1. Introduction
The development of renewable energy can effectively reduce the deficiency of global energy and reduce environmental pollution [
1]. Notably, wind energy has become one of the fastest-growing renewable energy sources [
2], serving as an environmentally friendly and clean energy source that can meet the requirements of human sustainable development [
3]. According to statistics related to WT (wind turbine) released by the World Wind Energy Association (WWEA) in early 2021, the total installed capacity of global WT in 2020 reached 744 GW [
4].
Despite the extensive promotion of WP, bringing about significant economic benefits, wind farms are also facing several challenges. Since the wind farms’ output power can be volatile and uncertain, after the wind farm is connected to the grid, there will be certain disturbances to the safe operation of the power system [
5]. To overcome such problems, accurate forecasting of the wind farm output power is necessary. Through forecasting, WP fluctuations can be determined in advance. As such, corresponding countermeasures can also be prepared in advance, and a reasonable power generation plan can be arranged, which not only ensures the safety of the grid, but also improves its reliability [
6].
In recent years, researchers have conducted extensive research on WP forecasting using numerous mainstream models, including physical models [
7], statistical models [
8,
9], and artificial intelligence (AI) models [
10,
11], among which AI models are the most widely studied.
AI models usually establish a high-dimensional nonlinear function to fit WP by minimizing training errors [
12]. The more widely used methods are mainly machine learning (ML) methods and artificial neural network (ANN) methods. ML methods mainly include Support Vector Regression (SVR), Least Square Support Vector Machine (LSSVM), and Extreme Learning Machine (ELM) networks [
13]. Kuilin Chen et al. [
14] used an unscented Kalman filter (UKF) for integration with SVR to establish an SVR-UKF forecasting model, which improved the forecasting accuracy of the SVR model. The ANN acts as a parallel processor with the ability of efficiently storing and figuring out experimental knowledge; it is suitable for solving complex nonlinear problems [
15]. D. Huang et al. [
16] used GA and BP neural networks to forecast the WP of a wind farm. This GA-BP model was beneficial in improving the correctness of WP forecasting. P. Guo et al. [
17] used GA to optimize the hyper-parameters of RBF and to predict the WP of a wind farm. As the theories and technology of neural networks have gradually developed and matured, more researchers have applied deep neural networks (DNN), such as convolutional neural networks (CNN) [
18], deep belief networks (DBN) [
19], and RNN [
20] to predict the WP of wind farms.
LSTM as a form of RNN, has been demonstrated to be suitable for analyzing long series data, and there have been an increasing number of studies on the forecasting of WP based on LSTM networks. In order to construct an LSTM network model that meets the requirements, it is necessary to adjust the relevant hyperparameters, and researchers often set the parameters according to their actual experience and priori knowledge. For different problems, it may be necessary to repeatedly manually tune the relevant parameters.
To address such issues, the parameters of LSTM are optimized using the MEBS algorithm; thus, constructing the MBES-LSTM forecasting model. The experimental results reveal that the optimized forecasting model can better predict the trend of WP and provide technical support for the refinement of wind farm management. The main contributions are highlighted as follows:
- (1)
The original BES algorithm was improved, and the improved BES algorithm was tested.
- (2)
The wind farm data collected by the SCADA system was cleaned and filtered to form a sample set and processed by means of an empirical mode decomposition (EMD) method.
- (3)
The parameters of the LSTM such as iteration number , learning rate , number of the first layer , number of the second layer , were optimized by the MBES algorithm, and the MBES-LSTM forecasting model was subsequently constructed.
- (4)
The processed WP data was used as the test sample with the PSO-RBF, PSO-SVM, LSTM, PSO-LSTM, BES-LSTM, and MBES-LSTM models to predict and compare performance.
The balance of this paper is organized as follows:
Section 2 describes the LSTM, BES, and MBES algorithm. Evaluation index, MBES-LSTM forecasting model, SCADA data preprocess, and relevant parameter settings are introduced in
Section 3.
Section 4 provides some graphical results, along with analysis. Finally,
Section 5 concludes this paper.
3. WP Forecast
3.1. MBES-LSTM Forecasting Model
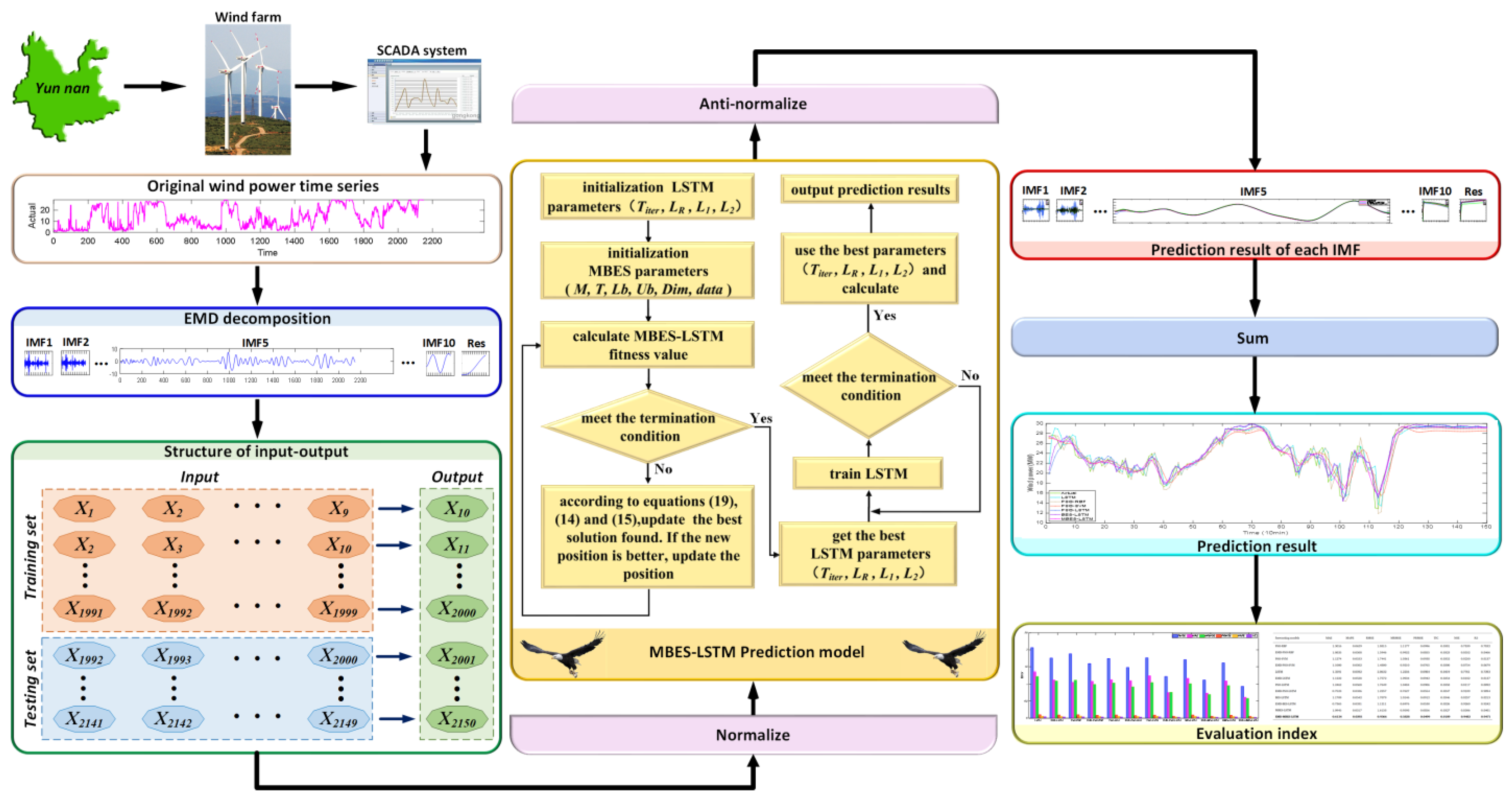
To reduce forecasting errors, SCADA data is decomposed using the EMD method after preprocessing. The flow chart of the MBES-LSTM WP forecasting model based on the EMD is shown in
Figure 4, and the specific steps were as follows:
Step 1: The EMD method was used to decompose the pre-processed WP time series data and to decompose the data into the intrinsic mode function (IMF).
Step 2: The data of each IMF was divided into a training set and a test set.
Step 3: The decomposition data from each IMF was normalized.
Step 4: The MBES-LSTM model was used for training and forecasting, respectively, and in this step:
- (1)
The LSTM parameter and the MBES algorithm parameters, including the bald eagle population , the maximum iterations , the upper limit of argument , the lower limit of argument , the dimension , and the sample data were initialized.
- (2)
The data of the fitness value was calculated. The mean square error obtained by training the LSTM network was used as the fitness value, and the value was updated in real-time as the bald eagle continued to operate; within the iteration range, Formulas (14), (15), and (19) were used to calculate the position of the bald eagle. If the current new position was better, the old position was updated.
- (3)
According to the optimal parameter combination, the LSTM network was trained, and testing samples were used to forecast and save the result of each IMF.
Step 5: The results of each IMF from Step 4 were anti-normalized.
Step 6: By linearly superimposing the forecasting results of each IMF, the final forecasting result was obtained.
Step 7: The relevant evaluation metrics were calculated.
3.2. Data Preprocessing and EMD Decomposition
In the present study, the actual operational SCADA data of a wind farm in Yunnan, China, from 1 August 2018 to 31 August 2018, was selected for the analysis of the calculation examples. The time resolution of the data was ten minutes. After data cleaning, the first 2150 groups were taken as experimental samples. The relevant features of the samples are shown in
Table 6.
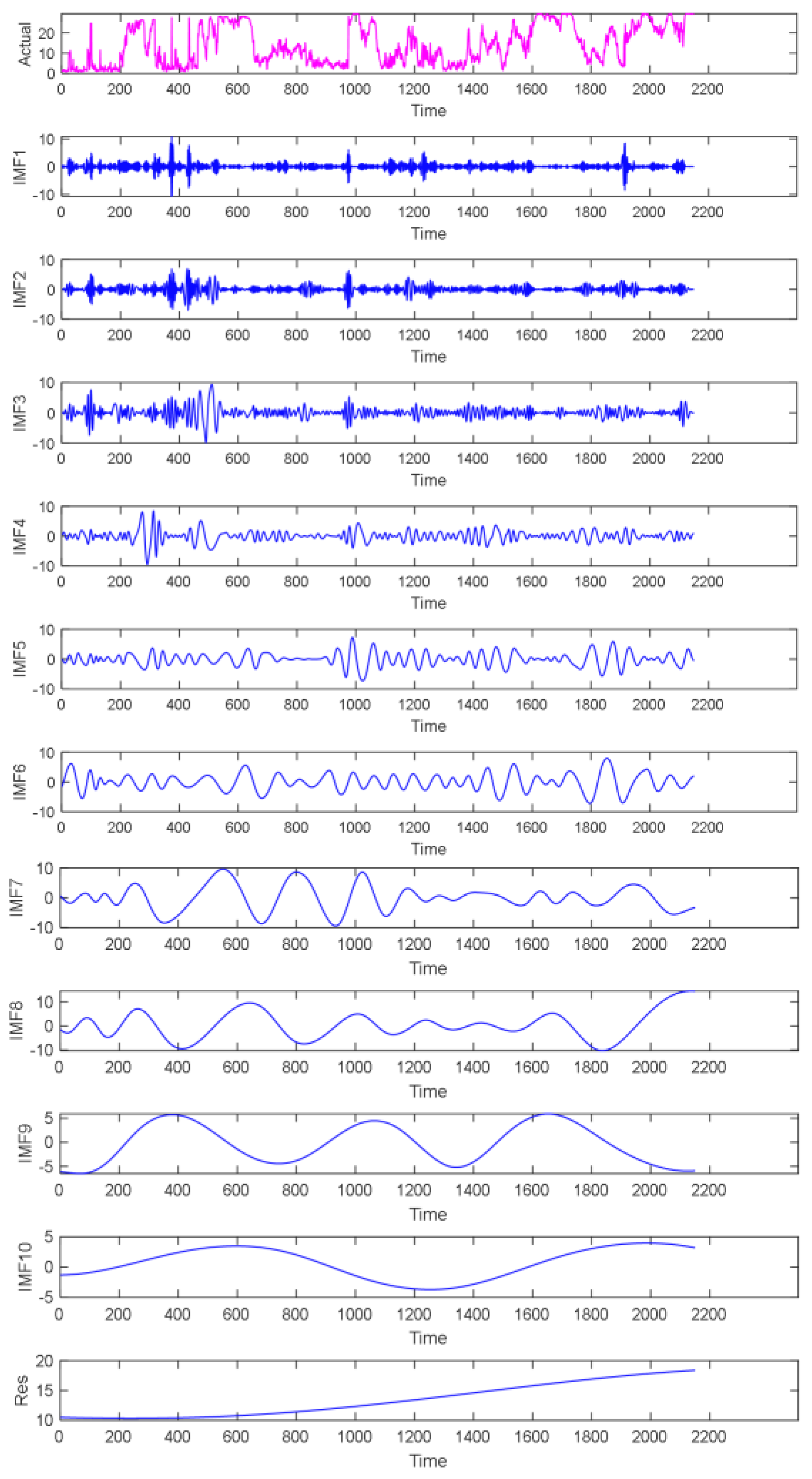
To further reduce the nonlinearity and strong volatility characteristics of the WP signal and enhance the forecasting precision, the EMD algorithm was first used to decompose the preprocessed SCADA data and then perform related calculations. The EMD decomposition results of the original WP data are shown in
Figure 5. A total of 10 IMF components and 1 remaining component were decomposed, and they are plotted in blue.
Figure 5 shows that the time characteristic scale of the eigenmode function component increased from IMF1 to IMF10, and the frequency changed from high to low.
3.3. Parameters Setting
In the present study, PSO-RBF and PSO-SVM models were established, and algorithms such as PSO, BES, and MBES were used to optimize the hyper-parameters of the LSTM. The relevant parameter values are shown in
Table 7.
3.4. Evaluation Indicators
To better assess the performance of the MBES-LSTM forecasting model, RMSE, MAE, MAPE, COV, CC, TIC, EC, and r2 were used in the present study. The specific expressions are as follows:
(1) The root mean square error (
RMSE) indicates the deviation between the predicted and actual values.
(2) The mean absolute error (
MAE) reflects the actual situation of the errors, and this value also becomes larger when the error is large.
(3) The mean absolute percentile error (
MAPE) is used to the measure forecast accuracy. Smaller
MAPE values indicate that the model is more accurate in predicting
(4) The coefficient of variance (
COV) [
24] reflects the degree of discretization of the data, with a larger value indicating a higher degree of data scattering.
(5) The correlation coefficient (CC) represents the relationship between the actual and predicted values. This value is close to 1 when the actual data is strongly correlated with the predicted data.
(6) The Theil’s inequality coefficient (
TIC) [
25], with a value range between [0, 1]. The smaller the
TIC value, the better the prediction accuracy of the model.
(7) The efficiency coefficient (
EC) [
26] is generally used to verify the goodness of fit of the model’s prediction results, and if the
EC is close to 1, the prediction quality of the model is good.
(8) The coefficient of determination
r2 (
r2) estimates the combined dispersion against the single dispersion of the observed and predicted series.
where
represents the WP observation value at time
t;
is the WP forecast value at time
t;
is the average WP observation;
is the average WP forecast; and
N is the number of samples in the
sequence.
4. Experimental Results and Discussion
In WP forecasting, the setting of related parameters directly affects the forecasting precision of the LSTM network. In the present study, the PSO, BES, and MBES algorithms were used to optimize the hyper-parameters such as
,
,
, and
. The LSTM-related parameter values and calculated errors in each IMF decomposition are shown in
Table 8.
Table 9 indicates the Loss and RMSE of the LSTM, PSO-LSTM, BES-LSTM, and MBES-LSTM models in the training set and the testing set. An observation can be made that the MBES-LSTM model trends towards small Loss and RMSE value in the training set and the testing set.
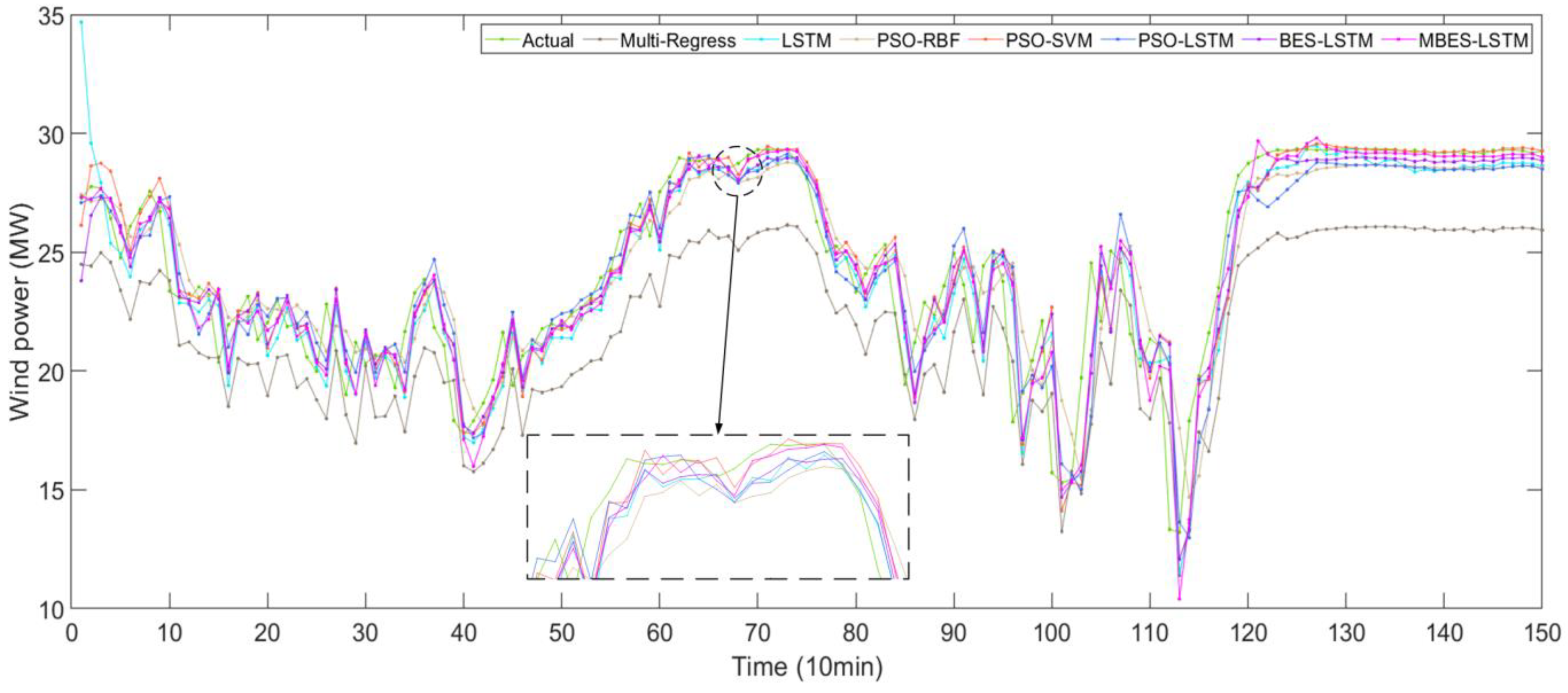
To further reflect the advantages of the MBES-LSTM forecasting model, some models were contrasted with other models such as the Multi-Regress, LSTM, PSO-RBF, PSO-SVM, PSO-LSTM, and BES-LSTM models.
Figure 6 shows a comparison diagram of the direct forecasting results of the models. It can be noted from
Figure 6 that the prediction line of the multi-regress model was far away from the actual line, indicating that the prediction results were poor, while the prediction lines of other models were near the actual lines.
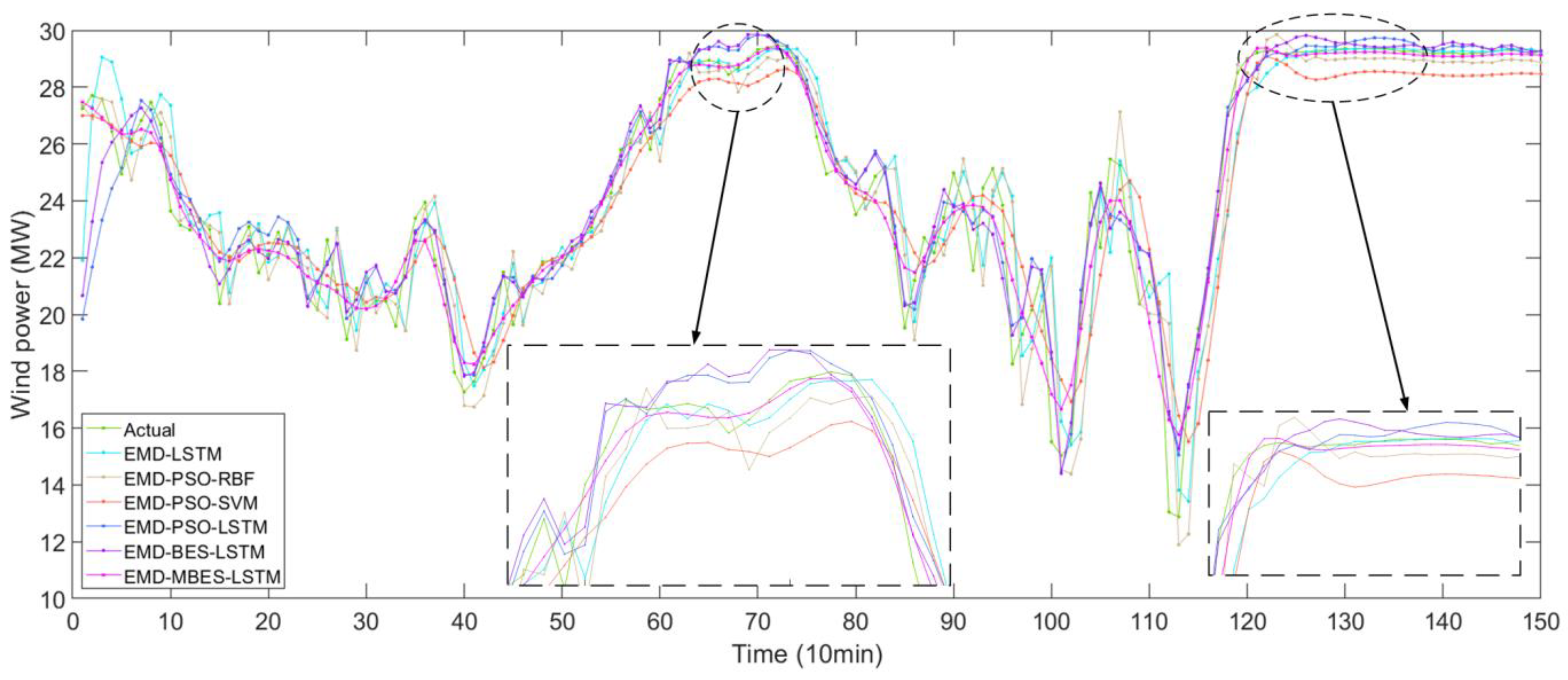
Figure 7 shows the forecasting results of different models based on the EMD algorithm.
In
Figure 6 and
Figure 7, the solid green line represent the actual values, while the remaining six colored lines represent the forecasted values. The closer their location to the green line, the higher the forecasting accuracy of the models. An observation can be made that the forecasting value line of the MBES-LSTM model was closer to the green line, which indicates that the forecasting precision of MBES-LSTM was the highest.
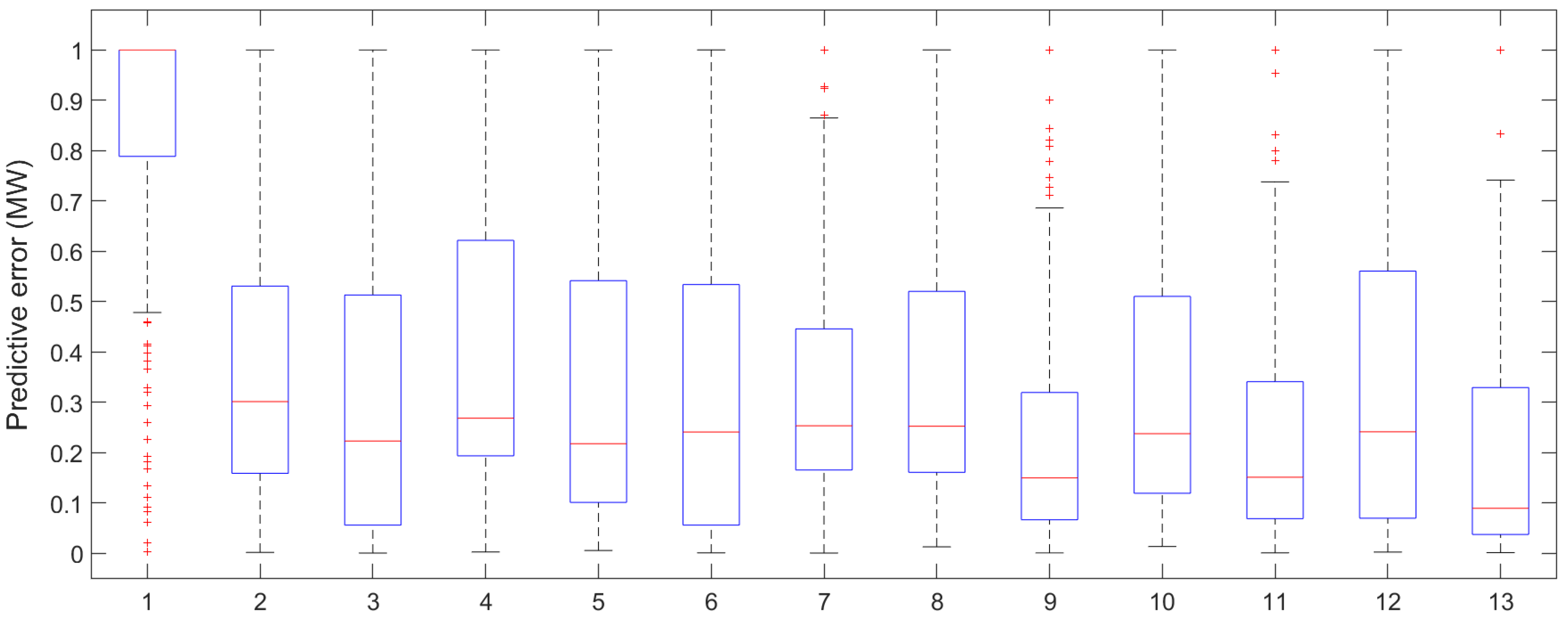
In order to more intuitively reflect the size of the forecasting error, a box-plot was drawn to graphically present the forecasting error, as shown in
Figure 8. According to the box-plot, the MBES-LSTM model based on EMD showed less errors.
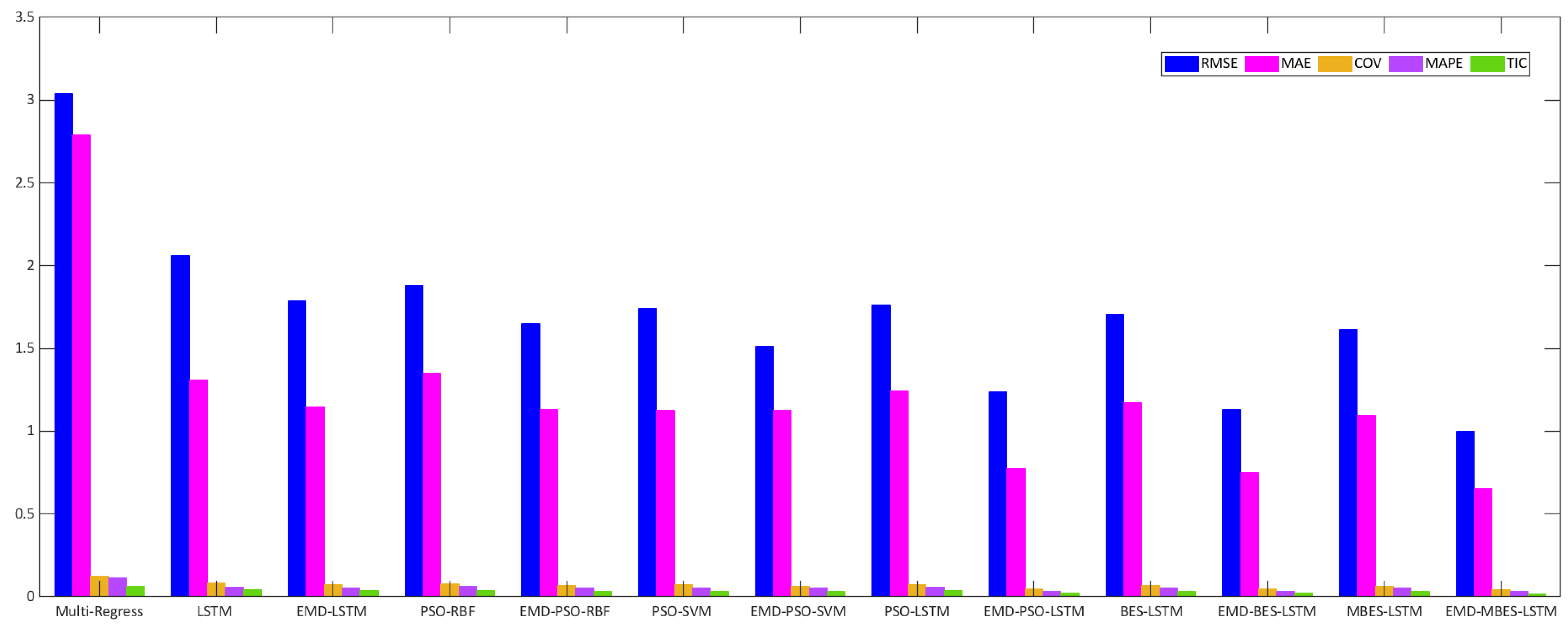
Formulas (20)–(27) were used to calculate the relevant evaluation indicators of each forecasting model. The calculation results are shown in
Table 10, according to which proposed EMD-MBES-LSTM model had the optimal forecasting performance, exhibiting the highest performance indexes.
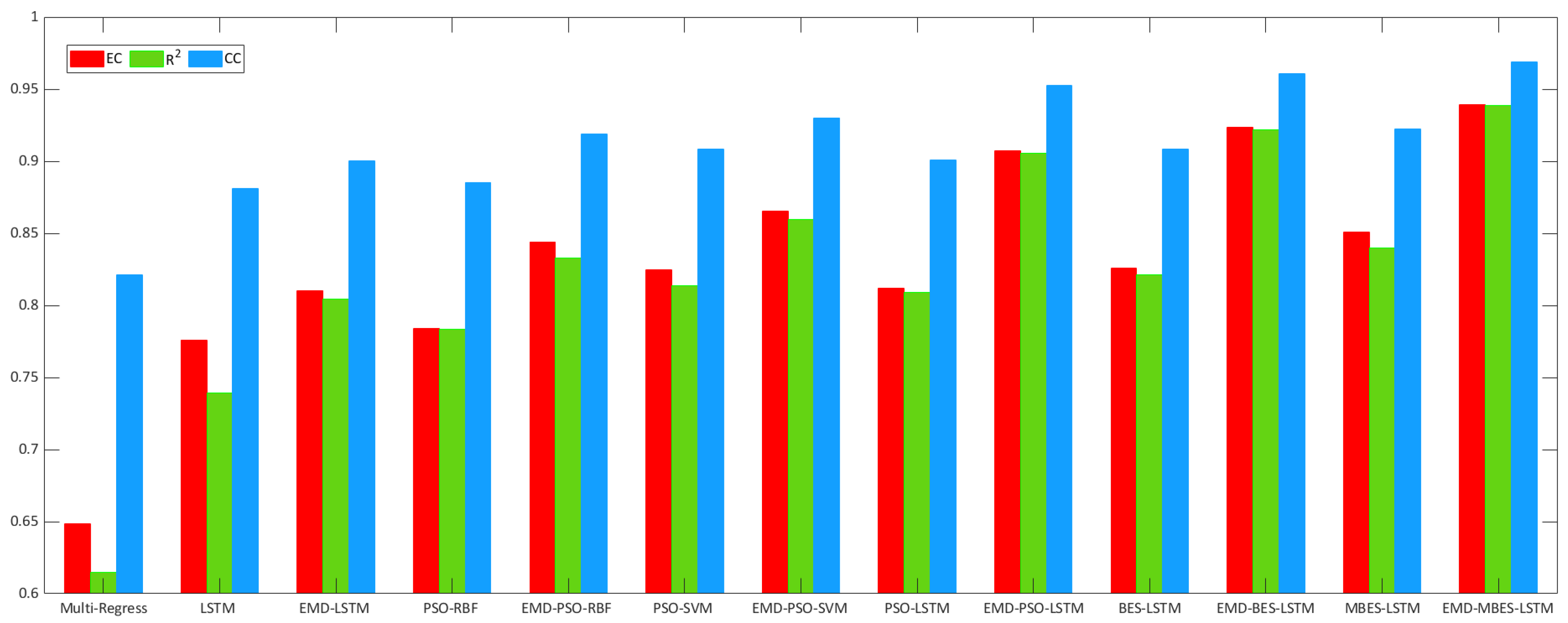
Figure 9 and
Figure 10 describe the relevant evaluation index histograms. In
Figure 9, the height of the blue column represents the RMSE of the Multi-Regress, LSTM, PSO-RBF, PSO-SVM, PSO-LSTM, BES-LSTM, and MBES-LSTM forecasting models; the height of the magenta column represents the MAE of every model; the height of the green column represents the TIC. In
Figure 10, the height of the red column represents the EC, and the height of the green column represents the r
2 of each model. From
Figure 9 and
Figure 10, an observation can be made that the MBES-LSTM model described in the present study showed the minimum evaluation error and highest evaluation coefficient, regardless of which evaluation standard was used.
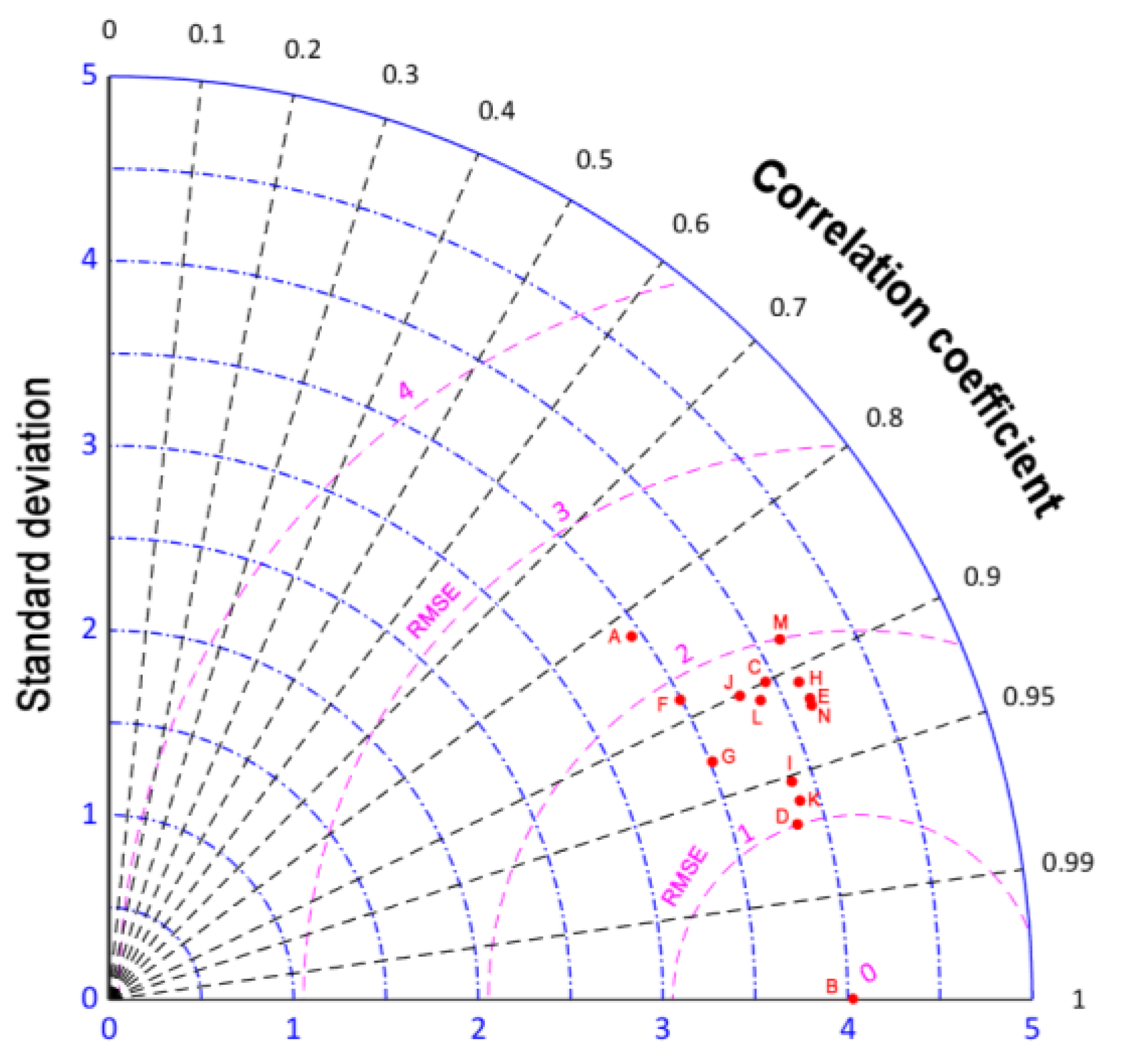
A Taylor diagram of the forecasting models is shown in
Figure 11. In
Figure 11, point D is closest to point B, indicating that point D had the best performance metrics. Specifically, the MBES-LSTM model based on EMD had the optimal predictive performance.
The MBES-LSTM model based on EMD has many advantages. Compared with the other models, there was a significant improvement in the forecasting accuracy in terms of WP forecasting. The MBES-LSTM model can be summarized as follows:
(1) The EMD algorithm was a significant factor in data preprocessing, and it significantly improved the forecasting accuracy. As can be seen from
Figure 6 and
Figure 7 and
Table 10, after EMD decomposition on LSTM, RMSE decreased by about 0.2751, MAE decreased by about 0.1607, and r
2 increased by about 0.0649.
(2) The proposed algorithm was evaluated through several different benchmark functions and was applied in the parameter estimation of LSTM. As can be seen from
Table 9 and
Table 10, compared with the standard bald eagle algorithm, the modified bald eagle algorithm had a positive effect on LSTM hyper-parameter optimization. After optimizing the related parameters of LSTM with the modified bald eagle algorithm, RMSE decreased by about 0.0922, MAE decreased by about 0.0764, and r
2 increased by about 0.0188.
5. Conclusions
Accurate forecasting of WP is integral for the safe dispatch of power systems and the operation management of wind farms. In the field of WP forecasting, LSTM is a commonly used in-depth learning algorithm. With the aim of solving the problem that the improper selection of LSTM related parameters may adversely affect the forecasting results of the LSTM, an MBES-LSTM WP short-term forecasting model was established in the present study.
(1) In the selection phase, the improvement of parameters is based on creating varied values for the learning parameter in each iteration, which helps to enhance the exploration of the MBES algorithm.
(2) The MBES algorithm was adopted to optimize the relevant parameters of the LSTM to form the MBES-LSTM model. In the WP forecasting test on the wind farm, the forecasting accuracy rate was better than that of the PSO-RBF, PSO-SVM, LSTM, PSO-LSTM, and BES-LSTM models.
Only historical WP data are used in the MBES-LSTM forecasting model. The WP is constantly affected by external factors, such as the wind direction, landforms, humidity, air temperature, and atmospheric pressure. Such factors will lead to rapidness, high nonlinearity, and uncertainty of WP changes, and thus, should be considered reasonable when establishing a multi-input forecasting model. In this way, the accuracy of WP forecasting can be further improved, which is also indicated for future study.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}