
Scattering Transform for Classification in Non-Intrusive Load Monitoring

 ,
,  , and
, and
Abstract
:1. Introduction
- CNN-based methods depends on trained filter coefficients, which raises the overall classification system complexity;
- Most part of the methods using CNN for NILM takes advantage of image-processing CNN approaches. These approaches use 2D data as input, which also raises the system overall complexity, once it is necessary to transform the original 1D electrical signal to a higher dimensional 2D data;
- As CNN filter coefficients are learned, large datasets are desirable, causing a data availability dependency problem.
- Disaggregate and classify NILM signals from publicity datasets with a novel ST-Based framework;
- Evaluate classification performance and compare it with state-of-the art techniques;
- Encourage future work to replace CNN with ST in the context of NILM;
- Encourage future smart meter real-time implementations, with a less computationally costly NILM classification method.
- The quality of the extracted features, obtaining superior results in terms of accuracy and FScore for most analyzed cases;
- No need for data augmentation, transfer learning techniques, or dataset composition to increase the classification accuracy.
2. Related Work
2.1. CNN for NILM Using Low-Frequency Data
2.2. CNN for NILM Using High-Frequency Data
2.3. Contributions and Originality of This Work
- A NILM classification framework using a convolutional-based network with the scattering transform, without the need to learn filter coefficients to extract features, reducing the amount of data required in the training process;
- An approach with better classification performance compared to the state-of-the-art methods for different publicly available datasets (LIT and PLAID);
- A time-frequency feature extraction technique that directly uses 1D data as input, reducing the overall complexity and increasing the class discriminability.
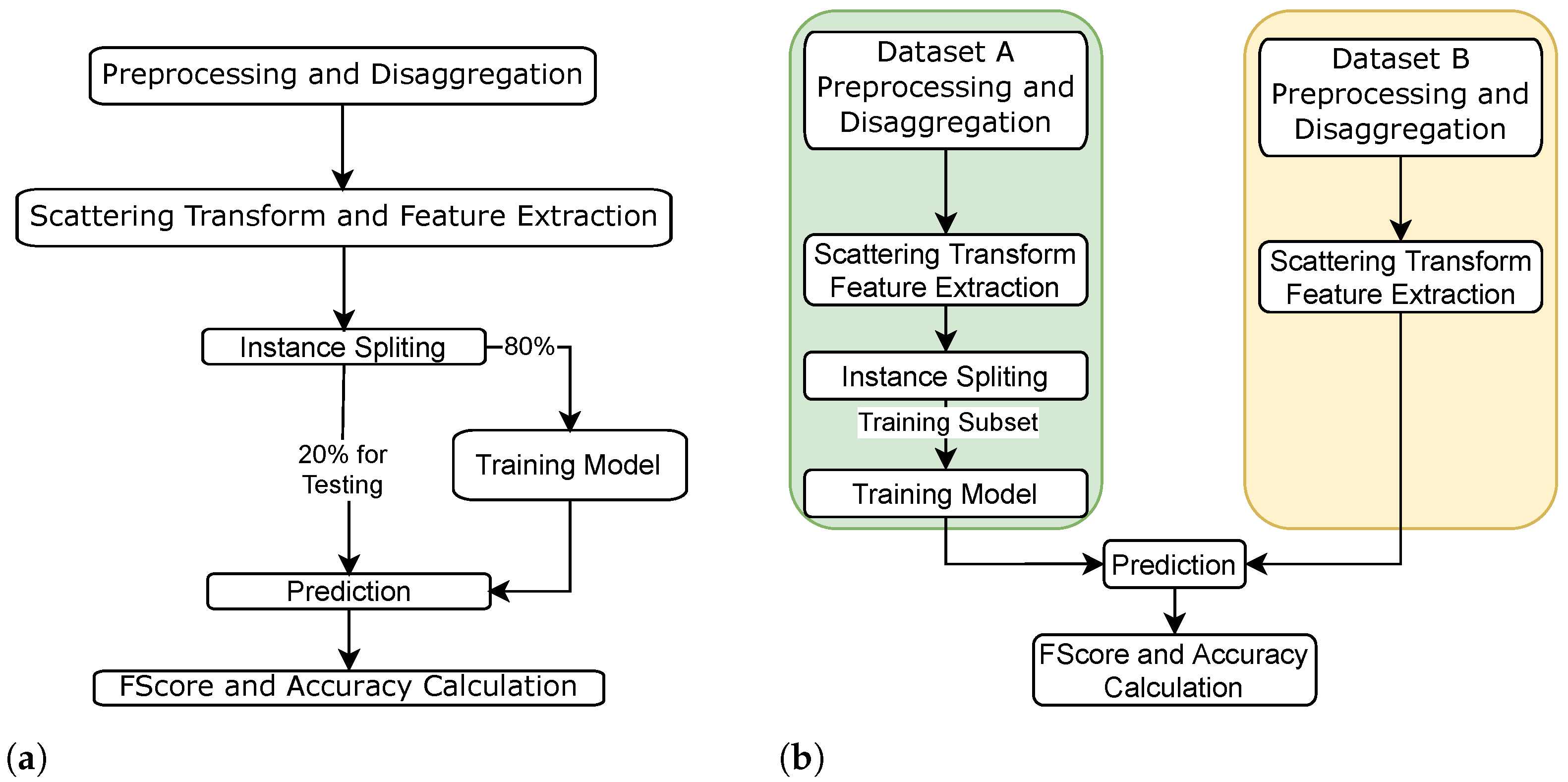
3. Proposed Classification Strategy
3.1. Lit Syntetic Dataset
3.2. Plaid Dataset
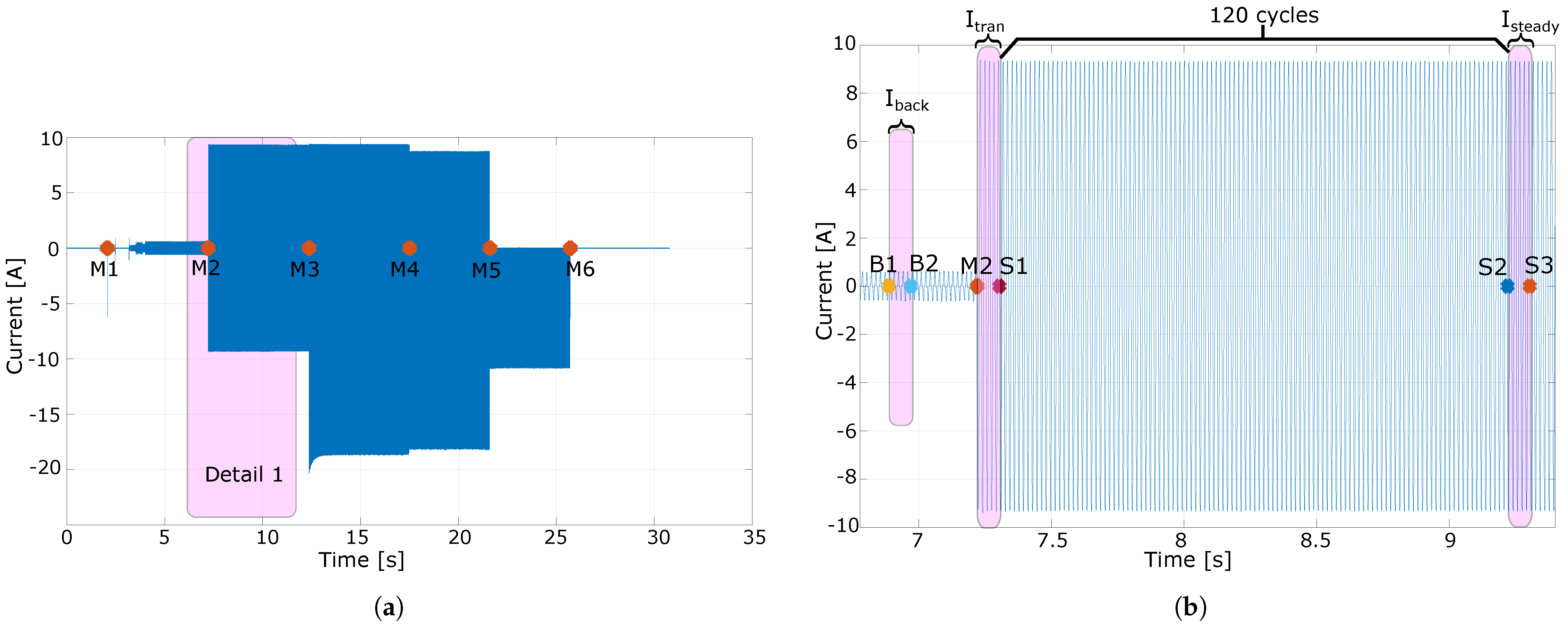
3.3. Preprocessing and Disaggregation
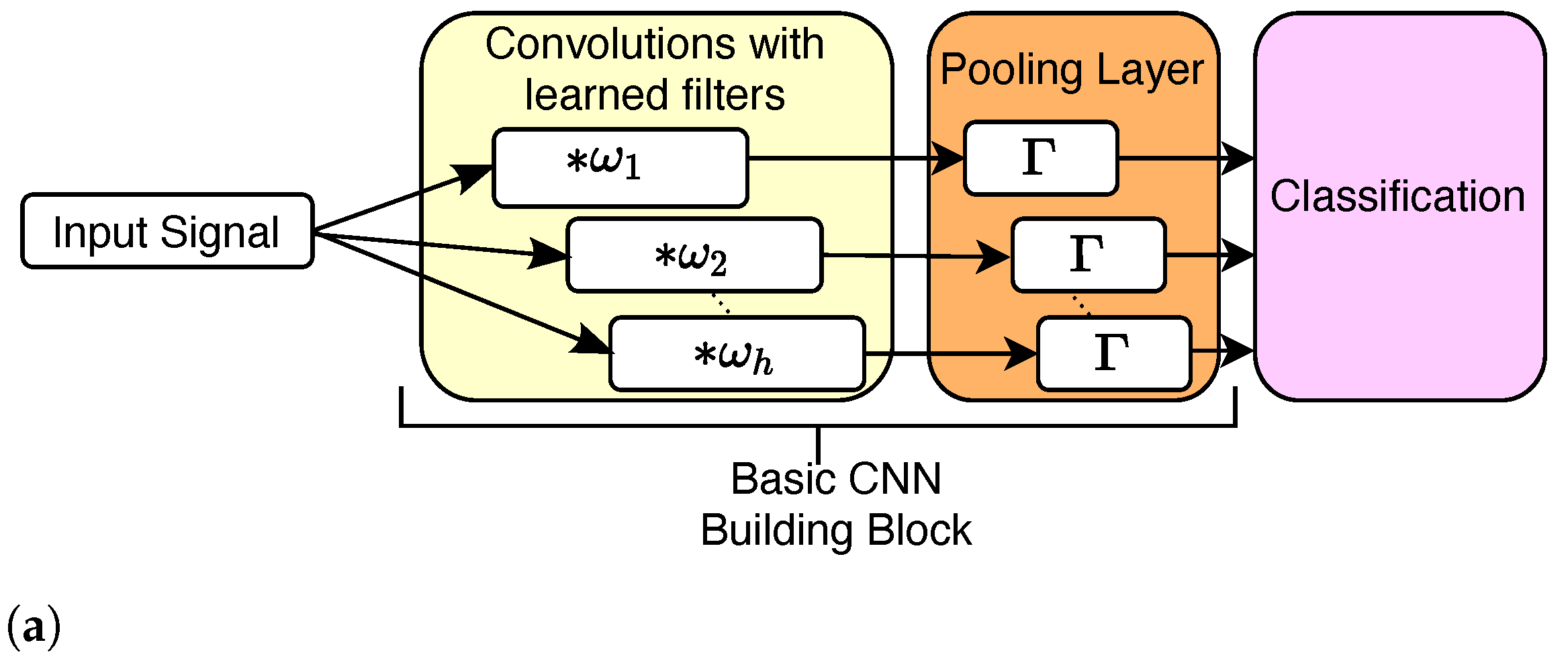
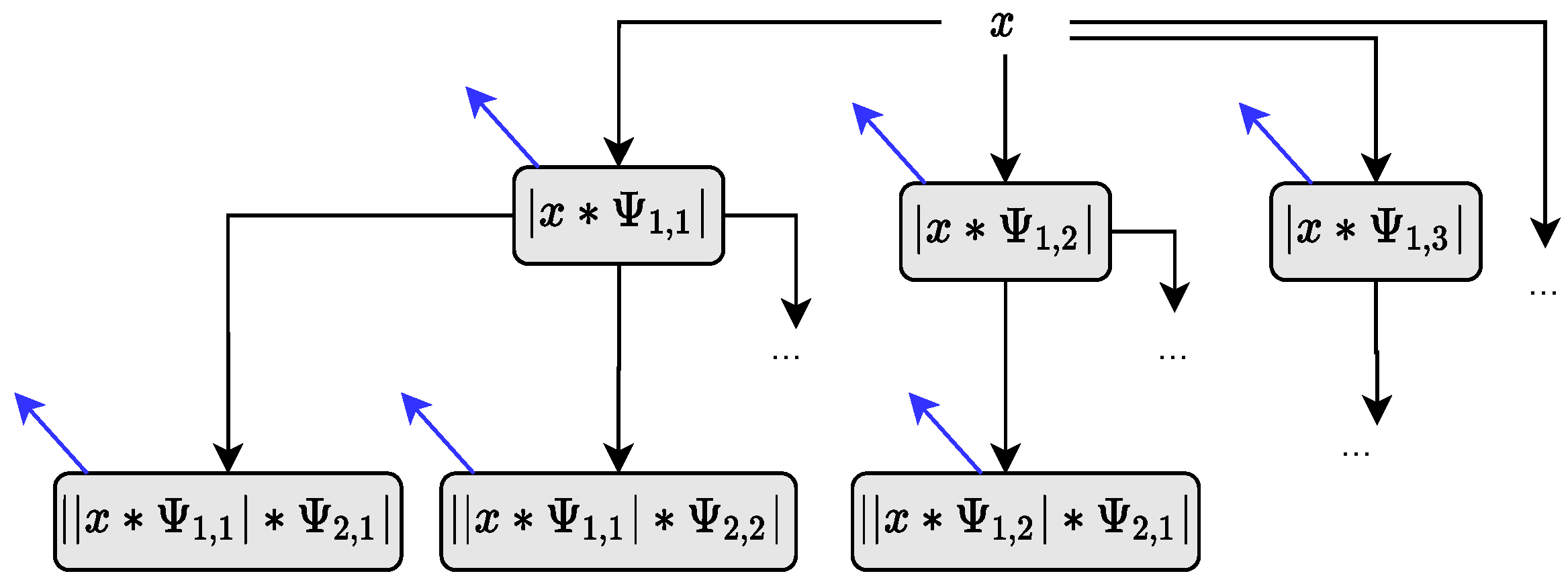
3.4. Feature Extraction
| Algorithm 1 Number of scattering coefficients. |
Input:Q and probability parameter (). Output:
|
Feature Calculation from Scattering Coefficients
3.5. Classification
- k-Nearest-Neighbors: this method classifies the test example by comparing it to the training dataset. The comparison is based on the Euclidean distance [46]. This method fully relies on the distances between test samples and the training set, and due to that, can be considered one of the simplest classification approaches [46]. However, it requires the storage of all training examples, which may be a limitation for embedded systems with more restrictive memory requirements [7].
- Decision Tree: this method employs several concatenated binary splits arranged in a tree structure. Each split (node of the tree) refers to a particular feature and the corresponding parameter value for the comparison. In the test stage, the example is evaluated at each node of the tree and the corresponding class is the majority class in the leaf node. The training process and the related splits are based on the information gain [46].
- Support Vector Machine: this classifier was proposed to maximize the separation margin between pairs of classes, based on a linear model (hyperplane) [47]. One of the great advantages of the SVM formulation is that it can be formulated as a convex optimization. Besides, the problem can be defined in terms of the dot product between the features. Therefore, by using the kernel trick, the dot product can be replaced by a dot product kernel in feature space using the kernel, allowing nonlinear separation between classes [46]. Here, we used the Gaussian kernel to evaluate nonlinear separations.
- Ensemble Method: this method combines different weak learner models by averaging the output of individual classifiers, improving the final accuracy [46]. Weak models usually have a poor individual response in terms of accuracy. However, combining the various classifiers tends to improve overall accuracy. One example is the random forest method that combines several decision trees to compose a final classification. The ensemble normally uses the following weak models: AdaBoostM1, AdaBoostM2, Bag, GentleBoost, LogitBoost, LPBoost, LSBoost, RobustBoost, RUSBoost, Subspace, and TotalBoost [46].
- Linear Discriminant Analysis: The LDA is a linear classifier that employs hyperplanes to differentiate data from two different classes. It assumes a normal distribution with an equal covariance matrix and equal priors for both classes. With that, the separating hyperplane is defined by reducing the dimensionality in such a way that it maximizes the separation between classes and minimizes the intraclass variance. So, its complexity, and consequently, overfitting, are reduced [46].
4. Results
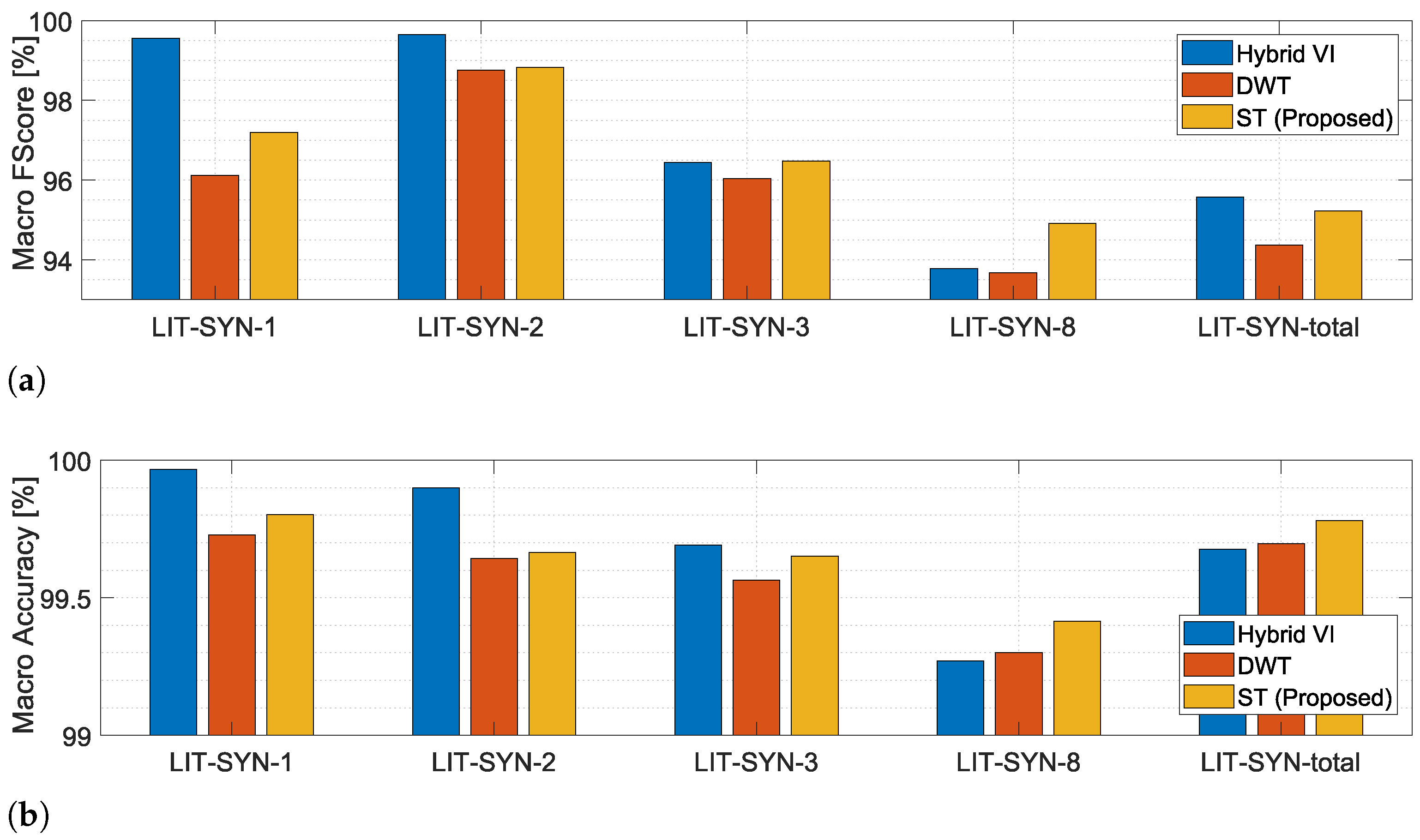
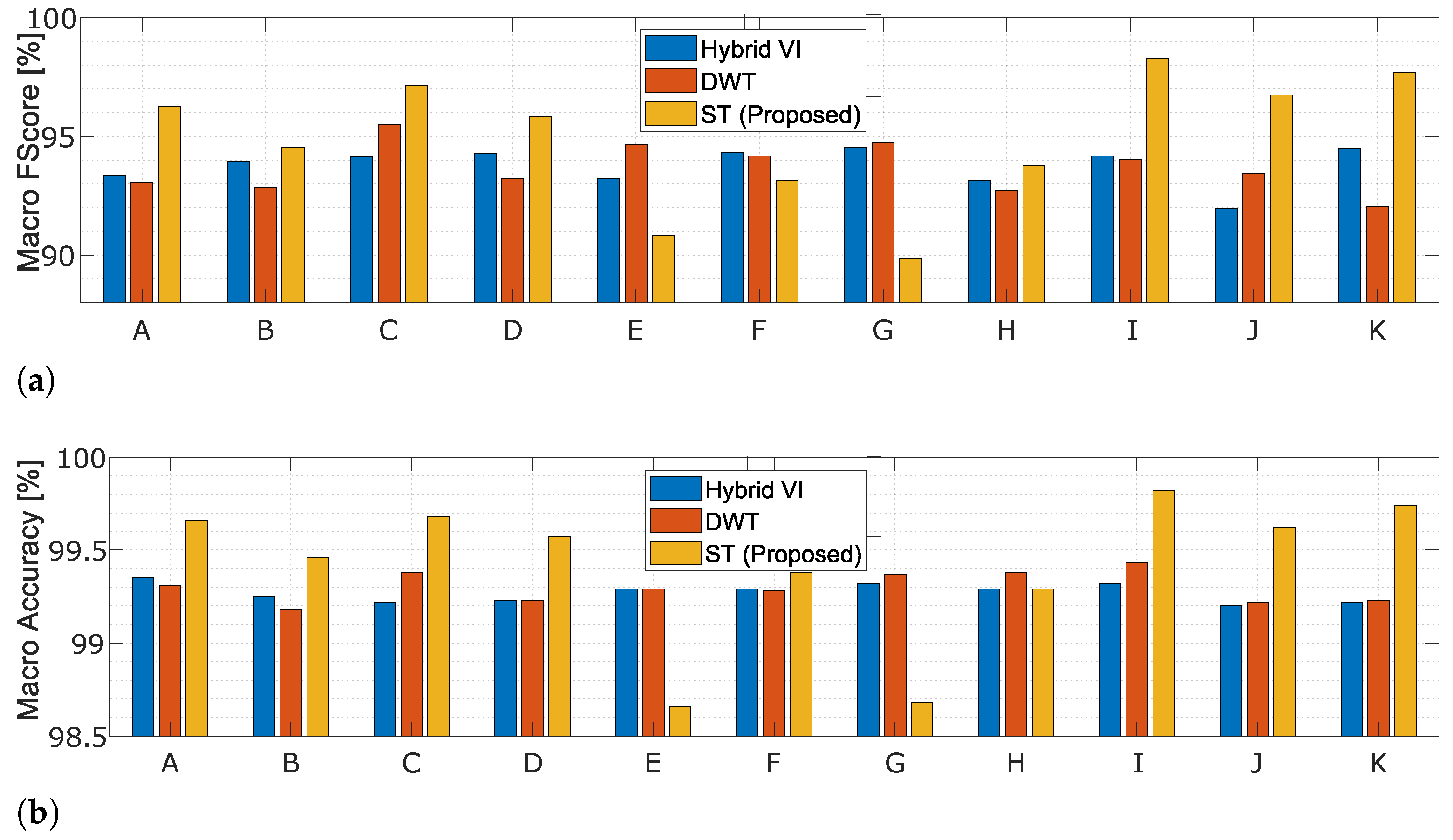
4.1. Lit-Syn Dataset
4.1.1. Results Using the Same Subset for Training and Testing
4.1.2. Results Using Different Subsets for Training and Testing
4.2. Plaid Dataset
5. Discussion and Comparison with Related Works
6. Conclusions
Practical Implications, Limitations, and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Moradzadeh, A.; Mohammadi-Ivatloo, B.; Abapour, M.; Anvari-Moghaddam, A.; Gholami Farkoush, S.; Rhee, S.B. A practical solution based on convolutional neural network for non-intrusive load monitoring. J. Ambient Intell. Humaniz. Comput. 2021, 8. [Google Scholar] [CrossRef]
- Administration, U.E.I. Use of Energy Explained Energy Use in Homes. 2019. Available online: https://www.eia.gov/energyexplained/use-of-energy/homes.php (accessed on 1 September 2021).
- Hart, G.W. Nonintrusive Appliance Load Monitoring. Proc. IEEE 1992, 80, 1870–1891. [Google Scholar] [CrossRef]
- Wójcik, A.; Łukaszewski, R.; Kowalik, R.; Winiecki, W. Nonintrusive Appliance Load Monitoring: An Overview, Laboratory Test Results and Research Directions. Sensors 2019, 19, 3621. [Google Scholar] [CrossRef] [Green Version]
- Zoha, A.; Gluhak, A.; Imran, M.A.; Rajasegarar, S. Non-intrusive load monitoring approaches for disaggregated energy sensing: A survey. Sensors 2012, 12, 16838–16866. [Google Scholar] [CrossRef] [Green Version]
- Faustine, A.; Pereira, L. Improved appliance classification in non-intrusive load monitoring usingweighted recurrence graph and convolutional neural networks. Energies 2020, 13, 3374. [Google Scholar] [CrossRef]
- Lazzaretti, A.; Renaux, D.; Lima, C.; Mulinari, B.; Ancelmo, H.; Oroski, E.; Pöttker, F.; Linhares, R.; Nolasco, L.; Lima, L.; et al. A Multi-Agent NILM Architecture for Event Detection and Load Classification. Energies 2020, 13, 4396. [Google Scholar] [CrossRef]
- Mulinari, B.M.; de Campos, D.P.; da Costa, C.H.; Ancelmo, H.C.; Lazzaretti, A.E.; Oroski, E.; Lima, C.R.E.; Renaux, D.P.B.; Pottker, F.; Linhares, R.R. A New Set of Steady-State and Transient Features for Power Signature Analysis Based on V-I Trajectory. In Proceedings of the IEEE PES Innovative Smart Grid Technologies Conference—Latin America (ISGT Latin America), Gramado, Brazil, 15–18 September 2019; pp. 1–6. [Google Scholar]
- Laughman, C.; Lee, K.; Cox, R.; Shaw, S.; Leeb, S.; Norford, L.; Armstrong, P. Power signature analysis. IEEE Power Energy Mag. 2003, 1, 56–63. [Google Scholar] [CrossRef]
- Su, Y.; Lian, K.; Chang, H. Feature Selection of Non-intrusive Load Monitoring System Using STFT and Wavelet Transform. In Proceedings of the 2011 IEEE 8th International Conference on e-Business Engineering, Beijing, China, 19–21 October 2011; pp. 293–298. [Google Scholar] [CrossRef]
- Gupta, S.; Reynolds, M.S.; Patel, S.N. Single point sensing using EMI for electrical event detection and classification. In Proceedings of the 12th ACM International Conference on Ubiquitous Computing, Copenhagen, Denmark, 26–29 September 2010; pp. 139–148. [Google Scholar]
- Yang, D.; Gao, X.; Kong, L.; Pang, Y.; Zhou, B. An Event-Driven Convolutional Neural Architecture for Non-Intrusive Load Monitoring of Residential Appliance. IEEE Trans. Consum. Electron. 2020, 66, 173–182. [Google Scholar] [CrossRef]
- Faustine, A.; Pereira, L. Multi-label learning for appliance recognition in NILM using fryze-current decomposition and convolutional neural network. Energies 2020, 13, 4154. [Google Scholar] [CrossRef]
- Himeur, Y.; Alsalemi, A.; Bensaali, F.; Amira, A. An intelligent nonintrusive load monitoring scheme based on 2D phase encoding of power signals. Int. J. Intell. Syst. 2021, 36, 72–93. [Google Scholar] [CrossRef]
- Mallat, S. Group Invariant Scattering. Commun. Pure Appl. Math. 2012, 65, 1331–1398. [Google Scholar] [CrossRef] [Green Version]
- Wiatowski, T.; Bolcskei, H. A Mathematical Theory of Deep Convolutional Neural Networks for Feature Extraction. IEEE Trans. Inf. Theory 2018, 64, 1845–1866. [Google Scholar] [CrossRef] [Green Version]
- Oyallon, E.; Belilovsky, E.; Zagoruyko, S. Scaling the Scattering Transform: Deep Hybrid Networks. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Andén, J.; Lostanlen, V.; Mallat, S. Joint Time-Frequency Scattering. IEEE Trans. Signal Process. 2019, 67, 3704–3718. [Google Scholar] [CrossRef] [Green Version]
- Saura, J.R.; Ribeiro-Soriano, D.; Palacios-Marqués, D. Setting B2B digital marketing in artificial intelligence-based CRMs: A review and directions for future research. Ind. Mark. Manag. 2021, 98, 161–178. [Google Scholar] [CrossRef]
- Renaux, D.P.B.; Pottker, F.; Ancelmo, H.C.; Lazzaretti, A.E.; Lima, C.R.E.; Linhares, R.R.; Oroski, E.; da Silva Nolasco, L.; Lima, L.T.; Mulinari, B.M.; et al. A dataset for non-intrusive load monitoring: Design and implementation. Energies 2020, 13, 5371. [Google Scholar] [CrossRef]
- Medico, R.; De Baets, L.; Gao, J.; Giri, S.; Kara, E.; Dhaene, T.; Develder, C.; Bergés, M.; Deschrijver, D. A voltage and current measurement dataset for plug load appliance identification in households. Sci. Data 2020, 7, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.; Wang, Q.; He, Z.; Chen, K.; Hu, J.; He, J. Convolutional sequence to sequence non-intrusive load monitoring. J. Eng. 2018. [Google Scholar] [CrossRef]
- Chen, H.; Wang, Y.H.; Fan, C.H. A convolutional autoencoder-based approach with batch normalization for energy disaggregation. J. Supercomput. 2020, 77, 2961–2978. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, Y.; Wang, Q.; Hu, J.; Fan, H.; He, J. Scale- And Context-Aware Convolutional Non-Intrusive Load Monitoring. IEEE Trans. Power Syst. 2020, 35, 2362–2373. [Google Scholar] [CrossRef] [Green Version]
- Massidda, L.; Marrocu, M.; Manca, S. Non-intrusive load disaggregation by convolutional neural network and multilabel classification. Appl. Sci. 2020, 10, 1454. [Google Scholar] [CrossRef] [Green Version]
- Kaselimi, M.; Protopapadakis, E.; Voulodimos, A.; Doulamis, N.; Doulamis, A. Multi-channel recurrent convolutional neural networks for energy disaggregation. IEEE Access 2019, 7, 81047–81056. [Google Scholar] [CrossRef]
- Zhou, X.; Li, S.; Liu, C.; Zhu, H.; Dong, N.; Xiao, T. Non-Intrusive Load Monitoring Using a CNN-LSTM-RF Model Considering Label Correlation and Class-Imbalance. IEEE Access 2021, 9, 84306–84315. [Google Scholar] [CrossRef]
- Matindife, L.; Sun, Y.; Wang, Z. Image-based mains signal disaggregation and load recognition. Complex Intell. Syst. 2021, 7, 901–927. [Google Scholar] [CrossRef]
- Zhou, X.; Feng, J.; Li, Y. Non-intrusive load decomposition based on CNN–LSTM hybrid deep learning model. Energy Rep. 2021, 7, 5762–5771. [Google Scholar] [CrossRef]
- Ding, D.; Li, J.; Zhang, K.; Wang, H.; Wang, K.; Cao, T. Non-intrusive load monitoring method with inception structured. Appl. Intell. 2021, 1–18. [Google Scholar] [CrossRef]
- Huber, P.; Calatroni, A.; Rumsch, A.; Paice, A. Review on deep neural networks applied to low-frequency nilm. Energies 2021, 14, 2390. [Google Scholar] [CrossRef]
- Ruano, A.; Hernandez, A.; Ureña, J.; Ruano, M.; Garcia, J. NILM Techniques for Intelligent Home Energy Management and Ambient Assisted Living: A Review. Energies 2019, 12, 2203. [Google Scholar] [CrossRef] [Green Version]
- Houidi, S.; Fourer, D.; Auger, F. On the use of concentrated time-frequency representations as input to a deep convolutional neural network: Application to non intrusive load monitoring. Entropy 2020, 22, 911. [Google Scholar] [CrossRef] [PubMed]
- Wu, Q.; Wang, F. Concatenate convolutional neural networks for non-intrusive load monitoring across complex background. Energies 2019, 12, 1572. [Google Scholar] [CrossRef] [Green Version]
- De Baets, L.; Ruyssinck, J.; Develder, C.; Dhaene, T.; Deschrijver, D. Appliance classification using VI trajectories and convolutional neural networks. Energy Build. 2018, 158, 32–36. [Google Scholar] [CrossRef] [Green Version]
- Morán, A.; Alonso, S.; Pérez, D.; Prada, M.A.; Fuertes, J.J.; Domínguez, M. Feature Extraction from Building Submetering Networks Using Deep Learning. Sensors 2020, 20, 3665. [Google Scholar] [CrossRef]
- Mukaroh, A.; Le, T.T.H.; Kim, H. Background load denoising across complex load based on generative adversarial network to enhance load identification. Sensors 2020, 20, 5674. [Google Scholar] [CrossRef]
- Athanasiadis, C.; Doukas, D.; Papadopoulos, T.; Chrysopoulos, A. A scalable real-time non-intrusive load monitoring system for the estimation of household appliance power consumption. Energies 2021, 14, 767. [Google Scholar] [CrossRef]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Khan, S.; Rahmani, H.; Shah, S.A.A.; Bennamoun, M. A Guide to Convolutional Neural Networks for Computer Vision. Synth. Lect. Comput. Vis. 2018, 8, 1–207. [Google Scholar] [CrossRef]
- Burrus, C.S.; Gopinath, R.A.; Guo, H. Introduction to Wavelets and Wavelet Transforms A Primer; Volume 67; Connexions: Huston, TX, USA, 1998. [Google Scholar]
- Bruna, J. Invariant Scattering Convolution Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1872–1886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jiang, J.; Kong, Q.; Plumbley, M.; Gilbert, N. Deep Learning Based Energy Disaggregation and On/Off Detection of Household Appliances. arXiv 2019, arXiv:1908.00941. [Google Scholar]
- Bruna, J.; Mallat, S. Classification with scattering operators. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1561–1566. [Google Scholar] [CrossRef] [Green Version]
- Bonamente, M. Appendix: Numerical Tables A. 1 The Gaussian Distribution and the Error Function; Springer: New York, NY, USA, 2017; Volume 4. [Google Scholar] [CrossRef]
- Cherkassky, V.S.; Mulier, F. Learning from Data: Concepts, Theory, and Methods, 1st ed.; John Wiley & Sons, Inc.: New York, NY, USA, 1998. [Google Scholar]
- Vapnik, V.N. Statistical Learning Theory; Wiley-Interscience: Hoboken, NJ, USA, 1998. [Google Scholar]
- Chang, H.H.; Lian, K.L.; Su, Y.C.; Lee, W.J. Power-Spectrum-Based Wavelet Transform for Nonintrusive Demand Monitoring and Load Identification. IEEE Trans. Ind. Appl. 2014, 50, 2081–2089. [Google Scholar] [CrossRef]
- Saura, J.R.; Palacios-Marqués, D.; Iturricha-Fernández, A. Ethical design in social media: Assessing the main performance measurements of user online behavior modification. J. Bus. Res. 2021, 129, 271–281. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]

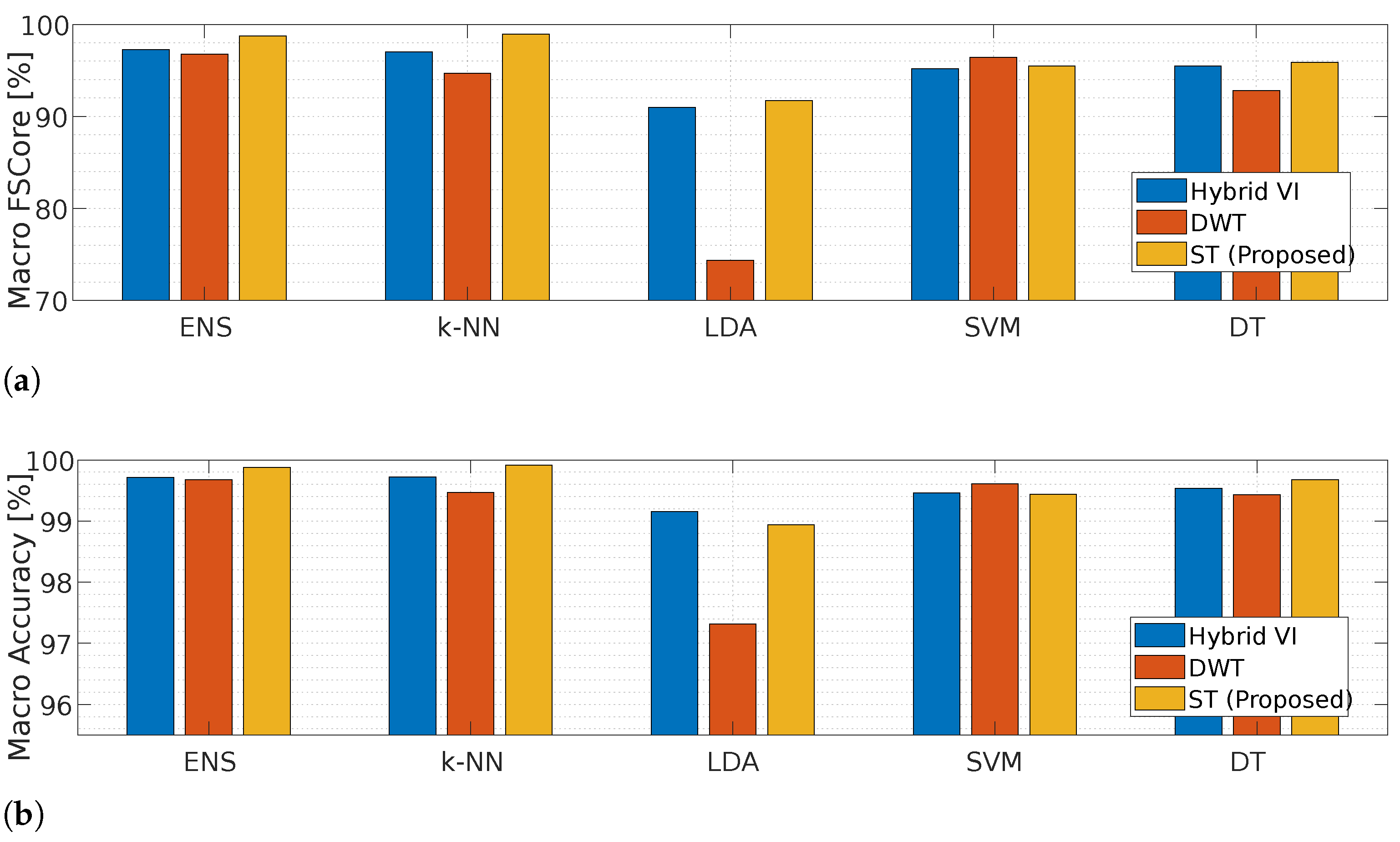
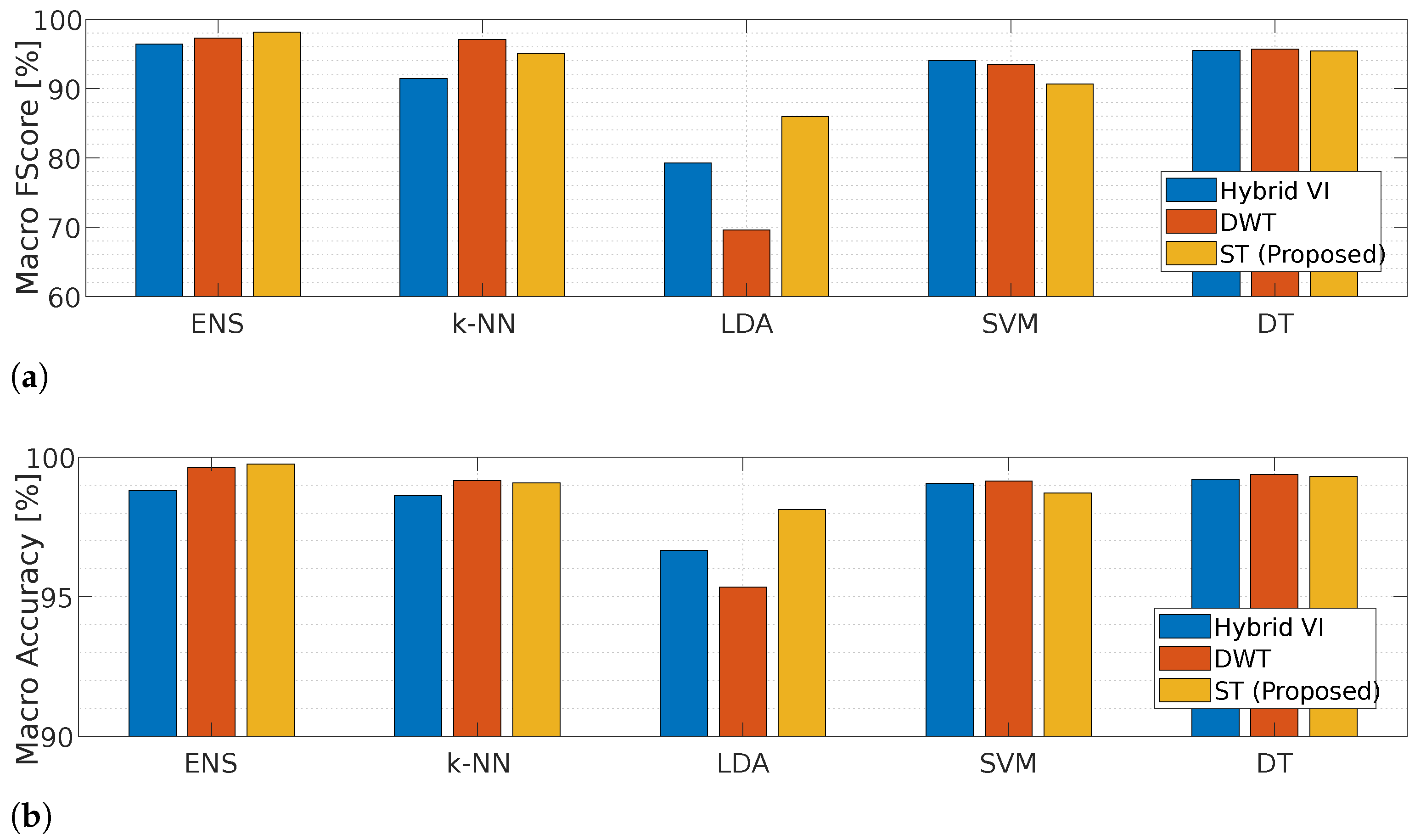

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Device | Rated Power (W) |
|---|---|---|
| 1 | Microwave Standby | 4.5 |
| 2 | LED Lamp | 6 |
| 3 | CRT Monitor | 10 |
| 4 | LED Panel | 13 |
| 5 | Fume Extractor | 23 |
| 6 | LED Monitor | 26 |
| 7 | Cell phone charger Asus | 38 |
| 8 | Soldering station | 40 |
| 9 | Cell phone charger Motorola | - |
| 10 | Laptop Lenovo | 70 |
| 11 | Fan | 80 |
| 12 | Resistor | 80 |
| 13 | Laptop Vaio | 90 |
| 14 | Incandescent Lamp | 100 |
| 15 | Drill Speed. 1 | 165 |
| 16 | Drill Speed. 2 | 350 |
| 17 | Oil heater power 1 | 520 |
| 18 | Oil heater power 2 | 750 |
| 19 | Microwave On | 950 |
| 20 | Air heater Nilko | 1120 |
| 21 | Hair dryer Eleganza—Speed 1 | 365 |
| 22 | Hair dryer Eleganza—Speed 2 | 500 |
| 23 | Hair dryer Super 4.0—Speed 1—Heater 1 | 660 |
| 24 | Hair dryer Super 4.0—Speed 1—Heater 2 | 1120 |
| 25 | Hair dryer Parlux—Speed 1—Heater 1 | 660 |
| 26 | Hair dryer Parlux—Speed. 2—Heater 1 | 885 |
| ID | Device | Rated Power (W) |
|---|---|---|
| 1 | Compact Fluorescent Lamp | 13 |
| 2 | Fridge | Not available |
| 3 | Fridge Defroster | Not available |
| 4 | Air Conditioner | 740 |
| 5 | Laptop | Not available |
| 6 | Vacuum Cleaner | Not available |
| 7 | Fan | 38 |
| 8 | Incandescent Light Bulb | 100 |
| 9 | Blender | Not available |
| 10 | Coffee Maker | 975 |
| 11 | Water Kettle | 1500 |
| 12 | Hair Iron | Not available |
| 13 | Iron Solder | 60 |
| Scenario | Selected Region | |||
|---|---|---|---|---|
| A | 30 | 20 | SS + T | 118 |
| B | 30 | 20 | T | 59 |
| C | 30 | 20 | SS | 59 |
| D | 20 | 5 | SS + T | 86 |
| E | 20 | 5 | T | 43 |
| F | 20 | 10 | SS + T | 102 |
| G | 20 | 10 | T | 51 |
| H | 20 | 10 | SS | 51 |
| I | 40 | 40 | SS + T | 134 |
| J | 40 | 40 | T | 67 |
| K | 40 | 40 | SS | 67 |
| Training Dataset | Testing Dataset | Accuracy | ||
|---|---|---|---|---|
| ST | DWT | V-I | ||
| LIT-SYN-1 | LIT-SYN-2 | 86.50 | 92.10 | 89.55 |
| LIT-SYN-1 | LIT-SYN-3 | 73.60 | 62.14 | 67.98 |
| LIT-SYN-1 | LIT-SYN-8 | 58.68 | 41.34 | 54.72 |
| LIT-SYN-T | LIT-SYN-1 | 99.88 | 99.16 | 99.76 |
| LIT-SYN-T | LIT-SYN-2 | 99.63 | 99.41 | 99.52 |
| LIT-SYN-T | LIT-SYN-3 | 99.56 | 99.02 | 98.42 |
| LIT-SYN-T | LIT-SYN-8 | 99.42 | 98.90 | 97.75 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Aguiar, E.L.; Lazzaretti, A.E.; Mulinari, B.M.; Pipa, D.R. Scattering Transform for Classification in Non-Intrusive Load Monitoring. Energies 2021, 14, 6796. https://doi.org/10.3390/en14206796
de Aguiar EL, Lazzaretti AE, Mulinari BM, Pipa DR. Scattering Transform for Classification in Non-Intrusive Load Monitoring. Energies. 2021; 14(20):6796. https://doi.org/10.3390/en14206796
Chicago/Turabian Stylede Aguiar, Everton Luiz, André Eugenio Lazzaretti, Bruna Machado Mulinari, and Daniel Rodrigues Pipa. 2021. "Scattering Transform for Classification in Non-Intrusive Load Monitoring" Energies 14, no. 20: 6796. https://doi.org/10.3390/en14206796
APA Stylede Aguiar, E. L., Lazzaretti, A. E., Mulinari, B. M., & Pipa, D. R. (2021). Scattering Transform for Classification in Non-Intrusive Load Monitoring. Energies, 14(20), 6796. https://doi.org/10.3390/en14206796