineated in
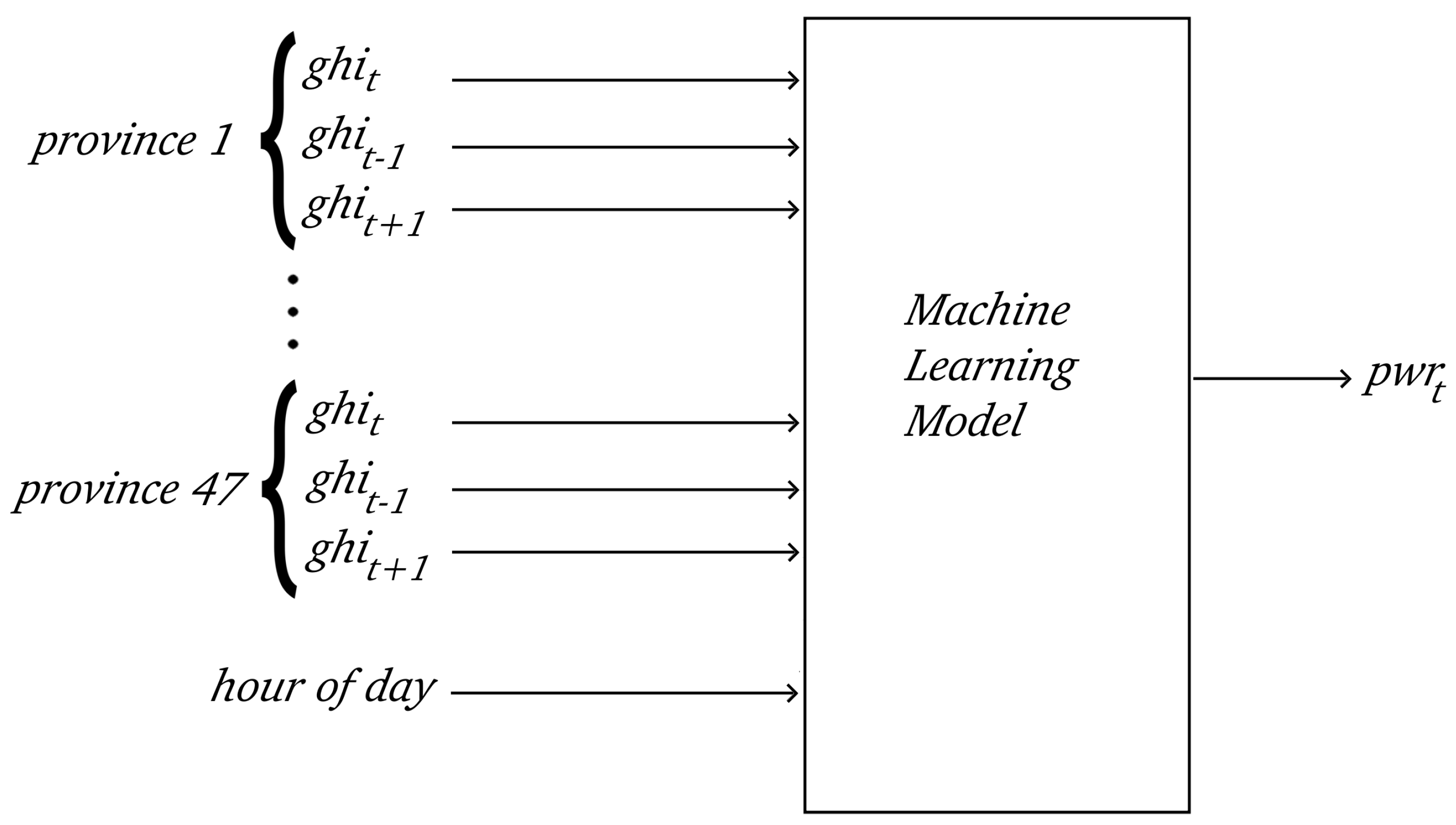
Section 3.1, the input data dimensions of these networks are directly proportional to the number of provinces in each respective zone. These zones and their respective number of provinces are outlined in
Table 1.
Performances
The performance of the tested machine learning approaches, including implementations with data augmentation techniques and hyperparameters tuning as described in
Section 3.2, in predicting electrical PV power across the different market zones was evaluated, with the Normalised Root Mean Square Error (NRMSE) serving as a key indicator. The NRMSE is defined as:
where
n is the number of observations,
is the actual value,
is the predicted value, and
is the range of the observed values. The NRMSE normalises the Root Mean Square Error (RMSE) by dividing it by the range of the observed values, making it a dimensionless measure that ranges from 0 to 100%. In practice, this range corresponds to the maximum observed production across the entire dataset, including both training and testing data, as production can be zero. NRMSE is a commonly used metric that provides a standardised measure of the prediction error, accounting for the scale of the target variable in these kinds of problems.
As previously mentioned, the various regions exhibit significantly different characteristics. While the resolution approach remains consistent, we tailored a distinct set of hyperparameters for each region to optimise model performance. To achieve this, we conducted an extensive GridSearch process with a five-fold cross-validation, iterating over a range of hyperparameters for each region. The GridSearch technique systematically explores a predefined set of hyperparameters for a machine learning algorithm, evaluating the model’s performance across various combinations. Specifically, for each considered set of hyperparameters, we performed 54 individual trainings, spanning an entire year from the first week of April 2022 to the first week of March 2023. Each training cycle was followed by testing the model on the subsequent week, and this process was repeated for all weeks of the year. Subsequently, we averaged the test results over the entire year interval to assess the overall performance of each model. Notably, every individual training and resulting model had its unique optimal set of hyperparameters. For clarity of presentation, we showcase only the optimal hyperparameter values, determined by selecting those with the highest frequency of occurrence among the 54 training iterations for each model. These summarised outcomes are detailed in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9.
All of the considered models and hyperparameters’ names and definitions refer to the implementation of the Python library Scikit-learn [
42], which was used in this work. All calculations were performed on a single machine equipped with an Intel Core i9-10900K processor clocked at 3.70 GHz with 10 cores and 32 GB RAM. The hyperparameters considered in the LR model, as shown in
Table 2, are fit intercept and positive. The fit intercept hyperparameter determines whether an intercept term is included in the model equation, accounting for the constant term. Meanwhile, the positive hyperparameter imposes non-negativity constraints on the coefficients, fostering interpretability and enhancing model robustness, particularly in scenarios where negative relationships are deemed implausible.
Table 2.
Hyperparameters for each zone for LR model.
Table 2.
Hyperparameters for each zone for LR model.
| Zone | Fit Intercept | Positive |
|---|
| 1 | True | True |
| 2 | False | False |
| 3 | False | False |
| 4 | False | False |
| 5 | False | False |
| 6 | True | False |
| 7 | True | False |
The hyperparameters considered in the SVR model, as shown in
Table 3, are
C,
,
, and kernel. The kernel hyperparameter determines the type of kernel function used to transform the input space into a higher-dimensional feature space, allowing for nonlinear mappings. Common choices for the kernel function include linear, polynomial, radial basis function (rbf), and sigmoid. Another essential hyperparameter is
C, which controls the regularisation strength by balancing the trade-off between maximising the margin and minimising the training error. Values between 0.1, 1, and 10 have been tested. Additionally, the epsilon hyperparameter specifies the margin of tolerance for errors in the training data. It defines a tube around the regression line within which no penalty is incurred, providing flexibility in accommodating deviations from the optimal solution. Values 0.1, 0.2, and 0.3 have been tested. Lastly, the
hyperparameter, applicable when using an RBF kernel, determines the influence of a single training. It represents the kernel coefficient, influencing the flexibility of the decision boundary. In the context of utilising Scikit-learn [
42], it offers two strategies for selecting the
hyperparameter: auto and scale. The auto option dynamically adjusts
based on the inverse of the number of features, while the scale option still dynamically adjusts
based on the inverse of the number of features, but also takes into account the unit variance. Through the mentioned GridSearch approach, the most effective strategy for enhancing model performance was identified.
Table 3.
Hyperparameters for each zone for SVR model.
Table 3.
Hyperparameters for each zone for SVR model.
| Zone | C | | | Kernel |
|---|
| 1 | 1 | 0.1 | scale | rbf |
| 2 | 1 | 0.1 | auto | rbf |
| 3 | 10 | 0.1 | scale | rbf |
| 4 | 1 | 0.1 | scale | rbf |
| 5 | 10 | 0.1 | scale | rbf |
| 6 | 10 | 0.1 | auto | rbf |
| 7 | 10 | 0.1 | scale | rbf |
The hyperparameters considered in the DTR model, as shown in
Table 4, are criterion, max depth, max features, min sample leaf, and min sample split. The criterion hyperparameter determines the function used to measure the quality of a split in the decision tree, with options such as Friedman mean squared error (mse), squared error, and absolute error. Meanwhile, the max depth hyperparameter specifies the maximum depth of the decision tree, allowing for the control of model complexity and overfitting. Value 5 and 10 have been tested, allowing for the None option for the default version. Additionally, the max features’ hyperparameter limits the number of features considered at each node, aiding in the prevention of overfitting by reducing the model’s complexity. The considered values are None, where it sets max features to the square root of the total number of features, and log2 where it sets max features to the base-2 logarithm of the total number of features. Furthermore, the min samples leaf hyperparameter sets the minimum number of samples required to be at a leaf node, while the min samples split hyperparameter determines the minimum number of samples required to split an internal node. A range of integer values from 1 to 4, and values 2, 5, and 10, have been explored, respectively.
Table 4.
Hyperparameters for each zone for DTR model.
Table 4.
Hyperparameters for each zone for DTR model.
| Zone | Criterion | Max Depth | Max Features | Min Sample Leaf | Min Sample Split |
|---|
| 1 | squared error | 10 | None | 4 | 5 |
| 2 | Friedman MSE | None | None | 4 | 10 |
| 3 | squared error | 10 | None | 4 | 2 |
| 4 | Friedman MSE | 10 | None | 4 | 10 |
| 5 | squared error | 10 | None | 4 | 2 |
| 6 | squared error | 10 | None | 4 | 10 |
| 7 | absolute error | 10 | None | 4 | 5 |
The hyperparameters considered in the RFR model, as shown in
Table 5, are max features and estimators. The max features hyperparameter determines the maximum number of features to consider when looking for the best split at each node in the decision trees that make up the random forest. The considered values are None, where it sets max features to the square root of the total number of features, and log2 where it sets max features to the base-2 logarithm of the total number of features. The estimators’ hyperparameter specifies the number of decision trees to be included in the random forest ensemble. A range of values from 100 to 500 with increments of 100 has been explored.
Table 5.
Hyperparameters for each zone for RFR model.
Table 5.
Hyperparameters for each zone for RFR model.
| Zone | Max Features | Estimators |
|---|
| 1 | log2 | 500 |
| 2 | log2 | 500 |
| 3 | None | 500 |
| 4 | log2 | 500 |
| 5 | None | 500 |
| 6 | None | 500 |
| 7 | None | 500 |
The hyperparameters considered in the KNNR model, as shown in
Table 6, are metric, neighbours, and weights. The metric hyperparameter was tested with both Euclidean and Manhattan distance metrics to measure the distance between data points in the feature space. For the neighbours hyperparameter, values of 3, 9, 27, and 81 were tested to determine the number of nearest neighbours to consider when making predictions for a new data point. Additionally, the weights hyperparameter was explored with both uniform and distance weighting schemes. When set to uniform, all neighboring points contribute equally to the prediction, while distance weighting gives more weight to closer neighbours, inversely proportional to their distance.
Table 6.
Hyperparameters for each zone for KNNR model.
Table 6.
Hyperparameters for each zone for KNNR model.
| Zone | Metric | Neighbours | Weights |
|---|
| 1 | Euclidean | 9 | distance |
| 2 | Euclidean | 9 | distance |
| 3 | Euclidean | 9 | distance |
| 4 | Euclidean | 9 | distance |
| 5 | Manhattan | 9 | distance |
| 6 | Euclidean | 9 | distance |
| 7 | Euclidean | 9 | distance |
The hyperparameters considered in the KRR model, as shown in
Table 7, are
, degree,
and kernel. The
hyperparameter controls the regularization strength, and values of 0.1, 1, and 10 were tested to explore the impact of different levels of regularisation. For the degree hyperparameter, polynomial degrees of 2, 3, and 4 were investigated to assess the polynomial complexity of the model. The
hyperparameter, which influences the kernel’s behaviour, was tested with values of None, 0.1, and 1.0. A value of None represents auto-selection. The SVR choice of kernel, includes linear, polynomial (poly), radial basis function (rbf), and sigmoid.
Table 7.
Hyperparameters for each zone for KRR model.
Table 7.
Hyperparameters for each zone for KRR model.
| Zone | | Degree | | Kernel |
|---|
| 1 | 0.1 | 2 | 0.1 | rbf |
| 2 | 0.1 | 4 | 0.1 | poly |
| 3 | 1 | 4 | 0.1 | poly |
| 4 | 0.1 | 4 | 0.1 | poly |
| 5 | 0.1 | 3 | None | poly |
| 6 | 0.1 | 4 | 0.1 | poly |
| 7 | 0.1 | 4 | 0.1 | poly |
The hyperparameters considered in the GB model, as shown in
Table 8, are learning rate, max depth, and estimators. For the learning rate hyperparameter, values of 0.05, 0.1, and 0.2 were tested to assess the impact of different rates of learning. Lower learning rates require more trees in the ensemble but can lead to better generalisation, while higher learning rates may result in faster learning but could overfit the training data. The max depth hyperparameter, which controls the maximum depth of each tree in the ensemble, was tested with depths of 3, 4, and 5. Deeper trees can capture more complex interactions in the data but may also lead to overfitting. Additionally, the n estimators hyperparameter, determining the number of boosting stages or trees in the ensemble, was explored with values of 50, 100, and 200. Increasing the number of estimators can lead to a more expressive model, but it also increases computational cost and the risk of overfitting.
Table 8.
Hyperparameters for each zone for GB model.
Table 8.
Hyperparameters for each zone for GB model.
| Zone | Learning Rate | Max Depth | Estimators |
|---|
| 1 | 0.05 | 3 | 200 |
| 2 | 0.05 | 4 | 200 |
| 3 | 0.1 | 3 | 200 |
| 4 | 0.1 | 3 | 200 |
| 5 | 0.1 | 4 | 200 |
| 6 | 0.1 | 4 | 200 |
| 7 | 0.1 | 4 | 200 |
The ensemble model implemented is a VotingRegressor, which combines predictions from three different regression models: KNNR, SVR, and GB. This ensemble is cooperative in nature, leveraging the predictions from each base model and aggregating them to produce a final prediction. The VotingRegressor is directly available in the Python library Scikit-learn [
42], enabling seamless integration and straightforward implementation of the ensemble approach. The hyperparameters considered in the ensemble, as shown in
Table 9, include weights which were tested with all possible combinations of values 1 and 2 for each of the three models. These weights reflect the relative importance assigned to each base model in the VotingRegressor ensemble. In this context, a weight of 1 signifies equal importance given to each model, while a weight of 2 implies a higher emphasis placed on a particular model compared to others.
Table 9.
Hyperparameters for each zone for KSVRGB model.
Table 9.
Hyperparameters for each zone for KSVRGB model.
| Zone | KNNR Weight | SVR Weight | GB Weight |
|---|
| 1 | 2 | 1 | 1 |
| 2 | 1 | 1 | 2 |
| 3 | 1 | 2 | 2 |
| 4 | 2 | 1 | 2 |
| 5 | 1 | 1 | 2 |
| 6 | 1 | 1 | 2 |
| 7 | 1 | 1 | 2 |
We evaluated the computing time required for predicting outcomes across the seven zones using each of the proposed ML models. As already mentioned, for each model, we conducted experiments over the course of one year, periodically retraining them to account for evolving data patterns. In our study, we conducted two experiments, labelled Exp1 and Exp2, in which we trained prediction models on the aforementioned temporal data. In the case of Exp1, we executed a total of 54 iterations (one per week) for each model and each region, training and validating the models on each prediction week. Throughout this process, we employed the GridSearch to identify the optimal hyperparameters in each iteration. Subsequently, in Exp2 we retrained the models on the same time interval, again with 54 iterations, this time fixing the hyperparameters to the initial values identified through only the first two training months as conducted in Exp1. This allowed us to assess the computational and qualitative impact of the chosen hyperparameters solution.
Table 10 presents the computational times for each experiment, each zone, and each model. The times, expressed in seconds, denote the average training time over the 54 weeks. The results, as expected, reveal a significant reduction in computing time when utilising fixed hyperparameters (Exp2) compared to the exhaustive tuning process (Exp1). In fact in calculating the training times, we include the process of searching the hyperparameters using the exhaustive GridSearch approach, which consists of calculating the five-fold cross-validation (training and testing the model five times) for each possible combination of the parameters inside the search ranges shown in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9. Despite the efficiency gains achieved by fixing hyperparameters,
Table 11 illustrates that the predictive performance, as quantified by the NRMSE percentage, remains relatively stable. Again, with the two scenarios Exp1, where hyperparameter tuning was performed at every retraining step, and Exp2, where the initial hyperparameters found were fixed for the remaining iterations. For each row and for each of the two experiments, the best value is highlighted in bold. Additionally, there are two extra final rows representing the average performance
across different zones of the models and the standard deviation
of the performances is computed as
. This finding suggests that the performance degradation resulting from using fixed hyperparameters is generally acceptable across the majority of zones and ML models considered. Additionally,
Table 11 reveals that Kernel Ridge Regression consistently outperformed other methods, yielding the lowest NRMSE values across all zones for Exp1 and in all cases for Exp2. This suggests that KRR effectively captures the underlying patterns and complexities of each market region, resulting in more accurate predictions. Furthermore, it is noteworthy that although the standard deviation is not the absolute lowest, it still maintains a very reasonable value of 0.4, indicating a consistent performance. These findings underscore the effectiveness of KRR as a robust modelling technique for electricity market forecasting, demonstrating its potential to enhance decision-making processes and optimise resource allocation strategies.
As previously mentioned, the use of production data with a one-hour lag as features constrains the temporal horizon to one hour. To extend the temporal horizon and demonstrate the utility of this feature, we introduce a third experiment (Exp3), wherein the same temporal data—specifically the 54 weeks of training data are utilised without the production-related features, i.e., the power produced at the previous hour. Not using the power at the previous hour as an input feature allows us to increase the forecast horizon to 24 h. Hyperparameters for all weeks are set to those obtained during the first two months of training, similar to Exp2.
Table 12 presents the predictive performance of Exp3 using the NRMSE percentage, where the best values are highlighted in bold. Without power features, the average error increases from 3% to 5.1%, while maintaining a consistent standard deviation of 0.4. This also alters the nature of the problem, with the most performing model in this case being, albeit marginally, the RFR rather than the KRR.
In
Figure 5 and
Figure 6 the performance results in terms of percentage NRMSE for each of the 54 weeks considered in every zone are illustrated.
Figure 5 highlights the outcomes achieved with the KRR model, which exhibited the highest performance, for Experiment Exp2. Meanwhile,
Figure 6 corresponds to Experiment Exp3, employing the RFR model. The main purpose of
Figure 5 and
Figure 6 relies on appreciating the behaviour of weekly test error during an entire year, highlighting a known seasonality effect (errors are lower during Spring, from March to April, and higher at the beginning of fall in September), and letting to appreciate the minimum and maximum weekly errors, as well as the average error (which is reported in
Table 11 and
Table 12), for all zones in the case of using the power as input,
Figure 5, or not using the power as input,
Figure 6.
Figure 7 and
Figure 8 present an example of performance comparison for Zone 1, Northern Italy, which is considered the most complex and representative region. Each figure illustrates the predictive performance over a sample day of a 7-day forecast.
Figure 7 depicts the resolution performance without lagging, meaning neither production data nor meteorological data with lagging are included, showcasing the predictive curves for each ML model alongside the actual realisation for comparison. The average NRMSE is 6.0%. Similar results are obtained for other zones.
In addition to evaluating the predictive performance for the upcoming week, we also assessed the degradation of prediction accuracy over a longer forecasting horizon. Using the same machine learning models, we extended the forecast period to three months, corresponding to nearly 13 weeks, without retraining. This experiment allowed us to investigate the degradation of the predictions with time as the models rely on an older training set with respect to the current data to be predicted. The results, depicted in
Figure 9, showcase the percentage NRMSE for each ML model across each predicted week in an example where the training period spans 2 months, or more precisely, 60 days starting from 1 February 2022. This analysis demonstrates that while there is a gradual increase in prediction error over time, the degradation remains within acceptable bounds. Specifically, it suggests that it may not be necessary to retrain the models on a weekly basis. Instead, retraining them on a monthly basis appears to be sufficient to maintain satisfactory prediction accuracy. This finding offers practical insights into the frequency of model retraining required for effective long-term forecasting in electricity markets.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}