

Renewable Scenario Generation Based on the Hybrid Genetic Algorithm with Variable Chromosome Length
 ,
,
Abstract
1. Introduction
2. Decomposition of Time Series
2.1. Net Load Calculation
2.2. Permutation Entropy of Time Series
2.3. Time Series Decomposition Method
3. Principle of Scenario Generation Method
3.1. Hybrid Genetic Algorithm with Variable Chromosome Length
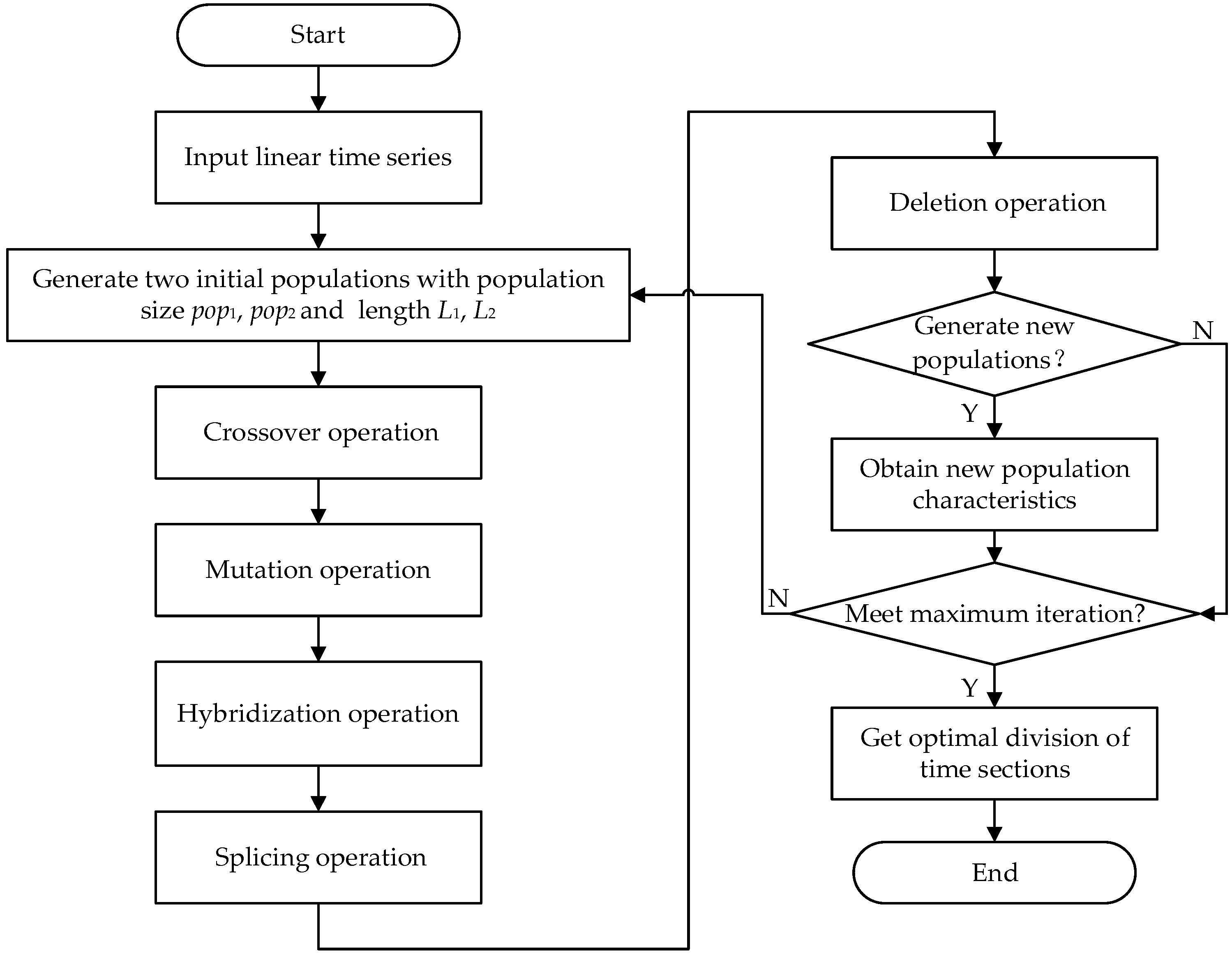
3.1.1. Framework of Proposed HGAVCL
- (1)
- Introduce hybridization operators, specify that the better individual perform hybridization with higher probability, and constrain the locations where chromosome segments can be hybridized.
- (2)
- Non-reproductive offspring produced is possible after the hybridization of organisms, and for this phenomenon, the survival factor ξ is proposed, which defines the survival probability of individuals after hybridization. The survival factor is calculated as,
- (3)
- Considering the problem of time series division, the phenomenon of chromosome splicing and deletion exists in the process of biological inheritance. The chromosome splicing and deletion algorithms are proposed to realize the autonomous search for the number of the divided time sections.
3.1.2. Procedure of Proposed HGAVCL
- (1)
- The initial population I and II are set up based on the chromosome length. Based on a priori knowledge, the initial population I and II of individuals are selected. The length of population I chromosome is L1 and the length of population II chromosome is L2. The chromosome length represents the number of the divided time sections and the chromosomes are coded using binary. The sizes of population I and II are pop1 and pop2, respectively.
- (2)
- The new individuals are generated by the crossover operation with the crossover probability pc.
- (3)
- The new individuals are generated by the mutation operation with the mutation probability pv.
- (4)
- The hybridization operations are performed between populations according to the hybridization probability ph, and if individuals are heritable based on growth factors, the new populations are generated.
- (5)
- The chromosome splicing is performed with splicing probability ps. If the fitness of the spliced individual is greater than the lowest fitness individual in the previous generation, the individual is extinguished.
- (6)
- The chromosome deletion operation is performed with the deletion probability pd. If the individual fitness is greater than that of the lowest fitness individual in the previous generation, the individual is extinguished.
- (7)
- The individual fitness of the population is calculated. The individuals of the population are selected via the Russian roulette method.
- (8)
- To ensure iterative convergence, the population extinction probability pe is set. After each round of iterations, the population with the largest fitness among the best individuals of each population dies out with pe.
- (9)
- Repeat the above steps (2)–(8) until the required number of iterations is satisfied.
- (10)
- The calculation process is shown in Figure 1.
3.2. Model of Linear Time Series
3.2.1. ARIMA Model
3.2.2. Parameter Calculation
3.2.3. Augmented Dickey–Fuller
3.2.4. Akaike’s Information Criterion
3.3. Model of Fluctuant Time Series
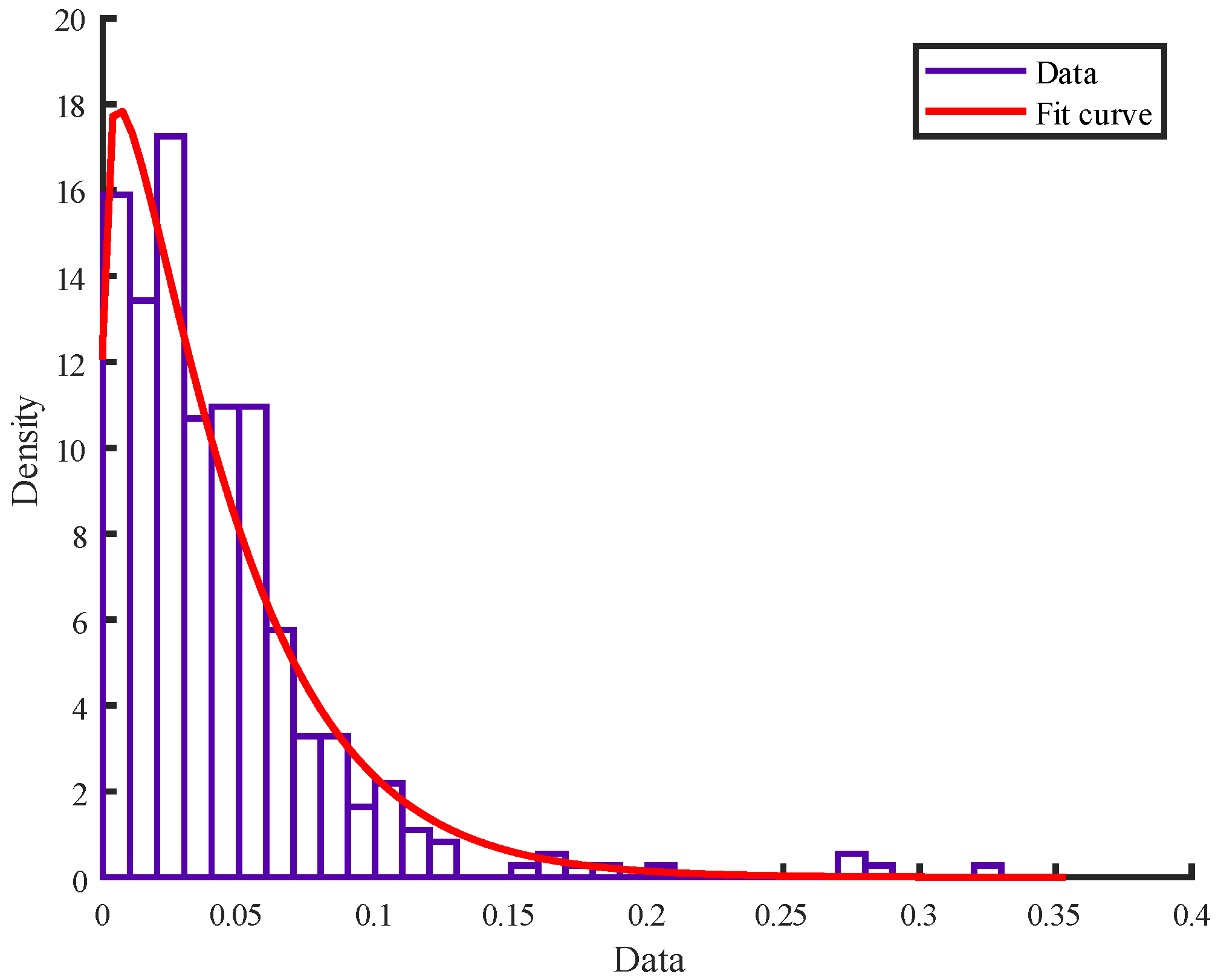
3.3.1. Copula Function
3.3.2. Copula Model Selection
3.3.3. Fluctuant Series Model Construction
4. Scenario Generation and Assessment
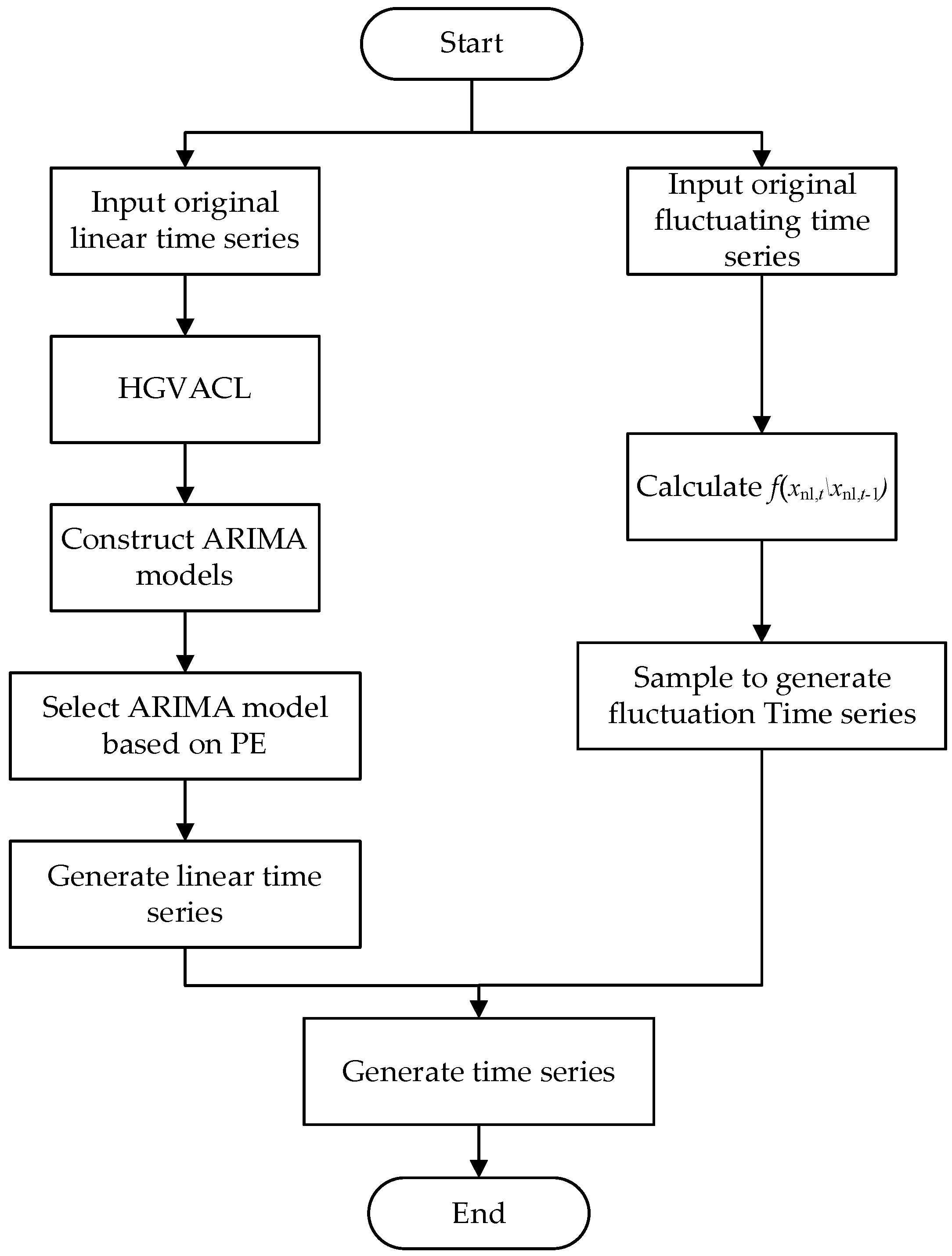
4.1. Scenario Generation Method
- (1)
- Input the original linear time series and fluctuating time series.
- (2)
- Generate the linear time series scenario:
- (1)
- Divide zones based on HGAVGL.
- (2)
- Construct ARIMA model of each zone.
- (3)
- ARIMA model is selected based on PE to generate linear partial scenarios.
- (3)
- Generate fluctuating time series scenario:
- (1)
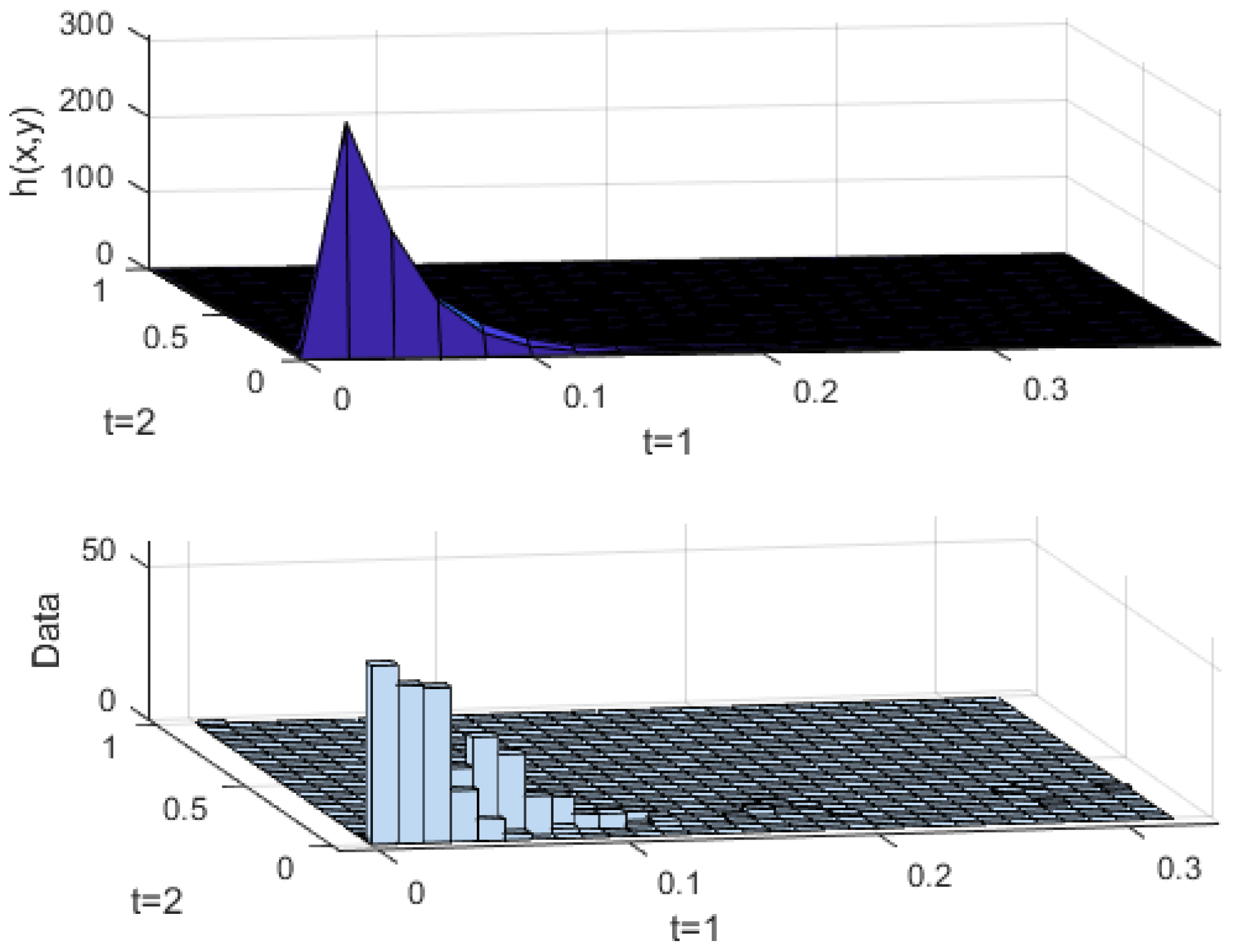
- Calculate f(xnl,t|xnl,t−1) based on Copula function.
- (2)
- Sample based on f(xnl,t|xnl,t−1) to generate fluctuating time series scenarios.
- (4)
- Combine linear and fluctuating time series to generate time series scenario.

4.2. Assessment Index
- (1)
- Time autocorrelation σ
- (2)
- Average offset rate μ
- (3)
- Climbing similarity Pe.
- (4)
- MAPE
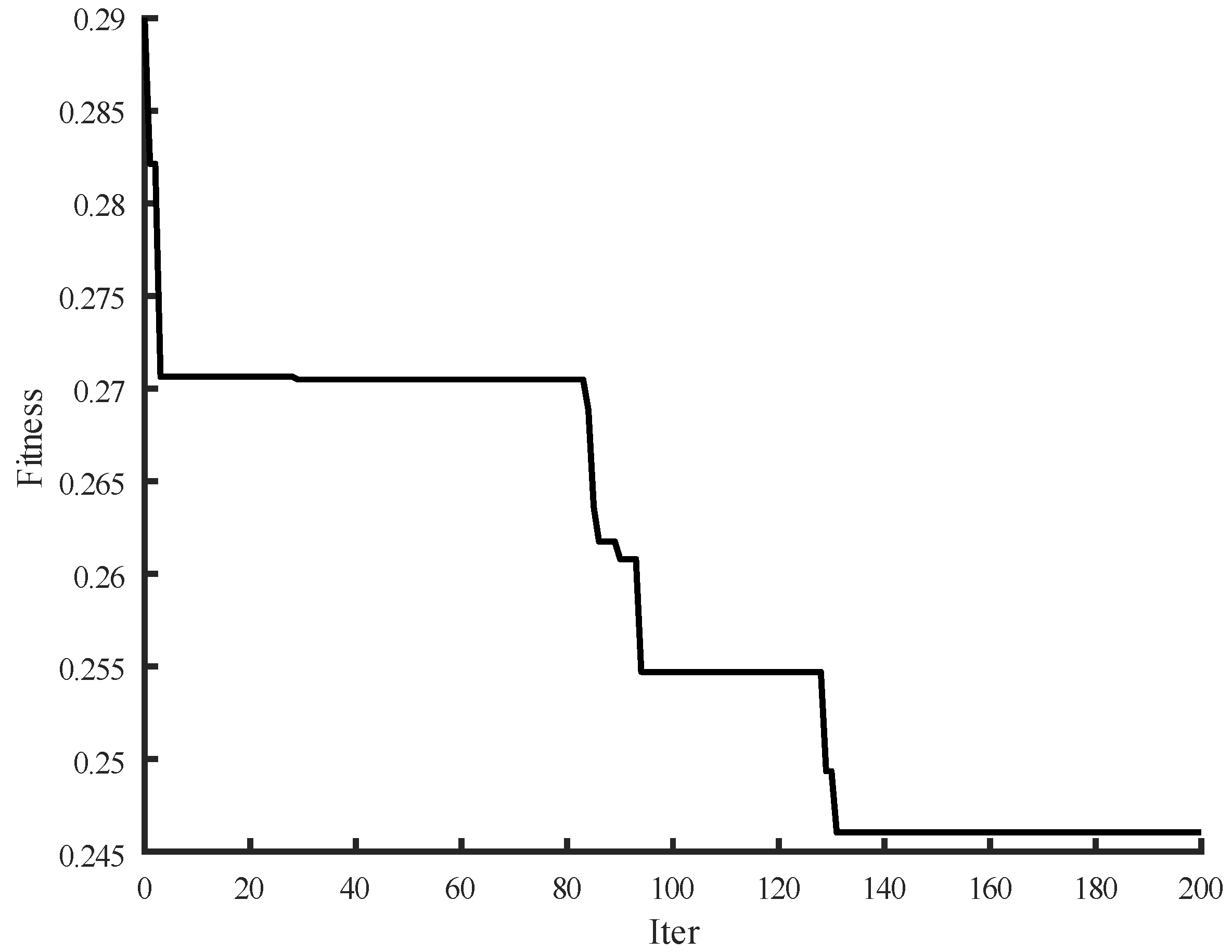
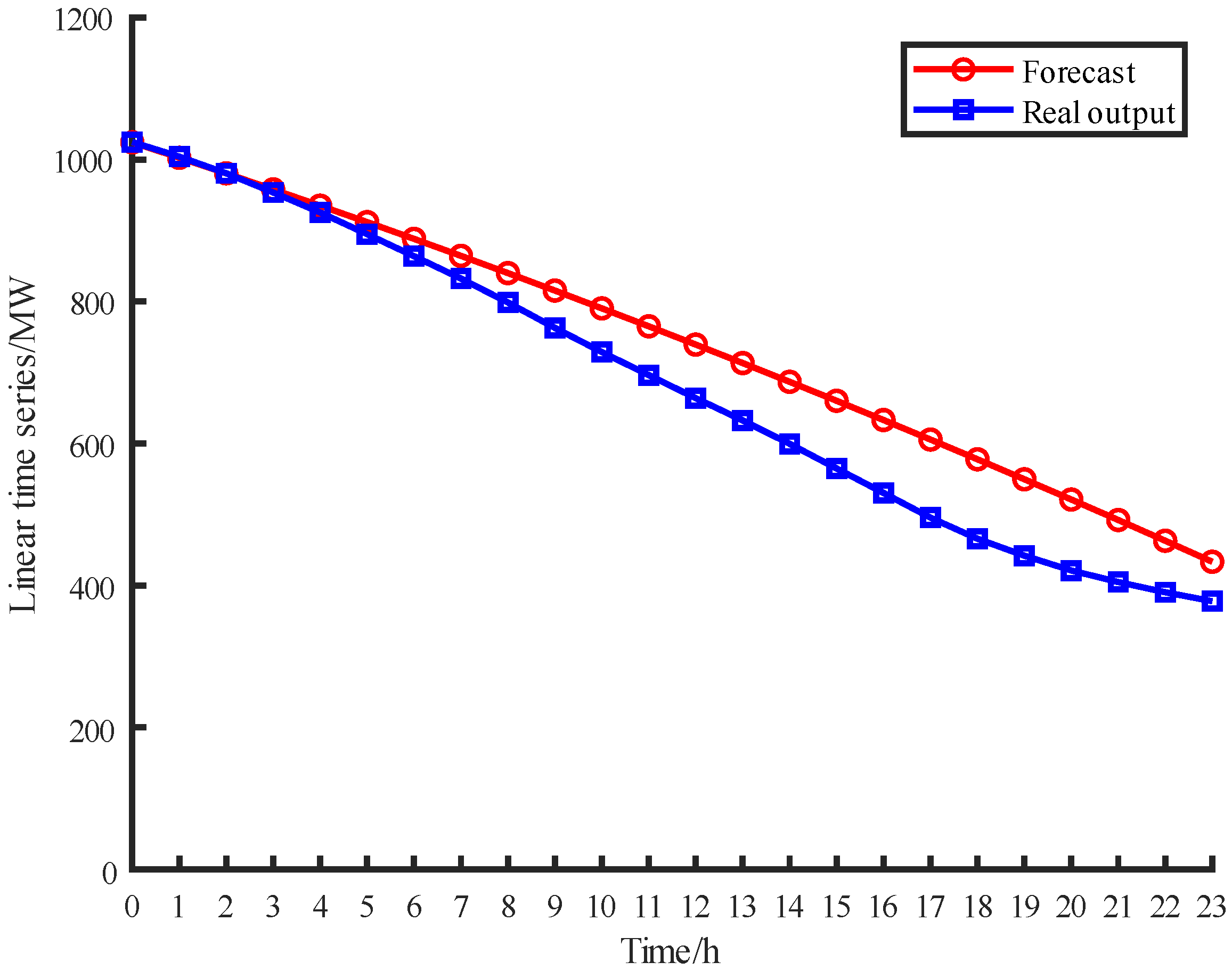
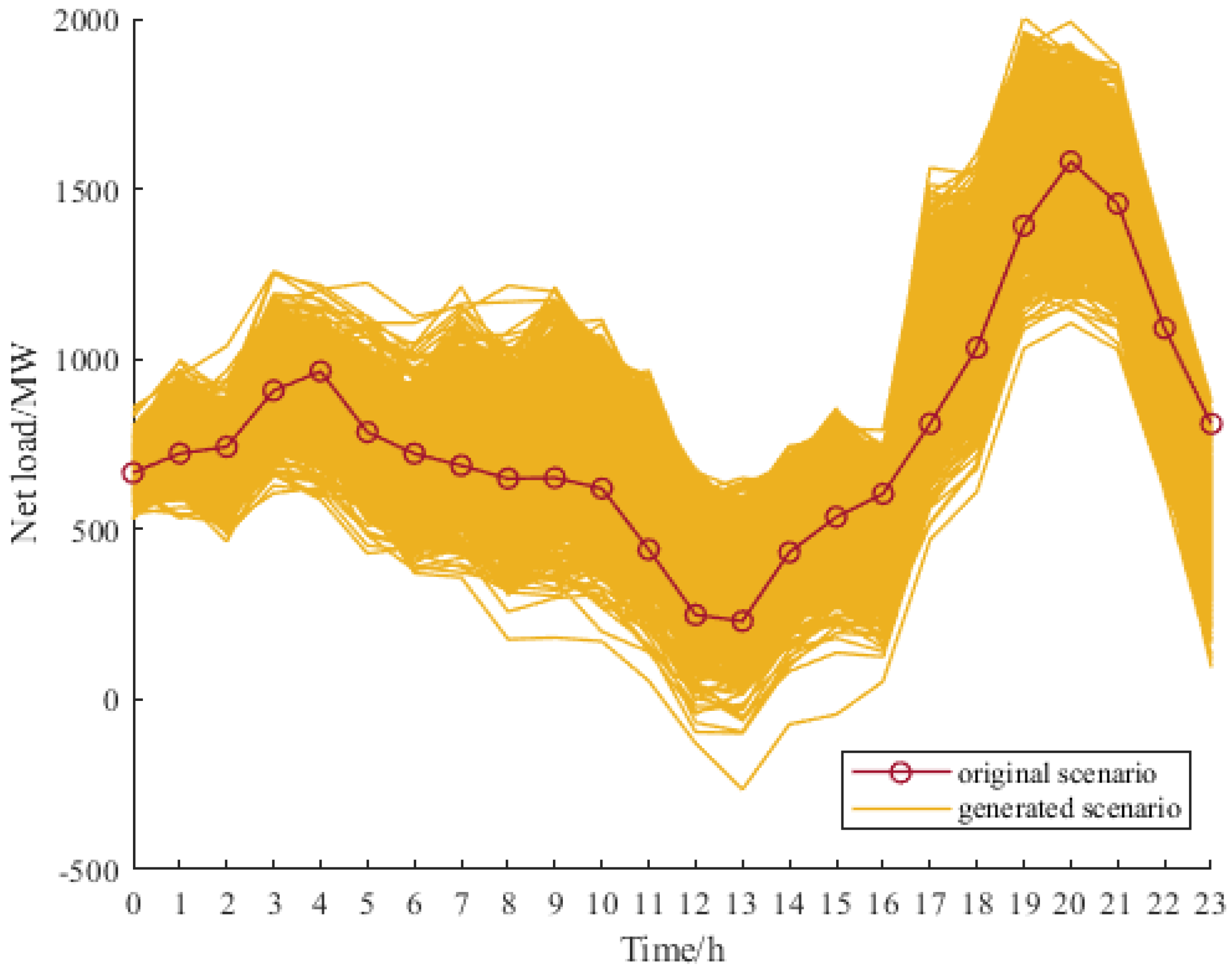
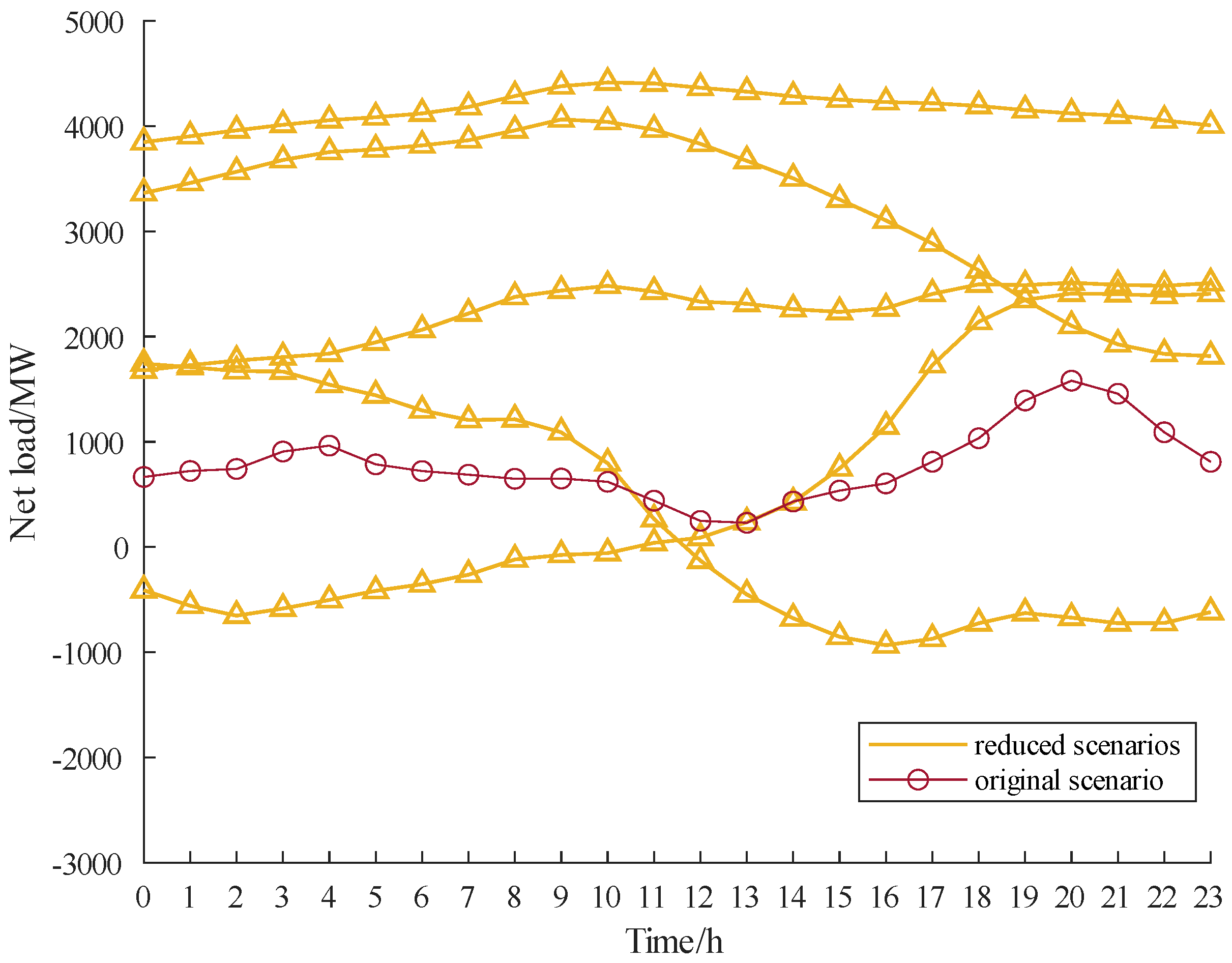
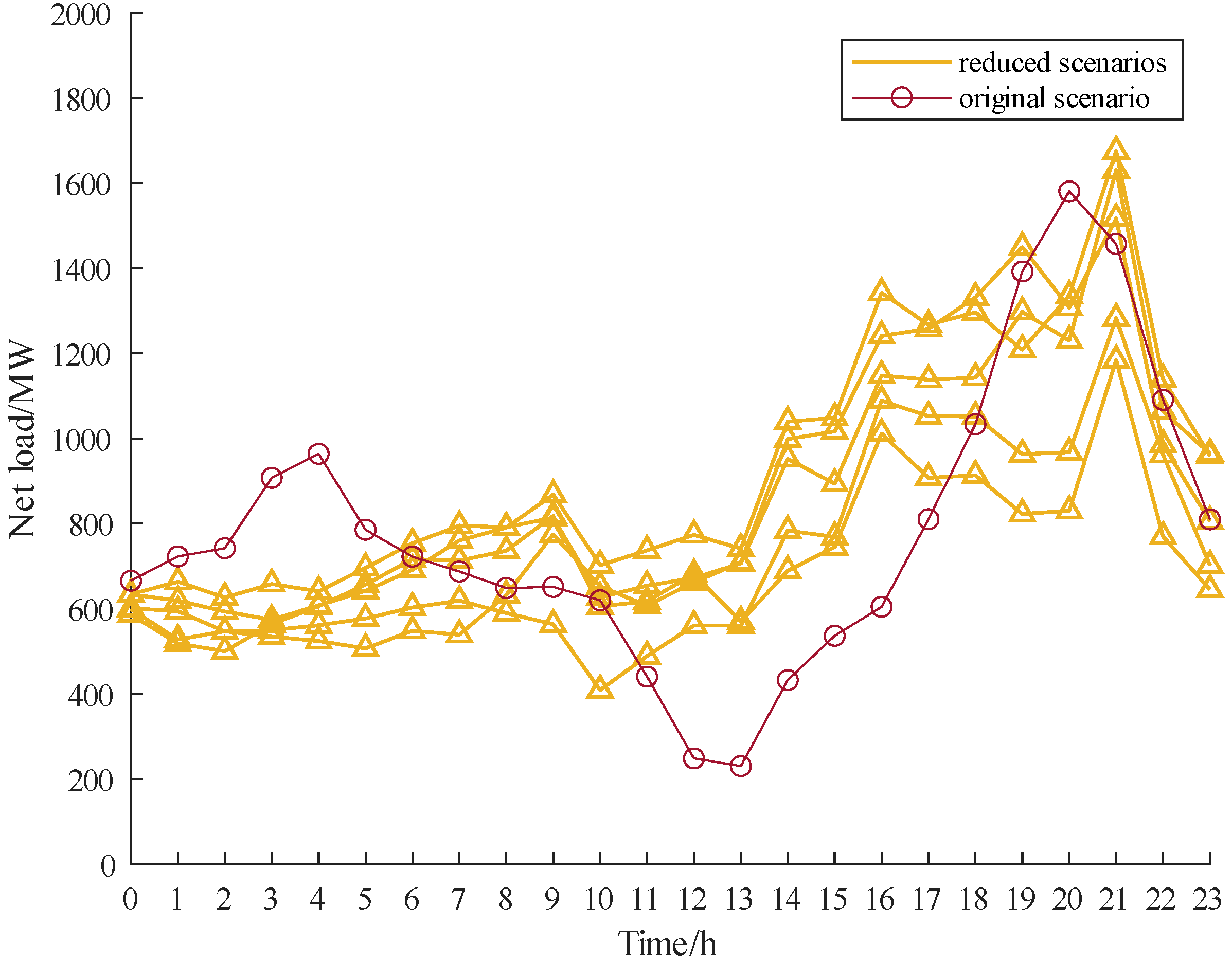
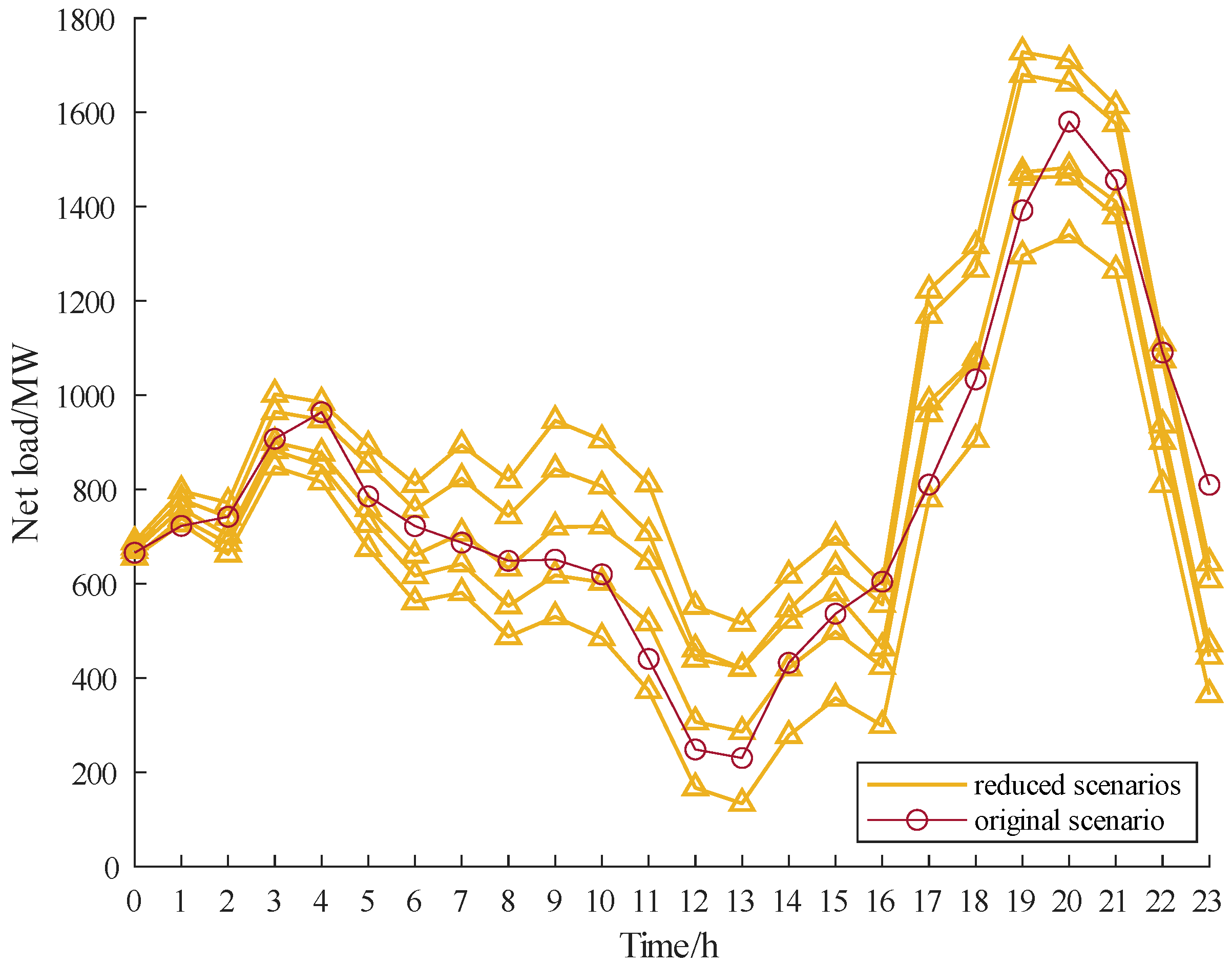
5. Case Study
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Cao, Y.; Wu, Q.; Zhang, H.; Li, C. Optimal Sizing of Hybrid Energy Storage System Considering Power Smoothing and Transient Frequency Regulation. Int. J. Electr. Power Energy Syst. 2022, 142, 108227. [Google Scholar] [CrossRef]
- Chen, L.; Shen, J.; Zhou, B.; Wang, Q.; Buja, G. Quantitative Analysis on the Proportion of Renewable Energy Generation Based on Broadband Feature Extraction. Appl. Sci. 2022, 12, 11159. [Google Scholar]
- Han, S.; He, M.; Zhao, Z.; Chen, D.; Xu, B.; Jurasz, J.; Liu, F.; Zheng, H. Overcoming the Uncertainty and Volatility of Wind Power: Day-Ahead Scheduling of Hydro-Wind Hybrid Power Generation System by Coordinating Power Regulation and Frequency Response Flexibility. Appl. Energy 2023, 333, 120555. [Google Scholar]
- Xu, Q.; Cao, Y.; Zhang, H.; Zhang, W.; Terzija, V. Bi-Level Dispatch and Control Architecture for Power System in China based on Grid-Friendly Virtual Power Plant. Appl. Sci. 2021, 11, 1282. [Google Scholar] [CrossRef]
- Cao, Y.; Wu, Q.; Zhang, H.; Li, C. Multi-Objective Optimal Siting and Sizing of BESS Considering Transient Frequency Deviation and Post-Disturbance Line Overload. Int. J. Electr. Power Energy Syst. 2023, 144, 108575. [Google Scholar]
- Hu, J.; Li, H. A New Clustering Approach for Scenario Reduction in Multi-Stochastic Variable Programming. IEEE Trans. Power Syst. 2019, 34, 3813–3825. [Google Scholar] [CrossRef]
- Wang, W.; Fang, X.; Cui, H.; Li, F.; Liu, Y.; Overbye, T.J. Transmission-and-Distribution Dynamic Co-Simulation Framework for Distributed Energy Resource Frequency Response. IEEE Trans. Smart Grid 2022, 13, 482–495. [Google Scholar]
- Camal, S.; Teng, F.; Michiorri, A.; Kariniotakis, G.; Badesa, L. Scenario Generation of Aggregated Wind, Photovoltaics and Small Hydro Production for Power Systems Applications. Appl. Energy 2019, 242, 1396–1406. [Google Scholar] [CrossRef]
- Nonvignon, T.Z.; Boucif, A.B.; Mhamed, M. A Copula-Based Attack Prediction Model for Vehicle-to-Grid Networks. Appl. Sci. 2022, 12, 3830. [Google Scholar] [CrossRef]
- Li, H.; Ren, Z.; Xu, Y.; Li, W.; Hu, B. A Multi-Data Driven Hybrid Learning Method for Weekly Photovoltaic Power Scenario Forecast. IEEE Trans. Sustain. Energy 2022, 13, 91–100. [Google Scholar] [CrossRef]
- Liao, W.; Yang, Z.; Chen, X.; Li, Y. Wind GMMN: Scenario Forecasting for Wind Power Using Generative Moment Matching Networks. IEEE Trans. Artif. Intell. 2022, 3, 843–850. [Google Scholar] [CrossRef]
- Lin, S.; Liu, C.; Shen, Y.; Li, F.; Li, D.; Fu, Y. Stochastic Planning of Integrated Energy System via Frank-Copula Function and Scenario Reduction. IEEE Trans. Smart Grid 2022, 13, 202–212. [Google Scholar] [CrossRef]
- Alves, D.K.; Ribeiro, R.L.; Costa, F.B.; Rocha, T.O.A. Real-Time Wavelet-Based Grid Impedance Estimation Method. IEEE Trans. Ind. Electron. 2019, 66, 8263–8265. [Google Scholar] [CrossRef]
- Zhao, J.; Mili, L. A Decentralized H-Infinity Unscented Kalman Filter for Dynamic State Estimation Against Uncertainties. IEEE Trans. Smart Grid 2019, 10, 4870–4880. [Google Scholar] [CrossRef]
- Mishra, C.; Vanfretti, L.; Jones, K.D. Synchrophasor Phase Angle Data Unwrapping Using an Unscented Kalman Filter. IEEE Trans. Power Syst. 2021, 36, 4868–4871. [Google Scholar] [CrossRef]
- Liu, G. Time Series Forecasting via Learning Convolutionally Low-Rank Models. IEEE Trans. Inf. Theory 2022, 68, 3362–3380. [Google Scholar] [CrossRef]
- Cardoso, C.A.V.; Cruz, G.L. Forecasting Natural Gas Consumption using ARIMA Models and Artificial Neural Networks. IEEE Lat. Am. Trans. 2016, 14, 2233–2238. [Google Scholar] [CrossRef]
- Wu, F.; Jing, R.; Zhang, X.P.; Wang, F.; Bao, Y. A Combined Method of Improved Grey BP Neural Network and MEEMD-ARIMA for Day-Ahead Wave Energy Forecast. IEEE Trans. Sustain. Energy 2021, 12, 2404–2412. [Google Scholar] [CrossRef]
- Yunus, K.; Thiringer, T.; Chen, P. ARIMA-Based Frequency-Decomposed Modeling of Wind Speed Time Series. IEEE Trans. Power Syst. 2016, 31, 2546–2556. [Google Scholar] [CrossRef]
- Jafari, A.; Khalili, T.; Babaei, E.; Bidram, A.A. Hybrid Optimization Technique Using Exchange Market and Genetic Algorithms. IEEE Access 2020, 8, 2417–2427. [Google Scholar] [CrossRef]
- Guo, J.; He, H.; Sun, C. ARIMA-Based Road Gradient and Vehicle Velocity Prediction for Hybrid Electric Vehicle Energy Management. IEEE Trans. Veh. Technol. 2019, 68, 5309–5320. [Google Scholar] [CrossRef]
- Xie, Y.; Jin, M.; Zou, Z.; Xu, G.; Feng, D.; Liu, W.; Long, D. Real-Time Prediction of Docker Container Resource Load Based on a Hybrid Model of ARIMA and Triple Exponential Smoothing. IEEE Trans. Cloud Comput. 2022, 10, 1386–1401. [Google Scholar] [CrossRef]
- Gangwar, P.; Mallick, A.; Chakrabarti, S.; Singh, S.N. Short-Term Forecasting-Based Network Reconfiguration for Unbalanced Distribution Systems With Distributed Generators. IEEE Trans. Ind. Inform. 2020, 16, 4378–4389. [Google Scholar] [CrossRef]
- Mhawi, D.N.; Hashem, S.H. Proposed Hybrid Correlation Feature Selection Forest Panalized Attribute Approach to Advance IDSs. Karbala Int. J. Mod. Sci. 2021, 7, 405–420. [Google Scholar]
- Montano, J.J.; Noreña, L.F.G.; Tobon, A.F.; Montoya, D.G. Estimation of the Parameters of the Mathematical Model of an Equivalent Diode of a Photovoltaic Panel Using a Continuous Genetic Algorithm. IEEE Lat. Am. Trans. 2022, 20, 616–623. [Google Scholar] [CrossRef]
- Souza, M.G.; Vallejo, E.E.; Estrada, K. Detecting Clustered Independent Rare Variant Associations Using Genetic Algorithms. IEEE/ACM Trans. Comput. Biol. Bioinform. 2021, 18, 932–939. [Google Scholar] [CrossRef]
- Huanca, D.H.; Pareja, L.A.G. Chu and Beasley Genetic Algorithm to Solve the Transmission Network Expansion Planning Problem Considering Active Power Losses. IEEE Lat. Am. Trans. 2021, 19, 1967–1975. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Zhao, Y. Joint Synchronization Estimation Based on Genetic Algorithm for OFDM/OQAM Systems. J. Syst. Eng. Electron. 2020, 31, 657–665. [Google Scholar]
- Oliveira, B.B.; Carravilla, M.A.; Oliveira, J.F. A Diversity-Based Genetic Algorithm for Scenario Generation. Eur. J. Oper. Res. 2022, 299, 1128–1141. [Google Scholar] [CrossRef]
- Kaushik, E.; Prakash, V.; Mahela, O.P.; Khan, B.; Abdelaziz, A.Y.; Hong, J.; Geem, Z.W. Optimal Placement of Renewable Energy Generators Using Grid-Oriented Genetic Algorithm for Loss Reduction and Flexibility Improvement. Energies 2022, 15, 1863. [Google Scholar] [CrossRef]
- Ahmar, A.S.; Botto-Tobar, M.; Rahman, A.; Hidayat, R. Forecasting the Value of Oil and Gas Exports in Indonesia using ARIMA Box-Jenkins. J. Inf. Vis. 2022, 3, 35–42. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Literature | Model | Method of Data Analysis | Characteristic |
|---|---|---|---|
| [17] | ARIMA | None | Traditional Model |
| [18] | ARIMA | MEEMD | Expanding single-dimensional data to multidimensional |
| [19] | ARIMA | Frequency Decomposition | Determined cutoff frequency from experiments (complex processing) |
| [20,21] | ARIMA | None | Eliminate non-smoothness factors of time series |
| [22] | ARIMA and triple exponential smoothing | None | Improved ARIMA parameter determination method(small time overhead) |
| [23] | ARIMA | Wavelet Transform | Expanding single-dimensional data to multidimensional |
| [24] | Random Forest | CFS | Identify redundant data features |
| ADF | 0 | 1 |
|---|---|---|
| d | 0 | 1 |
| AIC | p = 1 | p = 2 | p = 3 | p = 4 | p = 5 |
|---|---|---|---|---|---|
| q = 1 | −7049 | −7075 | −6850 | −6809 | −6807 |
| q = 2 | −6813 | −6868 | −7290 | −6807 | −6805 |
| q = 3 | −6811 | −6866 | −6807 | −6805 | −6803 |
| q = 4 | −7316 | −6864 | −6805 | −6803 | −6801 |
| q = 5 | −7241 | −7253 | −6746 | −7132 | −6902 |
| Zone | p1 | p2 | p3 | q1 | q2 | q3 | d |
|---|---|---|---|---|---|---|---|
| Zone 1 | 0.23 | 0.13 | 0 | −0.47 | 0 | 0 | 0 |
| Zone 2 | 0.96 | 0 | 0 | −0.34 | −0.42 | 0 | 1 |
| Zone 3 | −0.14 | 0.35 | 0.51 | −0.31 | −0.08 | −0.21 | 0 |
| Zone 4 | −0.47 | −0.64 | 0 | 1.07 | 1.01 | 0.93 | 1 |
| Zone 5 | −0.07 | 0.18 | 0.29 | −0.09 | −0.91 | 0 | 1 |
| Zone 6 | −0.46 | 0.13 | 0.36 | 1.46 | 0.48 | 0 | 2 |
| Zone | Length | MAPE | PE |
|---|---|---|---|
| Zone 1 | 751 | 0.1024 | 1.38 |
| Zone 2 | 1832 | 0.0145 | 1.32 |
| Zone 3 | 385 | 0.0514 | 1.28 |
| Zone 4 | 629 | 0.0283 | 1.31 |
| Zone 5 | 128 | 0.0283 | 0.29 |
| Zone 6 | 5035 | 0.2229 | 1.42 |
| Method | Time Autocorrelation σ | Average Offset Rate μ | Climbing Similarity Pe |
|---|---|---|---|
| MCS method | 0.0110 | 0.4673 | 0.8273 |
| Proposed approach | 0.0515 | 0.0396 | 0.9035 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Wang, L.; Cao, Y.; Ma, R.; Wang, Y.; Li, C.; Liu, R.; Zou, S. Renewable Scenario Generation Based on the Hybrid Genetic Algorithm with Variable Chromosome Length. Energies 2023, 16, 3180. https://doi.org/10.3390/en16073180
Liu X, Wang L, Cao Y, Ma R, Wang Y, Li C, Liu R, Zou S. Renewable Scenario Generation Based on the Hybrid Genetic Algorithm with Variable Chromosome Length. Energies. 2023; 16(7):3180. https://doi.org/10.3390/en16073180
Chicago/Turabian StyleLiu, Xiaoming, Liang Wang, Yongji Cao, Ruicong Ma, Yao Wang, Changgang Li, Rui Liu, and Shihao Zou. 2023. "Renewable Scenario Generation Based on the Hybrid Genetic Algorithm with Variable Chromosome Length" Energies 16, no. 7: 3180. https://doi.org/10.3390/en16073180
APA StyleLiu, X., Wang, L., Cao, Y., Ma, R., Wang, Y., Li, C., Liu, R., & Zou, S. (2023). Renewable Scenario Generation Based on the Hybrid Genetic Algorithm with Variable Chromosome Length. Energies, 16(7), 3180. https://doi.org/10.3390/en16073180