We developed a concept for an open digital energy R&D platform based on the requirements analysis [
5] and the related work presented in
Section 2. Besides the five different key services introduced by Werth et al. [
5], we added a sixth central key service containing functionalities required by all other key services:
Core. Since the naming of the key service
Best Practices led to several misunderstanding during the requirements analysis [
5], we renamed the key service to
Methods.
Figure 1 gives an overview on these six key services. This section describes all key services, their goals, and functionalities.
3.1. Core
The goal of Core is to support the other key services with basic functionalities not specific for the energy domain.
Work flows for the continuing development of the platform are defined based on a Technical Infrastructure and are usable for all key services. General Pages, including “About us” and “Privacy policy”, give an overview about the history, last developments, the involved institutions of the platform, and the privacy policy of the platform.
User Management provides central authentication, login, and registration for user accounts for all key services as well as linking to user accounts on other platforms, e.g., to ORCID (
https://orcid.org/, accessed on 7 January 2022) or Gitlab (
https://about.gitlab.com/, accessed on 7 January 2022).
Federated Search enables searching over the whole R&D platform. A search API is defined such that all key services can be accessed the same way and filters from the different key service can be used.
PID Service allows to create PIDs via an API for different entities on the platform, such as data description in Repository, institution profiles in Competence, or project descriptions in Transparency. These PIDs will not change over time and, therefore, allow persistent linking between the key services so that an institution in Competence can be used as responsible institution in the data description in Repository.
Ontology Service provides an access point to ontologies in the energy domain for all services, such as the Open Energy Ontology [
12], the common information model [
18], and others. By using common ontologies for the description of artifacts, such as data, software, or for the information stored in
Transparency or
Competence, the same words are used for the same things, improving the interoperability and search functionality of the platform.
3.2. Competence
The goal of Competence is to demonstrate multi-layered competences on the presented open digital energy R&D Platform. It also includes a presentation of its underlying research network considering subject-specific and user-oriented presentation, as well as easy and multi-sided access to competences. Competence enables information transfer via an API.
Competence consists of multiple functions to adequately present the competences and proficiencies of registered users and entities on the open digital energy R&D platform.
Figure 2 shows an overview of the different functionalities of
Competence.
The central function of
Competence is the
competence profile, allowing a proper presentation of the registered entities’ proficiencies. A clear representation of competences and research interests are requirements for this element identified by Werth et al. [
5].
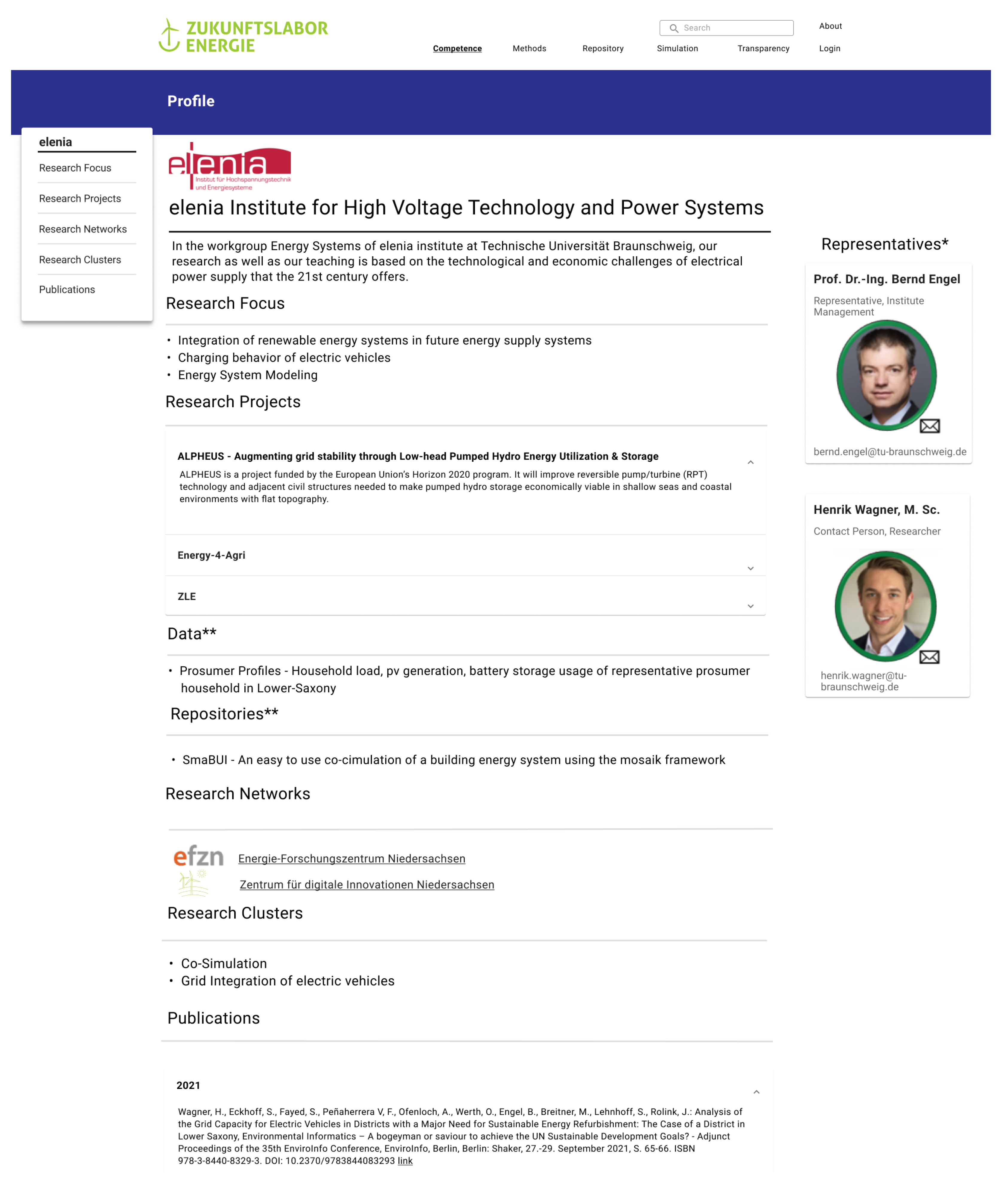
Figure 3 shows a mockup of the
Competence Profile. The level of detail respectively identification for each profile will be the workgroup-level (e.g., workgroup “Energy Systems” at elenia Institute for High Voltage Technologies and Power Systems (
https://tu-braunschweig.de/elenia/team/wimi, accessed on 16 March 2022)). Higher level of detail or person-specific profiles are not intended, as they will drastically increase the amount of needed profiles and therefore. maintenance effort.
Competence uses
Core’s
PID Service and
Federated Search to enable a persistent linking and finding of competences over all platform key services.
Profile Information includes all necessary content to describe a
Competence Profile. It consists of basic information about the stakeholder, a representative, and a contact person (see
Figure 3). The contact person should also be in charge of maintaining the profile. Moreover, the research focus, research projects, and current publications (including papers, data, and simulation models) but also open matching processes (see
Competence Matching) are listed together with memberships in other research networks. The implementation of
Profile Information may be following TIB VIVO but reducing the personal dissolution to the described workgroup level. Potential user-created and/or used
Methods, data or models (both from
Repository) are linked and listed in the
Profile Information (see
Figure 3). Generated or used scenarios from
Simulation are included in the
Profile Information. Activities in the
Public Forum of
Transparency and other shared information from
Transparency are also directly displayed in the
Profile Information. In this way,
Transparency works as a communication channel for the provision and spread of information. All of the
Profile Information is accessible by
Core’s
Federated Search.
Input Mask provides two different ways of entering information for the Profile creation. First, the questionnaire uses an interview-based format which leads through the profile creation process by questioning the needed information (e.g., “What is the shortcut of your research institute?”—elenia). The questions follow one after another and include useful hints as well as examples. This provides an interactive way which may reduce terminations of the profile creation process. Second, as another way to create a Competence Profile, the Input Mask provides prescribed answer boxes. For adequate search results, the Competence Taxonomy simplifies filling out the profile.
Updating Publications refreshes the profile’s literature reference by uploading and processing BibTex files, vastly reducing handling time. The publications can also be updated automatically by crawling listed publications (e.g., using the name of the profile representative) of a profile from Google Scholar.
Dead Man’s Switch flags profiles as inactive when they do not update their information (e.g., literature references) nor log in for a set amount of time (see
Figure 3 green circle around representatives pictures). In this way, up-to-date profiles are guaranteed, identified as a requirement [
5]. This increases the incentive to maintain the profiles and shows the active participation in the community of the research platform.
Research Clusters allow the grouping of competences based on a common research focus, e.g., co-simulation of energy, or membership, e.g., of a local research society, as it is done by the Energy Research Center of Lower Saxony. The clustering helps to synthesize groups of researchers which may not belong to the same institution or project but still focus on the same research topic. Moreover, it also provides a connecting point for new researchers. Additionally, displaying research clusters in the form of a word cloud (e.g., in the style of Mentimeter (
https://www.mentimeter.com/, accessed on 16 March 2022)) provides inspiration and arouses the curiosity of new users.
Competence Taxonomy unifies and simplifies filling out the entries in the profiles. This enables describing the same competences with the same definition, reducing less precise descriptions and enabling the formation of competence clusters and displaying them as described in the Research Clusters. Competence Taxonomy is derived from the Energy Ontology of Core.
All registered profiles are displayed on an interactive map (e.g., in the style of ZDIN’s resarch map (
https://www.zdin.de/digitales-niedersachsen/forschungslandkarte, accessed on 29 March 2022)) within the
Research Map. It includes filter functions (e.g., based on address or perimeter). Additionally, a network representation of
Research Clusters can be selected showing the geographical spread of in terms of
Research Clusters connected profiles.
Competence Matching helps to form new research consortia and alliances similar to Edecy. Each platform profile can initiate a new matching process (e.g., based an a current research proposal) and define the needed competences. Then, the matching algorithm identifies relevant registered profiles and invites them to participate in the matching process. Therefore, new research consortia and alliances can be formed as a result of the matching process.
3.3. Methods
The goal of Methods is to provide an overview of scientific methodologies in energy research, both general and platform-specific, during the different stages of research. It presents methods for conducting open energy research gathered from successful experiences and current research practices. Methods and standards for cooperative project development, scenario modeling, and data management are required to deliver ideas to structure and execute cooperative research. Additionally, Methods provides an introduction for the use of the different services of the platform, also showing how the key services can be used during the general methods. Therefore, it helps users to learn how to use our platform efficiently in their work.
The requirement analysis identified that this key service is mostly interesting for the research community, from beginners to experts, potentially interested in methodologies for open energy research [
5]. Therefore, this service is designed with these stakeholders in mind. Some functionalities of this key service may also be developed with different users under consideration (e.g., industrial partners, decision-makers, and citizens). Similar to openmod,
Methods is designed like a wiki, allowing to create, edit, search, and present content while also including connections to other key services, especially to
Core (
User Management, and
Federated Search).
Figure 4 gives a broad overview of the different parts of the
Methods element.
First,
General Methods for Open Energy Research provides an overview of experiences from research projects for different stages of the research cycle. The content entries include examples from project and application formulation linked to more information in
Transparency. The methods include, but are not limited to, the following: scientific project management and scientific research methods; modeling in energy research; information and examples on data management and analysis (data base management, licenses, FAIR data principles [
4]); and guidelines for publications and listing (or links) to themed conferences or journals. A first view of what is desired may be partially reflected in existing initiatives and communities for energy system modeling and simulation platforms, such as openmod or Open Science Framework. The structuring should use defined words from
Core’s
Ontology Service when possible. Additionally, it is desired that any registered platform user is able to create and edit content (via
User Management), with the rights to approve, revert, and delete content reserved for platform administrators.
Second, Platform Methods is linked thematically with the other platform key services. Guidelines for their use are introduced and linked to the General Methods for Open Energy Research. Introductory explanations are showcased with demonstrative examples under consideration of user profiles and degree of expertise providing explanations and coding templates for use of the platform. Examples for proper use of the online Simulation tool, Competence search functionalities, and Transparency services are to be showcased. The creation and change of this content is restricted to platform developers.
3.4. Repository
The goal of
Repository is to make data, models, and scenarios in the energy domain more FAIR. A metadata database is introduced to make these artifacts findable. Werth et al. identified the need to included not openly available artifacts [
5]. Therefore,
Repository includes information on openly and not openly available artifacts. Werth et al. identified a great potential for common harmonized interfaces [
5]. Therefore, they are supported by labeling and describing them and, therefore, increasing their visibility to improve the overall interoperability and reusability. Based on these standardized interfaces, data and models can be used within scenarios in
Simulation.
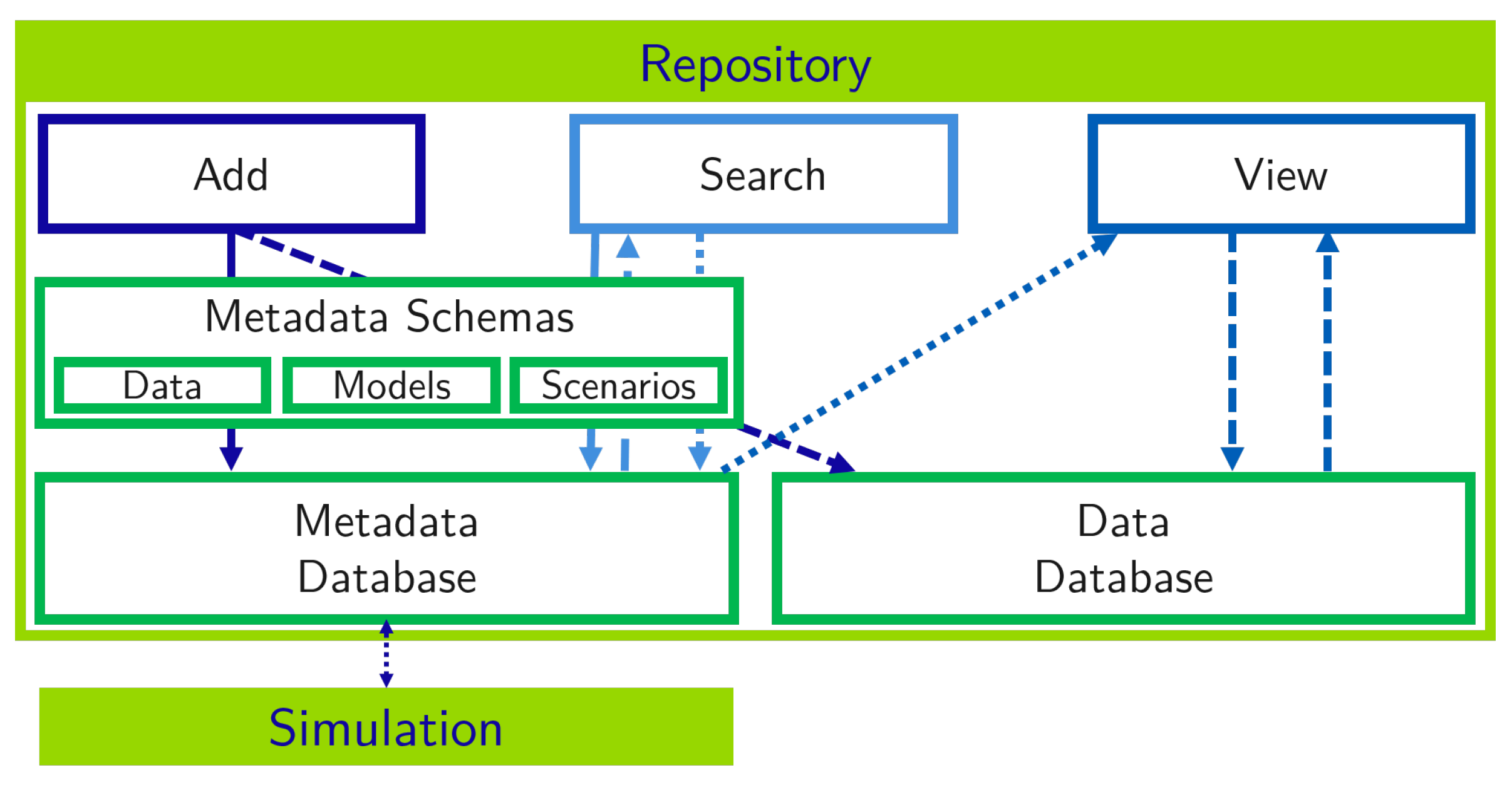
Figure 5 gives a brief overview of the main functionalities of
Repository focusing on three main classes of artifacts: data, models, and scenarios. These are described with metadata based on standardized
Metadata Schemas, so their description can be better compared and integrated into other key services like
Simulation. The metadata and data are stored in
Databases. Users can access
Repository via three functionalities:
Artifact Add,
Artifact Search, and
Artifact View.
Artifact Add enables users to add new artifacts with their description and, if possible, with their data. The addition of data is left optional, so data that are accessible only on request can be added as well, which was identified as a requirement by Werth et al. [
5]. An interactive form is provided to add the required information with questions based on the according metadata schema. Relevant information is automatically collected from a provided link to the artifact, e.g., from gitlab.
Artifact Add supports users to add links to entities in other key services, e.g.,
Research Projects in
Transparency, predefined ontologies from
Core, or other semantic web resources by presenting suggestions when input is typed.
Artifact Search should be developed in accordance with the API of Core’s Federated Search. All Databases should be searched for relevant entries, and the results can be filtered according to different elements of the Metadata Schemas.
Artifact View defines an artifact overview page for all artifacts presenting the most important information from the related metadata and links to other relevant resources. A preview and a graphical visualization for data are included into the page, similar to Kaggle (
https://www.kaggle.com/datasets, accessed on 7 January 2022). Additionally, the services offer to download data in different formats and time resolutions. For scenarios, it is possible to directly import them into
Simulation as shown in
Figure 6. Additionally, a comparison page enables to compare different artifacts.
Metadata Schemas are required to describe the artifacts in a standardized and machine-readable way. They are used to predefine the different elements needed to describe and categorize a certain artifact. For each element, the schema defines if a free value is allowed or if the use of a controlled vocabulary is required, e.g., domain-specific ontologies provided by
Core, to increase the interoperability of the metadata [
19]. Bio.tools shows how a well developed metadata schema can be the base for a registry for research software and, therefore, inspires the use of metadata schemas for this service.
The
Metadata Schemas for data, models, and scenarios can share some common elements while some elements will differ, similar to the way these different artifacts are described on the OEP. In general, the
Metadata Schemas include links to papers, projects, other relevant artifacts, and their description, e.g., in
Transparency; information about who is allowed to access the artifact (based on
Core’s
User Management); quality of the artifact, e.g., origin of the data, if they are reviewed and tested, and how often they are already reused in other studies; and the authors and others which can be partly inherited from DCAT (
https://www.w3.org/TR/vocab-dcat-2/, accessed on 7 January 2022) and a PID created by
Core’s
PID Service. To date, no common standard for metadata schemas exists in the energy domain [
20].
Repository builds on and extends different existing metadata schemas to increase interoperability, such as the metadata schemas for datasets of the Open Energy Platform and CodeMeta (
https://codemeta.github.io/, accessed on 7 January 2022) as metadata schema for research software. The metadata schema for scenarios, also used for
Simulation, requires the use of semantic web technologies [
6] to support automated scenario creation. Reder et al. collected requirements for the description of scenarios in energy research [
21]. These requirements will be used for the development of a metadata schema for scenarios as well.
Two types of
Databases are required for
Repository. For all artifacts,
Repository needs to store the metadata based on the defined schemas. For data,
Repository stores the data and allows access via an API which can be limited to specified user groups (as result of the requirements analysis, see [
5]). For all data, metadata are also required and stored in the according database. Artifacts from the
Databases can also be linked and displayed in
Competence’s
Profile Information.
3.5. Simulation
The goal of
Simulation is to provide an online co-simulation platform to couple different tools and models. Thus,
Simulation supports the reusability of different simulation tools and models to enable co-simulation of various scenarios by addressing typical use cases in interdisciplinary energy research. This key service extends co-simulation frameworks like mosaik by adding assistance to build complex scenarios based on the artifacts from
Repository. The focus lies on the combination of different domain-specific simulation tools and models into the co-simulation [
16]. Since the models and data are mainly derived from
Repository, the semantic-web based
Metadata Schemas for data, models, and scenarios are required and used as a foundation for
Simulation to list and connect compatible artifacts within the co-simulation platform.
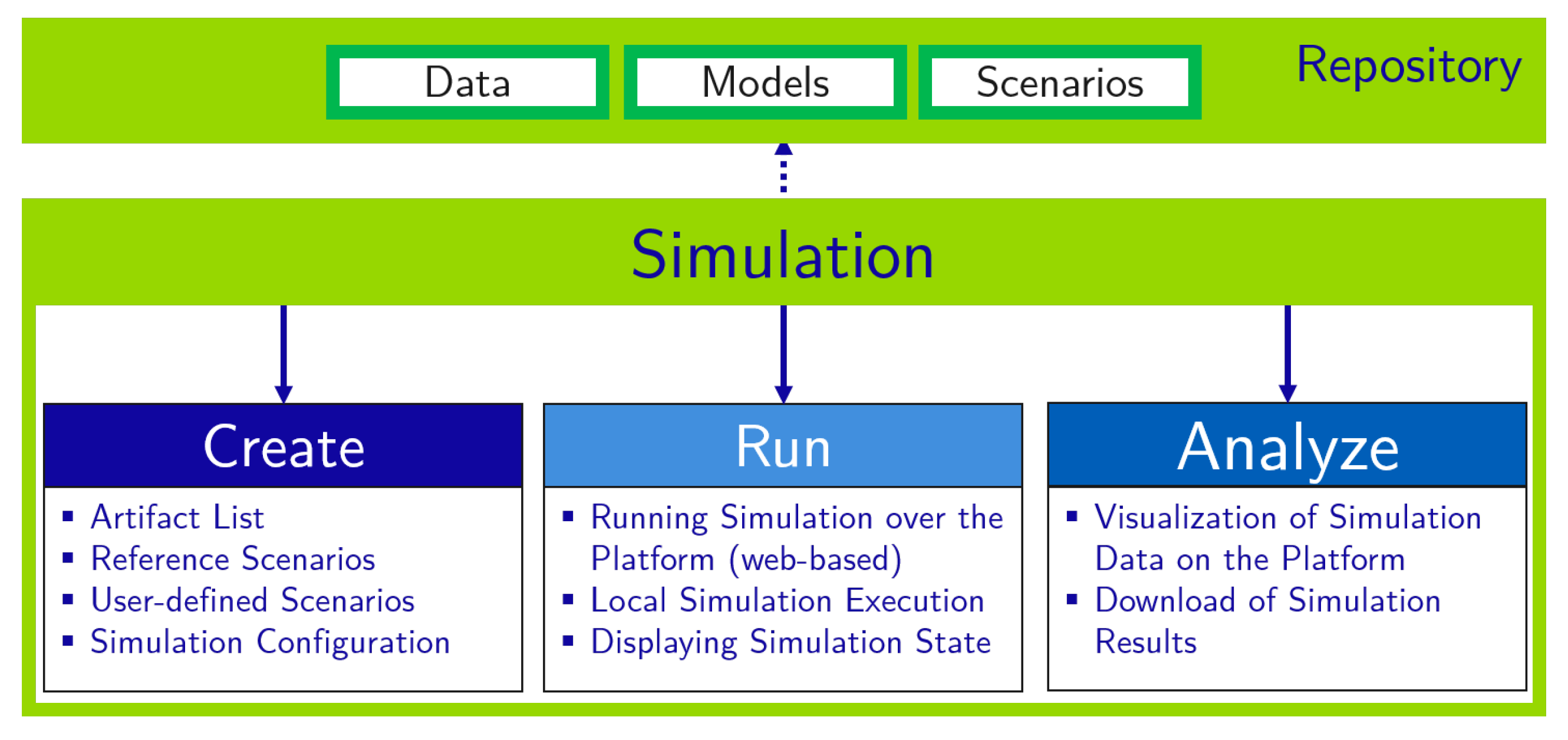
Figure 7 gives a brief overview of the main functionalities of the co-simulation platform and consists of three parts:
Simulation Create allows to extend scenarios from
Repository and to create user-defined scenarios.
Simulation Run includes the execution of the scenario and visualization during runtime.
Simulation Analyze enables to view and explore the simulation results including data visualization.
Simulation Create allows the users to customize predefined scenarios and to create new ones with a user-friendly web interface, such as the
open_plan tool (
https://open-plan.rl-institut.de/de/, accessed on 17 March 2022). In particular, the user-friendliness was identified as a requirement by Werth et al. [
5]. In addition, the
Maverig tool from mosaik (
https://gitlab.com/mosaik/tools/maverig, accessed on 17 March 2022), a graphical user interface for creating and visualizing smart grid simulations, can be used as a reference for the co-simulation platform. The scenarios are based on models and data with common interfaces, which are stored and labeled in
Repository. In this regard, an approach presented by Schwarz et. al [
6] can be used to assist in the planning of co-simulation based on semantic knowledge representation. It will be aligned with the
Energy Ontologies provided by
Core.
Simulation Run initializes and runs the simulation directly over the platform and locally. The co-simulation platform has a user-friendly interface for a simple run configuration. In addition, a node diagram with color-coded nodes for violations and failures (e.g., voltage levels, bottlenecks) are added to display the current grid state. An automated generated scenario script or configuration file (ontology-based) is provided for local execution via the platform. This file enables the automated creation and execution of scenarios within a co-simulation environment, such as mosaik.
Simulation Analyze includes the analysis of the simulation results. Therefore, the simulation results are displayed via a dashboard (e.g., via Grafana (
https://grafana.com/, accessed on 7 January 2022)) when the simulation is finished. This includes the presentation of selected parameters, key performance indicators (KPIs), and optimized results (e.g., primary and secondary energy, energy production from renewable energy sources, and local consumption). Furthermore, a benchmark comparison of scenarios is included to compare relevant characteristics. The
User Management of
Core is needed to save scenarios and simulation data within the user profile and to access them at any time. In addition, user-defined scenarios and simulation results can be directly saved into
Repository.
3.6. Transparency
The goal of
Transparency is to process, publish, and communicate the research and development content to promote a broader and interdisciplinary discussion among all respected types of stakeholders. It serves as a foundation to use these processed results in research-oriented teaching and education and enables a communication channel for distributing relevant information in the energy sector. We visualize the functionalities of
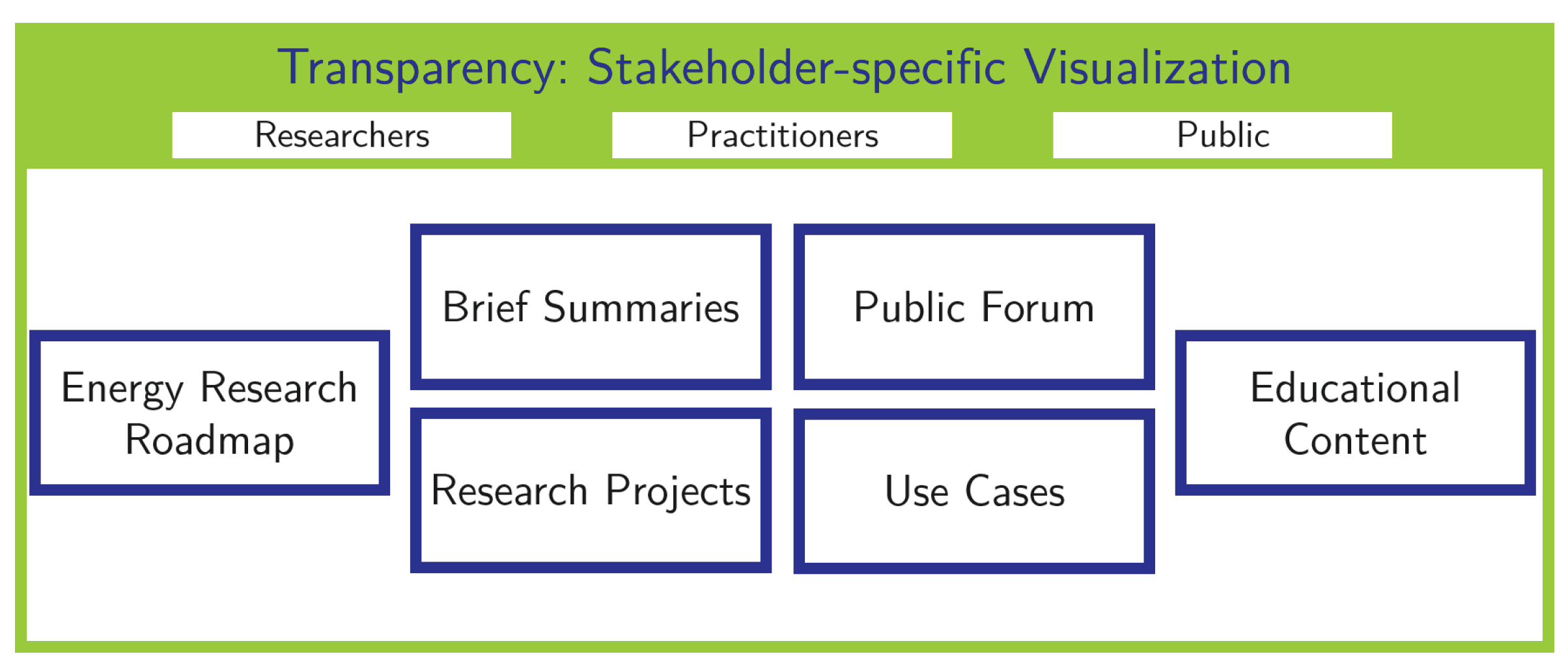
Transparency in
Figure 8.
The stakeholders of the platform, e.g., researchers, practitioners with different backgrounds, or citizens, are distinguishable in terms of characteristics, such as their knowledge base and intended purpose to use the platform. Hence, it is vital for the success of this key service to offer the content presented on the platform and their delivery channel in a stakeholder specific manner, as identified as requirement by Werth et al. [
5]. For this reason, the content of this key service is processed in multiple ways, e.g., advanced content and easy-to-understand content. From a technical perspective, the
User Management of
Core is required for
Transparency in terms of user-generated content, such as partners sharing information about projects. Furthermore,
Transparency uses profile information from the users already included in
Competence.
Transparency also benefits from the
Federated Search in terms of supporting users in finding and filtering for information they want to retrieve.
Transparency consists of several services to reach the above stated goals. For all functionalities, the quality, correctness, and neutrality of the content has to be ensured. Energiesystemforschung can serve as an orientation for this. The platform should be promoted toward the (mass) media and local authorities for reaching a broader part of the society.
An Energy Research Roadmap, including a trend cloud, can be established to gain a comprehensive overview over the past and future research in the energy sector. Here, on one hand, a scientific presentation can be beneficial. On the other hand, there should be a less complicated presentation for citizens and practitioners that are less experienced, but interested in the energy domain. A quick overview over trending topics in the energy sector can also be provided by implementing a word cloud.
While scientific papers are likely comprehensible for more experienced stakeholders in their published form, they can be processed into Brief Summaries to promote the tangibility and clarity of energy research for less experienced stakeholders. If existent, recordings of conference speeches can be published for the same reasons. Additionally, the social media content of researchers can be embedded on the platform. This information should be connected to the user profiles from Competence. Within the presentation of certain research topics, their practical relevance can be illustrated by realizing Use Cases. For example, certain simulations and their results can be demonstrated. The usage of anonymous profiles of energy communities, including their boundaries, can be linked. As another aspect of practical relevance, the presented content might contain implications for practical or private decisions. Artifacts from Repository used for the production of content, e.g., use cases, presented via Transparency can be linked.
Besides papers, Research Projects can also be briefly summarized to make the information more transparent for stakeholders. Here, the general information from enArgus can be included. Platform users are given the possibility to present their own Research Projects. Following this approach, the platform would work as a substitute for separate project websites. Research results and information about projects of partners from Competence can be processed and presented via Transparency. The Competence profiles of institutions involved as well as data and source code from Repository can be linked in the respective content presented in Transparency.
Educational Content, such as lecture slides, laboratory experiments, and lecture recordings, can be shared via the platform to be utilized for private educational purposes or for teaching in schools and universities. With this approach, a teaching and learning network, such as ATLANTIS (
https://www.elan-ev.de/projekte_atlantis.php, accessed on 7 January 2022), can be established. Therefore, the results of workshops, e.g., from existing projects can also be employed. Practitioners might be more interested in application-oriented educational content, which can be provided by processing certain existing educational content. Public courses, lecture slides, etc., are also displayed in the linked
Profile Information of
Competence.
Public Forum can be implemented to promote a dialogue within the platform’s community and the communication between researchers and other stakeholders, particularly citizens. The potential to develop into a place for citizen dialog was identified by Werth et al. [
5]. In this forum, users can direct questions toward researchers or discuss certain topics publicly, e.g., regulatory content. It remains to be evaluated to what extent a registration of users is reasonable or necessary and if there should be a separate forum only accessible to researchers besides the public forum which has to be taken into account by the
User Management of
Core.


 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}