
Noninvasive Detection of Appliance Utilization Patterns in Residential Electricity Demand †

 ,
,  ,
,  ,
,  , and
, and 
Abstract
1. Introduction
- We propose a methodology for the detection of utilization patterns in residential installations with a low computational cost;
- Our method is noninvasive because it does not require any personal information about the households;
- We show that the method for training Self Organizing Maps opens a wide range of analysis opportunities for the system status, starting from malfunction and fault detection.
2. Materials and Methods
2.1. Public Dataset Selected
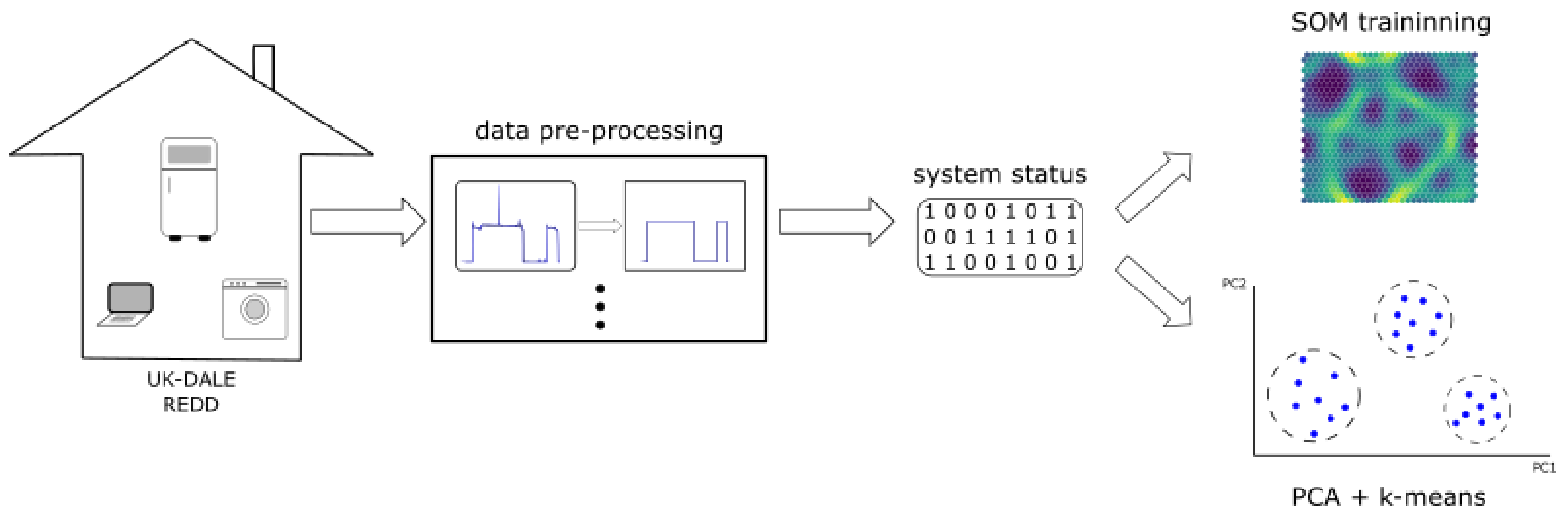
2.2. Methodology
- The synchronization of the individual channels by removing periods of sampling failure and adjusting small discrepancies between the time stamps of individual channels (some channels were 1 s ahead during some periods, for example);
- The removal of individual channels that contain a quantity of samples too different from the others in the household (the channels with a sample quantity of less than 25% of the average for the installation were removed);
- Definition of the real-power consumption threshold that defines the appliance status as on/1 or off/0; finally,
- The recording the system status set as binary vectors in a text file.
2.2.1. Principal Component Analysis
- The method does not require any parametrization, meaning that no additional information of the phenomenon is required.
- The method requires little computational effort.
- The variances associated with each projection direction can be interpreted as a measure of “how principal the component is”; the method lists the components ordered from the largest variance to the lowest.
- As the method is nonparametrical, it is impossible to set it in a wrong way and miss an important result.
- The method does not show any hidden information or suggest any conclusions; instead, it reduces redundancy and shows the data from an angle where the information is easier to visualize.
2.2.2. Applying PCA to the UK-DALE and REDD Data Sets
2.2.3. Clustering with k-Means
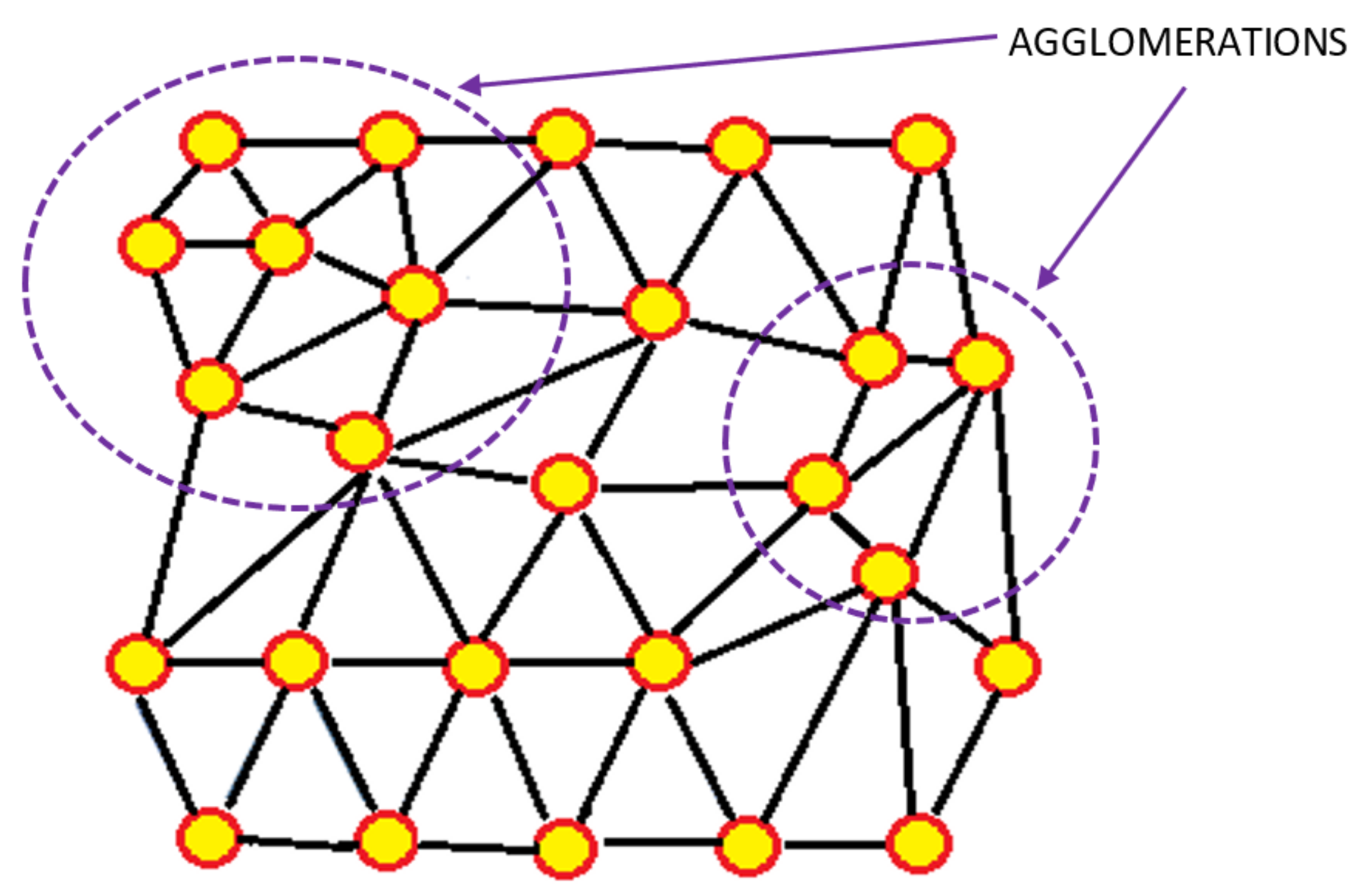
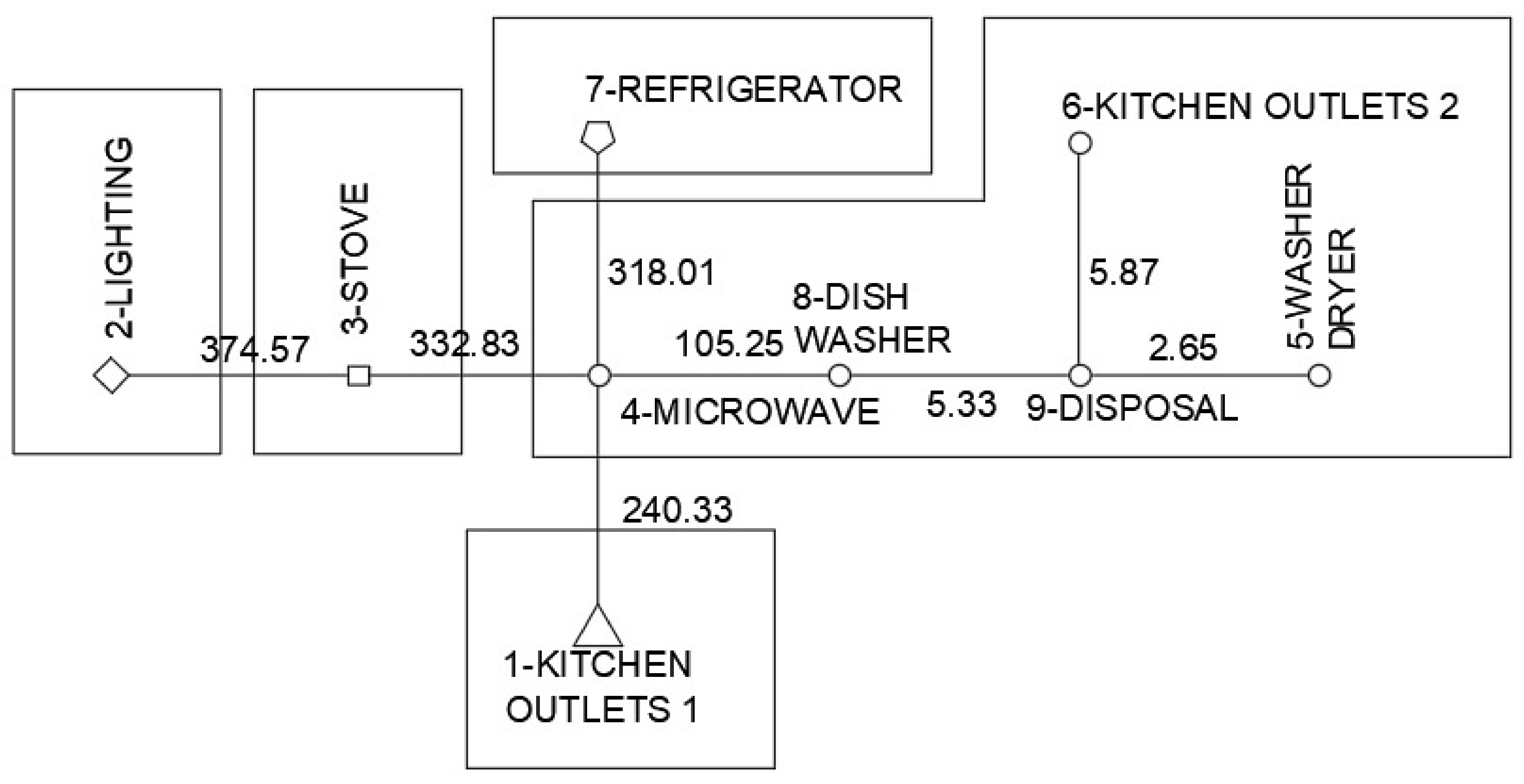
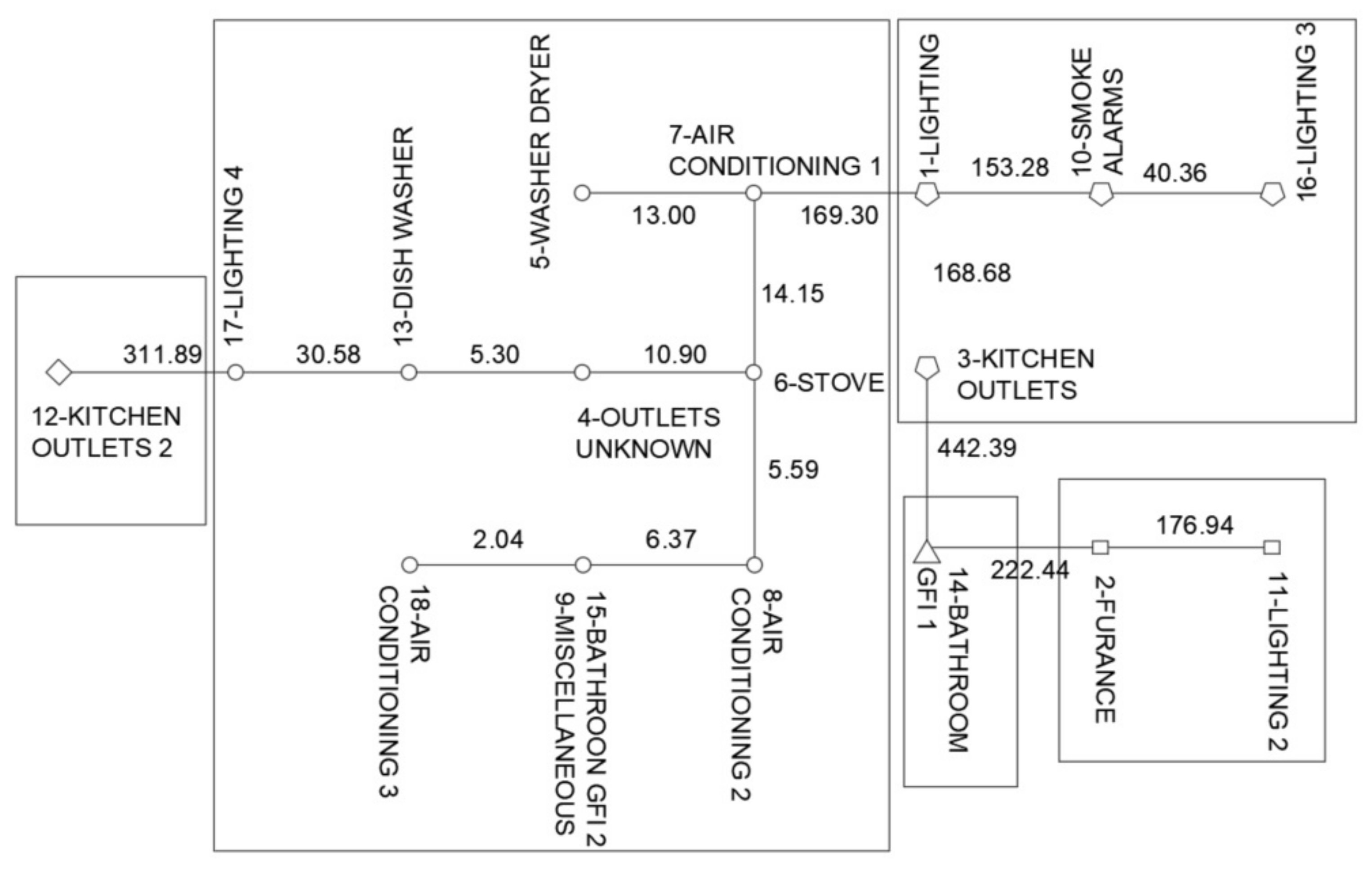
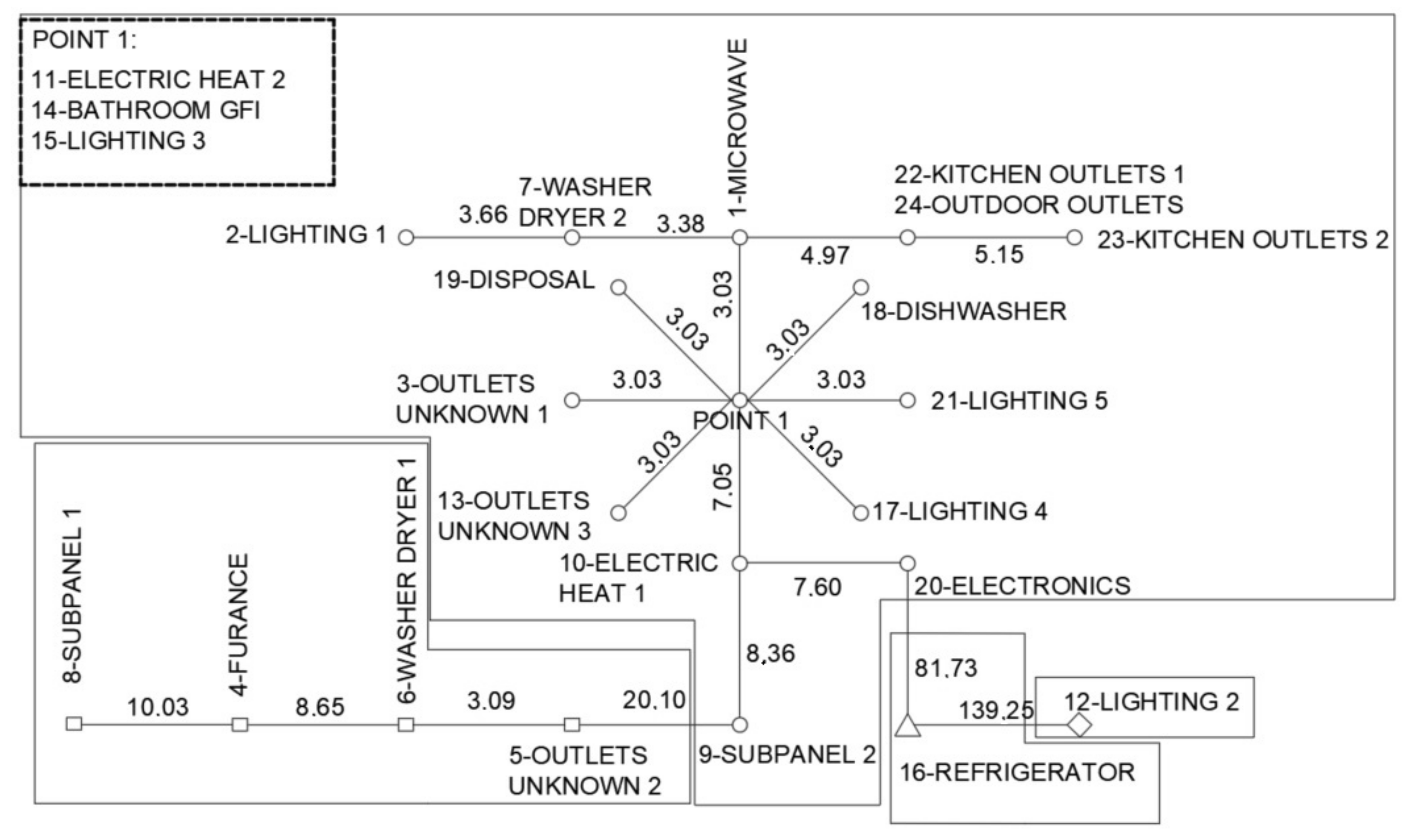
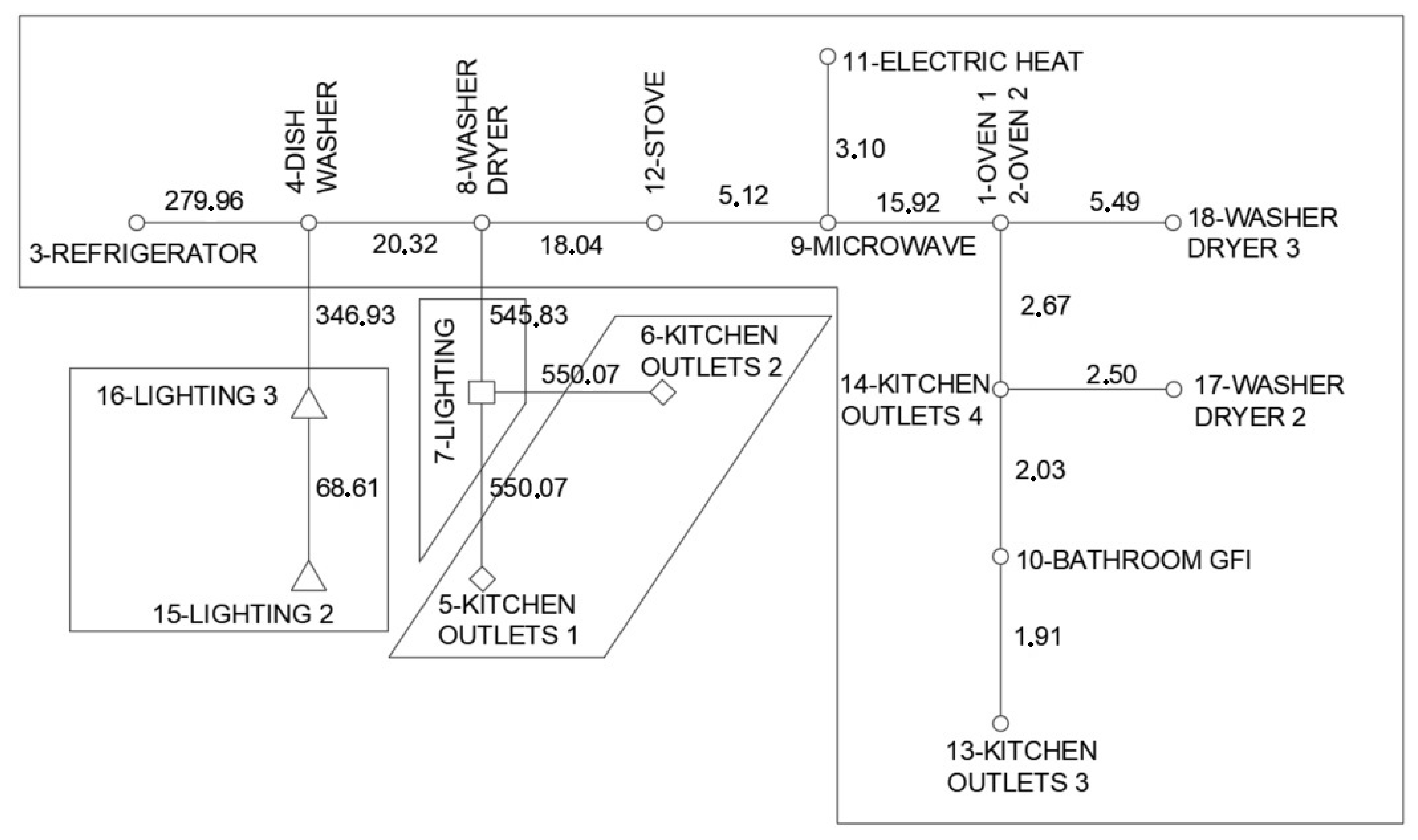
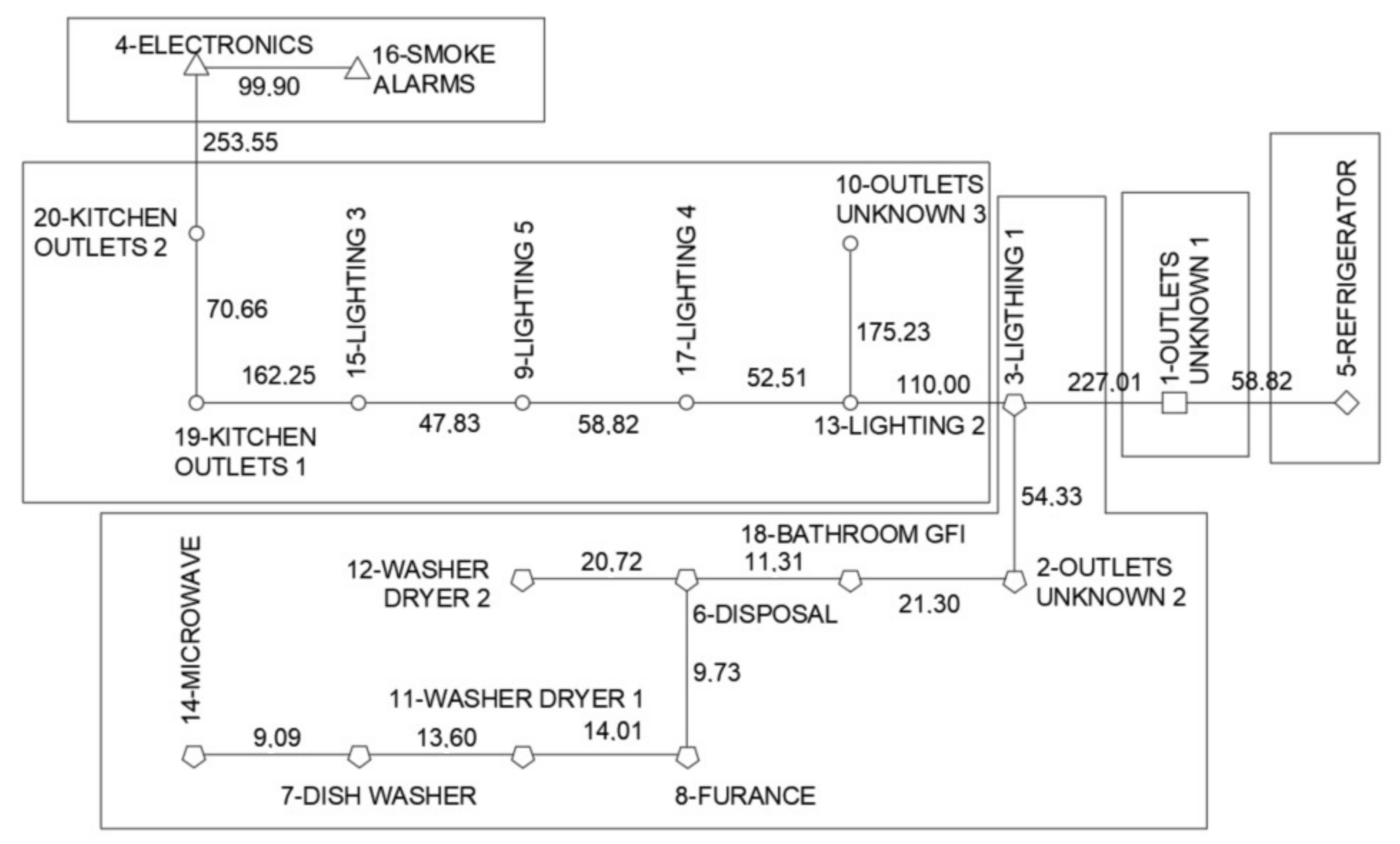
2.2.4. Minimum Spanning Tree
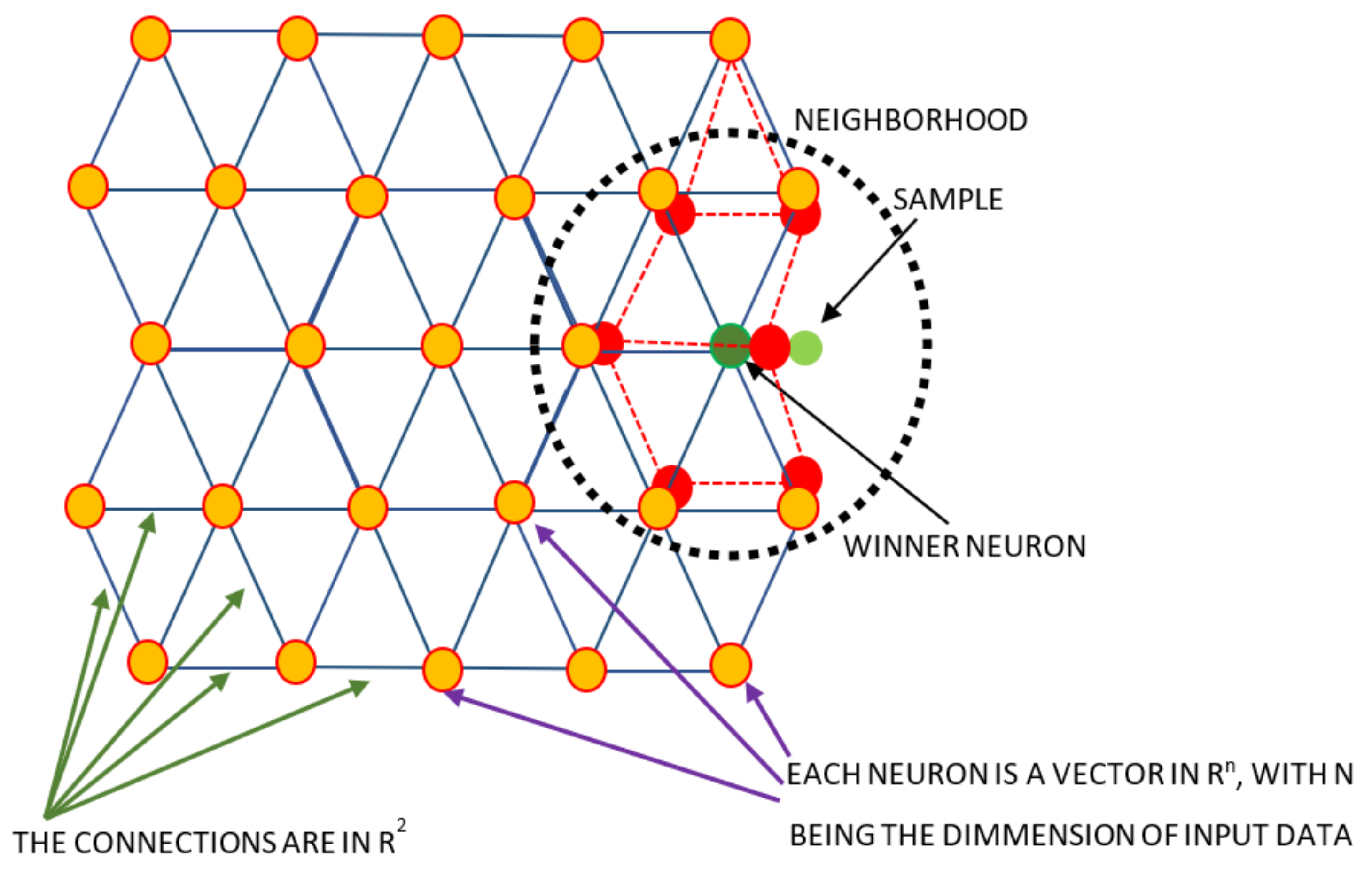
2.2.5. Self Organizing Maps
3. Results
3.1. Linear Method—PCA, k-Means, and MSP
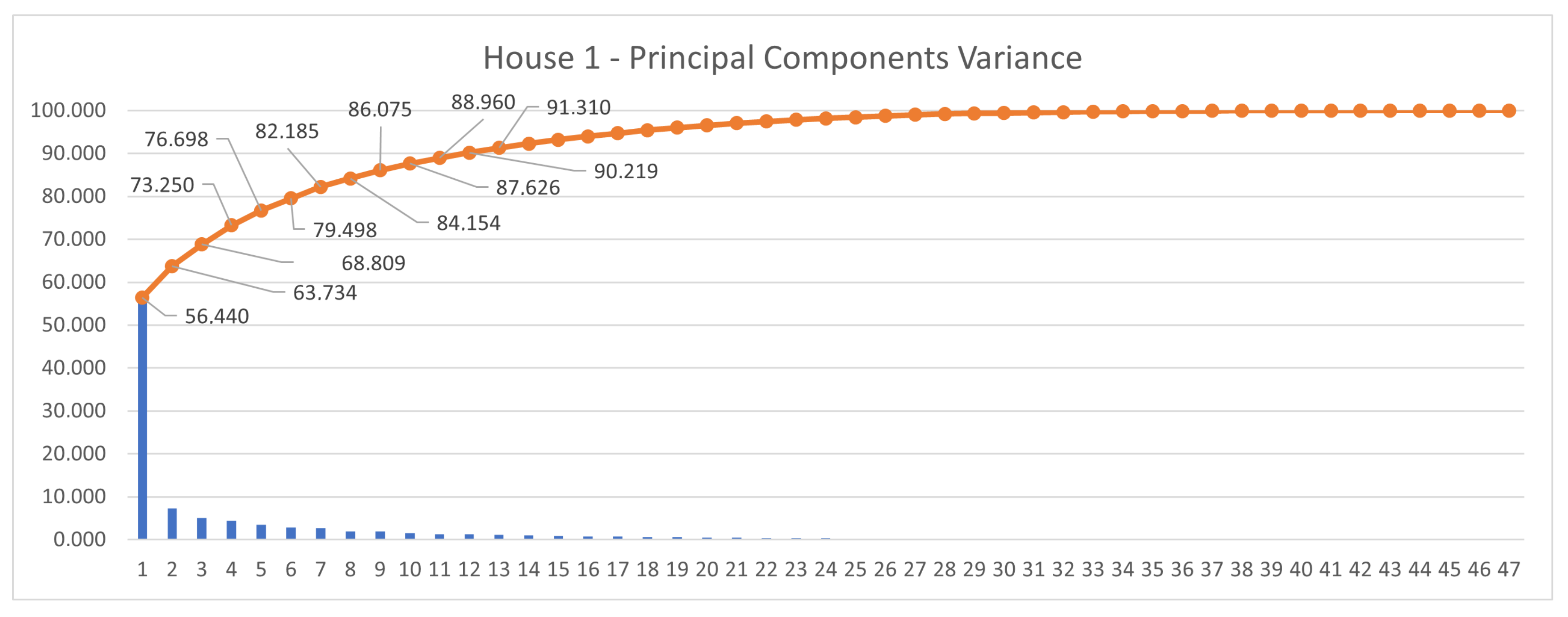
3.1.1. UK-DALE—Houses 1, 2, and 5
3.1.2. REDD—Houses 1 to 6
3.2. Nonlinear Method—Self Organizing Maps (SOM)
3.2.1. UK-DALE—Houses 1, 2, and 5
3.2.2. REDD—Houses 1 to 6
4. Discussion
4.1. PCA and k-Means for the UK-DALE and the REDD Datasets
4.2. Self Organizing Maps for the UK-DALE and REDD Datasets
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- García, S.; Parejo, A.; Personal, E.; Guerrero, J.I.; Biscarri, F.; León, C. A retrospective analysis of the impact of the COVID-19 restrictions on energy consumption at a disaggregated level. Appl. Energy 2021, 287, 116547. [Google Scholar] [CrossRef]
- Vega, A.; Amaya, D.; Santamaría, F.; Rivas, E. Active demand-side management strategies focused on the residential sector. Electr. J. 2020, 33, 106734. [Google Scholar] [CrossRef]
- Hussain, H.M.; Nardelli, P.H. A Heuristic-based Home Energy Management System for Demand Response. In Proceedings of the 2020 IEEE Conference on Industrial Cyberphysical Systems (ICPS), Tampere, Finland, 10–12 June 2020; Volume 1, pp. 285–290. [Google Scholar]
- Hui, H.; Ding, Y.; Shi, Q.; Li, F.; Song, Y.; Yan, J. 5G network-based Internet of Things for demand response in smart grid: A survey on application potential. Appl. Energy 2020, 257, 113972. [Google Scholar] [CrossRef]
- Wei, Y.; Xia, L.; Pan, S.; Wu, J.; Zhang, X.; Han, M.; Zhang, W.; Xie, J.; Li, Q. Prediction of occupancy level and energy consumption in office building using blind system identification and neural networks. Appl. Energy 2019, 240, 276–294. [Google Scholar] [CrossRef]
- Zhao, H.; Yan, X.; Ren, H. Quantifying flexibility of residential electric vehicle charging loads using non-intrusive load extracting algorithm in demand response. Sustain. Cities Soc. 2019, 50, 101664. [Google Scholar] [CrossRef]
- Cao, H.Â.; Beckel, C.; Staake, T. Are domestic load profiles stable over time? An attempt to identify target households for demand side management campaigns. In Proceedings of the IECON 2013-39th Annual Conference of the IEEE Industrial Electronics Society, Vienna, Austria, 10–13 November 2013; pp. 4733–4738. [Google Scholar]
- Chen, Y.C.; Chu, C.M.; Tsao, S.L.; Tsai, T.C. Detecting users’ behaviors based on nonintrusive load monitoring technologies. In Proceedings of the 2013 10th IEEE International Conference on Networking, Sensing and Control (ICNSC), Evry, France, 10–12 April 2013; pp. 804–809. [Google Scholar]
- Iyengar, S.; Irwin, D.; Shenoy, P. Non-intrusive model derivation: Automated modeling of residential electrical loads. In Proceedings of the Seventh International Conference on Future Energy Systems, Waterloo, ON, Canada, 21–24 June 2016; p. 2. [Google Scholar]
- Beckel, C.; Sadamori, L.; Staake, T.; Santini, S. Revealing household characteristics from smart meter data. Energy 2014, 78, 397–410. [Google Scholar] [CrossRef]
- Anderson, K.; Ocneanu, A.; Benitez, D.; Carlson, D.; Rowe, A.; Berges, M. BLUED: A fully labeled public dataset for event-based non-intrusive load monitoring research. In Proceedings of the 2nd KDD Workshop on Data Mining Applications in Sustainability (SustKDD), Beijing, China, 12–16 August 2012; pp. 1–5. [Google Scholar]
- Kolter, J.Z.; Johnson, M.J. REDD: A public data set for energy disaggregation research. In Proceedings of the Workshop on Data Mining Applications in Sustainability (SIGKDD), San Diego, CA, USA, 21–24 August 2011; Volume 25, pp. 59–62. [Google Scholar]
- Kelly, J.; Knottenbelt, W. The UK-DALE dataset, domestic appliance-level electricity demand and whole-house demand from five UK homes. Sci. Data 2015, 2, 150007. [Google Scholar] [CrossRef] [PubMed]
- Allcott, H. Social norms and energy conservation. J. Public Econ. 2011, 95, 1082–1095. [Google Scholar] [CrossRef]
- Ushakova, A.; Mikhaylov, S.J. Big data to the rescue? Challenges in analysing granular household electricity consumption in the United Kingdom. Energy Res. Soc. Sci. 2020, 64, 101428. [Google Scholar] [CrossRef]
- Narayanan, A.; De Sena, A.S.; Gutierrez-Rojas, D.; Melgarejo, D.C.; Hussain, H.M.; Ullah, M.; Bayhan, S.; Nardelli, P.H. Key Advances in Pervasive Edge Computing for Industrial Internet of Things in 5G and Beyond. IEEE Access 2020, 8, 206734–206754. [Google Scholar] [CrossRef]
- Jain, A.K.; Dubes, R.C. Algorithms for Clustering Data; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]
- Himeur, Y.; Alsalemi, A.; Bensaali, F.; Amira, A. An intelligent nonintrusive load monitoring scheme based on 2D phase encoding of power signals. Int. J. Intell. Syst. 2021, 36, 72–93. [Google Scholar] [CrossRef]
- Sa, A.; Thollander, P.; Cagno, E. Assessing the driving factors for energy management program adoption. Renew. Sustain. Energy Rev. 2017, 74, 538–547. [Google Scholar] [CrossRef]
- Luo, X.; Hong, T.; Chen, Y.; Piette, M.A. Electric load shape benchmarking for small-and medium-sized commercial buildings. Appl. Energy 2017, 204, 715–725. [Google Scholar] [CrossRef]
- Vercamer, D.; Steurtewagen, B.; Van den Poel, D.; Vermeulen, F. Predicting consumer load profiles using commercial and open data. IEEE Trans. Power Syst. 2015, 31, 3693–3701. [Google Scholar] [CrossRef]
- Naspolini, H.F.; Rüther, R. The effect of measurement time resolution on the peak time power demand reduction potential of domestic solar hot water systems. Renew. Energy 2016, 88, 325–332. [Google Scholar] [CrossRef]
- Bucher, C.; Betcke, J.; Andersson, G. Effects of variation of temporal resolution on domestic power and solar irradiance measurements. In Proceedings of the 2013 IEEE Grenoble Conference, Grenoble, France, 16–20 June 2013; pp. 1–6. [Google Scholar]
- Hernandez, J.; Sanchez-Sutil, F.; Cano-Ortega, A.; Baier, C. Influence of Data Sampling Frequency on Household Consumption Load Profile Features: A Case Study in Spain. Sensors 2020, 20, 6034. [Google Scholar] [CrossRef]
- Jonathon Shlens, A. Tutorial on Principal Component Analysis http://www.brainmapping.org/NITP/PNA. Readings 2005, 12, 10. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines; Pearson Education: London, UK, 2011. [Google Scholar]
- Hua, D.; Huang, F.; Wang, L.; Chen, W. Simultaneous disaggregation of multiple appliances based on non-intrusive load monitoring. Electr. Power Syst. Res. 2021, 193, 106887. [Google Scholar] [CrossRef]
- Cheriton, D.; Tarjan, R.E. Finding minimum spanning trees. SIAM J. Comput. 1976, 5, 724–742. [Google Scholar] [CrossRef]
- Athanasiadis, C.; Doukas, D.; Papadopoulos, T.; Chrysopoulos, A. A Scalable Real-Time Non-Intrusive Load Monitoring System for the Estimation of Household Appliance Power Consumption. Energies 2021, 14, 767. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, W.; Shen, Y.; Zhao, X.; Gao, S. Toward smart energy user: Real time non-intrusive load monitoring with simultaneous switching operations. Appl. Energy 2021, 287, 116616. [Google Scholar] [CrossRef]
- Himeur, Y.; Alsalemi, A.; Bensaali, F.; Amira, A. Smart non-intrusive appliance identification using a novel local power histogramming descriptor with an improved k-nearest neighbors classifier. Sustain. Cities Soc. 2021, 67, 102764. [Google Scholar] [CrossRef]
- Murray, D.; Stankovic, L.; Stankovic, V. An electrical load measurements dataset of United Kingdom households from a two-year longitudinal study. Sci. Data 2017, 4, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Smith, C.A. The Pecan Street Project: Developing the Electric Utility System of the Future. Ph.D. Thesis, University of Texas, Austin, TX, USA, 2009. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| House | Individual Channels | Time Monitored |
|---|---|---|
| UK-DALE HOUSE 1 | 52 | more than 4 years |
| UK-DALE HOUSE 2 | 18 | 193 days |
| UK-DALE HOUSE 3 | 4 | 35 days |
| UK-DALE HOUSE 4 | 5 | 151 days |
| UK-DALE HOUSE 5 | 24 | 122 days |
| REDD HOUSE 1 | 18 | 25 days |
| REDD HOUSE 2 | 9 | 11 days |
| REDD HOUSE 3 | 20 | 14 days |
| REDD HOUSE 4 | 18 | 19 days |
| REDD HOUSE 5 | 24 | 2.7 days |
| REDD HOUSE 6 | 15 | 13 days |
| House | Individual Channels | Variance Accumulated by the First 3 PCS [%] |
|---|---|---|
| 1 | 18 | 87.50 |
| 2 | 9 | 90.97 |
| 3 | 20 | 66.80 |
| 4 | 18 | 84.04 |
| 5 | 24 | 82.72 |
| 6 | 15 | 94.95 |
| House | Individual Channels | Clusters-k | Variance Accumulated [%] |
|---|---|---|---|
| 1 | 18 | 4 | 99.60 |
| 2 | 9 | 4 | 97.93 |
| 3 | 20 | 4 | 93.95 |
| 4 | 18 | 5 | 97.22 |
| 5 | 24 | 3 | 97.80 |
| 6 | 15 | 4 | 99.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Villar, F.S.; Nardelli, P.H.J.; Narayanan, A.; Moioli, R.C.; Azzini, H.; da Silva, L.C.P. Noninvasive Detection of Appliance Utilization Patterns in Residential Electricity Demand. Energies 2021, 14, 1563. https://doi.org/10.3390/en14061563
Villar FS, Nardelli PHJ, Narayanan A, Moioli RC, Azzini H, da Silva LCP. Noninvasive Detection of Appliance Utilization Patterns in Residential Electricity Demand. Energies. 2021; 14(6):1563. https://doi.org/10.3390/en14061563
Chicago/Turabian StyleVillar, Fernanda Spada, Pedro Henrique Juliano Nardelli, Arun Narayanan, Renan Cipriano Moioli, Hader Azzini, and Luiz Carlos Pereira da Silva. 2021. "Noninvasive Detection of Appliance Utilization Patterns in Residential Electricity Demand" Energies 14, no. 6: 1563. https://doi.org/10.3390/en14061563
APA StyleVillar, F. S., Nardelli, P. H. J., Narayanan, A., Moioli, R. C., Azzini, H., & da Silva, L. C. P. (2021). Noninvasive Detection of Appliance Utilization Patterns in Residential Electricity Demand. Energies, 14(6), 1563. https://doi.org/10.3390/en14061563