
Privacy-Preserving Fleet-Wide Learning of Wind Turbine Conditions with Federated Learning


Abstract
:1. Introduction
- A new privacy-preserving approach to wind turbine condition monitoring;
- A customization approach to tailor the federated model to individual WTs if the target variable distributions deviate across the WTs participating in the federated training;
- Federated training and customization are demonstrated in condition monitoring of bearing temperatures and active power.
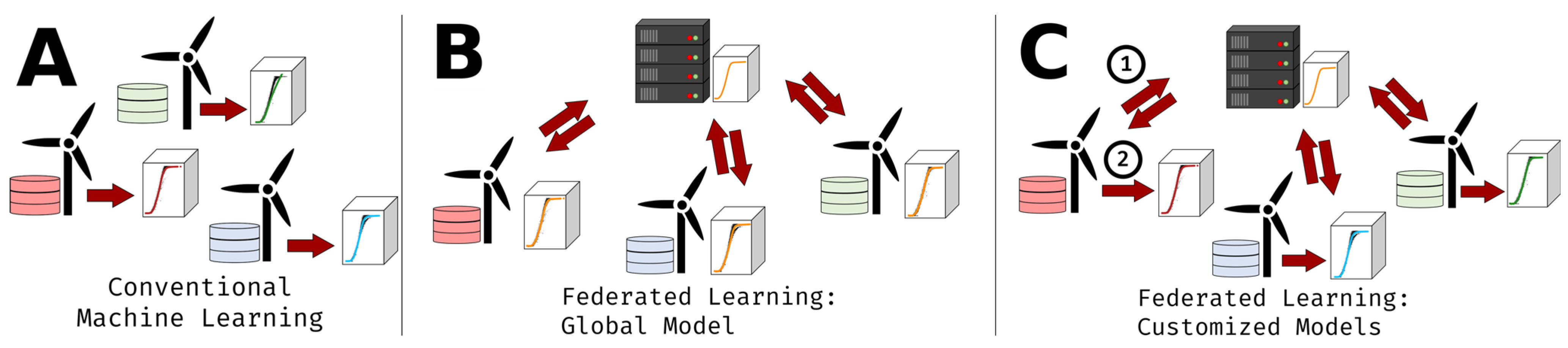
2. Federated Learning of Wind Turbine Conditions
2.1. Federated Learning
2.2. Federated Learning for Condition Monitoring
2.3. Customizing Federated Models to Individual WTs
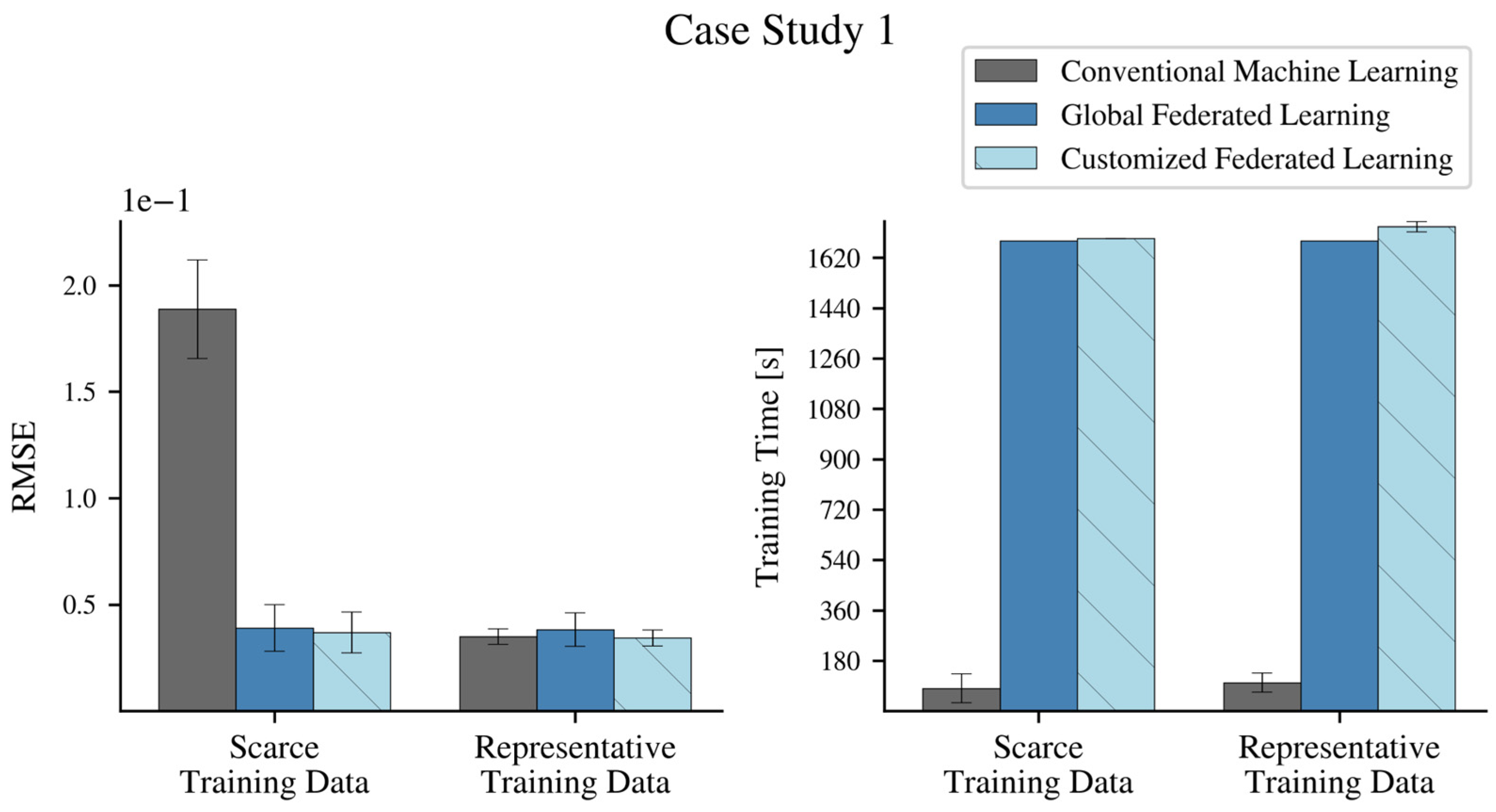
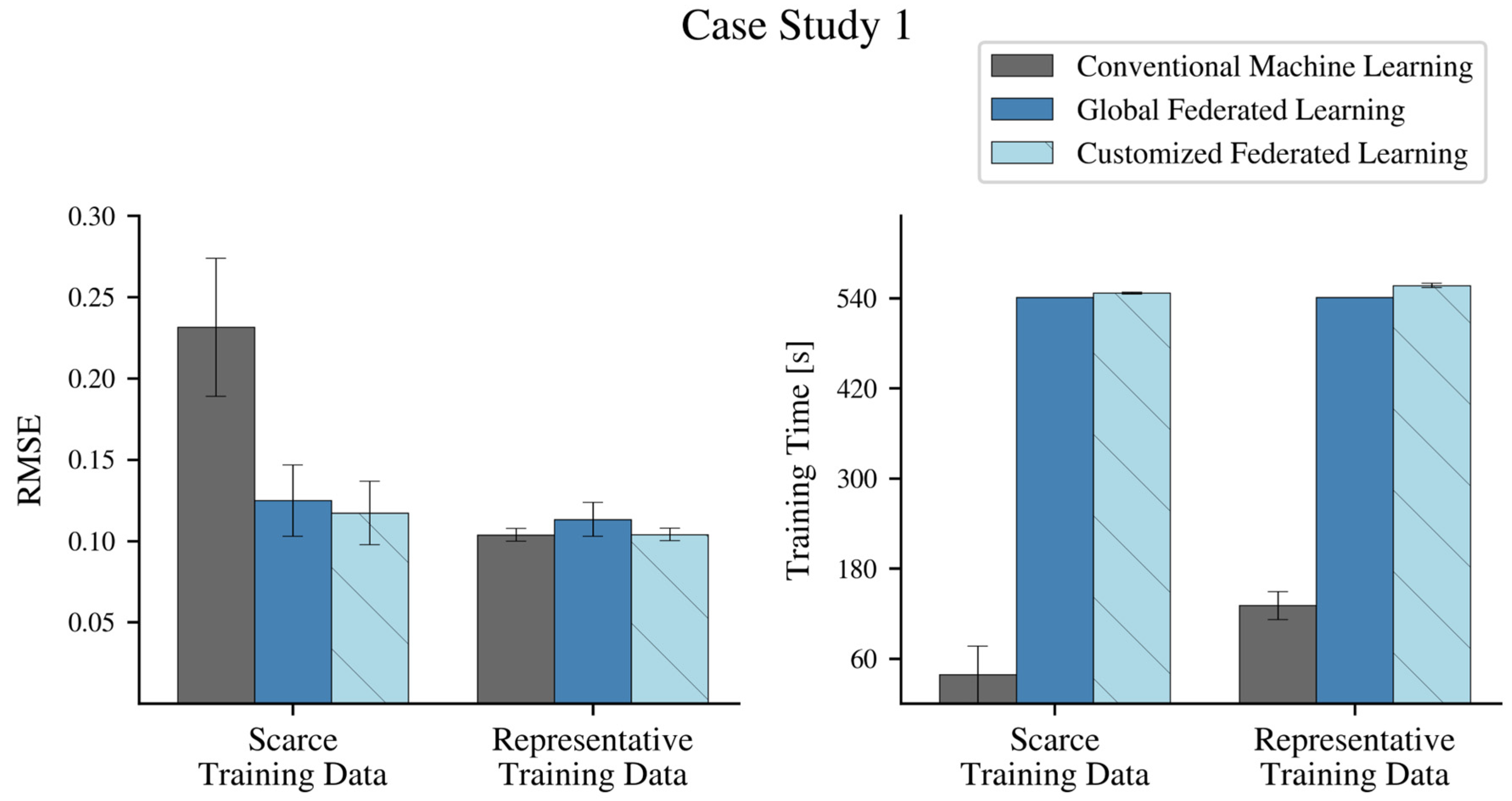
3. Case Studies: Federated Learning of Fault Detection Models
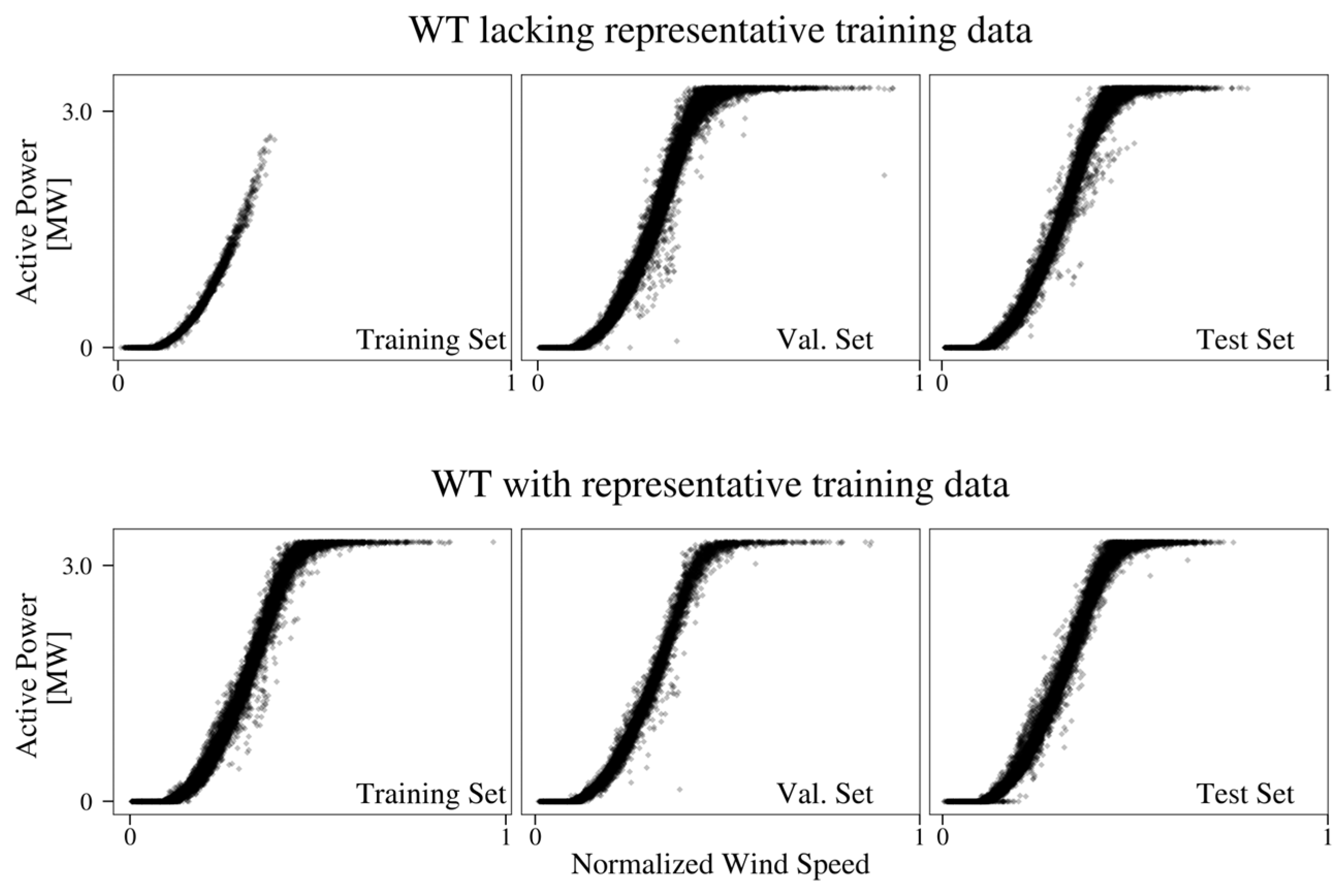
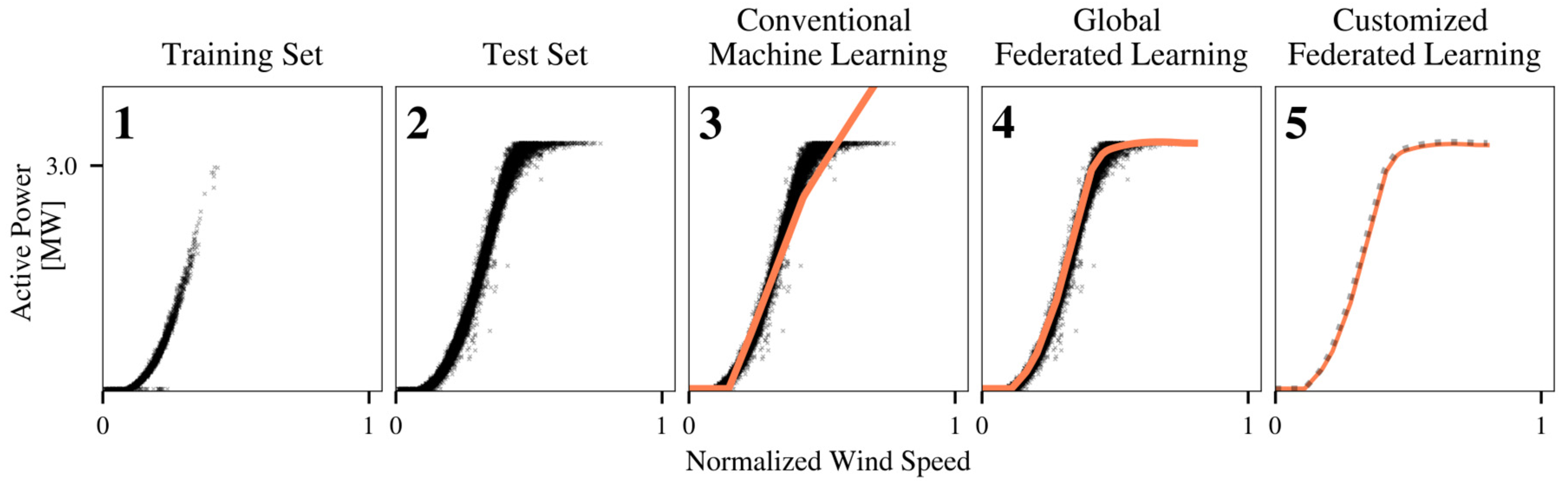
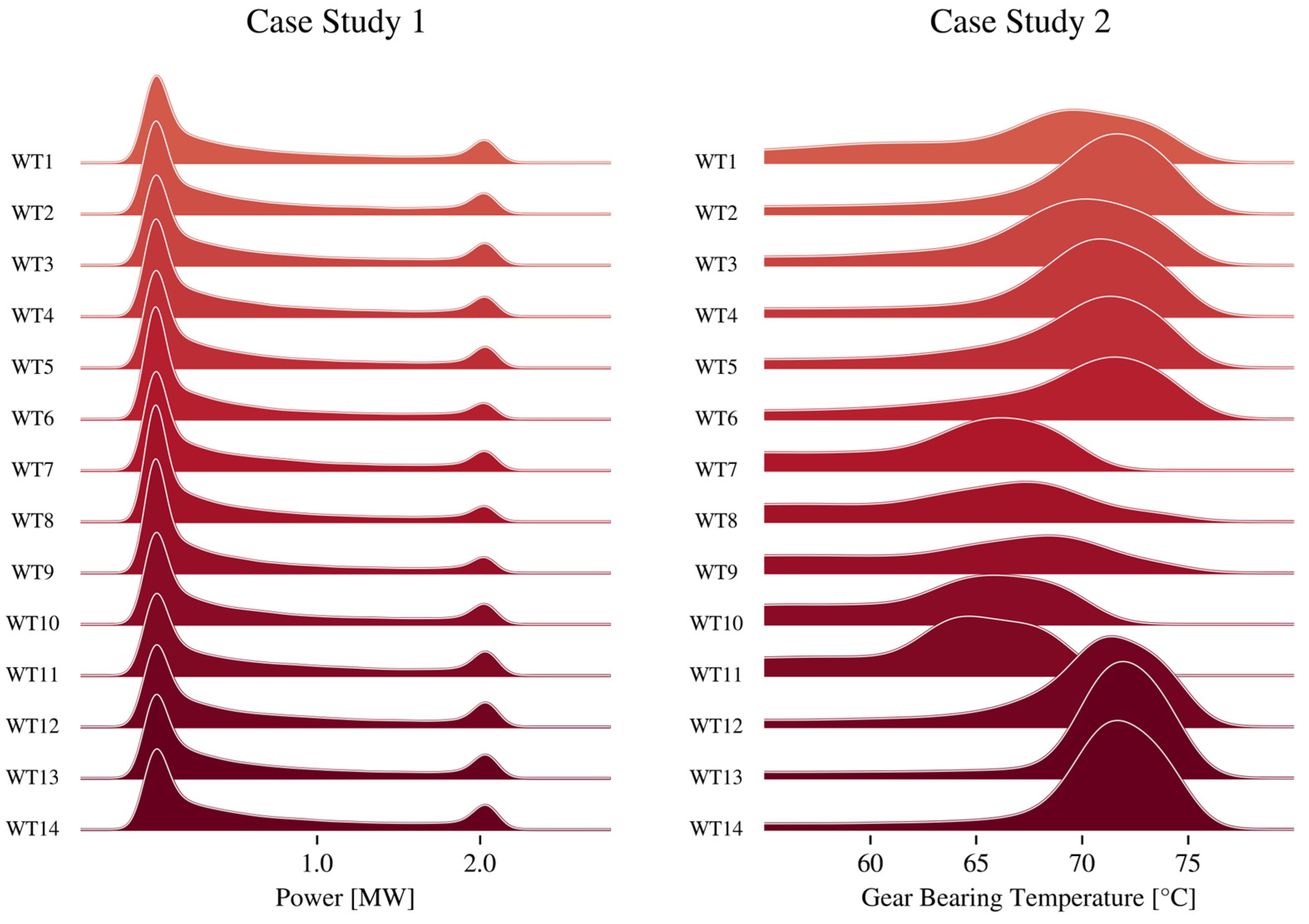
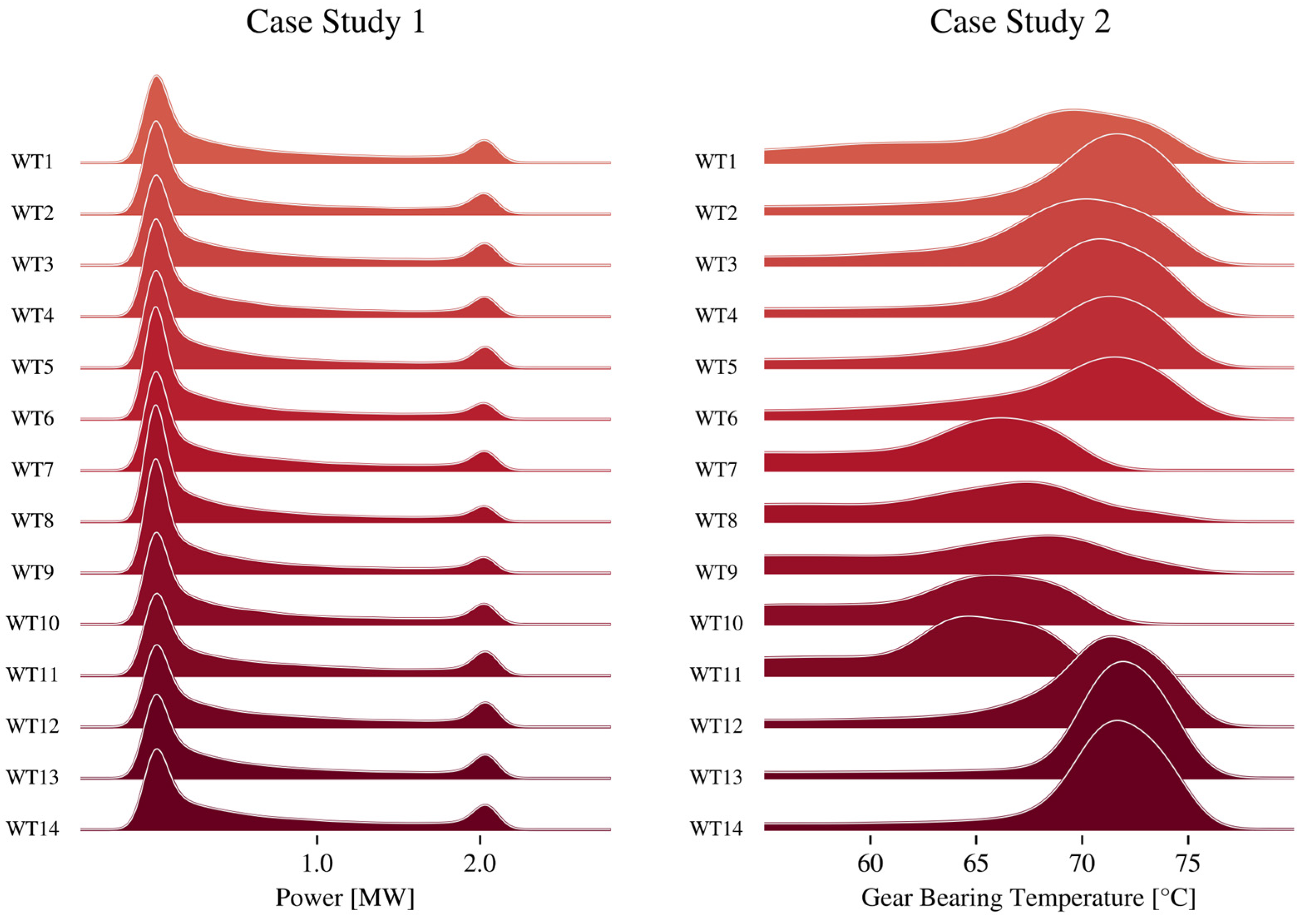
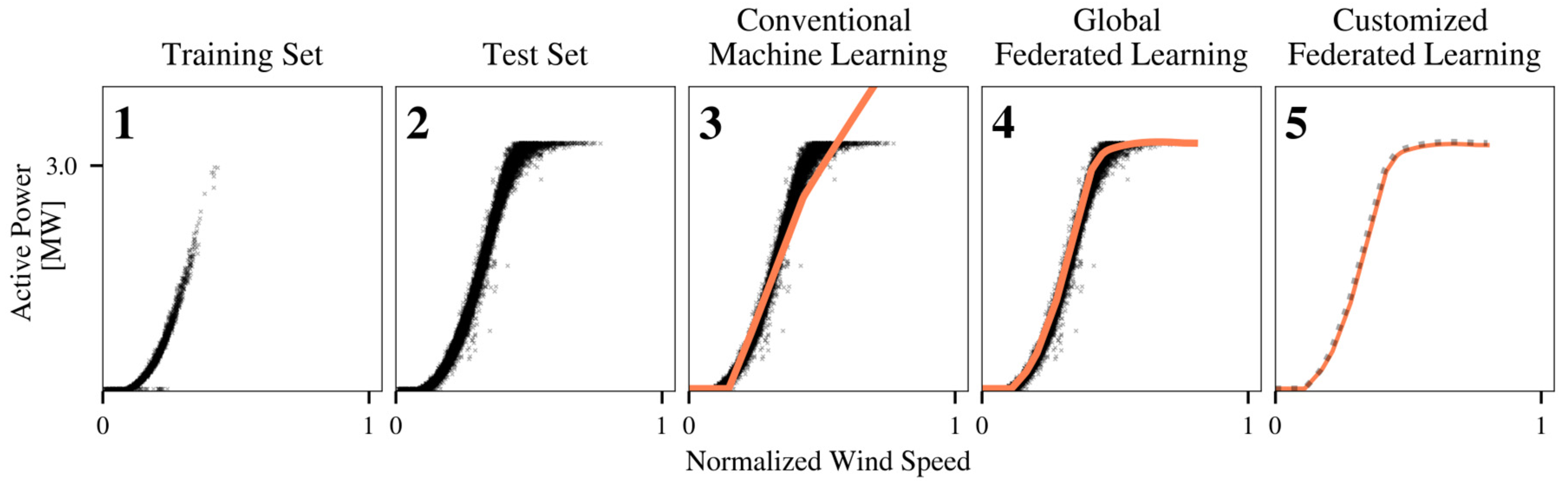
3.1. Federated Learning of Active Power Models
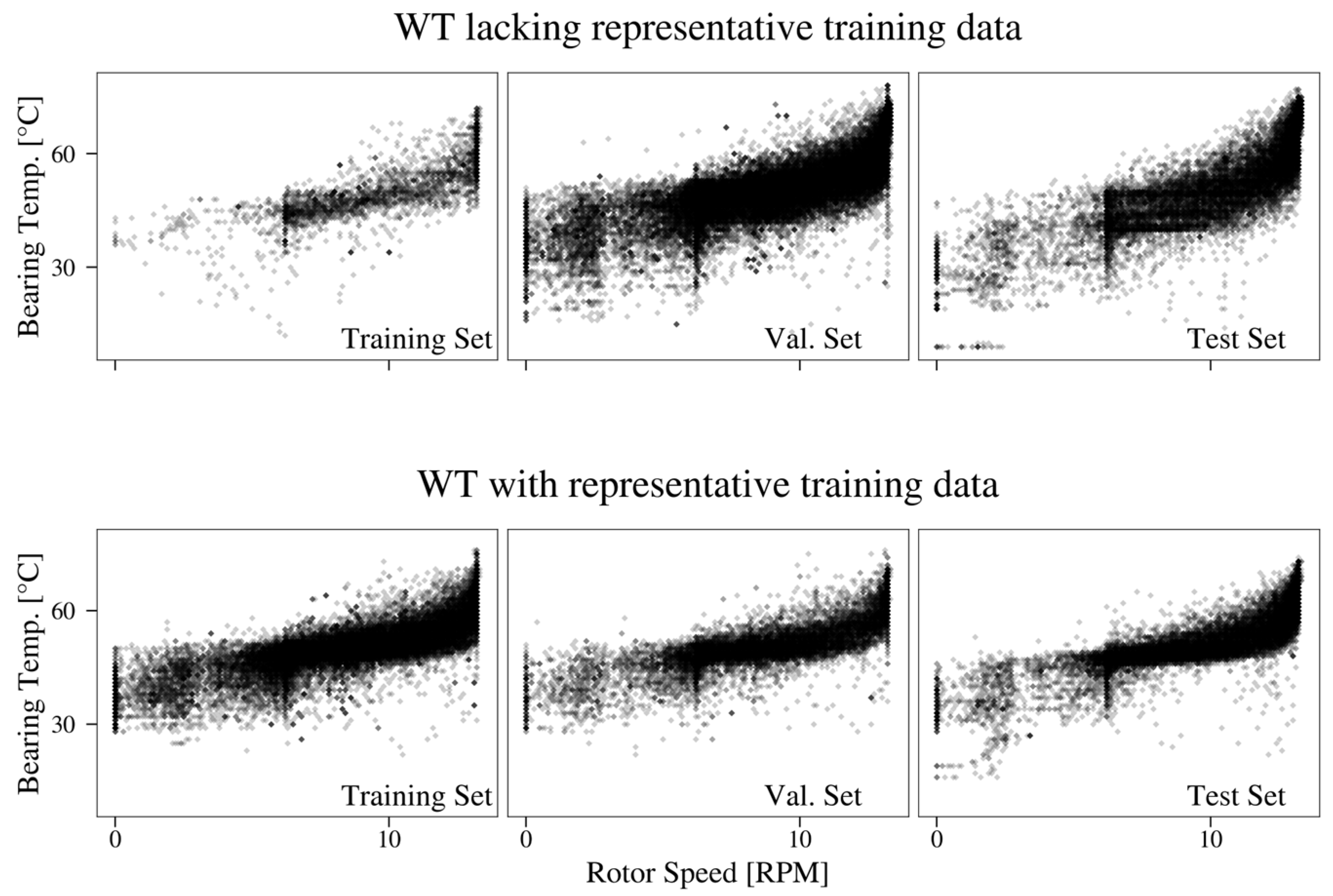
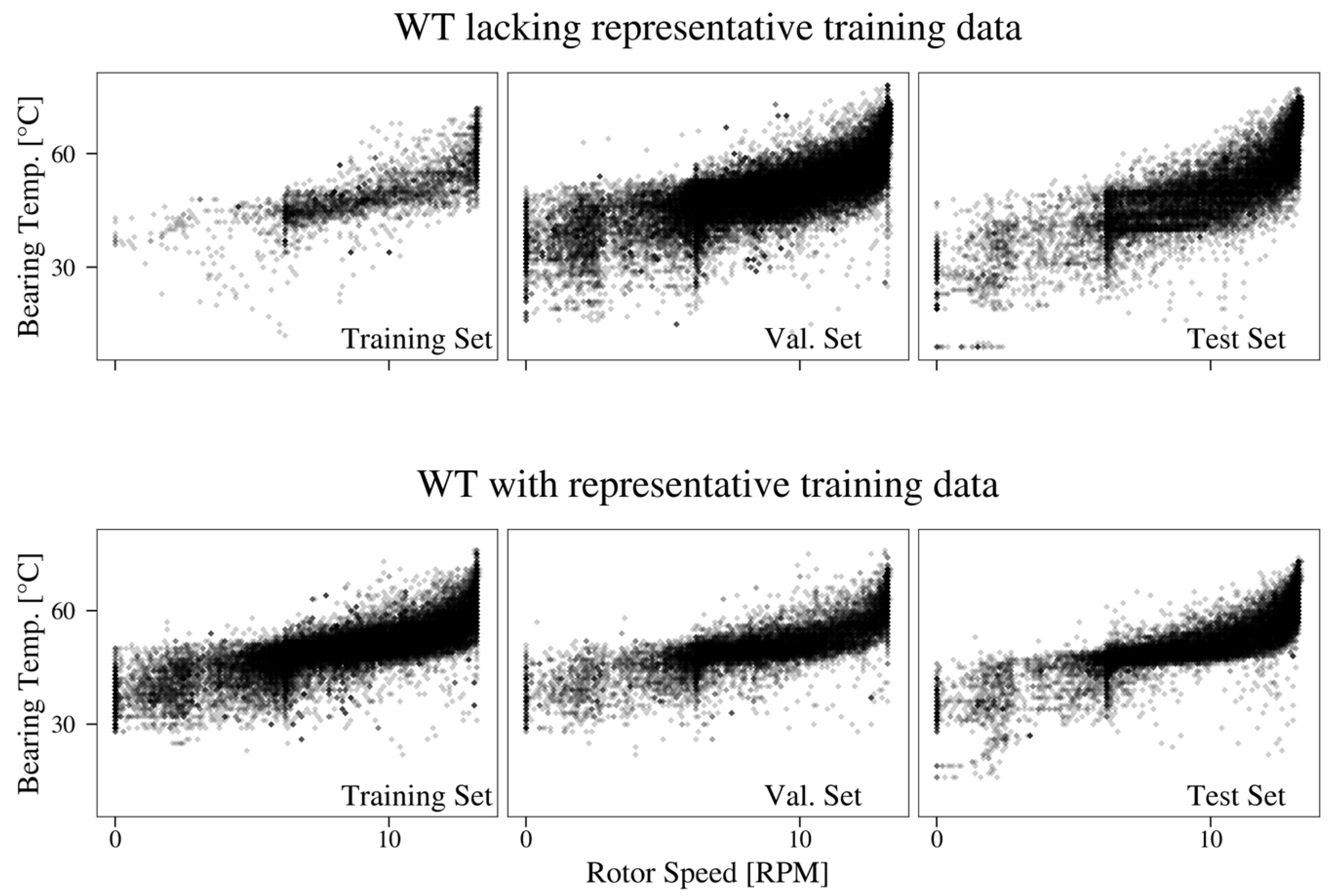
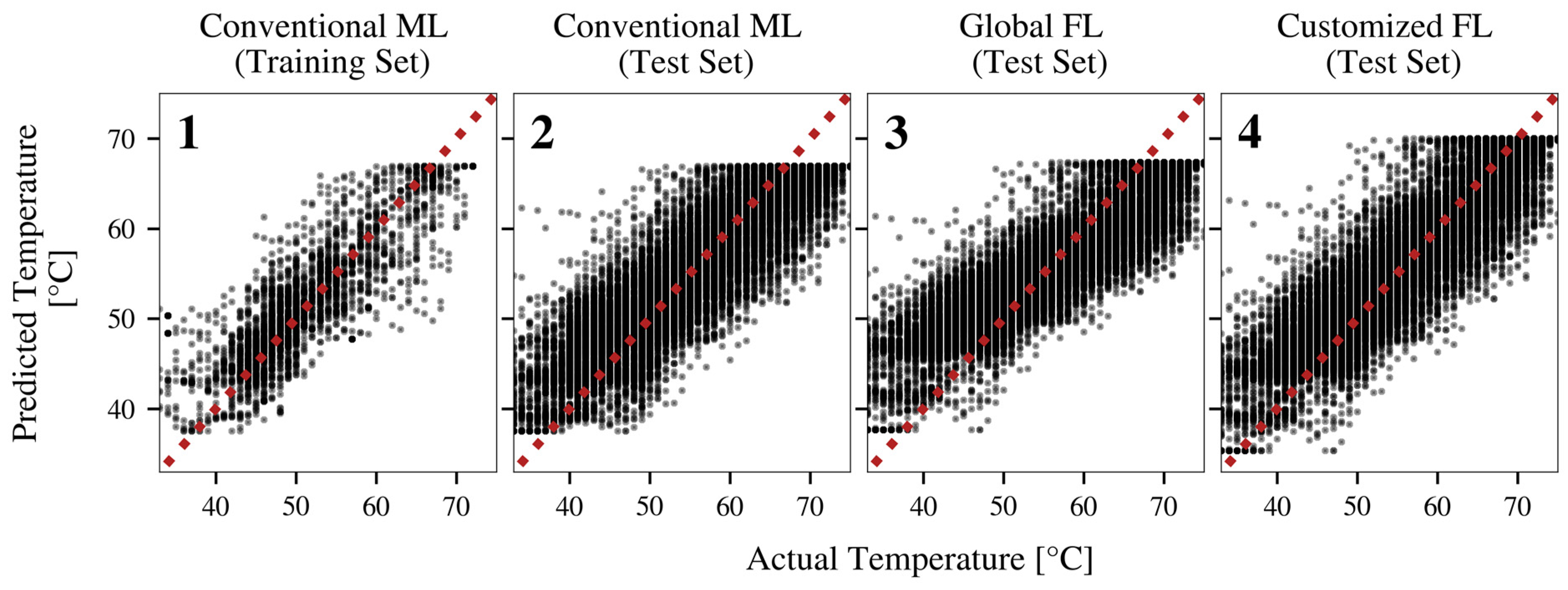
3.2. Federated Learning of Bearing Temperature Models
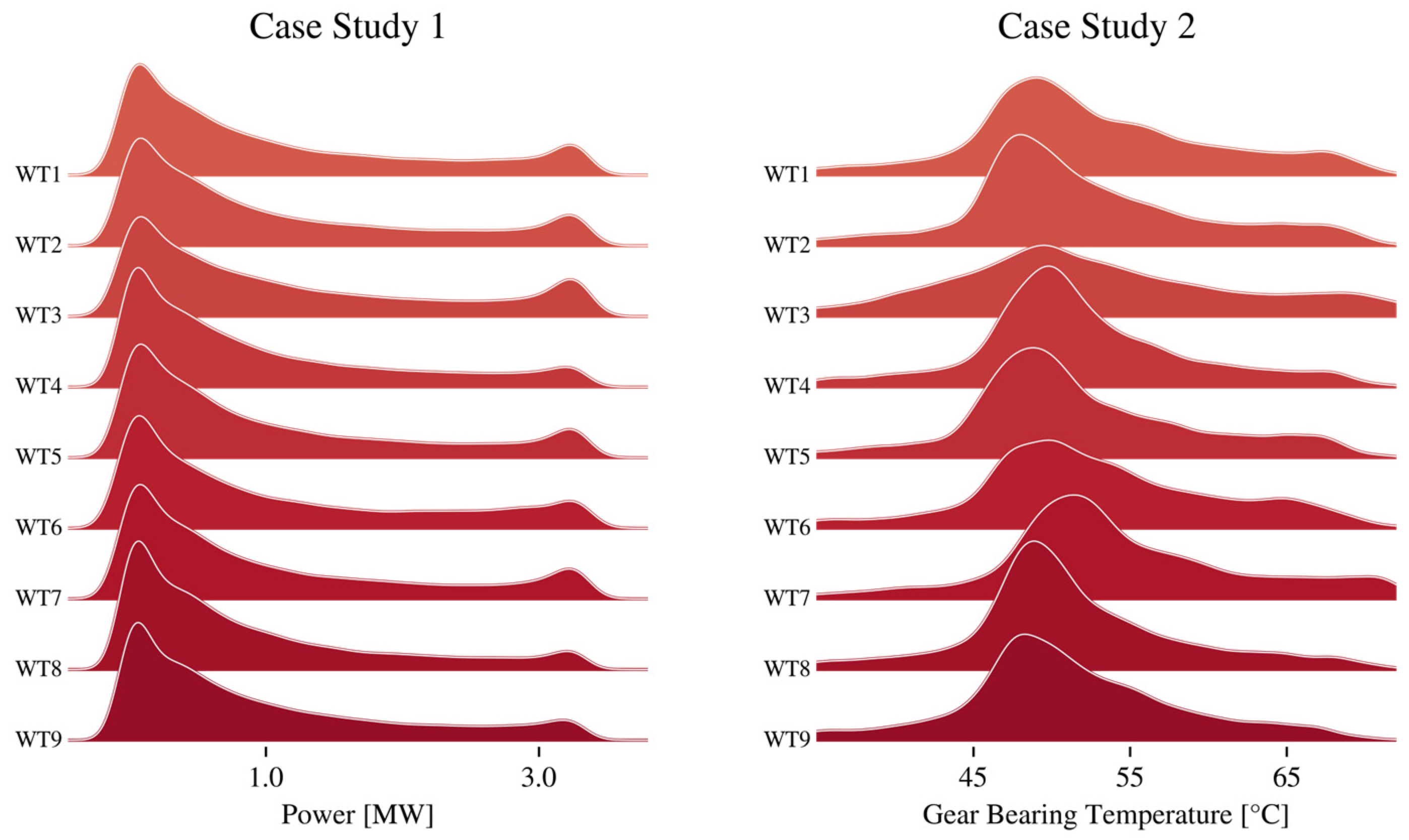
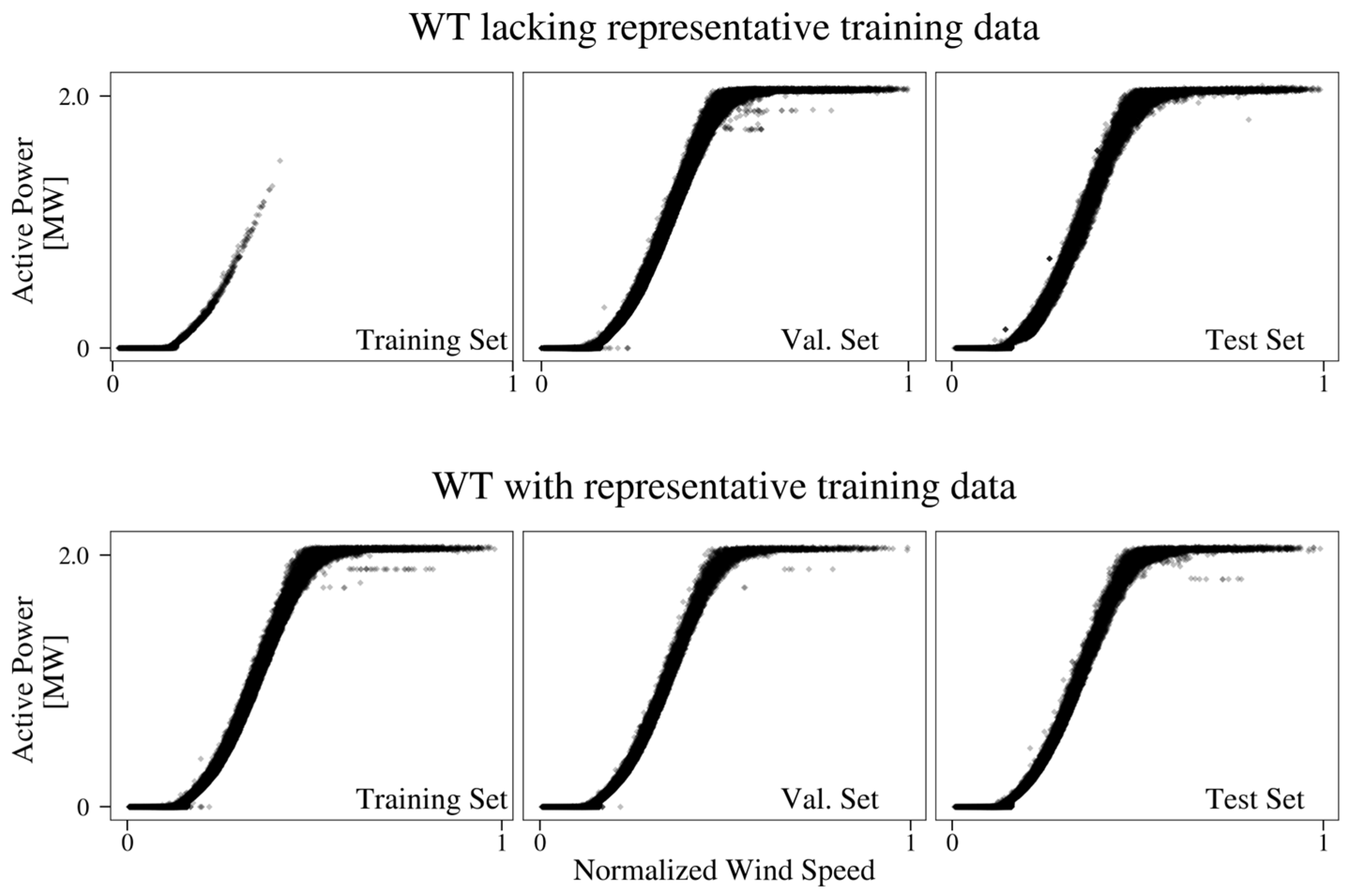
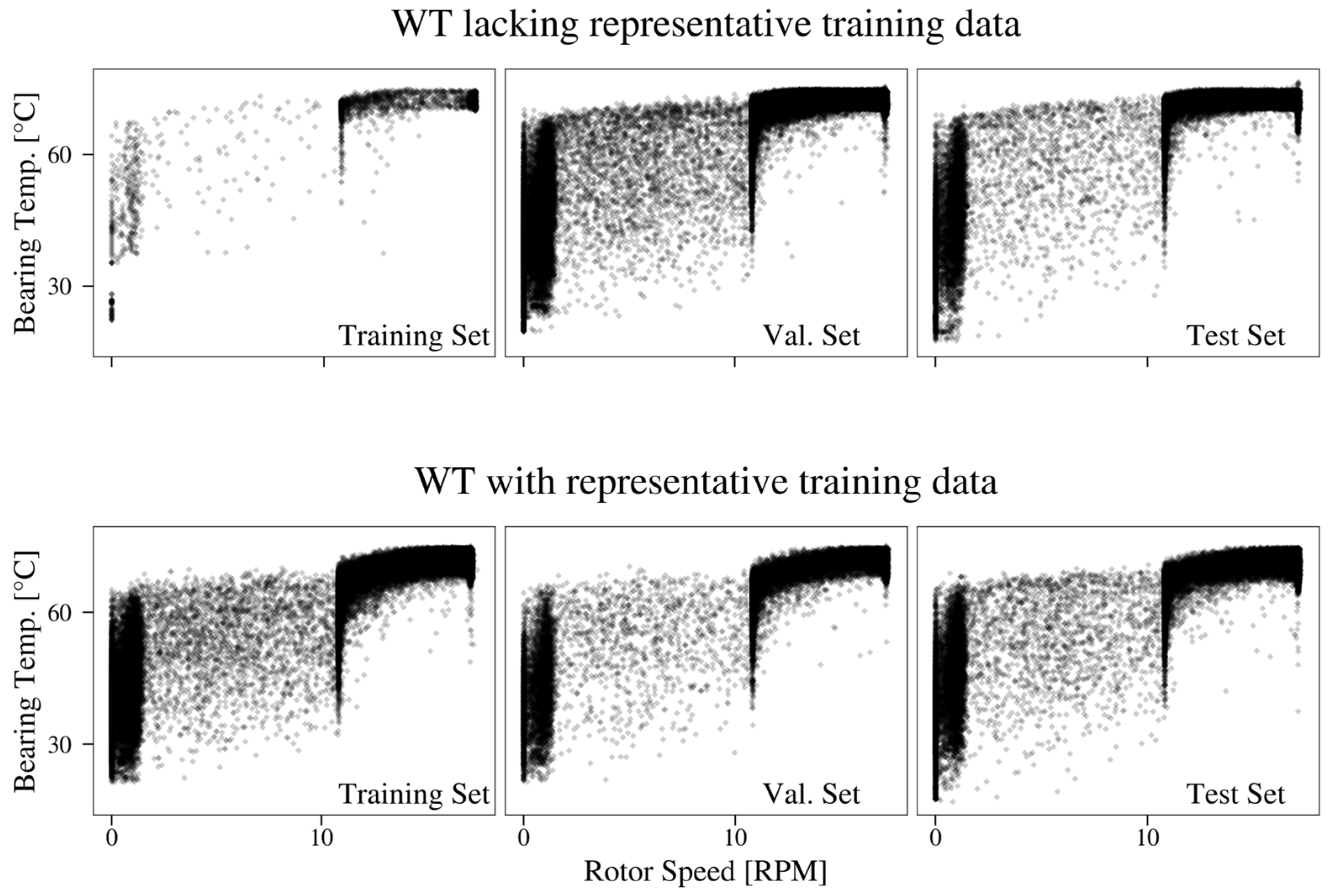
3.3. Heterogeneously Distributed Target Variables
4. Results
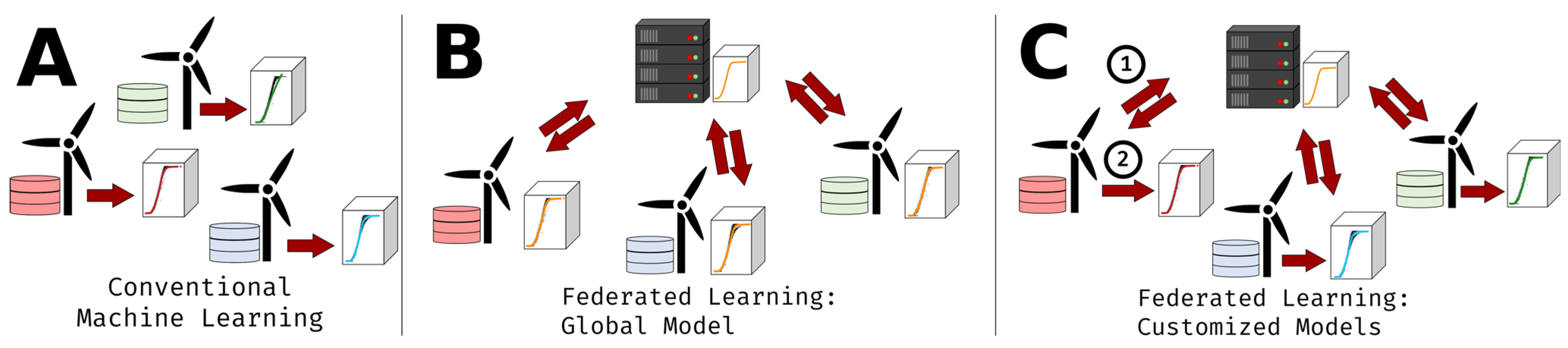
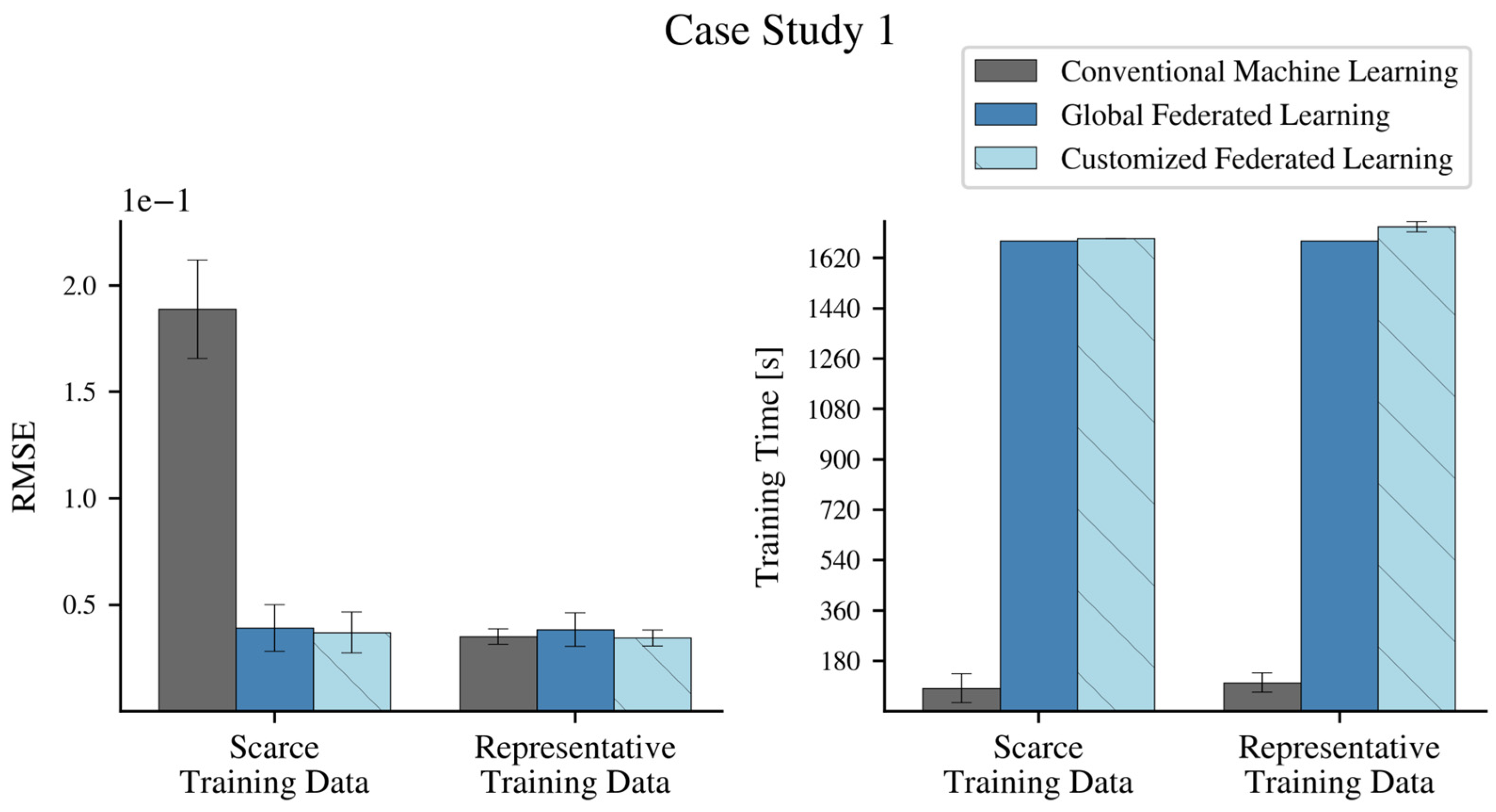
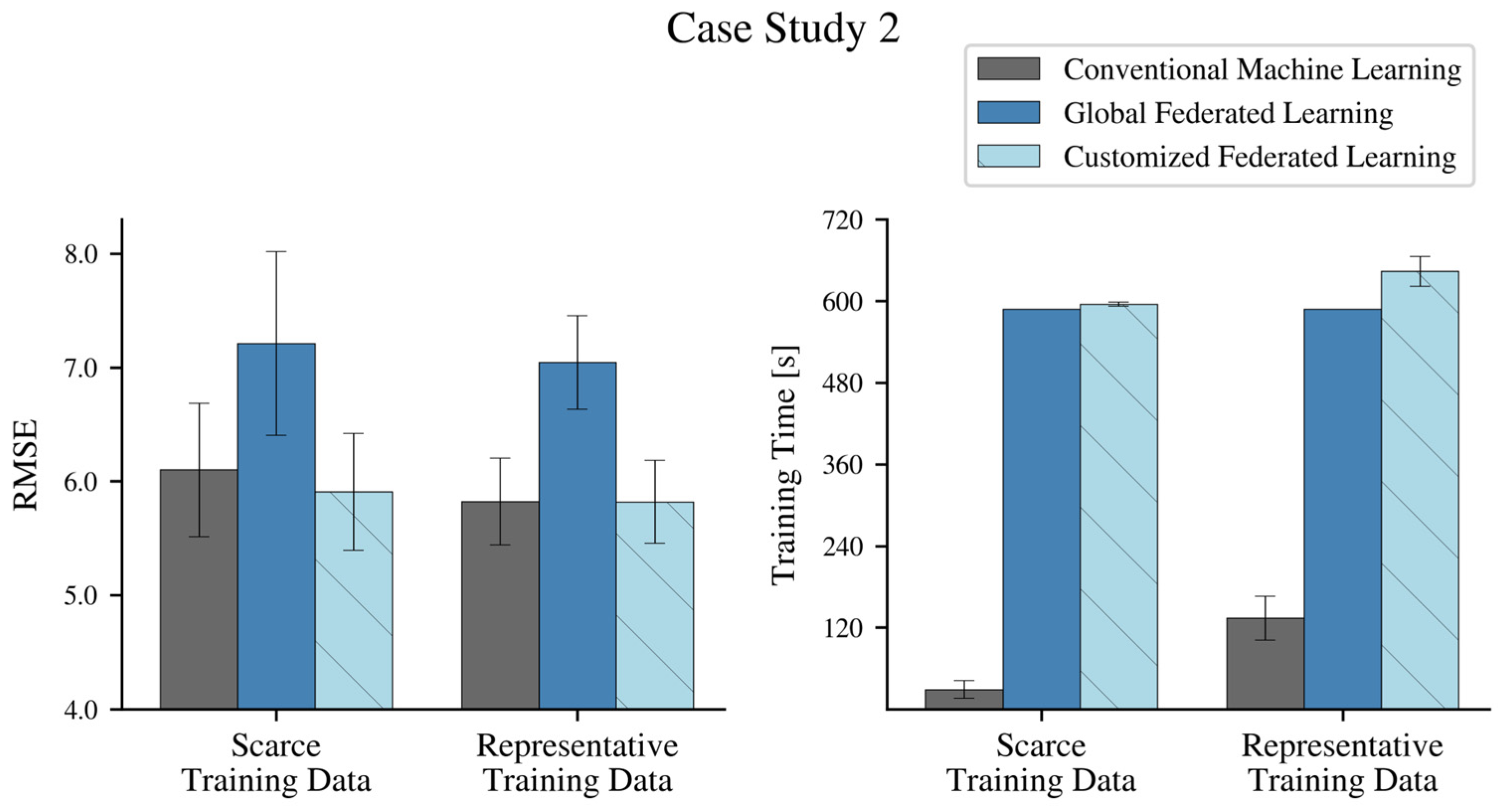
4.1. Federated Learning Strategies and Model Architecture
- A.
- Conventional machine learning of NBMs using only the local data of each WT,
- B.
- Federated learning of a single global NBM for all WTs,
- C.
- Customized federated learning of WT-specific NBMs.
4.1.1. Conventional Machine Learning
4.1.2. Federated Learning of a Single Global Model
4.1.3. Customized Federated Learning of Turbine-Specific Models
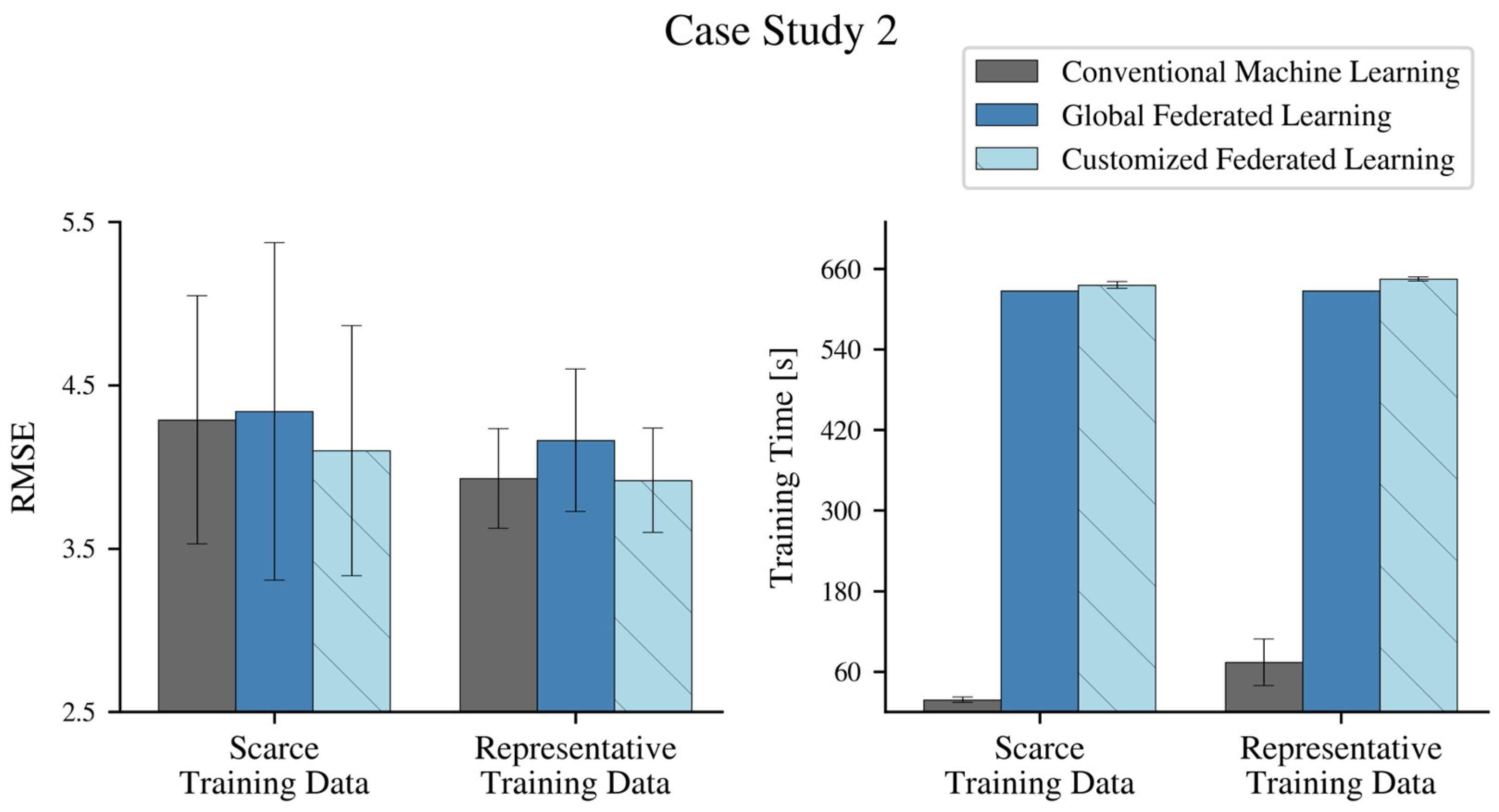
4.2. Federated Learning of Active Power Models
4.3. Federated Learning of Bearing Temperature Models
4.4. Second Wind Farm
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1. Model Selection
- Each fully connected neural network candidate always starts with the input layer.
- It ends with an output layer (1 unit, ReLU activation for strictly positive power, linear activation for the gear-bearing temperature).
- In between, the model can contain up to 3 hidden fully connected layers, with each layer consisting of either 4, 8, 12, or 16 units followed by an exponential linear unit (elu) activation.
- The algorithm samples a new learning rate (between 0.075 and 0.001 in case study 1 and between 0.001 and 0.000005 in case study 2) in each trial for the stochastic gradient descent optimizer (Nesterov Momentum 0.90, batch size 32), which minimizes the mean squared error over the training set.
Appendix A.2. Detailed Case Study Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | Training Time [s] | ||||||
|---|---|---|---|---|---|---|---|
| WT Index | Train. Dataset | Conv. ML (A) | Global FL (B) | Cust. FL (C) | Conv. ML (A) | Global FL (B) | Cust. FL (C) |
| 1 | Scarce | 0.279 | 0.110 | 0.115 | 22 | 541 | 547 |
| 2 | Scarce | 0.280 | 0.121 | 0.123 | 17 | 541 | 548 |
| 3 | Scarce | 0.200 | 0.113 | 0.087 | 19 | 541 | 549 |
| 4 | Scarce | 0.174 | 0.112 | 0.113 | 114 | 541 | 546 |
| 5 | Scarce | 0.224 | 0.168 | 0.148 | 21 | 541 | 545 |
| 6 | Repres. | 0.109 | 0.126 | 0.109 | 156 | 541 | 557 |
| 7 | Repres. | 0.106 | 0.120 | 0.106 | 117 | 541 | 561 |
| 8 | Repres. | 0.099 | 0.107 | 0.099 | 140 | 541 | 557 |
| 9 | Repres. | 0.101 | 0.100 | 0.102 | 109 | 541 | 553 |
| RMSE | Training Time [s] | ||||||
|---|---|---|---|---|---|---|---|
| WT Index | Train. Dataset | Conv. ML (A) | Global FL (B) | Cust. FL (C) | Conv. ML (A) | Global FL (B) | Cust. FL (C) |
| 1 | Scarce | 3.85 | 3.95 | 3.79 | 19 | 627 | 641 |
| 2 | Scarce | 5.78 | 6.39 | 5.61 | 15 | 627 | 632 |
| 3 | Scarce | 3.85 | 3.59 | 3.54 | 25 | 627 | 632 |
| 4 | Scarce | 3.77 | 3.85 | 3.65 | 17 | 627 | 643 |
| 5 | Scarce | 4.19 | 3.92 | 3.91 | 14 | 627 | 643 |
| 6 | Repres. | 3.90 | 4.28 | 3.86 | 46 | 627 | 643 |
| 7 | Repres. | 3.77 | 3.87 | 3.74 | 133 | 627 | 647 |
| 8 | Repres. | 4.43 | 4.82 | 4.45 | 52 | 627 | 641 |
| 9 | Repres. | 3.62 | 3.68 | 3.62 | 65 | 627 | 648 |
Appendix A.3. Customized Federated Learning
- Only finetuning the last layer (1 finetuned layer);
- Finetuning the last two layers (2 finetuned layers);
- Finetuning all trainable layers (3 finetuned layers),
| WT Index | Train Dataset | Customized FL, 1 Layer | Customized FL, 2 Layers | Customized FL, 3 Layers |
|---|---|---|---|---|
| 1 | Scarce | 0.0954 | 0.0954 | 0.0947 |
| 2 | Scarce | 0.1043 | 0.1066 | 0.1026 |
| 3 | Scarce | 0.0832 | 0.0825 | 0.0809 |
| 4 | Scarce | 0.1032 | 0.1038 | 0.1032 |
| 5 | Scarce | 0.1466 | 0.1473 | 0.1424 |
| 6 | Repres. | 0.0958 | 0.0956 | 0.0959 |
| 7 | Repres. | 0.0864 | 0.0859 | 0.0861 |
| 8 | Repres. | 0.0806 | 0.0807 | 0.0807 |
| 9 | Repres. | 0.0866 | 0.0864 | 0.0866 |
| WT Index | Train Dataset | Customized FL, 1 Layer | Customized FL, 2 Layers | Customized FL, 3 Layers |
|---|---|---|---|---|
| 1 | Scarce | 3.656 | 4.126 | 3.921 |
| 2 | Scarce | 4.942 | 5.066 | 4.960 |
| 3 | Scarce | 3.678 | 3.767 | 3.779 |
| 4 | Scarce | 3.702 | 3.952 | 3.863 |
| 5 | Scarce | 4.676 | 4.712 | 4.704 |
| 6 | Repres. | 3.710 | 3.713 | 3.720 |
| 7 | Repres. | 3.733 | 3.735 | 3.745 |
| 8 | Repres. | 5.670 | 5.720 | 5.697 |
| 9 | Repres. | 3.809 | 3.829 | 3.860 |
Appendix A.4. Second Wind Farm Dataset
| Parameter | Specification |
|---|---|
| Rotor diameter | 82 m |
| Rated active power | 2050 kW |
| Cut-in wind velocity | 3.5 m/s |
| Cut-out wind velocity | 25 m/s |
| Tower | Steel |
| Control type | Electrical pitch system |
| Gearbox | Combined planetary/spur |
Appendix A.4.1. Case Studies


Appendix A.4.2. Results
Federated Learning of Active Power Models
| RMSE | Training Time [s] | ||||||
|---|---|---|---|---|---|---|---|
| WT Index | Train. Dataset | Conv. ML (A) | Global FL (B) | Cust. FL (C) | Conv. ML (A) | Global FL (B) | Cust. FL (C) |
| 1 | Scarce | 0.182 | 0.032 | 0.031 | 127 | 1680 | 1688 |
| 2 | Scarce | 0.196 | 0.055 | 0.043 | 37 | 1680 | 1687 |
| 3 | Scarce | 0.191 | 0.033 | 0.033 | 40 | 1680 | 1688 |
| 4 | Scarce | 0.166 | 0.035 | 0.032 | 48 | 1680 | 1687 |
| 5 | Scarce | 0.240 | 0.031 | 0.031 | 185 | 1680 | 1687 |
| 6 | Scarce | 0.174 | 0.030 | 0.030 | 51 | 1680 | 1689 |
| 7 | Scarce | 0.172 | 0.057 | 0.058 | 79 | 1680 | 1688 |
| 8 | Repres. | 0.032 | 0.031 | 0.031 | 71 | 1680 | 1715 |
| 9 | Repres. | 0.031 | 0.039 | 0.031 | 130 | 1680 | 1737 |
| 10 | Repres. | 0.034 | 0.033 | 0.033 | 78 | 1680 | 1707 |
| 11 | Repres. | 0.040 | 0.048 | 0.040 | 84 | 1680 | 1714 |
| 12 | Repres. | 0.034 | 0.033 | 0.033 | 172 | 1680 | 1742 |
| 13 | Repres. | 0.033 | 0.032 | 0.032 | 81 | 1680 | 1763 |
| 14 | Repres. | 0.041 | 0.052 | 0.040 | 95 | 1680 | 1735 |
Federated Learning of Bearing Temperature Models
| RMSE | Training Time [s] | ||||||
|---|---|---|---|---|---|---|---|
| WT Index | Train. Dataset | Conv. ML (A) | Global FL (B) | Cust. FL (C) | Conv. ML (A) | Global FL (B) | Cust. FL (C) |
| 1 | Scarce | 5.857 | 5.413 | 5.407 | 10 | 588 | 591 |
| 2 | Scarce | 7.397 | 7.323 | 6.978 | 26 | 588 | 591 |
| 3 | Scarce | 6.146 | 7.810 | 6.131 | 35 | 588 | 598 |
| 4 | Scarce | 5.310 | 7.254 | 5.313 | 45 | 588 | 594 |
| 5 | Scarce | 5.918 | 6.968 | 5.700 | 23 | 588 | 599 |
| 6 | Scarce | 6.056 | 8.035 | 5.941 | 48 | 588 | 597 |
| 7 | Scarce | 6.021 | 7.667 | 5.888 | 18 | 588 | 593 |
| 8 | Repres. | 5.980 | 6.970 | 6.061 | 121 | 588 | 624 |
| 9 | Repres. | 5.962 | 6.503 | 5.910 | 100 | 588 | 664 |
| 10 | Repres. | 5.981 | 7.049 | 6.001 | 207 | 588 | 651 |
| 11 | Repres. | 6.094 | 6.780 | 6.108 | 115 | 588 | 611 |
| 12 | Repres. | 5.649 | 7.400 | 5.656 | 127 | 588 | 680 |
| 13 | Repres. | 6.128 | 7.826 | 6.013 | 142 | 588 | 637 |
| 14 | Repres. | 4.964 | 6.778 | 4.995 | 123 | 588 | 635 |

References
- Barthelmie, R.J.; Pryor, S.C. Climate Change Mitigation Potential of Wind Energy. Climate 2021, 9, 136. [Google Scholar] [CrossRef]
- Edenhofer, O.; Pichs-Madruga, R.; Sokona, Y.; Seyboth, K.; Kadner, S.; Zwickel, T.; Eickemeier, P.; Hansen, G.; Schlömer, S.; Von Stechow, C.; et al. (Eds.) Renewable Energy Sources and Climate Change Mitigation: Special Report of the Intergovernmental Panel on Climate Change, 1st ed.; Cambridge University Press: Cambridge, UK, 2011; ISBN 978-1-107-02340-6. [Google Scholar]
- IEA Renewables 2021; IEA: Paris, France, 2021; Available online: https://www.iea.org/reports/renewables-2021 (accessed on 7 September 2022).
- IEA World Energy Investment 2022; IEA: Paris, France, 2022; Available online: https://www.iea.org/reports/world-energy-investment-2022 (accessed on 7 September 2022).
- OECD; The World Bank; United Nations Environment Programme. Financing Climate Futures Rethinking Infrastructure: Rethinking Infrastructure; OECD: Paris, France, 2018; ISBN 978-92-64-30810-7. [Google Scholar]
- Carroll, J.; McDonald, A.; McMillan, D. Failure Rate, Repair Time and Unscheduled O&M Cost Analysis of Offshore Wind Turbines: Reliability and Maintenance of Offshore Wind Turbines. Wind. Energy 2016, 19, 1107–1119. [Google Scholar] [CrossRef]
- Faulstich, S.; Hahn, B.; Tavner, P.J. Wind Turbine Downtime and Its Importance for Offshore Deployment. Wind. Energy 2011, 14, 327–337. [Google Scholar] [CrossRef]
- Kusiak, A. Renewables: Share Data on Wind Energy. Nature 2016, 529, 19–21. [Google Scholar] [CrossRef] [PubMed]
- Leahy, K.; Gallagher, C.; O’Donovan, P.; O’Sullivan, D.T.J. Issues with Data Quality for Wind Turbine Condition Monitoring and Reliability Analyses. Energies 2019, 12, 201. [Google Scholar] [CrossRef]
- Clifton, A.; Barber, S.; Bray, A.; Enevoldsen, P.; Fields, J.; Sempreviva, A.M.; Williams, L.; Quick, J.; Purdue, M.; Totaro, P.; et al. Grand Challenges in the Digitalisation of Wind Energy. Wind. Energy Sci. Discuss. 2023, 8, 947–974. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; Singh, A., Zhu, J., Eds.; Volume 54, pp. 1273–1282. [Google Scholar]
- Acar, D.A.E.; Zhao, Y.; Matas, R.; Mattina, M.; Whatmough, P.; Saligrama, V. Federated Learning Based on Dynamic Regularization. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Asad, M.; Moustafa, A.; Ito, T. FedOpt: Towards Communication Efficiency and Privacy Preservation in Federated Learning. Appl. Sci. 2020, 10, 2864. [Google Scholar] [CrossRef]
- Mothukuri, V.; Parizi, R.M.; Pouriyeh, S.; Huang, Y.; Dehghantanha, A.; Srivastava, G. A Survey on Security and Privacy of Federated Learning. Future Gener. Comput. Syst. 2021, 115, 619–640. [Google Scholar] [CrossRef]
- Yin, X.; Zhu, Y.; Hu, J. A Comprehensive Survey of Privacy-Preserving Federated Learning: A Taxonomy, Review, and Future Directions. ACM Comput. Surv. 2022, 54, 1–36. [Google Scholar] [CrossRef]
- Fang, H.; Qian, Q. Privacy Preserving Machine Learning with Homomorphic Encryption and Federated Learning. Future Internet 2021, 13, 94. [Google Scholar] [CrossRef]
- Ma, J.; Naas, S.; Sigg, S.; Lyu, X. Privacy-preserving Federated Learning Based on Multi-key Homomorphic Encryption. Int. J. Intell. Syst. 2022, 37, 5880–5901. [Google Scholar] [CrossRef]
- Kou, L.; Wu, J.; Zhang, F.; Ji, P.; Ke, W.; Wan, J.; Liu, H.; Li, Y.; Yuan, Q. Image encryption for Offshore wind power based on 2D-LCLM and Zhou Yi Eight Trigrams. Int. J. Bio-Inspired Comput. 2023. [Google Scholar] [CrossRef]
- Cheng, Y.; Liu, Y.; Zhang, Z.; Li, Y. An Asymmetric Encryption-Based Key Distribution Method for Wireless Sensor Networks. Sensors 2023, 23, 6460. [Google Scholar] [CrossRef] [PubMed]
- Aledhari, M.; Razzak, R.; Parizi, R.M.; Saeed, F. Federated Learning: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Access 2020, 8, 140699–140725. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Nitin Bhagoji, A.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and Open Problems in Federated Learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.-Y. A Review of Applications in Federated Learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Luong, N.C.; Hoang, D.T.; Jiao, Y.; Liang, Y.-C.; Yang, Q.; Niyato, D.; Miao, C. Federated Learning in Mobile Edge Networks: A Comprehensive Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2031–2063. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated Learning for Mobile Keyboard Prediction. arXiv 2018. [Google Scholar] [CrossRef]
- Pichai, S. Google’s Sundar Pichai: Privacy Should Not Be a Luxury Good. N. Y. Times 2019, 8, 25. [Google Scholar]
- Liu, Y.; Yu, J.J.Q.; Kang, J.; Niyato, D.; Zhang, S. Privacy-Preserving Traffic Flow Prediction: A Federated Learning Approach. IEEE Internet Things J. 2020, 7, 7751–7763. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Zhang, K.; Maharjan, S.; Zhang, Y. Blockchain Empowered Asynchronous Federated Learning for Secure Data Sharing in Internet of Vehicles. IEEE Trans. Veh. Technol. 2020, 69, 4298–4311. [Google Scholar] [CrossRef]
- Thorgeirsson, A.T.; Scheubner, S.; Funfgeld, S.; Gauterin, F. Probabilistic Prediction of Energy Demand and Driving Range for Electric Vehicles With Federated Learning. IEEE Open J. Veh. Technol. 2021, 2, 151–161. [Google Scholar] [CrossRef]
- Zhang, X.; Fang, F.; Wang, J. Probabilistic Solar Irradiation Forecasting Based on Variational Bayesian Inference With Secure Federated Learning. IEEE Trans. Ind. Inform. 2021, 17, 7849–7859. [Google Scholar] [CrossRef]
- Lin, J.; Ma, J.; Zhu, J. A Privacy-Preserving Federated Learning Method for Probabilistic Community-Level Behind-the-Meter Solar Generation Disaggregation. IEEE Trans. Smart Grid 2022, 13, 268–279. [Google Scholar] [CrossRef]
- Liu, Q.; Yang, B.; Wang, Z.; Zhu, D.; Wang, X.; Ma, K.; Guan, X. Asynchronous Decentralized Federated Learning for Collaborative Fault Diagnosis of PV Stations. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1680–1696. [Google Scholar] [CrossRef]
- Cheng, X.; Tian, W.; Shi, F.; Zhao, M.; Chen, S.; Wang, H. A Blockchain-Empowered Cluster-Based Federated Learning Model for Blade Icing Estimation on IoT-Enabled Wind Turbine. IEEE Trans. Ind. Inform. 2022, 18, 9184–9195. [Google Scholar] [CrossRef]
- Tautz-Weinert, J.; Watson, S.J. Using SCADA Data for Wind Turbine Condition Monitoring—A Review. IET Renew. Power Gener. 2017, 11, 382–394. [Google Scholar] [CrossRef]
- Bilendo, F.; Badihi, H.; Lu, N.; Cambron, P.; Jiang, B. A Normal Behavior Model Based on Power Curve and Stacked Regressions for Condition Monitoring of Wind Turbines. IEEE Trans. Instrum. Meas. 2022, 71, 1–13. [Google Scholar] [CrossRef]
- Bilendo, F.; Meyer, A.; Badihi, H.; Lu, N.; Cambron, P.; Jiang, B. Applications and Modeling Techniques of Wind Turbine Power Curve for Wind Farms—A Review. Energies 2022, 16, 180. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F.; Achiche, S. Using Data-Mining Approaches for Wind Turbine Power Curve Monitoring: A Comparative Study. IEEE Trans. Sustain. Energy 2013, 4, 671–679. [Google Scholar] [CrossRef]
- Meyer, A. Multi-Target Normal Behaviour Models for Wind Farm Condition Monitoring. Appl. Energy 2021, 300, 117342. [Google Scholar] [CrossRef]
- Schlechtingen, M.; Santos, I.F.; Achiche, S. Wind Turbine Condition Monitoring Based on SCADA Data Using Normal Behavior Models. Part 1: System Description. Appl. Soft Comput. 2013, 13, 259–270. [Google Scholar] [CrossRef]
- Zaher, A.; McArthur, S.D.J.; Infield, D.G.; Patel, Y. Online Wind Turbine Fault Detection through Automated SCADA Data Analysis. Wind Energy 2009, 12, 574–593. [Google Scholar] [CrossRef]
- Badihi, H.; Zhang, Y.; Jiang, B.; Pillay, P.; Rakheja, S. A Comprehensive Review on Signal-Based and Model-Based Condition Monitoring of Wind Turbines: Fault Diagnosis and Lifetime Prognosis. Proc. IEEE 2022, 110, 754–806. [Google Scholar] [CrossRef]
- García Márquez, F.P.; Tobias, A.M.; Pinar Pérez, J.M.; Papaelias, M. Condition Monitoring of Wind Turbines: Techniques and Methods. Renew. Energy 2012, 46, 169–178. [Google Scholar] [CrossRef]
- Tchakoua, P.; Wamkeue, R.; Ouhrouche, M.; Slaoui-Hasnaoui, F.; Tameghe, T.; Ekemb, G. Wind Turbine Condition Monitoring: State-of-the-Art Review, New Trends, and Future Challenges. Energies 2014, 7, 2595–2630. [Google Scholar] [CrossRef]
- Wymore, M.L.; Van Dam, J.E.; Ceylan, H.; Qiao, D. A Survey of Health Monitoring Systems for Wind Turbines. Renew. Sustain. Energy Rev. 2015, 52, 976–990. [Google Scholar] [CrossRef]
- Dao, P.B. On Wilcoxon Rank Sum Test for Condition Monitoring and Fault Detection of Wind Turbines. Appl. Energy 2022, 318, 119209. [Google Scholar] [CrossRef]
- Wang, A.; Pei, Y.; Qian, Z.; Zareipour, H.; Jing, B.; An, J. A Two-Stage Anomaly Decomposition Scheme Based on Multi-Variable Correlation Extraction for Wind Turbine Fault Detection and Identification. Appl. Energy 2022, 321, 119373. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhu, C.; Tan, J.; Tan, Y.; Rao, L. Anomaly Detection and Condition Monitoring of Wind Turbine Gearbox Based on LSTM-FS and Transfer Learning. Renew. Energy 2022, 189, 90–103. [Google Scholar] [CrossRef]
- Sun, S.; Wang, T.; Yang, H.; Chu, F. Condition Monitoring of Wind Turbine Blades Based on Self-Supervised Health Representation Learning: A Conducive Technique to Effective and Reliable Utilization of Wind Energy. Appl. Energy 2022, 313, 118882. [Google Scholar] [CrossRef]
- Jonas, S.; Anagnostos, D.; Brodbeck, B.; Meyer, A. Vibration Fault Detection in Wind Turbines Based on Normal Behaviour Models without Feature Engineering. Energies 2023, 16, 1760. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, R.; Li, Z. Fault Detection Method for Wind Turbine Generators Based on Attention-Based Modeling. Appl. Sci. 2023, 13, 9276. [Google Scholar] [CrossRef]
- Black, I.M.; Richmond, M.; Kolios, A. Condition Monitoring Systems: A Systematic Literature Review on Machine-Learning Methods Improving Offshore-Wind Turbine Operational Management. Int. J. Sustain. Energy 2021, 40, 923–946. [Google Scholar] [CrossRef]
- Nunes, A.R.; Morais, H.; Sardinha, A. Use of Learning Mechanisms to Improve the Condition Monitoring of Wind Turbine Generators: A Review. Energies 2021, 14, 7129. [Google Scholar] [CrossRef]
- Pandit, R.; Astolfi, D.; Hong, J.; Infield, D.; Santos, M. SCADA Data for Wind Turbine Data-Driven Condition/Performance Monitoring: A Review on State-of-Art, Challenges and Future Trends. Wind Eng. 2023, 47, 422–441. [Google Scholar] [CrossRef]
- Stetco, A.; Dinmohammadi, F.; Zhao, X.; Robu, V.; Flynn, D.; Barnes, M.; Keane, J.; Nenadic, G. Machine Learning Methods for Wind Turbine Condition Monitoring: A Review. Renew. Energy 2019, 133, 620–635. [Google Scholar] [CrossRef]
- Smith, V.; Chiang, C.-K.; Sanjabi, M.; Talwalkar, A.S. Federated Multi-Task Learning. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Siemens Gamesa The Power of Big Data 2022. Available online: https://www.siemensgamesa.com/explore/innovations/digitalization (accessed on 7 September 2022).
- Meyer, A.; Brodbeck, B. Data-Driven Performance Fault Detection in Commercial Wind Turbines. In Proceedings of the PHM Society European Conference, Turin, Italy, 1–3 July 2020; Volume 5, p. 7. [Google Scholar]
- Kusiak, A.; Zheng, H.; Song, Z. On-Line Monitoring of Power Curves. Renew. Energy 2009, 34, 1487–1493. [Google Scholar] [CrossRef]
- Lydia, M.; Kumar, S.S.; Selvakumar, A.I.; Prem Kumar, G.E. A Comprehensive Review on Wind Turbine Power Curve Modeling Techniques. Renew. Sustain. Energy Rev. 2014, 30, 452–460. [Google Scholar] [CrossRef]
- Marvuglia, A.; Messineo, A. Monitoring of Wind Farms’ Power Curves Using Machine Learning Techniques. Appl. Energy 2012, 98, 574–583. [Google Scholar] [CrossRef]
- Shokrzadeh, S.; Jafari Jozani, M.; Bibeau, E. Wind Turbine Power Curve Modeling Using Advanced Parametric and Nonparametric Methods. IEEE Trans. Sustain. Energy 2014, 5, 1262–1269. [Google Scholar] [CrossRef]
- Wang, Y.; Hu, Q.; Li, L.; Foley, A.M.; Srinivasan, D. Approaches to Wind Power Curve Modeling: A Review and Discussion. Renew. Sustain. Energy Rev. 2019, 116, 109422. [Google Scholar] [CrossRef]
- Li, Q.; Diao, Y.; Chen, Q.; He, B. Federated Learning on Non-IID Data Silos: An Experimental Study. In Proceedings of the 2022 IEEE 38th International Conference on Data Engineering (ICDE), Kuala Lumpur, Malaysia, 9–12 May 2022; pp. 965–978. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. arXiv 2018. [Google Scholar] [CrossRef]
- Zhu, H.; Xu, J.; Liu, S.; Jin, Y. Federated Learning on Non-IID Data: A Survey. Neurocomputing 2021, 465, 371–390. [Google Scholar] [CrossRef]
- Huang, W.; Ye, M.; Shi, Z.; Li, H.; Du, B. Rethinking Federated Learning With Domain Shift: A Prototype View. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 16312–16322. [Google Scholar]
- Kouw, W.M.; Loog, M. An Introduction to Domain Adaptation and Transfer Learning. arXiv 2018. [Google Scholar] [CrossRef]
- Quinonero-Candela, J.; Sugiyama, M.; Schwaighofer, A.; Lawrence, N.D. Dataset Shift in Machine Learning; Mit Press: Cambridge, MA, USA, 2008; ISBN 9780262545877. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated Learning with Personalization Layers. arXiv 2019. [Google Scholar] [CrossRef]
- Shamsian, A.; Navon, A.; Fetaya, E.; Chechik, G. Personalized Federated Learning Using Hypernetworks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 9489–9502. [Google Scholar]
- Kulkarni, V.; Kulkarni, M.; Pant, A. Survey of Personalization Techniques for Federated Learning. In Proceedings of the 2020 Fourth World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4), London, UK, 27–28 July 2020; pp. 794–797. [Google Scholar]
- Tan, A.Z.; Yu, H.; Cui, L.; Yang, Q. Towards Personalized Federated Learning. IEEE Trans. Neural Netw. Learn. Syst. 2022, 1–17. [Google Scholar] [CrossRef]
- Collins, L.; Hassani, H.; Mokhtari, A.; Shakkottai, S. FedAvg with Fine Tuning: Local Updates Lead to Representation Learning. arXiv 2022. [Google Scholar] [CrossRef]
- Ohlendorf, N.; Schill, W.-P. Frequency and Duration of Low-Wind-Power Events in Germany. Environ. Res. Lett. 2020, 15, 084045. [Google Scholar] [CrossRef]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016. [Google Scholar] [CrossRef]
- Chollet, F. Others Keras 2015. Available online: https://keras.io/getting_started/faq/#how-should-i-cite-keras (accessed on 7 September 2022).
- O’Malley, T.; Bursztein, E.; Long, J.; Chollet, F.; Jin, H.; Invernizzi, L. Others KerasTuner 2019. Available online: https://github.com/keras-team/keras-tuner (accessed on 7 September 2022).
- Plumley, C. Penmanshiel Wind Farm Data; ZENODO: Geneva, Switzerland, 2022. [Google Scholar] [CrossRef]




| Federated model training process The central server selects the model architecture and initial weights. Then, it iterates the following steps: |
|
|
|
|
| Parameter | Specification |
|---|---|
| Rotor diameter | 112 m |
| Rated active power | 3300 kW |
| Cut-in wind velocity | 3 m/s |
| Cut-out wind velocity | 25 m/s |
| Tower | Steel monopole |
| Control type | Pitch-controlled variable velocity |
| Gearbox | Two planetary stages, one helical stage |
| Model Architecture (First Case Study) |
|---|
Loss: Mean Squared Error Optimizer: Stochastic Gradient Descent (learning rate = 0.013, batch size = 32) |
| Model Architecture (Second Case Study) |
|---|
Loss: Mean Squared Error Optimizer: Stochastic Gradient Descent (learning rate = 0.00035, batch size = 32) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jenkel, L.; Jonas, S.; Meyer, A. Privacy-Preserving Fleet-Wide Learning of Wind Turbine Conditions with Federated Learning. Energies 2023, 16, 6377. https://doi.org/10.3390/en16176377
Jenkel L, Jonas S, Meyer A. Privacy-Preserving Fleet-Wide Learning of Wind Turbine Conditions with Federated Learning. Energies. 2023; 16(17):6377. https://doi.org/10.3390/en16176377
Chicago/Turabian StyleJenkel, Lorin, Stefan Jonas, and Angela Meyer. 2023. "Privacy-Preserving Fleet-Wide Learning of Wind Turbine Conditions with Federated Learning" Energies 16, no. 17: 6377. https://doi.org/10.3390/en16176377
APA StyleJenkel, L., Jonas, S., & Meyer, A. (2023). Privacy-Preserving Fleet-Wide Learning of Wind Turbine Conditions with Federated Learning. Energies, 16(17), 6377. https://doi.org/10.3390/en16176377