
Fast Optimization of Injector Selection for Waterflood, CO2-EOR and Storage Using an Innovative Machine Learning Framework


Abstract
:1. Introduction
- Machine learning methods have been shown to be efficient in reducing the time required to evaluate the objective function. However, time consuming flow simulations are required to generate a representative training dataset.
- Optimization of injection well location is computationally expensive in real field applications. Many approaches are geared towards efficiently reducing the number of evaluations using approaches, such as coarsened grids [21] or using feature based maps [22,23]. Other studies also focus on pattern level analysis [16].
- Creating a representative training dataset for surrogate modelling can be computationally expensive. Many studies are confined to using simplified models for this reason.
- The investigation of CO2 injector location for optimal oil recovery and storage is relatively infrequent. Much research work is focused on waterflood injector selection or CO2 operational optimization.
- The selection of a single injection strategy with geological uncertainty is an underexplored endeavor.
- The effective use of the latest machine learning technologies as suitable proxies is an area of active research.
- Many studies in the literature use pattern scale or ‘toy’ models as case studies. It is difficult to scale these methodologies and workflows to a field level analysis. There is a relative lack of work done for injector location selection specifically for full field evaluations. The framework proposed in this study is designed to evaluate real reservoirs comprehensively without requiring excessive simulation time or compromising prediction accuracy. The novel use of streamline simulation and well region aggregations shorten the time required to generate the proxy training dataset.
- There is a lack of studies evaluating both secondary and tertiary flood injector selections. Many of the existing studies are focused on either waterflood or CO2 flood analysis. The proposed workflow is flexible and can be applied to a variety of flood projects.
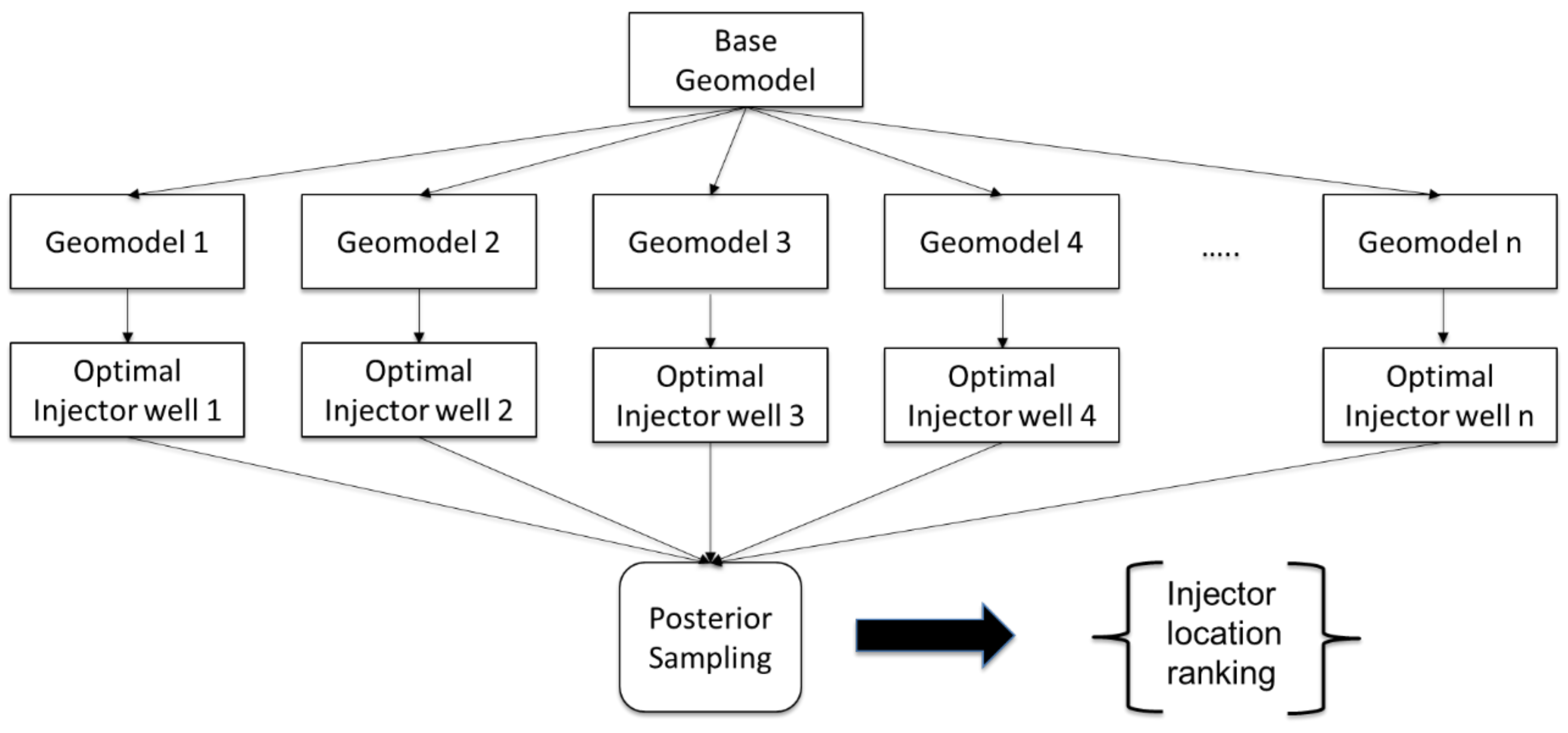
- Few studies address the selection of an optimal injection strategies from an ensemble of injection strategies arising out of geological uncertainty. Reservoir managers frequently make decisions with incomplete information. This is especially true early in the field development cycle. In the context of injection projects, the manager must decide on an injection strategy without having a complete understanding of the reservoir. For instance, there may be n number of geological realizations of a particular reservoir. Each realization may have a unique optimal injection well location; the reservoir manager may have up to n different injection locations to select. It may be computationally expensive to test each injection location on each geological realization in a brute force approach (resulting in up to n2 evaluations). Posterior sampling provides an efficient evaluation approach to determine which injection strategies consistently yield higher returns across the expected range of subsurface properties.
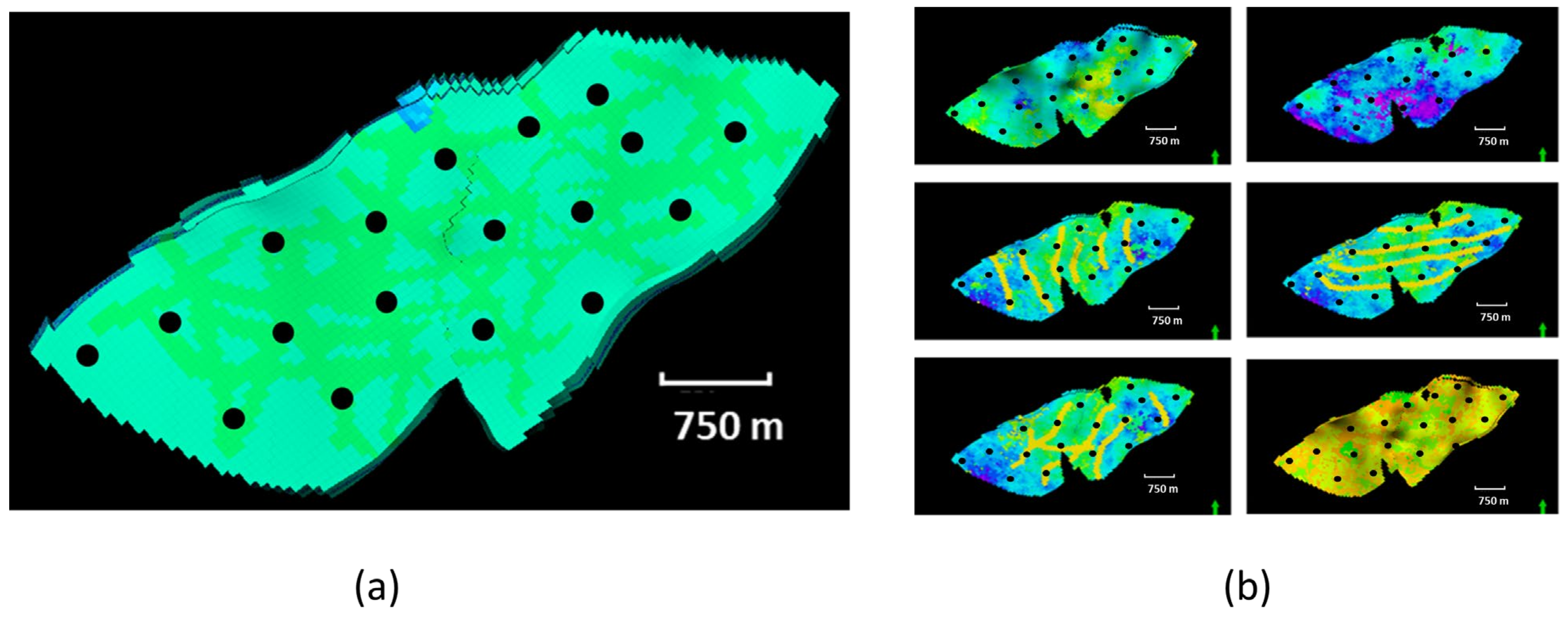
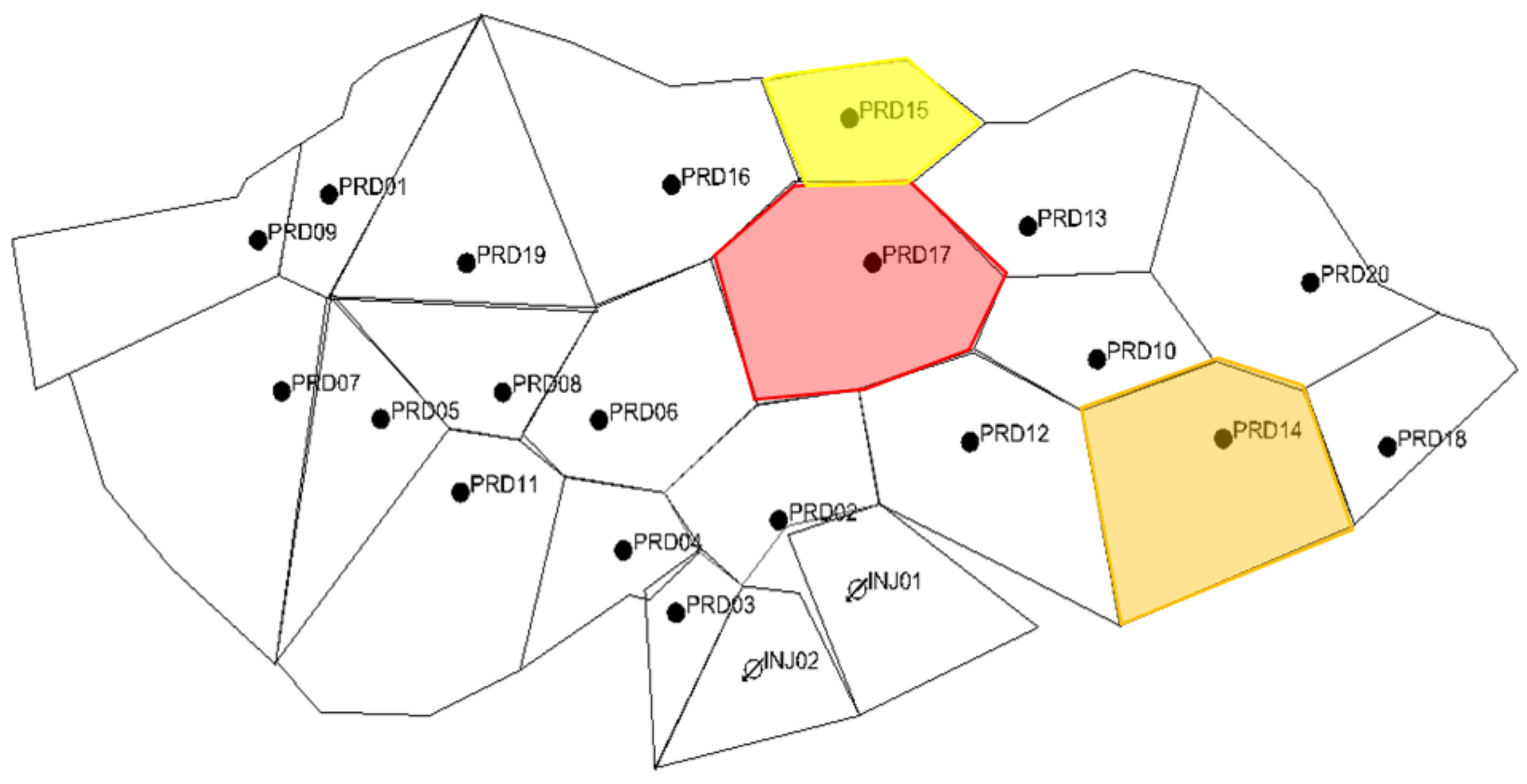
- Given existing production wells in a reservoir, where are the optimal injector locations to maximize oil recovery and/or CO2 storage? Figure 1a illustrates this challenge: with multiple production wells (marked as black dots), where are the optimal injection locations and are there existing production wells that can be converted to injectors?
- Given a diversity of geological models and possible injection strategies, which injection strategy should ultimately be implemented? The challenge highlighted in question 1 above is compounded if there is geological uncertainty. Figure 1b illustrates a set of different geological realizations. Each realization potentially has a unique optimal injection strategy. However, one injection strategy needs to be selected for field development.
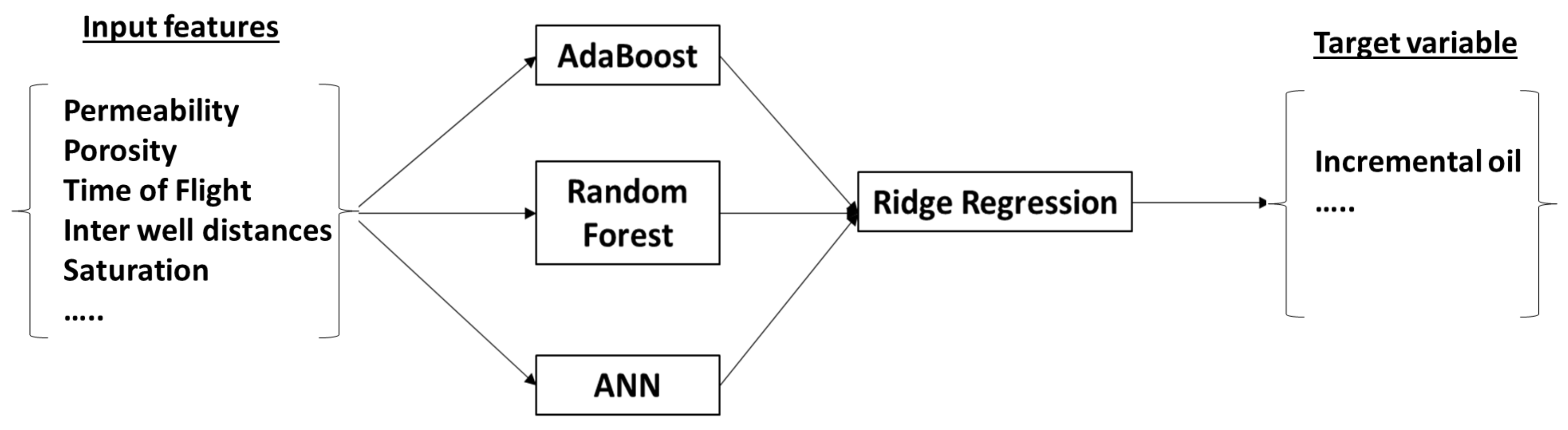
- A meta-learner (or Stacked learner) proxy based on a stack of models to improve accuracy.
- A novel well region concept to aggregate properties, reducing the number of potential well location evaluations.
- A streamlined simulation to reduce computational time for training dataset generation. Time-of-flight is used as a connectivity measure.
- A training dataset that consists of an ensemble of geological models to account for geological uncertainty.
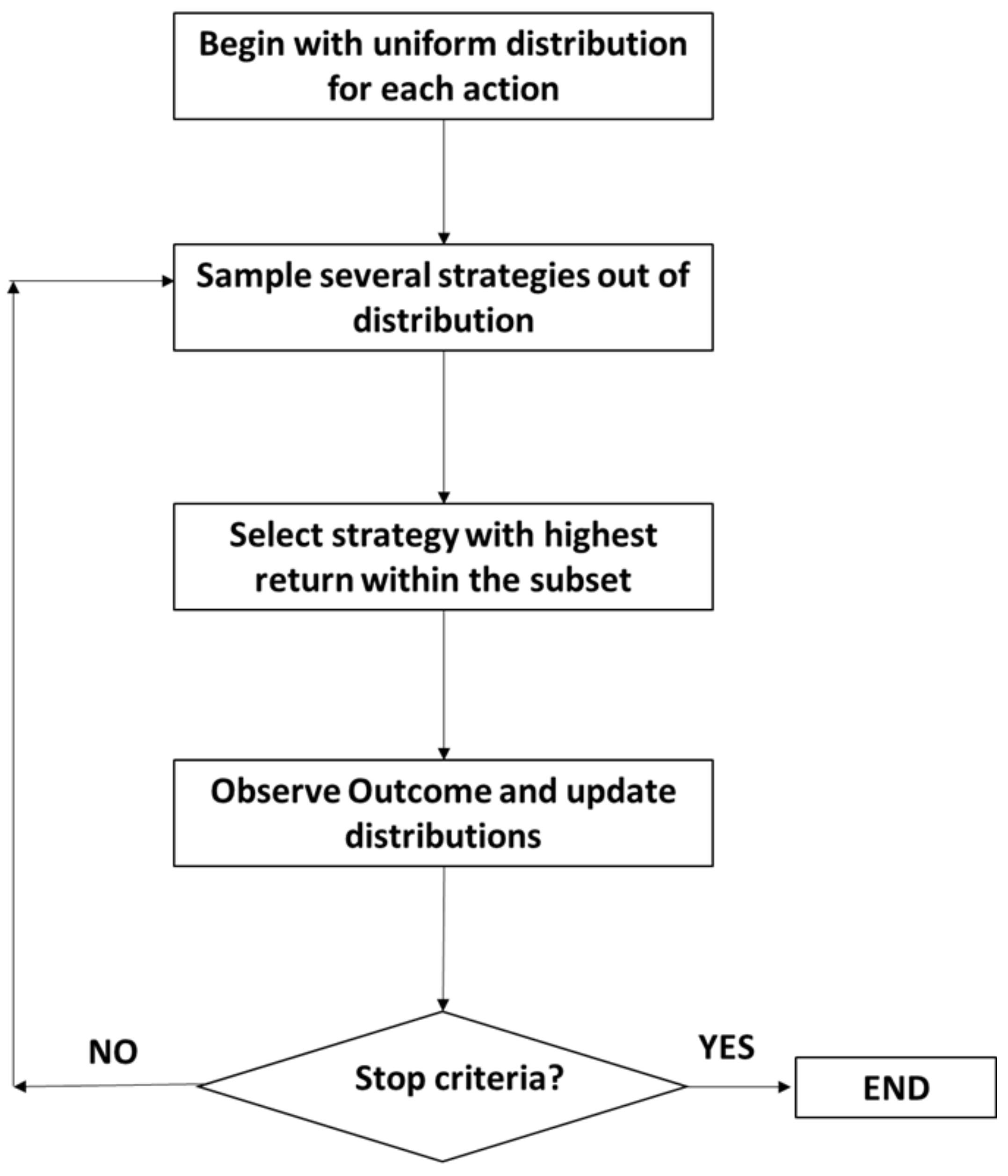
- A novel posterior sampling approach to select the best injection strategy from a diverse range of injection strategies and geological realizations.
2. Methodology
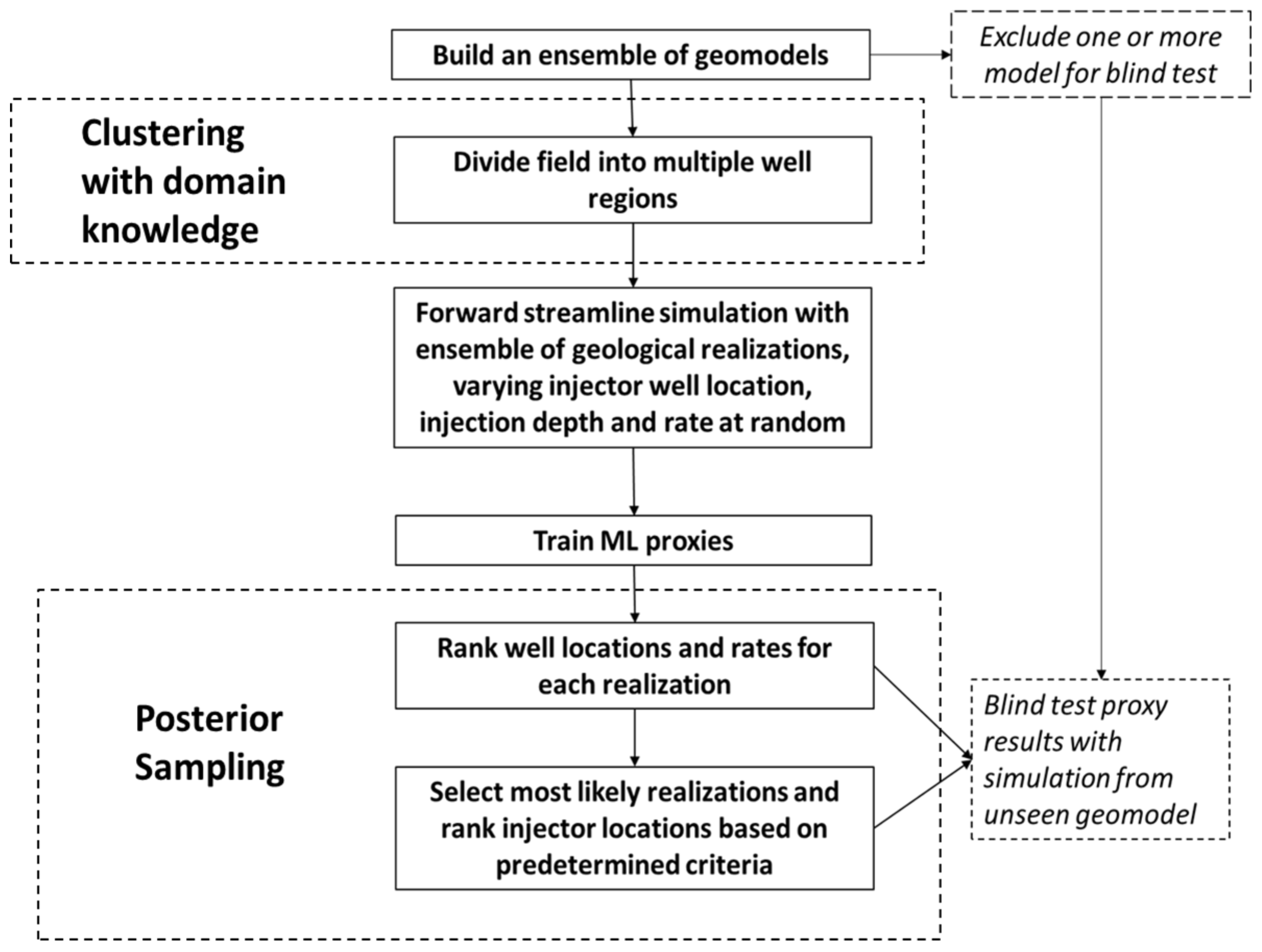
- The workflow begins with the construction of multiple geological models to capture the range of subsurface parametric uncertainty.
- Each geomodel is spatially divided into well regions guided by a clustering algorithm. Each region contains a single well.
- Forward streamline simulation runs are performed with the ensemble of geological models. For each run, one well is converted into an injection well. The injection depth and rate is also fixed. Each run has a unique injector well, depth and rate.
- Key geological and engineering parameters are extracted from each simulation run to build a training dataset.
- Machine Learning proxies are trained using the dataset. The proxies are trained to predict the well recoveries and/or storage potential.
- For a given geological realization, key parameters are provided to the proxy, and the injection location that maximizes certain objectives can be predicted.
- For multiple geological realizations, posterior sampling with the proxies is used to select the optimal injection locations across an ensemble of geological models.
2.1. Data Generation
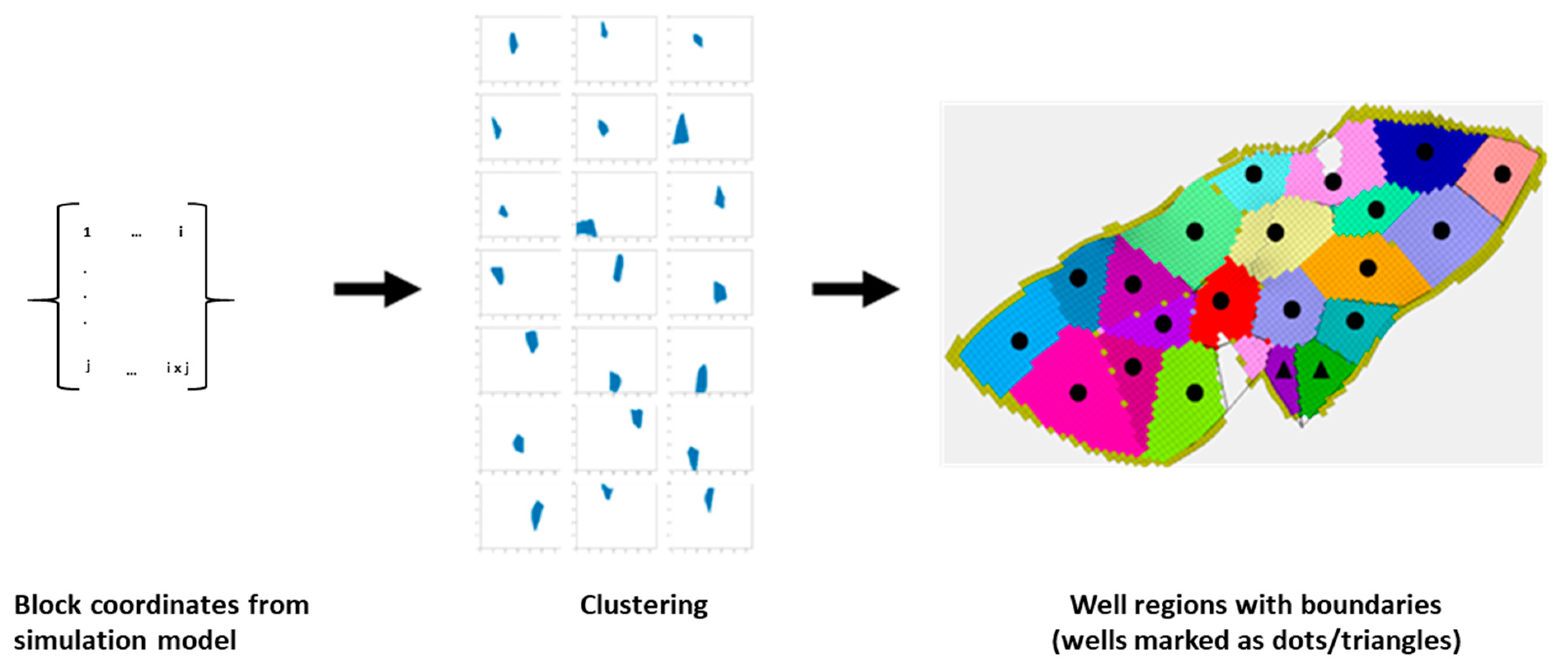
2.2. Well Regions
- The grid block locations for each block along the mid-point surface of the reservoir of interest.
- Define the centroids of the clusters around existing wells.
- Apply the K-means algorithm [27] to cluster points around centroids, with Equation (2)where dist(.) is the Euclidean distance, ci is the collection of centroids in set C and x is the data-point. Therefore the points closest to the centroids are clustered using the Euclidean distance metric.
- If the data density is insufficient, the clusters will not form adjacent boundaries. Therefore, to create adjacent spatial boundaries, Support Vector Classification (SVC) [28] is applied as follows:
- a.
- The clustered data points are projected to the feature space, given by Equation (3),
- b.
- The RBF kernel is used to transform the data following Equation (4)
- c.
- The classical statement of the SVC problem issubject to where . Here the goal is to maximize the margin (by minimizing , with a penalty term C. The dual problem can then be stated assubject to , with . Here, Q is a n by n positive semidefinite matrix. The terms are dual coefficients bounded by C.
- d.
- The solution of the optimization problem (Equation (6)) then yields the classification function that defines the decision boundaries,
- The boundaries are adjusted by the user based on structural features such as faults.
2.3. Meta-Learner Proxy
- The training dataset, X, consists of the input features (for example features listed in Table 2). Here , where n is the input data and p is the output, or target data).
- The dataset X is split into K- folds using k-fold cross validation. We used five folds. One fold is held as a validation set and the others used to train the three base learners. The trained models are tested on the data in the validation fold. This process is repeated so that all of the folds have been used as the validation dataset. In this manner, each data point has been used as a testing and training data point.
- The predictions from each base learner is stacked to create a matrix Z ( where L is the number of base learner algorithms.
- The meta learner is fitted on Z using ridge regression to minimize the following cost function,where n are the number of training observations, y′ are the predictions from the base learners, yi is the actual target data, wj is the fitting coefficient and is the tuning parameter.
2.4. Posterior Sampling
- A tuple D = {(m, a, r)} where m = state, a = action, r = reward.
- A likelihood function P(r|θ, a, m).
- Model parameters (θ).
- A prior distribution P(θ).
- A posterior distribution P(θ|D) ∝ P(D│θ)P(θ).
3. Results and Discussion
3.1. Waterflood Case Study
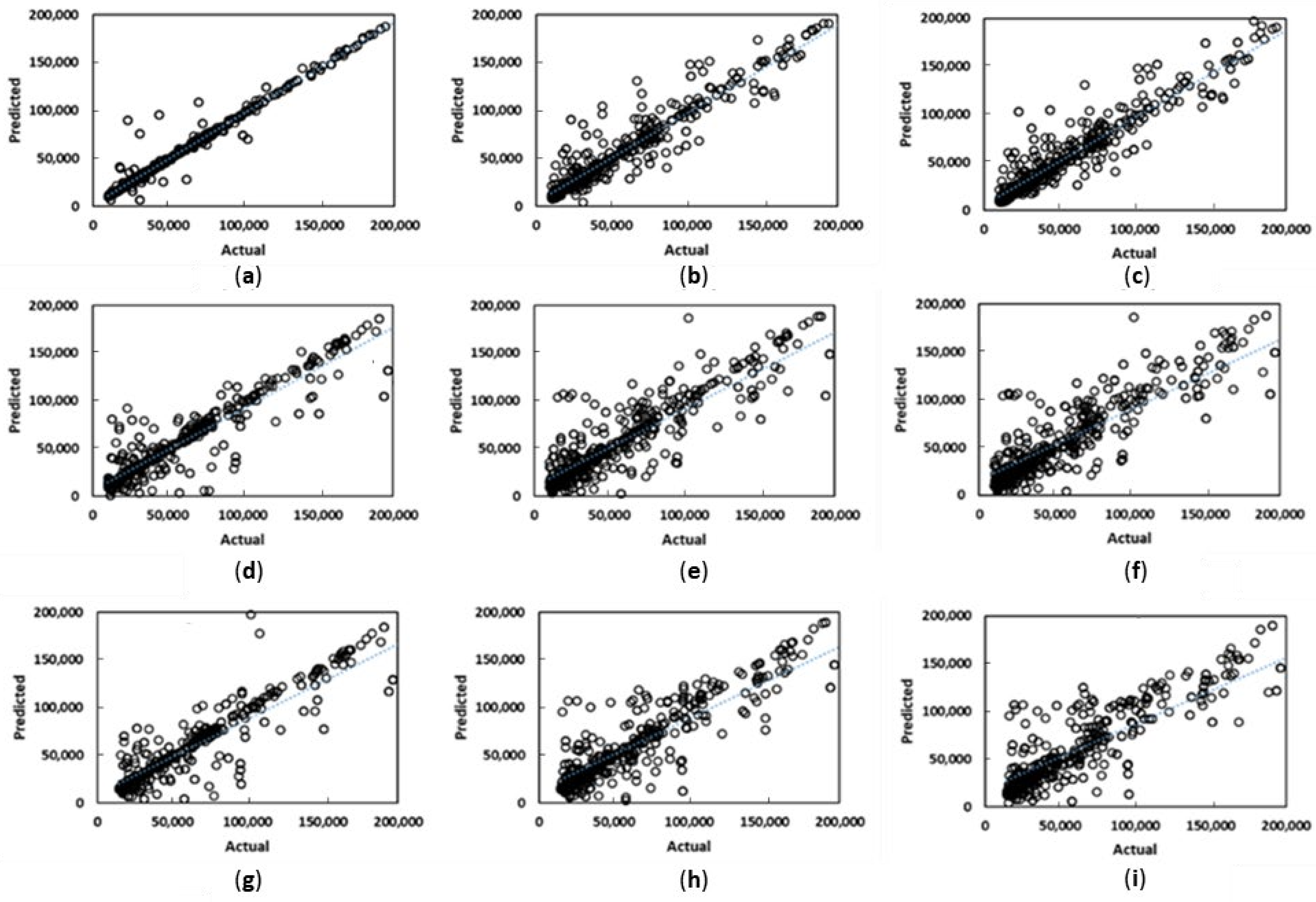
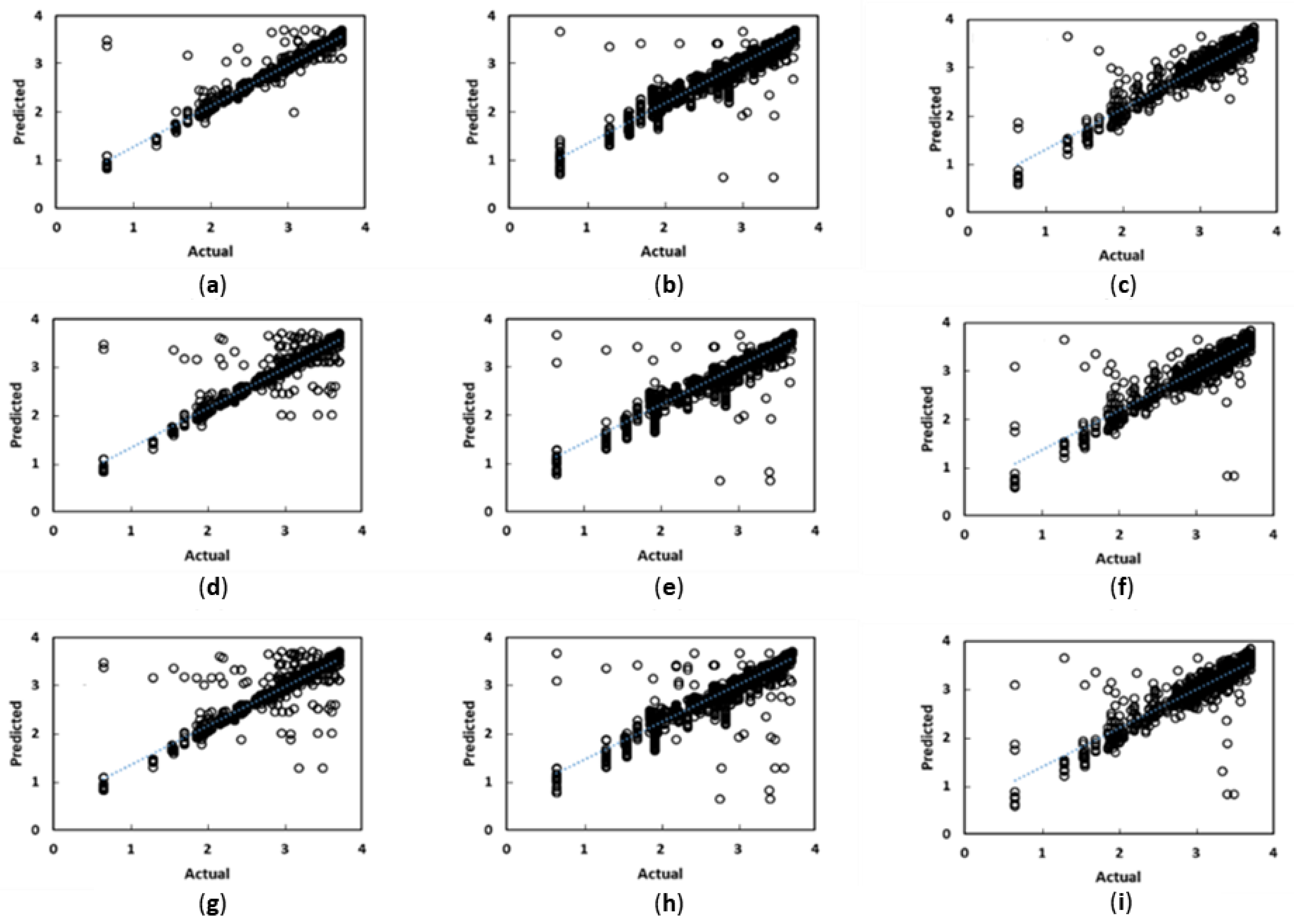
- Figure 7 compares the prediction performance for three proxies, for three training sample sizes. The prediction results from the proxies are on the ordinate and the numerical simulation results on the abscissa. The Stacked learner (combining AdaBoost, Random Forest and ANN models) performs best, highlighting the value of the meta-learner approach. The Stacked learner also had the smallest reduction in R2 scores as the samples reduced. The Stacked learner had a reduction of 11% from 3000 to 1000 samples, compared to 16–18% for the other models trained.
- The proxy performance demonstrates that the training features selected are adequately capturing the relationship between geological parameters and production; however, given the variation of geological parameters, a larger number of training instances is required to obtain accurate predictions. This is demonstrated by the loss of accuracy as the number of training samples are reduced (between 11–18% reduction in R2 scores).
- From Table 7, the RMSE values of the top performing model indicate that, for a given geomodel, the difference between the proxy prediction and actual values are approximately 6000 kls. With the average incremental oil of approximately 60,000, this yields a relative error of 10%. This margin of error is similar to history matching errors of oil reservoirs [35], where the calibration of numerical simulation models to observed data result in 5–20% relative error. This indicates that the predictive ability of the trained proxy is comparable to a calibrated numerical simulation model.
- The total training time for the models peaks at just above 4 s for the stacked learner. The total time taken to generate the data for training the proxies is approximately 20 h; each individual streamline simulation run takes 8 min. The time taken to evaluate the secondary phase recovery for each well location within each geological ensemble will take approximately 96 h (8 min × 12 models × 20 well locations × 3 perforation depths).
3.2. CO2 Injection for Storage Case Study
- The overall proxy accuracy is reasonably close to the waterflood proxy accuracy. The Stacked learner has an R2 score of 0.94 vs. 0.98 for the waterflood case. As before, the stacked proxy has an accuracy higher than that of the individual learners.
- The reduction of accuracy with lower sample sizes is similar in the CO2 case and waterflood case. Here, the stacked learner R2 scores reduce from 0.94 to 0.90 with the reduction in training samples from 3500 to 2000 samples. The accuracy loss with the stacker learner with fewer training samples is smaller than the loss with the other learners (8% vs. 11% R2 score reduction). This further highlights the value of the stacked or meta learner approach.
- The RMSE score for the stacked learner is 0.16 bscf. Given the average storage of 2.8 bcf, there is a 5% relative error. The MAE scores are 0.04 bscf. This indicates that, on average, for a given prediction, the error will be 0.04 bscf, or 1% of the mean storage. This demonstrates the accuracy and reliability of the trained proxy.
- The training time for the proxies (2–13 s) is still well below the time taken to run a single numerical simulation run (20 min for the miscible injection case). The time taken to generate storage predictions for all the possible injection locations is approximately 240 h (20 min × 12 geological models × 20 unique locations × 3 injection depths). The same evaluation was performed within seconds using the trained proxy.
3.3. CO2 EOR and Storage Case Study
- The overall proxy accuracy is similar to the CO2 storage proxy accuracy. The accuracy difference between the CO2 cases and the waterflood case is not significant (~4% difference for the Stacked learner). However, this does reflect the incresased complexity in the displacement process; the waterflood case involves immiscible displacement, whereas the CO2 injected is miscible with the insitu oil.
- The use of the combined equation provides an opportunity for the user to incorporate the effect of the tax incentives for carbon storage. Given that the proxies can evaluate storage potential within seconds, the impact of different oil prices and carbon tax brackets can be evaluated rapidly.
- The RMSE score for the stacked learner is USD 0.52 mm. Given the average storage of USD 4.8 mm, there is a 10% relative error. As discussed in Section 3.1, this error margin is reasonable and comparable to errors from numerical simulation results.
3.4. Blind Test Case Studies
- The proxy rankings match the well rankings suggested by numerical simulation. These rankings indicate which locations yield higher incremental oil recovery and/or CO2 storage when converted into injection sites (Table 11 and Table 12). Unsurprisingly, for the CO2 injection case, the optimal injection depths are preferentially lower rather than higher. The proxies are therefore able to locate the best injection locations both areally and vertically. The rate variation in Table 11 is limited by the restrictions placed on bottomhole injection pressure and voidage replacement ratio. A potential future work is to construct a more robust proxy to incorporate a larger rate variation for both producers and injectors.
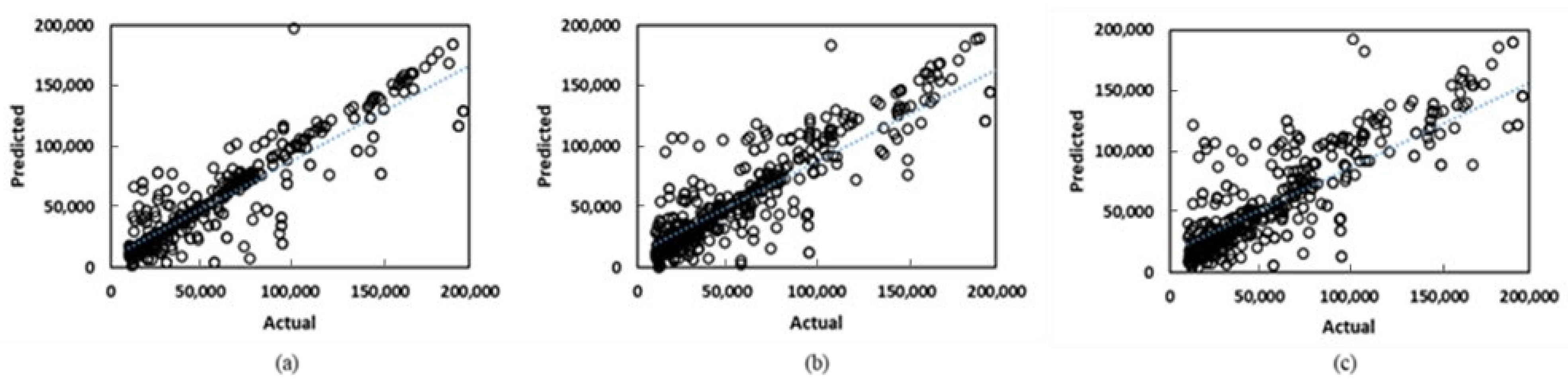
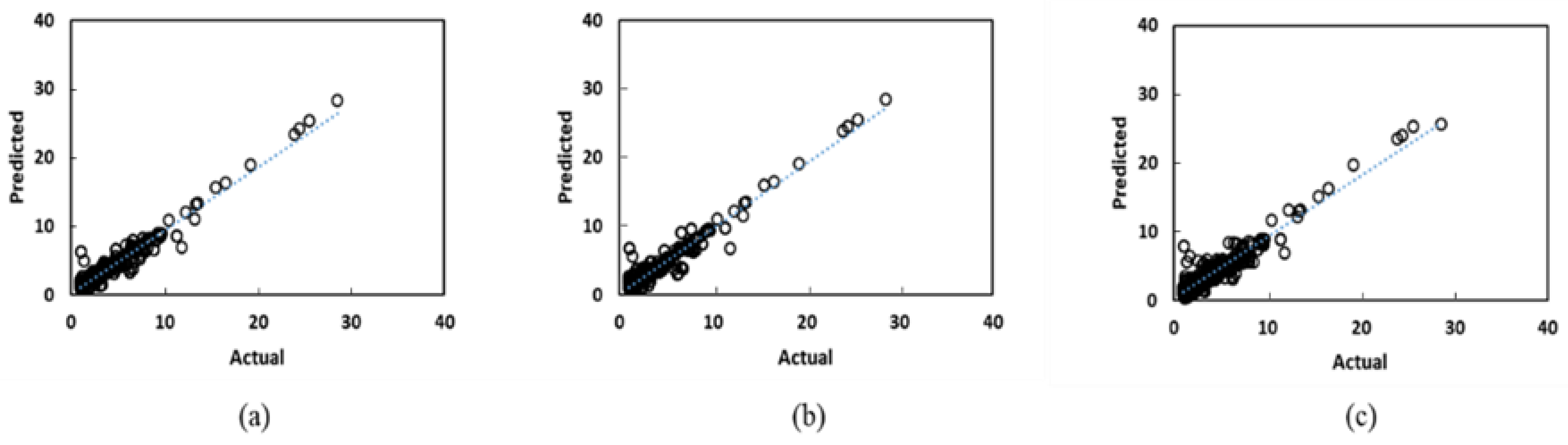
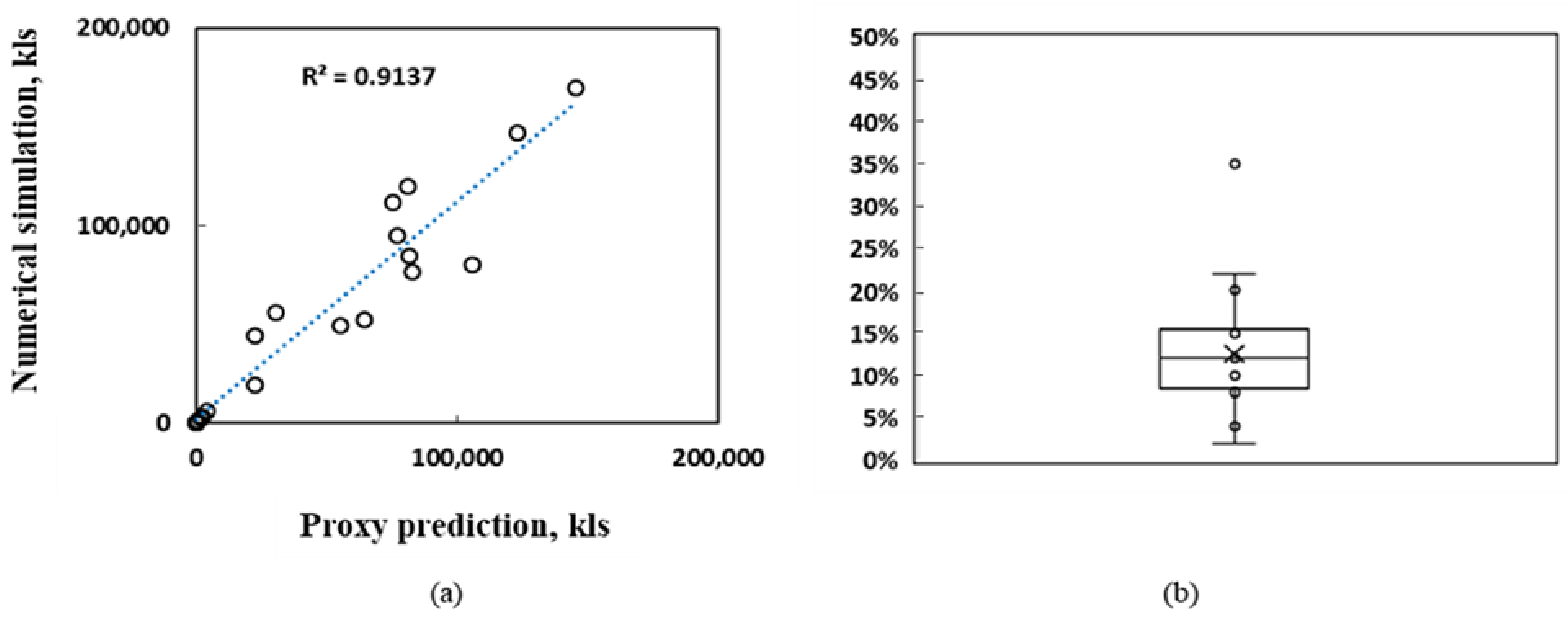
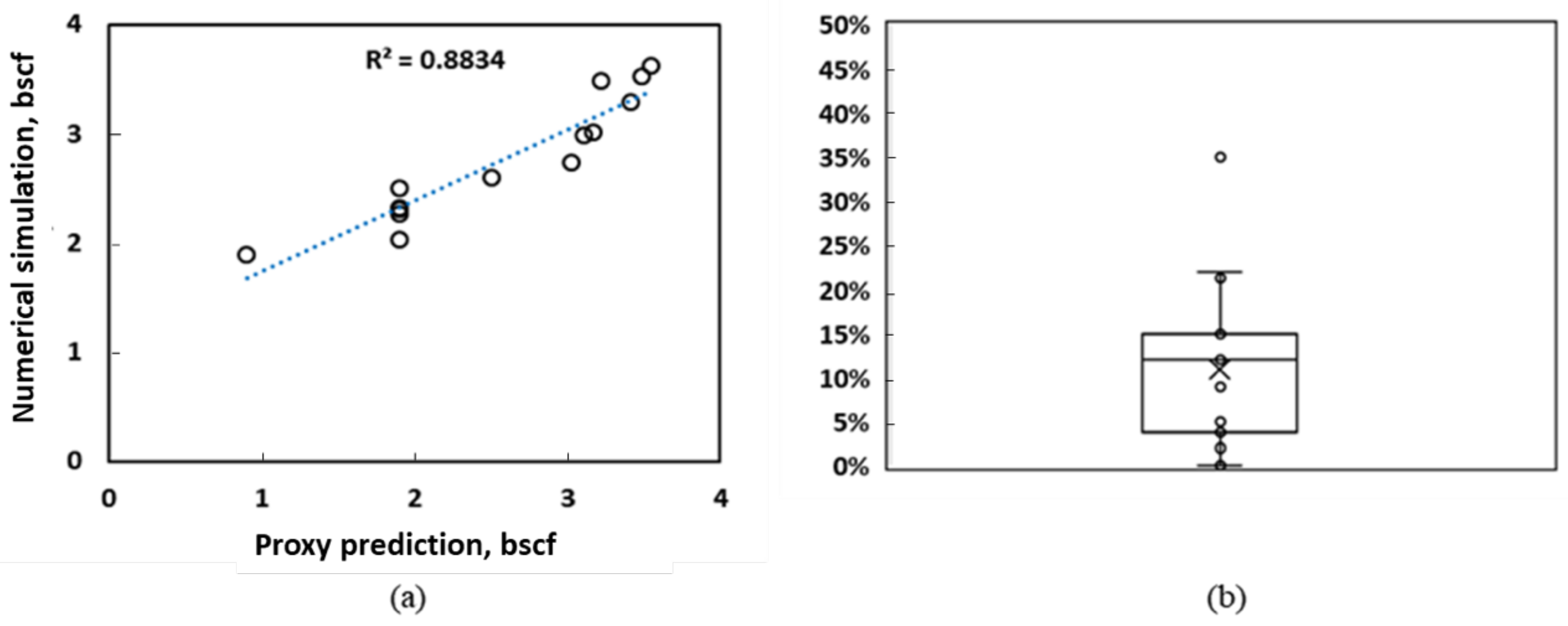
- From Figure 12a and Figure 13a, the R2 values are reasonable, ranging from 0.88 to 0.91. This highlights the ability of the proxy to generalize to an unseen dataset. This is an example of a case where the proxy is trained on a subset of a geological models, and used to predict incremental oil and/or CO2 storage potential from multiple geological realizations.
- The box and whisker plots in Figure 12b and Figure 13b indicate that the median error is 12–15%; the maximum error is 35%. As highlighted earlier, this error range is comparable to prediction errors from numerical simulation models [34]. This demonstrates that a trained proxy is able to replicate the predictive quality of expensive numerical simulations.
- Note that the well rankings, recoveries and storage potentials in Table 11and Table 12 are only valid for the geological realization tested. These rankings will likely change with different geological configurations i.e., different channel orientations and petrophysical properties. The selection of the optimal injection strategies across a range of geological realizations is discussed in Section 3.5.
3.5. Posterior Sampling to Determine Ideal Injection Location
- The proxy trained on a geological ensemble is able to predict reservoir responses for an unseen geomodel on a field scale. In particular, time-of-flight as a connectivity feature aids the proxies to generalize to range of petrophysical properties and channel distributions. Therefore, the reservoir manager is able use the proxy trained on a subset of geological models to predict responses for other geological realizations.
- The choice of training features also provides flexibility for proxies to be trained for a variety of flood projects. Unlike many previous methods, which are focused on one flood type, this approach is applicable for both water and gas floods, including misicble injection and CO2 storage.
- The workflow presents methods to significantly improve the time required for decision making. The prediction time for all proxies are within 5 s compared to 20 min for a single numerical simulation run. The posterior sampling approach efficiently evaluates injection strategies without requiring excessive simulation time.
4. Summary and Conclusions
- The well region aggregation aided by machine learning is able to efficiently reduce the number of location evaluations. The field scale geomodel was reduced to 20 potential injection locations. This allows the proxies and posterior sampling algorithm to rapidly identify the areas in the field that are optimal for injection.
- The time-of-flight metric carries valuable information about the connectivity between different well regions. When this metric was removed as a training feature, the accuracies of the models reduced from an R2 score of 0.98 to 0.87. Reservoir connectivity plays an important role in determining the success of an injection well. The use of the TOF coordinate as a training feature allowed the inter-well region connectivity to be described across a range of geological realizations. This was further demonstrated by the performance of the proxies on the blind tests. The proxies were able to predict with reasonable accuracies (R2 scores of 0.88 to 0.91) the expected incremental oil recovery or CO2 storage for an unseen geomodel.
- The meta-learner or Stacked proxy improves on the accuracy of individual proxies and provides robust predictions even under geological uncertainty. The Stacked proxy outperformed the individual learners by approximately 5–10% (R2 scores). The accuracy reduction with fewer training samples was smaller with the Stacked learner compared to the other models; the Stacked learner R2 scores reduced by an average of 10%. The other models had R2 scores reduce by up to 18%.
- The use of a geological ensemble (rather than a single geomodel) provided the proxies with a diverse training dataset. This aided the proxies to generalize to unseen geomodels. The reservoir used in the case study had multiple channel configurations, with variations in key petrophysical properties. Despite this complexity, the proxy prediction accuracy on the blind tests were within 90%, comparable to numerical simulation.
- The proxies provide prediction results several orders of magnitudes quicker compared to numerical simulation. In the blind test, the time taken for the proxy to perform predictions was under ten seconds. The same evaluation would take 13 h using conventional numerical simulation.
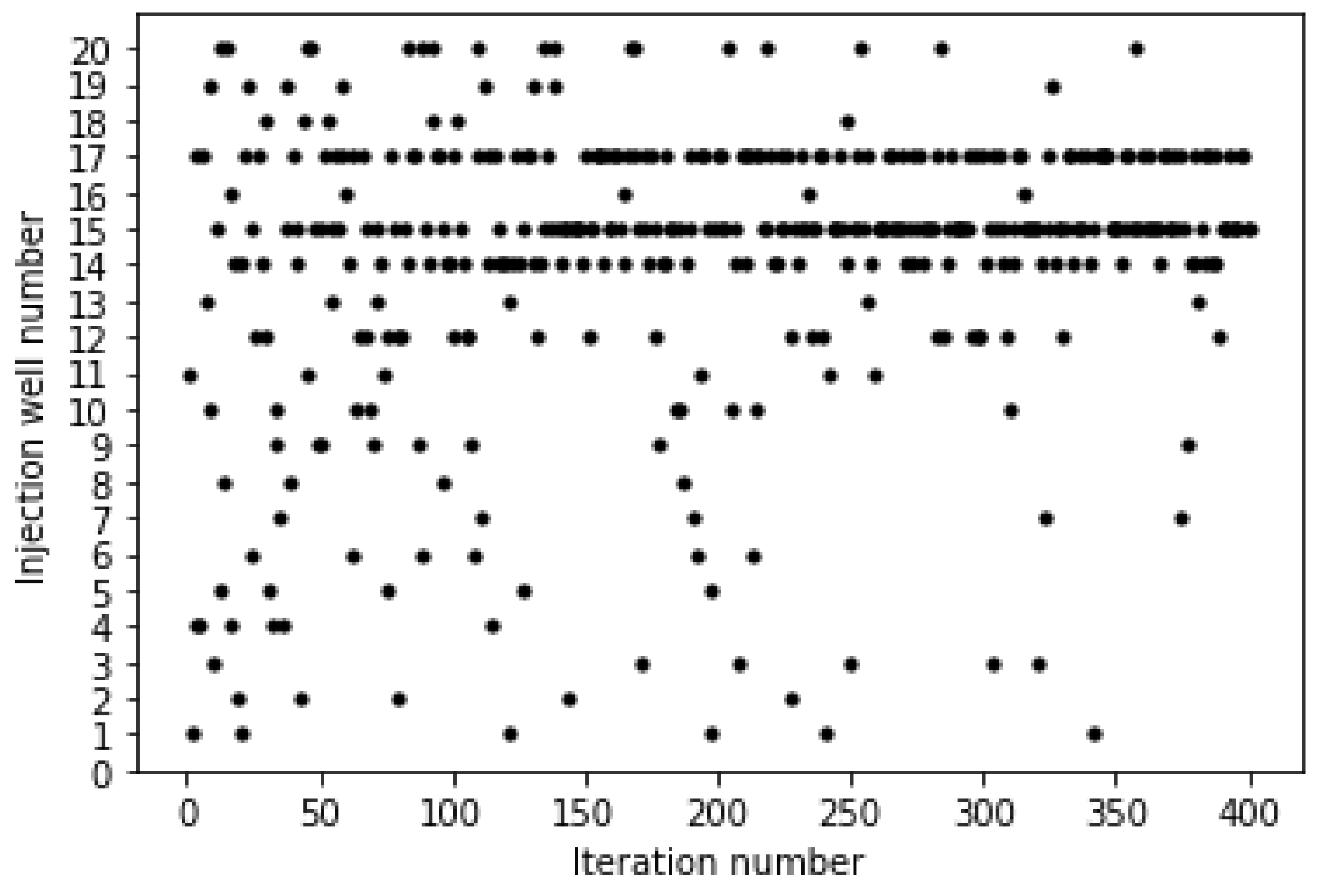
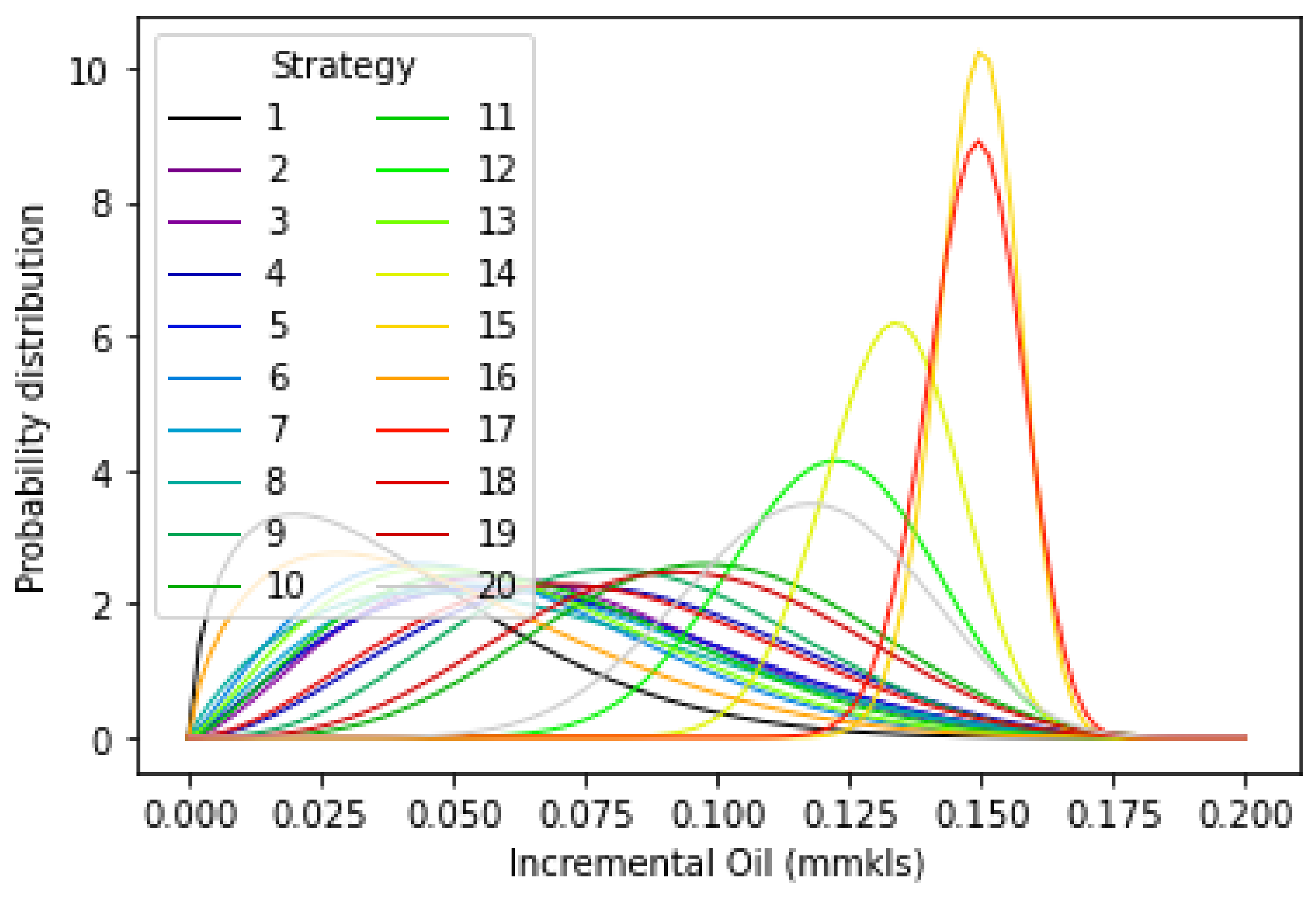
- The use of posterior sampling coupled with the proxy allows for rapid evaluations across various geomodels to decide on the optimal injection strategy without brute force evaluations. Given a geological ensemble and multiple injection strategies, the optimal injection strategy was discovered within 50–100 iterations, compared to a brute-force approach requiring 400 evaluations. When used with a proxy model, injector location evaluations can be performed under ten minutes compared to many hours using traditional numerical simulation.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| incremental oil production | |
| ω | Todd-Longstaff model mixing parameter |
| bscf | billion standard cubic feet |
| EOR | Enhanced Oil Recovery |
| klpd | kiloliters per day |
| kls | kiloliters |
| mm | million |
| mmskl | million kiloliters |
| PV | pore volume |
| RMSE | Root mean square error |
| Sw | water saturation |
| TOF | Time of flight |
| Cumulative oil production from injection | |
| Cumulative oil production, base case | |
| VRR | Voidage Replacement Ratio |
References
- Forouzanfar, F.; Reynolds, A.C. Joint optimization of number of wells, well locations and controls using a gradient-based algorithm. Chem. Eng. Res. Des. 2014, 92, 1315–1328. [Google Scholar] [CrossRef]
- Isebor, O.J.; Durlofsky, L.J. Biobjective optimization for general oil field development. J. Pet. Sci. Eng. 2014, 119, 123–138. [Google Scholar] [CrossRef]
- Bellout, M.C.; Ciaurri, D.E.; Durlofsky, L.J.; Foss, B.; Kleppe, J. Joint optimization of oil well placement and controls. Comput. Geosci. 2012, 16, 1061–1079. [Google Scholar] [CrossRef] [Green Version]
- Brito, D.U.; Durlofsky, L.J. Well control optimization using a two-step surrogate treatment. J. Pet. Sci. Eng. 2020, 187, 106565. [Google Scholar] [CrossRef] [Green Version]
- Rosenwald, G.W.; Green, D.W. A Method for Determining the Optimum Location of Wells in a Reservoir Using Mixed-Integer Programming. Soc. Pet. Eng. J. 1974, 14, 44–54. [Google Scholar] [CrossRef]
- Güyagüler, B.; Horne, R.N. Uncertainty Assessment of Well-Placement Optimization. SPE Reserv. Eval. Eng. 2004, 7, 24–32. [Google Scholar] [CrossRef]
- Farmer, C.L.; Fowkes, J.M.; Gould, N.I.M. Optimal Well Placement. In Proceedings of the 12th European Conference on the Mathematics of Oil Recovery, Oxford, UK, 6 September 2010. [Google Scholar] [CrossRef]
- Wilson, K.C.; Durlofsky, L.J. Optimization of shale gas field development using direct search techniques and reduced-physics models. J. Pet. Sci. Eng. 2013, 108, 304–315. [Google Scholar] [CrossRef]
- Litvak, M.L.; Gane, B.R.; Williams, G.; Mansfield, M.; Angert, P.F.; Macdonald, C.J.; McMurray, L.S.; Skinner, R.C.; Gregory, J.W. Field Development Optimization Technology. In Proceedings of the SPE Reservoir Simulation Symposium, Houston, TX, USA, 26–28 February 2007. [Google Scholar] [CrossRef]
- Onwunalu, J.E.; Litvak, M.L.; Durlofsky, L.J.; Aziz, K. Application of Statistical Proxies to Speed Up Field Development Optimization Procedures. In Proceedings of the Abu Dhabi International Petroleum Exhibition and Conference, Abu Dhabi, United Arab Emirates, 3–6 November 2008. [Google Scholar] [CrossRef]
- Janiga, D.; Czarnota, R.; Stopa, J.; Wojnarowski, P. Self-adapt reservoir clusterization method to enhance robustness of well placement optimization. J. Pet. Sci. Eng. 2018, 173, 37–52. [Google Scholar] [CrossRef]
- Chen, H.; Feng, Q.; Zhang, X.; Wang, S.; Zhou, W.; Geng, Y. Well placement optimization using an analytical formula-based objective function and cat swarm optimization algorithm. J. Pet. Sci. Eng. 2017, 157, 1067–1083. [Google Scholar] [CrossRef]
- Güyagüler, B.; Horne, R.N.; Rogers, L.; Rosenzweig, J.J. Optimization of Well Placement in a Gulf of Mexico Waterflooding Project. SPE Reserv. Eval. Eng. 2002, 5, 229–236. [Google Scholar] [CrossRef] [Green Version]
- Yeten, B.; Durlofsky, L.J.; Aziz, K. Optimization of Nonconventional Well Type, Location, and Trajectory. SPE J. 2003, 8, 200–210. [Google Scholar] [CrossRef]
- Akın, S.; Kok, M.V.; Uraz, I. Optimization of well placement geothermal reservoirs using artificial intelligence. Comput. Geosci. 2010, 36, 776–785. [Google Scholar] [CrossRef]
- You, J.; Ampomah, W.; Sun, Q.; Kutsienyo, E.J.; Balch, R.S.; Dai, Z.; Cather, M.; Zhang, X. Machine learning based co-optimization of carbon dioxide sequestration and oil recovery in CO2-EOR project. J. Clean. Prod. 2020, 260, 120866. [Google Scholar] [CrossRef]
- Thanh, H.V.; Sugai, Y.; Nguele, R.; Sasaki, K. Robust optimization of CO2 sequestration through a water alternating gas process under geological uncertainties in Cuu Long Basin, Vietnam. J. Nat. Gas Sci. Eng. 2020, 76, 103208. [Google Scholar] [CrossRef]
- Thanh, H.V.; Sugai, Y.; Sasaki, K. Application of artificial neural network for predicting the performance of CO2 enhanced oil recovery and storage in residual oil zones. Sci. Rep. 2020, 10, 18204. [Google Scholar] [CrossRef] [PubMed]
- Nwachukwu, A.; Jeong, H.; Pyrcz, M.; Lake, L.W. Fast evaluation of well placements in heterogeneous reservoir models using machine learning. J. Pet. Sci. Eng. 2018, 163, 463–475. [Google Scholar] [CrossRef]
- Nasir, Y.; Yu, W.; Sepehrnoori, K. Hybrid derivative-free technique and effective machine learning surrogate for nonlinear constrained well placement and production optimization. J. Pet. Sci. Eng. 2019, 186, 106726. [Google Scholar] [CrossRef]
- Aliyev, E.; Durlofsky, L.J. Multilevel Field Development Optimization Under Uncertainty Using a Sequence of Upscaled Models. Math. Geol. 2016, 49, 307–339. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, L.; Liu, M.; Cui, X.; Jiang, Z.; Bahar, A.; Pochampally, S.; Kelkar, M.G. Breaking the Barrier of Flow Simulation: Well Placement Design Optimization with Fast Marching Method and Geometric Pressure Approximation. In Proceedings of the SPE/IATMI Asia Pacific Oil & Gas Conference and Exhibition, Jakarta, Indonesia, 17–19 October 2017. [Google Scholar] [CrossRef]
- Lyu, Z.; Song, X.; Li, G. A semi-analytical method for the multilateral well design in different reservoirs based on the drainage area. J. Pet. Sci. Eng. 2018, 170, 582–591. [Google Scholar] [CrossRef]
- Huang, J.; Olalotiti-Lawal, F.; King, M.J.; Datta-Gupta, A. Modeling Well Interference and Optimal Well Spacing in Unconventional Reservoirs Using the Fast Marching Method. In Proceedings of the SPE/AAPG/SEG Unconventional Resources Technology Conference, Austin, TX, USA, 24–26 July 2017. [Google Scholar] [CrossRef]
- Iino, A.; Onishi, T.; Olalotiti-Lawal, F.; Datta-Gupta, A. Rapid Field-Scale Well Spacing Optimization in Tight and Shale Oil Reservoirs Using Fast Marching Method. In Proceedings of the Unconventional Resources Technology Conference, Houston, TX, USA, 23–25 July 2018. [Google Scholar] [CrossRef]
- Todd, M.; Longstaff, W. The Development, Testing, and Application of a Numerical Simulator for Predicting Miscible Flood Performance. J. Pet. Technol. 1972, 24, 874–882. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June 1967; Volume 1, pp. 281–297. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Van der Laan, M.J.; Polley, E.C.; Hubbard, A.E. Super learner. Stat. Appl. Genet. Mol. Biol. 2007, 6, 25. [Google Scholar] [CrossRef] [PubMed]
- Freund, Y.; E Schapire, R. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Thompson, W.R. On the likelihood that one unknown probability exceeds another in view of the evidence of two samples. Biometrika 1933, 25, 285–294. [Google Scholar] [CrossRef]
- Russo, D.; Van Roy, B.; Kazerouni, A.; Osband, I.; Wen, Z. A tutorial on Thompson Sampling. arXiv 2017, arXiv:1707.02038. [Google Scholar]
- Sadri, M.; Shariatipour, S.M.; Hunt, A.; Ahmadinia, M. Effect of systematic and random flow measurement errors on history matching: A case study on oil and wet gas reservoirs. J. Pet. Explor. Prod. Technol. 2019, 9, 2853–2862. [Google Scholar] [CrossRef] [Green Version]
- Han, J.; Lee, M.; Lee, W.; Lee, Y.; Sung, W. Effect of gravity segregation on CO2 sequestration and oil production during CO2 flooding. Appl. Energy 2016, 161, 85–91. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Grid block dimensions | 100 ft by 100 ft by 10 ft |
| Grid count | 230,000 |
| Pressure, bar | 350 |
| Average field Sw, frac | 0.4 |
| Average field porosity, frac | 0.22 |
| Average field horizontal permeability (kh), mD | 150 |
| Ratio of vertical to horizontal permeability, kv/kh, mD | 0.3 |
| Input Features | Output | |
|---|---|---|
| Well Region Properties | Well Properties | Well Properties |
| Porosity | Well-to-well distances | Incremental Oil production |
| Permeability | ||
| Time of flight | Distance to injector | |
| Initial water saturation | ||
| Current water saturation | Injection rate | |
| Initial reservoir pressure | ||
| Current reservoir pressure | Injection depth | |
| Dip angle | ||
| Todd Longstaff Parameters | Value |
|---|---|
| Mixing parameter, ω | 0.7 |
| Mixing exponent | −0.25 |
| Injected gas surface density, lb/ft3 | 0.12 |
| Parameter | Value | |
|---|---|---|
| Lower | Upper | |
| Field wide production, klpd | 215 | 235 |
| Field wide injection, klpd | 215 | 235 |
| VRR | 0.91 | 1.09 |
| Parameter | Value | |
|---|---|---|
| Lower | Upper | |
| Bottomhole pressure, ksc | 265 | 290 |
| CO2 Injection rate, res m3 | 55 | 75 |
| Cumulative PV CO2 injected, % | 41 | 45 |
| Input Features | Output | |
|---|---|---|
| Well Region Properties | Well Properties | Well Properties |
| Porosity | Well-to-well distances | Incremental Oil production |
| Permeability | ||
| Time of flight | Distance to injector | |
| Initial water saturation | ||
| Current water saturation | Injection rate | |
| Initial reservoir pressure | ||
| Current reservoir pressure | Injection depth | |
| Dip angle | ||
| Model | R2 | R | MAE | RMSE (kls) | Training Time (s) |
|---|---|---|---|---|---|
| Stacked learner | 0.98 | 0.96 | 1346 | 6240 | 4.4 |
| Adaboost | 0.95 | 0.91 | 1972 | 6330 | 1.7 |
| Random Forest | 0.94 | 0.88 | 4035 | 9701 | 1.2 |
| ANN | 0.84 | 0.71 | 7098 | 15,012 | 8.1 |
| Input Features | Output | |
|---|---|---|
| Well Region Properties | Well Properties | Well Region Properties |
| Porosity | Well-to-well distances | CO2 stored |
| Permeability | Distance to injector | |
| Time of flight | Cumulative Oil | |
| Initial water saturation | Perforation depth | |
| Current water saturation | Vertical displacement between well mid-perforations | |
| Initial reservoir pressure | ||
| Current reservoir pressure | ||
| Dip angle | Injection rate | |
| Model | R2 | R | MAE | RMSE (bscf) | Training Time (s) |
|---|---|---|---|---|---|
| Stacked learner | 0.94 | 0.88 | 0.04 | 0.16 | 10.2 |
| Adaboost | 0.9 | 0.81 | 0.06 | 0.18 | 5.5 |
| Random Forest | 0.87 | 0.76 | 0.1 | 0.19 | 2.5 |
| ANN | 0.85 | 0.72 | 0.12 | 0.22 | 12.5 |
| Model | R2 | R | MAE | RMSE ($mm) | Prediction Time (s) |
|---|---|---|---|---|---|
| Stacked learner | 0.94 | 0.88 | 0.29 | 0.52 | 4.4 |
| Adaboost | 0.93 | 0.86 | 0.51 | 0.91 | 1.5 |
| Random Forest | 0.89 | 0.79 | 0.6 | 0.9 | 0.5 |
| Proxy | Streamline Simulation | ||||
|---|---|---|---|---|---|
| Well Name | Injection Rate | Incremental Oil | Well Name | Injection Rate | Incremental Oil |
| klpd | kls | klpd | kls | ||
| PRD17 | 125 | 165,377 | PRD17 | 125 | 189,948 |
| PRD15 | 115 | 153,203 | PRD12 | 115 | 166,723 |
| PRD17 | 125 | 137,110 | PRD17 | 125 | 154,656 |
| PRD12 | 130 | 144,268 | PRD12 | 130 | 151,992 |
| PRD10 | 115 | 95,450 | PRD10 | 115 | 89,381 |
| Proxy | Streamline Simulation | ||||
|---|---|---|---|---|---|
| Well Name | Depth Tag | Net CO2 Stored | Well Name | Depth Tag | Net CO2 Stored |
| bscf | bscf | ||||
| PRD18 | 3 | 3.55 | PRD01 | 3 | 3.62 |
| PRD01 | 3 | 3.49 | PRD18 | 3 | 3.53 |
| PRD09 | 3 | 3.22 | PRD09 | 3 | 3.49 |
| PRD20 | 3 | 3.17 | PRD19 | 3 | 3.01 |
| PRD19 | 3 | 3.11 | PRD20 | 3 | 2.99 |
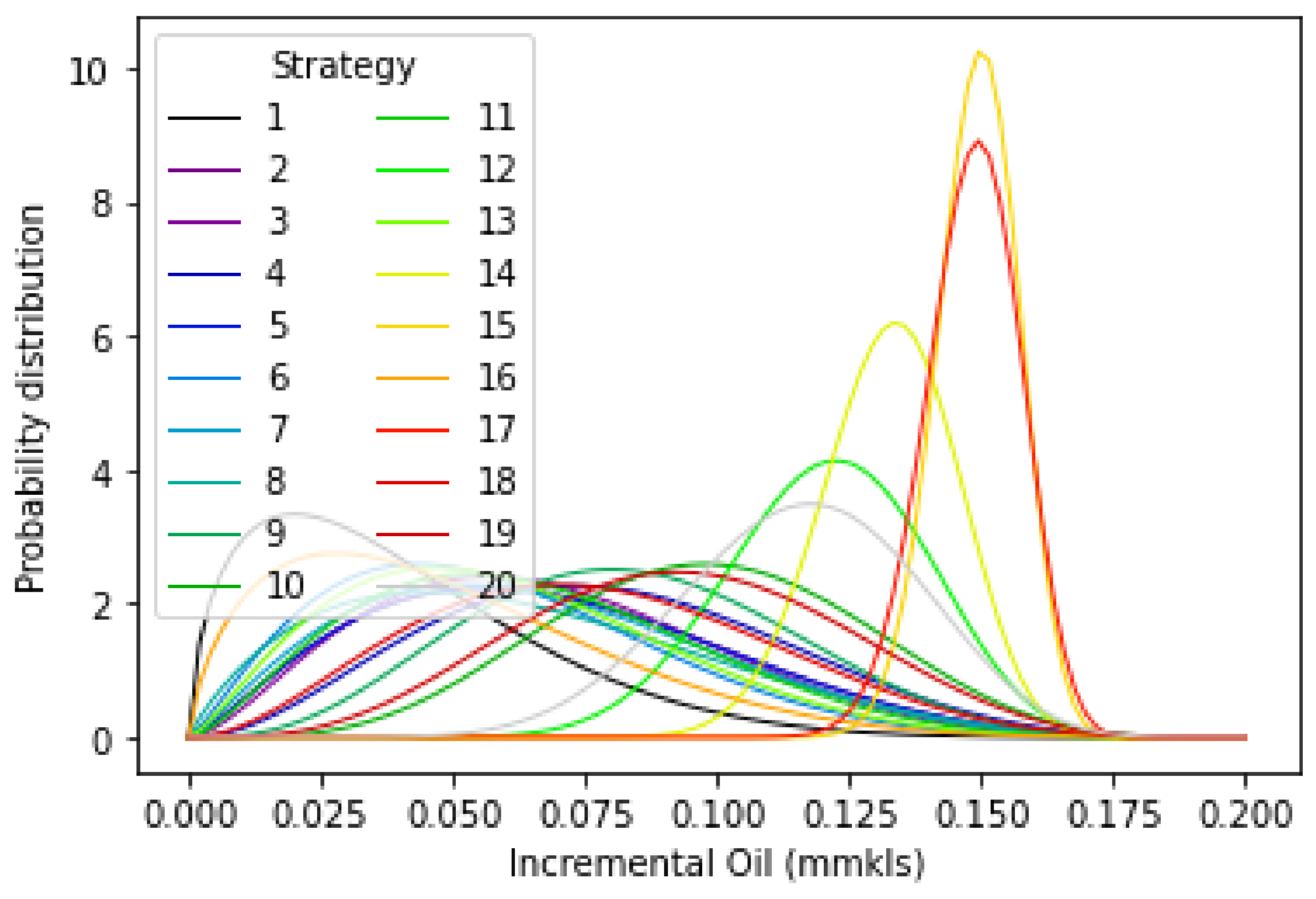
| Injector | Posterior Sampling (Proxy), mmkls | Streamline Simulation (Average), mmkls |
|---|---|---|
| 17 | 0.158 | 0.169 |
| 15 | 0.154 | 0.165 |
| 14 | 0.139 | 0.151 |
| 12 | 0.125 | 0.137 |
| 20 | 0.12 | 0.13 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Selveindran, A.; Zargar, Z.; Razavi, S.M.; Thakur, G. Fast Optimization of Injector Selection for Waterflood, CO2-EOR and Storage Using an Innovative Machine Learning Framework. Energies 2021, 14, 7628. https://doi.org/10.3390/en14227628
Selveindran A, Zargar Z, Razavi SM, Thakur G. Fast Optimization of Injector Selection for Waterflood, CO2-EOR and Storage Using an Innovative Machine Learning Framework. Energies. 2021; 14(22):7628. https://doi.org/10.3390/en14227628
Chicago/Turabian StyleSelveindran, Anand, Zeinab Zargar, Seyed Mahdi Razavi, and Ganesh Thakur. 2021. "Fast Optimization of Injector Selection for Waterflood, CO2-EOR and Storage Using an Innovative Machine Learning Framework" Energies 14, no. 22: 7628. https://doi.org/10.3390/en14227628
APA StyleSelveindran, A., Zargar, Z., Razavi, S. M., & Thakur, G. (2021). Fast Optimization of Injector Selection for Waterflood, CO2-EOR and Storage Using an Innovative Machine Learning Framework. Energies, 14(22), 7628. https://doi.org/10.3390/en14227628