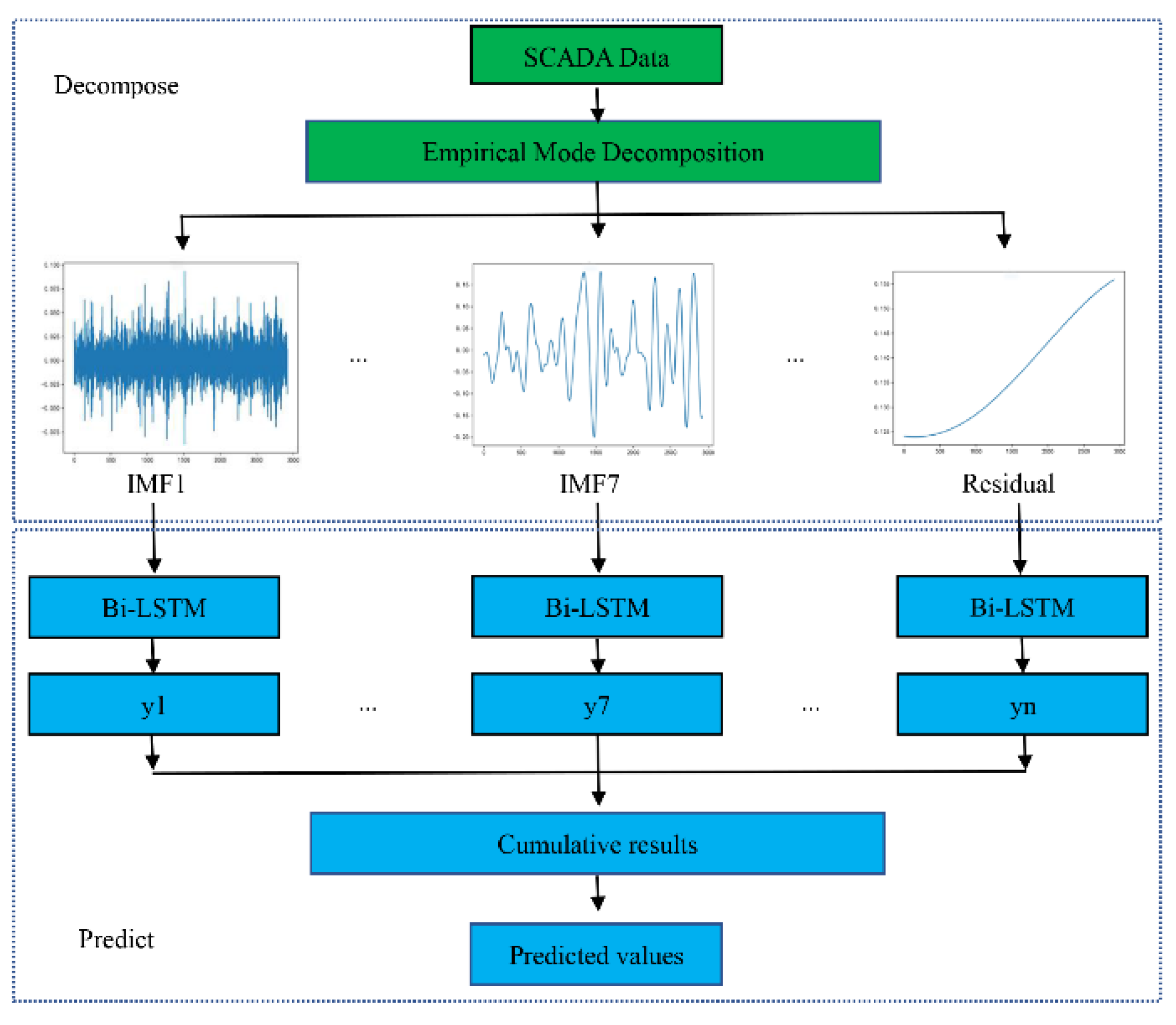
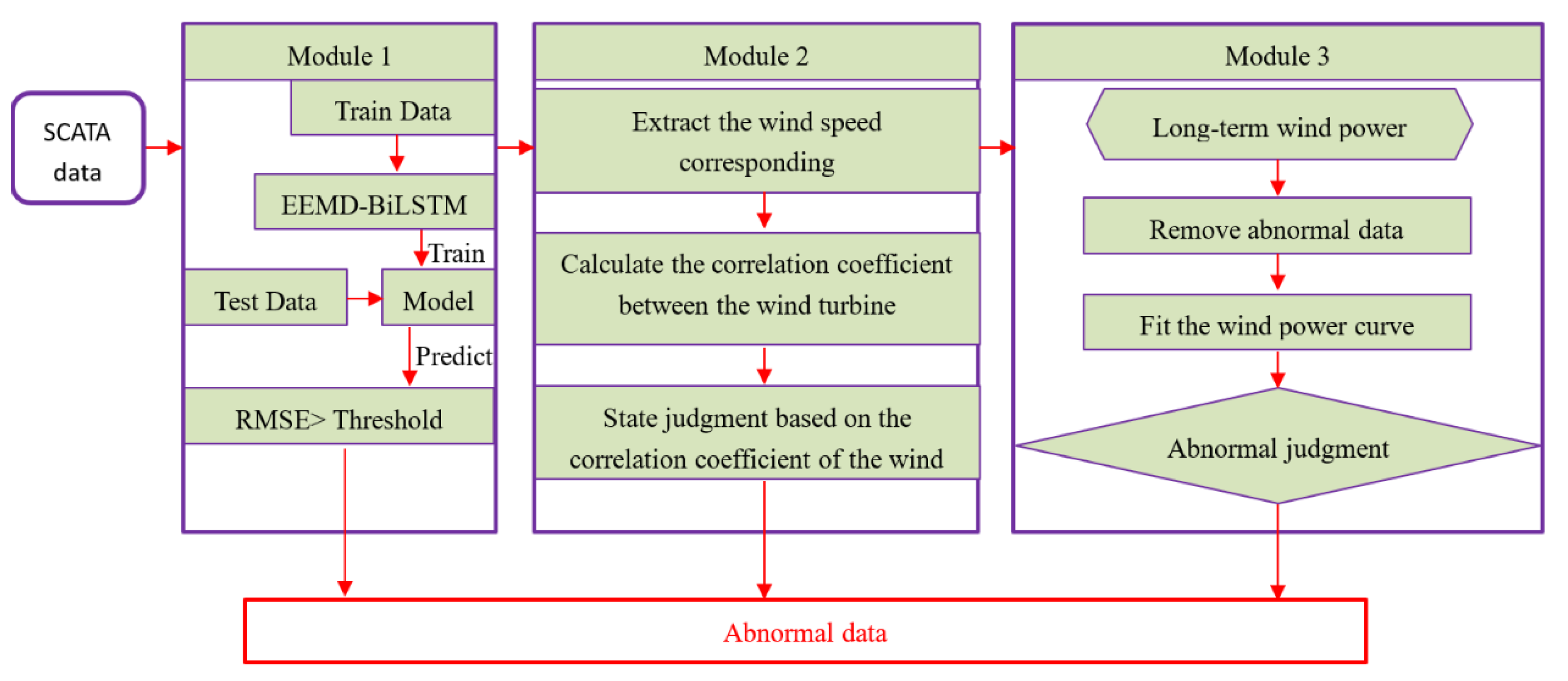
2.3.1. Dynamic Power Curve Fitting
The power generated by a wind turbine is proportional to the third power of the wind speed, which satisfies a certain functional relationship, that is, a power curve. A wind turbine power curve will be provided by the wind turbine manufacturer, but due to many external factors, the actual power curve of the wind turbine installed in the wind farm will be different from the manufacturer’s calibrated power curve, and the actual power curves of identical wind turbines will not be completely consistent at different sites. SCADA wind speed and wind power monitoring data can be used to establish a dynamic power curve, which can then be used to detect abnormal wind speeds of wind turbines.
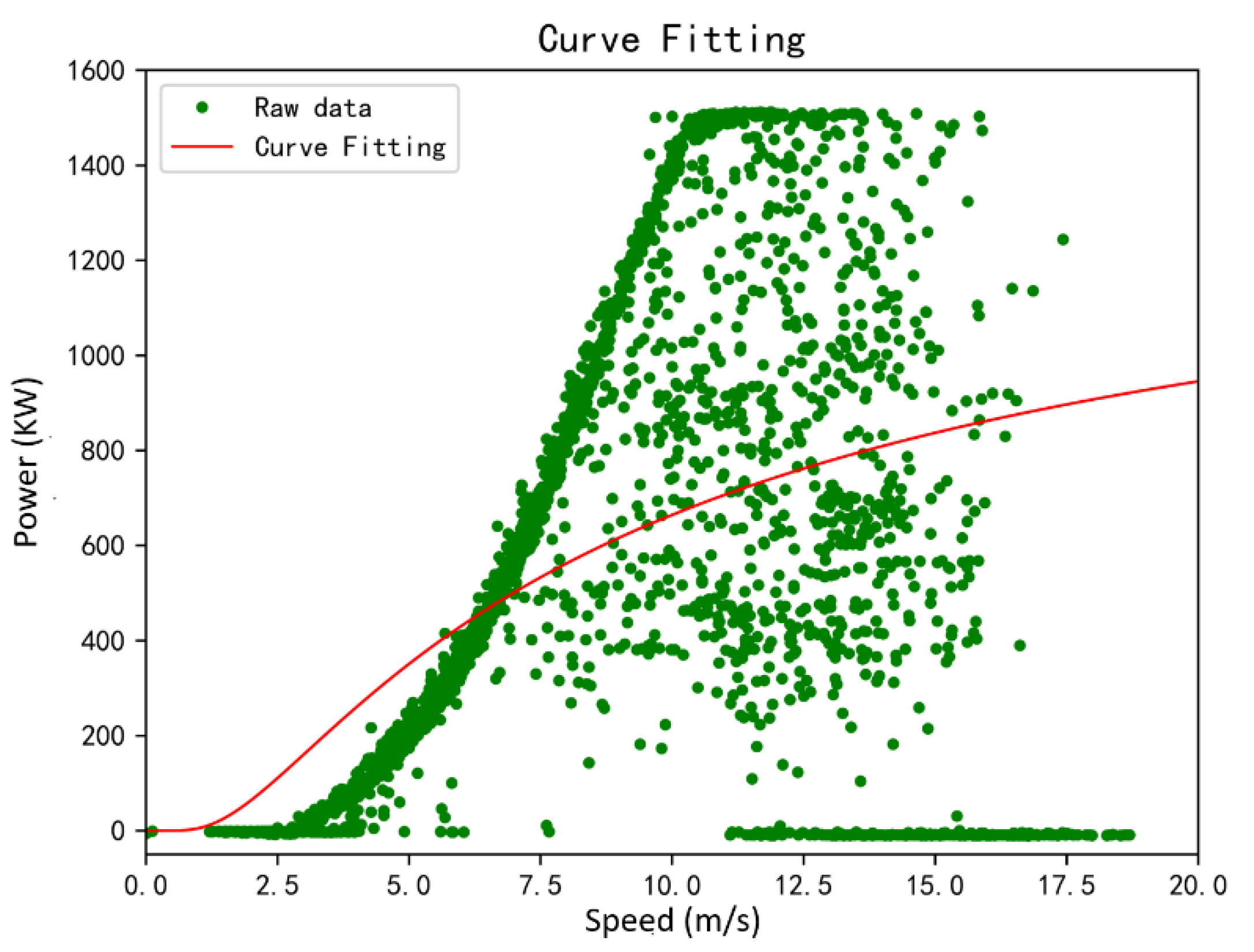
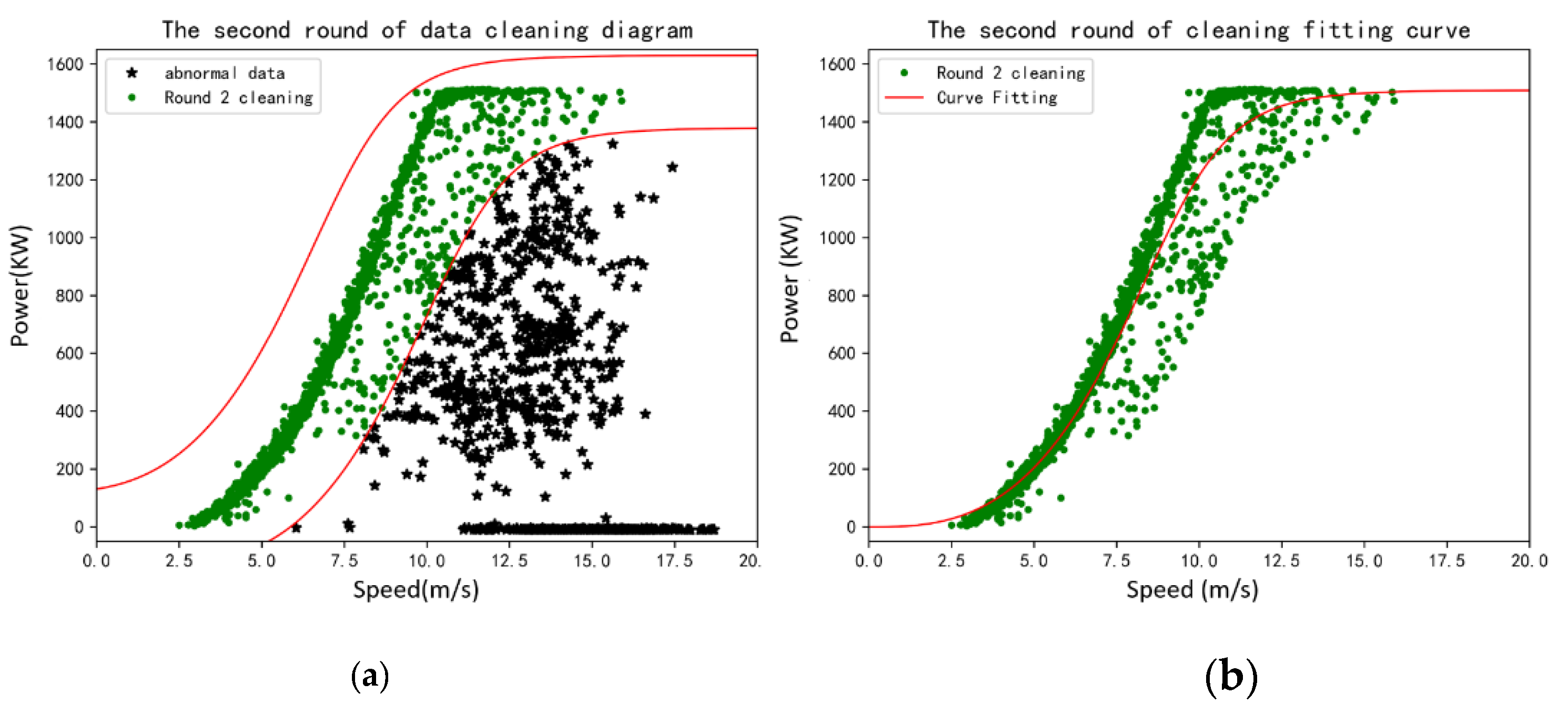
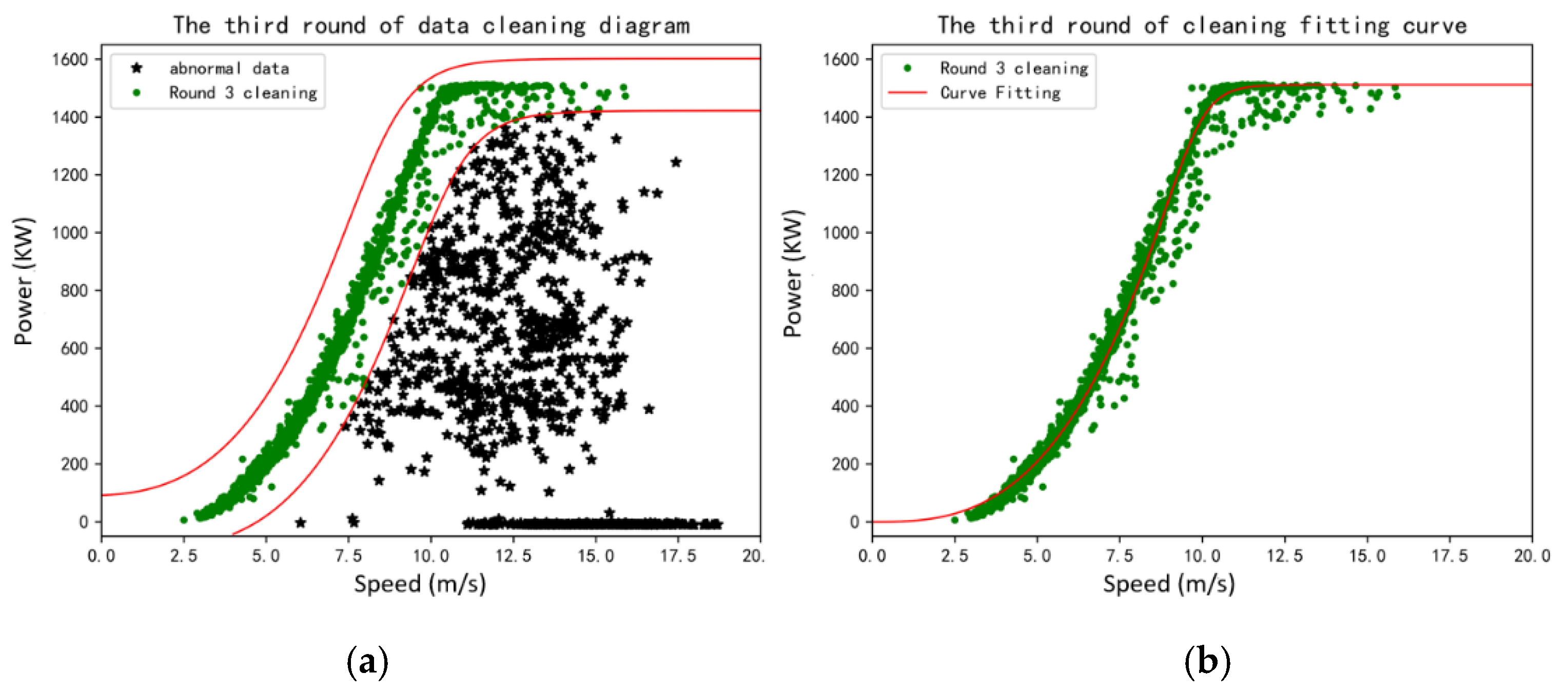
The actual power curve established based on the measured data of SCADA can be completed by the statistical fitting method. The actual power curve and the wind speed–power dispersion graph are general measures of wind turbine performance and contain important information about the overall health of the wind turbine. Many failures and performance degradation processes will be manifested in the measured power curve. The power curve generated from SCADA data can be used to detect wind turbine failures or give early indications of severe performance degradation. It also manifests abnormal SCADA data due to human interference, operation of the wind turbine, and other factors, such as icing, strong turbulence, etc.
The wind turbine power curve modeling methods of wind farms are divided into three categories, namely discrete methods, parametric methods, and non-parametric methods. Discrete methods mainly adopt a standardization algorithm based on Taylor series expansion and turbulence intensity [
25]. Parametric methods mainly include the piecewise average method (IEC) [
26], the piecewise linear model method [
27], polynomial fitting [
28], exponential fitting [
29], and four-parameter logistic function [
30]; non-parametric methods mainly include support vector basis, k-nearest neighbors, the decision tree, and the extreme random tree [
31,
32,
33]. The accuracy of the parametric methods is generally worse than that of the non-parametric methods, but the parametric methods are easier to deploy. Therefore, parametric methods are often used to model the wind speed–power characteristic curve in practical applications. The three methods used in this study are described below.
- (1)
Polynomial fitting method
Polynomial fitting uses polynomial expansion to fit all the observation points in the analysis area to obtain the objective analysis field of the observation data. The expansion coefficient (
a) is determined by least squares fitting. For the wind speed and power data points
of a given wind turbine, the following n-order polynomials can be used to fit:
The polynomial fitting method is simple to deploy, and the power curve modeling of wind turbines currently uses polynomial fitting modeling. However, the regional polynomial fitting of this method is not stable, and missing data will cause severe distortion of the fitting curves.
- (2)
Exponential fitting
The wind power curve is the most intuitive expression of the generating capacity of the unit. The power curve used for wind turbine performance analysis and evaluation is calculated from the measured wind power according to a certain algorithm.
where
is the power value,
is the rated maximum power value of the wind turbine,
is the wind speed value, and
,
, and
are the fitting curve parameters.
- (3)
Four-parameter logic function
The shape of the curve is determined by the vector parameter
= (
,
,
,
) of the logic function. The parameters of the logistic function can be estimated by the least square method, the maximum likelihood method, and the evolutionary programming method. Parameters can be obtained using the genetic algorithm, particle swarm optimization algorithm, and difference algorithm. The accuracy of the power curve model based on these methods is much higher than that obtained by the non-parametric method.
- (4)
Comparison of different power-curve fitting methods
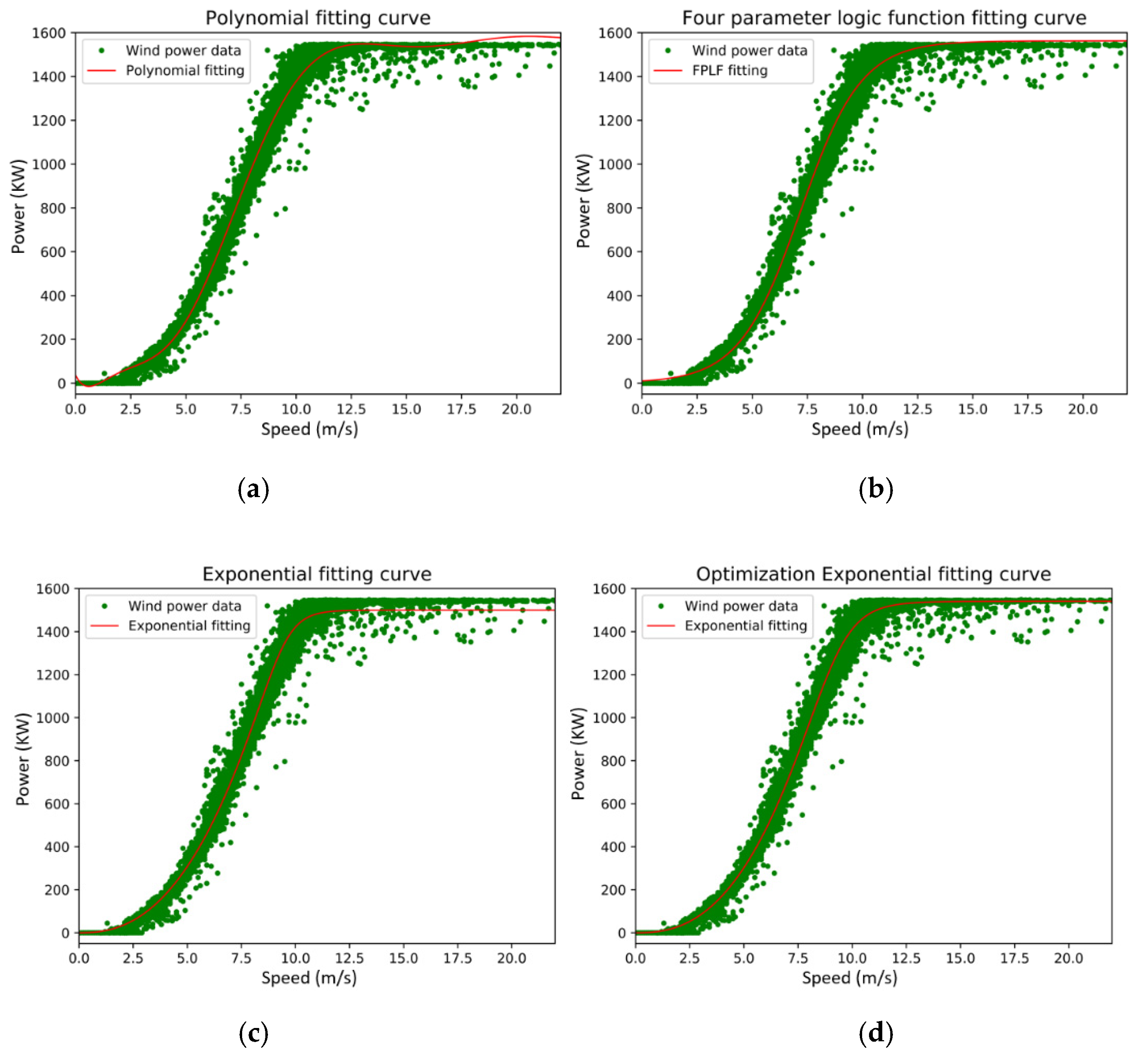
The polynomial fitting curve lacks inertia and is easily affected by abnormal data. When the wind speed reaches the maximum value and the wind speed is very small, oscillation is likely to occur. Feasible solutions require artificial reconstruction of data, which is more complicated. The four-parameter logic function is relatively more stable, but the maximum value part is prone to deviation. Non-parametric functions can better fit the wind power curve, but the relevant parameters of the fitted curve cannot be directly obtained, which is inconvenient for deployment in actual projects.
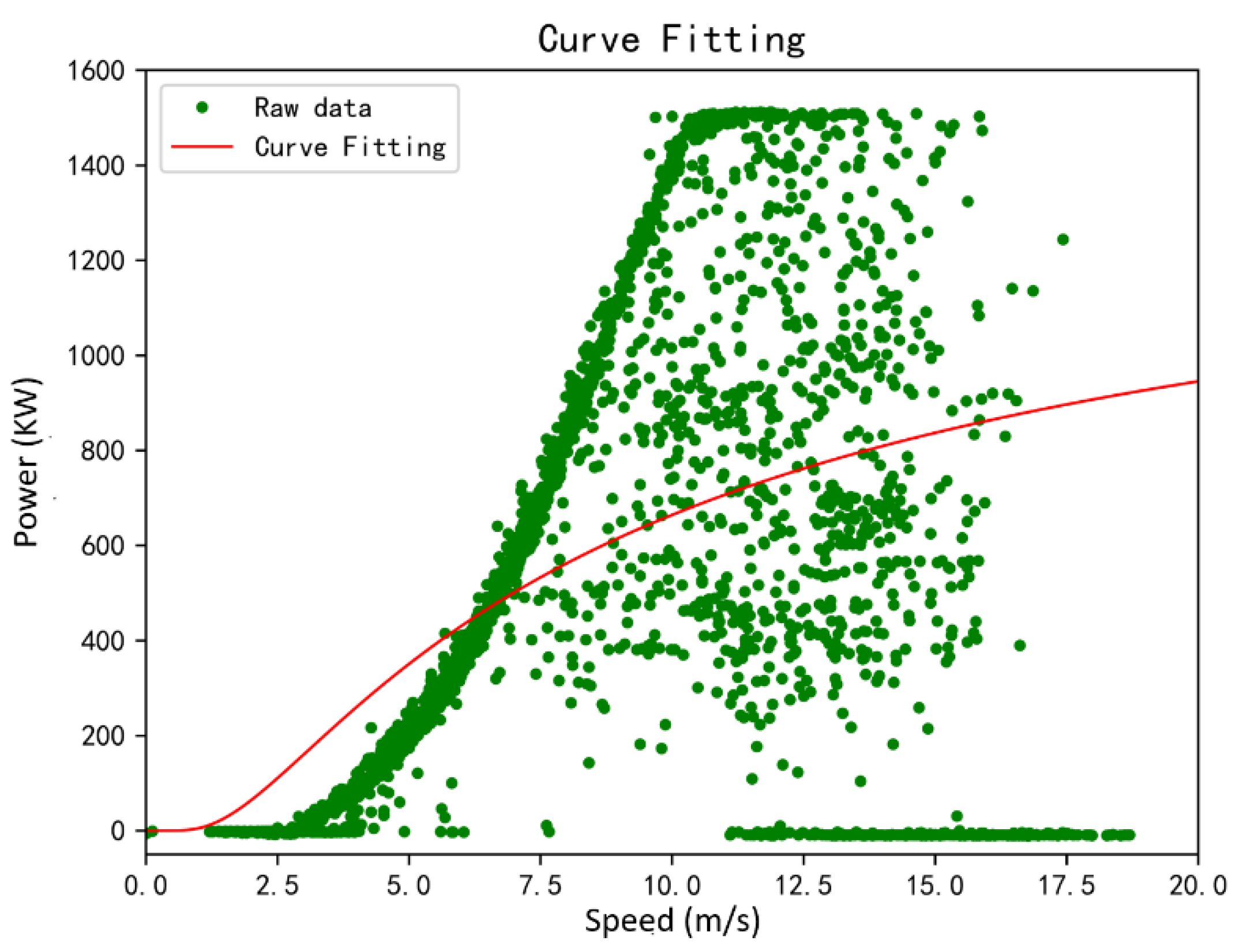
The maximum value of the curve of the exponential function method is closer to the actual curve, and there is a maximum coefficient, which can be easily determined according to the nominal power of the wind turbine or the maximum power value of the business operation. However, the maximum value of actual power may be abnormal data, so the maximum value is optimized.
in which
represents the power data that satisfy the wind speed—the power condition data value is in the top 1%, and
represents the median of these data.
The exponential fitting formula is improved as follows:
in which
is the power value,
is the wind speed value, and
,
and
are the fitting parameters. By fitting Equation (7) with the wind farm data using the Python curve_fit function,
,
, and
providing the objective function of Equation (7) and inputting historical data, the best fitting parameters are searched. The fitting curve parameters obtained by inputting one year of historical data can well reflect the curve trend.
When performing power curve fitting detection, it is necessary to verify the validity of wind speed. Therefore, the power–wind speed relationship can be written as Equation (7).
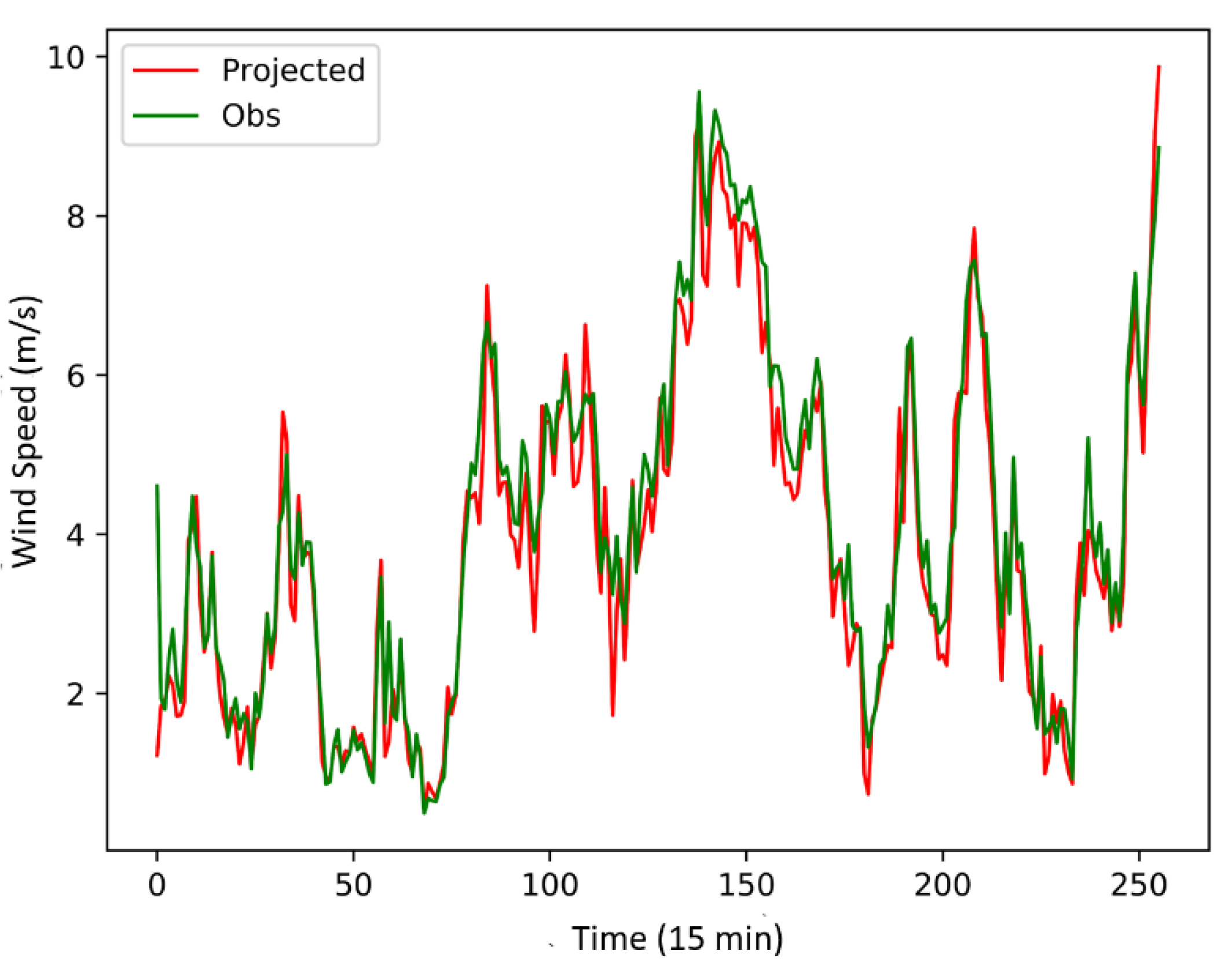
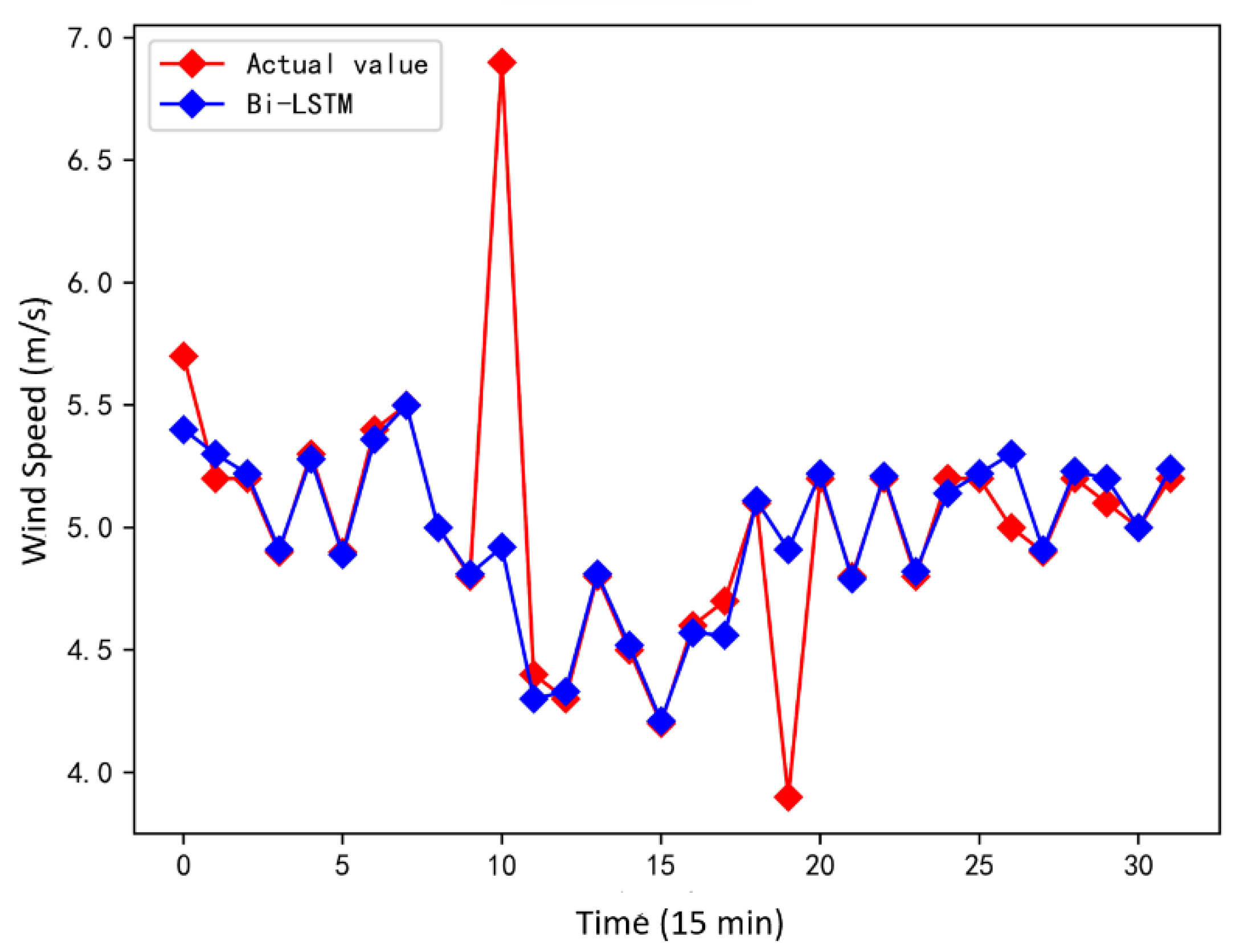
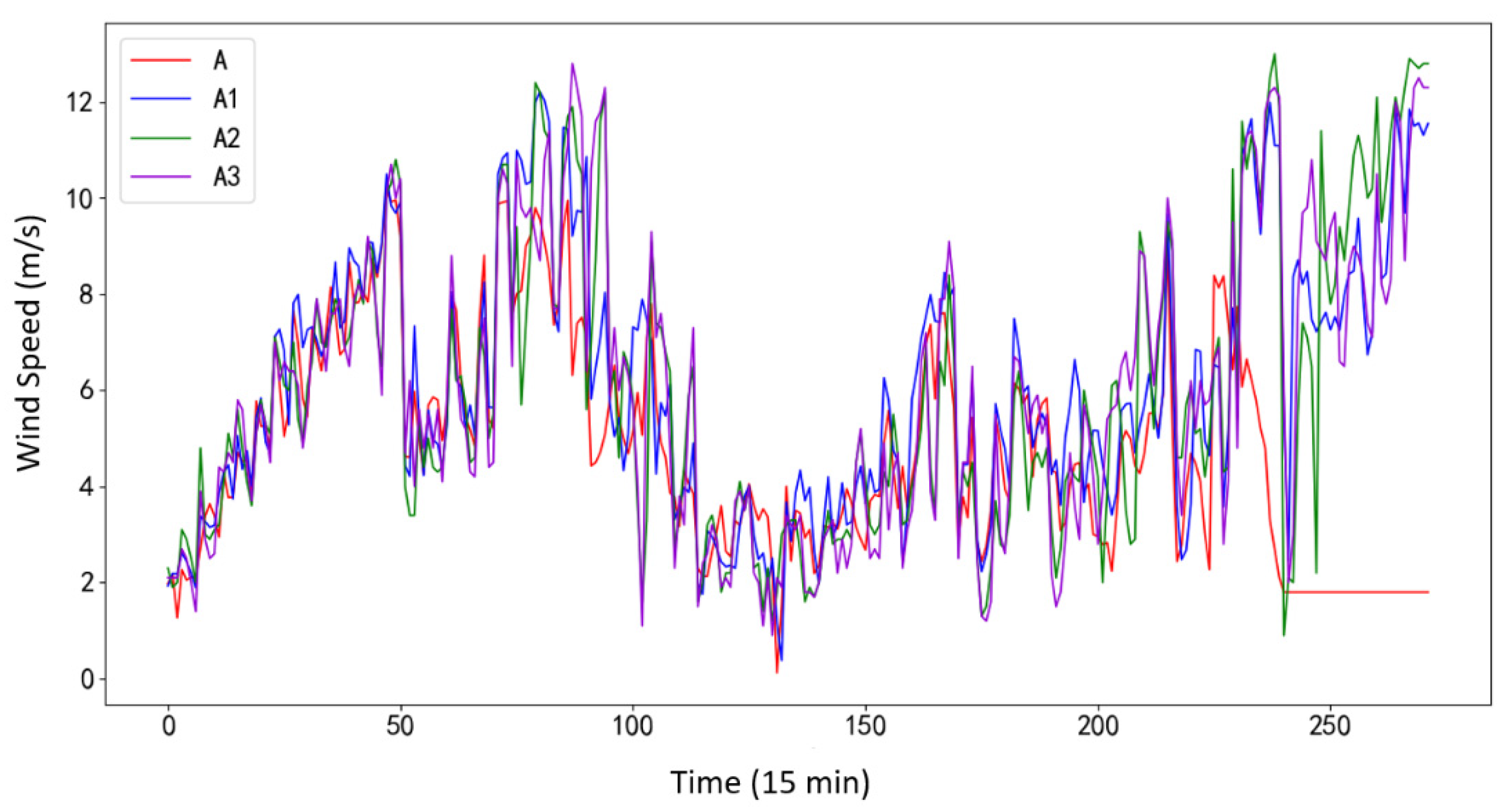
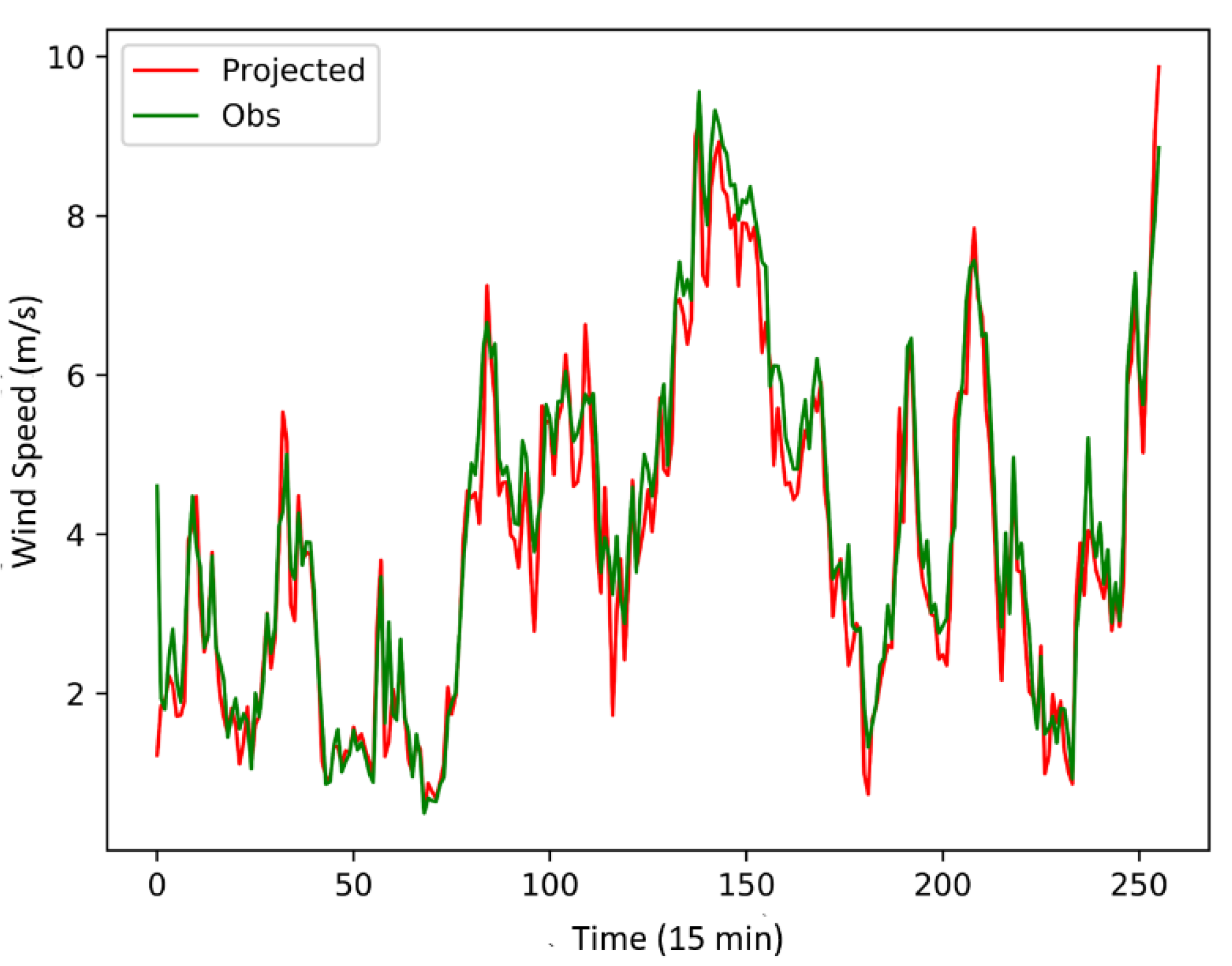
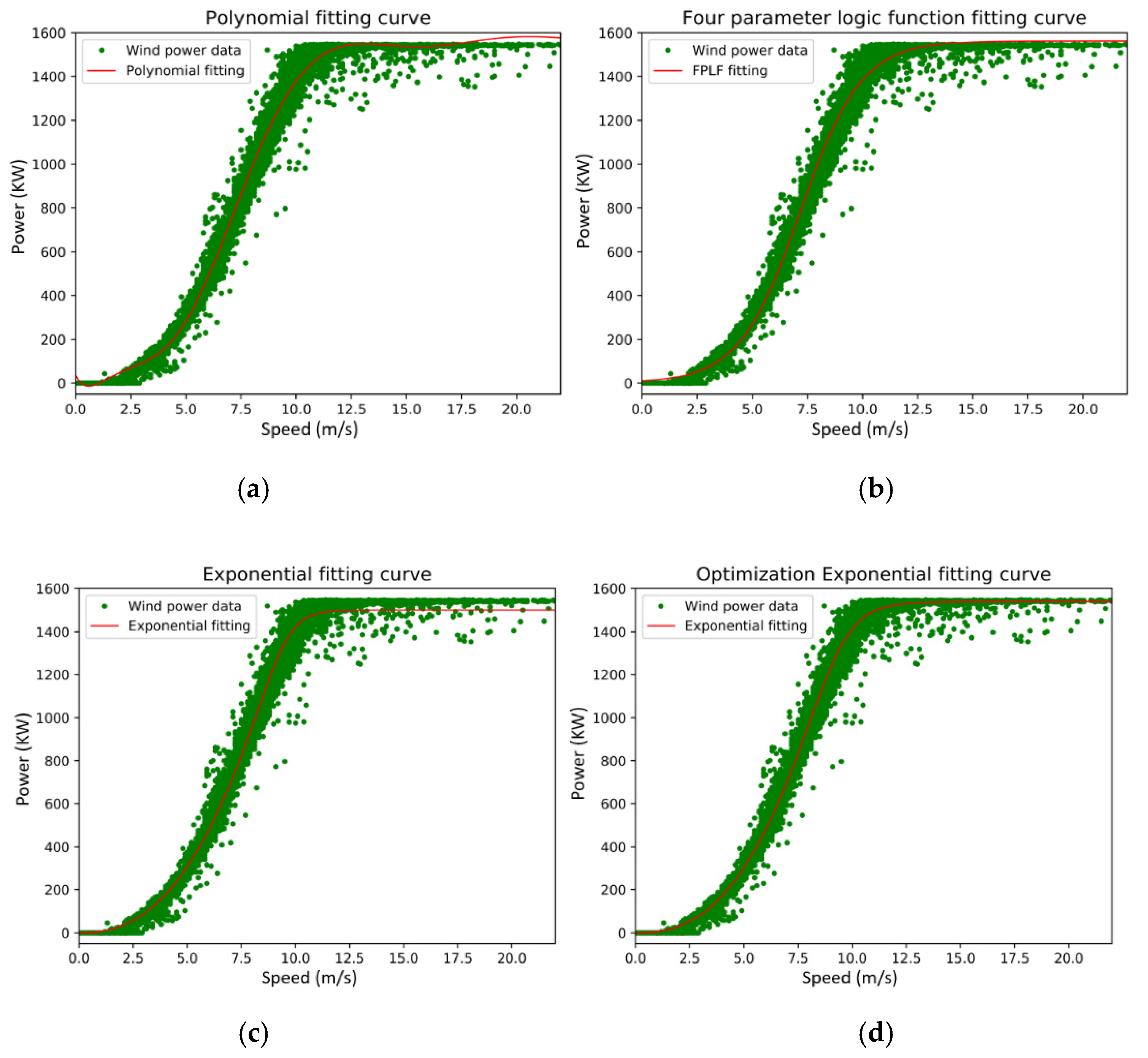
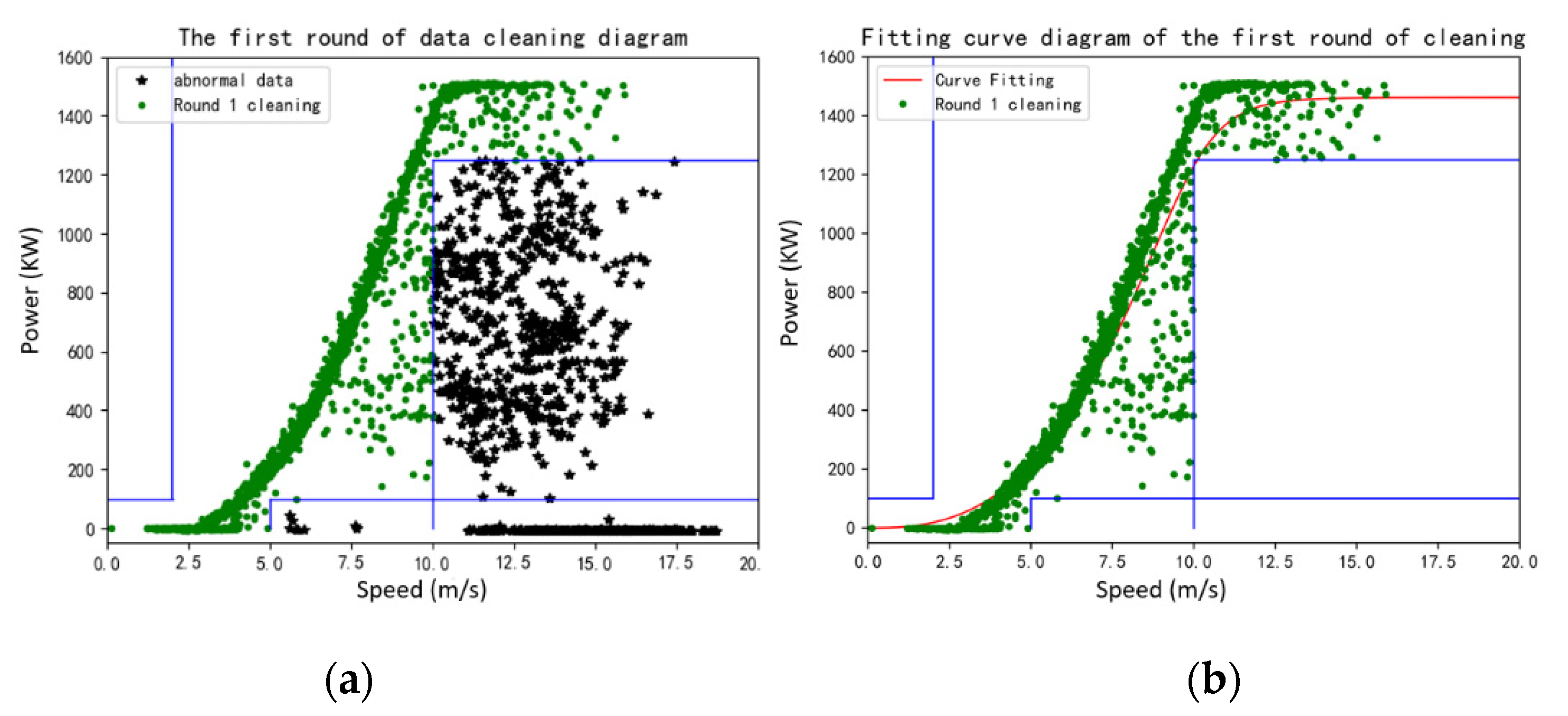
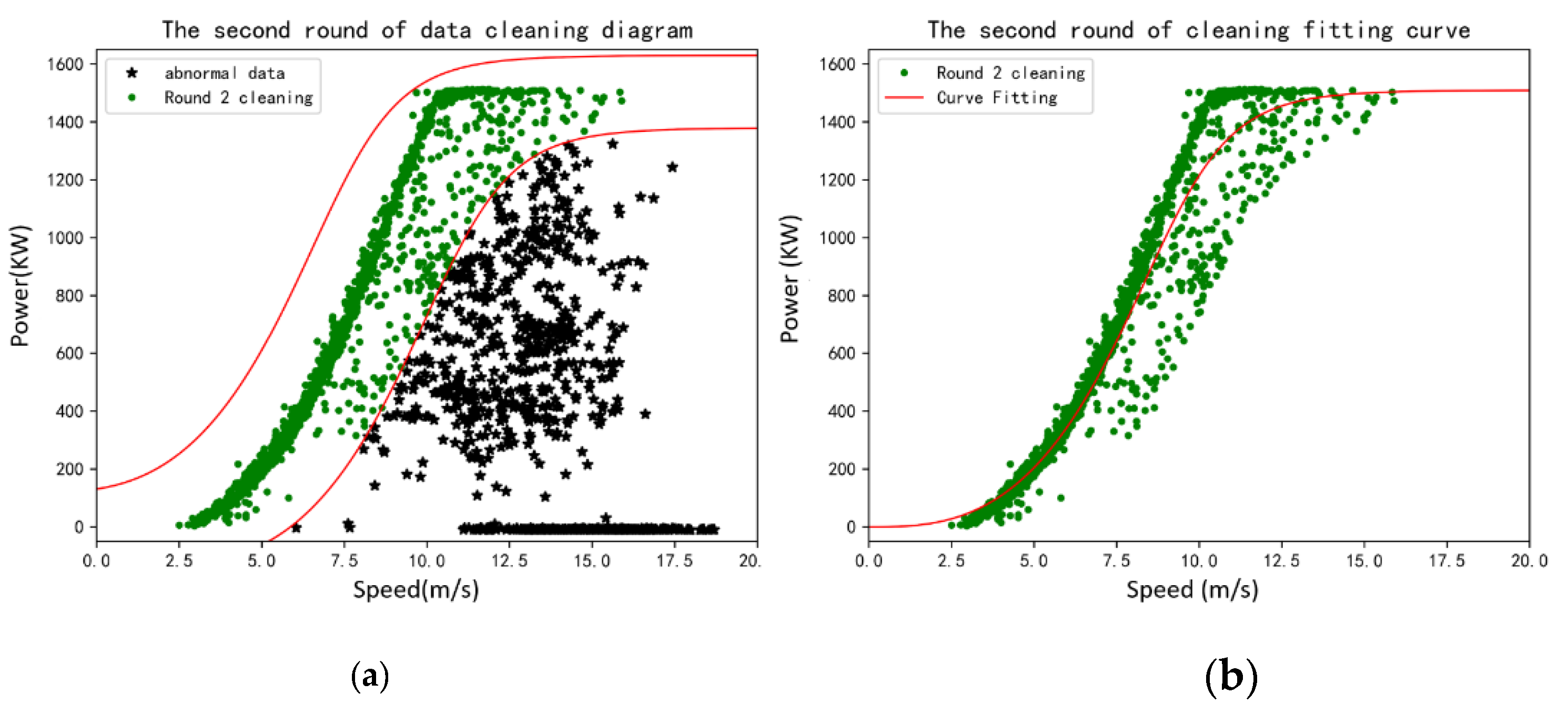
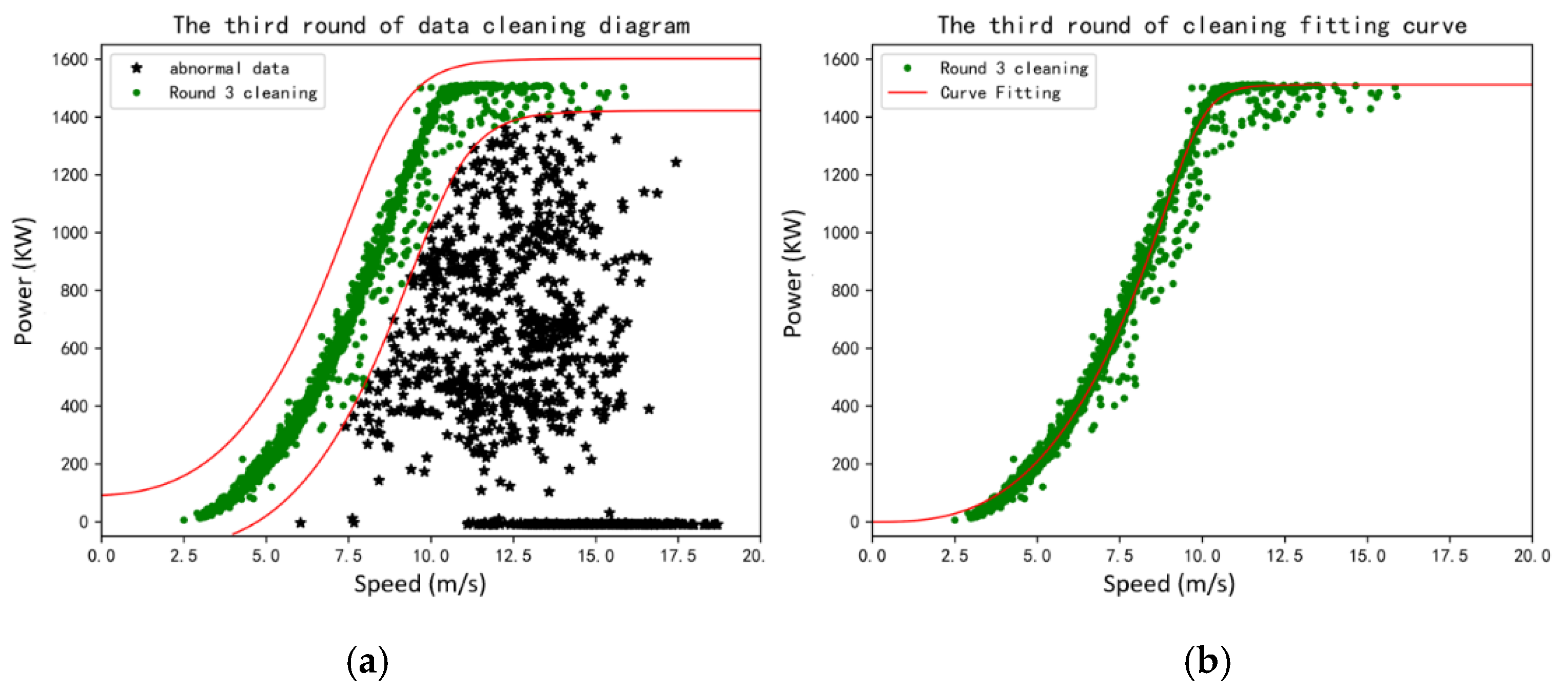
For the purpose of comparison, the above methods are employed to fit the same data of a wind turbine with a rated power of 1500 kW in the selected wind farm in northern Inner Mongolia, and the fitting results are shown in
Figure 6.
Table 7 gives the trained parameters of the four curve-fitting methods and the corresponding standard deviation. Although the optimized exponential fitting method does not significantly improve the STD compared with the polynomial fitting method, it has fewer control parameters and is convenient for practical deployment.
Figure 6 shows that in a well-performed wind turbine, all methods achieve reasonably good fitting curves, although there are evident differences in the wind ranges below the turbine cut-in speed and above label power capacity.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}