
A Review of the Applications of Explainable Machine Learning for Lithium–Ion Batteries: From Production to State and Performance Estimation

 ,
,  ,
,  , and
, and 
Abstract
:1. Introduction
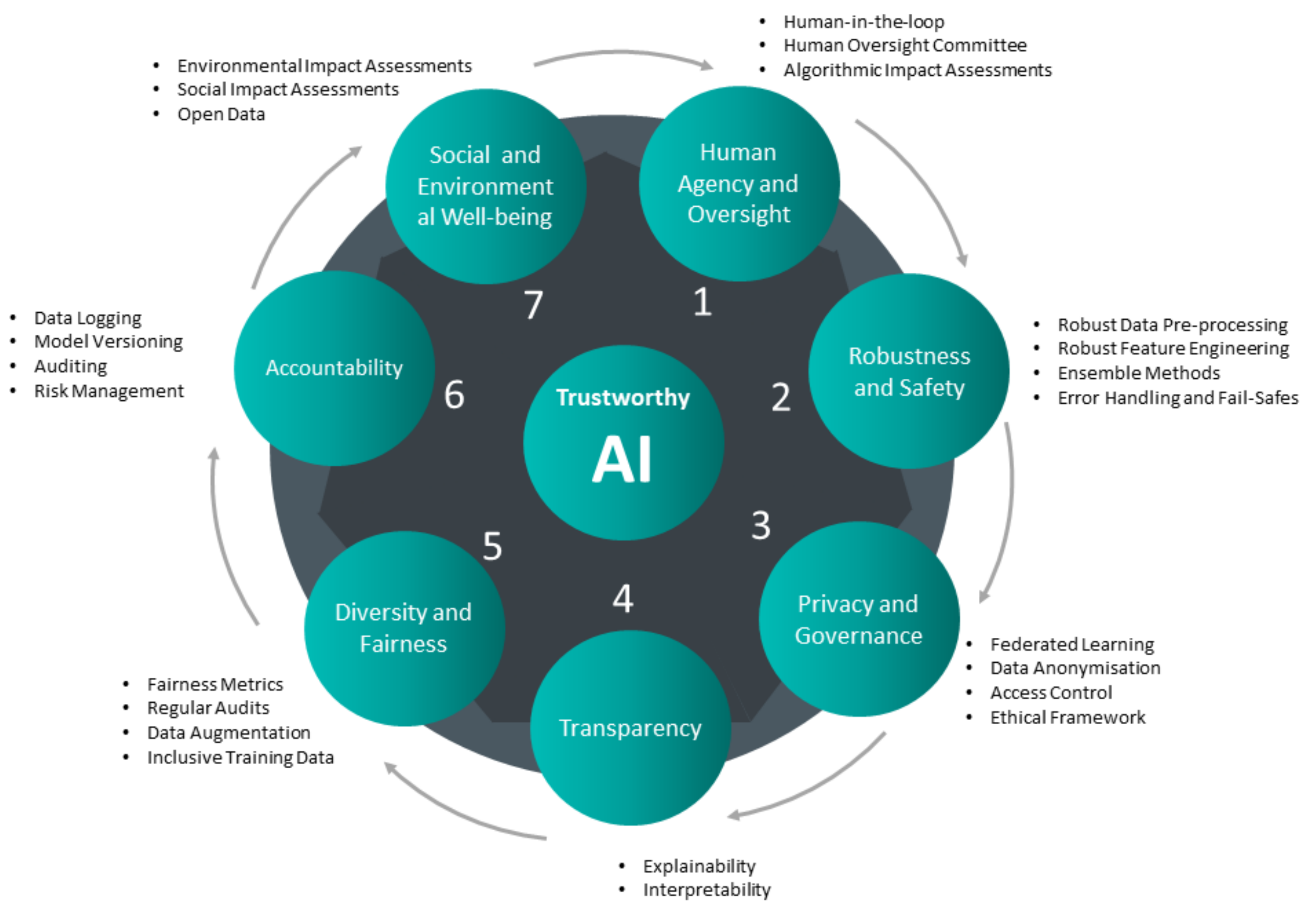
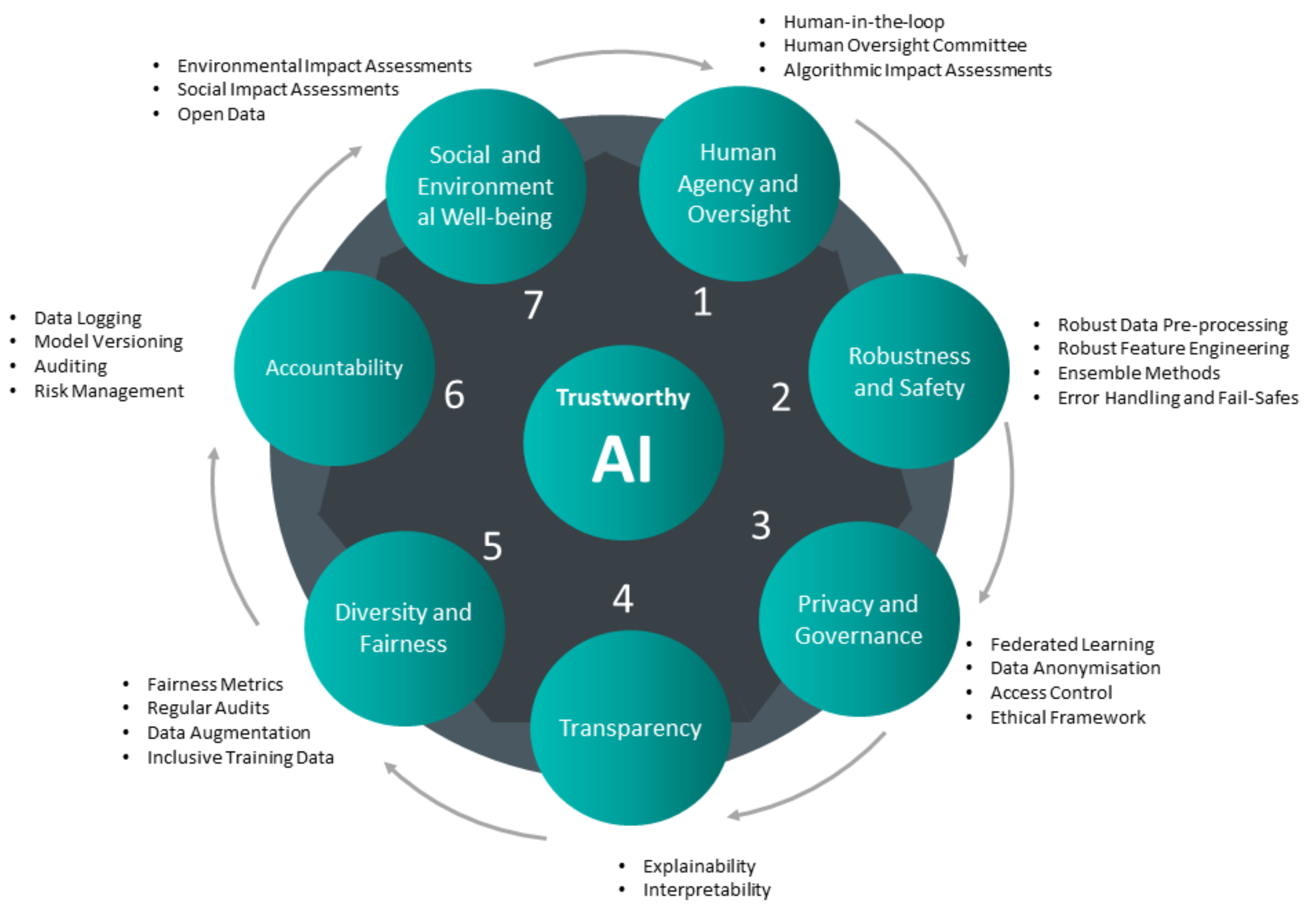
- Human agency and oversight: In order for the AI models to support humans, a proper oversight and supervision mechanism for their performance is necessary. This is attainable by human-in-the-loop concepts.
- Privacy and data governance: This aspect is focused on data protection, integrity, and discretion. It is necessary to be considerate of the requirements and the consequences of illegitimate access to the data.
- Robustness and safety: This is one of the most technical aspects of AI models’ trustworthiness. It is about models and methods to be resilient and robust to reasonable perturbations. Reliability and reproducibility under non-planned scenarios is the main concern of this aspect.
- Transparency: Models and methods integrated with AI algorithms are required to be transparent and traceable. This means they are needed to be more of white boxes than the black boxes of decision-making algorithms. Transparency is necessary to be adapted to each stakeholder’s specific terminology and concerns.
- Fairness and diversity: This is to make sure the algorithms are not biased toward a specific population or group of data. This could lead to discrimination in human-related applications or in poor performance and generalisation in technical applications.
- Social and environmental well-being: While it is expected that all AI systems benefit humans, it is not always clear how this is realised. This aspect is to make sure the implications and advantages on human lives and also on the environment are clarified.
- Accountability: This aspect tries to raise awareness regarding the reproducibility and traceability of the performed works by AI. Performing regular audits and assessments of the algorithms is an important method to make sure they perform well in critical applications.
- A review of the explainability techniques that are been utilised in the battery domain.
- The advantages and challenges of the explainability techniques.
- A categorisation and comparison of the XML methods applied for battery design and manufacturing.
- A review and summary the role of XML in the design and delivery of intelligent battery management systems.
- An identification of the challenges and research gaps in each category.
- A summary of key insights and the future research directions in the area of batteries and XML.
1.1. Materials and Methods
1.2. Structure of the Paper
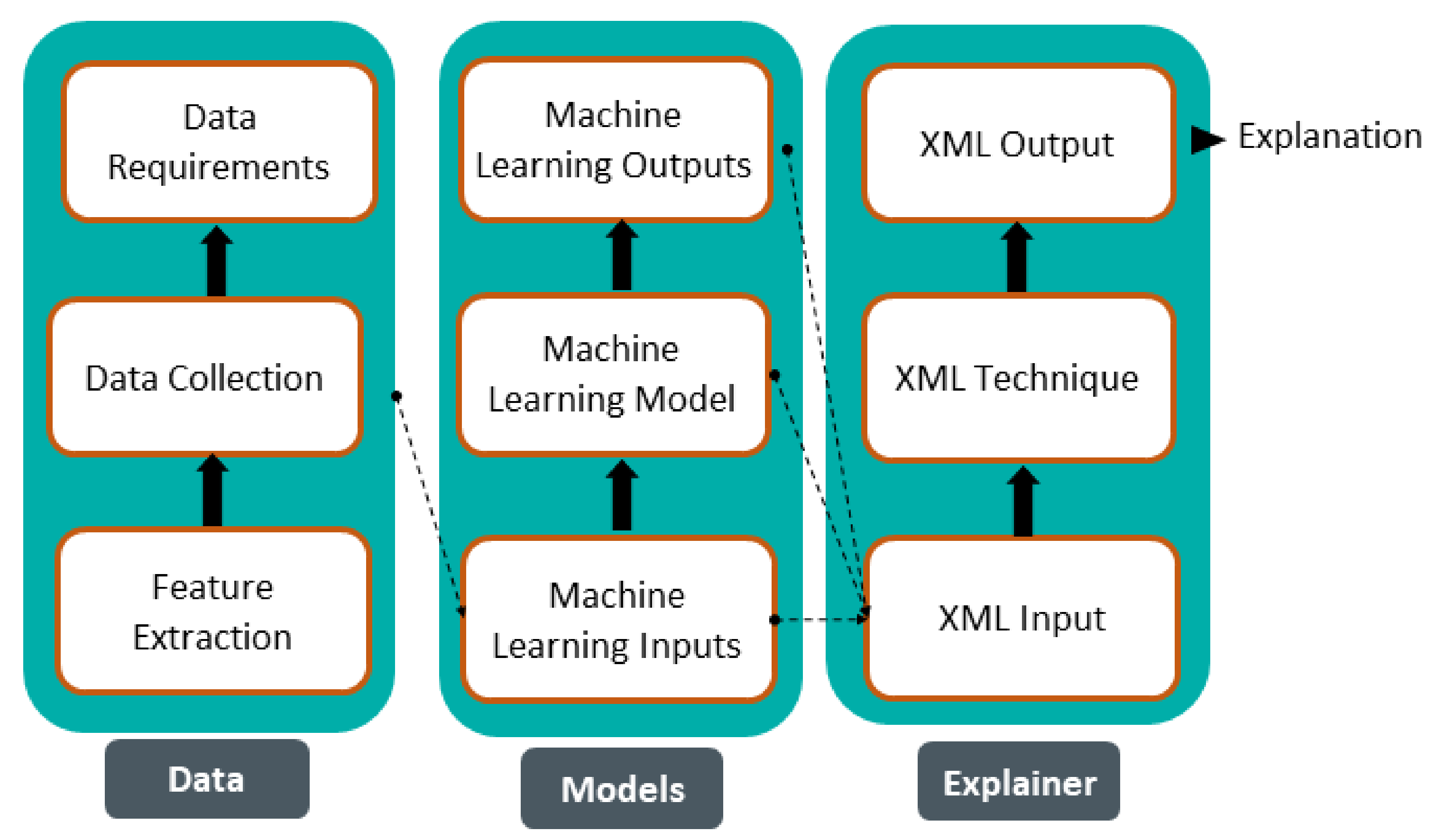
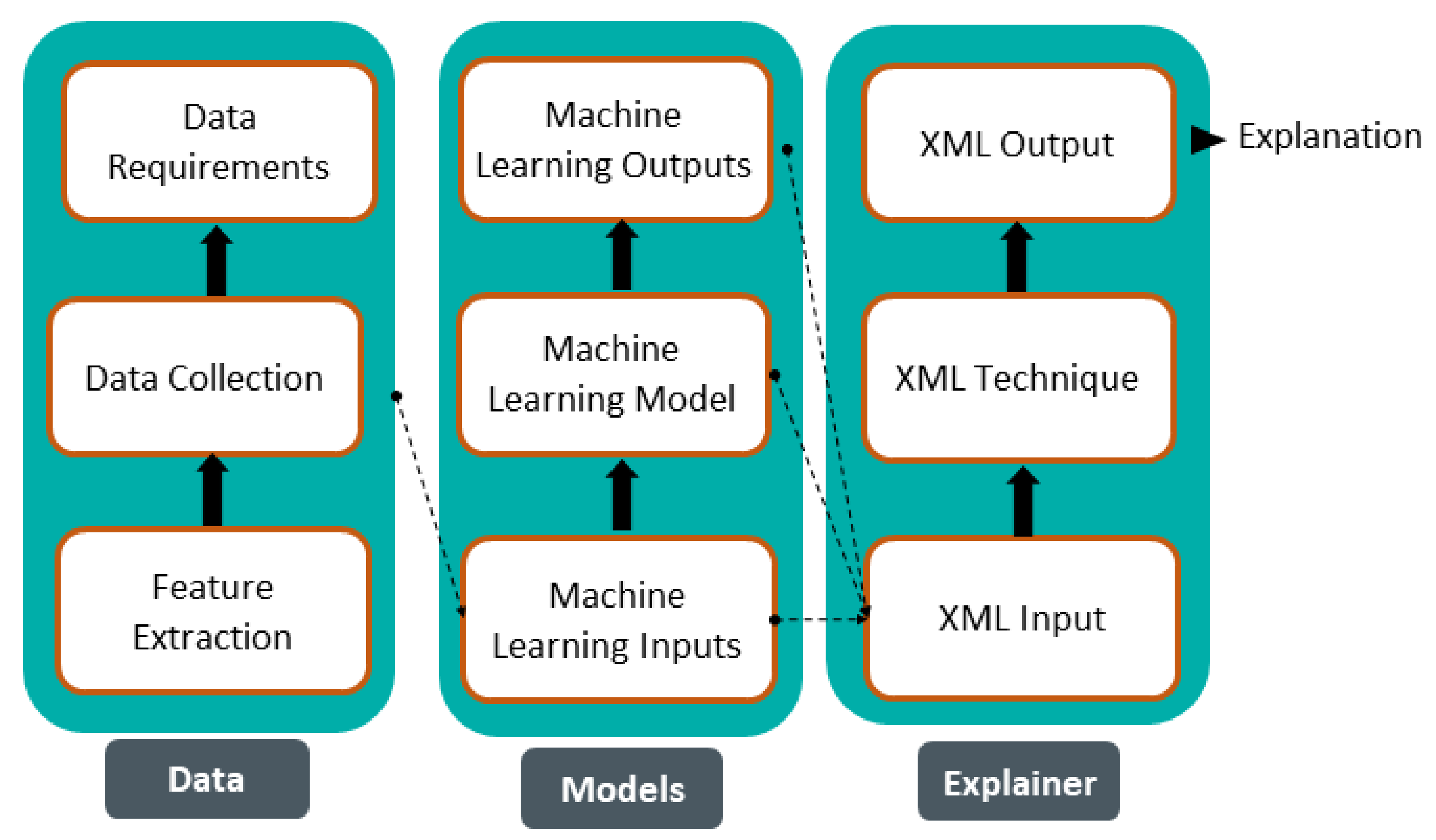
2. Explainable Machine Learning
2.1. Explainable vs. Interpretable ML
2.2. The Need for Explainability
- Data Management—Having XML enables developers to find vague points, missed information, and gaps in our training data.
- Model Selection—XML performs as a criterion for model selection to eliminate the models with vague or non-transparent reasoning from the list of options.
- Model Training—Having an appropriate model selected, XML helps to improve the hyper-parameter optimisation and polishing the model to gain better performance. XML simplifies hyper-parameter tuning, facilitating easy experimentation to find optimal settings. Moreover, XML helps in polishing the model, refining its performance and reliability. Thus, XML is instrumental in streamlining model training, yielding improved performance and more reliable outcomes.
- Model Verification—In model validation and verification, the goal is to define key performance indices and evaluate the trained model. In model verification, XML can be used as a metric to evaluate model behaviour in terms of weaknesses and model flaws as well as finding their main causes.
- Model monitoring—XML can be used as a diagnostics tool to link back the model results to the data and identify the sources of imperfect behaviour.
- Investigation of accident or incident—Having an issue with the ML on operation, local explainability can help us to understand why the decision is made in the wrong way.
- Run-time improvement—XML can help us to improve the models when new data and different situations are faced.
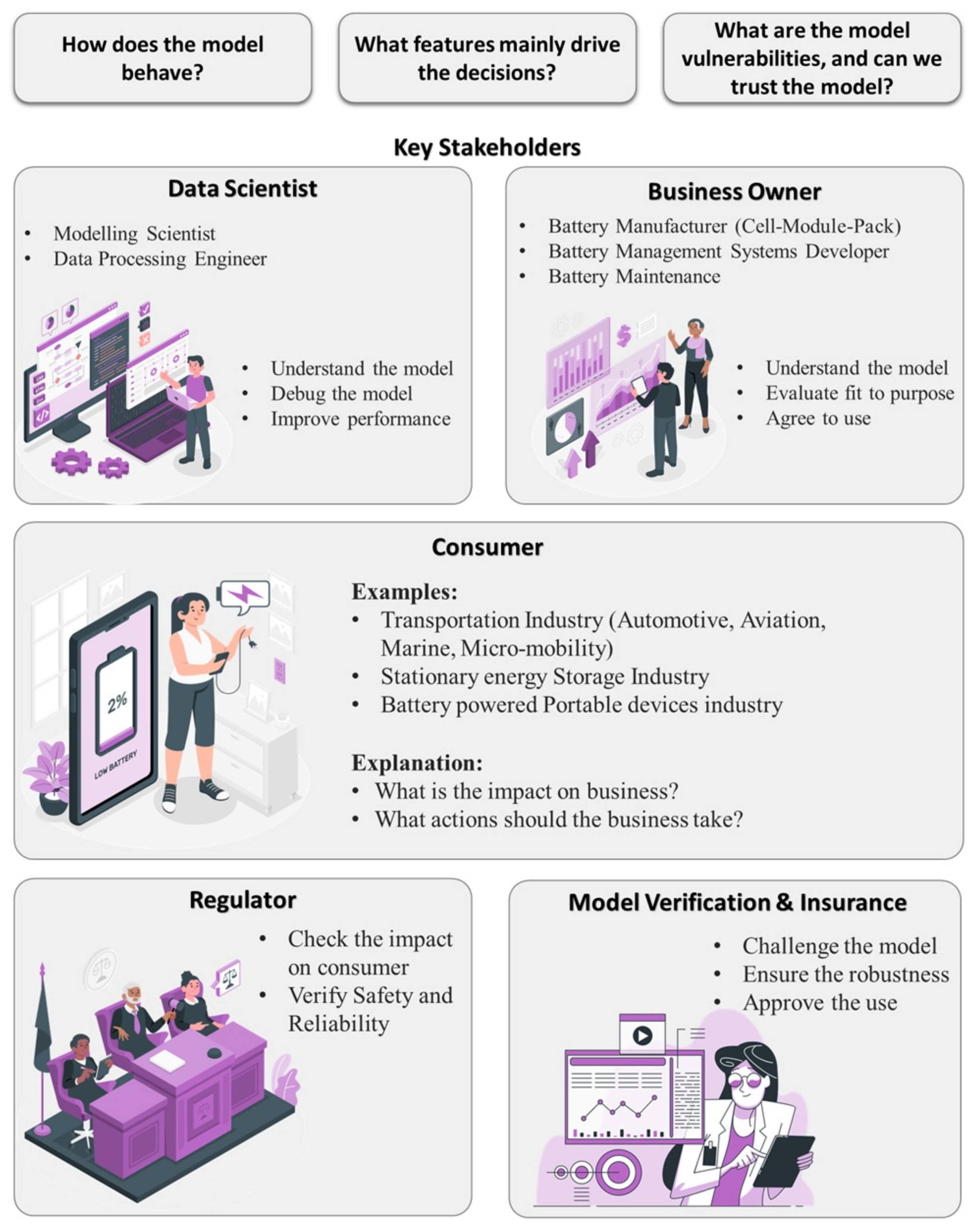
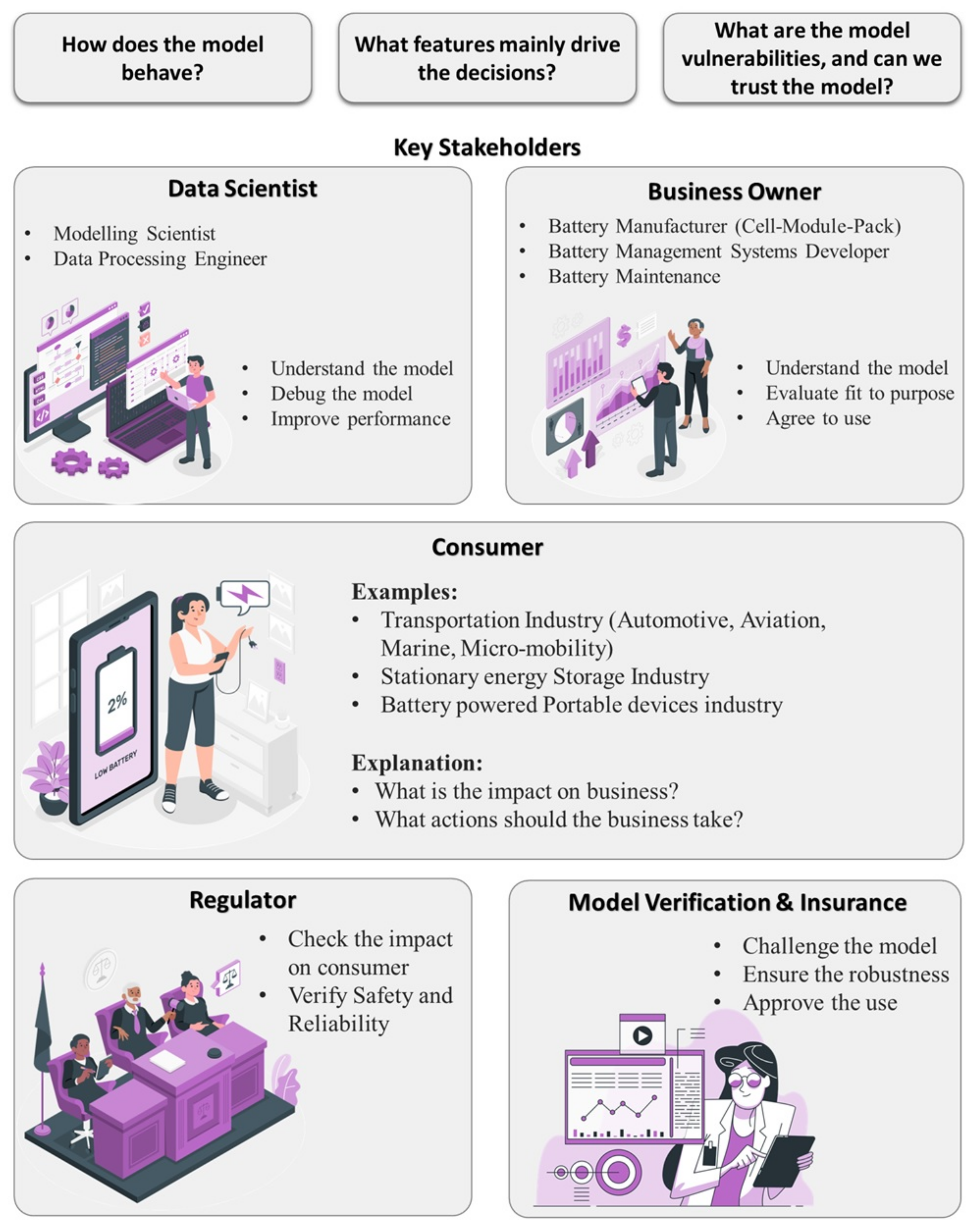
2.3. Role of Explainability among Key Stakeholders
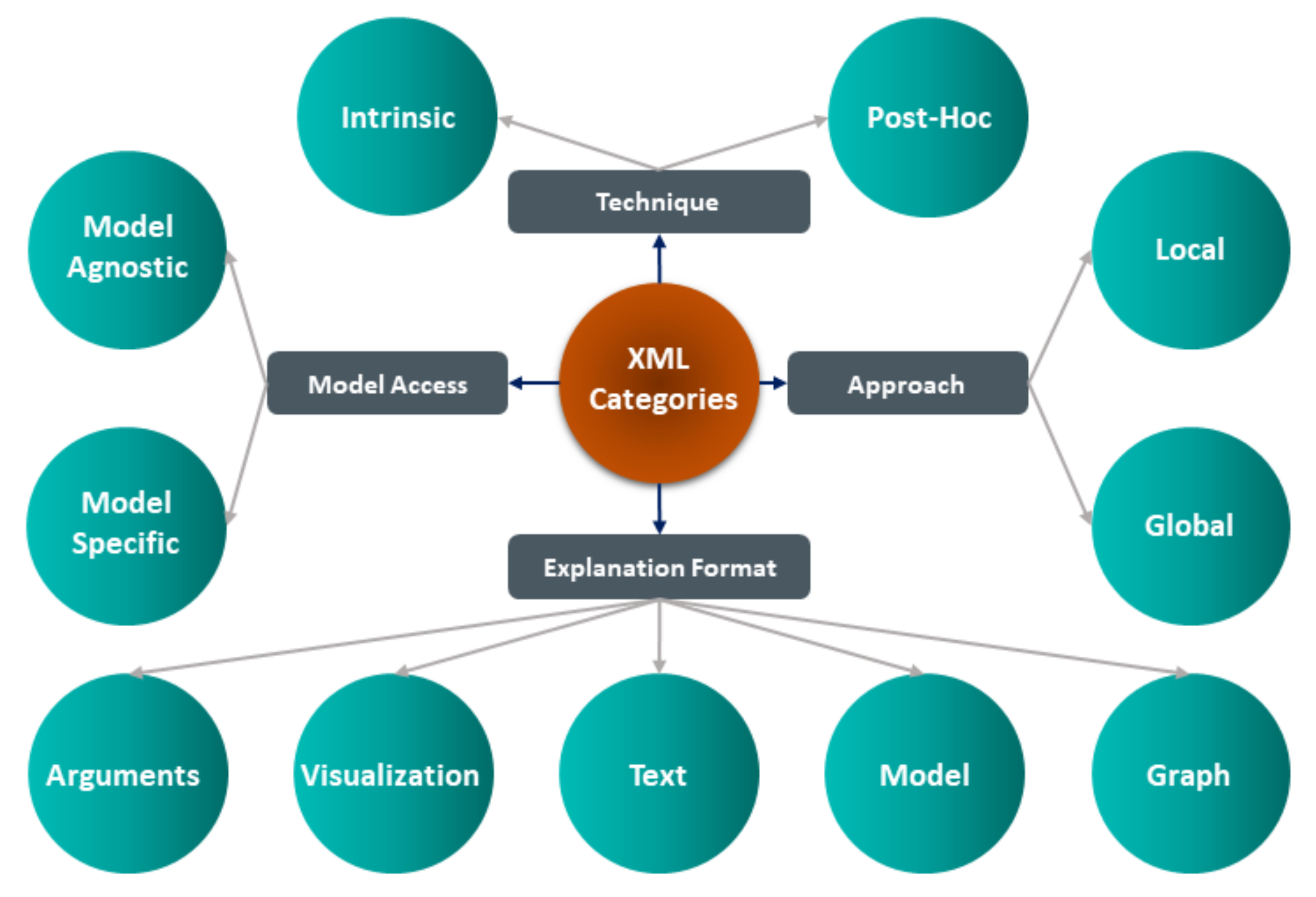
3. XML Categories and Methods
3.1. Partial Dependence Plot and Accumulated Local Effects
3.2. Feature Importance
3.2.1. Permutation Feature Importance
3.2.2. Gini Importance
3.2.3. LASSO
3.2.4. Saabas
3.2.5. Gain
3.2.6. Split Count
3.3. SHAP
3.4. Pearson Correlation
3.5. Explainability Considerations
3.5.1. Data Importance
3.5.2. Counterfactual Explanations
3.5.3. Explainability Weaknesses
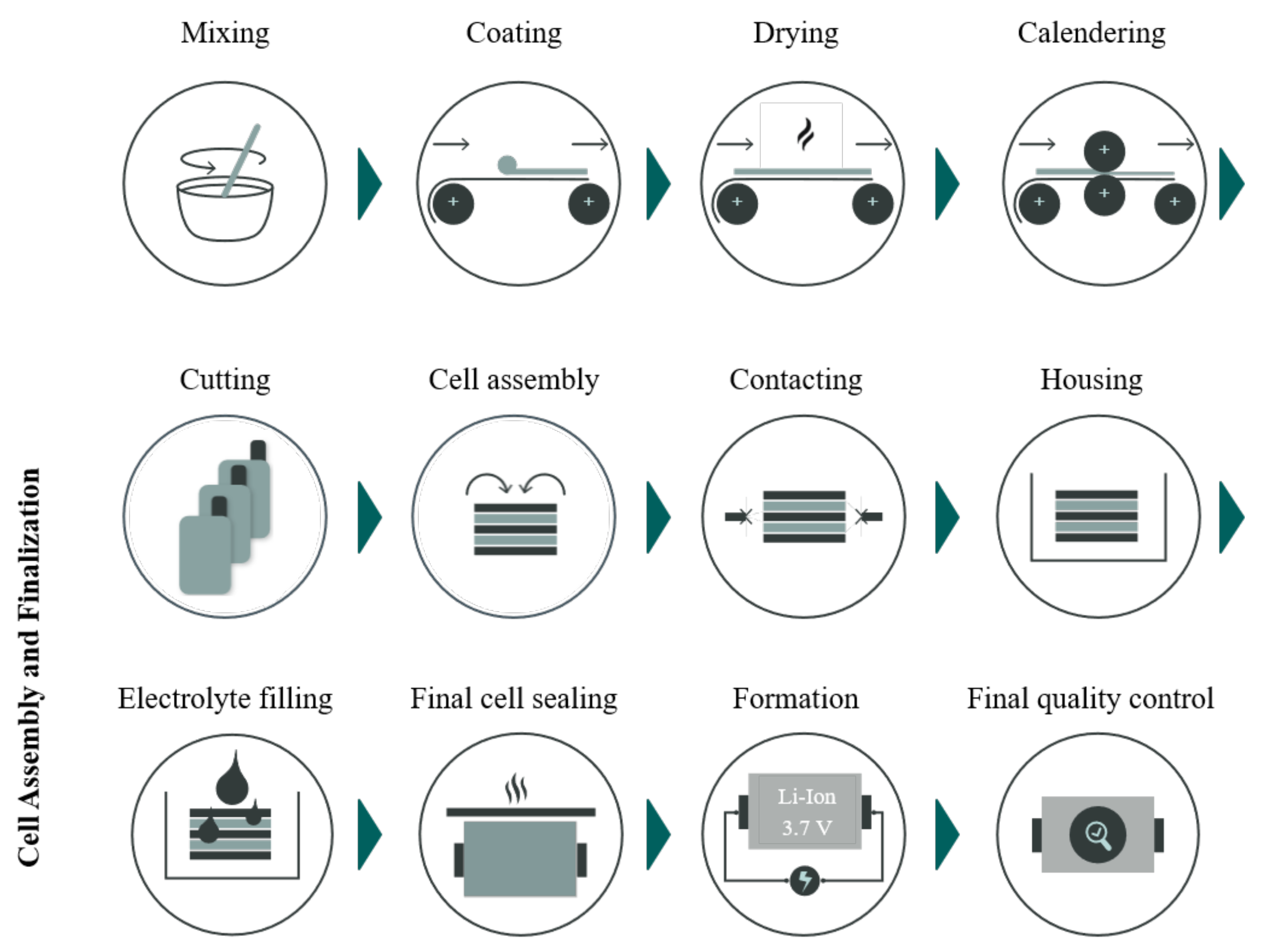
4. XML in LiB Electrode Manufacturing and Cell Production
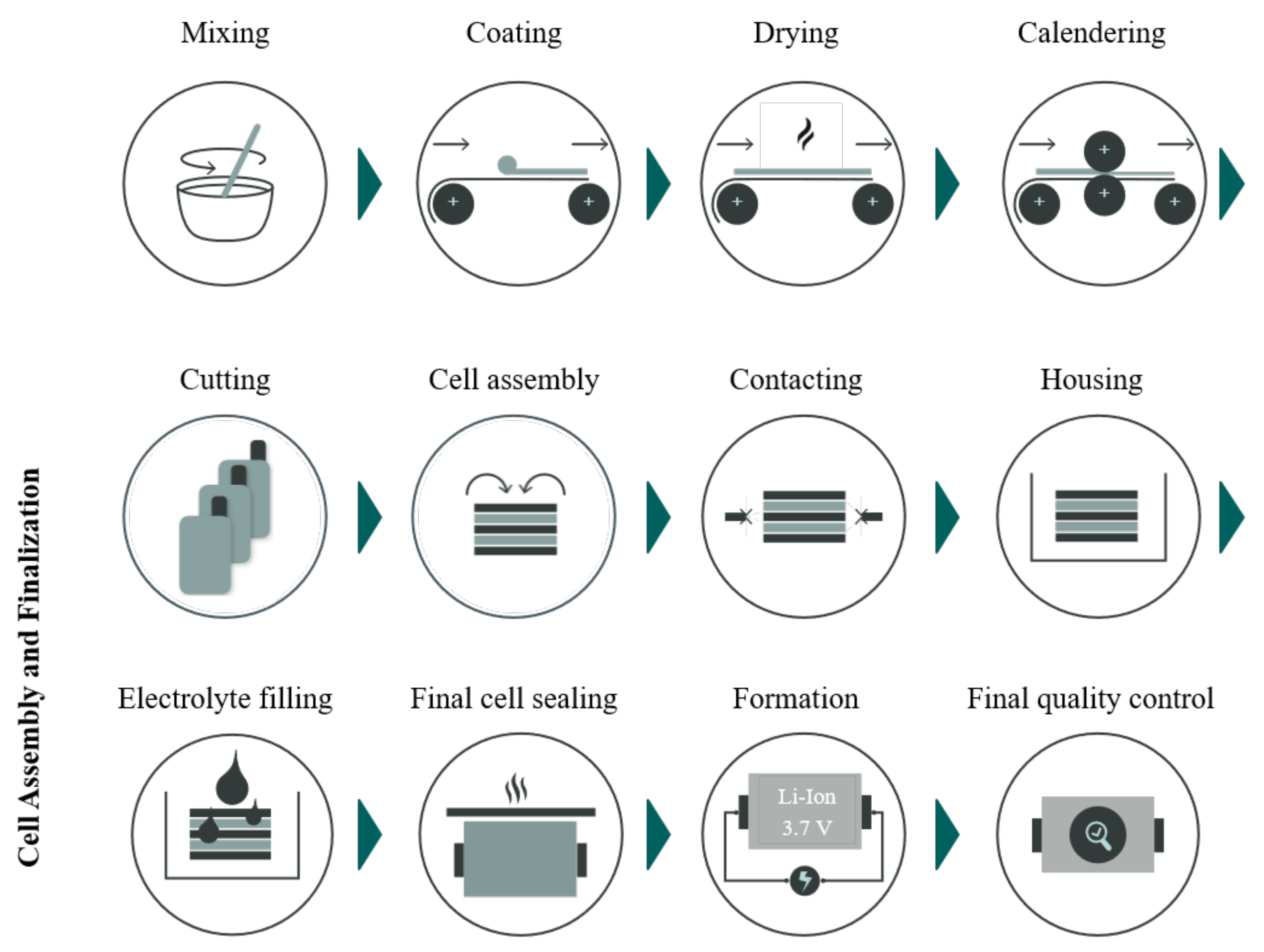
4.1. Formulation and Mixing
4.2. Coating and Calendaring
4.3. Cell Assembly and Finalisation
5. Application of XML in Battery Modelling and State Estimation
5.1. State of Health Estimation
5.2. State of Charge and Energy Estimation
6. Application of XML in Battery Management Systems (BMS)
7. Conclusions
7.1. Remarks and Challenges
- -
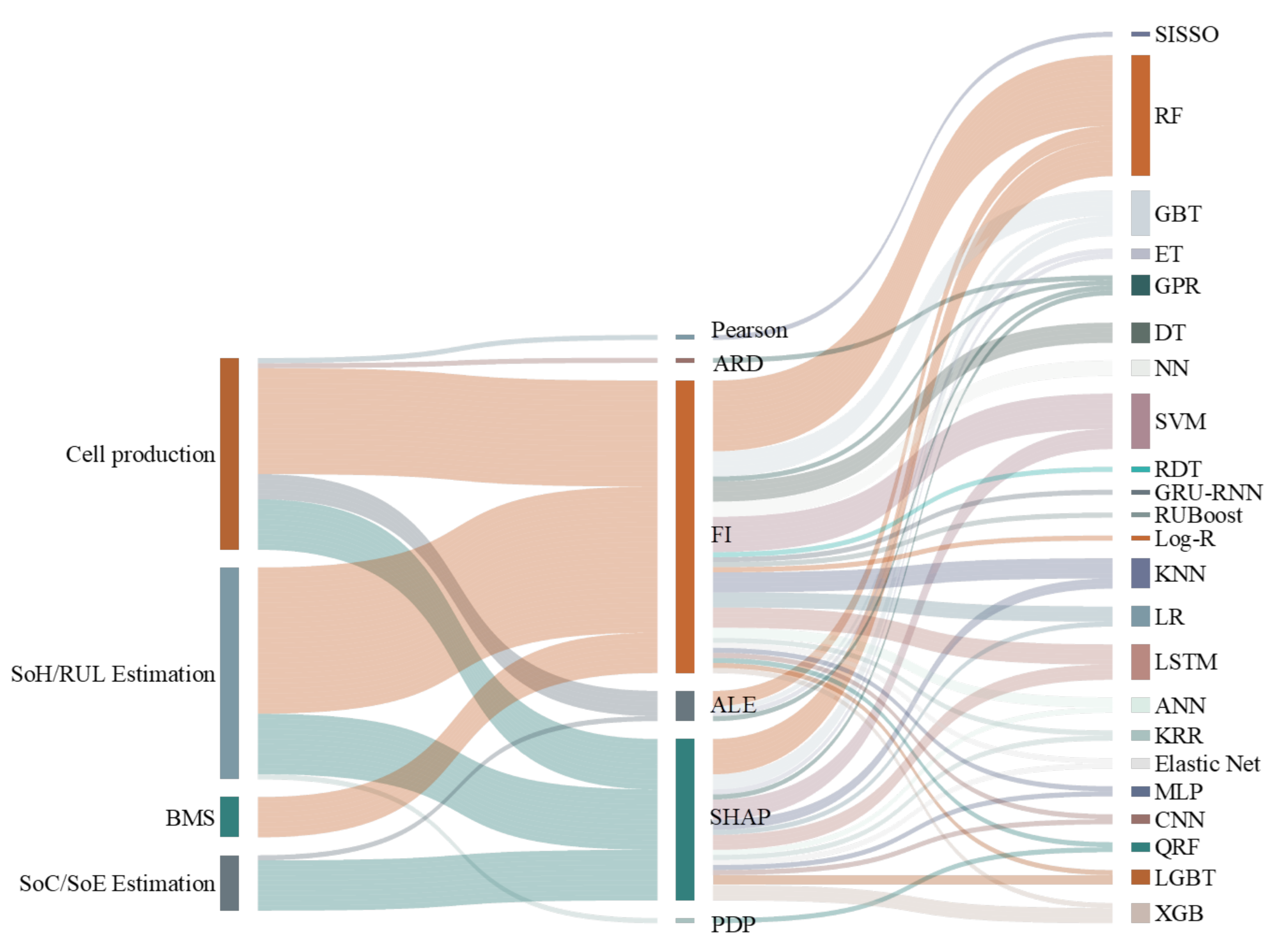
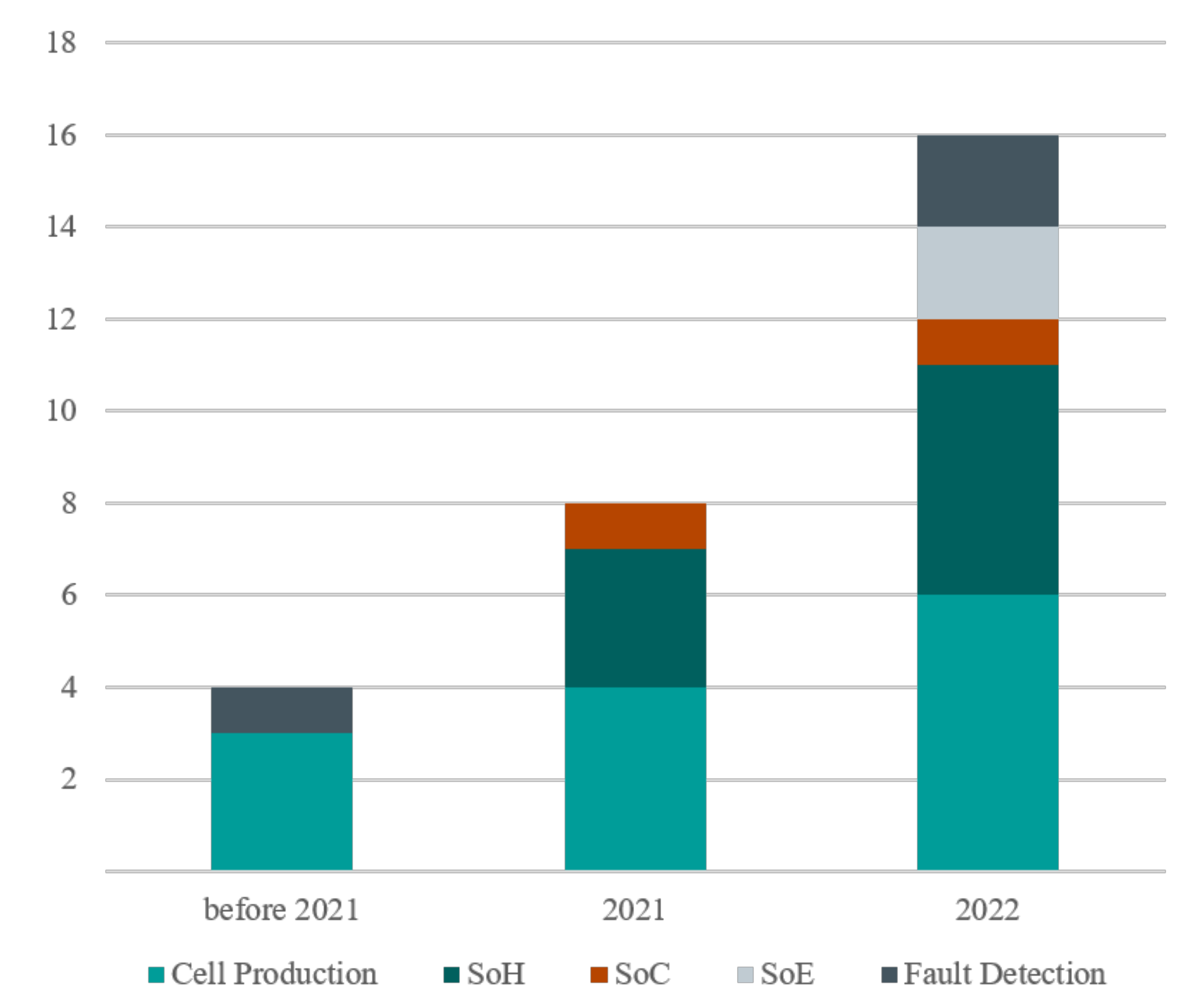
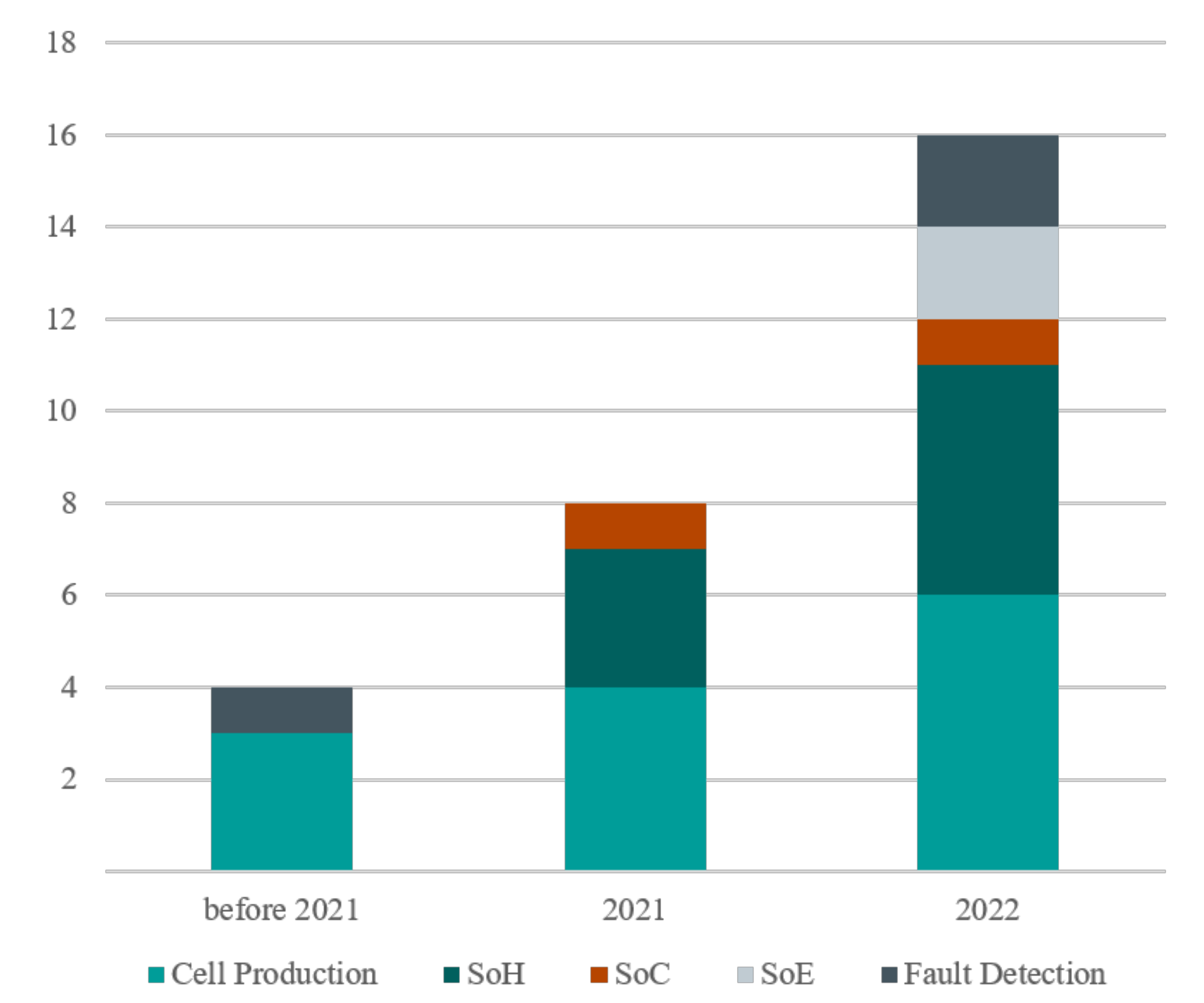
- Compared to the large number of studies in the domain of lithium–ion batteries that take advantage of data-driven approaches and mainly machine learning techniques for modelling, characterisation, fault detection and diagnosis, control, and management of those in manufacturing or applications, the number of the research studies that take it to the next step and focus on the explanation and interpretation is critically low. Dividing the research subjects of battery and electrification applications into three main sections of battery cell production, battery state estimation, and modelling, and battery management systems and control, the largest number of works can be found on battery cell production and battery health estimation or life prediction. This leaves the SoC and SoE estimation and the control algorithms via XML in the last place.
- -
- Focusing on the cell production research and based on the summary given by Table 1, it is evident that not all process steps have received the same level of attention in the literature. At this area, formation and coating processes are most often described by XML techniques (61.5% and 53%, respectively). This is followed by calendering and mixing processes with 30% and 23% of the total papers, respectively. Specifically, the drying process in electrode manufacturing has not been addressed so far in the XML battery research field. Additionally, the utilisation of XML methods throughout the entire process chain, including cell assembly and finalisation, has received limited attention.
- -
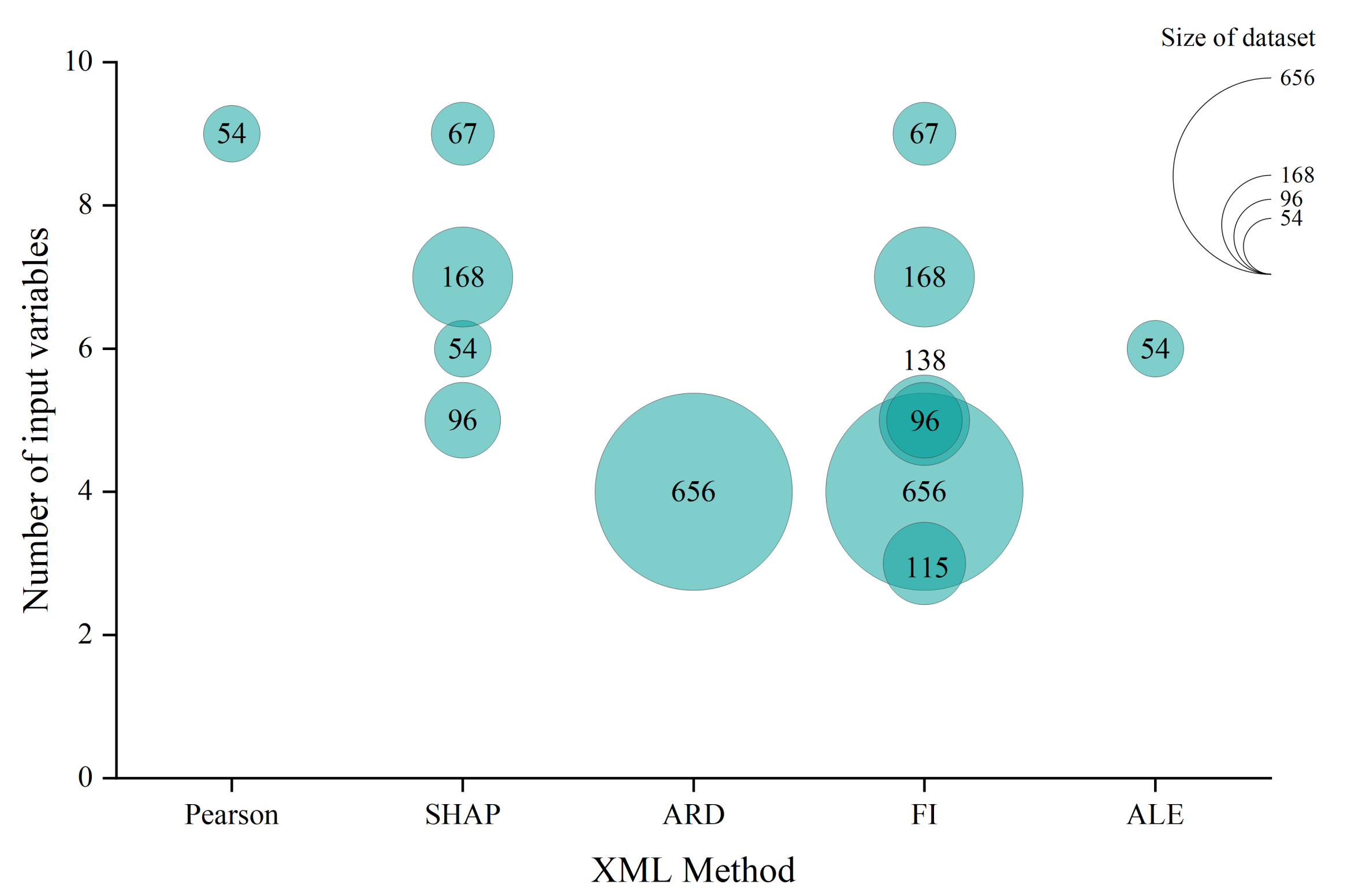
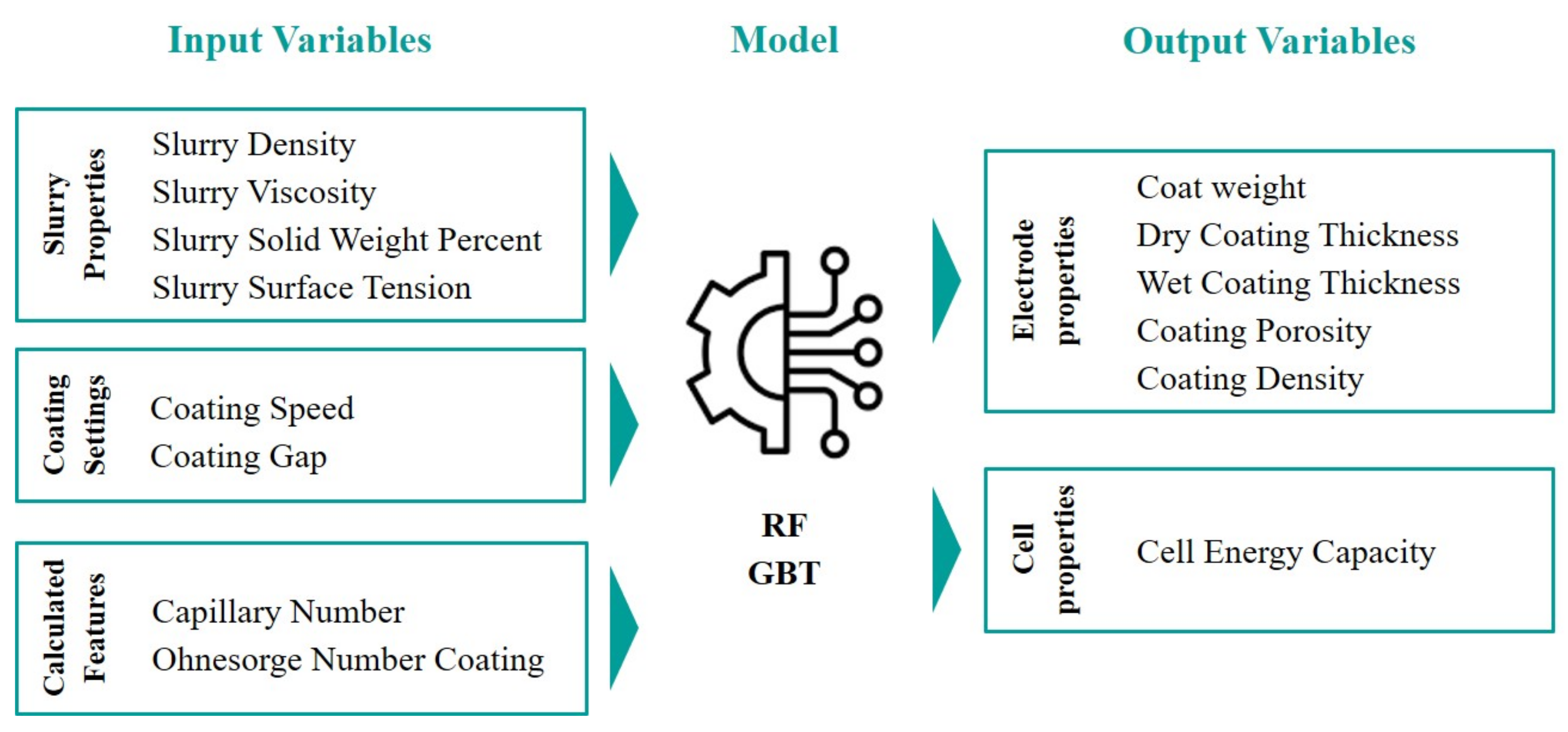
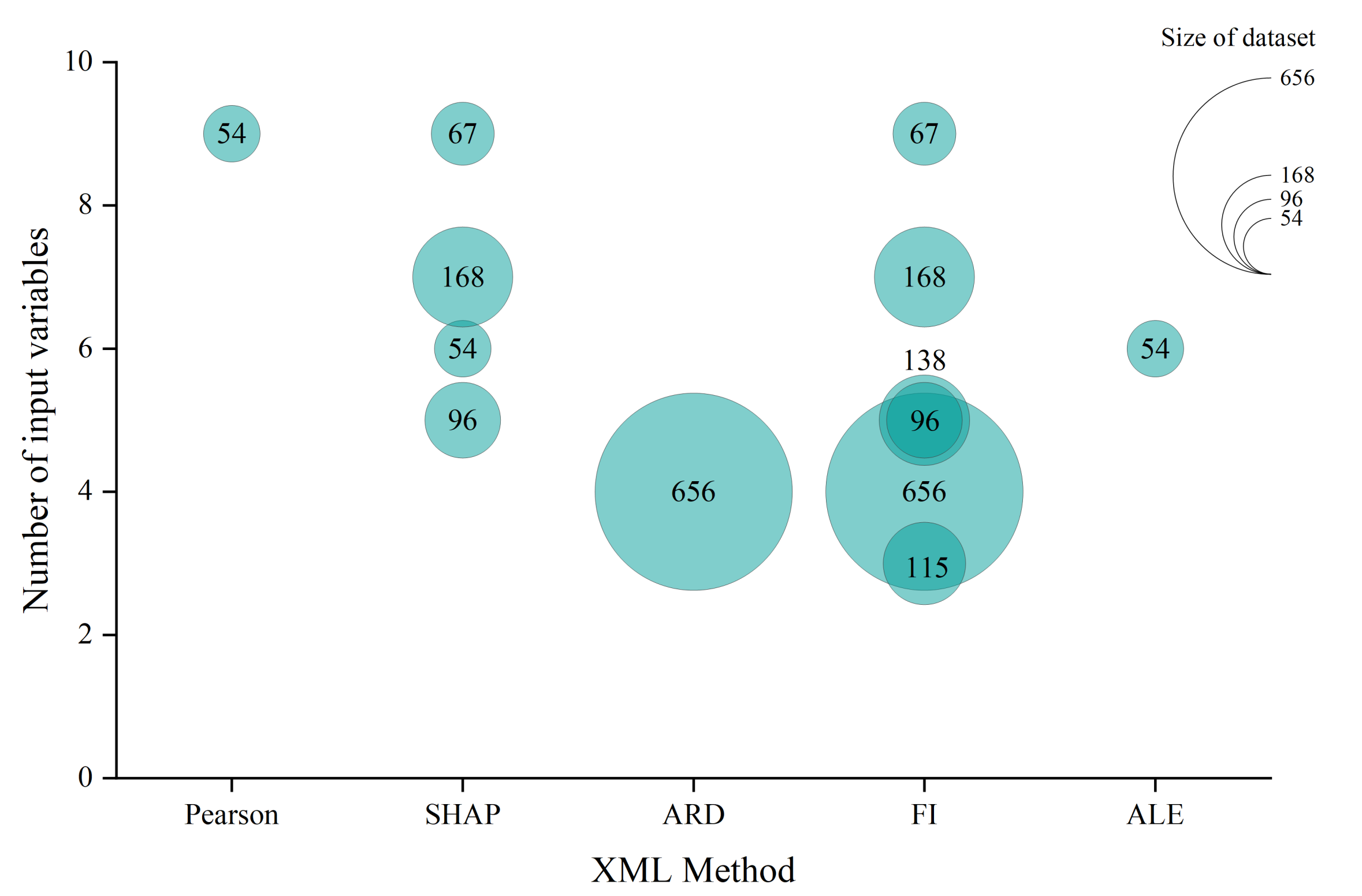
- One of the major advantages of XML techniques is to provide transparency and insights into the model. Given the intricate nature of the battery cell production chain, particularly in electrode manufacturing, where a high number of interrelated parameters are involved [139], this advantage is invaluable in terms of gaining profound process understanding and accelerating decision-making for process optimisation. Figure 8 shows the number of input variables in combination with the size of the dataset for studies in electrode manufacturing using XML methods. The majority of the studies are based on four to five input variables. However, the range varies from a minimum of three to a maximum of nine input variables. As the number of variables rises, the use of XML methods becomes increasingly valuable for overarching process optimisations. The majority of studies with a high number of variables revolve around variables from formulations. The current literature still lacks a comprehensive exploration of variations in production processes. However, it is essential to acknowledge that conducting a comprehensive analysis of battery cell production can be costly and require significant effort. To tackle this challenge, a combination of optimal DoE [140] and XML methods can be adopted, enabling a comprehensive cross-process analysis and optimisation.
- -
- Among the reviewed articles, and as summarised in Table 3, feature importance is the most common method used for explainability, having 62% of the articles dedicated to it. This leaves a smaller percentage of 30% and 15% to Shapley-based analysis and dependencies such as ALE and PDP. A total of 25% of the works address more than one explainability technique. It is worth mentioning that some of the other explainability techniques are not used at all in this content, for example, local interpretable model-agnostic explanations (LIMEs). This is also the case for the techniques of data importance analysis such as Data Shapely and Counterfactual explainability that were introduced in Section 3. Data Shapley is in particular very important to evaluate the value of the data; it helps to identify the most significant and contribution data points to the decisions/prediction and helps reduce the data size as a large dataset does not necessarily mean a more efficient one.
- -
- Through the review process of this work, it was identified that some studies refer to linera correlation analysis (mainly Pearson method) as a form of explanation for the models. While this is conceptually correct and the strength of the correlations between the variables can be used as a form of feature importance, the novel definition of XML would not categorise this type of analysis as an explanation [28].
- -
- In general, the small ratio of works that tend to address the explainable ML is believed to be due to a number of reasons. First, while the trustworthy AI concepts, and a major technical part of it, e.g., explainability and interpretability, are rather well defined and introduced to other research communities such as health care, social sciences, and finance, it is not yet defined or put into notice in the energy or battery domain. This is a major challenge because one of the main concerns of the users and the ML models in the battery field is still struggling with confidence and trust, and part of this is due to the black-box nature of the ML techniques. Providing information about how the ML framework is making decisions or performing predictions could add to the confidence of the users when attempting using those for new datasets.
7.2. Future Prospects
- All of the existing works on the XML are dedicated to lithium–ion batteries, and there are no studies that focus on the explainability of ML models for what is called “beyond lithium–ion” [141]. This is a serious challenge as the growing demand for the energy capacity and safety of rechargeable cells for electrification of transportation systems and e-mobility have made it clear that other types of cells (e.g., all-solid-state batteries, sodium–ion batteries) need to find their way into the market.
- What is investigated and proposed in the explainable ML for the battery field up to now has mainly been aimed to provide recommendations and analysis regarding the results. This means that XML has not yet been used for optimisation and improvement purposes in any of the mentioned categories of production, state estimation, or control. Taking the explanation results into account in the form of a feedback control scheme is something that is missing in the battery field and needs further investments.
- Explainability and interpretability are only one of the aspects of the trustworthy AI methods, as described in Section 1. This work has made an attempt to address this particular aspect, specifically for LiB research. However, other dimensions of trustworthiness have yet to be explored by the LiB research community. It is essential to investigate, address, and provide clarity on these aspects to enhance the trust and applicability of such models.
- As the summary of the findings in the Table 3 shows, there is a shortage of the research resources dedicated to the explanations of the NNs for modelling and prediction of lithium–ion batteries. Although the NNs has been widely adopted, especially in performance prediction of batteries [142,143], they are not yet equipped with the explainability techniques and this is definitely a clear area for improvement.
- One particular area of modelling and optimisation in the lithium–ion batteries is based on image data of its microstructure. Example studies are [144] for micro-structure reconstruction and [145] for capturing the impact of the cells’ mesostructure on its performance. There is also research that addresses the challenge of image segmentation (to separate/classify the active material particles, the binder, and the pores) before any modelling activities are performed [146,147]. While image-based studies are approached via various techniques of ML or deep learning (DL), the models’ or algorithms’ explainability has not yet been addressed. Such studies are crucial to understanding why a particular section of the images is identified to belong to a specific class or why a particular connection has been identified between the micro-structures’ characteristics and the cells’ performance.
- The previous point mentioned regarding the image data and explainability is also a missing area for the time series data in the battery field. This review has already listed a number of studies that have performed predictions of the state of health based on the cycling data of the cells at various conditions; however, they mainly use feature importance as explainability techniques and none of the particular techniques specific to the time series have been reported there [148]. Techniques based on back-propagation [149] and perturbation [150], which are tailored to the data type, are much more efficient in this case and could reveal interesting relations between factors and responses.
- As machine learning and artificial intelligent techniques are under continuous update and progress to make them adaptable to various datasets, the creation and development of novel explainability methods is critical. The basic requirement of testing such methods is the availability of a benchmark dataset that the methods can be tested against so the investigations show their advantages and weaknesses. Unfortunately, the lithium–ion battery community has not yet presented such benchmark dataset for this purpose. In fact, although there exist various open data resources such as [151,152,153], none of those have the ground truth explanation results reported in them, so there exists no case to compare the performance of the methods against that. Planning and creating such datasets is one future aspect that could be approached by the battery community in the future.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AdaBoost | Adaptive Boosting |
| ALE | Accumulated Local Effect |
| ARD | Automatic Relevance Determination |
| ANN | Artificial Neural Network |
| BASF | Badische Anilin-und Sodafabrik |
| BMSs | Battery Management Systems |
| CNN | Convolutional Neural Network |
| DALE s | Differential Accumulated Local Effects |
| DoE | Design of Experiments |
| DL | Deep Learning |
| DTs | Decision Trees |
| EoL | End of Life |
| EV | Electric Vehicle |
| eVTOL | Electric Vertical Take off and Landing |
| FP | Final Products |
| GBT | Gradient-Boosted Decision Tree |
| GPR | Gaussian Process Regressors |
| GRU | Gated Recurrent Unit |
| IAI | Interpretable artificial intelligent |
| IML | Interpretable Machine Learning |
| IP | Intermediate Products |
| KNNs | K-Nearest Neighbors |
| KRR | Kernel Ridge Regression |
| LASSO | Least Absolute Shrinkage and Selection Operator |
| LiB | Lithium–Ion Batteries |
| LightGBM | Light Gradient Boosted Trees |
| LIME s | Local Interpretable Model-Agnostic Explanations |
| Log-R | Logistic Regression |
| LR | Linear Regression |
| LSTM | Long Short Term Memory |
| MDI | Mean Decrease in Impurity |
| MLP | Multi-Layer Perceptron |
| NNs | Neural Networks |
| P2D | Pseudo-Two-Dimensional |
| PDP | Partial Dependency Plot |
| PMOA | Predictive Measure of Association |
| RF | Random forest |
| RMSE | Root Mean Square Error |
| RNN | Recursive Neural Network |
| RUBoost | Random Undersampling Boosting |
| RUE | Remaining Useful Energy |
| RUL | Remaining Useful Life |
| SHAP | SHapley Additive exPlanation |
| SISSO | Sure Independent Screening and Sparsifying Operator |
| SoC | State of Charge |
| SoH | State of Health |
| SoE | State of Energy |
| SVM | Support Vector Machine |
| SVRs | Support vector Regressors |
| XML | Explainable Machine Learning |
| XAI | Explainable Artificial Intelligence |
References
- Hesse, H.C.; Schimpe, M.; Kucevic, D.; Jossen, A. Lithium-ion battery storage for the grid—A review of stationary battery storage system design tailored for applications in modern power grids. Energies 2017, 10, 2107. [Google Scholar] [CrossRef]
- BASF. 2021. Available online: https://www.basf.com/cn/zh.html (accessed on 27 May 2023).
- Lombardo, T.; Duquesnoy, M.; El-Bouysidy, H.; Årén, F.; Gallo-Bueno, A.; Jørgensen, P.B.; Bhowmik, A.; Demortière, A.; Ayerbe, E.; Alcaide, F.; et al. Artificial intelligence applied to battery research: Hype or reality? Chem. Rev. 2021, 122, 10899–10969. [Google Scholar] [CrossRef]
- Li, Y.; Liu, K.; Foley, A.M.; Zülke, A.; Berecibar, M.; Nanini-Maury, E.; Van Mierlo, J.; Hoster, H.E. Data-driven health estimation and lifetime prediction of lithium-ion batteries: A review. Renew. Sustain. Energy Rev. 2019, 113, 109254. [Google Scholar] [CrossRef]
- European Union. Ethics Guidelines for Trustworthy AI. 2019. Available online: https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai (accessed on 10 July 2023).
- Li, B.; Qi, P.; Liu, B.; Di, S.; Liu, J.; Pei, J.; Yi, J.; Zhou, B. Trustworthy AI: From principles to practices. ACM Comput. Surv. 2023, 55, 1–46. [Google Scholar] [CrossRef]
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy artificial intelligence: A review. ACM Comput. Surv. (CSUR) 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on explainable artificial intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Haghi, S.; Hidalgo, M.F.V.; Niri, M.F.; Daub, R.; Marco, J. Machine Learning in Lithium-Ion Battery Cell Production: A Comprehensive Mapping Study. Batter. Supercaps 2023, 6, e202300046. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. AI a modern approach. Learning 2005, 2, 4. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Alloghani, M.; Al-Jumeily, D.; Mustafina, J.; Hussain, A.; Aljaaf, A. Supervised and Unsupervised Learning for Data Science; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Kwade, A.; Haselrieder, W.; Leithoff, R.; Modlinger, A.; Dietrich, F.; Droeder, K. Current status and challenges for automotive battery production technologies. Nat. Energy 2018, 3, 290–300. [Google Scholar] [CrossRef]
- Grant, P.S.; Greenwood, D.; Pardikar, K.; Smith, R.; Entwistle, T.; Middlemiss, L.A.; Murray, G.; Cussen, S.A.; Lain, M.J.; Capener, M.; et al. Roadmap on Li-ion battery manufacturing research. J. Physics Energy 2022, 4, 042006. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. (CSUR) 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Huang, X.; Jin, G.; Ruan, W. Machine Learning Safety; Springer Nature: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Hawkins, R.; Paterson, C.; Picardi, C.; Jia, Y.; Calinescu, R.; Habli, I. Assurance of Machine Learning for use in Autonomous Systems (AMLAS). Available online: https://www.york.ac.uk/assuring-autonomy/guidance/amlas (accessed on 30 April 2023).
- Hawkins, R.; Osborne, M.; Parsons, M.; Nicholson, M.; McDermid, J.; Habli, I. Guidance on the Safety Assurance of Autonomous Systems in Complex Environments (SACE). arXiv 2022, arXiv:2208.00853. [Google Scholar]
- Doshi-Velez, F.; Kim, B. Towards a rigorous science of interpretable machine learning. arXiv 2017, arXiv:1702.08608. [Google Scholar]
- Lipton, Z.C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Belle, V.; Papantonis, I. Principles and practice of explainable machine learning. Front. Big Data 2021, 4, 39. [Google Scholar] [CrossRef]
- EUregulatin. 2023. Available online: https://commission.europa.eu/strategy-and-policy/priorities-2019-2024_en (accessed on 27 May 2023).
- Young, S.R.; Rose, D.C.; Karnowski, T.P.; Lim, S.H.; Patton, R.M. Optimizing deep learning hyper-parameters through an evolutionary algorithm. In Proceedings of the Workshop on Machine Learning in High-Performance Computing Environments, St. Louis, MO, USA, 15 November 2015; pp. 1–5. [Google Scholar]
- Rossi, F. Building trust in artificial intelligence. J. Int. Aff. 2018, 72, 127–134. [Google Scholar]
- Spinner, T.; Schlegel, U.; Schäfer, H.; El-Assady, M. explAIner: A visual analytics framework for interactive and explainable machine learning. IEEE Trans. Vis. Comput. Graph. 2019, 26, 1064–1074. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Molnar, C. Interpretable Machine Learning. Available online: https://www.lulu.com/ (accessed on 30 June 2023).
- Apley, D.W.; Zhu, J. Visualizing the effects of predictor variables in black box supervised learning models. J. R. Stat. Soc. Ser. B Stat. Methodol. 2020, 82, 1059–1086. [Google Scholar] [CrossRef]
- Gkolemis, V.; Dalamagas, T.; Diou, C. DALE: Differential Accumulated Local Effects for efficient and accurate global explanations. In Proceedings of the Asian Conference on Machine Learning, PMLR, Bangkok, Thailand, 18–20 November 2023; pp. 375–390. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Auret, L.; Aldrich, C. Empirical comparison of tree ensemble variable importance measures. Chemom. Intell. Lab. Syst. 2011, 105, 157–170. [Google Scholar] [CrossRef]
- Díaz-Uriarte, R.; Alvarez de Andrés, S. Gene selection and classification of microarray data using random forest. BMC Bioinform. 2006, 7, 3. [Google Scholar] [CrossRef]
- Ishwaran, H. Variable importance in binary regression trees and forests. Electron. J. Statist. 2007, 1, 519–537. [Google Scholar] [CrossRef]
- Rodenburg, W.; Heidema, A.G.; Boer, J.M.; Bovee-Oudenhoven, I.M.; Feskens, E.J.; Mariman, E.C.; Keijer, J. A framework to identify physiological responses in microarray-based gene expression studies: Selection and interpretation of biologically relevant genes. Physiol. Genom. 2008, 33, 78–90. [Google Scholar] [CrossRef]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef]
- Nembrini, S.; König, I.R.; Wright, M.N. The revival of the Gini importance? Bioinformatics 2018, 34, 3711–3718. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Kukreja, S.L.; Löfberg, J.; Brenner, M.J. A least absolute shrinkage and selection operator (LASSO) for nonlinear system identification. IFAC Proc. Vol. 2006, 39, 814–819. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Erion, G.G.; Lee, S.I. Consistent individualized feature attribution for tree ensembles. arXiv 2018, arXiv:1802.03888. [Google Scholar]
- Saabas, A. Interpreting random forests. Diving Data 2014, 24. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer: New York, NY, USA, 2001. [Google Scholar]
- Chebrolu, S.; Abraham, A.; Thomas, J.P. Feature deduction and ensemble design of intrusion detection systems. Comput. Secur. 2005, 24, 295–307. [Google Scholar] [CrossRef]
- Huynh-Thu, V.A.; Irrthum, A.; Wehenkel, L.; Geurts, P. Inferring regulatory networks from expression data using tree-based methods. PLoS ONE 2010, 5, e12776. [Google Scholar] [CrossRef] [PubMed]
- Sandri, M.; Zuccolotto, P. A bias correction algorithm for the Gini variable importance measure in classification trees. J. Comput. Graph. Stat. 2008, 17, 611–628. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Lundberg, S.M.; Erion, G.; Chen, H.; DeGrave, A.; Prutkin, J.M.; Nair, B.; Katz, R.; Himmelfarb, J.; Bansal, N.; Lee, S.I. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2020, 2, 2522–5839. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Nair, B.; Vavilala, M.S.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.W.; Newman, S.F.; Kim, J.; et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2018, 2, 749. [Google Scholar] [CrossRef] [PubMed]
- Cohen, I.; Huang, Y.; Chen, J.; Benesty, J.; Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Pearson correlation coefficient. Noise Reduct. Speech Process. 2009, 2, 1–4. [Google Scholar]
- Faraji Niri, M.; Apachitei, G.; Lain, M.; Copley, M.; Marco, J. The Impact of Calendering Process Variables on the Impedance and Capacity Fade of Lithium-Ion Cells: An Explainable Machine Learning Approach. Energy Technol. 2022, 10, 2200893. [Google Scholar] [CrossRef]
- Ghorbani, A.; Zou, J. Data shapley: Equitable valuation of data for machine learning. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 2242–2251. [Google Scholar]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. JL Tech. 2017, 31, 841. [Google Scholar] [CrossRef]
- Karimi, A.H.; Schölkopf, B.; Valera, I. Algorithmic recourse: From counterfactual explanations to interventions. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Toronto, ON, Canada, 3–10 March 2021; pp. 353–362. [Google Scholar]
- Verma, S.; Boonsanong, V.; Hoang, M.; Hines, K.E.; Dickerson, J.P.; Shah, C. Counterfactual explanations and algorithmic recourses for machine learning: A review. arXiv 2020, arXiv:2010.10596. [Google Scholar]
- Stepin, I.; Alonso, J.M.; Catala, A.; Pereira-Fariña, M. A survey of contrastive and counterfactual explanation generation methods for explainable artificial intelligence. IEEE Access 2021, 9, 11974–12001. [Google Scholar] [CrossRef]
- Sokol, K.; Flach, P.A. Counterfactual Explanations of Machine Learning Predictions: Opportunities and Challenges for AI Safety. SafeAI@ AAAI 2019, 2301, 1–4. [Google Scholar]
- Baron, S. Explainable AI and Causal Understanding: Counterfactual Approaches Considered. Minds Mach. 2023, 33, 347–377. [Google Scholar] [CrossRef]
- De Toni, G.; Lepri, B.; Passerini, A. Synthesizing explainable counterfactual policies for algorithmic recourse with program synthesis. Mach. Learn. 2023, 112, 1389–1409. [Google Scholar] [CrossRef]
- Brughmans, D.; Melis, L.; Martens, D. Disagreement amongst counterfactual explanations: How transparency can be deceptive. arXiv 2023, arXiv:2304.12667. [Google Scholar]
- Bhatt, U.; Xiang, A.; Sharma, S.; Weller, A.; Taly, A.; Jia, Y.; Ghosh, J.; Puri, R.; Moura, J.M.; Eckersley, P. Explainable machine learning in deployment. In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 June 2020; pp. 648–657. [Google Scholar]
- Ghorbani, A.; Abid, A.; Zou, J. Interpretation of neural networks is fragile. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3681–3688. [Google Scholar]
- Slack, D.; Hilgard, S.; Jia, E.; Singh, S.; Lakkaraju, H. Fooling lime and shap: Adversarial attacks on post hoc explanation methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 8–10 August 2020; pp. 180–186. [Google Scholar]
- Li, J.; Fleetwood, J.; Hawley, W.B.; Kays, W. From materials to cell: State-of-the-art and prospective technologies for lithium-ion battery electrode processing. Chem. Rev. 2021, 122, 903–956. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, R.; Wang, J.; Wang, Y. Current and future lithium-ion battery manufacturing. IScience 2021, 24, 102332. [Google Scholar] [CrossRef]
- Wang, G.; Fearn, T.; Wang, T.; Choy, K.L. Machine-Learning Approach for Predicting the Discharging Capacities of Doped Lithium Nickel–Cobalt–Manganese Cathode Materials in Li-Ion Batteries. ACS Cent. Sci. 2021, 7, 1551–1560. [Google Scholar] [CrossRef]
- Liu, K.; Hu, X.; Meng, J.; Guerrero, J.M.; Teodorescu, R. RUBoost-based ensemble machine learning for electrode quality classification in Li-ion battery manufacturing. IEEE/ASME Trans. Mechatronics 2021, 27, 2474–2483. [Google Scholar] [CrossRef]
- Rynne, O.; Dubarry, M.; Molson, C.; Nicolas, E.; Lepage, D.; Prebe, A.; Ayme-Perrot, D.; Rochefort, D.; Dolle, M. Exploiting materials to their full potential, a Li-ion battery electrode formulation optimization study. ACS Appl. Energy Mater. 2020, 3, 2935–2948. [Google Scholar] [CrossRef]
- Niri, M.F.; Apachitei, G.; Lain, M.; Copley, M.; Marco, J. Machine learning for investigating the relative importance of electrodes’ N: P areal capacity ratio in the manufacturing of lithium-ion battery cells. J. Power Sources 2022, 549, 232124. [Google Scholar] [CrossRef]
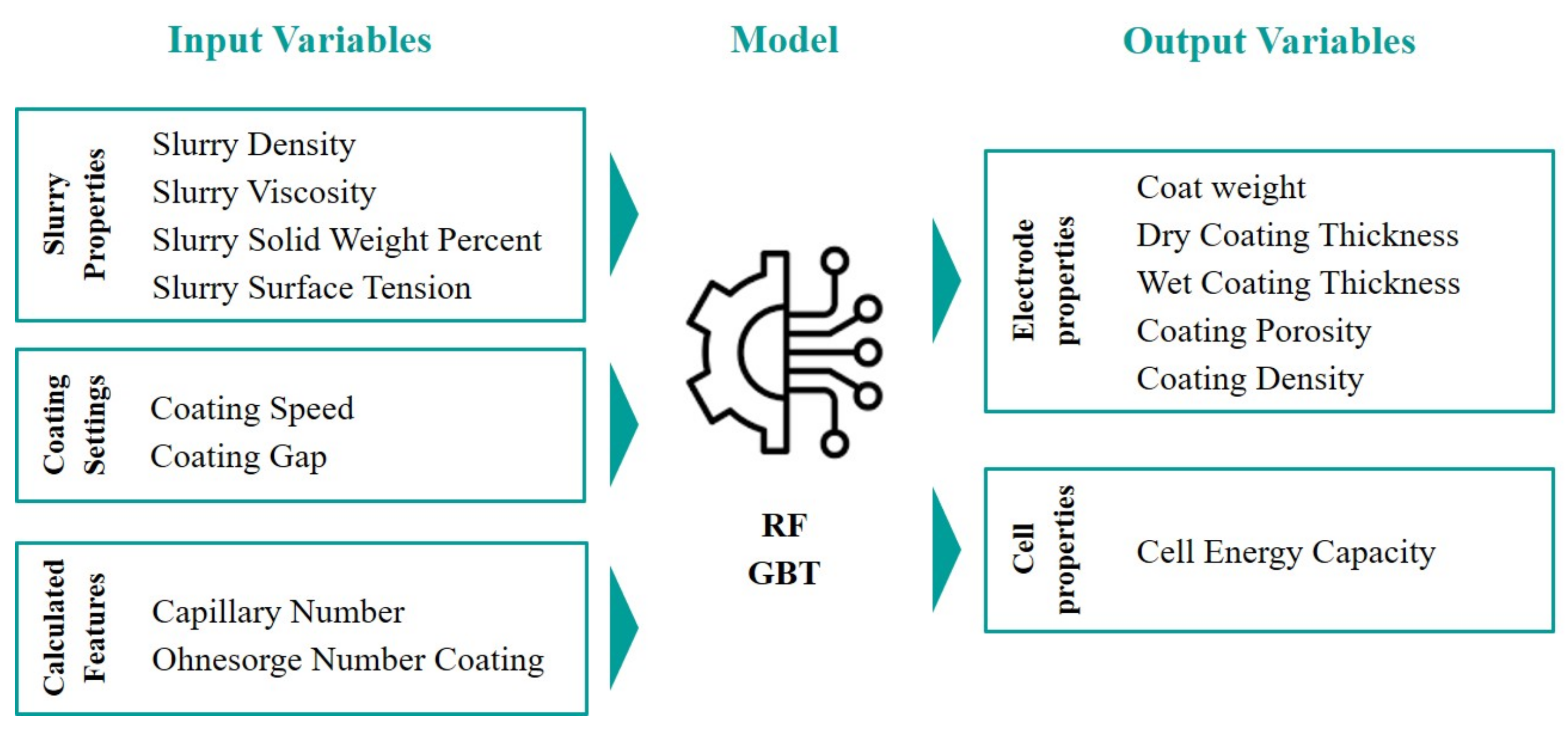
- Niri, M.F.; Reynolds, C.; Ramírez, L.A.R.; Kendrick, E.; Marco, J. Systematic analysis of the impact of slurry coating on manufacture of Li-ion battery electrodes via explainable machine learning. Energy Storage Mater. 2022, 51, 223–238. [Google Scholar] [CrossRef]
- Sandri, M.; Zuccolotto, P. Analysis and correction of bias in total decrease in node impurity measures for tree-based algorithms. Stat. Comput. 2010, 20, 393–407. [Google Scholar] [CrossRef]
- Xu, Z.; Huang, G.; Weinberger, K.Q.; Zheng, A.X. Gradient boosted feature selection. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 522–531. [Google Scholar]
- Cunha, R.P.; Lombardo, T.; Primo, E.N.; Franco, A.A. Artificial intelligence investigation of NMC cathode manufacturing parameters interdependencies. Batter. Supercaps 2020, 3, 60–67. [Google Scholar] [CrossRef]
- Liu, K.; Hu, X.; Zhou, H.; Tong, L.; Widanage, W.D.; Marco, J. Feature analyses and modeling of lithium-ion battery manufacturing based on random forest classification. IEEE/ASME Trans. Mechatronics 2021, 26, 2944–2955. [Google Scholar] [CrossRef]
- Liu, K.; Wei, Z.; Yang, Z.; Li, K. Mass load prediction for lithium-ion battery electrode clean production: A machine learning approach. J. Clean. Prod. 2021, 289, 125159. [Google Scholar] [CrossRef]
- Liu, K.; Peng, Q.; Li, K.; Chen, T. Data-based interpretable modeling for property forecasting and sensitivity analysis of Li-ion battery electrode. Automot. Innov. 2022, 5, 121–133. [Google Scholar] [CrossRef]
- Niri, M.F.; Liu, K.; Apachitei, G.; Román-Ramírez, L.A.; Lain, M.; Widanage, D.; Marco, J. Quantifying key factors for optimised manufacturing of Li-ion battery anode and cathode via artificial intelligence. Energy AI 2022, 7, 100129. [Google Scholar] [CrossRef]
- Liu, K.; Niri, M.F.; Apachitei, G.; Lain, M.; Greenwood, D.; Marco, J. Interpretable machine learning for battery capacities prediction and coating parameters analysis. Control Eng. Pract. 2022, 124, 105202. [Google Scholar] [CrossRef]
- Faraji Niri, M.; Liu, K.; Apachitei, G.; Roman Ramirez, L.; Widanage, W.D.; Marco, J. Data mining for quality prediction of battery in manufacturing process: Cathode coating process. In Proceedings of the 12th International Conference on Applied Energy, Bangkok, Thiland, 29 November–2 December 2020; Volume 11. [Google Scholar]
- Niri, M.F.; Liu, K.; Apachitei, G.; Ramirez, L.R.; Lain, M.; Widanage, D.; Marco, J. Machine learning for optimised and clean Li-ion battery manufacturing: Revealing the dependency between electrode and cell characteristics. J. Clean. Prod. 2021, 324, 129272. [Google Scholar] [CrossRef]
- Duquesnoy, M.; Lombardo, T.; Chouchane, M.; Primo, E.N.; Franco, A.A. Data-driven assessment of electrode calendering process by combining experimental results, in silico mesostructures generation and machine learning. J. Power Sources 2020, 480, 229103. [Google Scholar] [CrossRef]
- Turetskyy, A.; Thiede, S.; Thomitzek, M.; von Drachenfels, N.; Pape, T.; Herrmann, C. Toward data-driven applications in lithium-ion battery cell manufacturing. Energy Technol. 2020, 8, 1900136. [Google Scholar] [CrossRef]
- Turetskyy, A.; Wessel, J.; Herrmann, C.; Thiede, S. Data-driven cyber-physical system for quality gates in lithium-ion battery cell manufacturing. Procedia CIRP 2020, 93, 168–173. [Google Scholar] [CrossRef]
- Chang, W.Y. The state of charge estimating methods for battery: A review. Int. Sch. Res. Not. 2013, 2013, 1–7. [Google Scholar] [CrossRef]
- Shrivastava, P.; Soon, T.K.; Idris, M.Y.I.B.; Mekhilef, S. Overview of model-based online state-of-charge estimation using Kalman filter family for lithium-ion batteries. Renew. Sustain. Energy Rev. 2019, 113, 109233. [Google Scholar] [CrossRef]
- Shu, X.; Shen, S.; Shen, J.; Zhang, Y.; Li, G.; Chen, Z.; Liu, Y. State of health prediction of lithium-ion batteries based on machine learning: Advances and perspectives. Iscience 2021, 24, 103265. [Google Scholar] [CrossRef] [PubMed]
- Zenati, A.; Desprez, P.; Razik, H.; Rael, S. A methodology to assess the State of Health of lithium-ion batteries based on the battery’s parameters and a Fuzzy Logic System. In Proceedings of the 2012 IEEE International Electric Vehicle Conference, Greenville, SC, USA, 4–8 March 2012; pp. 1–6. [Google Scholar]
- Dubarry, M.; Qin, N.; Brooker, P. Calendar aging of commercial Li-ion cells of different chemistries—A review. Curr. Opin. Electrochem. 2018, 9, 106–113. [Google Scholar] [CrossRef]
- Vetter, J.; Novák, P.; Wagner, M.R.; Veit, C.; Möller, K.C.; Besenhard, J.; Winter, M.; Wohlfahrt-Mehrens, M.; Vogler, C.; Hammouche, A. Ageing mechanisms in lithium-ion batteries. J. Power Sources 2005, 147, 269–281. [Google Scholar] [CrossRef]
- Heiskanen, S.K.; Kim, J.; Lucht, B.L. Generation and evolution of the solid electrolyte interphase of lithium-ion batteries. Joule 2019, 3, 2322–2333. [Google Scholar] [CrossRef]
- Lin, N.; Jia, Z.; Wang, Z.; Zhao, H.; Ai, G.; Song, X.; Bai, Y.; Battaglia, V.; Sun, C.; Qiao, J.; et al. Understanding the crack formation of graphite particles in cycled commercial lithium-ion batteries by focused ion beam-scanning electron microscopy. J. Power Sources 2017, 365, 235–239. [Google Scholar] [CrossRef]
- Faraji-Niri, M.; Rashid, M.; Sansom, J.; Sheikh, M.; Widanage, D.; Marco, J. Accelerated state of health estimation of second life lithium-ion batteries via electrochemical impedance spectroscopy tests and machine learning techniques. J. Energy Storage 2023, 58, 106295. [Google Scholar] [CrossRef]
- Haifeng, D.; Xuezhe, W.; Zechang, S. A new SOH prediction concept for the power lithium-ion battery used on HEVs. In Proceedings of the 2009 IEEE Vehicle Power and Propulsion Conference, Dearborn, MI, USA, 7–11 September 2009; pp. 1649–1653. [Google Scholar]
- Zhu, J.; Mathews, I.; Ren, D.; Li, W.; Cogswell, D.; Xing, B.; Sedlatschek, T.; Kantareddy, S.N.R.; Yi, M.; Gao, T.; et al. End-of-life or second-life options for retired electric vehicle batteries. Cell Rep. Phys. Sci. 2021, 2, 100537. [Google Scholar] [CrossRef]
- Lee, G.; Kim, J.; Lee, C. State-of-health estimation of Li-ion batteries in the early phases of qualification tests: An interpretable machine learning approach. Expert Syst. Appl. 2022, 197, 116817. [Google Scholar] [CrossRef]
- Mawonou, K.S.; Eddahech, A.; Dumur, D.; Beauvois, D.; Godoy, E. State-of-health estimators coupled to a random forest approach for lithium-ion battery aging factor ranking. J. Power Sources 2021, 484, 229154. [Google Scholar] [CrossRef]
- Jiang, F.; He, Y.; Gao, D.; Zhou, Y.; Liu, W.; Yan, L.; Peng, J. An Accurate and Interpretable Lifetime Prediction Method for Batteries using Extreme Gradient Boosting Tree and TreeExplainer. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing & Communications; 7th Int Conf on Data Science & Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud & Big Data Systems & Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; pp. 1042–1048. [Google Scholar]
- Li, G.; Li, B.; Li, C.; Wang, S. State-of-health rapid estimation for lithium-ion battery based on an interpretable stacking ensemble model with short-term voltage profiles. Energy 2023, 263, 126064. [Google Scholar] [CrossRef]
- Granado, L.; Ben-Marzouk, M.; Saenz, E.S.; Boukal, Y.; Jugé, S. Machine learning predictions of lithium-ion battery state-of-health for eVTOL applications. J. Power Sources 2022, 548, 232051. [Google Scholar] [CrossRef]
- Zhang, H.; Su, Y.; Altaf, F.; Wik, T.; Gros, S. Interpretable Battery Cycle Life Range Prediction Using Early Cell Degradation Data. IEEE Trans. Transp. Electrif. 2022, 9, 2669–2682. [Google Scholar] [CrossRef]
- He, J.; Tian, Y.; Wu, L. A hybrid data-driven method for rapid prediction of lithium-ion battery capacity. Reliab. Eng. Syst. Saf. 2022, 226, 108674. [Google Scholar] [CrossRef]
- Ibraheem, R.; Strange, C.; dos Reis, G. Capacity and Internal Resistance of lithium-ion batteries: Full degradation curve prediction from Voltage response at constant Current at discharge. J. Power Sources 2023, 556, 232477. [Google Scholar] [CrossRef]
- Rouhi Ardeshiri, R.; Ma, C. Multivariate gated recurrent unit for battery remaining useful life prediction: A deep learning approach. Int. J. Energy Res. 2021, 45, 16633–16648. [Google Scholar] [CrossRef]
- Kim, S.W.; Oh, K.Y.; Lee, S. Novel informed deep learning-based prognostics framework for on-board health monitoring of lithium-ion batteries. Appl. Energy 2022, 315, 119011. [Google Scholar] [CrossRef]
- Wang, F.; Zhao, Z.; Zhai, Z.; Shang, Z.; Yan, R.; Chen, X. Explainability-driven model improvement for SOH estimation of lithium-ion battery. Reliab. Eng. Syst. Saf. 2023, 232, 109046. [Google Scholar] [CrossRef]
- Rieger, L.H.; Flores, E.; Nielsen, K.F.; Norby, P.; Ayerbe, E.; Winther, O.; Vegge, T.; Bhowmik, A. Uncertainty-aware and explainable machine learning for early prediction of battery degradation trajectory. Digit. Discov. 2023, 2, 112–122. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Refaeilzadeh, P.; Tang, L.; Liu, H. Cross-validation. Encycl. Database Syst. 2009, 5, 532–538. [Google Scholar]
- Melis, G.; Kočiskỳ, T.; Blunsom, P. Mogrifier lstm. arXiv 2019, arXiv:1909.01792. [Google Scholar]
- Saha, B.; Goebel, K. Battery Data Set. NASA AMES Prognostics Data Repository. 2007. Available online: https://www.nasa.gov/content/prognostics-center-of-excellence-data-set-repository (accessed on 10 January 2023).
- Bole, B.; Kulkarni, C.S.; Daigle, M. Adaptation of an electrochemistry-based li-ion battery model to account for deterioration observed under randomized use. In Proceedings of the Annual Conference of the PHM Society, Xi’an, China, 15–17 August 2014; Volume 6. [Google Scholar]
- Attia, P.M.; Grover, A.; Jin, N.; Severson, K.A.; Markov, T.M.; Liao, Y.H.; Chen, M.H.; Cheong, B.; Perkins, N.; Yang, Z.; et al. Closed-loop optimization of fast-charging protocols for batteries with machine learning. Nature 2020, 578, 397–402. [Google Scholar] [CrossRef]
- Lu, J.; Xiong, R.; Tian, J.; Wang, C.; Hsu, C.W.; Tsou, N.T.; Sun, F.; Li, J. Battery degradation prediction against uncertain future conditions with recurrent neural network enabled deep learning. Energy Storage Mater. 2022, 50, 139–151. [Google Scholar] [CrossRef]
- He, W.; Williard, N.; Osterman, M.; Pecht, M. Prognostics of lithium-ion batteries based on Dempster–Shafer theory and the Bayesian Monte Carlo method. J. Power Sources 2011, 196, 10314–10321. [Google Scholar] [CrossRef]
- eVTOL. 2021. Available online: https://electrek.co/guides/evtol/ (accessed on 30 June 2023).
- Severson, K.A.; Attia, P.M.; Jin, N.; Perkins, N.; Jiang, B.; Yang, Z.; Chen, M.H.; Aykol, M.; Herring, P.K.; Fraggedakis, D.; et al. Data-driven prediction of battery cycle life before capacity degradation. Nat. Energy 2019, 4, 383–391. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G., Jr. Regression quantiles. Econom. J. Econom. Soc. 1978, 33–50. [Google Scholar] [CrossRef]
- Xiong, R.; Cao, J.; Yu, Q.; He, H.; Sun, F. Critical review on the battery state of charge estimation methods for electric vehicles. IEEE Access 2017, 6, 1832–1843. [Google Scholar] [CrossRef]
- Marelli, S.; Corno, M. Model-based estimation of lithium concentrations and temperature in batteries using soft-constrained dual unscented Kalman filtering. IEEE Trans. Control. Syst. Technol. 2020, 29, 926–933. [Google Scholar] [CrossRef]
- Tran, N.T.; Vilathgamuwa, M.; Li, Y.; Farrell, T.; Teague, J. State of charge estimation of lithium ion batteries using an extended single particle model and sigma-point Kalman filter. In Proceedings of the 2017 IEEE Southern Power Electronics Conference (SPEC), Puerto Varas, Chile, 4–7 December 2017; pp. 1–6. [Google Scholar]
- Hossain, M.; Haque, M.; Arif, M.T. Kalman filtering techniques for the online model parameters and state of charge estimation of the Li-ion batteries: A comparative analysis. J. Energy Storage 2022, 51, 104174. [Google Scholar] [CrossRef]
- He, W.; Williard, N.; Chen, C.; Pecht, M. State of charge estimation for Li-ion batteries using neural network modeling and unscented Kalman filter-based error cancellation. Int. J. Electr. Power Energy Syst. 2014, 62, 783–791. [Google Scholar] [CrossRef]
- Chandran, V.; Patil, C.K.; Karthick, A.; Ganeshaperumal, D.; Rahim, R.; Ghosh, A. State of charge estimation of lithium-ion battery for electric vehicles using machine learning algorithms. World Electr. Veh. J. 2021, 12, 38. [Google Scholar] [CrossRef]
- Anton, J.C.A.; Nieto, P.J.G.; Viejo, C.B.; Vilán, J.A.V. Support vector machines used to estimate the battery state of charge. IEEE Trans. Power Electron. 2013, 28, 5919–5926. [Google Scholar] [CrossRef]
- Niri, M.F.; Bui, T.M.; Dinh, T.Q.; Hosseinzadeh, E.; Yu, T.F.; Marco, J. Remaining energy estimation for lithium-ion batteries via Gaussian mixture and Markov models for future load prediction. J. Energy Storage 2020, 28, 101271. [Google Scholar] [CrossRef]
- Niri, M.F.; Dinh, T.Q.; Yu, T.F.; Marco, J.; Bui, T.M.N. State of power prediction for lithium-ion batteries in electric vehicles via wavelet-Markov load analysis. IEEE Trans. Intell. Transp. Syst. 2020, 22, 5833–5848. [Google Scholar] [CrossRef]
- Hatherall, O.; Niri, M.F.; Barai, A.; Li, Y.; Marco, J. Remaining discharge energy estimation for lithium-ion batteries using pattern recognition and power prediction. J. Energy Storage 2023, 64, 107091. [Google Scholar] [CrossRef]
- Gu, X.; See, K.; Wang, Y.; Zhao, L.; Pu, W. The sliding window and SHAP theory—an improved system with a long short-term memory network model for state of charge prediction in electric vehicle application. Energies 2021, 14, 3692. [Google Scholar] [CrossRef]
- Shahriar, S.M.; Bhuiyan, E.A.; Nahiduzzaman, M.; Ahsan, M.; Haider, J. State of Charge Estimation for Electric Vehicle Battery Management Systems Using the Hybrid Recurrent Learning Approach with Explainable Artificial Intelligence. Energies 2022, 15, 8003. [Google Scholar] [CrossRef]
- Burzyński, D. Useful energy prediction model of a Lithium-ion cell operating on various duty cycles. Eksploat. Niezawodność 2022, 24, 317–329. [Google Scholar] [CrossRef]
- Nan, S.; Tu, R.; Li, T.; Sun, J.; Chen, H. From driving behavior to energy consumption: A novel method to predict the energy consumption of electric bus. Energy 2022, 261, 125188. [Google Scholar] [CrossRef]
- Alaoui, C. Hybrid vehicle energy management using deep learning. In Proceedings of the 2019 International Conference on Intelligent Systems and Advanced Computing Sciences (ISACS), Taza, Maroc, 26–27 December 2019; pp. 1–5. [Google Scholar]
- Samanta, A.; Chowdhuri, S.; Williamson, S.S. Machine learning-based data-driven fault detection/diagnosis of lithium-ion battery: A critical review. Electronics 2021, 10, 1309. [Google Scholar] [CrossRef]
- Jia, Y.; Li, J.; Yao, W.; Li, Y.; Xu, J. Precise and fast safety risk classification of lithium-ion batteries based on machine learning methodology. J. Power Sources 2022, 548, 232064. [Google Scholar] [CrossRef]
- Chen, K.; Zheng, F.; Jiang, J.; Zhang, W.; Jiang, Y.; Chen, K. Practical failure recognition model of lithium-ion batteries based on partial charging process. Energy 2017, 138, 1199–1208. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Statistical learning. In An Introduction to Statistical Learning: With Applications in R; Springer: Berlin/Heidelberg, Germany, 2021; pp. 15–57. [Google Scholar]
- Xu, C.; Li, L.; Xu, Y.; Han, X.; Zheng, Y. A vehicle-cloud collaborative method for multi-type fault diagnosis of lithium-ion batteries. eTransportation 2022, 12, 100172. [Google Scholar] [CrossRef]
- Haghi, S.; Summer, A.; Bauerschmidt, P.; Daub, R. Tailored Digitalization in Electrode Manufacturing: The Backbone of Smart Lithium-Ion Battery Cell Production. Energy Technol. 2022, 10, 2200657. [Google Scholar] [CrossRef]
- Román-Ramírez, L.A.; Marco, J. Design of experiments applied to lithium-ion batteries: A literature review. Appl. Energy 2022, 320, 119305. [Google Scholar] [CrossRef]
- Tian, Y.; Zeng, G.; Rutt, A.; Shi, T.; Kim, H.; Wang, J.; Koettgen, J.; Sun, Y.; Ouyang, B.; Chen, T.; et al. Promises and challenges of next-generation “beyond Li-ion” batteries for electric vehicles and grid decarbonization. Chem. Rev. 2020, 121, 1623–1669. [Google Scholar] [CrossRef] [PubMed]
- Cui, Z.; Wang, L.; Li, Q.; Wang, K. A comprehensive review on the state of charge estimation for lithium-ion battery based on neural network. Int. J. Energy Res. 2022, 46, 5423–5440. [Google Scholar] [CrossRef]
- Manoharan, A.; Begam, K.; Aparow, V.R.; Sooriamoorthy, D. Artificial Neural Networks, Gradient Boosting and Support Vector Machines for electric vehicle battery state estimation: A review. J. Energy Storage 2022, 55, 105384. [Google Scholar] [CrossRef]
- Faraji Niri, M.; Mafeni Mase, J.; Marco, J. Performance Evaluation of Convolutional Auto Encoders for the Reconstruction of Li-Ion Battery Electrode Microstructure. Energies 2022, 15, 4489. [Google Scholar] [CrossRef]
- Dahari, A.; Kench, S.; Squires, I.; Cooper, S.J. Fusion of complementary 2D and 3D mesostructural datasets using generative adversarial networks. Adv. Energy Mater. 2023, 13, 2202407. [Google Scholar] [CrossRef]
- Müller, S.; Sauter, C.; Shunmugasundaram, R.; Wenzler, N.; De Andrade, V.; De Carlo, F.; Konukoglu, E.; Wood, V. Deep learning-based segmentation of lithium-ion battery microstructures enhanced by artificially generated electrodes. Nat. Commun. 2021, 12, 6205. [Google Scholar] [CrossRef]
- Usseglio-Viretta, F.L.; Patel, P.; Bernhardt, E.; Mistry, A.; Mukherjee, P.; Allen, J.; Cooper, S.; Laurencin, J.; Smith, K. MATBOX: An Open-source Microstructure Analysis Toolbox for microstructure generation, segmentation, characterization, visualization, correlation, and meshing. SoftwareX 2022, 17, 100915. [Google Scholar] [CrossRef]
- Rojat, T.; Puget, R.; Filliat, D.; Del Ser, J.; Gelin, R.; Díaz-Rodríguez, N. Explainable artificial intelligence (xai) on timeseries data: A survey. arXiv 2021, arXiv:2104.00950. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Accurate and interpretable evaluation of surgical skills from kinematic data using fully convolutional neural networks. Int. J. Comput. Assist. Radiol. Surg. 2019, 14, 1611–1617. [Google Scholar] [CrossRef]
- Tonekaboni, S.; Joshi, S.; Duvenaud, D.; Goldenberg, A. Explaining Time Series by Counterfactuals. 2019. Available online: https://openreview.net/forum?id=HygDF1rYDB (accessed on 10 May 2023).
- Rashid, M.; Faraji-Niri, M.; Sansom, J.; Sheikh, M.; Widanage, D.; Marco, J. Dataset for rapid state of health estimation of lithium batteries using EIS and machine learning: Training and validation. Data Brief 2023, 48, 109157. [Google Scholar] [CrossRef]
- Lombardo, T.; Caro, F.; Ngandjong, A.C.; Hoock, J.B.; Duquesnoy, M.; Delepine, J.C.; Ponchelet, A.; Doison, S.; Franco, A.A. The ARTISTIC online calculator: Exploring the impact of lithium-ion battery electrode manufacturing parameters interactively through your browser. Batter. Supercaps 2022, 5, e202100324. [Google Scholar] [CrossRef]
- Román-Ramírez, L.A.; Apachitei, G.; Faraji-Niri, M.; Lain, M.; Widanage, D.; Marco, J. Experimental data of cathodes manufactured in a convective dryer at the pilot-plant scale, and charge and discharge capacities of half-coin lithium-ion cells. Data Brief 2022, 40, 107720. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Publication | Ref. | Formulation | Mixing | Coating | Drying | Calendering | Cutting | Cell Assembly |
|---|---|---|---|---|---|---|---|---|
| Duquesnoy et al., 2020 | [82] | x | x | |||||
| Faraji Niri et al., 2022 | [52] | x | ||||||
| Faraji Niri et al., 2022 | [78] | x | ||||||
| Faraji Niri et al., 2022 | [70] | x | x | |||||
| Faraji Niri et al., 2022 | [71] | x | x | |||||
| Liu et al., 2021 | [76] | x | x | |||||
| Liu et al., 2021 | [75] | x | x | |||||
| Liu et al., 2022 | [77] | x | x | |||||
| Liu et al., 2022 | [79] | x | ||||||
| Liu et al., 2022 | [68] | x | ||||||
| Turetskyy et al., 2020 | [84] | x | x | x | x | x | ||
| Turetskyy et al., 2020 | [83] | x | x | x | x | |||
| Wang et al., 2021 | [67] | x |
| Publication | Ref. | Correlation | Feature Importance | Dependency |
|---|---|---|---|---|
| Lee et al., 2022 | [96] | x | ||
| SHAP | ||||
| Mawonou et al., 2021 | [97] | x | ||
| Jiang et al., 2021 | [98] | x | ||
| SHAP | ||||
| Li et al., 2023 | [99] | x | x | |
| SHAP | ||||
| Granado et al., 2022 | [100] | x | ||
| Pearson | ||||
| Zhang et al., 2022 | [101] | x | x | |
| PDP | ||||
| He et al., 2022 | [102] | x | ||
| Ibraheem et al., 2023 | [103] | x | x | |
| Pearson | ||||
| Ardeshiri & Ma, 2021 | [104] | x | x | |
| Pearson | ||||
| Kim et al., 2022 | [105] | x | ||
| Wang et al., 2023 | [106] | x | ||
| Rieger et al., 2023 | [107] | x |
| Ref. | Tech | Model | Data Size | Data Type | |
|---|---|---|---|---|---|
| Cell Production | [70] | SHAP, ALEs | RF | 48 | IPP |
| [67] | SHAP, FI | RF, GBT, SVM, KNN, ANN, KRR | 168 | FPP | |
| [68] | FI | RUBoost | 138 | IPP | |
| [71] | ALEs, FI | RF, GBT | 67 | IP, FPP | |
| [75] | FI | RF | 656 | IPP | |
| [77] | FI | RF, DT, KNN, SVM | 656 | IPP | |
| [76] | ARD | GPR | 656 | IPP | |
| [79] | FI, ALEs | RF | 115 | FPP | |
| [78] | FI, SHAP | RF, GBT | 96/75 | IPP, FPP | |
| [82] | Pearson | SISSO | 54 | IPP | |
| [52] | SHAP, ALEs | ET | 54 | FPP | |
| [83] | FI | DT, RF | 167 | FPP | |
| [84] | FI | ANN, RF | 167 | FPP | |
| SoH/RUL Est. | [96] | SHAP | RF, GBT, SVM, MLP | 379 | BC |
| [99] | SHAP, FI | LGBT, RF, SVM, XGB, GPR | 300 | BC | |
| [98] | SHAP | XGB, Elastic Net, SVM | 124 | BC | |
| [97] | FI | RF, GBT, SVM, MLP | 180 K | DC | |
| [102] | FI | RF, LSTM | 6 | BC | |
| [106] | FI | LSTM, CNN, NN | 16 | BC | |
| [100] | FI | LR, SVM, KNN, RF, GBT | 22 | BC | |
| [103] | FI | RF, SVM, RDT | 158 | BC | |
| [104] | FI | GRU-RNN, LSTM | 4 | BC | |
| [105] | FI | NN | 124 | BC | |
| [107] | FI | LR, LSTM, NNs | 135 | BC | |
| [101] | FI, PDP | QRF | 135 | BC | |
| SoC/SoE Est. | [129] | SHAP | LSTM, LGBT, RF, KNN | 5 | DC |
| [130] | SHAP | CNN, LSTM | 4 | BC | |
| [131] | ALEs | GPR | 29 | BC | |
| [132] | SHAP | LSTM, XGB, RF, LR | 187.7K | DC | |
| BMS | [135] | FI | SVM, DT, RF, KNN, Log-R | 300K | BC |
| [136] | FI | LR, Elastic Net | 95 | BC | |
| [138] | FI | DT | 534 | BC |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faraji Niri, M.; Aslansefat, K.; Haghi, S.; Hashemian, M.; Daub, R.; Marco, J. A Review of the Applications of Explainable Machine Learning for Lithium–Ion Batteries: From Production to State and Performance Estimation. Energies 2023, 16, 6360. https://doi.org/10.3390/en16176360
Faraji Niri M, Aslansefat K, Haghi S, Hashemian M, Daub R, Marco J. A Review of the Applications of Explainable Machine Learning for Lithium–Ion Batteries: From Production to State and Performance Estimation. Energies. 2023; 16(17):6360. https://doi.org/10.3390/en16176360
Chicago/Turabian StyleFaraji Niri, Mona, Koorosh Aslansefat, Sajedeh Haghi, Mojgan Hashemian, Rüdiger Daub, and James Marco. 2023. "A Review of the Applications of Explainable Machine Learning for Lithium–Ion Batteries: From Production to State and Performance Estimation" Energies 16, no. 17: 6360. https://doi.org/10.3390/en16176360
APA StyleFaraji Niri, M., Aslansefat, K., Haghi, S., Hashemian, M., Daub, R., & Marco, J. (2023). A Review of the Applications of Explainable Machine Learning for Lithium–Ion Batteries: From Production to State and Performance Estimation. Energies, 16(17), 6360. https://doi.org/10.3390/en16176360