

Utilizing the Random Forest Method for Short-Term Wind Speed Forecasting in the Coastal Area of Central Taiwan


Abstract
1. Introduction
2. Methods and Data Sources
2.1. Random Forest Method
2.2. Artificial Neural Network Method
2.3. Persistence Methods
2.4. Data Sources
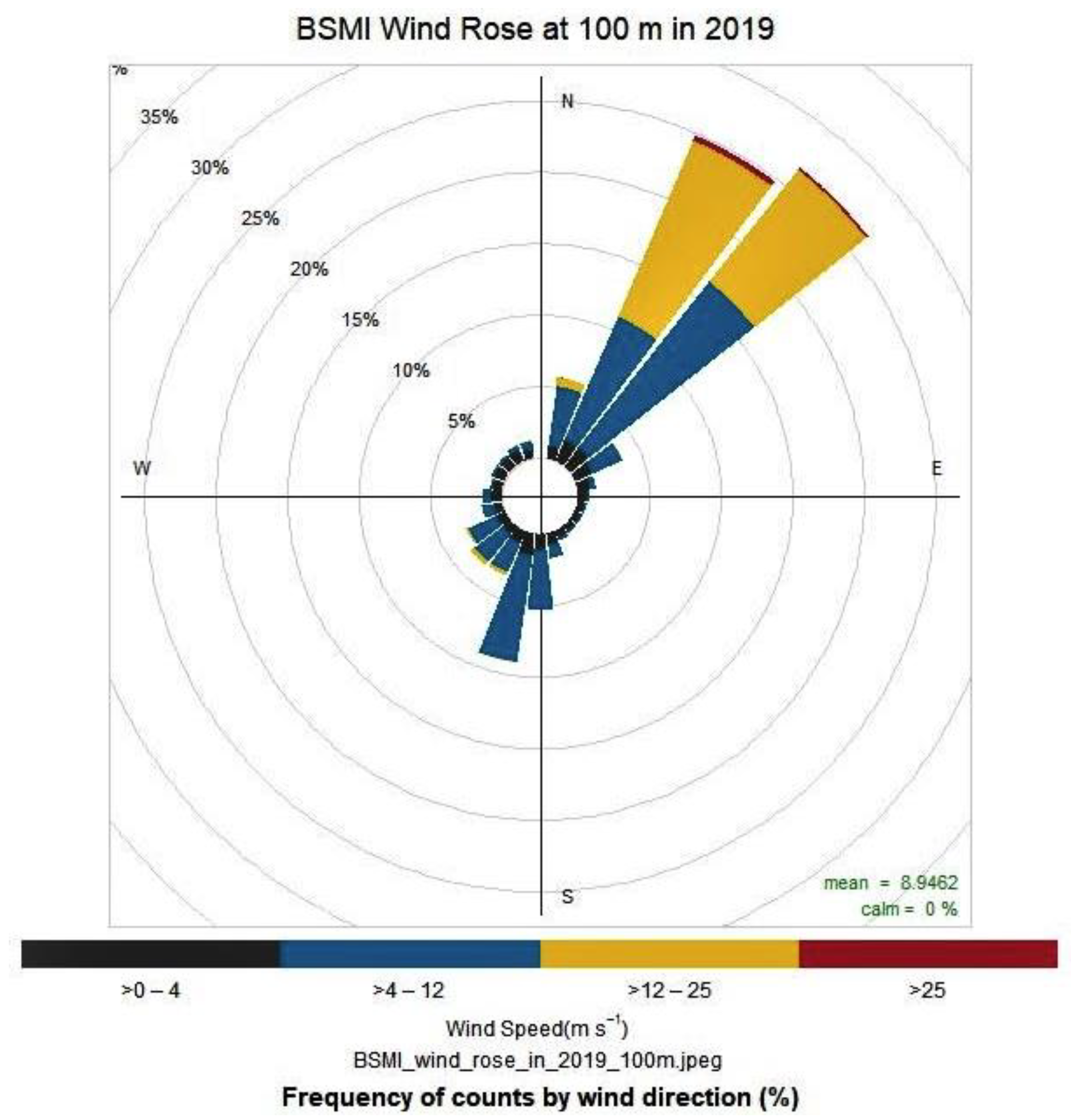
2.4.1. Wind Speeds and Directions of the Met Mast
2.4.2. Data of Buoys of the Central Weather Bureau (CWB)
- Wave height
- Air pressure
- The temperature difference between sea and air
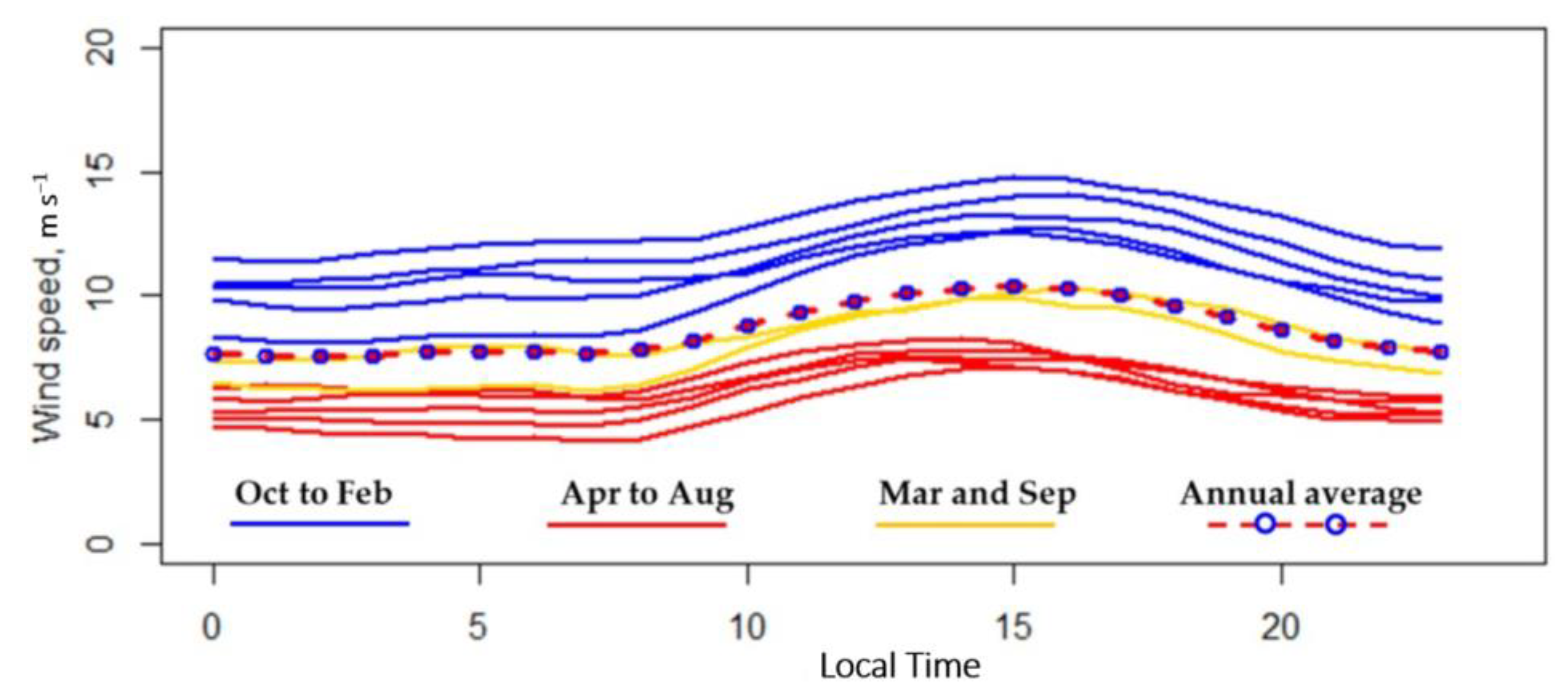
2.4.3. Data from the Weather Station
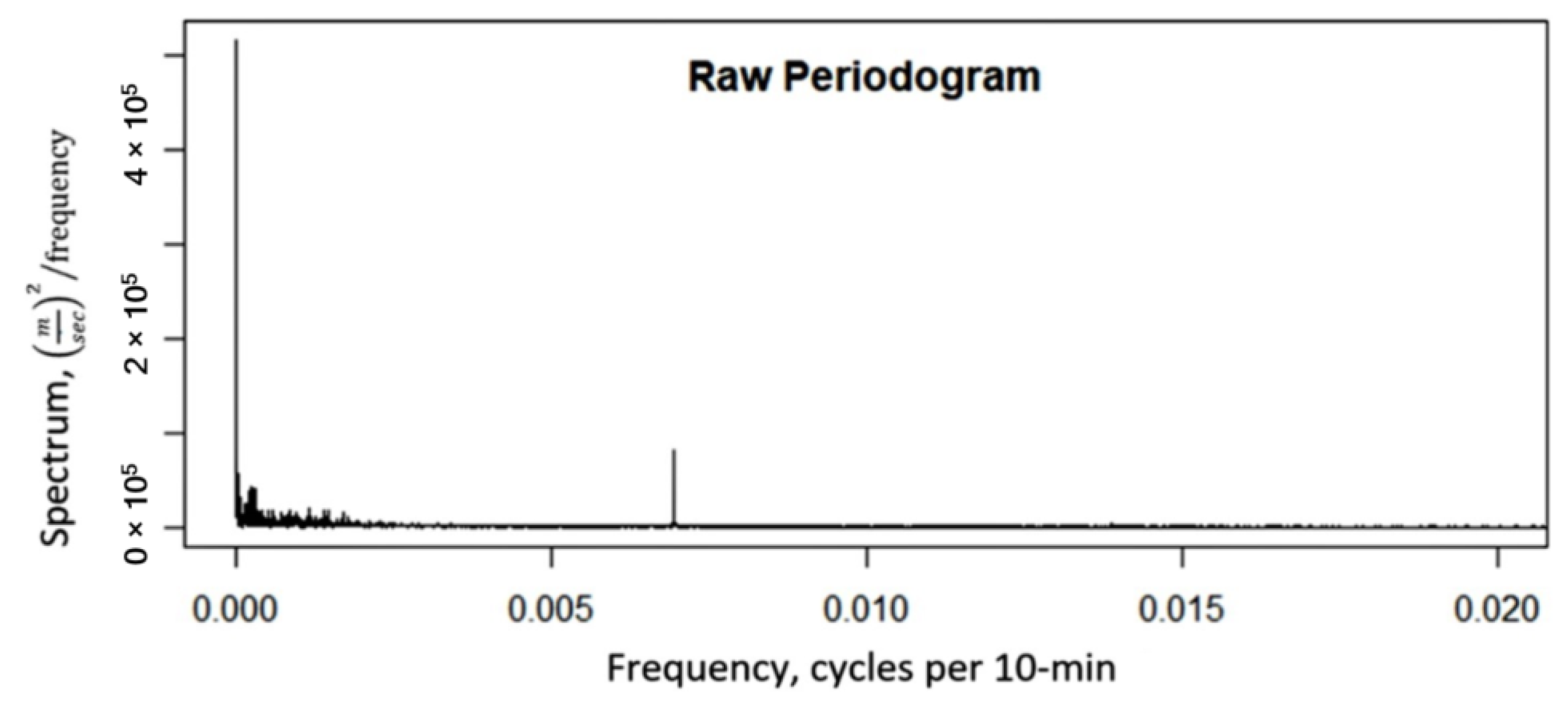
2.4.4. Periodic Components in Time Series Analysis
3. Results
4. Discussion
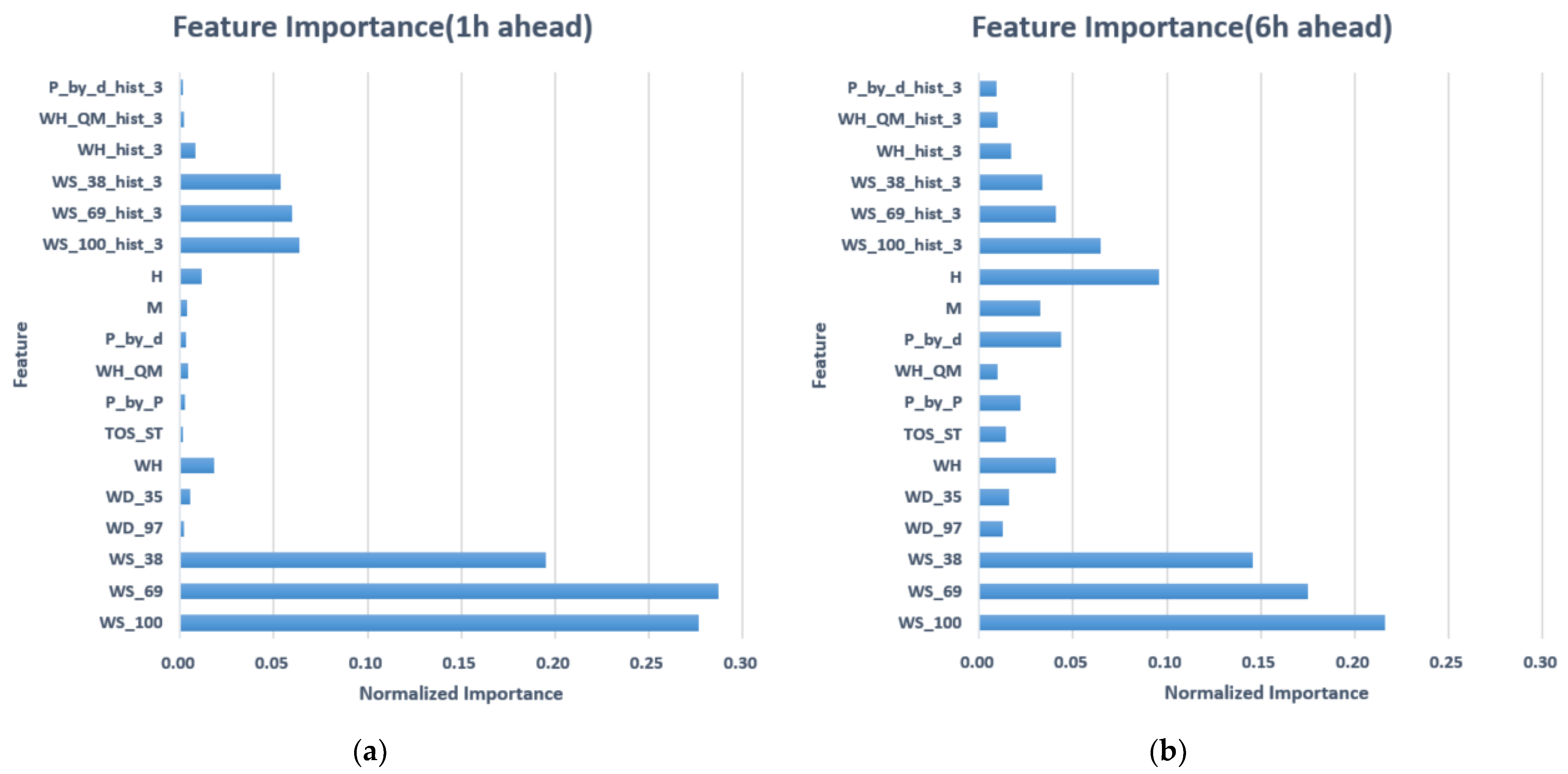
- The periodic components obtained from the time series analysis can effectively improve prediction accuracy. The improvement was more significant with the increase in lead time. At a lead time of six hours, the improvement of adding periodic components decreased the RMSE from 2.78 to 2.23 (accounting for a 44% improvement made by the random forest model, see Table 3). The diurnal variation was more evident than the monthly variation, as shown in the periodogram (Figure 4), which is consistent with the relative intensity of feature importance (Figure 6).
- Due to the significant effect of periodic components, the improvement by adding historical observation data (e.g., HS1, HS2, HS3) was very limited.
- With an increase in lead time, space-varying features (e.g., P_by_P, P_by_d) became more important. Eventually, they may have become as important as those space-fixed features (e.g., WH, WH_QM), which were more important at first.
- The atmospheric stability (e.g., TOS_ST, WSH) made quite apparent contributions. Based on our results, we suggest that the temperature difference (TOS_SH) replaces the difference in wind speed (WSH). Apart from the equivalent effect, the availability and accuracy of the former were better.
- By implementing feature engineering techniques, the RF model achieved a higher accuracy than a typical ANN model. In addition, we can extract important features from the feature importance analysis in the RF model. The important features extracted may be used in a more complicated model or integrated with the physical model in the future to improve the prediction accuracy.
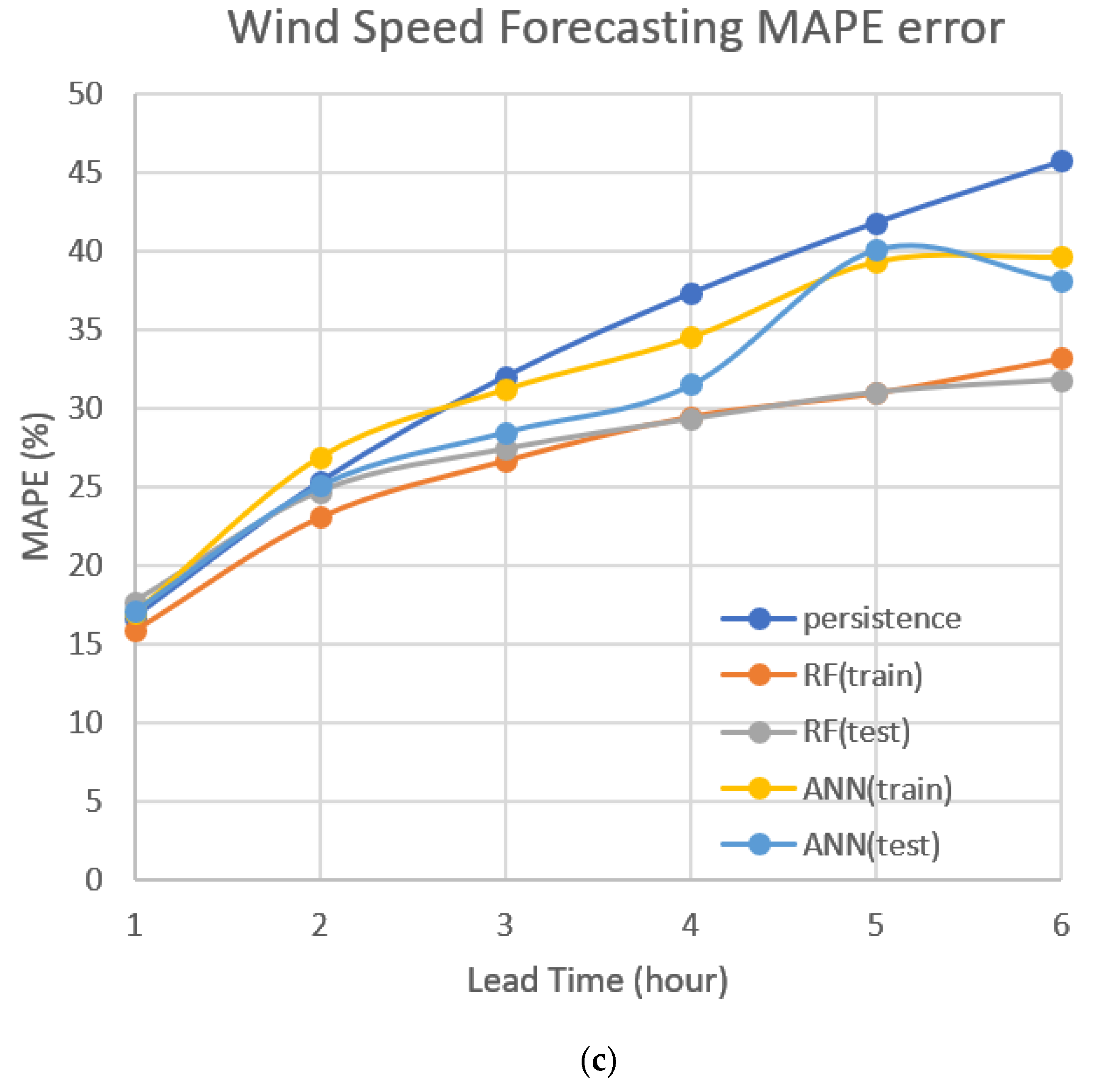
- As shown in Table 5, with a lead time of one hour, the MAPE of the RF (test) was worse than that of the persistence model, but the RMSE and MAE of the RF (test) were better than that of the persistence model. These may have been caused by error distribution. In the prediction of the RF model, there may have been larger absolute errors in the low wind speed interval, resulting in a larger MAPE obtained by dividing by the low wind speed (small denominator).
5. Conclusions
- The wind speed and direction at the same measuring location are the most important features when the lead time is short.
- As the lead time increases, the importance of the spatial and temporal variation features will gradually increase. The importance of the time-varying features will be higher than that of space-varying features.
- The periodic components in the time series data could significantly improve prediction accuracy. The magnitude of the periodic components in the periodogram agrees with their importance.
- The impact of atmospheric stability is significant. Based on the availability and accuracy of the data, it is recommended to replace the difference in wind speed at different heights of the met mast with the difference in the air and sea temperatures measured by the buoy as a feature.
- The wave height measured by the buoys arranged along the coastline helps improve the accuracy of wind speed prediction because of the correlation between waves and winds.
- The air pressure difference measured by the buoys and weather stations along and across the prevailing wind direction helps to improve the accuracy of wind speed prediction.
- The weather and geography vary from place to place, along with the effectiveness of new features. However, in the area of interest, the more distinct the prevailing wind direction, the higher the air–sea temperature difference, and the more apparent diurnal variation and monthly variation, the greater the effects expected.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gielen, D.; Boshell, F.; Saygin, D.; Bazilian, M.D.; Wagner, N.; Gorini, R. The role of renewable energy in the global energy transformation. Energy Strategy Rev. 2019, 24, 38–50. [Google Scholar] [CrossRef]
- Global Wind Atlas. The Global Wind Atlas is A free, Web-Based Application Developed to Help Policymakers, Planners, and Investors Identify High-Wind Areas for Wind Power Generation Virtually Anywhere in the World, and then Perform Preliminary Calculations. Available online: https://globalwindatlas.info/en/area/Taiwan. (accessed on 28 December 2022).
- Offshore Wind-Power Generation. 13 June 2019. Available online: https://english.ey.gov.tw/News3/9E5540D592A5FECD/34ff3d6b-412e-458d-afe9-01737d2da52d (accessed on 1 November 2020).
- MOEA Plans a New Target to Develop Further 10 GW of Offshore Wind Capacity Between 2026 to 2035—Anticipation of a Price Drop below the Average Consumer Price. 6 January 2020. Available online: https://www.moeaboe.gov.tw/ECW/english/news/News.aspx?kind=6&menu_id=958&news_id=16566 (accessed on 1 November 2020).
- Soman, S.S.; Zareipour, H.; Malik, O.; Mandal, P. A review of wind power and wind speed forecasting methods with different time horizons. In Proceedings of the North American Power Symposium 2010, Arlington, TX, USA, 26–28 September 2010; IEEE: Piscataway, NJ, USA, 2010. [Google Scholar]
- Jung, J.; Broadwater, R.P. Current status and future advances for wind speed and power forecasting. Renew. Sustain. Energy Rev. 2014, 31, 762–777. [Google Scholar] [CrossRef]
- Chai, S.; Xu, Z.; Lai, L.L.; Wong, K.P. An overview on wind power forecasting methods. In Proceedings of the 2015 International Conference on Machine Learning and Cybernetics (ICMLC), Guangzhou, China, 12–15 July 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Ramsay, J.O.; Dalzell, C. Some tools for functional data analysis. J. R. Stat. Soc. Ser. B Methodol. 1991, 53, 539–561. [Google Scholar] [CrossRef]
- Ullah, S.; Finch, C. Applications of functional data analysis: A systematic review. BMC Med. Res. Methodol. 2013, 13, 43. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.-L.; Chiou, J.-M.; Müller, H.-G. Functional data analysis. Annu. Rev. Stat. Its Appl. 2016, 3, 257–295. [Google Scholar] [CrossRef]
- Shah, I.; Lisi, F. Forecasting of electricity price through a functional prediction of sale and purchase curves. J. Forecast. 2020, 39, 242–259. [Google Scholar] [CrossRef]
- Zou, Y.; Su, B.; Chen, Y. Nonparametric Functional Data Analysis for Forecasting Container Throughput: The Case of Shanghai Port. J. Mar. Sci. Eng. 2022, 10, 1712. [Google Scholar] [CrossRef]
- Shah, I.; Jan, F.; Ali, S. Functional data approach for short-term electricity demand forecasting. Math. Probl. Eng. 2022, 2022, 6709779. [Google Scholar] [CrossRef]
- Kutrolli, G.; Benth, F.E. An Application of Functional Data Analysis to Forecast Weather Variables. 27 September 2019. Available online: https://ssrn.com/abstract=3766459 (accessed on 28 December 2022).
- Ghumman, A.R.; Ateeq-ur-Rauf AU, R.; Haider, H.; Shafiquzamman, M. Functional data analysis of models for predicting temperature and precipitation under climate change scenarios. J. Water Clim. Change 2020, 11, 1748–1765. [Google Scholar] [CrossRef]
- Jørgensen, K.L.; Shaker, H.R. Wind power forecasting using machine learning: State of the art, trends and challenges. In Proceedings of the 2020 IEEE 8th International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–14 August 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Lahouar, A.; Slama, J.B.H. Hour-ahead wind power forecast based on random forests. Renew. Energy 2017, 109, 529–541. [Google Scholar] [CrossRef]
- Shen, W.; Jiang, N.; Li, N. An EMD-RF based short-term wind power forecasting method. In Proceedings of the 2018 IEEE 7th Data Driven Control and Learning Systems Conference (DDCLS), Enshi, China, 25–28 May 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Demolli, H.; Dokuz, A.S.; Ecemis, A.; Gokcek, M. Wind power forecasting based on daily wind speed data using machine learning algorithms. Energy Convers. Manag. 2019, 198, 111823. [Google Scholar] [CrossRef]
- Januschowski, T.; Wang, Y.; Torkkola, K.; Erkkilä, T.; Hasson, H.; Gasthaus, J. Forecasting with trees. Int. J. Forecast. 2022, 38, 1473–1481. [Google Scholar] [CrossRef]
- Optis, M.; Perr-Sauer, J. The importance of atmospheric turbulence and stability in machine-learning models of wind farm power production. Renew. Sustain. Energy Rev. 2019, 112, 27–41. [Google Scholar] [CrossRef]
- Hanifi, S.; Liu, X.; Lin, Z.; Lotfian, S. A critical review of wind power forecasting methods—Past, present and future. Energies 2020, 13, 3764. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W. Short term wind speed forecasting in La Venta, Oaxaca, México, using artificial neural networks. Renew. Energy 2009, 34, 274–278. [Google Scholar] [CrossRef]
- Wang, Y.; Wu, L. On practical challenges of decomposition-based hybrid forecasting algorithms for wind speed and solar irradiation. Energy 2016, 112, 208–220. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W. Wind speed forecasting in three different regions of Mexico, using a hybrid ARIMA–ANN model. Renew. Energy 2010, 35, 2732–2738. [Google Scholar] [CrossRef]
- Cadenas, E.; Rivera, W.; Campos-Amezcua, R.; Heard, C. Wind speed prediction using a univariate ARIMA model and a multivariate NARX model. Energies 2016, 9, 109. [Google Scholar] [CrossRef]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning Proceedings; Elsevier: Amsterdam, The Netherlands, 1992; pp. 249–256. [Google Scholar]
- Piramuthu, S. Evaluating feature selection methods for learning in data mining applications. Eur. J. Oper. Res. 2004, 156, 483–494. [Google Scholar] [CrossRef]
- Guo, Z.; Zhao, W.; Lu, H.; Wang, J. Multi-step forecasting for wind speed using a modified EMD-based artificial neural network model. Renew. Energy 2012, 37, 241–249. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, N.; Wu, L.; Wang, Y. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Jursa, R. Variable selection for wind power prediction using particle swarm optimization. In Proceedings of the 9th Annual Conference on Genetic and Evolutionary Computation, London, UK, 7–11 July 2007. [Google Scholar]
- Gupta, R.; Kumar, R.; Bansal, A. Selection of Input Variables for the Prediction of Wind Speed in Wind Farms Based on Genetic Algorithm. Wind Eng. 2011, 35, 649–660. [Google Scholar] [CrossRef]
- Jursa, R.; Rohrig, K. Short-term wind power forecasting using evolutionary algorithms for the automated specification of artificial intelligence models. Int. J. Forecast. 2008, 24, 694–709. [Google Scholar] [CrossRef]
- Salcedo-Sanz, S.; Pastor-Sánchez, A.; Prieto, L.; Blanco-Aguilera, A.; García-Herrera, R. Feature selection in wind speed prediction systems based on a hybrid coral reefs optimization–Extreme learning machine approach. Energy Convers. Manag. 2014, 87, 10–18. [Google Scholar] [CrossRef]
- Senthil Kumar, P.; Lopez, D. Feature selection used for wind speed forecasting with data driven approaches. J. Eng. Sci. Technol. Rev. 2015, 8, 124–127. [Google Scholar] [CrossRef]
- Li, F.; Ren, G.; Lee, J. Multi-step wind speed prediction based on turbulence intensity and hybrid deep neural networks. Energy Convers. Manag. 2019, 186, 306–322. [Google Scholar] [CrossRef]
- Vassallo, D.; Krishnamurthy, R.; Fernando, H. Decreasing wind speed extrapolation error via domain-specific feature extraction and selection. Wind Energy Sci. 2020, 5, 959–975. [Google Scholar] [CrossRef]
- Zhu, Q.; Chen, J.; Shi, D.; Zhu, L.; Bai, X.; Duan, X.; Liu, Y. Learning temporal and spatial correlations jointly: A unified framework for wind speed prediction. IEEE Trans. Sustain. Energy 2019, 11, 509–523. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning: Methods and Applications; Zhang, C., Ma, Y., Eds.; Springer US: Boston, MA, USA, 2012; pp. 157–175. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin, Germany, 2009. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Lippmann, R. An introduction to computing with neural nets. IEEE ASSP Mag. 1987, 4, 4–22. [Google Scholar] [CrossRef]
- Mohandes, M.A.; Rehman, S.; Halawani, T. A neural networks approach for wind speed prediction. Renew. Energy 1998, 13, 345–354. [Google Scholar] [CrossRef]
- Madsen, H.; Pinson, P.; Kariniotakis, G.; Nielsen, H.A.; Nielsen, T.S. Standardizing the Performance Evaluation of Short-Term Wind Power Prediction Models. Wind Eng. 2005, 29, 475–489. [Google Scholar] [CrossRef]
- Cheng, K.-S.; Ho, C.-Y.; Teng, J.-H. Wind and Sea Breeze Characteristics for the Offshore Wind Farms in the Central Coastal Area of Taiwan. Energies 2022, 15, 992. [Google Scholar] [CrossRef]
- Stull, R.B. An Introduction to Boundary Layer Meteorology; Springer Science & Business Media: Berlin, Germany, 1988; Volume 13. [Google Scholar]
- Cheng, K.-S.; Ho, C.-Y.; Teng, J.-H. Wind Characteristics in the Taiwan Strait: A Case Study of the First Offshore Wind Farm in Taiwan. Energies 2020, 13, 6492. [Google Scholar] [CrossRef]
- Hasselmann, K.; Barnett, T.P.; Bouws, E.; Carlson, H.; Cartwright, D.E.; Enke, K.; Ewing, J.A.; Gienapp, H.; Hasselman, D.E.; Kruseman, P.; et al. Measurements of wind-wave growth and swell decay during the Joint North Sea Wave Project (JONSWAP). Ergaenzungsheft Zur Dtsch. Hydrogr. Z. Reihe A 1973, 12, 7–94. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Feature |
|---|---|
| WS_100 | Hourly wind speed at 100 m height of the met mast |
| WS_69 | Hourly wind speed at 69 m height of the met mast |
| WS_38 | Hourly wind speed at 38 m height of the met mast |
| WD_97 | Hourly wind direction at 97 m height of the met mast |
| WD_35 | Hourly wind direction at 35 m height of the met mast |
| WH | Wave height measured by Taichung buoy |
| TOS_ST | Difference between air temperature and sea temperature at Taichung buoy |
| P_by_P | Air pressure difference between Taichung Buoy and Wuqi weather station |
| WH_QM | Wave height measured by Cimei buoy |
| P_by_d | Air pressure difference between Hsinchu buoy and Cimei buoy |
| M | Month |
| H | Hour |
| WS_100_hist_3 | Average wind speed in the last 3 h at the height of 100 m of the met mast |
| WS_69_hist_3 | Average wind speed in the last 3 h at the height of 69 m of the met mast |
| WS_38_hist_3 | Average wind speed in the last 3 h at the height of 38 m of the met mast |
| WH_hist_3 | Average wave height measured at Taichung buoy in the last 3 h |
| WH_QM_hist_3 | Average wave height measured at Cimei buoy in the last 3 h |
| P_by_d_hist_3 | Average air pressure difference measured between Hsin Chu buoy and Cimei buoy in the last 3 h |
| Notation | Description |
|---|---|
| Persistence | Prediction of the persistence model |
| WSD | Prediction of features of WS_100, WS_69, WS_38, WD_97, WD_35 |
| +BY | Prediction of adding WH and WH_QM features |
| +P | Prediction of adding P_by_P and P_by_d features |
| +ASH | Prediction of adding wind shear feature for atmosphere stability |
| +AS | Prediction of adding TOS_ST feature for atmosphere stability |
| +TS | Prediction of adding M and H features for periodic components of wind speed |
| +HS1 | Prediction of adding last one hour of WS_100, WS_69, WS_38, WH, WH_QM, and P_by_d |
| +HS2 | Prediction of adding the average of last two hours of WS_100, WS_69, WS_38, WH, WH_QM, and P_by_d |
| +HS3 | Prediction of adding the average of last three hour values of WS_100, WS_69, WS_38, WH, WH_QM, and P_by_d |
| Lead Time | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| Persistence | 1.27 | 1.94 | 2.42 | 2.82 | 3.16 | 3.47 |
| WSD | 1.27 | 1.89 | 2.33 | 2.68 | 2.97 | 3.22 |
| WSD + BY | 1.26 | 1.86 | 2.27 | 2.59 | 2.88 | 3.12 |
| WSD + BY + P | 1.24 | 1.82 | 2.22 | 2.54 | 2.81 | 3.03 |
| WSD + BY + P + ASH | 1.22 | 1.74 | 2.09 | 2.37 | 2.61 | 2.83 |
| WSD + BY + P + AS | 1.21 | 1.73 | 2.07 | 2.34 | 2.57 | 2.78 |
| WSD + BY + P + AS + TS | 1.22 | 1.66 | 1.88 | 2.02 | 2.12 | 2.23 |
| WSD + BY + P + AS + TS + HS1 | 1.21 | 1.67 | 1.90 | 2.06 | 2.17 | 2.28 |
| WSD + BY + P + AS + TS + HS2 | 1.21 | 1.65 | 1.87 | 2.03 | 2.14 | 2.25 |
| WSD + BY + P + AS + TS + HS3 | 1.21 | 1.65 | 1.86 | 2.01 | 2.12 | 2.22 |
| 1 | 2 | 3 | 4 | 5 | 6 | ||
|---|---|---|---|---|---|---|---|
| ANN with simple features (train) | RMSE | 1.31 | 1.87 | 2.33 | 2.94 | 3.05 | 3.33 |
| MAE | 0.96 | 1.44 | 1.79 | 2.16 | 2.33 | 2.57 | |
| MAPE | 18.2 | 28.1 | 36.1 | 35.7 | 46.6 | 49.7 | |
| ANN with simple features (test) | RMSE | 1.27 | 1.84 | 2.28 | 2.67 | 2.91 | 3.12 |
| MAE | 0.94 | 1.40 | 1.74 | 2.06 | 2.26 | 2.43 | |
| MAPE | 18.2 | 25.3 | 33.6 | 35.7 | 43.5 | 47.5 | |
| ANN with all features (train) | RMSE | 1.25 | 1.82 | 2.13 | 2.37 | 2.58 | 2.93 |
| MAE | 0.89 | 1.39 | 1.56 | 1.95 | 2.06 | 2.29 | |
| MAPE | 17 | 26.9 | 31.2 | 34.5 | 39.3 | 39.6 | |
| ANN with all features (test) | RMSE | 1.24 | 1.73 | 2.03 | 2.29 | 2.6 | 2.78 |
| MAE | 0.9 | 1.34 | 1.57 | 1.93 | 2.06 | 2.2 | |
| MAPE | 17.1 | 25.1 | 28.5 | 31.5 | 40.1 | 38.1 |
| Lead Time | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| Persistence | RMSE | 1.27 | 1.94 | 2.42 | 2.82 | 3.16 | 3.47 |
| MAE | 0.92 | 1.44 | 1.82 | 2.14 | 2.42 | 2.67 | |
| MAPE | 16.7 | 25.3 | 32.0 | 37.3 | 41.8 | 45.7 | |
| RF (train) | RMSE | 1.18 | 1.63 | 1.88 | 2.06 | 2.19 | 2.32 |
| MAE | 0.89 | 1.22 | 1.39 | 1.50 | 1.57 | 1.62 | |
| MAPE | 15.9 | 23.1 | 26.7 | 29.5 | 31.0 | 33.2 | |
| RF (test) | RMSE | 1.21 | 1.61 | 1.84 | 2.01 | 2.11 | 2.19 |
| MAE | 0.86 | 1.21 | 1.39 | 1.53 | 1.63 | 1.73 | |
| MAPE | 17.7 | 24.7 | 27.4 | 29.3 | 31.0 | 31.8 | |
| ANN (train) | RMSE | 1.25 | 1.82 | 2.13 | 2.37 | 2.58 | 2.93 |
| MAE | 0.89 | 1.39 | 1.56 | 1.95 | 2.06 | 2.29 | |
| MAPE | 17.0 | 26.9 | 31.2 | 34.5 | 39.3 | 39.6 | |
| ANN (test) | RMSE | 1.24 | 1.73 | 2.03 | 2.29 | 2.60 | 2.78 |
| MAE | 0.90 | 1.34 | 1.57 | 1.93 | 2.06 | 2.20 | |
| MAPE | 17.1 | 25.1 | 28.5 | 31.5 | 40.1 | 38.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ho, C.-Y.; Cheng, K.-S.; Ang, C.-H. Utilizing the Random Forest Method for Short-Term Wind Speed Forecasting in the Coastal Area of Central Taiwan. Energies 2023, 16, 1374. https://doi.org/10.3390/en16031374
Ho C-Y, Cheng K-S, Ang C-H. Utilizing the Random Forest Method for Short-Term Wind Speed Forecasting in the Coastal Area of Central Taiwan. Energies. 2023; 16(3):1374. https://doi.org/10.3390/en16031374
Chicago/Turabian StyleHo, Cheng-Yu, Ke-Sheng Cheng, and Chi-Hang Ang. 2023. "Utilizing the Random Forest Method for Short-Term Wind Speed Forecasting in the Coastal Area of Central Taiwan" Energies 16, no. 3: 1374. https://doi.org/10.3390/en16031374
APA StyleHo, C.-Y., Cheng, K.-S., & Ang, C.-H. (2023). Utilizing the Random Forest Method for Short-Term Wind Speed Forecasting in the Coastal Area of Central Taiwan. Energies, 16(3), 1374. https://doi.org/10.3390/en16031374