


Handling Computation Hardness and Time Complexity Issue of Battery Energy Storage Scheduling in Microgrids by Deep Reinforcement Learning



Abstract
1. Introduction
- In this paper, the DRL technique is utilized to handle the time complexity and large dimension space associated with the NP-hardness of optimal charge/discharge scheduling of the BESS. For this purpose, the DRL structure and the state–action–reward tuple are appropriately designed. The continuous deep deterministic policy gradient (DDPG) is used as the training algorithm to avoid the curse of dimensionality issue.
- The DRL can also handle time complexity associated with the nonconvexity of optimization problems for the BESS scheduling and nonlinear power flow. Complementarity constraints should be imposed to avoid simultaneous charge/discharge of the BESS that makes the problem non-convex. Alternatively, using slack integer variables increases the computational burden of the optimization problem.
- Therefore, the trained DRL is practicable for real-time BESS scheduling in MGs for different applications, such as frequency (dynamics) support and ancillary services that are needed to cover intermittent RESs.
- The searching space algorithm is proven to be environment-free and adaptable for EMS in various MG architectures with different scales.
- In order to comprehensively reveal the advantages of this method, the optimization results are compared with the results of the mixed integer nonlinear programming (MINLP) and genetic algorithm (GA).
2. Microgrid Architecture and Modeling
2.1. PV Generation
2.2. Wind Turbine
2.3. Battery Energy Storage System (BESS) Modeling
2.4. Diesel Generator (DG)
2.5. Loads and Utility Grid (UG)
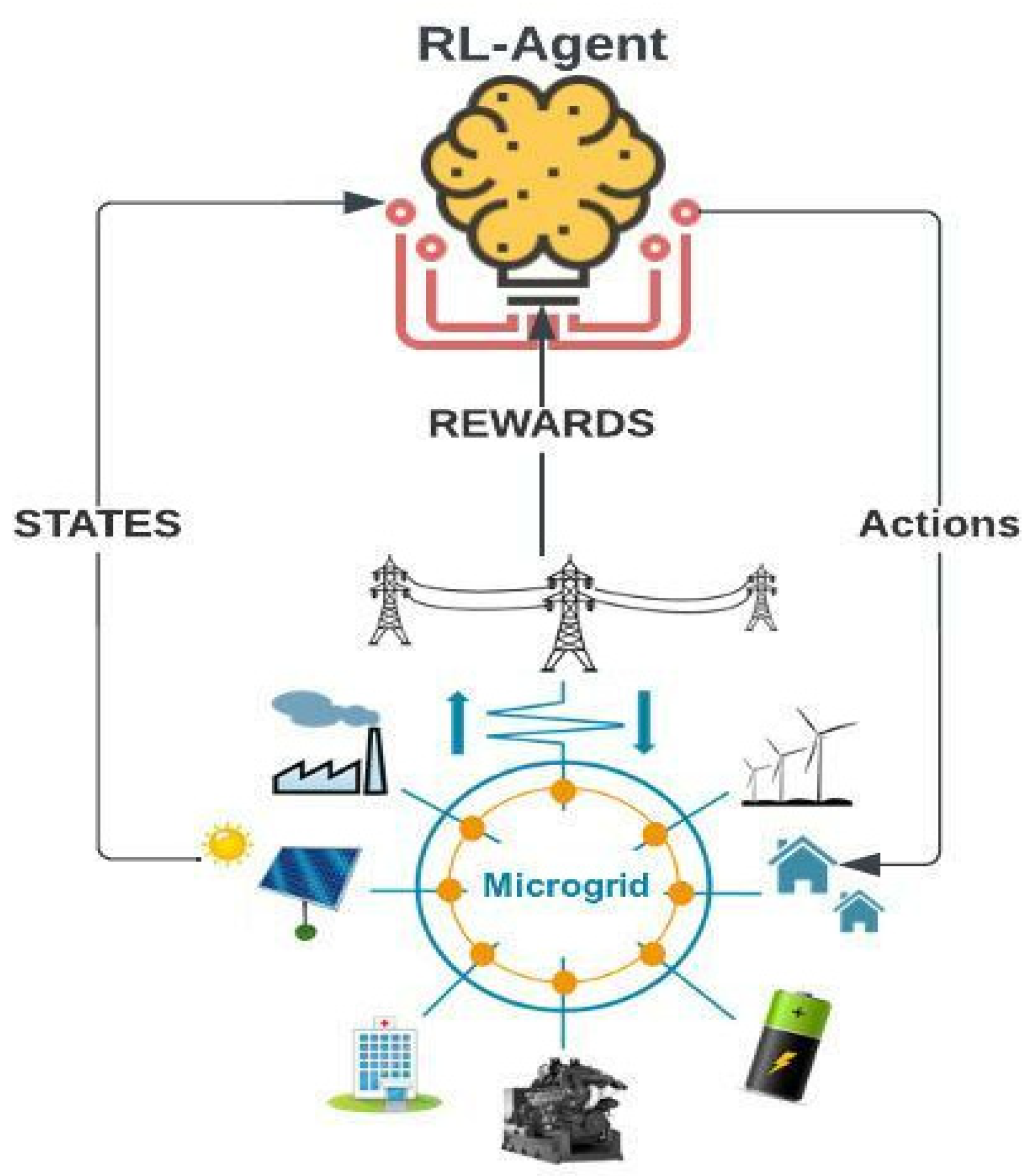
3. DRL-Based MG Energy Management System
3.1. Objective Function
3.2. State Space
3.3. Action Space
3.4. System Constraints
3.5. Reward Function
4. Deep Reinforcement Learning Algorithm
4.1. DRL Structure
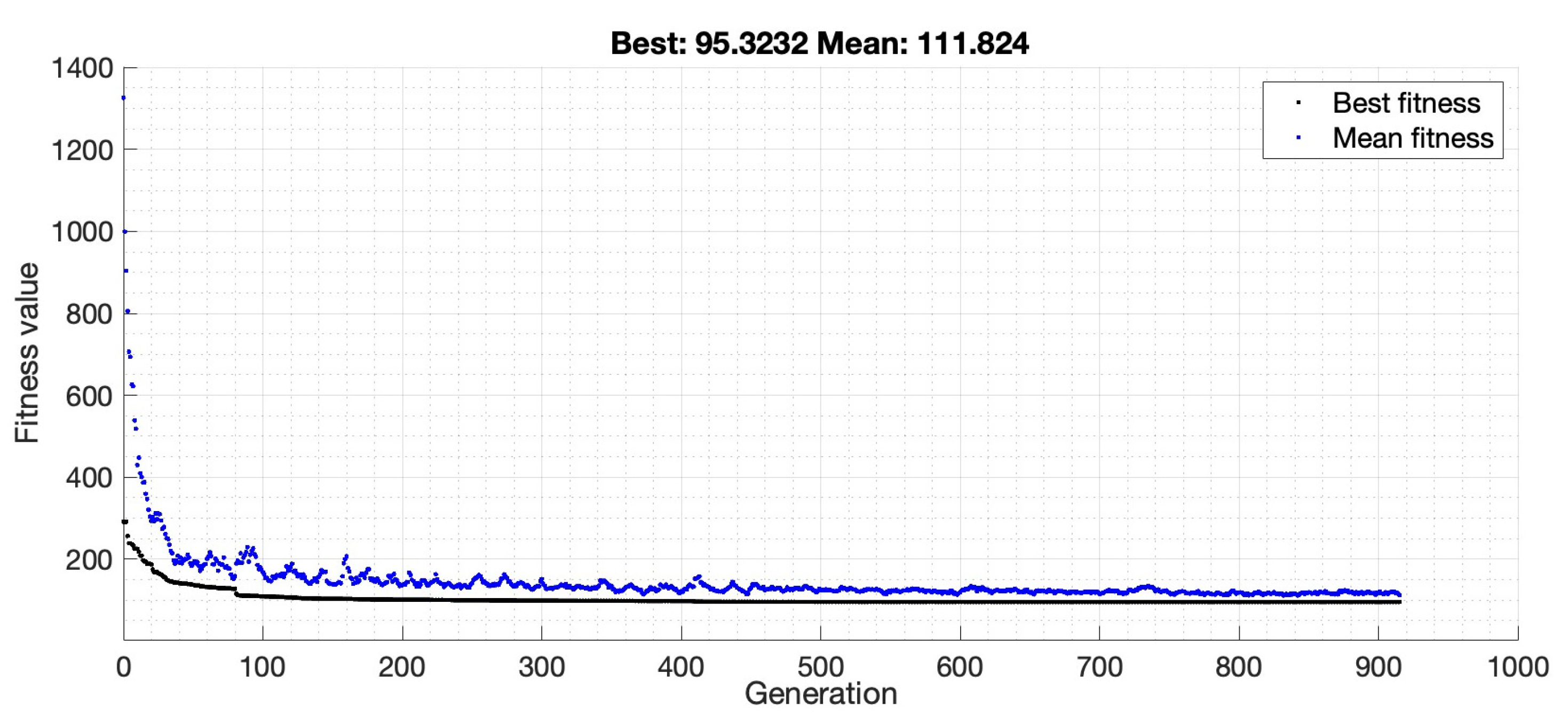
4.2. Deep Deterministic Policy Gradient (DDPG)
| Algorithm 1 Deep deterministic policy gradient | ||||
| 1: | Input: Initialize Q-function and policy, clean out replay buffer ; | |||
| 2: | Define objective parameters for Q-function and policy in and ; | |||
| 3: | Loop; | |||
| 4: | Based on current observation, generate state-action pair ; | |||
| 5: | Practice action in the environment; | |||
| 6: | Obtain the reward and move to next state , check the ending signal ; | |||
| 7: | to relay buffer ; | |||
| 8: | s’ is the last state and ending signal is true; | |||
| 9: | training episodes do; | |||
| 10: | from ; | |||
| 11: | Solve the objectives by transients ; | |||
| 12: | Obtain updated Q-function ; | |||
| 13: | Obtain updated policy ; | |||
| 14: | Update objective networks’ weight ; | |||
| 15: | end for; | |||
| 16: | end if; | |||
| 17: | until reward convergence. | |||
5. Case Study
5.1. Simulation Settings
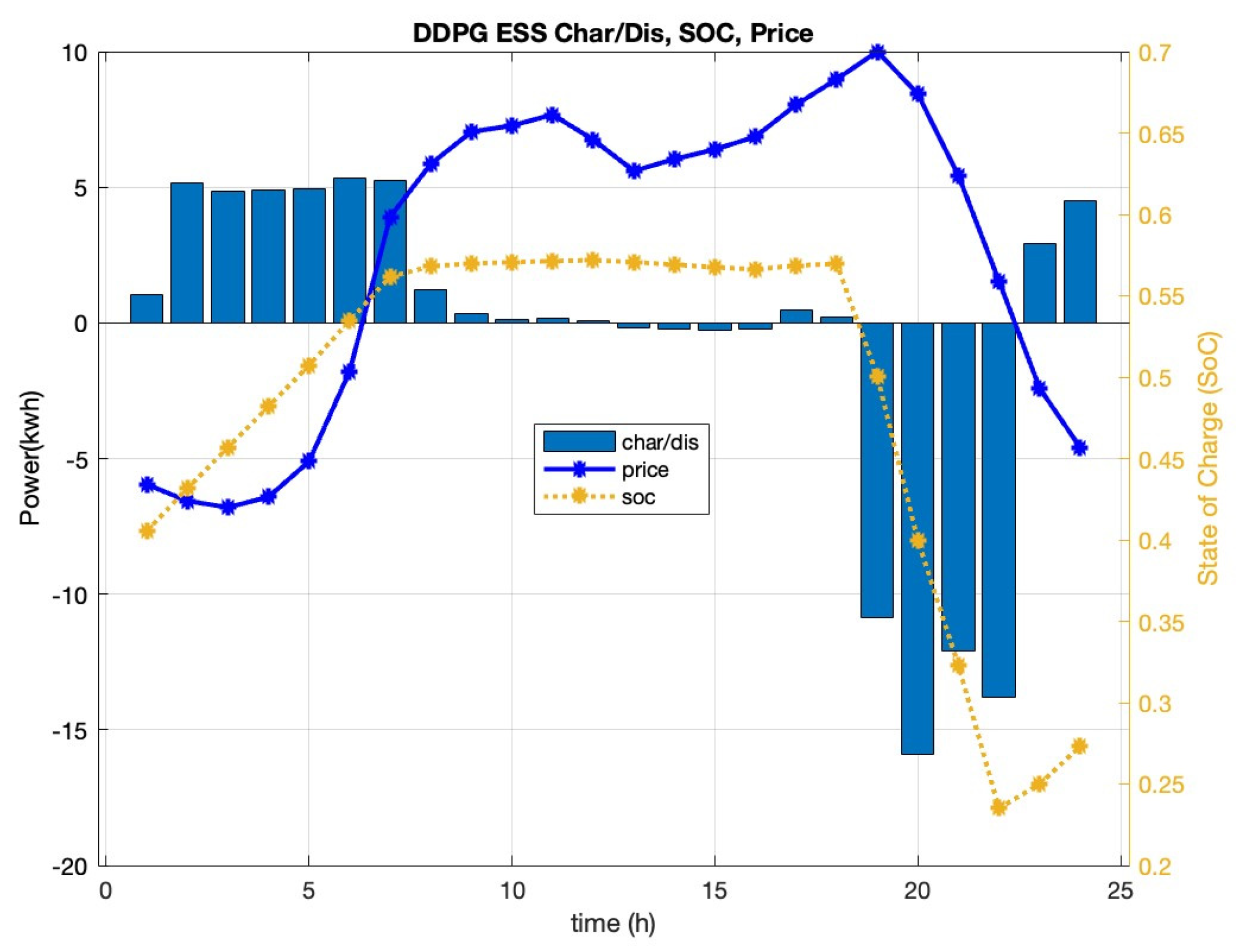
5.2. Simulation Results and Discussion
5.3. Results Comparision and Analysis
6. Conclusions
- The DRL agent tries a large number of trial-and-error episodes during training, by which all possible combinations of the BESS charge/discharge schedule, with various initial SoC, are tested. The DDPG optimizes the DRL network to maximize the rewards and thus minimizes the purchasing cost. This training process costs computational costs.
- In an MG with a simple structure and determinant load/weather, the DRL agent would cost more computation time for training compared with GA and MINLP. In the simulated scenario, the DRL achieved higher purchasing costs, but smaller computation time for real-time action.
- The training process of DRL would increase in a large-scale MG system, but after training, the DRL agent reveals superior computation for real-time performance.
- The DRL agent is able to deal with uncertainties that happened in MG, such as stochastic power generation produced by RESs in MG.
- When the EMS is adapted to a new location, e.g., replacing a new database with EMS, the DRL agent can quickly be adapted by training its deep neural network.
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BESSs | Battery energy storage system | ESS | Energy storage system |
| CNN | Conventional neural networks | GA | Genetic algorithm |
| DDPG | Deep deterministic policy gradient | GPU | Graphical process units |
| DER | Distributed energy resources | MGs | Microgrids |
| DG | Diesel generator | MINLP | Mixed integer nonlinear programming |
| DNN | Deep neural network | PV | Photovoltaic |
| DRL | Deep reinforcement learning | RESs | Renewable energy resources |
| DT | Decision tree | SoC | State of charge |
| DQN | Deep Q-network | TL | Transfer learning |
| EMS | Energy management system | WT | Wind turbine |
References
- Olivares, D.E.; Mehrizi-Sani, A.; Etemadi, A.H.; Cañizares, C.A.; Iravani, R.; Kazerani, M.; Hajimiragha, A.H.; Gomis-Bellmunt, O.; Saeedifard, M.; Palma-Behnke, R.; et al. Trends in microgrid control. IEEE Trans. Smart Grid 2014, 5, 1905–1919. [Google Scholar] [CrossRef]
- Moradi, M.H.; Eskandari, M.; Hosseinian, S. Operational Strategy Optimization in an Optimal Sized Smart Microgrid. IEEE Trans. Smart Grid 2015, 6, 1087–1095. [Google Scholar] [CrossRef]
- Tabar, V.S.; Jirdehi, M.A.; Hemmati, R. Energy management in microgrid based on the multi objective stochastic programming incorporating portable renewable energy resource as demand response option. Energy 2017, 118, 827–839. [Google Scholar] [CrossRef]
- Asadi, Y.; Eskandari, M.; Mansouri, M.; Savkin, A.V.; Pathan, E. Frequency and Voltage Control Techniques through Inverter-Interfaced Distributed Energy Resources in Microgrids: A Review. Energies 2022, 15, 8580. [Google Scholar] [CrossRef]
- Shi, W.; Li, N.; Chu, C.C.; Gadh, R. Real-time energy management in microgrids. IEEE Trans. Smart Grid 2015, 8, 228–238. [Google Scholar] [CrossRef]
- Eskandari, M.; Li, L.; Moradi, M.H.; Siano, P.; Blaabjerg, F. Optimal voltage regulator for inverter interfaced distributed generation units part I: Control system. IEEE Trans. Sustain. Energy 2020, 11, 2813–2824. [Google Scholar] [CrossRef]
- Eskandari, M.; Savkin, A.V. A Critical Aspect of Dynamic Stability in Autonomous Microgrids: Interaction of Droop Controllers through the Power Network. IEEE Trans. Ind. Inform. 2021, 18, 3159–3170. [Google Scholar] [CrossRef]
- Eskandari, M.; Savkin, A.V. On the Impact of Fault Ride-Through on Transient Stability of Autonomous Microgrids: Nonlinear Analysis and Solution. IEEE Transactions on Smart Grid 2021, 12, 999–1010. [Google Scholar] [CrossRef]
- Uzair, M.; Eskandari, M.; Li, L.; Zhu, J. Machine Learning Based Protection Scheme for Low Voltage AC Microgrids. Energies 2022, 15, 9397. [Google Scholar] [CrossRef]
- Zhou, N.; Liu, N.; Zhang, J.; Lei, J. Multi-objective optimal sizing for battery storage of PV-based microgrid with demand response. Energies 2016, 9, 591. [Google Scholar] [CrossRef]
- Mansouri, M.; Eskandari, M.; Asadi, Y.; Siano, P.; Alhelou, H.H. Pre-Perturbation Operational Strategy Scheduling in Microgrids by Two-Stage Adjustable Robust Optimization. IEEE Access 2022, 10, 74655–74670. [Google Scholar] [CrossRef]
- Rezaeimozafar, M.; Eskandari, M.; Amini, M.H.; Moradi, M.H.; Siano, P. A Bi-Layer Multi-Objective Techno-Economical Optimization Model for Optimal Integration of Distributed Energy Resources into Smart/Micro Grids. Energies 2020, 13, 1706. [Google Scholar] [CrossRef]
- Eskandari, M.; Rajabi, A.; Savkin, A.V.; Moradi, M.H.; Dong, Z.Y. Battery energy storage systems (BESSs) and the economy-dynamics of microgrids: Review, analysis, and classification for standardization of BESSs applications. J. Energy Storage 2022, 55, 105627. [Google Scholar] [CrossRef]
- Zheng, C.; Eskandari, M.; Li, M.; Sun, Z. GA-Reinforced Deep Neural Network for Net Electric Load Forecasting in Microgrids with Renewable Energy Resources for Scheduling Battery Energy Storage Systems. Algorithms 2022, 15, 338. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep reinforcement learning for multiagent systems: A review of challenges, solutions, and applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Mousavi, S.S.; Schukat, M.; Howley, E. Deep reinforcement learning: An overview. In Proceedings of the SAI Intelligent Systems Conference, London, UK, 7–8 September 2017; pp. 426–440. [Google Scholar]
- Hua, H.; Qin, Y.; Hao, C.; Cao, J. Optimal energy management strategies for energy Internet via deep reinforcement learning approach. Appl. Energy 2019, 239, 598–609. [Google Scholar] [CrossRef]
- Khooban, M.H.; Gheisarnejad, M. A novel deep reinforcement learning controller-based type-II fuzzy system: Frequency regulation in microgrids. IEEE Trans. Emerg. Top. Comput. Intell. 2020, 5, 689–699. [Google Scholar] [CrossRef]
- François-Lavet, V.; Taralla, D.; Ernst, D.; Fonteneau, R. Deep reinforcement learning solutions for energy microgrids management. In Proceedings of the European Workshop on Reinforcement Learning (EWRL 2016), Barcelona, Spain, 3–4 December 2016. [Google Scholar]
- Du, Y.; Zandi, H.; Kotevska, O.; Kurte, K.; Munk, J.; Amasyali, K.; Mckee, E.; Li, F. Intelligent multi-zone residential HVAC control strategy based on deep reinforcement learning. Appl. Energy 2021, 281, 116117. [Google Scholar] [CrossRef]
- Jin, X.; Lin, F.; Wang, Y. Research on Energy Management of Microgrid in Power Supply System Using Deep Reinforcement Learning. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, July 2021; Volume 804, Number 3. [Google Scholar]
- Yoldas, Y.; Goren, S.; Onen, A. Optimal Control of Microgrids with Multi-stage Mixed-integer Nonlinear Programming Guided Q-learning Algorithm. J. Mod. Power Syst. Clean Energy 2020, 8, 1151–1159. [Google Scholar] [CrossRef]
- Phan, B.C.; Lai, Y.C. Control strategy of a hybrid renewable energy system based on reinforcement learning approach for an isolated microgrid. Appl. Sci. 2019, 9, 4001. [Google Scholar] [CrossRef]
- Zeng, P.; Li, H.; He, H.; Li, S. Dynamic energy management of a microgrid using approximate dynamic programming and deep recurrent neural network learning. IEEE Trans. Smart Grid 2018, 10, 4435–4445. [Google Scholar] [CrossRef]
- Li, J.; Chen, S.; Wang, X.; Pu, T. Research on load shedding control strategy in power grid emergency state based on deep reinforcement learning. CSEE J. Power Energy Syst. 2022, 8, 1175. [Google Scholar]
- Antonopoulos, I.; Robu, V.; Couraud, B.; Kirli, D.; Norbu, S.; Kiprakis, A.; Flynn, D.; Elizondo-Gonzalez, S.; Wattam, S. Artificial intelligence and machine learning approaches to energy demand-side response: A systematic review. Renew. Sustain. Energy Rev. 2020, 30, 109899. [Google Scholar] [CrossRef]
- Kumari, A.; Tanwar, S. A reinforcement-learning-based secure demand response scheme for smart grid system. IEEE Internet Things J. 2021, 9, 2180–2191. [Google Scholar] [CrossRef]
- Lei, L.; Tan, Y.; Dahlenburg, G.; Xiang, W.; Zheng, K. Dynamic energy dispatch based on deep reinforcement learning in IoT-driven smart isolated microgrids. IEEE Internet Things J. 2020, 8, 7938–7953. [Google Scholar] [CrossRef]
- Huang, Y.; Li, G.; Chen, C.; Bian, Y.; Qian, T.; Bie, Z. Resilient distribution networks by microgrid formation using deep reinforcement learning. IEEE Trans. Smart Grid 2022, 13, 4918–4930. [Google Scholar] [CrossRef]
- Zhao, J.; Li, F.; Mukherjee, S.; Sticht, C. Deep Reinforcement Learning based Model-free On-line Dynamic Multi-Microgrid Formation to Enhance Resilience. IEEE Trans. Smart Grid 2022. [Google Scholar] [CrossRef]
- Garcia-Torres, F.; Bordons, C.; Ridao, M.A. Optimal Economic Schedule for a Network of Microgrids With Hybrid Energy Storage System Using Distributed Model Predictive Control. IEEE Trans. Ind. Electron 2019, 66, 1919–1929. [Google Scholar] [CrossRef]
- Wei, Q.; Liu, D.; Shi, G. A novel dual iterative Q-learning method for optimal battery management in smart residential environments. IEEE Trans. Ind. Electron 2015, 62, 2509–2518. [Google Scholar] [CrossRef]
- Du, Y.; Li, F. Intelligent multi-microgrid energy management based on deep neural network and model-free reinforcement learning. IEEE Trans. Smart Grid 2019, 11, 1066–1076. [Google Scholar] [CrossRef]
- Rana, M.J.; Zaman, F.; Ray, T.; Sarker, R. Real-time scheduling of community microgrid. J. Clean. Prod. 2021, 286, 125419. [Google Scholar] [CrossRef]
- Mocanu, E.; Mocanu, D.C.; Nguyen, P.H.; Liotta, A.; Webber, M.E.; Gibescu, M.; Slootweg, J.G. On-line building energy optimization using deep reinforcement learning. IEEE Trans. Smart Grid 2018, 10, 3698–3708. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Electricity Purchase (AUD/kWh) | Electricity Sells (AUD/kWh) |
|---|---|
| 1.1 | 0.85 |
| PV (kW) | WT (kW) | Load (kWh) | Price (AUD/kWh) |
|---|---|---|---|
| 0 | 50 | 50 | 0.434137 |
| 0 | 50 | 60 | 0.42391 |
| 0 | 50 | 60 | 0.42 |
| 0 | 50 | 54 | 0.426393 |
| 0 | 40 | 40 | 0.448192 |
| 10 | 30 | 40 | 0.503548 |
| 25 | 30 | 65 | 0.598517 |
| 30 | 40 | 79 | 0.63099 |
| 50 | 45 | 100 | 0.650717 |
| 60 | 45 | 120 | 0.654483 |
| 65 | 50 | 110 | 0.661257 |
| 75 | 45 | 77 | 0.645917 |
| 75 | 45 | 70 | 0.626667 |
| 70 | 55 | 68 | 0.633886 |
| 70 | 55 | 75 | 0.639901 |
| 60 | 60 | 90 | 0.647722 |
| 40 | 65 | 117 | 0.667376 |
| 27 | 60 | 125 | 0.683024 |
| 10 | 55 | 130 | 0.7 |
| 0 | 55 | 125 | 0.673981 |
| 0 | 60 | 130 | 0.623744 |
| 0 | 60 | 90 | 0.558902 |
| 0 | 55 | 80 | 0.493186 |
| 0 | 55 | 75 | 0.456695 |
| a | b | c |
|---|---|---|
| 0.001 | 0.15 | 77.44 |
| DDPG-Based DRL | MINLP | GA | |
|---|---|---|---|
| Purchasing Cost (AUD) | 87.333 | 45.772 | 88.406 |
| Computation Time (s) | 1.202061 | 2.745373 | 23.328163 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Eskandari, M.; Zheng, C.; Li, M. Handling Computation Hardness and Time Complexity Issue of Battery Energy Storage Scheduling in Microgrids by Deep Reinforcement Learning. Energies 2023, 16, 90. https://doi.org/10.3390/en16010090
Sun Z, Eskandari M, Zheng C, Li M. Handling Computation Hardness and Time Complexity Issue of Battery Energy Storage Scheduling in Microgrids by Deep Reinforcement Learning. Energies. 2023; 16(1):90. https://doi.org/10.3390/en16010090
Chicago/Turabian StyleSun, Zeyue, Mohsen Eskandari, Chaoran Zheng, and Ming Li. 2023. "Handling Computation Hardness and Time Complexity Issue of Battery Energy Storage Scheduling in Microgrids by Deep Reinforcement Learning" Energies 16, no. 1: 90. https://doi.org/10.3390/en16010090
APA StyleSun, Z., Eskandari, M., Zheng, C., & Li, M. (2023). Handling Computation Hardness and Time Complexity Issue of Battery Energy Storage Scheduling in Microgrids by Deep Reinforcement Learning. Energies, 16(1), 90. https://doi.org/10.3390/en16010090