
Thin Reservoir Identification Based on Logging Interpretation by Using the Support Vector Machine Method

Abstract
:1. Introduction
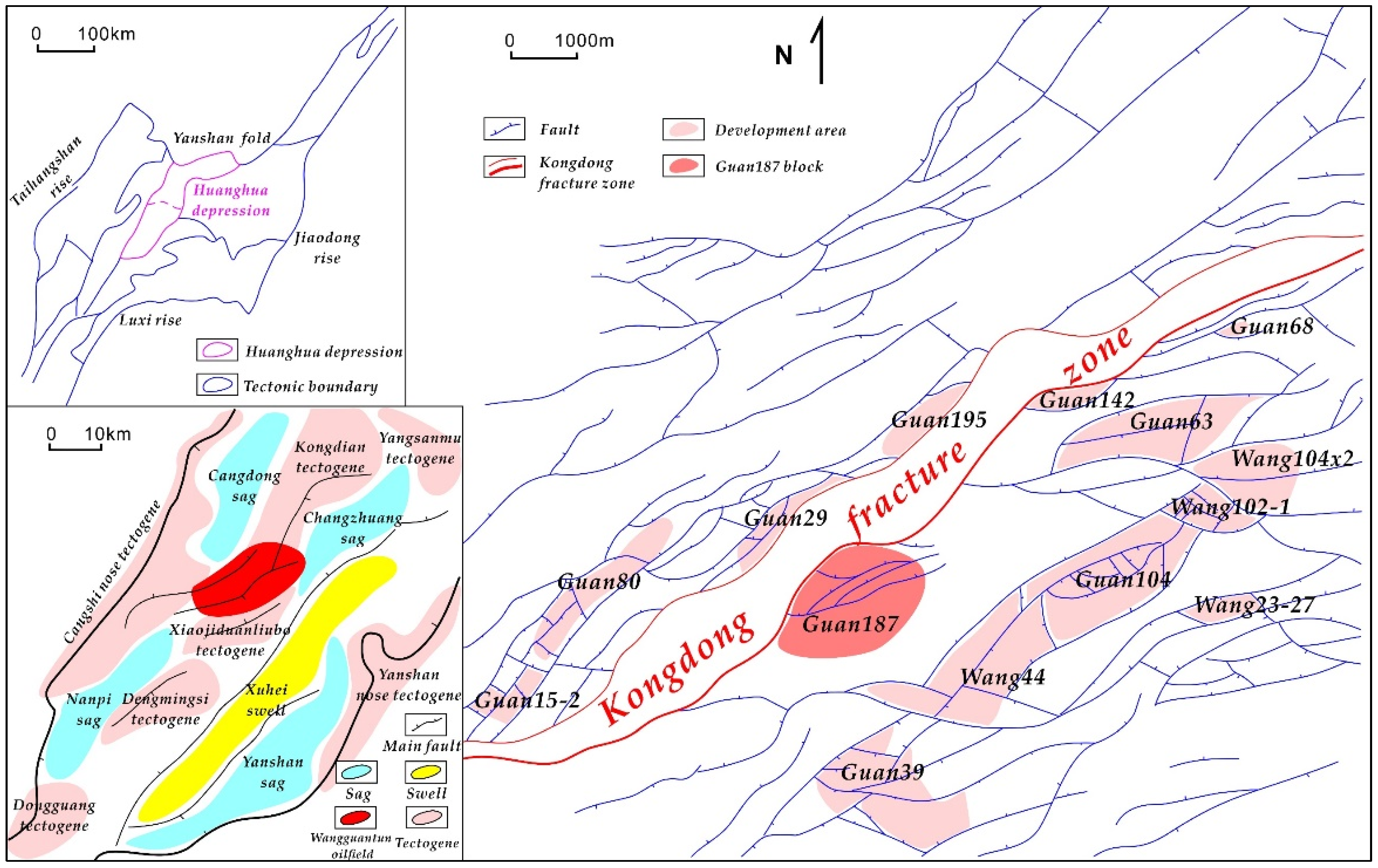
2. Overview of Research Area
3. SVM Classification Principle
3.1. Two-Class SVM
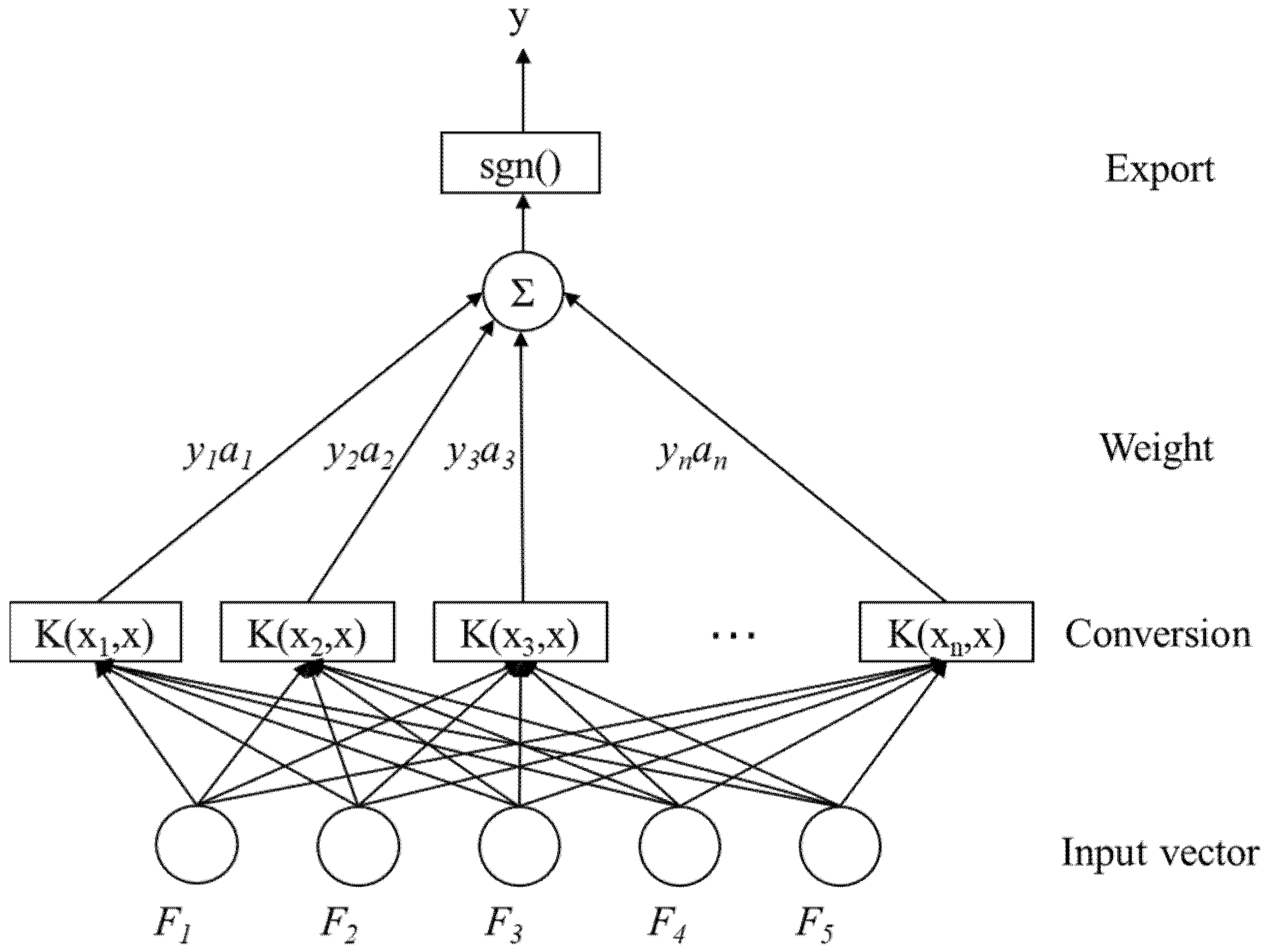
3.2. Multi-Class SVM
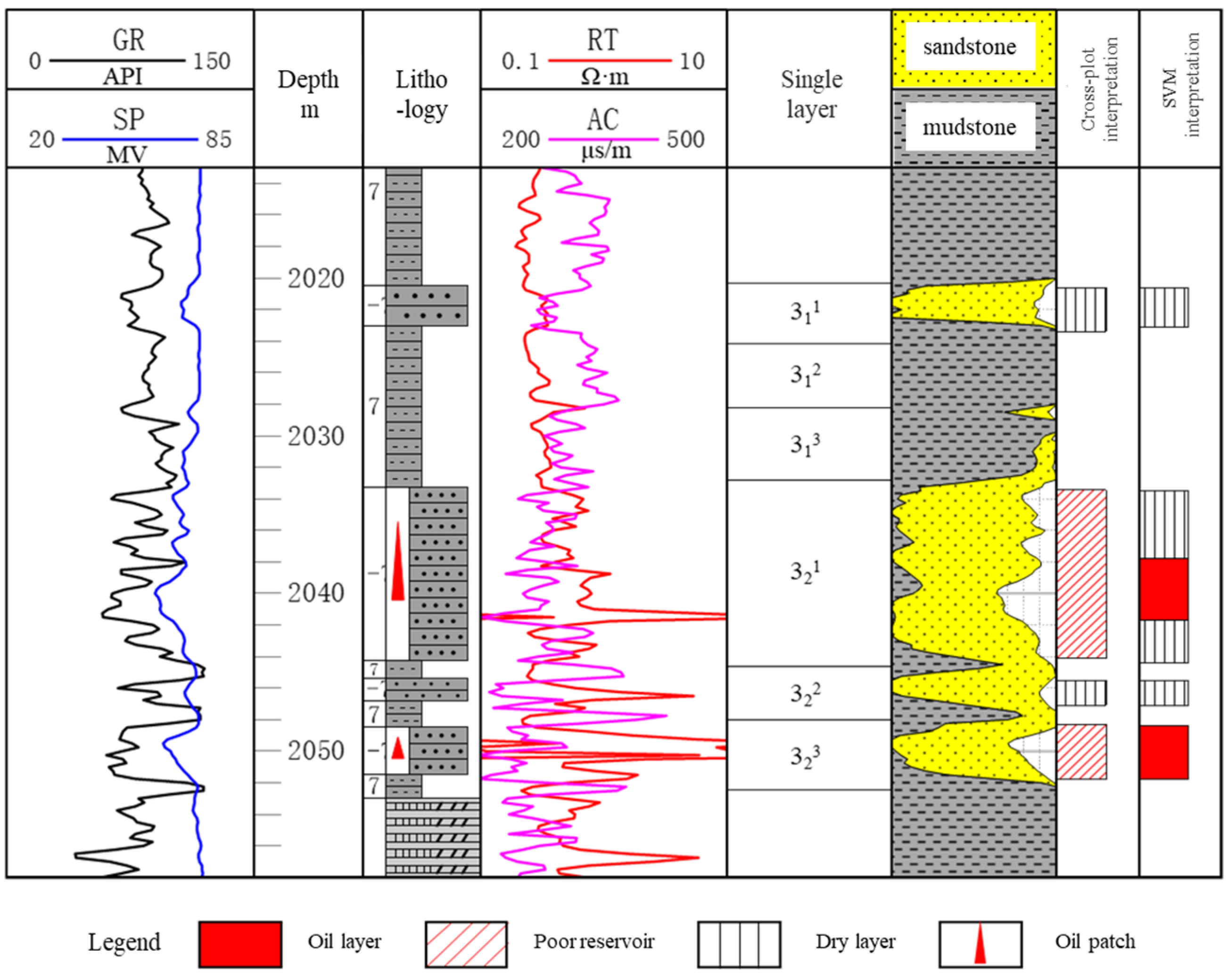
4. Application of SVM in Thin Reservoir Identification
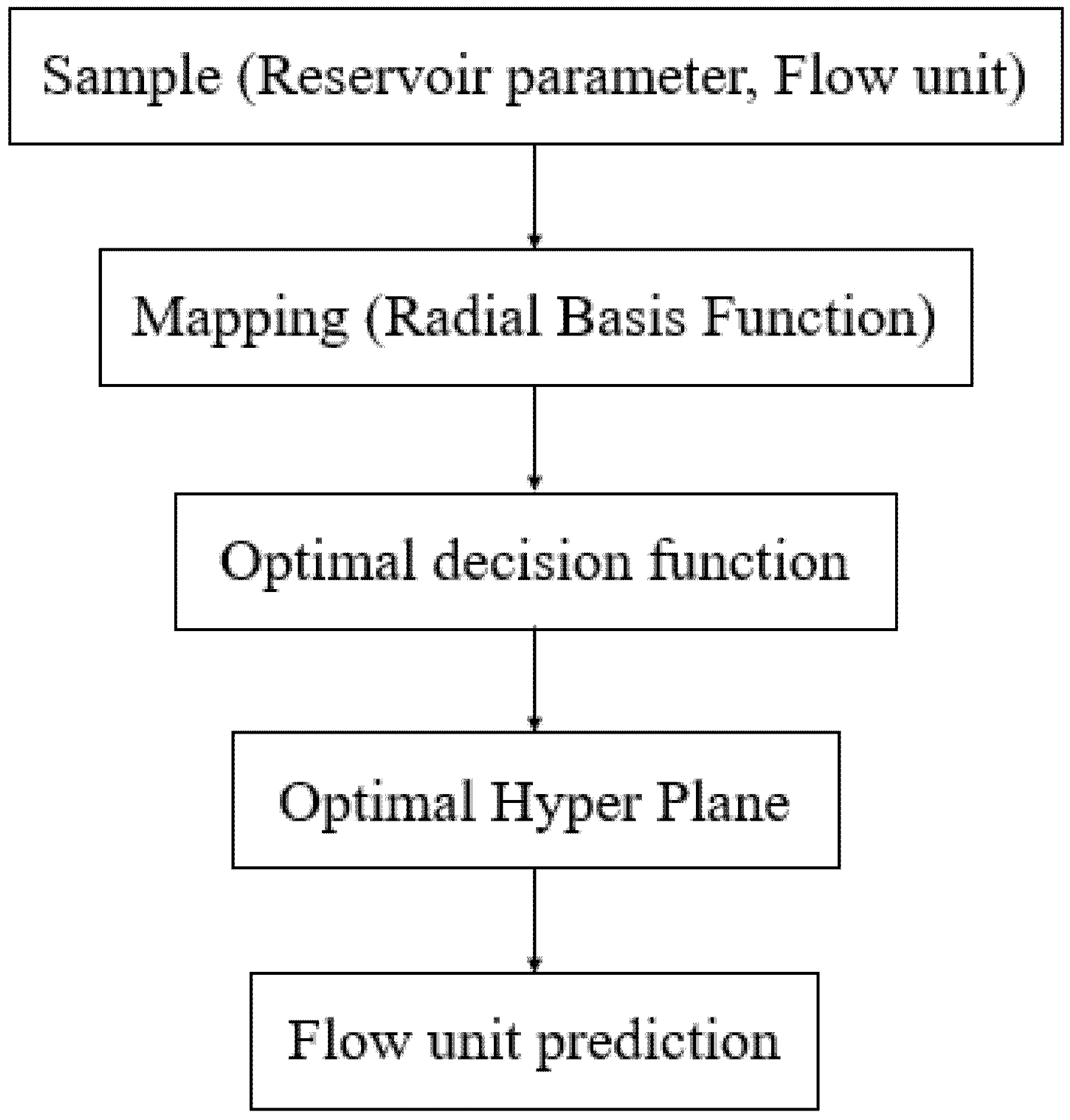
4.1. Model Building
4.1.1. Sample Set Selection
4.1.2. Normalization of Sample Data
4.1.3. Model Selection
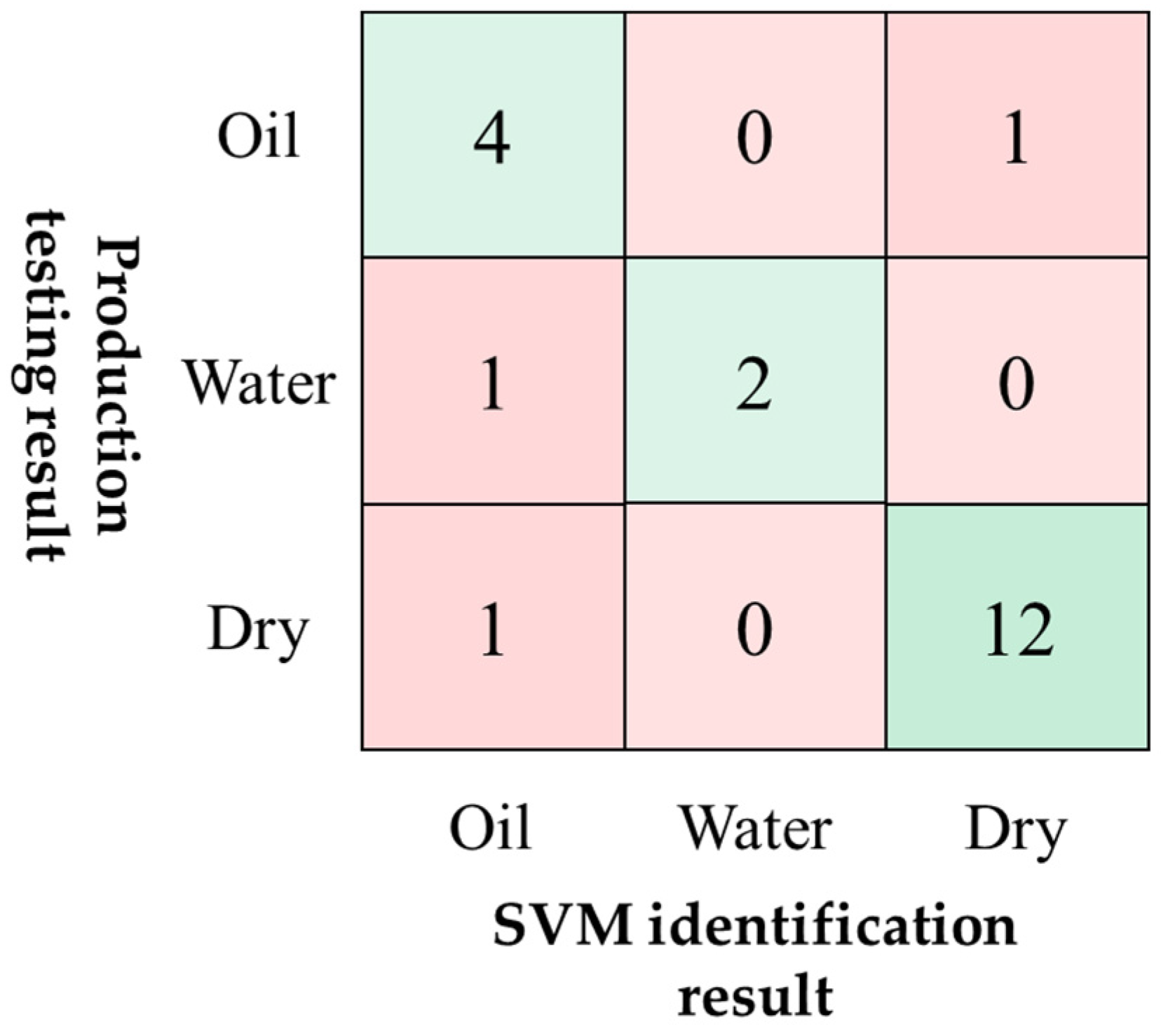
4.2. Application Effect and Analysis
5. Conclusions
- (1)
- The logging curves indirectly reflect the properties of the fluid in the reservoir. Well log data can be used to comprehensively identify the thin layers.
- (2)
- The accuracy of the SVM method for reservoir fluid identification is obviously higher than that of the conventional cross-plot identification method.
- (3)
- The SVM-based reservoir fluid identification model has high convergence accuracy and strong generalization ability, and can make full use of limited logging data information to obtain the optimal identification results. Especially in areas where the test data are lacking or the oil-water system is complex, this method can improve the identification accuracy of the oil-water dry layer. It has good reference values in actual logging reservoir evaluation and can be extended to lithology identification and reservoir parameter prediction.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, H. Study on remaining oil in the north of Daqing Oilfield. Acta Pet. Sin. 1993, 14, 72–80. [Google Scholar]
- Qadri, S.T.; Ahmed, W.; Haque, A.E.; Radwan, A.E.; Hakimi, M.H.; Abdel Aal, A.K. Murree Clay Problems and Water-Based Drilling Mud Optimization: A Case Study from the Kohat Basin in Northwestern Pakistan. Energies 2022, 15, 3424. [Google Scholar] [CrossRef]
- Haque, A.E.; Qadri, S.T.; Bhuiyan, M.A.H.; Navid, M.; Nabawy, B.S.; Hakimi, M.H.; Abd-El-Aal, A.K. Integrated wireline log and seismic attribute analysis for the reservoir evaluation: A case study of the Mount Messenger Formation in Kaimiro Field, Taranaki Basin, New Zealand. J. Nat. Gas Sci. Eng. 2022, 99, 104452. [Google Scholar] [CrossRef]
- Osinowo, O.O.; Ayorinde, J.O.; Nwankwo, C.P.; Ekeng, O.M.; Taiwo, O.B. Reservoir description and characterization of Eni field offshore Niger Delta, southern Nigeria. J. Pet. Explor. Prod. Technol. 2018, 8, 381–397. [Google Scholar] [CrossRef]
- Liu, J.; Wang, A.; Lang, F.; Zhang, J. A new technique for identifying the fliud in thin, poor and low resistivity pay zone. Well Logging Technol. 2000, 24, 515–517. [Google Scholar]
- Guo, H.; Huang, D.; Pan, G. Fluid identification and interpretation method of thin differential oil-water layer in low permeability reservoir. China Pet. Explor. 2001, 6, 31–33. [Google Scholar]
- Shan, X. The Research to Log Recognition Technology for Thin Oil Layer in Qilicun Oilfield. Bachelor’s Thesis, Xi’an Shiyou University, Xi’an, China, 2014; pp. 34–54. [Google Scholar]
- Tang, H.; Luo, M.; Yan, Q. Recognition and interpretation of water encroaching in thin and poor-quality pay zone. J. Southwest Pet. Inst. 2003, 25, 1–3. [Google Scholar]
- Hou, J.; Wang, J.; Wang, C.; Cheng, L. Application of thin & poor reservoir predicted technology to the Punan oilfield. Southwest Pet. Inst. 2006, 28, 53–56. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995; pp. 54–96. [Google Scholar]
- Luo, N. A New Method in Data Mining-Support Vector Machine. Softw. Guide 2008, 7, 30–31. [Google Scholar]
- Vapnik, V.; Levin, E.; Le, C.Y. Measuring the VC-Dimension of a Learning Machine. Neural Comput. 1994, 6, 851–876. [Google Scholar] [CrossRef]
- Yang, C. Genesis and accumulation of non-type natural gases in Huanghua depression, Dagang oilfield. Pet. Explor. Dev. 2006, 33, 335–339. [Google Scholar]
- Xia, R.; Tang, J. The development and evaluated patterns of Ordovician palaeo karst in the Huanghua depression. Pet. Explor. Dev. 2004, 31, 51–53. [Google Scholar]
- Jiao, Q.; Hou, J.; Xing, H. Anastomosing river sediment of the Zao 0 reservoir group in the Duanliubo oilfield, Huanghua depression. Pet. Explor. Dev. 2004, 31, 72–74. [Google Scholar]
- Ren, W. Fault structure characteristics of Guan-3 block in Wangguantun Oilfield. Petrochem. Ind. Technol. 2017, 8, 127. [Google Scholar]
- Zhang, X.; Hou, J.; Hu, C.; Liu, Y.; Wang, X.; Ji, L. Evaluation of reservoir permeability heterogeneity by principal component analysis—Taking Wangguantun oil field Wang 23–27 block for example. J. East China Univ. Technol. Nat. Sci. 2018, 41, 41–45. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory, 2nd ed.; Springer: New York, NY, USA, 1999; pp. 12–15. [Google Scholar]
- Lu, W.; Guo, J.; Dong, H.; Zhang, Y.; Lin, L. Evaluating Mine Geology Environmental Quality Using Improved SVM Method. J. Jilin Univ. Earth Sci. Ed. 2016, 46, 1511–1519. [Google Scholar]
- Peng, T.; Zhang, X. Review of support vector machine and its applications in petroleum exploration and development. Prog. Explor. Geophys. 2007, 30, 91–95. [Google Scholar]
- Yi, Z.; Lv, M. Intrusion Detection Method Based on Multi-class Support Vector Machines. Comput. Eng. 2007, 33, 167–169. [Google Scholar]
- Weston, J.; Watkins, C. Multi-Class Support Vector Machines; CSD-TR-98-04; Royal Holloway College: London, UK, 1998. [Google Scholar]
- Wang, Z.; Xue, X. Multi-Class Support Vector Machine; Springer: Berlin/Heidelberg, Germany, 2014; pp. 23–48. [Google Scholar]
- Ren, L.; Li, W.; Ci, X.; Shi, X.; Sun, Z.; Zheng, R. A Method for Identification of Cuttings in Petroleum Logging by LIBSVMs. Period. Ocean. Univ. China 2010, 40, 131–136. [Google Scholar]
- Xu, D.; Li, T.; Huang, B.; Li, N. Research on the identification of the lithology and fluid type of foreign M oilfield by using the cross-plot method. Prog. Geophys. 2012, 27, 1123–1132. [Google Scholar]
- Zhang, Y.; Tong, K.; Zheng, J.; Wang, D. Application of Support vector machine method in fluid identification of low resistivity reservoir. Geophys. Prospect. Pet. 2008, 47, 306–310. [Google Scholar]
- Tao, S.; Xiao, C.; Yang, B.; Cai, Y. The application of the artificial neural network in the log interpretation. Geophys. Prospect. Pet. 1995, 34, 90–102. [Google Scholar]
- Zhu, G.; Liu, S.; Yu, J. Support vector machine and its applications to function approximation. J. East China Univ. Sci. Technol. 2002, 28, 555–559. [Google Scholar]
- Yu, D.; Sun, J.; Zhang, Z.; Wu, J. Reservoir Fluid Property Identification with Support Vector Machine Method. Xinjiang Pet. Geol. 2005, 26, 675–677. [Google Scholar]
- Ivšinović, J.; Malvić, T. Comparison of Mapping Efficiency for Small Datasets using Inverse Distance Weighting vs. Moving Average, Northern Croatia Miocene Hydrocarbon Reservoir. Geologija 2022, 65, 47–57. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, Y. Performance Analysis of Support Vector Machines with Gauss Kernel. Comput. Eng. 2003, 29, 22–25. [Google Scholar]
- Yue, Y.; Yuan, Q. Application of SVM method in reservoir prediction. Geophys. Prospect. Pet. 2005, 44, 388–392. [Google Scholar]
- Wang, X.; Li, Z. Parameter determination of kernel function of support vector Machine based on grid search. Period. Ocean. Univ. China 2005, 35, 859–862. [Google Scholar]
- Chen, K.; Wu, L.; Chen, Y.; Wang, G. Classification and Recognition of Polyhalite in Chuanzhong Based on Support Vector Machine. Adv. Earth Sci. 2016, 31, 1041–1046. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stratigraphic System | Oil Group | Lithologic Character | |||
|---|---|---|---|---|---|
| System | Series | Group | Section | ||
| Neogene | Pliocene | Minghuazhen Formation | Light gray green, gray green sandstone, brown, brown red mudstone | ||
| Miocene | Guantao Formation | Relatively thick light green, gray white sandstone, mixed with gray green, purple mudstone | |||
| Paleogene | Oligocene | Dongying Formation | Gray argillaceous siltstone, mudstone, the lower mudstone is rich in ostracoda fossils | ||
| Shahejie Formation | Sha1 | It is mainly composed of biological limestone and dolomitic limestone, with oil shale and mudstone | |||
| Sha2 | Light green and gray sandstone interbedded with purple red and gray mudstone | ||||
| Sha3 | Sha31 | Biolithite limestone | |||
| Sha32 | Thick layer volcanic rock segment, dark basalt | ||||
| Sha33 | Gray mudstone, mixed with thin layer of light green fine sandstone, medium sandstone | ||||
| Eocene | Kongdian Formation | Kong1 | Zao 0 | Huge thick layer of paste rock | |
| Zao I | Brown red mudstone, mixed with brown siltstone, fine sandstone | ||||
| Zao II | It is mainly composed of gray-brown coarse sandstone and pebbled sandstone, mixed with gray-green and purplish red mudstone | ||||
| Zao III | It is mainly composed of brown fine sandstone, coarse sandstone and pebbled sandstone, mixed with gray-green and purple-red mudstone, and the bottom is mainly purple-red mudstone | ||||
| Zao IV | Grey sandstone, brown red mudstone | ||||
| Zao V | Grey sandstone, brown red mudstone | ||||
| Well | Layer | Production Testing Depth/m | Production Testing Result | SVM Identification Result | Cross-Plot Identification Result |
|---|---|---|---|---|---|
| G913-1 | 311 | 2235.6~2236.2 | Dry | Dry | Dry |
| 312 | 2243.7~2245.6 | Oil | Oil | Oil | |
| 313 | 2250.4~2251.9 | Oil | Oil | Oil | |
| 321 | 2259.0~2259.5 | Dry | Dry | Dry | |
| 322 | 2263.0~2264.2 | Dry | Dry | Dry | |
| 323 | 2270.7~2272.9 | Dry | Dry | Dry | |
| 324 | 2284.1~2286.3 | Water | Oil | Oil | |
| G913-2 | 311 | 2228.5~2229.5 | Dry | Dry | Dry |
| 312 | 2237.6~2238.6 | Oil | Oil | Oil | |
| 313 | 2243.6~2245.4 | Oil | Oil | Oil | |
| 321 | 2252.3~2258.8 | Dry | Dry | Dry | |
| 322 | 2262.9~2264.8 | Dry | Dry | Dry | |
| 323 | 2272.8~2275.1 | Dry | Dry | Dry | |
| 324 | 2280.4~2282.1 | Water | Water | Water | |
| G918-2 | 311 | 2203.1~2205.0 | Dry | Dry | Dry |
| 312 | 2226.1~2228.2 | Dry | Oil | Oil | |
| 313 | 2230.0~2231.9 | Dry | Dry | Dry | |
| 323 | 2239.3~2240.5 | Dry | Dry | Dry | |
| G12-13 | 321 | 2248.7~2251.0 | Oil | Dry | Dry |
| 323 | 2260.9~2262.3 | Dry | Dry | Dry | |
| 324 | 2265.7~2268.0 | Water | Water | Water | |
| Accuracy | 85.71% | 80.95% | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Li, Y.; Song, X.; Jin, L.; Wang, X. Thin Reservoir Identification Based on Logging Interpretation by Using the Support Vector Machine Method. Energies 2023, 16, 1638. https://doi.org/10.3390/en16041638
Zhou X, Li Y, Song X, Jin L, Wang X. Thin Reservoir Identification Based on Logging Interpretation by Using the Support Vector Machine Method. Energies. 2023; 16(4):1638. https://doi.org/10.3390/en16041638
Chicago/Turabian StyleZhou, Xinmao, Yawen Li, Xiaodong Song, Lingxuan Jin, and Xixin Wang. 2023. "Thin Reservoir Identification Based on Logging Interpretation by Using the Support Vector Machine Method" Energies 16, no. 4: 1638. https://doi.org/10.3390/en16041638
APA StyleZhou, X., Li, Y., Song, X., Jin, L., & Wang, X. (2023). Thin Reservoir Identification Based on Logging Interpretation by Using the Support Vector Machine Method. Energies, 16(4), 1638. https://doi.org/10.3390/en16041638