
MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images


Abstract
1. Introduction
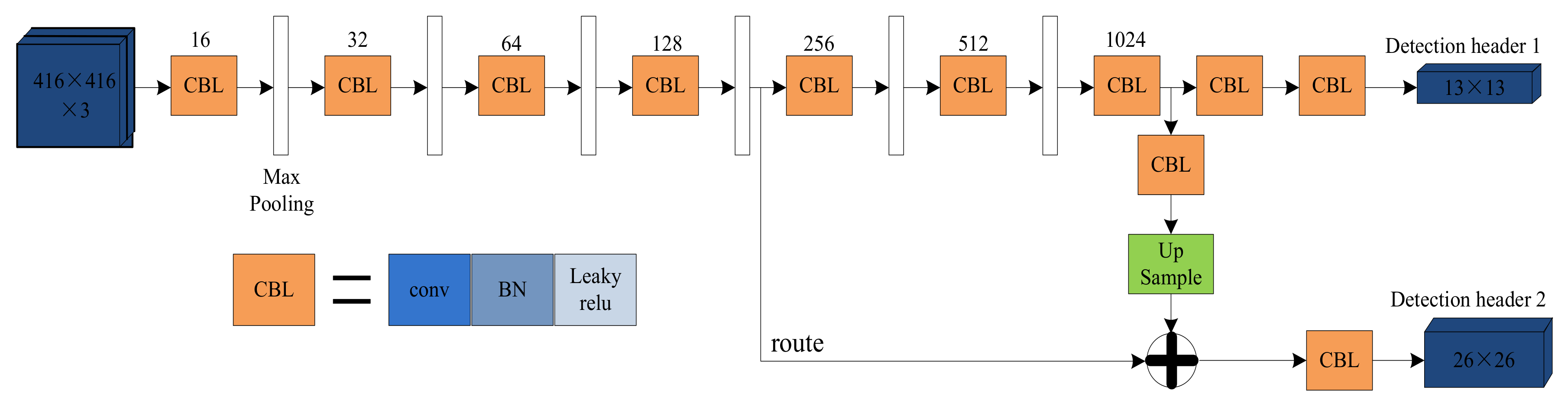
2. The Framework of YOLO-Tiny
3. Methodology
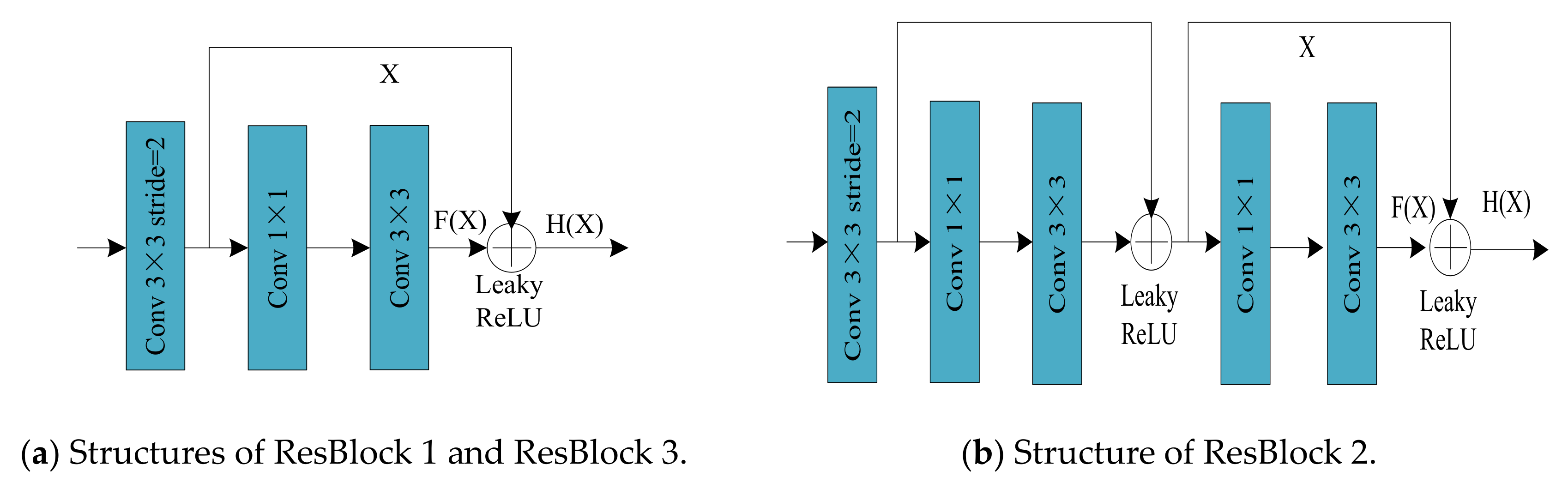
3.1. Structure of Backbone Network
3.2. The Feature Pyramid Network
3.3. Spatial Pyramid Pooling
4. Experiments Results and Discussion
4.1. Dataset Preparation
4.2. Anchor Boxes Clustering
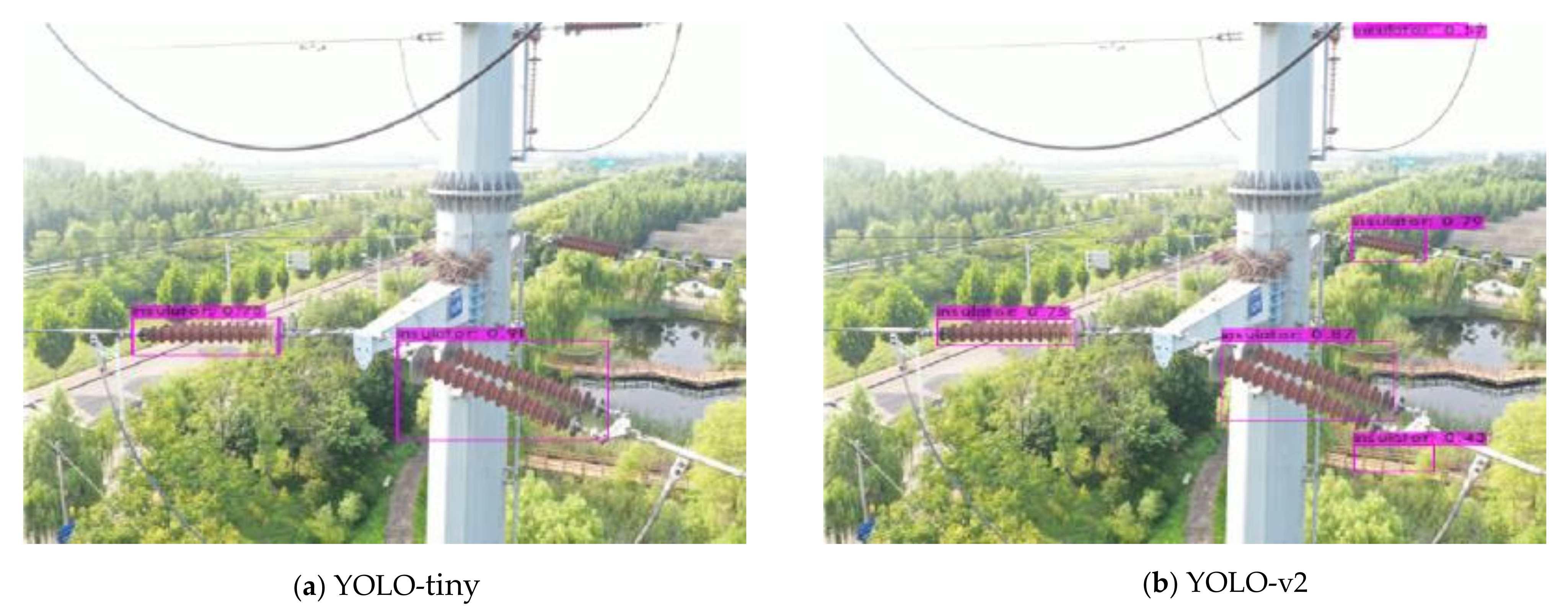
4.3. Quantitative and Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Park, K.C.; Motai, Y.; Yoon, J.R. Acoustic Fault Detection Technique for High-Power Insulators. IEEE Trans. Ind. Electron. 2017, 64, 9699–9708. [Google Scholar] [CrossRef]
- Wang, J.; Liang, X.; Gao, Y. Failure analysis of decay-like fracture of composite insulator. IEEE Trans. Dielectr. Electr. Insul. 2015, 21, 2503–2511. [Google Scholar] [CrossRef]
- Yuan, J.; Tong, W.; Li, B. Application of image processing in patrol inspection of overhead transmission line by helicopter. J. Power Sys. Technol. 2010, 12, 204–208. [Google Scholar]
- Nguyen, V.N.; Jenssen, R.; Roverso, D. Automatic autonomous vision-based power line inspection: A review of current status and the potential role of deep learning. Int. J. Electr. Power Energy Syst. 2018, 99, 107–120. [Google Scholar] [CrossRef]
- Katrasnik, J.; Pernus, F.; Likar, B. A Survey of Mobile Robots for Distribution Power Line Inspection. IEEE Trans. Power Del. 2010, 25, 485–493. [Google Scholar] [CrossRef]
- Yang, L.; Fan, J.; Liu, Y.; Li, E.; Peng, J.; Liang, Z. A Review on State-of-the-Art Power Line Inspection Techniques. IEEE Trans. Instrum. Meas. 2020, 69, 9350–9365. [Google Scholar] [CrossRef]
- Menendez, O.; Auat Cheein, F.A.; Perez, M.; Kouro, S. Robotics in Power Systems: Enabling a More Reliable and Safe Grid. IEEE Ind. Electron. Mag. 2017, 11, 22–34. [Google Scholar] [CrossRef]
- Zhao, Z.; Liu, N.; Wang, L. Localization of multiple insulators by orientation angle detection and binary shape prior knowledge. IEEE Trans. Dielectr. Electr. Insul. 2015, 22, 3421–3428. [Google Scholar] [CrossRef]
- Zhai, Y.; Wang, D.; Zhang, M.; Wang, J.; Guo, F. Fault detection of insulator based on saliency and adaptive morphology. Multimed. Tools Appl. 2017, 76, 12051–12064. [Google Scholar] [CrossRef]
- Wu, Q.; An, J.; Lin, B. A Texture Segmentation Algorithm Based on PCA and Global Minimization Active Contour Model for Aerial Insulator Images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2012, 5, 1509–1518. [Google Scholar] [CrossRef]
- Liao, S.; An, J. A robust insulator detection algorithm based on local features and spatial orders for aerial images. IEEE Geosci. Remote Sens. Lett. 2017, 12, 963–967. [Google Scholar] [CrossRef]
- Li, B.F.; Wu, D.L.; Cong, Y.; Xia, Y.; Tang, Y. A Method of Insulator Detection from Video Sequence. In Proceedings of the 2012 Fourth International Symposium on Information Science and Engineering, Shanghai, China, 14–16 December 2012; pp. 386–389. [Google Scholar] [CrossRef]
- Cheng, H.; Zhai, Y.; Chen, R.; Wang, D.; Dong, Z.; Wang, Y. Self-Shattering Defect Detection of Glass Insulators Based on Spatial Features. Energies 2019, 12, 543. [Google Scholar] [CrossRef]
- Zhai, Y.; Chen, R.; Yang, Q.; Li, X.; Zhao, Z. Insulator fault detection based on spatial morphological features of aerial images. IEEE Access 2018, 6, 35316–35326. [Google Scholar] [CrossRef]
- Masita, K.L.; Hasan, A.N.; Shongwe, T. Deep Learning in Object Detection: A Review. In Proceedings of the 2020 International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2020. [Google Scholar] [CrossRef]
- Zhao, Z.; Zhen, Z.; Zhang, L.; Qi, Y.; Kong, Y.; Zhang, K. Insulator Detection Method in Inspection Image Based on Improved Faster R-CNN. Energies 2019, 12, 1204. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unifified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Dalian, China, 26–28 July 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.; Gao, F.; Hu, P.; Xu, L.; Zhang, J.; Yu, Y.; Xue, J.; Li, J. Detection and Recognition for Fault Insulator Based on Deep Learning. In Proceedings of the 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018. [Google Scholar] [CrossRef]
- Miao, X.; Liu, X.; Chen, J.; Zhuang, S.; Fan, J.; Jiang, H. Insulator Detection in Aerial Images for Transmission Line Inspection Using Single Shot Multibox Detector. IEEE Access 2019, 9945–9956. [Google Scholar] [CrossRef]
- Ling, Z.; Zhang, D.; Qiu, R.; Jin, Z.; Zhang, Y.; He, X.; Liu, H. An accurate and real-time self-blast glass insulator location method based on faster R-CNN and U-net with aerial images. CSEE J. Power Energy Syst. 2019, 5, 474–482. [Google Scholar]
- Tao, X.; Zhang, D.; Wang, Z.; Liu, X.; Zhang, H.; Xu, D. Detection of Power Line Insulator Defects Using Aerial Images Analyzed With Convolutional Neural Networks. IEEE Trans. Syst. Man Cybern. Syst. 2018, 1486–1498. [Google Scholar] [CrossRef]
- Sadykova, D.; Pernebayeva, D.; Bagheri, M.; James, A. IN-YOLO: Real-time Detection of Outdoor High Voltage Insulators using UAV Imaging. IEEE Trans. Power Del. 2019, 35, 1599–1601. [Google Scholar] [CrossRef]
- Han, J.; Yang, Z.; Xu, H.; Hu, G.; Zhang, C.; Li, H.; Lai, S.; Zeng, H. Search Like an Eagle: A Cascaded Model for Insulator Missing Faults Detection in Aerial Images. Energies 2020, 13, 713. [Google Scholar] [CrossRef]
- Adou, M.W.; Xu, H.; Chen, G. Insulator Faults Detection Based on Deep Learning. In Proceedings of the International Conference on Anti- Counterfeiting, Security, and Identification, Xiamen, China, 25–27 October 2019. [Google Scholar] [CrossRef]
- Wang, X.; Xu, T.; Zhang, J.; Chen, S. SO-YOLO Based WBC Detection with Fourier Ptychographic Microscopy. IEEE Access 2018, 6, 51566–51576. [Google Scholar] [CrossRef]
- Fang, W.; Wang, L.; Ren, P. Tinier-YOLO: A Real-time Object Detection Method for Constrained Environments. IEEE Access 2019, 1–10. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, H.; Zhang, J.; Yang, W. A vehicle real-time detection algorithm based on YOLOv2 framework. In Proceedings of the International Conference on Real-time Image & Video Processing, Orlando, FL, USA, 16–17 April 2018. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed]
- Li, T.; Ma, Y.; Endoh, T. A Systematic Study of Tiny YOLO3 Inference: Toward Compact Brainware Processor with Less Memory and Logic Gate. IEEE Access 2020, 8, 142931–142955. [Google Scholar] [CrossRef]
- Sha, G.; Wu, J.; Yu, B. Detection of Spinal Fracture Lesions Based on Improved Yolo-tiny. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the 14th European Conference on Computer Vision, Scottsdale, AZ, USA, 3–7 November 2014; pp. 630–645. [Google Scholar] [CrossRef]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Li, Y.; Pei, X.; Huang, Q.; Jiao, L.; Shang, R.; Marturi, N. Anchor-Free Single Stage Detector in Remote Sensing Images Based on Multiscale Dense Path Aggregation Feature Pyramid Network. IEEE Access 2020, 8, 63121–63133. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Huang, Z.; Wang, J. DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection. arXiv 2019, arXiv:1903.08589. [Google Scholar] [CrossRef]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2020. [Google Scholar] [CrossRef]
- Kim, K.J.; Kim, P.K.; Chung, Y.S.; Choi, D.-H. Performance Enhancement of YOLOv3 by Adding Prediction Layers with Spatial Pyramid Pooling for Vehicle Detection. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018. [Google Scholar] [CrossRef]
- Wang, X.; Wang, S.; Cao, J.; Wang, Y. Data-driven based tiny-YOLOv3 method for front vehicle detection inducing SPP-net. IEEE Access 2020. [Google Scholar] [CrossRef]
- Han, J.; Yang, Z.; Zhang, Q.; Chen, C.; Li, H.; Lai, S.; Hu, G.; Xu, C.; Xu, H.; Wang, D.; et al. A Method of Insulator Faults Detection in Aerial Images for High-Voltage Transmission Lines Inspection. Appl. Sci. 2019, 9, 2009. [Google Scholar] [CrossRef]
- Available online: https://github.com/InsulatorData/InsulatorDataSet (accessed on 15 September 2020).
- Project of the Dark-Net Framework. Available online: https://github.com/AlexeyAB/darknet (accessed on 25 October 2020).
- Zhao, H.; Zhou, Y.; Zhang, L.; Peng, Y.; Hu, X.; Peng, H.; Cai, X. Mixed YOLOv3-LITE: A Lightweight Real-Time Object Detection Method. Sensors 2020, 20, 1861. [Google Scholar] [CrossRef] [PubMed]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Images Number | Training Set | Testing Set | Image Size | Insulator Number |
|---|---|---|---|---|
| 4500 | 3000 | 1500 | 416 × 416 | 8165 |
| K | K = 1 | K = 3 | K = 5 | K = 7 | K = 9 | K = 11 | K = 12 | K = 13 | K = 14 | K = 15 |
| IOU | 38.98% | 62.79% | 67.57% | 71.76% | 74.90% | 75.81% | 76.74% | 77.18% | 77.99% | 78.46% |
| model | YOLO-tiny network | MTI-YOLO network | ||||||||
| Anchor boxes | Scale 1 | (127 × 99), (258 × 81), (260 × 147) | (267 × 83), (159 × 120), (279 × 153) | |||||||
| Scale 2 | (85 × 21), (94 × 43), (228 × 47) | (63 × 116), (154 × 67), (250 × 47) | ||||||||
| Scale 3 | (78 × 20), (71 × 45), (122 × 32) | |||||||||
| Parameters | Configuration |
|---|---|
| CPU | Intel-CPU-i9-9900K, CPU/8 GHz, RAM/32 GB |
| GPU | Nvidia GeForce GTX 3080(10G) |
| Operating System | Windows 10 |
| Accelerated Environment | CUDA 11.1, cuDNN 8.0.5 |
| Training Framework | Dark-net |
| Visual Studio Framework | Visual Studio 2017, Open CV 3.4 |
| Input Size | Channel | Batch Size | Batch Size | Learning Rate |
|---|---|---|---|---|
| 416 × 416 | 3 | 64 | 16 | 0.001–0.00001 |
| Momentum | Saturation | Exposure | Hue | Training Step |
| 0.9 | 1.5 | 1.5 | 0.1 | 38,000 |
| Networks | Precision | Recall | AP | Running Times (ms) | FLOPs | Memory Usage (MB) |
|---|---|---|---|---|---|---|
| YOLO-tiny | 79% | 67% | 72.78% | 3.96 | 5.45 | 33.89 |
| YOLO-v2 | 74% | 85% | 80.88% | 4.56 | 29.34 | 197.57 |
| YOLO-v3 | 94% | 95% | 90.29% | 11.67 | 65.30 | 240.53 |
| Our network | 95% | 91% | 89.72% | 6.44 | 26.39 | 146.93 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, C.; Wu, Y.; Liu, J.; Han, J. MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images. Energies 2021, 14, 1426. https://doi.org/10.3390/en14051426
Liu C, Wu Y, Liu J, Han J. MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images. Energies. 2021; 14(5):1426. https://doi.org/10.3390/en14051426
Chicago/Turabian StyleLiu, Chuanyang, Yiquan Wu, Jingjing Liu, and Jiaming Han. 2021. "MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images" Energies 14, no. 5: 1426. https://doi.org/10.3390/en14051426
APA StyleLiu, C., Wu, Y., Liu, J., & Han, J. (2021). MTI-YOLO: A Light-Weight and Real-Time Deep Neural Network for Insulator Detection in Complex Aerial Images. Energies, 14(5), 1426. https://doi.org/10.3390/en14051426