

Best Practice Data Sharing Guidelines for Wind Turbine Fault Detection Model Evaluation
 , , , and
, , , and
Abstract
1. Introduction
1.1. Motivation
1.2. Literature Review
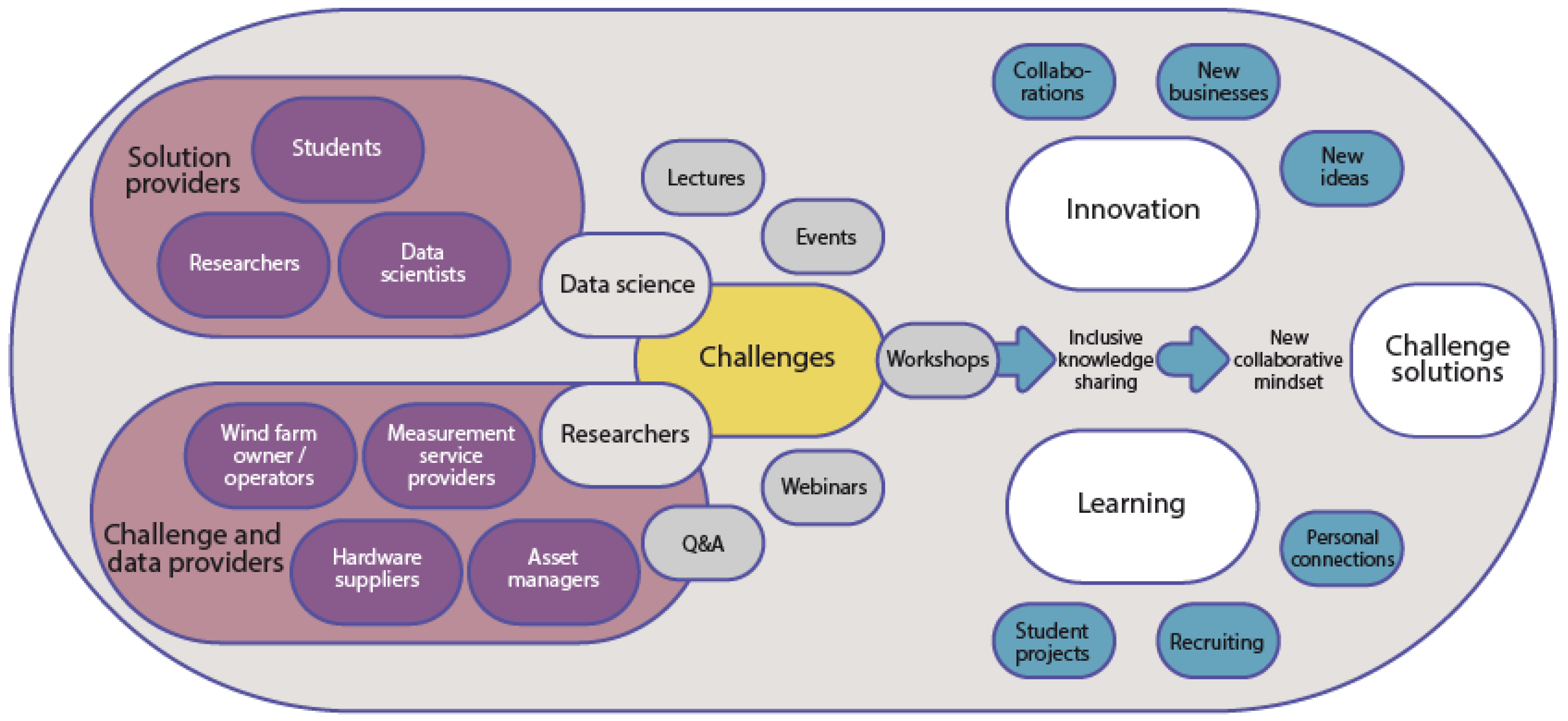
1.2.1. The WeDoWind Framework
1.2.2. Wind Turbine Fault Detection Based on SCADA Data
1.3. Contribution and Paper Organisation
2. Case Study Description
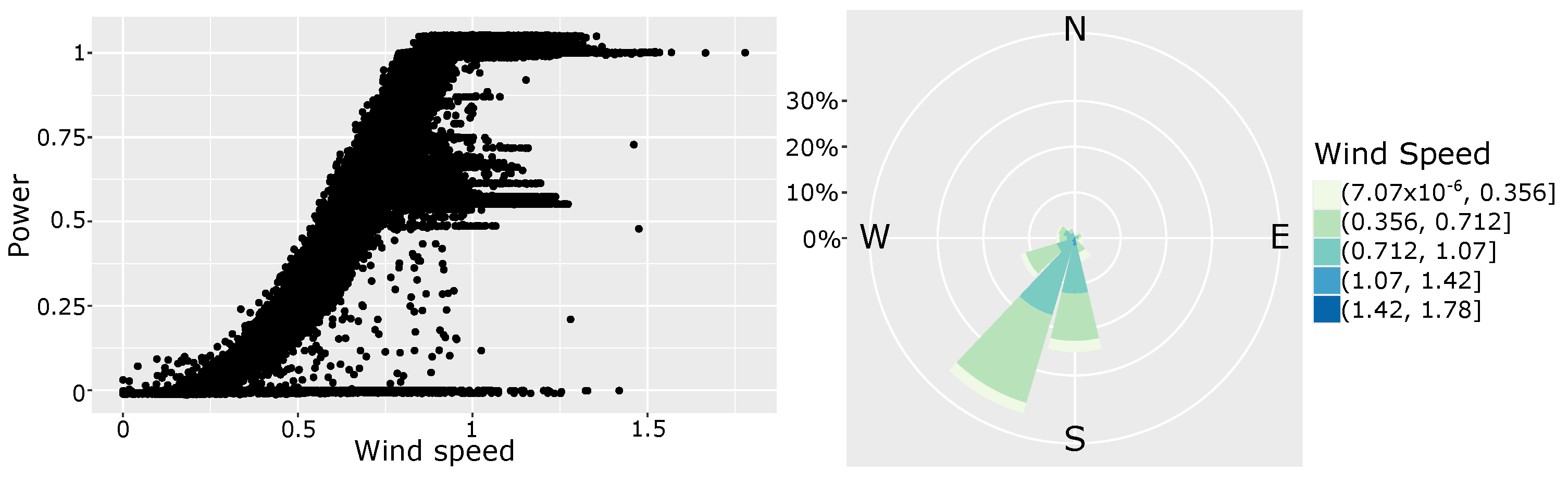
2.1. The Winji Gearbox Fault Detection Challenge
- The power of each wind turbine was normalised by the rated power.
- The location and type of wind turbines was not provided.
- The time stamps were all shifted by an unspecified amount of time.
- The detailed fault information was not provided. Instead, fault occurrence indicators were provided as binary indicators, i.e., fault or no fault.
2.2. The WeDoWind Framework
- A dedicated space called “WinJi Challenges” was created on the digital platform together with WinJi. The WeDoWind Challenge description, including direct links to download the data, was developed together with WinJi and posted inside this space.
- A public “call for participants” website was created with a direct link to the registration form (https://www.wedowind.ch/spaces/winji-challenges-space; accessed on 5 April 2023). This was shared within the wind energy community using social media.
- A process for allowing WinJi to decide who may participate or not was set up. This process was not intended to reduce accessibility to the WeDoWind Challenge, but instead to ensure that applicants were real people interested in the WeDoWind Challenge and not robots, bots or imposters.
- A “Getting Started Guide” to using the digital platform was created and explainer videos were recorded in order to help users interact on the platform.
- A series of online workshops were organised for the participants—a launch workshop, interim workshops every month and then a final workshop. These involved brainstorming sessions in small groups as well as question and answer sessions with WinJi. The sessions were documented on a digital whiteboard and recordings were posted in the digital space.
- Regular email updates were sent with specific questions and actions to encourage interaction. This included requests to summarise and comment on different possible methods, as well as discussions of evaluation methods.
- The space was regularly checked, cleaned and coordinated by the WeDoWind developers to ensure that the information was up-to-date and understandable.
- Regular updates were communicated on social media during the challenge.
3. Submitted Solutions
3.1. Description of Submitted Solutions
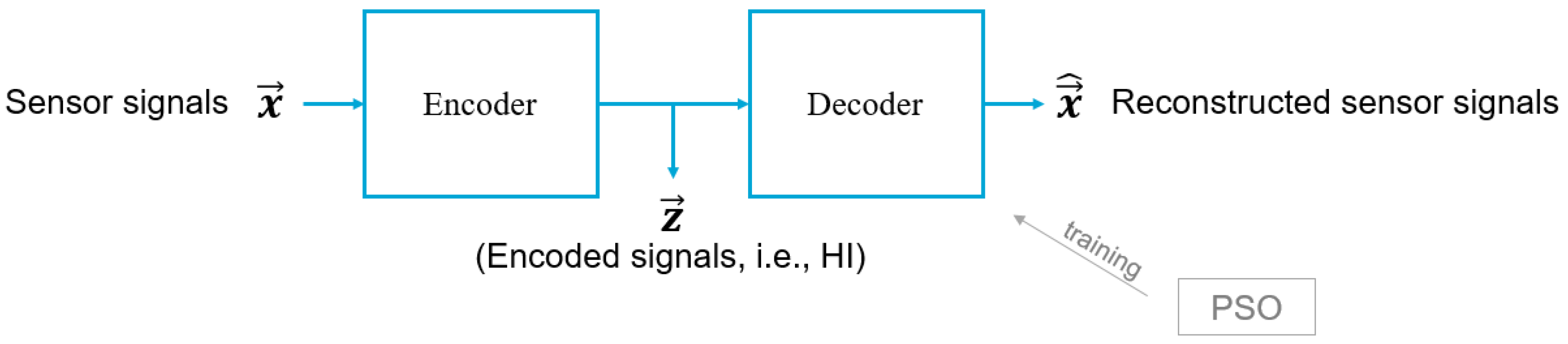
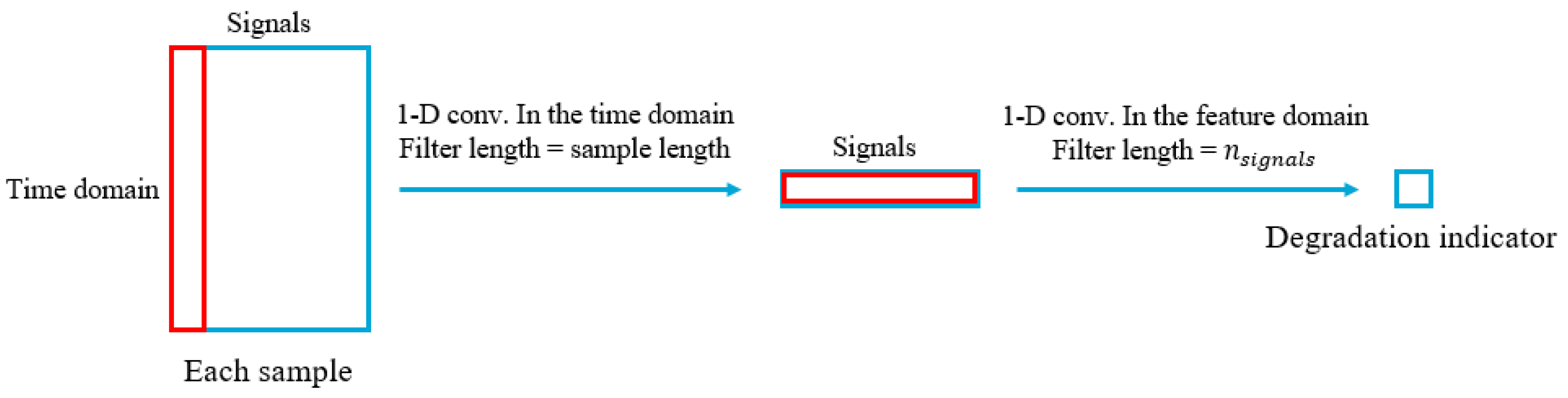
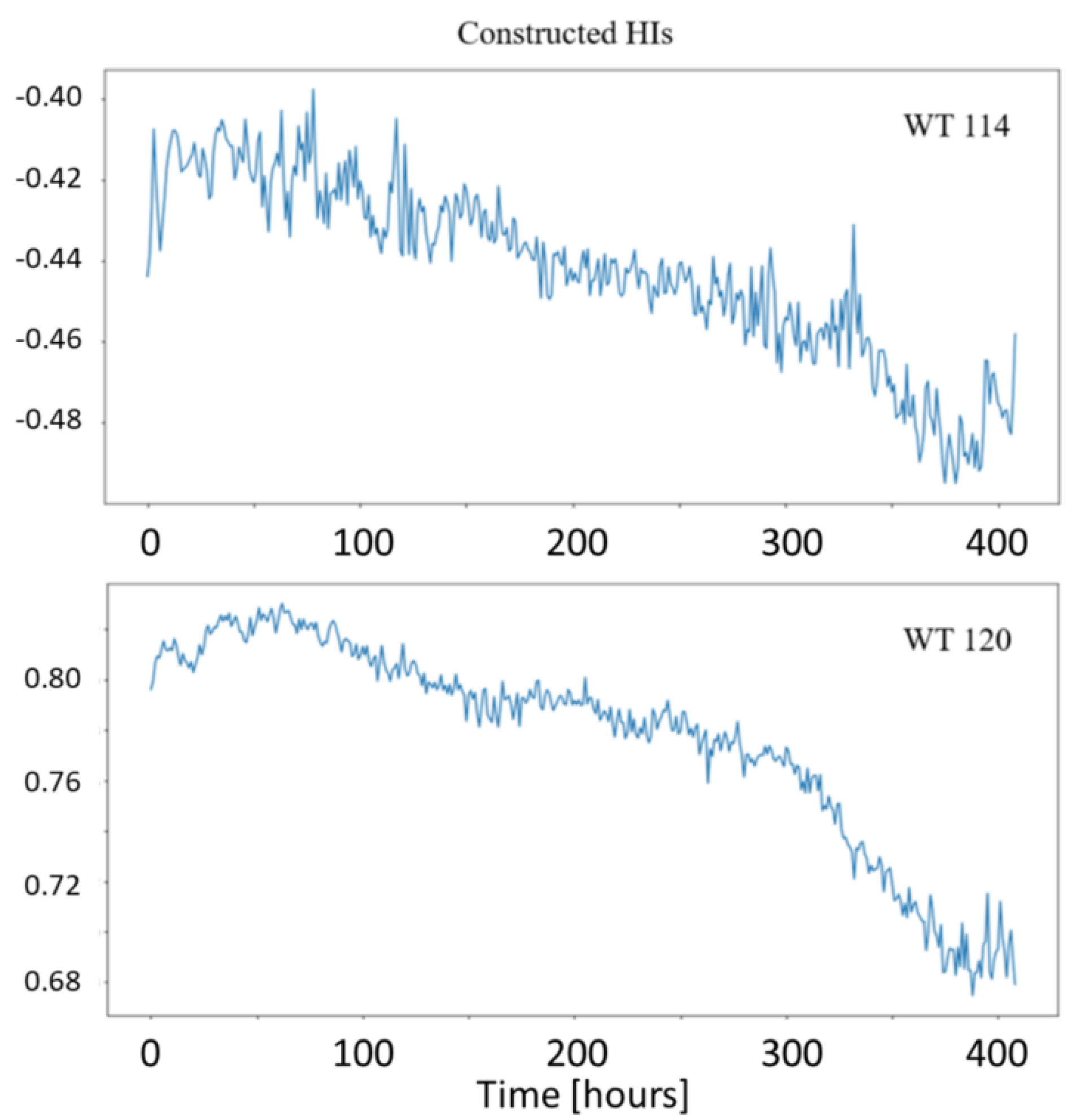
3.1.1. A Convolutional Autoencoder Trained with Particle Swarm Optimisation Algorithm for Constructing Health Indicators (CAE-PSO)
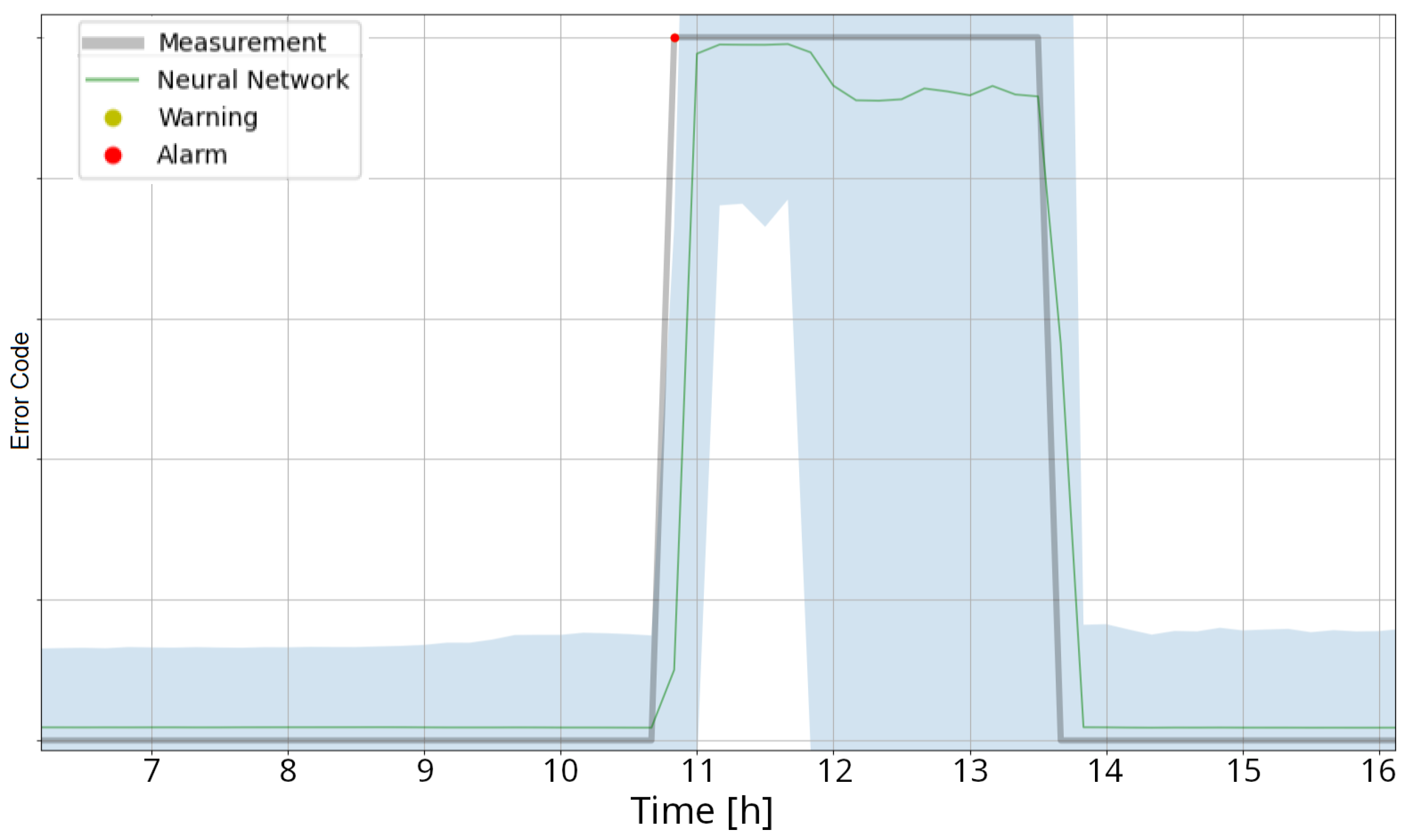
3.1.2. Performance Monitoring Using Deep Neural Networks (PM-DNN)
3.1.3. Direct Error Code Prediction Using DNNs (DEC-DNN)
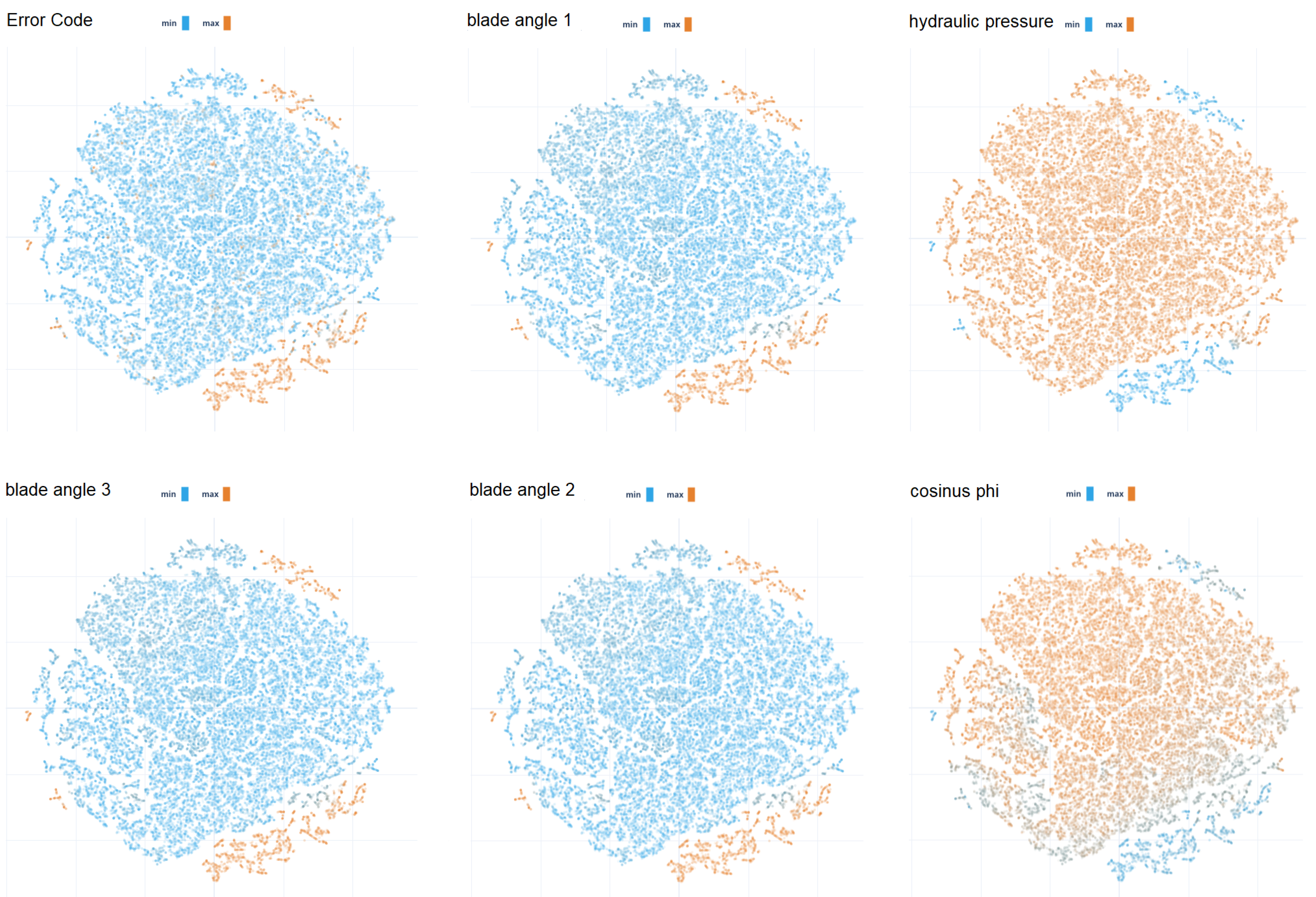
3.1.4. T-SNE Projection for Clustering (T-SNE)
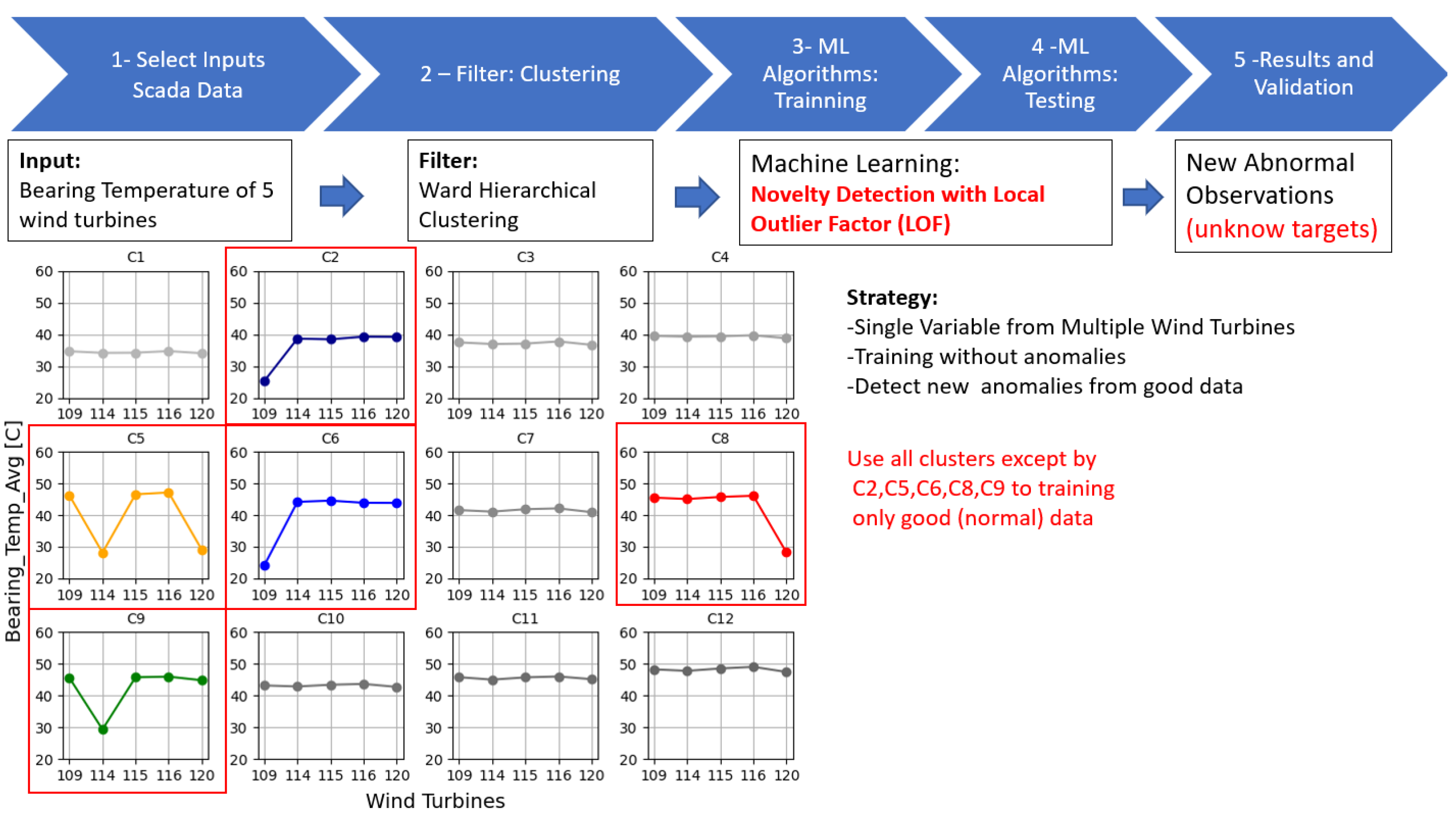
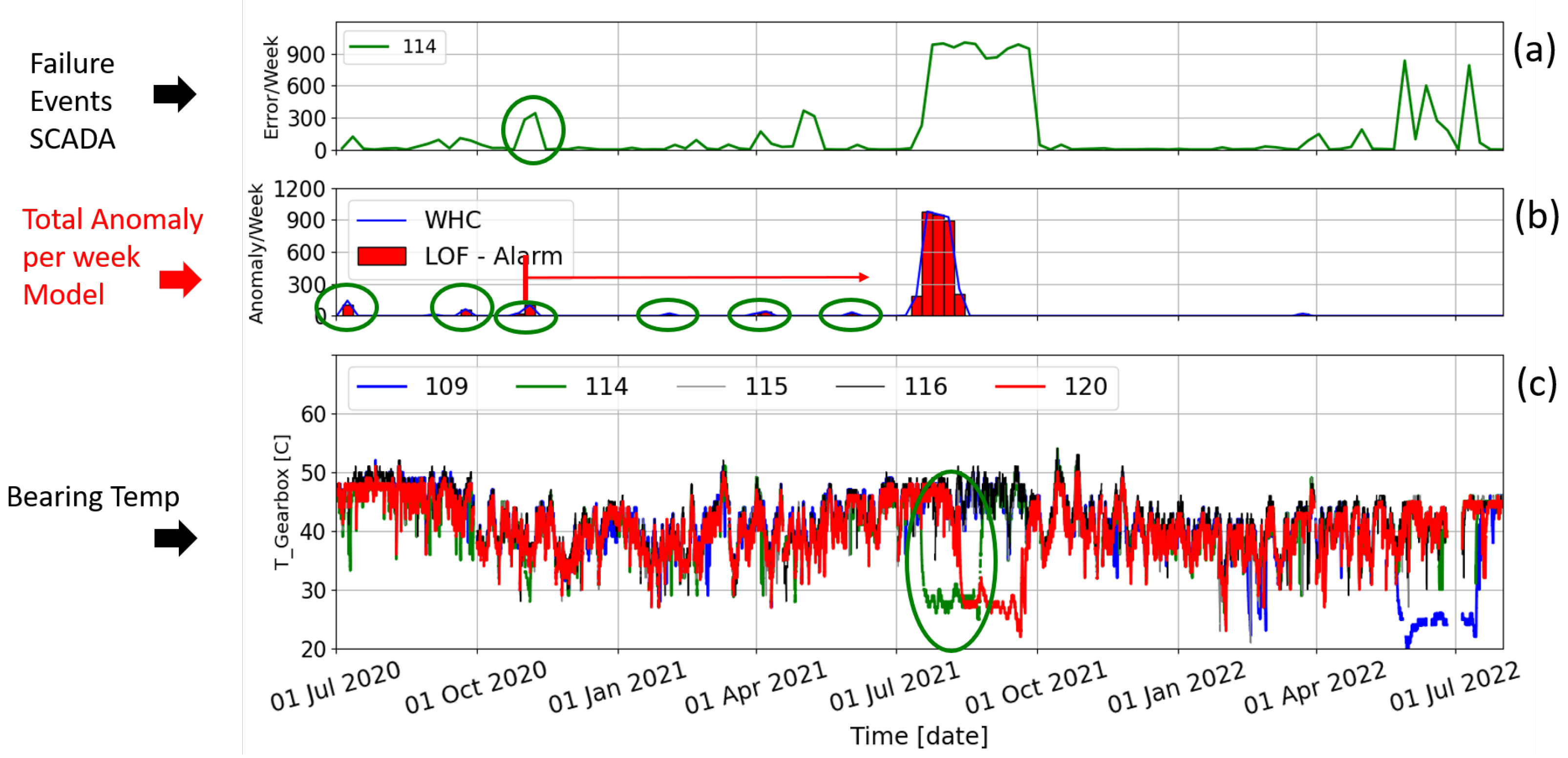
3.1.5. Combined Ward Hierarchical Clustering and Novelty Detection with Local Outlier Factor (WHC-LOF)
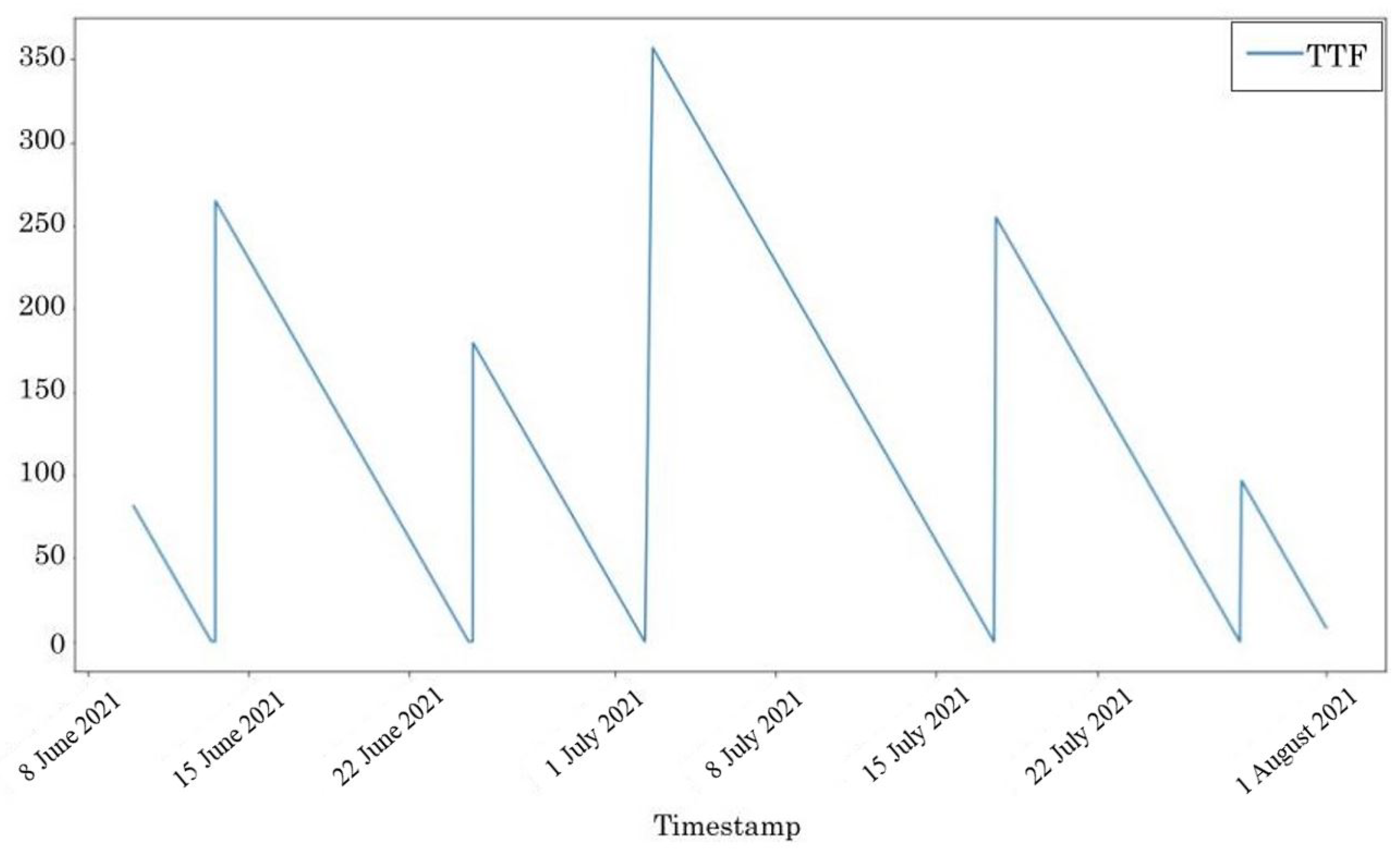
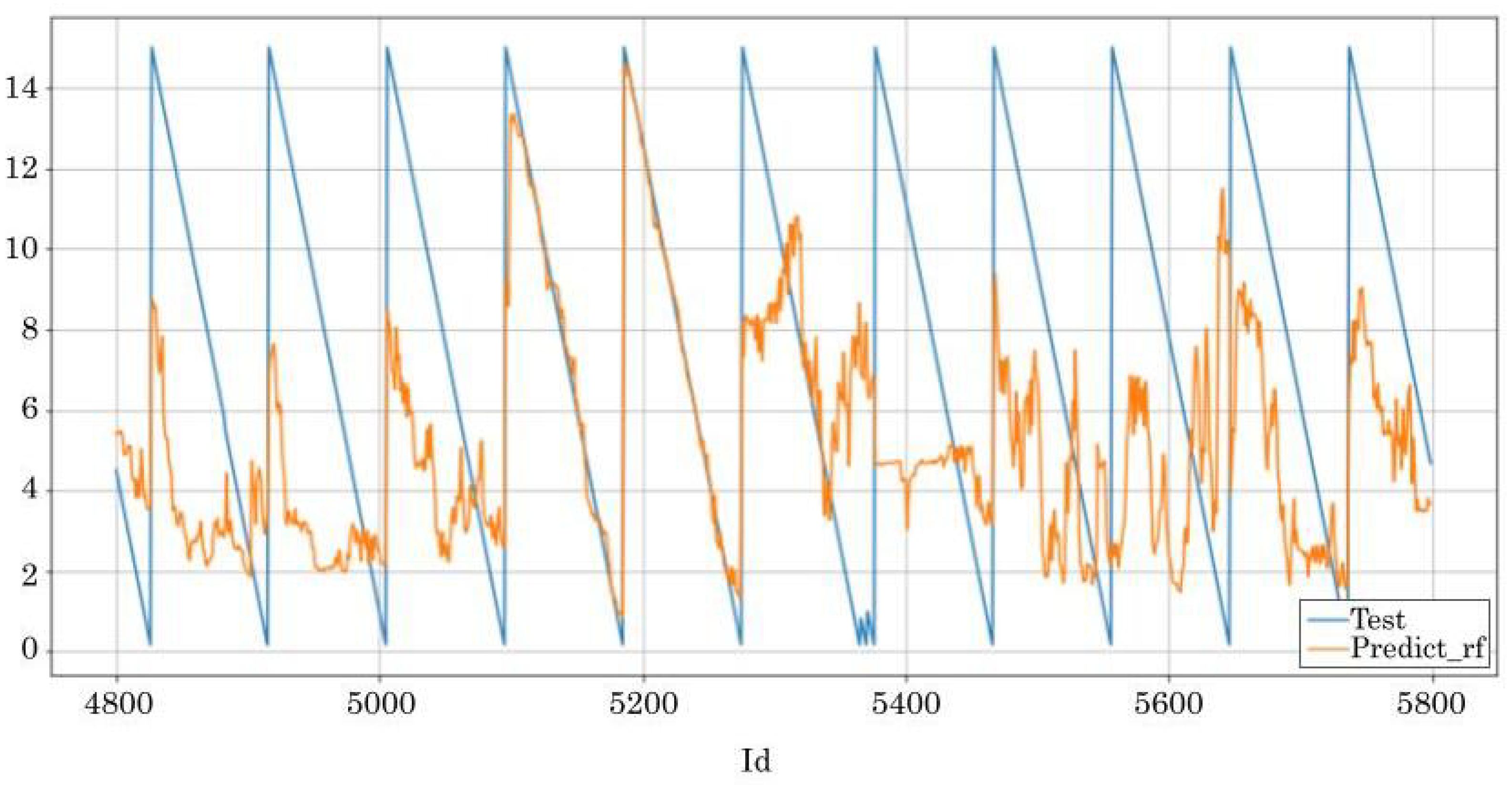
3.1.6. Time-to-Failure Prediction through Random Forest Regression (TTF-RFR)
- Order all gearbox data sets with the “datetime” column in descending order.
- Iterate through all the rows in every dataset.
- While iterating, identify the first failure (error code = 1) and create the TTF variable with value 0.
- In every subsequent row, input the difference between the previous and actual “datetime” columns in the TTF column. In this case, the difference was stored in hour units.
- Whenever the current row is an error code = 1 row, reset the TTF value to 0.
3.2. Results
3.2.1. A Convolutional Autoencoder Trained with Particle Swarm Optimisation Algorithm for Constructing Health Indicators (CAE-PSO)
3.2.2. Performance Monitoring Using Deep Neural Networks (PM-DNN)
3.2.3. Direct Error Code Prediction Using DNNs (DEC-DNN)
3.2.4. T-SNE Projection for Clustering (T-SNE)
3.2.5. Combined Ward Hierarchical Clustering and Novelty Detection with Local Outlier Factor (WHC-LOF)
3.2.6. Time-to-Failure Prediction Using Random Forest Regression (TTF-RFR)
3.3. Comparison and Evaluation of Solutions
- Access to more details of the different failure types. This could be performed in future WeDoWind Challenges; however, a trade-off needs to be made by Challenge Providers between anonymising the data and providing enough information to allow the challenge to be completed.
- Access to multiple data sets from more WTGs experiencing gearbox failure. Again, this could be done in future WeDoWind Challenges; however, in this case a decision balancing the amount of provided data and the expected quality of the results needs to be made by the Challenge Provider.
- Provision of a model or rule relating fault detection times or remaining useful lifetime to the estimated costs for repairs, replacements and inspections similar to the EDP one mentioned in Section 3.3. This could be done by the Challenge Provider in the future. Alternatively, this could even be developed by Solution Providers at the start of a Challenge, and facilitated by the moderator.
- Provision of a clear strategy for training and test periods in advance, as is common on other challenge-based platforms such as Kaggle (and as was the case in the previous WeDoWind EDP Challenge), by providing separate training and test data, or by defining how the participants should choose training and test data. In the future, if this is not provided by the Challenge Provider, it could be decided by the participants, and facilitated by the moderator.
- Participation in the Challenge by the Challenge Providers, and provision of details of their results and a description of their method. This can be recommended by the moderators at the start of a WeDoWind Challenge in the future. If there are confidentiality issues, they can take part in a reduced capacity, i.e., by only providing limited results.
- Provision of a pre-defined template or requirements, and even a pre-written analysis code, in order to improve the comparison process. This can be provided by Challenge Providers in future WeDoWind Challenges.
4. Discussion and Outlook
4.1. Best Practice Data Sharing Guidelines for Wind Turbine Fault Detection Model Evaluation
4.2. Applicability of the WeDoWind Framework
4.3. Outlook
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Clifton, A.; Barber, S.; Bray, A.; Enevoldsen, P.; Fields, J.; Sempreviva, A.M.; Williams, L.; Quick, J.; Purdue, M.; Totaro, P.; et al. Grand Challenges in the Digitalisation of Wind Energy. Wind Energy Sci. 2022. in review. [Google Scholar] [CrossRef]
- Wilkinson, M.; Dumontier, M.; Aalbersberg, I.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Barber, S. Co-Innovation for a Successful Digital Transformation in Wind Energy Using a New Digital Ecosystem and a Fault Detection Case Study. Energies 2022, 15, 5638. [Google Scholar] [CrossRef]
- Maria, S.A.; Allan, V.; Christian, B.; Robert, V.D.; Gregor, G.; Kjartansson, D.H.; Pilgaard, M.L.; Mattias, A.; Nikola, V.; Stephan, B.; et al. Taxonomy and Metadata for Wind Energy Research & Development. Zenodo, 12 December 2017. [Google Scholar] [CrossRef]
- Barber, S.; Clark, T.; Day, J.; Totaro, P. The IEA Wind Task 43 Metadata Challenge: A Roadmap to Enable Commonality in Wind Energy Data. Zenodo, 4 April 2022. [Google Scholar] [CrossRef]
- Bresciani, S.; Ciampi, F.; Meli, F.; Ferraris, A. Using big data for co-innovation processes: Mapping the field of data-driven innovation, proposing theoretical developments and providing a research agenda. Int. J. Inf. Manag. 2021, 60, 102347. [Google Scholar] [CrossRef]
- Lee, S.M.; Olson, D.L.; Trimi, S. Co-innovation: Convergenomics, collaboration, and co-creation for organizational values. Manag. Decis. 2012, 50, 817–831. [Google Scholar] [CrossRef]
- Dao, C.; Kazemtabrizi, B.; Crabtree, C. Wind turbine reliability data review and impacts on levelised cost of energy. Wind Energy 2019, 22, 1848–1871. [Google Scholar] [CrossRef]
- Zaher, A.; McArthur, S.; Infield, D.; Patel, Y. Online wind turbine fault detection through automated SCADA data analysis. Wind. Energy Int. J. Prog. Appl. Wind. Power Convers. Technol. 2009, 12, 574–593. [Google Scholar] [CrossRef]
- Butler, S.; Ringwood, J.; O’Connor, F. Exploiting SCADA system data for wind turbine performance monitoring. In Proceedings of the 2013 Conference on Control and Fault-Tolerant Systems (SysTol), Nice, France, 9–11 October 2013; pp. 389–394. [Google Scholar]
- Kusiak, A.; Verma, A. Analyzing bearing faults in wind turbines: A data-mining approach. Renew. Energy 2012, 48, 110–116. [Google Scholar] [CrossRef]
- Sun, P.; Li, J.; Wang, C.; Lei, X. A generalized model for wind turbine anomaly identification based on SCADA data. Appl. Energy 2016, 168, 550–567. [Google Scholar] [CrossRef]
- Bangalore, P.; Letzgus, S.; Karlsson, D.; Patriksson, M. An artificial neural network-based condition monitoring method for wind turbines, with application to the monitoring of the gearbox. Wind. Energy 2017, 20, 1421–1438. [Google Scholar] [CrossRef]
- Bach-Andersen, M.; Rømer-Odgaard, B.; Winther, O. Flexible non-linear predictive models for large-scale wind turbine diagnostics. Wind Energy 2017, 20, 753–764. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, H.; Zhang, L.; Feng, Z. Enhancing building energy efficiency using a random forest model: A hybrid prediction approach. Energy Rep. 2021, 7, 5003–5012. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine learning methods for wind turbine condition monitoring: A review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F. Comparative analysis of neural network and regression based condition monitoring approaches for wind turbine fault detection. Mech. Syst. Signal Process. 2011, 25, 1849–1875. [Google Scholar] [CrossRef]
- Fu, J.; Chu, J.; Guo, P.; Chen, Z. Condition Monitoring of Wind Turbine Gearbox Bearing Based on Deep Learning Model. IEEE Access 2019, 7, 57078–57087. [Google Scholar] [CrossRef]
- Gougam, F.; Rahmoune, C.; Benazzouz, D.; Varnier, C.A.C.; Nicod, J.M. Health Monitoring Approach of Bearing: Application of Adaptive Neuro Fuzzy Inference System (ANFIS) for RUL-Estimation and Autogram Analysis for Fault-Localization. In Proceedings of the 2020 Prognostics and Health Management Conference (PHM-Besançon), Besancon, France, 4–7 May 2020; pp. 200–206. [Google Scholar]
- Li, X.; Teng, W.; Peng, D.; Ma, T.; Wu, X.; Liu, Y. Feature fusion model based health indicator construction and self-constraint state-space estimator for remaining useful life prediction of bearings in wind turbines. Reliab. Eng. Syst. Saf. 2023, 233, 109124. [Google Scholar] [CrossRef]
- Xu, Z.; Bashir, M.; Liu, Q.; Miao, Z.; Wang, X.; Wang, J.; Ekere, N. A novel health indicator for intelligent prediction of rolling bearing remaining useful life based on unsupervised learning model. Comput. Ind. Eng. 2023, 176, 108999. [Google Scholar] [CrossRef]
- Ward, J.H. Hierarchical Grouping to Optimize an Objective Function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Breunig, M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying Density-Based Local Outliers. In Proceedings of the 2000 Acm Sigmod International Conference On Management Of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Ahmed, I.; Dagnino, A.; Ding, Y. Unsupervised Anomaly Detection Based on Minimum Spanning Tree Approximated Distance Measures and its Application to Hydropower Turbines. IEEE Trans. Autom. Sci. Eng. 2019, 16, 654–667. [Google Scholar] [CrossRef]
- Dao, P.B. A CUSUM-Based Approach for Condition Monitoring and Fault Diagnosis of Wind Turbines. Energies 2021, 14, 3236. [Google Scholar] [CrossRef]
- Xu, Q.; Lu, S.X.; Zhai, Z.; Jiang, C. Adaptive fault detection in wind turbine via RF and CUSUM. IET Renew. Power Gener. 2020, 14, 1789–1796. [Google Scholar] [CrossRef]
- Li, G.; Shi, J. Applications of Bayesian methods in wind energy conversion systems. Renew. Energy 2012, 43, 1–8. [Google Scholar] [CrossRef]
- Zhang, C.; Liu, Z.; Zhang, L. Wind turbine blade bearing fault detection with Bayesian and Adaptive Kalman Augmented Lagrangian Algorithm. Renew. Energy 2022, 199, 1016–1023. [Google Scholar] [CrossRef]
- Meng, L.; Su, Y.; Kong, X.; Lan, X.; Li, Y.; Xu, T.; Ma, J. A Probabilistic Bayesian Parallel Deep Learning Framework for Wind Turbine Bearing Fault Diagnosis. Sensors 2022, 22, 7644. [Google Scholar] [CrossRef] [PubMed]
- Pandit, R.; Astolfi, D.; Hong, J.; Infield, D.; Santos, M. SCADA data for wind turbine data-driven condition/performance monitoring: A review on state-of-art, challenges and future trends. Wind Eng. 2023, 47, 422–441. [Google Scholar] [CrossRef]
- Astolfi, D.; Pandit, R.; Terzi, L.; Lombardi, A. Discussion of Wind Turbine Performance Based on SCADA Data and Multiple Test Case Analysis. Energies 2022, 15, 5343. [Google Scholar] [CrossRef]
- Maron, J.; Anagnostos, D.; Brodbeck, B.; Meyer, A. Artificial intelligence-based condition monitoring and predictive maintenance framework for wind turbines. J. Phys. Conf. Ser. 2022, 2151, 012007. [Google Scholar] [CrossRef]
- Pohlert, T. Non-Parametric Trend Tests and Change-Point Detection. Thorsten Pohlert. 24 March 2015. Available online: https://www.researchgate.net/publication/274014742_trend_Non-Parametric_Trend_Tests_and_Change-Point_Detection_R_package_version_001?channel=doi&linkId=551298ec0cf268a4aaea93c9&showFulltext=true (accessed on 10 April 2023).
- Poli, R.; Kennedy, J.; Blackwell, T. Particle swarm optimization. Swarm Intell. 2007, 1, 33–57. [Google Scholar] [CrossRef]
- Faris, H.; Aljarah, I.; Mirjalili, S. Training feedforward neural networks using multi-verse optimizer for binary classification problems. Appl. Intell. 2016, 45, 322–332. [Google Scholar] [CrossRef]
- Mazurowski, M.A.; Habas, P.A.; Zurada, J.M.; Lo, J.Y.; Baker, J.A.; Tourassi, G.D. Training neural network classifiers for medical decision making: The effects of imbalanced datasets on classification performance. Neural Netw. 2008, 21, 427–436. [Google Scholar] [CrossRef]
- Zhang, Y.M.; Wang, H.; Mao, J.X.; Xu, Z.D.; Zhang, Y.F. Probabilistic Framework with Bayesian Optimization for Predicting Typhoon-Induced Dynamic Responses of a Long-Span Bridge. J. Struct. Eng. 2021, 147, 04020297. [Google Scholar] [CrossRef]
- Jha, G.K.; Thulasiraman, P.; Thulasiram, R.K. PSO based neural network for time series forecasting. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep Learning in Neural Networks: An Overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Sehnke, F.; Osendorfer, C.; R’uckstieß, T.; Graves, A.; Peters, J.; Schmidhuber, J. Parameter-exploring policy gradients. Neural Netw. 2010, 23, 551–559. [Google Scholar] [CrossRef]
- Sehnke, F. Efficient baseline-free sampling in parameter exploring policy gradients: Super symmetric pgpe. In Proceedings of the International Conference on Artificial Neural Networks, Sofia, Bulgaria, 10–13 September 2013; pp. 130–137. [Google Scholar]
- Sehnke, F.; Zhao, T. Baseline-free sampling in parameter exploring policy gradients: Super symmetric pgpe. In Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2015; pp. 271–293. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Nagy, G.I.; Barta, G.; Kazi, S.; Borbély, G.; Simon, G. GEFCom2014: Probabilistic solar and wind power forecasting using a generalized additive tree ensemble approach. Int. J. Forecast. 2016, 32, 1087–1093. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ruff, L.; Kauffmann, J.R.; Vandermeulen, R.A.; Montavon, G.; Samek, W.; Kloft, M.; Dietterich, T.G.; Müller, K.R. A Unifying Review of Deep and Shallow Anomaly Detection. Proc. IEEE 2021, 109, 756–795. [Google Scholar] [CrossRef]
- Orozco, R.; Sheng, S.; Phillips, C. Diagnostic Models for Wind Turbine Gearbox Components Using SCADA Time Series Data. In Proceedings of the 2018 IEEE International Conference on Prognostics and Health Management (ICPHM), Seattle, WA, USA, 11–13 June 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, Z.; Long, H.; Xu, J.; Liu, R. Wind Turbine Gearbox Failure Identification With Deep Neural Networks. IEEE Trans. Ind. Inform. 2017, 13, 1360–1368. [Google Scholar] [CrossRef]
- Arcos Jiménez, A.; Gómez Muñoz, C.Q.; García Márquez, F.P. Machine Learning for Wind Turbine Blades Maintenance Management. Energies 2018, 11, 13. [Google Scholar] [CrossRef]
- Tang, B.; Song, T.; Li, F.; Deng, L. Fault diagnosis for a wind turbine transmission system based on manifold learning and Shannon wavelet support vector machine. Renew. Energy 2014, 62, 1–9. [Google Scholar] [CrossRef]
- Avizienis, A.; Laprie, J.C.; Randell, B.; Landwehr, C. Basic concepts and taxonomy of dependable and secure computing. IEEE Trans. Dependable Secur. Comput. 2004, 1, 11–33. [Google Scholar] [CrossRef]
- Barber, S. GitLab Repository “WeDoWind—WinJi Gearbox Failure Detection”. 2023. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Solution | Method | Contributor | Type | Goal | Pre-Proc. | Time Res. | Training Period |
|---|---|---|---|---|---|---|---|
| CAE-PSO | CAE | TUD | Unsup. Learn. | Pred. RUL | N (0, 1) Norm. | Minutes | 100% |
| PM-DNN | DNN | ZSW | Sup. Learn. | Pred. Power Anomaly | N (0, 1) Norm. | Minutes | 80%–20% random Blocks |
| DEC-DNN | DNN | ZSW | Sup. Learn. | Pred. Error Code | N (0, 1) Norm. | Minutes | 80%–20% random Blocks |
| T-SNE | T-SNE | ZSW | Unsup. Learn. | Cluster Correlation | N (0, 1) Norm. | Minutes | 80%–20% random Blocks |
| WHC-LOF | LOF | FISC | Unsup. Learn. | Pred. Anom. + RUL | WHC | Weeks | 100% |
| TTF-RFR | RFR | MU | Sup. Learn. | TTF inference | Remove correlated features, stop instants | Hours | Leave one out (80%–20%) |
| TP 71 | FN 45 |
|---|---|
| FP 48 | TN - |
| Gearbox Left Out for Testing | MAE (h) |
|---|---|
| 115 | 3.72 |
| 116 | 3.57 |
| 120 | 3.68 |
| 109 | 3.83 |
| 114 | 3.76 |
| Solution | Summary of Main Results | Learning Outcomes Related to Data Sharing |
|---|---|---|
| CAE-PSO | HIs correlate with degradation, therefore can be used for early failure detection and RUL estimation. However, the result was not generalisable to other wind turbines. The model needs to be trained with data of several wind turbines. | More data sets are required from multiple WTGs experiencing gearbox failure. |
| PM-DNN | No systematic appearance of outliers before the occurrence of gearbox failures. The model cannot be used for prediction purposes, because True Positive rate is too low for a reliably predictor and the combination with oil temperature monitoring would result in an unfeasibly high True Negative rate. | More information about the optimisation goals (i.e., costs of TPs, FPs and FNs) are needed. More details of failure types are required. |
| DEC-DNN | The gearbox failures were not predicted by precursors of the failures but by inputs that are consequences of the failure. | None. |
| T-SNE | Several input variables were highly correlated with these clusters that represent high gearbox failure probability. The shown inputs with high correlation are all consequences of a gearbox failure, not causes. The method is therefore not sufficient to predict gearbox failures. | More details of failure types and detailed analysis with experts needed. |
| WHC-LOF | The method has potential but the complexity and variety of the behaviours before the turbine’s failure demand more data sets for training the algorithm and for the expert to understand and learn different FPs that may be considered as TP alarms and take the right decision to prevent the turbine failure. | More details of failure types and detailed analysis with experts needed. |
| TTF-RFR | With the information provided here, it was challenging to accurately characterise the gearbox time-to-failure. Time to failure could be predicted with MAE of 3.57–3.72 h. If more information about underlying failure modes were provided, the approach may be a practical solution through capturing the ageing trajectories and their dependencies. | More details of failure types and detailed analysis with experts needed. |
| Number | Guideline | Recommendation | Comments |
|---|---|---|---|
| 1 | Some information can be anonymised or normalised to maintain confidentiality | Wind turbine type, location and rated power are recommended | Reducing faults to binary codes can be very limiting for participants, especially if remaining useful lifetime is required |
| 2 | The details provided about failure types should be sufficient enough to allow models to be trained, in order to get the best compromise between information and confidentiality | 3-4 fault types are recommended | The “Basic concepts and taxonomy of dependable and secure computing” published by IEEE [54] is useful for describing failure types |
| 3 | Sufficient data sets containing multiple failures of various wind turbines should be provided, in order to obtain the best compromise between information and confidentiality | At least 3–4 different faults should occur in 3–4 different wind turbines | - |
| 4 | A model or rule relating fault detection times or remaining useful lifetime to the estimated costs for repairs, replacements and inspections should be provided in advance. | A cost model for repairs, replacements and inspections similar to the EDP one is recommended [3]. | If this cannot be done, the participants should make sure that this is discussed and agreed on at the start of the challenge. |
| 5 | A clear strategy for training and test periods should be provided in advance. | The provided data can be split into training and test data sets in advance. | If this cannot be done, the participants should ensure that this is discussed and agreed on at the start of the challenge. |
| 6 | The challenge provider should take part in the challenge. | In the best case, they should share both results and a description of their method. | If there are confidentiality issues, they can take part in a reduced capacity, i.e., by only providing results. |
| 7 | The challenge moderator should focus more on the goal of the challenge and actively do things to help the participants reach the goal. | Requiring the results to be submitted in a certain format or providing a template. | An analysis code can also be provided. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barber, S.; Izagirre, U.; Serradilla, O.; Olaizola, J.; Zugasti, E.; Aizpurua, J.I.; Milani, A.E.; Sehnke, F.; Sakagami, Y.; Henderson, C. Best Practice Data Sharing Guidelines for Wind Turbine Fault Detection Model Evaluation. Energies 2023, 16, 3567. https://doi.org/10.3390/en16083567
Barber S, Izagirre U, Serradilla O, Olaizola J, Zugasti E, Aizpurua JI, Milani AE, Sehnke F, Sakagami Y, Henderson C. Best Practice Data Sharing Guidelines for Wind Turbine Fault Detection Model Evaluation. Energies. 2023; 16(8):3567. https://doi.org/10.3390/en16083567
Chicago/Turabian StyleBarber, Sarah, Unai Izagirre, Oscar Serradilla, Jon Olaizola, Ekhi Zugasti, Jose Ignacio Aizpurua, Ali Eftekhari Milani, Frank Sehnke, Yoshiaki Sakagami, and Charles Henderson. 2023. "Best Practice Data Sharing Guidelines for Wind Turbine Fault Detection Model Evaluation" Energies 16, no. 8: 3567. https://doi.org/10.3390/en16083567
APA StyleBarber, S., Izagirre, U., Serradilla, O., Olaizola, J., Zugasti, E., Aizpurua, J. I., Milani, A. E., Sehnke, F., Sakagami, Y., & Henderson, C. (2023). Best Practice Data Sharing Guidelines for Wind Turbine Fault Detection Model Evaluation. Energies, 16(8), 3567. https://doi.org/10.3390/en16083567