
Hotspot-Aware Workload Scheduling and Server Placement for Heterogeneous Cloud Data Centers

 , ,
, , 
 ,
, 

Abstract
:1. Introduction
2. Related Work
- A generic approach for thermal hotspot-aware resource management of data centers using thermal profiles of servers is proposed. The proposed approach proactively predicts the outlet temperatures and helps avoid thermal hotspots in data centers.
- Hotspot-adaptive workload deployment algorithm (HAWDA) and hotspot-aware server relocation algorithm (HASRA) are developed and evaluated in terms of outlet temperature, power consumption, and server utilization of data center servers.
- A simulation study is implemented with HAWDA and HASRA using Alibaba cloud workload traces. HAWDA and HASRA are compared with the existing thermal-aware scheduling algorithm (TASA) and greedy-based scheduling algorithm minimizing total energy (GRANITE).
3. Background
4. Proposed Methodology
4.1. Workload Characterization
4.2. Evaluation Approach
4.3. Hotspot Adaptive Workload Deployment Algorithm
| Algorithm 1 The pseudocode of HAWDA. |
INPUT: Server , BatchList OUTPUT: Mapping of Batches deployed on Servers 1: Sort Server according to ascending order of inlet temperature and calculate 2: for in do 3: for in do 4: if then 5: Calculate for 6: if then 7: 8. if then 9: 10: end if 11: end if 12: end if 13: end for 14: // is assigned to 15: end for |
4.4. Hotspot Aware Server Relocation Algorithm
| Algorithm 2 The pseudocode of HASRA. |
INPUT: Server , OUTPUT: Relocation of hot servers to cooler regions. 1: Sort Server according to descending order of inlet temperature and calculate 2: for in for to do 3: Calculate for at maximum utilization 4: if then 5: for in from down to do 6: Calculate for at maximum utilization 7: if then 8: if then 9: switch location of and 10: end if 11: end if 12: end for 13: end if 14: end for |
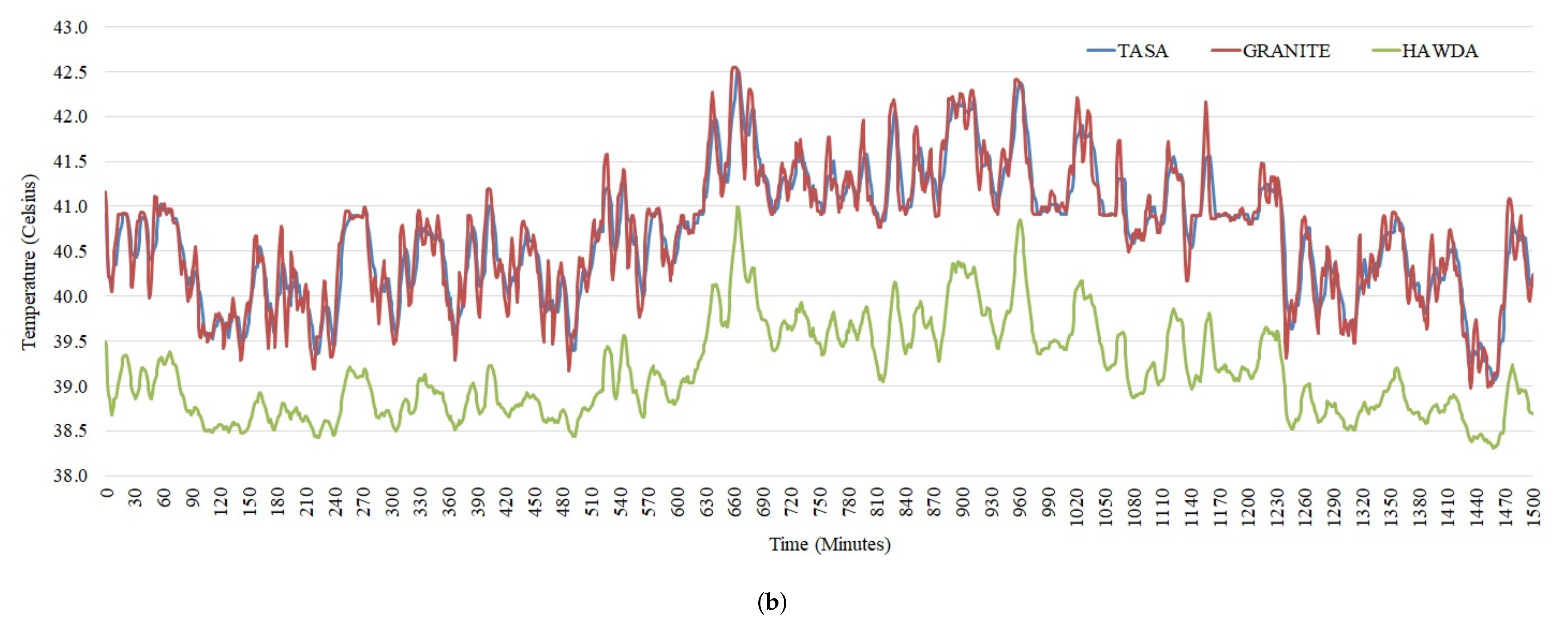
5. Results
5.1. Experiment Setup
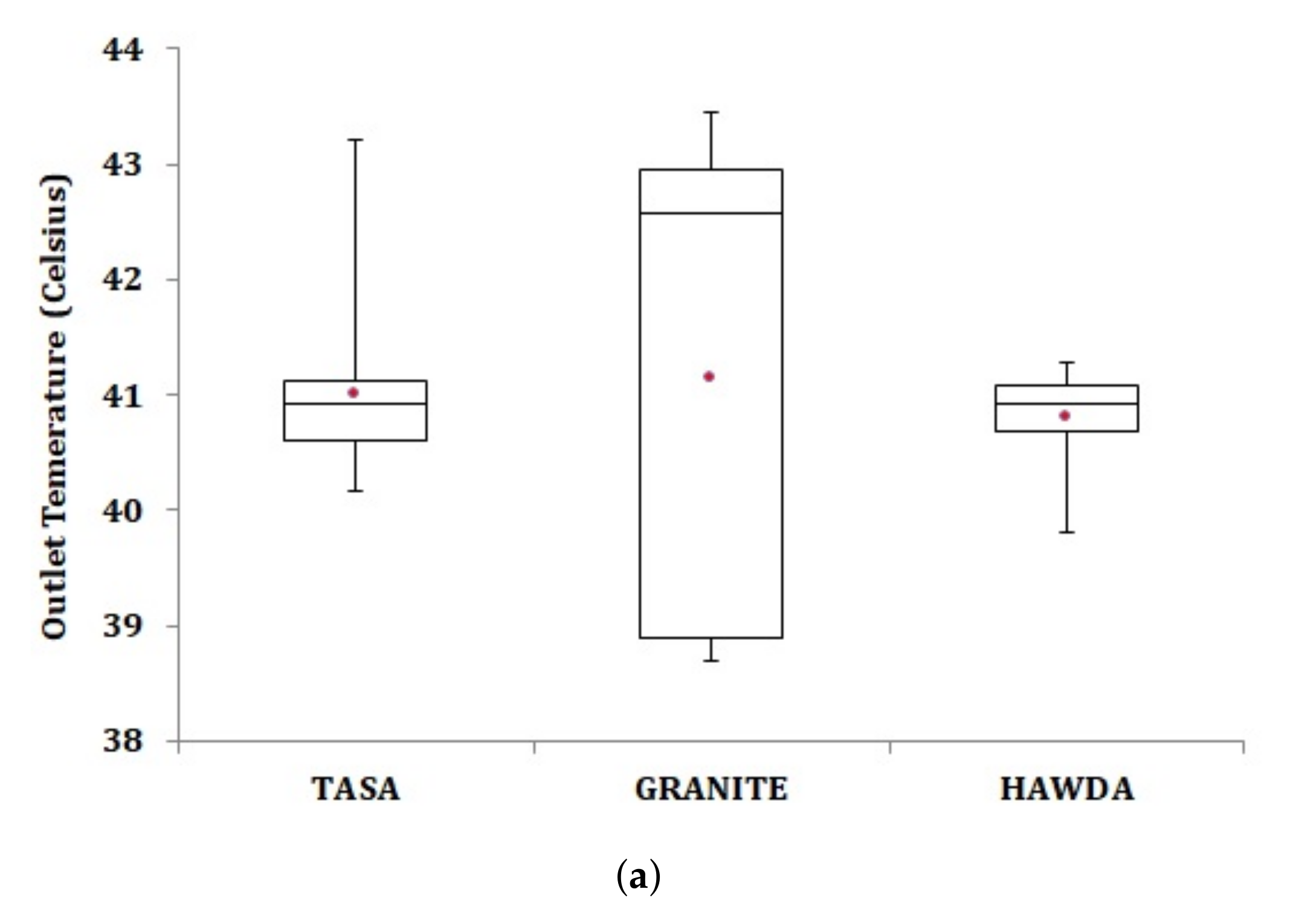
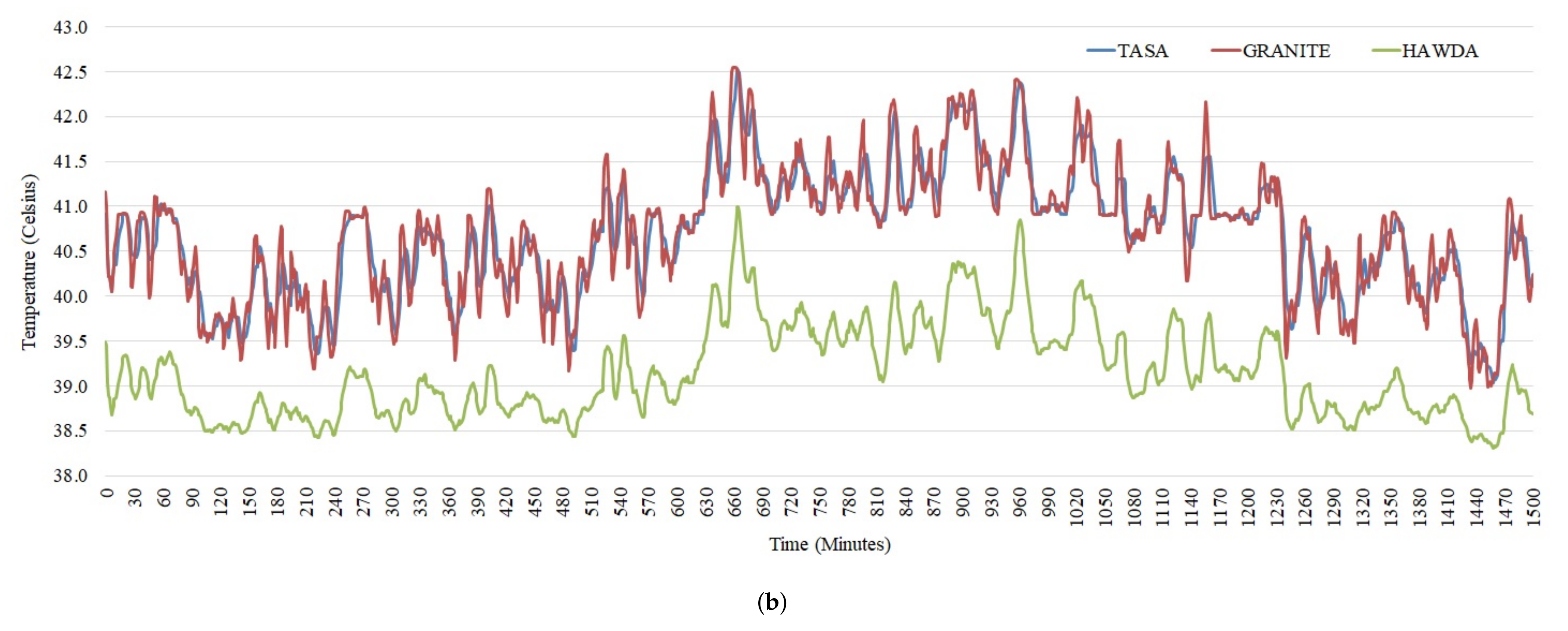
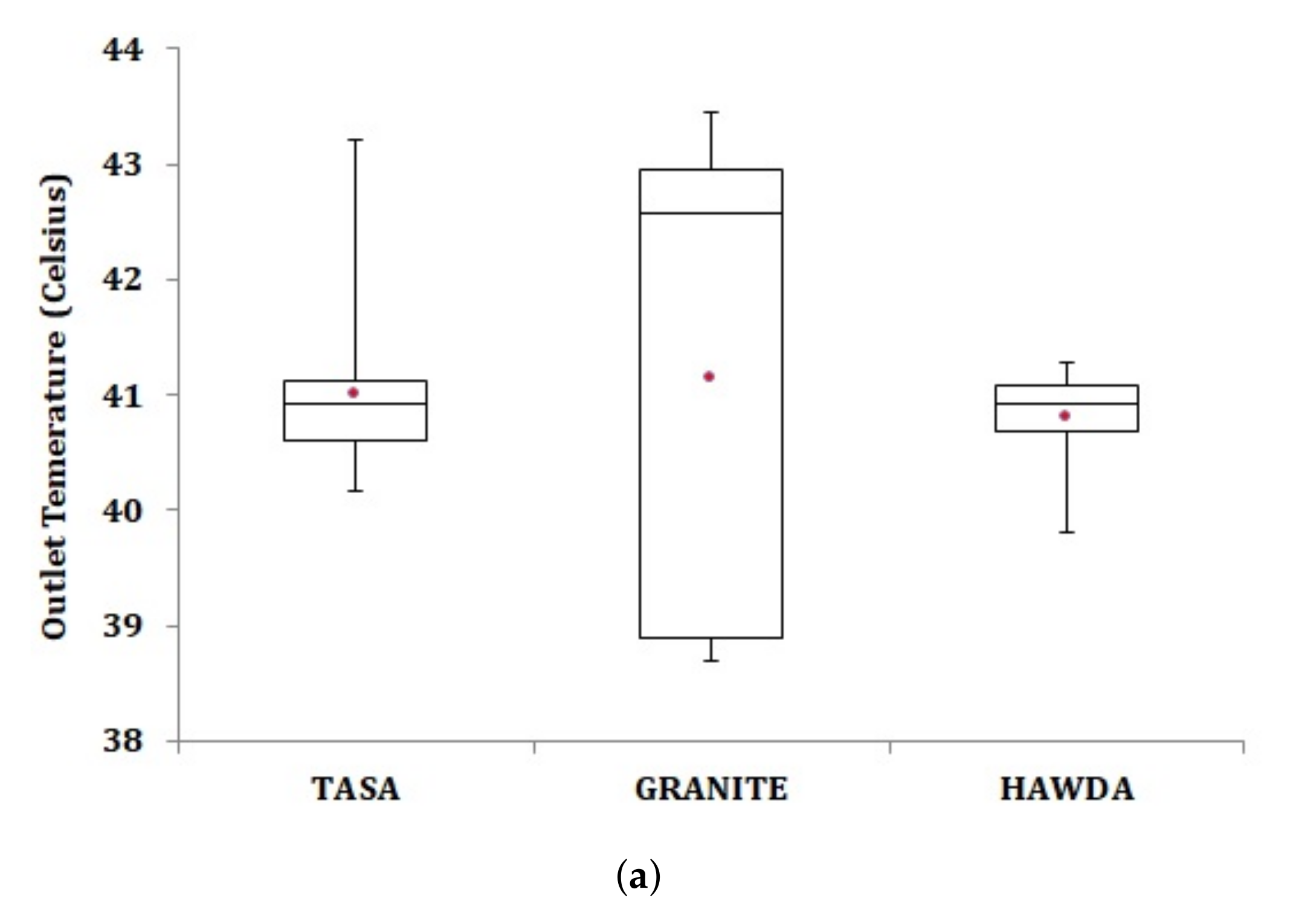
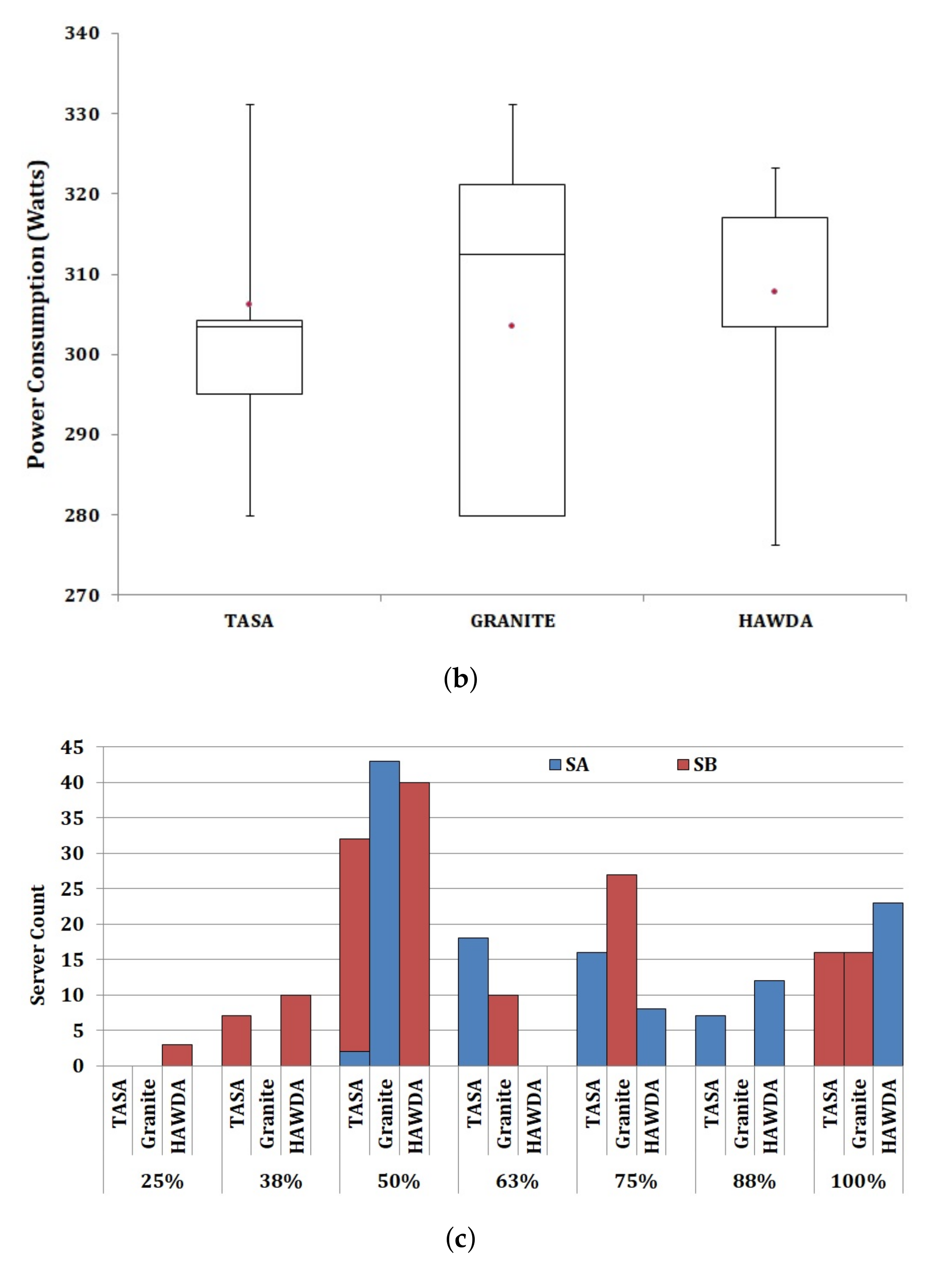
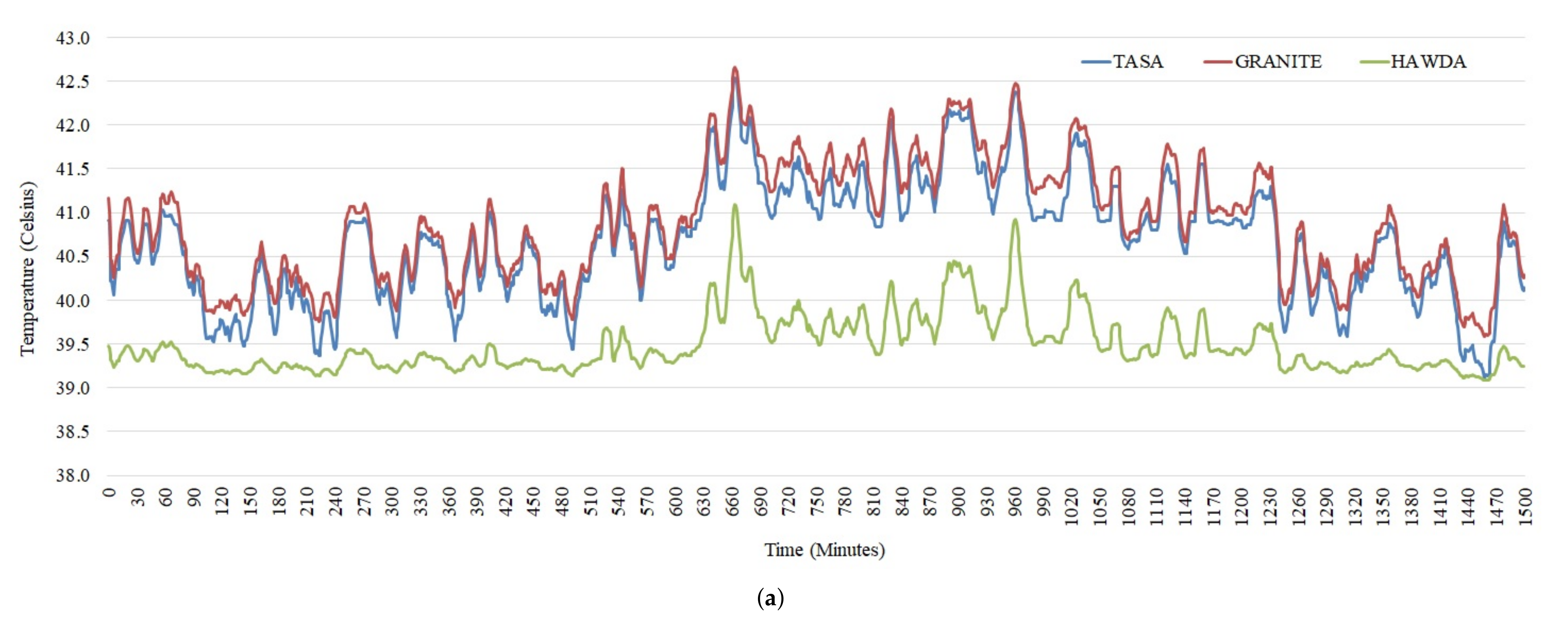
5.2. Workload Scheduling
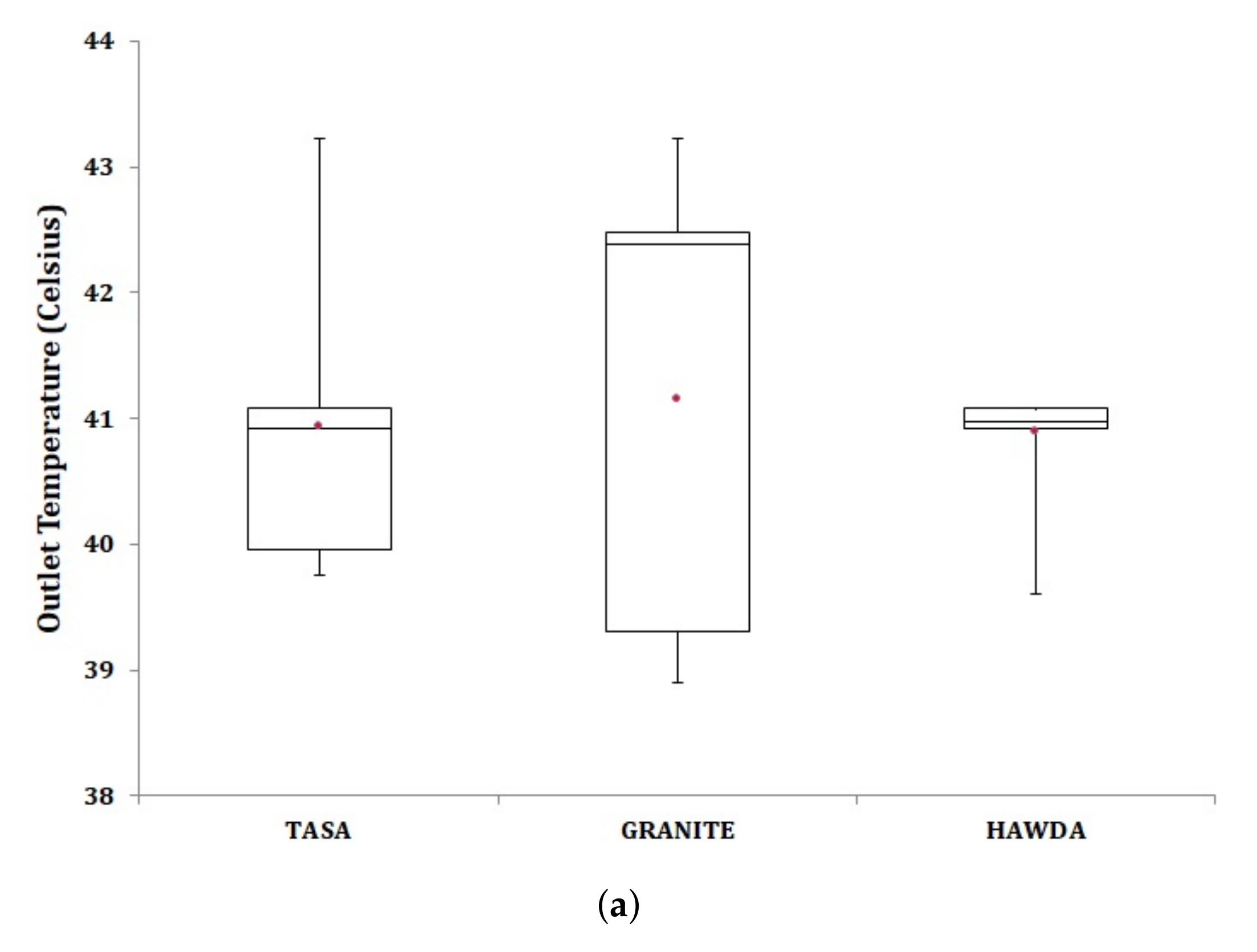
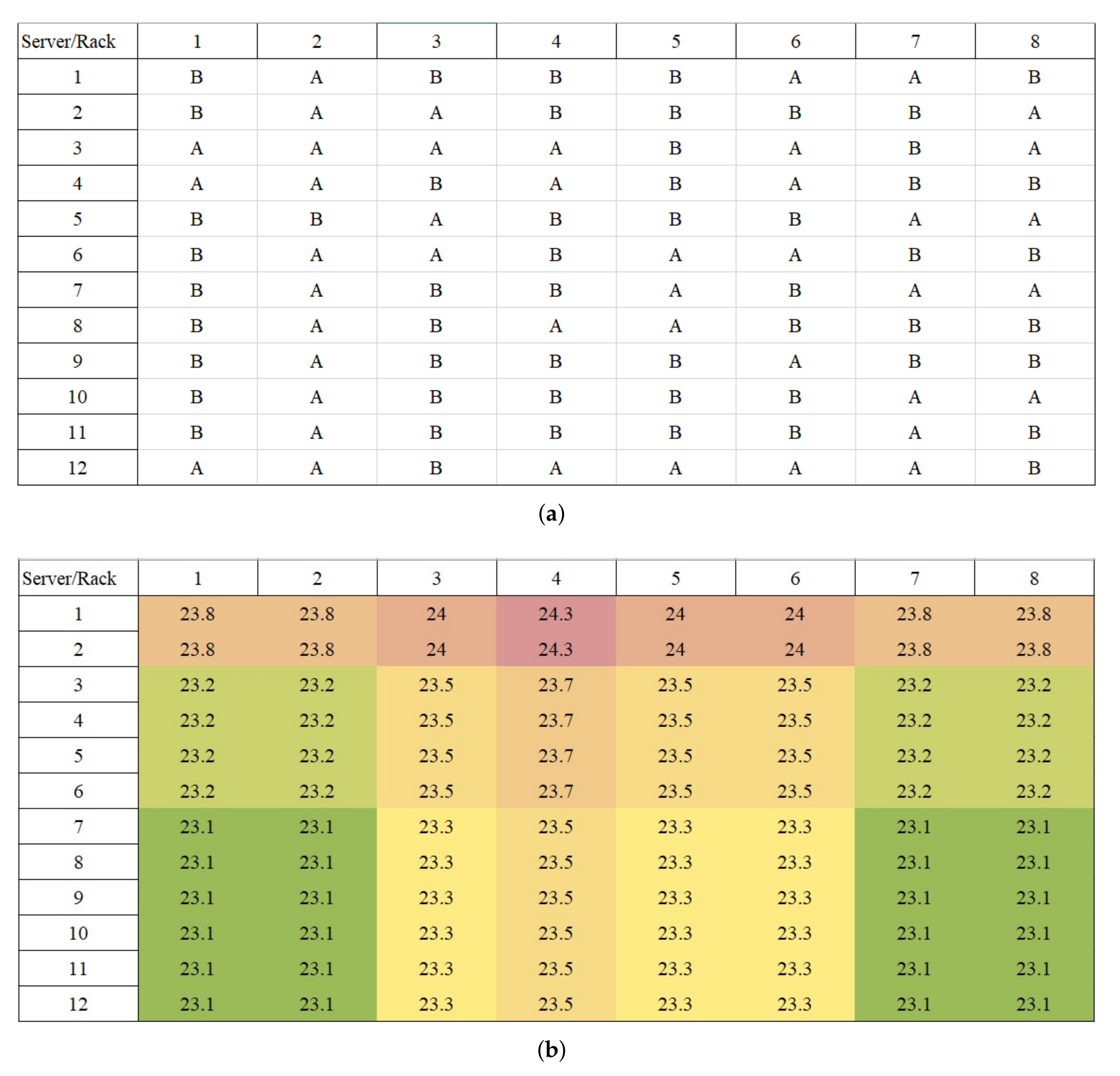
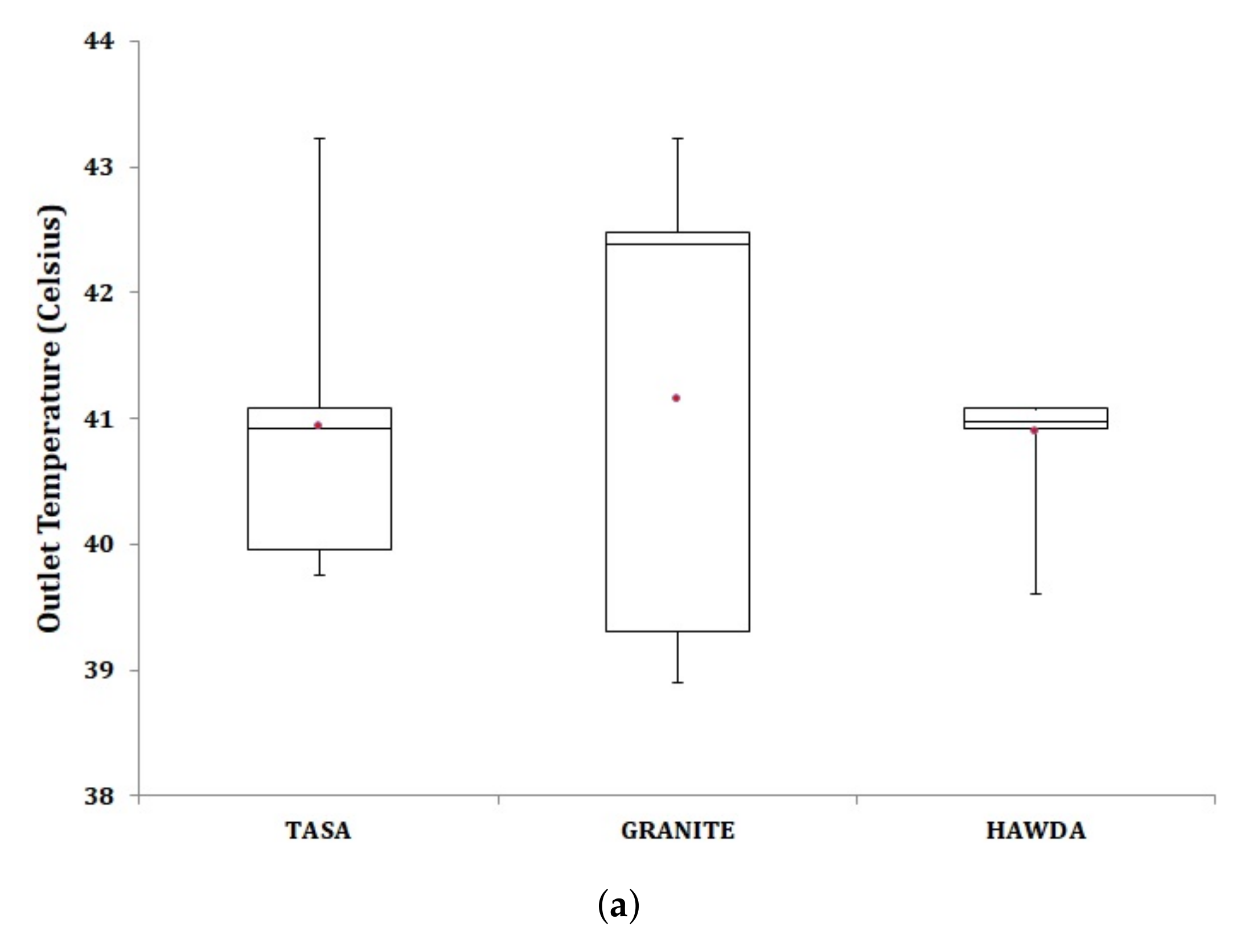
5.3. Workload Scheduling with Server Relocation
6. Discussion
6.1. Computing Capacity Utilization
6.2. Peak Outlet Temperature
6.3. Heat Flow from Servers
- i.
- We consider that the heat discharged from the server does not flow back into the server,
- ii.
- The heat generated by the memory, disk, and the motherboard is negligible, and
- iii.
- We consider that no external factor contributes to heat propagation in the data center facility.
6.4. Energy Consumption
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khalaj, A.H.; Scherer, T.; Halgamuge, S.K. Energy, environmental and economical saving potential of data centers with various economizers across Australia. Appl. Energy 2016, 183, 1528–1549. [Google Scholar] [CrossRef]
- Ni, J.; Bai, X. A review of air conditioning energy performance in data centers. Renew. Sustain. Energy Rev. 2017, 67, 625–640. [Google Scholar] [CrossRef]
- Li, X.; Jiang, X.; Garraghan, P.; Wu, Z. Holistic energy and failure aware workload scheduling in Cloud datacenters. Future Gener. Comput. Syst. 2018, 78, 887–900. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Gmach, D.; Hyser, C.; Wang, Z.; Bash, C.; Hoover, C.; Singhal, S. Integrated management of application performance, power and cooling in data centers. In Proceedings of the 2010 IEEE Network Operations and Management Symposium-NOMS 2010, Osaka, Japan, 19–23 April 2010; pp. 615–622. [Google Scholar]
- Yang, B.; Hamann, H.; Kephart, J.; Barabasi, S. Hotspot diagnosis on logical level. In Proceedings of the 2011 7th International Conference on Network and Service Management, Paris, France, 24–28 October 2011; pp. 1–5. [Google Scholar]
- Tang, Q.; Gupta, S.K.; Varsamopoulos, G. Thermal-aware task scheduling for data centers through minimizing heat recirculation. In Proceedings of the 2007 IEEE International Conference on Cluster Computing, Austin, TX, USA, 17–20 September 2007; pp. 129–138. [Google Scholar]
- Lee, E.K.; Kulkarni, I.; Pompili, D.; Parashar, M. Proactive thermal management in green datacenters. J. Supercomput. 2012, 60, 165–195. [Google Scholar] [CrossRef]
- Artman, P.; Moss, D.; Bennett, G. Dell™ Power-Edge™ 1650: Rack Impacts on Cooling for High Density Servers. 2002. Available online: http://www.dell.com/downloads/global/products/pedge/en/rack_coolingdense.doc (accessed on 22 December 2021).
- Banerjee, A.; Mukherjee, T.; Varsamopoulos, G.; Gupta, S.K. Cooling-aware and thermal-aware workload placement for green HPC data centers. In Proceedings of the International Conference on Green Computing, Chicago, IL, USA, 15–18 August 2010; pp. 245–256. [Google Scholar]
- Barroso, L.A.; Hölzle, U. The case for energy-proportional computing. Computer 2007, 40, 33–37. [Google Scholar] [CrossRef]
- Fan, X.; Weber, W.D.; Barroso, L.A. Power provisioning for a warehouse-sized computer. ACM SIGARCH Comput. Archit. News 2007, 35, 13–23. [Google Scholar] [CrossRef]
- Lefurgy, C.; Wang, X.; Ware, M. Server-level power control. In Proceedings of the 4th International Conference on Autonomic Computing (ICAC’07), Jacksonville, FL, USA, 11–15 June 2007; p. 4. [Google Scholar]
- Moore, J.D.; Chase, J.S.; Ranganathan, P.; Sharma, R.K. Making scheduling “Cool”: Temperature-aware workload placement in data centers. In Proceedings of the USENIX Annual Technical Conference, General Track, Marriot Anaheim, CA, USA, 10–15 April 2005; pp. 61–75. [Google Scholar]
- Chaudhry, M.T.; Chon, C.Y.; Ling, T.; Rasheed, S.; Kim, J. Thermal prediction models for virtualized data center servers by using thermal-profiles. Malays. J. Comput. Sci. 2016, 29, 1–14. [Google Scholar] [CrossRef]
- Wu, C.M.; Chang, R.S.; Chan, H.Y. A green energy-efficient scheduling algorithm using the DVFS technique for cloud datacenters. Future Gener. Comput. Syst. 2014, 37, 141–147. [Google Scholar] [CrossRef]
- McIntosh, S.; Kephart, J.O.; Lenchner, J.; Yang, B.; Feridun, M.; Nidd, M.; Tanner, A.; Barabasi, I. Semi-automated data center hotspot diagnosis. In Proceedings of the 2011 7th International Conference on Network and Service Management, Paris, France, 24–28 October 2011; pp. 1–7. [Google Scholar]
- Jonas, M.; Varsamopoulos, G.; Gupta, S.K. On developing a fast, cost-effective and non-invasive method to derive data center thermal maps. In Proceedings of the 2007 IEEE International Conference on Cluster Computing, Austin, TX, USA, 17–20 September 2007; pp. 474–475. [Google Scholar]
- Jonas, M.; Varsamopoulos, G.; Gupta, S.K. Non-invasive thermal modeling techniques using ambient sensors for greening data centers. In Proceedings of the 2010 39th International Conference on Parallel Processing Workshops, San Diego, CA, USA, 13–16 September 2010; pp. 453–460. [Google Scholar]
- Mukherjee, T.; Banerjee, A.; Varsamopoulos, G.; Gupta, S.K.; Rungta, S. Spatio-temporal thermal-aware job scheduling to minimize energy consumption in virtualized heterogeneous data centers. Comput. Netw. 2009, 53, 2888–2904. [Google Scholar] [CrossRef]
- Abbasi, Z.; Varsamopoulos, G.; Gupta, S.K. Thermal aware server provisioning and workload distribution for internet data centers. In Proceedings of the 19th ACM International Symposium on High Performance Distributed Computing, Chicago, IL, USA, 20–25 June 2010; pp. 130–141. [Google Scholar]
- Al-Qawasmeh, A.M.; Pasricha, S.; Maciejewski, A.A.; Siegel, H.J. Power and thermal-aware workload allocation in heterogeneous data centers. IEEE Trans. Comput. 2013, 64, 477–491. [Google Scholar] [CrossRef] [Green Version]
- Rodero, I.; Viswanathan, H.; Lee, E.K.; Gamell, M.; Pompili, D.; Parashar, M. Energy-efficient thermal-aware autonomic management of virtualized HPC cloud infrastructure. J. Grid Comput. 2012, 10, 447–473. [Google Scholar] [CrossRef]
- Zhang, S.; Chatha, K.S. Approximation algorithm for the temperature-aware scheduling problem. In Proceedings of the 2007 IEEE/ACM International Conference on Computer-Aided Design, San Jose, CA, USA, 4–8 November 2007; pp. 281–288. [Google Scholar]
- Kumar, M.R.V.; Raghunathan, S. Heterogeneity and thermal aware adaptive heuristics for energy efficient consolidation of virtual machines in infrastructure clouds. J. Comput. Syst. Sci. 2016, 82, 191–212. [Google Scholar] [CrossRef]
- Beloglazov, A.; Buyya, R. Optimal online deterministic algorithms and adaptive heuristics for energy and performance efficient dynamic consolidation of virtual machines in cloud data centers. Concurr. Comput. Pract. Exp. 2012, 24, 1397–1420. [Google Scholar] [CrossRef]
- Buyya, R.; Beloglazov, A.; Abawajy, J. Energy-efficient management of data center resources for cloud computing: A vision, architectural elements, and open challenges. arXiv 2010, arXiv:1006.0308. [Google Scholar]
- Nathani, A.; Chaudhary, S.; Somani, G. Policy based resource allocation in IaaS cloud. Future Gener. Comput. Syst. 2012, 28, 94–103. [Google Scholar] [CrossRef]
- Ahuja, N. Datacenter power savings through high ambient datacenter operation: CFD modeling study. In Proceedings of the 2012 28th Annual IEEE Semiconductor Thermal Measurement and Management Symposium (SEMI-THERM), San Jose, CA, USA, 18–22 March 2012; pp. 104–107. [Google Scholar]
- Rodero, I.; Lee, E.K.; Pompili, D.; Parashar, M.; Gamell, M.; Figueiredo, R.J. Towards energy-efficient reactive thermal management in instrumented datacenters. In Proceedings of the 2010 11th IEEE/ACM International Conference on Grid Computing, Brussels, Belgium, 25–28 October 2010; pp. 321–328. [Google Scholar]
- Banerjee, A.; Mukherjee, T.; Varsamopoulos, G.; Gupta, S.K. Integrating cooling awareness with thermal aware workload placement for HPC data centers. Sustain. Comput. Informatics Syst. 2011, 1, 134–150. [Google Scholar] [CrossRef]
- Wang, L.; von Laszewski, G.; Dayal, J.; Furlani, T.R. Thermal aware workload scheduling with backfilling for green data centers. In Proceedings of the 2009 IEEE 28th International Performance Computing and Communications Conference, Scottsdale, AZ, USA, 14–16 December 2009; pp. 289–296. [Google Scholar]
- Wang, L.; von Laszewski, G.; Dayal, J.; He, X.; Younge, A.J.; Furlani, T.R. Towards thermal aware workload scheduling in a data center. In Proceedings of the 2009 10th International Symposium on Pervasive Systems, Algorithms, and Networks, Kaoshiung, Taiwan, 14–16 December 2009; pp. 116–122. [Google Scholar]
- Tang, Q.; Gupta, S.K.S.; Varsamopoulos, G. Energy-efficient thermal-aware task scheduling for homogeneous high-performance computing data centers: A cyber-physical approach. IEEE Trans. Parallel Distrib. Syst. 2008, 19, 1458–1472. [Google Scholar] [CrossRef]
- Wang, L.; Khan, S.U.; Dayal, J. Thermal aware workload placement with task-temperature profiles in a data center. J. Supercomput. 2012, 61, 780–803. [Google Scholar] [CrossRef]
- Wang, Z.; Bash, C.; Hoover, C.; McReynolds, A.; Felix, C.; Shih, R. Integrated management of cooling resources in air-cooled data centers. In Proceedings of the 2010 IEEE International Conference on Automation Science and Engineering, Toronto, ON, Canada, 21–24 August 2010; pp. 762–767. [Google Scholar]
- Li, X.; Garraghan, P.; Jiang, X.; Wu, Z.; Xu, J. Holistic virtual machine scheduling in cloud datacenters towards minimizing total energy. IEEE Trans. Parallel Distrib. Syst. 2017, 29, 1317–1331. [Google Scholar] [CrossRef] [Green Version]
- Ding, H. Alibaba Cluster Trace Program. 2018. Available online: https://github.com/alibaba/clusterdata/tree/v2018 (accessed on 22 December 2021).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Server ID | CPU Usage% (GHz) | Net Increase in Outlet Temperature | Power (Watt) | Inlet Temperature |
|---|---|---|---|---|
| S1 | IDLE (4.76) | 12.1 | 242 | 23.7 |
| 33.3 (10.16) | 13.8 | 274 | ||
| 66.6 (15.57) | 14.3 | 295 | ||
| 100.0 (20.97) | 15.7 | 320 |
| Attributes | Server A (SA) | Server B (SB) |
|---|---|---|
| Server make | HP ProLiant | HP ProLiant |
| Processor type | Intel Xeon 5430 | Intel Xeon 5320 |
| No. of processors | 2 | 2 |
| No. of cores/processor | 4 | 4 |
| Clock speed | 2.66 GHz | 1.86 GHz |
| Total processing power | 21.28 GHz | 14.88 GHz |
| Hypervisor | VMware ESXi 5.1 | VMware ESXi 5.1 |
| Hyperthreading | Disabled | Disabled |
| Server ID | CPU Utilization (%) | Net Increase in Outlet Temperature | Power (Watt) | Inlet Temperature |
|---|---|---|---|---|
| IDLE | 11.72 | 203.44 | ||
| 12.5 | 12.43 | 223.98 | ||
| 25 | 13.22 | 243.87 | ||
| 37.5 | 14.7 | 265.5 | ||
| SA | 50 | 15.6 | 279.82 | See Figure 1b |
| 62.5 | 16.16 | 295.03 | ||
| 75 | 16.25 | 304.16 | ||
| 87.5 | 17.17 | 317.04 | ||
| 100 | 17.58 | 323.16 | ||
| IDLE | 14.46 | 231.78 | ||
| 12.5 | 15.24 | 255.06 | ||
| 25 | 16.3 | 276.22 | ||
| 37.5 | 17.79 | 290.64 | ||
| SB | 50 | 17.82 | 303.49 | See Figure 1b |
| 62.5 | 19.15 | 312.51 | ||
| 75 | 19.28 | 321.19 | ||
| 87.5 | 19.62 | 327.7 | ||
| 100 | 20.12 | 331.14 |
| Server/Rack | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 1 | A | A | A | A | A | A | A | A |
| 2 | A | A | A | A | A | A | A | A |
| 3 | B | B | A | A | A | A | B | B |
| 4 | B | B | A | A | A | A | B | B |
| 5 | B | B | A | A | A | A | B | B |
| 6 | B | B | A | A | A | A | B | B |
| 7 | B | B | B | A | A | B | B | B |
| 8 | B | B | B | A | A | B | B | B |
| 9 | B | B | B | A | B | A | B | B |
| 10 | B | B | B | A | B | B | B | B |
| 11 | B | B | B | A | B | B | B | B |
| 12 | B | B | B | A | A | A | B | B |
| Algorithm | Utilization (GHz) | Utilization (%) |
|---|---|---|
| TASA | 1158.68 | 70.6 |
| GRANITE | 1046.45 | 63.7 |
| HAWDA | 1185.48 | 72.2 |
| TASA+HASRA | 1105.91 | 67.4 |
| GRANITE+HASRA | 1046.45 | 63.7 |
| HAWDA+HASRA | 1167.05 | 71.1 |
| Computation Energy | Minimum | Maximum | Average | Standard Deviation | |
|---|---|---|---|---|---|
| (KWh) | (W) | (W) | (W) | (W) | |
| TASA | 391.704 | 5662.213 | 7076.863 | 6263.088 | 275.942 |
| GRANITE | 390.250 | 5676.713 | 7028.761 | 6239.840 | 252.557 |
| HAWDA | 391.691 | 5657.347 | 7086.049 | 6262.888 | 275.016 |
| TASA+HASRA | 391.685 | 5672.590 | 7083.192 | 6262.791 | 274.083 |
| GRANITE+HASRA | 390.250 | 5676.713 | 7028.761 | 6239.840 | 252.557 |
| HAWDA+HASRA | 391.723 | 5656.853 | 7094.053 | 6263.389 | 279.618 |
| Cooling Energy | Minimum | Maximum | Average | Standard Deviation | |
|---|---|---|---|---|---|
| (KWh) | (W) | (W) | (W) | (W) | |
| TASA | 14.238 | 207.468 | 255.949 | 227.660 | 9.453 |
| GRANITE | 14.324 | 208.727 | 257.707 | 229.029 | 9.165 |
| HAWDA | 14.217 | 206.867 | 255.741 | 227.315 | 9.389 |
| TASA+HASRA | 14.175 | 204.709 | 259.007 | 226.649 | 10.590 |
| GRANITE+HASRA | 13.720 | 200.418 | 248.842 | 219.374 | 8.991 |
| HAWDA+HASRA | 14.224 | 202.845 | 261.198 | 227.427 | 11.396 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamal, M.H.; Chaudhry, M.T.; Tahir, U.; Rustam, F.; Hur, S.; Ashraf, I. Hotspot-Aware Workload Scheduling and Server Placement for Heterogeneous Cloud Data Centers. Energies 2022, 15, 2541. https://doi.org/10.3390/en15072541
Jamal MH, Chaudhry MT, Tahir U, Rustam F, Hur S, Ashraf I. Hotspot-Aware Workload Scheduling and Server Placement for Heterogeneous Cloud Data Centers. Energies. 2022; 15(7):2541. https://doi.org/10.3390/en15072541
Chicago/Turabian StyleJamal, M. Hasan, M. Tayyab Chaudhry, Usama Tahir, Furqan Rustam, Soojung Hur, and Imran Ashraf. 2022. "Hotspot-Aware Workload Scheduling and Server Placement for Heterogeneous Cloud Data Centers" Energies 15, no. 7: 2541. https://doi.org/10.3390/en15072541
APA StyleJamal, M. H., Chaudhry, M. T., Tahir, U., Rustam, F., Hur, S., & Ashraf, I. (2022). Hotspot-Aware Workload Scheduling and Server Placement for Heterogeneous Cloud Data Centers. Energies, 15(7), 2541. https://doi.org/10.3390/en15072541