1. Introduction
In a multiple hydraulic actuator system, the load on each actuator results in different pressure levels. If the actuators are controlled by a load-sensing architecture with pressure-compensation valves and a single pump, the supply pressure is controlled according to the highest required pressure. This causes a mismatch between the pressures in the actuators and the supply that is compensated for by the throttling on the pressure-compensation valves. These resistive control losses are one of the major sources of energy losses in such hydraulic systems [
1,
2].
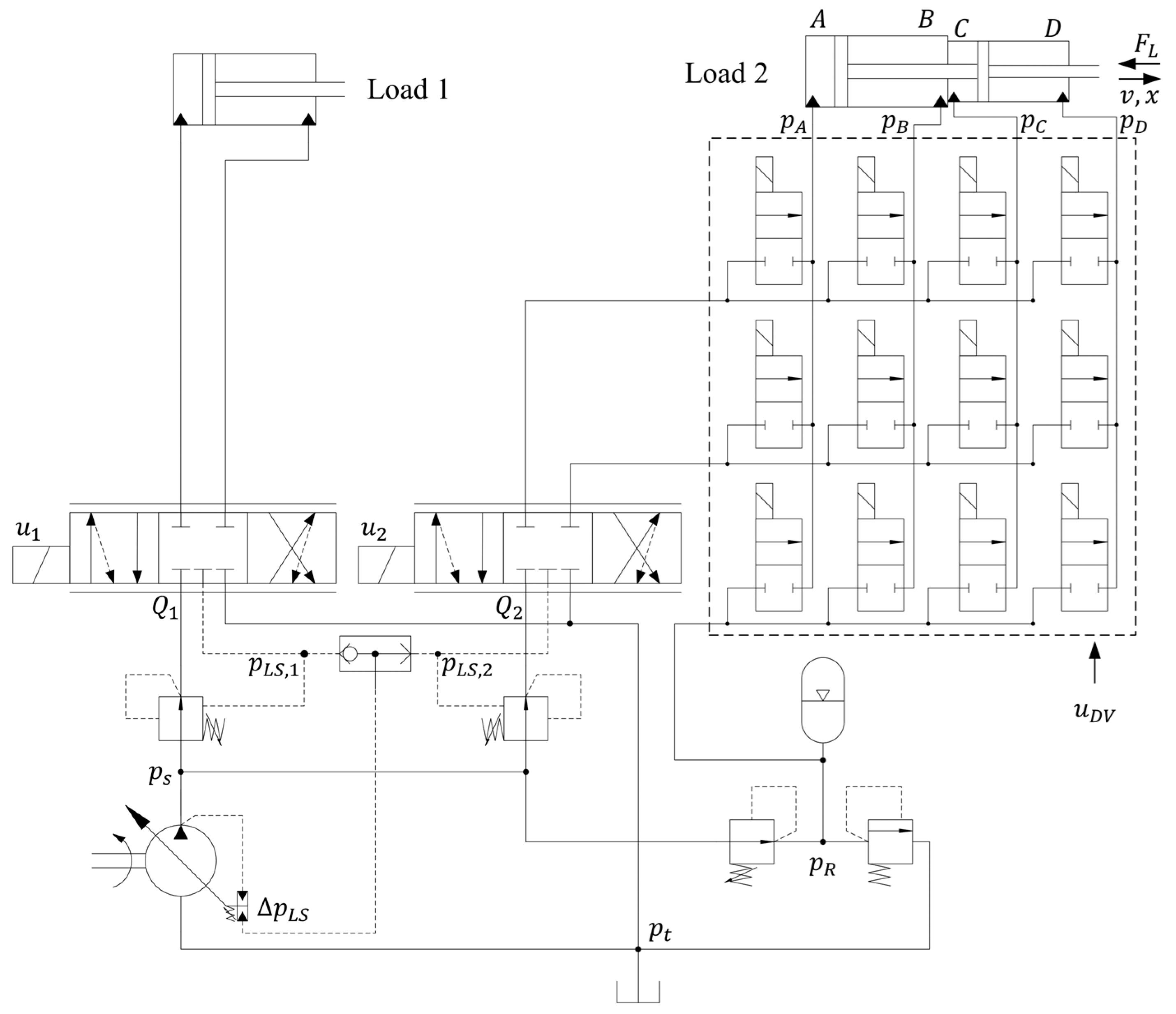
One way of reducing such losses is to use a multi-chamber actuator in one of the loads. A hydraulic diagram of a pressure-compensated valve-controlled load-sensing architecture, where Load 2 is driven by a multi-chamber actuator, is shown in
Figure 1.
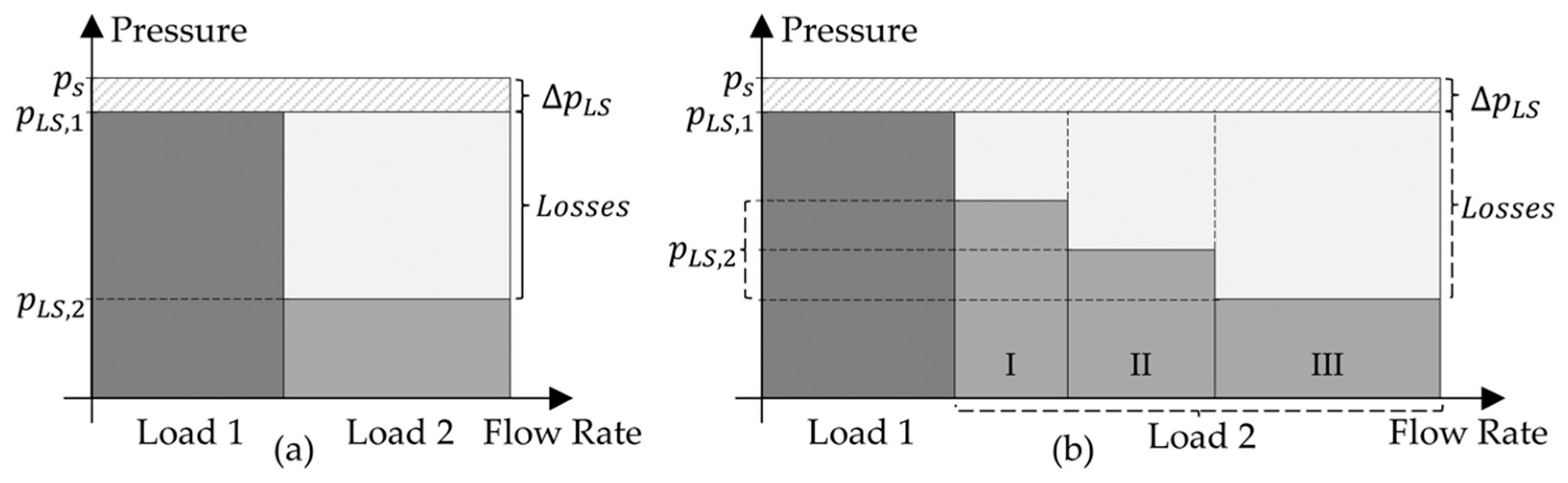
The set of on/off valves between the proportional valve and the actuator allows for the combinations of different chambers that define the possible actuator modes to be used. The capability to select different actuator modes allows the modulation of the resultant pressure from the load to make
similar to
. This is shown in the illustrative flow-pressure diagrams in
Figure 2.
The possibility to modulate the pressure,
Figure 2b, enables the reduction in resistive control losses. A conventional actuator,
Figure 2a, cannot perform this modulation and, thus, results in higher resistive control losses. A deeper discussion on this system architecture is provided in [
3].
This architecture has another degree of freedom to be controlled, which is the mode selection. The mode that minimises the losses is a function of the speed and forces of all the actuators, but because these vary along with the system operation, this is not a trivial problem to solve.
Multi-chamber actuators usually belong to architectures where the selection of modes is responsible for the control end goal, such as speed or position. The speed or position error is translated to a reference force that the multi-chamber actuator must exert. In [
4], this force reference is compared to the available forces for each mode, and the mode that results in the smallest force error is applied to the system. In [
5], a mode selection based on the minimisation of the force error is implemented, as in [
4]; however, there is no mention of avoiding frequent switching. In [
6], the same mode-selection strategy as in [
4] is compared to one that penalizes high-amplitude pressure changes between different modes. In [
7], the authors describe the operation of a controller that selects the mode that minimises the energy consumption, while still being able to drive the current load. In [
8], the mode selection is also based on a predefined range of force capacity for each mode. The implemented mode is the one that can exert the requested force, and the difference in force is controlled by the proportional pressure control in one of the chambers.
Model predictive control (MPC) is studied in [
9] to solve the problems related to force spikes when in mode switching. The mode selection is still performed based on minimising the force difference between the reference and the available modes and on minimising the energy losses associated with switching. The force difference is handled by means of throttle control, to adjust the pressure in each chamber to the calculated pressure reference. MPC is focused on minimising the force transients when switching. A similar study also using MPC is presented in [
10], where the results also indicate an advantage of MPC over simpler mode-selection strategies, as presented in [
4], for example.
Although not used for a multi-chamber actuator, the selection of modes in [
2] is performed based on the calculation of the capacity of each mode to overcome the current force over the actuator, while, apparently, minimising the pump pressure and flow rate.
The authors in [
11] describe a state machine to handle the mode selection based on, for example, the load pressure and pressure levels defined for each mode. The authors emphasise possible instability and non-smooth operation of the actuator during mode switching and suggest that these problems could be minimised by acting on the proportional valve control, which to some extent follows the ideas presented in [
8,
9]. In [
12], the mode selection of the independent metering valve system is also performed based on the current load force and the force capability of each mode.
The control problem here is not the same as the ones studied by the works presented above. Here, the mode selection acts as an enabler for the control end goal, which is still performed by the proportional valve. Therefore, the control goal for the multi-chamber actuator is to select a mode that enables the requested motion to be completed, while minimising the resistive control losses. From another point of view, the mode selector can be interpreted as performing energy management because the goal of using the multi-chamber actuator is to reduce energy losses. Instead of designing a controller for the mode selection based on the analytical equations of the energy losses in the system, in this work a controller for the mode selection based on RL was studied.
Reinforcement learning (RL), with neural networks as the actor and critic function approximators, has proven to be a powerful and successful control-development methodology for complex problems, such as playing Atari [
13]. The main advantages are automatic learning by interacting with the environment and finding optimised control solutions that are inherently difficult to be solved analytically. Additionally, machine learning algorithms also perform well in scenarios that they are not exactly trained for, which is likely to occur in the operation of mobile machines, due to their vast field of application.
In the control of mobile working machines, Ref. [
14] presents an approach based on RL, with the Q-learning algorithm for the control of hybrid system power to minimise fuel consumption. What the authors also show is the possibility of first training the controller with simulation models of the system and then applying the controller to the real system. An RL-based energy-management strategy is proposed in [
15] for hybrid construction machines. The authors use a combination of Dyna learning and Q-learning, but the study is limited to simulation results.
Other applications of RL for mobile machines include: Ref. [
16], where it is used, based on cameras, lidar, and motion and force sensors, to perform bucket loading of fragmented rock with a multi-objective target, including maximisation of the bucket loading; Ref. [
17], where it is trained for the motion control of a forestry crane while minimising energy consumption; and Ref. [
18], where it is used for the trajectory tracking control of an excavator arm, with the controller generating the valve-control signals directly.
It is observed in these papers that the development of RL controllers usually starts with a pre-training of the agent in a simulation environment. Advantages of this approach are: it avoids undesirable real-world consequences; it reduces costs associated with obtaining real experience; and the simulations typically run faster than real time [
19]. The reviewed papers also show the controller’s capacity to find and implement solutions for complex tasks.
This paper demonstrates, through simulation and experimental results, the training and implementation of a RL-based controller for the mode selection of a multi-chamber hydraulic actuator. The actuator is part of a multi-actuator load-sensing architecture driven by a single pump. The selection of different modes allows for the reduction in resistive losses in the control valves, due to a better match of pressures between actuators. A Deep Q-Learning (DQN) agent was created and trained to learn how to select the modes to minimise the system energy losses.
Paper Contribution and Objectives
Research on the topic of this paper has been presented in previous publications by our group. In [
3], the system architecture is described along with the potential efficiency improvements. The first implementation of the RL-based approach to control this system was studied and presented in [
20]. The present work builds on those previous publications, where the main difference from [
20] is the use of a load-sensing pump instead a constant pressure supply, which makes the learning task significantly harder and closer to a real, mobile system application.
The objective and, consequently, the contribution of this paper are to show experimental results demonstrating that RL can also be used to control complex hydraulic systems. In this case, it is about the selection of modes of multi-chamber actuators aiming to reduce resistive control losses. In particular, it is shown that RL finds an optimised control solution with reduced need for manually designing the controller. However, the study is limited to training the agent in simulation and not on continuing the learning after being deployed to the real system.
2. Available Modes, Model Description, and Control Structure
The multi-chamber actuator used in this study has four chambers and is connected to three supply lines (A/B/R). This gives a total of 87 possible modes. However, most modes are ruled out due to the reasons presented in [
3]. The modes used in this study are given in
Table 1. Mode 1 is the only mode that is not an agent’s decision, because it is implemented as a rule to ensure safe operation. The steady state force displayed in
Table 1 is calculated considering a pressure of 100 bar on port A and 15 bar on ports B and R. This is done to show which modes can exert higher force.
The model of the physical system was developed in the multi-domain system simulation tool HOPSAN [
21] and describes the motion of the boom arm as a function of the motion of the actuators. It also models the dynamic behaviour of the pressures, flow rates, internal leakage, and closing and opening of the valves. The model was validated against experimental results, with a detailed description presented in [
20].
The controller and training algorithm for the DQN agent were implemented in MATLAB/Simulink [
21]. During the training in simulation, the agent learns by interacting with the system. After training, the agent controls the real system.
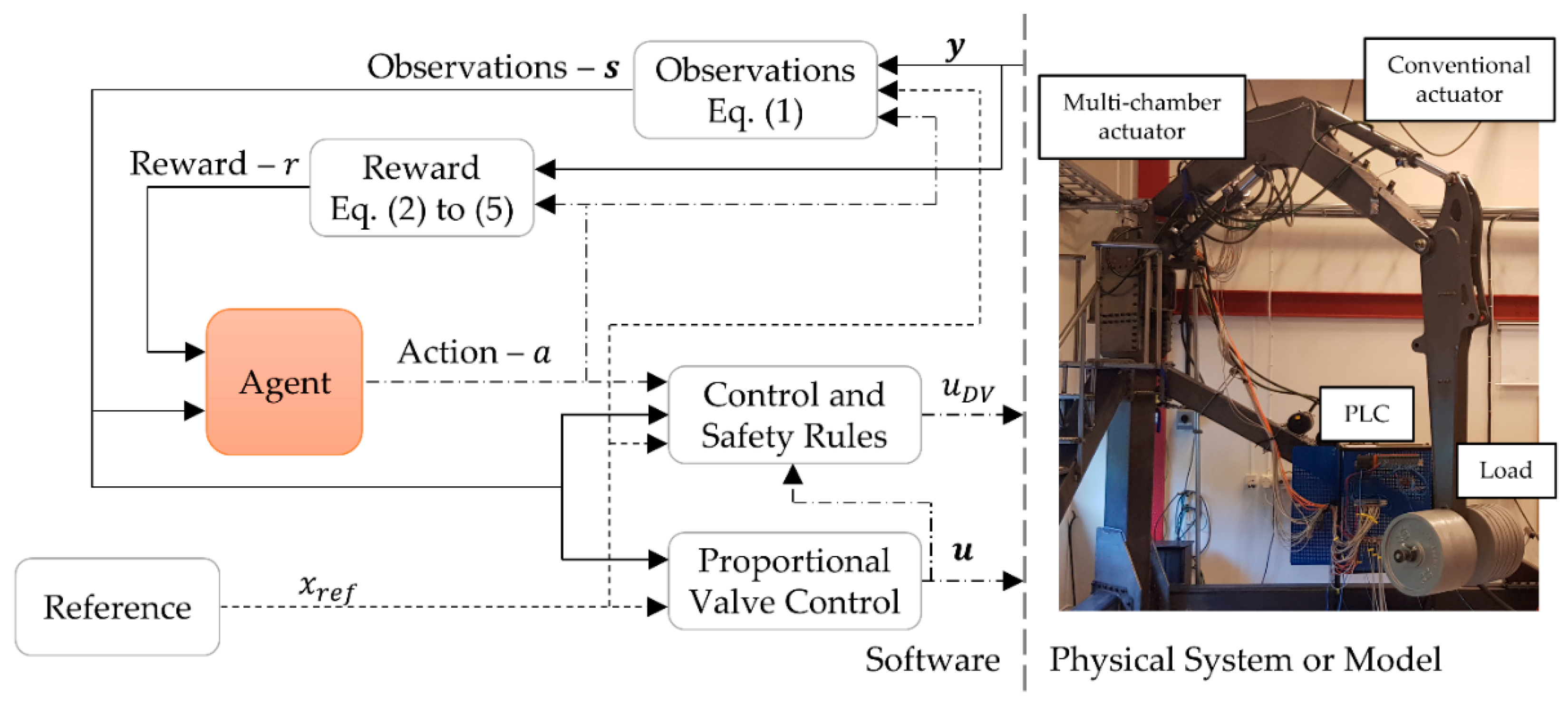
The actual controller of the system is not only composed of the trained agent selecting the optimal mode, it also contains other control and safety rules. An overview of the controller structure is shown in
Figure 3. The reward branch of the agent is only used during the training phase.
In
Figure 3, it is also seen how the interaction of the agent with the environment takes place during the learning phase and then in the controlling phase. Paraphrasing [
13] for the present control problem:
The agent interacts with the environment in a sequence of actions, observations, and rewards. At each agent time step , the agent observes the observations , selects an action from the set of modes (Table 1), and applies it to the environment. It observes the new observations and the reward . It tries to maximise the reward.From the RL perspective, everything that is not the agent is considered as the environment it is interacting with. It is important to make the environment in the simulation as close to the real environment as possible. For the control of hydraulic systems in mobile applications, along with having a sufficiently accurate model of the physical system, there is the need to include additional safety rules. Therefore, the environment is the combination of the system model and the additional rules. The added control and safety rules for this system are:
Apply mode 1 if ;
Limit the available modes according to position and external load;
Compensate due to the difference in areas in each mode; and
Use mode 4 for the lowering motion ( < 0.002 m).
The first rule is used because the valve has an overlap of 2 mm, so the on/off valves can be closed. The second rule prevents the agent from choosing a mode that cannot drive the load with the available maximum pump pressure, otherwise the load could fall. For the same operator control input signal to the proportional valve, the third rule ensures approximately the same actuator speed for the different modes, see [
3,
20] for details.
The fourth rule is implemented because the return motion, due to the much larger area of the actuator connected to the return than the supply, results in excessive throttling on the meter-out edge of the valve. This causes the pump to operate at maximum pressure due to a perceived high load, which causes the pressure-compensation valves to operate fully open and, thus, the compensation losses are close to zero. Thus, the selection of modes, based on minimising the compensation losses, does not work for the returning motion. Therefore, due to this design constraint, the return motion is not an agent’s decision.
While the RL agent is responsible for the mode selection, another P controller ’mimics’ the machine operator controlling the proportional valves. The P controller is implemented inside the proportional valves control block in
Figure 3.
3. Learning Setup for the Agent
The application has a continuous observation space (pressures, speed, etc.) and a discrete action space (modes to be selected). A DQN agent [
13,
22] is suitable for this type of observation and action space, and it mainly consists of a neural network calculating the value for taking a certain action given the current observations. The value is an estimation of the sum of the reward that the agent can collect over a future time horizon, by following a certain sequence of control actions. In this case, the network at each agent’s time step predicts the value of taking each action. A greedy function selects and implements in the system the action that has the highest estimated value, which is, in other words, the action that would lead to the best performance, according to the reward function. This agent is, thus, a non-linear map between the system states (observations of pressures, speed, position, …) and the optimised control action (modes). The reader is referred to [
13,
22] for a description of the type of agent and training algorithm.
Each agent action corresponds to one mode (
Table 1). Inside the ‘Control and Safety Rules’ block in
Figure 3, a lookup table maps the action to the corresponding vector
of the open/closed digital valves that implements the mode in the system.
The structure and parameters of the network are presented in
Table 2. No sensitivity analysis was performed to evaluate the size of the network on the performance of the task. However, the size of the network was chosen to be small.
The observations
used as input features are
where
is the previous action,
is the proportional valve control signal,
are the chambers’ pressures,
is the supply pressure,
is the load-sensing pressure for the conventional actuator,
is the actuator speed, and
is the position.
The reward function
to be maximised is composed of three terms,
The velocity term () penalizes the agent if a motion is requested (), and the multi-chamber actuator does not move with a minimum velocity. This encourages the agent to learn to meet a minimum control-performance requirement. The power loss term () is a penalty based on the hydraulic system control losses, to encourage the agent to find a mode that results in smaller energy losses due to pressure compensation. The switch term () penalizes the agent for frequent mode switching.
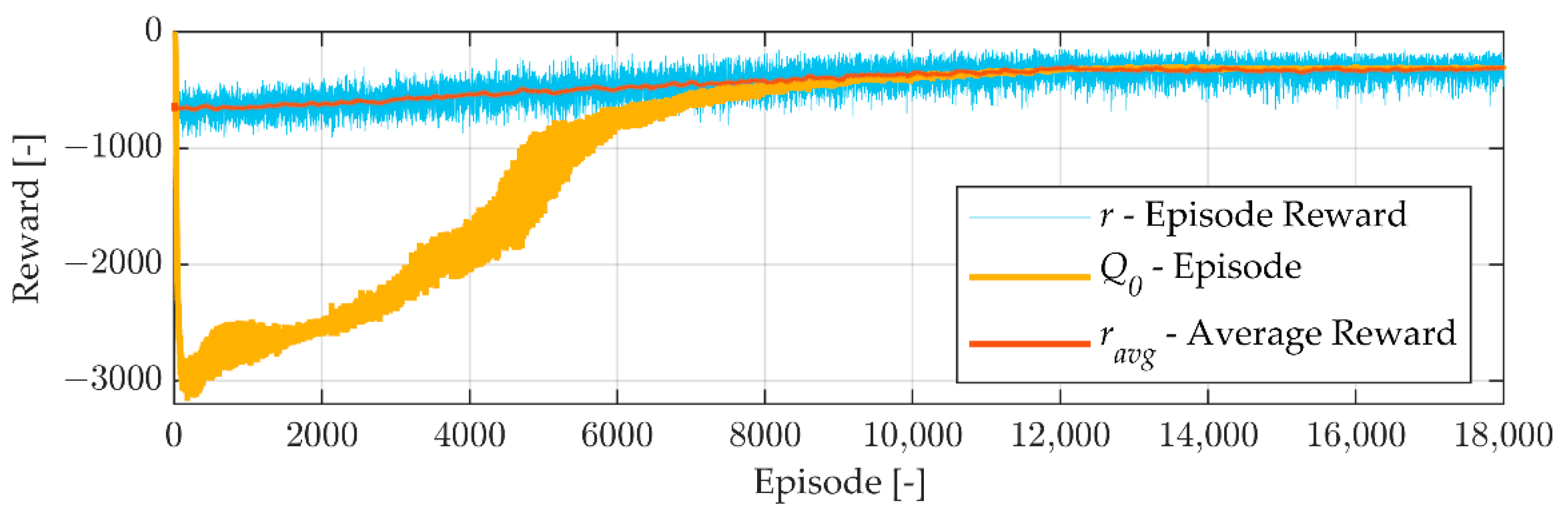
Table 3 presents the parameters and load cases used during training. To increase the agent’s robustness, noise is added to the measurements used as observations in the simulations.
is a uniformly distributed random variable with a maximum amplitude of 1.
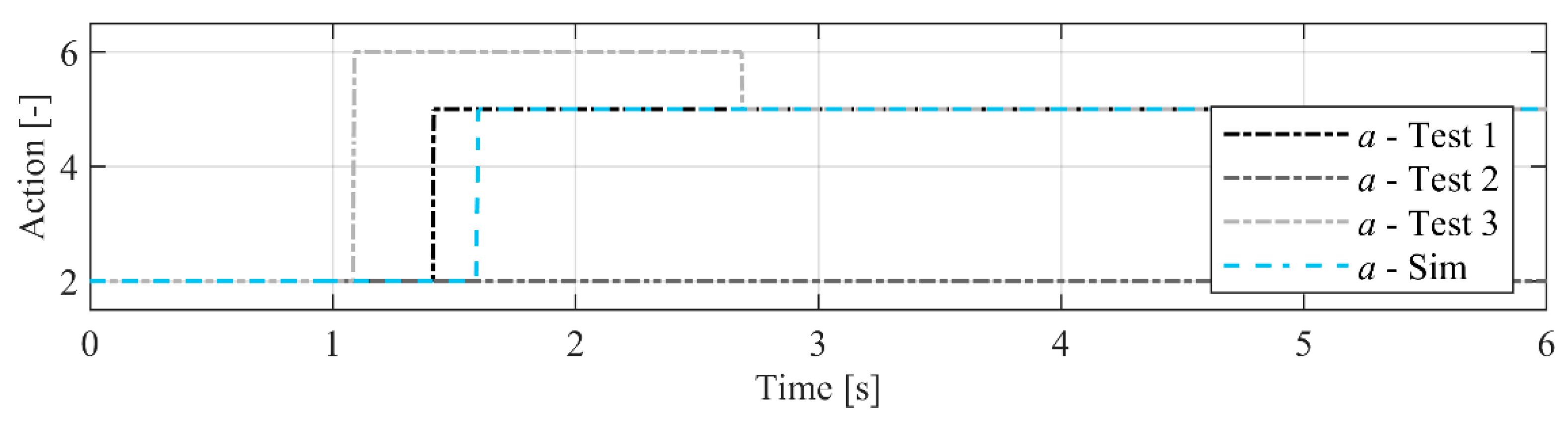
In a real system, the load pressure from the conventional actuator () varies according to the load. However, a simplification is made by setting it to constant values to allow for easier interpretation of the results both in the simulation and in the experiments. In the experiments, this signal is emulated with an additional hydraulic circuit. This means that the agent is exposed to 12 different scenarios of external load and pressure on the conventional actuator, and the task is to lift the load from an initial position to a final position while maximising the reward function.
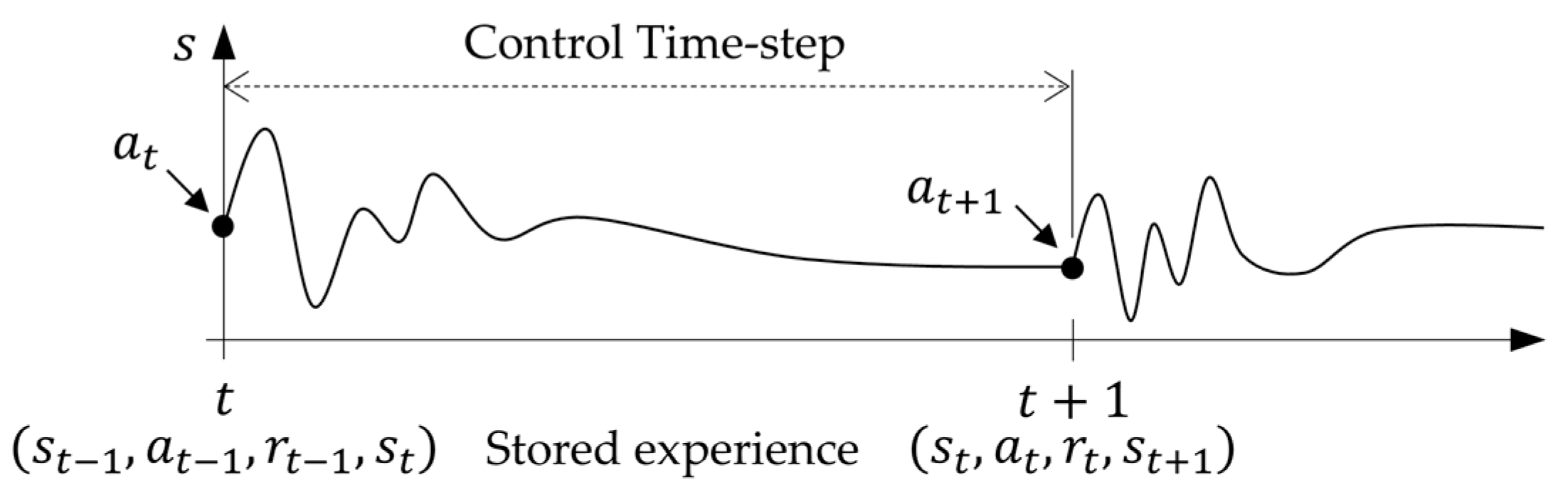
Dynamic systems have oscillations, and these must be taken into consideration when setting the agent-control time step, defining the reward function, and considering what type of information is stored as experience. This is represented in
Figure 4, by showing a dynamic response of the system state (
) due to an action
.
If the time step is too small, the stored experience will contain dynamic effects rather than steady-state conditions. This might affect the agent’s ability to learn because the reward function could give misinformation. However, the reward from the action at is only observed at because it is usually a function of the final state and the transition between the states. Therefore, the size of the control time step can be adjusted to avoid these effects. For the current system, the mode selection does not need to occur frequently to avoid unnecessary switching. Thus, the agent time step is set to avoid these oscillations.
5. Discussion
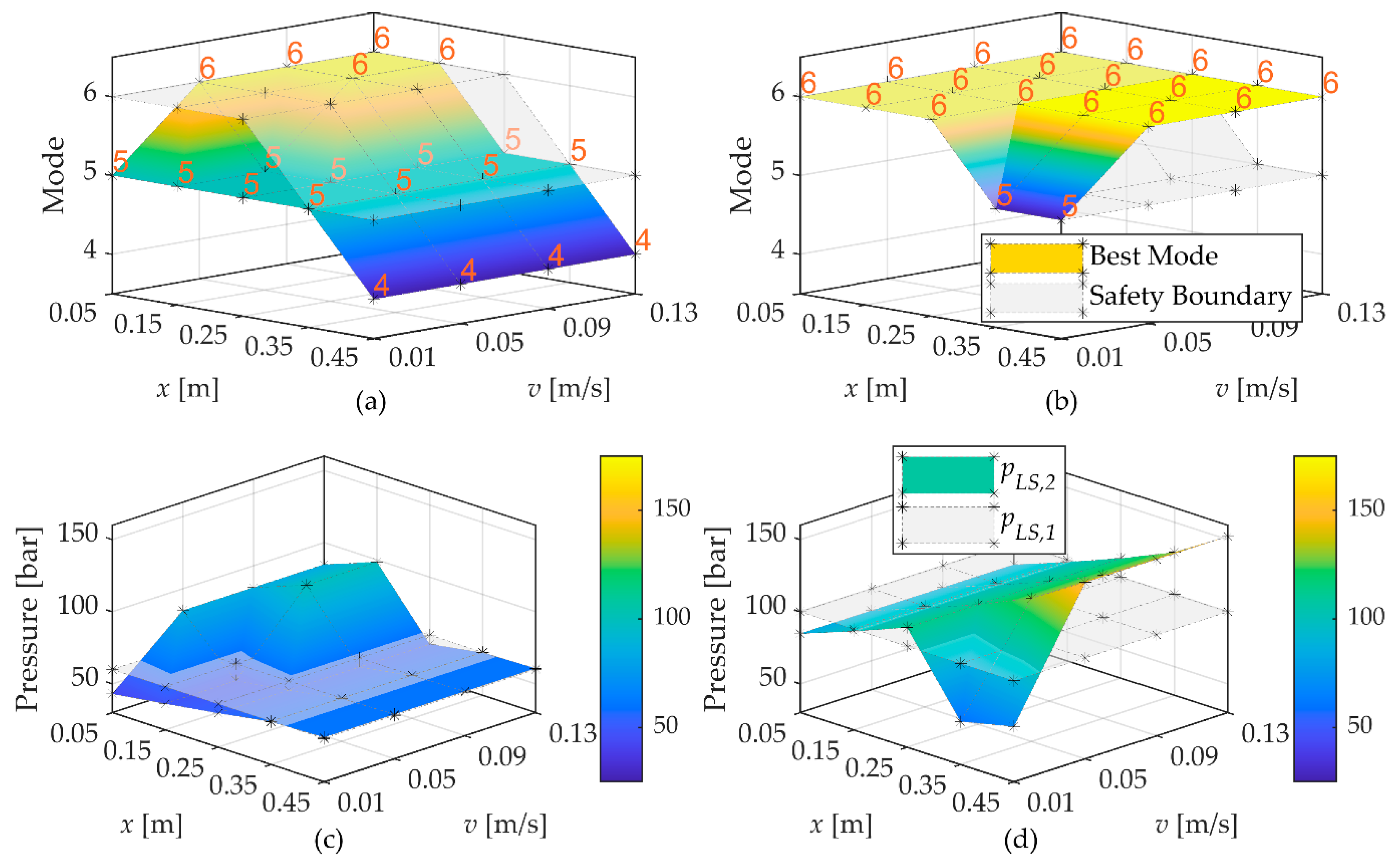
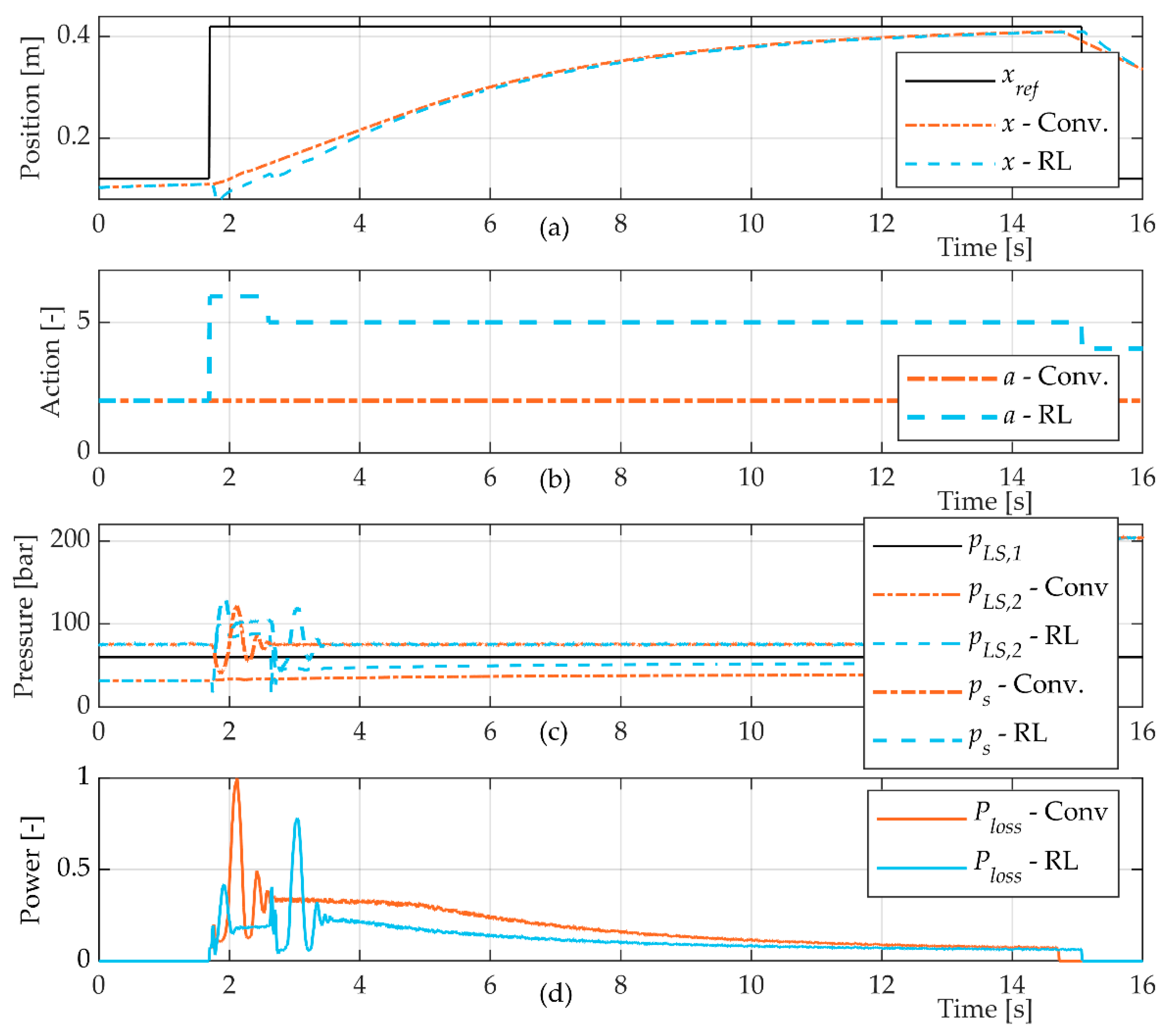
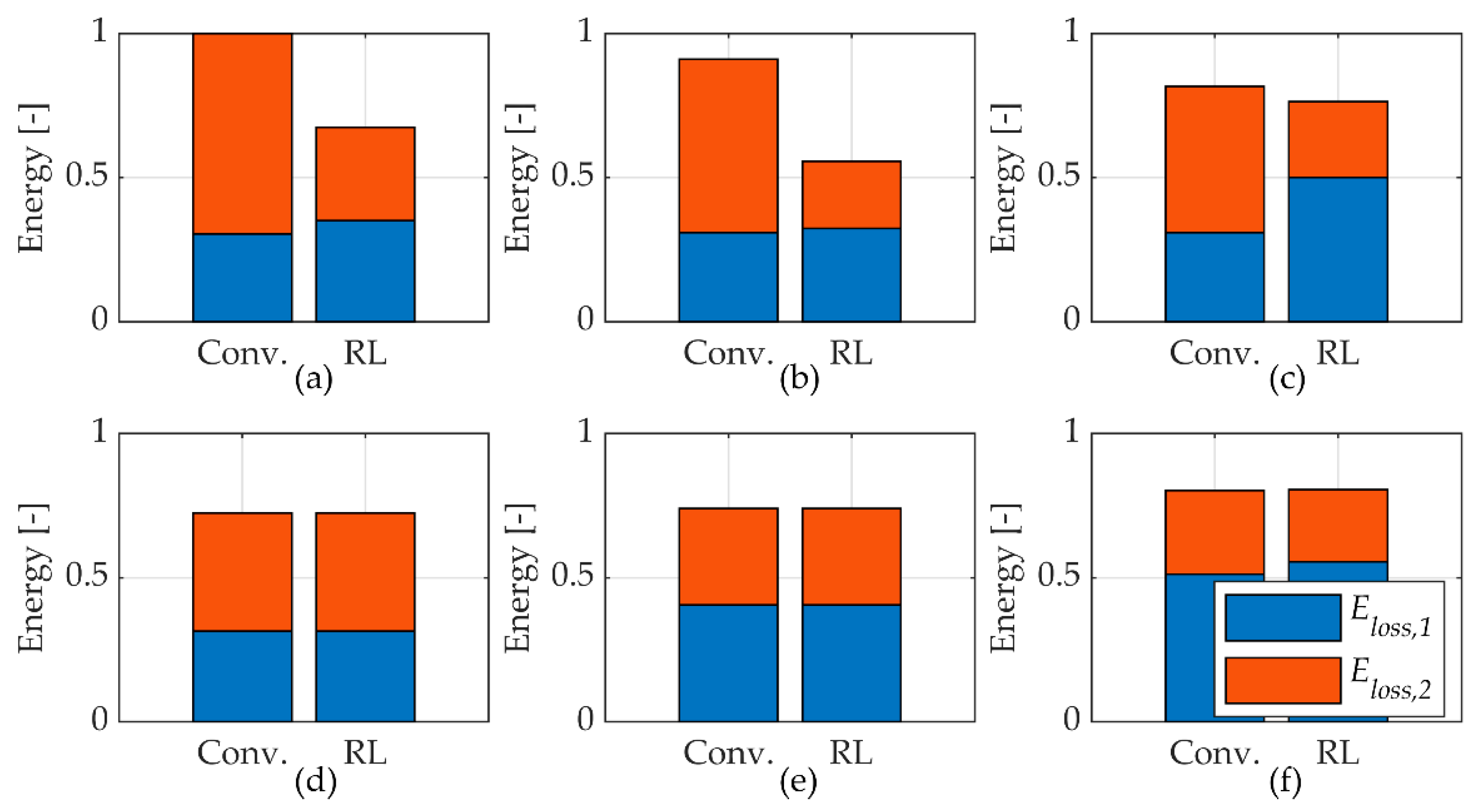
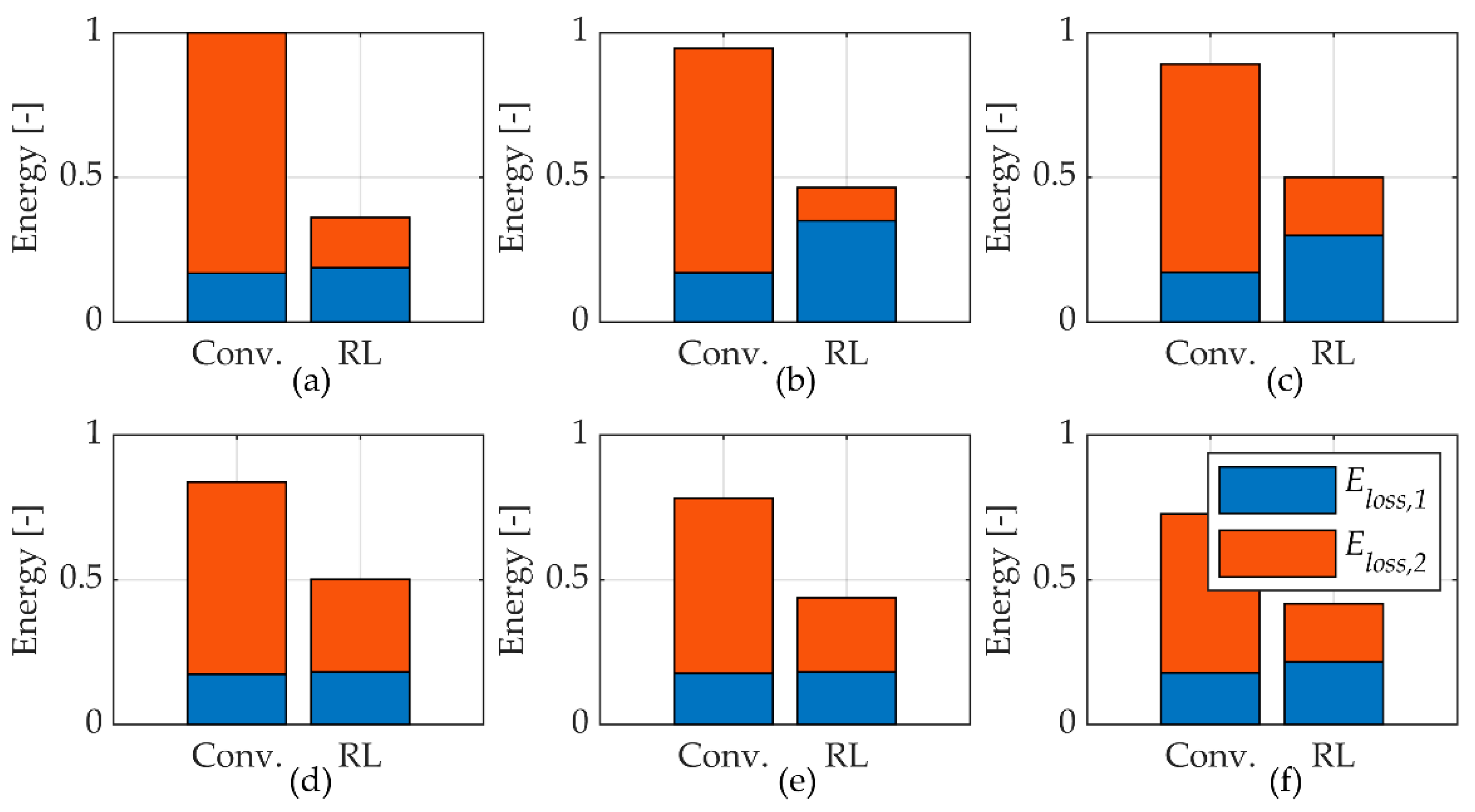
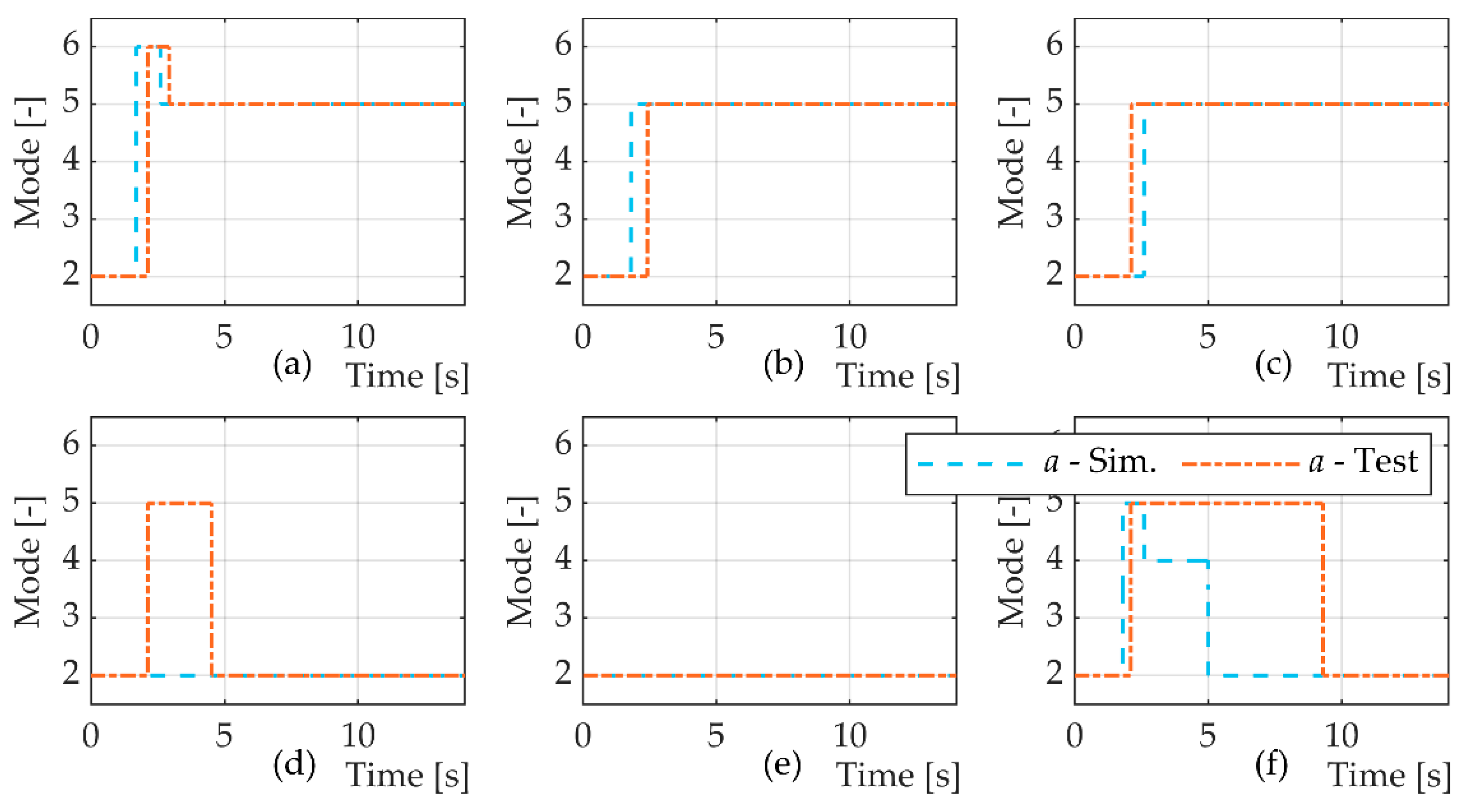
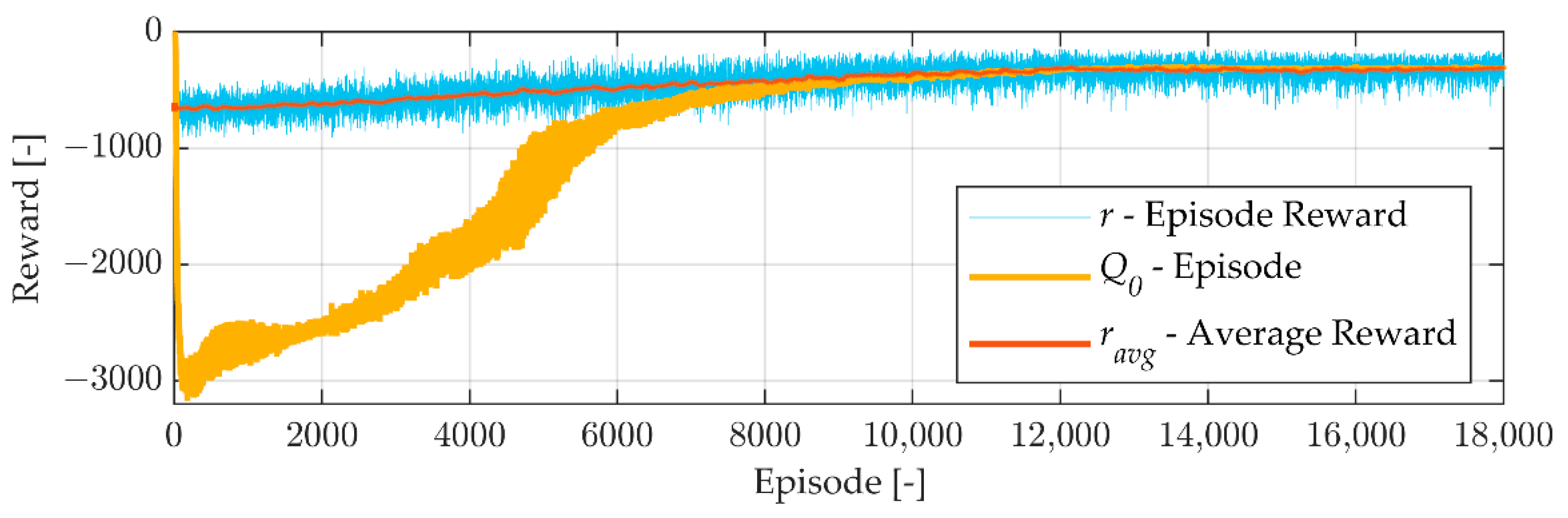
The energy analysis based on the simulation results showed the reduction in energy losses caused by the selection of suitable modes by the agent. However, this does not mean that the training of the agent converged to the global optimal solution that results in the lowest energy losses possible. The optimisation objective has other terms, and, therefore, the results presented in
Figure 6 are only an estimation of what are the best modes. Future studies should aim at finding the optimal solution and comparing this with what the agent finds during the training.
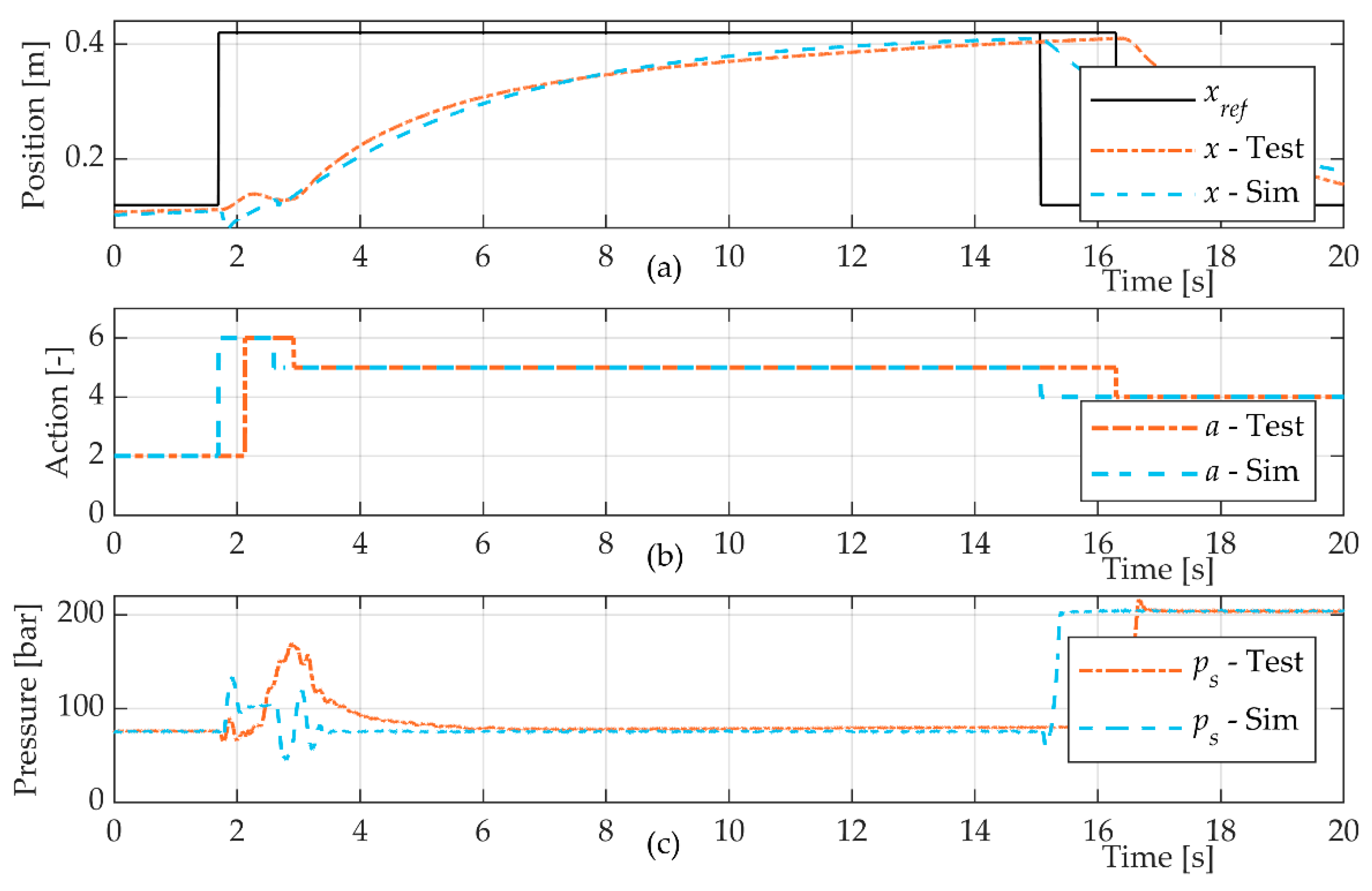
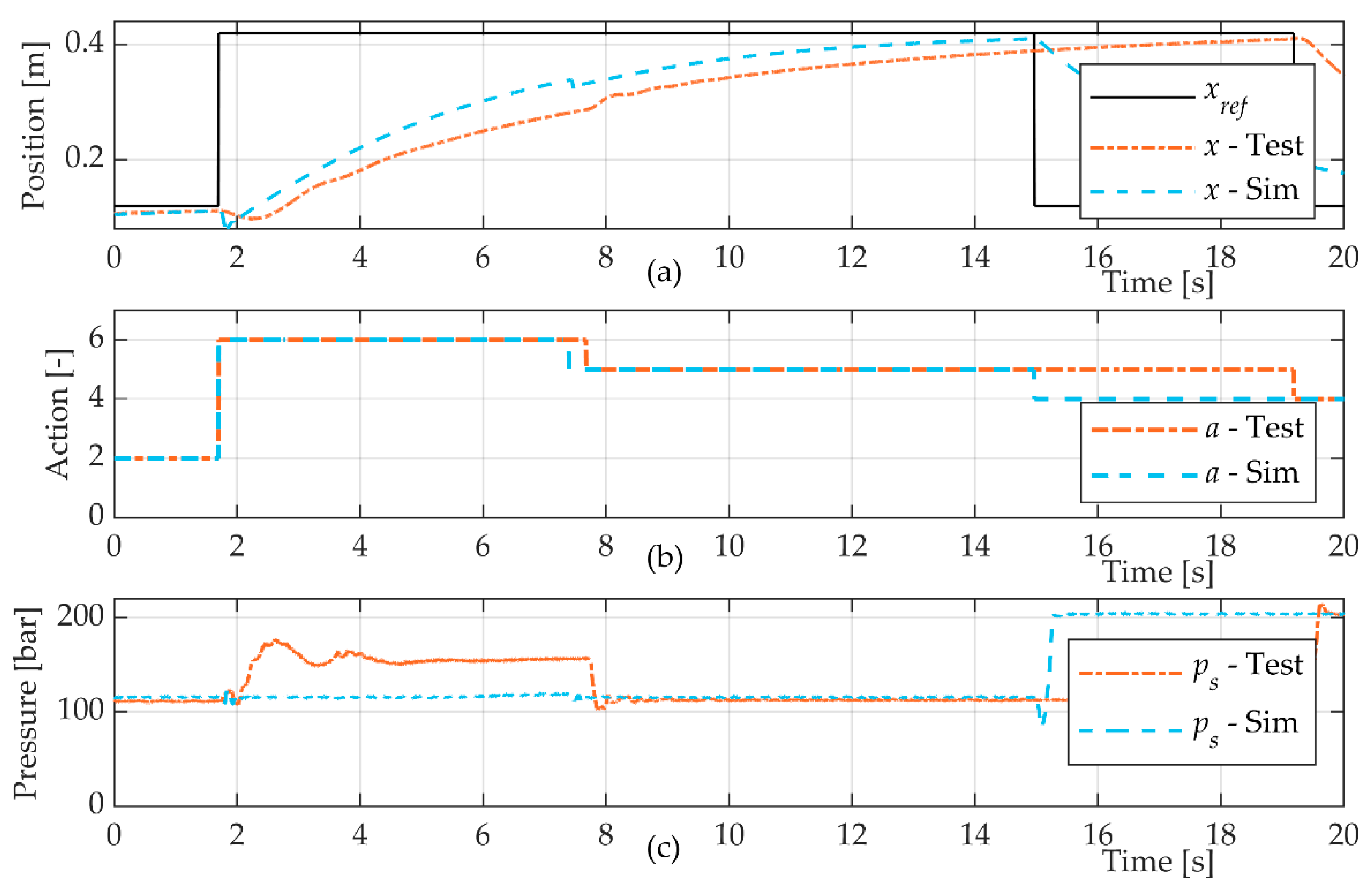
The model of the system was judged to be sufficiently accurate to describe the main characteristics and behaviours of the system. Still, there were deviations from the actual behaviour of the system. Although sufficient to pre-train the agent, it is likely that the performance of the agent could be further improved by letting it, in a safe manner, interact with the real system and train from those experiences in order to correct model deviations.
Machine learning-based controllers are a black-box type of controller. There is an inherent risk associated with them when deployed to control real systems, usually related to the controller operating outside the training domain. Therefore, it must be ensured that the control actions applied to the system do not lead to any unsafe and/or unstable behaviours. In this study, this was ensured by implementing safety rules that would overwrite the agent’s decisions when necessary.
One limitation of this study was that the agent was evaluated under approximately the same load conditions and tasks that it was trained for. In the simulation, random noise was introduced to all measurements from the system in order to increase its robustness in the experimental tests. However, there are still questions to be answered and an evaluation to be made regarding the robustness and generalisation capability of the agent. This is especially the case for more realistic load cases, such as digging and variable pressure.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}